GraphVAE:使用变分自动编码器生成小图
摘要
图的深度学习已成为具有许多应用的热门研究课题。 然而,过去的工作集中在学习图嵌入任务上,这与图像和文本生成模型的进展形成鲜明对比。 是否有可能将这一进展转移到图领域? 我们建议通过让解码器立即直接输出预定义最大尺寸的概率全连接图来回避与此类离散结构的线性化相关的障碍。 我们的方法被表述为变分自动编码器。 我们评估分子生成的挑战性任务。
1简介
图深度学习最近成为一个热门研究主题(Bronstein 等人,2017),在化学等领域具有有用的应用(Gilmer 等人,2017),医学(Ktena等人,2017),或计算机视觉(Simonovsky & Komodakis,2017)。 迄今为止,过去的工作主要集中在图形嵌入任务的学习上,即将输入图形编码为向量表示。 这与图像和文本生成模型的快节奏发展形成鲜明对比,图像和文本生成模型的生成样本质量大幅提高。 因此,如何将这一进展转移到图形领域,即从矢量表示对图形进行解码,是一个耐人寻味的问题。 此外,Gómez-Bombarelli 等人 (2016) 过去曾提到过对这种方法的渴望。
然而,对于基于梯度优化的方法来说,学习生成图是一个难题,因为图是离散结构。 与序列(文本)生成不同,图可以具有任意连接性,并且没有明确的最佳方法如何在步骤序列中线性化其构造。 另一方面,学习增量构建的顺序涉及离散决策,这些决策是不可微的。
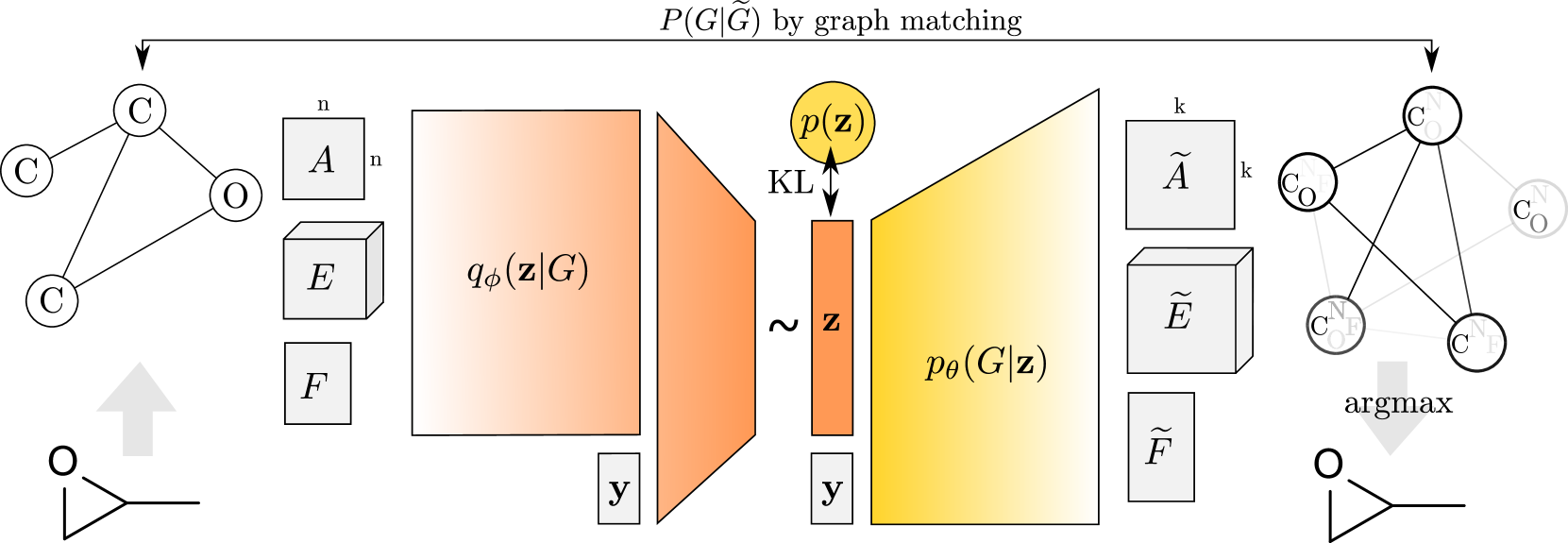
在这项工作中,我们建议通过让解码器立即直接输出预定义最大尺寸的概率全连接图来避开这些障碍。 在概率图中,节点和边的存在及其属性被建模为独立的随机变量。 该方法是在 Kingma & Welling (2013) 的变分自编码器 (VAE) 框架中制定的。
我们在化学信息学中展示了我们的方法,即 GraphVAE,用于分子生成任务。 分子数据集对于我们的生成模型来说是一个具有挑战性但又方便的测试平台,因为它们可以轻松地对解码样本进行定性和定量测试。 虽然我们的方法仅适用于生成较小的图,并且其性能还有改进的空间,但我们相信我们的工作是迈向强大而高效的图解码器的重要的第一步。
2相关工作
图解码器。
图生成在深度学习中很大程度上尚未被探索。 与我们最接近的工作是 Johnson (2017),他根据回答查询的输入句子序列逐步构建概率(多)图作为世界表示。 虽然我们的模型还输出概率图,但我们不假设具有可用的规定的构造转换顺序,并且我们将学习问题表述为自动编码器。
Xu 等人 (2017) 学习从输入图像生成场景图。 他们根据一组对象建议构建一个图,为每个节点和边提供初始嵌入,并使用消息传递来获得一致的预测。 相比之下,我们的方法是一种生成模型,它从单个不透明向量生成概率图,而无需明确指定节点数量或结构。
深度学习之前的相关工作包括随机图(Erdos & Rényi,1960;Barabási & Albert,1999)、随机块模型(Snijders & Nowicki,1997)或状态转移矩阵学习(Gong&Xiang,2003)。
离散数据解码器。
文本是最常见的离散表示。 那里的生成模型通常通过教师强制(Williams & Zipser,1989)以最大似然方式进行训练,这避免了通过在每个位置提供地面事实而不是过去的样本来通过输出离散化进行反向传播的需要步。 Bengio 等人 (2015) 认为这可能会导致暴露偏见,即可能会降低从自己的错误中恢复的能力。 最近,已经做出努力来克服这个问题。 值得注意的是,使用 Gumbel 分布计算可微近似(Kusner & Hernández-Lobato,2016)或通过学习强化学习中的随机策略来绕过问题(Yu 等人,2017)。 我们的工作还规避了不可微性问题,即通过在概率图上制定损失来解决。
分子解码器。
通过能够在连续的嵌入空间中搜索分子(Olivecrona 等人,2017),生成模型可能会成为满足某些标准的分子从头设计的前景。 考虑到这一点,我们提出了模型的条件版本。 虽然分子具有直观的图形表示形式,但该领域不得不求助于具有固定语法的文本表示,例如所谓的 SMILES 字符串,以利用 RNN 文本生成方面的最新进展( Olivecrona 等人, 2017; Segler 等人, 2017; Gómez-Bombarelli 等人, 2016)。 由于它们的语法很脆弱,往往会生成许多无效字符串,Kusner 等人 (2017) 最近通过将语法规则合并到解码中解决了这个问题。 虽然令人鼓舞,但他们的方法并不能保证语义(化学)有效性,与我们的方法类似。
