通过先验网络进行预测不确定性估计
摘要
估计人工智能系统预测的不确定性对于提高此类系统的安全性非常重要。 预测的不确定性可能是由于模型参数的不确定性、不可约的数据不确定性以及由于测试和训练数据分布之间的分布不匹配而导致的不确定性。 根据不确定性的来源,可能会采取不同的行动,因此能够区分它们很重要。 最近,定义了基线任务和指标,并开发了几种估计不确定性的实用方法。 然而,这些方法试图通过模型不确定性隐式地或作为数据不确定性来对由于分布不匹配而导致的不确定性进行建模。 这项工作提出了一种新的预测不确定性建模框架,称为先验网络 (PN),它明确地模拟分布不确定性。 PN 通过参数化预测分布上的先验分布来实现此目的。 这项工作重点关注分类的不确定性,并在 MNIST 和 CIFAR-10 数据集上识别分布外 (OOD) 样本和检测错误分类的任务中评估 PN,结果发现它们的性能优于以前的方法。 对合成数据和 MNIST 数据的实验表明,与之前的非贝叶斯方法不同,PN 能够区分数据和分布不确定性。
1简介
神经网络 (NN) 已成为解决计算机视觉 (CV) [1, 2, 3]、自然语言处理 (NLP) [4, 5, 6] 问题的主要方法t1>、语音识别 (ASR) [7, 8] 和生物信息学 (BI) [9, 10] 任务。 尽管监督学习性能令人印象深刻且不断改进,但神经网络往往会做出过于自信的预测[11],并且直到最近还无法提供预测中的不确定性度量。 估计模型预测的不确定性非常重要,因为它可以通过以知情的方式对模型的预测采取行动来提高人工智能系统[12]的安全性。 这对于错误成本很高的应用至关重要,例如自动驾驶车辆控制以及医疗、金融和法律领域。
最近,通过定义基线、任务和指标[13]以及开发估计不确定性的实用方法,深度学习的预测不确定性取得了显着进展。 一类方法源于贝叶斯神经网络[14,15,16,17]。 传统上,这些方法比非贝叶斯神经网络计算要求更高,概念更复杂。 至关重要的是,它们的性能取决于由于计算限制和参数先验分布的性质而进行的近似形式。 最近的发展是蒙特卡罗 Dropout [18] 技术,该技术使用多个随机前向传递的集合并计算集合的均值和扩展来估计预测不确定性。 该技术已成功应用于计算机视觉任务[19, 20]。 还提出了许多非贝叶斯集成方法。 一种基于显式训练 DNN 集合的方法(称为深度集合[11])可以产生对 MC dropout 的竞争性不确定性估计。 另一类方法是为回归[21]和分类[22]开发的,涉及以多任务方式显式训练模型以最小化其Kullback-Leibler( KL)发散到尖锐的域内预测后验和平坦的域外预测后验,其中域外输入是在训练期间从合成噪声分布或不同数据集采样的。 这些方法经过明确训练以检测分布外的输入,并具有在测试时计算效率更高的优点。
这些方法的主要问题是它们混淆了预测不确定性的不同方面,而预测不确定性是由三个独立因素造成的 - 模型不确定性、数据不确定性和分布不确定性 t2>。 模型不确定性或认知不确定性 [23],衡量给定训练数据估计模型参数的不确定性 - 这衡量模型的效果与数据匹配。 模型不确定性是可以减少的111达到可识别性限制。 在无限数据的限制下 产生等效的参数化。 随着训练数据大小的增加。 数据不确定性或任意不确定性 [23]是由于数据的自然复杂性而产生的不可约的不确定性,例如类别重叠、标签噪声、同方差和异方差噪声。 数据不确定性可以被视为“已知-未知” - 模型理解(知道)数据并可以自信地说明给定输入是否难以分类(未知)。 分布不确定性是由于训练分布和测试分布之间的不匹配(也称为数据集偏移[24])而产生的 - 这种情况经常出现在现实世界的问题中。 分布不确定性是一种“未知的未知”——模型不熟悉测试数据,因此无法自信地做出预测。 上面讨论的方法要么将分布不确定性与数据不确定性混为一谈,要么通过模型不确定性隐式建模分布不确定性,如下所示贝叶斯方法。 分别对 3 种预测不确定性进行建模的能力非常重要,因为模型可以根据不确定性的来源采取不同的操作。 例如,在主动学习任务中,检测分布不确定性将表明需要从该分布中收集训练数据。 这项工作通过扩展 [21, 22] 中所做的工作,同时从贝叶斯方法中汲取灵感,解决了对三种类型的预测不确定性的显式预测。
贡献摘要。 这项工作描述了先前获得不确定性估计的方法的局限性,并提出了一种用于建模预测不确定性的新框架,称为先验网络(PN),它允许将分布不确定性视为与不同的分布不确定性。数据不确定性和模型不确定性。 这项工作重点关注 PN 在分类任务中的应用。 此外,这项工作还讨论了每个不确定性来源背景下的一系列不确定性指标。 对合成数据和真实数据的实验表明,与之前的非贝叶斯方法不同,PN 能够区分数据不确定性 和分布不确定性。 最后,PN 在识别分布外 (OOD) 样本和检测错误分类的任务上进行了评估,如 [13] 中所述,它们在 MNIST 和 CIFAR-10 数据集上的表现优于之前的方法。
2 当前不确定性估计方法
本节描述当前预测不确定性估计的方法。 考虑输入特征 和标签 上的分布 。 对于图像分类, 对应于图像和 对象标签。 在贝叶斯框架中,分类模型的预测不确定性 222使用 的标准简写。 在有限数据集上进行训练将由数据(任意)不确定性和模型(认知)不确定性产生。 模型对数据不确定性的估计由给定一组模型参数的类标签的后验分布描述,模型不确定性由后验分布描述给定数据的参数分布(eq. 1)。
| (1) |
