capbtabbox表[][]
量化分类不确定性的证据深度学习
摘要
确定性神经网络已被证明可以学习各种机器学习问题的有效预测因子。 然而,由于标准方法是训练网络以最小化预测损失,因此生成的模型仍然不知道其预测置信度。 与通过权重不确定性间接推断预测不确定性的贝叶斯神经网络正交,我们提出使用主观逻辑理论对其进行显式建模。 通过在类概率上放置狄利克雷分布,我们将神经网络的预测视为主观意见,并学习通过确定性神经网络从数据中收集导致这些意见的证据的函数。 多类分类问题的最终预测器是另一个狄利克雷分布,其参数由神经网络的连续输出设置。 我们提供了关于新损失函数的特性如何改进不确定性估计的基本知识分析。 我们观察到,我们的方法在检测分布外查询和抵抗对抗性扰动方面取得了前所未有的成功。
1简介
当前十年已经开始,深度学习方法震撼了机器学习世界[20]。 得益于最近的发明,例如 dropout [30]、批量归一化 [13] 和跳过连接[11]。 使神经网络适应特定应用的进一步后果带来了前所未有的预测精度,在某些情况下超过了人类水平的性能[5, 4]。 一方面是人们对深度学习研究的兴趣和投资增加,另一方面是对其稳健性、样本效率、安全性和可解释性的迫切需求。
在有大量标记数据可用的设置中,通过遵循简短的经验规则列表来实现足够高的准确度的能力已被认为是理所当然的。 因此,即将到来的时代的主要挑战可能在于其他地方,而不是测试集准确性的提高。 例如,神经网络是否能够识别属于不相关数据分布的数据点? 如果我们在网上输入一组手写数字上的猫图片,是否可以简单地说“我不知道”? 更关键的是,网络能否保护其用户免受对抗性攻击? 这些问题已通过贝叶斯神经网络 (BNN) [8,18,26] 的一系列研究得到解决,贝叶斯神经网络通过近似后验预测分布的矩来估计预测不确定性。 这种整体方法寻求一种除了不确定性估计之外具有广泛实际用途的解决方案,例如自动模型选择和增强对过度拟合的免疫力。
在本文中,我们将重点放在不确定性估计问题上,并从证据理论的角度[7, 14]来处理它。 我们将分类网络的标准输出 softmax 解释为分类分布的参数集。 通过用狄利克雷密度的参数替换该参数集,我们将学习器的预测表示为可能的 softmax 输出的分布,而不是 softmax 输出的点估计。 换句话说,这个密度可以直观地理解为这些点估计的工厂。 所得模型具有特定的损失函数,该损失函数可根据使用标准反向传播的神经网络权重最小化。
在一组实验中,我们证明了该技术在高质量不确定性建模至关重要的两个应用中大幅优于最先进的 BNN。 具体来说,当输入的输入来自与训练样本不同的分布时,我们模型的预测分布比 BNN 更接近最大熵设置。 图 1 说明了我们的方法对输入数字的旋转做出的反应是多么明智。 由于它没有经过训练来处理旋转不变性,因此在大约 输入旋转后,它会急剧降低分类概率并增加预测不确定性。 标准 softmax 不断报告高旋转的不正确类别的高置信度。 最后,我们观察到我们的模型对于两个不同基准数据集的对抗性攻击显然更加稳健。
本文中的所有向量都是列向量,并以粗体表示,例如,其中第元素表示为。 我们使用 来指代 Hadamard(逐元素)乘积。
2 使用 Softmax 建模类别概率的缺陷
深度神经网络的黄金标准是使用softmax算子将输出层的连续激活转换为类概率。 最终模型可以解释为多项分布,其参数(即离散类概率)由神经网络输出确定。 对于类分类问题,观察到的元组的似然函数为
其中, 是多叉质量函数, 是由 参数化的任意神经网络 的第 个输出通道, 是 softmax 函数。 虽然连续神经网络负责调整类别概率的比率,但 softmax 将这些比率压缩为单纯形。 然后,最终的 softmax 压缩多项似然相对于神经网络参数 被最大化。 为了计算方便,优选最小化负对数似然的等效问题
这被广泛称为交叉熵损失。
值得注意的是,交叉熵损失的概率解释仅仅是最大似然估计(MLE)。 作为一种频率论技术,MLE 无法推断预测分布方差。 Softmax 还因神经网络输出上使用的指数导致预测类别的概率增大而臭名昭著。 结果是不可靠的不确定性估计,因为新观察到的预测标签的距离除了与其他类别的比较价值之外对结论没有用处。
3 不确定性和证据理论
