卷积神经网络的主动学习:核心集方法
摘要
卷积神经网络 (CNN) 已使用通用方法成功应用于许多识别和学习任务; 在非常大的监督示例数据集上训练深度模型。 然而,这种方法在实践中相当有限制,因为收集大量标记图像非常昂贵。 缓解这个问题的一种方法是提出智能方法,从一个非常大的集合中选择要标记的图像(即主动学习)。
我们的实证研究表明,文献中的许多主动学习启发式方法在批量设置中应用于 CNN 时并不有效。 受这些限制的启发,我们将主动学习的问题定义为核心集选择,即选择点集,使得在所选子集上学习的模型对于剩余数据点具有竞争力。 我们进一步提出了一个理论结果,该结果描述了使用数据点的几何形状的任何选定子集的性能。 作为主动学习算法,我们根据我们的特征选择预计会产生最佳结果的子集。 我们的实验表明,所提出的方法在图像分类实验中明显优于现有方法。
1简介
深度卷积神经网络 (CNN) 在计算机视觉和模式识别的许多研究领域(例如图像分类、对象检测和场景分割)取得了前所未有的成功。 尽管 CNN 在许多任务中普遍成功,但它们有一个主要缺点:他们需要大量的标记数据才能学习大量参数。 更重要的是,拥有更多数据几乎总是更好,因为 CNN 的准确性通常不会随着数据集大小的增加而饱和。 因此,人们一直渴望收集越来越多的数据。 尽管从算法的角度来看这是期望的行为(代表性能力通常越高越好),但标记数据集是一项耗时且昂贵的任务。 这些实际考虑提出了一个关键问题:“选择要标记的数据点的最佳方式是什么,以便在固定的标记预算下获得最高的准确性。”主动学习是常见的范例之一来解答这个问题。
主动学习的目标是找到有效的方法从未标记的数据点池中选择要标记的数据点,以最大限度地提高准确性。 尽管不可能获得普遍良好的主动学习策略(Dasgupta,2004),但存在许多启发式(Settles,2010),它们已被证明在以下方面有效:实践。 主动学习通常是一个迭代过程,其中在每次迭代中学习模型,并使用上述启发式方法从未标记点池中选择一组点进行标记。 我们在本文中尝试了许多启发式方法,发现它们在应用于 CNN 时并不有效。 我们认为,这种无效背后的主要因素是批量采集/采样引起的相关性。 在经典设置中,主动学习算法通常在每次迭代时选择一个点;然而,这对于 CNN 来说是不可行的,因为 i) 由于局部优化方法,单个点可能对准确性没有统计上的显着影响,并且 ii) 每次迭代都需要完整的训练直到收敛,这使得查询标签变得困难一对一。 因此,有必要在每次迭代时查询大子集的标签,即使对于适度小的子集大小也会产生相关样本。
为了针对批量采样情况定制主动学习方法,我们决定将主动学习定义为核心集选择问题。 核心集选择问题的目标是在给定大标记数据集的情况下找到一个小子集,以便在小子集上学习的模型在整个数据集上具有竞争力。 由于我们没有可用的标签,因此我们在不使用标签的情况下执行核心集选择。 为了解决 CNN 的未标记核心集问题,我们通过数据点的几何形状提供了数据集任何给定子集的平均损失与剩余数据点之间的严格界限。 作为主动学习算法,我们尝试选择一个子集以使该界限最小化。 此外,该界限的最小化结果相当于 k 中心问题(Wolf,2011),并且我们对该组合优化问题采用了有效的近似解决方案。 我们使用三个不同的数据集进一步根据经验研究了我们提出的算法针对图像分类问题的行为。 我们的实证分析充分证明了最先进的性能。
2相关工作
我们分别讨论以下类别的相关工作。 简而言之,我们的工作与现有方法的不同之处在于它将主动学习问题定义为核心集选择,我们考虑完全监督和弱监督的情况, 我们直接严格解决 CNN 的核心集选择问题,没有额外的假设。
主动学习主动学习已被广泛研究,大部分早期工作可以在Settles (2010)的经典综述中找到。 它涵盖了信息理论方法(MacKay,1992)、集成方法(McCallumzy & Nigamy,1998;Freund等人,1997)和基于不确定性的方法(Tong&Koller,2001;Joshi等人,2009;Li&Guo,2013)。
贝叶斯主动学习方法通常使用高斯过程等非参数模型来估计每个查询的预期改进(Kapoor等人,2007)或一组查询后的预期误差(Roy和麦卡勒姆,2001)。 这些方法并不直接适用于大型 CNN,因为它们无法扩展到大规模数据集。 Gal & Ghahramani (2016) 最近的方法显示了 dropout 和近似贝叶斯推理之间的等价性,从而能够将贝叶斯方法应用于深度学习。 尽管贝叶斯主动学习已被证明对小型数据集有效(Gal等人,2017),但我们的实证分析表明,由于批量采样,它们无法扩展到大规模数据集。
一个重要的类别是基于不确定性的方法,它试图使用启发式方法找到困难的例子,例如最高熵(Joshi等人,2009)和到决策边界的几何距离(Tong&Koller, 2001;布林克,2003)。 我们的实证分析发现它们对于 CNN 无效。
