通过对抗训练增强股票走势预测
摘要
本文为股票走势预测提供了一种新的机器学习解决方案,旨在预测股票价格在不久的将来会上涨还是下跌。 关键的新颖之处在于我们建议采用对抗性训练来提高神经网络预测模型的泛化能力。 这里对抗训练的合理性在于,股票预测的输入特征通常基于股票价格,股票价格本质上是一个随机变量,本质上是随着时间不断变化的。 因此,带有静态价格特征(例如,收盘价)的普通训练很容易过度拟合数据,不足以获得可靠的模型。 为了解决这个问题,我们建议添加扰动来模拟价格变量的随机性,并训练模型在小而有意的扰动下正常工作。 对两个真实世界股票数据的广泛实验表明,我们的方法优于最先进的解决方案 Xu 和 Cohen (2018),平均相对改进为 3.11% w.r.t。 准确性,验证对抗性训练对于股票预测任务的有用性。
1简介
股票市场是最大的金融市场之一,总价值达到80万亿美元222https://data.worldbank.org/indicator/CM.MKT.TRAD.CD?view=chart.。 预测股票的未来状况一直是股市中许多参与者的浓厚兴趣。 虽然众所周知,股票的确切价格是不可预测的Walczak (2001); Nguyen等人(2015),研究工作主要集中在预测股票价格走势——例如,价格是否会上涨/下跌,或者价格变化是否会超过阈值——这比股票价格更容易实现预测 Adebiyi 等人 (2014);冯等人 (2018);徐和科恩(2018)。
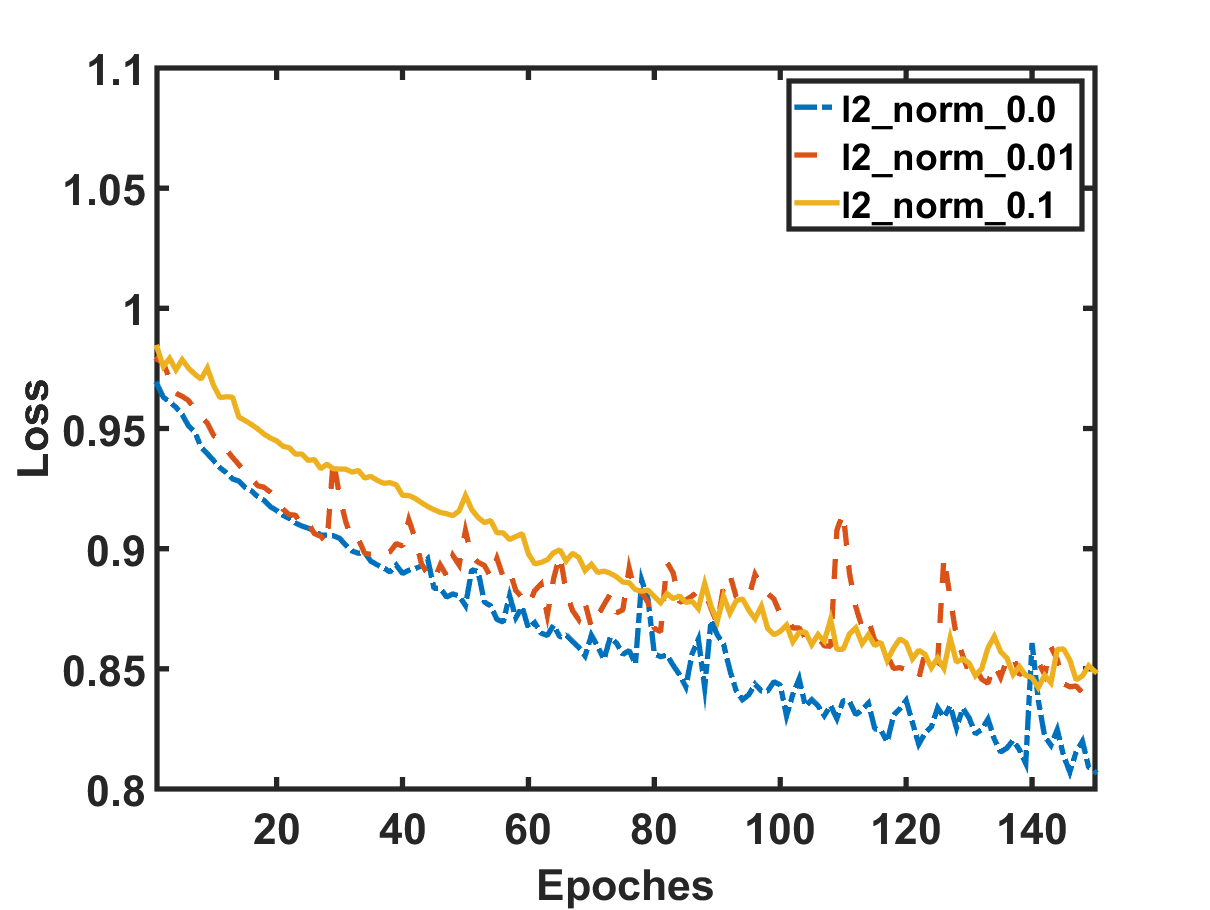
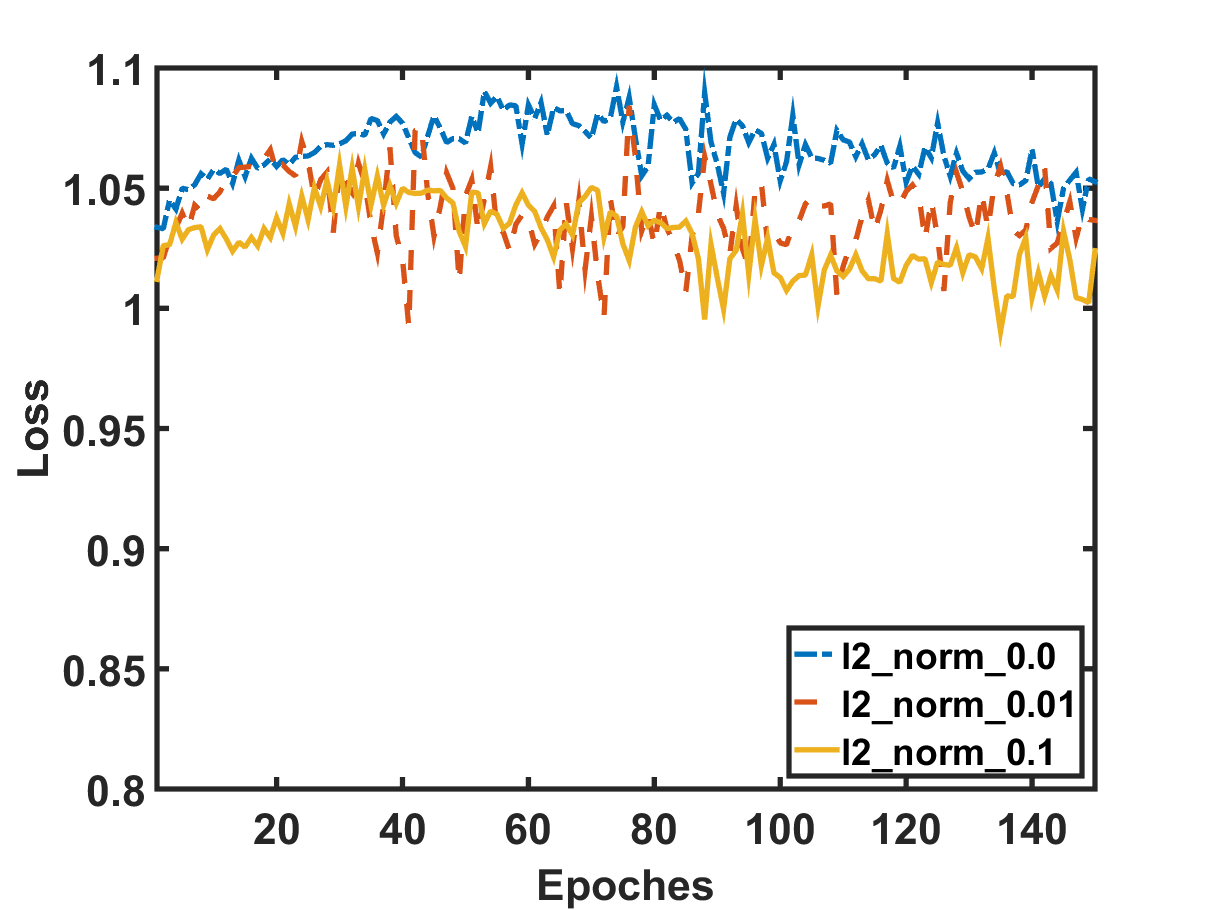
库存变动预测可以作为分类任务来解决。 在定义了一次描述股票的标签空间和特征后,我们可以应用标准的监督学习方法,例如支持向量机Huang等人(2005)和神经网络Xu和Cohen( 2018) 构建预测模型。 尽管在技术上可行,但我们认为,由于股票市场的高度随机性,这种方法可能会受到泛化能力较弱的影响。 图 1 提供了弱泛化的经验证据,我们将数据分为 和 按时间验证,并在 Qin 等人 (2017) 上训练 Attentive LSTM 模型股票的历史价格来预测其走势。 从图1(a)中,我们可以看到训练损失随着epoch的增加而逐渐减小,这符合预期。 然而,图1(b)所示的验证损失并没有呈现出下降的趋势;相反,它仅在初始化状态附近波动,没有明确的模式。 换句话说,在训练示例中学习的模型的好处并不能转化为预测未知验证示例的改进。 我们已经深入探索了正则化(不同线的结果),这是一种提高模型泛化能力的常用技术,但是情况并没有改善。
我们假设原因是标准分类方法被假设从静态输入中学习,例如图像中的像素值和文档中的术语频率。 当处理股票价格等随机变量时,静态输入假设不成立,此类方法不能很好地泛化。 具体来说,现有的股票预测方法通常会输入基于价格的特征,例如特定时间步长的价格或多个时间步长的平均价格 Edwards 等人 (2007);尼尔森等人 (2017). 由于股票的价格随着时间(在市场交易时间内)不断变化,基于价格的特征本质上是随机变量,与传统的静态输入有根本的不同。 更具体地说,训练实例的特征可以看作是从特定时间步的输入变量分布中提取的“样本”。 如果没有正确处理输入变量的随机性,该方法很容易对数据进行过拟合,并且泛化能力较弱。
在这项工作中,我们建议采用对抗性训练来解释股票市场的随机性,以学习股票走势预测模型。 我们的主要考虑是,给定具有固定输入特征的特定时间步长的训练示例,训练后的模型预计会对从输入变量的固有分布中提取的其他样本生成相同的预测。 为了实现这个想法,我们可以通过对输入特征添加小的扰动来生成额外的样本(随机性的模拟),并训练模型在干净的例子和扰动的例子上都表现良好。 这是计算机视觉任务中常用的对抗训练方法Kurakin等人(2017)。 然而,问题在于股票预测模型的特征通常是连续的(见图 2),因此对所有时间单位的特征添加扰动可能非常耗时;此外,它可能会导致不同单元的扰动之间出现无意的相互作用,这是不可控的。 为了解决这个问题,我们转而在模型的高层预测特征上添加扰动,例如,直接投射到最终预测的最后一层。 由于大多数深度学习方法在较高层中学习 Abstract 表示,因此它们的大小通常比输入大小小得多。 因此,在高级特征中添加扰动会更有效,同时也可以保留随机性。
我们在 Attentive LSTM 模型上实现了我们的对抗性训练建议,这是一种针对序列数据具有高度表达能力的模型。 我们在最后一层的预测特征中添加扰动,并动态优化扰动,使它们尽可能地改变模型的输出。 然后,我们对模型进行训练,使其在干净特征和扰动特征上都表现良好。 因此,对抗性训练过程可以理解为强制执行动态正则化器,它可以稳定模型训练并使模型在随机性下表现良好。
本文的主要贡献总结如下:
-
•
我们研究了股票走势预测的泛化难度,并强调了处理输入特征的随机性的必要性。
-
•
我们提出了一种对抗性训练解决方案来应对随机挑战,并将其应用于股票走势预测的深度学习模型上。
-
•
我们对两个公共基准进行了广泛的实验,验证了对几种最先进方法的改进,并表明对抗性学习使分类器更加稳健和更通用。
2 问题表述
我们使用粗体大写字母(例如,)和粗体小写字母(例如,)来表示矩阵和向量, 分别。 另外,普通小写字母(例如,)和希腊字母(例如,)用于表示分别为标量和超参数。 如果没有另外指定,所有向量都是列形式。 符号和分别代表双曲正切函数和S形函数。
股票走势预测任务的制定是学习一个预测函数,它将股票()从其顺序特征()映射到标签空间。 换句话说,带有参数 的函数 旨在根据最近 时间步中的连续特征 预测下一个时间步的存量 的变化。 是一个矩阵,表示过去 时间步长滞后的顺序输入特征(例如,开盘价和收盘价,详见表 1),其中 是特征的维度。
假设我们有 只股票,我们通过拟合它们的真实值标签 来学习预测函数,其中 (1/-1) 是真实值下一个时间步中的库存标签。 然后,我们将问题正式定义为:
输入:一组训练示例。
输出:预测函数,预测股票在接下来的时间步中的变动。
在实际场景中,我们通常可以访问每只股票的长期历史记录,并通过沿着历史记录移动滞后来为每只股票构建许多示例。 不过,为了简明扼要地介绍所提出的方法,我们使用了一个简化的表述,只考虑了一个特定的滞后期(即每只股票的一个训练实例),而没有考虑损失的一般性。
3 对抗性注意力 LSTM (Adv-ALSTM)
3.1注意力LSTM
Attentive LSTM(ALSTM)主要包含四个组件:特征映射层、LSTM层、时间注意力和预测层,如图2所示。
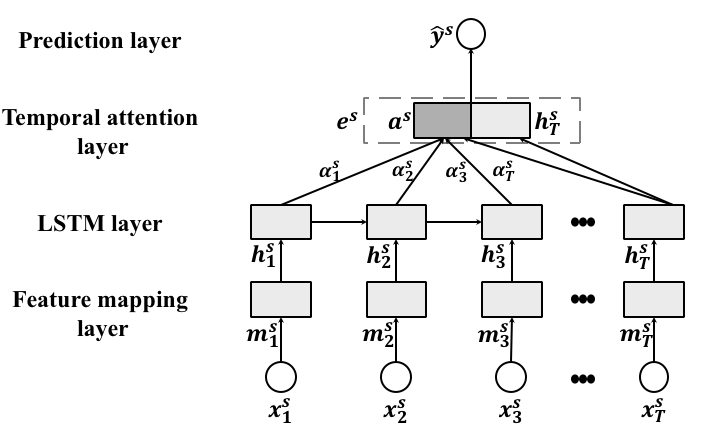
特征映射层。 之前的工作表明,更深的输入门将有利于 LSTM 时间结构的建模 Graves 等人 (2013);吴等人(2018). 受到他们成功的启发,我们采用全连接层将输入特征投影到潜在表示中。 在每个时间步,它的执行方式为 ,将输入特征投影到维度为 的潜在空间。 和是要学习的参数。
LSTM 层。 由于其捕获长期依赖性的能力,LSTM 已被广泛用于处理顺序数据 Qin 等人 (2017);陈等人(2018a). LSTM 的总体思想是将输入序列循环投影到隐藏表示序列中。 在每个时间步,LSTM 通过联合考虑输入 () 和先前的隐藏表示 () 来捕获隐藏表示 ()顺序依赖。 我们将其表述为,具体表述可参考Hochreiter and Schmidhuber (1997)。 为了捕获历史股票特征中的顺序依赖性和时间模式,应用 LSTM 层将 映射到维度为 的隐藏表示 。
时间注意力层。 注意力机制已广泛应用于基于 LSTM 的顺序学习问题解决方案~Cho 等人 (2014);陈等人(2018a). 注意力的思想是将不同时间步长的隐藏表示压缩为具有自适应权重的整体表示。 注意力机制旨在模拟这样一个事实:不同时间步长的数据可能对整个序列的表示有不同的贡献。 对于股票代表性,不同时间步长的状态也可能有不同的贡献。 例如,最高和最低价格滞后的日子可能对整体代表性有更高的贡献。 因此,我们使用注意机制将隐藏表示聚合为:
| (1) | ||||
其中、和是要学习的参数; 是对序列中的整体模式进行编码的聚合表示。
预测层。 我们不是直接从 进行预测,而是首先将 与最后一个隐藏状态 连接到股票的最终潜在表示中,
| (2) |
其中。 其背后的直觉是进一步强调最近的时间步长,这被认为可以为后续运动Fama and French (2012)提供信息。 对于,我们使用全连接层作为预测函数来估计分类置信度。 请注意,最终的预测是。
3.2 对抗训练
与大多数分类解决方案一样,ALSTM 的正常训练方式是最小化目标函数:
| (3) |
第一项是铰链损失Rosasco等人(2004),广泛用于优化分类模型(更多选择它的原因在本节末尾进一步解释)。 第二项是可训练参数的正则化器,以防止过度拟合。
尽管正常训练被广泛使用,但我们认为它不适合学习股票预测模型。 这是因为正常的训练假设输入是静态的,忽略这些特征的随机属性(训练示例是从输入变量的随机分布中抽取的样本)。 请注意,这些特征是根据股票价格计算的,股票价格随时间不断变化,并受到特定时间步Musgrave (1997)的随机交易行为的影响。 因此,正常的训练可能会导致模型过度拟合数据并且缺乏泛化能力(如图1所示)。 请注意,如果模型在随机性下表现良好,则会对从固有分布中抽取的样本做出相同的预测。 考虑到股票价格是连续的,我们的直觉是通过对静态输入特征添加小扰动来有意模拟样本。 通过强制对模拟样本进行相同的预测,该模型可以捕获随机性。
