随机网络蒸馏探索
摘要
我们为深度强化学习方法引入了探索奖励,该方法易于实现,并且对执行的计算增加的开销最小。 奖励是神经网络预测固定随机初始化神经网络给出的观察特征的误差。 我们还引入了一种灵活结合内在奖励和外在奖励的方法。 我们发现,随机网络蒸馏 (RND) 奖励与这种增加的灵活性相结合,可以在一些艰苦的 Atari 探索游戏上取得重大进展。 特别是,我们在《蒙特祖玛的复仇》上建立了最先进的性能,这是一款对于深度强化学习方法来说非常困难的游戏。 据我们所知,这是第一个在该游戏中在不使用演示或访问游戏底层状态的情况下实现优于人类平均表现的方法,并且偶尔可以完成第一关。
1简介
强化学习 (RL) 方法通过最大化策略的预期回报来发挥作用。 当环境具有密集的奖励时,这种方法很有效,通过采取随机的行动序列很容易找到这些奖励,但当奖励稀疏且难以找到时,这种方法往往会失败。 事实上,为每个想要 RL 代理解决的任务设计密集的奖励函数通常是不切实际的。 在这些情况下,有必要采用定向方式探索环境的方法。
强化学习的最新发展似乎表明,解决最具挑战性的任务(Silver 等人,2016;Zoph & Le,2016;Horgan 等人,2018;Espeholt 等人,2018;OpenAI,2018;OpenAI 等人,2018 ) 需要处理通过并行运行多个环境副本获得的大量样本。 鉴于此,希望有一种能够通过大量经验进行扩展的探索方法。 然而,许多最近引入的基于计数、伪计数、信息增益或预测增益的探索方法很难扩展到大量并行环境。
本文介绍了一种探索奖励,它实现起来特别简单,适用于高维观察,可以与任何策略优化算法一起使用,并且计算效率很高,因为它只需要批量处理神经网络的单次前向传递的经验。 我们的探索奖励是基于这样的观察:神经网络在与训练过的样本相似的样本上往往具有显着较低的预测误差。 这促使使用根据代理过去经验训练的网络的预测误差来量化新经验的新颖性。
正如许多作者指出的那样,最大化此类预测误差的代理往往会被预测问题的答案是输入的随机函数的转变所吸引。 例如,如果预测问题是在给定当前观察和智能体动作(前向动态)的情况下预测下一个观察,则试图最大化此预测误差的智能体将倾向于寻找随机转换,例如涉及随机改变静态噪声的转换。电视,或随机事件的结果,例如抛硬币。 这一观察结果促使人们使用量化预测相对改进而不是绝对误差的方法。 不幸的是,如前所述,此类方法很难有效实施。
我们提出了一种针对这种不良随机性的替代解决方案,通过使用预测问题定义探索奖励,其中答案是其输入的确定性函数。 也就是说,我们根据当前观察预测固定随机初始化神经网络的输出。
自 Mnih 等人 (2013) 的开创性工作以来,Atari 游戏一直是深度强化学习算法的标准基准。 Bellemare 等人 (2016) 在这些游戏中确定了奖励稀疏的艰苦探索游戏:《Freeway》、《Gravitar》、《Montezuma’s Revenge》、《Pitfall!》、《Private Eye》、《Solaris》和《Venture》。 强化学习算法往往在这些游戏中表现不佳,常常找不到任何积极的奖励。
特别是,《蒙特祖玛的复仇》被认为是 RL 智能体的一个难题,需要结合掌握多种游戏技能才能避免致命的障碍,并且即使在最佳玩法下也能找到彼此相距数百步的奖励。 通过访问专家演示(Pohlen 等人,2018;Aytar 等人,2018;Garmulewicz 等人,2018)、特殊访问底层仿真器状态的方法已经取得了重大进展(Tang 等人,2017;Stanton & Clune,2018),或两者(Salimans & Chen,2018)。 然而,如果没有这些帮助,蒙特祖玛的复仇中的探索问题进展缓慢,最好的方法只能找到大约一半的房间(Bellemare等人,2016)。 由于这些原因,我们在这种环境下对我们的方法进行了广泛的消融。
我们发现,即使完全忽略外在奖励,最大化 RND 探索奖励的智能体也能始终找到《蒙特祖玛的复仇》中一半以上的房间。 为了将探索奖励与外部奖励结合起来,我们引入了近端策略优化的修改(PPO,Schulman 等人(2017)),它为两个奖励流使用两个值头。 这允许对不同的奖励使用不同的折扣率,并结合偶发性和非偶发性回报。 有了这种额外的灵活性,我们最好的特工经常会在蒙特祖玛的复仇中找到第一层 24 个房间中的 22 个,并且偶尔(尽管不经常)通过第一层。 同样的方法在 Venture 和 Gravitar 上获得了最先进的性能。
2方法
2.1 探索奖励
探索奖励是一类鼓励代理探索的方法,即使环境的奖励很稀疏。 他们通过用新的奖励 替换 来实现这一点,其中 是与时间 的转换相关的探索奖励。
为了鼓励智能体访问新状态,新状态中的 最好高于经常访问的状态。 基于计数的探索方法提供了此类奖励的一个示例。 在具有有限数量状态的表格设置中,可以将 定义为状态 的访问计数 的递减函数。 特别是 和 已在之前的工作 中使用(Bellemare 等人,2016;Ostrovski 等人,2018)。 在非表格情况下,生成计数并不容易,因为大多数状态最多会被访问一次。 计数到非表格设置的一种可能的推广是伪计数(Bellemare等人,2016),它使用状态密度估计的变化作为探索奖励。 通过这种方式,即使对于过去未访问过的状态,从密度模型导出的计数也可以是正的,只要它们与之前访问过的状态相似。
另一种方法是将 定义为与代理转换相关的问题的预测误差。 此类问题的一般示例包括正向动力学(Schmidhuber,1991b;Stadie 等人,2015;Achiam & Sastry,2017;Pathak 等人,2017;Burda 等人,2018)和逆动力学 (Haber 等人,2018)。 如果可以获得有关环境的专门信息,也可以使用非通用预测问题,例如预测与代理交互的对象的物理属性(Denil 等人,2016)。 随着智能体收集更多与当前类似的经验,这种预测误差往往会减少。 因此,即使是像预测常数零函数这样的琐碎预测问题也可以作为探索奖励(Fox等人,2018)。
2.2 随机网络蒸馏
本文介绍了一种不同的方法,其中预测问题是随机生成的。 这涉及两个神经网络:一个固定且随机初始化的用于设置预测问题的目标网络,以及一个根据代理收集的数据进行训练的预测器网络。 目标网络对嵌入 进行观察,并通过梯度下降训练预测神经网络 ,以最小化相对于其参数的预期 MSE 。 这一过程将随机初始化的神经网络提炼为经过训练的神经网络。 对于与预测器训练的状态不同的新状态,预测误差预计会更高。
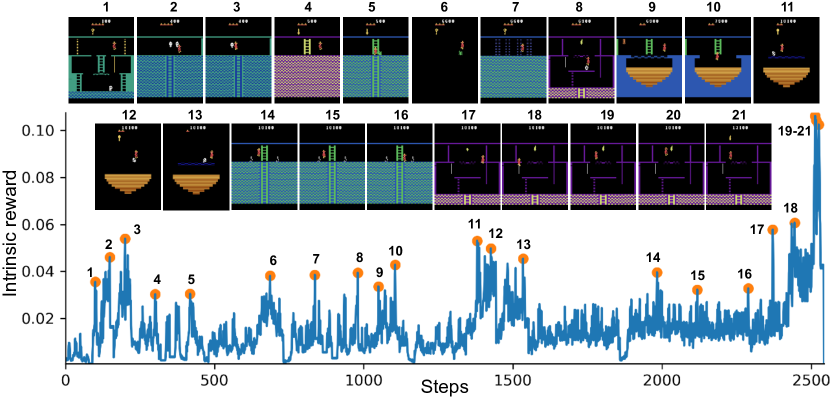
为了建立直觉,我们考虑在 MNIST 上建立这个过程的玩具模型。 我们训练一个预测神经网络,在由标签为 0 的图像和目标类别的混合图像组成的训练数据上模拟随机初始化的目标网络,改变类别的比例,但不改变训练示例的总数。 然后,我们在目标类未见过的测试示例上测试预测网络并报告 MSE。 在这个模型中,零扮演着之前多次出现过的状态的角色,目标类扮演着不经常访问过的状态的角色。 结果如图3所示。 该图显示,测试误差随着目标类中训练示例数量的变化而减少,这表明该方法可用于检测新颖性。 图1显示,在《蒙特祖玛的复仇》的一集中,新颖状态下的内在奖励很高。
对此方法的一个反对意见是,足够强大的优化算法可能会找到一个在任何输入上完美模仿目标随机网络的预测器(例如目标网络本身就是这样的预测器)。 然而,上述 MNIST 实验表明,标准的基于梯度的方法不会以这种不良的方式过度概括。
2.2.1 预测误差的来源
一般来说,预测误差可归因于多种因素:
-
1.