3方法
我们通过设计一个能够将连续代码空间中的向量转换为图的神经网络来完成图生成的任务。 我们的主要思想是输出一个概率全连接图,并使用标准图匹配算法将其与地面事实对齐。 该方法是由 Kingma & Welling (2013) 在变分自动编码器 (VAE) 框架中制定的,尽管其他形式的正则化自动编码器也同样适用(Makhzani 等人, 2015; Li等人,2015a)。 我们在下面简要回顾一下 VAE,并继续介绍我们新颖的图解码器以及适当的目标。
3.1 变分自动编码器
令为由邻接矩阵、边属性张量和节点属性矩阵指定的图。我们希望学习一个编码器和一个解码器来在图空间 与其连续嵌入 之间进行映射,见图 1。 在 VAE 的概率设置中,编码器由变分后验 定义,解码器由生成分布 定义,其中 和 是学习参数。 此外,作为正则化,对潜在代码表示施加先验分布;我们使用简单的各向同性高斯先验。 整个模型通过最小化负对数似然的上限(Kingma&Welling,2013)进行训练:
| (1) |
的第一项,即重建损失,强制采样生成的图与输入图 具有高度相似性。第二项 KL 散度对代码空间进行正则化,以允许直接从 而不是稍后从 采样 。 的维度通常相当小,因此鼓励自动编码器学习输入的高级压缩,而不是学习简单地复制任何给定的输入。 虽然正则化与输入空间无关,但必须针对每种输入模态专门设计重建损失。 下面,我们介绍我们的图解码器以及适当的重建损失。
3.2 概率图解码器
归根结底,图是离散的对象。 虽然这不会对编码构成挑战,图卷积网络的最新发展证明了这一点(Gilmer等人,2017),但迄今为止图生成一直是一个悬而未决的问题。 在文本序列生成的相关任务中,当前占主导地位的方法是按字符或按单词预测(Bowman等人,2016)。 然而,图可以具有任意连接性,并且没有明确的方法如何通过一系列步骤线性化它们的构造111虽然规范图排序的算法可用(McKay & Piperno,2014),Vinyals 等人(2015) 凭经验发现,在集合上学习时,线性化阶数很重要。. 另一方面,在没有逐步监督的训练过程中迭代构建离散结构涉及离散决策,这些决策是不可微分的,因此对于反向传播来说是有问题的。
幸运的是,如果我们将域限制为最大 节点上的所有图的集合,则任务会变得更加简单,其中 相当小(实际上最多可达数十个数量级) )。 在这种假设下,处理密集图表示在计算上仍然是容易处理的。 我们建议让解码器在 节点上立即输出概率全连接图 。 这有效地回避了上述两个问题。
在概率图中,节点和边的存在被建模为伯努利变量,而节点和边属性是多项式变量。 虽然本工作中没有讨论,但连续属性可以很容易地建模为由均值和方差表示的高斯变量。 我们假设所有变量都是独立的。
因此 表示的每个张量都有一个概率解释。 具体来说,预测的邻接矩阵包含节点的节点概率和节点的边概率。 边属性张量表示边的类概率,类似地,节点属性矩阵包含节点的类概率。
解码器本身是确定性的。 其架构是一个简单的多层感知器(MLP),最后一层有三个输出。 Sigmoid激活函数用于计算,而边缘和节点的softmax分别用于获得和。 在测试时,我们通常对 的(离散)点估计感兴趣,这可以通过在 和 。 请注意,这可能会导致在少于 个节点上生成离散图。
3.3重建损失
给定 节点上的离散输入图 及其在 节点上的概率重建 的特定情况,评估方程 3.1 需要计算似然性。
由于在 或 中没有强加特定的节点顺序,并且图的矩阵表示对于节点的排列不是不变的,因此比较两个图是困难的。 然而,3.4小节中进一步描述的近似图匹配可以获得二元分配矩阵,其中仅当节点是否则分配给 和 。
了解 可以在两个图之间映射信息。 具体来说,输入邻接矩阵被映射到预测图为,而预测节点属性矩阵和边属性矩阵切片被传输到输入图为和。 各变量的最大似然估计值(即交叉熵)如下:
| (2) |