登普斯特-谢弗证据理论 (DST) 是贝叶斯理论对主观概率的推广[7]。 它将信念质量分配给辨别框架的子集,这表示一组排他的可能状态,例如样本的可能类别标签。 信念质量可以分配给框架的任何子集,包括整个框架本身,它表示事实可以是任何可能状态的信念,例如,任何类别标签都是同等可能的。 换句话说,通过将所有信念质量分配给整个框架,人们将“我不知道”表达为对可能状态[14]的真相的意见。 主观逻辑 (SL) 将 DST 在辨别框架上的信念分配概念形式化为狄利克雷分布 [14]。 因此,它允许人们通过明确的理论框架使用证据理论的原理来量化信念质量和不确定性。 更具体地说,SL 通过为每个单子 提供信念质量 ,并提供总体不确定性质量 ,来考虑由 互斥单子(如类标签)组成的框架。 这些质量值都是非负的并且总和为一,即
其中 和 代表 。 单例 的置信质量 是使用单例的证据计算的。 令 为 单例导出的证据,然后置信度 和不确定性 计算为
| (1) |
其中。 请注意,不确定性与证据总数成反比。 当没有证据时,每个单例的置信度为零,不确定性为一。 与贝叶斯建模术语不同,我们将证据称为从数据中收集到的有利于将样本分类到特定类别的支持量的度量。 信念质量分配,即主观意见,对应于参数为 的狄利克雷分布。 也就是说,使用可以很容易地从相应的狄利克雷分布的参数中得出主观意见,其中被称为狄利克雷强度。
标准神经网络分类器的输出是每个样本的可能类别的概率分配。 然而,根据证据参数化的狄利克雷分布代表了每个此类概率分配的密度;因此,它对二阶概率和不确定性进行建模[14]。
狄利克雷分布是概率质量函数 (pmf) 的可能值的概率密度函数 (pdf)。 它的特征是参数并且由下式给出
其中 是 维单位单纯形,
是维多项式β函数[19]。
让我们假设我们有 作为 10 类分类问题的置信质量分配。 那么,图像分类的先验分布就变成了均匀分布,即——参数均为1的狄利克雷分布。 没有观察到的证据,因为信念群众都是零。 这意味着该意见对应于均匀分布,不包含任何信息,并且意味着完全不确定,即。 经过一些训练后让信念质量变成。 这意味着对观点的总信念是,剩余的是不确定性。 自起,狄利克雷强度计算为。 因此,第一类的新证据数量计算为。 在这种情况下,意见将对应于狄利克雷分布。
给定一个意见,单例的预期概率是相应狄利克雷分布的平均值,计算如下
| (2) |
当有关样本的观察与 属性之一相关时,相应的狄利克雷参数会递增,以使用新观察更新狄利克雷分布。 例如,检测图像上的特定图案可能有助于将其分类为特定类别。 在这种情况下,该类对应的狄利克雷参数应该递增。 这意味着样本分类的狄利克雷分布的参数可以解释每个类别的证据。
在本文中,我们认为神经网络能够形成狄利克雷分布的分类任务意见。 让我们假设是样本分类的狄利克雷分布的参数,那么是网络估计的总证据将示例 分配给 类。 此外,给定这些参数,可以使用方程 1 轻松计算分类的认知不确定性。
4学习形成意见
softmax 函数提供样本的类概率的点估计,但不提供相关的不确定性。 另一方面,多项意见或等效的狄利克雷分布可用于对类别概率的概率分布进行建模。 因此,在本文中,我们设计并训练神经网络,以形成其多项意见,将给定样本分类为狄利克雷分布,其中 是表示类别分配概率的单纯形。
我们的分类神经网络与经典神经网络非常相似。 唯一的区别是 softmax 层被替换为激活层,例如 ReLU,以确定非负输出,该输出被视为预测的证据向量狄利克雷分布。
给定样本,让表示网络预测的分类证据向量,其中是网络参数。 那么,对应的狄利克雷分布就有参数。 一旦计算出该分布的参数,其平均值,即,就可以作为类别概率的估计。
假设 是一个单击向量,它对所有 的观察结果 和 以及 进行编码,并且 是预测因子上的 Dirichlet 密度参数。 首先,我们可以将视为似然的先验,并通过积分类概率获得边际似然的负对数
| (3) |
并最小化 参数。 该技术被称为 II 类最大似然法。
或者,我们可以定义一个损失函数并计算其相对于类预测器的贝叶斯风险。 请注意,虽然方程 3 中的上述损失对应于 PAC 学习术语中的贝叶斯分类器,但我们下面将介绍的是吉布斯分类器。 对于交叉熵损失,贝叶斯风险将读取
| (4) |