训练数据量。 如果预测者很少看到类似的例子,则预测误差很高(认知不确定性)。
-
2.
随机性。 由于目标函数是随机的(任意不确定性),预测误差很高。 随机转变是正向动力学预测的此类误差的来源。
-
3.
模型指定错误。 预测误差较高是因为缺少必要的信息,或者模型类别太有限,无法适应目标函数的复杂性。
-
4.
学习动态。 预测误差很高,因为优化过程无法在模型类中找到最接近目标函数的预测器。
因素 1 允许人们将预测误差用作探索奖励。 在实践中,预测误差是由所有这些因素的组合引起的,但并非所有这些因素都是理想的。
例如,如果预测问题是前向动态,则因子 2 会导致“嘈杂的电视”问题。 这是一个思想实验,其中因前向动力学模型预测错误而获得奖励的代理会被环境中的局部熵源所吸引。 播放白噪声的电视就像抛硬币一样具有吸引力。
为了避免不理想的因素 2 和 3,Schmidhuber (1991a);Oudeyer 等人 (2007);Lopes 等人 (2012);Achiam & Sastry (2017) 等人采用的方法是测量预测模型在看到新数据点时的改进程度。 然而,这些方法往往计算成本昂贵,因此难以扩展。
RND 消除了因素 2 和 3,因为目标网络可以选择为确定性的并且位于预测网络的模型类内。
2.2.2 与不确定性量化的关系
RND预测误差与Osband等人(2018)引入的不确定性量化方法有关。 即,考虑数据分布的回归问题。 在贝叶斯设置中,我们会考虑映射 参数上的先验 并在更新证据后计算后验。
令 为函数 的分布,其中 由 得出, 由下式给出最小化预期预测误差
| (1) |
其中 是来自先验的正则化项(参见引理 3,Osband 等人 (2018))。 Osband 等人 (2018) 认为(类比贝叶斯线性回归的情况)集合 是后验的近似。
如果我们将回归目标 专门化为零,则优化问题 相当于从先验中提取随机抽取的函数。 从这个角度来看,预测器和目标网络输出的每个坐标将对应于集成的一个成员(在集成之间共享参数),并且 MSE 将是集成的预测方差的估计(假设系综是无偏见的)。 换句话说,蒸馏误差可以被视为预测常数零函数的不确定性的量化。
2.3 结合内在和外在回报
在仅使用内在奖励的初级知识实验中,将问题视为非偶发性的会带来更好的探索。 在这种情况下,回报不会在“游戏结束”时被截断。 我们认为这是在模拟环境中进行探索的自然方式,因为智能体的内在回报应该与它在未来可能发现的所有新状态相关,无论它们是全部发生在一个情节中还是分布在多个情节中。 (Burda 等人, 2018) 中还认为,使用情景内在奖励可能会将有关任务的信息泄露给代理。
我们还认为这更接近人类探索游戏的方式。 例如,假设爱丽丝正在玩电子游戏,并试图通过巧妙的策略到达一个可疑的秘密房间。 因为这个动作很棘手,所以游戏结束的机会很高,但如果爱丽丝成功了,她的好奇心得到的回报也会很高。 如果爱丽丝被建模为情景强化学习代理,那么如果她游戏结束,她未来的回报将恰好为零,这可能会使她过度规避风险。 游戏交给爱丽丝的真正成本是必须从头开始玩游戏所产生的机会成本(这对于玩游戏一段时间的爱丽丝来说可能不太有趣)。
然而,使用非情景回报作为外在奖励可以被这样一种策略所利用,该策略在接近游戏开始时找到奖励,通过游戏结束故意重新开始游戏,并在无限循环中重复此操作。
如何估计非偶发性内在奖励流和偶发性外在奖励流的组合价值并不明显。 我们的解决方案是观察回报与奖励是线性的,因此可以分别分解为外在回报和内在回报的总和。 因此,我们可以使用两个值头 和 分别使用它们各自的返回值来拟合它们,并将它们组合起来给出值函数 。 同样的想法也可以用于将奖励流与不同的折扣因素结合起来。
请注意,即使不尝试将情景和非情景奖励流或具有不同折扣因子的奖励流组合起来,拥有单独的价值函数仍然可能有好处,因为价值函数有一个额外的监督信号。 这对于探索奖励可能特别重要,因为外在奖励函数是平稳的,而内在奖励函数是非平稳的。
2.4 奖励和观察标准化
使用预测误差作为探索奖励的一个问题是,不同环境和不同时间点的奖励规模可能会有很大差异,因此很难选择适用于所有设置的超参数。 为了使奖励保持在一致的范围内,我们通过将内在奖励除以内在回报标准差的运行估计来标准化内在奖励。
观察归一化在深度学习中通常很重要,但在使用随机神经网络作为目标时至关重要,因为参数被冻结,因此无法调整以适应不同数据集的规模。 缺乏归一化可能会导致嵌入的方差极低并且携带的输入信息很少。 为了解决这个问题,我们使用连续控制问题中经常使用的观察归一化方案,通过减去运行平均值然后除以运行标准差来白化每个维度。 然后,我们将标准化观测值修剪在 -5 和 5 之间。 在开始优化之前,我们通过在环境中逐步执行少量步骤来初始化归一化参数。 我们对预测网络和目标网络使用相同的观察归一化,但不对策略网络使用相同的观察归一化。
3实验
我们首先在第 3.1 节中对《蒙特祖玛的复仇》进行仅内在奖励实验,以隔离 RND 奖金的归纳偏差,然后在第 3.2 节中对《蒙特祖玛的复仇》中的 RND 进行广泛消融-3.4 了解影响 RND 性能的因素,并通过与 3.6 节中 6 个硬探索 Atari 游戏的基线方法进行比较得出结论。 有关超参数和架构的详细信息,请读者参阅附录A.3和A.4。 大多数实验在每个环境中运行 3 万次长度为 的部署,并具有 并行环境,总共 十亿帧体验。
