量子电路学习
摘要
我们提出了一种经典量子混合算法,用于近期量子处理器上的机器学习,我们称之为量子电路学习。 由我们的框架驱动的量子电路通过调整其上实现的参数来学习给定的任务。 参数的迭代优化使我们能够绕过高深度电路。 理论研究表明,量子电路可以逼近非线性函数,数值模拟进一步证实了这一点。 所提出的框架将低深度量子电路和用于机器学习的经典计算机混合在一起,为近期量子设备在量子机器学习中的应用铺平了道路。
PAC:
有效的 PACS 出现在此处我简介
近年来,机器学习在包括量子物理领域在内的广泛领域获得了广泛关注Carleo and Troyer (2017); Rupp 等人 (2012); Broecker 等人 (2017); Ramakrishnan 等人 (2015); August 和 Ni (2017)。 由于量子信息处理有望为我们带来一些问题的指数级加速Shor (1997); Nielsen 和 Chuang (2010) 认为,通常的机器学习任务在量子计算机上执行时也可能会得到改进。 此外,为了学习复杂的量子系统,很自然地利用量子系统作为我们的计算资源。 多种用于量子计算机的机器学习算法被提出 克雷尼迪斯和普拉卡什; Wiebe 等人 (2012); Rebentrost 等人 (2014);曹等人 ,因为 Harrow-Hassidim-Lloyd (HHL) 算法 Harrow 等人 (2009) 使我们能够在量子计算机上执行基本的矩阵运算。 这些基于 HHL 的算法的核心是量子相位估计算法Nielsen and Chuang (2010),这需要高深度的量子电路。 为了规避高深度的量子电路,这仍然是硬件方面的一个长期目标,由相对较低深度的量子电路组成的经典量子混合算法,如量子变分本征解算器 Peruzzo 等人 (2014) ; Kandala 等人 (2017) (QVE) 和量子近似优化算法 Farhi 等人 ;法尔希和哈罗; Otterbach 等人 (2017) (QAOA) 已被建议。 在这些方法中,问题被编码到埃尔米特矩阵 中。 它相对于 ansatz 状态 的期望值 通过调整参数 进行迭代优化。 混合算法的中心思想是将问题分为两部分,每一部分都可以在经典计算机和量子计算机上轻松执行。
在本文中,我们提出了一种新的混合框架,称为量子电路学习(QCL),用于低深度量子电路的机器学习。 在 QCL 中,我们向量子电路提供输入数据,并迭代地调整电路参数,以便给出所需的输出。 引入基于梯度的系统参数优化来进行调整,就像前馈神经网络中使用的反向传播方法Bishop (2006)一样。 我们从理论上证明,如果电路具有足够数量的量子位,则由 QCL 框架驱动的量子电路可以逼近任何解析函数。 数值模拟证明了 QCL 框架学习非线性函数和执行简单分类任务的能力。 此外,我们通过模拟表明,6 量子位电路能够拟合具有完全连接的伊辛哈密顿量的 10 自旋系统中的 3 个自旋的动力学。 我们在这里强调,所提出的框架可以在近期设备上轻松实现。
II量子电路学习
II.1算法
我们的 QCL 框架旨在执行监督或无监督学习任务Bishop (2006)。 在监督学习中,算法提供一组输入和相应的教师数据。 该算法通过调整 学习输出接近教师 的 。 输出和教师可以是向量值的。 QCL将输出的计算分配给量子电路,并将参数的更新分配给经典计算机。 学习的目标是通过调整 来最小化成本函数,该函数是教师与输出的接近程度的度量。 例如,二次成本 经常用于回归问题。 另一方面,在无监督学习(例如聚类)中,仅提供输入数据,并且最小化一些不涉及教师的目标成本函数。
这里我们总结一下量子比特电路上的QCL算法:
-
1.
通过将单一输入门 应用于初始化的量子位 ,将输入数据 编码为某种量子态
-
2.
将 参数化酉 应用于输入状态并生成输出状态 。
-
3.
测量一些选定的可观察量的期望值。 具体来说,我们使用泡利运算符的子集。 使用一些输出函数,输出被定义为
-
4.
通过迭代调整电路参数,最小化教师和输出的成本函数。
-
5.