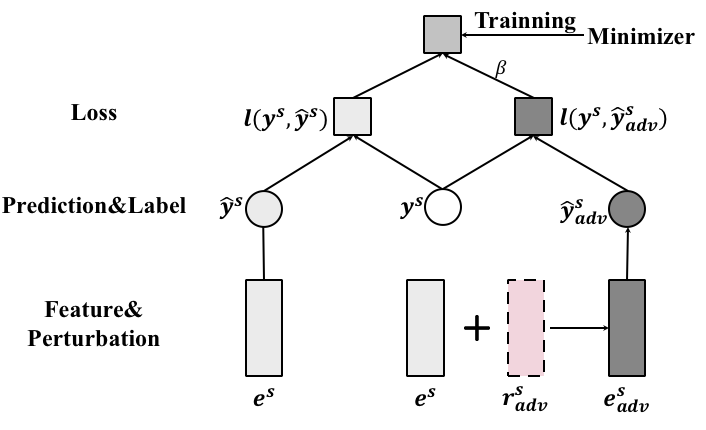
对抗训练 Goodfellow 等人 (2015); Kurakin 等人 (2017) 实现了上述直觉。 它使用干净的示例(即训练集中的示例)和对抗性示例(AE)Szegedy 等人 (2013) 来训练模型。 AE 是通过向干净示例的特征添加有意扰动而生成的恶意输入。 扰动,称为对抗性扰动(AP),是导致模型预测变化最大的方向。 尽管它在图像分类方面取得了成功Kurakin等人(2017),但直接应用于股票预测是不可行的。 这是因为计算扰动依赖于计算输入的梯度,这将非常耗时(由 LSTM 层时间步长的反向传播引起)。 此外,考虑到输入的梯度依赖于不同时间步长的事实,不同时间步长上的扰动之间可能存在无意的相互作用,这是不可控的。 为了解决这些问题,我们建议从潜在表示生成AE,如图3所示。
在介绍AE的计算之前,我们首先阐述Adv-ALSTM的目标函数:
| (4) |
第二项是对抗性损失,其中 是股票 AE 的分类置信度。 是一个超参数,用于平衡干净样本和对抗样本的损失。 通过最小化目标函数,鼓励模型正确分类干净的例子和对抗性的例子。 请注意,正确分类 AE 的模型可以对相同规模的任意扰动的示例做出正确的预测。 这是因为AP是导致模型预测变化最大的方向。 因此,对抗性学习可以使 ALSTM 捕获股票输入的随机特性。
在每次迭代中,AE () 的潜在表示由以下公式生成:
| (5) |
其中(在方程2中引入)是股票的最终潜在表示。 是关联的 AP。 是一个超参数,用于显式控制扰动的规模。 由于直接计算比较困难,因此我们采用快速梯度逼近方法Goodfellow等人(2015), 具体来说,计算的扰动是关于范数约束下的潜在表示的损失函数的梯度。 请注意,梯度表示损失函数在给定点处增加最多的方向,即,它将导致模型预测的最大变化。
图4说明了对抗性示例的生成。 在训练迭代中,给定一个损失大于 0 的干净示例(即 ),生成 AE。 然后更新模型以共同最小化干净示例和对抗性示例的损失,这将加强干净示例和决策边界之间的余量333 最小化AE的铰链损失是调整以放大,这会增加第一项。 图5(第4节)中的结果凭经验证明了强制保证金的效果。. 因此,模型将具有扰动的示例预测为与干净示例相同的类别将有利于模型。 也就是说,该模型可以正确预测从输入的固有随机分布中抽取的样本,捕获随机性。 虽然像支持向量机这样的传统模型也将决策边界推离了干净的例子,但对抗性训练会在训练过程中自适应地调整执行边际的强度,因为 AP () 在迭代过程中会发生变化。 请注意,我们选择铰链损失是为了鼓励训练过程更多地关注靠近决策边界的示例。
4实验
4.1实验设置
数据集。 我们在股票走势预测的两个基准上评估所提出的方法,ACL18 Xu and Cohen (2018) 和 KDD17 Zhang 等人 ( 2017)。
ACL18 包含 2014 年 1 月 1 日至 2016 年 1 月 1 日期间纳斯达克和纽约证券交易所市场 88 只高交易量股票的历史数据。 继Xu和Cohen(2018)之后,我们首先对齐历史中的交易日,即,删除缺乏历史价格的周末和公共假期。 然后,我们沿着对齐的交易日移动长度为 的滞后来构建候选示例(即,每个交易日的股票的一个示例)。 我们根据股票收盘价的变动百分比来标记候选示例444给定股票的候选示例,其滞后于,变动百分比计算为,其中是股票在日调整后的收盘价。. 移动百分比为 和 的示例分别被识别为正例和负例。 我们将识别出的示例暂时分为训练(2014年1月1日至2015年8月1日)、验证(2015年8月1日至2015年10月1日)和测试(2015年10月1日至2015年1月1日) 2016)。
KDD17 包括从 2007 年 1 月 1 日到 2016 年 1 月 1 日期间美国市场上 50 只股票的较长历史记录。 由于数据集最初是为了预测股票价格而不是走势而收集的,因此我们遵循与 ACL18 相同的方法来识别正面和负面示例。 然后,我们将示例暂时分为训练(2007 年 1 月 1 日到 2015 年 1 月 1 日)、验证(2015 年 1 月 1 日到 2016 年 1 月 1 日)和测试(2016 年 1 月 1 日到 2017 年 1 月 1 日) )。

| Features | Calculation | ||
|---|---|---|---|
| c_open, c_high, c_low | e.g., c_open | ||
| n_close, n_adj_close | e.g., n_close = | ||
|
e.g., 5-day = |
功能。 我们不使用原始 EOD 数据,而是定义 11 个时间特征 () 来描述股票 在交易日 的趋势。表1详细说明了与计算相关的功能。 我们定义这些特征的目的在于1) 对不同股票的价格进行归一化处理;2) 明确捕捉不同价格之间的相互作用(例如,开盘价和收盘价)。
