使用随机梯度哈密顿蒙特卡罗进行深度高斯过程推断
摘要
深度高斯过程 (DGP) 是高斯过程的分层推广,它将良好校准的不确定性估计与多层模型的高灵活性相结合。 这些模型面临的最大挑战之一是精确推断是难以处理的。 目前最先进的推断方法变分推断 (VI) 对后验分布采用高斯近似。 这可能是对通常是多峰的后验的潜在不良单峰近似。 在这项工作中,我们提供了后验非高斯性质的证据,并应用随机梯度哈密顿蒙特卡罗方法来生成样本。 为了有效地优化超参数,我们引入了移动窗口 MCEM 算法。 这导致在比其 VI 对应物更低的计算成本下获得明显更好的预测。 因此,我们的方法为 DGP 中的推断建立了新的最先进水平。
1 引言
深度高斯过程 (DGP) (Damianou 和 Lawrence,2013) 是多层预测模型,具有高度灵活性,可以准确地模拟不确定性。 特别是,它们已被证明在从小型 (500 个数据点) 到大型数据集 (500,000 个数据点) (Salimbeni 和 Deisenroth,2017; Bui 等人,2016; Cutajar 等人,2016) 的大量监督回归任务中表现良好。 与神经网络相比,它们的主要优势在于它们能够捕获其预测中的不确定性。 这使它们成为预测不确定性起着至关重要作用的任务的良好候选者,例如黑盒贝叶斯优化问题和各种安全关键应用,如自动驾驶汽车和医疗诊断。
深度高斯过程为高斯过程 (GP) (Williams 和 Rasmussen,1996) 引入了一个多层层次结构。 高斯过程 (GP) 是一种非参数模型,它假设任何有限输入集都具有联合高斯分布。 任何一对输入的协方差由协方差函数决定。 由于 GP 是非参数的并且可以进行解析计算,因此它可能是一个稳健的选择,但是,一个问题是选择协方差函数通常需要手动调整和对数据集的专业知识,而没有问题的先验知识,这是不可能的。 在多层层次结构中,隐藏层通过拉伸和扭曲输入空间来克服这一限制,从而形成一个贝叶斯“自调整”协方差函数,该函数适合数据而无需任何人工输入 (Damianou, 2015)。
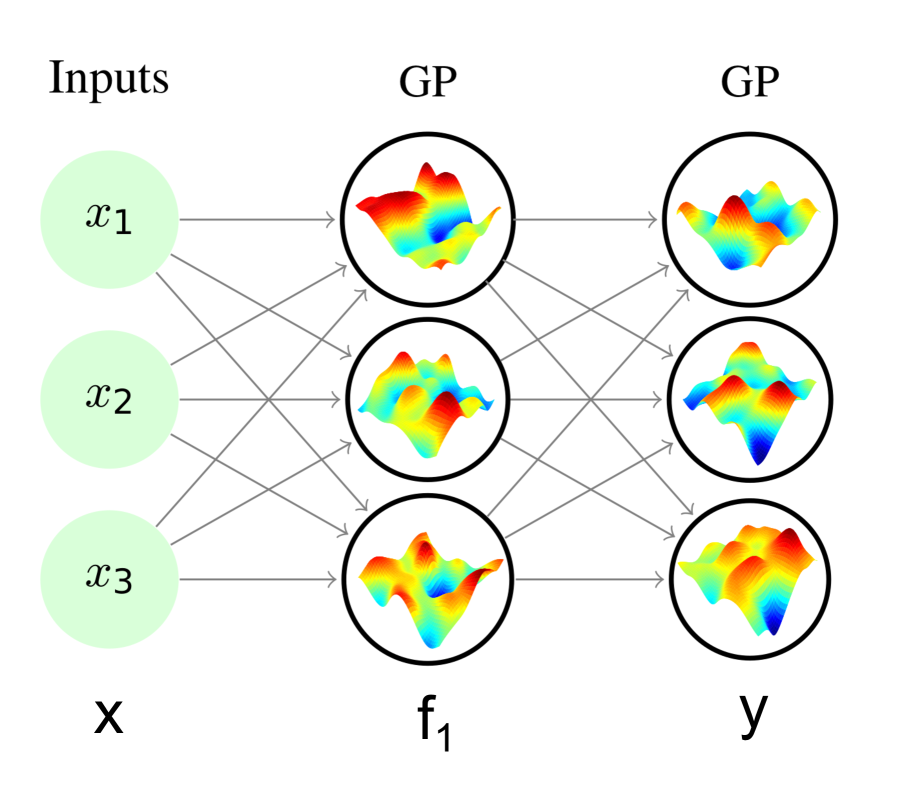
GP 的深度层次概括以完全连接的前馈方式进行。 前一层的输出作为下一层的输入。 但是,与神经网络的一个显著区别是,层输出是概率性的,而不是精确的值,因此不确定性会在网络中传播。 图 1 的左侧说明了具有单个隐藏层的概念。 隐藏层的输入是输入数据 ,隐藏层的输出 作为输出层的输入数据,输出层本身由 GP 组成。
由于处理逆协方差矩阵的计算成本很高,因此在大型数据集上对 GP 进行精确推断是不可行的。 相反,后验分布使用一小部分伪数据点 (100) 进行近似,这些数据点也称为诱导点 (Snelson 和 Ghahramani, 2006; Titsias, 2009; Quiñonero-Candela 和 Rasmussen, 2005)。 我们假设整篇论文都使用这种诱导点框架。 预测是使用诱导点进行的,以避免计算整个数据集的协方差矩阵。 在 GP 和 DGP 中,诱导输出都被视为需要边缘化的潜在变量。