我们假设 和 采用 one-hot 表示法进行编码。 该公式考虑了匹配和不匹配的节点和边的存在,但仅考虑匹配节点和边的属性。 此外,分别对节点和边缘进行平均在训练中显示出有益的效果,否则边缘将主导可能性。 总体重建损失是前面各项的加权和:
| (3) |
3.4图匹配
二阶)图匹配的目标是根据 和 的节点对 对于 和 的相似性,找到图 和 的节点之间的对应关系 。 它可以表示为 上相似性最大化的整数二次规划问题,通常通过将 松弛到连续域来近似: (Cho等人,2014)。 对于我们的用例,相似度函数定义如下:
| (4) |
第一项评估边对之间的相似性,第二项评估节点对之间的相似性, 是艾弗森括号。 请注意,分数考虑了特征兼容性( 和 )和存在兼容性(),这在经验上导致了训练期间更稳定的分配。 总结方程 3.3 和 3.4 背后的动机,我们的方法旨在找到最佳的图匹配,然后通过损失的梯度下降进一步改进它。 考虑到训练深度网络的随机方式,我们认为仅近似解决匹配步骤就足够了。 这在概念上类似于通过 (Vinyals 等人, 2015) 学习输出无序集的方法,其中寻求训练数据的最接近的排序。
在实践中,我们正在寻找一种对噪声对应具有鲁棒性的图匹配算法,该算法可以在 GPU 上以批处理模式轻松实现。 Cho 等人 (2014) 提出的最大池匹配(MPM)是一种遵循幂法迭代方案的简单而有效的算法,详细信息请参见附录A。 如果相似性张量是零填充的,则可以在批处理模式下使用,即即对于,并且迭代量是固定的。
最大池匹配输出连续分配矩阵。 不幸的是,在方程 3.3 中直接使用 而不是 的尝试表现不佳,直接最大化 或使用softmax或直通Gumbel softmax进行软离散化(Jang等人,2016)。 因此,我们使用匈牙利算法将 离散化为 以获得严格的一对一映射222某些预测节点未分配给。尽管 GPU 版本已经发布,但我们当前的实现在 CPU 上执行此步骤(Date & Nagi,2016)。. 虽然此操作是不可微的,但梯度仍然可以通过损失函数直接流向解码器,并且训练收敛可以顺利进行。 请注意,这种方法经常用于物体检测工作,例如 (Stewart 等人, 2016),其中一组检测需要与一组地面匹配真值边界框并在计算可微损失之前将其视为固定的。
3.5更多详情
编码器。
尽管任何其他图嵌入方法都适用,但具有边缘条件图卷积 (ECC) (Simonovsky & Komodakis,2017) 的前馈网络用作编码器。 由于我们的边缘属性是分类的,因此 ECC 中的过滤器生成网络的单个线性层就足够了。 由于图尺寸较小,除了全局池之外,编码器中没有使用池化,为此我们采用 Li 等人 (2015b) 的门控池化。 与 VAE 中通常的情况一样,我们将编码器制定为概率性的,并通过将最后一个编码器层输出解释为均值和方差的 特征来强制执行 的高斯分布,从而允许采样 为 ,使用重新参数化技巧 (Kingma & Welling,2013)。
解开嵌入。
在实践中,人们通常希望对生成的图的属性有更多的控制,而不是随机绘制图。 在这种情况下,我们遵循 Sohn 等人 (2015) 并在与每个输入图 关联的标签向量 上调节编码器和解码器。解码器 被馈送到 和 的串联,而在编码器 中, 被串联到图池层之前的每个节点的特征。 如果潜在空间的大小很小,则鼓励解码器利用标签中的信息。
局限性。
预计所提出的模型仅适用于生成小图。 这是由于 GPU 内存需求和参数数量()以及匹配复杂度()的增长造成的,当 值较高时,质量会略有下降。在第 4 节中,我们展示了高达 的结果。 尽管如此,对于许多应用程序来说,即使生成小图仍然非常有用。
4评估
我们通过评估两个大型有机分子公共数据集 QM9 和 ZINC 来展示我们的分子生成任务方法。
4.1 在化学信息学中的应用
图像和文本生成模型的定量评估一直很麻烦(Theis等人,2015),因为很难以自动化、客观的方式衡量生成样本的真实性。 因此,研究人员经常诉诸定性评估和嵌入图。 然而,除非图表是平面的且相当简单,否则人类判断图表的定性评估可能非常不直观。
幸运的是,我们发现分子的图形表示(以原子为节点、键为边的无向图)是生成模型的便捷测试平台。 一方面,生成的图可以很容易地在标准化结构图中可视化。 另一方面,可以使用软件包(RDKit 中的 SanitizeMol)或模拟来检查图表的化学有效性以及分子可以满足的许多其他属性。 这使得定性和定量测试成为可能。