这里,模型参数的不确定性导致了分布 上的分布。 预期分布是通过边缘化参数获得的。 不幸的是,使用贝叶斯规则获得真实的后验 是很困难的,并且有必要使用显式或隐式变分近似 [25, 26, 27, 28]:
| (2) |
此外,方程中的积分。 1 对于神经网络来说也很棘手,通常通过采样(等式3)来近似,使用蒙特卡罗 dropout 等方法 [18] 、 Langevin Dynamics [29] 或显式集成 [11]。 因此,
| (3) |
从 中采样得到的集合 中的每个 都是分类分布 333Where is a vector of probabilities: 是以输入为条件的类别标签 上的概率向量,可视化为单纯形上的一个点。 对于相同的,这个集合是单纯形上的点的集合(图1a),它可以被视为来自单纯形上的隐式条件分布的分类分布样本(图 1b)是通过模型参数的后验得出的。
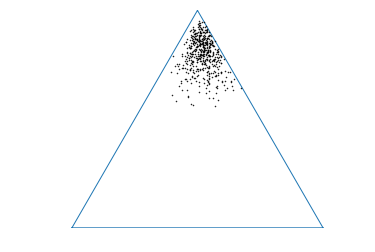

通过选择适当的近似推理方案和模型先验 贝叶斯方法旨在制作一个近似模型后验 ,使得集合 在以下区域中保持一致:训练数据,并且当输入 远离训练数据时变得越来越多样化。 因此,这些方法的目的是在单纯形上制作隐式条件分布(图 1b),其属性是,对于类似于训练数据的输入,它在单纯形的拐角处是尖锐的;对于分布外的输入,它在单纯形上是平坦的输入。 给定来自这种分布的集合,预期分布的熵将表明预测的不确定性。 然而,不可能从训练熵确定这种不确定性是否是由于高度的数据不确定性,或者输入是否远离数据区域。 有必要使用集合传播的度量(例如互信息)来评估由于模型不确定性而导致的预测不确定性。 这使得可以确定不确定性的来源。
然而,在实践中,对于具有数千万参数的深度分布式黑盒模型(例如 DNN),很难选择合适的模型先验和近似推理方案来制作模型后验,从而诱导具有所需的隐式分布。特性。 这使得很难保证当前最先进的深度学习方法所期望的诱导分布特性。 此外,创建集成的计算成本可能很高。
另一种非贝叶斯方法通过回归 [21] 和分类 [13, 22, 30] DNN 的预测后验导出不确定性度量。 在这里,DNN 经过显式训练 [22, 21] 来为分布外输入生成高熵后验分布。 这些方法很容易训练,推理的计算成本也很低。 然而,类上的高熵后验可能表明预测存在不确定性,因为类重叠区域中的分布内输入或远离训练数据的分布外输入。 因此,使用这些方法不可能稳健地确定不确定性的来源。 不确定性度量的进一步讨论可以在4节中找到。
3 先前网络
在描述了现有方法之后,本节提出了一种建模预测不确定性的替代方法,称为先验网络。 如前所述,贝叶斯方法旨在通过适当选择模型先验和近似推理方法,在具有某些所需属性的单纯形(图 1b)上的分布上构造隐式条件分布。 实际上,这是一项艰巨的任务,也是一个开放的研究问题。
这项工作建议使用称为先验网络的 DNN 来显式参数化单纯形分布上的分布,,并将其训练为其行为类似于贝叶斯方法中的隐式分布。 具体来说,当先验网络对其预测有信心时,它应该产生以单纯形的一个角为中心的尖锐分布(图2a)。 对于具有高度噪声或类别重叠(数据不确定性)的区域中的输入,先验网络应产生集中于单纯形中心的尖锐分布,这对应于有信心预测平坦类标签上的分类分布(已知-未知)(图2b)。 最后,对于“分布外”输入,先验网络应在单纯形上产生平坦分布,这表明映射 中存在很大的不确定性(未知-未知)(图 2c)。

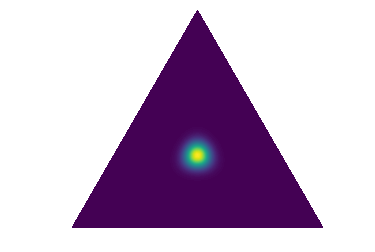
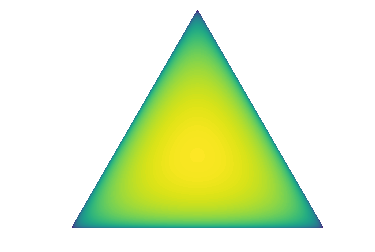
在贝叶斯框架中,分布不确定性,或由于测试和训练数据分布不匹配而导致的不确定性,被视为模型不确定性的一部分。 在这项工作中,它将被视为独立于数据不确定性或模型不确定性的不确定性来源。 先验网络将被明确构建以捕获数据不确定性和分布不确定性。 在先验网络中,数据不确定性由点估计分类分布描述,分布不确定性由预测分类分布 先验网络的参数 必须封装有关域内分布和将域内区域与其他区域分开的决策边界的知识。 先验网络的构建在3.1和3.2部分讨论。 在此之前,有必要先讨论一下它的理论性质。
考虑修改方程。 1 通过引入术语 如下:
| (4) |
在这个表达式中,数据、分布和模型不确定性现在分别由可解释的概率框架内的单独项建模。 不确定性之间的关系变得明确 - 模型不确定性影响分布不确定性的估计,进而影响数据不确定性的估计。 这是预料之中的,因为较大程度的模型不确定性将产生的较大变化,而的较大不确定性将导致较大的不确定性数据不确定性的估计。 因此,模型不确定性影响数据和分布不确定性的估计,而分布不确定性影响数据的估计不确定性。 这形成了一个层次模型 - 现在存在三层不确定性:类的后验分布、每个数据的先验分布和模型参数的全局后验分布。 之前已经针对非神经贝叶斯模型探索了类似的结构,例如潜在狄利克雷分配[31]。 然而,通常会添加额外的不确定性,以提高模型的灵活性,并通过边缘化或抽样来获得预测。 然而,在这项工作中,添加了额外的不确定性水平,以便能够提取额外的不确定性度量,具体取决于模型的边缘化方式。 例如,考虑将等式中的 边缘化。 4,从而重新得到eq. 1:
| (5) |
由于 上的分布在边缘化中丢失,因此不知道它在点估计周围的尖锐程度或平坦程度。 如果预期的分类 为“平坦”,现在尚不清楚这是由于高数据还是分布不确定性。 在这种情况下,有必要再次依靠评估 MC 系综传播的措施,例如互信息(第 4 节),来确定不确定性的来源。 因此,先验网络与以前的贝叶斯和非贝叶斯不确定性建模方法是一致的——它们可以被视为“不确定性工具箱中的额外工具”,它是专门为以概率可解释的方式捕获分布不匹配的影响而设计的。 。 或者,考虑边缘化等式中的。 4如下:
| (6) |
考虑到模型不确定性,这会产生数据和分布不确定性的预期估计。 等式。 6 可以看作是等式的修改。 1,其中训练模型被重新定义为 ,模型参数分布 现在取决于数据 和测试输入。 这明确地产生了贝叶斯方法隐式导出的单纯形上的分布。 4 节进一步讨论了如何从方程 4 的边缘化中导出不确定性度量。
不幸的是,就像等式一样。 1,等式中的边缘化。 6 通常很难处理,尽管它可以通过贝叶斯 MC 方法进行近似。 为简单起见,这项工作将假设给定适当的正则化和训练数据大小,参数的点估计(eq. 7)就足够了。
| (7) |
3.1狄利克雷先验网络
用于分类的先验网络参数化单纯形上的分布,例如狄利克雷(eq. 8)、狄利克雷分布的混合或 Logistic-Normal 分布。 在这项工作中,选择狄利克雷分布是因为其易于处理的分析特性。 狄利克雷分布是分类分布的先验分布,由其浓度参数 参数化,其中 是所有 的总和,称为狄利克雷分布的精度。 值越高,分布越尖锐。
| (8) |
参数化狄利克雷先验网络将被称为狄利克雷先验网络(DPN)。 DPN 将生成狄利克雷分布的浓度参数。
| (9) |
类标签的后验将由狄利克雷平均值给出:
| (10) |
如果 DPN 使用指数输出函数,其中 ,则标签 的预期后验概率由 softmax 的输出给出(eq. 11)。
| (11) |
因此,使用 softmax 输出函数进行分类的标准 DNN 可以被视为预测狄利克雷先验下的预期分类分布。 然而,平均值对 的任意缩放不敏感。 因此,控制狄利克雷清晰度的精度在标准交叉熵训练下是退化的。 有必要更改成本函数以显式训练 DPN,以根据输入数据在预期分类周围产生尖锐或平坦的先验分布。
3.2 狄利克雷先验网络训练
训练先验网络的方法可能有很多种,但本工作的重点并不是对所有方法进行研究。 这项工作考虑了一种基于 [21, 22] 和此处完成的工作来训练 DPN 的方法。 DPN 以多任务方式显式训练,以最小化模型与集中于适当类别的尖锐狄利克雷分布之间的 KL 散度(等式 12) -分布数据,以及模型与分布外数据的平坦狄利克雷分布之间的关系。 根据理由不足原则[32],选择平坦狄利克雷作为不确定分布,因为所有可能的分类分布都是等概率的。
| (12) |
为了使用此损失函数进行训练,必须定义分布内目标 和分布外目标 。 通过设置所有 可以简单地指定平坦狄利克雷分布。 然而,直接设置分发内目标并不方便。 相反,浓度参数 被重新参数化为 、目标精度和平均值 。 是训练时设置的超参数,均值就是用于分类的1-hot目标。 更复杂的是,学习稀疏的“1-hot”连续分布(实际上是 delta 函数)在定义的 KL 损失下具有挑战性,因为误差表面变得不太适合优化。 有两种解决方案 - 首先,可以平滑目标均值(eq. 15),这将少量概率密度重新分配到狄利克雷的其他角。 或者,教师-学生训练[33]可用于指定非稀疏目标手段。 这项工作中使用了平滑方法。 此外,交叉熵可以用作分布数据的辅助损失。
| (15) |
多任务训练目标(eq.12)需要来自域外分布的样本。 然而,真正的域外分布未知,并且样本不可用。 一种解决方案是使用生成模型[21, 22]综合生成域内区域边界上的点。 另一种方法是使用不同的真实数据集作为域外分布 [22] 中的一组样本。
4 不确定性测量
上一节介绍了一个用于建模不确定性的新框架。 本节探讨了在给定训练有素的 DNN、DPN 或贝叶斯 MC 集成的情况下量化不确定性的一系列措施。 讨论分为 4 类测量,具体取决于 eq 的方式。 4 被边缘化。 推导的细节可以在附录C中找到。
第一类从预期的预测分类 中导出不确定性的度量,给定等式的完全边缘化。 4 可以通过参数 的点估计或贝叶斯 MC 系综来近似。 第一个度量是预测类别(模式)的概率,或最大概率(等式16),它是[13,22,30,23,11]。
| (16) |
第二个度量是预测分布[23,18,11]的熵(等式17)。 它的行为类似于最大概率,但表示整个分布中包含的不确定性。
| (17) |
预期分布的最大概率和熵可以被视为预测中总不确定性的度量。
第二类措施考虑边缘化等式中的。 4,产生等式。 1。 分类标签 和模型参数 之间的互信息 (MI) [23] 是对集合 [18]的分布,用于评估由于模型不确定性而导致的预测不确定性。 因此,MI 隐含地捕捉了分布不确定性的要素。 MI 可以表示为由预期分布的熵捕获的总不确定性与由集合中每个成员的预期熵捕获的预期数据不确定性之间的差异(等式18)。 [34]中给出了这种解释。
| (18) |
第三类措施考虑边缘化等式中的。 4,产生等式。 6。 该类中的第一个度量是 和 之间的互信息(式 19),其行为方式与 和 之间的 MI 完全相同,但现在的传播明确是由于分布的不确定性,而不是模型的不确定性。
| (19) |
不确定性的另一个度量是 DPN 的微分熵(eq.20)。 当所有分类分布都是等概率时(当狄利克雷分布平坦时,即当狄利克雷先验中的样本种类最多时),此度量最大化。 微分熵非常适合测量分布不确定性,因为即使狄利克雷先验下的预期分类具有高熵,它也可能很低,并且还捕获数据不确定性的元素。
| (20) |
最后一类措施使用完整的方程。 4 并通过 和 之间的 MI 评估由于模型不确定性而导致的 的分布,这可以通过贝叶斯计算合奏接近。
5实验