其中 是 digamma 函数。 同样的方法也可以应用于平方和损失,导致
| (5) |
在上述三个选项中,我们根据我们的实证结果选择最后一个。 我们观察到方程 3 和 4 中的损失为类生成过高的置信质量,并且表现出比方程 5 相对不稳定的性能。 我们将对这些替代方案的缺点的理论研究留给未来的工作,而是强调下面首选损失的一些有利的理论特性。
方程 5 中损失的第一个优点是使用恒等式
我们得到以下易于解释的形式
通过分解一阶矩和二阶矩,训练损失旨在实现最小化神经网络专门针对集合中每个样本生成的狄利克雷实验的预测误差和方差的联合目标。 在此过程中,它优先考虑数据拟合而不是方差估计,正如下面的命题所保证的那样。
命题1。 对于任何,满足不等式。
捕捉方程 5 行为的下一步是研究它是否有拟合数据的趋势。 由于我们的下一个提议,我们保证了这一财产。
命题2。 对于具有正确标签 的给定样本 ,当新证据添加到 时, 会减少,而当证据被删除时, 会增加来自。
只要为所有类别生成任意多个证据,只要将大多数证据分配给真实类别,就可以实现良好的数据拟合。 然而,为了执行适当的不确定性建模,模型还需要学习反映观测性质的方差。 因此,当结果更加确定时,应该产生更多证据。 作为回报,它应该完全避免为它无法解释的观察结果生成证据。 我们的下一个命题为这种更好的行为模式提供了保证,这在不确定性建模文献中被称为习得损失衰减[16]。
命题3。 对于具有正确类标签 的给定样本 ,当从最大狄利克雷参数 中删除一些证据时, 会减小,例如那个。
放在一起时,上述命题表明,具有方程 5 中的损失函数的神经网络经过优化,可以为每个样本的正确类别标签生成更多证据,并通过删除过多的信息来帮助神经网络避免错误分类。误导性证据。 损失还倾向于通过增加证据来缩小其对训练集的预测的方差,但前提是生成的证据导致更好的数据拟合。 所有命题的证明都在附录中给出。
一批训练样本的损失可以通过对批次中每个样本的损失求和来计算。 在训练过程中,模型可能会发现数据中的模式,并根据这些模式生成特定类别标签的证据,以最大程度地减少总体损失。 例如,模型可能会发现 MNIST 图像上存在大圆形图案可能会导致数字零的证据。 这意味着当网络在样本上观察到这种模式时,应该增加数字零的输出,即类标签 的证据。 然而,当在训练过程中观察到反例(例如,具有相同圆形图案的数字六)时,应该通过反向传播来调整神经网络的参数,以生成更少量的该图案的证据,并最大限度地减少这些样本的损失,只要整体损失也减少。 不幸的是,当反例的数量有限时,降低生成证据的大小可能会增加总体损失,即使它减少了反例的损失。 因此,神经网络可能会生成一些错误标签的证据。 只要样本被网络正确分类,即正确类别标签的证据高于其他类别标签的证据,这种样本的误导性证据可能不是问题。 但是,如果无法正确分类,我们更希望样本的总证据缩减至零。 让我们注意,总证据为零的狄利克雷分布(即 )对应于均匀分布并指示总不确定性,即 。 我们通过将 Kullback-Leibler (KL) 散度项合并到我们的损失函数中来实现这一目标,该函数通过惩罚那些与“我不知道”状态无助于数据拟合的偏差来规范我们的预测分布。 这个正则化项的损失为
其中是退火系数,是当前训练epoch的索引,是均匀狄利克雷分布,最后 是从样本 的预测参数 中去除非误导性证据后的狄利克雷参数。 损失中的 KL 散度项可以计算为
其中表示个的参数向量,是gamma函数,是digamma 函数。 通过退火系数逐渐增加KL散度对损失的影响,我们允许神经网络探索参数空间并避免过早收敛到误分类样本的均匀分布,从而可以在未来的时期中正确分类。
5实验
为了可通约性,我们按照 Louizos 等人[24]研究的实验设置评估我们的方法。 我们使用具有 ReLU 非线性的标准 LeNet 作为神经网络架构。 所有实验均在 Tensorflow [1] 中实现,并且 Adam [17] 优化器已使用默认设置进行训练。1 11The implementation and a demo application of our model is available under https://muratsensoy.github.io/uncertainty.html
