关系循环神经网络
摘要
基于记忆的神经网络利用长期记住信息的能力来对时间数据进行建模。 然而,目前尚不清楚他们是否也有能力利用他们记住的信息进行复杂的关系推理。 在这里,我们首先确认我们的直觉,即标准内存架构可能难以完成大量涉及理解实体连接方式的任务,即涉及关系推理的任务。 然后,我们通过使用新的内存模块(关系内存核心(RMC))来改善这些缺陷,该模块采用多头点积注意力来允许内存交互。 最后,我们在一系列任务上测试 RMC,这些任务可能受益于跨顺序信息的更强大的关系推理,并在 RL 领域(例如 Mini PacMan)、程序评估和语言建模方面显示出巨大的收益,从而实现了最佳状态WikiText-103、Project Gutenberg 和 GigaWord 数据集上的艺术成果。
1简介
人类使用复杂的记忆系统来访问和推理重要信息,无论这些信息最初是何时被感知的[1, 2]。 在神经网络研究中,许多成功的顺序数据建模方法也使用记忆系统,例如 LSTM [3] 和记忆增强神经网络通常 [4, 5, 6, 7]. 在增强的内存容量、随着时间的推移有限的计算成本以及处理梯度消失的能力的支持下,这些网络学会将不同时间的事件关联起来,从而精通存储和检索信息。
在这里,我们建议考虑内存交互以及存储和检索是富有成效的。 尽管当前的模型可以学习划分和关联分布式矢量化记忆,但它们并不偏向于明确地这样做。 我们假设这种偏差可能会让模型更好地理解记忆是如何相关的,因此随着时间的推移可能会赋予它更好的关系推理能力。 我们首先通过开发一个玩具任务来强调顺序信息的关系推理,证明当前的模型确实在这个领域中举步维艰。 我们使用新的关系记忆核心(RMC)来解决和分析这个玩具问题,该核心使用多头点积注意力来允许记忆相互交互。 然后,我们将 RMC 应用于一系列任务,这些任务可能会从更明确的记忆-记忆交互中受益,因此,随着时间的推移,关系推理的能力可能会增加:部分观察到的强化学习任务、程序评估和维基文本上的语言建模 - 103、古腾堡计划和 GigaWord 数据集。
2 关系推理
我们将关系推理视为理解实体连接方式并利用这种理解来实现某些更高阶目标[8]的过程。 例如,考虑对各种树木到公园长椅的距离进行排序:对实体(树木和长凳)之间的关系(距离)进行比较和对比,以产生解决方案,如果人们孤立地推理每个单独实体的属性(位置),则无法达到这一点。
由于我们通常可以非常流畅地定义什么构成“实体”或“关系”,因此我们可以想象一系列可以用关系推理语言表达的神经网络归纳偏差1 11Indeed, in the broadest sense any multivariable function must be considered “relational.”。 例如,卷积核可以计算感受野内实体(像素)的关系(线性组合)。 之前的一些方法使关系归纳偏差更加明确:在消息传递神经网络中[例如[9,10,11,12],节点包含实体,并且使用应用于与边连接的节点的可学习函数来计算关系,或者有时将关系函数简化为源实体的加权和 [例如。 13、14]。 在关系网络中,[15,16,17]实体是通过利用输入图像中的空间局部性来获得的,该模型侧重于计算每个实体对之间的二元关系。 更进一步,一些方法强调通过采用简单的计算原理可以进行更强大的推理。通过认识到关系可能并不总是与空间中的邻近性相关,非局部计算可能能够更好地捕获彼此远离的实体之间的关系[18, 19].
在时域中,关系推理可以包括比较和对比在不同时间点看到的信息的能力[20]。 在这里,注意力机制[例如21, 22] 隐式执行某种形式的关系推理;如果先前的隐藏状态被解释为实体,那么使用注意力计算实体的加权和有助于消除普通 RNN 中存在的局部性偏差,从而允许嵌入使用内容而不是邻近性更好地相关。
由于我们当前的架构解决了复杂的时间任务,因此它们必须具有一定的时间关系推理能力。 然而,尚不清楚它们的归纳偏差是否有限制,以及这些限制是否会在需要特定类型的时间关系推理的任务中暴露出来。 例如,记忆增强神经网络 [4, 5, 6, 7] 使用基于槽的记忆矩阵解决了划分问题,但可能更难允许记忆交互或关联,一旦它们被编码,它们就会相互关联。 另一方面,LSTM [3, 23] 将所有信息打包到一个公共的隐藏记忆向量中,这可能会使划分和关系推理变得更加困难。
3型号
我们的指导设计原则是提供一个架构主干,模型可以在该架构上学习划分信息,并学习计算划分信息之间的交互。 为了实现这一目标,我们组装了 LSTM、记忆增强神经网络和非本地网络(特别是 Transformer seq2seq 模型 [22])的构建块。 与内存增量架构类似,我们考虑的是一组固定的内存插槽;不过,我们允许内存插槽之间使用注意力机制进行交互。 正如我们将描述的,与之前的工作相比,我们在单个时间步的记忆之间应用注意力,而不是在根据所有先前观察计算出的所有先前表示中应用注意力。
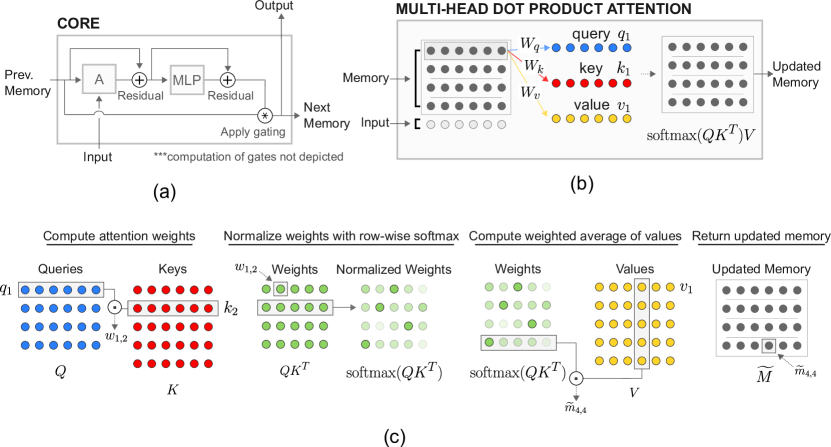
3.1 允许记忆使用多头点积注意力进行交互