通过检查独立于训练数据集的成本函数来评估性能。
II.2 与现有算法的关系
可以使用具有基于 HHL 的算法的高深度量子电路来最小化二次成本。 例如,参考文献。 Schuld 等人 (2016) 显示了详细的过程。 这种矩阵求逆方法类似于量子支持向量机Rebentrost 等人 (2014)。 与此相反,应用于回归问题的 QCL 通过迭代优化最大限度地降低了成本,成功地绕过了高深度电路。
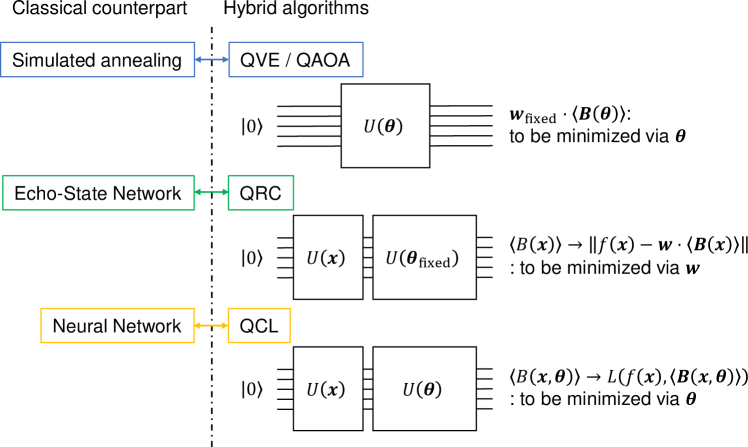
量子储层计算(QRC)Fujii and Nakajima (2017)也有类似的想法,从某种意义上说,它将中央优化过程传递给经典计算机。 在那里,输出被定义为 ,其中 是从由固定哈密顿量驱动的量子多体动力学中获取的一组可观测量, 是权重向量,在经典设备上进行调整以最小化成本函数。 这个想法源于所谓的回声状态网络方法Jaeger 和 Haas (2004)。 如果将 QRC 视为回声状态网络的量子版本,那么调节整个网络的 QCL 则可以视为基本神经网络的量子对应物。 在著名的混合量子算法QVE/QAOA中,通过调整参数来最小化测量期望值的加权和。 在那里,问题的输入(例如分子的几何形状或图形的拓扑)被编码为权重向量作为。 此过程对应于 QCL 的特殊情况,其中我们不使用输入酉 ,而是使用成本函数 。 图1总结并显示了QVE/QAOA、QRC和提出的QCL框架的比较。
II.3 逼近函数的能力
首先,为了简单起见,我们考虑输入数据是一维的情况。 对于更高维的输入,可以直接推广以下论点。
令和为输入数据和对应的输入状态密度算子。 可以通过一组保利算子 进行扩展,其中 作为系数 。 作用于 的参数化酉变换 创建输出状态,也可以通过 和 扩展输出状态。 现在,让 使得 . 是泡利可观测量本身的期望值,因此,输出是输入系数函数在对施加幺正性约束下的线性组合。
当教师 是一个分析函数时,我们至少在原则上可以证明,QCL 能够通过考虑具有由单量子位旋转创建的输入状态的简单情况来近似它。 量子系统的张量积结构在此分析中起着重要作用。 让我们考虑 量子位的状态:
| (1) |
可以为任何具有单量子位旋转的 生成此状态,即 ,其中 是第 个量子位的旋转围绕 轴,角度为 。 方程给出的状态。 (1) 相对于 具有高达 的更高阶项。 因此,对该状态的任意酉变换可以为我们提供任意阶多项式作为可观测值的期望值。 等式中的诸如 之类的术语。 (1) 可以增强其逼近函数的能力。
上面给出的示例中的重要注意事项是最高阶项 隐藏在可观察的 中。 从等式中提取 (1),需要使用纠缠门(例如受控非门)将非局部可观测量 转换为单量子位可观测量。 纠缠非局部运算是输出非线性的关键因素。