最近有一些基于优化的方法,可以权衡不确定性和多样性,以便在批处理模式主动学习设置中获得一组不同的困难示例。 Elhamifar 等人 (2013) 和 Yang 等人 (2015) 为此目的设计了一个离散优化问题,并使用其凸代理。 类似地,Guo (2010)提出了一个与矩阵划分类似的问题。 然而,这些论文中提出的优化算法使用 变量,其中 是数据点的数量。 因此,它们无法扩展到大型数据集。 还有许多针对特定类别的机器学习算法设计的基于池的主动学习算法,例如 k 最近邻和朴素贝叶斯 (Wei 等人, 2015)、逻辑回归 Hoi 等人 ( 2006); Guo & Schuurmans (2008),以及高斯噪声线性回归(Yu 等人, 2006)。 即使在与算法无关的情况下,也可以设计一种集合覆盖算法来使用子模块性(Guillory & Bilmes,2010;Golovin & Krause,2011)来覆盖假设空间。 另一方面,Demir 等人 (2011) 使用启发式方法,首先根据不确定性过滤池,然后使用多样性选择点进行标记。 我们的算法可以认为属于此类;但是,我们不使用任何不确定性信息。 我们的算法也是第一个应用于 CNN 的算法。 与我们最相似的是(Joshiy等人,2010)和(Wang&Ye,2015)。 Joshiy 等人 (2010) 使用类似的优化问题。 然而,他们没有提供理论依据或分析。 Wang & Ye(2015)提出像我们一样使用经验风险最小化;然而,他们试图最小化两个分布之间的差异(iid 之间的最大平均差异)。 数据集中的样本和主动选择的样本)而不是核心集损失。 此外,这两种算法也都没有在 CNN 上进行实验。 在我们的实验研究中,我们与(Wang & Ye,2015)进行比较。
最近,针对域转移设置中的 k-NN 类型算法,提出了一种与我们的方法类似的基于离散优化的方法(Berlind & Urner,2015)。 尽管我们的理论分析借鉴了他们的一些技术,但他们的结果仅对 k-NN 有效。
CNN 的主动学习算法最近也在(Wang 等人,2016;Stark 等人,2015)中提出。 Wang等人(2016)提出了一种基于启发式的算法,该算法直接为置信度高的数据点分配标签,并为置信度低的数据点查询标签。 此外,Stark等人(2015)专门针对识别验证码图像。 尽管他们的结果对于验证码识别很有希望,但他们的方法对于图像分类并不有效。 我们在第 5 节中讨论这两种方法的局限性。
在理论方面,研究表明贪婪主动学习在算法和数据不可知的情况下是不可能的(Dasgupta,2005)。 然而,依赖于数据的结果表明,确实可以获得比查询所有点具有更好样本复杂性的查询策略。 这些结果要么使用关于假设空间的数据依赖可实现性的假设,如(Gonen等人,2013),要么使用概念空间的数据依赖度量,称为不一致系数(Hanneke,2007). 还可以通过重要性采样使用贪婪算法在批量设置中执行主动学习(Ganti & Gray,2012)。 尽管上述算法享有理论保证,但它们不适用于大规模问题。
核心集选择 与我们的工作最接近的文献是核心集选择问题,因为我们将主动学习定义为核心集选择问题。 该问题考虑完全标记的数据集,并尝试选择它的子集,以便在所选子集上训练的模型将尽可能接近在整个数据集上训练的模型。 对于具体的学习算法,有SVM的核心集(Tsang等人,2005)和k-Means和k-Medians的核心集(Har-Peled & Kushal, 2005)。 然而,我们还不知道 CNN 有这种方法。
与我们最相似的算法是(Wei等人,2013)中的无监督子集选择算法。 它使用设施位置问题来找到数据集的多样化覆盖。 我们的算法的不同之处在于它使用稍微不同的设施位置问题表述。 我们使用极小极大 (Wolf, 2011) 形式,而不是最小和。 更重要的是,我们首次将该算法应用于主动学习问题,为CNN提供了理论保证。
弱监督深度学习 我们的论文也与半监督深度学习相关,因为我们在全监督和弱监督方案中都试验了主动学习。 早期的弱监督卷积神经网络算法之一是梯形网络(Rasmus等人,2015)。 最近,我们看到了对抗性方法,可以通过两人非合作游戏来学习数据分布(Salimans 等人,2016;Goodfellow 等人,2014;Radford 等人,2015)。 这些方法进一步扩展到特征学习(Dumoulin等人,2016;Donahue等人,2016)。 我们在实验中使用梯形网络;然而,我们的方法与弱监督学习算法的选择无关,并且可以利用任何模型。
3问题定义
在本节中,我们正式定义批量设置中的主动学习问题,并为本文的其余部分设置符号。 我们对在紧凑空间 和标签空间 上定义的 类分类问题感兴趣。 我们还考虑在假设类 () 上参数化的损失函数 ,例如深度学习算法的参数。 我们进一步假设特定于类的回归函数 对于所有 都是 -Lipschitz 连续的。