我们首先假设我们不需要考虑内存编码;也就是说,我们已经在矩阵 中存储了一些内存,并按行划分了内存 。 为了让记忆能够交互,我们采用多头点积注意力 (MHDPA) [22],也称为自注意力。 使用 MHDPA,每个存储器将关注所有其他存储器,并根据关注的信息更新其内容。
首先,使用简单的线性投影为矩阵 中的每个存储器(即行 )构建查询 ()、键 () 和值 ()。接下来,我们使用查询 对键 执行缩放点积关注。返回的标量可以通过一个 softmax 函数来产生一组权重,然后可以用它来返回 中值的加权平均值,即 ,其中 是用作缩放因子的关键向量的维度。 等效地:
| (1) |
的输出(我们将其表示为 )是一个与 具有相同维度的矩阵。 可以解释为对的建议更新,其中每个包含来自存储器的信息。 因此,在注意力的一个步骤中,每个记忆都会用来自其他记忆的信息进行更新,并且由模型来学习(通过参数 、 和 )如何在内存之间传输信息。
顾名思义,MHDPA 使用多个头。 我们实现了生成 组查询、键和值,使用唯一参数来计算每个头 的原始内存的线性投影。然后我们独立地对每个头应用注意力操作。 例如,如果 是一个 维度矩阵,并且我们使用两个注意力头,那么我们计算 和 ,其中 和 是 矩阵, 和 表示用于生成查询的线性投影的唯一参数、键和值以及 ,其中 直观地说,头对于让内存使用每个头向不同的目标共享不同的信息很有用。
3.2 编码新记忆
我们假设我们已经有了一个记忆矩阵。当然,当接收到新的输入时,需要对存储器进行编码。 假设 是一些随机初始化的内存。 通过对方程1进行简单修改,我们可以有效地将新信息合并到中:
| (2) |
其中我们使用 表示 和 的按行串联。 由于我们在计算键和值时使用 ,而在计算查询时仅使用 ,因此 是一个与 具有相同维度的矩阵t3>.因此,方程2是一个记忆大小保留注意力操作,包括对记忆和新观察的注意力。 值得注意的是,我们使用相同的注意力操作来有效地计算记忆交互并合并新信息。
我们还注意到,当内存由单个向量而不是矩阵组成时,此操作可能有用。 在这种情况下,模型可以通过学习如何处理输入(以存储器中已包含的内容为条件)来学习从输入中挑选哪些信息应写入向量存储器状态。 这在 LSTM 中可以通过门实现,尽管粒度不同。 在讨论中,我们回到这个想法,以及即使在单内存插槽情况下也可能通过磁头进行的划分。
3.3 在 LSTM 中引入递归和嵌入
假设我们有一个时间维度,每个时间步都有新的观察结果 。 由于和是相同的维度,我们可以通过首先随机初始化,然后用更新它来简单地引入递归在每个时间步。 我们选择通过将此更新嵌入到 LSTM 中来实现此目的。 假设对于二维 LSTM,记忆矩阵 可以解释为单元状态矩阵,通常表示为 。 我们可以使单个存储器 的操作与正常 LSTM 单元状态中的操作几乎相同,如下所示(下标被重载以表示矩阵中的行和时间步长;例如 是 在时间 的 行)。
| (3) | ||||
| (4) | ||||
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) | ||||
| (9) |
下括号表示对标准 LSTM 的修改。 在实践中,我们没有发现必要的输出门 - 请参阅脚注中的 URL,了解我们在 Sonnet 库中对该模型的 Tensorflow 实现 222https://github.com/deepmind/sonnet/blob/master/sonnet/python/modules/relational_memory.py,以及对于我们使用的确切公式,包括我们对 函数的选择(简而言之,我们发现具有层归一化的行/内存 MLP 效果最好)。 还有一个有趣的机会来引入一种不同类型的门控,我们称之为“记忆”门控,它类似于之前的门控思想[24, 3]。 我们可以通过转换 、、 为每个内存行生成标量门,而不是为每个单独的单元(“单元”门控)生成标量门。 、 、 和 从权重矩阵转换为权重向量,并用标量向量乘法替换门方程中的逐元素乘积。
由于参数、、、、、、和为每个共享,我们可以修改内存数量而不影响参数数量。 因此,调整存储器的数量和每个存储器的大小可用于平衡总体存储容量(等于中的单元或元素的总数)和参数的数量(成比例)。到的维度)。 我们在实验中发现,有些任务需要更多但不一定更大的内存,而其他任务(例如语言建模)需要更少但更大的内存。
因此,我们有许多可调整的参数:存储器的数量、每个存储器的大小、注意力头的数量、注意力的步数、门控方法和后注意力处理器. 在附录中,我们列出了每个任务的确切配置。
4实验
在这里,我们简要概述了应用 RMC 的任务,并引导读者阅读附录,了解每个任务的完整详细信息以及模型超参数设置的详细信息。
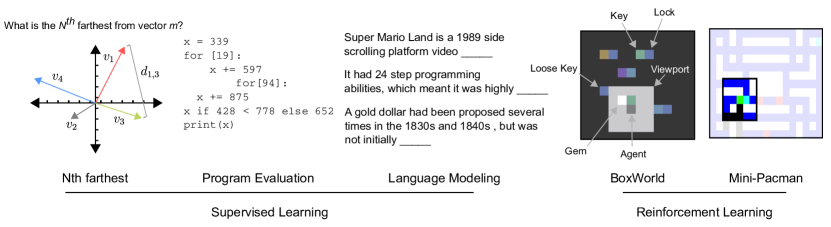
4.1 示例性监督任务
最远
最远任务旨在强调跨时间关系推理的能力。 输入是一串随机取样的向量,目标是一个问题的答案:"距离向量 最远的向量 (欧氏距离)是多少?"其中,向量值、其 ID、 和 是按序列随机采样的。 像复制任务那样简单地编码和检索信息是不够的。 相反,模型必须计算与参考向量 的所有成对距离关系,该参考向量也可能位于内存中,或者甚至可能尚未作为输入提供。 然后它必须隐式地对这些距离进行排序以产生答案。 我们强调,模型必须对向量之间的距离关系进行排序,而不是向量本身。