上述论点可以很容易地推广到多维输入。 假设我们给定了 维数据 ,并且希望每个数据都有高达 个 的更高项,那么将此数据编码为 -qubit 量子态 这些输入状态自动具有指数数量的独立函数,作为设置为量子位数量的系数。 量子系统的张量积结构很容易“计算”出诸如之类的积。
的幺正性条件可能有助于避免过度拟合问题,这对于它们在机器学习或回归方法中的性能至关重要。 在经典机器学习方法中处理它的一种方法是在成本函数中添加正则化项。 例如,岭回归将正则化项添加到二次成本函数中。 总体而言 被最小化。 权重向量对应于QCL中的矩阵元素。 然而,行向量的范数被酉性条件限制为统一,这防止了量子动力学酉性的过度拟合。 附录中给出了这方面的简单示例。
II.4可能的量子优势
通过上面的讨论我们已经表明,使用张量积产生的非线性可以逼近任何解析函数。 事实上,非线性基函数对于经典机器学习中使用的许多方法至关重要。 它们需要大量的基函数来创建高精度预测的复杂模型。 然而,学习的计算成本随着基函数数量的增加而增加。 为了避免这个问题,利用了所谓的内核技巧方法,它避免了直接使用大量它们,Bishop (2006)。 相比之下,QCL直接利用函数相对于量子比特数的指数数来对教师进行建模,这在经典计算机上基本上是难以处理的。 这是我们的框架可能具有的量子优势,这在之前的 QVE 或 QAOA 等方法中并不明显。
此外,现在让我们讨论 QCL 代表复杂函数的潜在能力。 假设我们想要通过经典神经网络学习 QCL 的输出,该输出允许在学习过程中使用无限的资源。 然后它必须学习量子电路的输入和输出之间的关系,通常包括通用量子细胞自动机Raussendorf (2005); Janzing 和 Wocjan (2005)。 使用 QCL 大小(量子位和门)的多项式大小的经典计算资源当然无法实现这一点。 这意味着 QCL 具有比经典对应物更复杂的功能的潜在能力。 需要进一步调查,包括学习成本以及哪些实际学习问题享有这样的优势。
II.5优化流程
在 QVE Peruzzo 等人 (2014) 中,建议使用 Nelder-Mead 等无梯度方法。 然而,当参数空间变大时,基于梯度的方法通常更优选。 在神经网络中,学习过程中使用反向传播方法Bishop (2006),它基本上是梯度下降。
要计算可观测量的期望值相对于电路参数 的梯度,假设酉 由酉变换链 组成状态,我们测量可观察的。 为了方便起见,我们使用符号。 然后 被指定为 我们假设是由泡利积生成的,即。 梯度计算为 虽然我们无法直接评估换向器,但任意运算符 的换向器的以下属性使我们能够计算量子电路上的梯度:
| (2) |
梯度可以通过以下方式评估
| (3) |
其中。 只需插入 生成的 旋转并测量相应的期望值 ,我们就可以评估可观察的 的精确梯度,通过 Li等人Li等人(2017)在目标量子系统控制脉冲优化研究中也采用了类似的方法。