对兼容类型的键和原子价的化学限制使得有效图的空间变得复杂并且分子生成具有挑战性。 事实上,边缘的一次添加或去除或者原子或键类型的改变都可以使分子在化学上无效。 相比之下,在类似 MNIST 的数字生成问题中翻转单个像素是没有问题的。
为了帮助网络在此应用中,我们介绍了三种补救措施。 首先,我们通过仅预测它们的(上)三角形部分来使解码器输出对称 和 ,因为无向图足以表示分子。 其次,我们使用分子是连接的先验知识,并且仅在测试时在可能节点 集上构造最大生成树,以便将其边 包含在离散中即使 最初也是对图进行逐点估计。 第三,我们不明确生成氢,而是在化学有效性检查期间将其添加为“填充”。
4.2 QM9 数据集
QM9数据集(Ramakrishnan等人,2014)包含约134k有机分子,最多9个重(非氢)原子,具有4个不同的原子序数和4种键类型,我们设置 、 和 。 我们留出 10k 样本用于测试,10k 样本用于验证(模型选择)。
我们将我们的无条件模型与 Gómez-Bombarelli 等人 (2016) (CVAE) 基于字符的生成器和 Kusner 等人 (2017) 基于语法的生成器进行比较(GVAE)。 我们对两个基线都使用了 Kusner 等人 (2017) 中的代码和架构,将最大输入长度调整为尽可能小的长度。 此外,我们展示了一个条件生成模型,用于生成分子的人工任务,给定重原子直方图作为 4 维标签 ,其成功可以很容易地验证。
设置。
编码器有两个图卷积层(32 和 64 通道),具有恒等连接、batchnorm 和 ReLU;接下来是Li等人(2015b)等式7中的图级输出公式,其中辅助网络是具有128个输出通道的单个全连接层(FCL);由输出的FCL最终确定。 解码器有 3 个 FCL(128、256 和 512 通道),具有批归一化和 ReLU;接下来是 FCL 的并行三元组来输出图张量。 我们设置 、、批量大小 32、75 MPM 迭代,并使用 Adam 进行 25 个时期的训练,学习率为 1e-3,=0.5。
嵌入可视化。
为了直观地判断模型学习嵌入 的质量和平滑度,我们可以通过两种方式遍历它:沿着切片和沿着线。 对于前者,我们随机选择两个 维正交向量,并在诱导的 2D 平面上以规则网格图案采样 。 对于后者,我们从测试集中随机选择两个具有相同标签的分子 并在它们的嵌入 之间进行插值。 这也评估了编码器,因此受益于低重建误差。
我们在图 2 中绘制了两个平面,分别用于 QM9 中的频繁标签(左)和不太频繁的标签(右)。 两张图像都显示了多种且相当平滑的分子混合。 左边的图像有许多有效样本广泛分布在整个平面上,因为大概自动编码器必须将数据库的很大一部分放入这个空间中。 右侧表现出更强的正则化效果,因为有效分子往往仅位于中心周围。
图 3 显示了几种插值的示例。 我们可以找到有意义的(第一、第二和第四行)和不太有意义的转变,尽管线上的许多样品没有形成化学上有效的化合物。



解码器质量指标。
条件解码器的质量可以通过生成图的有效性和多样性来评估。 对于给定的标签,我们绘制样本并计算其解码的离散点估计。
令 为来自 的化学有效分子列表, 为原子直方图等于 的化学有效分子列表。 我们对比率 和 感兴趣。 此外,令 为唯一正确图的分数, 为新颖的数据集外图的分数;如果,我们定义和。 最后,引入的指标按 QM9 中标签的频率进行聚合,例如 。 通过假设只有一个标签(即 )来评估无条件解码器。
在表 1 中,我们可以看到,平均 50% 的生成分子在化学上是有效的,并且在条件模型的情况下,大约 40% 具有解码器所依赖的正确标签。 较大的嵌入大小 的正则化程度较低,这通过较高数量的 样本和较低的条件模型精度来证明,因为解码器被迫减少对实际标签的依赖。 样本的比率显示出不太清晰的行为,可能是因为离散性能没有直接优化。 值得注意的是,在所有模型中,约有 60% 生成的分子不在数据集中,即网络在训练过程中从未见过它们。