3.1纯粹的探索
![[Uncaptioned image]](mnist.png)
![[Uncaptioned image]](int_only_arxiv.png)
在本节中,我们将探讨 RND 在没有任何外部奖励的情况下的表现。 在 2.3 节中,我们认为在非情景环境中使用 RND 进行探索可能更自然。 通过比较纯探索代理在情景和非情景环境中的性能,我们可以看到这种观察结果是否会转化为改进的探索性能。
我们在图 3 中报告了探索性能的两个衡量标准:平均情景回报,以及智能体在训练过程中找到的房间数量。 由于纯粹的探索代理不知道外部奖励或房间数量,因此它不会直接优化这些措施中的任何一个。 然而,在《蒙特祖玛的复仇》中获得一些奖励(例如获得开门的钥匙)需要在新房间中进入更有趣的状态,因此我们观察到外在奖励随着时间的推移而增加,直到某个点。 当智能体与某些对象交互时可以获得最佳回报,但是一旦这种交互变得重复,智能体就没有动力继续做同样的事情,因此回报并不总是很高。
3.2 结合偶发性和非偶发性回报
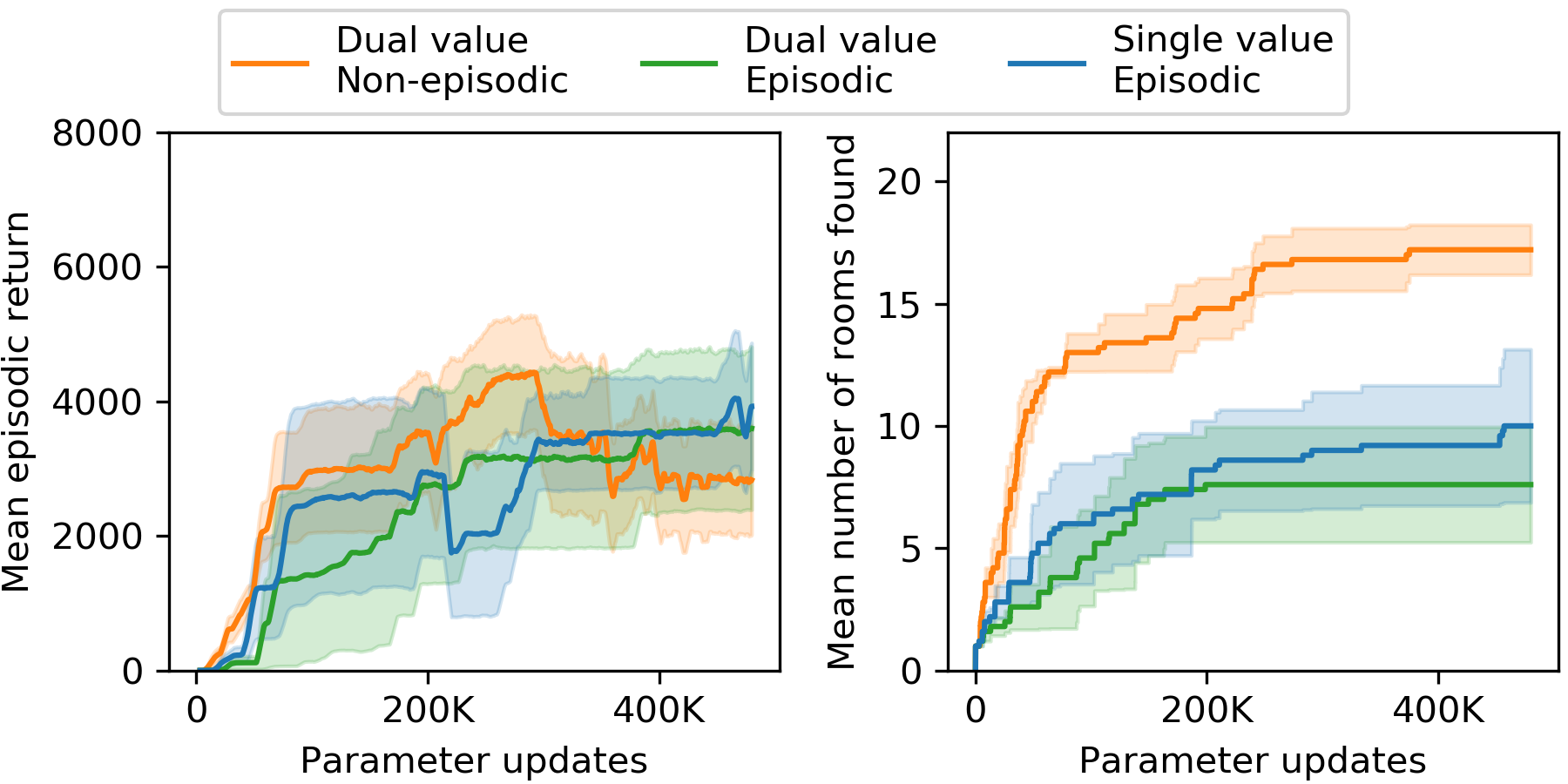
在第 3.1 节中,我们看到,在没有任何外在奖励的情况下进行探索时,非情景设置比情景设置带来更多的探索。 接下来我们考虑在我们结合内在奖励和外在奖励的情况下这是否成立。 正如 2.3 节中所讨论的,为了结合情景和非情景奖励流,我们需要两个价值头。 这也提出了一个问题:即使两个奖励流都是间歇性的,拥有两个价值头是否更好。 在图 4 中,我们将情景内在奖励与非情景内在奖励与情景外在奖励相结合进行比较,另外还比较了情景情况下的两个价值头与一个价值头。 折扣系数为。
(a) RNN policies

(b) CNN policies
在图 4 中,我们看到使用非情景内在奖励流增加了 CNN 和 RNN 策略探索的房间数量,与 3.1 节中的实验一致,但是差异不太明显,可能是因为外在奖励能够保留有用的行为。 我们还发现 CNN 实验的差异不太明显,并且 RNN 结果往往不太稳定,并且对于 的性能较差。
与我们的预期相反(第2.3节),在情景环境中使用两个值头并没有显示出比单个头有任何好处。 然而,拥有两个价值头对于组合具有不同特征的奖励流是必要的,因此所有进一步的实验都使用两个价值头。
3.3折扣系数
之前的实验(Salimans & Chen, 2018; Pohlen 等人, 2018; Garmulewicz 等人, 2018)使用专家演示解决蒙特祖玛的复仇,使用高折扣因子来实现最佳性能,使代理能够预测奖励在遥远的未来。 我们将 RND 代理的性能与 和 进行比较。 我们还研究了将 增加到 0.999 的效果。 结果如图6所示。
在图 6 中,我们看到将 增加到 0.999,同时将 保持在 0.99 可以极大地提高性能。 我们还发现,进一步将 增加到 0.999 会损害性能。 这与图 3 中的结果不一致,其中增加 并没有显着影响性能。
![[Uncaptioned image]](discount_arxiv.png)
![[Uncaptioned image]](scale_ablation_arxiv.png)
3.4 扩大训练规模
在本节中,我们报告实验,显示增加规模对训练的影响。 和 的内在奖励是非偶发性的。
为了保持内在奖励随时间下降的速率在不同数量的并行环境的实验中保持恒定,我们在训练预测器时对批量大小进行下采样,以匹配 32 个并行环境的批量大小(有关完整详细信息,请参阅附录 A.4)。 环境数量越大,训练策略的每次更新的批量大小就越大,而预测器网络批量大小保持不变。 由于内在奖励会随着时间的推移而消失,因此对于政策来说,学会寻找和利用这些短暂的奖励非常重要,因为它们充当了附近新状态的踏脚石。
图6显示,使用从更多并行环境收集的大量经验进行训练的代理在相似数量的更新后获得更高的平均回报。 他们也取得了更好的最终表现。 CNN 策略的这种效果似乎比 RNN 策略更早饱和。
我们让 RNN 实验在 32 个并行环境中运行更长时间,在处理 16 亿帧超过 160 万个参数更新后,最终达到 7,570 的平均回报。 其中一次运行访问了所有 24 个房间,并通过了一次第一级,实现了 17,500 的最佳回报。 在 1024 个并行训练环境中进行的 RNN 实验在结束时的平均回报为 10,070,并且一次运行的平均回报为 14,415。
3.5复发
《蒙特祖玛的复仇》是一个部分可观察的环境,尽管游戏状态的大部分可以从屏幕中推断出来。 例如,代理拥有的钥匙数量会显示在屏幕上,但不会显示钥匙的来源、过去使用过的钥匙数量或打开过哪些门。 为了处理这种部分可观察性,代理应该维护一个总结过去的状态,例如循环策略的状态。 因此,我们很自然地希望拥有经常性政策的代理商能够取得更好的表现。 与图4中的预期相反,经常性政策的表现比的非经常性政策差。 然而,在图 6 中,具有 的 RNN 策略在每个尺度上都优于 CNN 策略111图 6 中 CNN 策略的结果是通过 5 个随机种子的平均值获得的。 当我们为图 6 的最佳性能设置运行 10 个不同的种子时,我们发现性能存在很大差异。 这种差异可能是由于《蒙特祖玛的复仇》的结果分布主要受离散选择(例如从第一个房间向左或向右)的影响决定的,因此包含大量异常值。 此外,图 6 中的结果是使用我们的代码库的早期版本运行的,该版本与公开发布的版本之间的细微差异可能导致了这种差异。 图 6 中的结果是使用公开发布的代码重现的,因此我们建议未来的工作与这些结果进行比较。. 图 7 和 9 的比较表明,在多个游戏中,RNN 策略比 CNN 策略更频繁地优于 CNN。
