用于深度时空预测的跨城市迁移学习
摘要
时空预测是城市计算中的关键类型任务,例如交通流量和空气质量。 足够的数据通常是先决条件,特别是在采用深度学习时。 但不同城市的发展水平不平衡,仍有不少城市存在数据匮乏的问题。 为了解决这个问题,我们提出了一种用于深度时空预测任务的新型跨城市迁移学习方法,称为RegionTrans。 RegionTrans旨在有效地将知识从数据丰富的源城市转移到数据稀缺的目标城市。 更具体地说,我们首先学习一个城市间区域匹配函数,将每个目标城市区域与相似的源城市区域进行匹配。 神经网络旨在有效提取区域级表示以进行时空预测。 最后,提出了一种优化算法,利用区域匹配功能将学习到的特征从源城市转移到目标城市。 我们以全市人群流量预测作为示范实验,验证了RegionTrans的有效性。 结果表明,RegionTrans 可以减少高达 10.7% 的预测误差,从而优于最先进的微调深度时空预测模型。
1简介
时空预测涵盖了城市计算中的广泛应用[20],例如交通和空气质量预测。 近年来,随着大数据技术的发展,深度学习在时空预测中变得流行,例如:人群流量、出租车需求、降水预测,并实现了最先进的性能[7,12,18,19]。 然而,城市发展水平极不平衡,许多城市因数据匮乏而无法从这些成就中受益。 因此,如何帮助数据稀缺的城市也从深度学习等最新技术突破中获益,成为一个重要的研究问题,但迄今为止仍缺乏研究。
为了解决这个问题,在本文中,我们提出了一种用于深度时空预测任务的新的跨城市迁移学习方法,称为RegionTrans。 RegionTrans的目标是通过转移从数据中学到的知识来预测数据稀缺城市(目标城市)中某种类型的服务数据(例如人群流量) -丰富的城市(来源城市)。 RegionTrans的主要思想是找到具有相似模式的城际区域对,然后使用这些区域对作为代理,有效地将知识从源城市转移到目标城市。
在文献中,现有的深度学习方法通常旨在预测整个城市的现象[18, 19],因此很难实现区域级的知识转移。 为此,我们提出了一种新颖的深度迁移学习方法,而不是采用现有的深度神经网络进行城市范围的时空预测(例如 ST-ResNet [18])。 首先,我们设计一个区域匹配函数,根据短周期的服务数据或相关的辅助数据(如果适用)将每个目标城市区域链接到相似的源区域。 然后,在我们提出的网络结构中,为了捕获隐藏在服务数据中的时空模式,首先堆叠ConvLSTM层[12]。 之后,为了对区域表示进行编码,我们新添加了一个带有过滤器的Conv2D层,这是我们网络中使区域级传输可行的关键和基本组成部分。 最后,在目标城市的网络参数学习过程中,最小化城市间相似区域的区域表示之间的差异,从而实现区域级的跨城市知识转移。 以人流预测作为展示[18, 19],验证了RegionTrans的可行性和有效性。 简而言之,本文有以下贡献。
(i)据我们所知,这是第一项研究如何通过从数据丰富的源城市转移知识来促进数据稀缺的目标城市的深度时空预测的工作。
(ii)我们提出了一种新颖的深度迁移学习方法RegionTrans,用于通过区域级跨城市迁移进行时空预测任务。 RegionTrans 首先计算城市间区域相似度,然后堆叠 ConvLSTM 和 Conv2D( 滤波器)层以提取反映时空模式的区域级表示。 最后,将城市间相似区域的表征差异最小化,以促进区域级跨城市知识转移。
(iii) 以人群流量预测为例,我们的实验表明,与经过微调的最先进的时空预测方法相比,RegionTrans 可以减少高达 10.7% 的预测误差。
2相关工作
时空预测是城市计算中的一个基本问题[20]。 最近,深度学习被用于时空预测任务,并且当存在丰富的历史数据时,深度学习成为最先进的解决方案。 人们使用了各种深度模型,例如 CNN [19]、ResNet [18] 和 ConvLSTM [7, 12, 17]。 与这些工作相比,我们的工作的不同之处在于目标和方法。 我们的目标是将深度学习应用于服务数据周期较短的目标城市,从而提出RegionTrans来有效地将知识从数据丰富的源城市转移到目标城市。
