OrthoNet:多层网络数据聚类
摘要
网络数据出现在非常多样化的应用中,例如生物、社会或传感器网络。 因此,将网络节点聚类为类别或社区已成为机器学习和数据挖掘中非常常见的任务。 网络数据带有一些有关网络边缘的信息。 在某些情况下,甚至可以通过多个视图或层给出该网络信息,每个视图或层代表网络节点之间的不同类型的关系。 网络节点也越来越频繁地携带特征向量。 我们在本文中提出将通常仅考虑网络信息的节点聚类问题扩展到同时考虑网络信息和节点特征以学习特征空间的聚类友好表示的问题。 具体来说,我们设计了一种用于多层网络数据聚类的通用两步算法。 第一步将不同层的网络信息聚合成由网络拉普拉斯矩阵的几何平均值给出的图形表示。 第二步使用神经网络来学习与网络层给出的结构一致的特征嵌入。 我们提出了一种通过梯度下降有效训练神经网络的新颖算法,该算法鼓励神经网络输出跨越聚合拉普拉斯矩阵的主要特征向量,以捕获网络上的成对交互,并提供聚类友好的表示的特征空间。 我们通过对合成数据集和真实数据集进行的大量实验证明,我们的方法可以带来显着的改进。 最先进的多层图聚类算法,因为它在节点嵌入算法中明智地结合了节点特征和网络信息。
索引术语:
多层图、多视图网络、SPD 流形、谱聚类、无监督学习。我简介
网络数据在机器学习和数据科学中越来越受欢迎,因为它对应于生物、社会、计算机或传感器网络应用中的自然数据表示形式,仅举几个例子。 网络数据可以用图来数学描述,图的顶点和边分别对应于网络节点和链路。 即使在网络信息不明确的应用中,也可以使用图来对数据点之间的成对关系进行建模。 此外,应用程序通常依赖多个信息源来表征数据之间的关系。 这导致了多层网络表示,其中节点在网络层之间共享,每个层都描述网络节点之间不同类型的关系。 此外,通常可以将属性与网络节点相关联,网络节点可以表示不同形式的测量或信号。 例如,公共交通系统可以用多层图来表示,其中节点是交通枢纽,每一层描述不同的交通方式(公交线路、地铁线路等),节点属性是数字每个枢纽的旅客数量。 这显然会导致非常丰富的数据集,并且设计能够同时考虑多层网络和节点特征信息的机器学习方法变得非常重要。
许多机器学习和数据挖掘任务都考虑了多层网络,包括混合模型的推理、多视图学习、处理、聚类和社区检测。 我们在这里关注多层网络数据聚类问题,其目标是通过考虑节点上的特征向量和每层中的连接模式,将每个网络节点(跨不同层共享)分配到一个集群。 多层网络数据聚类与常见聚类方法的不同之处在于两个主要方面:(i)必须从多个网络层估计有关聚类成员资格的信息,而经典网络聚类仅考虑单层; (ii)聚类是通过考虑节点特征和网络信息来形成的,而图聚类算法通常仅依赖于网络信息。
在本文中,我们提出了一种多层网络数据聚类的通用方法,该方法利用对称正定(SPD)流形的黎曼几何和神经网络的能力来学习适当的节点嵌入。 鉴于联合考虑节点特征和网络信息的内在困难,我们提出了一种分两个连续步骤工作的建设性解决方案。 首先,我们计算与网络每一层相关的拉普拉斯矩阵的几何平均值。 将多层网络聚合成 SPD 矩阵形式的图形表示,使我们能够正确考虑跨层共享的拓扑。 其次,我们使用聚合的SPD矩阵和节点特征来执行深度谱聚类。 与拉普拉斯矩阵特征分解的标准方法不同,我们将谱聚类重新表述为受正交性约束的迹优化问题,并设计了一种新算法来解决它。 我们方法的独特之处在于隐式强制执行正交性约束,从而产生可微分的成本函数,可以通过梯度下降进行优化。 这允许我们使用神经网络来学习节点特征嵌入,从而在没有监督的情况下进行训练。 与谱聚类类似,目标是找到节点特征的非线性映射,以惩罚聚合 SPD 矩阵提供的成对相互作用,同时在低维空间中强制执行正交性约束以避免平凡的解决方案。
在不同数据集上的实验结果表明,由于网络和节点特征信息的有效结合,与基线多层网络数据聚类方法相比,该方法具有更好的聚类性能。 我们期望我们的算法能够为有效处理具有不同形式信息组合的丰富网络数据集提供新的通用解决方案。
二相关工作
人们提出了一系列广泛的方法来组合来自多层网络的信息,并且对聚类方法进行了大量的研究工作。 在本节中,我们回顾了有关多层网络聚合和图表示学习的文献。
II-A 多层网络聚合
总结多层图中信息的最直接方法是对其层[1,2,3]执行线性或凸组合。 虽然凸组合在某些情况下可能很有效,但它们可能无法捕获每层中存在的特异性。 在这方面,合并图层的更有效方法是利用矩阵幂均值族[4],或者将它们视为格拉斯曼流形[5]的点。