3.6与基线比较
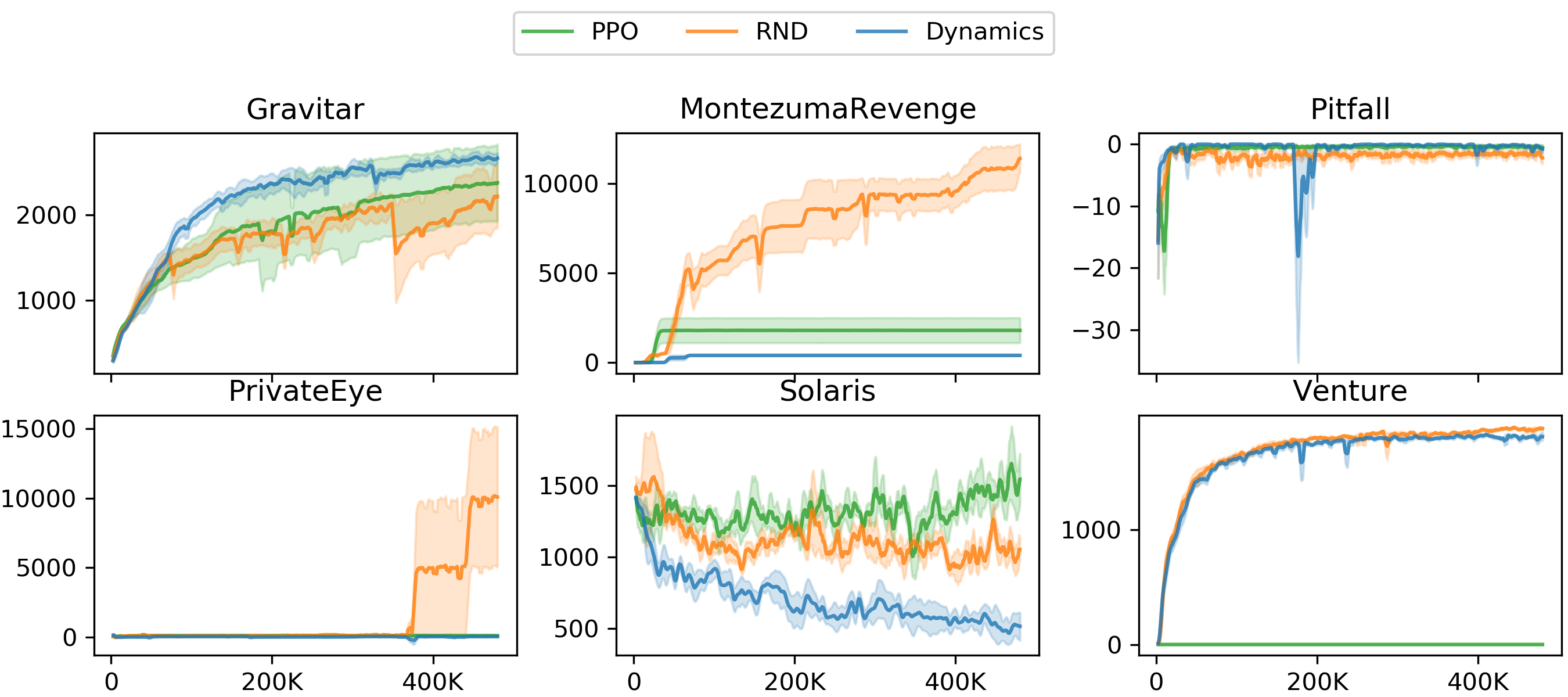
在本节中,我们将 RND 与两个基线进行比较:没有探索奖励的 PPO 和基于前向动态误差的替代探索奖励。 我们评估了 RND 在六款硬探索 Atari 游戏中的表现:Gravita、Montezuma’s Revenge、Pitfall!、Private Eye、Solaris 和 Venture。 我们首先比较没有内在奖励的基准 PPO 实施的绩效。 对于 RND, 的内在奖励是非偶发性的,而对于 PPO 和 RND 来说, 是非间歇性的。 RNN 策略的结果如图 7 所示,表 1 中进行了总结(CNN 策略另请参见图 9)。
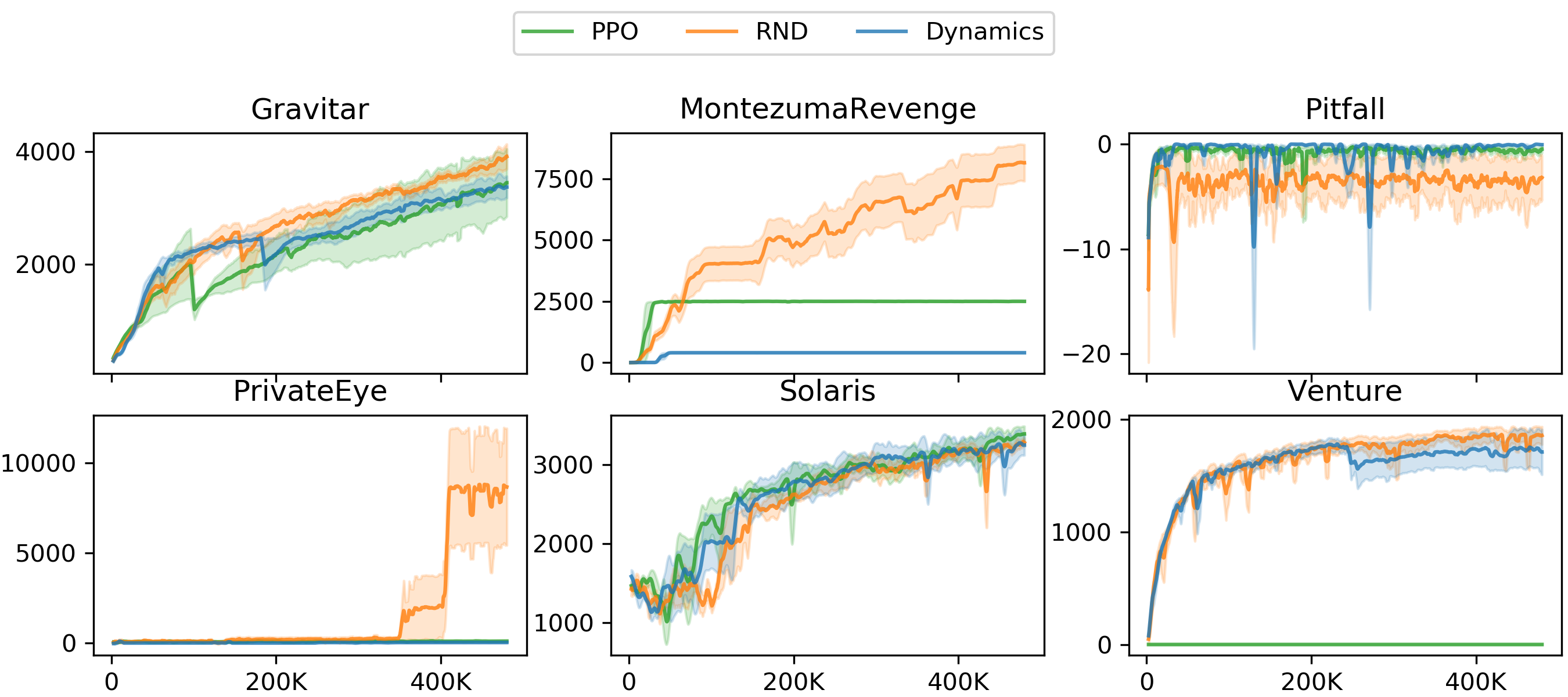
在 Gravitar 中,我们看到 RND 的性能并没有始终超过 PPO。 然而,两者都超过了 RNN 策略以及之前最先进技术的人类平均表现。 在《蒙特祖玛的复仇》和《冒险》中,RND 的表现明显优于 PPO,并且超过了最先进的表现和人类平均表现。 论陷阱! 两种算法都无法找到任何积极的奖励。 这是该游戏的典型结果,因为外在的正奖励非常稀疏。 在 Private Eye 上 RND 的性能超过了 PPO。 在 Solaris 上,RND 的性能与 PPO 相当。
接下来,我们考虑基于前向动态误差的替代探索奖励。 之前有许多作品使用了这样的奖励(Schmidhuber,1991b;Stadie 等人,2015;Achiam & Sastry,2017;Pathak 等人,2017;Burda 等人,2018)。 幸运的是,Burda训练等人(2018)表明,随机特征空间中的前向动力学模型在用于创建探索奖励时通常与任何其他特征空间一样有效。 这意味着我们可以轻松地实现同类比较并改变 RND 中的损失,以便预测器网络在给定当前观察和操作的情况下预测下一个观察的随机特征,同时保持我们方法的所有其他部分(例如对偶值)固定头、非偶发内在回报、标准化方案等。 这提供了定义探索奖励的预测问题的消融,同时也代表了一类使用前向动态误差的先前工作。 我们的期望是,这些方法应该非常相似,除非基于动力学的代理能够利用环境中的非确定性来获得内在奖励。
图7显示,基于动力学的探索在 Montezuma’s Revenge、PrivateEye 和 Solaris 上的表现明显低于采用相同 CNN 策略的 RND,在 Venture、Pitfall 和 Gravitar 上的表现也类似。 通过分析智能体在收敛时的行为,我们注意到在《蒙特祖玛的复仇》中,智能体在两个房间之间摇摆。 这会导致不可减少的高预测误差,因为粘性动作的非确定性使得我们无法知道,一旦智能体接近跨越房间边界,多走一步是否会导致其停留在同一个房间,或者穿越到下一个。 这是“嘈杂的电视”问题或2.2.1节中讨论的任意不确定性的表现。 PrivateEye 和 Pitfall! 中出现了类似的行为。 表 1 列出了每种算法的最终训练性能,以及之前工作的最新技术和人类平均表现。
| Gravitar | Montezuma’s Revenge | Pitfall! | PrivateEye | Solaris | Venture | |
|---|---|---|---|---|---|---|
| RND | 3,906 | 8,152 | -3 | 8,666 | 3,282 | 1,859 |
| PPO | 3,426 | 2,497 | 0 | 105 | 3,387 | 0 |
| Dynamics | 3,371 | 400 | 0 | 33 | 3,246 | 1,712 |
| SOTA | 2,2091 | 3,7002 | 0 | 15,8062 | 12,3801 | 1,8133 |
| Avg. Human | 3,351 | 4,753 | 6,464 | 69,571 | 12,327 | 1,188 |
3.7定性分析:与头骨共舞
通过观察 RND 代理,我们注意到,一旦它获得了它知道如何可靠地获得的所有外在奖励(根据外在价值函数判断),代理就会陷入一种行为模式,其中它不断与潜在危险的物体相互作用。 例如,在《蒙特祖玛的复仇》中,特工在移动的头骨上来回跳跃,在激光门之间移动,并上下消失的桥梁。 我们还在 Pitfall! 中观察到类似的行为。 这可能与这样一个事实有关:这种危险状态很难实现,因此与更安全的状态相比,很少在代理人过去的经验中体现出来。
4相关工作
探索。 基于计数的探索奖励是一种自然而有效的探索方式(Strehl & Littman,2008),并且大量工作研究了如何将计数奖励轻松地推广到大型状态空间(Bellemare等人,2016;Ostrovski 等人,2017;Machado 等人,2018;。