项目评估
学习执行 (LTE) 数据集[25] 由图灵完备的伪代码编程语言的算法片段组成,并且已损坏分为三类:添加、控制和完整程序。 输入是表示此类片段的字母数字词汇表上的字符序列,目标是数字字符序列,它是给定编程输入的执行输出。 鉴于这些片段涉及变量的符号操作,我们认为这可能会限制模型的关系推理能力;由于符号运算符可以解释为定义操作数之间的关系,因此成功的学习可以反映对这种关系的理解。 为了评估模型在经典序列任务上的性能,我们还评估了记忆任务,其中输出只是输入的排列形式,而不是对一组操作指令的评估。 进一步的实验细节请参见附录。
4.2强化学习
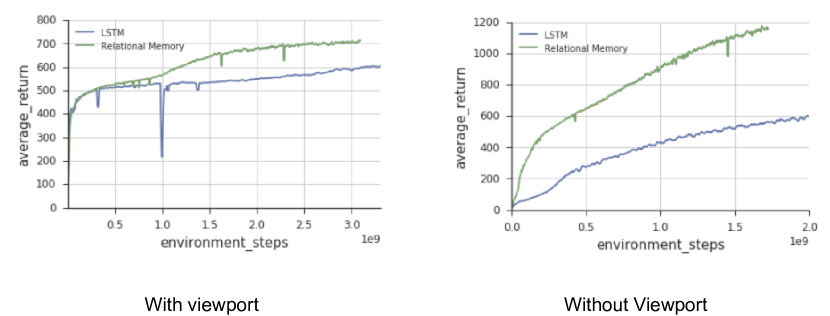
带视口的迷你吃豆人
我们遵循[26]中的Mini Pacman 的公式。 简而言之,特工在被鬼魂追赶的同时穿过迷宫收集食物。 但是,我们使用视口来实现此任务:一个围绕包含感知输入的代理的 窗口。 因此,该任务是部分可观察的,因为代理必须导航空间并通过此视口获取信息。 因此,代理必须预测记忆中幽灵的动态,并根据记忆中关于哪些食物已被拾取的信息,制定相应的导航计划。 我们还向读者指出附录中另一个名为 BoxWorld 的 RL 任务的描述和结果,该任务需要在内存空间中进行关系推理。
4.3语言建模
最后,我们研究基于单词的语言建模的任务。 给定一系列观察到的单词 ,我们对单词 的条件概率 进行建模。 语言模型可以直接应用于预测键盘和搜索短语完成,或者它们可以用作更大系统中的组件,例如机器翻译[27]、语音识别[28]和信息检索[29]。 RNN,尤其是 LSTM,已被证明在许多竞争性语言建模基准上是最先进的,例如 Penn Treebank [30, 31]、WikiText-103 [32, 33],以及十亿字基准[34, 35]。 作为一项顺序推理任务,语言建模使我们能够评估 RMC 随着时间的推移处理大量自然数据信息的能力,并将其与经过良好调整的模型进行比较。
我们专注于具有连续句子和适度大量数据的数据集。 WikiText-103 满足这组要求,因为它由在文章级别上以大致 训练标记进行重组的维基百科文章组成,两个风格不同的文本数据源也是如此:来自古腾堡计划的书籍333古腾堡计划。 (日期不详)。 2018 年 1 月 2 日检索自 www.gutenberg.org 以及来自 GigaWord v5 [36] 的新闻文章。 使用与 [32] 相同的处理,这些数据集分别由 训练标记和 训练标记组成,因此它们涵盖了一系列样式和语料库大小。 我们为所有三个数据集选择大约 的相似词汇量,该大小足以包含稀有单词和数值。
5结果
5.1 最远
这项任务揭示了在 维向量输入上训练时,我们的 LSTM 和 DNC 基线以及 RMC 之间存在明显差异。 LSTM 和 DNC 模型均未能超过 最佳批次精度,而 RMC 在训练结束时始终达到 (参见附录中的图 5)训练曲线)。 当使用 维向量增加任务难度时,RMC 实现了类似的性能,对高保真内存存储提出了更高的要求。 然而,与大多数模型配置成功的 维向量情况相比,这种性能不太稳健,只有少量种子/模型配置证明了这种性能。
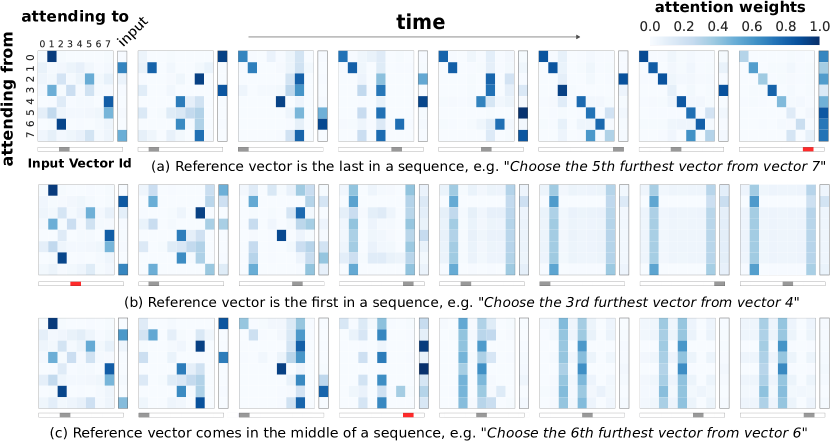
注意力分析揭示了 RMC 内部职能的一些显着特征。 图 3 显示了整个序列中 RMC 内存中的注意力权重:第一行包含最后观察到参考向量 的序列;在第二行首先观察到;在最后一行中,在序列的中间观察到了它。 在看到 之前,模型似乎将输入信息传输到一个或两个内存槽中,如这些槽的查询对输入键的高注意力权重所示。 在看到 后,最明显的是图中的第三行,模型倾向于改变其注意力行为,所有内存槽优先将注意力集中在 所关注的那些特定内存上。 > 被写入。 尽管这种注意力分析提供了一些有用的见解,但我们可以得出的结论是有限的,因为即使在单轮注意力之后,记忆也可能变得高度分布,从而使得对信息划分的任何解释都可能不准确。
5.2项目评估
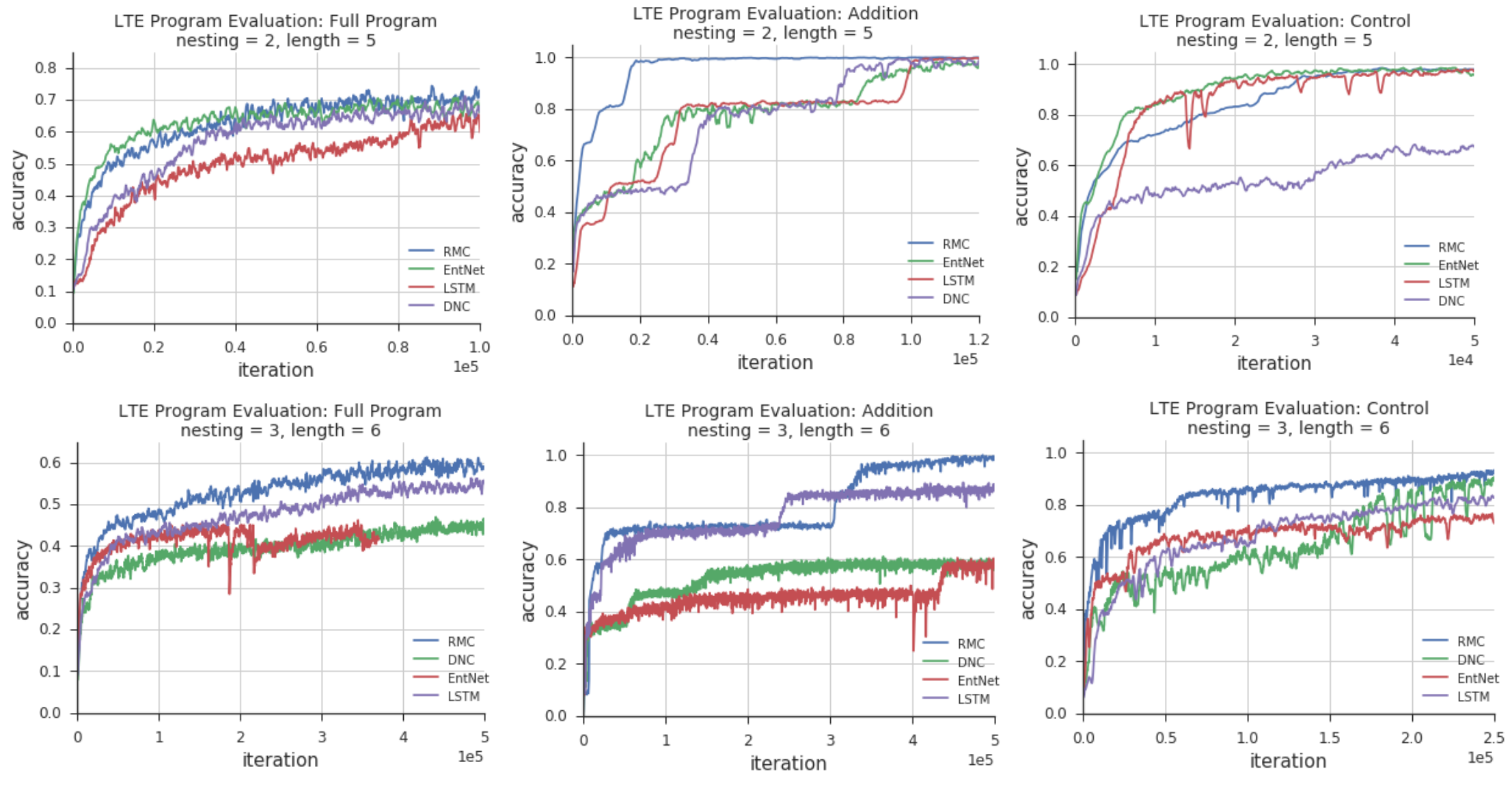
计划评估绩效通过学习执行任务[25]进行评估。 我们与 RMC 一起评估了许多基线,包括 LSTM [3, 37]、DNC [5] 和一组类似于循环实体网络 [ 38] (EntNet) - 附录中描述了其中每一个的配置。 最佳测试批次准确度结果如表1所示。 RMC 至少执行每项任务的所有基线。 它在 double 记忆任务上的性能略胜一筹,但两种模型都有效地解决了该任务。 此外,即使在评估模型性能时,RMC 的结果也优于 [25] 中使用教师强制的所有等效任务。 值得注意的是,当我们以非自回归方式训练时,即训练过程中没有老师强迫时,我们观察到了更好的结果。 这可能与放宽地面实况要求对提高模型泛化[39]以及性能的影响有关。 由于输出词符概率的独立性以及输出分布的尖锐单模态性质(即给定程序的答案不存在歧义),在这些任务中它可能更加明显。
