用于检测分布外样本和对抗性攻击的简单统一框架
摘要
以统计方式或对抗性方式检测与训练分布足够远的测试样本是在许多现实世界的机器学习应用中部署良好分类器的基本要求。 然而,众所周知,即使对于此类异常样本,具有 softmax 分类器的深度神经网络也会产生高度过度自信的后验分布。 在本文中,我们提出了一种简单而有效的方法来检测任何异常样本,该方法适用于任何预训练的 softmax 神经分类器。 我们在高斯判别分析下获得了关于深层模型(低层和高层)特征的类条件高斯分布,这导致了基于马哈拉诺比斯距离的置信度得分。 虽然大多数现有方法已被评估用于检测分布外样本或对抗性样本,但不能同时检测两者,但所提出的方法在我们的实验中实现了这两种情况的最先进性能。 此外,我们发现我们提出的方法在恶劣的情况下更加稳健,例如,当训练数据集具有噪声标签或样本数量较少时。 最后,我们通过将所提出的方法应用于类增量学习来证明该方法具有更广泛的用途:每当检测到分布外样本时,我们的分类规则就可以很好地合并新类,而无需进一步的深度模型。
1简介
深度神经网络(DNN)在许多分类任务上实现了高精度,例如语音识别[1]、目标检测[9]和图像分类[12 ]。 然而,测量预测不确定性仍然是一个具有挑战性的问题[20, 21]。 获得经过良好校准的预测不确定性是必不可少的,因为它在许多机器学习应用(例如主动学习[8]和新颖性检测[18])以及在现实世界的系统中部署 DNN 时[2],例如自动驾驶汽车和安全身份验证系统[6, 30]。
DNN 的预测不确定性与检测统计或对抗性远离分布内(即训练样本的分布)的异常样本的问题密切相关。 为了检测分布外(OOD)样本,最近的工作利用了后验分布的置信度[13, 21]。 例如,Hendrycks & Gimpel [13]提出了分类器后验分布的最大值作为基线方法,并通过处理 DNN 的输入和输出进行改进[21]. 为了检测对抗性样本,基于密度估计器提出了置信度分数,以在 DNN 的特征空间中表征它们[7]。 最近,Ma等人[22]提出了局部固有维数(LID),并通过经验表明,使用LID可以有效地估计测试样本的特征。 然而,这方面的大多数先前工作通常不会同时评估 OOD 和对抗性样本。 据我们所知,还没有一种通用检测器能够很好地完成这两项任务。
贡献。 在本文中,我们提出了一种简单而有效的方法,适用于任何预训练的 softmax 神经分类器(无需重新训练)来检测异常测试样本,包括 OOD 和对抗样本。 我们的高级想法是利用“生成”(基于距离)分类器的概念来测量 DNN 特征空间上测试样本的概率密度。 具体来说,我们假设预训练的特征可以通过类条件高斯分布很好地拟合,因为它的后验分布可以证明与高斯判别分析下的softmax分类器等效(参见第2.1节)我们的理由)。 在此假设下,我们使用相对于最接近的类条件分布的马哈拉诺比斯距离定义置信度得分,其中其参数被选择为经验类均值和训练样本的绑定经验协方差。 与传统观念相反,我们发现使用相应的生成分类器并不会牺牲 softmax 分类精度。 也许令人惊讶的是,它的置信度得分在多个其他任务中都远远优于基于 softmax 的置信度得分:检测 OOD 样本、检测对抗性样本和类增量学习。
我们使用深度卷积神经网络(如针对图像分类任务训练的 DenseNet [14] 和 ResNet [12] )在各种数据集上演示了所提方法的有效性,这些数据集包括 CIFAR [15] 、SVHN [28] 、ImageNet [5] 和 LSUN [32] 。 首先,对于检测 OOD 样本的问题,在所有测试案例中,所提出的方法都优于当前最先进的方法 ODIN [21]。 特别是,与 ODIN 相比,我们的方法将 ResNet 上的真阴性率 (TNR)(即检测到的 OOD(例如 LSUN)样本的比例)从 提高到 当 95% 的分布中(例如 CIFAR-100)样本被正确检测到时。 接下来,针对检测对抗样本的问题,例如由FGSM [10]、BIM [16]、DeepFool [26]等四种攻击方法生成的对抗样本 和 CW [3],我们的方法优于最先进的检测方法 LID [22]。 特别是,与 LID 相比,当正确检测到 95% 的正常 CIFAR-10 样本时,我们的 ResNet 将 CW 的 TNR 从 提高到 。
我们还发现,我们提出的方法在超参数的选择以及极端情况下更加稳健,例如,当训练数据集具有一些噪声、随机标签或少量数据样本时。 特别是,Liang 等人[21]使用OOD样本的验证集来调整ODIN的超参数,这通常是不可能的,因为关于OOD样本的知识无法先验地获得。 我们表明,所提出方法的超参数只能使用分布(训练)样本进行调整,同时保持其性能。 我们进一步表明,所提出的方法针对简单攻击(即 FGSM)进行了调整,可用于检测其他更复杂的攻击,例如 BIM、DeepFool 和 CW。
最后,我们将我们的方法应用于类增量学习[29]:新类逐渐添加到预先训练的分类器中。 由于新的类样本是从训练外分布中抽取的,因此很自然地期望人们可以使用我们提出的指标对它们进行分类,而无需重新训练深度模型。 受此启发,我们提出了一种简单的方法,通过简单地计算新类的类均值并更新所有类的关联协方差来随时容纳新类。 我们表明,所提出的方法优于其他基线方法,例如基于欧几里德距离的分类器和重新训练的 softmax 分类器。 这证明我们的方法有潜力应用于许多其他相关的机器学习任务,例如主动学习[8]、集成学习[19]和少样本学习[31]。
2来自生成分类器的基于马哈拉诺比斯距离的分数
给定带有 softmax 分类器的深度神经网络(DNN),我们提出了一种简单而有效的方法来检测异常样本,例如分布外(OOD)和对抗性样本。 我们首先提出基于高斯判别分析(GDA)下的诱导生成分类器的置信度评分,然后引入其他技术来提高其性能。 我们还讨论了置信度分数如何应用于增量学习。

2.1为什么采用马氏距离评分?
从 softmax 生成分类器的推导。 令 为输入, 为其标签。 假设给定一个预训练的 softmax 神经分类器: ,其中 和 是类 ,表示DNN倒数第二层的输出。 然后,在不对预训练的 softmax 神经分类器进行任何修改的情况下,假设类条件分布遵循多元高斯分布,我们就获得了生成分类器。 具体来说,我们定义具有绑定协方差的类条件高斯分布:其中是多元高斯分布的平均值属于类。 在这里,我们的方法基于 GDA 和 softmax 分类器之间的简单理论联系:GDA 下具有绑定协方差假设的生成分类器定义的后验分布等效于 softmax 分类器(更多详细信息请参阅补充材料)。 因此,softmax神经分类器的预训练特征也可能遵循类条件高斯分布。
为了根据预训练的 softmax 神经分类器估计生成分类器的参数,我们计算训练样本 的经验类均值和协方差:
| (1) |
其中 是带有标签 的训练样本数。这相当于在最大似然估计下将具有绑定协方差的类条件高斯分布拟合到训练样本。
基于马哈拉诺比斯距离的置信度得分。 使用上述导出的类条件高斯分布,我们使用测试样本 与最接近的类条件高斯分布之间的马哈拉诺比斯距离定义置信度得分 ,即
| (2) |
请注意,该度量对应于测量测试样本的概率密度的对数。 在这里,我们指出,异常样本可以在 DNN 的表示空间中得到更好的表征,而不是在先前工作中使用的基于 softmax 的后验分布的“标签过拟合”输出空间[13, 21] 用于检测它们。 这是因为即使对于远离 softmax 决策边界的异常样本,从后验分布获得的置信度也可以显示出高置信度。 Feinman 等人 [7] 和 Ma 等人 [22] 在某种意义上处理 DNN 特征以检测对抗性样本,但没有利用基于 Mahalanobis 距离的度量,即,他们在分数中仅使用欧几里得距离。 在本文中,我们证明马氏距离在各种任务中明显比欧几里得距离更有效。
对生成分类器的实验支持。 为了评估我们的假设,即 DNN 的训练特征支持 GDA 的假设,我们按如下方式测量分类精度:
| (3) |
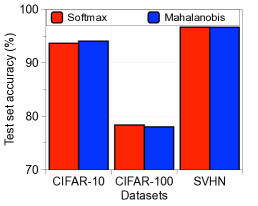
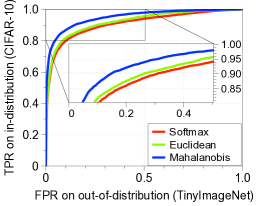
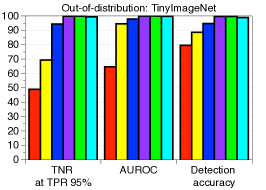
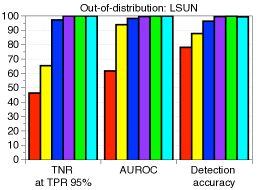
我们注意到,这对应于使用来自具有统一类先验的生成分类器的后验分布来预测类标签。 有趣的是,我们发现基于 Mahalanobis 距离的分类器(蓝色条)也实现了 softmax 准确率(红色条),而传统知识是从头开始训练的生成分类器通常比诸如 softmax 之类的判别式分类器表现更差。 为了进行视觉解释,图 1(a) 展示了由 t-SNE [23] 构建的 CIFAR-10 测试样本的最终特征的嵌入,其中点的颜色表示对应对象的类。 我们可以观察到所有十个类在嵌入空间中都清晰地分开,这支持了我们的直觉。 此外,我们还表明,基于马哈拉诺比斯距离的度量在检测分布外样本方面非常有用。 为了进行评估,我们使用简单的基于阈值的检测器通过计算测试样本 上的置信度得分 来获得接收者操作特征 (ROC) 曲线,并将其判定为正(即,分布中)如果 高于某个阈值。 考虑仅利用经验类均值的欧几里德距离进行比较。 我们在 CIFAR-10 上训练 ResNet,TinyImageNet 数据集 [5] 用于分布外。 如图1(c)所示,基于马哈拉诺比斯距离的度量(蓝色条)比欧几里得度量(绿色条)和softmax分布的最大值(红色条)表现更好。
2.2校准技术
输入预处理。 为了使分布内和分布外样本更加可分离,我们考虑向测试样本添加小的受控噪声。 具体来说,对于每个测试样本,我们通过添加小扰动来计算预处理样本,如下所示:
| (4) |
其中 是噪声大小, 是最接近类别的索引。 接下来,我们使用预处理的样本来测量置信度得分。 我们注意到,与对抗性攻击[10]不同,生成噪声是为了增加建议的置信度得分(2)。 在我们的实验中,这种扰动对于分离分布内和分布外样本具有更强的影响。 我们注意到在[21]中研究了类似的输入预处理,其中添加扰动以增加预测标签的softmax得分。 然而,我们的方法的不同之处在于,生成噪声是为了增加建议的指标。
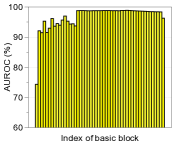
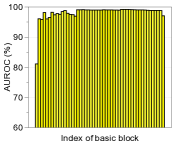
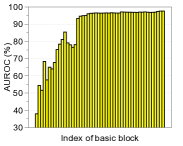
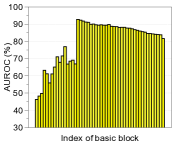
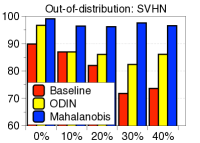
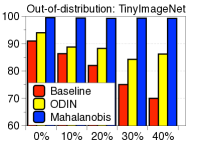
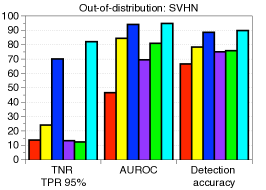
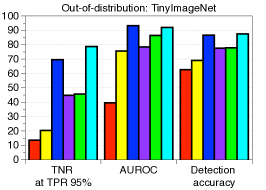
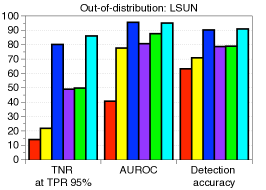
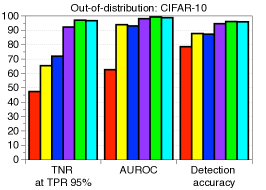
功能合奏。 为了进一步提高性能,我们考虑测量和组合来自最终特征和 DNN 中其他低级特征的置信度得分。 形式上,给定训练数据,我们提取 DNN 的第 个隐藏特征,用 表示,并计算它们的经验类均值和相关协方差,即 和。 然后,对于每个测试样本 ,我们使用 (2) 中的公式测量第 层的置信度得分。 人们可以预期,这种简单但自然的方案可以通过从低级特征中提取更多特定于输入的信息来获得更好的校准分数,从而带来额外的收益。 我们使用在 DenseNet [14] 的不同基本块上计算的置信度得分 (2) 来测量基于阈值的检测器的 ROC (AUROC) 曲线下面积CIFAR-10 数据集,ResNet 上的总体趋势相似。 图2展示了各种OOD样本的性能,例如SVHN [28]、LSUN [32]、TinyImageNet和DeepFool生成的对抗样本[26],其中使用平均池化来减少中间特征的维度(有关更多详细信息,请参阅第 3 节)。 如图2所示,与最终特征(例如LSUN、TinyImageNet和DeepFool)相比,在低级特征上计算的置信度得分通常提供更好的校准得分。 为了进一步提高性能,我们设计了一种特征集成方法,如算法1中所述。 我们首先从所有层中提取置信度得分,然后通过加权平均对它们进行积分:,其中和是第层及其权重。 在我们的实验中,遵循[22]中的类似策略,我们通过使用验证样本训练逻辑回归检测器来选择每层的权重。 我们注意到,即使在某些层的置信度分数无效的情况下,这种置信度分数的加权平均也可以防止整体性能下降:对于那些无效层,训练的权重(使用验证)将几乎为零。
2.3使用基于马哈拉诺比斯距离的分数进行班级增量学习
作为自然扩展,我们还表明,基于马哈拉诺比斯距离的置信度得分可以用于类增量学习任务[29]:每当有新的数据出现时,在基类上预训练的分类器就会逐步更新。出现具有相应样本的类。 众所周知,这项任务具有挑战性,因为人们必须用有限的记忆来处理灾难性的遗忘[24]。 为此,最近的工作一直致力于开发新的训练方法,其中涉及生成模型或数据采样,但采用这种训练方法可能会产生昂贵的来回成本。 基于所提出的置信度得分,我们开发了一种简单的分类方法,无需使用复杂的训练方法。 为此,我们首先假设分类器已经用一定数量的基类进行了良好的预训练,该假设在许多实际场景中是相当合理的。111例如,在大规模图像数据集上训练的最先进的 CNN 是现成的[12, 14],因此它们是许多计算机视觉任务的起点[9,18,25]。 在这种情况下,可以预期分类器不仅可以很好地检测 OOD 样本,而且还可能有利于区分新类,因为使用基类学习的表示可以表征新类。 受此启发,我们提出了一个基于 (3) 的马哈拉诺比斯距离分类器,它尝试通过简单地计算和更新类均值和协方差来适应新类,如算法 2。 我们的置信度分数的类别增量适应显示了其在未来广泛应用于新应用程序的潜力。
3实验结果
在本节中,我们使用深度卷积神经网络(例如 DenseNet [14] 和 ResNet [12])在各种视觉数据集上证明了所提出方法的有效性:CIFAR [15]、SVHN [28]、ImageNet [5] 和 LSUN [32]。 由于空间限制,我们在补充材料中提供了更详细的实验设置和结果。 我们的代码可在 https://github.com/pokaxpoka/deep_Mahalanobis_detector 获取。
|
|
|
|
|
|
|
|
||||||||||||||
| Baseline [13] | - | - | 32.47 | 89.88 | 85.06 | 85.40 | 93.96 | ||||||||||||||
| ODIN [21] | - | - | 86.55 | 96.65 | 91.08 | 92.54 | 98.52 | ||||||||||||||
| Mahalanobis (ours) | - | - | 54.51 | 93.92 | 89.13 | 91.56 | 95.95 | ||||||||||||||
| - | ✓ | 92.26 | 98.30 | 93.72 | 96.01 | 99.28 | |||||||||||||||
| ✓ | - | 91.45 | 98.37 | 93.55 | 96.43 | 99.35 | |||||||||||||||
| ✓ | ✓ | 96.42 | 99.14 | 95.75 | 98.26 | 99.60 |
3.1 检测分布外样本
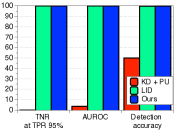
设置。 对于检测分布外(OOD)样本的问题,我们使用 100 层的 DenseNet 和 34 层的 ResNet 对 CIFAR-10、CIFAR-100 和 SVHN 数据集进行分类。 训练中使用的数据集是分布内(正)数据集,其他数据集被视为 OOD(负)。 我们仅使用测试数据集进行评估。 此外,TinyImageNet(即 ImageNet 数据集的子集)和 LSUN 数据集也作为 OOD 进行了测试。 为了进行评估,我们使用基于阈值的检测器来测量测试样本的一些置信度得分,然后如果置信度得分高于某个阈值,则将测试样本分类为分布内。 我们测量以下指标:95% 真阳性率 (TPR) 时的真阴性率 (TNR)、受试者工作特征曲线下面积 (AUROC)、精确率-召回率曲线下面积 (AUPR) 和检测率准确性。 为了进行比较,我们考虑基线方法[13],它将置信度得分定义为后验分布的最大值,以及最先进的ODIN[21],它将置信度得分定义为处理后的后验分布的最大值。
对于我们的方法,我们从 DenseNet(或 ResNet)的密集(或残差)块的每一端提取置信度分数。 为了提高计算效率,每个卷积层上特征图的大小通过平均池化来减小:,其中是通道数,是空间方面。 如算法 1 所示,逻辑回归检测器的输出用作我们案例中的最终置信度得分。 所有超参数均在单独的验证集上进行调整,该验证集由来自每个分布内和分布外对的 1,000 张图像组成。 与Ma等人[22]类似,逻辑回归检测器的权重是使用验证集中的嵌套交叉验证来训练的,其中类标签对于分布内样本分配为正,对于OOD分配为负样品。 由于实际中可能没有 OOD 验证数据集,我们还考虑使用 FGSM [10] 生成的分布内(正)样本和相应的对抗(负)样本来调整超参数。
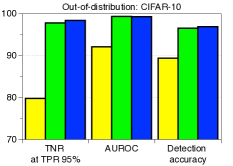
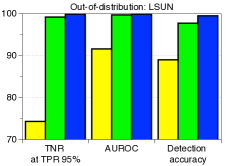
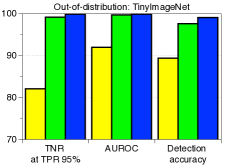
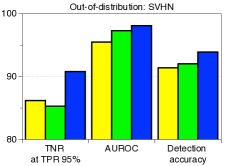
每种技术的贡献以及与 ODIN 的比较。 表1验证了我们建议的技术在与基线方法和ODIN的比较下的贡献。 当 SVHN 数据集用作 OOD 时,我们使用在 CIFAR-10 上训练的 ResNet 来测量检测性能。 我们逐步应用我们的技术来看到每个组件的逐步改进。 可以注意到,我们的方法明显优于没有特征集成和输入预处理的基线方法。 这意味着与后验分布相比,我们的方法可以非常有效地表征 OOD 样本。 通过利用特征集成和输入预处理,与ODIN相比,检测性能进一步提高。 表 2 的左侧列报告了 ODIN 对所有分布内和分布外数据集对的检测性能。 对于所有测试案例,我们的方法都优于基线和 ODIN。 特别是,与使用 DenseNet 的 ODIN 相比,我们的方法提高了 TNR,即检测到的 LSUN 样本的比例: 使用 DenseNet,正确检测到 95% 的 CIFAR-100 样本。
| In-dist (model) | OOD | Validation on OOD samples | Validation on adversarial samples | ||||
|---|---|---|---|---|---|---|---|
| TNR at TPR 95% | AUROC | Detection acc. | TNR at TPR 95% | AUROC | Detection acc. | ||
| Baseline [13] / ODIN [21] / Mahalanobis (ours) | Baseline [13] / ODIN [21] / Mahalanobis (ours) | ||||||
| CIFAR-10 (DenseNet) | SVHN | 40.2 / 86.2 / 90.8 | 89.9 / 95.5 / 98.1 | 83.2 / 91.4 / 93.9 | 40.2 / 70.5 / 89.6 | 89.9 / 92.8 / 97.6 | 83.2 / 86.5 / 92.6 |
| TinyImageNet | 58.9 / 92.4 / 95.0 | 94.1 / 98.5 / 98.8 | 88.5 / 93.9 / 95.0 | 58.9 / 87.1 / 94.9 | 94.1 / 97.2 / 98.8 | 88.5 / 92.1 / 95.0 | |
| LSUN | 66.6 / 96.2 / 97.2 | 95.4 / 99.2 / 99.3 | 90.3 / 95.7 / 96.3 | 66.6 / 92.9 / 97.2 | 95.4 / 98.5 / 99.2 | 90.3 / 94.3 / 96.2 | |
| CIFAR-100 (DenseNet) | SVHN | 26.7 / 70.6 / 82.5 | 82.7 / 93.8 / 97.2 | 75.6 / 86.6 / 91.5 | 26.7 / 39.8 / 62.2 | 82.7 / 88.2 / 91.8 | 75.6 / 80.7 / 84.6 |
| TinyImageNet | 17.6 / 42.6 / 86.6 | 71.7 / 85.2 / 97.4 | 65.7 / 77.0 / 92.2 | 17.6 / 43.2 / 87.2 | 71.7 / 85.3 / 97.0 | 65.7 / 77.2 / 91.8 | |
| LSUN | 16.7 / 41.2 / 91.4 | 70.8 / 85.5 / 98.0 | 64.9 / 77.1 / 93.9 | 16.7 / 42.1 / 91.4 | 70.8 / 85.7 / 97.9 | 64.9 / 77.3 / 93.8 | |
| SVHN (DenseNet) | CIFAR-10 | 69.3 / 71.7 / 96.8 | 91.9 / 91.4 / 98.9 | 86.6 / 85.8 / 95.9 | 69.3 / 69.3 / 97.5 | 91.9 / 91.9 / 98.8 | 86.6 / 86.6 / 96.3 |
| TinyImageNet | 79.8 / 84.1 / 99.9 | 94.8 / 95.1 / 99.9 | 90.2 / 90.4 / 98.9 | 79.8 / 79.8 / 99.9 | 94.8 / 94.8 / 99.8 | 90.2 / 90.2 / 98.9 | |
| LSUN | 77.1 / 81.1 / 100 | 94.1 / 94.5 / 99.9 | 89.1 / 89.2 / 99.3 | 77.1 / 77.1 / 100 | 94.1 / 94.1 / 99.9 | 89.1 / 89.1 / 99.2 | |
| CIFAR-10 (ResNet) | SVHN | 32.5 / 86.6 / 96.4 | 89.9 / 96.7 / 99.1 | 85.1 / 91.1 / 95.8 | 32.5 / 40.3 / 75.8 | 89.9 / 86.5 / 95.5 | 85.1 / 77.8 / 89.1 |
| TinyImageNet | 44.7 / 72.5 / 97.1 | 91.0 / 94.0 / 99.5 | 85.1 / 86.5 / 96.3 | 44.7 / 69.6 / 95.5 | 91.0 / 93.9 / 99.0 | 85.1 / 86.0 / 95.4 | |
| LSUN | 45.4 / 73.8 / 98.9 | 91.0 / 94.1 / 99.7 | 85.3 / 86.7 / 97.7 | 45.4 / 70.0 / 98.1 | 91.0 / 93.7 / 99.5 | 85.3 / 85.8 / 97.2 | |
| CIFAR-100 (ResNet) | SVHN | 20.3 / 62.7 / 91.9 | 79.5 / 93.9 / 98.4 | 73.2 / 88.0 / 93.7 | 20.3 / 12.2 / 41.9 | 79.5 / 72.0 / 84.4 | 73.2 / 67.7 / 76.5 |
| TinyImageNet | 20.4 / 49.2 / 90.9 | 77.2 / 87.6 / 98.2 | 70.8 / 80.1 / 93.3 | 20.4 / 33.5 / 70.3 | 77.2 / 83.6 / 87.9 | 70.8 / 75.9 / 84.6 | |
| LSUN | 18.8 / 45.6 / 90.9 | 75.8 / 85.6 / 98.2 | 69.9 / 78.3 / 93.5 | 18.8 / 31.6 / 56.6 | 75.8 / 81.9 / 82.3 | 69.9 / 74.6 / 79.7 | |
| SVHN (ResNet) | CIFAR-10 | 78.3 / 79.8 / 98.4 | 92.9 / 92.1 / 99.3 | 90.0 / 89.4 / 96.9 | 78.3 / 79.8 / 94.1 | 92.9 / 92.1 / 97.6 | 90.0 / 89.4 / 94.6 |
| TinyImageNet | 79.0 / 82.1 / 99.9 | 93.5 / 92.0 / 99.9 | 90.4 / 89.4 / 99.1 | 79.0 / 80.5 / 99.2 | 93.5 / 92.9 / 99.3 | 90.4 / 90.1 / 98.8 | |
| LSUN | 74.3 / 77.3 / 99.9 | 91.6 / 89.4 / 99.9 | 89.0 / 87.2 / 99.5 | 74.3 / 76.3 / 99.9 | 91.6 / 90.7 / 99.9 | 89.0 / 88.2 / 99.5 | |
|
|
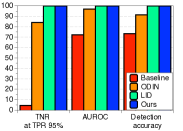
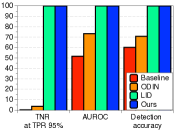
鲁棒性比较。 为了评估我们方法的稳健性,我们测量了仅使用 FGSM [10] 生成的分布内样本和对抗样本调整所有超参数时的检测性能。 如表2右栏所示,在某些情况下(例如,在 SVHN 上训练的 DenseNet),ODIN 与基线方法相比效果较差,而我们的方法仍然始终优于基线和 ODIN 。 我们注意到,我们的方法在没有 OOD 的情况下进行了验证,但对抗性样本甚至优于使用 OOD 验证的 ODIN。 我们还验证了我们的方法在各种训练设置下的稳健性。 由于我们的方法利用训练样本的经验类均值和协方差,因此需要注意的是,它可能会受到训练数据属性的影响。 为了验证鲁棒性,我们通过改变训练数据的数量并为 CIFAR-10 数据集上的训练数据分配随机标签来测量训练 ResNet 时的检测性能。 如图3所示,即使对于少量训练数据或有噪声的训练数据,我们的方法(蓝色条)也能保持较高的检测性能,而基线(红色条)和 ODIN(黄色条)则不然。 最后,我们指出,我们使用由标准交叉熵损失训练的 softmax 神经分类器的方法通常优于使用由置信度损失 [20] 训练的 softmax 神经分类器的 ODIN,其中涉及联合训练生成器和分类器进行校准后验分布,即使训练这样的模型在计算上更昂贵(有关更多详细信息,请参阅补充材料)。
3.2 检测对抗性样本
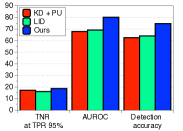
设置。 对于检测对抗性样本的问题,我们训练DenseNet和ResNet来对CIFAR-10、CIFAR-100和SVHN数据集进行分类,并使用相应的测试数据集作为正样本来衡量性能。 我们使用对抗性图像作为以下攻击方法生成的负样本:FGSM [10]、BIM [16]、DeepFool [26]和CW [3],详细解释可以在补充材料中找到。 为了进行比较,我们使用基于核密度(KD)[7]和预测不确定性(PU)(即后验分布的最大值)组合的逻辑回归检测器。 我们还比较了最先进的局部内在维度 (LID) 分数[22]。 遵循[7, 22]中的类似策略,我们随机选择10%的原始测试样本来训练逻辑回归检测器,其余测试样本用于评估。 在训练集中使用嵌套交叉验证,所有超参数都会得到调整。
| Model | Dataset (model) | Score | Detection of known attack | Detection of unknown attack | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FGSM | BIM | DeepFool | CW | FGSM (seen) | BIM | DeepFool | CW | |||
| DenseNet | CIFAR-10 | KD+PU [7] | 85.96 | 96.80 | 68.05 | 58.72 | 85.96 | 3.10 | 68.34 | 53.21 |
| LID [22] | 98.20 | 99.74 | 85.14 | 80.05 | 98.20 | 94.55 | 70.86 | 71.50 | ||
| Mahalanobis (ours) | 99.94 | 99.78 | 83.41 | 87.31 | 99.94 | 99.51 | 83.42 | 87.95 | ||
| CIFAR-100 | KD+PU [7] | 90.13 | 89.69 | 68.29 | 57.51 | 90.13 | 66.86 | 65.30 | 58.08 | |
| LID [22] | 99.35 | 98.17 | 70.17 | 73.37 | 99.35 | 68.62 | 69.68 | 72.36 | ||
| Mahalanobis (ours) | 99.86 | 99.17 | 77.57 | 87.05 | 99.86 | 98.27 | 75.63 | 86.20 | ||
| SVHN | KD+PU [7] | 86.95 | 82.06 | 89.51 | 85.68 | 86.95 | 83.28 | 84.38 | 82.94 | |
| LID [22] | 99.35 | 94.87 | 91.79 | 94.70 | 99.35 | 92.21 | 80.14 | 85.09 | ||
| Mahalanobis (ours) | 99.85 | 99.28 | 95.10 | 97.03 | 99.85 | 99.12 | 93.47 | 96.95 | ||
| ResNet | CIFAR-10 | KD+PU [7] | 81.21 | 82.28 | 81.07 | 55.93 | 83.51 | 16.16 | 76.80 | 56.30 |
| LID [22] | 99.69 | 96.28 | 88.51 | 82.23 | 99.69 | 95.38 | 71.86 | 77.53 | ||
| Mahalanobis (ours) | 99.94 | 99.57 | 91.57 | 95.84 | 99.94 | 98.91 | 78.06 | 93.90 | ||
| CIFAR-100 | KD+PU [7] | 89.90 | 83.67 | 80.22 | 77.37 | 89.90 | 68.85 | 57.78 | 73.72 | |
| LID [22] | 98.73 | 96.89 | 71.95 | 78.67 | 98.73 | 55.82 | 63.15 | 75.03 | ||
| Mahalanobis (ours) | 99.77 | 96.90 | 85.26 | 91.77 | 99.77 | 96.38 | 81.95 | 90.96 | ||
| SVHN | KD+PU [7] | 82.67 | 66.19 | 89.71 | 76.57 | 82.67 | 43.21 | 84.30 | 67.85 | |
| LID [22] | 97.86 | 90.74 | 92.40 | 88.24 | 97.86 | 84.88 | 67.28 | 76.58 | ||
| Mahalanobis (ours) | 99.62 | 97.15 | 95.73 | 92.15 | 99.62 | 95.39 | 72.20 | 86.73 | ||
与 LID 的比较和泛化分析。 表 3 的左侧列报告了所有正常对和对抗对的逻辑回归检测器的 AUROC 分数。 可以注意到,在大多数情况下,所提出的方法优于所有测试的方法。 特别是,当我们使用在 CIFAR-10 数据集上训练的 ResNet 检测 CW 样本时,我们的 LID 的 AUROC 从 提高到 。 与[22]类似,我们还评估了所提出的方法是否可以针对简单攻击进行调整,以检测其他更复杂的攻击。 为此,我们使用 FGSM 生成的样本训练逻辑回归检测器时测量检测性能。 如表3右栏所示,我们在 FGSM 上训练的方法可以准确检测更复杂的攻击,例如 BIM、DeepFool 和 CW。 尽管 LID 也可以很好地泛化,但我们的方法在大多数情况下仍然优于它。 一个自然出现的问题是 LID 是否可用于检测 OOD 样本。 我们确实将我们的方法的性能与补充材料中的 LID 的性能进行了比较,其中我们的方法在所有测试案例中仍然优于 LID。
3.3班级-增量学习
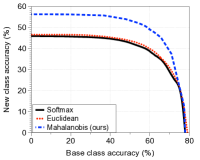
设置。 对于类增量学习的任务,我们训练了 34 层的 ResNet,用于分类 CIFAR-100 和下采样 ImageNet [4]。 如2.3节所述,我们假设分类器在一定数量的基类上进行预训练,并一一增量地提供具有相应数据集的新类。 具体来说,我们测试两种不同的场景:在第一种场景中,一半的 CIFAR-100 类是基类,其余的是新类。 在第二种情况下,CIFAR-100 中的所有类都被视为基类,而 ImageNet 中的 100 个类是新类。 所有场景均测试五次,然后取平均值。 每次试验都会随机生成班级分组。 为了进行比较,我们考虑一个 softmax 分类器,每当新的类数据出现时它就会进行微调,以及一个欧几里德分类器 [25],它试图通过仅计算类平均值来适应新的类。 对于softmax分类器,我们仅更新softmax层以实现接近零成本的训练[25],并遵循Rebuffi & Kolesnikov [29]中的内存管理:来自旧类别的少量样本被保存在有限的存储器中,其中存储器的大小与用于保存基于马哈拉诺比斯距离的分类器的参数的大小相匹配。 也就是说,为训练 softmax 分类器而保留的旧样本的数量被选择为学习类的数量和隐藏特征的维度(在我们的实验中为 )的总和。 为了进行评估,与[18]类似,我们首先通过调整新类别分数的附加偏差来绘制基础-新类别准确率曲线,并测量平均基础和新类别的曲线下面积(AUC)类准确性可能会导致基类和新类之间的性能衡量不平衡。
|
|
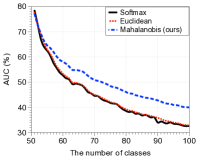
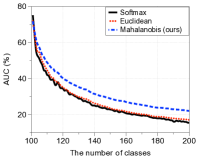
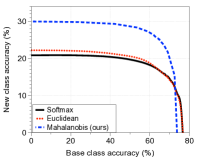
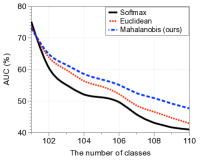
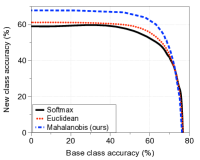
与其他分类器的比较。 图4比较了上述两种场景下方法在AUC方面的增量学习性能。 在每个子图中,绘制了相对于学习类数量的 AUC(左)和添加最后一个新类后的基础新类准确率曲线(右)。 随着新类别数量的增加,我们提出的基于马哈拉诺比斯距离的分类器明显优于其他方法,尽管图 4(b) 右图中在小范围内存在交叉(由于灾难性遗忘问题)。 特别是,我们提出的方法的 AUC 为 40.0%(22.1%),在添加所有新类后,优于 softmax 分类器的 32.7%(15.6%)和欧几里德距离分类器的 32.9%(17.1%)。第一个(第二个)实验。 我们还在补充材料中报告了 CIFAR-100 的类为基类、CIFAR-10 的类为新类的情况下的实验结果,总体趋势相似。 实验结果还证明了我们的置信度分数与其他可信分数相比的优越性。
4结论
在本文中,我们提出了一种简单而有效的方法来检测异常测试样本,包括分布外样本和对抗样本。 本质上,我们的主要思想是在LDA假设下引入生成分类器,并基于它定义新的置信度得分。 通过输入预处理和特征集成等校准技术,我们的方法在多个任务中表现非常出色:检测分布外样本、检测对抗性攻击和类增量学习。 我们还发现,我们提出的方法在超参数的选择以及极端情况下更加稳健,例如,当训练数据集具有一些噪声、随机标签或少量数据样本时。 我们相信我们的方法有潜力应用于许多其他相关的机器学习任务,例如主动学习[8]、集成学习[19]和少样本学习[31]。
致谢
这项工作得到了韩国政府 (MSIT) 资助的信息与通信技术促进研究所 (IITP) 赠款的部分支持(No.R0132-15-1005,在线和离线环境中的内容视觉浏览技术)、国家研究委员会韩国政府 (MSIP) 科学技术 (NST) 拨款(No. CRC-15-05-ETRI)、DARPA 可解释人工智能 (XAI) 计划 #313498、斯隆研究奖学金和 Kwanjeong 教育基金会奖学金。
参考
- Amodei et al. [2016a] Amodei, Dario, Ananthanarayanan, Sundaram, Anubhai, Rishita, Bai, Jingliang, Battenberg, Eric, Case, Carl, Casper, Jared, Catanzaro, Bryan, Cheng, Qiang, Chen, Guoliang, et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In ICML, 2016a.
- Amodei et al. [2016b] Amodei, Dario, Olah, Chris, Steinhardt, Jacob, Christiano, Paul, Schulman, John, and Mané, Dan. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016b.
- Carlini & Wagner [2017] Carlini, Nicholas and Wagner, David. Adversarial examples are not easily detected: Bypassing ten detection methods. In ACM workshop on AISec, 2017.
- Chrabaszcz et al. [2017] Chrabaszcz, Patryk, Loshchilov, Ilya, and Hutter, Frank. A downsampled variant of imagenet as an alternative to the cifar datasets. arXiv preprint arXiv:1707.08819, 2017.
- Deng et al. [2009] Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, and Fei-Fei, Li. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- Evtimov et al. [2018] Evtimov, Ivan, Eykholt, Kevin, Fernandes, Earlence, Kohno, Tadayoshi, Li, Bo, Prakash, Atul, Rahmati, Amir, and Song, Dawn. Robust physical-world attacks on machine learning models. In CVPR, 2018.
- Feinman et al. [2017] Feinman, Reuben, Curtin, Ryan R, Shintre, Saurabh, and Gardner, Andrew B. Detecting adversarial samples from artifacts. arXiv preprint arXiv:1703.00410, 2017.
- Gal et al. [2017] Gal, Yarin, Islam, Riashat, and Ghahramani, Zoubin. Deep bayesian active learning with image data. In ICML, 2017.
- Girshick [2015] Girshick, Ross. Fast r-cnn. In ICCV, 2015.
- Goodfellow et al. [2015] Goodfellow, Ian J, Shlens, Jonathon, and Szegedy, Christian. Explaining and harnessing adversarial examples. In ICLR, 2015.
- Guo et al. [2017] Guo, Chuan, Rana, Mayank, Cissé, Moustapha, and van der Maaten, Laurens. Countering adversarial images using input transformations. arXiv preprint arXiv:1711.00117, 2017.
- He et al. [2016] He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Deep residual learning for image recognition. In CVPR, 2016.
- Hendrycks & Gimpel [2017] Hendrycks, Dan and Gimpel, Kevin. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In ICLR, 2017.
- Huang & Liu [2017] Huang, Gao and Liu, Zhuang. Densely connected convolutional networks. In CVPR, 2017.
- Krizhevsky & Hinton [2009] Krizhevsky, Alex and Hinton, Geoffrey. Learning multiple layers of features from tiny images. 2009.
- Kurakin et al. [2016] Kurakin, Alexey, Goodfellow, Ian, and Bengio, Samy. Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533, 2016.
- Lasserre et al. [2006] Lasserre, Julia A, Bishop, Christopher M, and Minka, Thomas P. Principled hybrids of generative and discriminative models. In CVPR, 2006.
- Lee et al. [2018a] Lee, Kibok, Lee, Kimin, Min, Kyle, Zhang, Yuting, Shin, Jinwoo, and Lee, Honglak. Hierarchical novelty detection for visual object recognition. In CVPR, 2018a.
- Lee et al. [2017] Lee, Kimin, Hwang, Changho, Park, KyoungSoo, and Shin, Jinwoo. Confident multiple choice learning. In ICML, 2017.
- Lee et al. [2018b] Lee, Kimin, Lee, Honglak, Lee, Kibok, and Shin, Jinwoo. Training confidence-calibrated classifiers for detecting out-of-distribution samples. In ICLR, 2018b.
- Liang et al. [2018] Liang, Shiyu, Li, Yixuan, and Srikant, R. Principled detection of out-of-distribution examples in neural networks. In ICLR, 2018.
- Ma et al. [2018] Ma, Xingjun, Li, Bo, Wang, Yisen, Erfani, Sarah M, Wijewickrema, Sudanthi, Houle, Michael E, Schoenebeck, Grant, Song, Dawn, and Bailey, James. Characterizing adversarial subspaces using local intrinsic dimensionality. In ICLR, 2018.
- Maaten & Hinton [2008] Maaten, Laurens van der and Hinton, Geoffrey. Visualizing data using t-sne. Journal of machine learning research, 2008.
- McCloskey & Cohen [1989] McCloskey, Michael and Cohen, Neal J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation. Elsevier, 1989.
- Mensink et al. [2013] Mensink, Thomas, Verbeek, Jakob, Perronnin, Florent, and Csurka, Gabriela. Distance-based image classification: Generalizing to new classes at near-zero cost. IEEE transactions on pattern analysis and machine intelligence, 2013.
- Moosavi Dezfooli et al. [2016] Moosavi Dezfooli, Seyed Mohsen, Fawzi, Alhussein, and Frossard, Pascal. Deepfool: a simple and accurate method to fool deep neural networks. In CVPR, 2016.
- Murphy [2012] Murphy, Kevin P. Machine learning: a probabilistic perspective. 2012.
- Netzer et al. [2011] Netzer, Yuval, Wang, Tao, Coates, Adam, Bissacco, Alessandro, Wu, Bo, and Ng, Andrew Y. Reading digits in natural images with unsupervised feature learning. In NIPS workshop, 2011.
- Rebuffi & Kolesnikov [2017] Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander. icarl: Incremental classifier and representation learning. In CVPR, 2017.
- Sharif et al. [2016] Sharif, Mahmood, Bhagavatula, Sruti, Bauer, Lujo, and Reiter, Michael K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In ACM SIGSAC, 2016.
- Vinyals et al. [2016] Vinyals, Oriol, Blundell, Charles, Lillicrap, Tim, Wierstra, Daan, et al. Matching networks for one shot learning. In NIPS, 2016.
- Yu et al. [2015] Yu, Fisher, Seff, Ari, Zhang, Yinda, Song, Shuran, Funkhouser, Thomas, and Xiao, Jianxiong. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
补充材料:
用于检测分布外样本和对抗性攻击的简单统一框架
附录 A 高斯判别分析的预备知识
在本节中,我们描述判别和生成分类器[27]的基本概念。 形式上,将输入和标签的随机变量分别表示为 和 。 对于分类任务,判别分类器直接定义后验分布,即学习输入和标签之间的直接映射。 判别分类器的流行模型是 softmax 分类器,它定义后验分布如下: 其中 和 是类 与判别分类器相比,生成分类器定义了类条件分布和类先验,以便通过指定联合分布。 高斯判别分析(GDA)是一种流行的定义生成分类器的方法,它假设类条件分布遵循多元高斯分布,类先验遵循伯努利分布: 其中 是多元高斯分布的均值和协方差, 是 类的非归一化先验。该分类器已在各种机器学习领域(例如半监督学习[17]和增量学习[29])进行研究。
在本文中,我们重点关注 GDA 的特殊情况,也称为线性判别分析(LDA)。 除了高斯假设之外,LDA还假设所有类共享相同的协方差矩阵,即。 由于用这个假设抵消了二次项,生成分类器的后验分布可以表示如下:
可以注意到,上述形式的后验分布相当于将和分别视为其权重和偏差的softmax分类器。 这意味着在训练 softmax 分类器期间 可能适合高斯分布。
附录 B实验设置
在本节中,我们对3节中描述的所有实验进行详细解释。
B.1 检测分布外的实验设置
详细的模型架构和训练。 我们考虑两种最先进的神经网络架构:DenseNet [14] 和 ResNet [12]。 对于 DenseNet,我们的模型遵循与 Huang & Liu [14] 相同的设置:100 层,增长率 和 dropout 率 0。 此外,我们使用 34 层且 dropout 率为 0 的 ResNet。222ResNet 架构可在 https://github.com/kuangliu/pytorch-cifar 获取。 使用 softmax 分类器,并使用带有 Nesterov 动量的 SGD 最小化交叉熵损失来训练每个模型。 具体来说,我们训练 DenseNet 300 个周期,批量大小为 64,动量为 0.9。 对于 ResNet,我们将其训练 200 个周期,批量大小为 128,动量为 0.9。 学习率从 0.1 开始,在训练进度的 50% 和 75% 时分别下降 10 倍。 表4报告了DenseNet和ResNet在CIFAR-10、CIFAR-100和SVHN上的测试集错误。
数据集。 我们训练 DenseNet 和 ResNet,用于训练 CIFAR-10(或 100)和 SVHN 数据集的分类:前者由 50,000 和 10,000 个具有 10(或 100)个图像类的测试图像组成,后者由 73,257 个和 26,032 个具有 10 个图像类的测试图像组成。数字。333我们不使用额外的 SVHN 数据集进行训练。 相应的测试数据集用作分布内(正)样本来衡量性能。 我们使用真实图像作为分布外(负)样本:TinyImageNet 由 10,000 个测试图像组成,其中包含来自 ImageNet 图像子集的 200 个图像类。 LSUN 由 10 个不同场景的 10,000 张测试图像组成。 我们将 TinyImageNet 和 LSUN 的每个图像下采样到大小 。444LSUN 和 TinyImageNet 数据集可在 https://github.com/ShiyuLiang/odin-pytorch 获取。
经过测试的方法。 在本文中,我们考虑基线方法[13]和ODIN[21]进行比较。 Hendrycks & Gimpel [13]中的置信度得分是softmax后验分布的最大值,即。 ODIN 的核心思想是温标,其定义如下:
其中是温度缩放参数,是深度神经网络的最终特征向量。 对于每个数据,ODIN首先通过添加小扰动来计算预处理图像,如下所示:
其中 是噪声大小, 是预测标签。 接下来,ODIN 将预处理后的数据输入分类器,计算缩放预测分布的最大值,即 ,如果置信度得分高于此值,则将其分类为正(即分布内)某个阈值。 对于ODIN,扰动噪声从中选择,温度从中选择。
我们方法的超参数。 我们的方法中有两个超参数:(4) 中的噪声大小和特征集合的层索引。 对于所有实验,我们从 DenseNet(或 ResNet)的密集(或残差)块的每一端提取置信度分数。 为了提高计算效率,每个卷积层上特征图的大小通过平均池化来减小:,其中是通道数,是空间方面。 (4) 中的噪声大小是从 中选择的。
性能指标。 为了进行评估,我们测量以下指标来衡量置信度分数在区分分布内和分布外图像方面的有效性。
-
•
真阴性率 (TNR) 为 95% 真阳性率 (TPR)。 令 TP、TN、FP 和 FN 分别表示真阳性、真阴性、假阳性和假阴性。 我们测量TNR=TN/(FP+TN),当TPR=TP/(TP+FN)为95%时。
-
•
受试者工作特征曲线下面积 (AUROC)。 ROC 曲线是通过改变阈值绘制 TPR 与假阳性率 = FP / (FP+TN) 的图表。
-
•
精确率-召回率曲线下的面积 (AUPR)。 PR 曲线是通过改变阈值绘制精度 = TP / (TP+FP) 与召回率 = TP / (TP+FN) 的图表。 AUPR-IN(或-OUT)是AUPR,其中分布内(或分布外)样本被指定为正。
-
•
检测精度。 该指标对应于所有可能阈值的最大分类概率:
其中 是置信分数。 我们假设正例和负例在测试集中出现的概率相等,即。
请注意,AUROC、AUPR 和检测精度是与阈值无关的评估指标。
B.2 检测对抗性样本的实验设置
对抗性攻击。 对于检测对抗性样本的问题,我们考虑以下攻击方法:快速梯度符号法(FGSM)[10]、基本迭代法(BIM)[16]、 DeepFool [26] 和 Carlini-Wagner (CW) [3]。 FGSM 直接扰乱损失梯度方向的正常输入。 形式上,非目标对抗样本被构建为
其中 是噪声大小, 是地面实况标签, 是用于测量预测与地面实况之间距离的损失函数。 BIM是FGSM的迭代版本,以更小的步长多次应用FGSM。 形式上,非目标对抗样本被构建为
其中 表示我们将生成的图像剪切到 的 球内。 DeepFool 的工作原理是通过几何公式查找最接近的对抗性示例。 CW 是一种基于优化的方法,可以说是最有效的方法。 形式上,非目标对抗样本被构建为
其中 是惩罚参数, 是量化原始图像与其对抗图像之间距离的度量。 然而,与FGSM和BIM相比,这种方法在实践中要慢得多。 对于所有实验, 距离用作约束。 我们使用 FaceBook [11] 中的库来生成对抗样本。555代码可在 https://github.com/facebookresearch/adversarial_image_defenses 获取。 表4对抗性攻击的统计数据,包括对抗性攻击的平均扰动和分类准确性。
| CIFAR-10 | CIFAR-100 | SVHN | |||||
|---|---|---|---|---|---|---|---|
| Acc. | Acc. | Acc. | |||||
| DenseNet | Clean | 0 | 95.19% | 0 | 77.63% | 0 | 96.38% |
| FGSM | 0.21 | 20.04% | 0.21 | 4.86% | 0.21 | 56.27% | |
| BIM | 0.22 | 0.00% | 0.22 | 0.02% | 0.22 | 0.67% | |
| DeepFool | 0.30 | 0.23% | 0.25 | 0.23% | 0.57 | 0.50% | |
| CW | 0.05 | 0.10% | 0.03 | 0.16% | 0.12 | 0.54% | |
| ResNet | Clean | 0 | 93.67% | 0 | 78.34% | 0 | 96.68% |
| FGSM | 0.25 | 23.98% | 0.25 | 11.67% | 0.25 | 49.33% | |
| BIM | 0.26 | 0.02% | 0.26 | 0.21% | 0.26 | 2.37% | |
| DeepFool | 0.36 | 0.33% | 0.27 | 0.37% | 0.62 | 13.20% | |
| CW | 0.08 | 0.00% | 0.08 | 0.01% | 0.15 | 0.04% | |
经过测试的方法。 Ma等人[22]提出利用局部固有维数(LID)来表征对抗性子空间。 给定一个测试样本,LID定义如下:
其中 表示从分布中抽取的点样本中 与其第 个最近邻之间的距离, 表示最近邻居之间的最大距离。 我们通常从类似于我们的 DenseNet(或 ResNet)的密集(或残差)块的每一端提取 LID 分数。 给定测试样本 和带有标签 的训练样本集合 ,带宽 的高斯核密度定义如下:
其中。 对于LID和KD,我们使用来自Ma等人[22]的库。
超参数和训练。 遵循[7, 22]中的类似策略,我们随机选择10%的原始测试样本来训练逻辑回归检测器,其余测试样本用于评估。 训练集由三种类型的示例组成:对抗性、正常和噪声。 这里,噪声示例是通过向正常示例添加随机噪声来生成的。 在训练集中使用嵌套交叉验证,所有超参数(包括 KD 的带宽参数、LID 的最近邻居数量以及我们方法的输入噪声)都会得到调整。 具体来说,对于大小为 100 的小批量, 的值是从 中选择的,带宽是从 中选择的。 (4) 中的噪声大小是从 中选择的。
附录C更多实验结果
在本节中,我们提供更多的实验结果。
C.1 我们的方法在检测对抗性样本方面的稳健性
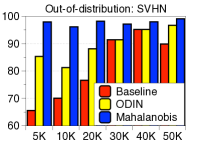
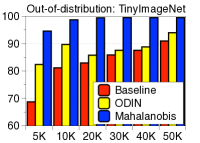
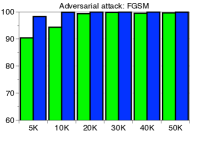
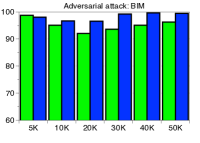
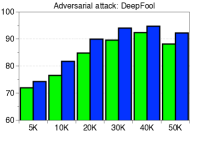
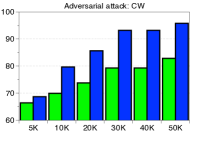
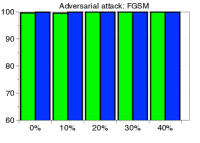
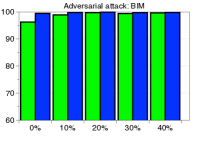
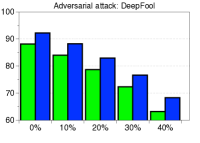
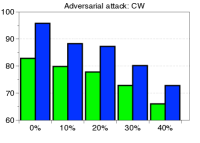
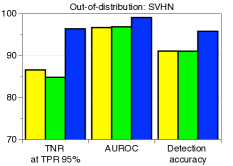
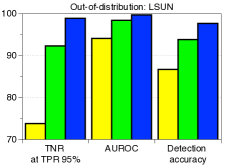
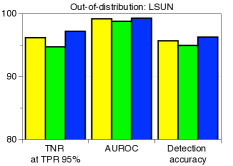
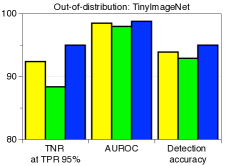
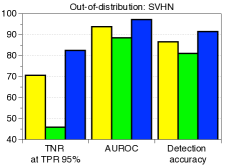
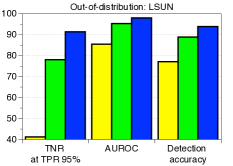
为了验证鲁棒性,我们通过改变训练数据的数量并为 CIFAR-10 数据集上的训练数据分配随机标签来测量训练 ResNet 时的检测性能。 如图5所示,我们的方法(蓝色条)在所有实验中都优于 LID(绿色条)。
|
|
|
C.2班级-增量学习
图6比较了CIFAR-100预训练和CIFAR-10作为新类时测试方法的AUC。 随着新类别数量的增加,我们提出的基于马哈拉诺比斯距离的分类器明显优于其他方法。 我们提出的方法的 AUC 为 47.7%,在添加所有新类后优于 softmax 分类器的 41.0% 和欧氏距离分类器的 43.0%。
C.3联合置信度损失的实验结果
此外,我们还指出,所提出的使用由标准交叉熵损失训练的 softmax 神经分类器的检测器通常优于使用由置信度损失 [19] 训练的 softmax 神经分类器的 ODIN 检测器,其中涉及联合训练生成器和分类器来校准后验分布。 此外,如果将我们的检测器与通过置信损失训练的模型一起使用,我们的检测器将提供进一步的改进。 换句话说,我们提出的方法可以改进任何预训练的 softmax 神经分类器。
|
|
C.4与 ODIN 的比较
| In-dist (model) | Out-of-dist |
|
|
|
|
|
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline [13] / ODIN [21] / Mahalanobis (ours) | |||||||||||
| CIFAR-10 (DenseNet) | SVHN | 40.2 / 86.2 / 90.8 | 89.9 / 95.5 / 98.1 | 83.2 / 91.4 / 93.9 | 83.1 / 78.8 / 96.6 | 94.7 / 98.3 / 99.2 | |||||
| TinyImageNet | 58.9 / 92.4 / 95.0 | 94.1 / 98.5 / 98.8 | 88.5 / 93.9 / 95.0 | 95.3 / 98.5 / 98.8 | 92.3 / 98.5 / 98.8 | ||||||
| LSUN | 66.6 / 96.2 / 97.2 | 95.4 / 99.2 / 99.3 | 90.3 / 95.7 / 96.3 | 96.5 / 99.3 / 99.3 | 94.1 / 99.2 / 99.1 | ||||||
| CIFAR-100 (DenseNet) | SVHN | 26.7 / 70.6 / 82.5 | 82.7 / 93.8 / 97.2 | 75.6 / 86.6 / 91.5 | 74.3 / 87.1 / 94.8 | 91.0 / 97.3 / 98.8 | |||||
| TinyImageNet | 17.6 / 42.6 / 86.6 | 71.7 / 85.2 / 97.4 | 65.7 / 77.0 / 92.2 | 74.2 / 85.6 / 97.6 | 69.0 / 84.5 / 97.2 | ||||||
| LSUN | 16.7 / 41.2 / 91.4 | 70.8 / 85.5 / 98.0 | 64.9 / 77.1 / 93.9 | 74.1 / 86.4 / 98.2 | 67.9 / 84.2 / 97.5 | ||||||
| SVHN (DenseNet) | CIFAR-10 | 69.3 / 71.7 / 96.8 | 91.9 / 91.4 / 98.9 | 86.6 / 85.8 / 95.9 | 95.7 / 95.2 / 99.6 | 82.8 / 84.5 / 95.8 | |||||
| TinyImageNet | 79.8 / 84.1 / 99.9 | 94.8 / 95.1 / 99.9 | 90.2 / 90.4 / 98.9 | 97.2 / 97.1 / 99.9 | 88.4 / 91.4 / 99.6 | ||||||
| LSUN | 77.1 / 81.1 / 100.0 | 94.1 / 94.5 / 99.9 | 89.1 / 89.2 / 99.3 | 97.0 / 97.0 / 99.9 | 87.4 / 90.5 / 99.7 | ||||||
| CIFAR-10 (ResNet) | SVHN | 32.5 / 86.6 / 96.4 | 89.9 / 96.7 / 99.1 | 85.1 / 91.1 / 95.8 | 85.4 / 92.5 / 98.3 | 94.0 / 98.5 / 99.6 | |||||
| TinyImageNet | 44.7 / 72.5 / 97.1 | 91.0 / 94.0 / 99.5 | 85.1 / 86.5 / 96.3 | 92.5 / 94.2 / 99.5 | 88.4 / 94.1 / 99.5 | ||||||
| LSUN | 45.4 / 73.8 / 98.9 | 91.0 / 94.1 / 99.7 | 85.3 / 86.7 / 97.7 | 92.5 / 94.2 / 99.7 | 88.6 / 94.3 / 99.7 | ||||||
| CIFAR-100 (ResNet) | SVHN | 20.3 / 62.7 / 91.9 | 79.5 / 93.9 / 98.4 | 73.2 / 88.0 / 93.7 | 64.8 / 89.0 / 96.4 | 89.0 / 96.9 / 99.3 | |||||
| TinyImageNet | 20.4 / 49.2 / 90.9 | 77.2 / 87.6 / 98.2 | 70.8 / 80.1 / 93.3 | 79.7 / 87.1 / 98.2 | 73.3 / 87.4 / 98.2 | ||||||
| LSUN | 18.8 / 45.6 / 90.9 | 75.8 / 85.6 / 98.2 | 69.9 / 78.3 / 93.5 | 77.6 / 84.5 / 98.4 | 72.0 / 85.7 / 97.8 | ||||||
| SVHN (ResNet) | CIFAR-10 | 78.3 / 79.8 / 98.4 | 92.9 / 92.1 / 99.3 | 90.0 / 89.4 / 96.9 | 95.1 / 94.0 / 99.7 | 85.7 / 86.8 / 97.0 | |||||
| TinyImageNet | 79.0 / 82.1 / 99.9 | 93.5 / 92.0 / 99.9 | 90.4 / 89.4 / 99.1 | 95.7 / 93.9 / 99.9 | 86.2 / 88.1 / 99.1 | ||||||
| LSUN | 74.3 / 77.3 / 99.9 | 91.6 / 89.4 / 99.9 | 89.0 / 87.2 / 99.5 | 94.2 / 92.1 / 99.9 | 84.0 / 85.5 / 99.1 | ||||||
| In-dist (model) | Out-of-dist |
|
|
|
|
|
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline [13] / ODIN [21] / Mahalanobis (ours) | |||||||||||
| CIFAR-10 (DenseNet) | SVHN | 40.2 / 70.5 / 89.6 | 89.9 / 92.8 / 97.6 | 83.2 / 86.5 / 92.6 | 83.1 / 72.1 / 94.5 | 94.7 / 97.4 / 99.0 | |||||
| TinyImageNet | 58.9 / 87.1 / 94.9 | 94.1 / 97.2 / 98.8 | 88.5 / 92.1 / 95.0 | 95.3 / 94.7 / 98.7 | 92.3 / 97.0 / 98.8 | ||||||
| LSUN | 66.6 / 92.9 / 97.2 | 95.4 / 98.5 / 99.2 | 90.3 / 94.3 / 96.2 | 96.5 / 97.7 / 99.3 | 94.1 / 98.2 / 99.2 | ||||||
| CIFAR-100 (DenseNet) | SVHN | 26.7 / 39.8 / 62.2 | 82.7 / 88.2 / 91.8 | 75.6 / 80.7 / 84.6 | 74.3 / 80.8 / 82.6 | 91.0 / 94.0 / 95.8 | |||||
| TinyImageNet | 17.6 / 43.2 / 87.2 | 71.7 / 85.3 / 97.0 | 65.7 / 77.2 / 91.8 | 74.2 / 85.8 / 96.2 | 69.0 / 84.7 / 97.1 | ||||||
| LSUN | 16.7 / 42.1 / 91.4 | 70.8 / 85.7 / 97.9 | 64.9 / 77.3 / 93.8 | 74.1 / 86.7 / 98.1 | 67.9 / 84.6 / 97.6 | ||||||
| SVHN (DenseNet) | CIFAR-10 | 69.3 / 69.3 / 97.5 | 91.9 / 91.9 / 98.8 | 86.6 / 86.6 / 96.3 | 95.7 / 95.7 / 99.6 | 82.8 / 82.8 / 95.1 | |||||
| TinyImageNet | 79.8 / 79.8 / 99.9 | 94.8 / 94.8 / 99.8 | 90.2 / 90.2 / 98.9 | 97.2 / 97.2 / 99.9 | 88.4 / 88.4 / 99.5 | ||||||
| LSUN | 77.1 / 77.1 / 100 | 94.1 / 94.1 / 99.9 | 89.1 / 89.1 / 99.2 | 97.0 / 97.0 / 99.9 | 87.4 / 87.4 / 99.6 | ||||||
| CIFAR-10 (ResNet) | SVHN | 32.5 / 40.3 / 75.8 | 89.9 / 86.5 / 95.5 | 85.1 / 77.8 / 89.1 | 85.4 / 77.8 / 91.0 | 94.0 / 93.7 / 98.0 | |||||
| TinyImageNet | 44.7 / 69.6 / 95.5 | 91.0 / 93.9 / 99.0 | 85.1 / 86.0 / 95.4 | 92.5 / 94.3 / 98.6 | 88.4 / 93.7 / 99.1 | ||||||
| LSUN | 45.4 / 70.0 / 98.1 | 91.0 / 93.7 / 99.5 | 85.3 / 85.8 / 97.2 | 92.5 / 94.1 / 99.5 | 88.6 / 93.6 / 99.5 | ||||||
| CIFAR-100 (ResNet) | SVHN | 20.3 / 12.2 / 41.9 | 79.5 / 72.0 / 84.4 | 73.2 / 67.7 / 76.5 | 64.8 / 48.6 / 69.1 | 89.0 / 84.9 / 92.7 | |||||
| TinyImageNet | 20.4 / 33.5 / 70.3 | 77.2 / 83.6 / 87.9 | 70.8 / 75.9 / 84.6 | 79.7 / 84.5 / 76.8 | 73.3 / 81.7 / 90.7 | ||||||
| LSUN | 18.8 / 31.6 / 56.6 | 75.8 / 81.9 / 82.3 | 69.9 / 74.6 / 79.7 | 77.6 / 82.1 / 70.3 | 72.0 / 80.3 / 85.3 | ||||||
| SVHN (ResNet) | CIFAR-10 | 78.3 / 79.8 / 94.1 | 92.9 / 92.1 / 97.6 | 90.0 / 89.4 / 94.6 | 95.1 / 94.0 / 98.1 | 85.7 / 86.8 / 94.7 | |||||
| TinyImageNet | 79.0 / 80.5 / 99.2 | 93.5 / 92.9 / 99.3 | 90.4 / 90.1 / 98.8 | 95.7 / 94.8 / 98.8 | 86.2 / 87.5 / 98.3 | ||||||
| LSUN | 74.3 / 76.3 / 99.9 | 91.6 / 90.7 / 99.9 | 89.0 / 88.2 / 99.5 | 94.2 / 93.0 / 99.9 | 84.0 / 85.0 / 98.8 | ||||||
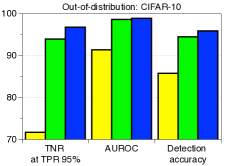
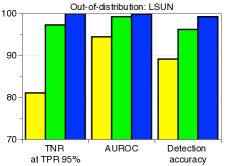
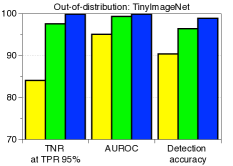
C.5 用于检测分布外样本的LID
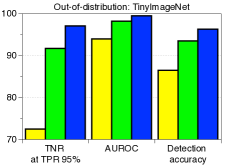
|
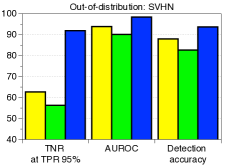
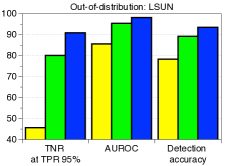
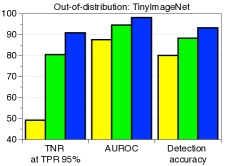
|
|
|
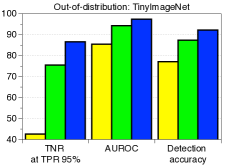
|
|
附录DImageNet数据集的评估
在本节中,我们使用包含 1000 个类的 ImageNet 2012 分类数据集 [5] 验证所提出方法的性能。 这些模型在 128 万张训练图像上进行训练,并在 5 万张验证图像上进行评估。 对于所有实验,我们使用预训练的 ResNet [12],该 ResNet 可从 https://github.com/pytorch/vision/blob/master/torchvision/models/resnet 获取。 py。 首先,我们根据预训练模型测量生成分类器的分类精度,如下所示:
其中 是经验类先验。 我们注意到,这对应于使用 LDA 假设的生成后验分布来预测类标签。 表7显示了ImageNet 2012数据集上的top-1分类精度。 值得注意的是,尽管 softmax 分类器在所有情况下都优于它,但所提出的生成分类器可以表现得相当好。 然而,我们注意到,随着训练精度的提高,它们之间的差距正在缩小,即预训练的模型学习了更强大的表示。
| Model |
|
|
|
|||
|---|---|---|---|---|---|---|
| ResNet (101 layers) | 86.55 | 75.66 | 73.49 | |||
| ResNet (18 layers) | 69.06 | 68.69 | 63.32 |
接下来,我们还使用 18 层的 ResNet 评估基于 Mahalanobis 距离的检测器在 ImageNet 2012 数据集上的检测性能。 为了进行评估,我们考虑检测 FGSM [10] 和 BIM [16] 生成的对抗性样本的问题。 与3.2节类似,我们从ResNet残差块的每一端提取置信度分数。 图10(a)和10(b)显示了各种检测器的性能。 人们可以注意到,所提出的基于马哈拉诺比斯距离的检测器优于包括 LID 在内的所有测试方法。 这些结果意味着我们的方法可以很好地适用于大规模数据集。

附录E针对马哈拉诺比斯距离检测器的自适应攻击
在本节中,我们通过生成垃圾图像来评估我们方法的鲁棒性,这些垃圾图像可能会在白盒设置中欺骗基于马哈拉诺比斯距离的检测器,即可以访问分类器的参数和马哈拉诺比斯距离的参数 -基于探测器。 在这里,我们指出,访问基于马哈拉诺比斯距离的检测器的参数,即样本均值和协方差,并不是温和的假设,因为需要有关训练数据的信息来计算它们。 为了攻击我们的方法,我们通过最小化马哈拉诺比斯距离来生成垃圾图像 ,如下所示:
其中 是目标类。 我们使用在 CIFAR-10 数据集上训练的 34 层 ResNet 测试两种不同的场景。 在第一个场景中,我们仅使用 DNN 的倒数第二层生成垃圾图像。 在第二种情况下,我们攻击 ResNet 残差块的每一端。 图11显示了通过最小化马哈拉诺比斯距离生成的样本。 尽管生成的样本看起来像随机噪声,但它成功地欺骗了预先训练的分类器,即它被分类为目标类。 我们测量了基线 [13]、ODIN [21]、LID [22] 和提出的基于 Mahalanobis 距离的检测器的检测性能。 如图10(c)和10(d)所示,我们的方法可以比测试方法更好地区分这两种场景的CIFAR-10测试图像和垃圾图像。 特别是,我们注意到输入预处理对于检测此类垃圾样本非常有用。 这些结果意味着我们提出的方法对攻击具有鲁棒性。
附录F生成和判别分类器的混合推理
在本文中,我们证明生成分类器在表征 OOD 和对抗样本等异常样本时非常有用。 这里需要注意的是,生成分类器可能会降低分类性能。 为了解决这个问题,我们引入了生成分类器和判别分类器的混合推理。 给定具有 GDA 假设的生成分类器,通过贝叶斯规则生成分类器的后验分布如下:
为了将其与标准 softmax 分类器的权重相匹配,生成分类器的参数必须满足以下条件:
其中 和 分别是类 的权重和偏差。 使用(1)中所示的经验协方差,可以推导另一个与softmax分类器具有相同决策边界的生成分类器的参数,如下所示:
在这里,我们将 归一化,以满足 的要求。 然后,使用这个生成分类器,我们定义了新的混合后验分布,它结合了基于 softmax 和基于样本的生成分类器:
其中 是超参数。 这种混合模型可以解释为 softmax 和生成分类器的集成,可以预期它可以提高分类性能。 表8比较了softmax、生成式和混合分类器的分类精度。 可以注意到,混合模型提高了分类准确性,其中我们使用验证集确定两个目标之间的最佳调整参数。 我们还指出,这种混合模型可用于检测异常样本,我们将来会在其中执行这些任务。
| Model | Dataset |
|
|
|
|||
|---|---|---|---|---|---|---|---|
| DenseNet | CIFAR-10 | 95.16 | 94.76 | 95.00 | |||
| CIFAR-100 | 77.64 | 74.01 | 77.71 | ||||
| SVHN | 96.42 | 96.32 | 96.34 | ||||
| ResNet | CIFAR-10 | 93.61 | 94.13 | 94.11 | |||
| CIFAR-100 | 78.08 | 77.86 | 77.96 | ||||
| SVHN | 96.62 | 96.58 | 96.59 |