III数值模拟
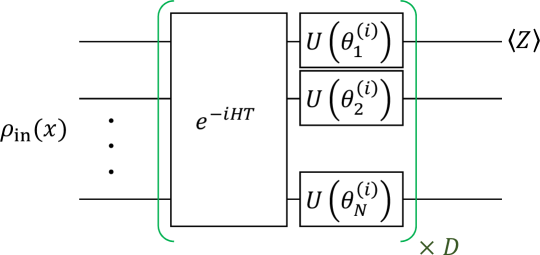
我们通过对图2、和形式的量子电路进行数值模拟,展示了QCL框架在几个原型机器学习任务中的性能。 图2中的是单个量子位的任意旋转。 我们使用分解。 是全连接横向伊辛模型的哈密顿量:
| (4) |
系数和是从上的均匀分布中随机抽取的。 进化时间固定为10。 本节中显示的结果是由具有相同系数的哈密顿量生成的。 在这里我们注意到,我们已经检查了使用不同的哈密顿量可以实现类似的结果。 这种形式的哈密顿量下的动力学可以产生高度纠缠态,并且通常对于大量量子位来说,不能在经典计算机上有效地模拟。 等式。 (4) 是捕获离子或超导量子位中相互作用的基本形式,这使得时间演化很容易通过实验实现。 使用均匀分布在 上的随机数进行初始化。 在所有数值模拟中,输出均取自 期望值。 为了模拟采样,我们添加了小高斯噪声,其标准差 由 确定,其中 和 是样本和计算出的期望值,到。 111 使用Python库QuTip Johansson等人(2013)进行仿真。 我们使用SciPy优化库中提供的BFGS方法Nocedal and Wright (2006)来优化参数。
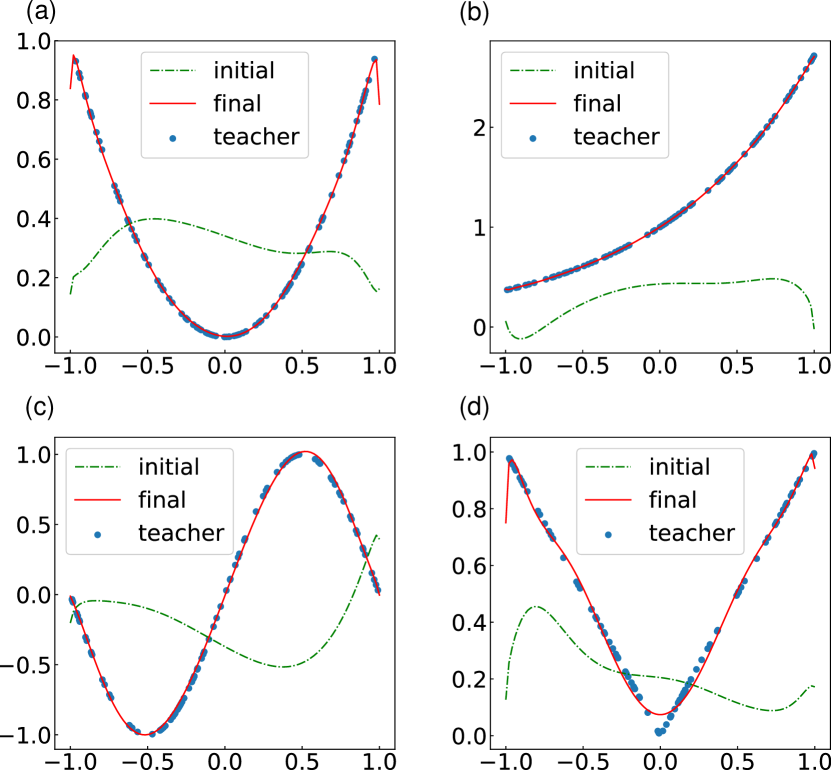
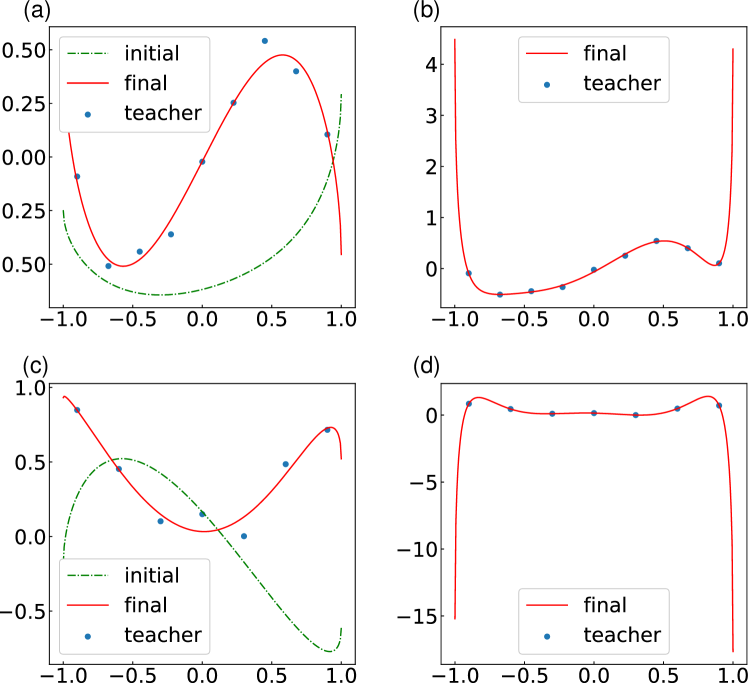
首先,我们对 进行拟合,以演示非线性函数 Bishop (2006) 的可表示性。 我们使用正常的二次损失作为成本函数。 教师样本数量为100。 输出取自第一个量子位的期望值,如图2所示。 在此模拟中,我们允许输出乘以一个初始化为 1 的常量 。 该常数和同时被优化。 输入状态 是通过将 应用到初始化的量子位 来准备的。 这个酉创建了一个类似于等式的状态。 (1)。
结果如图3所示。 所有功能都可以通过所提出的 QCL 框架驱动的量子电路很好地近似。 为了逼近高度非线性函数,例如 或非解析函数 ,QCL 引入了最初隐藏在非局部算子中的高阶项。 (图3(d))由于其非解析特性,拟合结果相对较差。 一个可能的解决方案是采用不同的函数作为输入函数,例如勒让德多项式。 尽管输入函数的选择会影响QCL的性能,但结果表明,具有简单输入的QCL具有输出多种函数的能力。
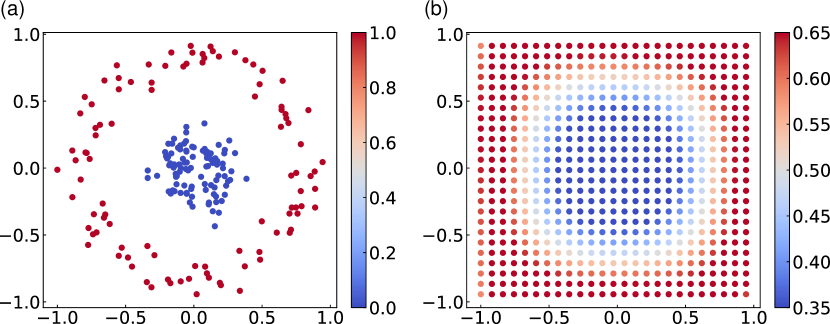