不同的聚合策略包括将来自各个层的信息直接集成到学习过程底层的优化问题中。 示例包括co-EM聚类算法[6]、基于协同训练[8]的[7]中的聚类方法和co -正则化[9],以及[10]中的联合融合和聚类方法。 当在数据中不容易找到多个视图的统一表示时,这些方法可能很有用。 在[11]中,每个图层都被建模为格拉斯曼流形上的子空间,并且通过找到最小化到所有层的投影距离之和的子空间来组合它们。
与本文更接近的是,[11] 中的工作在 Grassmann 流形中执行聚合。 然而,它缺乏对图层中包含的信息的有意义的总结,并且忽略了可能分配给图节点的任何属性。 所提出的方法的主要新颖之处在于。 [11]在于引入了一种新的数值算法来结合SPD流形中图层的特征,并设计了一种考虑携带节点相关信息的特征的新方法。
II-B 图表示学习
在图和网络的研究中,社区检测是指将内部连接比网络其余部分更紧密的节点分组在一起的问题[12,13,14,15]。 在本文中,我们主要关注基于谱分析的图聚类[16]。 谱聚类可以与降维联系起来,其目的是将图和/或高维数据表示到低维空间(也称为嵌入),同时保留图拓扑结构和节点内容信息。 在这方面,最流行的技术之一是将图节点嵌入到由对应于最小特征值[17, 18]图拉普拉斯矩阵的特征向量跨越的子空间中。 t1>,其中可以通过 K-means 算法[19]轻松检测簇。 这种方法的扩展考虑在问题表述中引入适当的约束,目的是传达有关聚类分析的一些先验知识[20, 21]。 或者,可以在模块化最大化问题 [22, 23] 中使用图拉普拉斯矩阵的第一个 特征向量。 另一种方法取决于图 [24] 上主成分分析 (PCA) 的解释,它再次将图结构链接到由图拉普拉斯矩阵的顶部特征向量跨越的子空间。 此外,文献中已经提出了许多用于图表示学习的方法,例如多维缩放(MDS)[25]、拉普拉斯特征图[26]、IsoMap [27]、LLE [28]、矩阵分解 [29, 30]、随机游走 [31] 和深度学习方法[32,33,34,35]。
[33, 35] 中的工作提出学习一个非线性映射,将数据点嵌入到其关联图拉普拉斯矩阵的特征空间中,然后对它们进行聚类。 与[33, 35]不同,我们使用多层图信号,并提出了一种新的非线性图学习算法。 在这方面,我们方法的独创性在于对优化问题的重新表述,其中我们用直接注入成本函数的可微运算代替正交约束。 在这方面,我们方法的主要优点是避免像[33]中那样在投影训练步骤和梯度步骤之间交替的复杂性,因为后者可能会减慢过程。
III OrthoNet框架
III-A 问题表述
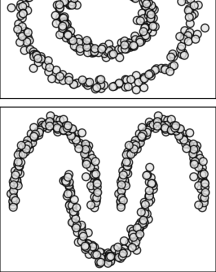
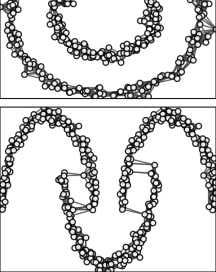
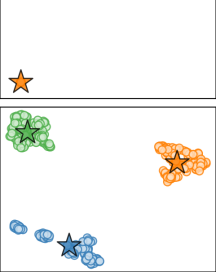
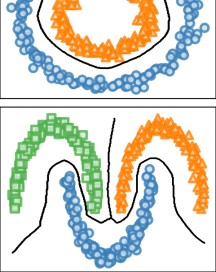
我们对多层图的聚类感兴趣
| (1) |
定义在 层边共享的一组 的 顶点上。111在本文中,术语图和网络、顶点和节点以及多层、多视图和多路复用可以互换使用。 对于每个层,都有一个具有(非负)相似边缘权重的图。 我们用 表示 的加权邻接矩阵,用 表示所有 的顶点度对角矩阵 。 的拉普拉斯矩阵因此定义为
| (2) |
我们进一步假设多层图 的每个顶点都与 维特征相关联,并且我们将此类网络数据表示为
| (3) |
我们的目标是通过考虑 的多层结构和节点特征 对图顶点进行聚类,而不需要任何有关图层和节点之间实际关系的先验信息。特点。 然而,我们依赖下面列出的三个最小假设。
-
1.
节点连接。 在多个图层中连接的节点更有可能属于同一个集群。
-
2.
层间互补。 各个层至少提供有关聚类结构的部分信息。
-
3.
特征相关性。 同一集群中的节点的特征可能比不同集群中的节点的特征更具相关性。
在跨层共享的拓扑提供的信息既不完全存在于数据中也不单独存在于每个层中的情况下,此设置特别有用。
由于我们不假设图层和节点特征之间有任何先验模型,因此我们的目标是从数据中发现它们的关系。 为此,我们提出了一种学习方法,利用跨层共享的拓扑来驱动特征映射的无监督训练。 我们定义了一个学习目标,鼓励将强连接节点的特征映射到潜在空间的紧密向量。 通过这样做,学习到的映射与谱聚类具有相似性,并产生节点特征的聚类友好表示。
在节点连通性意味着特征相关性的情况下(参见我们的假设),映射实际上学习将相关特征表示为潜在空间的紧密向量,从而产生整个特征空间的聚类友好表示。 这使得可以获得泛化到任何特征向量的分类器,包括但不限于与图节点相关联的特征向量。