| Model | Add | Control | Program | Copy | Reverse | Double |
|---|---|---|---|---|---|---|
| LSTM [3, 37] | 99.8 | 97.4 | 66.1 | 99.8 | 99.7 | 99.7 |
| EntNet [38] | 98.4 | 98.0 | 73.4 | 91.8 | 100.0 | 62.3 |
| DNC [5] | 99.4 | 83.8 | 69.5 | 100.0 | 100.0 | 100.0 |
| Relational Memory Core | 99.9 | 99.6 | 79.0 | 100.0 | 100.0 | 99.8 |
| WikiText-103 | Gutenberg | GigaWord | |||
| Valid. | Test | Valid | Test | Test | |
| LSTM [40] | - | 48.7 | - | - | - |
| Temporal CNN [41] | - | 45.2 | - | - | - |
| Gated CNN [42] | - | 37.2 | - | - | - |
| LSTM [32] | 34.1 | 34.3 | 41.8 | 45.5 | 43.7 |
| Quasi-RNN [43] | 32 | 33 | - | - | - |
| Relational Memory Core | 30.8 | 31.6 | 39.2 | 42.0 | 38.3 |
5.3迷你吃豆人
在带有视口的 Mini Pacman 中,RMC 比 LSTM 多获得了大约 点( 与 ),并且当使用完整观察进行训练时,RMC 几乎达到了LSTM 的性能提高了一倍( 与 ,图 10)。
5.4语言建模
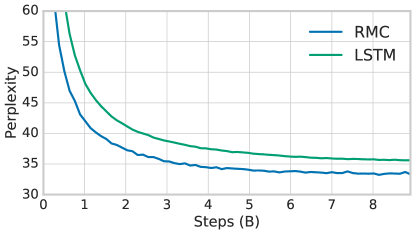
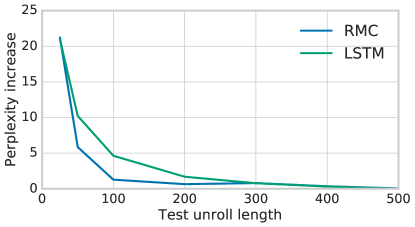
对于所有三种语言建模任务,我们在使用关系内存核心时观察到较低的困惑度,与最佳已发布结果相比,困惑度下降了 。 虽然很小,但这构成了 % 的相对改进,并且在不同规模和风格的任务中似乎是一致的。 对于 WikiText-103,我们发现这可以与 LSTM 架构 [5, 32]、卷积模型 [42] 和混合循环卷积模型 [43 ]。
6讨论
许多其他方法已经通过使用先前状态的不断增长的缓冲区[21, 22]成功地对顺序信息进行建模。 这些模型可以更好地捕获长距离交互,因为它们的计算不会因时间局部邻近性而产生偏差。 然而,当时间步数很大甚至无限时,例如在在线强化学习中(例如在现实世界中),这些模型存在严重的扩展问题。 因此,需要做出一些决定,涉及应存储的过去嵌入缓冲区的大小、是否应该是滚动窗口、计算应如何缓存和跨时间传播等。 这些考虑因素使得很难在这些在线环境中直接比较这些方法。 尽管如此,我们相信,将纯粹的循环方法与随时间扩展的方法相结合可能是一项富有成果的追求:也许模型会在一段时间内无损地积累记忆,然后学会在循环核心中压缩它,然后再继续处理后续的记忆。块。
我们提出了一些机制的直觉,可以更好地装备复杂关系推理的模型。 也就是说,通过明确允许记忆通过 MHDPA 相互交互、与输入交互或两者交互,我们证明了在需要跨时间关系推理的任务上的性能得到了提高。 然而,我们想强调的是,虽然这些直觉指导了我们的模型设计,并且在最远任务中对模型的分析与我们的直觉一致,但我们不一定能提出任何具体的主张:我们的设计选择对模型关系推理能力的因果影响,或者模型内发生的计算以及它们如何映射到思考关系推理的传统方法。 因此,我们主要将我们的结果视为功能改进的证据——如果一个模型能够更好地解决需要关系推理的任务,那么它必须具有更强的关系推理能力,即使我们并不确切知道为什么它的容量会增加。 从这个角度来看,RMC 可以从多个角度进行有益的观察,并且这些优势可以为进一步改进提供想法。
我们的模型具有多种机制来形成并允许内存向量之间的交互:将内存矩阵按行切片为槽,按列切片为头。 每个都有自己的优点(槽上的计算共享参数,而拥有更多的头和更大的内存大小可以利用更多的参数)。 我们还不了解其中的相互作用,但我们注意到一些实证研究结果。 首先,在最远的任务中,具有单个内存插槽的模型在具有更多注意力头时表现更好,尽管在所有情况下它的表现都比具有多个内存插槽的模型差。 其次,在语言建模中,我们的模型使用单个内存插槽。 这里选择单个内存的原因主要是因为LM一般需要大量的参数(因此单个内存槽的尺寸很大),并且无法快速运行具有大量参数的模型参数和多个内存插槽。 因此,我们不一定声称单个内存槽最适合语言建模,相反,我们强调内存数量和单个内存大小之间有趣的权衡,这可能是可以调整的特定于任务的比率。 此外,在程序评估中,中间解决方案在子任务( 插槽和磁头)上运行良好,尽管有些在 内存下表现最佳,而另一些则在 下表现最佳。