另一类探索方法依赖于预测动力学的误差(Schmidhuber,1991b;Stadie 等人,2015;Achiam & Sastry,2017;Pathak 等人,2017;Burda 等人,2018)。 正如 2.2 节中所讨论的,这些方法在随机或部分可观察的环境中会遇到“嘈杂的电视”问题。 这激发了通过量化不确定性(Still & Precup,2012;Houthooft 等人,2016)或预测改进措施(Schmidhuber,1991a;Oudeyer 等人,2007;Lopes 等)进行探索的工作。人,2012;阿希姆和萨斯特里,2017)。
其他探索方法包括对抗性自我博弈(Sukhbaatar 等人, 2018)、最大化赋权(Gregor 等人, 2017)、参数噪声(Plappert 等人) ,2017;Fortunato 等人,2017),识别不同的策略(Eysenbach 等人,2018;Achiam 等人,2018),并使用价值函数集合(Osband 等)人,2016;陈等人,2017)。
蒙特祖玛的复仇。 早期基于神经网络的强化学习算法在 Atari 游戏的很大一部分上取得了成功(Mnih 等人,2015;2016;Hessel 等人,2017)未能在《蒙特祖玛的复仇》上取得有意义的进展,而不是可靠地找到离开第一个房间的路。 这并不一定是探索的失败,因为即使是随机代理,每几十万步就会在第一个房间中找到一次钥匙,并且每几百万步就会逃离第一个房间。 事实上,无需特殊的探索方法就可以可靠地实现约 2,500 的平均回报(Horgan 等人,2018;Espeholt 等人,2018;Oh 等人,2018)。
将 DQN 与伪计数探索奖励 Bellemare 等人 (2016) 相结合,创造了新的最先进性能,探索了 15 个房间并获得了 6,600 的最佳回报。 此后多部作品也取得了类似的表现(O’Donoghue 等人,2017;Ostrovski 等人,2018;Machado 等人,2018;Osband 等人,2018),但没有超过。
对底层 RAM 状态的特殊访问还可以用于通过手工制作探索奖励来改进探索(Kulkarni 等人,2016;Tang 等人,2017;Stanton & Clune,2018)。 即使有这样的访问权限,以前的工作所取得的性能仍低于人类的平均性能。
专家论证可以有效地简化《蒙特祖玛的复仇》中的探索问题,并有多项工作(Salimans & Chen, 2018; Pohlen 等人, 2018; Aytar 等人, 2018; Garmulewicz 等人, 2018) 取得了与人类专家相当或更好的性能。 从专家演示中学习受益于游戏的决定论。 建议的训练方法 (Machado 等人, 2017) 是为了防止智能体简单地记住正确的动作序列,即使用粘性动作(即随机重复先前的动作),但在这些作品中尚未使用。 在这项工作中,我们使用粘性动作,因此不依赖决定论。
随机特征。 随机初始化神经网络的特征在监督学习的背景下得到了广泛的研究(Rahimi & Recht, 2008; Saxe 等人, 2011; Jarrett 等人, 2009; Yang 等人, 2015)。 最近,它们被用于探索(Osband 等人,2018;Burda 等人,2018)。 Osband 等人 (2018) 的工作为2.2 节中讨论的随机网络蒸馏提供了动机。
矢量化值函数。 Pong 等人 (2018) 发现矢量化价值函数(坐标对应于奖励的加性因子)改进了他们的方法。 Bellemare 等人 (2017) 将值参数化为值头的线性组合,用于估计离散回报的概率。 然而,那里使用的贝尔曼备份方程本身并不是矢量化的。
5讨论
本文介绍了一种基于随机网络蒸馏的探索方法,并通过实验证明该方法能够对几种奖励非常稀疏的 Atari 游戏进行定向探索。 这些实验表明,通过相对简单的通用方法,硬探索游戏的进展是可能的,特别是在大规模应用时。 他们还建议,能够将内在奖励流与外在奖励流分开处理的方法(例如通过具有单独的价值头)可以从这种灵活性中受益。
我们发现 RND 探索奖励足以处理局部探索,即探索短期决策的后果,例如是否与特定对象交互或避免它。 然而,涉及长期协调决策的全球探索超出了我们的方法的范围。
为了解决《蒙特祖玛的复仇》的第一关,特工必须进入一个锁在两扇门后面的房间。 整个关卡中有四把钥匙和六扇门。 四把钥匙中的任何一把都可以打开六扇门中的任何一扇,但会在此过程中被消耗。 因此,为了打开最后两扇门,特工必须放弃打开两扇更容易找到的门,并且打开它们会立即得到奖励。
为了激励这种行为,代理应该获得足够的内在奖励来保存密钥,以平衡早期使用密钥带来的外在奖励的损失。 从我们对 RND 代理行为的分析来看,它没有足够大的动机去尝试这种策略,而且很少偶然发现它。
解决这个以及需要高水平探索的类似问题是未来工作的重要方向。
参考
- Achiam & Sastry (2017) Joshua Achiam and Shankar Sastry. Surprise-based intrinsic motivation for deep reinforcement learning. arXiv:1703.01732, 2017.