前面的部分讨论了对预测不确定性的不同方面进行建模,并提出了几种量化不确定性的方法。 本节在两组实验中比较了所提出的方法和以前的方法。 第一个实验说明了 DPN 相对于其他非贝叶斯方法在合成数据上的优势[22, 30],第二组实验评估了 MNIST 和 CIFAR-10 上的 DPN,并将它们与 DNN 和通过 Monte-Carlo Dropout (MCDP) 生成的集成用于错误分类检测和分布外数据检测的任务。 附录 A 中描述了实验设置,附录 B 中描述了其他实验。
5.1合成实验
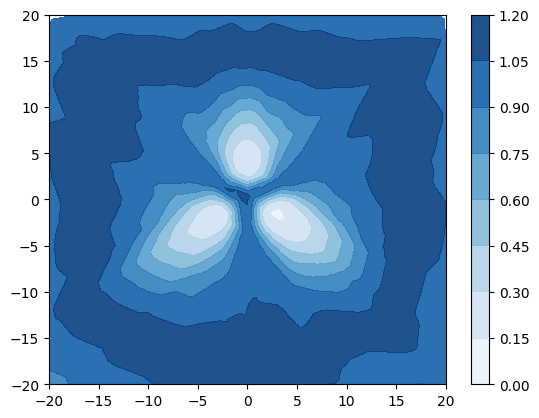
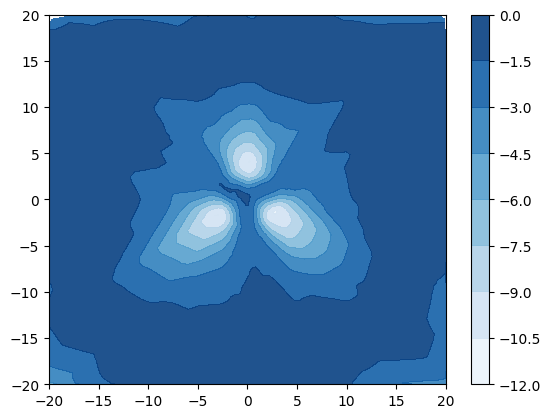
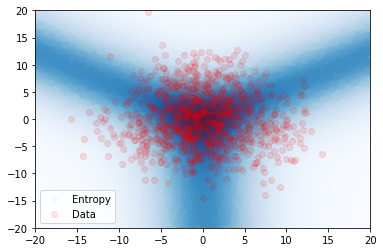
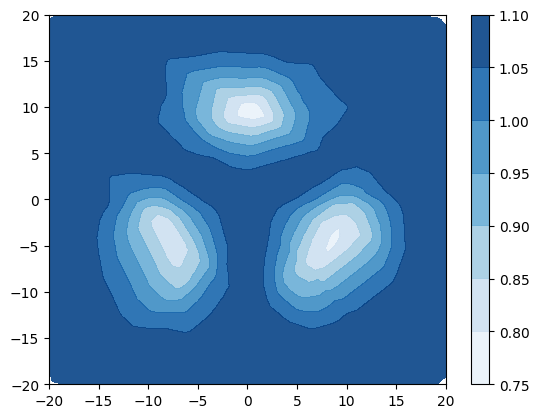
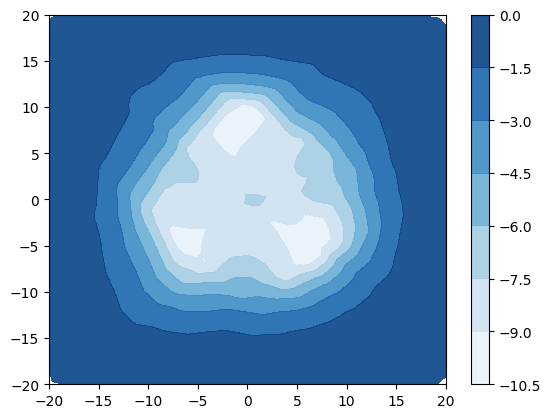
设计了一项综合实验来说明使用源自 [22, 30] 的不确定性度量来检测分布外样本的局限性。 创建了一个简单的数据集,其中包含 3 个具有等距均值和绑定各向同性方差 的高斯分布类。 当 时,类不重叠(图 3a),当 时,类重叠(图 3d) 。 类别标签上的 true 后验熵在图 3a 和 3d 中以蓝色绘制,这表明当类别不同时熵仅在决策边界上很高,但是当类重叠时,熵在数据区域内也很高。 根据该数据训练具有 1 个隐藏层、50 个神经元的小型 DPN。 图 3b 和 3c 显示,当类别不同时,DPN 的预测后验熵和 DPN 的微分熵具有相同的行为 - 在数据和其他地方较高,从而可以区分分布内和分布外区域。 然而,图 3e 和 3f 表明,当类重叠程度较大时,熵和微分熵具有不同的行为 - 熵在类重叠且远离训练数据,使得难以在决策边界区分分布外样本和分布内样本。 相比之下,训练数据的整个区域的微分熵较低,外部的微分熵较高,从而可以清楚地区分分布内区域和分布外区域。

5.2MNIST 和 CIFAR-10 实验
在 MNIST 和 CIFAR-10 数据集[35, 36]上运行域内误分类检测实验和分布外 (OOD) 输入检测实验,以评估 DPN 估计不确定性的能力。 错误分类检测实验涉及在给定不确定性度量的情况下检测给定的预测是否不正确。 错误分类被选择为正类。 错误分类检测实验在 MNIST valid+test 集和 CIFAR-10 测试集上运行。 分布外检测实验涉及在给定不确定性度量的情况下检测输入是否分布外。 选择分布外样本作为正类。 缩小至 28x28 像素的 OMNIGLOT 数据集 [37] 被用作 MNIST 的真实“OOD”数据。 随机选择 15000 个 OMNIGLOT 数据样本,形成一组平衡的正样本(OMNIGLOT)和负样本(MNIST 有效+测试)。 对于 CIFAR-10,考虑了三个 OOD 数据集 - SVHN、LSUN 和 TinyImagetNet (TIM)[38,39,40]。 所考虑的两种基线方法从 DNN [13] 的类后验或通过应用于同一 DNN [23, 18] 的 MC dropout 生成的集合导出不确定性度量。 第 4 节中描述的所有不确定性度量都针对这两项任务进行了探索,以便了解哪种可以产生最佳性能。 在两个实验中,性能均通过 ROC (AUROC) 和精确召回 (AUPR) 曲线下面积进行评估,如 [13] 中所示。
Data Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. MNIST DNN 98.0 98.6 - - 26.6 25.0 - - 0.4 MCDP 97.2 97.2 96.9 - 33.0 29.0 27.8 - 0.4 DPN 99.0 98.9 98.6 92.9 43.6 39.7 30.7 25.5 0.6 CIFAR10 DNN 92.4 92.3 - - 48.7 47.1 - - 8.0 MCDP 92.5 92.0 90.4 - 48.4 45.5 37.6 - 8.0 DPN 92.2 92.1 92.1 90.9 52.7 51.0 51.0 45.5 8.5
表 1 显示,DPN 在错误分类检测性能方面始终优于 DNN 和 MC dropout ensemble (MCDP),尽管与 DNN 或 MCDP 相比,DPN 的准确性下降可以忽略不计。 最大概率产生最好的结果,紧随其后的是预测分布的熵。 这是预期的,因为最大概率与预测类别直接相关,而其他度量则捕获整个分布的不确定性。 性能差异在 AUPR 上更为明显,它对不平衡的类很敏感。
表 2 显示,对于 MNIST 和 CIFAR-10 数据集,DPN 在 OOD 样本检测中始终优于基线。 在 MNIST 上,DPN 能够使用最大概率、熵和微分熵对所有样本进行完美分类。 在 CIFAR-10 数据集上,DPN 始终大幅优于基线。 虽然针对 SVHN 和 LSUN 的高性能是预期的,但由于 LSUN、SVHN 和 CIFAR-10 有很大不同,针对 TinyImageNet(也是真实对象的数据集,因此更接近 CIFAR-10)的高性能更令人印象深刻。 奇怪的是,MC dropout 并不总是比标准 DNN 产生更好的结果,这支持了贝叶斯分布很难在分布上实现所需行为的断言。