DGP 中当前最先进的推断方法是双随机变分推断 (DSVI) (Salimbeni 和 Deisenroth, 2017),它已被证明优于期望传播 (Minka, 2001; Bui 等人, 2016),并且在具有概率反向传播的贝叶斯神经网络 (Hernández-Lobato 和 Adams, 2015) 和具有早期推断方法的贝叶斯神经网络(如变分推断 (Graves, 2011)、随机梯度朗之万动力学 (Welling 和 Teh, 2011) 和混合蒙特卡洛 (Neal, 1993))方面也具有更好的性能。 然而,DSVI 的一个缺点是它用高斯逼近后验分布。 我们有很高的信心表明,对于我们在这项工作中检查的每个数据集,后验分布都是非高斯分布的。 这一发现促使人们使用具有更灵活的后验近似值的推断方法。
在这项工作中,我们应用了一种对 DGP 来说是新方法的推断方法,即随机梯度哈密顿蒙特卡洛 (SGHMC),这是一种能够准确有效地捕获后验分布的抽样方法。 为了将基于抽样的推断方法应用于 DGP,我们必须解决优化大量超参数的问题。 为了解决这个问题,我们提出了移动窗口蒙特卡洛期望最大化,这是一种获得超参数最大似然 (ML) 估计的新方法。 这种方法速度快、效率高,并且通常适用于任何概率模型和 MCMC 抽样器。
人们可能认为,与 DSVI 等变分方法相比,SGHMC 等抽样方法的计算量更大。 然而,在 DGP 中,从后验分布中抽样并不昂贵,因为它不需要重新计算逆协方差矩阵,而逆协方差矩阵仅依赖于超参数。 此外,在 VI 设置中,计算逐层方差的成本更高。
最后,我们对各种监督回归和分类任务进行了实验。 我们通过实验证明,我们的工作在较低的计算成本下显着提高了中等大型数据集的预测效果。
我们的贡献可以概括为三点。
-
1.
证明后验分布的非高斯性。 我们提供了证据表明,我们在这项工作中检查的每个回归数据集都具有非高斯后验分布。
-
2.
我们使用 SGHMC 直接从 DGP 的后验分布中采样。 实验表明,这种新的推理方法优于先前的工作。
-
3.
我们引入了移动窗口 MCEM,这是一种新颖的算法,可用于在使用 MCMC 采样器进行推理时有效地优化超参数。
2 背景与相关工作
本节介绍了用于回归的高斯过程和深度高斯过程的背景,并建立了本文中使用的符号。
2.1 单层高斯过程
高斯过程定义了给定一组输入-输出对 和 的函数 上的后验分布。 在 GP 模型下,假设函数值 (其中 表示 )是联合高斯的,并具有固定的协方差函数 。 的条件分布通过似然函数 获得。 一个常用的似然函数是 (恒定高斯噪声)。
精确推理的计算成本是 ,这使得它对于大型数据集而言在计算上不可行。 一种常见的方法是使用一组伪数据点 、 (Snelson and Ghahramani, 2006; Titsias, 2009),并将联合概率密度函数写成
给定诱导输出 的 的分布可以表示为 ,其中
其中,符号 指的是两组点 、 之间的协方差矩阵,其中元素为 ,其中 和 分别是 和 的第 个和第 个元素。
为了获得 的后验,必须对 进行边缘化,得到方程
注意,在给定 的情况下, 与 条件独立。
对于单层 GPs,可以使用变分推断 (VI) 进行边缘化。 VI 用变分后验 来逼近联合后验分布 ,其中 。
这种 的选择允许对边际 进行精确推断
| (1) | ||||
变分参数 和 需要被优化。 这是通过最小化真实后验和近似后验之间的 Kullback-Leibler 散度来完成的,这等效于最大化边际似然的较低界 (证据较低界或 ELBO):
2.2 深度高斯过程
