在近期处理器上使用量子神经网络
进行分类
摘要
我们引入了一种量子神经网络 QNN,它可以表示经典或量子的标记数据,并通过监督学习进行训练。 量子电路由一系列参数相关的酉变换组成,这些变换作用于输入量子态。 对于二元分类,在指定的读出量子位上测量单个泡利算子。 测量的输出是量子神经网络对输入状态的二进制标签的预测。 首先,我们看看对由带有二进制标签的 n 位字符串组成的经典数据集进行分类。 输入量子态是对应于样本串的n位计算基础状态。 我们展示了如何设计由两个量子位酉组成的电路,该电路可以正确表示任何 n 位布尔函数的标签。 对于某些标签功能,电路呈指数级增长。 我们引入了参数相关的酉,可以通过标记数据的监督学习进行调整。 我们研究了一个现实世界数据的示例,该数据由手写数字的下采样图像组成,每个手写数字都被标记为两个不同数字之一。 我们通过经典模拟表明,可以找到允许 QNN 学习正确区分两个数据集的参数。 然后,我们讨论将数据呈现为与不同标签值相对应的计算基础状态的量子叠加。 在这里,我们通过模拟证明学习是可能的。 我们考虑使用 QNN 来学习一般量子态的标签。 通过例子我们证明这是可以做到的。 我们的工作是探索性的,依赖于小型量子系统的经典模拟。 这里提出的 QNN 是在设计时考虑到近期量子处理器的。 因此,可以在近期门模型量子计算机上运行此 QNN,其功能可以超出模拟所能探索的范围。
1 简介和设置
机器学习形式的人工智能在让经典计算机对数据进行分类方面取得了巨大进步[1][2]。 在这里,我们想象一个由字符串组成的大数据集,其中每个字符串都带有一个二进制标签。 为简单起见,我们假设没有标签噪声,以便我们可以确信附加到每个字符串的标签是正确的。 我们得到一个训练集,它是一组 字符串样本及其标签。 目标是利用这些信息能够正确预测未见过的示例的标签。 显然,只有当标签函数具有底层结构时才能做到这一点。 如果标签函数是随机的,我们可能能够从训练集中学习(或拟合 参数)标签,但我们将无法说出有关以前未见过的示例的标签的任何内容。 现在想象一个现实世界的例子,其中数据集由像素化图像组成,每个图像都被正确标记以表明图像中是否有狗或猫。 在这种情况下,经典神经网络可以学习将新图像正确分类为狗或猫。 我们不会回顾这是如何在经典环境中完成的,而是立即转向能够学习对数据进行分类的量子神经网络。 我们继续使用“神经”这个词来描述我们的网络,因为机器学习社区已经采用这个术语,认识到与神经科学的联系现在只是历史性的。 此处回顾了在机器学习中利用量子资源的其他方法[3][4]。
具体来说,假设数据集由字符串 组成,其中每个 都是一个取值 或 的位,并且二进制标签 选择为 或 。 为简单起见,假设数据集由所有 字符串组成。 我们有一个作用于 量子位的量子处理器,我们忽略了对辅助量子位的可能需求。 最后一个量子位将用作读数。 量子处理器对输入状态实现酉变换。 我们的酉系统来自于一些酉系统工具箱,可能是通过实验考虑来确定的[5]。 所以我们有一组基本单位
| (1) |
每个都作用于量子位的子集,并取决于连续参数 ,其中为简单起见,每个单位只有一个控制参数。 现在我们选择一组 并使其统一
| (2) |
这取决于参数。 对于每个 我们构建计算基础状态
| (3) |
其中读出位已设置为 1。 将酉作用于输入状态给出状态
| (4) |
然后,在读出量子位上,我们测量泡利算子,例如 ,我们称之为 。 这给出了 或 。 我们的目标是让测量结果对应输入字符串的正确标签,即。 通常测量结果是不确定的。 我们预测的标签值是和之间的实数,
| (5) |
如果在 (4) 的多个副本中测量 ,则这是观察到的结果的平均值。
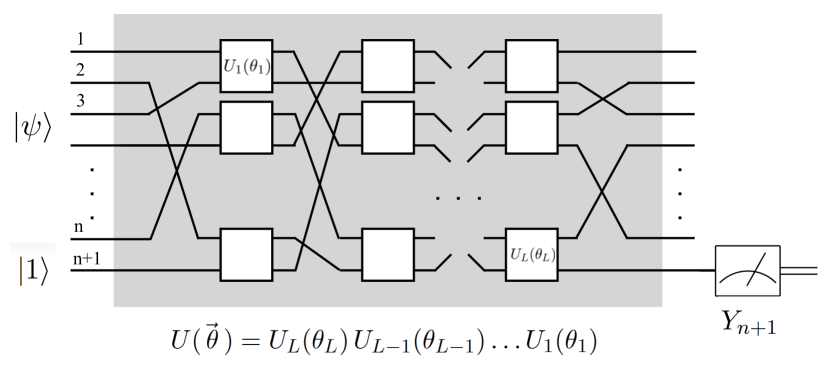
我们的目标是找到参数,使预测标签接近真实标签。 我们将解决这样的参数是否存在(表示)的问题以及是否可以有效地找到这样的最佳参数(学习)的问题。 对于给定电路,即选择酉、一组参数以及输入字符串,请考虑样本损失
| (6) |
请注意,我们使用的样本损失在边际(标签和预测标签值的乘积)中是线性的,并且其最小值为 0(不是负无穷大),因为预测标签值自动限制在 -1 和 1 之间。 假设量子神经网络运行良好,因此对于每个输入 ,测量总是给出正确的标签。 这意味着参数 存在并且已被发现,使得所有输入 的样本损失为 0。
给定一组带有标签的字符串训练集,我们现在描述如何使用量子处理器来找到实现学习任务的参数,也就是说,我们描述了监督学习量子神经网络。 现在我们假设我们的电路足够丰富,存在允许我们表示标签的参数。 从随机参数 开始,或者可能是一个受启发的选择。 从训练集中选择一个字符串 。 使用量子处理器构建
| (7) |
并测量最后一个量子位的。 执行此操作足够多次,以便对 的预期值进行良好估计,然后通过方程 (6) 计算损失。 现在我们想对参数做一个小的改变,以减少训练示例上的损失。 我们可以通过从附近的 随机采样来做到这一点。 或者我们可以计算损失相对于的梯度,然后朝减少损失的方向迈出一小步。 (稍后将详细介绍如何获取梯度。) 这给了我们新的参数。 我们现在采用一个新的训练示例 并通过量子测量估计损失。 现在稍微改变 来稍微减少这种损失。 调用新参数。 我们可以继续以这种方式生成一个序列 的整个训练样本集。 如果学习成功,我们会发现使用参数,作用于状态的运算符将产生一个状态,当输出量子位时测量后将给出正确的标签。 如果 来自训练集,我们可以声称我们已经拟合了训练数据。 如果 位于训练集之外,例如来自指定的测试集,我们会说学习已推广到未见过的示例。
