struc2vec:从结构身份学习节点表示
摘要。
结构同一性是一种对称概念,根据网络结构及其与其他节点的关系来识别网络节点。 过去几十年来,人们在理论和实践中对结构同一性进行了研究,但直到最近才用表征学习技术来解决它。 这项工作提出了 struc2vec,这是一种新颖且灵活的框架,用于学习节点结构身份的潜在表示。 struc2vec 使用层次结构来衡量不同尺度下的节点相似性,并构建多层图来编码结构相似性并生成节点的结构上下文。 数值实验表明,用于学习节点表示的最先进技术无法捕获更强的结构同一性概念,而 struc2vec 在此任务中表现出更加优越的性能,因为它克服了先前方法的局限性。 因此,数值实验表明 struc2vec 提高了更多依赖于结构同一性的分类任务的性能。
1. 介绍
在几乎所有网络中,节点往往具有一种或多种功能,这些功能在很大程度上决定了它们在系统中的角色。 例如,社交网络中的个体具有社会角色或社会地位(Lorrain and White,1971;Sailer,1978),而蛋白质-蛋白质相互作用(PPI)网络中的蛋白质则发挥特定功能(Singh 等人,2008;Atias 和 Sharan,2012)。 直观上,此类网络中的不同节点可能执行类似的功能,例如公司社交网络中的实习生或小区 PPI 网络中的催化剂。 因此,节点通常可以根据其在网络中的功能划分为等效的类。
尽管此类功能的识别通常利用节点和边缘属性,但当节点功能仅由网络结构定义时,会出现更具挑战性和更有趣的场景。 在这种情况下,甚至节点的标签也不重要,重要的是它们与其他节点(边)的关系。 事实上,数学社会学家自 20 世纪 70 年代起就开始研究这个问题,定义和计算社交网络中个体的结构身份(Lorrain 和 White,1971;Sailer,1978;Pizarro,2007). 除了社会学之外,网页在网络图中的作用是网络结构中出现的身份(在本例中为中心和权威)的另一个例子,正如 Kleinberg 的著名著作所定义的(Kleinberg,1999) 。
确定节点结构身份的最常见实用方法是基于距离或递归。 前者使用利用节点邻域的距离函数来测量所有节点对之间的距离,然后执行聚类或匹配将节点放入等效类(Leicht等人,2006;Fouss等人) ,2007)。 后者构建相对于相邻节点的递归,然后迭代展开直至收敛,最终值用于确定等效类(Kleinberg,1999;Blondel等人,2004;Zager和Verghese,2008). 虽然这些方法各有优点和缺点,但我们提供了一种替代方法,一种基于节点结构身份表示的无监督学习(待介绍)。

最近在学习网络中节点的潜在表示方面所做的努力在执行分类和预测任务方面非常成功(Grover和Leskovec,2016;Narayanan等人,2016;Perozzi等人,2014;Tang等人,2015). 特别是,这些工作使用其邻域的广义概念作为上下文对节点进行编码(例如,随机游走的 步骤,或具有共同邻居的节点)。 简而言之,具有相似节点集的邻域的节点应该具有相似的潜在表示。 但邻域是一个本地概念,由网络中的某种邻近概念定义。 因此,具有结构相似但相距较远的邻域的两个节点将不会具有相似的潜在表示。 图1说明了该问题,其中节点和扮演相似的角色(即具有相似的本地结构),但在网络中相距很远。 由于它们的邻域没有公共节点,因此最近的方法无法捕获它们的结构相似性(正如我们很快就会展示的那样)。
值得注意的是,为什么最近的学习节点表示的方法,例如 DeepWalk (Perozzi 等人, 2014) 和 node2vec (Grover and Leskovec,2016) 在分类任务中取得成功,但在结构等价任务中往往会失败。 关键点是,大多数真实网络中的许多节点特征都表现出很强的同质性(例如,具有相同政治倾向的两个博客比随机连接更有可能连接)。 具有给定特征的节点的邻居更有可能具有相同的特征。 因此,网络中和潜在表示中“接近”的节点将倾向于共享特征。 同样,网络中“远”的两个节点往往会在潜在表示中分离,而与它们的本地结构无关。 因此,结构等价将无法在潜在表示中正确捕获。 然而,如果对更多依赖于结构同一性而不是同质性的特征进行分类,那么最近的方法可能会被更好地捕获结构等价性的潜在表示所超越(正如我们很快就会展示的那样)。
我们的主要贡献是一个灵活的框架,用于学习节点结构身份的潜在表示,称为 struc2vec。 它是通过潜在表征研究结构同一性的替代且强大的工具。 struc2vec的关键思想是:
-
•
独立于节点和边属性及其在网络中的位置来评估节点之间的结构相似性。 因此,具有相似局部结构的两个节点将被视为独立于其邻域中的网络位置和节点标签。 我们的方法也不需要连接网络,并识别不同连接组件中结构相似的节点。
-
•
建立一个层次结构来衡量结构相似性,允许对结构相似性的含义逐渐采取更严格的概念。 特别是,在层次结构的底部,节点之间的结构相似性仅取决于它们的程度,而在层次结构的顶部,相似性取决于整个网络(从节点的角度来看)。
-
•
为节点生成随机上下文,这些节点是通过遍历多层图(并且不是原始网络)的加权随机游走观察到的结构相似节点的序列。 因此,经常出现在相似上下文中的两个节点可能具有相似的结构。 语言模型可以利用此类上下文来学习节点的潜在表示。