在本节中,我们比较了以下方法: (a) L2对应于具有softmax输出和权重衰减的标准确定性神经网络, (二) 辍学指[8]中使用的不确定性估计模型, (三) 深度合奏指[21]中使用的模型, (四) FFG指[18]中使用的带有加性参数化[26]的贝叶斯神经网络, (五) 多国国家金融集团指[24]中使用的结构化变分推理方法, (六) EDL是我们建议的方法。
我们在 MNIST 和 CIFAR10 数据集上测试了这些方法的预测不确定性。 我们还使用快速梯度符号方法[10]生成的对抗性示例来比较它们的性能。
5.1 预测不确定性性能
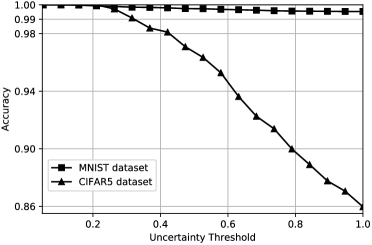
我们在第一个和第二个卷积层使用大小为 的 和 滤波器,以及全连接层的 500 个隐藏单元来训练 MNIST 的 LeNet 架构。 其他方法也使用与[24]中描述的先验和后验相同的架构进行训练。 每种方法在 MNIST 测试集上的分类性能如表3所示。 该表表明我们的方法的性能与竞争对手相当。 因此,我们对不确定性估计的扩展不会降低模型容量。 让我们注意,该表可能会误导我们的方法,因为在计算整体准确性时,完全不确定的预测(即 )也被视为失败;这种零证据的预测意味着模型拒绝做出预测(即说“我不知道”)。 图 3 绘制了如果 EDL 拒绝高于变化的不确定性阈值的预测,测试精度如何变化。 值得注意的是,随着不确定性阈值的降低,相关不确定性小于阈值的预测的准确性会增加并变为 。
| Method | MNIST | CIFAR 5 |
|---|---|---|
| L2 | 99.4 | 76 |
| Dropout | 99.5 | 84 |
| Deep Ensemble | 99.3 | 79 |
| FFGU | 99.1 | 78 |
| FFLU | 99.1 | 77 |
| MNFG | 99.3 | 84 |
| EDL | 99.3 | 83 |
我们的方法使用方程 1 直接量化不确定性。 然而,其他方法使用熵来衡量预测的不确定性,如[24]中所述,即预测的不确定性被认为随着预测概率的熵的增加而增加。 公平地说,我们在本文的其余部分使用相同的指标来评估预测不确定性;我们使用方程2来计算类别概率。
在我们的第一组评估中,我们使用相同的 LeNet 架构在 MNIST split 上训练模型,并在 notMNIST 数据集上进行测试,该数据集包含字母,而不是数字。 因此,我们期望预测具有最大熵(即不确定性)。 在图 4 的左侧面板中,我们显示了使用 MNIST 数据集训练的所有模型在可能的熵 范围内的经验 CDF。 靠近图右下角的曲线是理想的,它表示所有预测中的最大熵[24]。 很明显,我们模型的不确定性估计明显优于基线方法。
我们还研究了 [24] 中建议的设置,它使用 CIFAR10 中类的子集进行训练,其余部分用于分布外不确定性测试。 为了公平比较,我们跟随作者并使用大型 LeNet 版本,其中每个卷积层包含 滤波器,并为全连接层提供 隐藏单元。 对于训练,我们使用 CIFAR10 集中前五个训练类别 {dog、frog、horse、ship、truck} 的样本。 训练后的模型在相同类别的测试样本上的准确率如表3所示。 图 3 显示,随着预测不确定性的降低,EDL 提供了更加准确的预测。
为了评估模型的预测不确定性,我们在 CIFAR10 数据集最后五个类别(即{飞机、汽车、鸟、猫、鹿})的样本上进行了测试。 因此,这些样本的预测都不正确,我们预计预测具有很高的不确定性。 我们的结果如图4右侧所示。 该图表明,与其他方法相比,EDL 的预测具有更多的不确定性。
5.2 对抗性示例的准确性和不确定性
我们还针对对抗性示例[10]评估了我们的方法。 对于之前实验中训练的每个模型,使用 Cleverhans 对抗性机器学习库 [28] 中的快速梯度符号方法生成对抗性示例,并使用不同的对抗性扰动系数值 。 这些示例是使用模型的权重生成的,随着 值的增加,对模型做出正确的预测变得更加困难。 我们使用对抗性示例来测试训练后的模型。 然而,为了公平起见,Deep Ensemble 模型被排除在这组实验中,因为它是在对抗性示例上进行训练的。