基线。 我们比较以下几种方法:
-
•
MOM 动量 (MOM) 是一种技术指标,用于预测过去 10 天内每个示例的趋势为负或正。
-
•
MR 均值回归 (MR) 将每个示例的走势预测为最新价格向 30 天移动平均线的相反方向。
-
•
LSTM 是一个具有 LSTM 层和预测层的神经网络Nelson 等人 (2017)。 我们调整三个超参数,隐藏单元的数量 ()、滞后大小 () 和正则化项的权重 ()。
-
•
ALSTM 是 Attentive LSTM Qin 等人 (2017),它是通过正常训练进行优化的。 与LSTM类似,我们也调整、和。
-
•
StockNet 使用变分自动编码器 (VAE) 对股票输入进行编码,以捕获随机性,并使用时间注意力来建模不同时间步长的重要性Xu 和 Cohen (2018). 在这里,我们将表 1 中的时间特征作为输入,并调整其隐藏大小、丢失率和辅助率 ()。
评估指标。 我们使用两个指标来评估预测性能:准确度 (Acc) 和马修斯相关系数 (MCC) Xu 和 Cohen (2018),其范围在 和 。 请注意,更高的指标值可以证明更好的性能。
参数设置。 我们使用 Tensorflow 实现 Adv-ALSTM,并使用小批量 AdamDiederik 和 Jimmy (2015) 对其进行优化,批量大小为 1,024,初始学习率为 0.01 。 我们在验证集上搜索 Adv-ALSTM 的最佳超参数。 对于、和,Adv-ALSTM继承了ALSTM的最佳设置,分别通过网格搜索在 [4, 8, 16, 32]、[2, 3, 4, 5, 10, 15] 和 [0.001, 0.01, 0.1, 1] 范围内选择。 我们进一步将 和 分别调整在 [0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1] 和 [0.001, 0.005, 0.01, 0.05, 0.1] 范围内。 当 Adv-ALSTM 在五次不同运行的验证集上表现最佳时,我们报告了平均测试性能。 代码可以通过https://github.com/hennande/Adv-ALSTM访问。
4.2实验结果
性能比较。 表2分别显示了比较方法在 Acc 和 MCC 两个数据集上的预测性能。 从表中,我们有以下观察结果:
-
•
Adv-ALSTM 在所有情况下都取得了最佳结果。 与基线相比,Adv-ALSTM 在ACL18(KDD17)上表现出 4.02% 和 42.19%(2.14% 和 56.12%)的改进)分别关于 Acc 和 MCC 的数据集。 这证明了对抗性训练的有效性,这可能是由于通过在训练过程中自适应模拟扰动来增强模型泛化能力。
-
•
具体来说,与通过 VAE 捕获股票输入的随机性的 StockNet 相比,Adv-ALSTM 取得了显着的改进。 我们假设原因是 StockNet 无法明确模拟随机扰动的规模和方向,因为它在训练过程中依赖于蒙特卡罗采样。
-
•
在基线中,ALSTM 比 LSTM 平均优于 1.93% 和 48.69%。 Acc和MCC,验证了注意力Qin等人(2017)的影响。 此外,MOM和MR的表现比预期的所有基于机器学习的方法都要差,这证明历史模式有助于股票预测任务。
| Method | ACL18 | KDD17 | ||
|---|---|---|---|---|
| Acc | MCC | Acc | MCC | |
| MOM | 47.01—– | -0.0640—– | 49.75—– | -0.0129—– |
| MR | 46.21—– | -0.0782—– | 48.46—– | -0.0366—– |
| LSTM | 53.185e-1 | 0.06745e-3 | 51.624e-1 | 0.01836e-3 |
| ALSTM | 54.907e-1 | 0.10437e-3 | 51.947e-1 | 0.02611e-2 |
| StockNet | 54.96—– | 0.0165—– | 51.934e-1 | 0.03355e-3 |
| Adv-ALSTM | 57.20—– | 0.1483—– | 53.05—– | 0.0523—– |
| RI | 4.02% | 42.19% | 2.14% | 56.12% |
RI denotes the relative improvement of Adv-ALSTM compared to the best baseline. The performance of StockNet is directly copied from Xu and Cohen (2018).