- Achiam et al. (2018) Joshua Achiam, Harrison Edwards, Dario Amodei, and Pieter Abbeel. Variational option discovery algorithms. arXiv preprint arXiv:1807.10299, 2018.
- Aytar et al. (2018) Yusuf Aytar, Tobias Pfaff, David Budden, Tom Le Paine, Ziyu Wang, and Nando de Freitas. Playing hard exploration games by watching YouTube. arXiv preprint arXiv:1805.11592, 2018.
- Bellemare et al. (2016) Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation. In NIPS, 2016.
- Bellemare et al. (2017) Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. arXiv preprint arXiv:1707.06887, 2017.
- Burda et al. (2018) Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A. Efros. Large-scale study of curiosity-driven learning. In arXiv:1808.04355, 2018.
- Chen et al. (2017) Richard Y Chen, John Schulman, Pieter Abbeel, and Szymon Sidor. UCB and infogain exploration via -ensembles. arXiv:1706.01502, 2017.
- Cho et al. (2014) Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- Denil et al. (2016) Misha Denil, Pulkit Agrawal, Tejas D Kulkarni, Tom Erez, Peter Battaglia, and Nando de Freitas. Learning to perform physics experiments via deep reinforcement learning. arXiv preprint arXiv:1611.01843, 2016.
- Espeholt et al. (2018) Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. IMPALA: Scalable distributed Deep-RL with importance weighted actor-learner architectures. arXiv preprint arXiv:1802.01561, 2018.
- Eysenbach et al. (2018) Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. arXiv preprint, 2018.
- Fortunato et al. (2017) Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. Noisy networks for exploration. arXiv:1706.10295, 2017.
- Fox et al. (2018) Lior Fox, Leshem Choshen, and Yonatan Loewenstein. Dora the explorer: Directed outreaching reinforcement action-selection. International Conference on Learning Representations, 2018.
- Fu et al. (2017) Justin Fu, John D Co-Reyes, and Sergey Levine. EX2: Exploration with exemplar models for deep reinforcement learning. NIPS, 2017.
- Garmulewicz et al. (2018) Michał Garmulewicz, Henryk Michalewski, and Piotr Miłoś. Expert-augmented actor-critic for vizdoom and montezumas revenge. arXiv preprint arXiv:1809.03447, 2018.
- Gregor et al. (2017) Karol Gregor, Danilo Jimenez Rezende, and Daan Wierstra. Variational intrinsic control. ICLR Workshop, 2017.