所提出的学习框架可以表述为联合优化问题,即找到代表所有层的图以及允许其节点聚类的映射。 一般来说,这个任务解决起来很复杂,特别是因为我们没有对图层和节点特征之间的交互进行假设。 我们将在下一节中提出解决此问题的建设性解决方案。
III-B 提议的方法
我们的方法基于使用多层图信息的思想,特别是跨层一致出现的信息,来驱动节点特征映射的无监督学习。 考虑到这个联合优化问题的内在困难,我们在两个连续步骤中提出了一种替代解决方案,详细信息如下。
一旦从多层图中学习了映射 ,节点特征将转换为
| (6) |
矩阵 提供了图节点的聚类友好表示。 这是由我们的学习目标保证的,它鼓励映射 将强连接节点的特征表示为 的紧密向量,同时强制这些向量的正交性将它们分成单独的组。 因此, 的行可以使用 K-means 进行聚类,以将代表性图连接最紧密的节点分组在一起。
此外,由于连接节点的特征是相关的(参见我们的假设),映射实际上学会了将相关特征表示为潜在空间的紧密向量。 这导致了整个特征空间的聚类友好表示,因为学习到的映射可以应用于任何特征向量,而不仅仅是与图节点相关的特征向量。 因此,可以根据训练时在图上计算的嵌入 到聚类中心 的距离对通用特征向量 进行分类,产生分类器定义为
| (7) |
图1概述了所提出的框架。222我们框架的最低要求是至少有一个单层图,每个节点都有一个属性(在这种情况下,第一步被删除),但是附加的层和属性通常对性能有益,只要它们至少提供部分信息即可。 在没有给出节点特征的情况下,可以为每个节点[36]分配一个one-hot指示向量。 相反,如果没有给出图,则可以直接从数据构建一个或多个层,例如,通过计算特征子集上的几个最近邻图。 尽管从数据派生的层可能看起来像是冗余信息,但这是图像处理中的常见做法[37,38,39],例如,相似补丁的非局部图被有效地用作先验信息信息来捕获数据中的远程相关性。 有关拟议框架的两个主要步骤的更多详细信息将在下一节中提供。
IV 层聚合
IV-A 问题表述
我们现在介绍层聚合的公式,它利用 SPD 流形的黎曼几何原理,将单个层 的拉普拉斯矩阵 合并为描述代表图 的单一 SPD 矩阵。
算术平均值和几何平均值的概念通常用于对正数进行平均,可以自然地推广到一组有限的 SPD 矩阵。 这种概括基于均值运算的变分特征,即找到最小化其与一组 SPD 矩阵 的距离的 SPD 矩阵 ,即
| (8) |
其中表示 SPD矩阵的流形,是合适的距离。
IV-B 几何平均数
当通过欧氏距离计算SPD矩阵之间的相异度时,问题(8)的解是的算术平均值。 然而,后者对于合并来自不同层的信息来说并不是最优的,矩阵幂均值[4]给出了图聚类的更好替代方案,它可以完美地恢复从随机样本中采样的互补层的聚类。当电源转到时块模型。
可以基于黎曼距离[40]定义不同系列的矩阵幂均值。 在这种情况下,几何平均值作为机器学习中令人感兴趣的特殊情况而出现[41, 42]。 SPD 矩阵 的几何平均值对应于问题 (8) 的黎曼距离解333请注意,拉普拉斯矩阵上的主对数没有明确定义,因为它们只是半正定矩阵。 为了避免这个问题,我们添加了一个小的对角线位移以确保正定性。 换句话说,我们隐含地假设 ,其中 是一个小的正常数。
| (9) |
其中表示SPD矩阵的主对数。
IV-C 数值计算
我们建议通过计算各个拉普拉斯矩阵的几何平均值来聚合图层。 形式上,当 是 (9) 中给出的黎曼距离时,几何平均值作为问题 (8) 的解出现。 然而,该问题承认 没有封闭形式的解决方案。 因此,我们通过 Fréchet-Karcher 梯度流[43]来数值计算几何平均值,其迭代定义如下
| (10) |
上面的是初始化,是步长,表示对称矩阵的指数。 对于这里考虑的测地凸问题[44],黎曼梯度下降以的速率收敛到最优解。 实际上,使用 进行一次迭代就足以找到解决方案的良好近似值。 由于矩阵对数和指数的存在,此操作的时间复杂度为 。
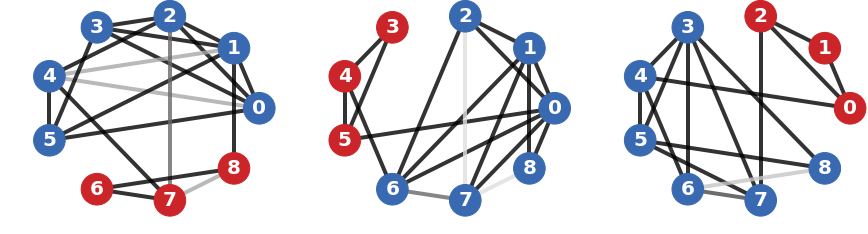
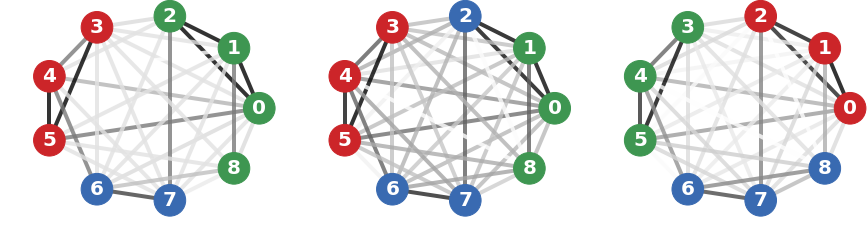
IV-D 说明性示例
图2展示了层聚合的示例,其中将建议的几何平均值与算术平均值和投影平均值[11]进行比较。 在这个例子中,原始图由三层组成,仅提供有关聚类结构的部分信息。 几何平均值产生代表所有层的图,因为谱聚类设法从中恢复出现在各个层中的三个块。 相反,算术平均值倾向于低估边 的重要性,尽管它出现在两层中,而投影平均值倾向于高估边 的重要性,尽管它存在仅出现在一层中,导致节点和分配错误。