| Datasets | Acc | MCC |
|---|---|---|
| ACL18 | 55.082e0 | 0.11034e-2 |
| KDD17 | 52.435e-1 | 0.04058e-3 |
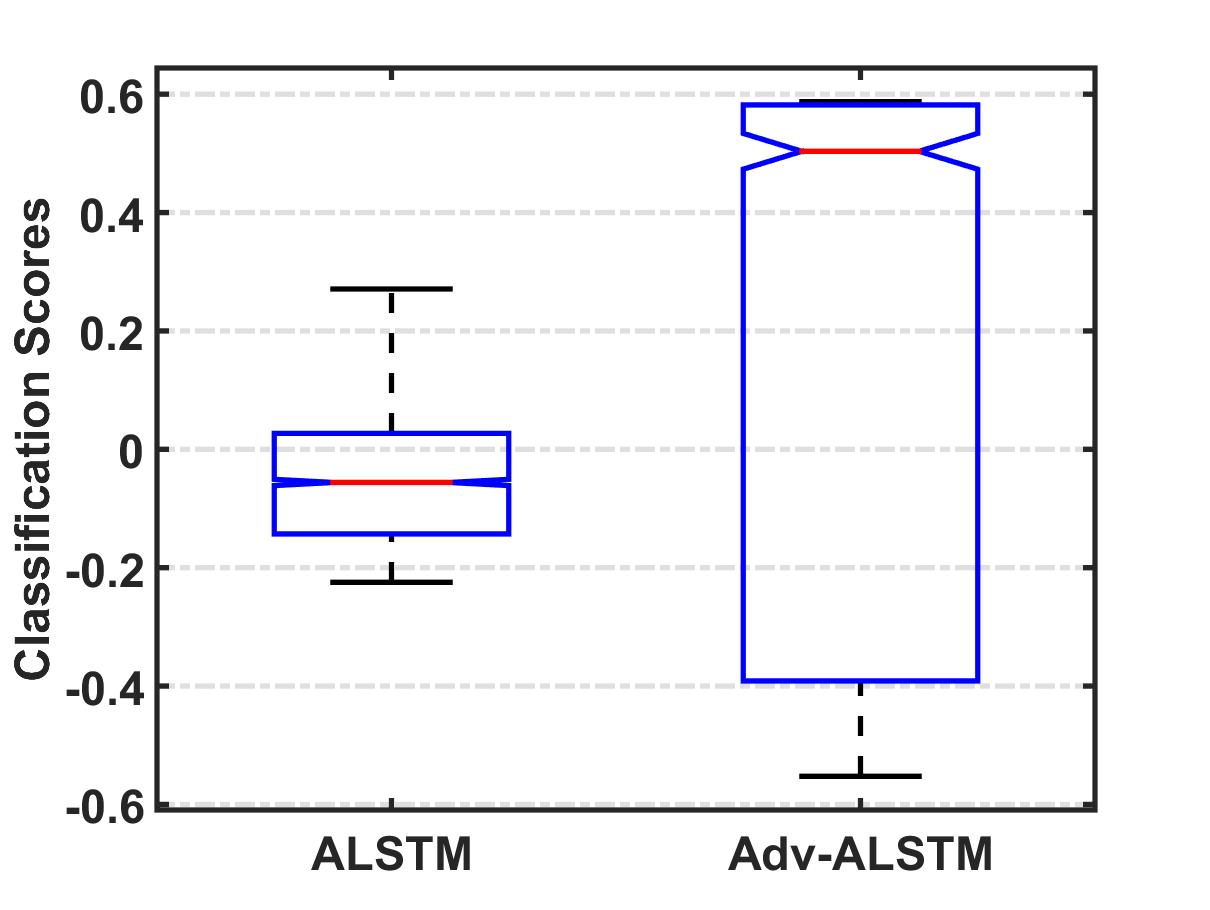
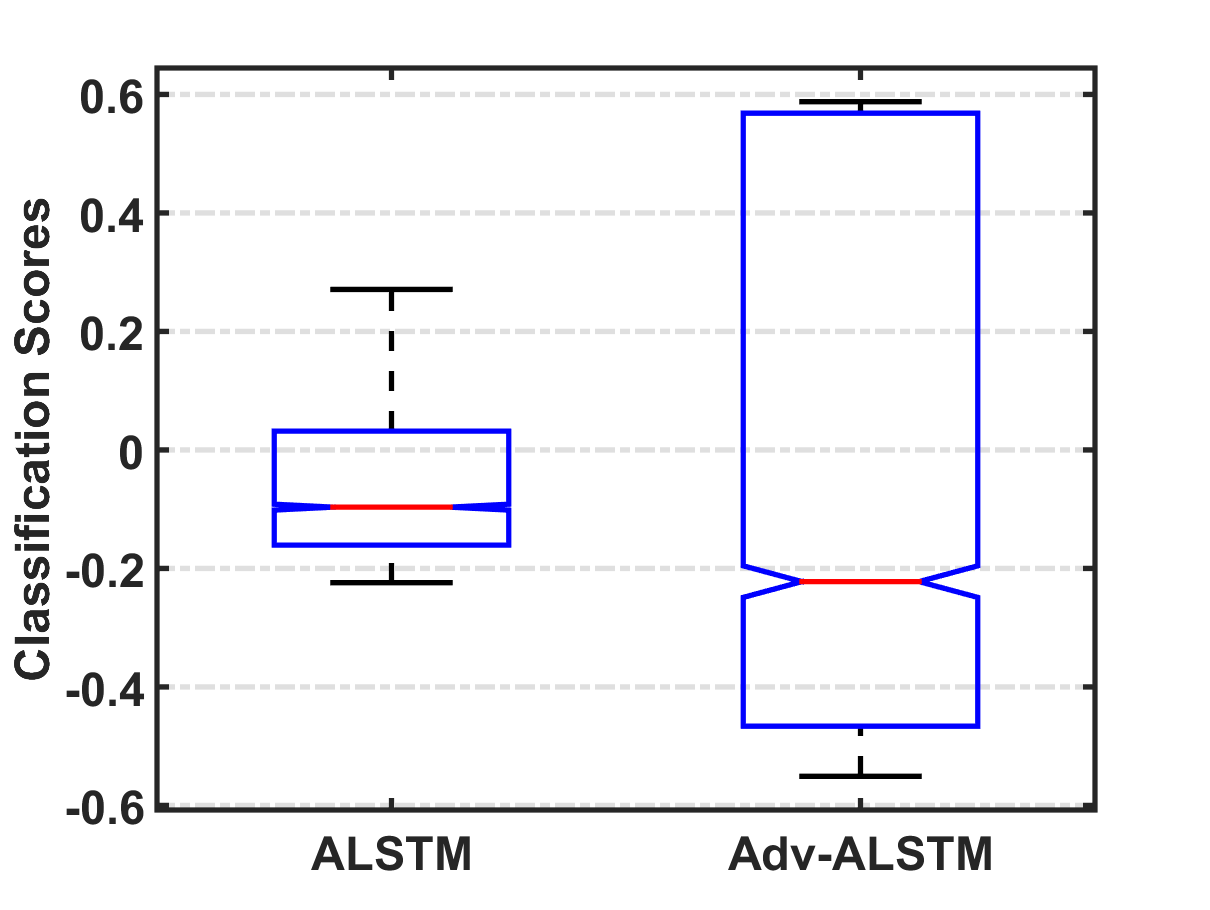
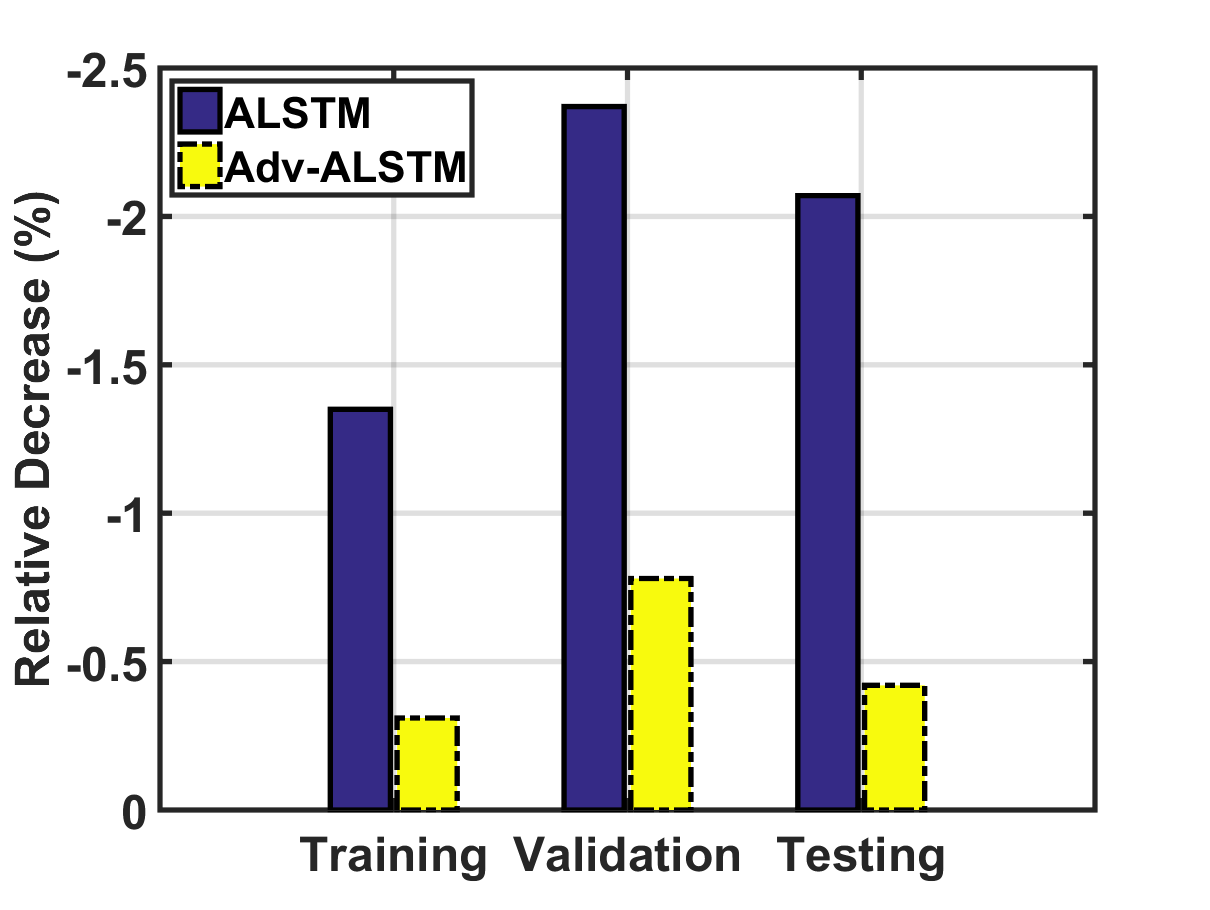
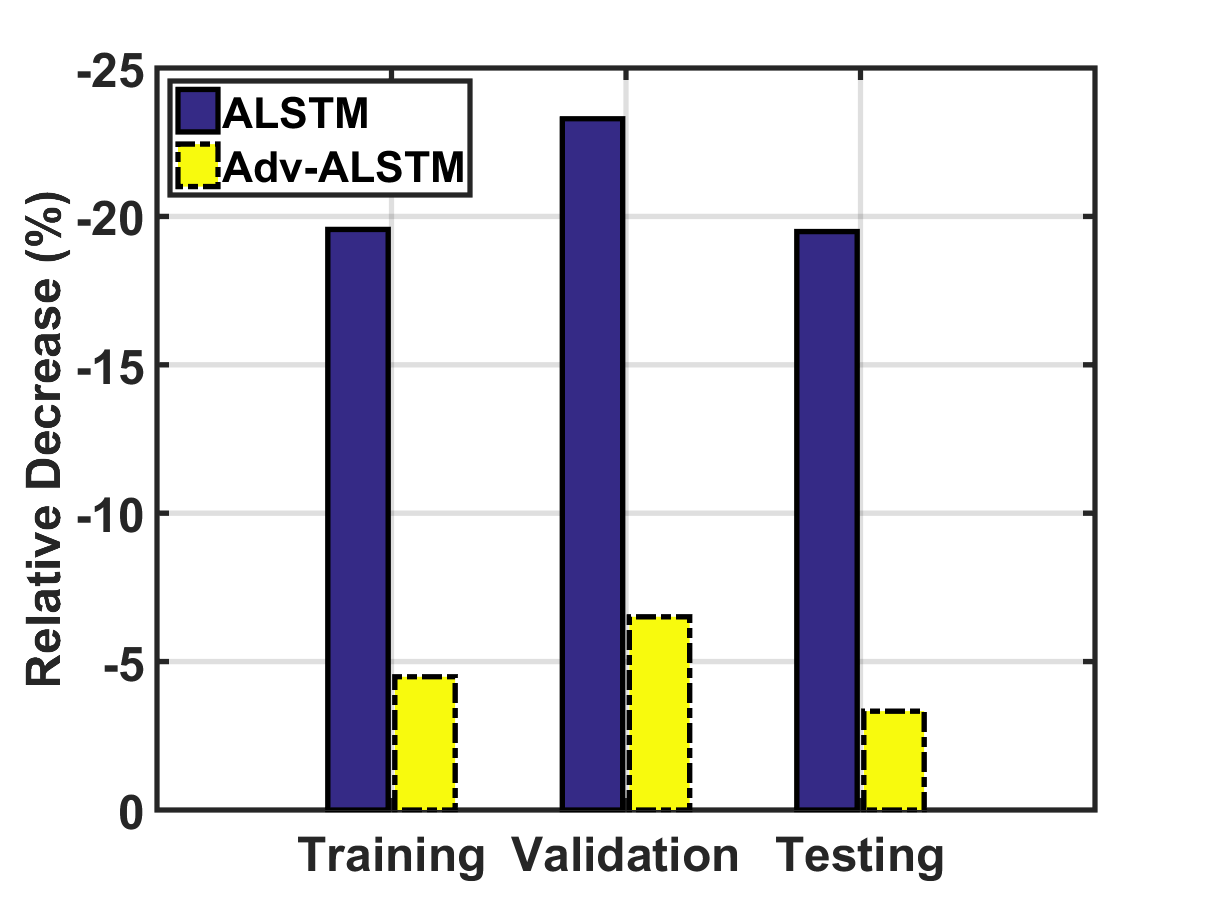
随机扰动VS.对抗性扰动。
我们通过比较对抗性扰动和随机扰动进一步研究对抗性训练的有效性。 Rand-ALSTM 是 Adv-ALSTM 的变体,它通过向干净示例的输入添加随机扰动来生成附加示例。 表3显示了Rand-ALSTM在两个数据集上的性能。 通过与表2交叉比较,我们观察到: 1)与Rand-ALSTM相比,Adv-ALSTM取得了显着的改进。 例如,它的性能w.r.t。 ACL18 上的 Acc 比 Rand-ALSTM 提高了 3.95%。 它表明对抗性扰动有助于股票预测,类似于原始图像分类任务 Goodfellow 等人 (2015) 中报告的情况。 2) Rand-ALSTM 优于 ALSTM,后者纯粹使用干净的示例进行训练,平均提高了 0.64% w.r.t。 Acc 上的两个数据集。 这凸显了处理库存特征的随机性的必要性。
对抗性训练的影响。 我们现在研究对抗性训练的影响来回答:1)对抗性训练是否强制干净示例和决策边界之间的余量。 2)对抗训练是否增强了模型针对对抗样本的鲁棒性。 请注意,我们仅显示 ACL18 数据集上的结果,因为 KDD17 上的结果承认相同的观察结果。
强制保证金。 回想一下,Adv-ALSTM 和 ALSTM 之间的唯一区别是对抗性训练和标准训练的学习参数。 因此,我们通过比较 Adv-ALSTM 和 ALSTM 分配的干净示例的分类置信度(值越大表示决策边界的余量越大)来回答第一个问题。 图5说明了ALSTM和Adv-ALSTM分配的分类置信度的分布。 可以看出,Adv-ALSTM的置信度分布在一个范围内(大致为[-0.6,0.6]),大约是ALSTM的1.5倍( [-0.2,0.3])。 它表明对抗性训练将决策边界推离了干净的例子,这被认为有助于增强模型的鲁棒性和泛化能力。