我们刚刚描述的是经典机器学习中所谓的“随机梯度下降”的实现。随机性来自于训练示例是从集合中随机抽取的事实。 当学习成功时,在处理足够的训练示例后,参数会稳定在可以正确预测标签的位置。 导致成功的参数值可能有很多,因此,即使参数的数量非常大,从随机点开始也可能会得到好的解决方案。 在使用神经网络的传统机器学习中,参数(称为权重)显示为对内部向量线性作用的矩阵中的条目。 在将向量乘以其他权重相关矩阵之前,这些向量的分量会受到非线性作用。 构建成功的机器学习实现的一部分艺术是引入正确的非线性。 在我们的设置中,每个酉都作用于前一个酉的输出,并且没有明确引入非线性。 我们指定的是量子演化后要测量的参数化幺正集合和算子。 想象一下集合中的各个酉 (1) 都是以下形式
| (8) |
其中 是作用于几个量子位的广义泡利,即 是来自集合 的运算符作用于几个量子位的张量积。 对 的导数给出一个范数以 1 为界的运算符。 因此,损失函数相对于 的梯度受参数数量 的限制。 这意味着梯度不会爆炸,这样我们就可以避免在经典神经网络中计算梯度时可能出现的众所周知的问题。 经典机器学习领域的研究人员最近开始研究使用酉变换控制梯度爆炸的优势 [6][7][8] [9]。 请注意,在我们的例子中,这种优势是免费的。
2表示
在讨论学习之前,我们希望确定我们的量子神经网络能够表达任何二值标签函数,尽管我们将看到电路深度的成本可能很高(另请参见[10])。 有、位字符串,相应地有个可能的标签函数。 给定一个标签函数,考虑其操作在计算基础上定义的操作符状态为
| (9) |
换句话说,它的作用是将输出量子位绕其 x 轴旋转 乘以字符串 的标签。 相应地,
| (10) |
在此公式中, 在计算基础上被解释为运算符对角线。 请注意,由于 只能是 或 我们有
| (11) |
这表明至少在某种程度上我们有一种用量子电路表示任何标签函数的方法。
我们现在展示如何将 写为两个量子位酉的乘积。 对于此讨论,可以方便地切换到布尔变量 并将我们的标签函数 视为 ,其中 为 0, 1 值。 现在我们可以使用 到 位来表示任何布尔函数:
| (12) |
加法为mod2,系数均为0或1。 请注意,存在 系数,并且由于它们各自为 0 或 1,我们看到确实有 布尔函数被表示。 该公式可以呈指数级增长。 现在我们可以将 (9) 中的标签相关单一 写为
| (13) |
其中是运算符,计算基础上的对角线,对应于。 (13) 中 中的每一项都乘以 ,因此每一项都与其他项交换。 Reed-Muller 公式中的每个非零项都会在 中引起输出量子位上的受控位翻转。 要了解这一点,请考虑涉及位 2、7 和 9 的三位术语。 这对应于运算符
| (14) |
它作用于第一个 量子位的计算基础状态,是恒等式,除非 在这种情况下它是 。 我们从早期的工作[11]中知道,任何作用于量子位的受控单量子位元,其中控制位于第一个位上,可以写为 两个量子位酉的乘积。 因此,任何以 Reed-Muller 公式(例如 RM 项)表示的标签函数都可以写为 RM 交换 量子位运算符的乘积,并且每个都可以写为 两个量子位酉。
我们的量子表示结果类似于经典表示定理[12][13]。 这表明任何布尔标签函数都可以在深度三神经网络上表示,内层的大小为 。 当然,如此巨大的矩阵无法在传统计算机上表示。 在我们的例子中,我们自然地在指数维度的希尔伯特空间中工作,但我们可能需要指数电路深度来表达某些函数。 哪些函数可以在量子电路上紧凑地表示,而不能在经典网络上表示,这是一个开放的研究领域。 为此,我们现在探讨一些例子。
2.1表示子集奇偶校验和子集多数
考虑标签函数,它是位子集的奇偶校验。 调用子集,如果在子集中,则调用;如果不在子集中,则调用子集。 子集奇偶校验标签的 Reed-Muller 公式为
| (15) |
这只是 (12) 的线性部分,其中加法也是 mod2。 这就产生了实现子集奇偶校验的酉:
| (16) |
请注意,由于 和 的属性,指数中的加法自动为 mod2。 该电路由(至多) 组成,将两个量子位运算符交换,读出量子位位于所有两个量子位门中。 传统上,在标准神经网络上表示子集奇偶校验需要三层。
现在考虑子集多数的标签函数。 如果子集中的大多数位为 1,则标签为 1,否则标签为 。 使用 变量表示子集多数是最简单的。 那么子集多数标签可以写为
| (17) |
其中我们假设子集的大小是奇数,以避免在总和为 0 时偶数情况下出现歧义。 尽管这是一种编写子集多数的紧凑方式,但它不是 Reed Muller 形式。 我们可以将子集多数写成 (12) 的形式,但 (17) 对于我们当前的讨论来说更方便。
现在考虑单一
| (18) |
我们将立即指定 。 共轭 给出
| (19) |
所以我们有那个
| (20) |
的最大值是 ,因此如果我们将 设置为等于 ,我们就得到了
| (21) |
这意味着,如果我们重复测量 并将预期值向上舍入为 1 或向下舍入为 ,我们可以获得完美的分类误差,尽管单个样本损失值不是 1 或。 在经典机器学习子集多数中,多数是一个易于表达的标签,因为通过一层,整个数据集上的标签可以用单个超平面分隔。
3学习
在介绍和设置部分中,我们讨论了如何在每个新的训练示例中修改 以便减少样本损失。 我们现在将明确说明实现这一目标的两种策略,尽管其他策略可能会做得更好。 使用参数 和给定的训练示例 ,我们首先估计 (6) 给出的样本损失。 为此,我们在状态 (4) 下重复测量 。 为了以大于 99% 的概率实现在真实样本损失 范围内的样本损失估计,我们需要至少进行 次测量。
一旦很好地估计了样本损失,我们就需要计算样本损失相对于 的梯度。 一种直接的方法是一次改变 的一个组件。 对于每个更改的组件,我们需要重新计算损失,其中一个组件中的 与 存在少量差异。 回想一下,我们可以通过对称差来获得函数导数的二阶精确估计,