我们实现了一个 struc2vec 实例,并通过对玩具示例和真实网络的数值实验展示了其潜力,将其性能与 DeepWalk (Perozzi 等人,2014) 和 node2vec (Grover 和 Leskovec,2016) – 两种用于学习节点潜在表示的最先进技术,并与 RolX (Henderson 等人, 2012) – 一种识别节点角色的最新方法。 我们的结果表明,虽然 DeepWalk 和 node2vec 未能捕获结构同一性的概念,但 struc2vec 在这项任务上表现出色 - 即使原始网络是受到强随机噪声(随机边缘去除)的影响。 我们还表明,struc2vec 在分类任务中表现出色,其中节点标签更多地依赖于结构身份(即,带有代表机场活动的标签的空中交通网络)。
2. 相关工作
在过去的几十年里,在(欧几里得)空间中嵌入网络节点受到了不同社区的广泛关注。 该技术对于利用网络数据的机器学习应用程序非常有用,因为节点嵌入可以直接用于分类和聚类等任务。
在自然语言处理(Bengio等人,2003)中,为稀疏数据生成密集嵌入有着悠久的历史。 最近,Skip-Gram (Mikolov 等人, 2013b; Mikolov 等人, 2013a) 被提出作为一种学习文本数据(例如句子)嵌入的有效技术。 除其他属性外,学习的语言模型将语义相似的单词在空间中彼此靠近。
从网络学习语言模型最早由DeepWalk(Perozzi等人,2014)提出。 它使用随机游走从网络生成节点序列,然后由 Skip-Gram 将其视为句子。 直观上,网络中靠近的节点往往具有相似的上下文(序列),因此具有彼此接近的嵌入。 这个想法后来被node2vec(Grover and Leskovec,2016)扩展。 通过提出有偏二阶随机游走模型,node2vec 在生成顶点上下文时提供了更大的灵活性。 特别是,可以设计驱动有偏随机游走的边权重,以尝试捕获顶点同质性和结构等价性。 然而,一个基本的限制是,如果结构相似的节点的距离(跳数)大于 Skip-Gram 窗口,则它们永远不会共享相同的上下文。
subgraph2vec (Narayanan 等人, 2016) 是另一种最近学习有根子图嵌入的方法,与之前的技术不同,它不使用随机游走来生成上下文。 或者,节点的上下文仅由其邻居定义。 此外,subgraph2vec 通过将具有相同局部结构的节点嵌入到空间中的同一点来捕获结构等效性。 尽管如此,结构等价的概念非常严格,因为它被定义为 Weisfeiler-Lehman 同构检验(Shervashidze 等人,2011)所规定的二元属性。 因此,结构上非常相似(但测试失败)并且具有不重叠邻居的两个节点在空间上可能并不接近。
与subgraph2vec类似,最近在学习更丰富的网络节点表示方面做出了相当大的努力(Wang等人,2016;Cao等人,2016)。 然而,构建明确捕获结构同一性的表示是一个相对正交的问题,尚未受到太多关注。 这是struc2vec的重点。
最近仅使用网络结构来明确识别节点角色的方法是RolX(Henderson等人,2012)。 这种无监督方法基于枚举节点的各种结构特征,找到更适合该联合特征空间的基础向量,然后为每个节点分配已识别角色(基础)上的分布,从而允许跨角色的混合成员资格。 如果没有明确考虑节点相似性或节点上下文(在结构方面),RolX 可能会错过结构上等效的节点对(待显示)。
3。 struc2vec
考虑学习捕获网络中节点的结构身份的表示的问题。 成功的方法应该表现出两个所需的属性:
-
•
节点的潜在表示之间的距离应该与其结构相似性密切相关。 因此,具有相同本地网络结构的两个节点应该具有相同的潜在表示,而具有不同结构标识的节点应该相距很远。
-
•
潜在表示不应依赖于任何节点或边属性,包括节点标签。 因此,结构相似的节点应该具有紧密的潜在表示,独立于其邻域中的节点和边属性。 节点的结构身份必须与其在网络中的“位置”无关。
考虑到这两个属性,我们提出了struct2vec,一个用于学习节点潜在表示的通用框架,由四个主要步骤组成,如下:
-
(1)
确定图中不同邻域大小的每个顶点对之间的结构相似性。 这在节点之间的结构相似性度量中引入了层次结构,提供了更多信息来评估层次结构每个级别的结构相似性。
-
(2)
构建一个加权多层图,其中网络中的所有节点都存在于每一层中,并且每一层对应于测量结构相似性的层次结构的级别。 此外,每层内每个节点对之间的边权重与其结构相似性成反比。
-
(3)
使用多层图为每个节点生成上下文。 特别地,多层图上的偏置随机游走用于生成节点序列。 这些序列可能包括结构更相似的节点。
-
(4)
应用一种技术从节点序列给出的上下文中学习潜在表示,例如 Skip-Gram。
请注意,struct2vec 非常灵活,因为它不强制要求任何特定的结构相似性度量或表征学习框架。 接下来,我们详细解释 struct2vec 的每个步骤,并提供一种严格的方法来对结构相似性进行分层度量。
3.1. 测量结构相似性
struct2vec 的第一步是在不使用任何节点或边属性的情况下确定两个节点之间的结构相似性。 此外,这种相似性度量应该是分层的,可以应对不断增加的邻域大小,捕获更精细的结构相似性概念。 直观上,具有相同度数的两个节点在结构上相似,但如果它们的邻居也具有相同的度数,那么它们在结构上更加相似。