作为第二个演示,执行了分类问题,这是机器学习中的一个重要任务系列。 图4(a)显示了训练数据集,蓝色和红色点分别表示类别0和类别1。 在这里,我们训练量子电路根据每个训练输入数据点 进行分类。 我们将每个输入 的教师 定义为 0 类的二维向量 ,以及 1 类的 。 教师样本数为 200 个(0 班 100 个,1 班 100 个)。 输出取自前 2 个量子位的 Pauli 算子的期望值,并通过 softmax 函数 进行转换。 对于 维向量 ,softmax 函数返回 维向量 及其第 个元素是。 因此输出由定义 对于成本函数,我们使用交叉熵。 输入状态是通过将 应用于初始化的量子位 来准备的。 是 除以 2 的余数。 在此任务中,乘法常数 固定为 1。
学习输出如图4(b)所示。 我们看到 QCL 对于非线性分类任务也同样有效。 可以使用例如核技巧支持向量机来经典地执行相同的任务。 与 QCL 方法相反,Kernel-trick 方法放弃了直接使用与量子位数量有关的大量基函数,QCL 方法在某些约束下使用指数级数量的基函数。 从这个意义上说,QCL 可以从量子计算机的使用中受益。
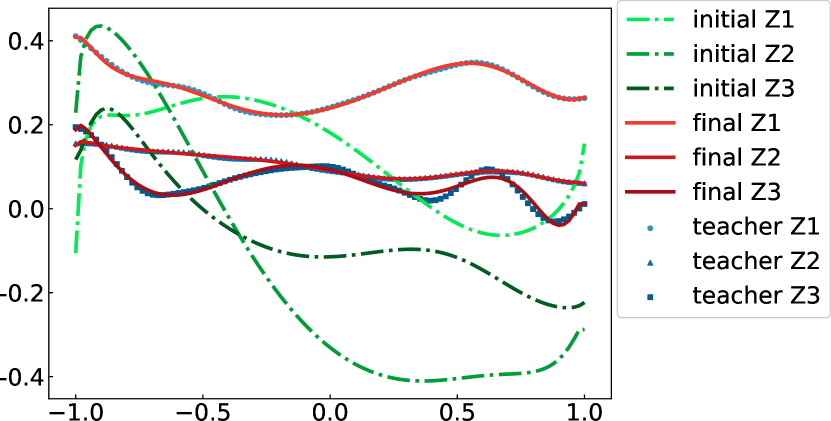
最后,我们展示了 QCL 执行量子多体动力学拟合任务的能力。 全连通横向伊辛哈密顿方程下10自旋系统的动力学仿真预先执行(4)以生成教师数据。 系数和取自上的均匀分布,与电路中哈密顿量的系数无关。 动态从初始化状态开始。 进化开始时的瞬态在持续时间内被丢弃。 在实际应用中,可以采用从具有未知哈密顿量的量子系统中通过实验获得的动力学作为教师数据。 习得动态是 期间 3 次旋转的 期望值。 的这个跨度由 统一映射到 上,以便正确引入输入门。 输出取自电路的第一、第二和第三量子位的期望值。 采用二次成本函数。 教师样本数量为每人100人。 乘法常数固定为1。
结果如图5所示。 值得注意的是,使用调谐 6 量子位电路的 3 个可观测量可以同时很好地拟合复杂 10 自旋系统的 3 个可观测量。 尽管这里执行的任务不是通常所说的量子模拟,但我们相信我们提供了一种使用近期量子计算机学习量子多体动力学的替代方法。 还可以通过对输出的导数来提取系统哈密顿量的部分信息,这可以使用计算梯度的相同方法容易地执行。
四结论
我们在近期可实现的量子计算机上提出了一个机器学习框架。 我们的方法充分利用了量子系统的指数级大空间,将简单注入的非线性函数与低深度电路混合以近似复杂的非线性函数。 数值结果显示了表示函数、分类和拟合相对较大的量子系统的能力。 此外,理论研究表明 QCL 能够为我们提供处理高维回归或分类任务的方法,这在经典计算机上是不切实际的。 我们最近了解到相关作品Cincio 等人;法尔希和内文; Benedetti 等人 ;舒尔德和基洛兰(2018);哈金斯等人 (2018);刘和王(2018); Schuld 等人 (2018); Fanizza 等人 (2018); Benedetti 等人 (2018).
*
附录A统一性避免过度拟合