迁移学习解决了标记数据稀缺时的机器学习问题[11]。 在城市计算中,当目标服务或基础设施是新的时,通常会出现数据稀缺问题。 解决城市数据稀缺问题通常有两种策略。 首先是利用目标城市的辅助数据来帮助构建目标应用程序。 示例包括使用温度来推断湿度,反之亦然[14],以及利用出租车 GPS 轨迹来检测共享汽车[13]。 二是寻找数据充足的源头城市进行知识转移。 郭等人设计了一个利用协同过滤和AutoEncoder的跨城市迁移学习框架来进行连锁店选址推荐[3]。 由于我们的问题是预测而不是推荐,因此无法应用[3]中的方法。 另一项相关工作是[15],提出了一种跨城市迁移学习算法FLORAL来预测空气质量类别。 将 FLORAL 应用到我们的任务中存在两个困难:(1)许多时空预测任务是回归任务,但 FLORAL 是为分类而设计的; (2) FLORAL 不是为深度学习而设计的。 据我们所知,RegionTrans是第一个用于深度时空预测的跨城市迁移学习框架。
3问题表述
定义1. 地区 [19]。 城市 被划分为 个相同大小的网格(例如,)。 每个网格称为一个区域,记为。我们使用来表示坐标为的城市区域。 城市中的整个区域集表示为。
定义2。 城市图像时间序列. 我们将城市 的数据时间戳集表示为:
| (1) |
其中 是时间戳的数量, 是当前/最后一个时间戳。 为了简洁起见,我们像之前的研究[18, 19]一样考虑等长时间戳(例如一小时)。 对于特定时间戳,我们有一个城市图像,其中个像素,其中每个像素代表一个特定的数据相应区域(Def. 1),
| (2) |
然后,我们定义一个城市图像时间序列如下:
| (3) |
现实中,各种城市数据都可以建模为上述城市图像时间序列,例如人群流量、天气状况、空气质量等。
定义3. 服务时空数据. 服务数据是要预测的目标数据类型。 我们将服务时空数据定义为存储服务数据的城市图像时间序列:
| (4) |
其中是时间戳的区域的服务数据。
本文中,目标城市服务数据匮乏,而源城市服务数据丰富,即。 考虑到这一点,我们提出了这个问题。
问题。跨城市传输时空预测。 鉴于目标城市 的服务数据较少,而源城市 的服务数据丰富,我们的目标是学习一个函数 来预测下一个时间戳的目标城市:
| (5) | ||||
| where | (6) |
根据实际应用需求,误差指标可以是平均绝对误差、均方根误差等。
示例。人流预测。 我们以人群流量预测[18, 19]为例来具体说明上述问题。 因此,服务数据是人群流入或流出。 源城市的人流记录可能会持续几年(),但目标城市可能只有几天(),因为服务刚刚启动。 值得注意的是,天气、工作日/周末等外部环境因素在人流预测中也很重要[18]。 稍后我们将证明我们提出的方法很容易添加从上下文因素中提取的外部特征。
4 区域传输
为了解决上述问题,我们提出了一种深度迁移学习方法RegionTrans,包括三个阶段。 首先,我们学习一个城际区域匹配函数,将每个目标区域链接到相似的源区域。 其次,设计神经网络结构来提取区域级时空模式。 最后,提出了一个优化流程,以促进城市之间的区域级转移。
4.1 城市间相似区域匹配
RegionTrans的第一步是找到一个匹配函数,将目标城市的每个区域映射到源城市。 目标是找到与目标区域具有相似时空模式的源区域。 为此,我们提出了两种寻找的策略。
与短周期的服务数据匹配。 虽然目标城市只有很少的服务数据,但这仍然可以为构建提供提示。 我们关注源城市和目标城市都有服务数据的时间跨度(即),然后计算每个目标区域与源之间的相关性(例如Pearson系数)区域以及相应的服务数据。 最后,对于每个目标区域,我们选择相关值最大的源区域。 正式地,
| (7) | ||||
| (8) | ||||
| (9) |