从基线来看,CVAE 只能输出很少的有效样本(如预期),而 GVAE 生成的有效样本数量最多 (60%),但方差非常低(小于 10%)。 此外,我们通过使用身份分配 来研究图匹配的重要性,从而学习在训练集中重现特定的节点排列,这对应于 rdkit 中 SMILES 字符串的规范排序。 这种消融模型(在表 1 中表示为 NoGM)产生了许多较低种类的有效样本,并且令人惊讶的是,在这方面优于 GVAE。 相比之下,我们的模型可以同时在两个指标上取得良好的性能。
| ELBO | |||||||
|---|---|---|---|---|---|---|---|
| 条件。 | Ours | -0.578 | -0.722 | 0.565 | 0.467 | 0.314 | 0.598 |
| Ours | -0.504 | -0.617 | 0.511 | 0.416 | 0.484 | 0.635 | |
| Ours | -0.492 | -0.585 | 0.520 | 0.406 | 0.583 | 0.613 | |
| Ours | -0.475 | -0.557 | 0.458 | 0.353 | 0.666 | 0.661 | |
| 无条件 | Ours | -0.660 | -0.916 | 0.485 | 0.485 | 0.457 | 0.575 |
| Ours | -0.537 | -0.744 | 0.542 | 0.542 | 0.618 | 0.617 | |
| Ours | -0.486 | -0.656 | 0.517 | 0.517 | 0.695 | 0.570 | |
| Ours | -0.482 | -0.628 | 0.557 | 0.557 | 0.760 | 0.616 | |
| NoGM | -2.388 | -2.553 | 0.810 | 0.810 | 0.241 | 0.610 | |
| CVAE | – | – | 0.103 | 0.103 | 0.675 | 0.900 | |
| GVAE | – | – | 0.602 | 0.602 | 0.093 | 0.809 |
可能性。
除了上面介绍的特定于应用程序的指标之外,我们还报告了 VAE 文献中常用的证据下界 (ELBO),它对应于我们符号中的 。 在表 1 中,我们使用每个图表使用单个 样本来说明测试集的平均界限。 我们观察到,由于较大的 提供了更多的自由度,因此重建损失和 KL 散度都减少了。 然而,ELBO和之间似乎没有很强的相关性,这使得模型选择有些困难。
隐式节点概率。
我们的解码器假设节点和边概率独立,这允许孤立的节点或边。 进一步利用分子是连通图的事实,我们研究了将节点概率作为边概率的函数的效果。 具体来说,我们将节点 的概率视为其最可能边缘的概率:。
表 2 中对 QM9 的评估显示,在条件和无条件条件下,、 和 指标都有明显改进环境。 然而,这是以较低的变异性和较高的重建损失为代价的。 这表明虽然新约束很有用,但模型无法完全应对。
| ELBO | |||||||
|---|---|---|---|---|---|---|---|
| 条件。 | Ours/imp | -0.784 | -0.919 | 0.572 | 0.482 | 0.238 | 0.718 |
| Ours/imp | -0.671 | -0.776 | 0.611 | 0.518 | 0.307 | 0.665 | |
| Ours/imp | -0.618 | -0.714 | 0.566 | 0.448 | 0.416 | 0.710 | |
| Ours/imp | -0.627 | -0.713 | 0.583 | 0.451 | 0.475 | 0.681 | |
| 不条件。 | Ours/imp | -0.857 | -1.091 | 0.533 | 0.533 | 0.228 | 0.610 |
| Ours/imp | -0.737 | -0.932 | 0.562 | 0.562 | 0.420 | 0.758 | |
| Ours/imp | -0.634 | -0.797 | 0.587 | 0.587 | 0.459 | 0.730 | |
| Ours/imp | -0.642 | -0.777 | 0.571 | 0.571 | 0.520 | 0.719 |