图5显示了在 MNIST 数据集上训练的模型的结果。 它在左侧面板上显示了准确性,在右侧面板上显示了不确定性估计。 不确定性是根据预测熵与最大熵的比率来估计的,在图中称为%最大熵。 让我们注意,MNIST 和 CIFAR5 数据集的最大熵分别为 和 。 该图表明,对于对抗性示例,Dropout 具有最高的准确率,如图左图所示;然而,如右图所示,它对所有预测都过于自信。 也就是说,它对自己的错误预测抱有很高的信心。 然而,EDL代表了预测不确定性和准确性之间的良好平衡。 它将非常高的不确定性与错误的预测联系起来。 我们在 CIFAR5 数据集上进行相同的实验。 图6展示了结果,这表明EDL将更高的不确定性与错误的预测相关联。 另一方面,其他模型对自己的错误预测过于自信。
6相关工作
学习不确定性预测变量的历史与现代贝叶斯机器学习方法的出现同时发生。 沿着这条线的一个主要分支是高斯过程(GP)[29],它在做出准确预测和为其预测的不确定性提供可靠测量方面非常强大。 它们的预测能力已在不同的环境中得到了证明,例如迁移学习[15]和深度学习[32]。 其不确定性计算的价值确立了主动学习的最先进水平[12]。 由于 GP 是非参数模型,因此它们没有确定性或随机模型参数的概念。 GP 在不确定性建模中的一个显着优势是,尽管它们能够将各种非线性预测函数拟合到数据,但它们的预测方差可以以封闭形式计算。 因此它们是通用预测因子[31]。
预测不确定性建模的另一项研究是对模型参数采用先验分布(当模型是参数化时),推断后验分布,并使用所得后验预测分布的高阶矩来解释不确定性。 BNN 也属于这一类[25]。 BNN 通过对突触连接权重应用先验分布来解释参数不确定性。 由于连续层之间的非线性激活,权重的后验结果的计算很困难。 近似技术的改进,例如变分贝叶斯 (VB) [2, 6, 27, 23, 9] 和随机梯度哈密顿蒙特卡罗 (SG-HMC) [3] 专门为 BNN 的可扩展推理量身定制是一个活跃的研究领域。 尽管 BNN 具有巨大的预测能力,但其后验预测分布无法以封闭形式计算。 最先进的技术是用蒙特卡罗积分来近似后验预测密度,这给不确定性估计带来了显着的噪声因素。 与这种方法正交,我们绕过了预测器的不确定性来源,并通过确定性神经网络从数据中学习其超参数来直接对狄利克雷后验进行建模。
7结论
在这项工作中,我们通过在类概率上放置狄利克雷分布并将神经网络输出分配给其参数来设计分类的预测分布。 我们通过最小化关于 L2 范数损失的贝叶斯风险来拟合这种预测分布,该损失由信息论复杂性项正则化。 由此产生的预测器是类概率的狄利克雷分布,它提供了比标准 softmax 输出深度网络的点估计更详细的不确定性模型。 我们通过建立从其预测到主观逻辑的信念质量和不确定性分解的链接,从证据推理的角度解释该预测器的行为。 我们的预测器在两个不确定性建模基准中显着提高了现有技术水平:i)分布外查询的检测,以及 ii)对抗性扰动的耐受性。
致谢
这项研究由美国陆军研究实验室和英国国防部根据协议号 W911NF-16-3-0001 赞助。 本文件中包含的观点和结论属于作者的观点和结论,不应被解释为代表美国陆军研究实验室、美国政府、英国国防部或英国政府明示或暗示的官方政策。 美国和英国 尽管此处有任何版权注释,政府仍有权出于政府目的复制和分发重印本。 此外,Sensoy 博士感谢美国陆军研究实验室在 W911NF-16-2-0173 拨款下的支持。
参考
- [1] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al. Tensorflow: A system for large-scale machine learning. In OSDI, volume 16, pages 265–283, 2016.
- [2] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wiestra. Weight uncertainty in neural networks. In ICML, 2015.
- [3] T. Chen, E. Fox, and C. Guestrin. Stochastic gradient Hamiltonian Monte Carlo. In ICML, 2017.