我们考虑采样的大量数据点 上方的空间为 ,其中 。 我们进一步考虑随机均匀选择的初始数据点池作为。
主动学习算法只能访问和。 换句话说,它只能看到初始子采样池中点的标签。 此外,还给出了可向神谕询问的查询预算 ,以及学习算法 ,该算法可在给出标记集 的情况下输出一组参数 。 池问题的主动学习可以简单地定义为
| (1) |
换句话说,主动学习算法可以选择个额外点并让它们由预言机标记,以最小化未来的预期损失。 我们的表述与主动学习的经典定义之间存在一些差异。 经典方法考虑预算为 1 () 的情况,但单点在深度学习机制中的影响可以忽略不计,因此我们考虑批量情况。 考虑多轮比赛也是很常见的。 我们还通过解决单轮标签的短视方法来遵循多轮公式:
| (2) |
尽管我们将其应用于多轮,但为了简洁起见,我们仅讨论第一次迭代,其中 。
在每次迭代中,主动学习算法有两个阶段:1. 识别一组数据点并将它们呈现给要标记的预言机,2. 使用新的和先前标记的数据点训练分类器。 第二阶段(训练分类器)可以以完全或弱监督的方式完成。 完全监督是仅使用标记的数据点来训练分类器的情况。 弱监督是指训练还利用尚未标记的点的情况。 尽管现有文献仅关注全监督模型的主动学习,但我们考虑了这两种情况并进行了实验。
4方法
4.1 以主动学习为背景
在经典的主动学习设置中,算法通过查询预言机(即 )来一一获取标签。 遗憾的是,这在训练 CNN 时并不可行,因为由于局部优化算法, 单个点不会对模型产生显著的统计影响。 由于许多感兴趣的实际问题规模非常大,因此训练与点数一样多的模型是不可行的。 因此,我们关注批量主动学习问题,其中主动学习算法在每次迭代时选择一个中等大的点集由预言机标记。
为了设计在批量设置中有效的主动学习策略,我们考虑在(1)中正式定义的主动学习损失的以下上限:
| (3) | ||||
我们感兴趣的数量是使用小标记子集 () 学习的模型的总体风险。 总体风险由模型在标记子集上的训练误差、整个数据集 () 上的泛化误差和项来控制我们将其定义为核心集损失。 核心集损失只是有标签的点集的平均经验损失与包括未标记点的整个数据集的平均经验损失之间的差异。 根据经验,人们广泛观察到 CNN 具有很高的表达能力,导致训练误差非常低,并且它们通常能够很好地泛化各种视觉问题。 此外,CNN 的泛化误差也得到了理论研究,并显示其受 Xu & Mannor (2012) 限制。 因此,主动学习的关键部分是核心集损失。 根据这一观察,我们将主动学习问题重新定义为:
| (4) |
非正式地,给定初始标签集 () 和预算 (),我们试图找到一组点来查询标签 ()这样当我们学习一个模型时,模型在标记子集上的性能和在整个数据集上的性能将尽可能接近。
4.2 CNN 核心集
我们在 (4) 中定义的优化目标不可直接计算,因为我们无法访问所有标签(即 未标记)。 因此,在本节中,我们给出了可以优化的目标函数的上限。
我们首先给出任何损失函数的这个界限,即固定真实标签 和参数 的 Lipschitz 函数,然后证明具有 ReLu 非线性的 CNN 的损失函数满足以下条件:财产。 我们还依赖于零训练误差假设。 尽管零训练误差并不是一个完全现实的假设,但我们的实验表明所得的上限非常有效。 我们陈述以下定理;
Theorem 1。
给定 i.i.d. 从抽取的样本作为,以及点集。 如果损失函数对于所有是-Lipschitz连续并且以为界,则回归函数为-Lipschitz, 是 的 覆盖,以及 ;概率至少为 ,
由于我们假设核心集的训练误差为零,因此核心集损失等于整个数据集的平均误差。 我们以这种形式陈述定理与(3)一致。 我们在图 1 中可视化这个定理,并将其证明推迟到附录。 在该定理中,“集合是集合的覆盖”表示以为中心的半径为的一组球的每个成员都可以覆盖整个。 非正式地,该定理表明我们可以将核心集损失与覆盖半径限制在一起,并且速率为零的项仅取决于 。这是一个有趣的结果,因为这个界限不依赖于标记点的数量。 换句话说,提供的标签不会减少核心组的损失,除非它减少了覆盖半径。
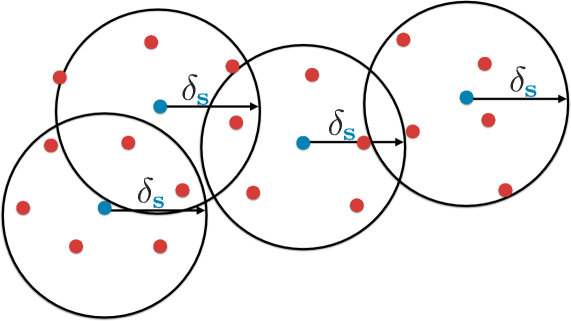
为了证明这个界限适用于 CNN,我们通过以下引理证明了 CNN 损失函数相对于输入图像的 Lipschitz 连续性:固定真实标签,其中最大池和受限线性单元是非线性度和损失定义为所需类别概率与 soft-max 输出之间的 距离。 文献中,CNN 通常与交叉熵损失一起用于分类问题。 事实上,尽管我们在理论研究中使用 损失,但我们也使用交叉熵损失进行实验。 尽管我们的理论研究没有扩展到交叉熵损失,但我们的实验表明,所得算法对于交叉熵损失非常有效。
Lemma 1.