| (22) |
为了实现这一点,您需要知道每个 的 估计误差不比 更差。 为了估计 顺序 ,我们需要顺序 测量。 因此,例如,使用对称差,我们可以通过进行 阶测量来使梯度的每个分量精确到 阶。 这需要重复 次才能获得完整的渐变。
有一种替代策略用于计算梯度 [14] 的每个分量,该策略在各个酉均为 (8) 形式时有效。 考虑样本损失 (6) 相对于 的导数,而 与具有广义保利算子 的单元式 相关联。 现在
| (23) |
请注意, 和 都是酉运算符。 定义酉算子
| (24) |
所以我们将 (6) 重新表示为
| (25) |
可以被视为由 酉组成的量子电路,每个酉都仅依赖于几个量子位。 我们可以使用我们的量子设备让作用于。 使用辅助量子位,我们可以测量 (25) 的右侧。 要了解这是如何完成的,请从
| (26) |
并以 进行操作,条件是辅助量子位为 1。 这会产生
| (27) |
对辅助量子位执行 Hadamard 给出
| (28) |
现在测量辅助量子位。 得到的概率为
| (29) |
因此,通过重复测量,我们可以得到对虚部的良好估计,从而转化为梯度的第 fl 个分量的估计。 此方法避免了上一段中概述的近似梯度带来的数值精度问题。 代价是我们需要添加一个辅助量子位并运行一个深度为的电路。
给定梯度的准确估计,我们需要一个如何更新 的策略。 令为损失相对于的梯度。 现在我们要向的方向改变。 对于 中的最低顺序,我们有
| (30) |
我们希望将损失降至最低 0,因此第一个想法是
| (31) |
这样做可能会使当前训练示例的损失接近 0,但这样做可能会产生不良影响,使其他示例的损失变得更糟。 通常的机器学习技术是引入一个较小的学习率,然后设置
| (32) |
成功的机器学习艺术的一部分是明智地设置学习率,该学习率可能会随着学习的进行而变化。
我们还没有可用的量子计算机,但我们可以使用传统计算机来模拟量子过程。 当然,这仅在少量比特下才可能,因为希尔伯特空间维度为。 该模拟有一个很好的特点,一旦计算出量子态(4),我们就可以直接评估的期望值,而无需进行任何测量。 同样对于我们模拟的系统,各个酉的形式为 (8),我们可以直接计算表达式 (23)。 因此,在我们的模拟中,我们可以准确地评估梯度,而无需借助有限差分方法。
3.1 学习子集奇偶校验
作为我们的第一个例子,我们考虑学习子集奇偶校验。 回想一下,给定一个子集 ,由 (16) 给出的单一 将在所有输入字符串上表达子集奇偶校验,且样本损失为零。 为了学习,我们需要一组依赖于具有以下属性的参数的幺正:对于每个子集,都有一个生成的参数设置。 实现此目的的一个简单方法是使用 参数
| (33) |
我们看到,如果 在子集中,则 的表示是完美的;如果 不在子集中,则 的表示是完美的。 我们建立了一个数值模拟来看看我们是否可以学习这些最佳参数。 从 6 位到 16 位,从随机 开始,我们发现通过随机梯度下降,我们可以用远少于 的样本来学习子集奇偶校验标签函数,因此可以成功预测未见过的例子的标签。 我们还发现引入 10% 的标签噪声并不会妨碍学习。
然而,我们刚刚描述的是低位数的成功,我们现在认为,随着位数变得更大,子集奇偶校验变得不可能学习。 首先请注意,我们可以显式计算 的预期值
| (34) |
使用标签 ,我们可以将其插入由 (6) 给出的样本损失中。 但现在我们可以计算所有 字符串的样本损失的平均值,因为我们有明确的标签和期望公式 (34)。 根据 mod4 的值和集合 中的位数,有不同但看起来相似的公式。 具体来说,考虑是4的倍数并且集合包含所有位的情况。 在这种情况下,样本损失的所有输入的平均值(称为经验风险)为
| (35) |
我们看到,当所有 均为 时,该值达到最小值。 想象一下在 上搜索该函数的最小值。刚刚显示的函数以指数方式接近 1,除了以最佳角度为中心的指数小子体积之外。 因此,除了接近最佳角度之外,梯度呈指数小。 因此,即使我们能够获得经验风险,也无法使用基于梯度的方法来找到最佳角度,因为对于足够大的 ,梯度将低于机器精度。 当然,对于给定的训练示例,损失的梯度通常不会很小。 但平均值接近零的事实意味着各个梯度中没有足够的偏差,无法让随机梯度下降算法漂移到最佳角度附近的微小区域。
我们刚才所展示的是论文“基于梯度的深度学习的失败”[15]中探讨的现象的具体示例。 在这里,作者考虑了网络可以表达(或者如果您愿意的话可以表示)大量标签函数的情况下的机器学习。 权重的不同设置会产生不同的功能。 它们的限制是函数是正交的。 在这种情况下,他们表明,(几乎)任何权重值的经验风险梯度与用于标记数据的函数无关。 这意味着梯度不能用来区分标签函数。 在我们的例子中,我们有 不同的子集奇偶校验函数,它们确实是正交的,因此我们陷入了论文的诅咒,我们的方法注定会遇到大位数。 只要我们坚持我们的基本设置,我们就无法打破这个魔咒。
关于学习子集奇偶校验的警告。 在经典设置中,如果您有 线性独立的标记数据字符串,那么您可以使用线性代数来识别与标签关联的子集。 一旦确定了子集,就可以立即推广到所有其他输入。 在量子设置中,如果数据呈现为所有字符串的均匀叠加,其中每一项的系数具有由标签给出的 或 因子,则子集可以对叠加态[16]执行Hadamard后即可发现。 (准备此状态需要两次调用标签函数,作用于所有 系数的均匀叠加。) 然而我们不知道如何将此技巧应用于其他标签函数。
3.2 学习子集多数
回想一下,我们可以使用酉运算符 (18) 来表示子集多数,并将 设置为 。 通过根据 (21) 对 的预期值进行阈值设置,我们可以实现零分类误差。 我们感兴趣的是拥有一个参数相关的统一体,其中有与不同子集相对应的参数设置。 考虑统一