令 表示考虑中的无向、无权网络,其中顶点集 和边集 ,其中 表示节点数在网络中和其直径。 让 表示距离 中的 恰好为 的节点集(跳数)。请注意, 表示 的邻居集,一般来说, 表示距离 处的节点环。令表示一组节点的有序度序列。
通过比较距 和 距离 的环的有序度序列,我们可以强加一个层次结构来测量结构相似性。 特别是,在考虑 跳时,让 表示 和 之间的结构距离邻域(距离小于或等于 的所有节点以及其中的所有边)。 我们特别定义:
| (1) |
其中测量有序度序列和和之间的距离。 请注意,根据定义, 在 中是非递减的,并且只有当 或 的节点距离 时才会定义 。此外,在 的定义中使用距离 的环,会强制比较距离 和 相同的节点的度序列。最后,请注意,如果 和 的 跳邻域同构,并将 映射到 ,那么 。
最后一步是确定比较两个度数序列的函数。 请注意, 和 可以具有不同的大小,并且其元素是 范围内的任意整数,并且可能重复。 我们采用动态时间规整(DTW)来测量两个有序度序列之间的距离,这种技术可以更好地应对不同大小的序列并松散地比较序列模式(Rakthanmanon等人,2013;Salvador和Chan,2004) 。
通俗地说,DTW 找到两个序列 和 之间的最佳比对。 给定序列元素的距离函数,DTW将每个元素匹配到,使得匹配元素之间的距离总和最小。 由于序列和的元素是节点的度数,因此我们采用以下距离函数:
| (2) |
请注意,当时,则。 因此,两个相同的有序度序列将具有零距离。 另请注意,通过取最大值和最小值之间的比率,度数 1 和度数 2 比度数 101 和 102 差异更大,这是测量节点度数之间的距离时所需的属性。 最后,虽然我们使用 DTW 来评估两个有序度序列之间的相似性,但我们的框架可以采用任何其他成本函数。
3.2. 构建上下文图
我们构建了一个多层加权图来编码节点之间的结构相似性。 回想一下, 表示原始网络(可能未连接), 表示其直径。 让 表示多层图,其中层 是使用节点的 跳邻域定义的。
每个层由带有节点集的加权无向完整图形成,因此具有边。 层中两个节点之间的边权重由下式给出:
| (3) |
请注意,仅当定义了 时才定义边,并且权重与结构距离成反比,并且假设值小于或等于 1,仅当 时才等于 1。 请注意,结构上与 类似的节点在 的各个层上将具有更大的权重。
我们使用有向边连接各层,如下所示。 每个顶点都连接到其上下层中对应的顶点(层允许)。 因此,层 中的每个顶点 都连接到层 和 中相应的顶点 。 各层之间的边权重如下:
| (4) |
其中是与相关的边的数量,其权重大于层中完整图的平均边权重。尤其:
| (5) |
其中。 因此, 衡量节点 与层 中其他节点的相似性。请注意,如果 在当前层中有许多相似的节点,那么它应该更改层以获得更精细的上下文。 请注意,通过向上移动一层,相似节点的数量只会减少。 最后, 函数只是减少给定层中与 类似的潜在大量节点的数量级。
最后,请注意 具有 个顶点和最多 个加权边。 在3.5节中我们讨论如何降低生成和存储的复杂度。
3.3. 为节点生成上下文
多层图用于为每个节点生成结构上下文。 请注意, 完全不使用标签信息来捕获 中节点之间的结构相似性。 与之前的工作一样,struct2vec 使用随机游走来生成节点序列来确定给定节点的上下文。 特别是,我们考虑一种有偏随机游走,它围绕 移动,根据 的权重进行随机选择。在每一步之前,随机游走首先决定是换层还是在当前层游走(随机游走有概率停留在当前层)。
假设它将停留在当前层,则在层 中从节点 步进到节点 的概率由下式给出:
| (6) |
其中 是层 中顶点 的归一化因子,简单地由下式给出:
| (7) |
请注意,随机游走会优先选择在结构上与当前顶点更相似的节点,避免与当前顶点结构相似性很小的节点。 因此,节点 的上下文可能具有结构相似的节点,而与它们在原始网络 中的标签和位置无关。
以概率,随机游走决定换层,并以概率成比例移动到层或层(层允许)中的相应节点到边缘权重。 尤其:
| (8) |
请注意,每次步行器进入图层时,它都会将当前顶点作为其上下文的一部分,与图层无关。 因此,顶点 可能在层 中具有给定上下文(由该层的结构相似性确定),但在层 处具有该上下文的子集t2>,因为当我们移动到更高层时,结构相似性不会增加。 这种跨层的分层上下文的概念是所提出的方法的一个基本方面。
最后,对于每个节点 ,我们在第 0 层的相应顶点开始随机游走。 随机游走具有固定且相对较短的长度(步数),并且该过程重复一定次数,从而产生多个独立游走(即节点的多个上下文)。
3.4. 学习语言模型
最近的语言建模技术已广泛用于学习词嵌入,并且只需要句子集即可生成有意义的表示。 非正式地,该任务可以定义为学习给定上下文的单词概率。 特别是,Skip-Gram (Mikolov 等人, 2013a) 已被证明可以有效地学习各种数据的有意义的表示。 为了将其应用到网络中,使用人工生成的节点序列而不是单词句子就足够了。 在我们的框架中,这些序列是通过多层图 上的偏置随机游走生成的。给定一个节点,Skip-Gram 的目标是最大化序列中其上下文的可能性,其中节点的上下文由以其为中心的大小为 的窗口给出。
在这项工作中,我们使用 Hierarchical Softmax,其中条件符号概率是使用二元分类器树计算的。 对于每个节点 ,Hierarchical Softmax 在分类树中分配一个特定路径,由一组树节点 定义,其中 。 在此设置中,我们有:
| (9) |
其中 是树中每个节点中存在的二元分类器。 请注意,由于 Hierarchical Softmax 在二叉树上运行,因此我们有 。
我们根据方程 (9) 给出的优化问题来训练 Skip-Gram。 请注意,虽然我们使用 Skip-Gram 来学习节点嵌入,但任何其他学习文本数据潜在表示的技术都可以在我们的框架中使用。
3.5. 复杂性和优化
为了构造,必须计算每层的每个节点对之间的结构距离,即对于,以及. 但是, 使用两个度数序列之间的 DTW 计算结果。 虽然 DTW 的经典实现具有复杂性 ,但快速技术具有复杂性 ,其中 是最大序列 的大小(Salvador 和 Chan, 2004)。 让 表示网络中的最大度。 然后,对于任何节点和层,度数序列的大小。由于每层都有对,计算层所有距离的复杂度为。 最终的复杂度为。 接下来,我们将描述一系列优化,这些优化将显着减少框架的计算和内存需求。
减少度数序列的长度(OPT1)。
尽管 层的度数序列的长度受 限制,但对于某些网络,即使对于较小的 (例如,对于 序列已经是)。 为了降低比较大序列的成本,我们建议按如下方式压缩有序度序列。 对于序列中的每个度数,我们计算该度数出现的次数。 压缩的有序度序列是具有度和出现次数的元组。 由于网络中的许多节点往往具有相同的度,因此实际上压缩的有序度序列可以比原始的小一个数量级。
减少成对相似度计算的数量(OPT2)。
虽然原始框架评估每一层的每个节点对之间的相似性,但显然这似乎是不必要的。 考虑两个度数差异很大的节点(例如 2 和 20)。 即使对于,它们的结构距离也会很大,因此中它们之间的边缘将具有非常小的权重。 因此,当为这些节点生成上下文时,随机游走不太可能遍历该边。 因此, 中没有这条边不会显着改变模型。
对于每个级别 ,我们将每个节点的成对相似性计算数量限制为 。让 表示将成为 中 邻居的节点集,这对于每个级别都是相同的。 应该具有与 结构最相似的节点。 为了确定 ,我们采用与 度数最相似的节点。 这可以通过对网络中所有节点的有序度序列(对于节点 的度)执行二分搜索,并在每个方向上取 个连续节点来有效计算搜索完成后。 因此,计算具有复杂性。 计算所有节点的 具有复杂性 ,这也是对网络度进行排序所需要的。 至于内存要求, 的每一层现在将具有 边缘,而不是 。
减少层数(OPT3)。
中的层数由网络直径 给出。 然而,对于许多网络来说,直径可能比平均距离大得多。 此外,评估两个节点之间的结构相似性的重要性随着 值的任意大而降低。特别地,当接近时,环的度数序列的长度变得相对较短,因此与。 因此,我们将 中的层数限制为固定常数 ,捕获最重要的层以评估结构相似性。 这显着减少了构造 的计算和内存需求。
尽管上述优化的组合会影响框架为结构相似的节点生成良好表示的能力,但我们将证明它们的影响是边际的,有时甚至是有益的。 因此,减少框架的计算和内存需求的好处大大超过了它的缺点。 最后,我们在以下位置提供 struc2vec:https://github.com/leoribeiro/struc2vec
4. 实验评估
接下来,我们在不同的场景中评估 struct2vec,以说明其在捕获节点结构身份方面的潜力,同时也考虑到学习节点表示的最先进技术。
4.1. 杠铃图
我们将表示为-杠铃图,它由两个完整的图和组成(每个图都有 节点)由长度为 的路径图 连接。两个节点和充当桥梁。 使用 表示 ,我们将 连接到 ,将 连接到 ,从而连接三个图。
杠铃图具有大量具有相同结构特性的节点。 让 和 。 请注意,所有节点 在结构上都是等效的,从严格意义上讲,任何一对此类节点之间都存在自同构。 此外,我们还发现所有节点对 (对于 )以及对 在相同的强意义上在结构上是等效的。 图2a说明了图,其中结构等效的节点具有相同的颜色。
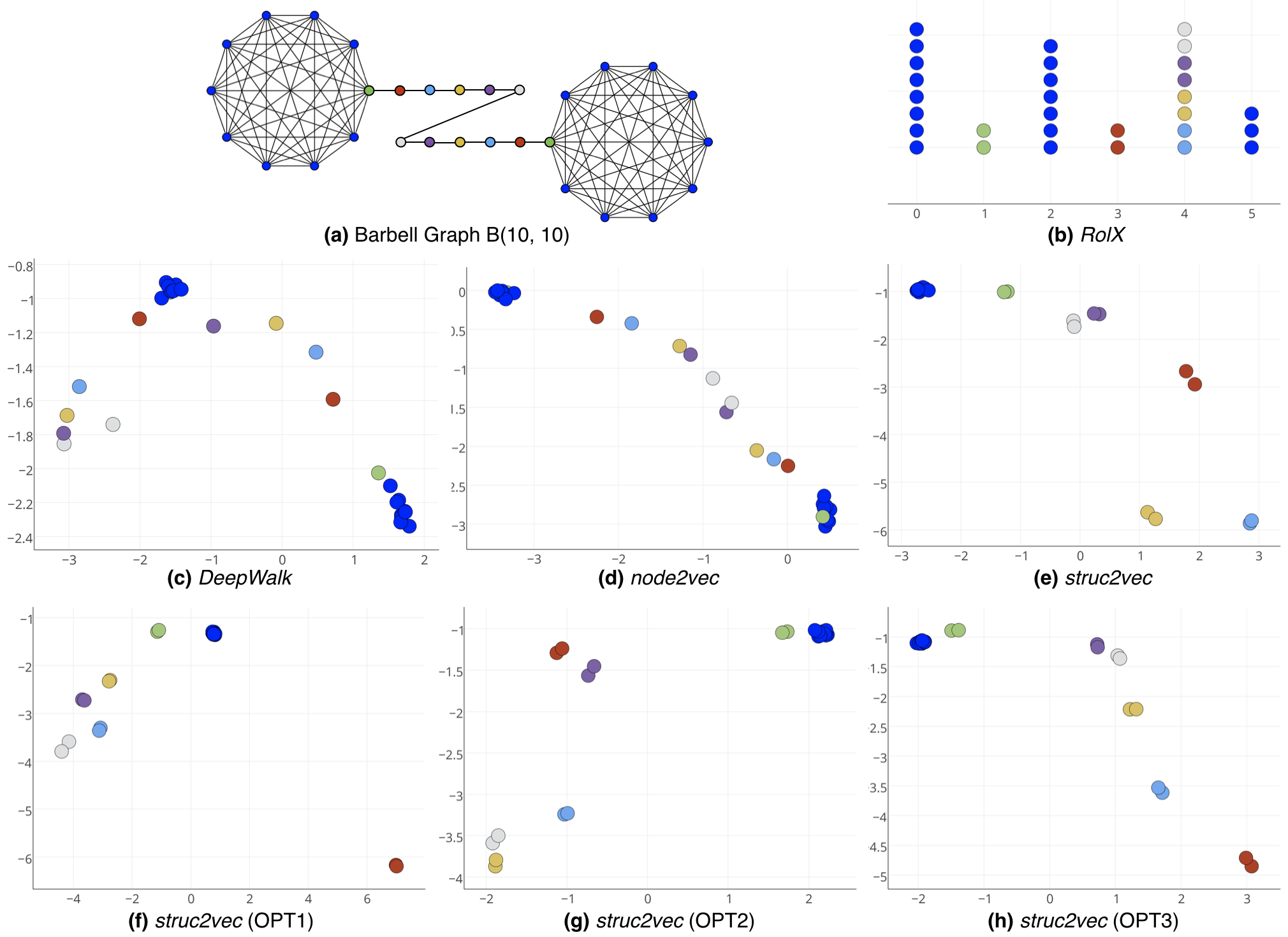
因此,我们期望 struct2vec 学习捕获上述结构等效性的顶点表示。 每个结构上等效的节点对应该具有相似的潜在表示。 此外,学习到的表示还应该捕获结构层次结构:虽然节点 并不等同于节点 或 ,但我们可以清楚地看到,从从结构上看它更类似于(比较它们的程度就足够了)。
图2显示了DeepWalk、node2vec和struct2vec针对学习到的潜在表示。 DeepWalk 未能捕获结构等价,这是预期的,因为它的设计初衷并不是考虑结构特性。 如图所示,即使参数 和 具有不同的变化,node2vec 也不会捕获结构特性。 事实上,它主要学习图形距离,将图形中较近(以跳数为单位)的潜在空间节点放置得更近。 node2vec 的另一个限制是 Skip-Gram 的窗口大小使得 和 中的节点不可能出现在同一上下文中。
另一方面,struct2vec 学习正确分离等效类的表示,将结构等效的节点放置在潜在空间中彼此靠近的位置。 请注意,相同颜色的节点紧密地组合在一起。 此外, 和 放置在靠近 和 中节点表示的位置,因为它们是桥。 最后,请注意,这三种优化都不会对表示的质量产生任何显着影响。 事实上,结构上等效的节点在 OPT1 下的潜在表示中彼此更加接近。