5相关工作
5.1 股市走势预测
最近关于股票走势预测的研究主要分为两类:技术分析和基本面分析(FA)。 技术分析(TA)以股票的历史价格为特征来预测其走势。 深度模型下 TA 矿山库存变动的最新方法 Lin 等人 (2017);尼尔森等人 (2017);冲等人(2017). 其中,像 LSTM 这样的循环神经网络已成为捕捉股票价格时间模式的关键组件 Nelson 等人 (2017);林等人(2017). 此外,其他先进的神经模型,例如卷积神经网络(CNN)Lin 等人(2017)和深度玻尔兹曼机Chong 等人(2017),也被证明可以有利于捕捉股票价格的非线性。
除了价格特征外,FA还考察相关的经济、金融等定性和定量因素Hu等人(2018);张等人 (2018);李等人 (2018);徐和科恩(2018)。 例如,Xu 和 Cohen Xu and Cohen (2018) 结合了来自社交媒体的信号(反映了一般用户的意见),以增强股票走势预测。 具体来说,他们使用 VAE 通过联合编码历史价格和提及该股票的推文来学习股票表示。 此外,Zhang等人。 Zhang 等人 (2018) 通过耦合矩阵和张量分解框架进一步考虑与股票或关联公司相关的新闻事件。
TA 和 FA 研究都表明价格特征在股票走势预测中起着至关重要的作用。 然而,现有的大多数研究都假设股票价格是静止的,因此缺乏处理其随机性的能力。 StockNet Xu and Cohen (2018) 是唯一通过 VAE 解决此问题的例外。 VAE 将输入编码为潜在分布,并强制使用相同的预测对潜在分布中的样本进行解码。 一般来说,背后的原理与随机扰动的模拟类似,因为潜在分布中的一个样本可以被视为向潜在表示添加随机扰动。 与我们的方法相比,我们的扰动是有意生成的,这表明模型会产生最难的示例来获得目标预测。 此外,所提出的方法可以很容易地适应其他股票走势预测的解决方案。
5.2 对抗性学习