- Haber et al. (2018) Nick Haber, Damian Mrowca, Li Fei-Fei, and Daniel LK Yamins. Learning to play with intrinsically-motivated self-aware agents. arXiv preprint arXiv:1802.07442, 2018.
- Hessel et al. (2017) Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. arXiv preprint arXiv:1710.02298, 2017.
- Horgan et al. (2018) Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado Van Hasselt, and David Silver. Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933, 2018.
- Houthooft et al. (2016) Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, and Pieter Abbeel. VIME: Variational information maximizing exploration. In NIPS, 2016.
- Jarrett et al. (2009) Kevin Jarrett, Koray Kavukcuoglu, Yann LeCun, et al. What is the best multi-stage architecture for object recognition? In Computer Vision, 2009 IEEE 12th International Conference on, pp. 2146–2153. IEEE, 2009.
- Kingma & Ba (2015) Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. ICLR, 2015.
- Kulkarni et al. (2016) Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in neural information processing systems, pp. 3675–3683, 2016.
- Lopes et al. (2012) Manuel Lopes, Tobias Lang, Marc Toussaint, and Pierre-Yves Oudeyer. Exploration in model-based reinforcement learning by empirically estimating learning progress. In NIPS, 2012.
- Machado et al. (2017) Marlos C Machado, Marc G Bellemare, Erik Talvitie, Joel Veness, Matthew Hausknecht, and Michael Bowling. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. arXiv preprint arXiv:1709.06009, 2017.
- Machado et al. (2018) Marlos C Machado, Marc G Bellemare, and Michael Bowling. Count-based exploration with the successor representation. arXiv preprint arXiv:1807.11622, 2018.
- Mnih et al. (2013) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Mnih et al. (2015) Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, February 2015.
- Mnih et al. (2016) Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In ICML, 2016.
- O’Donoghue et al. (2017) Brendan O’Donoghue, Ian Osband, Remi Munos, and Volodymyr Mnih. The uncertainty Bellman equation and exploration. arXiv preprint arXiv:1709.05380, 2017.
- Oh et al. (2018) Junhyuk Oh, Yijie Guo, Satinder Singh, and Honglak Lee. Self-imitation learning. arXiv preprint arXiv:1806.05635, 2018.
- OpenAI (2018) OpenAI. OpenAI Five. https://blog.openai.com/openai-five/, 2018.
- OpenAI et al. (2018) OpenAI, :, M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba. Learning Dexterous In-Hand Manipulation. ArXiv e-prints, August 2018.
- Osband et al. (2016) Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped DQN. In NIPS, 2016.
- Osband et al. (2018) Ian Osband, John Aslanides, and Albin Cassirer. Randomized prior functions for deep reinforcement learning. arXiv preprint arXiv:1806.03335, 2018.
- Ostrovski et al. (2017) Georg Ostrovski, Marc G Bellemare, Aaron van den Oord, and Rémi Munos. Count-based exploration with neural density models. arXiv:1703.01310, 2017.
- Ostrovski et al. (2018) Georg Ostrovski, Marc G Bellemare, Aaron van den Oord, and Rémi Munos. Count-based exploration with neural density models. International Conference for Machine Learning, 2018.
- Oudeyer et al. (2007) Pierre-Yves Oudeyer, Frdric Kaplan, and Verena V Hafner. Intrinsic motivation systems for autonomous mental development. Evolutionary Computation, 2007.
- Pathak et al. (2017) Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. In ICML, 2017.
- Plappert et al. (2017) Matthias Plappert, Rein Houthooft, Prafulla Dhariwal, Szymon Sidor, Richard Y Chen, Xi Chen, Tamim Asfour, Pieter Abbeel, and Marcin Andrychowicz. Parameter space noise for exploration. arXiv:1706.01905, 2017.
- Pohlen et al. (2018) Tobias Pohlen, Bilal Piot, Todd Hester, Mohammad Gheshlaghi Azar, Dan Horgan, David Budden, Gabriel Barth-Maron, Hado van Hasselt, John Quan, Mel Večerík, et al. Observe and look further: Achieving consistent performance on Atari. arXiv preprint arXiv:1805.11593, 2018.
- Pong et al. (2018) Vitchyr Pong, Shixiang Gu, Murtaza Dalal, and Sergey Levine. Temporal difference models: Model-free deep RL for model-based control. arXiv preprint arXiv:1802.09081, 2018.
- Rahimi & Recht (2008) Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in neural information processing systems, pp. 1177–1184, 2008.
- Salimans & Chen (2018) Tim Salimans and Richard Chen. Learning Montezuma’s Revenge from a single demonstration. https://blog.openai.com/learning-montezumas-revenge-from-a-single-demonstration/, 2018.
- Saxe et al. (2011) Andrew M Saxe, Pang Wei Koh, Zhenghao Chen, Maneesh Bhand, Bipin Suresh, and Andrew Y Ng. On random weights and unsupervised feature learning. In ICML, pp. 1089–1096, 2011.
- Schmidhuber (1991a) Jürgen Schmidhuber. Curious model-building control systems. In Neural Networks, 1991. 1991 IEEE International Joint Conference on, pp. 1458–1463. IEEE, 1991a.
- Schmidhuber (1991b) Jürgen Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. In Proceedings of the First International Conference on Simulation of Adaptive Behavior, 1991b.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, Jan 2016. ISSN 0028-0836. doi: 10.1038/nature16961.
- Stadie et al. (2015) Bradly C Stadie, Sergey Levine, and Pieter Abbeel. Incentivizing exploration in reinforcement learning with deep predictive models. NIPS Workshop, 2015.
- Stanton & Clune (2018) Christopher Stanton and Jeff Clune. Deep curiosity search: Intra-life exploration improves performance on challenging deep reinforcement learning problems. arXiv preprint arXiv:1806.00553, 2018.
- Still & Precup (2012) Susanne Still and Doina Precup. An information-theoretic approach to curiosity-driven reinforcement learning. Theory in Biosciences, 2012.
- Strehl & Littman (2008) Alexander L Strehl and Michael L Littman. An analysis of model-based interval estimation for markov decision processes. Journal of Computer and System Sciences, 74(8):1309–1331, 2008.
- Sukhbaatar et al. (2018) Sainbayar Sukhbaatar, Ilya Kostrikov, Arthur Szlam, and Rob Fergus. Intrinsic motivation and automatic curricula via asymmetric self-play. In ICLR, 2018.
- Tang et al. (2017) Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, Xi Chen, Yan Duan, John Schulman, Filip DeTurck, and Pieter Abbeel. # exploration: A study of count-based exploration for deep reinforcement learning. In NIPS, 2017.
- Yang et al. (2015) Zichao Yang, Marcin Moczulski, Misha Denil, Nando de Freitas, Alex Smola, Le Song, and Ziyu Wang. Deep fried convnets. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1476–1483, 2015.
- Zoph & Le (2016) Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.