最后,我们将RolX应用于杠铃图(结果如图2(b))。 总共确定了六个角色,其中一些角色确实精确地捕获了结构等效性(角色 1 和 3)。 但是,结构上等效的节点(在 和 中)被放置在三个不同的角色(角色 0、2 和 5)中,而角色 4 包含路径中的所有剩余节点。 因此,尽管在为节点分配角色时RolX确实捕获了一些结构等效的概念,但struct2vec更好地识别和分离结构等效。
4.2. 空手道网
Zachary 空手道俱乐部(Zachary,1977)是一个由 34 个节点和 78 个边组成的网络,其中每个节点代表一个俱乐部成员,边表示两个成员是否在俱乐部外进行过互动。 在这个网络中,边通常被解释为成员之间友谊的标志。
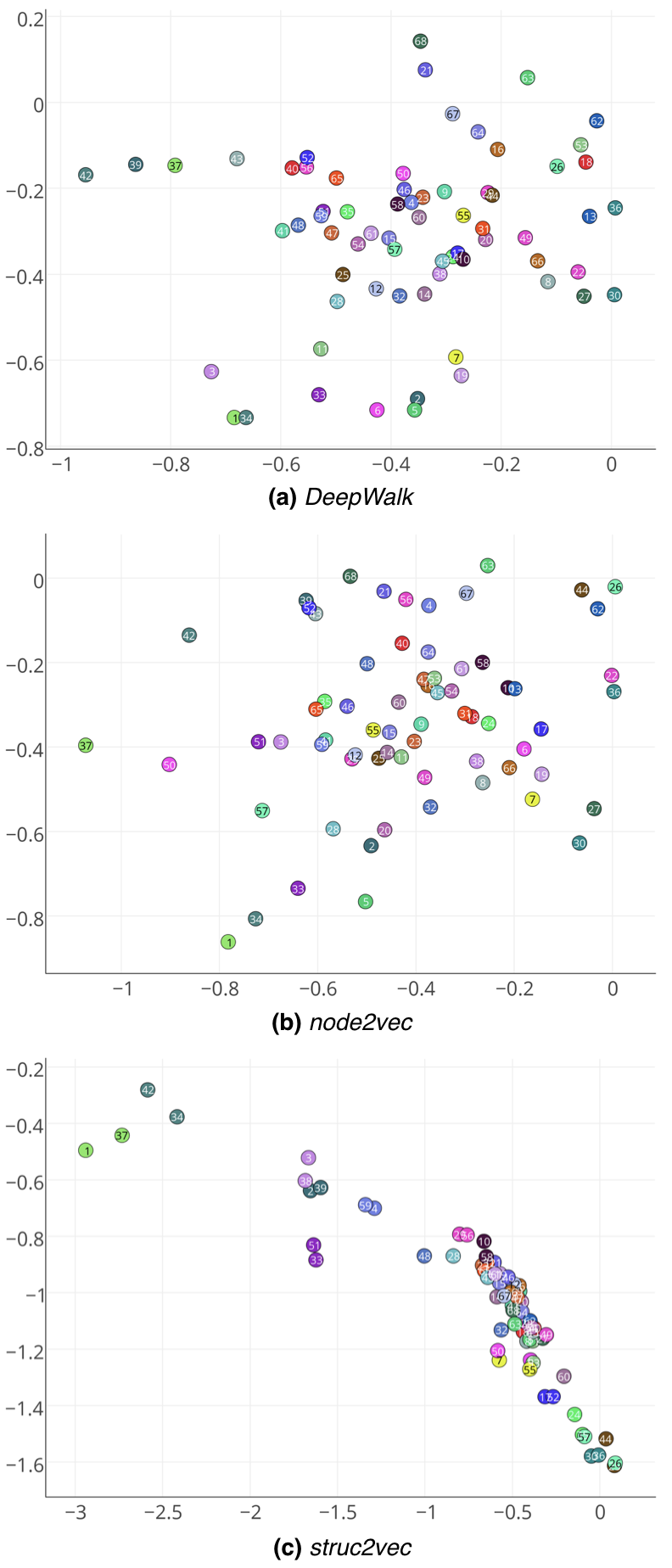
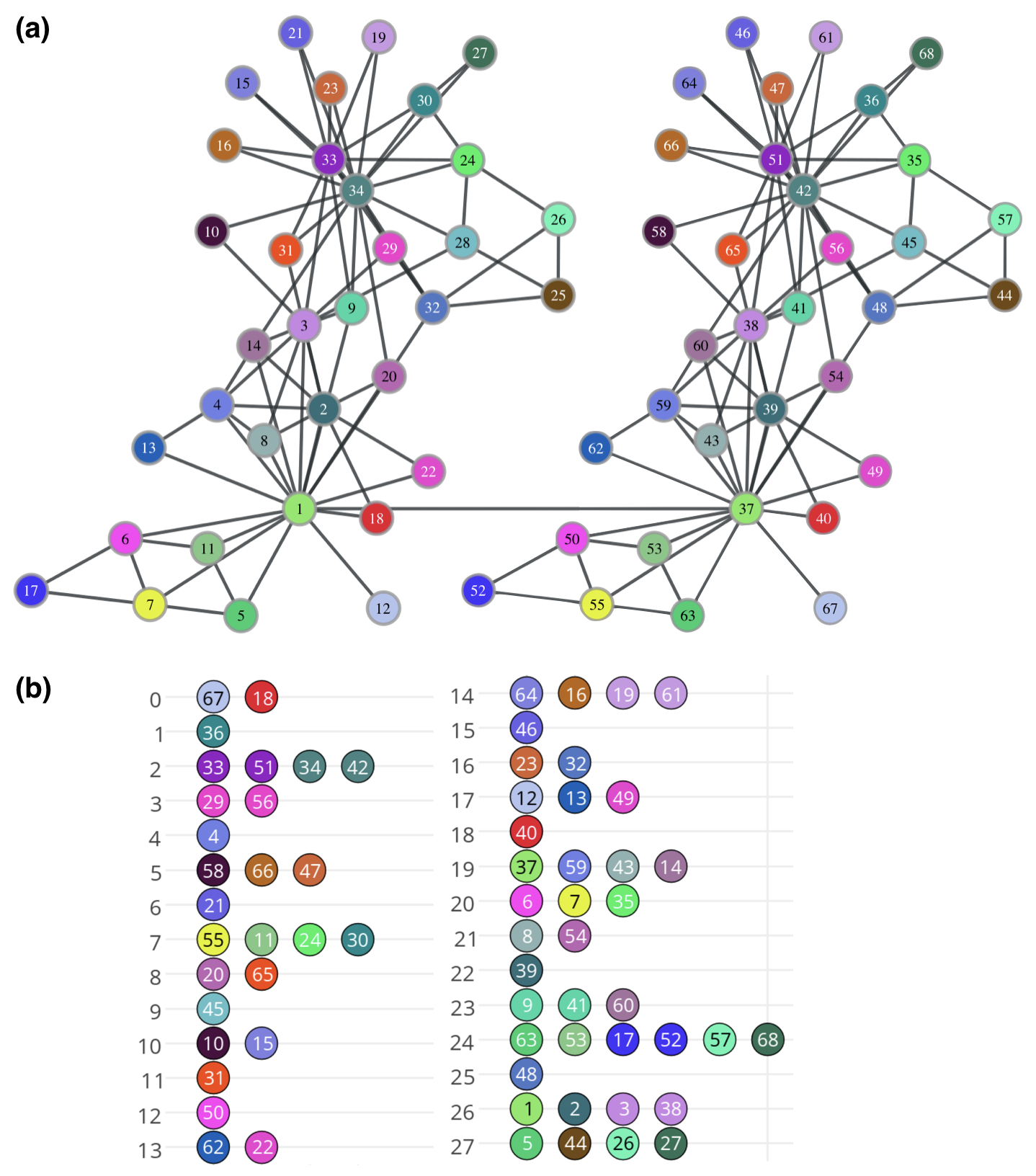
我们构建了一个由空手道俱乐部网络的两个副本和组成的网络,其中每个节点都有一个镜像节点 。 我们还通过在镜像节点对 和 之间添加一条边来连接两个网络。 尽管这对于我们的框架来说不是必需的,但 DeepWalk 和 node2vec 不能将图的不同连接组件中的相同上下文节点放置在相同的上下文节点中。 因此,我们添加边缘以便与两个基线进行更公平的比较。 图4a显示了镜像网络,其中对应的网络对具有相同的颜色。
图3显示了DeepWalk、node2vec和struct2vec学习到的表示。 显然,Deepwalk 和 node2vec 无法在潜在空间中对结构等效的节点(包括镜像节点)进行分组。
struct2vec 再次成功地学习了正确捕获节点结构特性的特征。 镜像对(即具有相同颜色的节点)在潜在空间中保持紧密在一起,并且表示分组在一起的方式存在复杂的结构层次结构。
例如,请注意节点 、 及其对应的镜像( 和 )位于潜在空间。 有趣的是,这些正是代表俱乐部教练 Mr. Hi 和他的管理员 John A. 的节点。 该网络是在两人之间的冲突将俱乐部成员分为两组后聚集的——以 Mr. Hi 或 John A. 为中心。 因此,节点和在网络中具有特定且相似的领导者角色。 请注意,即使它们之间没有边缘,struct2vec 也会捕获它们的函数。
潜在空间中的另一个可见簇由节点 和 及其镜像组成。 这些节点在网络中也具有特定的结构身份:它们都具有高度并且还连接到至少一个领导者。 最后,节点和(潜在空间中的最右边)具有非常接近的表示,这与它们的结构角色一致:两者都具有低度并且距离领导者。
struct2vec 还捕获非平凡的结构等价。 请注意,节点 和 (粉色和黄色)被映射到潜在空间中的接近点。 令人惊讶的是,这两个节点在结构上是等效的——图中存在将一个节点映射到另一个节点的自同构。 一旦我们注意到节点 和 在结构上也是等效的,并且 是节点
最后,图 4b 显示了镜像空手道网络中 RolX 识别的角色(识别了 28 个角色)。 请注意,领导者 和 被置于不同的角色。 (节点)的镜像也被放置在不同的角色中,而(节点)的镜像被放置在不同的角色中。与具有相同的角色。 总共 7 对(共 34 对)被分配了相同的角色。 然而,还发现了一些其他结构相似性 - 例如,节点 和 在结构上是等效的,并且被分配了相同的角色。 同样,RolX 似乎捕获了网络节点之间结构相似性的一些概念,但 struct2vec 可以使用潜在表示更好地识别和分离结构等价性。
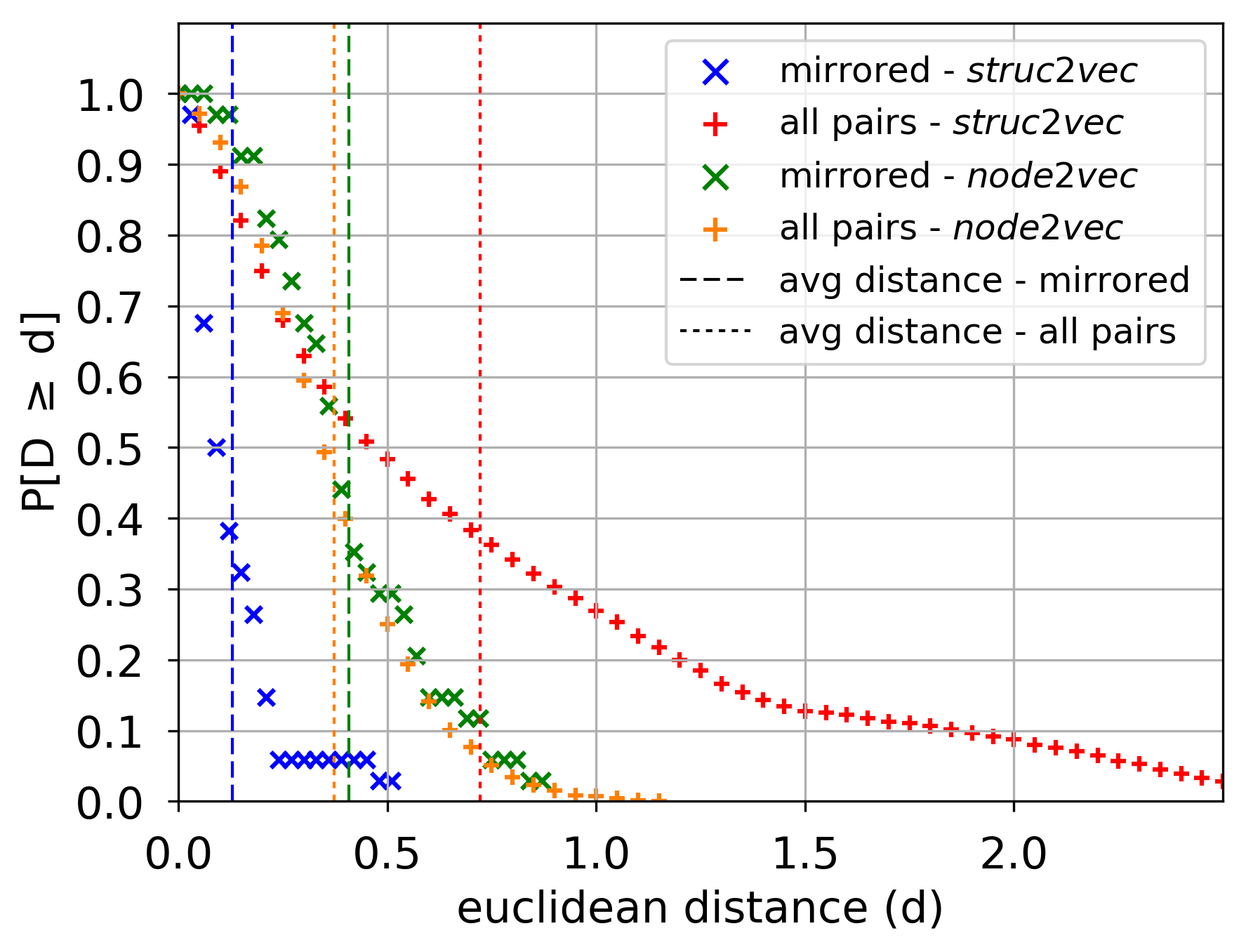
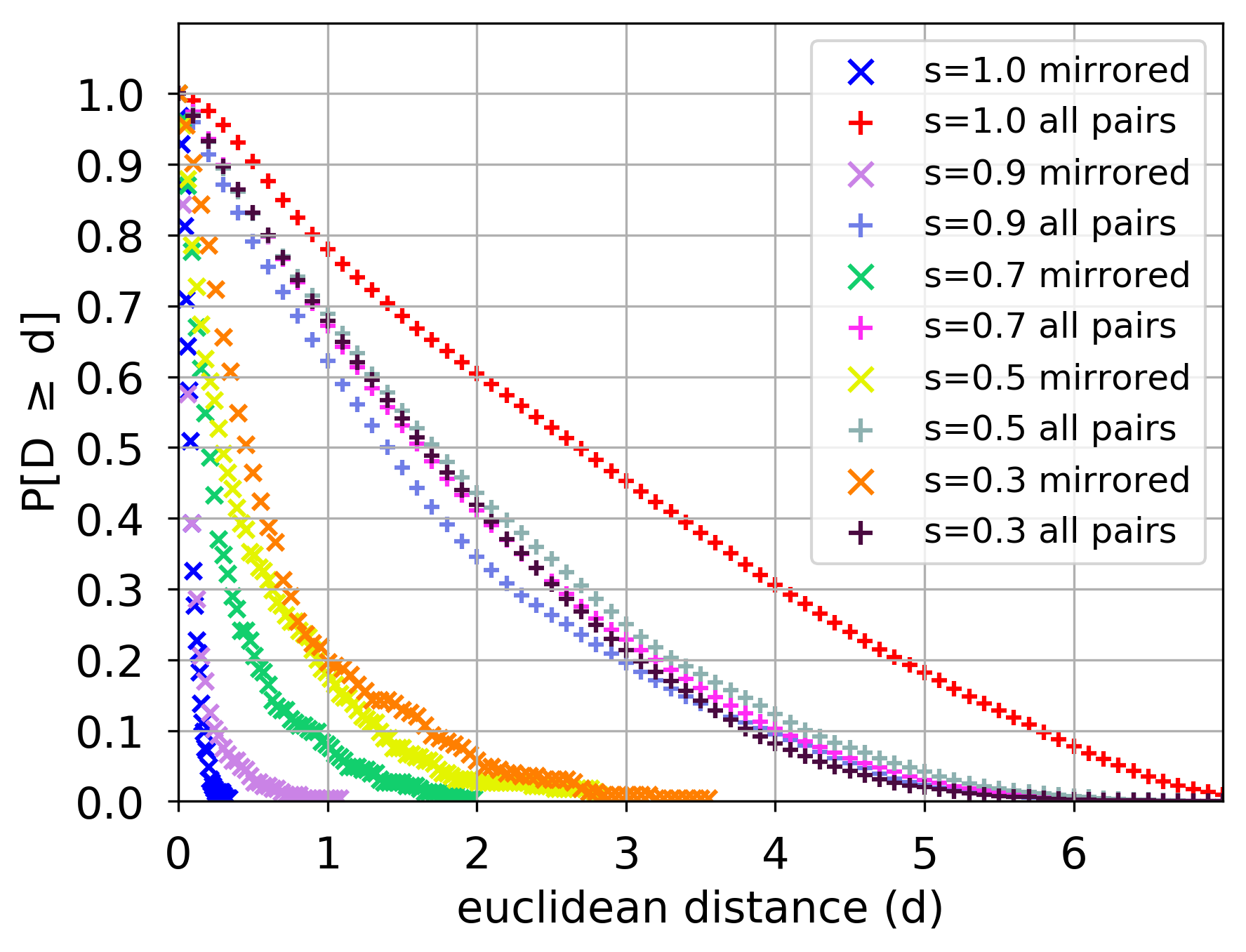
考虑节点的潜在表示之间的距离。 我们测量镜像节点对应的对之间以及所有节点对之间的距离分布(使用图 3 中所示的表示)。 图5显示了node2vec和struc2vec学习到的表示的两个距离分布。 对于node2vec,两个分布实际上是相同的,表明镜像对之间的距离与所有对之间的距离很好地融合。 相比之下,struc2vec 显示出两种截然不同的分布:94% 的镜像节点对的距离小于 0.25,而 68% 的所有节点对的距离大于 0.25。 此外,所有节点对之间的平均距离比镜像对大 5.6 倍,而对于 node2vec 来说,这个比率略小于 1。
为了更好地表征结构距离和 struc2vec 学习到的潜在表示中的距离之间的关系,我们计算所有节点对的两个距离之间的相关性。 特别是,对于每一层 ,我们计算 之间的 Spearman 和 Pearson 相关系数,如方程 (1) 所示,以及之间的欧氏距离学习表示中的 和 。 表 1 中显示的镜像空手道网络的结果确实证实了两个系数捕获的每一层的两个距离之间存在非常强的相关性。 这表明 struc2vec 确实在潜在空间中捕获了该方法所采用的结构相似性度量。
Layer Pearson (p-value) Spearman (p-value) 0 0.83 (0.0) 0.74 (0.0) 2 0.71 (0.0) 0.65 (0.0) 4 0.70 (0.0) 0.57 (0.0) 6 0.74 (0.0) 0.57 (2.37)
4.3. 边缘去除的鲁棒性
我们说明了该框架在存在噪声的情况下有效表示结构特性的潜力。 特别是,我们从网络中随机删除边,直接改变其结构。 我们采用简约的边缘采样模型来实例化两个结构相关的网络(Pedarsani和Grossglauser,2011)。