4.3 ZINC 数据集
ZINC数据集(Irwin等人,2012)包含约25万个类药物有机分子,由多达38个重原子组成,具有9个不同的原子序数和4种键类型,我们设置, 和 并使用与 QM9 相同的拆分策略。 我们研究无条件生成模型的可扩展程度。
设置。
该设置与 QM9 相同,但具有更宽的编码器(64、128、256 通道)。
解码器质量指标。
我们使用 的最佳模型已存档 ,这显然比 QM9 更差。 使用隐式节点概率没有带来任何改进。 作为比较,CVAE 未能生成任何有效样本,而 GVAE 则实现了 (模型由 Kusner 等人 (2017)、 提供)。
我们将如此低的性能归因于产生化学相关不一致的可能性通常要高得多(可能的边缘数量呈二次方增长)。 为了确认性能和图大小之间的关系,我们只保留不大于节点的图,对应于ZINC的21%,并获得( 用于 节点,ZINC 的 92%)。 为了验证该问题可能不是由我们提出的图匹配损失引起的,我们在下面对其进行综合评估。
匹配的稳健性。
使用我们的相似性函数 进行图形匹配的鲁棒行为对于 GraphVAE 的良好性能非常重要。 在这里,我们单独研究图匹配,以研究其可扩展性。 为此,我们将高斯噪声 添加到输入图 的每个张量,截断并重新归一化以保留其概率解释,以创建其噪声版本 。 我们对自身 之间的匹配质量感兴趣,在 和 之间使用噪声分配矩阵 。 简单地检查 的身份的优点是等效节点排列的不变性。
在表3中,我们分别改变了每个张量的和,并报告了来自 ZINC 的 100 个随机样本的平均精确度(计算方式与等式 3.3 中的损失相同),样本大小最高可达 节点。 虽然我们观察到更强的噪声会导致预期的精度下降,但在固定噪声水平下增加 的行为相当稳健,最敏感的是邻接矩阵。 请注意,由于随机变量的维度不同,各个表的准确度不具有可比性。 我们可以得出结论,匹配过程的质量并不是可扩展性的主要障碍。
| Noise | ||||||
|---|---|---|---|---|---|---|
| 99.55 | 99.52 | 99.45 | 99.4 | 99.47 | 99.46 | |
| 90.95 | 89.55 | 86.64 | 87.25 | 87.07 | 86.78 | |
| 82.14 | 81.01 | 79.62 | 79.67 | 79.07 | 78.69 | |
| 97.11 | 96.42 | 95.65 | 95.90 | 95.69 | 95.69 | |
| 92.03 | 90.76 | 89.76 | 89.70 | 88.34 | 89.40 | |
| 98.32 | 98.23 | 97.64 | 98.28 | 98.24 | 97.90 | |
| 97.26 | 97.00 | 96.60 | 96.91 | 96.56 | 97.17 |
5结论
在这项工作中,我们解决了在变分自动编码器的背景下从连续嵌入生成图的问题。 我们在两个最大图尺寸不同的分子数据集上评估了我们的方法。 虽然我们实现了在小分子上学习合理质量的嵌入,但我们的解码器很难捕获较大分子的复杂化学相互作用。 尽管如此,我们相信我们的方法是迈向更强大的解码器的重要第一步,并将激发社区的兴趣。
未来的工作有很多途径可以遵循。 除了改进当前方法的明显愿望(例如,通过合并更强大的先验分布或添加用于纠正错误的循环机制),我们还希望通过将其应用于化学中的实际问题来将其扩展到概念证明之外,例如优化某些特性或预测化学反应。 与基于 SMILES 的解码器相比,基于图的解码器的优点是除了基本结构之外还可以预测原子和键的详细属性,这在这些任务中可能很有用。 我们的自动编码器还可以用于预训练图形编码器,以便在小数据集上进行微调(Goh等人,2017)。
致谢
我们感谢 Shell Xu Hu 对变分方法的讨论,Shinjae Yoo 的项目动机,以及匿名审稿人的评论。
参考
- Barabási & Albert (1999) Barabási, Albert-László and Albert, Réka. Emergence of scaling in random networks. Science, 286(5439):509–512, 1999.