与长周期辅助数据匹配(如果适用)。 由于目标城市的服务数据较少,上述基于服务数据的源区域和目标区域之间的相关相似度可能不太可靠。 在现实中,有时我们可以找到与服务数据相关的另一个可公开访问的辅助数据,这可能有助于更鲁棒地计算城际区域相似度。 例如,根据文献[16],为了预测人群流量,公共社交媒体签到可以是一个有用的代理。 也就是说,我们不是使用短周期的人流数据,而是使用长周期的公开可用的签到数据来建立两个区域之间的相关性。
| (10) |
其中是持续较长时间的辅助数据(例如,签到号码)。
4.2 具有区域表示的深度时空神经网络
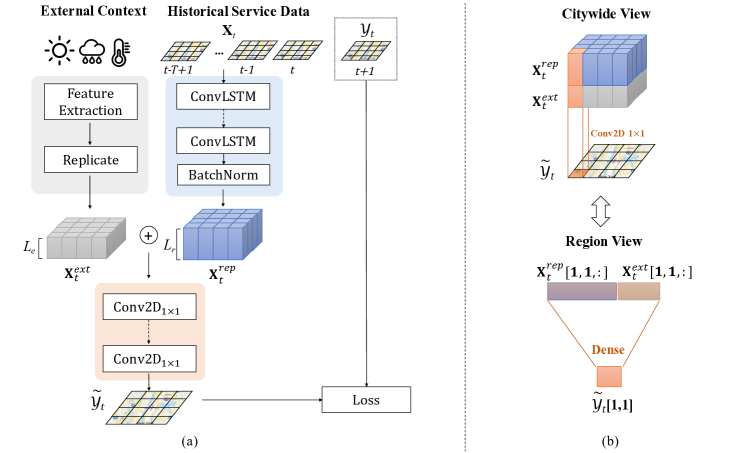
现有的深度时空模型往往采用整个城市的数据进行端到端预测(例如ST-ResNet[18]),无法用于区域级别的传输。 因此,我们设计了一种具有区域表示的时空预测新网络,如图1(a)所示。
输入和输出。 首先我们说明所提出的网络的输入和输出111为了清楚起见,我们在符号中省略了下标,因为本节中提到的所有符号都在城市中。:
| as the length of the input time series | (11) | |||
| as input for prediction | (12) | |||
| (13) | ||||
| (14) | ||||
| (15) |
我们的网络目标是最小化预测 和实际 之间的平方误差:
| (16) |
网络结构。 ConvLSTM 层用作神经网络学习时空模式的基本组件[12]。 在网络的第一部分,我们使用一组堆叠的 ConvLSTM 层来构造区域级隐藏表示 ,如等式 1 中定义的。 17(我们很快将详细说明为什么这可以被视为区域级表示)。 得到后,我们将外部上下文因素纳入网络结构中。 外部上下文因素定义为,它是每个区域上长度为的特征向量(例如,天气、温度、工作日/节假日one-hot编码[18 ])。 通过连接 和 形成表示 ,我们采用了多个带有 滤波器的卷积 2D 层 (Conv2D1×1 [9])来预测下一个时间戳服务数据。 形式上,时空神经网络可以表述如下:
| as ConvLSTM layers | (17) | |||
| as merge layer | (18) | |||
| as Conv2D1×1 layers | (19) | |||
| as region representation | (20) | |||
| as prediction output | (21) |
地区代表性。 如图1(b)所示,Conv2D1×1将产生空间不变的结果,这意味着隐藏向量和预测分别表示区域的时空表示和预测结果。 与现有的没有区域级隐藏表示的端到端全市深度时空预测模型[18, 19]相比,我们的网络设计对于迁移学习具有以下优势:
(i) 细粒度区域级传输。 现有的方法将城市的数据作为一个整体进行预测,我们只能将知识从整个源城市转移到目标城市(例如,通过微调)。 如果两个城市总体上不相似,则传输性能可能会很差。 由于我们的网络结合了区域表示,因此我们可以基于区域相似性进行细粒度的知识转移(下一小节中的详细算法)。 只要我们能够找到城市之间相似的区域对,就可以进行有效的转移。
(ii)不同规模城市之间的换乘。 由于我们的神经网络结构可以从区域视图中看到(图1(b)),即使两个城市具有不同的大小(即),也可以训练在源城市上建立模型,然后将学习到的网络参数传输到区域级别的目标城市。 然而,对于端到端的网络结构[18, 19],如果我们想通过微调将学习模型从源城市转移到目标城市,两个城市必须是相同的尺寸。
4.3基于区域的跨城市网络参数优化
利用所提出的网络结构,我们在源城市及其丰富的时空服务数据中训练了一个深度模型。 我们将 表示为从源城市学习的网络参数。 然后,以作为预训练的网络参数,提出一种基于区域的跨城市优化算法,以细化目标城市上的网络参数,考虑短周期目标城市内的服务数据和城际区域匹配功能。
在细化目标城市的网络参数时,第一个目标是最小化目标城市的预测误差:
| (22) |
给定匹配函数,我们优化的第二个目标是最小化匹配区域对之间的表示分歧。 更具体地说,对于每个时间戳 ,我们尝试最小化目标区域与其匹配源区域的网络隐藏表示之间的平方误差。 从形式上来说,第二个目标如下:
| (23) |
其中是当最后一个输入时间戳为时目标区域的隐藏表示; 是匹配源区域的表示; 是计算区域对之间的相关值(第4.1),以便在优化时为更相似的区域分配更大的权重。 然后,结合这两个目标会导致以下优化过程:
| (24) |
其中 是在最小化表示差异或最小化预测误差之间进行权衡的权重。 然后,我们可以使用最先进的网络参数学习算法,例如SGD和ADAM,来获取网络参数根据公式:目标城市 24(以源城市学习到的网络参数作为初始化值)。 Alg 中总结了优化过程的详细伪代码。 1.
Input:
: Pre-trained network parameters on source city with a long period of service data
: target city training data
: source city training data
: inter-city similar-region matching function
Output:
: network parameters for the target city
4.4备注:划分-匹配-转移原则
在这里,我们详细阐述了 RegionTrans 背后的关键原理,我们将其称为 divide-match-transfer。 也就是说,对于目标城市域和源城市域,我们不是将知识作为一个整体从源转移到目标,而是首先将两个域划分为一组区域,或称为子域。 然后,我们在目标子域和源子域之间建立匹配。 最后,利用匹配的跨子域对,我们进行知识转移。 先前的迁移学习理论研究[1,2,10]已经证明源域和目标域之间的特征分布差异是影响迁移学习性能的关键因素。 那么,如果我们能够建立合理的跨子域匹配(即两个匹配的子域之间的特征分布差异变得比原来的两个域更小),那么我们很可能可以提高迁移学习的性能。 由于这是对divide-match-transfer原理的直观理解,我们将在未来的工作中从理论上研究其属性。
考虑到divide-match-transfer原则,RegionTrans可以看作是时空预测任务的实现。 对于一个城市来说,地区是一个自然的、具有语义意义的划分。 匹配建立在可用的短周期服务数据或长周期相关辅助数据(如果适用)的基础上,使匹配的城际区域对具有相似的时空模式。 除了RegionTrans之外,我们相信divide-match-transfer原则可以进一步指导迁移学习算法的设计,以实现时空预测之外的更多任务。
5实验:人流预测
在实验中,我们使用城市计算中重要的时空预测任务人群流量预测[18, 19]来验证RegionTrans的有效性。
5.1设置
数据集。 继之前对人群流量[5,18,19]的研究之后,我们使用自行车流量数据进行评估。 三个自行车流量数据集收集自 华盛顿特区。使用芝加哥和纽约市。 每个数据集涵盖两年期间(2015-2016)。 在所有城市中,选取的中心区域作为研究区域。 该区域被分割为 区域(即每个区域都是 )。 对于每个评估场景,我们选择一个城市作为源城市,另一个城市作为目标城市。 我们假设源城市拥有所有历史人流数据,但目标城市仅存在有限时段(例如一天)的人流数据。 选择最近两个月的数据进行测试。
公制。 评估指标是均方根误差(RMSE)。 与[18]相同,报告的RMSE是流入和流出的平均RMSE。
网络实施。 我们在实验中实现的网络结构有两层 ConvLSTM,带有 过滤器和 32 个隐藏状态,以生成 。 以作为输入,有一层具有32个隐藏状态的Conv2D1×1,后面是另一层Conv2D1×1链接到输出人群流量预测。 对于外部上下文因素,例如温度、风速、天气和日期类型,我们使用与[18]相同的特征提取方法,得到长度为28的外部特征向量。 我们还需要在等式中设置。 24 平衡表示差异和预测误差之间的优化权衡。 我们将 设置为 0.75 作为默认值。 使用ADAM作为优化算法[8]。