该模型的工作原理是采用固定图 并通过以概率 独立采样每条边 来生成图 。 因此, 的每条边以 的概率出现在 中。使用 再次重复该过程以生成另一个图形 。 因此,和通过在结构上相关,而控制结构相关的量。 请注意,当 、 和 是同构时,而当 时,所有结构同一性都会丢失。
我们将边缘采样模型应用于从 Facebook 提取的egonet(224 个节点,3192 个边缘,最大度数 99,最小度数 1)(Leskovec 和 Mccauley,2012) 来生成 和 的 具有不同的值。我们重新标记 中的节点(以避免相同的标签),并将两个图的并集视为我们框架的输入网络。 请注意,该图至少有两个连接的组件(对应于 和 ),并且每个节点(在 中)都有一个对应的对(在 )。
图6显示了不同取值下相应节点对与所有节点对之间的距离(二维潜在空间)分布(相应平均值见表2)。 对于 ,两个距离分布显着不同,所有对的平均距离比相应对的平均距离大 21 倍。 更有趣的是,当 时,两个分布仍然有很大不同。 请注意,虽然进一步减小 不会显着影响所有对的距离分布,但它会慢慢增加相应对的分布。 然而,即使(这意味着原始边缘同时出现在和中的概率为0.09,) ,框架仍然将相应的节点放置在更靠近的潜在空间中。
该实验表明,即使存在结构噪声,该框架在揭示节点的结构身份方面也具有鲁棒性,此处通过边缘去除进行建模。
s Corresponding - avg (std) All nodes - avg (std) 1.0 0.083 (0.05) 1.780 (1.354) 0.9 0.117 (0.142) 1.769 (1.395) 0.3 0.674 (0.662) 1.962 (1.445)
4.4. 分类
网络节点潜在表示的一个常见应用是分类。 当节点标签与其结构身份的相关性高于其邻居标签的相关性时,可以利用 struc2vec 来完成此任务。 为了说明这种潜力,我们考虑空中交通网络:未加权、无向的网络,其中节点对应于机场,边缘表示商业航班的存在。 机场将被分配一个与其活动水平相对应的标签,以航班或人员来衡量(如下所述)。 我们考虑以下数据集(为本研究收集):
-
•
巴西空中交通网络: 数据收集自国家民航局 (ANAC)111http://www.anac.gov.br/从2016年1月到12月。 该网络有 131 个节点,1,038 个边(直径为 5)。 机场活动是通过相应年份的着陆和起飞总数来衡量的。
-
•
美国空中交通网络: 数据收集自交通统计局222https://transtats.bts.gov/从2016年1月到10月。 该网络有 1,190 个节点,13,599 条边(直径为 8)。 机场活动是根据相应时期经过(到达加离开)机场的总人数来衡量的。
-
•
欧洲空中交通网络: 数据收集自欧盟统计局 (Eurostat)333http://ec.europa.eu/。 该网络有 399 个节点,5,995 条边(直径为 5)。 机场活动是通过相应时期的着陆次数和起飞次数来衡量的。
对于每个机场,我们会根据其活动分配四个可能的标签之一。 特别是,对于每个数据集,我们使用从经验活动分布中获得的四分位数将数据集分为四组,为每个组分配不同的标签。 因此,标签 1 分配给活跃度较低的 25% 机场,依此类推。 请注意,所有类别(标签)都具有相同的大小(机场数量)。 而且,等级更多地与机场所扮演的角色相关。
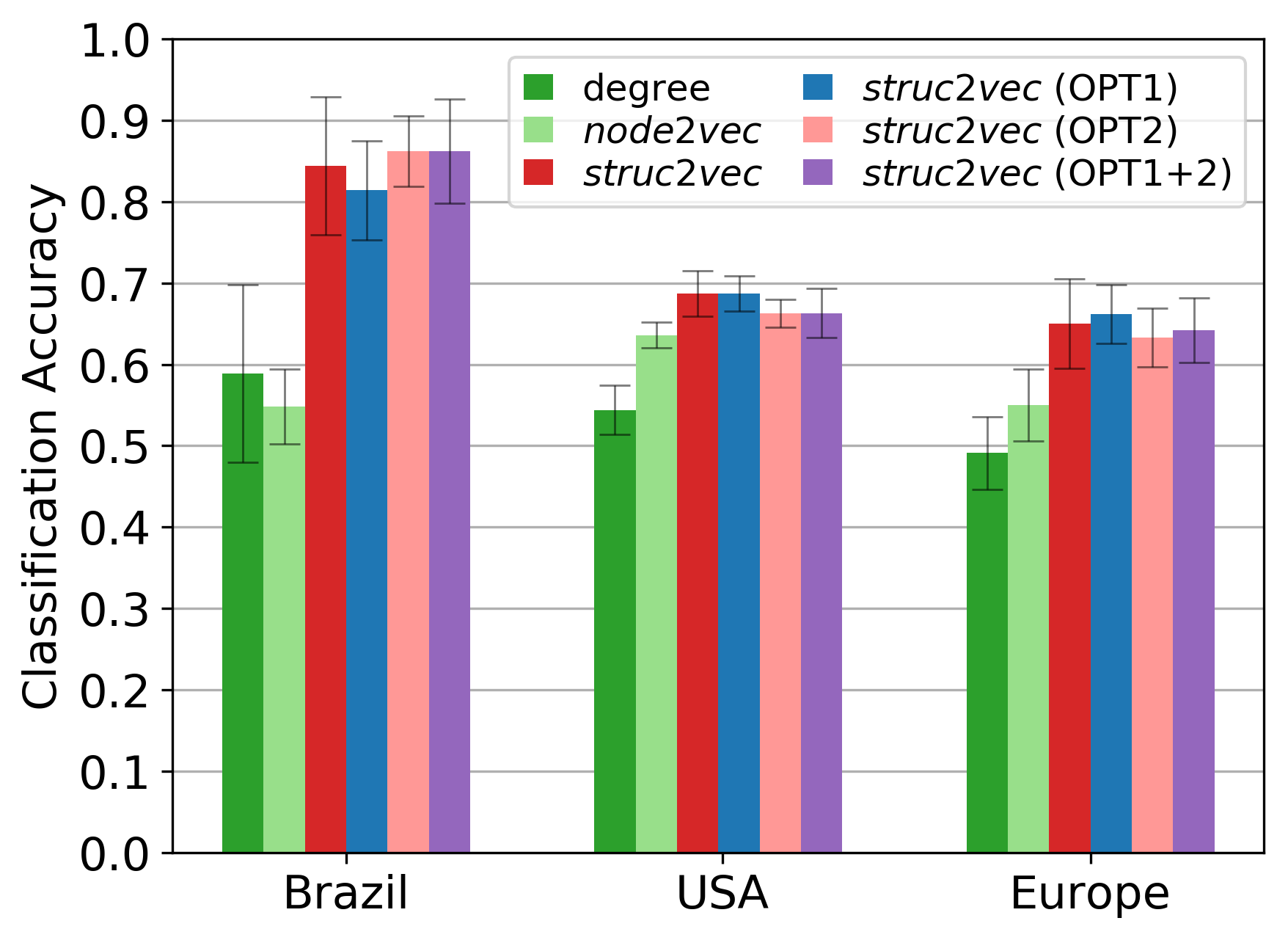
我们使用 struc2vec 和 node2vec 学习每个空中交通网络节点的潜在表示,并使用网格搜索为每种情况选择最佳超参数。 请注意,此步骤不使用任何节点标签信息。 每个节点的潜在表示成为特征,然后用于训练监督分类器(具有 L2 正则化的一对一逻辑回归)。 我们还只将节点度视为一个特征,因为它捕获了结构同一性的一个非常基本的概念。 最后,由于班级规模相同,我们仅使用准确性来评估表现。 使用随机样本来训练分类器(80% 的节点用于 ),实验重复 10 次,我们报告平均性能。
图7显示了所有空中交通网络的不同特征的分类性能。 显然,struc2vec 优于其他方法,并且其优化影响很小。 对于巴西网络,struc2vec 与 node2vec 相比,分类精度提高了 50%。 有趣的是,对于该网络,node2vec 的平均性能(略)低于节点度,这表明节点的结构身份在分类中所起的重要性。
4.5. 可扩展性
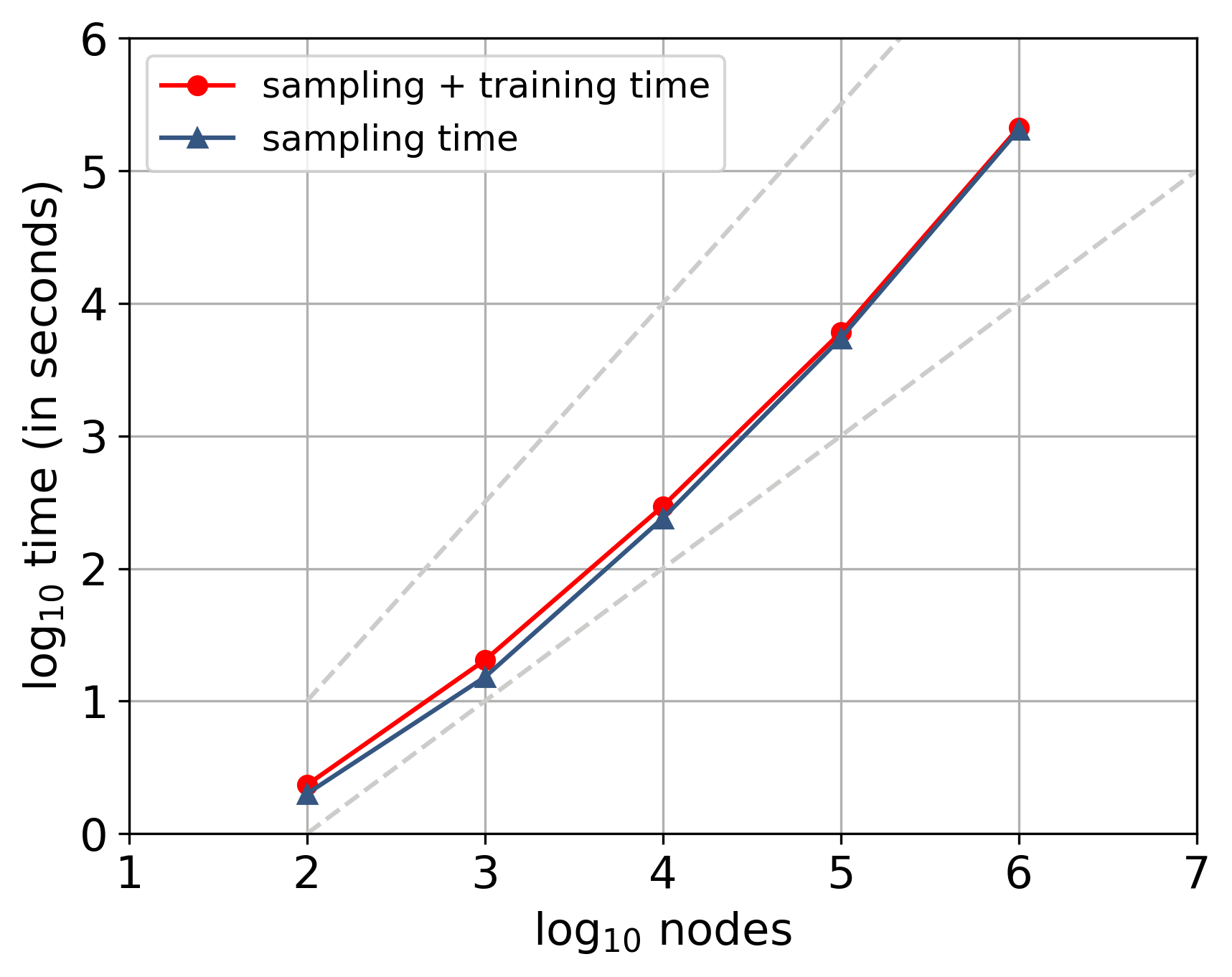
为了说明其可扩展性,我们将具有前两次优化的 struc2vec 应用于 Erdös-Rényi 随机图模型的实例(使用 128 维,每个节点 10 次行走,行走长度 80,Skip-Gram 窗口10)。 我们计算图上 10 次独立运行的平均执行时间,图的大小从 100 到 1,000,000 个节点,平均度数为 10。 为了加快语言模型的训练速度,我们使用带有负采样的 Skip-Gram (Mikolov 等人, 2013b)。 图 8 显示了执行时间(以双对数尺度表示),表明 struc2vec 超线性缩放,但比 更接近线性(虚线)。 因此,尽管在最坏情况下时间和空间复杂度不利,但实际上 struc2vec 可以应用于非常大的网络。
5. 结论