- Bengio et al. (2015) Bengio, Samy, Vinyals, Oriol, Jaitly, Navdeep, and Shazeer, Noam. Scheduled sampling for sequence prediction with recurrent neural networks. In NIPS, pp. 1171–1179, 2015.
- Bowman et al. (2016) Bowman, Samuel R., Vilnis, Luke, Vinyals, Oriol, Dai, Andrew M., Józefowicz, Rafal, and Bengio, Samy. Generating sentences from a continuous space. In CoNLL, pp. 10–21, 2016.
- Bronstein et al. (2017) Bronstein, Michael M, Bruna, Joan, LeCun, Yann, Szlam, Arthur, and Vandergheynst, Pierre. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34(4):18–42, 2017.
- Cho et al. (2014) Cho, Minsu, Sun, Jian, Duchenne, Olivier, and Ponce, Jean. Finding matches in a haystack: A max-pooling strategy for graph matching in the presence of outliers. In CVPR, pp. 2091–2098, 2014.
- Date & Nagi (2016) Date, Ketan and Nagi, Rakesh. Gpu-accelerated hungarian algorithms for the linear assignment problem. Parallel Computing, 57:52–72, 2016.
- Erdos & Rényi (1960) Erdos, Paul and Rényi, Alfréd. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci, 5(1):17–60, 1960.
- Gilmer et al. (2017) Gilmer, Justin, Schoenholz, Samuel S., Riley, Patrick F., Vinyals, Oriol, and Dahl, George E. Neural message passing for quantum chemistry. In ICML, pp. 1263–1272, 2017.
- Goh et al. (2017) Goh, Garrett B., Siegel, Charles, Vishnu, Abhinav, and Hodas, Nathan O. Chemnet: A transferable and generalizable deep neural network for small-molecule property prediction. arXiv preprint arXiv:1712.02734, 2017.
- Gómez-Bombarelli et al. (2016) Gómez-Bombarelli, Rafael, Duvenaud, David K., Hernández-Lobato, José Miguel, Aguilera-Iparraguirre, Jorge, Hirzel, Timothy D., Adams, Ryan P., and Aspuru-Guzik, Alán. Automatic chemical design using a data-driven continuous representation of molecules. CoRR, abs/1610.02415, 2016.
- Gong & Xiang (2003) Gong, Shaogang and Xiang, Tao. Recognition of group activities using dynamic probabilistic networks. In ICCV, pp. 742–749, 2003.
- Irwin et al. (2012) Irwin, John J., Sterling, Teague, Mysinger, Michael M., Bolstad, Erin S., and Coleman, Ryan G. ZINC: A free tool to discover chemistry for biology. Journal of Chemical Information and Modeling, 52(7):1757–1768, 2012.
- Jang et al. (2016) Jang, Eric, Gu, Shixiang, and Poole, Ben. Categorical reparameterization with gumbel-softmax. CoRR, abs/1611.01144, 2016.
- Johnson (2017) Johnson, Daniel D. Learning graphical state transitions. In ICLR, 2017.
- Kingma & Welling (2013) Kingma, Diederik P. and Welling, Max. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2013.
- Ktena et al. (2017) Ktena, Sofia Ira, Parisot, Sarah, Ferrante, Enzo, Rajchl, Martin, Lee, Matthew C. H., Glocker, Ben, and Rueckert, Daniel. Distance metric learning using graph convolutional networks: Application to functional brain networks. In MICCAI, 2017.
- Kusner & Hernández-Lobato (2016) Kusner, Matt J. and Hernández-Lobato, José Miguel. GANS for sequences of discrete elements with the gumbel-softmax distribution. CoRR, abs/1611.04051, 2016.
- Kusner et al. (2017) Kusner, Matt J., Paige, Brooks, and Hernández-Lobato, José Miguel. Grammar variational autoencoder. In ICML, pp. 1945–1954, 2017.