损失函数定义为类概率与卷积神经网络的 softmax 输出之间的 2-范数,其中定义了 卷积层(带有 max-pool 和 ReLU)和 全连接层C 类别上的模型是 -固定类别概率和网络参数的输入的 Lipschitz 函数。
这里,是每个神经元输入权重的最大总和(正式定义见附录)。 虽然它通常是无界的,但它可以任意小,而不改变损失函数的行为(即保持任何数据点 的标签不变)。 我们将证明推迟到附录,并得出结论:CNN 具有我们在定理 1 中提出的界限。
为了通过计算执行主动学习,我们使用这个上限。 换句话说,感兴趣的实际问题变成。 该问题相当于 k 中心问题(也称为最小-最大设施位置问题)(Wolf,2011)。 在下一节中,我们将解释如何在实践中使用贪心近似来解决 k 中心问题。
4.3 解决k中心问题
到目前为止,我们已经为核心集选择问题的损失函数提供了一个上限,并表明最小化它相当于k-Center问题(最小最大设施位置(Wolf,2011) )) 可以直观地定义如下;选择 中心点,使数据点与其最近中心之间的最大距离最小化。 从形式上来说,我们正在尝试解决:
| (5) |
尽管贪心算法给出了很好的初始化,但实际上我们可以通过迭代查询最优值的上限来改进 解决方案。 换句话说,我们可以设计一个算法来判断是否。 为此,我们定义了一个由参数化的混合整数程序(MIP),其可行性表明。 一种直接的算法是使用此 MIP 作为子例程,并在贪婪算法的结果与其一半之间执行二分搜索,因为保证最优解包含在该范围内。 在构造这个 MIP 的同时,我们还尝试解决 k-Center 算法的弱点之一,即鲁棒性。 为了使 k 中心问题具有鲁棒性,我们假设离群值 的数量有上限,这样我们的算法就可以选择不覆盖最多 个无监督数据点。 这个混合整数程序可以写成:
| (6) | ||||||
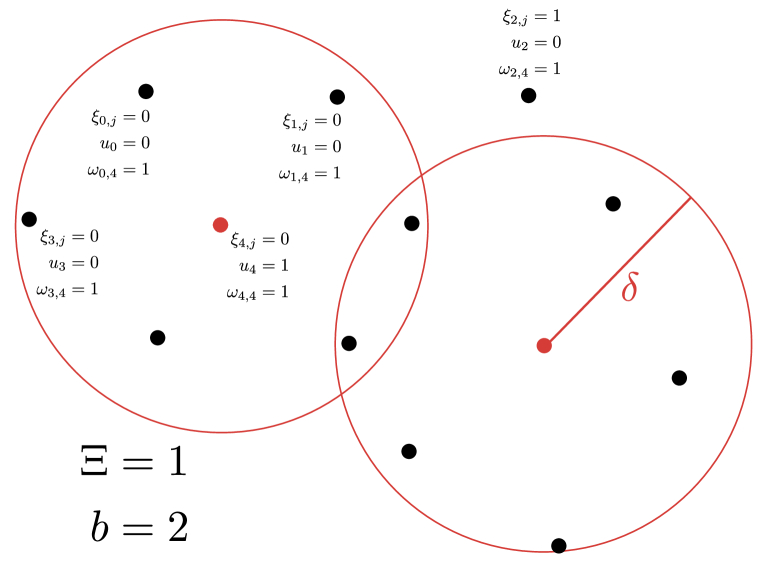
在此公式中,如果 数据点被选为中心,则 为 1;如果 点被 点覆盖,则 为 ;如果 点是离群点,且被 点覆盖,而没有 约束,则 为 1;否则为 。 并且,变量是二进制的 。 我们在图2中进一步可视化这些变量,并在算法2中给出该方法的细节。
4.4实现细节
关键的设计选择之一是距离度量。 我们使用最终全连接层激活之间的 距离作为距离。 对于弱监督学习,我们使用梯形网络(Rasmus等人,2015),对于所有实验,我们使用VGG-16(Simonyan & Zisserman,2014)作为CNN建筑学。 我们根据He等人(2016)初始化所有卷积滤波器。 我们使用 RMSProp 优化了所有模型,使用 Tensorflow (Abadi 等人,2016),学习率为 。 我们在每次迭代后从头开始训练 CNN。
我们使用 Gurobi (Inc., 2016) 框架来检查 (6) 中定义的 MIP 的可行性。 作为异常值的上限,我们使用 ,其中 是未标记点的数量。
5实验结果