结构同一性是网络中的对称概念,其中节点是根据网络结构来识别的。 这个概念与网络中节点所扮演的功能或角色密切相关,这是社会科学和硬科学中的一个重要问题。
我们提出了 struc2vec,这是一种新颖且灵活的框架,用于学习捕获网络中节点的结构身份的表示。 struc2vec 通过考虑由节点的有序度序列定义的层次度量来评估节点对的结构相似性,并使用加权多层图来生成上下文。
我们已经证明,与 DeepWalk、node2vec 等最先进的技术相比,struc2vec 在捕获节点的结构特性方面表现出色> 和RolX。 它通过明确关注结构同一性来克服它们的局限性。 毫不奇怪,我们还表明 struc2vec 在分类任务中表现出色,其中节点标签更依赖于其角色或结构身份。 最后,生成表示的不同模型往往会捕获不同的属性,我们认为在考虑可能的节点表示时,结构同一性显然很重要。
参考
- (1)
- Atias and Sharan (2012) Nir Atias and Roded Sharan. 2012. Comparative analysis of protein networks: hard problems, practical solutions. Commun. ACM 55 (2012).
- Bengio et al. (2003) Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A Neural Probabilistic Language Model. JMLR (2003).
- Blondel et al. (2004) V Blondel, A Gajardo, M Heymans, P Senellart, and P Van Dooren. 2004. A measure of similarity between graph vertices: Applications to synonym extraction and web searching. SIAM review (2004).
- Cao et al. (2016) Shaosheng Cao, Wei Lu, and Qiongkai Xu. 2016. Deep Neural Networks for Learning Graph Representations. In AAAI.
- Fouss et al. (2007) F Fouss, A Pirotte, J Renders, and M Saerens. 2007. Random-Walk Computation of Similarities Between Nodes of a Graph with Application to Collaborative Recommendation. IEEE Trans. on Knowl. and Data Eng. (2007).
- Grover and Leskovec (2016) Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable Feature Learning for Networks. In ACM SIGKDD.
- Henderson et al. (2012) K Henderson, B Gallagher, T Eliassi-Rad, H Tong, S Basu, L Akoglu, D Koutra, C Faloutsos, and L Li. 2012. Rolx: structural role extraction & mining in large graphs. In ACM SIGKDD.
- Kleinberg (1999) Jon M Kleinberg. 1999. Authoritative sources in a hyperlinked environment. Journal of the ACM (JACM) (1999).
- Leicht et al. (2006) Elizabeth A Leicht, Petter Holme, and Mark EJ Newman. 2006. Vertex similarity in networks. Physical Review E 73 (2006).
- Leskovec and Mcauley (2012) Jure Leskovec and Julian J Mcauley. 2012. Learning to discover social circles in ego networks. In NIPS.
- Lorrain and White (1971) Francois Lorrain and Harrison C White. 1971. Structural equivalence of individuals in social networks. The Journal of mathematical sociology 1 (1971).
- Mikolov et al. (2013a) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013a. Efficient Estimation of Word Representations in Vector Space. In ICLR Workshop.