在深度为 的 DGP 中,每一层都是一个 GP,它对一个函数 进行建模,该函数的输入为 ,输出为 ,其中 () 如图 1 的左侧所示。 各层的诱导输入用 表示,其对应的诱导输出为 。
联合概率密度函数可以类似于 GP 模型的情况写成:
| (2) |
2.3 推断
推断的目标是对诱导输出 和层输出 进行边缘化,并逼近边际似然 。 本节讨论关于推理的先前工作。
双随机变分推理
DSVI 是变分推理对 DGP 的扩展 (Salimbeni and Deisenroth, 2017),它用独立的多元高斯分布 近似诱导输出 的后验分布。
层输出自然遵循等式 1 中的单层模型:
然后,通过对层输出进行小批量采样来估计得到的 ELBO 中的第一项,以允许扩展到大型数据集。
基于采样的高斯过程推理
在相关工作中,Hensman et al. (2015) 在单层 GP 中使用混合 MC 采样。 他们考虑对 GP 超参数和诱导输出进行联合采样。 由于采样 GP 超参数的成本很高,因此这项工作无法直接扩展到 DGP。 此外,它使用了一种代价高昂的方法,贝叶斯优化,来调整采样器的参数,这进一步限制了它在 DGP 中的适用性。
3 深度高斯过程后验分析
采用新的推理方法而不是变分推理是受 VI 对后验分布做出的限制性形式的启发。 变分假设是 采用多元高斯分布的形式,该分布假设层之间相互独立。 虽然在单层模型中,对后验分布进行高斯近似可以得到证明是正确的 (Williams and Rasmussen, 1996),但对于 DGP 来说情况并非如此。
| Toy Problem | DSVI | SGHMC | Mode A | Mode B | |
|---|---|---|---|---|---|
![[Uncaptioned image]](x4.png) 图 2: 具有 7 个数据点的玩具问题。
图 2: 具有 7 个数据点的玩具问题。
|
Layer 1 | ![[Uncaptioned image]](x5.png) |
![[Uncaptioned image]](x6.png) |
![[Uncaptioned image]](x7.png) |
![[Uncaptioned image]](x8.png) |
| Layer 2 | ![[Uncaptioned image]](x9.png) |
![[Uncaptioned image]](x10.png) |
![[Uncaptioned image]](x11.png) |
![[Uncaptioned image]](x12.png) |
首先,我们通过一个玩具问题来说明 DGP 中的后验分布可能是多峰的。 接着,我们提供证据表明,我们在本工作中考虑的每个回归数据集都导致了非高斯后验分布。
多峰玩具问题
二层 DGP () 后验的多峰性在玩具问题(表 2)上得到了证明。 为了便于演示,我们做出了一个简化的假设,即 ,因此似然函数没有噪声。 这个玩具问题有两个最大后验 (MAP) 解(模式 A 和模式 B)。 该表显示了 DSVI 每层处的变分后验。 我们可以看到,它随机地拟合了其中一个模式(取决于初始化),而完全忽略了另一个。 另一方面,像 SGHMC 这样的采样方法(如下一节中所实现)探索了这两个模式,因此提供了对后验的更好近似。
经验证据
为了进一步支持我们关于后验多峰性的主张,我们提供了一些经验证据表明,对于现实世界数据集,后验不是高斯的。