- (19) Landrum, Greg. RDKit: Open-source cheminformatics. URL http://www.rdkit.org.
- Li et al. (2015a) Li, Yujia, Swersky, Kevin, and Zemel, Richard S. Generative moment matching networks. In ICML, pp. 1718–1727, 2015a.
- Li et al. (2015b) Li, Yujia, Tarlow, Daniel, Brockschmidt, Marc, and Zemel, Richard S. Gated graph sequence neural networks. CoRR, abs/1511.05493, 2015b.
- Makhzani et al. (2015) Makhzani, Alireza, Shlens, Jonathon, Jaitly, Navdeep, and Goodfellow, Ian J. Adversarial autoencoders. CoRR, abs/1511.05644, 2015.
- McKay & Piperno (2014) McKay, Brendan D. and Piperno, Adolfo. Practical graph isomorphism, II. Journal of Symbolic Computation, 60(0):94 – 112, 2014. ISSN 0747-7171.
- Olivecrona et al. (2017) Olivecrona, Marcus, Blaschke, Thomas, Engkvist, Ola, and Chen, Hongming. Molecular de novo design through deep reinforcement learning. CoRR, abs/1704.07555, 2017.
- Ramakrishnan et al. (2014) Ramakrishnan, Raghunathan, Dral, Pavlo O, Rupp, Matthias, and von Lilienfeld, O Anatole. Quantum chemistry structures and properties of 134 kilo molecules. Scientific Data, 1, 2014.
- Segler et al. (2017) Segler, Marwin H. S., Kogej, Thierry, Tyrchan, Christian, and Waller, Mark P. Generating focussed molecule libraries for drug discovery with recurrent neural networks. CoRR, abs/1701.01329, 2017.
- Simonovsky & Komodakis (2017) Simonovsky, Martin and Komodakis, Nikos. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In CVPR, 2017.
- Snijders & Nowicki (1997) Snijders, Tom A.B. and Nowicki, Krzysztof. Estimation and prediction for stochastic blockmodels for graphs with latent block structure. Journal of Classification, 14(1):75–100, Jan 1997.
- Sohn et al. (2015) Sohn, Kihyuk, Lee, Honglak, and Yan, Xinchen. Learning structured output representation using deep conditional generative models. In NIPS, pp. 3483–3491, 2015.
- Stewart et al. (2016) Stewart, Russell, Andriluka, Mykhaylo, and Ng, Andrew Y. End-to-end people detection in crowded scenes. In CVPR, pp. 2325–2333, 2016.
- Theis et al. (2015) Theis, Lucas, van den Oord, Aäron, and Bethge, Matthias. A note on the evaluation of generative models. CoRR, abs/1511.01844, 2015.
- Vinyals et al. (2015) Vinyals, Oriol, Bengio, Samy, and Kudlur, Manjunath. Order matters: Sequence to sequence for sets. arXiv preprint arXiv:1511.06391, 2015.
- Williams & Zipser (1989) Williams, Ronald J. and Zipser, David. A learning algorithm for continually running fully recurrent neural networks. Neural Computation, 1(2):270–280, 1989.
- Xu et al. (2017) Xu, Danfei, Zhu, Yuke, Choy, Christopher Bongsoo, and Fei-Fei, Li. Scene graph generation by iterative message passing. In CVPR, 2017.
- Yu et al. (2017) Yu, Lantao, Zhang, Weinan, Wang, Jun, and Yu, Yong. Seqgan: Sequence generative adversarial nets with policy gradient. In AAAI, 2017.
附录
附录A最大池化匹配
本节我们简要回顾一下 Cho 等人 (2014) 的最大池化匹配算法。 在其宽松形式中,图和的节点之间的连续对应矩阵是基于节点对的相似性确定的 表示为矩阵元素。
让 表示 的按列副本。 松弛图匹配问题被表示为二次规划任务,使得、和。 选择的优化策略被导出为与具有迭代更新规则的幂法等效。 起始对应被初始化为uniform,迭代规则直至收敛;在我们的用例中,我们运行固定数量的迭代。
在图匹配的上下文中,矩阵向量乘积 可以解释为对匹配候选者的求和池:,其中 和 表示节点和的邻居集合。 作者认为,该公式受到无信息或不相关元素的强烈影响,并提出了一个更强大的最大池版本,该版本仅考虑每个邻居的最佳成对相似性:。
附录 B 非正则化自动编码器
VAE 中的正则化不利于训练数据的完美重建,尤其是对于小嵌入大小。 为了理解我们的架构的重建能力,我们在本节中将其训练为非正则化,即使用确定性编码器并且在方程3.1中没有KL散度项。