| (36) |
现在,如果 在子集中,则使用 ;如果 不在子集中,则使用 ,则使用 表示所选子集上的子集多数。 现在,我们询问是否可以根据所选子集的大部分标记给定的训练集来学习正确的 。 请注意,训练样本 的预测标签值为
| (37) |
因此向上或向下舍入给出的预测标签为
| (38) |
这个结果可以直接解释为具有单个神经元的经典神经网络,该神经元取决于权重 。 是神经元作用于输入的结果。 非线性来自应用符号函数。 但我们知道,由于数据可以用一个超平面分隔,因此这是一个可以用单个神经元轻松学习的标签。 同样的推理使我们得出这样的结论:我们的 QNN 可以被有效地训练来表示子集多数。 我们确实在小规模数值模拟中看到 QNN 能够以低样本复杂度学习子集多数。
3.3 学习区分数字
经典神经网络可以对手写数字进行分类。 典型示例来自 MNIST 数据集,该数据集由 55,000 个训练样本组成,这些样本是 28 x 28 手写数字的像素化图像,这些数字已被人类标记为代表从 0 到 9 的十个数字之一 [17]. 许多机器学习入门课程都使用此数据集作为研究简单神经网络的测试平台。 因此,我们很自然地会看到我们的量子神经网络是否可以处理 MNIST 数据。 没有明显的方法可以通过分析来解决这个问题,因此我们求助于模拟。 这里的限制是,我们只能使用具有一个读出位的 17 量子位量子计算机的经典模拟器轻松处理 16 位数据。 因此,我们使用 MNIST 数据的下采样版本,其中包含 4 x 4 像素化图像。 使用一个读出位,我们无法标记十位数字,因此我们选择两位数字,例如 3 和 6,并将数据集减少为仅包含标记为 3 或 6 的样本,并询问量子网络是否可以区分输入样本。
55,000 个训练样本分为每个数字大约 5,500 个样本的组。 但经过仔细检查,我们发现对应于数字 3 的样本由 797 个不同的 16 位字符串组成,而对于数字 6,则由 617 个不同的 16 位字符串组成。 图像很模糊,实际上有 197 个不同的字符串被标记为 3 和 6。 对于我们的数字区分任务,我们决定通过删除不明确的字符串来将贝叶斯误差减少到 0。 回到每个数字的 5,500 个样本并删除不明确的字符串,留下 3514 个标记为 3 的样本和 2517 个标记为 6 的样本。 我们将这些组合起来形成一个包含 6031 个样本的训练集
作为一个基本知识步骤,我们将标记的样本呈现给经典神经网络。 在这里,我们运行一个 Matlab 分类器,其一个内层由 10 个神经元组成。 每个神经元有 16 个系数权重和 1 个偏置权重,因此内部层有 170 个参数,输出层有 4 个参数。 经典网络可以轻松找到训练集分类误差小于百分之一的权重。 Matlab 程序还会查看泛化误差,但为此它会随机选择 15% 的输入数据用于测试集。 由于输入数据集重复出现了相同的 16 位字符串,因此测试集并不是纯粹未见过的示例。 泛化误差仍然小于百分之一。
我们现在转向量子分类器。 在这里,我们对如何设计量子电路几乎没有指导。 我们决定限制我们的酉工具包由一个和两个形式(7)的量子位运算符组成。 我们将一个量子位 视为作用于 17 个量子位中任何一个的 和 。 对于两个量子位酉,我们将任意一对不同量子位之间的 视为 和 。 我们尝试的第一件事是随机选择 500 个(或 1000 个)这样的酉元。 随机性与选择 9 种门类型中的哪一种以及门应用于哪些量子位有关。 从随机训练 500 个(或 1000 个)角度开始,在提供数百个样本后,分类误差稳定在 10% 左右。 但单个字符串的样本损失通常仅略低于 1,这对应于大多数刺痛的量子成功概率略高于 50%。 这里的趋势是正确的,但我们希望做得更好。
经过一番尝试后,我们尝试将门设置限制为 和 ,第二个量子位始终是读出量子位,第一个量子位是其他 16 个量子位之一。 这里的动机是相关联的幺正有效地将读出量子位围绕 方向旋转由数据量子位控制的量。 完整的 层有 16 个参数,就像完整的 层一样。 我们尝试了 3 层 与 3 层 的交替,总共 96 个参数。 在这里,我们发现,从一组随机角度开始,在看到少于完整样本集的数据后,我们可以获得百分之二的分类误差。
这里的成就是我们证明了量子神经网络可以学习对现实世界数据进行分类。 诚然,数据集可以很容易地通过经典网络进行分类。 并且以固定的低位数工作排除了任何有关缩放的讨论。 但我们的工作是探索性的,不需要太多努力,我们就拥有了一个可以对现实世界数据进行分类的量子电路。 现在的任务是完善量子神经网络,使其表现更好。 希望我们能找到一些指导门组选择的原则(或只是灵感)。
3.4叠加呈现的经典数据
我们专注于经典数据的监督学习,其中数据一次将一个样本字符串呈现给量子神经网络。 有了量子资源,似乎很自然地会问数据是否可以表示为量子态,量子态是与批量样本[18]相关的计算基础状态的叠加。 再次关注二元分类。 我们可以将样本空间分为标记为的样本和标记为的样本。 考虑各州
| (39) |
其中 和 是归一化因子。 此时,我们对这些阶段没有任何有启发的选择,在下面的示例中,我们只是将它们全部设置为 0。 这些状态中的每一个都可以被视为包含具有相同标签的所有样本的批次。 请注意,QNN 自然提供两种不同的批量学习策略。 在(39)中,我们将不同的样本组合成单个叠加状态,然后在合适的损失函数上评估梯度。 或者,我们可以一次计算 (6) 一个样本的梯度,然后像传统批量学习中那样对梯度进行平均。 这里我们主要关注第一种方法。