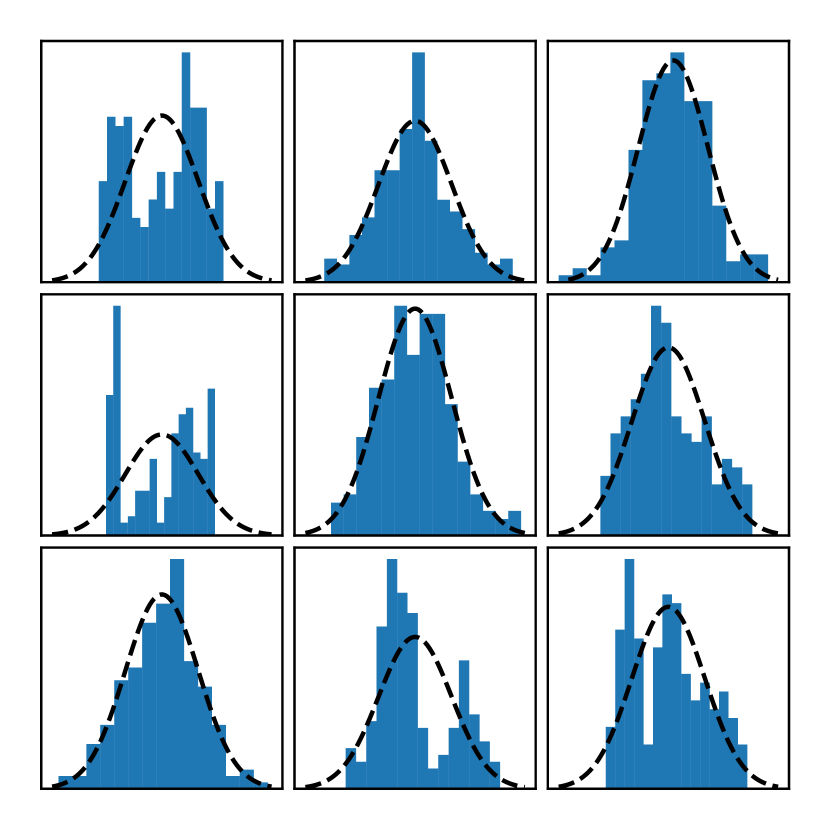
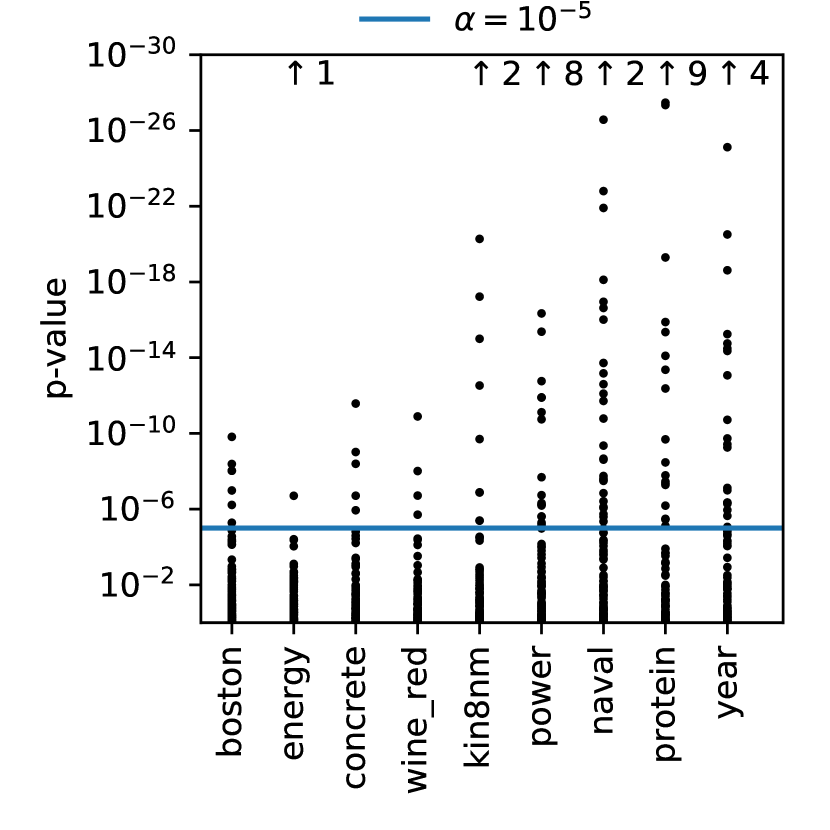
我们进行了以下分析。 考虑一个零假设,即数据集下的后验分布是一个多元高斯分布。 这个零假设意味着每个诱导输出的分布都是高斯分布。 我们使用下一节中描述的用于 DGP 的 SGHMC 实现,检查了 SGHMC 为每个诱导输出生成的近似后验样本。 为了推导出 p 值,我们对高斯性应用了峰度检验 (Cramer, 1998)。 该检验通常用于识别多峰分布,因为这些分布通常具有明显更高的峰度(也称为四阶矩)。
对于每个数据集,我们计算 100 个随机选择的诱导输出的 p 值,并将结果与概率阈值 进行比较。 应用 Bonferroni 校正到 以考虑大量同时假设检验。 结果显示在图 2 的右侧。 由于每个数据集的 p 值都低于阈值,我们可以肯定地说,所有这些数据集都具有非高斯后验分布,置信度为 99%。
4 基于采样的深度高斯过程推理
与 VI 不同,当使用采样方法时,我们无法访问近似后验分布 来生成预测。 相反,我们必须依赖从后验生成的近似样本,这些样本反过来可以用于进行预测 (Dunlop et al., 2017; Hoffman, 2017)。
在实践中,运行一个包含两个阶段的采样过程。 燃烧阶段用于确定模型和采样器的超参数。 采样器的超参数使用启发式自动调优方法选择,而 DGP 的超参数使用新颖的移动窗口 MCEM 算法优化。
在采样阶段,采样器使用固定的超参数运行。 由于连续样本高度相关,我们每 50 次迭代保存一个样本,并生成 200 个样本用于预测。
一旦获得后验样本,就可以通过组合每个样本的预测来获得混合分布,从而进行预测。 请注意,使用此采样器进行预测并不比 DSVI 更昂贵,因为 DSVI 需要对层输出进行采样才能进行预测。
4.1 随机梯度哈密顿蒙特卡洛
SGHMC (Chen 等人,2014) 是一种马尔可夫链蒙特卡洛采样方法 (Neal,1993),用于从诱导输出的难以处理的后验分布中生成样本 ,完全来自随机梯度估计。
通过引入辅助变量 ,采样过程提供了来自联合分布 的样本。 描述 MCMC 过程的方程可以与哈密顿动力学相关联 (Brooks 等人,2011; Neal,1993)。 负对数后验 充当势能,而 则充当动能:
在 HMC 中,精确的运动描述需要在每个更新步骤中计算梯度 ,这对于大型数据集来说是不切实际的,因为在等式 2 中将层输出积分出来的成本很高。 此积分可以通过蒙特卡洛采样评估的下界来近似 (Salimbeni 和 Deisenroth,2017):
其中 是来自层输出的预测分布的蒙特卡洛样本: 。 这导致了估计
我们可以用它来近似梯度,因为 。
Chen 等人 (2014) 表明,如果使用以下更新方程,即使使用随机梯度估计(通过对数据进行子采样获得)仍然可以进行近似后验采样:
其中 是摩擦项, 是质量矩阵, 是费舍尔信息矩阵,而 是步长。
SGHMC 的一个缺点是它有多个参数 (, , , ),如果不了解模型和数据,就很难设置这些参数。 我们使用 Springenberg 等人 (2016) 的自动调整方法来设置这些参数,该方法已被证明适用于贝叶斯神经网络 (BNN)。 DGP 和 BNN 的相似性强烈表明,相同的方法适用于 DGP。
