深度神经网络在多个智能体上的分布式学习
摘要
在医疗保健和金融等领域,标记数据和计算资源的短缺是开发机器学习算法时的一个关键问题。 为了解决训练和基于神经网络的系统部署中标记数据稀缺的问题,我们提出了一种基于多个数据源的深度神经网络的新技术。 我们的方法允许使用来自多个实体的数据以分布式方式训练深度神经网络。 我们在现有数据集上评估我们的算法,并表明它获得的性能类似于在单台机器上训练的常规神经网络。 我们进一步扩展它,在使用少量标记样本进行训练时纳入半监督学习,并分析可能出现的任何安全问题。 当原始数据无法直接共享时,我们的算法为数据敏感应用中深度神经网络的分布式训练铺平了道路。
关键词:
多方计算、深度学习、分布式系统1简介
深度神经网络已成为图像、视频和生物传感器等高维数据分类和预测的最新技术。 生物医学和健康等领域的新兴技术将受益于构建用于预测和推理的深度神经网络,通过自动化人类参与并降低运营成本。 然而,深度神经网络的训练可能是数据密集型的,需要准备从多个实体[1, 2]收集的大规模数据集。 深度神经网络通常包含数百万个参数,并且需要巨大的计算能力来进行训练,这使得单个数据存储库很难对其进行训练。
为了在现实世界的应用中获得最佳精度,可能需要足够深的神经架构,需要大量的超级计算资源和工程监督。 此外,由于与共享去匿名数据相关的隐私和道德问题,深度学习在这些领域的应用有时可能具有挑战性。 虽然许多此类数据实体对开发新的深度学习算法感兴趣,但他们也可能有义务保密其用户数据,这使得在构建机器学习管道时使用这些数据变得更具挑战性。 在本文中,我们试图通过提出使用多个数据源和单个超级计算资源来训练神经网络的方法来解决这些问题。
2相关工作
深度神经网络已被证明是对图像[3]、音频和视频[4]等高维数据进行分类和分割的有效工具。 深度模型可以深达数百层[5],并且可能具有数百万个参数,需要大量计算资源,因此需要研究分布式训练方法[6]. 有趣的技术包括分布式梯度优化[7, 8]、延迟更新的在线学习[9]以及内核的哈希和简化[10] 。 此类技术可用于训练跨多台机器的超大规模深度神经网络[11],或在单台机器上高效利用多个 GPU[12]。 在本文中,我们提出了一种结合来自多个不同来源的数据的分布式计算技术。
安全计算仍然是计算机科学中的一个具有挑战性的问题[13]。 该问题的一类解决方案涉及采用不经意的传输协议在多项式时间内对多个实体执行安全点积[14]。 虽然这种方法很安全,但由于资源需求,在考虑大规模数据集时有点不切实际。 [14] 中提出的更实用的方法涉及仅共享 SIFT 和 HOG 特征,而不是实际的原始数据。 然而,如[15]所示,利用创建这些特征向量的方法的先验知识,可以非常准确地反转这些特征向量。 神经网络已被证明对添加噪声具有极其鲁棒性,其去噪和重构特性使得安全计算它们变得困难[16]。 神经网络还被证明能够仅从部分输入 [17] 恢复整个图像,从而使简单的混淆方法变得惰性。
神经网络在金融和健康等敏感领域的广泛应用,需要开发分布式和安全训练[18,19,20]以及神经网络分类的方法。 在分布式和安全处理范例下,神经网络训练的所有者无法访问用于神经网络[21]的实际原始数据。 这还包括云计算中的安全范例[22, 23]、虚拟化[24]和面向服务的架构[25]. 安全范例还可以扩展到神经激活和(超)参数。 此类算法形成了涉及多方安全计算的更广泛的多方协议问题领域内的子集[26, 27]。 一些有趣的解决方案包括使用 Ada-boost 联合训练分类器集合[28],使用随机旋转扰动进行同态伪加密[29]以及应用同态密码系统来执行安全计算[30]。
3理论
在本文中,我们提出了新技术,可用于在多个数据源上训练深度神经网络,同时减少直接共享原始标记数据的需要。 具体来说,我们解决了在多个数据实体(Alice(s))和一个超级计算资源(Bob)上训练深度神经网络的问题。 我们的目标是解决这个问题,同时满足以下要求:
-
1.
单个数据实体(Alice)不需要与 Bob 或其他数据资源共享数据。
-
2.
超级计算资源(Bob)想要控制神经网络的架构
-
3.
Bob还保留了一部分推理所需的网络参数。
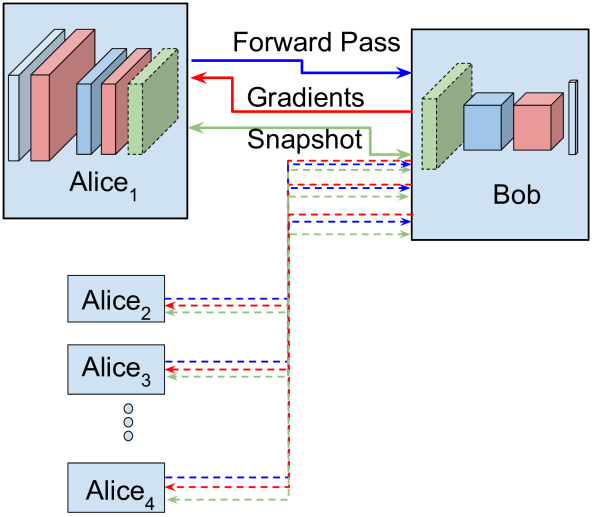
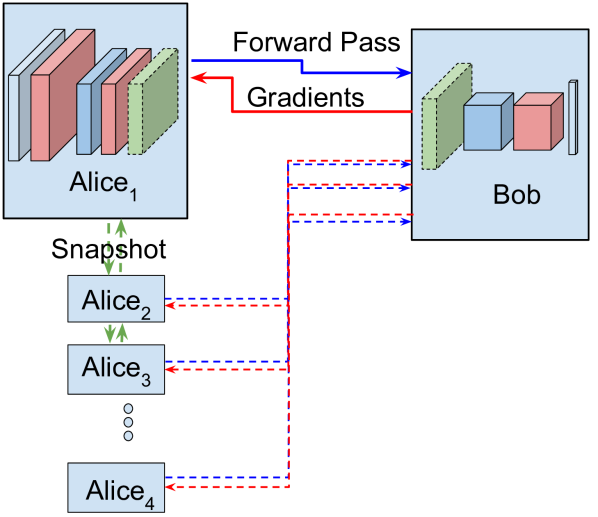
在接下来的部分中,我们将展示如何在多个数据实体(Alice(s))和超级计算资源(Bob)之间训练神经网络。 技术将包括将数据编码到不同的训练空间并将其传输到深度神经网络的方法。 我们将进一步探索第三方如何使用该神经网络进行分类和推理。 我们的算法可以使用一个或多个数据实体来运行,并且可以以点对点或集中模式运行。 请参见图1了解算法模式的示意图。
3.1 单个实体上的分布式训练
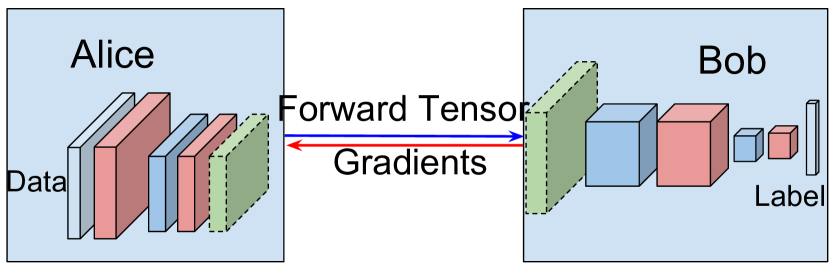
我们将首先以最简单的形式描述该算法,该算法考虑使用来自单个实体和超级计算资源的数据来训练神经网络。 让我们将深度神经网络定义为函数 ,可以使用层序列 进行拓扑描述。 对于给定的输入 (),该函数的输出由 给出,该输出是通过按顺序应用层 计算得出的。
让 表示用于计算最后一层梯度的定制损失函数。 梯度可以在每个层上反向传播,以生成先前层的梯度并更新当前层。 我们将使用 表示一层上的反向传播过程,使用 表示整个神经网络上的反向传播过程。 与前向传播类似,整个神经网络上的反向传播由顺序向后传递 组成。 请注意,在对各个感知器进行前向传递之后,后向传递将需要激活。
最后,表示通过网络向实体发送数据的过程。 一开始,Alice 和 Bob 随机初始化他们的参数。 然后,Alice 迭代其数据集并将编码表示传输给 Bob。 然后鲍勃计算损失和梯度并将梯度发送回爱丽丝。 算法1描述了如何使用单个数据源训练深度神经分类器。
3.1.1 正确性
在这里,我们分析使用分布式算法的训练是否产生与正常训练过程相同的结果。 在正常的训练过程中,我们首先计算前向传递,然后计算损失梯度。 这些梯度将被反向传播以刷新权重。
由于前向传播涉及各个层的顺序应用,我们同意 与 相同。 因此,顺序计算和传输以及随后计算剩余层的过程在功能上与同时应用所有层相同。 同样,由于微分中的链式法则,反向传播 在功能上与 的顺序应用相同。 因此,我们可以得出结论,我们的算法将产生与正常训练过程相同的结果。
3.2 在多个实体上进行分布式训练
这里我们演示如何将3.1中描述的算法扩展到使用多个数据实体进行训练。 在定义神经网络前向和后向传播时,我们将使用与 3.1 中使用的数学符号相同的数学符号。 在算法2中,我们演示了当存在个数据实体时如何扩展我们的算法,每个数据实体都用表示。
在算法2中的第一个初始化步骤中,Bob向Alice发送第一个层的拓扑描述1。 Alice 和 Bob 使用标准系统级库来随机初始化其参数。 然后,Bob 将 Alice1 设置为用于训练的最后一个代理,并开始使用 Alice1 的数据进行训练。 我们修改 1 并添加一个以循环方式使用来自多个实体的数据的步骤,从而允许分布式学习框架。 然而,为了保持一致性,Alicej 可能需要在开始训练之前更新权重。 我们通过提供两种涉及点对点和集中式配置的独立方法来解决这个问题。 在集中式模式下,Alice将加密的权重文件上传到Bob或第三方服务器。 当新的爱丽丝希望训练时,它会下载并解密这些权重。 在点对点模式下,Bob将最后训练的Alice的地址发送到当前训练方,Alice使用它来连接并下载加密的权重。 两种方法的实现细节可以在补充材料中看到。 一旦权重更新,Alicej 就会继续训练。 由于在集中式和点对点模式下初始化相同的权重,因此两种模式的训练最终结果是相同的。
3.2.1 正确性
我们分析使用我们的算法进行训练是否会产生与在一台机器上组合所有数据进行训练时相同的结果(假设到达多个实体的数据保留顺序并且随机权重使用相同的初始化)。 算法的正确性源于这样一个事实:Bob 和至少一个 Aliceo 在迭代k 时具有与常规训练相同的神经网络参数。 我们使用归纳技术来证明情况确实如此。
引理1
在迭代k 处训练的神经网络与仅由一个实体训练的神经网络相同。
基本情况: Alice1…N 中的一个在第一次迭代开始时具有正确的权重。
证明: Alice1 随机初始化权重,Bob 在第一次迭代期间使用这些权重。 我们假设这种初始化在使用单个实体进行训练时是一致的。 如果另一个 Alicej 尝试训练,它会将权重刷新为正确的值。
递归案例: 断言:如果 Alicej 在迭代开始时具有正确的权重i,那么它在迭代开始时也会具有正确的权重。
证明: Alicej 执行反向传播作为迭代 中的最后一步。 由于这种反向传播在功能上等同于一次应用于整个神经网络的反向传播,因此 Alicej 在一次训练迭代结束时继续拥有正确的参数。 ( 在功能上与 的顺序应用相同,如 3.1.1 中所述)。
3.3 半监督应用
在本节中,我们描述如何修改分布式神经网络训练算法,以在数据点较少时结合半监督学习和生成损失。 在标记数据样本较少的情况下,合理的方法包括使用无监督学习[31]来学习分层表示。 使用无监督学习和自动编码器生成的压缩表示可直接用于分类[32]。 此外,我们可以结合生成训练和预测片段的损失来执行半监督学习,在更少的样本上添加正则化组件[33]。
在这里,我们演示了如何使用算法 1 的修改版本来训练自动编码器和半监督学习器。 当使用少量标记数据进行训练时,这种无监督学习方法非常有用。 我们假设 Alice 的 层中,前一个 层是编码器,其余的 层属于其解码器。 表示编码器上的前向传播(由顺序应用 计算)。 表示解码器层的应用。 在前向传播期间,Alice 通过所有 层传播数据,并将 层的输出发送给 Bob。 Bob 通过 传播 Alice 的输出张量并计算分类器损失(逻辑回归)。
让 定义神经网络的预测部分(Bob 拥有的最后 层)中的逻辑回归损失,并让 定义自动编码器(完全由 Alice 所有)。 Bob 可以使用其 softmax 层计算 ,并且可以将使用此损失计算的梯度反向传播到层 ,从分类器网络 [] 给出梯度。 Alicei 可以计算自动编码器梯度,并可以通过其解码器网络 [] 反向传播它。 我们可以通过组合两个损失的加权和来促进半监督学习。 权重是一个添加的超参数,可以在训练期间调整。
| (1) |
在初始化步骤之后,Alice 通过其网络传播其数据,并将编码器部分的输出发送给 Bob。 Bob 执行完整的前向和后向操作,将梯度发送给 Alice。 然后,Alice 将其解码器网络的损失与从 Bob 接收的梯度相结合,并使用它们执行反向传播(请参阅算法 3 了解详细说明)。
3.4在线学习
使用我们的算法的另一个优点是,只要有新的注释数据,就可以通过提供前向传播的 Bob 输出来以在线方式执行训练。 一开始,Alicei 可以使用种子随机初始化权重,并将种子发送给 Alice1…N,从而避免进一步的网络开销,而不是传输整个神经网络。 当 Alice 在点对点模式下被请求提供权重时,它可以简单地共享权重更新,并在训练过程中将其添加到其参数中。 权重更新的组合值可以通过从当前权重减去训练开始时的权重来计算。 为了安全起见,Alice 还可以将加密的权重更新上传到集中式权重服务器,从而在使用中间人攻击时更难以对实际权重进行逆向工程。 Alice 可以通过将其初始权重与从集中式权重服务器(或 Alice,取决于模式)下载的后续权重更新相结合来刷新权重。 为了促进中心化模式,我们可以修改算法2的第6步,将其替换为从权重服务器下载加密权重的请求。 训练结束后,Alicej 可以将新的加密权重上传到权重服务器(请参阅算法2中的步骤15)。
3.5 分析安全问题
虽然对安全性进行严格的信息理论分析超出了本文的范围,但在这里我们概述了为什么重建 Alice 发送的数据极具挑战性。 算法的安全性在于Bob能否反转Alice在前向传播过程中使用的参数()。 Bob 确实可以为 Alice 传输的压缩表示构建一个解码器,但它需要 Alice 透露其神经网络部分的当前参数[15]。
在本节中,我们提出一个论点,只要其层(用 表示)包含至少一个全连接层,Bob 就无法发现 Alice 使用的参数。 我们将使用“配置”一词来表示网络拓扑的同构变化,这会导致功能相同的神经网络。
引理2
假设 M 层是一个包含 N 个输出的全连接层,那么 M 层至少有 N 个! 功能上等效的“配置”。
证明:我们构建一个 M 层并转置 N 个输出神经元。 神经元的输出被重新排序,而不会改变权重或以任何方式影响学习。 由于有 这些神经元的可能排序至少为 根据权重的初始化方式,可以进行独特的配置。
Bob 必须至少经历 可能的配置来反转Alice应用的转换。 由于,这将需要在大小的层中指数级的时间。例如,如果全连接层有 4096 个神经元,并且每个配置都可以在一秒钟内进行测试,那么 Bob 需要比当前宇宙年龄更长的时间才能计算出 Alice 使用的参数。
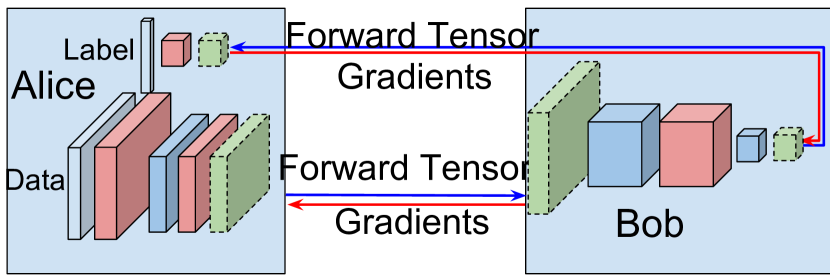
3.6 无标签传播的训练
4 数据集和实现
我们使用标准的异步RPC通信库json来实现。 最重要的是,一旦使用 SSL 建立安全连接,我们就会为训练实施自定义协议。 我们的协议定义了几个网络原语(作为远程函数实现),我们将其大致分为 3 个部分(1)训练请求、(2)张量传输和(3)权重更新。 请参阅附录以获取网络原语的完整列表。 我们在补充材料中描述了这三个网络原语类别。
4.1混合 NIST
混合 NIST (MNIST) 数据库 [34] 包含从邮政编码中采样的手写数字,是国家科学技术研究所提供的更大数据集的子集。 MNIST 总共包含 70,000 个样本,分为 60,000 个训练样本和 10,000 个测试样本。 原始二值图像被重新格式化并空间标准化以适合 边界框。 使用抗锯齿技术将黑白(双层)图像转换为灰度图像。 最后,通过计算像素的质心并在 图像的中心移动和叠加图像,将数字放置在 网格中。
4.2加拿大高级研究所
加拿大高级研究所 (CIFAR-10) 数据集是微小图像数据集(包含 8000 万张图像)的标记子集。 它由分布在 10 个不同类别标签上的 60,000 张 彩色图像组成。 该数据集由 50,000 个训练样本和 10,000 个测试图像组成。 图像均匀分布在 10 个类中,每个类的训练批次恰好包含 6000 个图像。 这些类别是互斥的,来自不同标签的图像之间不存在语义重叠。 我们使用 GCA 白化对图像进行归一化,并在训练前应用全局均值减法。 同一数据集还包括称为 CIFAR-100 的 100 类变体。
4.3ILSVRC(ImageNet)2012
该数据集包含大约 120 万张图像,标记有或不存在 1000 个对象类别。 它还包括 150,000 张用于验证和测试目的的图像。 这 1000 个对象类别是较大数据集 (ImageNet) 的子集,其中包括跨越 10,000 个对象类别的 1000 万张图像。 对象类别可以是内部节点或叶节点,但不重叠。 数据集包含不同大小的图像,这些图像在训练前调整为 并减去平均值。
5实验与应用
我们使用 caffe[35] 的 python 绑定来实现我们的算法和协议。 我们在各种大小(50K - 1M)和类别(10、100 或 1000 个类别)的数据集上测试我们的实现。 我们证明我们的方法适用于一系列不同的拓扑,并通过实验验证在多个代理上训练时的相同结果。 所有数据集都经过相同次数的训练,以进行公平评估。
在3.2.1中,我们展示了为什么我们的算法应该给出与正常过程相同的结果。 我们通过在各种数据集和拓扑(包括 MNIST、ILSVRC 12 和 CIFAR 10)上实施和训练来实验验证我们方法的正确性。 表1列出了数据集和拓扑及其测试精度。 通过将正确标记的样本数与测试数据点的总数进行比较来计算测试精度。. 如表1所示,当以分布式方式在多个代理上进行训练时,网络收敛到相似的精度。
| Dataset | Topology | Accuracy (Single Agent) | Accuracy using our method | Epochs |
|---|---|---|---|---|
| MNIST | LeNet [34] | 99.18 % | 99.20 % | 50 |
| CIFAR 10 | VGG [36] | 92.45 % | 92.43 % | 200 |
| CIFAR 100 | VGG [36] | 66.47 % | 66.59 % | 200 |
| ILSVRC 12 | AlexNet [3] | 57.1 % | 57.1 % | 100 |
5.1 与现有方法的比较
我们将我们的方法与现代最先进的方法进行比较,包括大批量全局 SGD [37] 和联合平均方法 [38]。 我们使用联合平均和联合 SGD 的最佳超参数选择来执行几种不同的比较。 我们比较了使用深度模型时的客户端计算成本,并证明使用我们的算法进行训练时客户端的计算负担显着降低(见图3)。 我们还分析了最先进的深度网络(包括 ResNet 和 VGG)在 CIFAR-10 和 CIFAR-100 上的传输成本。 当考虑大量客户时,我们展示了更高的验证准确性和更快的收敛速度。
与联合 SGD 和联合平均[38]相比,我们证明了计算和通信带宽的显着减少。 减少计算要求可以解释为,虽然联合平均需要在客户端对整个神经网络进行前向传递和梯度计算,但我们的方法仅需要前几层进行这些计算,从而显着降低了计算要求(如图所示) 3)。 尽管联合平均需要的迭代次数比大规模 SGD 少得多,但它仍然优于我们的方法,该方法只需要在客户端进行一小部分计算。
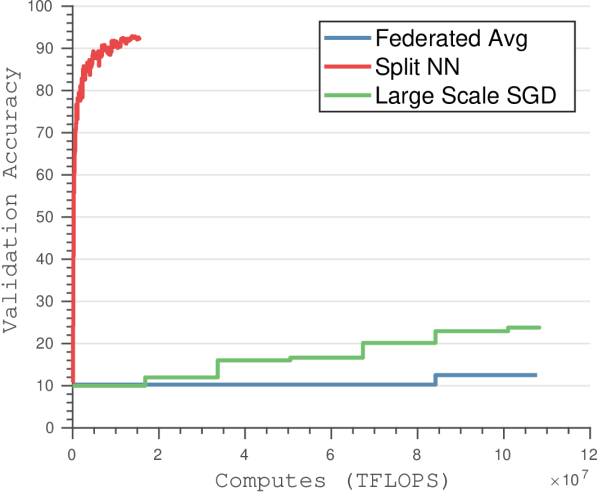
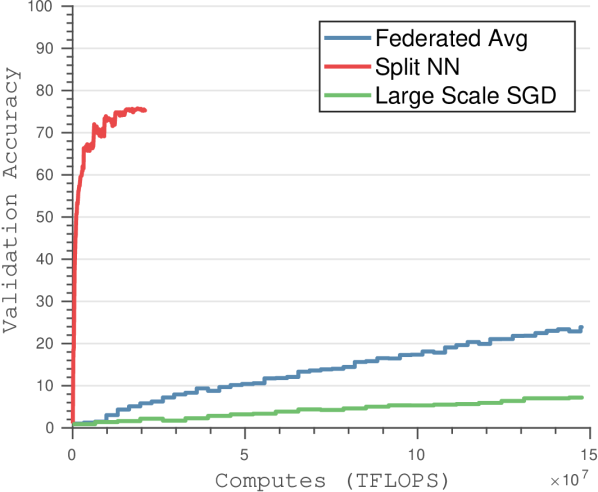
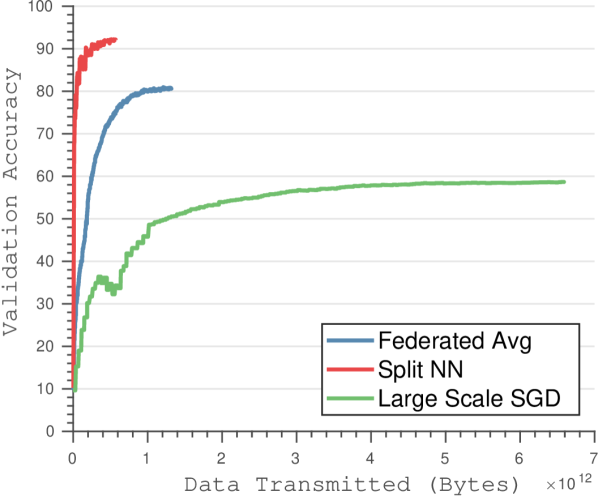
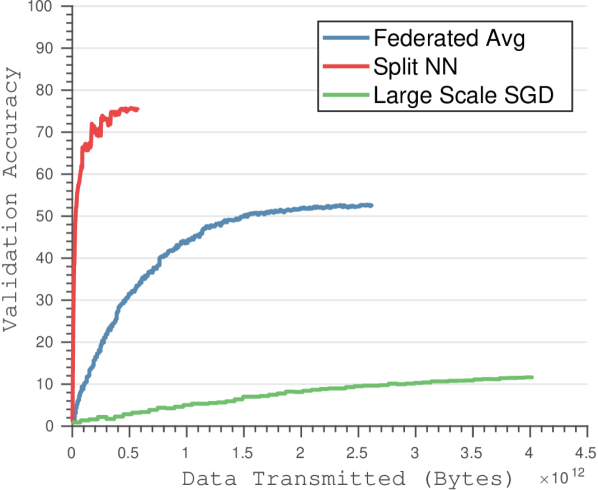
通信带宽的减少可归因于以下事实:联合平均涉及将整个神经网络的梯度更新从所有客户端传输到中央服务器,同时将更新的权重传输到每个客户端(请参阅图4)。 虽然联合平均算法能够在更少的传输周期内收敛,但每个传输周期都需要大量的数据下载和上传到客户端和服务器。 分裂神经网络算法通过将客户端神经网络的大小限制为仅前几层来减少传输的数据量,从而大大减少训练期间传输的数据总量。 此外,联合平均无法为更多数量的客户端实现最佳精度,因为参数空间中的一般非凸优化平均模型可能会产生任意糟糕的模型([39]中描述的现象)。
5.2数据量对最终精度的影响
| Dataset | Accuracy using 1 agent (10 %) | Accuracy using 5 agents (50 % of data) | Accuracy using all agents |
|---|---|---|---|
| MNIST | 97.54 | 98.93 | 99.20 |
| CIFAR 10 | 72.53 | 89.05 | 92.45 |
| CIFAR 100 | 36.03 | 59.51 | 66.59 |
| ILSVRC 12 | 27.1 | 56.3* | 57.1 |
我们的方法的一个重要好处在于它能够组合多个数据源。 当使用深度神经网络时,较大的数据集已被证明比较小的数据集表现得更好。 我们通过实验证明了通过将数据集均匀划分为 10 个智能体并使用 1、5 或 10 个智能体训练拓扑来汇集多个智能体的好处。 我们观察到,添加更多代理会导致准确性显着提高。 请参阅表2,分析我们在现实场景中添加更多数据源时准确性将如何提高。
6 结论和未来的工作
在本文中,我们提出了在多个数据存储库上训练深度神经网络的新方法。 我们还提出了如何在不透露实际原始数据的情况下训练神经网络的算法,同时减少对单个数据源的计算要求。 我们描述了如何修改该算法以在半监督训练模式下工作,从而大大减少 所需的标记样本数量。 我们为算法的正确性提供数学保证。
我们设计了一种新协议,可以轻松实现分布式训练算法。 我们使用流行的计算机视觉数据集(例如 CIFAR-10 和 ILSVRC12)进行性能验证,并表明我们的算法产生与标准训练程序相同的结果。 我们还展示了该算法如何通过组合来自多个资源的数据在低数据场景中发挥作用。 当数据共享不可能时,这种方法对于使用专有数据源进行训练是有益的。 它在生物医学成像等领域也很有价值,因为它可以在不泄露患者个人详细信息的情况下训练深度神经网络,并最大限度地减少设备所需的计算资源。
在本文中,我们描述了一种在多个数据存储库和计算资源上训练单个网络拓扑的方法。 这种方法的合理扩展可以是通过每次迭代传输所有分类器的前向和后向张量来训练分类器集合。 深度神经网络分类器集成可以包含多个执行分类的单独深度神经网络拓扑。 通过计算每个神经网络的前向和后向函数来单独训练网络拓扑,并在测试阶段使用多数投票来组合结果以产生分类。 我们可以通过为每个神经网络生成单独的前向和后向传播张量并在每次迭代期间传输它们来训练这样的集成。 这相当于逐个训练各个网络,但通过将各种网络的迭代组合在一起可以节省时间。 事实证明,集成分类器能够更安全地抵御网络复制攻击,并且在现实应用中表现更好[40]。
在未来的工作中,可以使用学生-教师方法共享学习的神经网络,以传输神经网络学习的信息[41]。 训练阶段结束后,Alice 和 Bob 可以使用主(教师)神经网络的输出,将任何公开可用的数据集用于辅助(学生)神经网络。 Alice 可以通过先前训练的网络的层从公共数据集中传播相同的训练样本,Bob 可以通过其网络传播它们。 Bob 可以使用其各层的输出,通过对同一数据样本进行前向-后向操作来训练学生网络。 这样,来自分布式训练网络的知识可以转移到另一个可以共享供公众使用的网络。 此类算法有助于在健康、产品和金融等多个领域引入深度学习,在这些领域,用户数据是昂贵的商品,并且需要保持匿名。
Tor 之类的逐层计算可以允许在多个节点上训练这个网络,每个节点只承载几个层。 这种方法不仅可以帮助保护数据,还可以帮助保护共享数据和执行分类的人员的身份。 在类似于 Tor 的设置中,添加了无法访问数据或完整网络拓扑的附加实体 Eve0…M。 每个 Eve 都有几个网络层。 在前向传播过程中,Alice 会计算 ,并将其传递给 Eve0,后者再将其传递给 Eve1,依此类推,直到传递到 EveM。 EveM 类似于 Tor 网络中的出口节点,它将张量传递给 Bob。 同样,在反向传播时,Bob 会计算 ,并将其发送给 EveM,Eve 再将其发送给 EveM-1,依此类推,直到到达 Eve0,然后到达 Alice。 网络层的洋葱式组织可用于保持 Alice 身份的机密性。
我们的算法不仅可以应用于分类任务,还可以应用于回归和分割任务。 我们还可以在 LSTM 和循环神经网络上使用它。 在生成梯度时,Bob 这边可以使用不同的损失函数(欧几里德)来轻松解决此类神经网络问题。
参考
参考
- [1] A. Chervenak, I. Foster, C. Kesselman, C. Salisbury, S. Tuecke, The data grid: Towards an architecture for the distributed management and analysis of large scientific datasets, Journal of network and computer applications 23 (3) (2000) 187–200.
- [2] J. C.-I. Chuang, M. A. Sirbu, Distributed network storage service with quality-of-service guarantees, Journal of Network and Computer Applications 23 (3) (2000) 163–185.
- [3] A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [4] A. Karpathy, L. Fei-Fei, Deep visual-semantic alignments for generating image descriptions, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015) 3128–3137.
- [5] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [6] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, A. Senior, P. Tucker, K. Yang, Q. V. Le, et al., Large scale distributed deep networks, in: Advances in neural information processing systems, 2012, pp. 1223–1231.
- [7] R. Mcdonald, M. Mohri, N. Silberman, D. Walker, G. S. Mann, Efficient large-scale distributed training of conditional maximum entropy models, in: Advances in Neural Information Processing Systems, 2009, pp. 1231–1239.
- [8] M. Zinkevich, M. Weimer, L. Li, A. J. Smola, Parallelized stochastic gradient descent, in: Advances in neural information processing systems, 2010, pp. 2595–2603.
- [9] J. Langford, A. J. Smola, M. Zinkevich, Slow learners are fast, Advances in Neural Information Processing Systems 22 (2009) 2331–2339.
- [10] Q. Shi, J. Petterson, G. Dror, J. Langford, A. L. Strehl, A. J. Smola, S. Vishwanathan, Hash kernels, in: International Conference on Artificial Intelligence and Statistics, 2009, pp. 496–503.
- [11] A. Agarwal, J. C. Duchi, Distributed delayed stochastic optimization, in: Advances in Neural Information Processing Systems, 2011, pp. 873–881.
- [12] A. Agarwal, O. Chapelle, M. Dudík, J. Langford, A reliable effective terascale linear learning system., Journal of Machine Learning Research 15 (1) (2014) 1111–1133.
- [13] S. K. Sood, A combined approach to ensure data security in cloud computing, Journal of Network and Computer Applications 35 (6) (2012) 1831–1838.
- [14] S. Avidan, M. Butman, Blind vision, European Conference on Computer Vision (2006) 1–13.
- [15] A. Dosovitskiy, T. Brox, Inverting visual representations with convolutional networks, arXiv preprint arXiv:1506.02753.
- [16] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, P.-A. Manzagol, Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion, Journal of Machine Learning Research 11 (Dec) (2010) 3371–3408.
- [17] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, A. A. Efros, Context encoders: Feature learning by inpainting, arXiv preprint arXiv:1604.07379.
- [18] J. Secretan, M. Georgiopoulos, J. Castro, A privacy preserving probabilistic neural network for horizontally partitioned databases, 2007 International Joint Conference on Neural Networks (2007) 1554–1559.
- [19] A. Chonka, Y. Xiang, W. Zhou, A. Bonti, Cloud security defence to protect cloud computing against http-dos and xml-dos attacks, Journal of Network and Computer Applications 34 (4) (2011) 1097–1107.
- [20] B. Wu, J. Wu, E. B. Fernandez, M. Ilyas, S. Magliveras, Secure and efficient key management in mobile ad hoc networks, Journal of Network and Computer Applications 30 (3) (2007) 937–954.
- [21] M. Barni, C. Orlandi, A. Piva, A privacy-preserving protocol for neural-network-based computation, Proceedings of the 8th workshop on Multimedia and security (2006) 146–151.
- [22] Y. Karam, T. Baker, A. Taleb-Bendiab, Security support for intention driven elastic cloud computing, in: Computer Modeling and Simulation (EMS), 2012 Sixth UKSim/AMSS European Symposium on, IEEE, 2012, pp. 67–73.
- [23] S. Subashini, V. Kavitha, A survey on security issues in service delivery models of cloud computing, Journal of network and computer applications 34 (1) (2011) 1–11.
- [24] M. Mackay, T. Baker, A. Al-Yasiri, Security-oriented cloud computing platform for critical infrastructures, Computer Law & Security Review 28 (6) (2012) 679–686.
- [25] T. Baker, M. Mackay, A. Shaheed, B. Aldawsari, Security-oriented cloud platform for soa-based scada, in: Cluster, Cloud and Grid Computing (CCGrid), 2015 15th IEEE/ACM International Symposium on, IEEE, 2015, pp. 961–970.
- [26] O. Goldreich, S. Micali, A. Wigderson, How to play any mental game, Proceedings of the nineteenth annual ACM symposium on Theory of computing (1987) 218–229.
- [27] A. C.-C. Yao, How to generate and exchange secrets, Foundations of Computer Science, 1986., 27th Annual Symposium on (1986) 162–167.
- [28] Y. Zhang, S. Zhong, A privacy-preserving algorithm for distributed training of neural network ensembles, Neural Computing and Applications 22 (1) (2013) 269–282.
- [29] K. Chen, L. Liu, A random rotation perturbation approach to privacy preserving data classification.
- [30] C. Orlandi, A. Piva, M. Barni, Oblivious neural network computing via homomorphic encryption, EURASIP Journal on Information Security 2007 (2007) 18.
- [31] H.-C. Shin, M. R. Orton, D. J. Collins, S. J. Doran, M. O. Leach, Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4d patient data, IEEE transactions on Pattern Analysis and Machine Intelligence 35 (8) (2013) 1930–1943.
- [32] A. Coates, A. Karpathy, A. Y. Ng, Emergence of object-selective features in unsupervised feature learning, in: Advances in Neural Information Processing Systems, 2012, pp. 2681–2689.
- [33] J. Weston, F. Ratle, H. Mobahi, R. Collobert, Deep learning via semi-supervised embedding, in: Neural Networks: Tricks of the Trade, Springer, 2012, pp. 639–655.
- [34] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel, Backpropagation applied to handwritten zip code recognition, Neural computation 1 (4) (1989) 541–551.
- [35] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, T. Darrell, Caffe: Convolutional architecture for fast feature embedding, arXiv preprint arXiv:1408.5093.
- [36] K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556.
- [37] J. Chen, R. Monga, S. Bengio, R. Jozefowicz, Revisiting distributed synchronous sgd, arXiv preprint arXiv:1604.00981.
- [38] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, et al., Communication-efficient learning of deep networks from decentralized data, arXiv preprint arXiv:1602.05629.
- [39] I. J. Goodfellow, O. Vinyals, A. M. Saxe, Qualitatively characterizing neural network optimization problems, arXiv preprint arXiv:1412.6544.
- [40] P. M. Granitto, P. F. Verdes, H. A. Ceccatto, Neural network ensembles: evaluation of aggregation algorithms, Artificial Intelligence 163 (2) (2005) 139–162.
- [41] N. Papernot, M. Abadi, Ú. Erlingsson, I. Goodfellow, K. Talwar, Semi-supervised knowledge transfer for deep learning from private training data, arXiv preprint arXiv:1610.05755.