在图2的例子中,边、、和的合并> 对于正确恢复三个集群至关重要。 它们的权重的微小变化会导致算术平均值和投影平均值的不同聚类。 几何平均值的情况并非如此,它为不同层上的各种边缘权重提供了一致的聚合。 事实上,众所周知,黎曼距离对所有特征值给予同等的重要性,无论其大小如何。 因此,几何平均值对边权值的小波动更加鲁棒,因此更适合保留多层图的结构信息。
V 节点特征嵌入
V-A 问题表述
我们现在提出特征嵌入的公式,它依赖于节点属性 和代表性图 的拉普拉斯矩阵 。
目标是估计一个映射,该映射将强连接节点的特征表示为潜在空间中的接近点。 也就是说,对于相似度较大的 ,我们希望 和 之间的距离较小,这相当于最小化
| (11) |
其中 在 (6) 中定义。 然而,仅此目标不足以学习导致有效聚类的嵌入,因为通过将所有点映射到相同的输出向量,成对距离的总和可以被最小化。 为了避免平凡的解决方案,我们可以借用谱聚类的思想,即嵌入点必须彼此正交[33, 35],产生
| (12) |
矩阵将图节点表示为潜在空间的向量。 直观上,同一簇内的节点应该映射到接近的向量,而来自不同簇的节点应该彼此间隔开,以便潜在空间可以很容易地聚类。 通过在正交性约束上优化成对距离的总和, 的行往往会被分成 簇,这些簇是通过将图中连接性更强的顶点分组在一起而形成的。 这确实类似于谱聚类,444通过设置、和,与谱聚类的联系变得明显,从而得到。 它在聚类[17,18,45]之前使用拉普拉斯矩阵的频谱进行降维。 图 1 给出了节点特征嵌入的说明性示例,其中映射 由具有四个全连接层和 ReLU 激活的神经网络实现。
请注意,已经提出了许多用于图 [32] 上表示学习的公式。 然而,分类场景和聚类场景之间存在明显的区别,在分类场景中,度量学习方法已经很成熟[46,47,48,49,50]。 在后一种情况下,大多数方法采用基于两个映射函数的模型:将每个节点嵌入低维向量的编码器和恢复高维向量的解码器。来自学习的嵌入的维度图信息(例如,节点位置)。 特别是,需要解码器来定义自监督损失函数,该函数测量解码的相似度值与图中真实相似度值之间的差异。
问题(12)的特殊之处在于解码器被正交性约束取代。 这种解决方案的优点是映射可以直接学习图提供的结构信息,而不是通过自我监督间接使用它。 此外,映射可以通过从到的任何参数函数来实现。 这包括神经网络,其唯一要求是最终有一层 单元。 在实践中,具有少量全连接层或图卷积层[32]的小型神经网络足以有效地解开低维空间中的数据。
V-B 提出的优化算法
我们建议使用基于梯度下降的优化算法来解决问题(12)。 该优化问题的主要困难来自于正交性约束,因为它是在要估计的映射上强制执行的,而不是优化参数,从而排除了基于交替优化的标准技术[51]。 虽然这个问题最近在[33, 35]中得到了解决,但我们提出了一种基于隐式约束优化的替代算法,它扩展了我们的基本知识工作[52]。
我们的想法是,问题 (12) 中的正交性约束可以通过使用 的 QR 分解的上三角矩阵 隐式强制执行,定义作为
| (13) |
其中 是半正交矩阵。 事实上,当是满秩的,或者等效地是正定的,它的QR分解是唯一的,并且等于乔列斯基分解
| (14) |
因此,可以通过将矩阵与相乘来提取半正交因子,即
| (15) |
这种考虑允许我们将问题 (12) 重写为
| (16) | ||||
| (17) |
在上面的重构中,项不再是半正交矩阵。 现在,通过从 的 Cholesky 分解中得到的因子 来隐式执行该约束,从而确保乘积 是 的半正交矩阵。 这使得嵌入 远离琐碎的解决方案成为可能。
V-C 梯度下降
问题 (16) 中涉及的所有操作都是可微的,前提是映射 由可微运算符(例如神经网络)定义。 具体来说,(16)中定义的代价函数的梯度可以分解为
| (18) |
雅可比行列式 w.r.t. (源自附录)读取
| (19) |
由于这个结果,可以通过梯度下降找到问题(16)的解决方案,其迭代总结在算法1中。 使用这种方法解决问题 (16) 有几个优点。 我们避免了投影步骤和梯度步骤之间交替的复杂性[33],因为交替方法可能会减慢收敛到最优解的速度。 此外,我们可以通过随机近似[35, 52]来降低梯度更新的复杂性。