我们使用三个不同的数据集测试了我们的算法的分类问题。 我们在 CIFAR (Krizhevsky & Hinton, 2009) 数据集上进行图像分类实验,在 SVHN(Netzer 等人, 2011) 数据集上进行数字分类实验。 CIFAR (Krizhevsky & Hinton, 2009) 数据集有两个任务;一种是超过 10 个类的粗粒度,一种是超过 100 个类的细粒度。 我们对两者都进行了实验。
我们将我们的方法与以下基线进行比较:随机:从未标记的池中随机选择要均匀标记的点。 最佳经验不确定性: 遵循(Gal等人,2017)中的经验设置,我们使用最大熵、BALD和变异比率进行主动学习,将软最大输出视为概率。 我们只报告每个数据集表现最好的一个,因为它们的表现彼此相似。 深度贝叶斯主动学习(DBAL)(Gal 等人,2017): 我们执行蒙特卡罗 dropout 以获得改进的不确定性度量,并仅报告每个数据集的最大熵、BALD 和变异比率中表现最佳的采集函数。 最佳 Oracle 不确定性: 我们还报告了一种性能最佳的预言机算法,该算法使用整个数据集的标签信息。 对于所有未标记的示例,我们用 替换不确定性。 我们通过将选择要查询的 点的概率设置为 来从此函数的标准化形式中对查询进行采样。 k-Median:选择要标记的点作为k-Median(k等于预算)算法的聚类中心。 批处理模式判别-代表性主动学习(BMDR)(Wang & Ye,2015): 基于 ERM 的方法利用不确定性并最小化独立同分布之间的 MMD。 来自数据集和主动选择的点的样本。 CEAL (王等人,2016): CEAL (Wang 等人, 2016) 是一种专门针对 CNN 提出的弱监督主动学习方法。 我们将其纳入弱监督分析中。
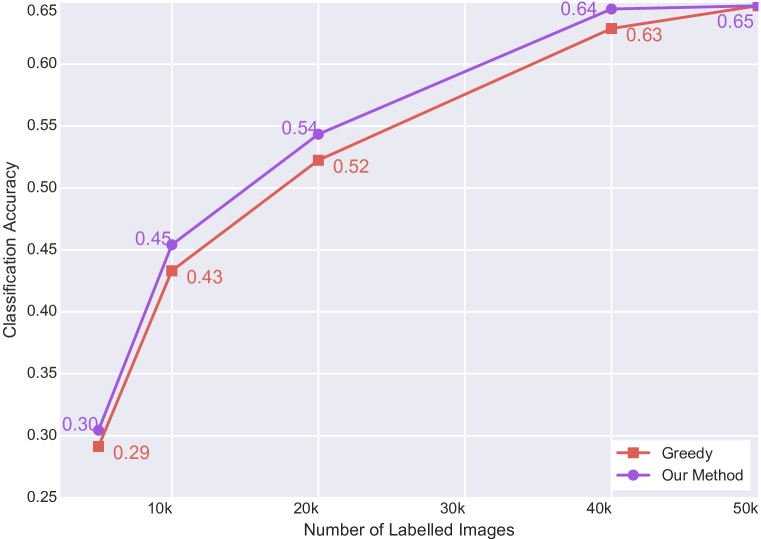
我们对全监督模型的主动学习和弱监督模型的主动学习进行了实验。 在我们的实验中,我们从数据集中均匀随机采样的一小组图像作为初始池。 弱监督模型可以访问标记的示例以及未标记的示例。 完全监督的模型只能访问标记的数据点。 我们对初始标记点池进行五次随机初始化来运行所有实验,并使用平均分类精度作为指标。 我们绘制准确性与标记点数量的关系。 我们还将误差线绘制为标准差。 我们迭代地运行查询算法;换句话说,我们解决了精度与标记示例数量图上每个点的离散优化问题。 我们在图4和4中展示了结果。
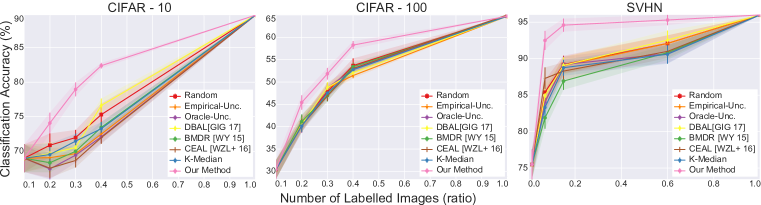
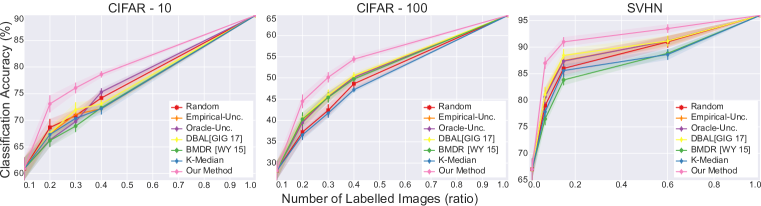
图4和4表明我们的算法在所有实验中都优于所有其他基线;对于弱监督模型的情况,有很大的差距。 我们相信我们的方法在弱监督情况下的有效性归因于更好的特征学习。 弱监督模型提供更好的特征空间,从而产生准确的几何形状。 由于我们的方法是几何的,因此它在更好的特征空间下表现得更好。 我们还观察到,与 CIFAR-10 和 SVHN 相比,我们的算法在 CIFAR-100 中的效果较差。 使用我们的理论分析可以很容易地解释这一点。 我们对核心集损失的限制随着类别的数量而变化,因此类别越少越好。