方法。 对于 RegionTrans,我们实现了两种变体:
-
•
RegionTrans (S-Match):仅通过目标城市Service数据的短周期学习城际区域匹配函数,即人群流动。
-
•
RegionTrans (A-Match):通过长周期的辅助数据学习城际区域匹配函数,即Foursquare check-在数据中。 我们使用一年签到数据作为辅助数据,因为它是人群流量的有用指示,如先前的研究[16]所示。 请注意,我们已经收集了华盛顿特区和芝加哥的签到数据,因此 RegionTrans (A-Match) 可用于华盛顿特区 芝加哥之间的知识转移。
我们将 RegionTrans 与两种类型的基线进行比较。 第一种类型仅使用目标城市的短人群数据历史来训练其预测模型:
-
•
ARIMA:统计学中广泛使用的时间序列预测方法[6]。
-
•
DeepST [19]:基于卷积网络的深度时空神经网络。 完整的 DeepST 模型具有三个组成部分:接近度、周期和趋势。 但period和trend组件只有在训练数据分别持续超过1天和7天时才能激活。 因此,如果目标城市没有足够的数据,我们就必须停用相应的组件。
-
•
ST-ResNet [18]:基于残差网络[4]的深度时空神经网络。 与 DeepST 相同,ST-ResNet 具有三个组件。 然后,我们在实验中采用与 DeepST 相同的方式调整 ST-ResNet。
第二种类型是在源城市数据上训练一个深度模型,并用目标城市数据微调它:
-
•
DeepST (FT):微调 DeepST。
-
•
ST-ResNet (FT):微调 ST-ResNet。
正如第 2 节中提到的。 4.2,DeepST和ST-ResNet对城市人群流量进行整体预测,因此我们无法在两个不同规模的城市之间微调它们的模型。 因此,为了便于比较,我们的实验选择了两个城市相同的面积大小。 请注意,RegionTrans能够在两个不同规模的城市之间传递知识,因此更加灵活。
5.2结果
| D.C.Chicago | ChicagoD.C. | D.C.NYC | NYCD.C. | |||||
| 1-day | 3-day | 1-day | 3-day | 1-day | 3-day | 1-day | 3-day | |
| Target Data Only | ||||||||
| ARIMA | 0.740 | 0.694 | 0.707 | 0.661 | 0.360 | 0.341 | 0.707 | 0.661 |
| DeepST | 0.771 | 0.711 | 1.075 | 0.767 | 0.350 | 0.359 | 1.075 | 0.767 |
| ST-ResNet | 0.914 | 0.703 | 0.869 | 0.738 | 0.376 | 0.349 | 0.869 | 0.738 |
| Source & Target Data | ||||||||
| DeepST (FT) | 0.652 | 0.611 | 0.672 | 0.619 | 0.363 | 0.369 | 0.713 | 0.711 |
| ST-ResNet (FT) | 0.667 | 0.615 | 0.695 | 0.623 | 0.385 | 0.349 | 0.696 | 0.691 |
| RegionTrans (S-Match) | 0.605 | 0.594 | 0.631 | 0.602 | 0.328 | 0.305 | 0.665 | 0.593 |
| RegionTrans (A-Match) | 0.587 | 0.576 | 0.600 | 0.581 | / | / | / | / |
