∎
22email: yu.kong@rit.edu 33机构文字:傅云 44institutetext:美国马萨诸塞州波士顿东北大学 ECE 系和 CIS 学院
44email: yunfu@ece.neu.edu
人类行为识别和预测:一项调查
摘要
得益于计算机视觉和机器学习的快速发展,视频分析任务已经从推断当前状态转变为预测未来状态。 基于视觉的动作识别和视频预测就是这样的任务,其中动作识别是基于完整的动作执行来推断人类动作(当前状态),动作预测是基于不完整的动作执行来预测人类动作(未来状态)。 这两项任务因其在现实世界中的爆炸性应用而成为最近特别流行的话题,例如视觉监控、自动驾驶车辆、娱乐和视频检索等。 在过去的几十年里,为了建立一个强大而有效的动作识别和预测框架,人们进行了许多尝试。 在本文中,我们调查了动作识别和预测方面完整的最先进技术。 还提供了现有的模型、流行的算法、技术难点、流行的动作数据库、评估协议和有前景的未来方向,并进行了系统的讨论。
1简介
人类的每一个行为,无论多么微不足道,都是为了某种目的而进行的。 例如,为了完成一项体育锻炼,患者使用他/她的手、手臂、腿、躯干、身体等与环境互动并做出反应。这样的动作表示可以观察到的一切,无论是裸眼或通过视觉传感器测量。 通过人类视觉系统,我们可以了解行动者的动作和目的。 我们可以很容易地知道一个人正在锻炼,并且可以有一定把握地猜测这个人的动作是否符合指令。 然而,在各种现实场景中使用人类劳动来监控人类行为(例如智能康复和视觉监控)的成本太高。 机器能像人一样执行任务吗?
人工智能研究的最终目标之一是打造一台能够准确理解人类行为和意图的机器,使其能够更好地为我们服务。 想象一下,患者正在家里进行康复锻炼,他/她的机器人助手能够识别患者的动作,分析锻炼的正确性,并防止患者受到进一步的伤害。 这样的智能机器将带来巨大的好处,因为它可以节省去看治疗师的次数,降低医疗成本,并使远程锻炼成为现实。 其他重要应用包括视觉监控、娱乐和视频检索也需要分析视频中的人类行为。 这些应用程序的核心是能够理解人类行为的计算算法。 与人类视觉系统类似,算法应该在观察整个或部分人类动作执行后生成标签BobickTPAMI2001; RyooICCV2011 . 构建此类算法通常在计算机视觉研究中解决,该研究研究如何使计算机从数字图像和视频中获得高级理解。
计算机视觉研究中研究的术语人类动作从简单的肢体运动到多肢体和人体的联合复杂运动。 这个过程是动态的,因此通常通过持续几秒钟的视频来传达。 尽管可能很难对计算机视觉社区中研究的人类行为给出正式的定义,但我们提供了一些社区中使用的示例。 Typical example actions are, 1) an individual action in KTH dataset SchuldtICPR2004 (Fig. 2(a)), which contains simple daily actions such as “clapping” and “running”; 2) a human interaction in UT-Interaction dataset RyooICCV2009 (Fig. 2(b)), which consists of human interactions including “handshake” and “push”; 3) a human-object interaction in UCF Sports dataset RodriguezCVPR2008 (Fig. 2(c)), which comprises of sport actions and human-object interactions; 4) a group action in Hollywood 2 dataset MarszalekCVPR2009 (Fig. 2(d)); 5) an action captured by a RGB-D sensor in UTKinect dataset XiaCVPRW2012 (Fig. 2(e)); and 6) a multi-view action in Multicamera dataset Singh2010 (Fig. 2(f)) capturing human actions from multiple camera views. 在所有这些例子中,人类的行为都试图实现某个目标,其中一些目标只需简单地移动手臂即可实现,而另一些则需要通过几个步骤来完成。

计算机科学和工程的技术进步使机器能够理解视频中的人类行为。 计算机视觉社区有两个基本主题,即基于视觉的人类动作识别和预测:
-
1.
动作识别:从包含完整动作执行的视频中识别出人类动作。
-
2.
动作预测:从暂时不完整的视频数据中推理人类动作。


动作识别是计算机视觉领域的一项基本任务,它根据视频中完整的动作执行来识别人类动作(见图3(a))BobickTPAMI2001 ; EfrosICCV2003;韦恩兰德CVIU2006;拉普捷夫IJCV2005;刘CVPR2009;唐CVPR2012; TranICCV2015 . 它已经被研究了几十年,并且由于广泛的现实应用,仍然是一个非常受欢迎的话题,包括视频检索CiptadiECCV2014,视觉监控HuTIP2007;辛格2010等 研究人员付出了巨大的努力来创建一个模仿人类能力的智能系统,该系统可以在杂乱的环境中识别复杂的人类行为。 然而,对于机器来说,视频中的动作只是像素数组。 机器不知道如何将这些像素转换为有效的表示,以及如何从表示中推断出人类的行为。 这两个问题被认为是动作识别中的动作表示和动作分类,并且有很多尝试LaptevIJCV2005; RaptisCVPR2013;吉TPAMI2013; CarreiraCVPR2017的提出就是为了解决这两个问题。
相反,动作预测是事前视频理解任务,关注未来状态。 在某些现实场景中(例如,车辆事故和犯罪活动),智能机器无法等待整个操作执行后再对其中包含的操作做出反应。 例如,能够在危险驾驶情况发生之前预测它;反对事后承认它。 这被称为动作预测任务,其中可以从时间上不完整的视频中识别和推断标签的方法(参见图3(b))RyooICCV2011;孔ECCV2014; KongCVPR2017,与期望看到从完整视频中提取的整套动作动态的动作识别方法不同。
动作识别和动作预测之间的主要区别在于何时做出决定。 人类动作识别是在观察到整个动作执行后推断出动作标签。 该任务一般适用于非紧急场景,例如视频检索、娱乐等。 然而,行动预测是在完全观察整个执行过程之前进行推断,这在某些场景中尤为重要。 例如,如果车辆上的智能系统能够在交通事故发生之前预测它,那将非常有帮助;反对事后承认危险事故事件。
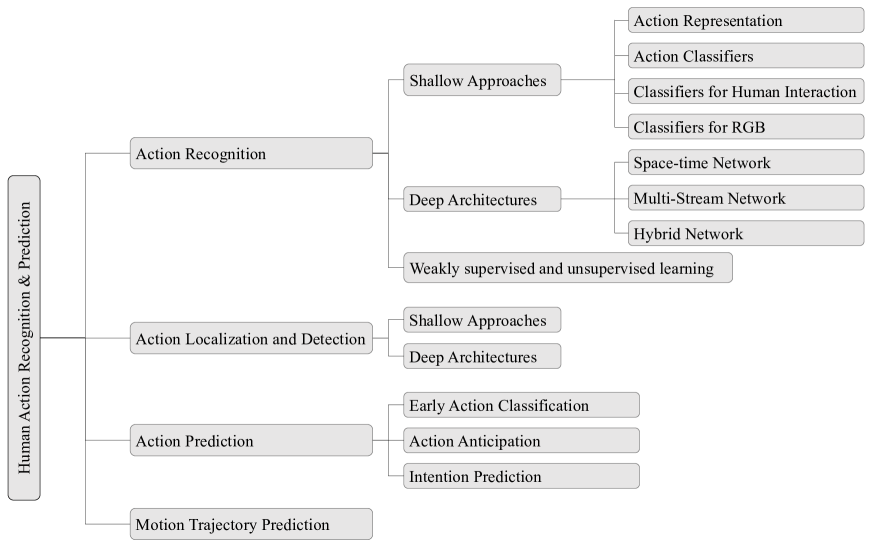
在本次调查中,我们将主要讨论动作识别和预测方面的最新进展。 为了方便本文的导航,图1说明了本文讨论的主题,并且还包括了代表性的作品。 与最近的调查论文HerathIVC2017不同; PoppeIVC2010,本文还介绍了动作预测方面的研究。 人类动作识别和预测与人类手势分析、步态识别和事件识别等其他计算机视觉任务密切相关。 在这项调查中,我们重点研究基于视觉的识别和预测通常涉及一个或多个人的视频中的动作。 输入是一系列视频帧,输出是动作标签。 我们还对从 RGB-D 视频中学习人类行为感兴趣。 现有的一些研究YaoPAMI2012; YaoECCV2012旨在从静态图像中学习动作,这不是本文的重点。 本文将首先概述动作识别和预测的最新研究,描述流行的人类动作数据集,然后详细讨论几个有趣的未来方向。
1.1 实际应用
动作识别和预测算法为许多现实世界的应用提供了支持(示例如图4所示)。 最先进的算法WangECCV2016; FeichtenhoferCVPR2017;孔AAAI2018; MaCVPR2016显着减少了分析大规模视频数据的人力,并提供了对正在进行的视频数据的当前状态和未来状态的理解。
1.1.1视觉监控
安全问题在我们的日常生活中变得越来越重要,也是当今最常讨论的话题之一。 受监视的场所通常允许某些人类行为,而不允许其他行为 HuTIP2007 。 通过摄像机网络的输入WeinlandCVIU2006; Singh2010,基于动作识别的视觉监控系统JiTPAMI2013;西蒙扬NIPS2014; KarpathyCVPR2014和预测RyooICCV2011;孔ECCV2014; KongCVPR2017算法可以增加视频中抓获犯罪分子的机会,并降低犯罪行为带来的风险。 例如,在波士顿马拉松爆炸现场,如果我们有这样一个智能视觉监控系统,可以通过观察犯罪分子的可疑行为来预警公众,那么受害者的生命就可以得到挽救。 摄像头还让一些人感到更安全,因为他们知道罪犯正在被监视。
1.1.2视频检索
如今,由于技术的快速发展,人们可以轻松地在互联网上上传和共享视频。 然而,根据视频内容管理和检索视频正成为一个巨大的挑战,因为大多数搜索引擎使用关联的文本数据来管理视频数据Ramezani2016。 标签、标题、描述和关键字等文本数据可能不正确、模糊且不相关,从而导致视频检索不成功 Zhai2013 。 另一种方法是分析视频中的人类行为,因为大多数视频都包含这样的提示。 例如,在CiptadiECCV2014中,研究人员通过计算动作表征之间的相似度创建了一个视频检索框架,并使用该框架来检索课堂环境中自闭症儿童的视频。 与传统的人类动作识别任务相比,视频检索任务依赖于检索排序而不是分类Ramezani2016。
1.1.3娱乐
近年来,游戏行业吸引了越来越多、越来越多样化的人群。 舞蹈和体育游戏等基于全身游戏的新一代游戏增加了游戏对各个年龄段家庭成员的吸引力。 为了准确感知人类动作,这些游戏使用经济高效的 RGB-D 传感器(例如、Kinect ShottonPAMI2013),提供额外的深度通道数据XiaCVPR2013;杨CVPR2014; HadfieldCVPR2013 . 该深度数据对整个场景的丰富结构信息进行编码,并促进动作识别任务,因为它简化了类内运动变化并减少了杂乱的背景噪声KongCVPR2015;孔IJCV2017;贾MM2014;刘IJCAI2013 .
1.1.4 人机交互
人机交互广泛应用于家庭和工业环境中。 想象一下,一个人正在与机器人交互,并要求它执行某些任务,例如“递一杯水”或“执行组装任务”。 这样的交互需要机器人和人类之间的通信,而视觉通信是最有效的方式之一RyooHRI2015; KoppulaTPAMI2016 .
1.1.5自动驾驶汽车
动作预测算法RyooIJCV2011; KongTPAMI2016 可能是自动驾驶汽车中最有潜力、也可能是最重要的构建组件之一。 动作预测算法可以预测一个人的意图PeiICCV2011;李TPAMI2014; KoppulaTPAMI2016 在短时间内。 在紧急情况下,配备动作预测算法的车辆可以预测行人在接下来几秒钟内的未来动作或运动轨迹,这对于避免碰撞至关重要。 通过使用所谓的兴趣点或卷积神经网络KongCVPR2017分析动作早期阶段的人体运动特征,动作预测算法KongCVPR2017; KongTPAMI2016可以通过分析动作演化来了解可能的动作,而不需要观察整个动作执行过程。
1.2研究挑战
尽管人类动作识别和预测方面已经取得了重大进展,但由于这些任务中的几个重大挑战,最先进的算法仍然会对动作进行错误分类。

1.2.1 类内和类间变化
众所周知,人们对于同样的行为会有不同的表现。 对于给定的语义有意义的动作,例如“跑步”,一个人可以跑快,慢,甚至跳和跑。 也就是说,一个动作类别可能包含多种不同风格的人体动作。 此外,可以从不同的角度捕捉同一动作的视频。 它们可以在人类主体的前面、主体的侧面,甚至主体的顶部拍摄,显示不同视图中的外观变化(见图5)。 此外,不同的人在执行同一动作时可能会表现出不同的姿势。 所有这些因素都会导致类内外观和姿势变化较大,这会混淆许多现有的动作识别算法。 这些变化在现实世界的动作数据集 KarpathyCVPR2014 上会更大; caba2015activitynet 。 这引发了对可以部署在现实场景中的更先进的动作识别算法的研究。 此外,不同的行动类别也存在相似之处。 例如,“跑步”和“行走”涉及相似的人类运动模式。 这些相似之处也很难区分智能机器,从而导致错误分类。

1.2.2 杂乱的背景和相机运动
有趣的是,许多人类动作识别算法在室内受控环境中运行得很好,但在室外不受控环境中则不然。 这主要是由于背景噪音造成的。 事实上,大多数现有的活动特征,例如定向梯度直方图LaptevCVPR2008和兴趣点DollarICCVW2005也会编码背景噪声,从而降低识别性能。 相机运动是实际应用中应考虑的另一个因素。 由于相机运动显着,无法准确提取动作特征。 为了更好地提取动作特征,应对相机运动进行建模和补偿WangICCV2013。 其他与环境相关的问题,如光照条件、视点变化、动态背景等也将成为阻碍动作识别算法在实际场景中使用的挑战。
1.2.3 注释数据不足
尽管现有的动作识别接近KlaserBMVC2008;刘CVPR2011; NieblesECCV2010训练在实验室环境中的小规模数据集上表现出了令人印象深刻的性能,但由于它们无法在大规模数据集上运行,因此将它们推广到现实世界的应用程序确实具有挑战性。 最近的深度方法WangECCV2016; FeichtenhoferCVPR2017 在不受控制的设置中捕获的数据集上显示了有希望的结果,但它们通常需要大量带注释的训练数据。 HMDB51 KuehneICCV2011 和 UCF-101 Soomro2012 等动作数据集包含数千个视频,但对于训练具有数百万个参数的深度网络来说仍然远远不够。 尽管Youtube-8M abu2016youtube和Sposrts-1M数据集KarpathyCVPR2014提供了数百万个动作视频,但它们的注释是通过检索方法生成的,因此可能不准确。 在此类数据集上进行训练会损害动作识别算法的性能,因为动作识别算法不能容忍不准确的标签。 但是,某些数据注释可能是可用的,这将导致训练设置混合有标记数据和未标记数据。 因此,设计能够从标记数据和未标记数据中学习动作的动作识别算法势在必行。
1.2.4 动作词汇
动作可以分为不同的级别、动作、原子动作、复合动作、事件等。 这定义了一个动作层次结构,并且层次结构高级别的复杂动作可以分解为较低级别的动作组合。 如何定义和分析这些不同类型的行为非常重要。
1.2.5 可预测性不均匀
并非所有框架都具有同等的歧视性。 如RaptisCVPR2013所示; Vahdat2011,视频可以通过一小组关键帧有效地表示。 这表明许多帧是冗余的,并且有区别的帧可能出现在视频中的任何位置。 然而,动作预测方法RyooICCV2011;孔ECCV2014;马CVPR2016; LanECCV2014 要求视频的开始部分具有辨别力,以便最大限度地提高可预测性。 为了解决这个问题,上下文信息被转移到视频 KongCVPR2017 的开始部分,但由于判别信息不足,性能仍然受到限制。
此外,动作的可预测性也不同LiTPAMI2014; KongCVPR2017 . 如 KongCVPR2017 所示,某些动作可以立即预测,而其他动作则需要更多帧来观察。 然而,在实际场景中,有必要尽早预测任何动作。 这就需要我们创建通用的动作预测算法,能够对大部分或全部动作做出准确且早期的预测。
2 人类对行为的感知
人类动作,特别是那些涉及全身和肢体(例如手臂和腿)的动作以及与环境的交互,包含有关执行者的意图、目标、精神状态等的丰富信息。理解动作他人的意图和意图是我们拥有的最重要的社交技能之一,而人类视觉系统提供了特别丰富的信息源来支持这项技能Blake2007。 与静态图像相比,视频中的人类动作提供了更可靠、更具表现力的信息,因此在了解其他人在做什么时比图像更有说服力 Darwin1872 。 我们可以从人类行为中得知许多信息,包括行为类别 Mass1971 、情感暗示 Clarke2005 、身份 Cutting1977 ; Troje2005 ,性别 Sumi2000 ; Troje2002等 人类视觉系统针对人类运动的感知进行了精细优化Decety1999。
人类的动作理解是由复杂的认知机制执行的复杂的认知能力。 这样的机制可以分解为三个主要组成部分,包括动作识别、意图理解和叙事理解Keestra2015。 Ricoeur Ricoeur1992建议,可以通过一系列相互关联的问题来采取行动,包括谁、什么、为什么、如何、何地和何时。 三个问题按优先顺序排列,为行动提供了不同的视角:行动是什么、为什么要采取行动以及谁是行动者。 前两个问题的计算模型已在动作识别中进行了广泛研究BlankICCV2005;佩雷斯BMVC2010;崔ICCVW2009;马萨莱克CVPR2009;库恩ICCV2011;吉TPAMI2013; TranICCV2015 和预测 RyooICCV2011 ;孔ECCV2014;马CVPR2016; CaoCVPR2013计算机视觉界的研究。 最后一个问题“谁是施事者”指的是施事者的身份,或者说社会角色,它提供了对其背后“谁”的更彻底的理解,因此被称为叙事理解Ricoeur1992。 计算机视觉界很少有工作研究这个问题LanCVPR2012; RamanathanCVPR2013 .
一些人类行为是目标导向的,即通过执行一个或一系列行为来完成目标。 理解此类行为对于预测行为的影响或结果至关重要。 作为人类,在给定特定情境或环境限制的情况下,我们通过评估个人行为可能导致的最终状态来推断个人的行为目标。 该推论可能是通过镜像神经元系统的直接匹配过程做出的,该过程将观察到的动作映射到我们自己对该动作的运动表征Rizzolatti2004;里佐拉蒂2010 . 根据直接匹配假设,对一个人的行动目标的预测很大程度上依赖于观察者的行动词汇或知识。 进行动作预测的另一个线索来自情绪或注意力信息,例如面部表情和目光或其他人。 由于将这些线索与其所指对象联系起来的特定关系,此类参考信息使观察者注意特定对象。 这些心理和认知发现将有助于设计行动预测方法。
3动作识别
典型的动作识别流程图通常包含两个主要组成部分SchuldtICPR2004;王IJCV2013; PoppeIVC2010,动作表示和动作分类。 动作表示组件基本上将动作视频转换为特征向量LaptevIJCV2005;美元ICCVW2005;王IJCV2015; Scovanner2007 或一系列向量 NieblesECCV2010 ; KongCVPR2017; MorencyCVPR2007 ,动作分类组件从向量 LiuCVPR2011 推断动作标签;斯明奇塞斯库ICCV2005; ShiIJCV2011 . 近日,深网JiTPAMI2013; TranICCV2015; FeichtenhoferCVPR2017将这两个组件合并到一个统一的端到端可训练框架中,总体上进一步提高了分类性能。 在本节中,我们将讨论动作表示、动作分类和深度网络方面的最新工作。

3.1 浅层方法
3.1.1 动作表示
动作识别中第一个也是最重要的问题是如何在视频中表示动作。 视频中出现的人类动作在运动速度、摄像机视图、外观和姿势变化等方面有所不同,这使得动作表示成为一个非常具有挑战性的问题。 一个成功的动作表示方法应该能够有效地计算、有效地表征动作,并且能够最大化动作之间的差异,以最小化分类错误。
动作识别的主要挑战之一是某一动作类别的外观和姿势变化很大,这使得识别任务变得困难。 动作表示的目标是将动作视频转换为特征向量,提取人类动作的代表性和判别性信息,并最小化变化,从而提高识别性能。 动作表示方法可以大致分为整体特征和局部特征,这将在接下来讨论。
在动作识别领域已经进行了许多尝试,将动作视频转换为有判别性和代表性的特征,以便最小化类内差异并最大化类间差异。 在这里,我们关注手工制作动作表示方法,这意味着这些方法中的参数是由专家预先定义的。 这与深度网络不同,深度网络可以自动从数据中学习参数。
整体表现
视频中的人类动作会在 3D 体积中生成时空形状。 这种时空形状既编码了人体各个时刻姿态的空间信息,也编码了人体的动态信息。 整体表示方法捕获整个人体的运动信息,为动作识别提供丰富且富有表现力的运动信息。 然而,整体表示往往对噪声敏感。 它捕获某个矩形区域内的信息,因此可能会引入来自人体主体和杂乱背景的不相关信息和噪声。
BobickTPAMI2001 中的一项开创性工作提出了运动能量图像 (MEI) 和运动历史图像 (MHI),将动态人体运动编码为单个图像。 如图6所示,这两种方法都适用于轮廓。 MEI 方法显示运动发生的“位置”:表示运动的空间分布,突出显示的区域表明发生的动作和观看条件。 除了 MEI 之外,MHI 方法还显示运动发生的“地点”和“方式”。 MHI 上的像素强度是该位置运动历史的函数,其中较亮的值对应于最近的运动。
尽管 MEI 和 MHI 在动作识别方面显示出有希望的结果,但它们对观点变化很敏感。 为了解决这个问题,WeinlandCVIU2006将BobickTPAMI2001推广到3D运动历史体积(MHV),以消除最终动作表示中的视点依赖性。 MHV 依赖于从多个摄像机视图获得的 3D 体素,并显示结果体积中的 3D 占用情况。 然后使用傅里叶变换来创建位置和旋转不变的特征。

为了捕捉人类行为中的时空信息,GorelickPAMI2007; BlankICCV2005利用泊松方程提取各种形状属性以进行动作表示和分类。 他们的方法以时空体积作为输入。 然后,该方法发现运动身体部位的时空显着性,并使用泊松方程局部计算方向。 通过对体积内的每个点进行加权平均,这些局部属性最终转换为全局特征。 YilmazCVPR2005 中提出了另一种描述形状和运动的方法。 在该方法中,首先通过计算帧之间的对应关系来生成时空体积。 然后,通过分析体积的微分几何表面特性来获取时空特征。
除了计算动作表示的轮廓或形状之外,还可以根据视频计算运动信息。 一种典型的运动信息是通过所谓的光流算法Lucas1981计算的;霍恩1981; SunCVPR2010,指示两个连续帧上物体的视运动模式。 假设帧上的照明条件不变,光流计算水平轴和垂直轴上的运动。 Efros 等人的早期工作EfrosICCV2003将流场分为四个通道(见图7),连续捕获水平和垂直运动帧。 此方法后来在WangPAMI2010中被用来描述人体和身体部位的特征。
当地代表处
局部表示仅识别具有显着运动信息的局部区域,因此本质上克服了整体表示中的问题。 时空利息点等成功方法DollarICCVW2005;拉普捷夫ICCV2003;克拉泽BMVC2008; BregonzioCVPR2009和运动轨迹WangCVPR2011; WangIJCV2013展示了它们对翻译、外观变化等的鲁棒性。 与整体特征不同,局部特征描述了人在时空区域的局部运动。 检测这些区域是因为这些区域内的运动信息比周围区域更具信息性和显着性。 检测后,通过提取区域中的特征来描述区域。
时空兴趣点(STIP)LaptevICCV2003;基于 LaptevIJCV2005 的方法是最重要的本地表示之一。 拉普捷夫的开创性工作LaptevICCV2003; LaptevIJCV2005将Harris角点检测器Harris1988扩展到时空域。 将时空可分离高斯核应用于视频以获得其响应函数,以发现空间和时间维度上的大运动变化(见图8)。 DollarICCVW2005中提出了一种替代方法,该方法检测密集的兴趣点。 2D 高斯平滑核仅沿空间维度应用,1D Gabor 滤波器应用于时间维度。 在每个兴趣点周围,提取原始像素值、梯度和光流特征并将其连接成一个长向量。 对向量应用主成分分析以降低维度,然后采用 k 均值聚类算法来创建这些特征向量的码本并生成视频 SchuldtICPR2004 的一个向量表示。 Bregonzio 等人BregonzioCVPR2009使用Gabor滤波器检测时空兴趣点。 时空兴趣点也可以通过时空Hessian矩阵WillemsECCV2008来检测。 其他检测算法通过将 2D 检测器的对应部分扩展到时空域来检测时空兴趣点,例如 3D SIFT Scovanner2007 、 HOG3D KlaserBMVC2008 、局部三元模式 YeffetCVPR2009等。已经提出了几种描述符来描述检测到的兴趣点的小区域内的运动和外观信息,例如光流和梯度。 在局部邻域计算的光流特征进一步聚合在直方图中,称为光流直方图(HOF)LaptevCVPR2008,并与HOG特征相结合DalalCVPR2005; KlaserBMVC2008 代表复杂的人类活动KlaserBMVC2008 ;拉普捷夫CVPR2008;王BMVC2009 . 计算光流场上的梯度来构建所谓的运动边界直方图(MBH),用于描述轨迹WangBMVC2009。
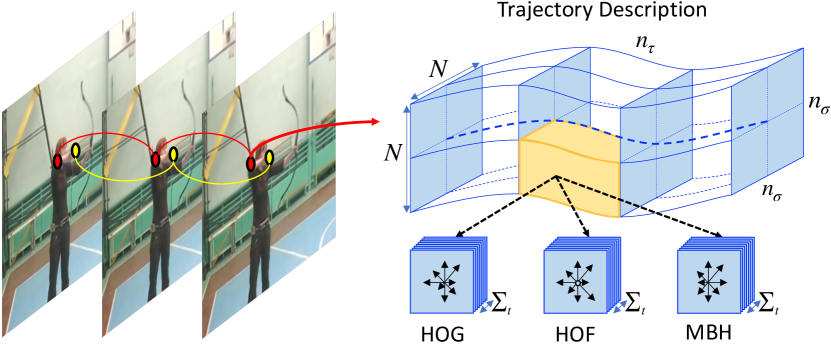
然而,时空兴趣点只能捕获短时间持续时间内的信息,而无法捕获长期持续时间的信息。 最好跟踪这些兴趣点并描述它们的运动属性的变化。 特征轨迹是捕获此类长时间信息的直接方法WangBMVC2009;王CVPR2011; RaptisECCV2010 . 为了获得轨迹特征,在 MessingICCV2009 中,首先使用 Harris3D 兴趣点和 KLT 跟踪器 Lucas1981 检测和跟踪兴趣点。 SunCVPR2009 中的方法通过匹配连续帧上相应的 SIFT 点来查找轨迹。 该方法捕获分层上下文信息,以生成更准确、更鲁棒的轨迹表示。 轨迹由 HOG、HOF 和 MBH 特征的串联来描述WangCVPR2011;王IJCV2013; JainCVPR2013(见图9)、轨迹内和轨迹间描述符 SunCVPR2009 或 HOG/HOF 和平均描述符 RaptisECCV2010 。 为了减少相机运动的副作用,WangICCV2013; WangIJCV2015首先找到两帧之间的对应关系,然后使用RANSAC来估计单应性。
3.1.2 动作分类器
计算出动作表示后,应该从确定各种动作类别的类别边界的训练样本中学习动作分类器。 动作分类器大致可以分为以下几类:
直接分类
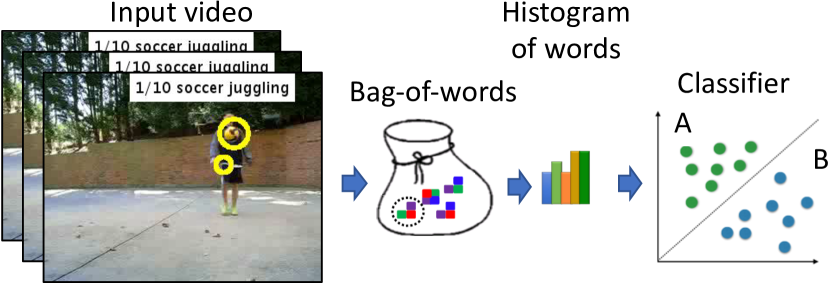
此类方法将动作视频总结为特征向量,然后使用现成的分类器(例如支持向量机SchuldtICPR2004)直接将向量分类为动作类别;拉普捷夫CVPR2008; MarszalekCVPR2009 ,k-最近邻 (k-NN) BlankICCV2005 ;拉普捷夫ICCV2007; TranECCV2008等 在这些方法中,使用动作形状GorelickPAMI2007以整体方式表征动作动态; BlankICCV2005 ,或使用所谓的词袋模型,该模型使用视觉词的直方图 BlankICCV2005 捕获局部运动模式;拉普捷夫ICCV2007;舒尔德ICPR2004;拉普捷夫CVPR2008; MarszalekCVPR2009 。
事实上,词袋方法在过去几年中受到了很多关注。 如图10所示,这些方法首先使用时空兴趣点检测器DollarICCVW2005检测局部显着区域;舒尔德ICPR2004;拉普捷夫IJCV2005; KlaserBMVC2008 。 在每个 3D 兴趣点周围提取梯度和光流等特征。 采用主成分分析来降低特征的维数。 那么所谓的视觉词可以通过k-means聚类SchuldtICPR2004或者Fisher向量PerronninCVPR2006来计算。 最后,动作可以用视觉词的直方图来表示,并且可以由诸如支持向量机之类的分类器来识别。 词袋模型已被证明对外观和姿势变化不敏感 WangBMVC2009 。 然而,它没有考虑人类行为的时间特征及其结构信息,这可以通过顺序方法来解决ShiIJCV2011; RaptisCVPR2013 和时空方法分别为RyooICCV2009。
顺序方法
这一系列工作使用序列状态模型(例如隐马尔可夫模型 (HMM) DuongCVPR2005)捕获外观或姿势的时间演变;拉伊科CVPR2007; IkizlerCVPR2007 ,条件随机场 (CRF) SminchisescuICCV2005 ;王CVPR2006;王CVPR2007; MorencyCVPR2007和结构化支持向量机(SSVM)NieblesECCV2010;王CVPR2012;唐CVPR2012; ShiIJCV2011 . 这些方法将视频视为时间段或帧的组合。 DuongCVPR2005中的工作考虑了人类在房间内的常规轨迹,并使用两层HMM对该轨迹进行建模。 RaptisCVPR2013 的最新工作表明,可以学习代表性关键姿势以更好地表示人类行为。 该方法丢弃时间序列中的许多无信息姿势,并构建更紧凑的姿势序列进行分类。 然而,这些顺序方法主要使用帧的整体特征,这些特征对背景噪声敏感,并且通常在具有挑战性的数据集上表现不佳。
时空方法
尽管直接方法在一些动作数据集上显示出了有希望的结果SchuldtICPR2004;拉普捷夫CVPR2008; MarszalekCVPR2009,他们没有考虑局部特征之间的时空相关性,也没有考虑兴趣点的全局时空分布的潜在有价值的信息。 WuCVPR2011解决了这个问题,它利用相对坐标特征学习全局高斯混合模型(GMM),并使用多个GMM来描述多个尺度下局部区域上兴趣点的分布。 yuan20133d提出了兴趣点之上的全局特征来捕获兴趣点的详细几何分布。 该特征是通过扩展 3D 离散 Radon 变换计算的。 这种特征捕获了兴趣点的几何信息,并且对几何变换和噪声具有鲁棒性。 兴趣点的时空分布由(DPCM)yuan2014modeling中的定向金字塔共生矩阵来描述。 DPCM表征局部特征的共现统计以及并发特征之间的时空位置关系。 图是结构化对象建模的强大工具,wu2014 human中使用它来捕获局部特征之间的时空关系。 使用局部特征作为二图模型的顶点,并通过边来表征帧内和帧间局部特征之间的关系。 wu2014 human 中提出了一种新颖的上下文相关图内核(CGK)家族来衡量两个图模型之间的相似性。 尽管上述方法取得了可喜的结果,但它们仅限于小数据集,因为它们的方法中兴趣点之间的相关性在大数据集上是爆炸性的。
基于部分的方法
人体是结构化对象,因此使用身体部位的运动信息来建模人类行为很简单。 基于部位的方法考虑来自整个人体以及身体部位的运动信息。 这种方法的好处是它本质上捕捉了身体部位之间的几何关系,这是区分人类行为的重要线索。 FantiCVPR2005提出了星座模型,对身体部位的位置、外观和速度进行建模。 受FantiCVPR2005的启发,NieblesCVPR2007提出了一种基于部位的分层模型,其中部位由模型假设生成,局部视觉词由身体部位生成(参见图11)。
WongCVPR2007中的方法将局部视觉词视为部分,并对部分之间的结构信息进行建模。 这项工作在 NieblesIJCV2008 中得到了进一步扩展,作者假设一个动作是从多项分布生成的,然后每个视觉词都是从以该动作为条件的分布生成的。 这些基于部分的生成模型通过判别模型进一步改进,以获得更好的分类性能WangNIPS2008;王PAMI2010 . 在WangNIPS2008; WangPAMI2010,在他们的模型中,一部分被视为隐藏变量。 它对应于正能量最大的显着区域。
多种学习方法
人类动作视频可以通过时间变化的人类轮廓来描述。 然而,这些轮廓的表示通常是高维的,阻碍了我们有效的动作识别。 为了解决这个问题,WangCVPR2007提出了流形学习方法; JiaCVPR2008 降低轮廓表示的维数并将其嵌入到非线性低维动态形状流形中。 WangCVPR2007中的方法采用核PCA进行降维,发现流形中动作的非线性结构。 然后,使用二链因式分解CRF模型将低维空间中的轮廓特征分类为人类动作。 JiaCVPR2008提出了一种新颖的流形嵌入方法,该方法找到了最大化与不同类别的轮廓相关的时间子空间之间的主轴的最佳嵌入。 尽管这些方法往往在动作识别方面取得非常高的性能,但它们严重依赖于干净的人体轮廓,而这在现实场景中可能很难获得。

中级特征方法
词袋模型已被证明对背景噪声具有鲁棒性,但可能缺乏足够的表达能力来描述存在较大外观和姿势变化的情况下的动作。 此外,由于低级特征和高级动作之间存在巨大的语义差距,它们可能无法很好地表示动作。 为了解决这两个问题,分层方法WangPAMI2010;崔CVPR2011;刘CVPR2011; KongPAMI2014被提出学习额外的表示层,并期望更好地抽象低级特征以进行分类。
分层方法从低级特征中学习中级特征,然后将其用于识别任务。 学习到的中级特征可以被认为是从用于训练或由专家指定的同一数据库中发现的知识。 最近,语义描述或属性(见图12)在动作识别中得到广泛研究。 这些语义被定义并进一步引入到活动分类器中,以表征复杂的人类行为KongECCV2012;孔PAMI2014;刘CVPR2011 . 其他分层方法,例如RaptisCVPR2013; Vahdat2011 从观察到的帧中选择关键姿势,这也会在模型学习过程中学习更好的动作表示。 由于使用了人类知识,这些方法显示出优异的结果,但需要额外的注释,这是劳动密集型的。
特征融合方法
融合视频中的多种类型的特征是一种流行且有效的动作识别方法。 由于这些特征是从相同的视觉输入生成的,因此它们是相互关联的。 然而,相互关系很复杂,并且在现有的融合方法中通常被忽视。 luo2014learning解决了这个问题,其中使用最大边缘距离学习方法结合全局时间动态和局部视觉时空外观特征来进行人类动作识别。 yuan2013multi-task提出了一种多任务稀疏学习(MTSL)模型,用于融合多种特征进行动作识别。 他们假设多个学习任务共享先验,每种特征对应一个先验,并利用任务之间的相关性来更好地融合多个特征。 yang2015multi-feature提出了一种多特征最大边缘分层贝叶斯模型(M3HBM),通过将分层生成模型(HGM)和判别最大边缘分类器相结合来学习高级表示。统一的贝叶斯框架。 HGM 通过从多种特征模态学习到的潜在时空模式 (STP) 的分布来表示动作。 这项工作在 yuan2016fusing 中得到了进一步扩展,将空间兴趣点与上下文感知内核结合起来进行动作识别。 具体来说,视频集被建模为优化的概率超图,并且使用强大的上下文感知内核来测量视频之间的高阶关系。
3.1.3 人类交互的分类器
人与人之间的互动在日常生活中很常见。 识别人类互动的重点是多人执行的动作,例如“握手”、“说话”等。 尽管一些早期的工作如LaptevCVPR2008;柳州ICCV2009;于BMVC2010;马萨莱克CVPR2009; LiuCVPR2009使用包含人类交互的动作视频,它们以与单人动作识别相同的方式识别动作。 具体来说,交互被视为一个整体,并表示为包括视频中所有人的运动描述符。 然后采用诸如线性支持向量机之类的动作分类器来对交互进行分类。 尽管已经取得了合理的性能,但这些方法没有明确考虑交互的内在方法,也没有考虑交互人员之间的共现信息。 此外,他们没有从群体中提取每个人的动作,因此他们的方法无法推断每个交互者的动作标签。
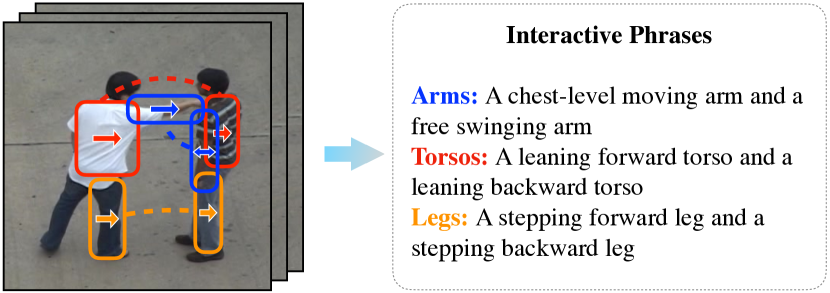
个体动作共现是人类交互识别中的一个有价值的信息。 在OliverPAMI2000中,动作共现是通过耦合一个人与另一个交互人的运动状态来捕获的。 “拥抱”、“推”、“嗨五”等人类互动通常涉及频繁的亲密身体接触,因此某些身体部位可能会被遮挡。 为了可靠地找到身体部位,Ryoo 和 Aggarwal RyooCVPR2006 利用身体部位跟踪器提取视频中的每个人,然后应用上下文无关语法来建模人与人之间的空间和时间关系。 PerezPAMI2012 采用人体探测器来定位每个人。 使用结构化学习技术 FelzenszwalbCVPR2008 捕获个体之间的空间关系。 ChoiCVPR2011 捕获了一群人的时空背景,包括人体姿势、速度和个体的时空分布,以识别人类互动。 他们的方法在没有密切身体接触(例如“过马路”、“交谈”或“等待”)的集体行动中显示出了可喜的结果。 他们进一步扩展了可以同时跟踪和识别人类交互的工作ChoiECCV2012。 ChoiECCV2012 中提出了交互的分层表示,它对原子动作、交互和集体动作进行建模。 LanPAMI2012中的方法也利用了层次表示的思想,研究了利用人群上下文的集体活动识别问题。 与这些方法不同的是,Vahdat2011中的工作将交互中的个体表示为一组关键姿势,并对关键姿势的时空关系进行建模以进行交互识别。 在我们早期的工作KongPAMI2014; KongECCV2012提出了一种基于语义描述的方法,通过学习的运动关系来表示复杂的人类交互(见图12)。 我们建议学习描述身体部位之间运动关系的短语,而不是直接建模动作共现。 这将更详细地描述复杂的交互,并将人类知识引入模型中。 由于特征与人的分配不明确,所有这些方法在密切身体接触的交互中可能表现不佳。 为了解决这个问题,KongECCVW2014提出了一种补丁感知模型来学习用于交互识别的判别性补丁,并确定补丁级别的分配。
3.1.4 RGB-D 视频分类器
RGB-D 视频的动作识别已受到广泛关注 WangECCV2012 ;王JCVPR2012;哈德菲尔德CVPR2013;夏CVPR2013;刘IJCAI2013; OreifejCVPR2013 由于经济高效的 Kinect 传感器 ShottonPAMI2013 的出现。 与传统 RGB 视频相比,RGB-D 视频提供了额外的深度通道,使我们能够捕获 3D 结构信息,这对于减少背景噪声和简化类内运动变化非常有用Ni2011;王CVPR2012; OreifejCVPR2013;哈德菲尔德CVPR2013; Ofli2013 .
已经针对使用深度数据的识别任务提出了有效的特征,例如定向 4D 法线的直方图 OreifejCVPR2013 ; YangCVPR2014和深度时空兴趣点XiaCVPR2013; HadfieldCVPR2013 . 深度序列的特征可以通过 LuoICCV2013 进行编码,或者用于构建 actionlet WangCVPR2012 进行识别。 LuCVPR2014提出了一种高效的深度数据二进制范围样本特征。 这种二值深度特征速度很快,并且对于尺度、视点和背景的变化具有不变性。 SungICRA2012 的工作; KoppulaICML2013 构建了分层动作图结构来对 RGB-D 视频中的动作和子动作进行建模。 最近的工作LiuIJCAI2013也表明可以使用深度学习技术来学习RGB-D数据的特征。
LiCVPRW2010中的方法; OreifejCVPR2013;杨CVPR2014;哈德菲尔德CVPR2013;王ECCV2012; LuoICCV2013仅使用深度数据,因此如果缺少深度数据就会失败。 HuCVPR2015 研究了联合使用 RGB 和深度数据进行动作识别;贾MM2014;林CVPR2014;刘IJCAI2013;王CVPR2012; KongCVPR2015 . 然而,它们只学习两种模态之间共享的特征,而不学习模态特定的或私有的特征。 为了解决这个问题,KongIJCV2017联合学习了共享特征和私有特征,它学习了额外的分类判别信息,并且表现出了比HuCVPR2015更优越的性能;贾MM2014;林CVPR2014;刘IJCAI2013;王CVPR2012; KongCVPR2015 . KongCVPR2015中的方法; KongIJCV2017还表明,即使在训练或测试中缺少一种模式,他们也可以实现较高的识别性能。
辅助信息也被证明在 RGB-D 动作识别中非常有用。 HuCVPR2015 使用了 Kinect 传感器提供的骨骼数据;王CVPR2012; KongIJCV2017,并且已被证明在动作识别方面非常有效。 HuCVPR2015中的方法为包括骨架特征和局部HOG特征在内的各类特征学习共享特征空间,并将这些特征投影到共享空间上进行动作识别。 与这项工作不同的是,KongIJCV2017中的方法联合学习RGB-D和骨架特征以及动作分类器。 KongIJCV2017中的投影矩阵是通过使用投影特征最小化投影后的噪声和分类误差来学习的。 JiaMM2014研究了利用辅助数据库提高识别性能; LinCVPR2014,其中假设动作由辅助数据库中的条目重建。
3.2 深层架构
尽管全局和局部特征取得了巨大成功,但这些手工制作的特征需要大量的人力和领域专家知识来开发有效的特征提取方法。 此外,它们通常不能很好地概括大型数据集。 近年来,使用深度学习技术的特征学习由于能够学习强大的特征并且可以很好地泛化而受到越来越多的关注JiTPAMI2013; TranICCV2015;多纳休CVPR2015;西蒙扬NIPS2014 . 深度网络在动作识别方面的成功还可以归因于将网络扩展到数千万个参数和大量标记数据集。 最近的深度网络VarolTPAMI2017; TranICCV2015; FeichtenhoferCVPR2017; KarCVPR2017 在各种动作数据集上取得了令人惊讶的高识别性能。
通过深度学习技术学习的动作特征已得到广泛研究YangECCV2012;王MM2014;泰勒ECCV2010;孙CVPR2014;普罗茨IJCAI2011; LeCVPR2011;卡帕斯CVPR2014;吉TPAMI2013;吉ICML2010;哈桑ECCV2014; BengioPAMI2013; SimonyanNIPS2014 近年来。 开发用于动作识别的深度网络的两个主要变量是卷积运算和时间建模,导致网络的几行。

卷积运算是动作识别深层网络的基本组成部分之一,它使用核矩阵聚合小空间(或时空)邻域中的像素值。 2D 与 3D 卷积: 图像上的 2D 卷积(图13(a))是深度网络中的基本操作之一,因此在视频帧上使用 2D 卷积非常简单。 KarpathyCVPR2014中的工作提出了基于2D CNN模型的单帧架构,并为每一帧提取了特征向量。 这种 2D 卷积网络 (2D ConvNet) 还具有使用在大规模图像数据集(例如 ImageNet)上预训练的网络的优势。 然而,2D ConvNet 本身并不对时间信息进行建模,并且需要对此类信息进行额外的聚合或建模。
由于视频中存在多个帧,3D 卷积(图13(b))可以更直观地捕获短时间内的时间动态。 使用3D卷积,3D卷积网络(3D ConvNets)直接创建时空数据的层次表示JiICML2010;吉TPAMI2013;泰勒ECCV2010; TranICCV2015 . 然而,问题是它们比 2D ConvNets 有更多的参数,这使得它们难以训练。 此外,他们无法享受 ImageNet 预训练的好处。
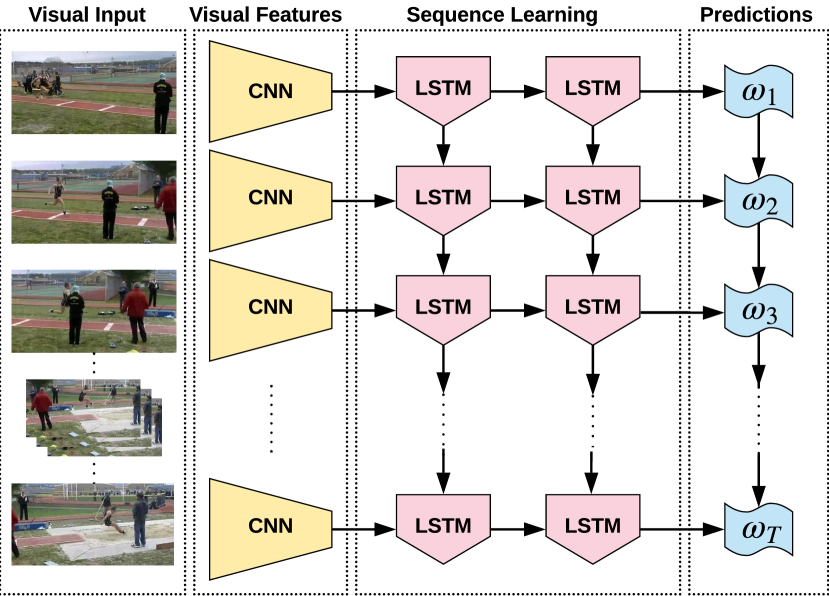
设计深度网络的另一个关键变量是时间建模。 一般来说,时间建模大致有三种方法。 一种直接的方法是直接对几个连续帧应用 3D 卷积 JiICML2010 ;吉TPAMI2013;泰勒ECCV2010; TranICCV2015; CarreiraCVPR2017 . 因此,3D 卷积核中的时间维度将捕获这些帧中的时间动态。 这些方法的局限性之一是它们可能无法重用在大规模图像数据集上预先训练的 2D ConvNet。 另一种方法是通过使用多个流来模拟时间动态SimonyanNIPS2014; FeichtenhoferCVPR2016;卡雷拉CVPR2017;格德哈CVPR2017; KarCVPR2017 . 网络中名为流网的流在光流帧上进行训练,其本质上捕获相邻两帧中的运动信息。 然而,这些方法在很大程度上忽视了视频的长期时间结构。 这些方法通常使用 2D 卷积,因此它们可以轻松利用针对静态图像预训练的新超深架构和模型。 第三类方法使用时间池KarCVPR2017; GirdharCVPR2017 或聚合以捕获视频中的时间信息。 可以通过使用 2D ConvNets DonahueCVPR2015 之上的 LSTM 模型来执行聚合; NgCVPR2015 .
3.2.1 时空网络
时空网络是 2D ConvNet 的直接扩展,因为它们使用 3D 卷积捕获时间信息。
JiICML2010中的方法是使用卷积神经网络(CNN)进行动作识别的开创性工作之一。 它们对相邻帧执行 3D 卷积,从而从空间和时间维度提取特征。 他们的 3D CNN 网络架构从 硬连线内核开始,包括gray、gradient-x、gradient-y、optflow-x 和 optflow-y,从而产生 特征图。 然后网络重复3D卷积和下采样,并使用全连接层生成128维特征向量用于动作分类。 在后来的扩展JiTPAMI2013中,作者通过鼓励网络学习接近高级运动特征的特征向量(例如词袋表示)来规范网络以编码长期动作信息SIFT 特征。
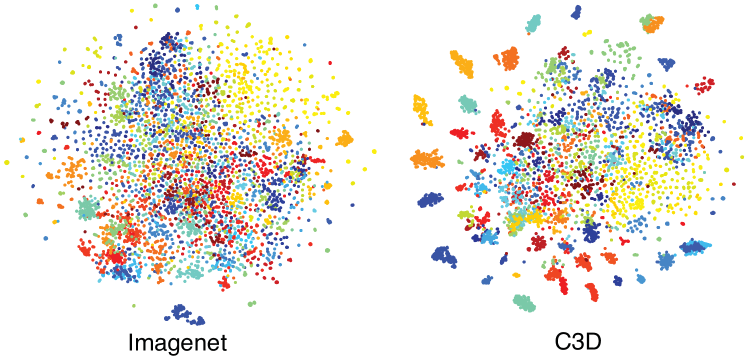
3D ConvNet JiICML2010 ; JiTPAMI2013 后来扩展到一种名为 C3D TranICCV2015 的现代深度架构,可以在大规模数据集上学习。 C3D网络包含卷积层、最大池化层、全连接层和softmax损失层,受机器内存限制和计算承受能力。 他们的工作表明,C3D 可以学习更好的视频特征嵌入(见图14)。 结果表明,带有线性分类器的 C3D 方法可以在包括动作识别和对象识别在内的各种视频分析基准上优于或接近最先进的方法。
尽管如此,3D ConvNets JiICML2010 ;吉TPAMI2013;用于动作识别的 TranICCV2015 相对较浅,最多可达 层。 为了进一步提高 3D ConvNet 的泛化能力,CarreiraCVPR2017 通过沿时间维度重复 2D 滤波器,将用于图像分类的非常深的网络膨胀到时空特征提取器中,从而允许网络重用预先训练的 2D 滤波器在 ImageNet 上。 这项工作还表明,Kinetics 数据集上的预训练在 UCF-101 和 HMDB51 数据集上实现了更好的识别精度。 QiuICCV2017提出了另一种构建深度3D ConvNet的解决方案,它使用一个卷积层和一个卷积的组合来代替标准 3D 卷积。
3D ConvNet 的一个局限性是它们通常考虑非常短的时间间隔,例如 TranICCV2015 中的 16 帧,因此无法捕获长期时间信息。 为了解决这个问题,VarolTPAMI2017增加了3D卷积的时间范围,并且经验表明它们可以显着提高识别性能。
3.2.2 多流网络
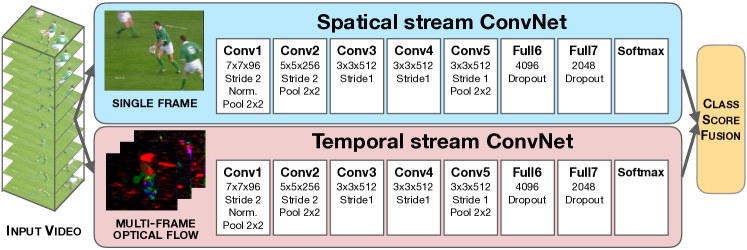
多流网络利用多个卷积网络对动作视频中的外观和运动信息进行建模。 尽管KarpathyCVPR2014中的网络取得了巨大的成功,但其结果明显不如最好的手工制作的浅层表示WangIJCV2015;王IJCV2013 . 为了解决这个问题,SimonyanNIPS2014的一项成功工作探索了一种与双流假设Goodale1992相关的新架构。 他们的架构包含两个独立的流,一个空间 ConvNet 和一个时间 ConvNet(见图15)。 前者从静止图像中学习动作,后者基于光流场进行识别。
双流网络SimonyanNIPS2014直接融合了各自softmax函数生成的两个流的输出,这可能不适合长时间收集信息。 WangCVPR2015提出了一种改进,使用双流网络获取多尺度卷积特征图,并将特征图与检测到的轨迹汇集在一起,计算以轨迹为中心的ConvNet响应。 这种方案将深层特征编码为受采样轨迹约束的有效描述符。 NgCVPR2015 研究了双流网络中的时间特征池化,能够在池化层之后进行视频级预测。 GirdharCVPR2017 中的工作还提出了一种名为 ActionVLAD 的新型池化层,它聚合不同图像部分和时间跨度中的卷积特征描述符。 他们还使用 ActionVLAD 将外观和运动流组合在一起。 名为时间线性编码DibaCVPR2017的网络聚合从视频中采样的时间特征,然后投影到低维特征空间上。 通过这样做,可以捕获不同帧中的长程时间结构并将其编码为紧凑的表示。 KarCVPR2017中提出的AdaScan评估了下一帧的重要性,因此在视频级表示中仅会池化信息性帧,而忽略非信息性帧。 他们的 AdaScan 方法使用多层感知器来计算下一帧的重要性,给定当前帧之前的临时池化特征。 然后,重要性得分将用作特征池操作的权重,以聚合下一帧。 尽管有效,但大多数特征编码方法缺乏考虑时空信息。 为了解决这个问题,DutaCVPR2017的工作提出了一种新的深度特征编码方法。 更具体地说,他们提出了局部最大池化,根据特征的相似性对特征进行分组,然后执行最大池化。 此外,他们对特征的位置进行最大池化和求和池化以实现时空编码。
双流网络中的时间采样在Temporal Segment Networks (TSN)WangECCV2016中提出。 在 TSN 中,通过分析从完整视频片段中随机采样的帧形成的短视频片段来收集远程动态。 这里的想法是,直接分析密集采样的视频序列是没有意义的,因为视频中的连续帧包含大量冗余。 此外,一些动作会在不同的时间尺度上显现出来,例如冲刺,与蹲下相比,它需要在很长一段时间内进行多次动作。 原始的 TSN 网络 WangECCV2016 是基于 SimonyanNIPS2014 的双流架构。 时间段的预测是通过将共识函数应用于使用预训练的深度 CNN 分类网络提取的帧特征来进行总结。 至于共识功能,使用了简单的池化操作。 该网络的优点是它可以享受使用大型预训练分类网络进行特征提取的好处。 为了提高zhou2018temporal中时间采样的性能,建议在不同时间尺度上进行采样,并用全连接网络代替池化操作,该网络应对帧的时间顺序进行编码。 TSN 还可以合并到另一个动作识别框架中,如 qiu2019learning 中所示。 最近,Liu 等人 no_frames尝试使用所有视频帧进行分类,基于相似帧应具有相似激活值的假设,沿时间维度对激活进行聚类。 然而,该方法动态选择簇数量的能力受到限制。 Wang 等人 tdn提出了时间差分网络(TDN),旨在识别整个视频中的动作。 TDN 包含用于编码局部运动信息的短期时间差模块和用于捕获跨段运动的长期时间差模块。
双流网络的主要问题之一SimonyanNIPS2014;王CVPR2015; NgCVPR2015 的缺点是它们不允许两个流之间进行交互。 然而,这样的交互对于学习时空特征确实很重要。 为了解决这个问题,Feichtenhofer 等人FeichtenhoferCVPR2016提出了一系列空间融合函数,使相同像素位置的通道响应具有相同的对应关系。 这些融合层放置在两个流的中间,允许它们之间进行交互。 他们进一步在两个流之间注入残余连接FeichtenhoferNIPS2016; FeichtenhoferCVPR2017 ,并允许流通过相反流的输入 FeichtenhoferCVPR2017 进行乘法缩放。 这种策略弥合了两个流之间的差距,并允许在学习时空特征中进行信息传递。
3.2.3 混合网络
聚合时间信息的另一种解决方案是在 CNN 之上添加循环层(例如 LSTM),以构建混合网络DonahueCVPR2015; NgCVPR2015 . 这种混合网络利用了 CNN 和 LSTM 的优点,因此在捕获空间运动模式、时间顺序和远程依赖性方面显示出了有希望的结果WangCVPR2015;迪巴CVPR2017; KarCVPR2017 .
Donahue 等人DonahueCVPR2015 探索了 LSTM 在对 2D ConvNet 生成的帧特征的时间序列进行建模时的使用。 如图16所示,LSTM的递归性质允许其网络生成可变长度的文本描述,并识别视频中的人类动作。 Ng 等人NgCVPR2015比较了时间池和在 CNN 之上使用 LSTM。 他们讨论了六种类型的时间池化方法,包括慢速池化和卷积池化,并根据经验表明,添加 LSTM 层通常比时间池化小幅优于时间池化,因为它捕获了帧的时间顺序。 WuMM2015提出了一种使用CNN和LSTM的混合网络。 他们使用双流 CNN SimonyanNIPS2014 从视频帧中提取运动特征,然后输入双向 LSTM 来建模长期时间依赖性。 提出了一种正则化融合方案,以捕获外观和运动特征之间的相关性。
混合网络也已应用于基于骨架的动作识别。 骨骼数据可以通过 Kinect 等深度传感器或姿势估计算法轻松获得。 在这些方法中,混合深度神经网络Shahroudy_2016_NTURGBD;朱2016co;刘2016空间; ke2017新; yan2018spatial是为了对身体各个关节的结构信息以及身体运动的时间信息进行建模而开发的。 循环神经网络广泛用于捕获由有序关节组成的特征 Shahroudy_2016_NTURGBD ;朱2016co; liu2016spatio . Temporal CNN ke2017new也被用来捕捉结构化身体关节的特征。 最近,图卷积网络表现出了优于 RNN 和 Temporal CNN 的性能,并成为捕获关节结构信息的支柱。 Yan 等人 yan2018spatial提出了一种时空图卷积来同时学习结构和时间信息。 Si 等人 si2019attention应用GCN-LSTM对骨架的时间依赖性进行建模,并提出了一种注意力模型来学习每个关节的重要性。
| Approaches | Pros | Cons | |
| Shallow | Direct SchuldtICPR2004 ; WangICCV2013 | Easy and quick to use. | Performance is limited. |
| Sequential MorencyCVPR2007 ; ShiIJCV2011 | Models temporal evolution. | Sensitive to noise. | |
| Space-time wu2014human ; WuCVPR2011 | Captures spatiotemporal structures. | Limited to small datasets. | |
| Part-based WangPAMI2010 ; NieblesECCV2010 | Models body parts at a finer level. | Limited to small datasets. | |
| Manifold WangCVPR2007 ; JiaCVPR2008 | Tend to achieve high performance. | Rely on human silhouettes. | |
| Mid-level feature ChoiCVPR2011 ; LiuCVPR2011 | Introduce knowledge to models. | Require extra annotations. | |
| Feature fusion yuan2013multi-task ; yuan2016fusing | Tend to achieve high performance. | Slow in feature extraction. | |
| Deep | Space-time JiTPAMI2013 ; TranICCV2015 | Natural extension of 2D convolution. | Short temporal interval. |
| Multi-stream SimonyanNIPS2014 ; FeichtenhoferCVPR2017 | Able to use pre-trained 2D ConvNets. | Int. b/w networks is difficult. | |
| Hybrid DonahueCVPR2015 ; NgCVPR2015 | Easy to build using existing networks. | Difficult to fine-tune. |
3.3 使用有限数据/标签进行学习
由于训练深度神经网络的必要性,最近的视频变得非常大。 例如,Youtube-8M 数据集 abu2016youtube 由超过 万个视频组成。 对于如此大规模的数据集,对所有视频数据进行注释是昂贵的并且几乎不可能。 尽管搜索引擎被赋予了动作标签并用于检索视频,但它们也会犯错误,因此编译后的视频数据可能会有噪音。 一种解决方案是以弱监督方式或无监督方式学习动作模型。 因此,模型不一定需要完全注释的视频数据,并且可以在非常有限或没有监督信号的情况下学习。 最近还引入了少样本学习来在低样本制度下进行学习。
3.3.1 弱监督行动学习
弱监督学习方法laptev2008learning;博雅诺夫斯基2014弱; ghadiyaram2019large 是为了处理每个视频都没有完全注释的场景而开发的。 一种有前途的应用场景是理解未经修剪的视频中的人类动作,其中视频中各种动作的时间边界没有注释。 这样的学习能力增强了大多数现有的动作识别方法TranICCV2015;孔TPAMI2018;西蒙扬NIPS2014;王CVPR2015; NgCVPR2015,因为需要对所有动作视频进行修剪,这是昂贵且耗时的。
具有脚本数据的电影是评估弱监督动作学习方法的典型场景。 Laptev 等人的开创性工作laptev2008learning提出了一种新颖的电影真实动作数据集。 注释是使用电影脚本制作的。 Duchenel 等人 duchenne2009automatic 遵循了这项工作,并解决了动作模型的弱监督学习问题以及给定相应电影脚本的视频中动作实例的本地化问题。
另一种类型的工作是弱监督动作理解,给出视频中出现的按时间顺序排列的动作类列表。 例如,Bojanowski 等人 bojanowski2014weakly将该问题表述为弱监督时间分配,并提出了一种将动作标签分配给视频中时间片段的聚类方法。 Huang 等人 huang2016connectionist 采用语音识别中的连接主义时态分类模型来执行弱监督动作标记。
最近的工作将弱监督动作表示学习扩展到具有无序动作列表的未修剪视频。 Wang 等人 WangCVPR2017提出了UntrimmedNet,通过在端到端框架中学习动作模型和推理动作实例的时间持续时间来理解未修剪的视频。 Ghadiyaram 等人 ghadiyaram2019large 利用大规模噪声标记网络视频来学习用于视频动作识别的预训练模型。
3.3.2 无监督和自监督行动学习
近年来,无监督或自监督表示学习变得越来越流行,因为它允许利用训练数据中的监督信号(而不是由人类给出)对深度神经网络进行预训练。 这种预先训练的模型有利于下游任务,例如动作识别和定位。 许多尝试利用时间相干性、运动一致性和时间连续性作为监督,这将在下面讨论。
帧的时间顺序是视频的典型自由监督信号。 给定打乱或未打乱的视频,动作模型学习判断帧序列是否有序 misra2016shuffle ;费尔南多2017自我 . 另一个相关任务是训练模型来告诉混洗视频帧的实际顺序 lee2017unsupervised 。 Xu 等人 xu2019self将顺序预测任务从帧扩展到剪辑。 这有助于使用时间顺序监督训练 3D CNN 框架。 Buchler 等人 buchler2018improving 应用深度强化学习根据新排列的预期效用来采样新排列,以适应网络状态。
视频中物体的运动也可以用作监督。 Wang 等人 wang2015unsupervised基于 Siamese-Triplet 网络,使用视觉跟踪找到了相应的对。 Purushwalkam et al. purushwalkam2016pose 使用姿势作为自由监督,因为相似的姿势应该具有相似的运动。 Wang 等人 wang2017transitive探索了不同的自监督方法来学习对对象块之间的变化不变的表示,这是通过运动线索提取的。 Gan 等人 gan2018geometry使用几何线索流场和视差图来学习视频表示。
3.3.3 小样本学习
少样本学习旨在从极简数据集中学习可靠的模型。 在极端情况下,某些类别可能没有训练样本,这称为零样本学习。 大多数样本工作的目标是识别图像,而只有少数样本解决了视频动作识别的挑战。 CMN_few_shot提出了一种复合内存网络(CMN),它通过检索存储在 CMN 架构内存中的相似视频来预测未见过的视频。 ProtoGAN protoGAN 通过称为类原型传输网络 (CPTN) 的特征聚合器网络学习类原型向量,然后为识别分类器生成附加视频特征。 神经图匹配 (NGM) 网络 NGMN_few_shot 是一种基于图的方法,可生成 3D 动作视频的图表示,并通过图表示的相似性来匹配未看过的视频和已看过的视频。 ashish_few_shot提出了一个零样本动作识别框架,它将每个动作类建模为概率分布,分布参数是动作类属性的线性组合。 属性的权重是从标记样本中学习的。 少样本动作识别的一项挑战是时间长度的变化。 时间注意力关系网络 (TARN) TARN 使用注意力模块来对齐视频片段,并学习对齐表示之间的距离度量,以进行少样本和零样本学习。 动作关系网络 (ARN) ARN_few_shot 将查询集和支持集的视频剪辑特征编码到幂归一化自相关矩阵 (AM) 中,关系网络从中学习捕获关系。 与 ARN 类似,有序时间对齐模块 (OTAM) OTAM_few_shot 通过嵌入网络提取每帧特征,然后计算距离矩阵的对齐分数。 时间关系 CrossTransformers (TRX) TRX 通过使用 CrossTransformer 注意力模块将每个子序列与支持集中的所有子序列进行匹配,对查询视频进行分类。
3.4总结
深层网络在动作识别研究中占主导地位,但浅层方法仍然有用。 与深层网络相比,浅层方法易于训练,并且通常在小型数据集上表现良好。 最近的浅层方法,例如使用线性 SVM 改进的密集轨迹 WangICCV2013 在大型数据集上也显示出了有希望的结果,因此它们最近在与深度网络 TranICCV2015 的比较中仍然被广泛使用;瓦罗尔TPAMI2017; FeichtenhoferCVPR2017 。 如果数据集很小,或者每个视频都表现出需要建模的复杂结构,那么首先使用浅层方法会很有帮助。 不过,互联网上有很多预训练的深度网络,例如 C3D TranICCV2015 和 TSN WangECCV2016 可以轻松使用。 尝试这些方法并将模型调整到特定的数据集也会很有帮助。 表1总结了动作识别方法的优缺点。
4 动作定位和检测
为了识别和预测动作,机器需要知道视频中的动作在哪里。 这是通过动作定位和检测来实现的,它找出视频中包含某些人类动作的时空区域。 近年来,这两项任务都吸引了大量的研究。 与图像域中的对象定位和检测进行类比,与动作定位相比,还需要动作检测来识别视频中发生的每个动作的动作类型。 基于特征学习范式,相关工作可以分为浅层学习方法和深度学习方法,对此我们将进行全面的文献综述。 表2总结了一些最新的检测方法,并比较了阈值0.3、0.4和0.5的结果。 mAP@ 表示不同 IOU 阈值下的平均精度,用于衡量每个动作类别的平均预测。
| mAP@0.5 | mAP@0.4 | mAP@0.3 | |||
|---|---|---|---|---|---|
| End-to-End yeung2016end | 17.1 | 26.4 | 36.0 | ||
| Multi-stage ShouCVPR2016 | 19.0 | 28.7 | 36.3 | ||
| TURN GaoICCV2017 | 24.5 | 35.3 | 46.3 | ||
|
25.6 | 33.3 | - | ||
|
28.9 | 35.6 | 44.8 | ||
| SSN ZhaoICCV2017 | 29.8 | 41.0 | 51.9 | ||
|
35.8 | 43.1 | 51.1 | ||
|
36.1 | 43.0 | 51.2 | ||
| BSN lin2018bsn | 36.9 | 45.0 | 53.5 | ||
| MGG UNet liu2019multi | 37.4 | 46.8 | 53.9 | ||
| BMN lin2019bmn | 38.8 | 47.4 | 56.0 |
4.1 浅层方法
早期作品 KaramanTHUMOS2014 ; WangTHUMOS2014首先使用时间分割或滑动窗口方法将动作检测制定为分类任务。 在这些工作中,未修剪的视频被分割成短视频剪辑,并提取多个特征供支持向量机(SVM)等分类器识别动作类型。 最终,视频中出现的动作及其时间位置被确定。 jian 等人 JainCVPR2014提出从视频中生成一组边界框,称为用于动作定位的小管。 然而,这些方法受到手工特征工程和多阶段模型调整的影响,导致检测结果相当不准确。
4.2 深层架构
最近的动作定位和检测方法充分利用深度神经网络来学习更好的视频特征表示。 为此,Shou 等人 ShouCVPR2016提出首先从长视频中生成行动建议。 然后,将定位网络引入到经过训练的动作分类网络中以识别动作标签。 他们的行动建议的想法启发了许多后来的研究EscorciaECCV2016;受CVPR2017;王CVPR2017;赵ICCV2017;徐2017r;高ICCV2017; ChaoCVPR2018 . 对于这些方法,Escorcia 等人 EscorciaECCV2016提出了一种深度行动建议(DAP)方法,该方法实现了高效率并具有良好的泛化能力。 为了检测帧级粒度的人类行为,Shou 等人 ShouCVPR2017提出了一种端到端学习框架,其中在 3D 之上设计了 CDC 卷积滤波器卷积网络。 为了对每个动作实例的时间结构进行建模,Zhao 等人 ZhaoICCV2017提出了一种具有时间金字塔和称为时间动作分组(TAG)的结构化分段网络(SSN)行动建议生成模型。 由于动作检测与物体检测类似,Chao等人ChaoCVPR2018重新审视了最广泛使用的物体检测方法Faster R-CNN,并提出了一种时间动作定位网络(TAL-Net)来解决尚未解决的挑战,包括动作持续时间的巨大变化、时间上下文建模和多流特征融合。 Song 等人 SongCVPR2019指出,动作的模糊过渡状态和长期时间上下文对于准确的动作检测至关重要。 因此,他们提出了一种转换感知上下文网络,并被证明对于未修剪的视频数据集非常有效。 为了对动作建议之间的关系进行建模,Zeng 等人 ZengICCV2019最近提出引入图卷积神经网络(GCN)进行时间动作定位。 Song 等人 SongTMM2019介绍了可以利用时间信息的动作模式树(AP-Tree)。 受传统从粗到精检测思想的启发,Yang 等人 YangCVPR2019提出了一种用于视频动作检测的时空渐进学习方法,在现有的基础上取得了显着的性能基准。 最近,Xu 等人 XuICCV2019提出了在线动作检测的重要性,并提出了一种时间循环网络(TRN),通过同时执行在线动作检测和预测,显着优于状态最先进的。 Chen et al. woo 将参与者定位和动作分类任务统一到同一主干中,与 SOTA 方法相比,这降低了模型复杂性并提高了效率。 Li 等人 Three_birds设计了两个辅助借口任务来回收有限的标记数据,有利于特征提取和预测。
与以前需要对动作实例进行大规模帧级注释的全监督方法不同,弱监督方法仅需要视频或剪辑级动作注释,因此在实践中更有前景。 Wang 等人 WangCVPR2017提出了一种弱监督动作检测模型,直接在未修剪的视频数据上学习,取得了与全监督模型相当的性能动作检测方法。 最近,Yu 等人 YuICCV2019将时间结构挖掘(TSM)方法引入了弱监督动作检测问题。 在他们的方法中,动作实例被建模为多阶段过程,以便可以利用阶段滤波器来计算置信度分数,指示动作发生概率。 对于弱监督动作定位问题,近年来也引起了人们的广泛关注。 高等人gao2021woad提出了一种弱监督框架,该框架由两个模块组成,一个模块生成动作边界的伪地面事实,用于监督动作识别模块。 Yang 等人 uncertainty_action_detection提出将不确定性纳入生成的伪标签中以减少噪声。 为了应对有限时间注释的挑战,Yang 等人 YangCVPR2018使用匹配网络的一次性学习技术进行时间动作定位。 Narayan 等人 NarayanICCV2019引入了一种新颖的损失函数,包括动作分类损失、多标签中心损失和计数损失,设定了新的现状弱监督动作定位的艺术。
除了使用视觉数据之外,其他数据模式(例如骨架和 RGB-D 数据)也可以用于时间动作定位和检测。 为了学习判别性骨骼关节的特征,Song等人SongTIP2018引入了一种用于动作识别和检测的时空注意力LSTM模型。 为了处理多模态环境中的模态差异,Luo 等人 LuoECCV2018提出了一种图蒸馏方法,从大规模多模态数据集中学习特权信息在源域中,他们的模型可以有效地部署到模态稀缺的目标域中。 对于连续动作流场景,Dawar 等人 DawarSensors2018 设计了一种多模态融合系统,将深度相机数据和可穿戴惯性传感器信号结合起来进行动作检测。
5 动作预测
过去几十年来,事后动作识别得到了广泛的研究,并取得了丰硕的成果。 最先进的方法DonahueCVPR2015;格德哈CVPR2017; WangECCV2016能够在观察整个动作执行后准确给出动作标签。 然而,在许多现实场景中(例如,车辆事故和犯罪活动),智能系统无法等待整个视频,然后才对其中包含的动作做出反应。 例如,能够在危险驾驶情况发生之前预测它;反对事后承认它。 此外,如果自动驾驶车辆能够预测街道上行人的运动轨迹并避免碰撞,而不是识别碰撞行人后的轨迹,那就太好了。 不幸的是,大多数现有的动作识别方法都不适合这种早期分类任务,因为它们期望从完整视频中看到整套动作动态,然后做出决策。
与动作识别方法不同,动作或运动预测111本文中,动作预测是指预测动作类别的任务,运动预测是指预测运动轨迹的任务。 本文不讨论视频预测,因为它关注的是视频中的运动而不是人类的运动。 在动作执行结束之前对未来进行推理并推断标签。 这些标签可以是离散的动作类别,也可以是运动轨迹上的连续位置。 做出迅速反应的能力使得动作/运动预测方法在时间敏感的任务中更具吸引力。 然而,动作/运动预测确实具有挑战性,因为必须对部分动作视频做出准确的决策。

5.1 动作预测
动作预测任务大致可以分为两类:短期预测和长期预测。 前者是短期预测,主要针对短时动作视频,通常持续几秒钟,例如 UCF-101 和 Sports-1M 数据集中的动作视频。 此任务的目标是根据暂时不完整的动作视频推断动作标签。 形式上,给定一个包含 帧的不完整动作视频 ,即 ,目标是推断动作标签 : 。 这里,不完整动作视频包含完整动作执行的开始部分,其仅包含一个动作。 后一种,长期预测或意图预测,根据当前观察到的人类行为推断未来的行为。 它旨在对动作转换进行建模,因此专注于持续几分钟的长时间视频。 换句话说,这个任务预测未来将要发生的动作。 更正式地说,给定一个动作视频 ,其中 可能是完整或不完整的动作执行,目标是推断下一个动作 。 这里,和是两个独立的、语义上有意义的、时间上相关的动作。
| Methods | Year | 0.1@BIT | 0.5@BIT | 0.1@UTI-1 | 0.5@UTI-1 | 0.1@UCF-101 | 0.5@UCF-101 | 0.1@Sports-1M | 0.5@Sports-1M |
|---|---|---|---|---|---|---|---|---|---|
| Integral BoW RyooICCV2011 | 2011 | ||||||||
| MSSC CaoCVPR2013 | 2013 | ||||||||
| Poselet RaptisCVPR2013 | 2013 | - | - | - | - | ||||
| HM LanECCV2014 | 2014 | - | - | - | - | ||||
| MTSSVM KongECCV2014 | 2014 | ||||||||
| MMAPM KongTPAMI2016 | 2016 | - | - | - | |||||
| DeepSCN KongCVPR2017 | 2017 | - | - | ||||||
| GLTSD LaiTIP2018 | 2018 | - | - | - | - | - | |||
| mem-LSTM KongAAAI2018 | 2018 | - | - | - | - |
5.1.1 早期行动分类
该任务旨在早期识别人类行为,即基于时间不完整的视频(见图17)。 目标是在仅观察视频的开始部分时实现高识别精度。 观察到的视频包含未完成的动作,因此使预测任务具有挑战性。 虽然这个任务可以通过动作识别方法来解决RaptisCVPR2013;瓦赫达2011;姚PAMI2012; YaoECCV2012,它们是为了识别完整的动作执行而开发的,并且没有针对部分动作观察进行优化,使得动作识别方法不适合在早期阶段预测动作。 表3提供了在四个数据集上进行早期动作分类的一些结果。

大多数短期动作预测方法遵循KongECCV2014中描述的问题设置,如图18所示。 为了模拟顺序数据到达,具有 帧的完整视频 被分割为 片段。 因此,每个段都包含 帧。 不同视频的视频长度可能有所不同,从而导致其片段的长度不同。 对于长度为 的视频,其第 段 () 包含从第 帧开始到第 帧的帧。 第帧。 时间部分视频或部分观察 被定义为由视频的开始片段组成的时间子序列。 部分视频的进度级别 由部分视频中包含的片段数量定义:。 部分视频的观察比为:。
动作预测方法旨在识别未完成的动作视频。 Ryoo RyooICCV2011提出了用于动作预测的积分词袋(IBoW)和动态词袋(DBoW)方法。 每个进度级别的动作模型是通过对同一类别中特定进度级别的特征进行平均来计算的。 然而,如果同一类别的动作视频具有较大的外观变化,并且对异常值敏感,则学习到的模型可能不具有代表性。 为了克服这两个问题,Cao 等人CaoCVPR2013通过使用稀疏编码学习特征库来构建动作模型,并在似然计算中使用重建误差。 Li 等人LiECCV2012探索了长时间动作预测问题。 然而,他们的工作通过运动速度峰值来检测片段,这可能不适用于复杂的室外数据集。 与CaoCVPR2013相比; LiECCV2012; RyooICCV2011、KongECCV2014 结合了一个重要的先验知识,即当有新的观察结果可用时,信息性行动信息会增加。 此外,KongECCV2014中的方法对片段的标签一致性进行了建模,这在他们的方法中没有提出。 Lan 等人从干扰社交的角度出发, LanECCV2014提出了用于动作预测的“分层动作”,能够捕捉动作发生前人类动作的典型结构被执行。 提出了一种早期事件检测器HoaiCVPR2012来定位不完整事件的开始和结束帧。 他们的方法首先在模型约束中引入单调递增的评分函数,该函数已广泛应用于各种动作预测方法KongECCV2014;孔TPAMI2016; MaCVPR2016 . 与上述方法不同,RyooHRI2015研究了第一人称场景下的动作预测问题,它允许机器人在人机交互过程中预测人的动作。
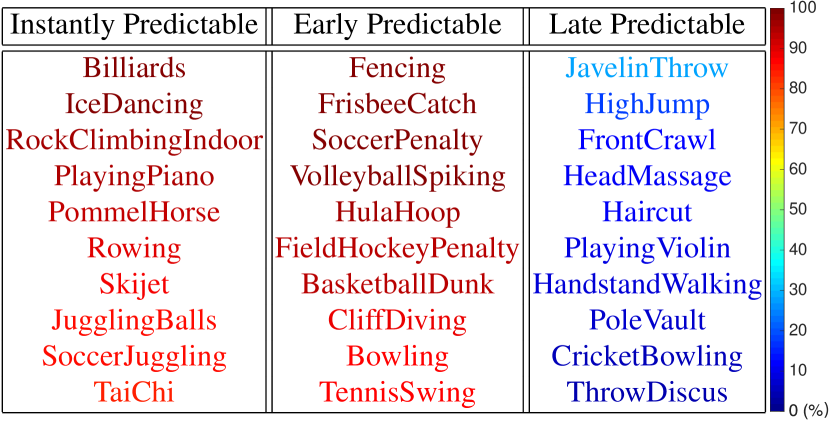
深度学习方法也在动作预测中得到了体现。 MaCVPR2016 中的工作提出了一种新的单调递减损失函数,用于学习 LSTM 进行动作预测。 受此启发,KongCVPR2017的工作采用了自动编码器来对顺序上下文信息进行建模以进行动作预测。 该方法从完全观察的视频中学习此类信息,并将其转移到部分观察的视频中。 我们强制要求传输的信息量按时间顺序排列,以便对非同质动作片段的时间顺序进行建模。 我们证明了操作的可预测性有所不同,并在图 19 中显示了前 10 个即时、早期和晚期可预测操作。 我们还研究了流行的双流框架 SimonyanNIPS2014 的动作预测问题。 在KongAAAI2018中,我们提出使用内存来存储难以预测的训练样本,以提高早期的预测性能。 KongAAAI2018中使用的内存模块测量每个样本的可预测性,并将存储那些具有挑战性的样本。 这样的内存保留了大量的样本,并允许我们创建复杂的分类边界,这对于在开始阶段区分部分视频特别有用。
5.1.2 动作预期
动作预期旨在从动作历史 red 中预测未来的动作。 这项任务对于许多现实世界的应用程序来说都是基础。 例如,监控摄像头可以在交通事故发生之前发出警报,机器人可以通过预测人类行为robotic_antic来制定更好的计划和决策。 动作预期是一项具有挑战性的任务,因为模型不仅需要检测动作,还需要根据所看到的动作推断未来的动作。 RED red 使用编码器-解码器 LSTM 结构根据提取的历史视频帧表示来预测未来的视频表示。 同样,furnari2020rulstm 中使用了两个 LSTM 来总结过去并推断以自我为中心的视频的未来。 Vondrick 中的工作训练 CNN 以无监督的方式将未来的表示与过去的表示回归。 fernando 提出了过去和未来视频表示之间的三个相似性度量,即 Jaccard 向量相似性、Jaccard 互相关性和用于早期动作预期的协方差的 Jaccard Frobenius 内积。 通过使用变分自动编码器学习未来动作的分布,在 vae_anticip 中预测未来动作。 Qiuhong 中的工作通过结合时间参数和跳过连接一次性预测不同未来时间戳的动作。 suris2021learning 使用双曲空间来预测未来的动作,因为它可以通过紧凑的层次结构来表示动作。 在ke2021future中,作者提出了一个模型,该模型由用于建模动作开始时间的不确定性的条件VAE和用于预测动作是否会发生的MLP组成。 最近,Rohit21 提出了一种称为 Anticipative Video Transformer 的新模型,以及用于动作预期的自监督未来预测损失。
5.1.3 意图预测
在实践中,某些类型的动作包含多种原始动作模式并表现出复杂的时间安排,例如“做菜”。 通常,这些复杂动作的长度比短期动作的长度长。 对这些长期行为的预测引起了人们的极大兴趣,因为它使我们能够了解“将会发生什么”,包括复杂的人类行为的最终目标以及人们在不久的将来可能采取的预期行为。
然而,由于人类未来行为的巨大不确定性,长期行为预测极具挑战性。 认知科学表明,上下文信息对于动作理解至关重要,因为它们通常发生在特定场景下的某些对象交互中。 因此,将交互对象与人类行为一起考虑将有助于实现准确的长期行为预测。 这些知识可以为“现在发生了什么?”两个问题提供有价值的线索。以及“接下来会发生什么?”。 它还限制了使用交互对象进行潜在操作的搜索空间。 例如,如果观察到“一个人抓杯子”的动作,则该人很可能会“喝饮料”,而不是“接电话”。 因此,考虑这种上下文的预测方法有望提供从动作和对象之间的上下文约束中受益的机会。
Pei 等人PeiICCV2011利用与或图方法解决了目标推理和意图预测问题,其中体现了随机上下文敏感语法。 他们对代理-对象交互进行建模,并生成单个事件的所有可能的解析图。 结合所有可能性生成输入视频的解释并实现全局最大后验概率。 他们还表明,使用分层事件上下文可以很大程度上减少原子动作识别中的歧义。 Li 等人LiECCV2012提出了一种使用概率后缀树(PST)的长期动作预测方法,该方法捕获复杂动作中动作原语之间的可变马尔可夫依赖性。 例如,如图20所示,婚礼可以分解为“牵手”、“跪下”、“亲吻”和“戴戒指”等原语。 在他们的扩展LiTPAMI2014中,对象上下文被添加到预测模型中,这使得能够预测“做菜”等动作中发生的人与对象交互。 他们的工作首先引入了“可预测性”的概念,并使用预测累积函数(PAF)来表明某些行为可以早期预测,而另一些行为则无法早期预测。 KoppulaTPAMI2016 研究了人类行为和物体可供性的预测。 他们提出了一种预期时间条件随机场(ATCRF)来模拟三种类型的上下文信息,包括动作基元的层次结构、对象及其可供性之间丰富的时空相关性以及对象和人类的运动预期。 为了找到最可能的运动,ATCRF 被视为粒子,它们随时间传播以表示未来可能动作的分布。 girase2021loki 中的工作引入了一个名为 LOKI(LOng 术语和关键意图)的自动驾驶新数据集。 作者还提出了一个长期目标提议网络和一个场景图细化和轨迹解码器模块,用于联合预测行人的未来轨迹和意图。 在 bhattacharyya2021euro 中,作者提供了一个新的数据集,用于密集城市场景中的行人轨迹预测。 进一步设计了Joint--cVAE来有效地模拟行人和车辆之间的交互,该模型通过优化ELBO进行训练rasouli2021bifold中的作者提出了一种多任务学习该框架根据多模态数据预测行人的轨迹和行为。 他们提出了一种双折特征融合来有效地融合多种模态,同时还提出了语义图作为训练期间分类交互建模模型的附加输入。

5.2总结
6 运动轨迹预测
除了预测人类行为之外,以人为中心的预测的另一个关键方面是运动轨迹预测,其目的是预测行人的移动路径。 运动轨迹预测是我们与生俱来的能力,它可以推理出目标人可能的目的地和运动轨迹。 我们可以很有把握地预测,一个人会在人行道上行走,而不是在街道上行走,并且在行走过程中会避开任何障碍物。 因此,研究如何让机器做同样的工作是很有趣的。 表4显示了ETH/UCF数据集上的ADE和FDE结果。 ADE 和 FDE 是运动轨迹预测的标准指标。 有些作品不报告 FDE 结果。
| ADE | FDE | |
|---|---|---|
| Social GAN GuptaCVPR2018 | 0.58 | - |
| Sophie sadeghian2019sophie | 0.54 | - |
| CGNS li2019conditional | 0.49 | - |
| Social BiGAT kosaraju2019social | 0.48 | - |
| Next liang2019peeking | 0.46 | - |
| Social-STCNN mohamed2020social | 0.44 | - |
| MANTRA marchetti2020mantra | 0.32 | 0.65 |
| Transformer TF giuliari2021transformer | 0.31 | - |
| PECNet mangalam2020not | 0.29 | 0.48 |
| Social-NCE liu2020social | 0.19 | 0.40 |
| SGNet wang2021stepwise | 0.18 | 0.35 |
| AgentFormer yuan2021agentformer | 0.18 | 0.29 |
| Y-Net mangalam2020goals | 0.18 | 0.27 |
基于视觉的运动轨迹预测对于视觉监控和自动驾驶汽车等实际应用至关重要(见图21),其中行人未来运动模式的推理至关重要。 大量工作通过聚类轨迹来学习运动模式ZhouCVPR2011;莫里斯和TPAMI2011;金ICCV2011; HuTIP2007 . 然而,预测人未来的运动轨迹确实具有挑战性,因为预测不能单独预测。 在拥挤的环境中,人类会根据邻居的行为来调整自己的动作。 他们可能会停下来或改变路径以适应其他人或附近的环境。 在动态环境中联合建模如此复杂的依赖关系确实很困难。 此外,预测的轨迹不仅应该是物理上可接受的,而且还应该社会上可接受的 GuptaCVPR2018 。 行人在行走时始终尊重个人空间,从而让路。 在拥挤的环境中,人与人以及人与物体的互动通常是微妙而复杂的,这使得问题变得更具挑战性。 此外,在拥挤的环境中存在多种未来预测,这些都是社会可以接受的。 因此,需要对多模态预测进行不确定性估计。
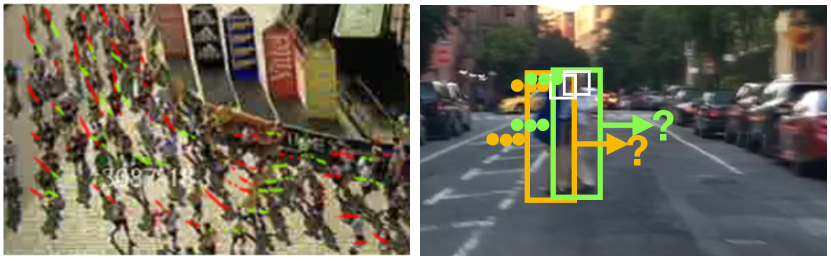
KitaniECCV2012 研究了通过理解物理场景来预测轨迹和目的地,这是计算机视觉界轨迹预测的开创性工作之一。 所提出的方法模拟了物理环境对人类行为选择的影响。 作者将最先进的语义场景理解与逆最优控制 (IOC) 或逆强化学习的思想相结合AbbeelICML2004; ZiebartAAAI2008 . 在这项工作中,人体运动被建模为一系列决策过程,并通过最大化奖励来做出预测。 Lee 和 Kitani LeeWACV2016 将 KitaniECCV2012 扩展到动态环境。 将状态奖励函数扩展到静态和动态状态函数的线性组合,以更新动态环境中的预测分布。 然而,IOC 仅限于受控设置,因为行人目的地的目标状态需要先验。 为了放宽这一假设,Mainprice2016 中引入了目标集的概念; DraganICRA2011,定义了目标任务空间。 AlahiCVPR2014中的工作引入了百万条轨迹的大规模数据集,通过对行人的社交互动进行建模来研究轨迹预测问题。 他们通过所谓的社交亲和力图捕获了一个人的邻近轨迹的空间位置。 轨迹预测任务被表述为最大后验估计问题,并将起点和目的地先验知识引入模型中。 BallanECCV2016中的方法更进一步,通过考虑人与场景的交互来概括轨迹预测。 场景地图 TurekECCV2010 的功能属性在 BallanECCV2016 中学习,而不是仅仅使用场景的语义标签(例如、草地、街道等) > ,它允许预测模型了解同一类的代理如何从一个补丁移动到另一个补丁。 这为我们提供了到达最终目的地的丰富导航模式。 场景语义也被用来预测多个物体的动态FouheyCVPR2014;黄ECCV2008; KooijECCV2014; KretzschmarICRA2014 . Kooji 等人KooijECCV2014专注于从接近车辆的角度预测行人过马路的路径意图。 他们的方法建立在动态贝叶斯网络(DBN)的基础上,该网络根据三个线索考虑行人的停车决定,包括是否存在接近的车辆、行人的意识以及场景的空间布局。 Walker 等人在 WalkerCVPR2014 中预测了视觉场景中主体(例如汽车)的行为。 Ziebart 等人ZiebartIROS2009提出了一种基于规划的轨迹预测方法。
由于深度网络的最新进展,运动轨迹预测问题可以使用 RNN/LSTM 网络来解决 AlahiCVPR2016 ;李CVPR2017;苏JCAI2017; GuptaCVPR2018,具有生成长序列的能力。 更具体地说,使用单个 LSTM 模型来解释一个人的轨迹,并提出了 LSTM 中的社交池层来对 LSTM 之间的依赖关系进行建模,并保留空间信息 AlahiCVPR2016 。 与之前的工作KitaniECCV2012相比;李WACV2016;阿拉希CVPR2014;巴兰ECCV2016; KooijECCV2014,AlahiCVPR2016中的方法是端到端可训练的,并且在复杂场景中具有良好的泛化能力。 LeeCVPR2017 中提出了一种编码器-解码器框架,用于在更自然的场景中进行路径预测,在这些场景中,代理相互交互并动态地适应其未来的行为。 过去的轨迹在 RNN 中进行编码,然后使用由单独的 RNN 实现的另一个解码器生成未来的轨迹假设。 该方法还扩展了逆最优控制(IOC)LeeWACV2016; KitaniECCV2012 转变为深度模型,该模型在机器人控制 Finn2016 和驱动 Wulfmeier2016 任务中显示出良好的结果。 所提出的 Deep IOC 用于对所有可能的假设进行排名。 使用 CNN 模型捕获场景上下文,该模型是 RNN 编码器输入的一部分。 GuptaCVPR2018中提出了Social-GAN网络来解决LeeCVPR2017中L2损失的限制。 使用对抗性损失,GuptaCVPR2018 可以潜在地学习多个社会可接受的轨迹的分布,而不是学习训练数据中的平均轨迹。 dendorfer2021mg 中的工作提出了一种多生成器模型 (MGM),以解决使用单个生成器生成的样本超出分布范围的问题。 首先通过路径模块网络预测不同轨迹类型的分类分布,从中选择生成器对未来轨迹进行采样。 因此,该模型可以选择特定于场景的生成器并停用不合适的生成器。 narayanan2021divide提出了一种分而治之的方法,可以防止赢家通吃目标下轨迹预测中的模式崩溃问题。 zhao2021you 中的工作提出了一种目标条件轨迹预测模型,该模型利用最近的示例进行目标位置查询,并考虑多模态和物理约束。
7数据集
本节讨论一些流行的动作视频数据集,包括在受控和非受控环境中捕获的动作。 详细列表如表5所示。 这些数据集在人类受试者数量、背景噪声、外观和姿势变化、相机运动等方面有所不同,并已广泛用于各种算法的比较。
| Datasets | Year | Videos | Views | Actions | Subjects | Modality | Env. |
|---|---|---|---|---|---|---|---|
| KTH SchuldtICPR2004 | 2004 | 600 | 1 | 6 | 25 | RGB | Controlled |
| Weizmann BlankICCV2005 | 2005 | 90 | 1 | 10 | 9 | RGB | Controlled |
| INRIA XMAS WeinlandCVIU2006 | 2006 | 390 | 5 | 13 | 10(3 times) | RGB | Controlled |
| IXMAS YuanCVPR2009 | 2006 | 1,148 | 5 | 11 | - | RGB | Controlled |
| UCF Sports RodriguezCVPR2008 | 2008 | 150 | - | 10 | - | RGB | Uncontrolled |
| Hollywood LaptevCVPR2008 | 2008 | - | - | 8 | - | RGB | Uncontrolled |
| Hollywood2 MarszalekCVPR2009 | 2009 | 3,669 | - | 12 | 10 | RGB | Uncontrolled |
| UCF 11 LiuCVPR2009a | 2009 | 1,100+ | - | 11 | - | RGB | Uncontrolled |
| CA ChoiICCVW2009 | 2009 | 44 | - | 5 | - | RGB | Uncontrolled |
| MSR-I YuanCVPR2009 | 2009 | 63 | - | 3 | 10 | RGB | Controlled |
| MSR-II YuanPAMI2010 | 2010 | 54 | - | 3 | - | RGB | Crowded |
| MHAV MuHAVi2010 | 2010 | 238 | 8 | 17 | 14 | RGB | Controlled |
| UT-I UT-Interaction-Data | 2010 | 60 | 2 | 6 | 10 | RGB | Uncontrolled |
| TV-I PerezBMVC2010 | 2010 | 300 | - | 4 | - | RGB | Uncontrolled |
| MSR-A LiCVPRW2010 | 2010 | 567 | - | 20 | 1 | RGB-D | Controlled |
| Olympic NieblesECCV2010 | 2010 | 783 | - | 16 | - | RGB | Uncontrolled |
| HMDB51 KuehneICCV2011 | 2011 | 6849 | - | 51 | - | RGB | Uncontrolled |
| CAD-60 SungAAAIW2011 | 2011 | 60 | - | 12 | 4 | RGB-D | Controlled |
| BIT-I KongECCV2012 | 2012 | 400 | - | 8 | 50 | RGB | Controlled |
| LIRIS wolf2014evaluation | 2012 | 828 | 1 | 10 | - | RGB | Controlled |
| MSRDA WangJCVPR2012 | 2012 | 320 | - | 16 | 10 | RGB-D | Controlled |
| UCF50 ReddyMVA2012 | 2012 | 50 | - | 50 | - | RGB | Uncontrolled |
| UCF101 Soomro2012 | 2012 | 13,320 | - | 101 | - | RGB | Uncontrolled |
| MSR-G Kurakin2012 | 2012 | 336 | - | 12 | 1 | RGB-D | Controlled |
| UTKinect-A XiaCVPRW2012 | 2012 | 200 | - | 10 | - | RGB-D | Controlled |
| ASLAN GrossPAMI2012 | 2012 | 3,698 | - | 432 | - | RGB | Uncontrolled |
| MSRAP OreifejCVPR2013 | 2013 | 360 | - | 6 pairs | 10 | RGB-D | Controlled |
| CAD-120 Koppula2013 | 2013 | 120 | - | 12 | 4 | RGB-D | Controlled |
| THUMOS’14 THUMOS14 | 2014 | 413 | 1 | 20 | – | RGB | Uncontrolled |
| Sports-1M KarpathyCVPR2014 | 2014 | 1,133,158 | - | 487 | - | RGB | Uncontrolled |
| 3D Online YuACCV2014 | 2014 | 567 | - | 20 | - | RGB-D | Uncontrolled |
| FCVID FCVID | 2015 | 91,233 | - | 239 | - | RGB | Uncontrolled |
| ActivityNet caba2015activitynet | 2015 | 28,000 | - | 203 | - | RGB | Uncontrolled |
| YouTube-8M abu2016youtube | 2016 | 8,000,000 | - | 4,716 | - | RGB | Uncontrolled |
| Charades nturgb60 | 2016 | 9,848 | 2 | 157 | - | RGB | Controlled |
| NTU-RGB+D Shahroudy_2016_NTURGBD | 2016 | 56,680 | - | 120 | 106 | RGB+D+IR+Skeleton | Controlled |
| PKU-MMD (Phase 1) PKUMMD2017 | 2017 | 1076 | 3 | 51 | 66 | RGB+D+IR+Skeleton | Uncontrolled |
| PKU-MMD (Phase 2) PKUMMD2017 | 2017 | 2000 | 3 | 49 | 13 | RGB+D+IR+Skeleton | Uncontrolled |
| NEU-UB | 2017 | 600 | - | 6 | 20 | RGB-D | Controlled |
| Kinetics kay2017kinetics | 2017 | 500,000 | - | 600 | - | RGB | Uncontrolled |
| AVA gu2017ava | 2017 | 57,600 | - | 80 | - | RGB | Uncontrolled |
| 20BN-Something-Something goyal2017something | 2017 | 108,499 | - | 174 | - | RGB | Uncontrolled |
| SLAC zhao2017slac | 2017 | 520,000 | - | 200 | - | RGB | Uncontrolled |
| Moments in Time monfortmoments | 2017 | 1,000,000 | - | 339 | - | RGB | Uncontrolled |
| EPIC-Kitchens damen2018scaling | 2018 | 90,000+ | - | 397 | 32 | RGB | Uncontrolled |
| COIN COIN2019 | 2019 | 11,827 | 1 | 180 | – | RGB | Uncontrolled |
| HACS Segments HACS2019 | 2019 | 50,000+ | 1 | 200 | – | RGB | Uncontrolled |
| HAA00 haa500 | 2021 | 10,000 | - | 500 | - | RGB | Uncontrolled |
| MultiSports multi-sports | 2021 | 3200 | - | 4 | - | RGB | Uncontrolled |
7.1 受控动作视频数据集
我们首先描述在受控设置中捕获的单个操作数据集,然后列出包含两个或更多人参与操作的数据集。 我们还讨论了使用经济高效的 Kinect 传感器捕获的一些 RGB-D 动作数据集。
7.1.1 个人行动数据集
Weizmann 数据集 BlankICCV2005 是用于人类动作识别的流行视频数据集。 数据集包含个动作类,例如个不同主体执行的“行走”、“慢跑”、“挥手”,总共提供个视频序列。 这些视频是在简单的背景下使用静态相机拍摄的。
KTH 数据集 SchuldtICPR2004 由 种人类动作(拳击、拍手、挥手、慢跑、跑步和行走)组成,重复次数为 场景中的不同主体(户外、尺度变化的户外、穿着不同衣服的户外和室内)。 数据集中有 600 个动作视频。
INRIA XMAS多视图数据集 WeinlandCVIU2006编译用于多视图动作识别。 它包含从 视图(包括顶视图摄像头)捕获的视频。 该数据集由 个动作组成,每个动作由 参与者重复 次。
7.1.2 群体行动数据集
UT-Interaction 数据集 UT-Interaction-Data 由 组具有不同背景和相机设置的 视频组成。 这些视频包含 6 类人与人的互动:握手、拥抱、踢、指、拳和推。
BIT-Interaction 数据集 KongECCV2012 包含 类人类交互(弓、拳击、握手、击掌、拥抱、踢、拍和Push),每节课有 个视频。 视频是在具有杂乱背景、部分遮挡的身体部位、移动物体以及主体外观、比例、照明条件和视点变化的真实场景中捕获的。
TV-Interaction 数据集 PerezBMVC2010 包含 具有人类交互的视频剪辑。 这些视频被分为交互类别:握手、击掌、拥抱和亲吻,并注释了人的上半身、离散的头部方向和交互。
MultiSports 数据集 multi-sports 是一个多人数据集,包含 运动类别的 视频片段。 该数据集包含带有 边界框的 动作实例,这有助于更细粒度的时空动作检测和定位。
7.2 无约束数据集
尽管上述数据集为动作训练研究奠定了坚实的基础,但它们是在受控环境中捕获的,可能无法用于现实场景中的方法。 为了解决这个问题,研究人员从互联网上收集了动作视频,并编制了大规模的动作数据集,这将在下面讨论。
UCF101数据集 Soomro2012已广泛应用于动作识别研究。 它包含从 Youtube 收集的真实视频。 它包含 个操作类别,总共有 个视频。 UCF101 在动作方面提供了最大的多样性,并且在相机运动、物体外观和姿势、物体尺度、视点、杂乱背景、照明条件等方面存在较大变化。 该数据集大致可分为 5 类:1)人与物体交互 2)仅身体运动 3)人与人交互 4)演奏乐器 5)体育。 应该指出的是,许多剪辑都是从同一视频中收集的。 因此,不同的剪辑可能具有相同的人物或相同的场景,或者相同的灯光等。 这似乎与实际场景不同,因此难度有限。
HMDB51数据集 KuehneICCV2011包含总共约6849个视频剪辑,分布在大量动作类别中。 每个类别至少包含 个视频剪辑。 除了动作类别的标签之外,每个剪辑还用动作标签以及描述剪辑属性的元标签进行注释,例如可见的身体部位、摄像机运动、摄像机视点、参与该剪辑的人数动作和视频质量。 这些动作可以分为五类,包括一般面部动作(例如微笑、咀嚼、说话)、带有对象操作的面部动作(例如抽烟、吃、喝)、一般身体动作(例如侧手翻、拍手、攀爬)、与物体交互的身体动作(例如梳头、接球、拔剑)、人类交互的身体动作(例如击剑、拥抱、踢某人)。 该数据集还有两个不同的类别,即“无运动”和“相机运动”。 该数据集极具挑战性,主要是因为存在显着的相机/背景运动。 为了消除相机运动,可以使用标准图像拼接技术来对齐剪辑的帧。
Kinetics CarreiraCVPR2017 数据集包含 个人类动作类别和大约 个视频剪辑,包括人与物体的交互和人与人的交互互动。 这些视频是通过匹配其标题和准备好的动力学动作列表从 YouTube 编译的。 之后,通过跟踪谷歌图像搜索上的操作对视频进行分段,然后由亚马逊的 Mechanical Turk(AMT)进行标记。 最后,使用机器学习技术对该数据集进行清理和去噪。 与之前的数据集不同的是,该数据集中的一个片段可能依次包含多个不同的动作,但它仅被分为一个动作类别。 这意味着这些剪辑没有完整的动作标签。 正如他们的工作中所描述的,由于标签不完整,应该使用 top-5 度量。 在同一动作类别中,剪辑是从不同的视频中捕获的,包括电视和电影视频。 因此,存在很大的外观变化,例如,剪辑中的人可能有不同的年龄、身高、衣服等等,并且存在各种类型的相机运动/抖动、背景杂乱。 此外,每个剪辑持续约 10 秒,并且具有可变的分辨率。
Sports-1M 数据集 KarpathyCVPR2014 包含 个视频 URL,这些视频 URL 已自动标注了 487 个标签。 它是最大的视频数据集之一。 该数据集中包含非常多样化的体育视频,例如少林功夫、咏春拳等。 由于非常大的外观和姿势变化、显着的相机运动、嘈杂的背景运动等,该数据集极具挑战性。
THUMOS’14 数据集THUMOS14 包含超过 20 小时的体育视频。 尽管训练集是标有 20 个动作类的修剪视频,但验证集和测试集分别包括 200 个和 213 个未修剪视频。 该数据集是动作检测和定位中使用最广泛的数据集。
ActivityNet 数据集 ActivityNet2015 有两个版本用于动作检测和定位。 第一个是 Activity v1.2,涵盖 100 个活动类别,包含 4,819 个训练视频和 2,383 个验证视频。 另一个版本是 Activity v1.3,其中包含 10,024 个训练视频和 4,926 个用于验证 200 个活动类别的视频。
PKU-MMD数据集PKUMMD2017 是一个大规模多模态数据集,专注于长连续序列动作检测和多模态动作分析。 第一阶段包含 51 个动作类别,由 66 个不同的主体在 3 个摄像机视图中执行。 每个视频持续约 分钟,包含大约 20 个动作实例。 第二阶段包含 49 个动作类别的 2,000 个短视频序列,由 13 名主体在 3 个摄像机视图中执行。 每个视频持续约 分钟,包含大约 7 个动作实例。
AVA 数据集 AVA2018 提供约15分钟长的影片剪辑的视听注释。 对于 AVA Action 子集,它包含 430 个视频,其中 235 个用于训练,64 个用于验证,131 个用于测试。 每个视频有 15 分钟,以 1 秒为间隔进行注释。
COIN数据集COIN2019 是最近发布的大规模数据集,用于解决教学视频分析问题。 它包含180个不同班级的11,827个日常活动视频。 与其他动作数据集不同,COIN 数据集中的人类动作是具有实用语义的分层结构。
HACS 数据集HACS2019 也是最近发布的用于动作定位和识别的大规模数据集。 对于 HACS 片段子集,它包含 139K 个动作片段,这些动作片段密集注释在 50K 个未修剪的视频中,涵盖 200 个动作类别。
20BN-SOMETHING-SOMETHING 数据集 goyal2017something 是一个显示人类与日常物体交互的数据集。 在数据集中,人类对日常物体执行预定义的动作。 它包含跨 类的 视频剪辑。 该数据集能够学习对象和世界的物理属性的视觉表示。
Moments-in-Time 数据集 monfortmoments 是一个用于动作理解的大规模视频数据集。 它包含分布在 类别中的超过 3 秒的标记视频剪辑。 视频的视觉元素包括人、动物、物体或自然现象。 该数据集致力于构建能够抽象和推理复杂人类行为的模型。
EPIC-Kitchens 数据集 damen2018scaling 是最大的第一人称视觉数据集之一。 它由头戴式摄像头录制的 小时视频和 动词类和 名词类组成。 这些视频在不同的城市和不同风格的厨房拍摄,并通过对象边界框划分为个动作片段。 此外,这些视频包含人类同时执行不同的厨房任务。 为了更好地注释这些操作,在数据集中收集了操作的语音注释。
HAA500数据集haa500是一个以人为中心的原子动作数据集。 它由 原子类组成,其中 是体育/竞技, 是演奏乐器, 是游戏和爱好,和 是日常操作。
7.3 RGB-D 动作视频数据集
上述所有数据集均由 RGB 摄像机捕获。 最近,由于超深度数据通道,人们越来越关注使用经济高效的 Kinect 传感器来捕获人类动作。 与 RGB 数据通道相比,额外深度数据通道优雅地提供了场景结构,可用于简化类内运动变化并减少杂乱的背景噪声 KongIJCV2017 。 下面列出了流行的 RGB-D 动作数据集。
MSR Daily Activity dataset WangJCVPR2012:有类动作:喝、吃、看书、打电话、在纸上写字、使用笔记本电脑,使用吸尘器,打起精神,静坐,扔纸,玩游戏,躺在沙发上,散步,弹吉他,站起来,坐下。 所有这些操作均由主体执行。 有 RGB 样本和 深度样本可用。
3D在线动作数据集 YuACCV2014针对三个评估任务进行编译:相同环境动作识别、跨环境动作识别和连续动作识别。 该数据集包含从 RGB-D 传感器捕获的人类动作或人机交互视频。 它包含动作类别,例如喝水、吃饭、看手机。
CAD-120 数据集 Koppula2013 包含 长时间日常活动的 RGB-D 动作视频。 它还使用 Kinect 传感器捕获。 动作视频由 主体执行。 该数据集包含12种动作类型,例如漱口、打电话、做饭、在白板上写字等。数据集中提供了跟踪的骨骼、RGB图像和深度图像。
UTKinect-Action 数据集 utkinect-action3d 由 Kinect 设备捕获。 数据集中包含高级动作类别,例如步行、坐下等。 该数据集包含 200 个动作视频,记录了三个通道:RGB、深度和骨骼关节位置。
NTU-RGB+D nturgb60 ; nturgb120 数据集包含 动作类和 视频样本。 最近,它已扩展到 动作类和 nturgb120 中的另一个 视频示例。 所有样本均通过 Kinect 传感器从 不同受试者采集。 为每个样本提供 RGB 视频、深度图序列、3D 骨骼数据和红外 (IR) 视频。 与之前的数据集相比,环境条件的变化更大,包括具有光照变化的不同背景。
8 动作识别和预测的评估协议
由于应用目的不同,动作识别和预测技术的评估方式也不同。
浅层动作识别方法如SchuldtICPR2004;尼布尔斯CVPR2007; WuCVPR2011通常在小规模数据集上进行评估,例如Weizmann数据集BlankICCV2005、KTH数据集SchuldtICPR2004、UCF Sports数据集RodriguezCVPR2008 。 这些数据集上普遍使用留一法训练方案,并且通常采用混淆矩阵来显示每个动作类别的识别准确性。 对于顺序方法,例如 WangNIPS2008 ; WangPAMI2010,经常使用每帧识别精度。 在 MarszalekCVPR2009 中; TangCVPR2012,每个单独的动作类别也采用了近似精度-召回曲线下面积的平均精度。 深度网络CarreiraCVPR2017; TranICCV2015; VarolTPAMI2017 通常在 UCF-101 Soomro2012 和 HMDB51 KuehneICCV2011 等大型数据集上进行评估,因此只能报告每个数据集上的整体识别性能。 请参阅 HerathIVC2017 了解最新动作识别方法在各种数据集上的性能列表。
大多数动作预测方法RyooICCV2011;曹CVPR2013;孔ECCV2014; KongCVPR2017 在现有的动作数据集上进行了评估。 与动作识别中使用的评估方法不同,动作预测方法报告了每个观察比率(范围从到)的识别准确度。 正如KongCVPR2017中所述,这些方法的目标是在动作视频的开始阶段实现较高的识别准确率,以便尽早准确地识别动作。 表3总结了动作预测方法在各种数据集上的性能。
有几种流行的指标可用于评估运动轨迹预测方法,包括平均位移误差 (ADE)、最终位移误差 (FDE) 和平均非线性位移错误(ANDE)。 ADE 是对轨迹的所有估计点和地面实况点计算的均方误差。 FDE 定义为预测最终目的地与地面真实最终目的地之间的距离。 ANDE 是人与人交互产生的轨迹非线性转向区域的 MSE。
存在多种指标来评估动作检测和定位方法。 回想一下,召回率 (R) 衡量的是真阳性数量与真阳性和假阴性总数的比值。 平均召回率 (AR) 是多个并集交集 (IoU) 值的召回率平均值。 AR 与 AN 曲线下的面积 (AUC) 衡量检测方法区分正面和负面提案的能力。 另一个指标称为平均精度 (mAP) @ ,其中 表示不同的 IoU 阈值,用于测量每个动作类别的平均预测 (AP)。
9 未来方向
在本节中,我们将讨论一些可能值得探索的动作识别和预测研究的未来方向。
数据集。 近年来,为了推进动作识别和预测的研究,人们付出了巨大的努力来收集不同类型的动作视频数据集。 然而,在这些数据集上训练的现有动作识别和预测模型仍然难以推广到现实场景,可能是因为这些数据集无法涵盖实际场景中可能发生的所有方面。 首先,大多数视频数据集是在良好的照明和天气条件下收集的。 然而,这个假设在实践中可能并不成立。 无论天气如何,视觉监控系统可能需要每天 24 小时运行。 不幸的是,现有的方法仍然很难推广到恶劣的照明条件或极端天气。 其次,有些数据集仅限于某些场景,例如UCF101包含体育视频和在厨房捕获的EPIC-Kitchens数据集。 尽管一个训练有素的模型可能在一种场景中表现良好,但在新场景中可能表现不佳。 这可能是由于新环境、摄像机运动、外观变化等等在之前的场景中未曾见过。 最后但并非最不重要的一点是,现有的基于深度神经网络的方法需要大量数据进行训练。 然而,视频数据在某些研究领域可能受到限制,例如生物医学研究或人类康复研究。 是否可以使用 UnReal unreal ; 等游戏引擎创建和渲染虚拟训练视频数据unrealcv基于现有小规模数据? 这可以作为直接将深度神经网络推广到小规模数据的替代解决方案。 所有这些挑战给动作识别研究带来了新的问题,并促使我们收集新的数据集来推进研究。
受益于图像模型。 就像计算机视觉社区的其他发展趋势一样,深层架构最近在动作识别研究中占据主导地位。 然而,在视频上训练深度网络很困难,因此受益于在图像或其他来源上预训练的深度模型将是一个更好的探索解决方案。 此外,图像模型在捕捉物体的空间关系方面做得很好,这也可以在动作理解中得到利用。 探索如何使用膨胀 CarreiraCVPR2017 或域适应 TangNIPS2012 的思想将知识从图像模型转移到视频模型是很有趣的。
时间范围的可解释性。 图像模型的可解释性已经被讨论过,但在视频模型中还没有被广泛讨论。 如SatkinECCV2010所示; RaptisCVPR2013,并非所有帧对于动作识别都同样重要;只有少数是批评性的。 因此,有一些事情需要深入了解视频模型的时间可解释性。 首先,动作,尤其是持续时间较长的动作可以被视为原语序列。 拥有这些基元的可解释性将会很有趣,例如这些基元在动作中如何在时域中组织,它们如何对分类任务做出贡献,我们是否可以在不牺牲识别性能的情况下只使用其中的少数几个来实现快速分类训练? 此外,动作的时间特征也不同。 有些动作可以在早期阶段被理解,有些动作需要更多的框架来观察。 有趣的是为什么这些行为可以被早期预测,以及机器捕获的显着信号是什么。 这种理解将有助于开发更有效的行动预测模型。
从多模态数据中学习。 人类每天都在观察多模态数据,包括视觉、音频、文本等。 这些多模态数据有助于理解每种类型的数据。 例如,阅读一本书可以帮助我们重建视觉场景的相应部分。 然而,很少有工作关注使用多模态数据的动作识别/预测。 使用多模态数据有助于对复杂动作的视觉理解,因为文本数据等多模态数据包含人类赋予的丰富语义知识。 除了可以被视为动词的动作标签之外,文本数据还可能包括其他实体,例如名词(对象)、介词(场景的空间结构)、形容词和副词等。 尽管在动作识别和人机交互中已经探索了从名词和介词学习,但很少有研究致力于从形容词和副词学习。 此类学习任务提供了更多关于人类行为的描述性信息,例如运动强度,从而使细粒度的动作理解成为现实。
学习长期时间相关性。 多模态数据还能够从数据中学习视觉实体之间的长期时间相关性,这可能很难直接从视觉数据中学习。 长期时间相关性表征了长序列中发生的动作的连续顺序,这类似于我们大脑存储的内容。 当我们想要回忆某件事时,一种模式会唤起下一种模式,暗示长期视频中的关联。 视觉实体之间的交互对于理解长期相关性也至关重要。 通常,在特定场景设置下,某些动作会随着某些对象交互而发生。 因此,它不仅需要涉及动作,还需要对物体、场景及其与动作的时间安排进行解释,因为这些知识可以为“现在正在发生的事情”和“接下来会发生什么”提供有价值的线索。 这项学习任务还允许我们预测长时间序列中的动作。
动作的物理方面。 动作识别和预测是相当针对视频的高级方面的任务,而不是专注于寻找编码基本物理属性的动作原语。 最近,人们对学习世界的物理方面越来越感兴趣,它研究细粒度的行为。 一个例子是 goyal2017something 中引入的东西数据集,用于研究人与物体的交互。 有趣的是,该数据集提供了标签或文本描述模板,例如“将[某物]放入[某物]”,来描述人与物体、物体与物体之间的交互。 这使我们能够学习能够理解世界物理方面的模型,包括人类行为、物体与物体的相互作用、空间关系等。
尽管我们可以从动作视频中推断出大量信息,但仍有一些物理方面难以推断。 我们想知道是否可以更进一步,从视频中了解更多物理方面,例如运动方式、力、加速度等? Physics-101 WuNIPS2015在对象中研究了这个问题,但是我们可以将其扩展到动作中吗? 需要一个包含此类细粒度信息的新动作数据集。 为了实现这一目标,我们正在进行的工作是提供包含带有肌电图信号的人类动作的数据集,我们希望该数据集有利于细粒度的动作识别。
没有注释的学习动作。 对于越来越大的动作数据集,例如 Something-Something goyal2017something 和 Sports-1M KarpathyCVPR2014 ,手动标记变得令人望而却步。 使用搜索引擎自动标注KarpathyCVPR2014; abu2016youtube 、视频字幕和电影脚本 MarszalekCVPR2009 ; LaptevCVPR2008 在某些领域是可能的,但仍然需要手动验证。 众包 goyal2017something 将是一个更好的选择,但仍然面临标签多样性问题,并且可能会生成不正确的操作标签。 此外,几乎所有动作数据集中的视频都是时间分割的,每个视频中只有一个动作。 然而,这种假设并不成立,因为视频可能是流式传输的,并且很难知道流式视频中动作执行的确切开始和结束帧。 这促使我们开发更强大、更高效的动作识别/预测方法,可以自动从未标记的视频或未修剪的视频中学习。
开放世界中的行动。 现实世界中的人类动作识别本质上是一个开放集问题,要求模型同时识别已知动作类并拒绝未知动作GengTPAMI2020;包ICCV2021 . 然而,现有的开放集识别(OSR)研究工作主要集中在图像模态ScheirerTPAMI2012;谢勒TPAMI2014;张TPAMI2016;本代尔CVPR2016;奥扎CVPR2019;佩雷拉CVPR2020 ; ChenECCV2020 ,除了一些关于视频的作品 ShuICME2018 ; RoitbergIV2020 和其他模式 YangPR2019 。 由于以下挑战,这些工作通常不能很好地处理视频数据。 首先,视频的时间性质导致人类行为的高度多样性,这对于 OSR 模型来说是一个挑战,当给定具有未知时间动态的人类行为时,OSR 模型要意识到它不知道什么。 此外,视频数据中的静态偏差(即视频背景和前景演员的出现)很容易被深度学习模型过度拟合。 该模型最终几乎无法识别无偏见的开放视觉世界中的未知行为。 这些挑战促使近期的工作BaoICCV2021为开放集动作识别(OSAR)建立一个不确定性感知且无偏见的模型。 由于开放世界的行为可以被视为分布外(OOD)数据,因此开发更先进的 OOD 检测方法来解决 OSAR 环境下人类行为的分布变化在未来是有前途的。
10结论
大数据和强大模型的可用性将人类行为的研究重点从理解现在转移到推理未来。 我们对视频动作识别和预测的最先进技术进行了完整的调查。 近几十年来,这些技术变得特别有趣,因为它们在几个关注人体运动的新兴领域中具有前景和实际应用。 我们研究了现有尝试的几个方面,包括手工特征设计、模型和算法、深层架构、数据集和系统性能评估协议。 本次调查还讨论了未来的研究方向。
参考
- (1) Unreal engine. https://www.unrealengine.com/
- (2) UnrealCV. https://unrealcv.org
- (3) Abbeel, P., Ng, A.: Apprenticeship learning via inverse reinforcement learning. In: ICML (2004)
- (4) Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., Vijayanarasimhan, S.: Youtube-8m: A large-scale video classification benchmark. arXiv preprint arXiv:1609.08675 (2016)
- (5) Alahi, A., Fei-Fei, V.R.L.: Socially-aware large-scale crowd forecasting. In: CVPR (2014)
- (6) Alahi, A., Goel, K., Ramanathan, V., Robicquet, A., Fei-Fei, L., Savarese, S.: Social lstm: Human trajectory prediction in crowded spaces. In: CVPR (2016)
- (7) Ballan, L., Castaldo, F., Alahi, A., Palmieri, F., Savarese, S.: Knowledge transfer for scene-specific motion prediction. In: ECCV (2016)
- (8) Bao, W., Yu, Q., Kong, Y.: Evidential deep learning for open set action recognition. In: ICCV (2021)
- (9) Bendale, A., Boult, T.E.: Towards open set deep networks. In: CVPR (2016)
- (10) Bengio, Y., Courville, A., Vincent, P.: Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence (2013)
- (11) Bhattacharyya, A., Reino, D.O., Fritz, M., Schiele, B.: Euro-pvi: Pedestrian vehicle interactions in dense urban centers. In: CVPR (2021)
- (12) Bishay, M., Zoumpourlis, G., Patras, I.: Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition. In: BMVC (2019)
- (13) Blake, R., Shiffrar, M.: Perception of human motion. Annu. Rev. Psychol. 58, 47–73 (2007)
- (14) Blank, M., Gorelick, L., Shechtman, E., Irani, M., Basri, R.: Actions as space-time shapes. In: Proc. ICCV (2005)
- (15) Bobick, A., Davis, J.: The recognition of human movement using temporal templates. IEEE Trans Pattern Analysis and Machine Intelligence 23(3), 257–267 (2001)
- (16) Bojanowski, P., Lajugie, R., Bach, F., Laptev, I., Ponce, J., Schmid, C., Sivic, J.: Weakly supervised action labeling in videos under ordering constraints. In: European Conference on Computer Vision, pp. 628–643. Springer (2014)
- (17) Bregonzio, M., Gong, S., Xiang, T.: Recognizing action as clouds of space-time interest points. In: CVPR (2009)
- (18) Buchler, U., Brattoli, B., Ommer, B.: Improving spatiotemporal self-supervision by deep reinforcement learning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 770–786 (2018)
- (19) Cao, K., Ji, J., Cao, Z., Chang, C.Y., Niebles, J.C.: Few-shot video classification via temporal alignment. In: CVPR (2020)
- (20) Cao, Y., Barrett, D., Barbu, A., Narayanaswamy, S., Yu, H., Michaux, A., Lin, Y., Dickinson, S., Siskind, J., Wang, S.: Recognizing human activities from partially observed videos. In: CVPR (2013)
- (21) Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: CVPR (2017)
- (22) Chao, Y.W., Vijayanarasimhan, S., Seybold, B., Ross, D.A., Deng, J., Sukthankar, R.: Rethinking the Faster R-CNN architecture for temporal action localization. In: CVPR (2018)
- (23) Chen, G., Qiao, L., Shi, Y., Peng, P., Li, J., Huang, T., Pu, S., Tian, Y.: Learning open set network with discriminative reciprocal points. In: ECCV (2020)
- (24) Chen, S., Sun, P., Xie, E., Ge, C., Wu, J., Ma, L., Shen, J., Luo, P.: Watch only once: An end-to-end video action detection framework. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 8178–8187 (2021)
- (25) Choi, W., Savarese, S.: A unified framework for multi-target tracking and collective activity recognition. In: ECCV, pp. 215–230. Springer (2012)
- (26) Choi, W., Shahid, K., Savarese, S.: What are they doing? : Collective activity classification using spatio-temporal relationship among people. In: Computer Vision Workshops (ICCV Workshops), 2009 IEEE 12th International Conference on, pp. 1282 –1289 (2009)
- (27) Choi, W., Shahid, K., Savarese, S.: Learning context for collective activity recognition. In: CVPR (2011)
- (28) Chung, J., hsin Wuu, C., ru Yang, H., Tai, Y.W., Tang, C.K.: Haa500: Human-centric atomic action dataset with curated videos. In: ICCV (2021)
- (29) Chunhui, L., Yueyu, H., Yanghao, L., Sijie, S., Jiaying, L.: Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding. arXiv preprint arXiv:1703.07475 (2017)
- (30) Ciptadi, A., Goodwin, M.S., Rehg, J.M.: Movement pattern histogram for action recognition and retrieval. In: D. Fleet, T. Pajdla, B. Schiele, T. Tuytelaars (eds.) Computer Vision – ECCV 2014, pp. 695–710. Springer International Publishing, Cham (2014)
- (31) Clarke, T., Bradshaw, M., Field, D., Hampson, S., Rose, D.: The perception of emotion from body movement in point-light displays of interpersonal dialogue. Perception 24, 1171–80 (2005)
- (32) Cutting, J., Kozlowski, L.: Recognition of friends by their work: gait perception without familarity cues. Bull. Psychon. Soc. 9, 353–56 (1977)
- (33) Dai, X., Singh, B., Zhang, G., Davis, L., Chen, Y.: Temporal context network for activity localization in videos. 2017 IEEE International Conference on Computer Vision (ICCV) pp. 5727–5736 (2017)
- (34) Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: CVPR (2005)
- (35) Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: European Conference on Computer Vision (2018)
- (36) Darwin, C.: The Expression of the Emotions in Man and Animals. London: John Murray (1872)
- (37) Dawar, N., Kehtarnavaz, N.: Action detection and recognition in continuous action streams by deep learning-based sensing fusion. IEEE Sensors Journal 18(23), 9660–9668 (2018)
- (38) Decety, J., Grezes, J.: Neural mechanisms subserving the perception of human actions. Neural mechanisms of perception and action 3(5), 172–178 (1999)
- (39) Dendorfer, P., Elflein, S., Leal-Taixé, L.: Mg-gan: A multi-generator model preventing out-of-distribution samples in pedestrian trajectory prediction. In: ICCV (2021)
- (40) Diba, A., Sharma, V., Gool, L.V.: Deep temporal linear encoding networks. In: CVPR (2017)
- (41) Dollar, P., Rabaud, V., Cottrell, G., Belongie, S.: Behavior recognition via sparse spatio-temporal features. In: ICCV VS-PETS (2005)
- (42) Donahue, J., Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., Darrell, T.: Long-term recurrent convolutional networks for visual recognition and description. In: CVPR (2015)
- (43) Dragan, A., Ratliff, N., Srinivasa, S.: Manipulation planning with goal sets using constrained trajectory optimization. In: ICRA (2011)
- (44) Duchenne, O., Laptev, I., Sivic, J., Bach, F., Ponce, J.: Automatic annotation of human actions in video. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 1491–1498. IEEE (2009)
- (45) Duong, T.V., Bui, H.H., Phung, D.Q., Venkatesh, S.: Activity recognition and abnormality detection with the switching hidden semi-markov model. In: CVPR (2005)
- (46) Duta, I.C., Ionescu, B., Aizawa, K., Sebe, N.: spatio-temporal vector of locally max pooled features for action recognition in videos. In: CVPR (2017)
- (47) Dwivedi, S.K., Gupta, V., Mitra, R., Ahmed, S., Jain, A.: Protogan: Towards few shot learning for action recognition. In: ICCVW (2019)
- (48) Efros, A., Berg, A., Mori, G., Malik, J.: Recognizing action at a distance. In: ICCV, vol. 2, pp. 726 –733 (2003)
- (49) Escorcia, V., Caba Heilbron, F., Niebles, J.C., Ghanem, B.: DAPs: Deep action proposals for action understanding. In: ECCV (2016)
- (50) Fabian Caba Heilbron Victor Escorcia, B.G., Niebles, J.C.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 961–970 (2015)
- (51) Fanti, C., Zelnik-Manor, L., Perona, P.: Hybrid models for human motion recognition. In: CVPR (2005)
- (52) Feichtenhofer, C., Pinz, A., Wildes, R.P.: Spatiotemporal residual networks for video action recognition. In: NIPS (2016)
- (53) Feichtenhofer, C., Pinz, A., Wildes, R.P.: Spatiotemporal multiplier networks for video action recognition. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7445–7454. IEEE (2017)
- (54) Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network fusion for video action recognition. In: CVPR (2016)
- (55) Felzenszwalb, P., McAllester, D., Ramanan, D.: A discriminatively trained, multiscale, deformable part model. In: CVPR (2008)
- (56) Fernando, B., Bilen, H., Gavves, E., Gould, S.: Self-supervised video representation learning with odd-one-out networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3636–3645 (2017)
- (57) Fernando, B., Herath, S.: Anticipating human actions by correlating past with the future with jaccard similarity measures. In: CVPR (2021)
- (58) Finn, C., Levine, S., Abbeel, P.: Guided cost learning: deep inverse optimal control via policy optimization. In: arXiv preprint arXiv:1603.00448 (2016)
- (59) Fouhey, D.F., Zitnick, C.L.: Predicting object dynamics in scenes. In: CVPR (2014)
- (60) Furnari, A., Farinella, G.M.: Rolling-unrolling lstms for action anticipation from first-person video. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) (2020)
- (61) Gan, C., Gong, B., Liu, K., Su, H., Guibas, L.J.: Geometry guided convolutional neural networks for self-supervised video representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5589–5597 (2018)
- (62) Gao, J., Yang, Z., Chen, K., Sun, C., Nevatia, R.: TURN TAP: Temporal unit regression network for temporal action proposals. In: ICCV (2017)
- (63) Geng, C., Huang, S.j., Chen, S.: Recent advances in open set recognition: A survey. IEEE transactions on pattern analysis and machine intelligence (2020)
- (64) Ghadiyaram, D., Tran, D., Mahajan, D.: Large-scale weakly-supervised pre-training for video action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12046–12055 (2019)
- (65) Girase, H., Gang, H., Malla, S., Li, J., Kanehara, A., Mangalam, K., Choi, C.: Loki: Long term and key intentions for trajectory prediction. In: ICCV (2021)
- (66) Girdhar, R., Ramanan, D., Gupta, A., Sivic, J., Russell, B.: Actionvlad: Learning spatio-temporal aggregation for action classification. In: CVPR (2017)
- (67) Giuliari, F., Hasan, I., Cristani, M., Galasso, F.: Transformer networks for trajectory forecasting. In: 2020 25th International Conference on Pattern Recognition (ICPR), pp. 10335–10342. IEEE (2021)
- (68) Goodale, M.A., Milner, A.D.: Separate visual pathways for perception and action. Trends in Neurosciences 15(1), 20–25 (1992)
- (69) Gorelick, L., Blank, M., Shechtman, E., Irani, M., Basri, R.: Actions as space-time shapes. Transactions on Pattern Analysis and Machine Intelligence 29(12), 2247–2253 (2007)
- (70) Goyal, R., Kahou, S.E., Michalski, V., Materzynska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., et al.: The” something something” video database for learning and evaluating visual common sense. In: Proc. ICCV (2017)
- (71) Gu, C., Sun, C., Ross, D.A., Vondrick, C., Pantofaru, C., Li, Y., Vijayanarasimhan, S., Toderici, G., Ricco, S., Sukthankar, R., et al.: AVA: A video dataset of spatio-temporally localized atomic visual actions. In: CVPR (2018)
- (72) Gu, C., Sun, C., Vijayanarasimhan, S., Pantofaru, C., Ross, D.A., Toderici, G., Li, Y., Ricco, S., Sukthankar, R., Schmid, C., et al.: Ava: A video dataset of spatio-temporally localized atomic visual actions. arXiv preprint arXiv:1705.08421 (2017)
- (73) Guo, M., Chou, E., Huang, D.A., Song, S., Yeung, S., Fei-Fei, L.: Neural graph matching networks for fewshot 3d action recognition. In: ECCV (2018)
- (74) Gupta, A., Johnson, J., Fei-Fei, L., Savarese, S., Alahi, A.: Social gan: Socially acceptable trajectories with generative adversarial networks. In: CVPR (2018)
- (75) Hadfield, S., Bowden, R.: Hollywood 3d: Recognizing actions in 3d natural scenes. In: CVPR. Portland, Oregon (2013)
- (76) Harris, C., Stephens., M.: A combined corner and edge detector. In: Alvey Vision Conference (1988)
- (77) Hasan, M., Roy-Chowdhury, A.K.: Continuous learning of human activity models using deep nets. In: ECCV (2014)
- (78) Heilbron, F.C., Escorcia, V., Ghanem, B., Niebles, J.C.: ActivityNet: A large-scale video benchmark for human activity understanding. In: CVPR (2015)
- (79) Herath, S., Harandi, M., Porikli, F.: Going deeper into action recognition: A survey. Image and Vision Computing (2017)
- (80) Hoai, M., la Torre, F.D.: Max-margin early event detectors. In: CVPR (2012)
- (81) Horn, B., Schunck, B.: Determining optical flow. Artificial Intelligence 17, 185–203 (1981)
- (82) Hu, J.F., Zheng, W.S., Lai, J., Zhang, J.: Jointly learning heterogeneous features for rgb-d activity recognition. In: CVPR (2015)
- (83) Hu, W., Xie, D., Fu, Z., Zeng, W., Maybank, S.: Semantic-based surveillance video retrieval. Image Processing, IEEE Transactions on 16(4), 1168–1181 (2007)
- (84) Huang, D.A., Fei-Fei, L., Niebles, J.C.: Connectionist temporal modeling for weakly supervised action labeling. In: European Conference on Computer Vision, pp. 137–153. Springer (2016)
- (85) Huang, D.A., Kitani, K.M.: Action-reaction: Forecasting the dynamics of human interaction. In: ECCV (2008)
- (86) Ikizler, N., Forsyth, D.: Searching video for complex activities with finite state models. In: CVPR (2007)
- (87) Jain, M., van Gemert, J., Jegou, H., Bouthemy, P., Snoek, C.G.: Action localization with tubelets from motion. In: CVPR (2014)
- (88) Jain, M., Jégou, H., Bouthemy, P.: Better exploiting motion for better action recognition. In: CVPR (2013)
- (89) Ji, S., Xu, W., Yang, M., Yu, K.: 3d convolutional neural networks for human action recognition. In: ICML (2010)
- (90) Ji, S., Xu, W., Yang, M., Yu, K.: 3d convolutional neural networks for human action recognition. IEEE Trans. Pattern Analysis and Machine Intelligence (2013)
- (91) Jia, C., Kong, Y., Ding, Z., Fu, Y.: Latent tensor transfer learning for rgb-d action recognition. In: ACM Multimedia (2014)
- (92) Jia, K., Yeung, D.Y.: Human action recognition using local spatio-temporal discriminant embedding. In: CVPR (2008)
- (93) Jiang, Y.G., Liu, J., Roshan Zamir, A., Toderici, G., Laptev, I., Shah, M., Sukthankar, R.: THUMOS challenge: Action recognition with a large number of classes. http://crcv.ucf.edu/THUMOS14/ (2014)
- (94) Jiang, Y.G., Wu, Z., Wang, J., Xue, X., Chang, S.F.: Exploiting feature and class relationships in video categorization with regularized deep neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 40(2), 352–364 (2018). DOI 10.1109/TPAMI.2017.2670560. URL https://doi.org/10.1109/TPAMI.2017.2670560
- (95) Jingen Liu, J.L., Shah, M.: Recognizing realistic actions from videos ”in the wild”. In: CVPR (2009)
- (96) Jiyang Gao Zhenheng Yang, R.N.: Red: Reinforced encoder-decoder networks for action anticipation. In: BMVC (2017)
- (97) Kar, A., Rai, N., Sikka, K., Sharma, G.: Adascan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos. In: CVPR (2017)
- (98) Karaman, S., Seidenari, L., Bimbo, A.D.: Fast saliency based pooling of fisher encoded dense trajectories. In: ECCV THUMOS Workshop (2014)
- (99) Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Large-scale video classification with convolutional neural networks. In: CVPR (2014)
- (100) Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
- (101) Ke, Q., Bennamoun, M., An, S., Sohel, F., Boussaid, F.: A new representation of skeleton sequences for 3d action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3288–3297 (2017)
- (102) Ke, Q., Fritz, M., Schiele, B.: Time-conditioned action anticipation in one shot. In: CVPR (2019)
- (103) Ke, Q., Fritz, M., Schiele, B.: Future moment assessment for action query. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (2021)
- (104) Keestra, M.: Understanding human action. integraiting meanings, mechanisms, causes, and contexts. TRANSDISCIPLINARITY IN PHILOSOPHY AND SCIENCE: APPROACHES, PROBLEMS, PROSPECTS pp. 201–235 (2015)
- (105) Khurram Soomro, A.R.Z., Shah, M.: Ucf101: A dataset of 101 human action classes from videos in the wild (2012). CRCV-TR-12-01
- (106) Kim, K., Lee, D., Essa, I.: Gaussian process regression flow for analysis of motion trajectories. In: ICCV (2011)
- (107) Kitani, K.M., Ziebart, B.D., Bagnell, J.A., Hebert, M.: Activity forecasting. In: ECCV (2012)
- (108) Klaser, A., Marszalek, M., Schmid, C.: A spatio-temporal descriptor based on 3d-gradients. In: BMVC (2008)
- (109) Kliper-Gross, O., Hassner, T., Wolf, L.: The action similarity labeling challenge. IEEE Transactions on Pattern Analysis and Machine Intelligence 34(3) (2012)
- (110) Kong, Y., Fu, Y.: Modeling supporting regions for close human interaction recognition. In: ECCV workshop (2014)
- (111) Kong, Y., Fu, Y.: Bilinear heterogeneous information machine for rgb-d action recognition. In: CVPR (2015)
- (112) Kong, Y., Fu, Y.: Max-margin action prediction machine. TPAMI 38(9), 1844 – 1858 (2016)
- (113) Kong, Y., Fu, Y.: Max-margin heterogeneous information machine for rgb-d action recognition. International Journal of Computer Vision (IJCV) 123(3), 350–371 (2017)
- (114) Kong, Y., Gao, S., Sun, B., Fu, Y.: Action prediction from videos via memorizing hard-to-predict samples. In: AAAI (2018)
- (115) Kong, Y., Jia, Y., Fu, Y.: Learning human interaction by interactive phrases. In: Proc. European Conf. on Computer Vision (2012)
- (116) Kong, Y., Jia, Y., Fu, Y.: Interactive phrases: Semantic descriptions for human interaction recognition. In: PAMI (2014)
- (117) Kong, Y., Kit, D., Fu, Y.: A discriminative model with multiple temporal scales for action prediction. In: ECCV (2014)
- (118) Kong, Y., Tao, Z., Fu, Y.: Deep sequential context networks for action prediction. In: CVPR (2017)
- (119) Kong, Y., Tao, Z., Fu, Y.: Adversarial action prediction networks. IEEE TPAMI (2018)
- (120) Kooij, J.F.P., Schneider, N., Flohr, F., Gavrila, D.M.: Context-based pedestrian path prediction. In: European Conference on Computer Vision, pp. 618–633. Springer (2014)
- (121) Koppula, H.S., Gupta, R., Saxena, A.: Learning human activities and object affordances from rgb-d videos. International Journal of Robotics Research (2013)
- (122) Koppula, H.S., Saxena, A.: Anticipating human activities for reactive robotic response. In: IROS (2013)
- (123) Koppula, H.S., Saxena, A.: Learning spatio-temporal structure from rgb-d videos for human activity detection and anticipation. In: ICML (2013)
- (124) Koppula, H.S., Saxena, A.: Anticipating human activities using object affordances for reactive robotic response. IEEE transactions on pattern analysis and machine intelligence 38(1), 14–29 (2016)
- (125) Kosaraju, V., Sadeghian, A., Martín-Martín, R., Reid, I., Rezatofighi, S.H., Savarese, S.: Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. arXiv preprint arXiv:1907.03395 (2019)
- (126) Kretzschmar, H., Kuderer, M., Burgard, W.: Learning to predict trajecteories of cooperatively navigation agents. In: International Conference on Robotics and Automation (2014)
- (127) Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: Hmdb: A large video database for human motion recognition. In: ICCV (2011)
- (128) Kurakin, A., Zhang, Z., Liu, Z.: A real-time system for dynamic hand gesture recognition with a depth sensor. In: EUSIPCO (2012)
- (129) Lai, S., Zhang, W.S., Hu, J.F., Zhang, J.: Global-local temporal saliency action prediction. IEEE Transactions on Image Processing 27(5), 2272–2285 (2018)
- (130) Lan, T., Chen, T.C., Savarese, S.: A hierarchical representation for future action prediction. In: European Conference on Computer Vision, pp. 689–704. Springer (2014)
- (131) Lan, T., Sigal, L., Mori, G.: Social roles in hierarchical models for human activity. In: CVPR (2012)
- (132) Lan, T., Wang, Y., Yang, W., Robinovitch, S.N., Mori, G.: Discriminative latent models for recognizing contextual group activities. TPAMI 34(8), 1549–1562 (2012)
- (133) Laptev, I.: On space-time interest points. IJCV 64(2), 107–123 (2005)
- (134) Laptev, I., Lindeberg, T.: Space-time interest points. In: ICCV, pp. 432–439 (2003)
- (135) Laptev, I., Marszalek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies. In: CVPR (2008)
- (136) Laptev, I., Marszałek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies (2008)
- (137) Laptev, I., Perez, P.: Retrieving actions in movies. In: ICCV (2007)
- (138) Le, Q.V., Zou, W.Y., Yeung, S.Y., Ng, A.Y.: Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In: CVPR (2011)
- (139) Lee, H.Y., Huang, J.B., Singh, M., Yang, M.H.: Unsupervised representation learning by sorting sequences. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 667–676 (2017)
- (140) Lee, N., Choi, W., Vernaza, P., Choy, C.B., Torr, P.H., Chandraker, M.: Desire: Distant future prediction in dynamic scenes with interacting agents. In: CVPR (2017)
- (141) Lee, N., Kitani, K.M.: Predicting wide receiver trajectories in american football. In: WACV2016
- (142) Li, J., Ma, H., Tomizuka, M.: Conditional generative neural system for probabilistic trajectory prediction. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6150–6156. IEEE (2019)
- (143) Li, K., Fu, Y.: Prediction of human activity by discovering temporal sequence patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(8), 1644–1657 (2014)
- (144) Li, K., Hu, J., Fu, Y.: Modeling complex temporal composition of actionlets for activity prediction. In: ECCV (2012)
- (145) Li, W., Zhang, Z., Liu, Z.: Action recognition based on a bag of 3d points. In: CVPR workshop (2010)
- (146) Li, Y., Chen, L., He, R., Wang, Z., Wu, G., Wang, L.: Multisports: A multi-person video dataset of spatio-temporally localized sports actions. In: ICCV (2021)
- (147) Li, Z., Yao, L.: Three birds with one stone: Multi-task temporal action detection via recycling temporal annotations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4751–4760 (2021)
- (148) Liang, J., Jiang, L., Niebles, J.C., Hauptmann, A.G., Fei-Fei, L.: Peeking into the future: Predicting future person activities and locations in videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5725–5734 (2019)
- (149) Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: Bmn: Boundary-matching network for temporal action proposal generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3889–3898 (2019)
- (150) Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: Bsn: Boundary sensitive network for temporal action proposal generation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
- (151) Lin, Y.Y., Hua, J.H., Tang, N.C., Chen, M.H., Liao, H.Y.M.: Depth and skeleton associated action recognition without online accessible rgb-d cameras. In: CVPR (2014)
- (152) Liu, J., Kuipers, B., Savarese, S.: Recognizing human actions by attributes. In: CVPR (2011)
- (153) Liu, J., Luo, J., Shah, M.: Recognizing realistic actions from videos “in the wild”. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (2009)
- (154) Liu, J., Shahroudy, A., Perez, M., Wang, G., Duan, L.Y., Kot, A.C.: Ntu rgb+d 120: A large-scale benchmark for 3d human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence 42(10), 2684–2701 (2020)
- (155) Liu, J., Shahroudy, A., Xu, D., Wang, G.: Spatio-temporal lstm with trust gates for 3d human action recognition. In: European Conference on Computer Vision, pp. 816–833. Springer (2016)
- (156) Liu, L., Shao, L.: Learning discriminative representations from rgb-d video data. In: IJCAI (2013)
- (157) Liu, X., Pintea, S.L., Nejadasl, F.K., Booij, O., van Gemert, J.C.: No frame left behind: Full video action recognition. In: CVPR (2021)
- (158) Liu, Y., Ma, L., Zhang, Y., Liu, W., Chang, S.F.: Multi-granularity generator for temporal action proposal. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3604–3613 (2019)
- (159) Liu, Y., Yan, Q., Alahi, A.: Social nce: Contrastive learning of socially-aware motion representations. arXiv preprint arXiv:2012.11717 (2020)
- (160) Lu, C., Jia, J., Tang, C.K.: Range-sample depth feature for action recognition. In: CVPR (2014)
- (161) Lucas, B.D., Kanade, T.: An iterative image registration technique with an application to stereo vision. In: Proceedings of Imaging Understanding Workshop (1981)
- (162) Luo, G., Yang, S., Tian, G., Yuan, C., Hu, W., Maybank, S.J.: Learning human actions by combining global dynamics and local appearance. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(12), 2466–2482 (2014)
- (163) Luo, J., Wang, W., Qi, H.: Group sparsity and geometry constrained dictionary learning for action recognition from depth maps. In: ICCV (2013)
- (164) Luo, Z., Hsieh, J.T., Jiang, L., Carlos Niebles, J., Fei-Fei, L.: Graph distillation for action detection with privileged modalities. In: ECCV (2018)
- (165) Ma, S., Sigal, L., Sclaroff, S.: Learning activity progression in lstms for activity detection and early detection. In: CVPR (2016)
- (166) Mainprice, J., Hayne, R., Berenson, D.: Goal set inverse optimal control and iterative re-planning for predicting human reaching motions in shared workspace. In: arXiv preprint arXiv:1606.02111 (2016)
- (167) Mangalam, K., An, Y., Girase, H., Malik, J.: From goals, waypoints & paths to long term human trajectory forecasting. arXiv preprint arXiv:2012.01526 (2020)
- (168) Mangalam, K., Girase, H., Agarwal, S., Lee, K.H., Adeli, E., Malik, J., Gaidon, A.: It is not the journey but the destination: Endpoint conditioned trajectory prediction. In: European Conference on Computer Vision, pp. 759–776. Springer (2020)
- (169) Marchetti, F., Becattini, F., Seidenari, L., Bimbo, A.D.: Mantra: Memory augmented networks for multiple trajectory prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7143–7152 (2020)
- (170) Marszałek, M., Laptev, I., Schmid, C.: Actions in context. In: IEEE Conference on Computer Vision & Pattern Recognition (2009)
- (171) Mass, J., Johansson, G., Jason, G., Runeson, S.: Motion perception I and II [film]. Boston: Houghton Mifflin (1971)
- (172) Mehrasa, N., Jyothi, A.A., Durand, T., He, J., Sigal, L., Mori, G.: A variational auto-encoder model for stochastic point processes. In: CVPR (2019)
- (173) Messing, R., Pal, C., Kautz, H.: Activity recognition using the velocity histories of tracked keypoints. In: ICCV (2009)
- (174) Mingfei Gao Yingbo Zhou, R.X.R.S.C.X.: Woad: Weakly supervised online action detection in untrimmed videos. In: CVPR (2021)
- (175) Mishra, A., Verma, V., Reddy, M.K.K., Subramaniam, A., Rai, P., Mittal, A.: A generative approach to zero-shot and few-shot action recognition (2018)
- (176) Misra, I., Zitnick, C.L., Hebert, M.: Shuffle and learn: unsupervised learning using temporal order verification. In: European Conference on Computer Vision, pp. 527–544. Springer (2016)
- (177) Mohamed, A., Qian, K., Elhoseiny, M., Claudel, C.: Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14424–14432 (2020)
- (178) Monfort, M., Zhou, B., Bargal, S.A., Yan, T., Andonian, A., Ramakrishnan, K., Brown, L., Fan, Q., Gutfruend, D., Vondrick, C., et al.: Moments in time dataset: one million videos for event understanding
- (179) Morency, L.P., Quattoni, A., Darrell, T.: Latent-dynamic discriminative models for continuous gesture recognition. In: CVPR (2007)
- (180) Morrisand, B., Trivedi, M.: Trajectory learning for activity understanding: Unsupervised, multilevel, and long-term adaptive approach. Pattern Analysis and Machine Intelligence, IEEE Transactions on 33(11), 2287–2301 (2011)
- (181) Narayan, S., Cholakkal, H., Khan, F.S., Shao, L.: 3C-Net: Category count and center loss for weakly-supervised action localization. In: ICCV (2019)
- (182) Narayanan, S., Moslemi, R., Pittaluga, F., Liu, B., Chandraker, M.: Divide-and-conquer for lane-aware diverse trajectory prediction. In: CVPR (2021)
- (183) Ng, J.Y.H., Hausknecht, M., Vijayanarasimhan, S., Vinyals, O., Monga, R., Toderici, G.: Beyond short snippets: Deep networks for video classification. In: CVPR (2015)
- (184) Ni, B., Wang, G., Moulin, P.: RGBD-HuDaAct: A color-depth video database for human daily activity recognition. In: ICCV Workshop on CDC3CV (2011)
- (185) Niebles, J.C., Chen, C.W., Fei-Fei, L.: Modeling temporal structure of decomposable motion segments for activity classification. In: ECCV (2010)
- (186) Niebles, J.C., Fei-Fei, L.: A hierarchical model of shape and appearance for human action classification. In: CVPR (2007)
- (187) Niebles, J.C., Wang, H., Fei-Fei, L.: Unsupervised learning of human action categories using spatial-temporal words. International Journal of Computer Vision 79(3), 299–318 (2008)
- (188) Ofli, F., Chaudhry, R., Kurillo, G., Vidal, R., Bajcsy, R.: Berkeley mhad: A comprehensive multimodal human action database. In: Proceedings of the IEEE Workshop on Applications on Computer Vision (2013)
- (189) Oliver, N.M., Rosario, B., Pentland, A.P.: A bayesian computer vision system for modeling human interactions. PAMI 22(8), 831–843 (2000)
- (190) Oreifej, O., Liu, Z.: Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In: CVPR (2013)
- (191) Oza, P., Patel, V.M.: C2AE: Class conditioned auto-encoder for open-set recognition. In: CVPR (2019)
- (192) Patron-Perez, A., Marszalek, M., Reid, I., Zissermann, A.: Structured learning of human interaction in tv shows. PAMI 34(12), 2441–2453 (2012)
- (193) Patron-Perez, A., Marszalek, M., Zisserman, A., Reid, I.: High five: Recognising human interactions in tv shows. In: Proc. British Conference on Machine Vision (2010)
- (194) Pei, M., Jia, Y., Zhu, S.C.: Parsing video events with goal inference and intent prediction. In: ICCV, pp. 487–494. IEEE (2011)
- (195) Perera, P., Morariu, V.I., Jain, R., Manjunatha, V., Wigington, C., Ordonez, V., Patel, V.M.: Generative-discriminative feature representations for open-set recognition. In: CVPR (2020)
- (196) Perrett, T., Masullo, A., Burghardt, T., Mirmehdi, M., Damen, D.: Temporal-relational crosstransformers for few-shot action recognition. In: CVPR (2021)
- (197) Perronnin, F., Dance, C.: Fisher kernels on visual vocabularies for image categorization. In: CVPR (2006)
- (198) Plotz, T., Hammerla, N.Y., Olivier, P.: Feature learning for activity recognition in ubiquitous computing. In: IJCAI (2011)
- (199) Poppe, R.: A survey on vision-based human action recognition. Image and Vision Computing 28, 976–990 (2010)
- (200) Purushwalkam, S., Gupta, A.: Pose from action: Unsupervised learning of pose features based on motion. arXiv preprint arXiv:1609.05420 (2016)
- (201) Qiu, Z., Yao, T., Mei, T.: Learning spatio-temporal representation with pseudo-3d residual network. In: ICCV (2017)
- (202) Qiu, Z., Yao, T., Ngo, C.W., Tian, X., Mei, T.: Learning spatio-temporal representation with local and global diffusion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12056–12065 (2019)
- (203) Rajko, S., Qian, G., Ingalls, T., James, J.: Real-time gesture recognition with minimal training requirements and on-line learning. In: CVPR (2007)
- (204) Ramanathan, V., Yao, B., Fei-Fei, L.: Social role discovery in human events. In: CVPR (2013)
- (205) Ramezani, M., Yaghmaee, F.: A review on human action analysis in videos for retrieval applications. Artificial Intelligence Review 46(4), 485–514 (2016)
- (206) Raptis, M., Sigal, L.: Poselet key-framing: A model for human activity recognition. In: CVPR (2013)
- (207) Raptis, M., Soatto, S.: Tracklet descriptors for action modeling and video analysis. In: ECCV (2010)
- (208) Rasouli, A., Rohani, M., Luo, J.: Bifold and semantic reasoning for pedestrian behavior prediction. In: CVPR (2021)
- (209) Reddy, K.K., Shah, M.: Recognizing 50 human action categories of web videos. Machine Vision and Applications Journal (2012)
- (210) Ricoeur, P.: Oneself as another (K. Blamey, Trans.). Chicago: University of Chicago Press (1992)
- (211) Rizzolatti, G., Craighero, L.: The mirror-neuron system. Annu. Rev. Neurosci. 27, 169–192 (2004)
- (212) Rizzolatti, G., Sinigaglia, C.: The functional role of the parieto-frontal mirror circuit: interpretations and misinterpretations. Nat. Rev. Neurosci. 11, 264–274 (2010)
- (213) Rodriguez, M.D., Ahmed, J., Shah, M.: Action mach: A spatio-temporal maximum average correlation height filter for action recognition. In: CVPR (2008)
- (214) Rohit, G., Kristen, G.: Anticipative video transformer. In: ICCV (2021)
- (215) Roitberg, A., Ma, C., Haurilet, M., Stiefelhagen, R.: Open set driver activity recognition. In: IVS (2020)
- (216) Ryoo, M., Aggarwal, J.: Recognition of composite human activities through context-free grammar based representation. In: CVPR, vol. 2, pp. 1709–1718 (2006)
- (217) Ryoo, M., Aggarwal, J.: Spatio-temporal relationship match: Video structure comparison for recognition of complex human activities. In: ICCV, pp. 1593–1600 (2009)
- (218) Ryoo, M., Aggarwal, J.: Stochastic representation and recognition of high-level group activities. IJCV 93, 183–200 (2011)
- (219) Ryoo, M., Fuchs, T.J., Xia, L., Aggarwal, J.K., Matthies, L.: Robot-centric activity prediction from first-person videos: What will they do to me? In: Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, pp. 295–302. ACM (2015)
- (220) Ryoo, M.S.: Human activity prediction: Early recognition of ongoing activities from streaming videos. In: ICCV (2011)
- (221) Ryoo, M.S., Aggarwal, J.K.: UT-Interaction Dataset, ICPR contest on Semantic Description of Human Activities (SDHA). http://cvrc.ece.utexas.edu/SDHA2010/Human_Interaction.html (2010)
- (222) S Singh, S.V., Ragheb, H.: Muhavi: A multicamera human action video dataset for the evaluation of action recognition methods. In: 2nd Workshop on Activity monitoring by multi-camera surveillance systems (AMMCSS), pp. 48–55 (2010)
- (223) Sadeghian, A., Kosaraju, V., Sadeghian, A., Hirose, N., Rezatofighi, H., Savarese, S.: Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1349–1358 (2019)
- (224) Satkin, S., Hebert, M.: Modeling the temporal extent of actions. In: ECCV (2010)
- (225) Scheirer, W.J., Jain, L.P., Boult, T.E.: Probability models for open set recognition. IEEE transactions on pattern analysis and machine intelligence 36(11), 2317–2324 (2014)
- (226) Scheirer, W.J., de Rezende Rocha, A., Sapkota, A., Boult, T.E.: Toward open set recognition. IEEE transactions on pattern analysis and machine intelligence 35(7), 1757–1772 (2012)
- (227) Schüldt, C., Laptev, I., Caputo, B.: Recognizing human actions: A local svm approach. In: IEEE ICPR (2004)
- (228) Scovanner, P., Ali, S., Shah, M.: A 3-dimensional sift descriptor and its application to action recognition. In: Proc. ACM Multimedia (2007)
- (229) Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: Ntu rgb+d: A large scale dataset for 3d human activity analysis. In: IEEE Conference on Computer Vision and Pattern Recognition (2016)
- (230) Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: Ntu rgb+d: A large scale dataset for 3d human activity analysis. In: CVPR (2016)
- (231) Shi, Q., Cheng, L., Wang, L., Smola, A.: Human action segmentation and recognition using discriminative semi-markov models. IJCV 93, 22–32 (2011)
- (232) Shotton, J., Girshick, R., Fitzgibbon, A., Sharp, T., Cook, M., Finocchio, M., Moore, R., Kohli, P., Criminisi, A., Kipman, A., Blake, A.: Efficient human pose estimation from single depth images. PAMI (2013)
- (233) Shou, Z., Chan, J., Zareian, A., Miyazawa, K., Chang, S.F.: CDC: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In: CVPR (2017)
- (234) Shou, Z., Wang, D., Chang, S.F.: Temporal action localization in untrimmed videos via multi-stage CNNs. In: CVPR (2016)
- (235) Shu, Y., Shi, Y., Wang, Y., Zou, Y., Yuan, Q., Tian, Y.: ODN: Opening the deep network for open-set action recognition. In: ICME (2018)
- (236) Si, C., Chen, W., Wang, W., Wang, L., Tan, T.: An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1227–1236 (2019)
- (237) Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: NIPS (2014)
- (238) Singh, S., Velastin, S.A., Ragheb, H.: Muhavi: A multicamera human action video dataset for the evaluation of action recognition methods. In: Advanced Video and Signal Based Surveillance (AVSS), 2010 Seventh IEEE International Conference on, pp. 48–55. IEEE (2010)
- (239) Sminchisescu, C., Kanaujia, A., Li, Z., Metaxas, D.: Conditional models for contextual human motion recognition. In: International Conference on Computer Vision (2005)
- (240) Song, H., Wu, X., Zhu, B., Wu, Y., Chen, M., Jia, Y.: Temporal action localization in untrimmed videos using action pattern trees. IEEE Transactions on Multimedia (TMM) 21(3), 717–730 (2019)
- (241) Song, L., Zhang, S., Yu, G., Sun, H.: TACNet: Transition-aware context network for spatio-temporal action detection. In: CVPR (2019)
- (242) Song, S., Lan, C., Xing, J., Zeng, W., Liu, J.: Spatio-temporal attention-based LSTM networks for 3d action recognition and detection. IEEE Transactions on Image Processing (TIP) 27(7), 3459–3471 (2018)
- (243) Su, H., Zhu, J., Dong, Y., Zhang, B.: Forecast the plausible paths in crowd scenes. In: IJCAI (2017)
- (244) Sumi, S.: Perception of point-light walker produced by eight lights attached to the back of the walker. Swiss J. Psychol. 59, 126–32 (2000)
- (245) Sun, D., Roth, S., Black, M.J.: Secrets of optical flow estimation and their principles. In: CVPR (2010)
- (246) Sun, J., Wu, X., Yan, S., Cheong, L., Chua, T., Li, J.: Hierarchical spatio-temporal context modeling for action recognition. In: CVPR (2009)
- (247) Sun, L., Jia, K., Chan, T.H., Fang, Y., Wang, G., Yan, S.: Dl-sfa: Deeply-learned slow feature analysis for action recognition. In: CVPR (2014)
- (248) Sung, J., Ponce, C., Selman, B., Saxena, A.: Human activity detection from rgbd images. In: AAAI workshop on Pattern, Activity and Intent Recognition (2011)
- (249) Sung, J., Ponce, C., Selman, B., Saxena, A.: Unstructured human activity detection from rgbd images. In: ICRA (2012)
- (250) Surís, D., Liu, R., Vondrick, C.: Learning the predictability of the future. In: CVPR (2021)
- (251) Tang, K., Fei-Fei, L., Koller, D.: Learning latent temporal structure for complex event detection. In: CVPR (2012)
- (252) Tang, K., Ramanathan, V., Fei-Fei, L., Koller, D.: Shifting weights: Adapting object detectors from image to video. In: Advances in Neural Information Processing Systems (2012)
- (253) Tang, Y., Ding, D., Rao, Y., Zheng, Y., Zhang, D., Zhao, L., Lu, J., Zhou, J.: COIN: A large-scale dataset for comprehensive instructional video analysis. In: CVPR (2019)
- (254) Taylor, G.W., Fergus, R., LeCun, Y., Bregler, C.: Convolutional learning of spatio-temporal features. In: ECCV (2010)
- (255) Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: ICCV (2015)
- (256) Tran, D., Sorokin, A.: Human activity recognition with metric learning. In: ECCV (2008)
- (257) Troje, N.: Decomposing biological motion: a framework for analysis and synthesis of human gait patterns. J. Vis. 2, 371–87 (2002)
- (258) Troje, N., Westhoff, C., Lavrov, M.: Person identification from biological motion: effects of structural and kinematic cues. Percept. Psychophys 67, 667–75 (2005)
- (259) Turek, M., Hoogs, A., Collins, R.: Unsupervised learning of functional categories in video scenes. In: ECCV (2010)
- (260) Vahdat, A., Gao, B., Ranjbar, M., Mori, G.: A discriminative key pose sequence model for recognizing human interactions. In: ICCV Workshops, pp. 1729 –1736 (2011)
- (261) Varol, G., Laptev, I., Schmid, C.: Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017)
- (262) Vondrick, C., Pirsiavash, H., Torralba, A.: Anticipating visual representations from unlabeled video. In: CVPR (2016)
- (263) Walker, J., Gupta, A., Hebert, M.: Patch to the future: Unsupervised visual prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3302–3309 (2014)
- (264) Wang, C., Wang, Y., Xu, M., Crandall, D.J.: Stepwise goal-driven networks for trajectory prediction. arXiv preprint arXiv:2103.14107 (2021)
- (265) Wang, H., Klaser, A., Schmid, C., Liu, C.L.: Dense trajectories and motion boundary descriptors for action recognition. IJCV 103(60-79) (2013)
- (266) Wang, H., Kläser, A., Schmid, C., Liu, C.L.: Action Recognition by Dense Trajectories. In: IEEE Conference on Computer Vision & Pattern Recognition, pp. 3169–3176. Colorado Springs, United States (2011). URL http://hal.inria.fr/inria-00583818/en
- (267) Wang, H., Oneata, D., Verbeek, J., Schmid, C.: A robust and efficient video representation for action recognition. IJCV (2015)
- (268) Wang, H., Schmid, C.: Action recognition with improved trajectories. In: IEEE International Conference on Computer Vision. Sydney, Australia (2013). URL http://hal.inria.fr/hal-00873267
- (269) Wang, H., Ullah, M.M., Klser, A., Laptev, I., Schmid, C.: Evaluation of local spatio-temporal features for action recognition. In: BMVC (2009)
- (270) Wang, J., Liu, Z., Chorowski, J., Chen, Z., Wu, Y.: Robust 3d action recognition with random occupancy patterns. In: ECCV (2012)
- (271) Wang, J., Liu, Z., Wu, Y., Yuan, J.: Mining actionlet ensemble for action recognition with depth cameras. In: CVPR (2012)
- (272) Wang, K., Wang, X., Lin, L., Wang, M., Zuo, W.: 3d human activity recognition with reconfigurable convolutional neural networks. In: ACM Multimedia (2014)
- (273) Wang, L., Qiao, Y., Tang, X.: Action recognition and detection by combining motion and appearance features. In: ECCV THUMOS Workshop (2014)
- (274) Wang, L., Qiao, Y., Tang, X.: Action recognition with trajectory-pooled deep-convolutional descriptors. In: CVPR (2015)
- (275) Wang, L., Suter, D.: Recognizing human activities from silhouettes: Motion subspace and factorial discriminative graphical model. In: CVPR (2007)
- (276) Wang, L., Tong, Z., Ji, B., Wu, G.: Tdn: Temporal difference networks for efficient action recognition. In: CVPR, pp. 1895–1904 (2021)
- (277) Wang, L., Xiong, Y., Lin, D., Van Gool, L.: UntrimmedNets for weakly supervised action recognition and detection. In: CVPR (2017)
- (278) Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Gool, L.V.: Temoral segment networks: Toward good practices for deep action recognition. In: ECCV (2016)
- (279) Wang, S.B., Quattoni, A., Morency, L.P., Demirdjian, D., Darrell, T.: Hidden conditional random fields for gesture recognition. In: CVPR (2006)
- (280) Wang, X., Gupta, A.: Unsupervised learning of visual representations using videos. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2794–2802 (2015)
- (281) Wang, X., He, K., Gupta, A.: Transitive invariance for self-supervised visual representation learning. In: Proceedings of the IEEE international conference on computer vision, pp. 1329–1338 (2017)
- (282) Wang, Y., Mori, G.: Learning a discriminative hidden part model for human action recognition. In: NIPS (2008)
- (283) Wang, Y., Mori, G.: Hidden part models for human action recognition: Probabilistic vs. max-margin. PAMI (2010)
- (284) Wang, Z., Wang, J., Xiao, J., Lin, K.H., Huang, T.S.: Substructural and boundary modeling for continuous action recognition. In: CVPR (2012)
- (285) Weinland, D., Ronfard, R., Boyer, E.: Free viewpoint action recognition using motion history volumes. Computer Vision and Image Understanding 104(2-3), 249–257 (2006)
- (286) Willems, G., Tuytelaars, T., Gool, L.: An efficient dense and scale-invariant spatio-temporal interest poing detector. In: ECCV (2008)
- (287) Wolf, C., Lombardi, E., Mille, J., Celiktutan, O., Jiu, M., Dogan, E., Eren, G., Baccouche, M., Dellandréa, E., Bichot, C.E., et al.: Evaluation of video activity localizations integrating quality and quantity measurements. Computer Vision and Image Understanding 127, 14–30 (2014)
- (288) Wong, S.F., Kim, T.K., Cipolla, R.: Learning motion categories using both semantic and structural information. In: CVPR (2007)
- (289) Wu, B., Yuan, C., Hu, W.: Human action recognition based on context-dependent graph kernels. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2609–2616 (2014)
- (290) Wu, J., Yildirim, I., Lim, J.J., Freeman, W.T., Tenenbaum, J.B.: Galileo: Perceiving physical object properties by integrating a physics engine with deep learning. In: Advances in Neural Information Processing Systems, pp. 127–135 (2015)
- (291) Wu, X., Xu, D., Duan, L., Luo, J.: Action recognition using context and appearance distribution features. In: CVPR (2011)
- (292) Wu, Z., Wang, X., Jiang, Y.G., Ye, H., Xue, X.: Modeling spatial-temporal clues in a hybrid deep learning framework for video classification. In: ACM Multimedia (2015)
- (293) Wulfmeier, M., Wang, D., Posner, I.: Watch this: scalable cost function learning for path planning in urban environment. In: arXiv preprint arXiv:1607:02329 (2016)
- (294) Xia, L., Aggarwal, J.: Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera. In: CVPR (2013)
- (295) Xia, L., Chen, C., Aggarwal, J.: View invariant human action recognition using histograms of 3d joints. In: Computer Vision and Pattern Recognition Workshops (CVPRW), 2012 IEEE Computer Society Conference on, pp. 20–27. IEEE (2012)
- (296) Xia, L., Chen, C.C., Aggarwal, J.K.: View invariant human action recognition using histograms of 3d joints. In: CVPRW (2012)
- (297) Xu, D., Xiao, J., Zhao, Z., Shao, J., Xie, D., Zhuang, Y.: Self-supervised spatiotemporal learning via video clip order prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10334–10343 (2019)
- (298) Xu, H., Das, A., Saenko, K.: R-c3d: Region convolutional 3d network for temporal activity detection. In: Proceedings of the IEEE international conference on computer vision, pp. 5783–5792 (2017)
- (299) Xu, H., Das, A., Saenko, K.: Two-stream region convolutional 3d network for temporal activity detection. IEEE transactions on pattern analysis and machine intelligence 41(10), 2319–2332 (2019)
- (300) Xu, M., Gao, M., Chen, Y.T., Davis, L.S., Crandall, D.J.: Temporal recurrent networks for online action detection. In: ICCV (2019)
- (301) Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Thirty-Second AAAI Conference on Artificial Intelligence (2018)
- (302) Yang, H., He, X., Porikli, F.: One-shot action localization by learning sequence matching network. In: CVPR (2018)
- (303) Yang, S., Yuan, C., Wu, B., Hu, W., Wang, F.: Multi-feature max-margin hierarchical bayesian model for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1610–1618 (2015)
- (304) Yang, W., Zhang, T., Yu, X., Qi, T., Zhang, Y., Wu, F.: Uncertainty guided collaborative training for weakly supervised temporal action detection. In: CVPR (2021)
- (305) Yang, X., Tian, Y.: Super normal vector for activity recognition using depth sequences. In: CVPR (2014)
- (306) Yang, X., Yang, X., Liu, M.Y., Xiao, F., Davis, L.S., Kautz, J.: STEP: Spatio-temporal progressive learning for video action detection. In: CVPR (2019)
- (307) Yang, Y., Hou, C., Lang, Y., Guan, D., Huang, D., Xu, J.: Open-set human activity recognition based on micro-doppler signatures. Pattern Recognition 85, 60–69 (2019)
- (308) Yang, Y., Shah, M.: Complex events detection using data-driven concepts. In: ECCV (2012)
- (309) Yao, B., Fei-Fei, L.: Action recognition with exemplar based 2.5d graph matching. In: ECCV (2012)
- (310) Yao, B., Fei-Fei, L.: Recognizing human-object interactions in still images by modeling the mutual context of objects and human poses. TPAMI 34(9), 1691–1703 (2012)
- (311) Yeffet, L., Wolf, L.: Local trinary patterns for human action recognition. In: CVPR (2009)
- (312) Yeung, S., Russakovsky, O., Mori, G., Fei-Fei, L.: End-to-end learning of action detection from frame glimpses in videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2678–2687 (2016)
- (313) Yilmaz, A., Shah, M.: Actions sketch: A novel action representation. In: CVPR (2005)
- (314) Yu, G., Liu, Z., Yuan, J.: Discriminative orderlet mining for real-time recognition of human-object interaction. In: ACCV (2014)
- (315) Yu, T., Ren, Z., Li, Y., Yan, E., Xu, N., Yuan, J.: Temporal structure mining for weakly supervised action detection. In: ICCV (2019)
- (316) Yu, T.H., Kim, T.K., Cipolla, R.: Real-time action recognition by spatiotemporal semantic and structural forests. In: BMVC (2010)
- (317) Yuan, C., Hu, W., Tian, G., Yang, S., Wang, H.: Multi-task sparse learning with beta process prior for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 423–429 (2013)
- (318) Yuan, C., Li, X., Hu, W., Ling, H., Maybank, S.J.: 3d r transform on spatio-temporal interest points for action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 724–730 (2013)
- (319) Yuan, C., Li, X., Hu, W., Ling, H., Maybank, S.J.: Modeling geometric-temporal context with directional pyramid co-occurrence for action recognition. IEEE Transactions on Image Processing 23(2), 658–672 (2014)
- (320) Yuan, C., Wu, B., Li, X., Hu, W., Maybank, S.J., Wang, F.: Fusing r features and local features with context-aware kernels for action recognition. International Journal of Computer Vision 118(2), 151–171 (2016)
- (321) Yuan, J., Liu, Z., Wu, Y.: Discriminative subvolume search for efficient action detection. In: IEEE Conference on Computer Vision and Pattern Recognition (2009)
- (322) Yuan, J., Liu, Z., Wu, Y.: Discriminative video pattern search for efficient action detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2010)
- (323) Yuan, Y., Weng, X., Ou, Y., Kitani, K.: Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. arXiv preprint arXiv:2103.14023 (2021)
- (324) Zeng, R., Huang, W., Tan, M., Rong, Y., Zhao, P., Huang, J., Gan, C.: Graph convolutional networks for temporal action localization. In: ICCV (2019)
- (325) Zhai, X., Peng, Y., Xiao, J.: Cross-media retrieval by intra-media and inter-media correlation mining. Multimedia Systems 19(5), 395–406 (2013)
- (326) Zhang, H., Patel, V.M.: Sparse representation-based open set recognition. IEEE transactions on pattern analysis and machine intelligence 39(8), 1690–1696 (2016)
- (327) Zhang, H., Zhang, L., Qi, X., Li, H., Torr, P.H.S., Koniusz, P.: Few-shot action recognition with permutation-invariant attention. In: ECCV (2020)
- (328) Zhao, H., Torralba, A., Torresani, L., Yan, Z.: HACS: Human action clips and segments dataset for recognition and temporal localization. In: ICCV (2019)
- (329) Zhao, H., Wildes, R.P.: Where are you heading? dynamic trajectory prediction with expert goal examples. In: ICCV (2021)
- (330) Zhao, H., Yan, Z., Wang, H., Torresani, L., Torralba, A.: Slac: A sparsely labeled dataset for action classification and localization. arXiv preprint arXiv:1712.09374 (2017)
- (331) Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Tang, X., Lin, D.: Temporal action detection with structured segment networks. In: ICCV (2017)
- (332) Zhou, B., Andonian, A., Oliva, A., Torralba, A.: Temporal relational reasoning in videos. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 803–818 (2018)
- (333) Zhou, B., Wang, X., Tang, X.: Random field topic model for semantic region analysis in crowded scenes from tracklets. In: CVPR (2011)
- (334) Zhu, L., Yang, Y.: Compound memory networks for few-shot video classification. In: ECCV (2018)
- (335) Zhu, W., Lan, C., Xing, J., Zeng, W., Li, Y., Shen, L., Xie, X.: Co-occurrence feature learning for skeleton based action recognition using regularized deep lstm networks. In: Thirtieth AAAI Conference on Artificial Intelligence (2016)
- (336) Ziebart, B., Maas, A., Bagnell, J., Dey, A.: Maximum entropy inverse reinforcement learning. In: AAAI (2008)
- (337) Ziebart, B., Ratliff, N., Gallagher, G., Mertz, C., Peterson, K., Bagnell, J., Hebert, M., Dey, A., Srinivasa, S.: Planning-based prediction for pedestrians. In: IROS (2009)