总而言之,我们的结果表明,记忆交互的显式建模与程序评估、比较推理和语言建模一起提高了强化学习任务的性能,证明了在循环神经网络中灌输关系推理能力的价值。
致谢
我们感谢 Caglar Gulcehre、Matt Botvinick、Vinicius Zambaldi、Charles Blundell、Sébastien Racaniere、Chloe Hillier、Victoria Langston 以及 DeepMind 团队中的许多其他人提供的批评反馈、讨论和支持。
参考
- [1] Daniel L Schacter and Endel Tulving. Memory systems 1994. Mit Press, 1994.
- [2] Barbara J Knowlton, Robert G Morrison, John E Hummel, and Keith J Holyoak. A neurocomputational system for relational reasoning. Trends in cognitive sciences, 16(7):373–381, 2012.
- [3] Sepp Hochreiter and Jurgen Schmidhuber. Long short term memory. Neural Computation, Volume 9, Issue 8 November 15, 1997, p.1735-1780, 1997.
- [4] Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
- [5] Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626):471, 2016.
- [6] Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. In International conference on machine learning, pages 1842–1850, 2016.
- [7] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. End-to-end memory networks. In Advances in neural information processing systems, pages 2440–2448, 2015.
- [8] James A Waltz, Barbara J Knowlton, Keith J Holyoak, Kyle B Boone, Fred S Mishkin, Marcia de Menezes Santos, Carmen R Thomas, and Bruce L Miller. A system for relational reasoning in human prefrontal cortex. Psychological science, 10(2):119–125, 1999.
- [9] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. arXiv preprint arXiv:1704.01212, 2017.
- [10] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2009.
- [11] Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard S. Zemel. Gated graph sequence neural networks. ICLR, 2016.
- [12] Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al. Interaction networks for learning about objects, relations and physics. In Advances in neural information processing systems, pages 4502–4510, 2016.
- [13] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- [14] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018.
- [15] Adam Santoro, David Raposo, David G Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Tim Lillicrap. A simple neural network module for relational reasoning. In Advances in neural information processing systems, pages 4974–4983, 2017.