与基线比较。 表 1 显示了我们对 D.C. 芝加哥和 D.C. NYC 的结果。 在所有场景中,RegionTrans 都能始终优于最佳基线,其中最大的改进是将预测误差降低高达 10.7%。 特别是,当目标城市的记录历史较短时,RegionTrans的改进通常更为显着。 这表明引入的城市间相似区域对对于迁移学习很有价值,尤其是在目标数据极其稀缺的情况下。 在 RegionTrans 的两个变体中,RegionTrans (A-Match) 更好,如 D.C. 芝加哥所示。 这意味着,如果存在适当类型的辅助数据,则可以比仅使用短周期的服务数据建立更好的城际区域匹配。 如果辅助数据不可用,使用有限时段的服务数据进行区域匹配仍然可以产生竞争变体RegionTrans(S-Match),该变体显着优于所有基线。
另一个重要的观察结果是,在两个不同城市之间转移知识时,RegionTrans 比基线更稳健。 在实验中的三个城市中,华盛顿特区和芝加哥的人口相似,而纽约市的人口要多得多。 这表明华盛顿特区芝加哥之间的知识转移可能更容易,而华盛顿特区纽约市之间的知识转移可能更困难。 我们的结果也验证了这一点,因为 DeepST 和 ST-ResNet 通过在 D.C. 芝加哥的微调得到了很大的改进;但在 D.C. NYC,微调后的 DeepST 和 ST-ResNet 出现负迁移,导致性能比 ARIMA 更差,这表明直接将整个城市的知识从D.C. 到 NYC 无效。 相比之下,RegionTrans 始终实现比所有基线更低的错误,验证了来自华盛顿特区的知识仍然可以有效地转移到纽约市。 RegionTrans 能够避免负迁移的主要原因是,虽然 D.C. 和 NYC 总体上不相似,但我们仍然可以找到具有相似时空模式的城际区域对(例如中央商务区)来促进跨城市知识转移。
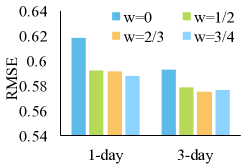
调整。 我们调整等式中的。 24 查看它将如何影响性能。 越大,最小化相似区域表示差异的权重就越高。 图2显示了结果。 如果我们设置 ,即忽略迁移学习中的城市间相似区域表示,则性能明显比 时差,错误率高出 5%。 这凸显了我们提出的城市间相似区域匹配方案在跨城市知识转移中的有效性。 对于的其他设置,性能差异很小。 当我们的目标城市人流数据周期很短(例如一天)时,较大的 表现会稍好一些。
计算时间。 实验平台配备Intel Xeon CPU E5-2650L、128 GB RAM和Nvidia Tesla M60 GPU。 我们在 CentOS 中使用 TensorFlow 实现了 RegionTrans。 在两年的数据上训练源城市模型大约需要 20 分钟,而对于 1 天和 3 天的数据,目标城市模型的迁移学习分别需要大约 50 分钟和 100 分钟。 这种运行时间效率在现实部署中是可以接受的。
6结论
在本文中,为了解决城市计算中时空预测任务中的数据稀缺问题,我们提出了一种新颖的跨城市深度迁移学习框架,称为RegionTrans,具有三个阶段。 (1)我们使用短周期的服务数据,或长周期的辅助数据(如果适用)来获得城市间区域时空动态的相似性。 (2)我们设计了一个深层时空模型,其隐藏层专门用于存储区域级潜在表示。 (3)我们提出了一种网络参数优化算法,通过考虑城市间相似区域对的潜在表示,将知识从源城市转移到目标城市。
未来,我们计划在多个方向上扩展RegionTrans。 首先,我们尝试从理论上分析RegionTrans的属性及其背后的divide-match-transfer原理。 显然,迁移学习的性能取决于目标区域和源区域的匹配程度;因此,对匹配质量和最终传输性能之间的关系进行数学建模将是我们未来的主要工作。 其次,我们将考虑一个更一般的场景,其中有多个数据丰富的源城市可用。 如果我们能够结合多源城市的可转移知识,可能会取得更好的绩效。 最后,我们计划将 RegionTrans 扩展到预测之外的时空学习任务,例如设施部署。
参考
- [1] Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation. In Advances in neural information processing systems, pages 137–144, 2007.