原始问题 (12) 和建议的重新表述 (16) 之间的等价性仍然存在问题。 根据 Courant-Fischer 定理,问题 (12) 的解 非常接近矩阵 的 最小特征向量,直到映射的表示能力。 然而,问题 (16) 得出的解 并非如此,它只跨越矩阵 [54] 的最小 特征向量。 要看到这一点,请注意,我们可以重写 (16) 中重新表述的成本函数,如下所示:
| (20) | ||||
| (21) | ||||
| (22) |
在 的情况下,这可以归结为瑞利商
| (23) |
其极小值是的最小特征向量。对于 ,函数 (22) 对于 的右乘是不变的,因此可以通过跨越 的最小特征向量。这在我们的上下文中并不重要,因为嵌入空间中的基础变化不会影响聚类,使我们能够学习有效的映射 而无需显式计算 的特征向量>。另请注意,我们可以直接最小化 (22),如 [35]1> 中所示。 在这方面,所提出的成本函数可能更适合优化,因为它导致对称梯度,从而提高训练期间的稳定性。
六实验结果
VI-A 初步知识
我们将我们的方法与六种聚类算法进行比较。 称为 SC-ML [11]、MIMOSA [3] 和 PLM [4] 的方法分两个步骤工作:它们聚合多层图的拉普拉斯矩阵,然后对所得(单层)图进行谱聚类。555对于具有 节点的单层图,对图拉普拉奇矩阵 最小特征值相关的特征向量形成的矩阵 的行进行 K 均值聚类计算,以便将图中连接最紧密的顶点归为一组。 不同之处在于聚合步骤,该步骤分别通过凸组合或使用幂拉普拉斯均值在格拉斯曼流形中执行。 此外,称为 GMC [10] 的方法联合执行层聚合和频谱嵌入,所得嵌入矩阵使用 -means 进行聚类。 称为 SpectralNet [33] 的方法根据数据点(特征)构建图表,通过解决问题 (12) 来估计非线性映射,然后将特征嵌入到低维空间,它们用 K 均值聚类。 我们还报告了仅在节点特征上的 K 均值聚类的性能,而不使用多层图携带的结构信息。
所有方法都使用其默认超参数。 至于我们的方法,称为 OrthoNet,我们将映射实现为具有四个大小为 --- 和 PReLU 激活 [55],其中 是所需簇的数量,并使用 AmsGrad 方法[53]< 进行优化/t6> 使用学习率。 我们使用三个标准来衡量聚类性能:纯度、归一化互信息 (NMI) 和调整兰德指数 (RI)。 它们测量两个分区的一致性,忽略排列,并且不要求具有相同数量的簇。 接近零的值表示两项分配在很大程度上是独立的,而接近一的值表示显着一致。 所有实验均在 2.5 GHz、128GB RAM 的 40 核 Intel Xeon CPU 上使用 Python/Numpy/PyTorch 进行。
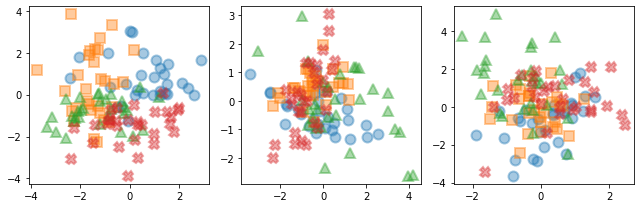
VI-B 数据集
在我们的实验中,我们考虑了几个合成和真实的数据集。 合成数据集由任意大小 的 点云组成,每个点云均由具有 组件的 维高斯混合模型生成具有不同的均值和协方差矩阵,如图3所示。 我们在每个点云上构建一个 20 最近邻 (-NN) 图,并将边权重设置为相邻点对之间的欧几里得距离的倒数。 这给了我们 层。 然后,我们将云中的数据点连接起来,从而为多层图中的每个节点形成大小为 的特征向量,其中跨层节点的对齐方式通过构造可知。 目标是恢复生成数据点的 组件。
然后我们考虑几个真实的数据集。 IMDB 数据库允许访问电影的演员、导演、编剧和制作公司、电影的奖项(获奖和提名)、票房以及导演/演员/编剧的票房。 在无法获取预算数据的情况下,目标是将电影分为 预算范围:低成本(低于 百万美元)、中低成本(低于 10 百万美元) 、中等成本(低于 40 百万美元)、中高成本(低于 100 百万美元)、高成本(高于 100 百万美元)。 为了在 IMDB 数据上构建多层图,我们将共享一个或多个演员、导演或编剧的电影连接起来,形成 图形层。 此外,每部电影都与属性相关联:票房、奖项和导演票房。
此外,Yelp 是一个流行的对本地企业进行评论和评级的网站。 在我们的实验中,我们只提取星级、文本评论和评论评价(用户可以将评论标记为“酷”、“有用”和“有趣”),忽略数据集中的其他信息。 目标是将企业分为 评级级别:低(1 或 2 星)、中(3 星)、高(4 或 5 星)。 要在 Yelp 数据上构建多层图,我们按如下步骤进行。 使用情感分析对文本评论进行预处理。 这会产生 范围内的极性分数,我们在此基础上构建 -NN 图。 我们还在评论评估上构建了一个 -NN 图,从而生成 图层。 此外,每个业务都关联有属性:情感分析分数、评论评估分数。