一个有趣的观察是,最先进的批处理模式主动学习基线(BMDR (Wang & Ye,2015))不一定比贪婪的表现更好。 我们认为这是因为它仍然使用不确定性信息,并且软最大概率不能很好地代表不确定性。 我们的方法不使用任何不确定性。 而且,以有原则的方式将不确定性纳入我们的方法是一个悬而未决的问题,也是一个富有成效的未来研究方向。 另一方面,基于纯聚类的批量主动学习基线(k-Medoids)也不是有效的。 我们相信这是相当直观的,因为簇句子很可能是初始 iid 很好地覆盖的点。 样品。 因此,这种基于聚类的方法无法对数据分布的尾部进行采样。
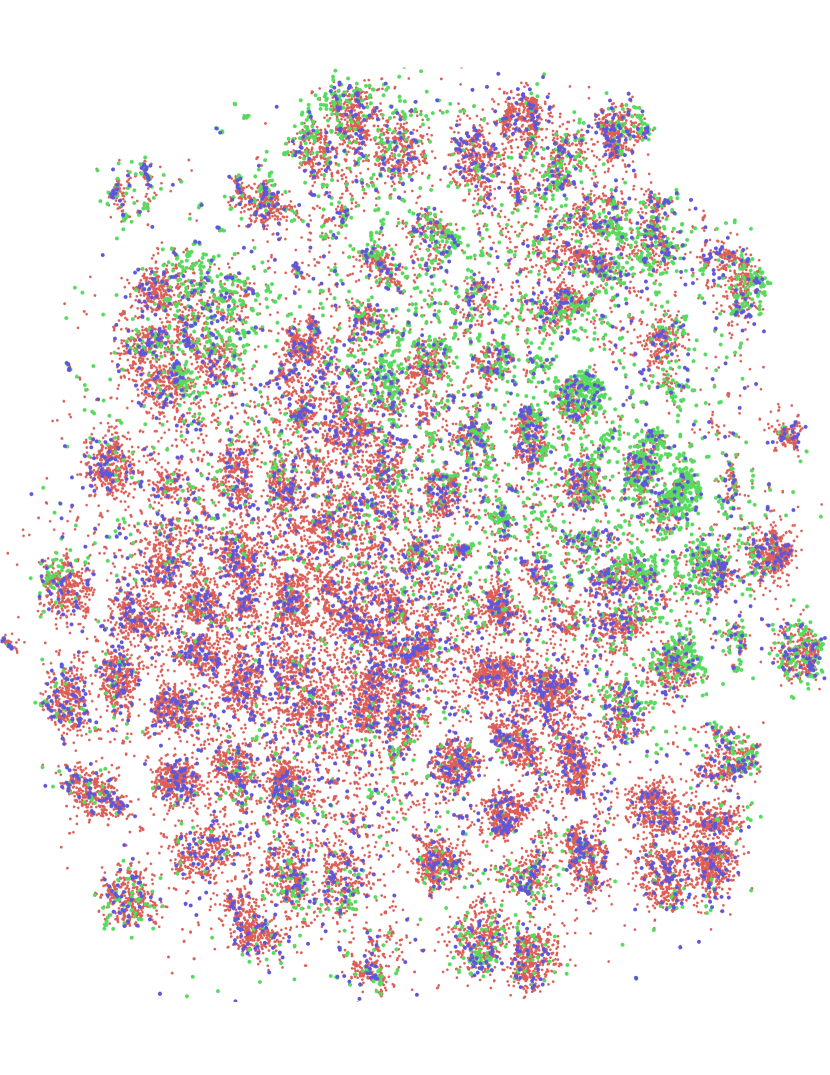
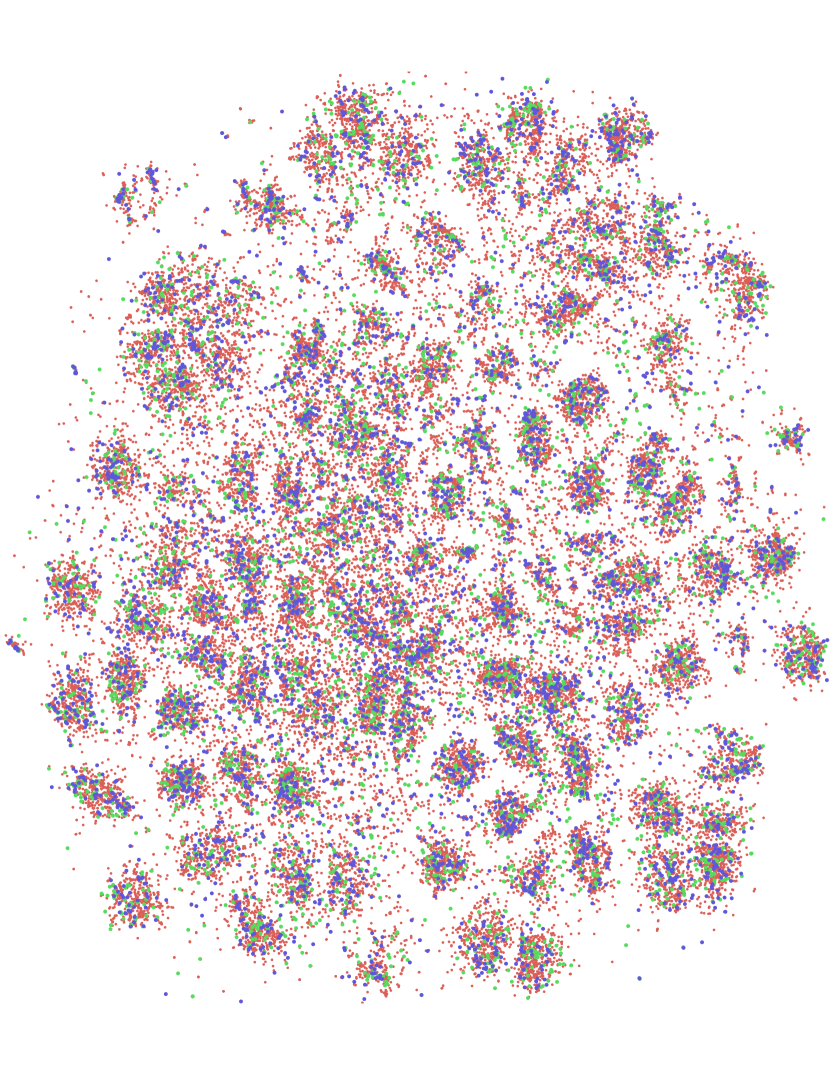
我们的结果表明,预言机不确定性信息和不确定性的贝叶斯估计都是有帮助的,因为它们比经验不确定性基线有所改进;然而,它们在批量设置中仍然无效,因为随机采样优于它们。 我们认为这是由于批量设置中主动学习所导致的查询标签的相关性。 我们通过 tSNE (Maaten & Hinton,2008) 嵌入进行定性分析,进一步研究这一点。 我们使用通过标记示例学习的特征来计算所有点的嵌入,并可视化通过我们的方法采样的点以及预言不确定性。 该可视化表明,由于样本之间的相关性,基于不确定性的方法无法覆盖证实我们假设的大部分空间。
k-中心解的最优性: 我们提出的方法使用 k-Center 问题的贪婪 2-OPT 解决方案作为初始化,并检查混合整数规划 (MIP) 的可行性。 我们使用定义的 MIP 的 LP 松弛并使用分支定界来获得整数解。 应该研究解决这个昂贵的 MIP 所获得的效用。 我们比较了 MIP111On Intel Core i7-5930K@3.50GHz and 64GB memory与表5中2-OPT解决方案的运行时间。 我们还在 CIFAR-100 数据集上比较了最佳 k-Center 解决方案和图 6 中的 2-OPT 解决方案获得的精度。
| Distance | Greedy | MIP | MIP | |
| Matrix | (2-OPT) | (iteration) | (total) | Total |
| 104.2 | 2 | 7.5 | 244.03 | 360.23 |
6结论
我们研究 CNN 的主动学习问题。 我们的实证分析表明,由于批量采样引起的相关性,基于经典不确定性的方法对 CNN 的适用性有限。 我们将主动学习问题重新表述为核心集选择,并研究 CNN 的核心集问题。 我们通过广泛的实证研究进一步验证了我们的算法。 三个数据集的实证结果显示了大幅度的最先进性能。
参考
- Abadi et al. (2016) Martin Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv:1603.04467, 2016.