Data Model AUROC AUPR ID OOD Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. MNIST OMNI DNN 98.7 98.8 - - 98.3 98.5 - - MCDP 99.2 99.2 99.3 - 99.0 99.1 99.3 - DPN 100.0 100.0 99.5 100.0 100.0 100.0 97.5 100.0 CIFAR10 SVHN DNN 90.1 90.8 - - 84.6 85.1 - - MCDP 89.6 90.6 83.7 - 84.1 84.8 73.1 - PN 98.1 98.2 98.2 98.5 97.7 97.8 97.8 98.2 CIFAR10 LSUN DNN 89.8 91.4 - - 87.0 90.0 - - MCDP 89.1 90.9 89.3 - 86.5 89.6 86.4 - DPN 94.4 94.4 94.4 94.6 93.3 93.4 93.4 93.3 CIFAR10 TIM DNN 87.5 88.7 - - 84.7 87.2 - - MCDP 87.6 89.2 86.9 - 85.1 87.9 83.2 - DPN 94.3 94.3 94.3 94.6 94.0 94.0 94.0 94.2
上述实验表明,使用微分熵和互信息等度量相对于标准熵几乎没有什么好处。 然而,这是因为 MNIST 和 CIFAR-10 是低数据不确定性数据集 - 所有类别都是不同的。 有趣的是,当类别不太明显时,狄利克雷先验的微分熵是否能够比熵更好地区分域内数据和分布外数据。 为此,在 MNIST 数据集上的训练和评估期间,将具有标准偏差 噪声的零均值各向同性高斯噪声添加到 DNN 和 DPN 的输入中。 表3显示,在存在强噪声的情况下,熵和MI无法成功区分域内和分布外样本,而使用微分熵的性能几乎没有下降。
Ent. M.I. D.Ent. 0.00> 3.01> 0.02> 3.03> 0.04> 3.05> DNN8> 98.89> 58.40> -1> -2> -3> -4>7> MCDP6> 98.87> 58.48>99.39>79.10>-1>-2>5>DPN 4> 100.05> 51.86> 99.57> 22.38> 100.09> 99.89> t40>3> 6>
6结论
这项工作描述了先前在不确定性来源的背景下进行预测不确定性估计的局限性,并建议将分布外 (OOD) 输入视为一个单独的不确定性来源,称为分布不确定性。 为此,这项工作提出了一个称为先验网络(PN)的新颖框架,它允许在一致的概率可解释框架内单独处理数据、分布和模型不确定性 。 这些 PN 的一种特殊形式应用于分类,即狄利克雷先验网络 (DPN)。 在 MNIST 和 CIFAR-10 数据集上的 OOD 检测任务中,DPN 比 MC Dropout 和标准 DNN 能产生更准确的分布不确定性估计。 DPN 在错误分类检测任务上也优于其他方法。 在他们评估的不确定性类型的背景下提出和分析了一系列不确定性度量。 值得注意的是,预测分布的最大概率在误分类检测方面产生了最佳结果。 DPN 的微分熵最适合 OOD 检测,尤其是当类别不太明显时。 这在合成实验和噪声损坏的 MNIST 任务中得到了说明。 可以在 DPN 测试时分析计算不确定性度量,从而相对于集成方法降低计算成本。 研究了用于图像分类的 PN 后,将它们应用于其他任务计算机视觉、NLP、机器翻译、语音识别和强化学习是很有趣的。 最后,有必要探索回归任务的先验网络。
致谢
本文报告了剑桥大学剑桥评估部分支持的研究。 这项工作的部分资金还来自 DTA EPSRC 和 Google 研究奖。 我们还要感谢 CUED 机器学习小组的成员,特别是 Richard Turner 博士,他们进行了富有成效的讨论。
参考
- [1] Ross Girshick, “Fast R-CNN,” in Proc. 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [2] Karen Simonyan and Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in Proc. International Conference on Learning Representations (ICLR), 2015.
- [3] Ruben Villegas, Jimei Yang, Yuliang Zou, Sungryull Sohn, Xunyu Lin, and Honglak Lee, “Learning to Generate Long-term Future via Hierarchical Prediction,” in Proc. International Conference on Machine Learning (ICML), 2017.
- [4] Tomas Mikolov et al., “Linguistic Regularities in Continuous Space Word Representations,” in Proc. NAACL-HLT, 2013.
- [5] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean, “Efficient Estimation of Word Representations in Vector Space,” 2013, arXiv:1301.3781.