另一个数据集“100 片叶子”包含 植物物种的 特征的 样本。 我们在 不同的特征子集上构建 -NN 图:形状描述符、精细尺度边缘和纹理直方图。 目标是根据植物种类对观察结果进行聚类。
最后,“Mfeat”手写数字数据集包含 数字(0-9)的 特征的 个样本。 我们在 不同的特征组上构建 -NN 图。 目标是根据数字对观察结果进行聚类。
| Spectral clustering | OrthoNet | ||||||
|---|---|---|---|---|---|---|---|
| (graph only) | (graph + features) | ||||||
| Dataset | Layer aggregation | Purity | NMI | RI | Purity | NMI | RI |
| Synthetic | |||||||
| Nodes: 2000 – Clusters: 5 | None | 0.9375 | 0.8626 | 0.8568 | 0.9395 | 0.8647 | 0.8610 |
| Layers: 1 – Features: 8 | |||||||
| Synthetic | Average | 0.9475 | 0.8437 | 0.8731 | 0.9535 | 0.8614 | 0.8873 |
| Nodes: 2000 – Clusters: 5 | SC-ML | 0.9555 | 0.8634 | 0.8919 | 0.9580 | 0.8718 | 0.8977 |
| Layers: 4 – Features: 8 | SPD | 0.9705 | 0.9075 | 0.9275 | 0.9720 | 0.9113 | 0.9312 |
| Mfeat | |||||||
| Nodes: 2000 – Clusters: 6 | None | 0.7900 | 0.7489 | 0.6558 | 0.8000 | 0.7631 | 0.6752 |
| Layers: 1 – Features: 650 | |||||||
| Mfeat | Average | 0.8395 | 0.8410 | 0.7622 | 0.8515 | 0.8371 | 0.7761 |
| Nodes: 2000 – Clusters: 6 | SC-ML | 0.8775 | 0.8780 | 0.8339 | 0.8920 | 0.8860 | 0.8438 |
| Layers: 6 – Features: 650 | SPD | 0.9130 | 0.8953 | 0.8575 | 0.9555 | 0.9128 | 0.9057 |
| Data | K-means | SC-ML | GMC | PLM | MIMOSA | SpectralNet | OrthoNet |
|---|---|---|---|---|---|---|---|
| Synthetic | (Nodes: 10000, Features: 8, Layers: 4, Clusters: 5) | ||||||
| Purity | 0.9901 | 0.9858 | 0.3996 | 0.9886 | 0.9868 | 0.9940 | 0.9948 |
| NMI | 0.9664 | 0.9545 | 0.7299 | 0.9621 | 0.9566 | 0.9720 | 0.9756 |
| RI | 0.9756 | 0.9652 | 0.4763 | 0.9910 | 0.9896 | 0.9840 | 0.9827 |
| Time | 0.10 s | 153.84 s | 1345 s | 408.62 s | 1418 s | 464.31 s | 785.84 s |
| YELP | (Nodes: 1600, Features: 2, Layers: 2, Clusters: 3) | ||||||
| Purity | 0.8656 | 0.7748 | 0.7007 | 0.7616 | 0.7168 | 0.9460 | 0.9570 |
| NMI | 0.6265 | 0.3329 | 0.3925 | 0.6754 | 0.1395 | 0.6810 | 0.7910 |