- Berlind & Urner (2015) C. Berlind and R. Urner. Active nearest neighbors in changing environments. In ICML, 2015.
- Brinker (2003) Klaus Brinker. Incorporating diversity in active learning with support vector machines. In ICML, volume 3, pp. 59–66, 2003.
- Cook et al. (1998) William J Cook, William H Cunningham, William R Pulleyblank, and Alexander Schrijver. Combinatorial optimization, volume 605. Springer, 1998.
- Dasgupta (2004) Sanjoy Dasgupta. Analysis of a greedy active learning strategy. In NIPS, 2004.
- Dasgupta (2005) Sanjoy Dasgupta. Analysis of a greedy active learning strategy. In L. K. Saul, Y. Weiss, and L. Bottou (eds.), Advances in Neural Information Processing Systems 17, pp. 337–344. MIT Press, 2005. URL http://papers.nips.cc/paper/2636-analysis-of-a-greedy-active-learning-strategy.pdf.
- Demir et al. (2011) Begüm Demir, Claudio Persello, and Lorenzo Bruzzone. Batch-mode active-learning methods for the interactive classification of remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 49(3):1014–1031, 2011.
- Donahue et al. (2016) Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial feature learning. arXiv:1605.09782, 2016.
- Dumoulin et al. (2016) Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Alex Lamb, Martin Arjovsky, Olivier Mastropietro, and Aaron Courville. Adversarially learned inference. arXiv:1606.00704, 2016.
- Elhamifar et al. (2013) Ehsan Elhamifar, Guillermo Sapiro, Allen Yang, and S Shankar Sasrty. A convex optimization framework for active learning. In ICCV, 2013.
- Freund et al. (1997) Yoav Freund, H Sebastian Seung, Eli Shamir, and Naftali Tishby. Selective sampling using the query by committee algorithm. Machine learning, 28(2-3), 1997.
- Gal & Ghahramani (2016) Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning, 2016.
- Gal et al. (2017) Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. arXiv preprint arXiv:1703.02910, 2017.
- Ganti & Gray (2012) Ravi Ganti and Alexander Gray. Upal: Unbiased pool based active learning. In Artificial Intelligence and Statistics, pp. 422–431, 2012.
- Golovin & Krause (2011) Daniel Golovin and Andreas Krause. Adaptive submodularity: Theory and applications in active learning and stochastic optimization. Journal of Artificial Intelligence Research, 42:427–486, 2011.
- Gonen et al. (2013) Alon Gonen, Sivan Sabato, and Shai Shalev-Shwartz. Efficient active learning of halfspaces: an aggressive approach. The Journal of Machine Learning Research, 14(1):2583–2615, 2013.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS, 2014.
- Guillory & Bilmes (2010) Andrew Guillory and Jeff Bilmes. Interactive submodular set cover. arXiv:1002.3345, 2010.
- Guo (2010) Yuhong Guo. Active instance sampling via matrix partition. In Advances in Neural Information Processing Systems, pp. 802–810, 2010.
- Guo & Schuurmans (2008) Yuhong Guo and Dale Schuurmans. Discriminative batch mode active learning. In Advances in neural information processing systems, pp. 593–600, 2008.
- Hanneke (2007) Steve Hanneke. A bound on the label complexity of agnostic active learning. In Proceedings of the 24th international conference on Machine learning, pp. 353–360. ACM, 2007.
- Har-Peled & Kushal (2005) Sariel Har-Peled and Akash Kushal. Smaller coresets for k-median and k-means clustering. In Annual Symposium on Computational geometry. ACM, 2005.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Hoi et al. (2006) Steven CH Hoi, Rong Jin, Jianke Zhu, and Michael R Lyu. Batch mode active learning and its application to medical image classification. In Proceedings of the 23rd international conference on Machine learning, pp. 417–424. ACM, 2006.
- Inc. (2016) Gurobi Optimization Inc. Gurobi optimizer reference manual, 2016. URL http://www.gurobi.com.