4.2 移动窗口马尔可夫链期望最大化
优化超参数 (协方差函数、诱导输入和似然函数的参数) 对于 MCMC 方法来说很困难 (Turner 和 Sahani,2011)。 简单的优化方法(在采样器进行的过程中优化它们)失败了,因为随后的样本高度相关,结果是,超参数只是适应了这个移动的、后验估计的点。
蒙特卡罗期望最大化 (MCEM) (Wei 和 Tanner,1990) 是期望最大化算法的自然扩展,它使用后验样本获得超参数的最大似然估计。 MCEM 在两个步骤之间交替进行。 E 步从后验中采样,而 M 步最大化样本和数据的平均对数联合概率:
E 步:
M 步:
其中 。
然而,MCEM 存在一个重大缺陷:如果 M 步中使用的样本数 太少,那么超参数就有可能过度拟合这些样本。 另一方面,如果 太高,则 M 步的计算成本会变得过高。 此外,在 M 步中, 通过梯度上升法最大化,这意味着计算成本随 线性增加。
为了解决这个问题,我们引入了 MCEM 的一种新扩展,称为移动窗口 MCEM。 我们的方法以与之前描述的朴素方法相同的成本优化超参数,同时避免了其过拟合问题。
移动窗口 MCEM 背后的想法是将 E 步和 M 步交织在一起。 我们不是生成新的样本,然后最大化 直到收敛,而是维护一组样本,并向 的最大值迈出小步。 在 E 步中,我们生成一个新的样本并将其添加到集合中,同时丢弃最旧的样本(因此称为移动窗口)。 之后是 M 步,在此步骤中,我们从集合中随机抽取一个样本,并使用它来向 的最大值迈出近似梯度步。 图 3 左侧的算法 1 展示了移动窗口 MCEM 的伪代码。
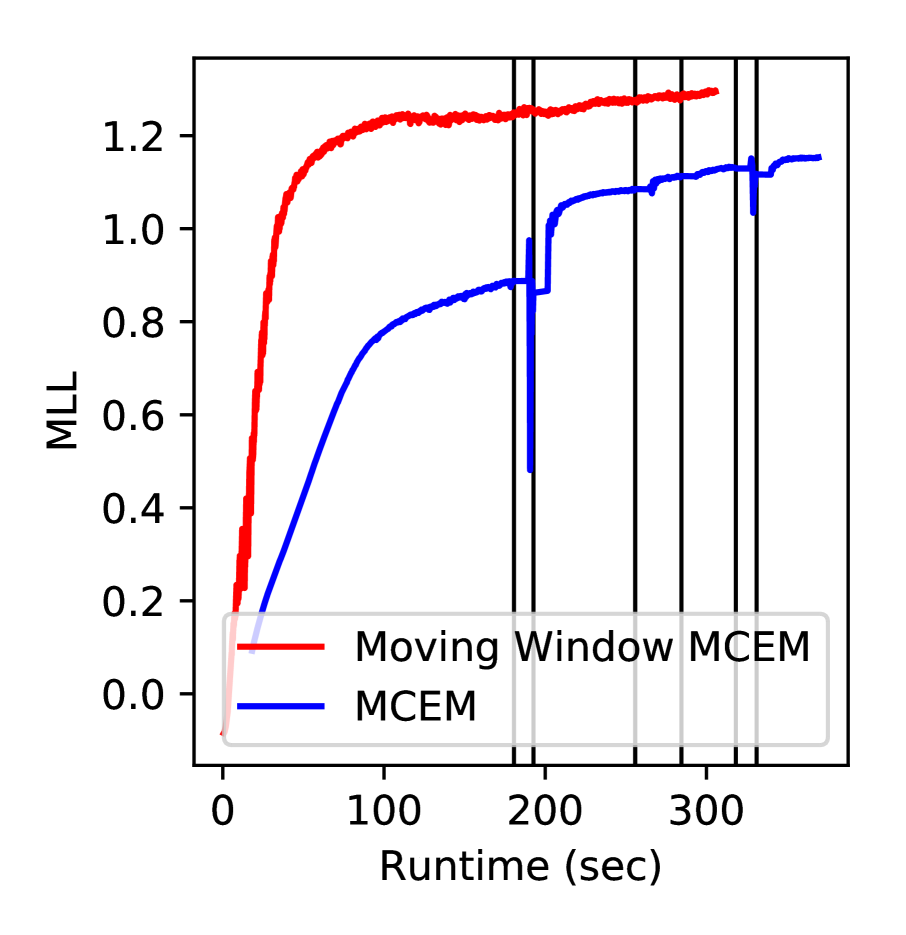
与 MCEM 相比,它有两个优势。 首先,每个超参数更新的成本是恒定的,并且不会随着 的增加而增加,因为它只需要一个样本。 其次,移动窗口 MCEM 的收敛速度比 MCEM 快。 图 3 的中间图展示了这一点。 MCEM 迭代地拟合特定后验样本集的超参数。 由于超参数和后验样本高度耦合,这种交替更新方案收敛速度很慢 (Neath et al., 2013)。 为了减轻这个问题,移动窗口 MCEM 通过在每次梯度步骤之后生成一个新样本来不断更新其样本种群。
为了在图 3 的中心生成图表,我们将测试集上的预测对数似然绘制成算法迭代次数,以证明移动窗口 MCEM 比 MCEM 的优越性能。 对于 MCEM,我们使用了一组大小为 (更大的 会减慢该方法),我们在 500 个 MCMC 步长上生成这组数据。 对于移动窗口 MCEM,我们使用了一个窗口大小为 。 本实验中使用的模型是一个在 kin8nm 数据集上训练的具有一个隐藏层的 DGP。
5 解耦深度高斯过程
本节介绍了一种扩展 DGP 的方法,它能够使用大量诱导点而不会显着影响性能。 此方法仅适用于 DSVI 的情况,因此我们在实验中将其视为一个基线模型。
利用 GP 作为高斯测度的对偶公式,已经证明, 和 (式 1)不一定由相同的诱导点集参数化 (Cheng 和 Boots,2017,2016)。 在 DGP 的情况下,这意味着可以使用两组独立的诱导点。 一组用于计算逐层平均值,另一组用于计算逐层方差。