返回方程 (9),它给出与任何标签函数相关的酉。 请注意,状态 的该运算符的期望值是 ,而状态 的期望值是 。 这是因为酉在数据量子位的计算基础上是对角的,因此交叉项消失并且相位不相关。 现在考虑一个参数相关的酉,它在数据量子位的计算基础上是对角的。 使该算子作用于 所获得的状态 的期望值是量子神经网络预测的标签为 的所有样本的平均值。标签值。 对于状态 也是如此。 换句话说,如果 在数据量子位的计算基础上是对角线,那么
| (40) |
是整个样本空间的经验风险。 如果发现参数 使其为 0,则量子神经网络将正确预测训练集中任何输入的标签。
为了测试这个想法,我们研究了上一节中描述的两位数区分任务。 状态 是通过叠加与标记为数字 3 的所有字符串对应的计算基础状态而形成的。 我们选择相位全部为 0。 请注意,字符串会重复出现,因此会以不同的权重添加不同的基础状态。 类似地,状态 是对应于标记为 6 的字符串的基本状态的量子叠加。 首先,我们使用了一个在数据量子位的计算基础上呈对角线的门组。 一个简单的选择是 和 ,其中 始终作用于数据量子位,而 X 始终作用于读数。 这产生了参数。 这些门表达式 (40) 是该量子神经网络完整数据集的经验风险。 对于给定的输入参数选择,我们可以进行数值评估 (40)。 从随机选择参数开始,我们进行梯度下降以降低经验风险。 经验风险值稳定在 0.5 左右。 回想一下,根据我们的约定,值 1 对应于随机猜测,0 表示完美。 我们通过查看输入字符串随机样本的分类误差来测试学习结果。 这里的误差只有几个百分点。 请注意,我们没有遵循良好的机器学习方法,因为我们的测试字符串包含在叠加状态中。 但这里的要点是,我们可以建立一个可以用现实世界数据的叠加态进行训练的量子神经网络。
我们还将门集扩展到数据量子位计算基础上对角线之外的门集。 现在表达式(40)不再可以直接解读为量子神经网络作用于整个样本空间的经验风险。 仍然将其驱动至较低值至少意味着状态 和 已正确标记。 我们使用了一次对 MNIST 数据进行分类时使用的门集。 这些是 和 门,其中第一个量子位是数据量子位,第二个始终作用于读出。 我们再次能够将 (40) 驱动到 0.5 左右的值,并且量子神经网络在单个数据样本的测试集上具有较低的分类误差。
人们很自然地会问,使用量子批次进行学习,即与具有相同标签的字符串相对应的计算基础状态的叠加,是否比通过呈现与单个标签字符串相对应的顺序状态进行学习“更好”。 如果我们在非叠加情况下呈现新的训练示例时跟踪单个样本损失,我们会看到样本损失看似随机波动,直到平均趋势下降到较低值。 在量子批量情况下,如果我们跟踪经验风险的进展,它会平稳下降,直到稳定在局部最小值。 我们做了数值实验来对比量子批量学习和个体样本学习。 通过在 17 量子位模拟器上运行 16 位数据,我们发现在单个测试样本上获得可比较(或更好)的泛化误差所需的样本复杂性提高了一个数量级以上。 鉴于量子批次情况下的经验风险 (40) 是比单个样本损失 (6) 更“平滑”的参数函数,可能有更好的策略来最小化它比我们采用的梯度下降法。
3.5 学习量子态的性质
到目前为止,我们专注于使用量子神经网络从经典数据中学习标签。 样本数据被编码为量子态,或者是与数据串相关的计算基础状态,或者是这些状态的叠加。 但对于量子网络,输入一般量子态是很自然的,希望能够学习对作为量子态属性的标签进行分类。 现在没有经典神经网络可以尝试这项任务,因为经典网络不接受量子态作为输入。 基本思想是向量子网络呈现一个 -qubit 状态 ,并将读出量子位设置为 1 。 因此,给定一个单一的 ,我们将状态
| (41) |
然后测量。 目标是使测量结果与状态的某些二值标签相对应。 我们现在来看一个例子。
考虑哈密顿量 ,它是局部项的总和,附加假设它是无迹的,因此我们知道存在正和负特征值。 给定任何量子态 ,我们根据哈密顿量的期望值是正还是负来标记状态:
| (42) |
考虑运营商
| (43) |
我们将 取为小且正的值。 现在
| (44) |
所以对于足够小的 这接近
| (45) |
我们的预测标签的期望值与真实标签一致。 从这个意义上说,我们用具有较小分类误差的量子电路来表达标签函数。 出现错误的原因是 (44) 的右侧仅约等于 (45)。 然而,如果我们将取得远小于范数的倒数,我们就可以使误差变小。
具体来说,考虑一个图,其中在每条边上都有一个 耦合,其系数为随机选择的 +1 或 -1。 哈密顿量是
| (46) |
其中总和仅限于图中的边,并且 为 +1 或 -1。 假设中有项。我们可以首先选择 角度 并考虑实现以下形式的酉电路:
| (47) |
如果我们选择 ,我们就会在 (43) 中给出运算符 ,这确保我们可以表示标签 (42 )通过选择 小。 我们可以问是否可以学习这些权重。
我们的量子态 存在于 维希尔伯特空间中,我们可能不期望能够学习正确标记所有这些状态。 我们考虑的哈密顿量具有位结构,因此我们可能会限制也具有位结构的量子态。 例如,它们可以通过将几个量子位酉应用到一些简单的产品状态来构建。 在这种情况下,我们只会呈现这种形式的训练状态,并且只在这种形式的状态上测试我们的电路。
我们做了一个简单的数值实验,并在此报告。 使用 8 个数据量子位和 1 个输出量子位,我们抛出了一个随机 3 正则图,该图相应地具有 12 条边。 在本例中,有 12 个参数 用于构成运算符 (47)。 对于我们的训练状态,我们使用依赖于 8 个随机角度的乘积状态。 该状态是通过旋转 8 个量子位中的每一个而形成的,每个量子位都以相关 算子的本征态开始,围绕 轴旋转相关的随机角度。 测试状态以相同的方式形成。 由于状态是从连续体中随机选择的,我们可以确信训练集和测试集是不同的。 在呈现大约 1000 个测试状态后,量子网络正确标记了 97% 的测试状态。 我们扩展了幺正类以包含更多参数。 在这里,我们引入了两层 和 单位,其形式为 (7),其中第一个运算符作用于 8 个数据量子位之一,第二个运算符作用于读出量子位。 这又引入了 32 个参数,总共 44 个参数。 在看到大约 1000 个训练示例后,我们发现我们的学习过程再次可以实现 3% 的分类误差。