- [2] John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman. Learning bounds for domain adaptation. In Advances in neural information processing systems, pages 129–136, 2008.
- [3] Bin Guo, Jing Li, Vincent W. Zheng, Zhu Wang, and Zhiwen Yu. Citytransfer: Transferring inter- and intra-city knowledge for chain store site recommendation based on multi-source urban data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 1(4):135:1–135:23, January 2018.
- [4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [5] Minh X Hoang, Yu Zheng, and Ambuj K Singh. Fccf: forecasting citywide crowd flows based on big data. In SIGSPATIAL, page 6, 2016.
- [6] Rob J Hyndman and George Athanasopoulos. Forecasting: principles and practice. OTexts, 2014.
- [7] Jintao Ke, Hongyu Zheng, Hai Yang, and Xiqun Michael Chen. Short-term forecasting of passenger demand under on-demand ride services: A spatio-temporal deep learning approach. Transportation Research Part C: Emerging Technologies, 85:591–608, 2017.
- [8] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [9] Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. In ICLR, 2014.
- [10] Yishay Mansour, Mehryar Mohri, and Afshin Rostamizadeh. Domain adaptation: Learning bounds and algorithms. In COLT, 2009.
- [11] Sinno Jialin Pan and Qiang Yang. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2010.
- [12] Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Advances in neural information processing systems, pages 802–810, 2015.
- [13] Leye Wang, Xu Geng, Jintao Ke, Chen Peng, Xiaojuan Ma, Daqing Zhang, and Qiang Yang. Ridesourcing car detection by transfer learning. arXiv preprint arXiv:1705.08409, 2017.
- [14] Leye Wang, Daqing Zhang, Dingqi Yang, Animesh Pathak, Chao Chen, Xiao Han, Haoyi Xiong, and Yasha Wang. Space-ta: Cost-effective task allocation exploiting intradata and interdata correlations in sparse crowdsensing. ACM Transactions on Intelligent Systems and Technology, 9(2):20, 2017.
- [15] Ying Wei, Yu Zheng, and Qiang Yang. Transfer knowledge between cities. In KDD, pages 1905–1914, 2016.
- [16] Dingqi Yang, Daqing Zhang, and Bingqing Qu. Participatory cultural mapping based on collective behavior data in location-based social networks. ACM Transactions on Intelligent Systems and Technology, 7(3):30, 2016.
- [17] Huaxiu Yao, Fei Wu, Jintao Ke, Xianfeng Tang, Yitian Jia, Siyu Lu, Pinghua Gong, and Jieping Ye. Deep multi-view spatial-temporal network for taxi demand prediction. In AAAI, 2018.
- [18] Junbo Zhang, Yu Zheng, and Dekang Qi. Deep spatio-temporal residual networks for citywide crowd flows prediction. In AAAI, pages 1655–1661, 2017.
- [19] Junbo Zhang, Yu Zheng, Dekang Qi, Ruiyuan Li, and Xiuwen Yi. Dnn-based prediction model for spatio-temporal data. In SIGSPATIAL, page 92, 2016.
- [20] Yu Zheng, Licia Capra, Ouri Wolfson, and Hai Yang. Urban computing: concepts, methodologies, and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 5(3):38, 2014.