在变分推断设置中,计算逐层方差的成本显着高于计算逐层平均值的成本。 这意味着可以使用更大的诱导点集来计算逐层平均值,并使用更小的诱导点集来计算逐层方差,从而在不影响计算成本的情况下提高预测性能。
不幸的是,Cheng 和 Boots (2017) 提倡的参数化具有较差的收敛特性。 ELBO 中的依赖关系导致了一个高度非凸的优化问题,从而导致高方差梯度。 为了解决这个问题,我们使用了一种不同的参数化方法,它消除了依赖关系并实现了稳定的收敛。 这些问题的更多细节可以在补充材料中找到。
6 实验
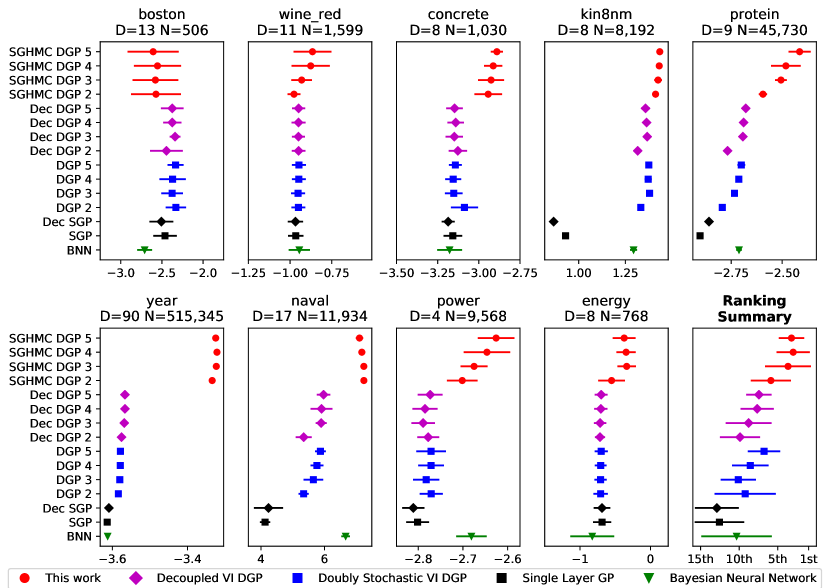
我们进行了实验 3 33我们的代码基于 TensorFlow (Abadi 等人,2015) 计算库,并且可以在 https://github.com/cambridge-mlg/sghmc_dgp 上公开获取。 在 9 个 UCI 基准数据集上,这些数据集从小型 (500 个数据点) 到大型 (500,000) 不等,以便与基线进行公平比较。 在每个回归任务中,我们测量了平均测试对数似然 (MLL) 并比较了结果。 图 4 显示了 MLL 值及其在 10 次重复中的标准差。
遵循 Salimbeni 和 Deisenroth (2017),在所有模型中,我们将学习率设置为默认的 0.01,小批量大小设置为 10,000,迭代次数设置为 20,000。 一次迭代涉及从窗口中抽取一个样本,并通过梯度下降更新超参数,如算法 1 中图 3 左侧所示。 深度从 0 个隐藏层到 4 个隐藏层不等,每层有 10 个节点。 协方差函数是一个标准的平方指数函数,每个维度都有单独的长度尺度。 我们进行了随机的 0.8-0.2 训练测试拆分。 在 年 数据集中,我们使用了一个固定的训练-测试分割,以避免“制作者效应”,确保来自给定艺术家的任何歌曲都不会同时出现在训练集和测试集中。
基线: 我们实验的主要基线是双随机 DGP。 为了进行忠实的比较,我们使用了与原始论文中相同的参数。 在诱导点数量方面(诱导输入始终在潜在维度之间共享),我们测试了两个变体。 首先,原始的耦合版本,每层具有 个诱导点(DGP)。 其次,一个解耦版本(Dec DGP),均值为 个点,方差为 个点。 选择这些数字是为了使单次迭代的运行时间与耦合版本相同。 耦合(SGP: )和解耦(Dec SGP: ,)单层 GP 提供了进一步的基线。 最终的基线是具有三个隐藏层和每层 50 个节点的稳健贝叶斯神经网络(BNN) (Springenberg 等人,2016)。
SGHMC DGP (这项工作): 此模型的架构与基线模型相同。 使用了 个诱导输入以保持与基线一致。 预热阶段包含 20,000 次迭代,之后是采样阶段,在此阶段,在 10,000 次迭代过程中抽取了 200 个样本。
MNIST 分类
SGHMC 在分类问题上也很有效。 使用 Robust-Max (Hernández-Lobato 等人,2011) 似然函数,我们将模型应用于 MNIST 数据集。 SGP 模型和 Dec SGP 模型分别达到了 96.8% 和 97.7% 的准确率。 关于深度模型,表现最好的模型是 Dec DGP 3,准确率为 98.1%,其次是 SGHMC DGP 3,准确率为 98.0%,最后是 DGP 3,准确率为 97.8%。 (Salimbeni 和 Deisenroth,2017) 报告了 DGP 3 略高的值,为 98.11%。 这种差异可以归因于参数的不同初始化。
哈佛清洁能源项目
此回归数据集是为哈佛清洁能源项目 (Hachmann 等人,2011) 生成的。 它测量了有机光伏分子效率。 它是一个高维数据集(60,000 个数据点和 512 个二元特征),众所周知,它可以从深度模型中受益。 SGHMC DGP 5 建立了新的最先进的预测性能,测试 MLL 为 。 DGP 2-5 达到 。 此数据集的其他可用结果是使用期望传播的 DGP 的 和使用 的 BNN 的 (Bui 等人,2016)。
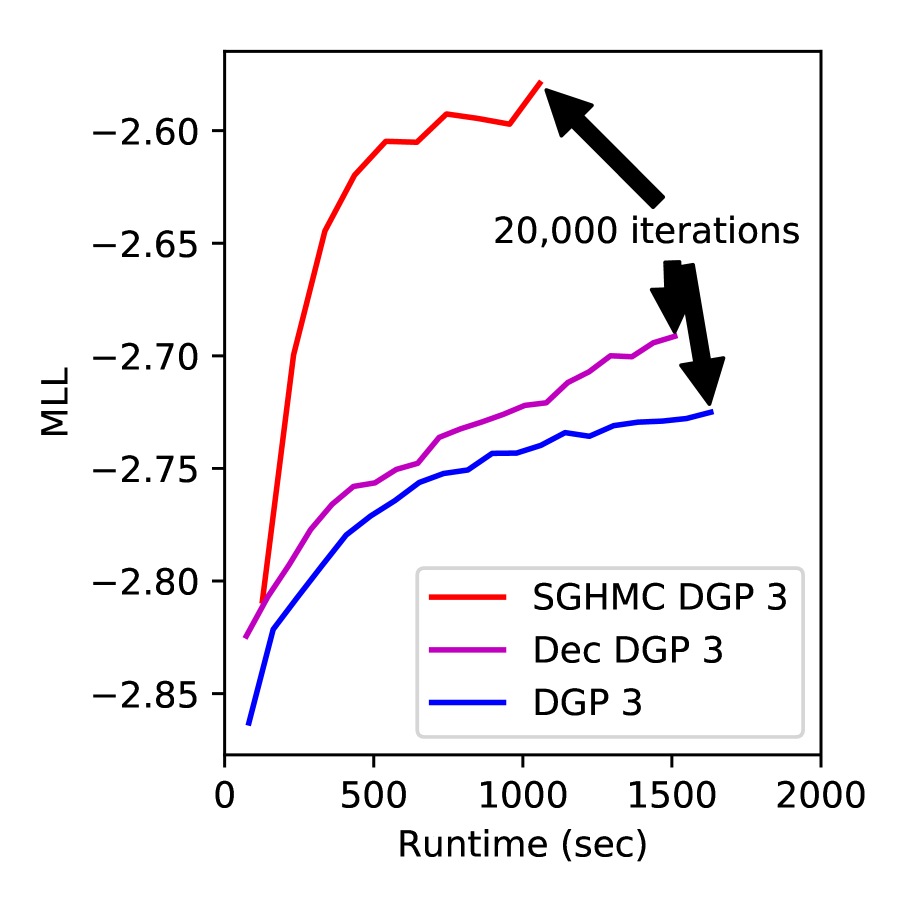
运行时间
为了支持我们关于 SGHMC 的计算成本低于 DSVI 的说法,我们在 蛋白质 数据集(图 3 中的右侧图)上绘制了训练过程的不同阶段的测试 MLL。 SGHMC 收敛速度更快,并且收敛到比 DSVI 更高的极限。 SGHMC 在 时间内达到了目标 20,000 次迭代。
7 结论
本文描述并展示了一种 DGPs 中的新推理方法 SGHMC,该方法从通常的诱导点框架中的后验分布中采样。 我们描述了一种新颖的移动窗口 MCEM 算法,该算法已被证明能够以快速有效的方式优化超参数。 这显著提高了中等规模数据集的性能,同时降低了计算成本,从而为 DGPs 中的推理建立了新的最先进水平。
致谢
我们感谢 Adrià Gariga-Alonso、John Bronskill、Robert Peharz 和 Siddharth Swaroop 的宝贵意见,并感谢英特尔和 EPSRC 的慷慨支持。
Juan José Murillo-Fuentes 感谢西班牙政府(TEC2016-78434-C3-R)和欧盟(MINECO/FEDER,UE)的资助。
参考文献
- Abadi et al. (2015) M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/. Software available from tensorflow.org.
- Brooks et al. (2011) S. Brooks, A. Gelman, G. Jones, and X.-L. Meng. Handbook of Markov chain Monte Carlo. CRC press, 2011.
- Bui et al. (2016) T. Bui, D. Hernández-Lobato, J. Hernandez-Lobato, Y. Li, and R. Turner. Deep Gaussian processes for regression using approximate expectation propagation. In International Conference on Machine Learning, pages 1472–1481, 2016.
- Chen et al. (2014) T. Chen, E. Fox, and C. Guestrin. Stochastic gradient Hamiltonian Monte Carlo. In International Conference on Machine Learning, pages 1683–1691, 2014.