我们简单的数值示例表明,量子神经网络可以学习对来自希尔伯特空间子集的标记量子态进行分类。 学习的概括超出了训练集。 注意事项:我们用于训练和测试 QNN 的状态来自作用于简单乘积状态的简单幺正。 因此,对这些状态有一个经典的描述。 人们可以想象 QNN 的一个经典竞争对手,它采用输入状态的描述和量子哈密顿量的描述,并询问标签 (42) 是否可以通过纯经典过程来学习。 但希望我们在这里所演示的内容能够在量子计量学或量子网络的其他用途中得到应用,这些量子网络对量子态进行分类,而对于量子态的紧凑经典描述是不可用的。
4结论与展望
在不久的将来,我们将拥有具有足够数量的量子位和足够高的门保真度的门模型量子计算机,以运行足够深度的电路来执行经典计算机无法模拟的任务[19][20][21][22][23]。 设计在此类设备上运行的量子算法的一种方法是让硬件架构确定使用哪些门集[5]。 在本文中,与之前的工作[24][25]相比,我们建立了一个用于量子设备上监督学习的通用框架,该框架特别适合在我们希望在短期内推出量子处理器。
首先,我们展示了使用量子设备对经典数据进行分类的通用框架。 使用标记的经典数据作为输入,我们将输入字符串映射到呈现给量子设备的计算基础状态。 然后在读出量子位上测量泡利算子。 目标是使测量结果与输入字符串的正确二进制标签相对应。 我们展示了如何设计一个原则上可以表示 位数据的所有布尔标签函数的量子神经网络。 该电路是两个量子位酉的序列,但对于某些标签函数,电路可能需要在 中呈指数长度。这种表示结果,类似于经典的表示结果,使我们能够转向学习的问题。
我们想象运行的量子电路是由一个和两个量子位酉组成的序列,每个量子位酉都取决于几个参数。 这些酉可能来自实验者提供的门工具包。 如果没有纠错,可以应用的门的数量受到各个门保真度和可以容忍的最终误差的限制。 在理论研究中,我们可以想象可以访问任何一组运行良好的本地门。 对于给定的一组门,仍然不清楚可以表示或学习哪些标签函数。 为了学习,我们从参数化门集开始,并向量子设备提供数据样本。 输出量子位被测量,可能会重复测量以获得良好的精度。 然后稍微改变参数,以使输出更有可能对应于正确的标签。 这种更新参数(或机器语言用语中的权重)的方法是传统监督学习环境中倾向于对数据进行分类的标准做法。 最终目标是能够正确分类训练期间未见过的数据。
作为我们方法的演示,我们研究了使用量子神经网络来区分数字。 在这里,我们使用了两个不同手写数字的下采样图像的数据集。 每个图像由 16 个数据位和一个标签组成,该标签说明图像代表两个数字中的哪一个。 由于尚未获得实际的 17 个量子位无错误的量子计算机,我们运行了一台经典计算机作为量子设备的模拟器。 我们选择了一个简单的参数化门集,并从随机参数开始。 使用随机梯度下降,我们能够学习以小误差标记数据的参数。 这项练习证明了我们的量子方法可用于对现实世界数据进行分类的原理。
通过量子网络,尝试以叠加方式呈现经典数据似乎是很自然的。 单个量子态是计算基础状态的叠加,每个状态代表“批次”样本中的单个样本,可以被视为该批次的量子编码。 这里,组件上的不同相会产生不同的量子态。 回到我们的数字区分示例,我们形成了两个量子态,每个量子态都是与所选数字之一对应的所有数据样本的均匀(零相位角)叠加。 任一状态都可以呈现给量子神经网络。 然后我们可以测量两种状态之间 期望值的差异。 这是经验风险的量子模拟。 借助手头的模拟器,我们对这种差异进行数值评估,这是所有输入样本的一次性图片。 对参数进行梯度下降,我们发现参数值可以使量子电路在测试数据上具有较低的分类误差。
当然,经典数据并不以量子叠加的形式出现。 因此,要运行之前的协议,必须将数据读入准备叠加的量子设备中。 叠加被量子网络消耗,因此为了运行梯度下降,必须制作叠加的新副本。 或者也许可以在一开始就制作叠加的许多副本并存储以供以后使用。 这里有探索降低计算成本的策略的空间。
我们还研究了学习作为一般量子态属性的标签。 这里的想法是向量子神经网络呈现量子状态,并训练网络来预测未见过的示例状态的标签。 具体来说,我们考虑了一个具有正特征值和负特征值的局部哈密顿量的量子系统。 如果哈密顿量的期望值为正,则量子态的标签为 ;如果期望值为负,则标签为 。 维希尔伯特空间中的所有状态都有这样的标签。 但我们将注意力限制在那些可以通过将局部酉变换应用于简单乘积状态(例如全 0 计算基础状态)而得到的状态。 通过这种方式,所探索的状态具有与哈密顿量相同的位结构。 我们在 量子比特上进行了数值模拟,看看这个想法是否能够落地。 在这里,我们向参数化电路展示了产品状态。 我们发现可以学习参数,使量子网络能够在新示例上正确预测哈密顿量期望值的符号。
我们的工作为构建量子神经网络制定了一个特定的框架,可用于对经典数据和量子数据进行监督学习。 我们的数值工作受到以下事实的限制:在经典机器上只能模拟小型量子设备。 如果需要比我们愿意花费的资源和精力更多的资源和精力,就可以进行 40 个量子位模拟。 但我们的模拟是探索性的,对于如何选择门组几乎没有(或没有)指导,我们采用了每次试验有限模拟时间的策略,这样我们就可以尝试许多不同的电路。 采用这种方法,我们的量子比特数不超过 17 个。 根据我们的数据,我们无法证明监督学习相对于传统竞争对手有任何量子优势。 当然,以标记的量子态作为输入,足够复杂以至于不存在简洁的经典描述,也没有经典对应物,因此无法进行比较。 我们所做的是证明量子神经网络可以用来对数据进行分类。
尽管如此,我们的框架仍有望在近期无法进行经典模拟的量子设备上实现。 可能有些任务只有量子设备才能处理。 在足够大的尺寸下,可能会看到量子方法相对于相应的经典方法的优势。 近期可用的量子处理器可能只允许适度数量的输入变量。 在这种情况下,可以通过使用经典量子混合架构来加速 QNN 在现实世界任务中的应用,其中神经网络的第一层以经典方式实现,只有通常较小的最后层被实现为 QNN。
传统的机器学习从诞生到建立监督学习的通用框架花了很多年的时间。 我们正处于量子神经网络设计的探索阶段。 返回图1。 在我们的框架中,量子态作为输入,测量单个量子位以给出预测的标签。 请注意,我们不使用量子位 到 中包含的信息。这样做可以激发新颖的网络设计[26]。 位于输入和输出之间的量子电路有无穷无尽的选择。 我们希望其他人能够发现能够发挥量子神经网络全部功能的选择。
致谢
我们要感谢拉里·阿博特、杰弗里·戈德斯通和塞缪尔·古特曼分享他们的人类智慧。 我们要感谢 Matthew Coudron 在 Google 暑期实习期间进行的宝贵讨论,感谢 Vincent Vanhoucke 鼓励我们将 QNN 应用于 MNIST 的低分辨率版本,感谢 Vasil Denchev 提供实施帮助,感谢 Nan Ding 分享他的机器学习智慧。 我们还感谢查尔斯·萨格斯提供的技术援助。 EF 得到了美国国家科学基金会(编号为 CCF-1525130)的国家科学基金会和陆军研究办公室(W911NF-17-1-0433 号合同)的部分支持。
参考
- [1] Y. LeCun, Y. Bengio and G. Hinton “Deep Learning” In Nature 521 Nature Publishing Group, a division of Macmillan Publishers Limited. All Rights Reserved., 2014
- [2] I. Goodfellow, Y. Bengio and A. Courville “Deep Learning” MIT Press. Cambridge, MA, 2016
- [3] J. Biamonte et al. “Quantum machine learning” In Nature 549, 2017, pp. 195–202 arXiv:1611.09347 [quant-ph]
- [4] M. Schuld, I. Sinayskiy and F. Petruccione “An introduction to quantum machine learning” In Contemporary Physics 56, 2015, pp. 172–185 arXiv:1409.3097 [quant-ph]
- [5] E. Farhi, J. Goldstone, S. Gutmann and H. Neven “Quantum Algorithms for Fixed Qubit Architectures” In ArXiv e-prints, 2017 arXiv:1703.06199 [quant-ph]
- [6] M. Arjovsky, A. Shah and Y. Bengio “Unitary Evolution Recurrent Neural Networks” In ArXiv e-prints, 2015 arXiv:1511.06464 [cs.LG]
- [7] V. Dunjko, Y.-K. Liu, X. Wu and J. M. Taylor “Super-polynomial and exponential improvements for quantum-enhanced reinforcement learning” In ArXiv e-prints, 2017 arXiv:1710.11160 [quant-ph]
- [8] C. Trabelsi et al. “Deep Complex Networks” In ArXiv e-prints, 2017 arXiv:1705.09792
- [9] S. L. Hyland and G. Rätsch “Learning Unitary Operators with Help From u(n)” In ArXiv e-prints, 2016 arXiv:1607.04903 [stat.ML]
- [10] S. Yoo, J. Bang, C. Lee and J. Lee “A quantum speedup in machine learning: finding an N-bit Boolean function for a classification” In New Journal of Physics 16.10, 2014, pp. 103014 DOI: 10.1088/1367-2630/16/10/103014
- [11] Barenco Adriano al “Elementary gates for quantum computation” In Phys. Rev. A52, 1995, pp. 3457 arXiv:quant-ph/9503016 [quant-ph]
- [12] G. Cybenko “Approximations by superpositions of sigmoidal functions” , Mathematics ofControl, Signals, and Systems” In Mathematics of Control, Signals, and Systems 2, 1989
- [13] Kurt Hornik “Approximation capabilities of multilayer feedforward networks” In Neural Networks 4.2, 1991, pp. 251 –257 URL: http://www.sciencedirect.com/science/article/pii/089360809190009T
- [14] J. Romero et al. “Strategies for quantum computing molecular energies using the unitary coupled cluster ansatz” In ArXiv e-prints, 2017 arXiv:1701.02691 [quant-ph]
- [15] Shai Shalev-Shwartz, Ohad Shamir and Shaked Shammah “Failures of Deep Learning” In CoRR abs/1703.07950, 2017 arXiv: http://arxiv.org/abs/1703.07950
- [16] D. Ristè et al. “Demonstration of quantum advantage in machine learning” In ArXiv e-prints, 2015 arXiv:1512.06069 [quant-ph]
- [17] LeCun Yann and Cortes Corinna “MNIST handwritten digit database”, http://yann.lecun.com/exdb/mnist/, 2010 URL: http://yann.lecun.com/exdb/mnist/
- [18] Patrick Rebentrost, Masoud Mohseni and Seth Lloyd “Quantum Support Vector Machine for Big Data Classification” In Phys. Rev. Lett. 113 American Physical Society, 2014, pp. 130503 DOI: 10.1103/PhysRevLett.113.130503
- [19] J. S. Otterbach et al. “Unsupervised Machine Learning on a Hybrid Quantum Computer” In ArXiv e-prints, 2017 arXiv:1712.05771 [quant-ph]
- [20] , Online URL: https://www-03.ibm.com/press/us/en/pressrelease/53374.wss
- [21] R. Barends al. “Superconducting quantum circuits at the surface code threshold for fault tolerance” In Nature 508 Nature Publishing Group, a division of Macmillan Publishers Limited. All Rights Reserved., 2014
- [22] A. D. Córcoles et.al. “Demonstration of a quantum error detection code using a square lattice of four superconducting qubits” In Nature Communications 6 The Author(s) SN -, 2015
- [23] S. Debnath et. al. “Demonstration of a small programmable quantum computer with atomic qubits” In Nature 536 Macmillan Publishers Limited, part of Springer Nature. All rights reserved., 2016
- [24] Y. Cao, G. Giacomo Guerreschi and A. Aspuru-Guzik “Quantum Neuron: an elementary building block for machine learning on quantum computers” In ArXiv e-prints, 2017 arXiv:1711.11240 [quant-ph]
- [25] K. H. Wan, O. Dahlsten, R. Kristjánsson and M. S. Kim “Quantum generalisation of feedforward neural networks” In npj Quantum Information 3, 2017, pp. 36 arXiv:1612.01045 [quant-ph]
- [26] J. Romero, J. P. Olson and A. Aspuru-Guzik “Quantum autoencoders for efficient compression of quantum data” In Quantum Science and Technology 2.4, 2017, pp. 045001 DOI: 10.1088/2058-9565/aa8072