- [16] David Raposo, Adam Santoro, David Barrett, Razvan Pascanu, Timothy Lillicrap, and Peter Battaglia. Discovering objects and their relations from entangled scene representations. arXiv preprint arXiv:1702.05068, 2017.
- [17] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen Wei. Relation networks for object detection. arXiv preprint arXiv:1711.11575, 2017.
- [18] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. arXiv preprint arXiv:1711.07971, 2017.
- [19] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. arXiv preprint arXiv:1806.02919, 2018.
- [20] Juan Pavez, Héctor Allende, and Héctor Allende-Cid. Working memory networks: Augmenting memory networks with a relational reasoning module. arXiv preprint arXiv:1805.09354, 2018.
- [21] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. ICLR, abs/1409.0473, 2015.
- [22] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010, 2017.
- [23] Alex Graves. Generating sequences with recurrent neural networks. CoRR, abs/1308.0850, 2013.
- [24] Felix A Gers, Jürgen Schmidhuber, and Fred Cummins. Learning to forget: Continual prediction with lstm. 1999.
- [25] Wojciech Zaremba and Ilya Sutskever. Learning to execute. arXiv preprint arXiv:1410.4615v3, 2014.
- [26] Théophane Weber, Sébastien Racanière, David P Reichert, Lars Buesing, Arthur Guez, Danilo Jimenez Rezende, Adria Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, et al. Imagination-augmented agents for deep reinforcement learning. arXiv preprint arXiv:1707.06203, 2017.
- [27] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- [28] Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk, Philemon Brakel, and Yoshua Bengio. End-to-end attention-based large vocabulary speech recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on, pages 4945–4949. IEEE, 2016.
- [29] Djoerd Hiemstra. Using language models for information retrieval. 2001.
- [30] Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, and William W Cohen. Breaking the softmax bottleneck: a high-rank rnn language model. arXiv preprint arXiv:1711.03953, 2017.
- [31] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
- [32] Jack W Rae, Chris Dyer, Peter Dayan, and Timothy P Lillicrap. Fast parametric learning with activation memorization. arXiv preprint arXiv:1803.10049, 2018.
- [33] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- [34] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
- [35] Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013.
- [36] Robert Parker, David Graff, Junbo Kong, Ke Chen, and Kazuaki Maeda. English gigaword fifth edition ldc2011t07. dvd. Philadelphia: Linguistic Data Consortium, 2011.
- [37] Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. How to construct deep recurrent neural networks. arXiv preprint arXiv:1312.6026, 2013.
- [38] Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, and Yann LeCun. Tracking the world state with recurrent entity networks. In Fifth International Conference on Learning Representations, 2017.
- [39] Navdeep Jaitly Noam Shazeer Samy Bengio, Oriol Vinyals. Scheduled sampling for sequence prediction with recurrent neural networks. In Advances in Neural Information Processing Systems 28, 2015.
- [40] Edouard Grave, Armand Joulin, and Nicolas Usunier. Improving neural language models with a continuous cache. arXiv preprint arXiv:1612.04426, 2016.
- [41] Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Convolutional sequence modeling revisited. 2018.
- [42] Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. arXiv preprint arXiv:1612.08083, 2016.
- [43] Stephen Merity, Nitish Shirish Keskar, James Bradbury, and Richard Socher. Scalable language modeling: Wikitext-103 on a single gpu in 12 hours. 2018.
- [44] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [45] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems 27, 2014.
- [46] Vinicius Zambaldi, David Raposo, Adam Santoro, Victor Bapst, Yujia Li, Igor Babuschkin, Karl Tuyls, David Reichert, Timothy Lillicrap, Edward Lockhart, Murray Shanahan, Victoria Langston, Razvan Pascanu, Matthew Botvinick, Oriol Vinyals, and Peter Battaglia. Relational deep reinforcement learning. arXiv preprint, 2018.
- [47] Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Importance weighted actor-learner architectures: Scalable distributed deep-rl with importance weighted actor-learner architectures. arXiv preprint arXiv:1802.01561, 2018.
附录 A 进一步的任务详细信息、分析和模型配置
在以下部分中,我们提供有关实验和模型配置的更多详细信息。 在描述模型时,我们有时会引用以下术语:
-
•
“totalunits”:内存矩阵中元素的总数。相当于每个内存的大小乘以内存的数量。
-
•
“num head”:注意力头的数量;即,为存储器生成的唯一查询、键和值集的数量。
-
•
“内存槽位”或“内存数量”:相当于矩阵中的行数。
-
•
“num block”:每个时间步执行的注意力迭代次数。
-
•
“门类型”:每个单元或每个内存插槽的门控
A.1 最远
输入由八个随机采样的序列组成,来自均匀分布的维向量和向量标签,编码为one-hot向量采样无需更换。 标签是采样的,因此与向模型呈现向量的时间点不对应。 附加到每个向量标签输入的是任务规范(即该序列的 和 的值),也编码为 one-hot 向量。 因此,时间步的输入是40维向量。
对于所有模型(RMC、LSTM、DNC),我们使用 Adam 优化器 [44],批量大小为 ,学习率在 和,并使用 softmax 交叉熵损失函数进行训练。 所有模型都具有等效的 4 层 MLP(每层具有 ReLu 非线性的 单元)来处理其输出以生成 softmax 的 logits。 学习率似乎并不影响性能,因此我们在最终实验中选择了 。
对于 LSTM 和 DNC,架构参数似乎对模型性能没有影响。 对于 LSTM,我们尝试了从 到 单位的隐藏大小,对于 DNC,我们尝试了 、 或 内存、、 或 内存大小(我们将其与控制器 LSTM 大小绑定)和 、 或 DNC 使用 层 LSTM 控制器。
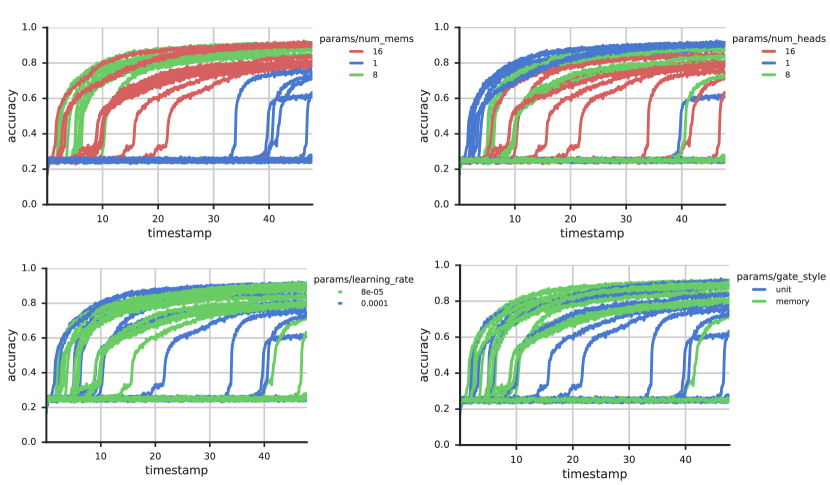
对于 RMC,我们使用 、 或 内存以及 总单元(因此,每个内存的大小为 )、、 或 头、 注意力块以及两个 'unit ”和“记忆”门控方法。 图4显示了根据挂钟时间缩放的超参数扫描结果(具有更多但较小内存的模型比具有较少但较大内存的模型运行得更快,我们选择将模型与等效模型进行比较内存矩阵中的总单元数)。
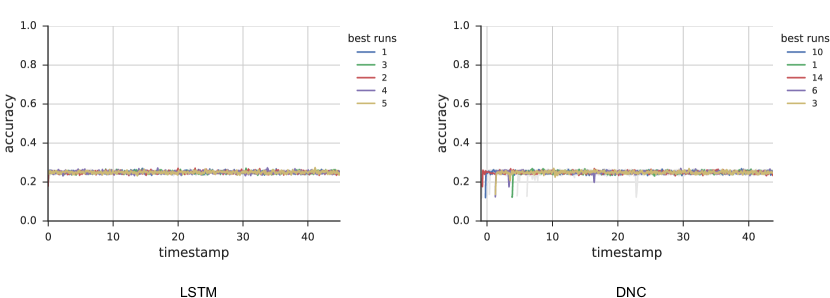
A.2项目评估
为了进一步研究关系结构对工作记忆和符号表征的影响,我们转向了一系列问题,这些问题为 RMC 作为广义计算模型的适应性提供了见解。 学习执行 (LTE) 数据集[25] 为评估我们的模型解决此类问题的能力提供了一个良好的起点。 示例问题的形式为线性时间、常量内存、小程序。
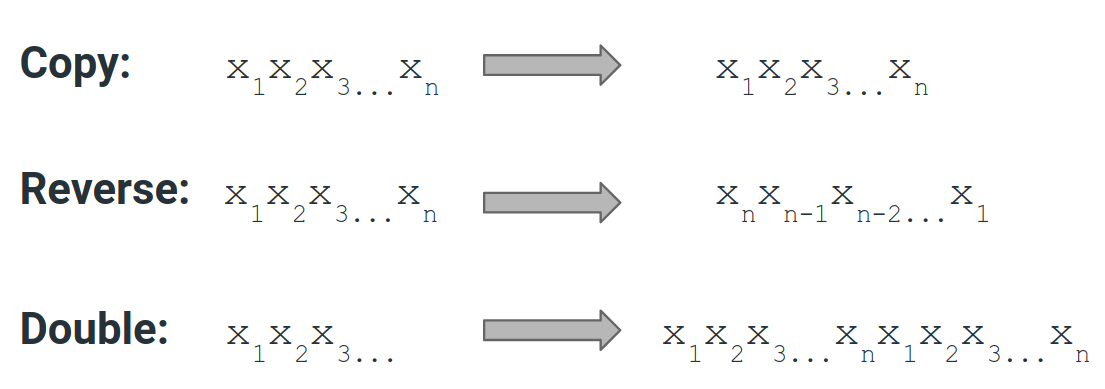
训练样本是在运行中分批 生成的。 使用 Adam 优化器和 学习率对每个模型进行 K 次迭代训练。 样本通过文字长度和嵌套深度进行参数化,定义了程序片段中终端值的长度和程序操作嵌套的级别。 在每个批次中,对文字长度和嵌套值进行统一采样,直至每个批次的最大值 - 这与 [25] 中的 Mix 课程策略一致。 我们使用所有样本的最大嵌套和文字长度值针对一批 样本评估模型,并报告最高分数。 每个任务的示例示例可以在图 6 和图 7 中找到。 还值得注意的是,模数运算应用于加法、控制和完整程序样本,以便将输出限制为最大文字长度(如果 for 循环较长)。

顺序模型由编码器和解码器组成,每个编码器和解码器均采用循环神经网络[45, 25]的形式。 一旦编码器处理完输入序列,编码器的状态将用于初始化解码器状态,并随后生成目标序列(程序输出)。 所有模型的输出都通过 4 层 MLP(所有层的大小为 和输出 ReLU),以在输出序列的每一步生成输出嵌入。
在[25]中,教师强制用于解码阶段的训练和测试。 在我们的实验中,我们首先在训练期间探索教师强制,但在评估模型 [45] 时,使用上一步中的模型预测作为下一步解码器的输入。 我们还考虑了在训练解码器 [39] 时完全限制对真实情况的依赖以及使用仅在训练期间使用模型预测的非自回归机制的潜在影响。 事实证明,这种方法往往会产生最强的结果。
以下是在所有任务中表现最佳的一组内存模型的编码器/解码器配置。 使用 RMC,我们扫描了两个和四个内存,以及两个和四个注意力头,总内存大小为 和 (跨内存划分),单次自注意力传递每步和标量内存门控。 对于基线,LSTM 是一个两层模型,我们扫描每层具有 和 单元的模型,跳过连接并在最后一层连接逐层输出。 DNC使用内存大小,字大小,四个读头和一个写头,一个2层控制器扫过, 和 每层潜在单位,大于此设置往往会损害性能。 同样对于 DNC,LSTM 控制器用于解决程序评估问题,前馈控制器用于记忆。 最后,对总内存大小为或的 EntNet 与、、或存储单元进行了比较,其中总内存大小由各存储单元分担,各单元的状态相加产生输出。 报告的所有结果均来自给定模型的最强性能超参数设置。
A.3 视口 BoxWorld
我们研究了 BoxWorld 的一个变体,它是一个基于像素的、高度组合的强化学习环境,需要基于关系推理的规划,最初是在 [46] 中开发的。 它由 像素网格组成:灰色像素表示背景,单独的彩色像素是可以拾取的钥匙,彩色像素的对偶是锁和钥匙,其中对偶的右侧像素表示锁的颜色(以及打开锁所需的钥匙的颜色),左侧像素表示代理打开锁时将获得的钥匙的颜色。 该代理由深灰色像素表示,有四个动作:向上、向下、向左、向右 。 为了使此任务需要在内存空间中进行关系推理,代理只能感知访问 RGB 窗口或视口,并附加一个额外的帧来表示当前拥有的键的颜色。 任务的目标是在空间中导航,观察钥匙锁组合,然后选择正确的钥匙锁序列,以便最终获得奖励宝石(由白色像素表示)。
每个关卡都有一个独特的钥匙锁对序列,必须遍历这些钥匙锁才能到达宝石。 有几个重要因素使这项任务变得困难:首先,钥匙一旦使用就会消失。 由于我们包含“干扰”分支(即导致死胡同的关键锁定路径),因此代理必须能够向前看,并推理出通往宝石的适当路径,以免陷入困境。 其次,钥匙和锁的位置是随机的,使得这项任务完全没有任何空间偏差。 这强调了在记忆中根据钥匙和锁的抽象关系而不是根据它们的空间位置来推理钥匙和锁之间的关系的能力。 出于这个原因,我们怀疑基于 CNN 的方法可能会遇到困难,因为它们的归纳偏差与空间中邻近事物的相关性有关。
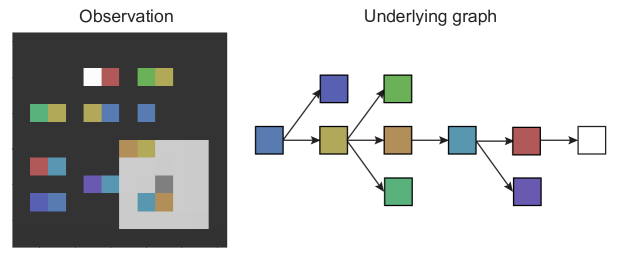
要收集锁定的钥匙,特工必须拥有匹配的钥匙颜色(一次只能持有一把钥匙)并走过锁,之后锁就会消失。 只有这样,代理才有可能拿起相邻的钥匙。 每个关卡都是按程序生成的,每个关卡中只能有一个以白色宝石结尾的独特序列。 为了生成关卡,我们首先对随机图(树)进行采样,该图定义了可以遍历的可能路径,包括干扰路径。 示例路径如图9所示。
我们在采样池中总共使用了 个键和 个锁(即颜色)来生成每个级别。 三个主要因素决定了关卡的难度:(1)到宝石的路径长度(即锁的数量); (2) 干扰分支的数量; (3) 干扰分支的路径长度。 对于训练,我们使用的解决方案路径长度至少为 1,最多为 5,确保未经训练的智能体有很小的概率偶然达到目标,至少在较简单的级别上如此。 我们采样干扰分支的数量在 0 到 5 之间,长度为 1。
视口观察通过两个卷积层进行处理,具有 和 内核, 内核大小和步长 。 每层都使用 ReLU 非线性。 我们使用了两个额外的特征图来标记卷积输出,标记每个像素/单元的绝对空间位置(和),标记由和之间均匀分布的值组成。 然后将生成的堆栈传递给 RMC,其中包含四个内存、四个头、总内存大小 (在头和内存之间划分)、每步一次自注意力传递和标量内存门控。 对于基线,我们将 RMC 替换为具有 输出通道、 内核且步长为 1 的 ConvLSTM。
我们在演员-评论家设置中使用了这种架构,使用分布式重要性加权演员-学习者架构[47]。 该代理由 参与者(生成经验轨迹)和一个学习者组成,该学习者使用参与者直接学习策略 和基线函数 ' 的经历。 模型更新是使用参与者通过队列提供的小批量 轨迹在 GPU 上执行的。 该代理的熵成本为 ,折扣 () 为 ,展开长度为 步骤。 调整学习率,取 和 之间的值。 非正式地,我们注意到我们可以使用 A3C 设置来复制这些结果,尽管训练需要更长的时间。
智能体因收集宝石而获得 奖励,因在解决方案路径中打开盒子而获得 奖励,因打开干扰器盒子而获得 奖励。 收集宝石或打开干扰器盒后,关卡立即终止。
A.3.1结果
我们在 BoxWorld 级别上训练了一个使用 RMC 增强的重要性加权 Actor-Learner 架构代理,需要打开至少 1 个到最多 5 个盒子。 干扰分支的数量从 0 到 5 个随机抽样。 该代理在任务中取得了很高的性能,正确解决了 步骤之后的 关卡。 使用 ConvLSTM 进行增强的同一智能体表现明显较差,仅达到 。
A.4语言建模
我们使用 Adam 训练循环记忆核心,使用学习率 并将梯度剪裁为最大 L2 范数 。 时间反向传播被截断为窗口长度 。 该模型使用 Nvidia Tesla P100 GPU 进行同步训练。 每个 GPU 均使用 批次进行训练,因此总批次大小为 。 我们使用 (具有 0.5 的 dropout)作为词嵌入大小,并将词嵌入矩阵参数与输出 softmax 联系起来。
我们浏览了以下模型架构参数:
-
•
内存中的总单位
-
•
注意头
-
•
内存数量
-
•
MLP层
-
•
注意块
并选择 总单元、 磁头、 内存、 层 MLP 和 基于 WikiText-103 上的验证错误的注意力块。 由于训练费用,我们在 GigaWord 和 Project Gutenberg 中使用了相同的参数,而没有进行额外的扫描。
| K | KK | K | All | |
|---|---|---|---|---|
| LSTM [32] | 39.4 | 6.5e3 | 3.7e4 | 53.5 |
| LSTM + Hebbian Softmax [32] | 33.2 | 3.2e3 | 1.6e4 | 43.7 |
| RMC | 28.3 | 3.1e3 | 6.9e4 | 38.3 |