- Cheng and Boots (2016) C.-A. Cheng and B. Boots. Incremental variational sparse Gaussian process regression. In Advances in Neural Information Processing Systems, pages 4410–4418, 2016.
- Cheng and Boots (2017) C.-A. Cheng and B. Boots. Variational inference for Gaussian process models with linear complexity. In Advances in Neural Information Processing Systems, pages 5190–5200, 2017.
- Cramer (1998) D. Cramer. Fundamental Statistics for Social Research: Step-by-Step Calculations and Computer Techniques Using SPSS for Windows. Routledge, New York, NY, 10001, 1998. ISBN 0415172039.
- Cutajar et al. (2016) K. Cutajar, E. V. Bonilla, P. Michiardi, and M. Filippone. Random feature expansions for deep Gaussian processes. arXiv preprint arXiv:1610.04386, 2016.
- Damianou (2015) A. Damianou. Deep Gaussian processes and variational propagation of uncertainty. PhD thesis, University of Sheffield, 2015.
- Damianou and Lawrence (2013) A. Damianou and N. Lawrence. Deep Gaussian processes. In Artificial Intelligence and Statistics, pages 207–215, 2013.
- Dunlop et al. (2017) M. M. Dunlop, M. Girolami, A. M. Stuart, and A. L. Teckentrup. How deep are deep Gaussian processes? arXiv preprint arXiv:1711.11280, 2017.
- Graves (2011) A. Graves. Practical variational inference for neural networks. In Advances in Neural Information Processing Systems, pages 2348–2356, 2011.
- Hachmann et al. (2011) J. Hachmann, R. Olivares-Amaya, S. Atahan-Evrenk, C. Amador-Bedolla, R. S. Sánchez-Carrera, A. Gold-Parker, L. Vogt, A. M. Brockway, and A. Aspuru-Guzik. The Harvard clean energy project: large-scale computational screening and design of organic photovoltaics on the world community grid. The Journal of Physical Chemistry Letters, 2(17):2241–2251, 2011.
- Hensman et al. (2015) J. Hensman, A. G. Matthews, M. Filippone, and Z. Ghahramani. MCMC for variationally sparse Gaussian processes. In Advances in Neural Information Processing Systems, pages 1648–1656, 2015.
- Hernández-Lobato et al. (2011) D. Hernández-Lobato, J. M. Hernández-Lobato, and P. Dupont. Robust multi-class Gaussian process classification. In Advances in neural information processing systems, pages 280–288, 2011.
- Hernández-Lobato and Adams (2015) J. M. Hernández-Lobato and R. Adams. Probabilistic backpropagation for scalable learning of Bayesian neural networks. In International Conference on Machine Learning, pages 1861–1869, 2015.
- Hoffman (2017) M. D. Hoffman. Learning deep latent Gaussian models with Markov chain Monte Carlo. In International Conference on Machine Learning, pages 1510–1519, 2017.
- Minka (2001) T. P. Minka. Expectation propagation for approximate Bayesian inference. In Proceedings of the Seventeenth conference on Uncertainty in artificial intelligence, pages 362–369. Morgan Kaufmann Publishers Inc., 2001.
- Neal (1993) R. M. Neal. Probabilistic inference using Markov chain Monte Carlo methods. 1993.
- Neath et al. (2013) R. C. Neath et al. On convergence properties of the Monte Carlo EM algorithm. In Advances in Modern Statistical Theory and Applications: A Festschrift in Honor of Morris L. Eaton, pages 43–62. Institute of Mathematical Statistics, 2013.
- Quiñonero-Candela and Rasmussen (2005) J. Quiñonero-Candela and C. E. Rasmussen. A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research, 6(Dec):1939–1959, 2005.
- Salimbeni and Deisenroth (2017) H. Salimbeni and M. Deisenroth. Doubly stochastic variational inference for deep Gaussian processes. In Advances in Neural Information Processing Systems, pages 4591–4602, 2017.
- Snelson and Ghahramani (2006) E. Snelson and Z. Ghahramani. Sparse Gaussian processes using pseudo-inputs. In Y. Weiss, B. Schölkopf, and J. C. Platt, editors, Advances in Neural Information Processing Systems 18, pages 1257–1264. MIT Press, 2006.
- Springenberg et al. (2016) J. T. Springenberg, A. Klein, S. Falkner, and F. Hutter. Bayesian optimization with robust Bayesian neural networks. In Advances in Neural Information Processing Systems, pages 4134–4142, 2016.
- Titsias (2009) M. Titsias. Variational learning of inducing variables in sparse Gaussian processes. In D. van Dyk and M. Welling, editors, Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, volume 5 of Proceedings of Machine Learning Research, pages 567–574, Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA, 16–18 Apr 2009. PMLR.
- Turner and Sahani (2011) R. E. Turner and M. Sahani. Two problems with variational expectation maximisation for time-series models. Bayesian Time series models, 1(3.1):3–1, 2011.
- Wei and Tanner (1990) G. C. Wei and M. A. Tanner. A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithms. Journal of the American statistical Association, 85(411):699–704, 1990.
- Welling and Teh (2011) M. Welling and Y. W. Teh. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), pages 681–688, 2011.
- Williams and Rasmussen (1996) C. K. Williams and C. E. Rasmussen. Gaussian processes for regression. In Advances in neural information processing systems, pages 514–520, 1996.