在本附录中,我们演示了一个简单的示例,该示例支持我们在正文中的主张,即变换的单一性可以有效避免过度拟合。 我们使用少量训练数据集执行一维拟合任务,以查看避免过度拟合的情况。 为了观察单位性效应,我们将乘法常数 固定为单位。 为简单起见,这里我们使用与正文相同形式的 3 量子位电路,其中 并使用 作为输入门。 在这种情况下,QCL使用的基函数集合是。 因此,为了进行比较,我们使用相同的基函数集运行一个简单的经典线性回归程序。
图6(a)和(b)显示了对数据点进行拟合的任务结果,添加了标准差的高斯噪声,分别使用 QCL 和经典回归。 结果表明,可能由于变换的幺正性,QCL 接受最终输出中的一些错误,而经典的 QCL 不接受最终输出中的任何错误,即过拟合。 与 QCL 上的 约束相反,本例中的经典算法输出具有 的权重向量。 图6(c)和(d)显示了对数据点进行拟合的任务结果,添加了标准差的高斯噪声,分别使用 QCL 和经典回归。 再次,可以进行相同的观察。 在这种情况下,经典算法得到的权重向量表现出。
参考
- Carleo and Troyer (2017) G. Carleo and M. Troyer, Science 355, 602 (2017).
- Rupp et al. (2012) M. Rupp, A. Tkatchenko, K.-R. Müller, and O. A. von Lilienfeld, Phys. Rev. Lett. 108, 058301 (2012).
- Broecker et al. (2017) P. Broecker, J. Carrasquilla, R. G. Melko, and S. Trebst, Sci. Rep. 7, 8823 (2017).
- Ramakrishnan et al. (2015) R. Ramakrishnan, P. O. Dral, M. Rupp, and O. A. von Lilienfeld, J. Chem. Theory Comput. 11, 2087 (2015).
- August and Ni (2017) M. August and X. Ni, Phys. Rev. A 95, 012335 (2017).
- Shor (1997) P. W. Shor, SIAM J. Comput. 26, 1484 (1997).
- Nielsen and Chuang (2010) M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, Cambridge, 2010).
- (8) I. Kerenidis and A. Prakash, arXiv:1704.04992 .