对抗性学习已通过训练分类模型来防御对抗性示例进行了深入研究,这些示例是故意生成的以扰乱模型。 现有的对抗性学习工作主要集中在图像分类等计算机视觉任务Goodfellow 等人 (2015); iyato 等人 (2017); Kurakin 等人 (2017);杨等人 (2018);陈等人 (2018b). 由于图像特征通常是连续实值的特性,对抗样本直接在特征空间中生成。 最近,一些工作将对抗性学习扩展到具有离散输入的任务,例如文本分类(单词序列)iyato 等人(2017)、推荐(用户和项目 ID)He 等人(2018)、图节点分类(图拓扑)Dai 等人(2018);冯等人 (2019). 这些作品不是在特征空间中,而是通过单词、用户(项目)和节点嵌入等输入的嵌入来生成对抗性示例。 尽管这项工作受到这些对抗性学习研究工作的启发,但它针对的是一个独特的任务——股票走势预测,其中数据是具有随机属性的时间序列。 据我们所知,这项工作是第一个探索时间序列分析中对抗性训练潜力的工作。
6结论
在本文中,我们表明,用于股票走势预测的神经网络解决方案可能会受到泛化能力较弱的影响,因为它们缺乏处理股票特征随机性的能力。 为了解决这个问题,我们提出了一种Adversarial Attentive LSTM解决方案,它利用对抗训练来模拟模型过程中的随机性。 我们对两个基准数据集进行了广泛的实验,并验证了所提出的解决方案的有效性,这表明在股票走势预测中考虑股票价格随机性的重要性。 此外,结果表明对抗性训练增强了预测模型的鲁棒性和泛化性。
未来,我们计划探索以下方向:1)我们有兴趣测试Adv-ALSTM在更多资产(例如商品)的运动预测中的应用。 2)我们计划将对抗训练应用于具有不同结构的股票运动解决方案,例如CNN Lin等人(2017)。 3)我们将探讨对抗性训练对股票走势预测的基本面分析方法的影响。
参考
- Adebiyi et al. [2014] A. Adebiyi, A. Adewumi, and C. Ayo. Comparison of arima and artificial neural networks models for stock price prediction. JAM, 2014.