- [4] D. Ciresan, A. Giusti, L.M. Gambardella, and J. Schmidhuber. Deep neural networks segment neuronal membranes in electron microscopy images. In NIPS, 2012.
- [5] D. C. Ciresan, U. Meier, J. Masci, and J. Schmidhuber. Multi-column deep neural network for traffic sign classification. Neural Networks, 32:333–338, 2012.
- [6] M. Welling D. Kingma, T. Salimans. Variational dropout and the local reparameterization trick. In NIPS, 2015.
- [7] A.P. Dempster. A generalization of Bayesian inference. In Classic works of the Dempster-Shafer theory of belief functions, pages 73–104. Springer, 2008.
- [8] Y. Gal and Z. Ghahramani. Bayesian convolutional neural networks with bernoulli approximate variational inference. ICLR Workshops, 2016.
- [9] Y. Gal and Z. Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In ICML, 2016.
- [10] I.J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- [11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [12] N. Houlsby, F. Huszar, Z. Ghahramani, and J.M. Hernández-Lobato. Collaborative Gaussian processes for preference learning. In NIPS, 2012.
- [13] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
- [14] A. Josang. Subjective Logic: A Formalism for Reasoning Under Uncertainty. Springer, 2016.
- [15] M. Kandemir. Asymmetric transfer learning with deep Gaussian processes. In ICML, 2015.
- [16] A. Kendall and Y. Gal. What uncertainties do we need in Bayesian deep learning for computer vision? In NIPS, 2017.
- [17] D.P. Kingma and J. Ba. Adam: A method for stochastic optimisation. In ICLR, 2015.
- [18] D.P. Kingma, T. Salimans, and M. Welling. Variational dropout and the local reparameterization trick. In NIPS, 2015.
- [19] S. Kotz, N. Balakrishnan, and N.L. Johnson. Continuous Multivariate Distributions, volume 1. Wiley, New York, 2000.
- [20] A. Krizhevsky, I. Sutskever, and G.E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
- [21] B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In NIPS, 2017.
- [22] Y. LeCun, P. Haffner, L. Bottou, and Y. Bengio. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision, 1999.
- [23] Y. Li and Y. Gal. Dropout inference in Bayesian neural networks with alpha-divergences. In ICML, 2017.
- [24] C. Louizos and M. Welling. Multiplicative normalizing flows for variational bayesian neural networks. In ICML, 2017.
- [25] D.J. MacKay. Probable networks and plausible predictions – a review of practical Bayesian methods for supervised neural networks. Network: Computation in Neural Systems, 6(3):469–505, 1995.
- [26] D. Molchanov, A. Ashukha, and D. Vetrov. Variational dropout sparsifies deep neural networks. In ICML, 2017.
- [27] D. Molchanov, A. Ashukha, and D. Vetrov. Variational dropout sparsifies deep neural networks. In ICML, 2017.
- [28] N. Papernot, N. Carlini, I. Goodfellow, R. Feinman, F. Faghri, A. Matyasko, K. Hambardzumyan, Y.-L. Juang, A. Kurakin, R. Sheatsley, et al. Cleverhans v2. 0.0: An adversarial machine learning library. arXiv preprint arXiv:1610.00768, 2016.
- [29] C.E. Rasmussen and C.I. Williams. Gaussian Processes for Machine Learning. MIT Press, 2006.
- [30] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15:1929–1958, 2016.
- [31] D. Tran, R. Ranganath, and D. Blei. The variational Gaussian process. In ICLR, 2016.
- [32] A.G. Wilson. Deep kernel learning. In AISTATS, 2016.
附录: (5) 中函数损失的命题
命题1。 对于任何,满足不等式。
作为 和 我们得到
现在考虑 ,然后
作为 ,我们得到
命题2。 对于具有正确标签 的给定样本 ,当新证据添加到 时, 会减少,而当证据被删除时, 会增加来自。
对于 ,它小于 ,因为
类似地,当 时, 变得大于
命题3。 对于具有正确类标签 的给定样本 ,当从最大狄利克雷参数 中删除一些证据时, 会减小,例如那个。
当从中删除一些证据时,减少。 因此,所有 的 都会增加 ,从而 ,因为预期值之和必须为 1(2)。 令 为删除证据后狄利克雷分布的 分量的更新期望值。 那么,移除证据之前的可以写为
删除证据后更新为
差异 变为
对于 始终为正(s.t. )并随着增加而最大化