- [6] Tomas Mikolov, Martin Karafiát, Lukás Burget, Jan Cernocký, and Sanjeev Khudanpur, “Recurrent Neural Network Based Language Model,” in Proc. INTERSPEECH, 2010.
- [7] Geoffrey Hinton, Li Deng, Dong Yu, George Dahl, Abdel rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara Sainath, and Brian Kingsbury, “Deep neural networks for acoustic modeling in speech recognition,” Signal Processing Magazine, 2012.
- [8] Awni Y. Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, and Andrew Y. Ng, “Deep speech: Scaling up end-to-end speech recognition,” 2014, arXiv:1412.5567.
- [9] Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad, “Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission,” in Proc. 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 2015, KDD ’15, pp. 1721–1730, ACM.
- [10] Babak Alipanahi, Andrew Delong, Matthew T. Weirauch, and Brendan J. Frey, “Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning,” Nature Biotechnology, vol. 33, no. 8, pp. 831–838, July 2015.
- [11] B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [12] Dario Amodei, Chris Olah, Jacob Steinhardt, Paul F. Christiano, John Schulman, and Dan Mané, “Concrete problems in AI safety,” http://arxiv.org/abs/1606.06565, 2016, arXiv: 1606.06565.
- [13] Dan Hendrycks and Kevin Gimpel, “A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks,” http://arxiv.org/abs/1610.02136, 2016, arXiv:1610.02136.
- [14] David JC MacKay, “A practical bayesian framework for backpropagation networks,” Neural computation, vol. 4, no. 3, pp. 448–472, 1992.
- [15] David JC MacKay, Bayesian methods for adaptive models, Ph.D. thesis, California Institute of Technology, 1992.
- [16] Geoffrey E. Hinton and Drew van Camp, “Keeping the neural networks simple by minimizing the description length of the weights,” in Proc. Sixth Annual Conference on Computational Learning Theory, New York, NY, USA, 1993, COLT ’93, pp. 5–13, ACM.
- [17] Radford M. Neal, Bayesian learning for neural networks, Springer Science & Business Media, 1996.
- [18] Yarin Gal and Zoubin Ghahramani, “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning,” in Proc. 33rd International Conference on Machine Learning (ICML-16), 2016.
- [19] A. Kendall, Y. Gal, and R. Cipolla, “Multi-Task Learning Using Uncertainty to Weight Losses for Scene Geometry and Semantics,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [20] A. Kendall and Y. Gal, “What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision,” in Proc. Conference on Neural Information Processing Systems (NIPS), 2017.
- [21] A. Malinin, A. Ragni, M.J.F. Gales, and K.M. Knill, “Incorporating Uncertainty into Deep Learning for Spoken Language Assessment,” in Proc. 55th Annual Meeting of the Association for Computational Linguistics (ACL), 2017.
- [22] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin, “Training confidence-calibrated classifiers for detecting out-of-distribution samples,” International Conference on Learning Representations, 2018.
- [23] Yarin Gal, Uncertainty in Deep Learning, Ph.D. thesis, University of Cambridge, 2016.
- [24] Joaquin Quiñonero-Candela, Dataset Shift in Machine Learning, The MIT Press, 2009.
- [25] Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra, “Weight Uncertainty in Neural Networks,” in Proc. International Conference on Machine Learning (ICML), 2015.
- [26] Alex Graves, “Practical variational inference for neural networks,” in Advances in neural information processing systems, 2011, pp. 2348–2356.
- [27] Christos Louizos and Max Welling, “Structured and efficient variational deep learning with matrix gaussian posteriors,” in International Conference on Machine Learning, 2016, pp. 1708–1716.
- [28] Diederik P Kingma, Tim Salimans, and Max Welling, “Variational dropout and the local reparameterization trick,” in Advances in Neural Information Processing Systems, 2015, pp. 2575–2583.
- [29] Max Welling and Yee Whye Teh, “Bayesian Learning via Stochastic Gradient Langevin Dynamics,” in Proc. International Conference on Machine Learning (ICML), 2011.
- [30] Shiyu Liang, Yixuan Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” in Proc. International Conference on Learning Representations, 2018.
- [31] David M. Blei, Andrew Y. Ng, and Michael I. Jordan, “Latent Dirichlet Allocation,” Journal of Machine Learning Research, vol. 3, pp. 993–1022, Mar. 2003.
- [32] Kevin P. Murphy, Machine Learning, The MIT Press, 2012.
- [33] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean, “Distilling the knowledge in a neural network,” 2015, arXiv:1503.02531.
- [34] Stefan Depeweg, José Miguel Hernández-Lobato, Finale Doshi-Velez, and Steffen Udluft, “Decomposition of uncertainty for active learning and reliable reinforcement learning in stochastic systems,” arXiv preprint arXiv:1710.07283, 2017.
- [35] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the ieee, vol. 86, pp. 2278–2324, 1998.
- [36] Alex Krizhevsky, “Learning multiple layers of features from tiny images,” 2009.
- [37] Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum, “Human-level concept learning through probabilistic program induction,” Science, vol. 350, no. 6266, pp. 1332–1338, 2015.
- [38] Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay D. Shet, “Multi-digit number recognition from street view imagery using deep convolutional neural networks,” 2013, arXiv:1312.6082.
- [39] Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao, “LSUN: construction of a large-scale image dataset using deep learning with humans in the loop,” 2015, arXiv:1506.03365.
- [40] Stanford CS231N, “Tiny ImageNet,” https://tiny-imagenet.herokuapp.com/, 2017.
- [41] M Buscema, “Metanet: The theory of independent judges,” Substance Use & Misuse, vol. 33, no. 2, pp. 439–461, 1998.
- [42] Martín Abadi et al., “TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems,” 2015, Software available from tensorflow.org.
- [43] Timothy Dozat, “Incorporating Nesterov Momentum into Adam,” in Proc. International Conference on Learning Representations (ICLR), 2016.