| RI | 0.5912 | 0.5192 | 0.6010 | 0.8433 | 0.6603 | 0.7322 | 0.9044 |
| Time | 0.016 s | 1.54 s | 7.3 s | 5.10 s | 115.67 s | 82.04 s | 6.42 s |
| IMDB | (Nodes: 550, Features: 3, Layers: 3, Clusters: 5) | ||||||
| Purity | 0.8280 | 0.8817 | 0.7007 | 0.8495 | 0.5358 | 0.7310 | 0.8925 |
| NMI | 0.2331 | 0.3614 | 0.1563 | 0.2260 | 0.0953 | 0.2200 | 0.5056 |
| RI | 0.0219 | 0.2680 | 0.5245 | 0.7437 | 0.4347 | 0.1810 | 0.6909 |
| Time | 0.04 s | 0.31 s | 2.21 s | 20.89 s | 50.6 s | 30.35 s | 19.68 s |
| 100 Leaves | (Nodes: 1600, Features: 192, Layers 3, Clusters: 100) | ||||||
| Purity | 0.6987 | 0.9487 | 0.8237 | 0.8229 | – | 0.7840 | 0.9712 |
| NMI | 0.8452 | 0.9717 | 0.9292 | 0.9079 | – | 0.8370 | 0.9812 |
| RI | 0.5578 | 0.9129 | 0.4974 | 0.9819 | – | 0.3530 | 0.9478 |
| Time | 1.12 s | 1.86 s | 8.09 s | 4.06 s | – | 770 s | 4.17 s |
| Mfeat | (Nodes: 2000, Features: 650, Layers: 6, Clusters: 10) | ||||||
| Purity | 0.5470 | 0.8775 | 0.8820 | 0.8780 | 0.2215 | 0.7685 | 0.9555 |
| NMI | 0.5744 | 0.8780 | 0.9041 | 0.8807 | 0.3549 | 0.7480 | 0.9128 |
| RI | 0.4293 | 0.8339 | 0.8496 | 0.9692 | 0.9960 | 0.6343 | 0.9057 |
| Time | 0.71 s | 3.45 s | 24.05 s | 11.82 s | 13.04 s | 95.12 s | 10.85 s |
VI-C 图聚类:单层与多层
我们通过评估在几个特征子集上构建多层图(而不是在整个特征上构建单层图)的重要性来开始分析。 为此,我们比较了在给定数据集上构建图形的两种替代策略。
-
•
单层图。 对于每个样本,我们将所有可用特征连接到一个向量中。 然后,我们使用这些向量构建单个 k-NN 图。
-
•
多层图。 对于每个样本,我们将可用特征分成不同的子集(参见第 VI-B 节)。 然后,我们在每个子集上构建一个单独的 k-NN 图,并将它们堆叠成多层图。
表 I 报告了使用上述图形构建策略在两个数据集(合成数据集和 Mfeat)上的聚类性能。 我们直接对单层图进行谱聚类和OrthoNet聚类,得到表I第一行和第三行中报告的两组指标。 在多层图上,我们首先使用三种不同的方法聚合各层:算术平均值(平均值)、Grassman 流形中的投影平均值(SC-ML)和 SPD 流形中的几何平均值(建议)。 然后,我们对每个聚合图执行谱聚类或 OrthoNet 聚类,得到表I第二行和第四行中报告的六组指标。 在这两种情况下,谱聚类仅依赖于图,而 OrthoNet 既依赖于图又依赖于特征。
在谱聚类(表左侧)和OrthoNet聚类(表右侧)获得的结果中,所提出的方法(SPD+OrthoNet)实现了最佳性能。 这从经验上证实了
-
•
出于节点聚类的目的,多层图比单层图携带更丰富的信息,
-
•
SPD流形中的几何平均值是层聚合的适当且有效的选择,
-
•
图节点上特征的存在可以改善多层图的聚类。
VI-D 多层图聚类:性能评估