附录A附录
A.1强化学习算法
通过修改用于模型训练的奖励(即 ),探索奖励可以与任何 RL 算法一起使用。 我们将提出的探索奖励与基线强化学习算法 PPO (Schulman 等人,2017)结合起来。 PPO 是一种策略梯度方法,我们发现只需很少的调整即可获得良好的性能。 有关算法详细信息,请参阅算法 1。
A.2 RND伪代码
A.3 预处理细节
表 2 包含我们如何预处理实验环境的详细信息。 我们遵循 Machado 等人 (2017) 中的建议使用粘性动作,以使环境具有非确定性,从而不可能记住动作序列。 在表 4 中,我们显示了策略和价值网络的其他预处理详细信息。 在表 4 中,我们显示了预测器和目标网络的其他预处理详细信息。
| Hyperparameter | Value |
| Grey-scaling | True |
| Observation downsampling | (84,84) |
| Extrinsic reward clipping | |
| Intrinsic reward clipping | False |
| Max frames per episode | 18K |
| Terminal on loss of life | False |
| Max and skip frames | 4 |
| Random starts | False |
| Sticky action probability | 0.25 |
| Hyperparameter | Value |
|---|---|
| Frames stacked | 4 |
| Observation | |
| normalization |
| Hyperparameter | Value |
|---|---|
| Frames stacked | 1 |
| Observation | |
| normalization |
A.4 PPO和RND超参数
| Hyperparameter | Value |
| Rollout length | 128 |
| Total number of rollouts per environment | 30K |
| Number of minibatches | 4 |
| Number of optimization epochs | 4 |
| Coefficient of extrinsic reward | 2 |
| Coefficient of intrinsic reward | 1 |
| Number of parallel environments | 128 |
| Learning rate | |
| Optimization algorithm | Adam (Kingma & Ba (2015)) |
| 0.95 | |
| Entropy coefficient | 0.001 |
| Proportion of experience used for training predictor | 0.25 |
| 0.999 | |
| 0.99 | |
| Clip range | |
| Policy architecture | CNN |
RND 的初始知识实验仅在 32 个并行环境中运行。 我们预计,增加并行环境的数量将允许策略更快地适应短暂的内在奖励,从而提高性能。 然而,如果预测网络学习得更快,这种影响可能会减轻。 为了避免在从 32 个环境扩展到 128 个环境时出现这种情况,我们通过以保持概率 随机删除批次中的元素来保持预测器网络的有效批次大小相同。 同样,在 256 和 1,024 个环境的实验中,我们丢弃了具有相应概率 和 的预测变量的经验。
A.5架构
在本文中,我们使用两种策略架构:RNN 和 CNN。 两者都包含与 (Mnih 等人,2015) 标准架构中的卷积编码器相同的卷积编码器。 RNN 架构还包含 GRU (Cho 等人, 2014) 单元来捕获更长的上下文。 选择策略的层大小,以便参数数量紧密匹配。 目标网络和预测网络的架构也具有与(Mnih等人,2015)中的卷积编码器相同的卷积编码器,后面是密集层。 本文随附的代码中给出了确切的详细信息。
A.6附加实验结果
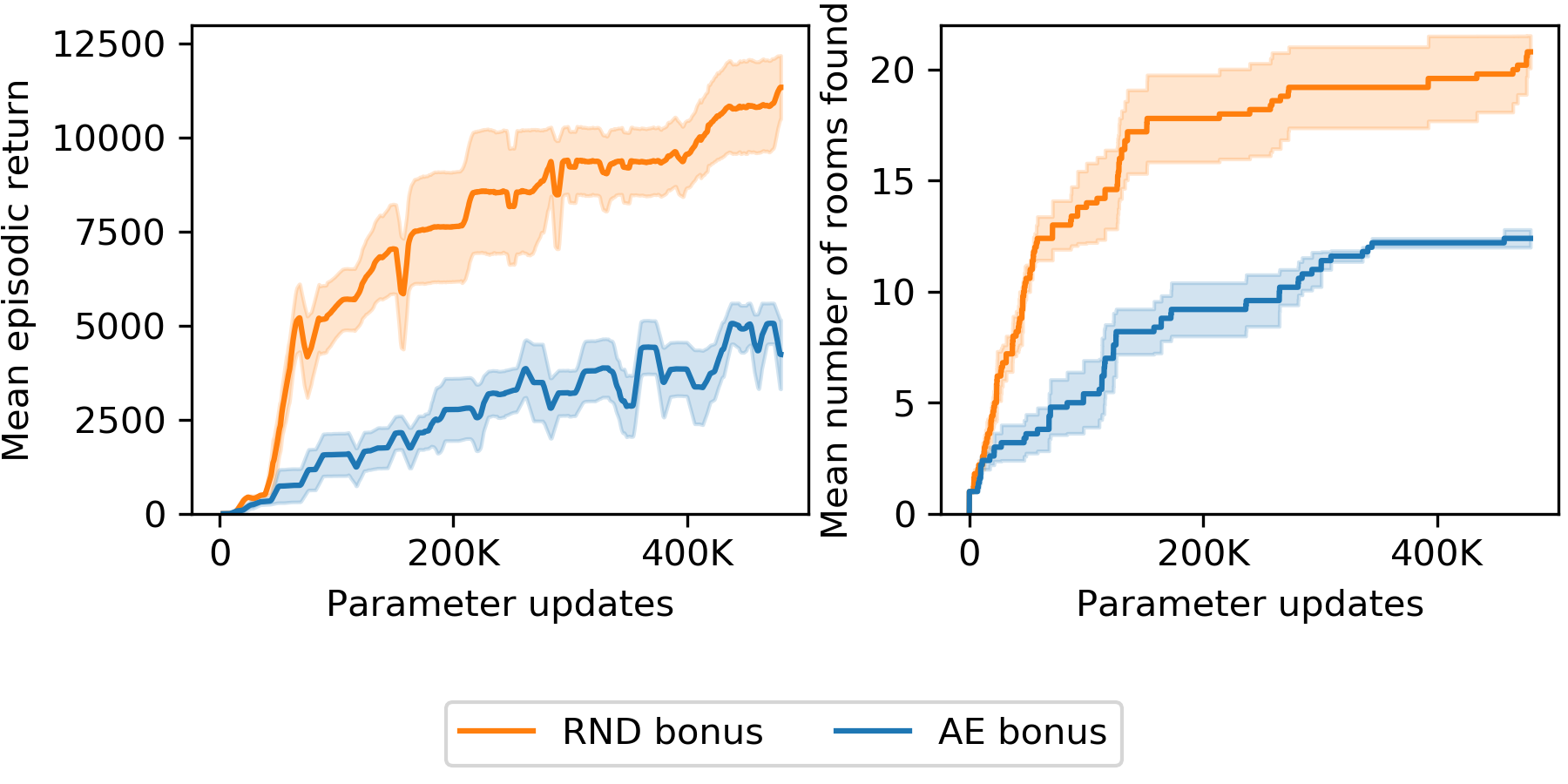
图 8 将 RND 的性能与相同算法进行了比较,但探索奖励定义为自动编码器的重建误差。 自动编码任务本质上与随机网络蒸馏类似,因为它也消除了 2.2.1 部分中的第二个(尽管不一定是第三个)预测误差源。 实验表明,自动编码任务也可以成功用于探索。
图9比较了 RND 与 PPO 的性能以及 CNN 策略的基于动态预测的基线。
A.7其他实验细节
在表 6 中,我们显示了每个实验使用的种子数量,并按数字索引。
| Figure number | Number of seeds |
|---|---|
| 1 | NA |
| 2 | 10 |
| 3 | 5 |
| 4 | 5 |
| 5 | 10 |
| 6 | 5 |
| 7 | 3 |
| 8 | 5 |
| 9 | 5 |