附录 A实验设置和数据集
对于核心实验和附加实验,模型均在 MNIST [35]、SVHN [38] 和 CIFAR [36] 数据集上进行训练。 数据集大小可以在表4中找到。
Dataset Train Valid Test Classes MNIST 55000 5000 10000 10 SVHN 73257 - 26032 CIFAR-10 50000 - 10000 CIFAR-100 50000 - 10000 100
除了上述数据集外,还有 OMNIGLOT [37]、SEMEION [41]、LSUN [39] 和 TinyImagenet [ 40]数据集用于分布外输入检测实验。 对于这些数据集,仅使用其测试集,如表 4 中所述。 TinyImagenet 的大小从 64x64 调整为 32x32,OMNIGLOT 使用双线性插值调整为 28x28。
Dataset Size OMNIGLOT 32460 SEMEION1> 15932>0> LSUN4> 100005>3> tinyImagenet7> 100008>6>
对于所有数据集,输入特征从范围 0 到 255 重新缩放到范围 -1.0 和 1.0。 在 MNSIT 和 SVHN 数据集上训练的模型没有进行额外的预处理。 对于在 CIFAR-10 上训练的模型,图像随机左右翻转、移动 4 像素并旋转 15 度,作为数据增强的一种形式。
所有实验的所有网络都是使用 VGG [2] 图像分类架构的变体构建的。 模型在 Tensorflow [42] 中实现。 每个数据集使用的架构的详细信息可以在表6中找到。 对于卷积层,使用 dropout 的保留概率高于全连接层。
Dataset Arch. Activation Conv Depth FC Layers FC units MNIST VGG-6 ReLU 4 1 100 SVHN VGG-16 Leaky ReLU 13 2 2048 CIFAR-10 VGG-16 Leaky ReLU 13 2 2048
所有模型的训练配置如表7所示。 有趣的是,由于噪声数据的正则化效应,DPN 需要使用较少的 dropout。 所有模型均使用 NADAM 优化器[43]进行训练。 对于在 MNIST 上训练的模型,使用了指数衰减的学习率。 在 SVHN 和 CIFAR-10 上训练的模型使用 1 周期学习率,其中学习率在半个周期内从初始学习率线性增加到初始学习率的 10 倍,然后在剩余的周期内线性下降回初始学习率。的周期。 然后,剩余训练周期的学习率线性下降,直到 1e-6。 这种方法已被证明既可以作为调节器,也可以加速模型[cycle-lr]的训练。
Dataset Model Dropout LR Cycle Len. Epochs CE weight OOD data MNIST DNN 0。50 1e-3 - 30 - - - DPN 0.95 1e-3 - 10 1e3 0.0 MNIST FA SVHN DNN 0.50 1e-3 30 40 - - - DPN 0.50 7.5e-4 30 40 1e3 1.0 CIFAR-10 CIFAR-10 DNN 0.50 1e-3 30 45 - - - DPN 0.70 7.5e-4 70 100 1e2 1.0 CIFAR-100
对于在 MNIST 数据上训练的 DPN,使用具有 50 维潜在空间的因子分析模型来合成分布外数据。 在标准因子分析中,潜在向量具有各向同性标准正态分布。 为了推动 FA 模型在域内区域的边界生成数据,增加了潜在分布的方差。
附录 B其他实验
除了5节中描述的核心实验之外,还进行了进一步的实验。 在附录 B.1 中,针对其他分布外数据集对 5.2 节中描述的 MNIST DNN 和 DPN 进行了评估。 在附录 B.2 和 B.3 中,DPN 在 SVHN [38] 和 CIFAR-10 [36] 上进行训练 数据集,分别对错误分类检测和分布外输入检测任务进行评估。
B.1 其他 MNIST 实验
在表 8 中,针对 SEMEION、SVHN 和 CIFAR-10 数据集运行分布外输入检测。 SEMEION 是一个灰度手写 16x16 数字的数据集,其与 MNIST 的主要区别在于图像边缘和数字之间没有填充。 对于这些实验,SEMEION 数字被放大到 28x28。 对于 SVHN 和 CIFAR-10 实验,图像被转换为灰度并下采样到 28x28 大小。
这里的目的是研究 OOD 数据与域内数据的相似性如何影响分布外输入检测性能。 这里,SEMEION 是与 MNIST 最相似的数据集,因为它也是由灰度手写数字组成。 SVHN 也是一个包含数字 0-9 的数据集,但不太相似,因为这些数字现在嵌入了街道标志中。 CIFAR-10 是最不同的,因为它是真实对象的数据集。 在表 8 中提供的所有实验中,DPN 均优于基线。 所有模型的性能在 SEMEION 上最差,在 CIFAR-10 上最好,这说明随着数据集变得不那么清晰,OOD 检测变得更具挑战性。 请注意,由于 SEMEION 是一个非常小的数据集,因此不可能获得一组平衡的 MNIST 和 SEMEION 图像,因此在此特定实验中,AUPR 是比 AUROC 更好的性能指标。
OOD Data Model AUROC AUPR Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. SEMEION DNN 92.7 92.9 - - 76.4 76.7 - - MCDP 95.2 95.3 95.4 - 84.1 84.2 87.3 - DPN 99.5 99.6 99.1 99.7 96.9 97.5 90.8 98.6 SVHN DNN 98.7 98.9 - - 98.5 98.7 - - MCDP 98.2 98.4 98.1 - 98.0 98.3 97.9 - DPN 99.9 100.0 99.5 100.0 99.9 100.0 98.5 100.0 CIFAR10 DNN 99.4 99.5 - - 99.3 99.4 - - MCDP 99.1 99.3 98.9 - 98.9 99.2 98.6 - DPN 100.0 100.0 99.5 100.0 100.0 100.0 98.2 100.0
B.2 SVHN 实验
本节介绍 SVHN 数据集上的错误分类和分布外输入检测实验。 在 SVHN 上训练的 DPN 使用 CIFAR-10 数据集作为噪声数据集,而不是使用因子分析、VAE 或 GAN 等生成模型。 研究合成复杂数据集的分布外数据的适当方法超出了本工作的范围。
表9描述了SVHN上的错误分类检测实验。 请注意,所有模型都实现了可比的分类误差 (4.3-5.1%)。 根据 AUPR,DPN 的性能优于基线,但在 AUROC 中使用所有措施进行错误分类检测时,其性能较低。
Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. DNN 90.1 91.8 - - 47.7 46.8 - - 4.3 MCDP 92.0 92.2 92.0 - 46.4 43.5 40.4 - 4.3 DPN 90.1 90.1 90.1 91.2 55.3 54.8 54.8 46.0 5.1
表10分别报告了 SVHN 与 CIFAR-10、CIFAR-100、LSUN 和 TinyImageNet 数据集的分布外检测性能。 在所有实验中,DPN 始终达到最高性能。 请注意,DPN 使用 CIFAR-10 作为训练分布外数据集,因此它在保留的 CIFAR-10 数据集上实现近乎完美的性能也就不足为奇了。 有趣的是,与在 MNIST 或 CIFAR-10 上训练的网络相比,SVHN 上的 DNN 和 MCDP 之间的差距更大。
OOD Data Model AUROC AUPR Max.P Ent. M.I. D. Max.P Ent. M.I. D.Ent. CIFAR10 DNN 92.5 93.8 - - 91.4 92.1 - - MCDP 95.6 96.0 96.3 - 94.4 95.0 95.8 - DPN 99.9 99.9 99.9 99.9 100.0 100.0 100.0 99.9 CIFAR100 DNN 92.4 93.8 - - 91.4 92.1 - - MCDP 94.2 94.8 95.4 - 94.2 94.8 95.4 - DPN 99.8 99.8 99.8 99.8 99.8 99.8 99.8 99.8 LSUN DNN 91.9 93.4 - - 90.7 91.3 - - MCDP 95.9 96.3 97.0 - 94.9 95.3 96.8 - DPN 100.0 100.0 100.0 100.0 99.9 99.9 99.9 100.0 TIM DNN 93.1 94.2 - - 91.8 92.5 - - MCDP 96.3 96.7 97.1 - 95.3 95.8 96.8 - DPN 100.0 100.0 100.0 100.0 99.9 99.9 99.9 100.0
B.3 CIFAR-10 实验
本节介绍 CIFAR-10 数据集上的错误分类和分布外输入检测实验的结果。 在 CIFAR-10 上训练的 DPN 使用 CIFAR-100 数据集作为分布外训练数据集。 CIFAR-100 与 CIFAR-10 类似,但描述的对象与 CIFAR-10 不同,因此不存在类重叠。 这是最具挑战性的一组实验,因为视觉上 CIFAR-10 与 CIFAR-100、LSUN 和 TinyImageNet 更加相似,因此分布外输入检测可能比 MNIST 和 SVHN 等更简单的任务更困难。
表11给出了CIFAR-10上误分类检测实验的结果。 所有模型都实现了可比的分类误差 (8-8.5%),其中 DPN 的性能略高于 AUPR 的基线。
Model AUROC AUPR % Err. Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. DNN 92.4 92.3 - - 48.7 47.1 - - 8.0 MCDP 92.5 92.0 90.4 - 48.4 45.5 37.6 - 8.0 DPN 92.2 92.1 92.1 90.9 52.7 51.0 51.0 45.5 8.5
表12报告了CIFAR-10与CIFAR-100、SVHN、LSUN和TinyImageNet数据集的分布外检测结果。 在所有实验中,DPN 都实现了最佳性能,比之前的基线性能有了更大的提升。 请注意,CIFAR-100 用作 DPN 的 OOD 训练数据,因此期望其具有高性能。 TinyImageNet 与 CIFAR-10 最相似(除了 CIFAR-100),也是最具挑战性的 OOD 检测任务,因为基线方法在其上实现了最低的性能。 值得注意的是,在每个实验中,基线方法的性能明显低于以前,特别是使用 MCDP 的互信息作为不确定性的度量。 这表明相对于复杂任务的分布,控制贝叶斯分布的行为确实很困难。 这组实验清楚地表明,先验网络在比 MNIST 更困难的数据集上表现良好,并且能够优于之前提出的贝叶斯和非贝叶斯方法。
OOD Data Model AUROC AUPR Max.P Ent. M.I. D.Ent. Max.P Ent. M.I. D.Ent. CIFAR100 DNN 86.4 87.2 - - 82.6 84.3 - - MCDP 86.4 87.5 85.7 - 83.0 84.9 81.5 - DPN 95.6 95.7 95.7 95.8 95.1 95.1 95.1 95.5 SVHN DNN 90.1 90.8 - - 84.6 85.1 - - MCDP 89.6 90.6 83.7 - 84.1 84.8 73.1 - DPN 98.1 98.2 98.2 98.5 97.7 97.8 97.8 98.2 LSUN DNN 89.8 91.4 - - 87.0 90.0 - - MCDP 89.1 90.9 89.3 - 86.5 89.6 86.4 - DPN 94.4 94.4 94.4 94.6 93.3 93.4 93.4 93.3 TIM DNN 87.5 88.7 - - 84.7 87.2 - - MCDP 87.6 89.2 86.9 - 85.1 87.9 83.2 - DPN 94.3 94.3 94.3 94.6 94.0 94.0 94.0 94.2
附录 C不确定性度量和 KL 散度的推导
本附录提供了推导,并展示了如何计算第 4 节中讨论的 DNN/DPN 和贝叶斯蒙特卡洛集成的不确定性度量。 此外,它还描述了如何计算两个狄利克雷分布之间的 KL 散度。
C.1 贝叶斯MC集成的预测分布熵
可以使用以下推导来计算贝叶斯 MC 集成的预测后验熵,该推导取自 Yarin Gal 的博士论文 [23]。
C.2 Dirichlet先验网络的微分熵
微分熵的推导仅引用狄利克雷分布的标准结果。 值得注意的是,是的函数,是digamma函数,是伽玛函数。
C.3 贝叶斯MC集成的互信息
可以使用以下推导来计算贝叶斯 MC 集成的类标签和参数之间的互信息,该推导也取自 Yarin Gal 的博士论文 [23]:
C.4 狄利克雷先验网络的互信息
DPN 的标签 y 和分类 之间的互信息可以如下计算,使用 MI 是期望分布的熵与分布的期望熵之差的事实。
该推导中的第二项是非标准结果。 分布的期望熵可以通过以下方式计算:
这里,通过注意到如果通过在相关浓度上加 1 来考虑额外因子 ,则可以使用 Dirichlet 分布的 期望的标准结果来计算期望参数 并乘以 以获得正确的归一化常数。
C.5 两个狄利克雷分布之间的 KL 散度
两个狄利克雷分布 和 之间的 KL 散度可以以封闭形式获得,如下所示: