HotpotQA:多样化、可解释的数据集
多跳问答
摘要
现有的问答 (QA) 数据集无法训练 QA 系统执行复杂的推理并提供答案解释。 我们引入了 HotpotQA,这是一个新数据集,包含 113k 个基于维基百科的问答对,具有四个关键特征:(1)问题需要对多个支持文档进行查找和推理才能回答; (2) 问题是多样化的,并且不受任何预先存在的知识库或知识图式的限制; (3)我们提供推理所需的句子级支持事实,允许QA系统在强监督下进行推理并解释预测; (4)我们提供了一种新型的事实比较问题来测试QA系统提取相关事实并进行必要比较的能力。 我们表明,HotpotQA 对于最新的 QA 系统来说具有挑战性,并且支持事实使模型能够提高性能并做出可解释的预测。
1简介
A 段,返回奥林巴斯:
[1] 《重返奥林匹斯》是另类摇滚乐队 Malfunkshun 的唯一一张专辑。 [2] 该专辑在乐队解散以及主唱 Andrew Wood(后来的 Mother Love Bone)于 1990 年因吸毒过量去世后发行。 [3] Pearl Jam 乐队的 Stone Gossard 编辑了这些歌曲,并在他的唱片公司 Loosegroove Records 上发行了这张专辑。
B段,母爱之骨:
[4] Mother Love Bone是一支美国摇滚乐队,于1987年在华盛顿州西雅图成立。 [5]乐队活跃于1987年至1990年。 [6] 主唱安德鲁·伍德 (Andrew Wood) 的个性和作曲帮助该乐队登上了 20 世纪 80 年代末/90 年代初西雅图音乐界蓬勃发展的顶峰。 [7] 伍德在乐队首张专辑《Apple》预定发行前几天去世,从而结束了乐队成功的希望。 [8]几个月后这张专辑终于发行了。
问:《Apple》发行前不久去世的母爱骨成员的前乐队是什么?
答:马尔芬克顺
支持事实: 1, 2, 4, 6, 7
通过自然语言进行推理和推理的能力是智力的一个重要方面。 问答(QA)任务提供了一种可量化、客观的方式来测试智能系统的推理能力。 为此,人们提出了一些大规模的 QA 数据集,这在这个方向上引发了重大进展。 然而,现有数据集存在局限性,阻碍了机器推理相对于自然语言的进一步发展,特别是在测试 QA 系统执行多跳推理的能力时,系统必须使用来自多个实体的信息进行推理。一份文件即可得出答案。
首先,一些数据集主要侧重于测试单个段落或文档内的推理能力,或单跳推理。 例如,在 SQuAD Rajpurkar 等人 (2016) 中,问题被设计为以单个段落作为上下文来回答,实际上大多数问题都可以通过将问题与单个句子匹配来回答在该段落中。 因此,它在测试系统在更大背景下进行推理的能力方面表现不佳。 TriviaQA Joshi 等人 (2017) 和 SearchQA Dunn 等人 (2017) 通过使用信息检索来收集多个文档以形成给定现有问题的上下文,从而创建更具挑战性的设置 -答案成对。 尽管如此,大多数问题都可以通过将问题与一个段落中的几个附近的句子进行匹配来回答,但这种方法是有限的,因为它不需要更复杂的推理(例如,跨多个段落)。
其次,针对多跳推理的现有数据集,例如 QAngaroo Welbl 等人 (2018) 和 ComplexWebQuestions Talmor and Berant (2018),是使用现有知识库(KB)构建的。 因此,这些数据集受到它们使用的知识库模式的限制,因此问题和答案的多样性本质上是有限的。
第三,上述所有数据集仅提供远程监督;也就是说,系统只知道答案是什么,但不知道导致答案的支持事实是什么。 这使得模型很难了解潜在的推理过程,也很难做出可解释的预测。
为了解决上述挑战,我们的目标是创建一个需要对多个文档进行推理的 QA 数据集,并以自然语言进行推理,而不将其自身限制于现有的知识库或知识模式。 我们还希望它能够为系统提供对答案实际源自哪些文本的强有力的监督,以帮助指导系统执行有意义且可解释的推理。
我们提出 火锅QA111这个名字来源于前三位作者在火锅店讨论中得出的中心思想。,满足这些需求的大规模数据集。 HotpotQA 是通过基于维基百科文章的众包收集的,其中向众包工作人员展示多个支持上下文文档,并明确要求提出需要对所有文档进行推理的问题。 这确保它涵盖更自然的多跳问题,并且在设计时没有考虑任何预先存在的知识库模式。 此外,我们还要求众包工作者提供他们用来回答问题的支持事实,我们也将这些事实作为数据集的一部分提供(示例见图1)。 我们为 HotpotQA 精心设计了数据收集管道,因为高质量多跳问题的收集并非易事。 我们希望这条管道也能为这一方向的未来工作带来启发。 最后,我们还收集了一种新颖的问题类型——比较问题——作为 HotpotQA 的一部分,其中我们要求系统在某些共享属性上比较两个实体,以测试他们对语言和常见概念的理解,例如作为数值大小。 我们在 https://HotpotQA.github.io 上公开提供 HotpotQA。
2 数据采集
我们工作的主要目标是收集需要多跳推理的多样化且可解释的问答数据集。 一种方法是基于知识库定义推理链 Welbl 等人 (2018);塔尔莫和贝兰特 (2018)。 然而,生成的数据集受到实体关系的不完整性和问题类型缺乏多样性的限制。 相反,在这项工作中,我们专注于基于文本的问答,以使问题和答案多样化。 总体设置是,给定一些上下文段落(例如,几个段落或整个网络)和一个问题,QA 系统通过从上下文中提取一段文本来回答问题,类似于 Rajpurkar 等人( 2016)。 我们还确保有必要执行多跳推理才能正确回答问题。
收集基于文本的多跳问题并非易事。 在我们的试点研究中,我们发现简单地向众包工作者提供任意一组段落会适得其反,因为对于大多数段落集,很难提出有意义的多跳问题。 为了应对这一挑战,我们精心设计了一个管道来收集基于文本的多跳问题。 下面,我们将重点介绍我们管道中的关键设计选择。
构建维基百科超链接图。
我们使用整个英语维基百科转储作为我们的语料库。222https://dumps.wikimedia.org/ 在这个语料库中,我们做了两个观察:(1)维基百科文章中的超链接通常自然地包含上下文中两个(已经消除歧义的)实体之间的关系,这可能用于促进多跳推理; (2) 每篇文章的第一段通常包含大量可以有意义的方式查询的信息。 根据这些观察,我们从所有维基百科文章的第一段中提取了所有超链接。 通过这些超链接,我们构建了一个有向图 ,其中每条边表示文章第一段有一个超链接 到文章。
生成候选段落对。
使用 生成有意义的段落对进行多跳问答,我们首先考虑一个示例问题“Radiohead 的歌手和词曲作者何时出生?”要回答这个问题,首先需要推理出“Radiohead 的歌手兼词曲作者”是“Thom Yorke”,然后在文本中找出他的生日。 我们称“Thom Yorke”为 桥梁实体 在这个例子中。 给定优势 在超链接图中的中,的实体通常可被视为连接和的桥梁实体。据我们观察,通常决定了和之间共享上下文的主题,但并非所有的都是如此。 适合收集多跳问题。 例如,像国家这样的实体在维基百科中经常被提及,但不一定与所有传入链接有很多共同点。 例如,对于众包工作者来说,提出有关 IPv4 协议等高科技实体的有意义的多跳问题也很困难。 为了缓解这个问题,我们将桥接实体限制在维基百科中一组手动策划的页面(参见附录 A)。在策划一组页面 后,我们通过从超链接图中采样边 来创建候选段落对,使得 .
比较问题。
除了使用桥接实体收集的问题外,我们还收集另一种类型的多跳问题——比较问题。 主要思想是,比较同一类别的两个实体通常会产生有趣的多跳问题,例如“谁效力过更多 NBA 球队,迈克尔·乔丹还是科比·布莱恩特?”为了便于收集此类问题,我们手动整理了 42 个类似实体的列表(表示为 )来自维基百科。333这是通过手动整理维基百科“列表的列表的列表”中的列表来实现的(https://wiki.sh/y8qv )。 一个例子是“地球上最高的山脉”。 为了生成候选段落对,我们从同一列表中随机抽取两个段落并将它们呈现给众包工作者。
为了增加多跳问题的多样性,我们还在比较问题中引入了是/否问题的子集。 通过提供新的方法来要求系统对两个段落进行推理,这补充了比较问题的原始范围。 例如,考虑实体 Iron Maiden(来自英国)和 AC/DC(来自澳大利亚)。 诸如“Iron Maiden 或 AC/DC 是来自英国吗?”之类的问题并不理想,因为即使只访问过那篇文章,人们也会推断出答案是“铁娘子”。 对于是/否问题,人们可能会问“铁娘子和AC/DC来自同一个国家吗?”,这需要对这两段进行推理。
据我们所知,基于文本的比较问题是一种新颖的问题类型,以前的数据集尚未考虑过。 更重要的是,回答这些问题通常需要算术比较,例如比较出生日期的年龄,这对未来的模型开发提出了新的挑战。
收集支持事实。
为了增强问答系统的可解释性,我们希望它们输出一组支持事实 当答案生成时,必须得出答案。 为此,我们还从众包工作者那里收集了决定答案的句子。 这些支撑事实可以对注意哪些句子起到强有力的监督作用。 此外,我们现在可以通过将预测的支持事实与真实事实进行比较来测试模型的可解释性。
数据收集的整体流程如算法1所示。
3 处理和基准设置
我们在 Amazon Mechanical Turk 上总共收集了 112,779 个有效示例444https://www.mturk.com/ 使用 ParlAI 接口Miller 等人 (2017)(参见附录 A)。为了将潜在的单跳问题与所需的多跳问题隔离开来,我们首先拆分出一个名为 train-easy 的数据子集>。具体来说,我们从贡献最大的 turker 中随机抽取问题(每个 Turker 3-10 个),并将他们的所有问题分类到 train-easy 设置样本中的绝大多数是否只需要对其中一个段落进行推理。 我们对这些火鸡进行了抽样,因为他们贡献了我们 70% 以上的数据。 这 火车方便 集合包含 18,089 个大多数是单跳的示例。
我们基于当前最先进的架构实现了一个问答模型,我们将在第 5.1 节中详细讨论该模型. 基于该模型,我们对剩余的多跳示例进行了三重交叉验证。 在这些示例中,模型能够以高置信度正确回答 60% 的问题(通过对模型损失进行阈值确定)。 这些正确回答的问题(总共 56,814 个,占多跳示例的 60%)被拆分并标记为 火车中型 子集,它也将用作我们训练集的一部分。
拆分出train-easy和train-medium,我们留下了困难的例子。 由于我们的最终目标是解决多跳问答,因此我们专注于最新建模技术无法回答的问题。 因此,我们将开发和测试集限制为困难示例。 具体来说,我们将困难示例随机分为四个子集, 训练-hard、dev、测试-distractor和测试-fullwiki。表1中列出了有关数据拆分的统计数据。在第5节中,我们将展示将训练-易、训练-中和训练-难结合起来的效果。 训练模型可产生最佳性能,因此我们使用组合训练集作为默认训练集。 两个测试集 test-distractor 和 test-fullwiki 用于两种不同的基准设置,我们接下来介绍。
| Name | Desc. | Usage | # Examples |
|---|---|---|---|
| train-easy | single-hop | training | 18,089 |
| train-medium | multi-hop | training | 56,814 |
| train-hard | hard multi-hop | training | 15,661 |
| dev | hard multi-hop | dev | 7,405 |
| test-distractor | hard multi-hop | test | 7,405 |
| test-fullwiki | hard multi-hop | test | 7,405 |
| Total | 112,779 | ||
我们创建两个基准设置。 在第一个设置中,为了挑战模型在存在噪声的情况下找到真正的支持事实,对于每个示例,我们使用二元组 tf-idf Chen 等人 (2017) 从维基百科检索 8 段: 干扰因素,使用问题作为查询。 我们将它们与 2 个黄金段落(用于收集问题和答案的段落)混合以构建干扰项设置。 2 个黄金段落和 8 个干扰项在输入模型之前会被打乱。 在第二种设置中,我们通过要求模型回答给定所有未指定黄金段落的所有维基百科文章的第一段的问题来充分测试模型定位相关事实以及推理它们的能力。 这个完整的 wiki 设置真正测试了系统在野外多跳推理能力的性能。555由于我们要求众包工作者在问题中使用完整的实体名称,因此大多数问题在完整的 wiki 设置中都是明确的。 这两种设置具有不同的难度,需要从阅读理解到信息检索的各种技术。 如表所示 1,我们对这两个设置使用单独的测试集,以避免泄漏信息,因为黄金段落可用于干扰设置中的模型,但不应在完整的 wiki 设置中访问。
我们还尝试了解模型在train-medium分割上的良好性能。人工分析发现,train-medium中多跳问题的比例与困难示例相似(train-medium中的多跳问题比例为93.3%) medium vs. dev 中的 92.0%),但其中一种问题类型在 train-medium 中出现的频率更高 与硬分割相比(类型 II:0>train-medium1> 中为 32.0%,而 2>dev< 中为 15.0% /t13>,参见第 4>4 类型 II 问题的定义)。 这些观察结果表明,如果有足够的训练数据,可以训练现有的神经架构来回答多跳问题的某些类型和某些子集。 然而, 当不只存在黄金段落时,train-medium仍然具有挑战性——我们在附录中显示C 这些例子的检索问题和它们的困难表兄弟一样困难。
4 数据集分析
在本节中,我们分析数据集中涵盖的问题类型、答案类型和多跳推理类型。
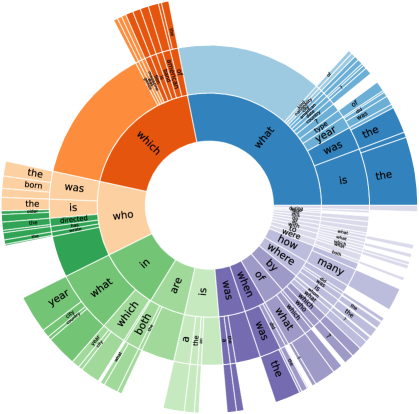
问题类型。
我们启发式地识别了每个收集到的问题的问题类型。 为了识别问题类型,我们首先找到 中心疑问词 (CQW)在问题中。 自从 HotpotQA包含比较问题和是/否问题,我们将其视为疑问词 WH 词、系词(“is”、“are”)和助动词(“does”、“did”)。 由于问题通常涉及以 WH 词开头的关系从句,因此如果可以在前三个标记中找到 CQW,我们将 CQW 定义为问题中的第一个问题词,否则定义为最后一个问题词。 然后,我们通过提取 CQW 右侧最多 2 个标记的单词以及左侧的词符(如果它是几个常见介词之一)来确定问题类型(例如,在“inwhich”和“inwhich”的情况下) “通过谁”)。
我们将问题类型的分布可视化如图2,并标记 250 多个问题中共有的问题。 如图所示,我们的数据集涵盖了围绕实体、位置、事件、日期和数字的各种问题,以及旨在比较两个实体的是/否问题(“A 和 B 都是……吗?”),以举几个例子。
答案类型。
我们进一步从数据集中抽取了 100 个示例,并在表 2 中呈现了答案类型。可以看到,HotpotQA 涵盖了广泛的答案类型,这与我们最初对问题类型的分析相符。 我们发现大多数问题都是关于文章中的实体(68%),并且不可忽略的数量的问题还询问各种属性,例如日期(9%)和其他描述性属性,例如数字(8%)和形容词(4%)。
| Answer Type | % | Example(s) |
|---|---|---|
| Person | 30 | King Edward II, Rihanna |
| Group / Org | 13 | Cartoonito, Apalachee |
| Location | 10 | Fort Richardson, California |
| Date | 9 | 10th or even 13th century |
| Number | 8 | 79.92 million, 17 |
| Artwork | 8 | Die schweigsame Frau |
| Yes/No | 6 | - |
| Adjective | 4 | conservative |
| Event | 1 | Prix Benois de la Danse |
| Other proper noun | 6 | Cold War, Laban Movement Analysis |
| Common noun | 5 | comedy, both men and women |
| Reasoning Type | % | Example(s) |
|---|---|---|
| Inferring the bridge entity to complete the 2nd-hop question (Type I) | 42 |
Paragraph A: The 2015 Diamond Head Classic was a college basketball tournament … Buddy Hield was named the tournament’s MVP.
Paragraph B: Chavano Rainier ”Buddy” Hield is a Bahamian professional basketball player for the Sacramento Kings of the NBA… Q: Which team does the player named 2015 Diamond Head Classic’s MVP play for? |
| Comparing two entities (Comparison) | 27 |
Paragraph A: LostAlone were a British rock band … consisted of Steven Battelle, Alan Williamson, and Mark Gibson…
Paragraph B: Guster is an American alternative rock band … Founding members Adam Gardner, Ryan Miller, and Brian Rosenworcel began… Q: Did LostAlone and Guster have the same number of members? (yes) |
| Locating the answer entity by checking multiple properties (Type II) | 15 |
Paragraph A: Several current and former members of the Pittsburgh Pirates – … John Milner, Dave Parker, and Rod Scurry…
Paragraph B: David Gene Parker, nicknamed ”The Cobra”, is an American former player in Major League Baseball… Q: Which former member of the Pittsburgh Pirates was nicknamed ”The Cobra”? |
| Inferring about the property of an entity in question through a bridge entity (Type III) | 6 |
Paragraph A:
Marine Tactical Air Command Squadron 28 is a United States Marine Corps aviation command and control unit based at Marine Corps Air Station Cherry Point…
Paragraph B: Marine Corps Air Station Cherry Point … is a United States Marine Corps airfield located in Havelock, North Carolina, USA … Q: What city is the Marine Air Control Group 28 located in? |
| Other types of reasoning that require more than two supporting facts (Other) | 2 |
Paragraph A: … the towns of Yodobashi, Okubo, Totsuka, and Ochiai town were merged into Yodobashi ward. … Yodobashi Camera is a store with its name taken from the town and ward.
Paragraph B: Yodobashi Camera Co., Ltd. is a major Japanese retail chain specializing in electronics, PCs, cameras and photographic equipment. Q: Aside from Yodobashi, what other towns were merged into the ward which gave the major Japanese retail chain specializing in electronics, PCs, cameras, and photographic equipment it’s name? |
多跳推理类型。
我们还从开发和测试集中抽取了 100 个示例,并对回答每个问题所需的推理类型进行了手动分类。 除了比较两个实体之外,回答这些问题还需要三种主要类型的多跳推理,我们在表中显示 3 并附有示例。
大多数问题需要每个段落中至少有一个支持事实来回答。 大多数抽样问题(42%)需要链式推理(表中的类型 I),其中读者必须首先识别桥实体,然后才能通过填写桥来回答第二跳。 回答这些问题的一种策略是将它们分解为连续的单跳问题。 桥实体还可以隐式地用于帮助推断与其相关的其他实体的属性。 在某些问题(类型 III)中,所讨论的实体与桥实体共享某些属性(例如,它们并置),我们可以通过桥实体推断其属性。 另一种类型的问题涉及通过同时满足多个属性来定位答案实体(类型 II)。 在这里,为了回答这个问题,我们可以找到满足所提到的每个属性的所有实体的集合,并进行交集以获得最终答案。 比较两个实体(比较)的问题还要求系统了解两个实体的相关属性(例如国籍),有时需要算术,例如计数(如表中所示)或比较数值(“谁年龄更大”) ,A还是B?”)。 最后,我们发现有时问题需要两个以上的支持事实才能回答(其他)。 在我们的分析中,我们还发现,对于表中显示的所有示例,土耳其人提供的支持事实与此处显示的有限上下文完全匹配,表明收集的支持事实是高质量的。
除了上述推理类型外,我们还估计大约 6% 的抽样问题可以用两段之一来回答,其中 2% 无法回答。 我们还随机抽取了 100 个样本 训练中等和训练困难 综合起来,推理类型的比例为:I型38%、II型29%、比较20%、其他7%、III型2%、单跳2%、无解2%。
5 实验
5.1 模型架构与训练
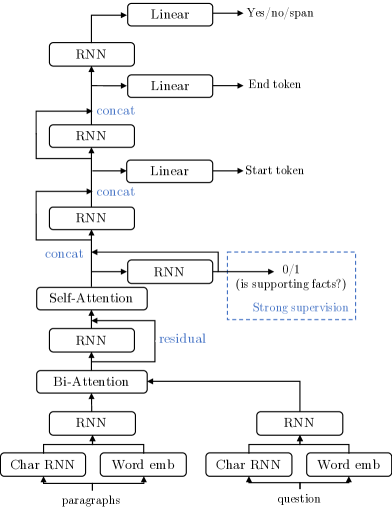
为了测试领先的 QA 系统在我们的数据上的性能,我们重新实现了 Clark 和 Gardner (2017) 中描述的架构作为我们的基线模型。 我们注意到,我们在没有权重平均的情况下实现的性能非常接近作者在 SQuAD 上报告的性能(在 F 中大约差 1 个点)1)。 我们实现的模型包含了问答领域的最新技术进步,包括字符级模型、自注意力 Wang 等人 (2017) 和双向注意力 Seo 等人 (2017) t1>. 结合这三个关键组件正在成为标准实践,以及各种最先进或有竞争力的架构Liu 等人 (2018);克拉克和加德纳(2017);王等人 (2017); Seo 等人 (2017);潘等人 (2017);萨兰特和贝兰特 (2018); SQuAD 上的 Xiong 等人 (2018) 可以被视为与我们实现的模型类似。 为了适应是/否问题,我们还在最后一个循环层之后添加了一个三路分类器,以产生“是”、“否”和基于跨度的答案的概率。 在解码过程中,我们首先使用 3 路输出来确定答案是“是”、“否”还是文本范围。 如果是文本跨度,我们进一步搜索最可能的跨度。
事实证明强有力的监督。
为了评估基线模型在预测可解释的支持事实方面的性能,以及它们在多大程度上提高了 QA 性能,我们还设计了一个组件,将如此强大的监督纳入我们的模型中。 对于每个句子,我们在第一个和最后一个位置连接自注意力层的输出,并使用二元线性分类器来预测当前句子是支持事实的概率。 我们最小化该分类器的二元交叉熵损失。 该目标与多任务学习环境中的正常问答目标联合优化,并且它们共享相同的低级表示。 使用这个分类器,还可以在支持事实预测的任务上评估模型,以衡量其可解释性。 我们的整体架构如图所示 3. 虽然可以构建一个管道系统,但在这项工作中,我们专注于端到端的系统,它更容易调整并且训练速度更快。
5.2 结果
| Setting | Split | Answer | Sup Fact | Joint | |||
|---|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | ||
| distractor | dev | 44.44 | 58.28 | 21.95 | 66.66 | 11.56 | 40.86 |
| distractor | test | 45.46 | 58.99 | 22.24 | 66.62 | 12.04 | 41.37 |
| full wiki | dev | 24.68 | 34.36 | 5.28 | 40.98 | 2.54 | 17.73 |
| full wiki | test | 25.23 | 34.40 | 5.07 | 40.69 | 2.63 | 17.85 |
| Set | MAP | Mean Rank | Hits@2 | Hits@10 |
|---|---|---|---|---|
| dev | 43.93 | 314.71 | 39.43 | 56.06 |
| test | 43.21 | 314.05 | 38.67 | 55.88 |
| Setting | Br EM | Br F1 | Cp EM | Cp F1 |
|---|---|---|---|---|
| distractor | 43.41 | 59.09 | 48.55 | 55.05 |
| full wiki | 19.76 | 30.42 | 43.87 | 50.70 |
| Setting | EM | F1 |
|---|---|---|
| our model | 44.44 | 58.28 |
| – sup fact | 42.79 | 56.19 |
| – sup fact, self attention | 41.59 | 55.19 |
| – sup fact, char model | 41.66 | 55.25 |
| – sup fact, train-easy | 41.61 | 55.12 |
| – sup fact, train-easy, train-medium | 31.07 | 43.61 |
| gold only | 48.38 | 63.58 |
| sup fact only | 51.95 | 66.98 |
我们在两个基准设置中评估我们的模型。 在完整的 wiki 设置中,为了在 5,000,000 多个 wiki 段落中实现高效的 tf-idf 检索,给定一个问题,我们首先使用基于倒排索引的过滤策略返回最多 5,000 个段落的候选池666详情请参阅附录C。 然后使用bigram tf-idf选择池中的前10个段落作为最终候选段落。777我们选择最终候选的数量为 10,以与干扰项设置保持一致,其中候选项为 2 个黄金段落加 8 个干扰项。检索性能如表5. 检索这 10 个段落后,我们使用在干扰项设置中训练的模型来评估其在这些最终候选段落上的表现。
继之前的工作Rajpurkar等人(2016)之后,我们使用精确匹配(EM)和F1 作为两个评价指标。 为了评估模型的可解释性,我们进一步引入了两组涉及支持事实的指标。 第一组侧重于直接评估支持事实,即 EM 和 F1 与黄金集相比,在支持事实句子集上。 第二组具有联合指标,结合了对答案范围的评估和支持事实,如下所示。 对于每个示例,考虑到其答案范围的精确度和召回率()和支持事实(),分别计算联合F1 作为
仅当两个任务实现完全匹配时,联合 EM 才为 1,否则为 0。 直观上,这些指标会惩罚在任一任务上表现不佳的系统。 所有指标均按示例进行评估,然后对评估集中的示例进行平均。
表中报告了我们的模型在基准设置上的性能4,其中所有数字都是在对支持事实进行严格监督的情况下获得的。 从分散注意力的设置到完整的wiki设置,扩大上下文的范围增加了回答问题的难度。 完整的 wiki 设置中的性能要低得多,这对现有的基于检索的问答技术提出了挑战。 总体而言,所有设置中的模型性能均显着低于人类性能,如第 1 节所示 5.3,这表明未来的工作需要更多的技术进步。
我们还通过测量支持事实预测性能来研究模型的可解释性。 我们的模型实现了 60+ 支持事实预测 F1和40关节F1,这表明在可解释性方面还有进一步改进的空间。
表中6,我们细分不同问题类型的表现。 在干扰项设置中,比较问题的 F 较低1 分数高于涉及桥梁实体的问题(如第 2 节中定义),这表明更好地建模这种新颖的问题类型可能需要更好的神经架构。 在完整的 wiki 设置中,桥接实体问题的性能显着下降,而比较问题的性能仅略有下降。 这是因为两个实体通常都出现在比较问题中,从而降低了检索难度。 结合Table中的检索性能 5,我们认为表4中完整wiki设置的恶化 很大程度上是由于检索这两个实体的困难。
我们在干扰器环境中进行消融研究,并在表中报告结果7. 自注意力模型和角色级模型都对最终性能有显着贡献,这与之前的工作一致。 这意味着针对单跳 QA 的技术在我们的环境中仍然有些有效。 此外,取消对支持事实的强有力监督会降低性能,这证明了我们方法的有效性和支持事实的有用性。 我们通过仅考虑支持事实作为模型的预言机上下文输入来建立强监督上限的估计,这实现了 10+ F1 比不使用支持事实的改进。 与我们模型中强监督的增益相比(F 2 点1),我们提出的纳入支持事实监督的方法很可能不是最优的,我们将更好建模的挑战留给未来的工作。 最后,我们展示了合并所有数据分割(轻松训练、中等训练和困难训练)产生最佳性能,该设置被采用作为默认设置。
5.3 建立人类绩效
为了在我们的数据集上确定人类的表现,我们从开发和测试集中随机抽取了 1,000 个示例,并让至少另外三位 Turker 为这些示例提供了答案和支持事实。 作为基线,我们将数据收集过程中的原始 Turker 作为预测,将新收集的答案和支持事实作为参考,来评估人类的表现。 对于每个示例,我们选择最大化 F 的答案和支持事实参考1 分数来报告最终指标,以减少歧义的影响Rajpurkar等人(2016)。
如表8,原始众包工作者在找到支持事实和正确回答问题方面都取得了非常高的表现。 如果基线模型一开始就提供了正确的支持段落,那么它在寻找支持事实方面可以与众包工作者持平,但在找到实际答案方面仍然存在不足。 当存在干扰段落时,基线模型和众包工作者在两项任务上的性能差距都会扩大到 EM 和 F 均为 30%1。
通过取最大 EM 和 F1,我们进一步确定了 HotpotQA 中人类表现的上限 对于每个示例。 在这里,我们依次使用每个 Turker 的答案作为预测,并将其与所有其他工人的答案进行评估。 从表中可以看出 8,大多数指标都接近 100%,这说明在大多数示例中,至少有一部分 Turkers 彼此同意,显示出注释者间的高度一致性。 我们还注意到,众包工作者对支持事实的认同较少,这可能反映出这项任务本质上比回答问题更加主观。
| Setting | Answer | Sp Fact | Joint | |||
|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | |
| gold only | 65.87 | 74.67 | 59.76 | 90.41 | 41.54 | 68.15 |
| distractor | 60.88 | 68.99 | 30.99 | 74.67 | 20.06 | 52.37 |
| Human | 83.60 | 91.40 | 61.50 | 90.04 | 52.30 | 82.55 |
| Human UB | 96.80 | 98.77 | 87.40 | 97.56 | 84.60 | 96.37 |
6 相关工作
最近提出的各种大规模 QA 数据集可以分为四类。
单文档数据集。
SQuAD Rajpurkar 等人 (2016, 2018) 问题相对简单,因为它们通常需要段落中不超过一个句子来回答。
多文档数据集。
TriviaQA Joshi 等人 (2017) 和 SearchQA Dunn 等人 (2017) 包含伴随多个文档作为上下文的问题答案对。 这进一步挑战了 QA 系统适应更长上下文的能力。 然而,由于支持文档是在问题答案与信息检索配对后收集的,因此不能保证问题涉及多个文档之间有趣的推理。
基于 KB 的多跳数据集。
最近的数据集,例如 QAngaroo Welbl 等人 (2018) 和 复杂的网络问题 Talmor 和 Berant (2018) 探索使用预先存在的知识库 (KB) 和预定义逻辑规则来生成有效的 QA 对的不同方法,以测试 QA 模型执行多跳推理的能力。 问题和答案的多样性在很大程度上受到固定的知识库模式或逻辑形式的限制。 此外,由于知识库的不完整性,某些问题可能可以通过一个文本句子来回答。
自由格式的答案生成数据集。
MS MARCO Nguyen 等人 (2016) 包含来自 Bing 搜索的 10 万个用户查询以及人工生成的答案。 系统生成自由格式的答案,并通过 ROUGE-L 和 BLEU-1 等自动指标进行评估。 然而,这些指标的可靠性值得怀疑,因为它们已被证明与人类判断的相关性较差Novikova 等人 (2017)。
7 结论
我们介绍HotpotQA,一个大规模问答数据集,旨在促进 QA 系统的开发,该系统能够对不同的自然语言执行可解释的多跳推理。 我们还提供了一种新型的事实比较问题来测试系统提取和比较文本中各种实体属性的能力。
致谢
这项工作的部分资金来自 Facebook ParlAI 研究奖。 ZY、WWC 和 RS 得到 Google 拨款、DARPA 拨款 D17AP00001、ONR 拨款 N000141512791、N000141812861 和 Nvidia NVAIL 奖的支持。 SZ 和 YB 得到蒙特利尔大学 Mila 的支持。 PQ 和 CDM 得到美国国家科学基金会的支持,批准号为: IIS-1514268。 本材料中表达的任何意见、发现、结论或建议均为作者的观点,并不一定反映国家科学基金会的观点。
参考
- Chen et al. (2017) Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer open-domain questions. In Association for Computational Linguistics (ACL).
- Clark and Gardner (2017) Christopher Clark and Matt Gardner. 2017. Simple and effective multi-paragraph reading comprehension. In Proceedings of the 55th Annual Meeting of the Association of Computational Linguistics.
- Dunn et al. (2017) Matthew Dunn, Levent Sagun, Mike Higgins, Ugur Guney, Volkan Cirik, and Kyunghyun Cho. 2017. SearchQA: A new Q&A dataset augmented with context from a search engine. arXiv preprint arXiv:1704.05179.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
- Liu et al. (2018) Xiaodong Liu, Yelong Shen, Kevin Duh, and Jianfeng Gao. 2018. Stochastic answer networks for machine reading comprehension. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics.
- Manning et al. (2014) Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language processing toolkit. In Association for Computational Linguistics (ACL) System Demonstrations, pages 55–60.
- Miller et al. (2017) Alexander H Miller, Will Feng, Adam Fisch, Jiasen Lu, Dhruv Batra, Antoine Bordes, Devi Parikh, and Jason Weston. 2017. ParlAI: A dialog research software platform. arXiv preprint arXiv:1705.06476.
- Nguyen et al. (2016) Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems (NIPS).
- Novikova et al. (2017) Jekaterina Novikova, Ondřej Dušek, Amanda Cercas Curry, and Verena Rieser. 2017. Why we need new evaluation metrics for NLG. In Proceedings of the Conference on Empirical Methods in Natural Language Processing.
- Pan et al. (2017) Boyuan Pan, Hao Li, Zhou Zhao, Bin Cao, Deng Cai, and Xiaofei He. 2017. Memen: Multi-layer embedding with memory networks for machine comprehension. arXiv preprint arXiv:1707.09098.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don’t know: Unanswerable questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Salant and Berant (2018) Shimi Salant and Jonathan Berant. 2018. Contextualized word representations for reading comprehension. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics.
- Seo et al. (2017) Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. In Proceedings of the International Conference on Learning Representations.
- Talmor and Berant (2018) Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics.
- Wang et al. (2017) Wenhui Wang, Nan Yang, Furu Wei, Baobao Chang, and Ming Zhou. 2017. Gated self-matching networks for reading comprehension and question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 189–198.
- Welbl et al. (2018) Johannes Welbl, Pontus Stenetorp, and Sebastian Riedel. 2018. Constructing datasets for multi-hop reading comprehension across documents. Transactions of the Association of Computational Linguistics.
- Xiong et al. (2018) Caiming Xiong, Victor Zhong, and Richard Socher. 2018. DCN+: Mixed objective and deep residual coattention for question answering. In Proceedings of the International Conference on Learning Representations.
- Yang et al. (2018) Zhilin Yang, Saizheng Zhang, Jack Urbanek, Will Feng, Alexander H Miller, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Mastering the dungeon: Grounded language learning by mechanical turker descent. In Proceedings of the International Conference on Learning Representations.
附录A 数据收集详情
A.1 数据预处理
我们下载了2017年10月1日的英文维基百科转储,并使用WikiExtractor提取了文本和超链接。888https://github.com/attardi/wikiextractor 我们使用斯坦福 CoreNLP 3.8.0 Manning 等人 (2014) 进行单词和句子标记化。 我们使用生成的句子边界来收集支持事实,并使用词符边界来检查 Turker 是否提供了涵盖整个标记范围的答案,以避免无意义的部分单词答案。
A.2 进一步的数据收集细节
有关策划维基百科页面的详细信息。
为了确保采样的候选段落对能够直观地让众包工作者提出高质量的多跳问题,我们从 WikiProject 的热门页面列表中手动筛选了 591 个类别。999https://wiki.sh/y8qu对于每个类别,我们从图 中抽取 对,其中 属于所考虑的类别,并手动检查 对是否可以提出多跳问题。. 选择允许多跳问题的可能性较高的那些类别。
奖金结构。
为了激励众包工作者更有效地产生更高质量的数据,我们遵循Yang等人(2018),并采用奖金结构。 我们在数据收集过程中混合了两种设置。 在第一种设置中,我们每 200 个示例奖励顶级(就示例数量而言)的工作人员。 在第二种设置中,工作人员根据他们的生产力(以每小时的示例数量来衡量)获得奖金。
A.3 人群工作者界面
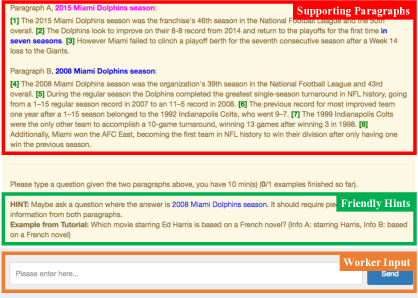
我们的众包工作者界面基于 ParlAI Miller 等人 (2017),这是一个开源项目,可促进对话系统的开发和通过对话界面进行数据收集。 我们通过将收集工作流程转换为面向系统的对话框,采用 ParlAI 来收集问题答案对。 这使我们能够更好地控制 turkers 的输入,并为 turkers 提供循环反馈或有用的提示,以帮助 Turkers 完成任务,从而加快收集过程。
请见图4 有关数据收集期间工作人员界面的示例。
附录B 进一步的数据分析
为了进一步了解HotpotQA中数据的多样性,我们进一步可视化了数据集中问题长度的分布,如图5. 除了正文中显示的类型多样之外,问题的长度也有很大差异,表明复杂程度和所涵盖的细节不同。
附录C 完整的 Wiki 设置详细信息
C.1 倒排索引过滤策略
在完整的wiki设置中,我们采用高效的基于倒排索引的过滤策略来进行预备知识候选段落检索。 我们在算法中提供详细信息 2,这里我们设置控制阈值 在我们的实验中。 对于一些问题 ,其对应的黄金段落可能不包含在输出候选池中,我们将此类缺失的黄金段落的排名设置为 因此,本文报告的 MAP 和 Mean Rank 均为其真实值的上限。
C.2 比较 train-medium Split 与 Hard One
表9显示了 train-medium 分割与dev和test等硬示例之间的比较 在完整的 wiki 设置中的检索指标下。 正如我们所看到的,两者之间的性能差距 train-medium 拆分及其 dev/test 接近,这意味着 train-medium split 与完整 wiki 设置下的困难示例具有相似的难度,其中检索模型作为第一个处理步骤是必要的。
| Set | MAP | Mean Rank | CorAns Rank |
|---|---|---|---|
| train-medium | 41.89 | 288.19 | 82.76 |
| dev | 42.79 | 304.30 | 97.93 |
| test | 45.92 | 286.20 | 74.85 |