- Chen et al. [2018a] J. Chen, C. Ngo, F. Feng, and T. Chua. Deep understanding of cooking procedure for cross-modal recipe retrieval. In MM, pages 1020–1028. ACM, 2018.
- Chen et al. [2018b] L. Chen, H. Zhang, J. Xiao, W. Liu, and S. Chang. Zero-shot visual recognition using semantics-preserving adversarial embedding networks. In CVPR, pages 1043–1052, 2018.
- Cho et al. [2014] K. Cho, M. Van, C. Gulcehre, et al. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In EMNLP, pages 1724–1734, 2014.
- Chong et al. [2017] E. Chong, C. Han, and F. Park. Deep learning networks for stock market analysis and prediction: Methodology, data representations, and case studies. ESA, 83:187–205, 2017.
- Dai et al. [2018] H. Dai, H. Li, T. Tian, X. Huang, L. Wang, J. Zhu, and L. Song. Adversarial attack on graph structured data. In ICML, pages 1115–1124, 2018.
- Diederik and Jimmy [2015] K. Diederik and B. Jimmy. Adam: A method for stochastic optimization. ICLR, 2015.
- Edwards et al. [2007] R. Edwards, J. Magee, and C. Bassetti. Technical analysis of stock trends. CRC press, 2007.
- Fama and French [2012] E. F. Fama and K. R. French. Size, value, and momentum in international stock returns. JFE, 105(3):457–472, 2012.
- Feng et al. [2018] F. Feng, X. He, X. Wang, C. Luo, Y. Liu, and T. Chua. Temporal relational ranking for stock prediction. TOIS, 2018.
- Feng et al. [2019] F. Feng, X. He, J. Tang, and T. Chua. Graph adversarial training: Dynamically regularizing based on graph structure. arXiv, 2019.
- Goodfellow et al. [2015] I. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. ICLR, 2015.
- Graves et al. [2013] A. Graves, A. Mohamed, and G. Hinton. Speech recognition with deep recurrent neural networks. In ICASSP, pages 6645–6649. IEEE, 2013.
- He et al. [2018] X. He, Z. He, X. Du, and T. Chua. Adversarial personalized ranking for recommendation. In SIGIR, pages 355–364, 2018.
- Hochreiter and Schmidhuber [1997] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Hu et al. [2018] Z. Hu, W. Liu, J. Bian, X. Liu, and T. Liu. Listening to chaotic whispers: A deep learning framework for news-oriented stock trend prediction. In WSDM, pages 261–269, 2018.
- Huang et al. [2005] W. Huang, Y. Nakamori, and S. Wang. Forecasting stock market movement direction with support vector machine. COR, 32(10):2513–2522, 2005.
- iyato et al. [2017] MT. iyato, A. M. Dai, and I. Goodfellow. Adversarial training methods for semi-supervised text classification. ICLR, 2017.
- Kurakin et al. [2017] A. Kurakin, I. Goodfellow, and S. Bengio. Adversarial machine learning at scale. ICLR, 2017.
- Li et al. [2018] Q. Li, Y. Chen, J. Wang, Y. Chen, and H. Chen. Web media and stock markets: A survey and future directions from a big data perspective. TKDE, 30(2):381–399, 2018.
- Lin et al. [2017] T. Lin, T. Guo, and K. Aberer. Hybrid neural networks for learning the trend in time series. In IJCAI, pages 2273–2279, 2017.
- Musgrave [1997] G. Musgrave. A random walk down wall street. Business Economics, 32(2):74–76, 1997.
- Nelson et al. [2017] D. Nelson, A. Pereira, and R. Oliveira. Stock market’s price movement prediction with lstm neural networks. In IJCNN, pages 1419–1426. IEEE, 2017.
- Nguyen et al. [2015] T. H. Nguyen, K. Shirai, and J. Velcin. Sentiment analysis on social media for stock movement prediction. ESA, 42(24):9603–9611, 2015.
- Qin et al. [2017] Y. Qin, D. Song, H. Cheng, W. Cheng, G. Jiang, and G. Cottrell. A dual-stage attention-based recurrent neural network for time series prediction. In IJCAI, pages 2627–2633, 2017.
- Rosasco et al. [2004] L. Rosasco, E. D. Vito, A. Caponnetto, M. Piana, and A. Verri. Are loss functions all the same? Neural Computation, 16(5):1063–1076, 2004.
- Szegedy et al. [2013] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. arXiv, 2013.
- Walczak [2001] S. Walczak. An empirical analysis of data requirements for financial forecasting with neural networks. JMIS, 17(4):203–222, 2001.
- Wu et al. [2018] L. Wu, C. Quan, C. Li, and D. Ji. Parl: Let strangers speak out what you like. In CIKM, pages 677–686. ACM, 2018.
- Xu and Cohen [2018] Y. Xu and S. Cohen. Stock movement prediction from tweets and historical prices. In ACL, volume 1, pages 1970–1979, 2018.
- Yang et al. [2018] X. Yang, H. Zhang, and J. Cai. Shuffle-then-assemble: Learning object-agnostic visual relationship features. In ECCV, pages 36–52, 2018.
- Zhang et al. [2017] L. Zhang, C. Aggarwal, and G. Qi. Stock price prediction via discovering multi-frequency trading patterns. In SIGKDD, pages 2141–2149. ACM, 2017.
- Zhang et al. [2018] X. Zhang, Y. Zhang, S. Wang, Y. Yao, B. Fang, and P. Yu. Improving stock market prediction via heterogeneous information fusion. KBS, 143:236–247, 2018.