- Wiebe et al. (2012) N. Wiebe, D. Braun, and S. Lloyd, Phys. Rev. Lett. 109, 050505 (2012).
- Rebentrost et al. (2014) P. Rebentrost, M. Mohseni, and S. Lloyd, Phys. Rev. Lett. 113, 130503 (2014).
- (11) Y. Cao, G. G. Guerreschi, and A. Aspuru-Guzik, arXiv:1711.11240 .
- Harrow et al. (2009) A. W. Harrow, A. Hassidim, and S. Lloyd, Phys. Rev. Lett. 103, 150502 (2009).
- Peruzzo et al. (2014) A. Peruzzo, J. McClean, P. Shadbolt, M. Yung, X. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, Nat. Commun. 5 (2014).
- Kandala et al. (2017) A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, Nature 549, 242 (2017).
- (15) E. Farhi, J. Goldstone, and S. Gutmann, arXiv:1411.4028 .
- (16) E. Farhi and A. W. Harrow, arXiv:1602.07674 .
- Otterbach et al. (2017) J. S. Otterbach, R. Manenti, N. Alidoust, A. Bestwick, M. Block, B. Bloom, S. Caldwell, N. Didier, E. S. Fried, S. Hong, P. Karalekas, C. B. Osborn, A. Papageorge, E. C. Peterson, G. Prawiroatmodjo, N. Rubin, C. A. Ryan, D. Scarabelli, M. Scheer, E. A. Sete, P. Sivarajah, R. S. Smith, A. Staley, N. Tezak, W. J. Zeng, A. Hudson, B. R. Johnson, M. Reagor, M. P. da Silva, and C. Rigetti, (2017), arXiv:1712.05771 .
- Bishop (2006) C. M. Bishop, Pattern Recognition and Machine Learning (Spriger, New York, 2006).
- Schuld et al. (2016) M. Schuld, I. Sinayskiy, and F. Petruccione, Phys. Rev. A 94, 022342 (2016).
- Fujii and Nakajima (2017) K. Fujii and K. Nakajima, Phys. Rev. Appl. 8, 024030 (2017).
- Jaeger and Haas (2004) H. Jaeger and H. Haas, Science 304, 78 (2004).
- Raussendorf (2005) R. Raussendorf, Phys. Rev. A 72, 022301 (2005), 0412048v1 .
- Janzing and Wocjan (2005) D. Janzing and P. Wocjan, Quantum Inf. Process. 4, 129 (2005).
- Li et al. (2017) J. Li, X. Yang, X. Peng, and C. Sun, Phys. Rev. Lett. 118, 150503 (2017).
- Note (1) The simulation is carried on using Python library QuTip Johansson et al. (2013). We use BFGS method Nocedal and Wright (2006) provided in SciPy optimization library for optimization of parameters.
- (26) L. Cincio, Y. Subasi, A. T. Sornborger, and P. J. Coles, arXiv:1803.04114 .
- (27) E. Farhi and H. Neven, arXiv:1802.06002 .
- (28) M. Benedetti, D. Garcia-Pintos, Y. Nam, and A. Perdomo-Ortiz, arXiv:1801.07686 .
- Schuld and Killoran (2018) M. Schuld and N. Killoran, (2018), arXiv:1803.07128 .
- Huggins et al. (2018) W. Huggins, P. Patel, K. B. Whaley, and E. M. Stoudenmire, (2018), arXiv:1803.11537 .
- Liu and Wang (2018) J.-G. Liu and L. Wang, (2018), arXiv:1804.04168 .
- Schuld et al. (2018) M. Schuld, A. Bocharov, K. Svore, and N. Wiebe, (2018), arXiv:1804.00633 .
- Fanizza et al. (2018) M. Fanizza, A. Mari, and V. Giovannetti, (2018), arXiv:1805.03477 .
- Benedetti et al. (2018) M. Benedetti, E. Grant, L. Wossnig, and S. Severini, (2018), arXiv:1806.00463 .
- Johansson et al. (2013) J. Johansson, P. Nation, and F. Nori, Comput. Phys. Commun. 184, 1234 (2013).
- Nocedal and Wright (2006) J. Nocedal and S. Wright, Numerical Optimization (Springer, New York, 2006).