- Mikolov et al. (2013b) T Mikolov, I Sutskever, K Chen, G Corrado, and J Dean. 2013b. Distributed Representations of Words and Phrases and their Compositionality. In NIPS.
- Narayanan et al. (2016) A Narayanan, M Chandramohan, L Chen, Y Liu, and S Saminathan. 2016. subgraph2vec: Learning Distributed Representations of Rooted Sub-graphs from Large Graphs. In Workshop on Mining and Learning with Graphs.
- Pedarsani and Grossglauser (2011) Pedram Pedarsani and Matthias Grossglauser. 2011. On the privacy of anonymized networks. In ACM SIGKDD.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: Online Learning of Social Representations. In ACM SIGKDD.
- Pizarro (2007) Narciso Pizarro. 2007. Structural Identity and Equivalence of Individuals in Social Networks Beyond Duality. International Sociology 22 (2007).
- Rakthanmanon et al. (2013) T Rakthanmanon, B Campana, A Mueen, G Batista, B Westover, Q Zhu, J Zakaria, and E Keogh. 2013. Addressing big data time series: Mining trillions of time series subsequences under dynamic time warping. ACM TKDD (2013).
- Sailer (1978) Lee Douglas Sailer. 1978. Structural equivalence: Meaning and definition, computation and application. Social Networks (1978).
- Salvador and Chan (2004) S Salvador and P Chan. 2004. FastDTW: Toward accurate dynamic time warping in linear time and space. In Workshop on Min. Temp. and Seq. Data, ACM SIGKDD.
- Shervashidze et al. (2011) N Shervashidze, P Schweitzer, E van Leeuwen, K Mehlhorn, and K Borgwardt. 2011. Weisfeiler-Lehman Graph Kernels. JMLR (2011).
- Singh et al. (2008) R Singh, J Xu, and B Berger. 2008. Global alignment of multiple protein interaction networks with application to functional orthology detection. PNAS (2008).
- Tang et al. (2015) Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. 2015. LINE: Large-scale Information Network Embedding. In WWW.
- Wang et al. (2016) Daixin Wang, Peng Cui, and Wenwu Zhu. 2016. Structural Deep Network Embedding. In ACM SIGKDD.
- Zachary (1977) Wayne W Zachary. 1977. An information flow model for conflict and fission in small groups. Journal of anthropological research (1977).
- Zager and Verghese (2008) Laura A Zager and George C Verghese. 2008. Graph similarity scoring and matching. Applied mathematics letters (2008).