- Joshi et al. (2009) Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image classification. In CVPR, 2009.
- Joshiy et al. (2010) A. J. Joshiy, F. Porikli, and N. Papanikolopoulos. Multi-class batch-mode active learning for image classification. In 2010 IEEE International Conference on Robotics and Automation, pp. 1873–1878, May 2010. doi: 10.1109/ROBOT.2010.5509293.
- Kapoor et al. (2007) Ashish Kapoor, Kristen Grauman, Raquel Urtasun, and Trevor Darrell. Active learning with gaussian processes for object categorization. In ICCV, 2007.
- Krizhevsky & Hinton (2009) Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. 2009.
- Li & Guo (2013) Xin Li and Yuhong Guo. Adaptive active learning for image classification. In CVPR, 2013.
- Maaten & Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008.
- MacKay (1992) David JC MacKay. Information-based objective functions for active data selection. Neural computation, 4(4):590–604, 1992.
- McCallumzy & Nigamy (1998) Andrew Kachites McCallumzy and Kamal Nigamy. Employing em and pool-based active learning for text classification. In ICML, 1998.
- Netzer et al. (2011) Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp. 5, 2011.
- Radford et al. (2015) Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434, 2015.
- Rasmus et al. (2015) Antti Rasmus, Mathias Berglund, Mikko Honkala, Harri Valpola, and Tapani Raiko. Semi-supervised learning with ladder networks. In NIPS, 2015.
- Roy & McCallum (2001) Nicholas Roy and Andrew McCallum. Toward optimal active learning through monte carlo estimation of error reduction. ICML, 2001.
- Salimans et al. (2016) Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In NIPS, 2016.
- Settles (2010) Burr Settles. Active learning literature survey. University of Wisconsin, Madison, 52(55-66):11, 2010.
- Simonyan & Zisserman (2014) Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014.
- Stark et al. (2015) Fabian Stark, Caner Hazırbas, Rudolph Triebel, and Daniel Cremers. Captcha recognition with active deep learning. In GCPR Workshop on New Challenges in Neural Computation, 2015.
- Tong & Koller (2001) Simon Tong and Daphne Koller. Support vector machine active learning with applications to text classification. JMLR, 2(Nov):45–66, 2001.
- Tsang et al. (2005) Ivor W Tsang, James T Kwok, and Pak-Ming Cheung. Core vector machines: Fast svm training on very large data sets. JMLR, 6(Apr):363–392, 2005.
- Wang et al. (2016) Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. Cost-effective active learning for deep image classification. Transactions on Circuits and Systems for Video Technology, 2016.
- Wang & Ye (2015) Zheng Wang and Jieping Ye. Querying discriminative and representative samples for batch mode active learning. ACM Transactions on Knowledge Discovery from Data (TKDD), 9(3):17, 2015.
- Wei et al. (2013) Kai Wei, Yuzong Liu, Katrin Kirchhoff, and Jeff A Bilmes. Using document summarization techniques for speech data subset selection. In HLT-NAACL, 2013.
- Wei et al. (2015) Kai Wei, Rishabh K Iyer, and Jeff A Bilmes. Submodularity in data subset selection and active learning. In ICML, 2015.
- Wolf (2011) Gert W Wolf. Facility location: concepts, models, algorithms and case studies., 2011.
- Xu & Mannor (2012) Huan Xu and Shie Mannor. Robustness and generalization. Machine learning, 86(3):391–423, 2012.
- Yang et al. (2015) Yi Yang, Zhigang Ma, Feiping Nie, Xiaojun Chang, and Alexander G Hauptmann. Multi-class active learning by uncertainty sampling with diversity maximization. International Journal of Computer Vision, 113(2):113–127, 2015.
- Yu et al. (2006) Kai Yu, Jinbo Bi, and Volker Tresp. Active learning via transductive experimental design. In Proceedings of the 23rd international conference on Machine learning, pp. 1081–1088. ACM, 2006.
附录 A 引理 1 的证明
证明。
我们将首先证明在 类上定义的 softmax 函数是 -Lipschitz 连续的。 很容易证明对于任何可微函数,
其中和是的雅可比矩阵。
Softmax 函数定义为
为了简洁起见,我们将 表示为 。 雅可比矩阵将是,
现在,上述矩阵的弗罗贝尼乌斯范数将是,
很容易看出是的最优解,因此,将代入上式,我们得到。
现在,考虑两个输入 和 ,这样它们在层 的表示是 和 。 让我们将任何卷积层或全连接层视为。 如果我们假设,对于任何卷积层或全连接层,我们可以说:
另一方面,使用 以及最大池层可以写成卷积层,这样只有一个权重是 ,其他权重是 ,我们可以说明 ReLU 和 max-pool 层,
结合soft-max层的Lipschitz常数,
使用倒三角不等式作为
我们可以得出结论,对于任何固定的和,损失函数是-Lipschitz。 ∎
附录B定理1的证明
在开始证明之前,我们先陈述 Berlind & Urner (2015) 的权利要求 1。 修复一些和。 然后,
证明。
我们将从边界 开始证明。 我们有一个条件,表明 球中 周围存在 ,使得 具有 损失。
由于滥用符号,我们用 表示 。 我们在中使用权利要求1,在中使用回归函数的Lipschitz性质和损失界。 然后,我们可以进一步将剩余项限制为:
其中最后一步来自这样一个事实:经过训练的训练分类器假设在点上有 损失。 如果我们将它们结合起来,
我们进一步使用 Hoeffding’s Bound 并得出结论,概率至少为 ,
∎