表II报告了与上一小节中提到的最先进方法的更广泛的比较。666由于集群数量较多(100 个),我们无法在“100 leaves”数据集上运行 MIMOSA。 在合成数据集上,OrthoNet 和 SpectralNet 表现最好,而基于聚合的技术实际上是等效的。 这可能与以下事实有关:信号与此类数据的相关性比单独的图表(由信号构建的图表)更相关。 在其他数据集上,OrthoNet 是迄今为止表现最好的,尤其是在 NMI 分数方面。 这个结果可能是由于图层携带的信息更丰富,而这些信息无法转化为特征。 由于 SpectralNet 在特征向量上建立相似距离(使用最近邻或 Siamese 网络),因此它不能依赖多层图带来的好处。 相反,所提出的方法可以利用多层图和特征向量携带的信息,从而获得更好的聚类性能。 然而,由于计算 SPD 矩阵的几何平均值的计算成本很高,因此这种改进是随着执行时间的增加而实现的。
VI-E 泛化到新数据
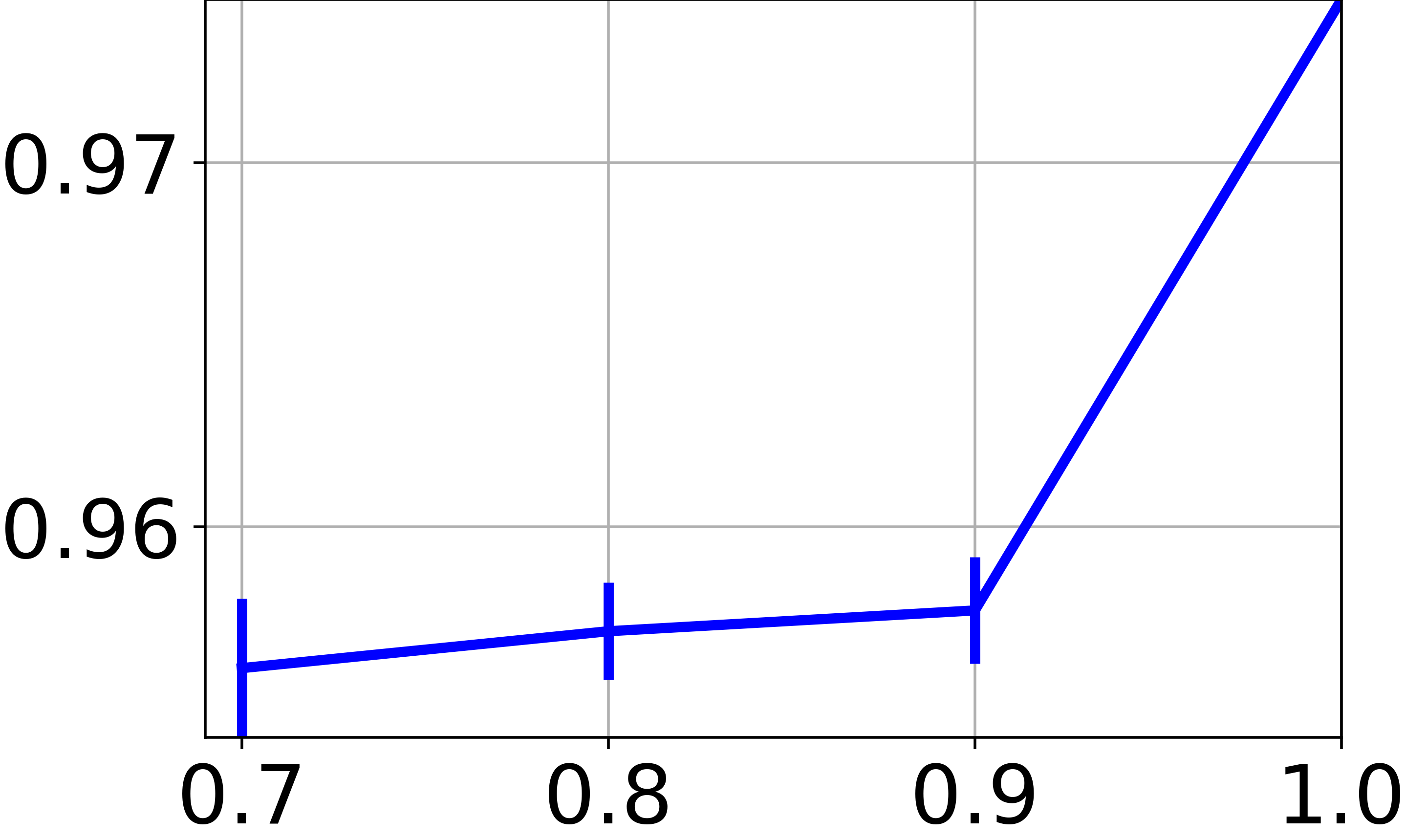
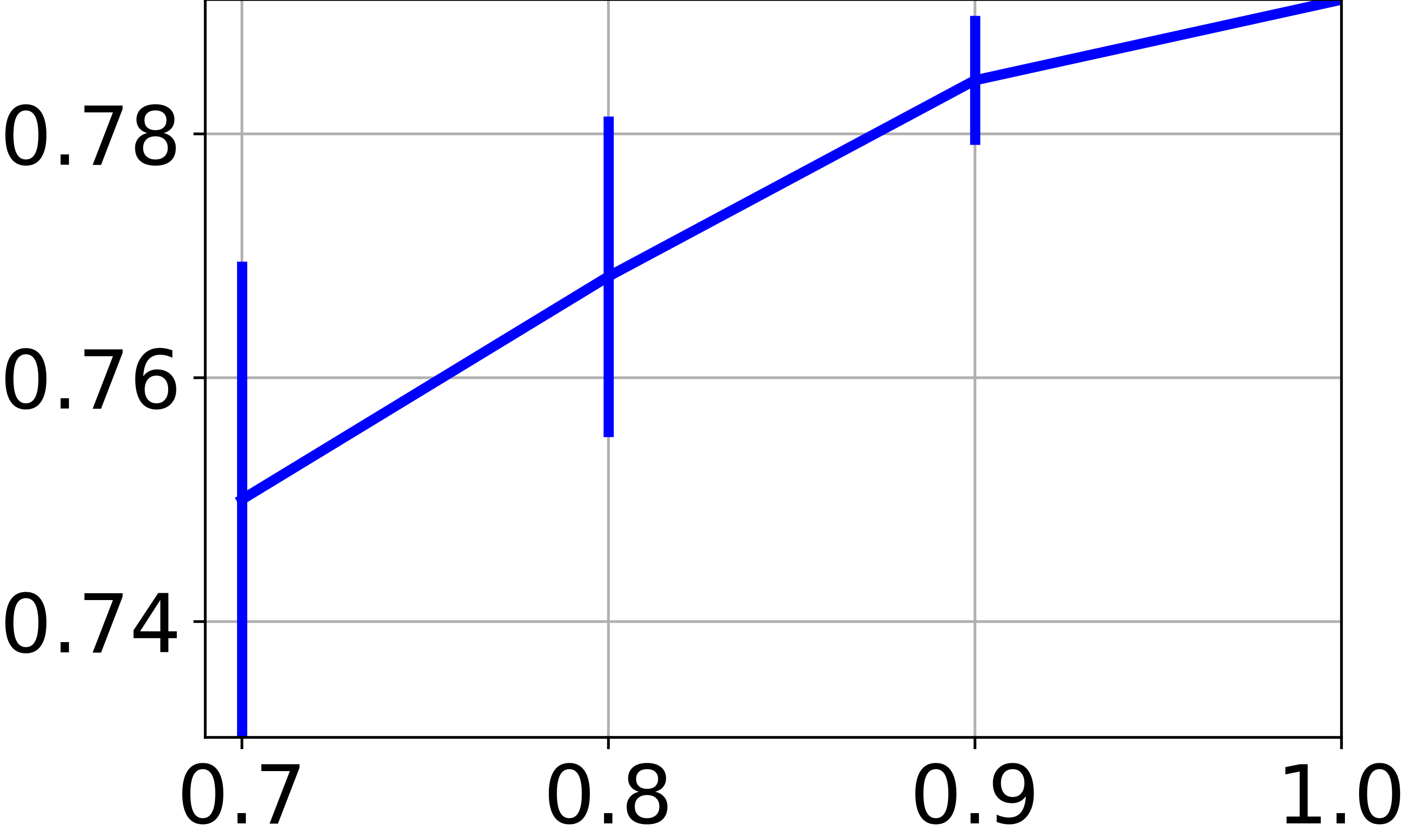
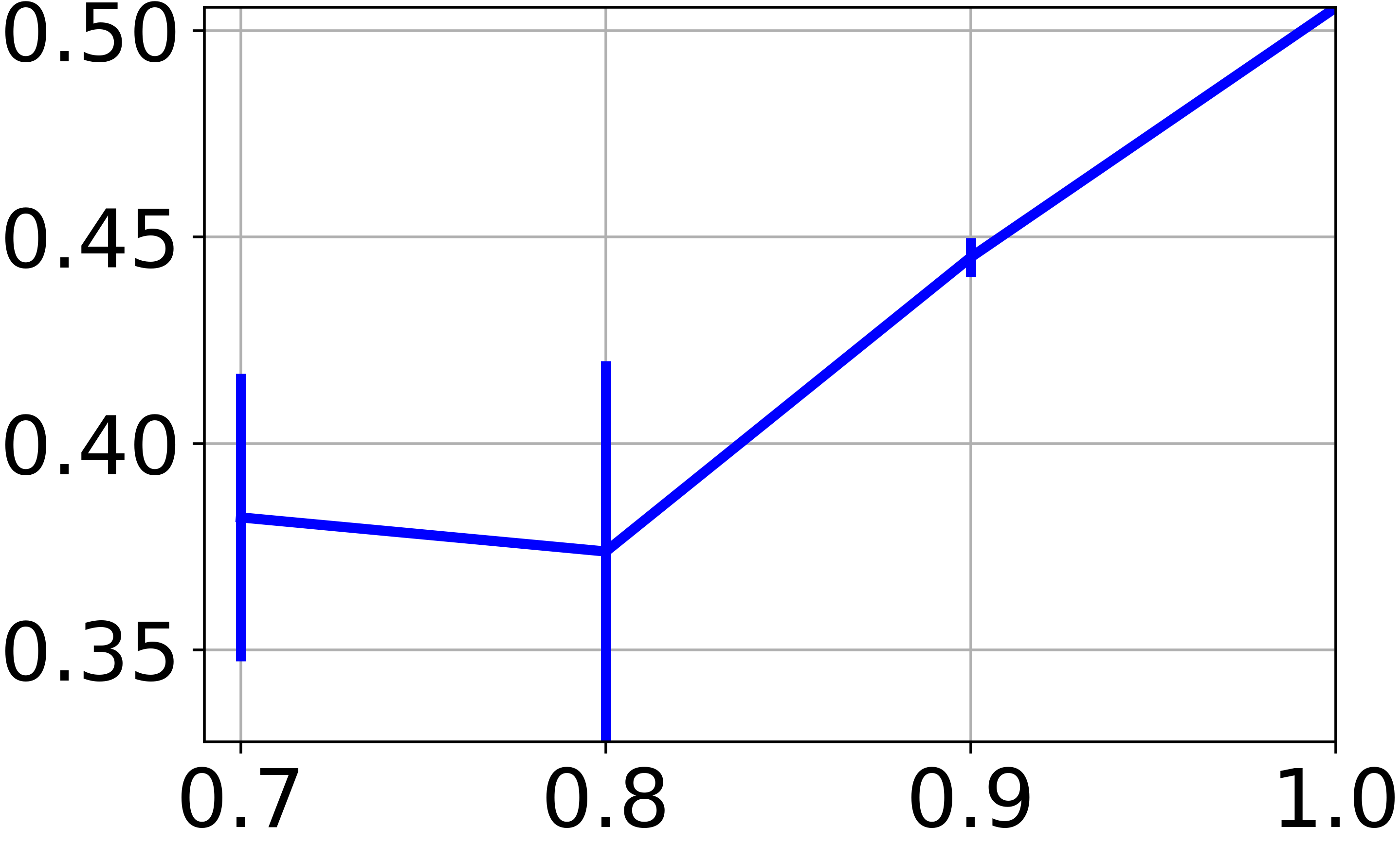
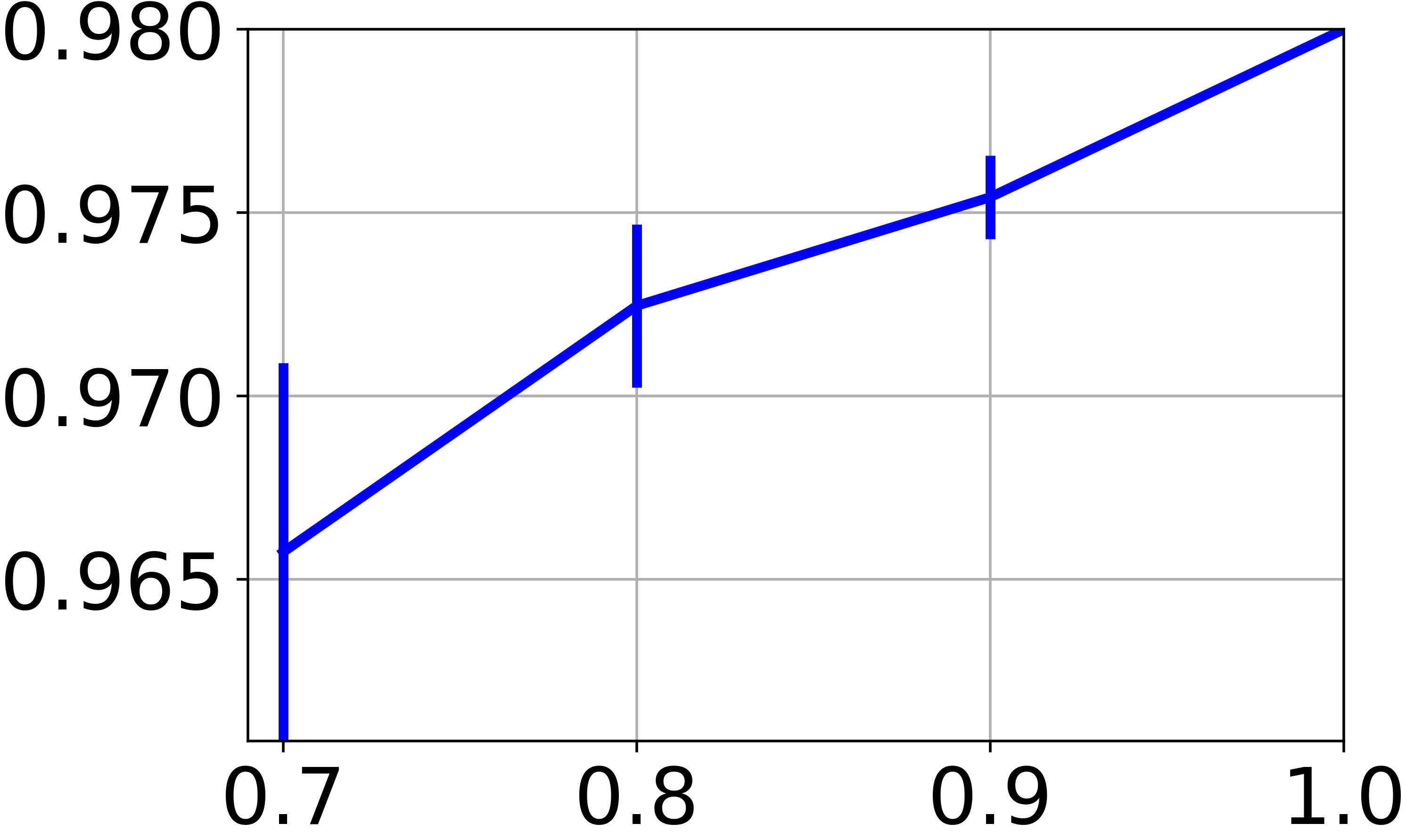
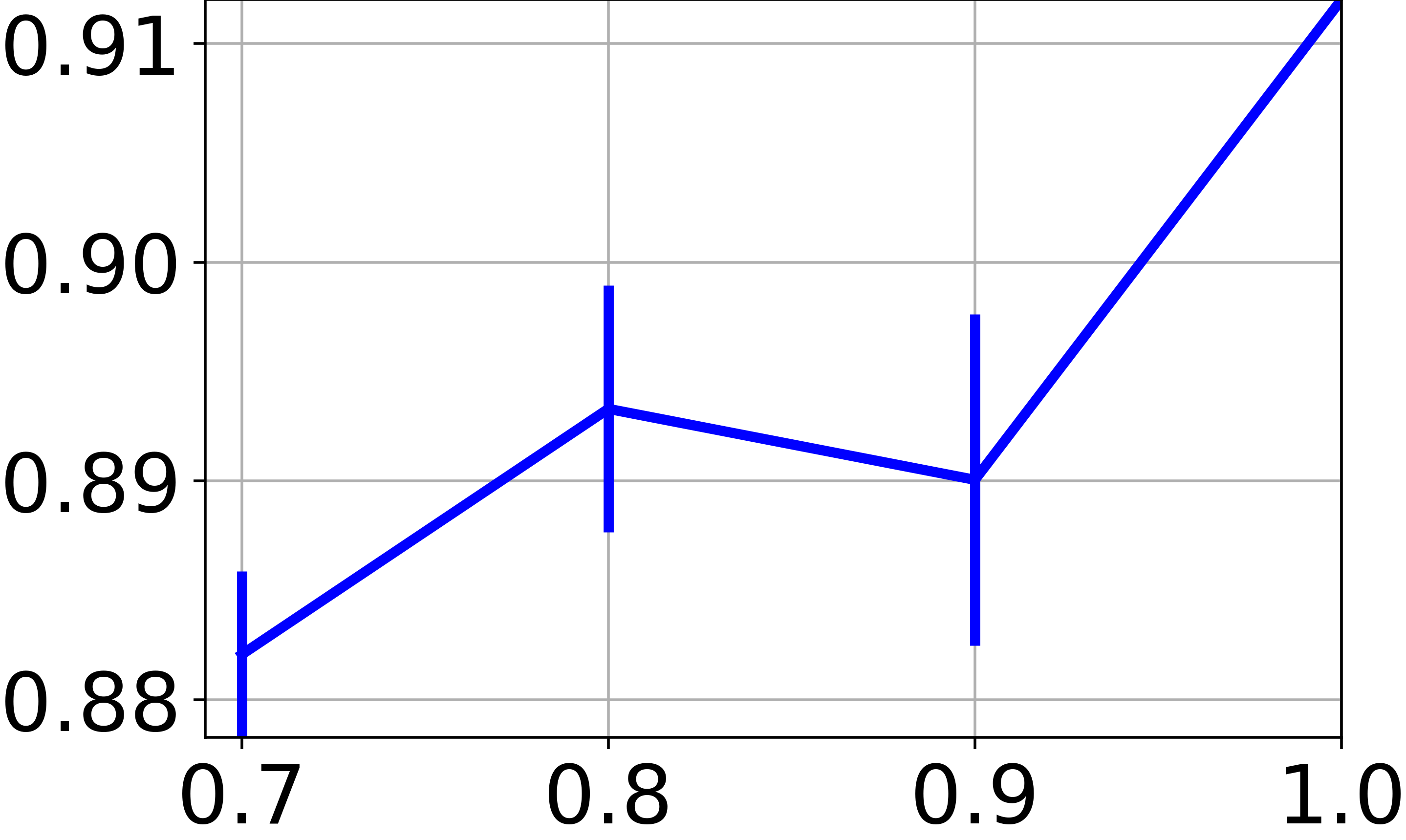
在我们的方法中,我们训练一个神经网络来找到特征空间的聚类友好表示。 虽然到目前为止我们专注于图节点特征的聚类,但我们现在希望评估对以前从未见过的新特征向量(即不与任何图节点关联)进行分类的能力。 这里的困难在于我们处理一个完全无监督的场景,因此基于将数据拆分为训练集和测试集的实验协议并没有真正的意义。 为了与表II中报告的技术进行公平比较,我们在可用图节点的子集上训练,然后评估 在所有可用的特征向量上。 特别是,图 4e 报告了在 、、 和 图节点。 对于所有小于 的分数,我们在图表的随机子集上重复训练 10 次,并报告分数的平均值和标准差。 结果显示,当对较小的图进行训练时,性能会适度下降。 这表明,只要图表携带足够的信息,学习的神经网络就有能力推广到新数据。
七结论
我们提出了一种基于两步方法的多层网络数据聚类框架。 我们首先计算 SPD 流形中拉普拉斯矩阵的几何平均值,然后使用受谱聚类启发的公式,使用结果图以无监督的方式在节点特征上训练神经网络。 后一步采用新的优化算法来解决,该算法以隐式方式处理神经网络输出的正交性约束,以便跨越聚合拉普拉斯矩阵的主要特征向量,而无需显式计算它们。 实验结果表明,与最先进的多层网络聚类相比,该方法在不同数据集上具有更好的聚类性能,以及经过训练的神经网络泛化到新数据的能力。 未来工作的有趣观点包括通过通用方法对节点特征进行更好的建模,以同时聚合多层信息与网络数据。
[梯度的推导]
| Operation | Differential of a variable | Differential of | Jacobian of w.r.t. a variable |
|---|---|---|---|
| - | |||
参考
- [1] A. Argyriou, M. Herbster, and M. Pontil, “Combining graph laplacians for semi-supervised learning,” in Advances in Neural Information Processing Systems 18, Y. Weiss, B. Schölkopf, and J. C. Platt, Eds. Montréral, canada: MIT Press, Dec. 2006, pp. 67–74.
- [2] L. Tang, X. Wang, and H. Liu, “Community detection via heterogeneous interaction analysis,” Data Mining and Knowledge Discovery, vol. 25, no. 1, pp. 1–33, Jul. 2012.
- [3] P.-Y. Chen and A. O. Hero, “Multilayer spectral graph clustering via convex layer aggregation: Theory and algorithms,” IEEE Transactions on Signal and Information Processing over Networks, vol. 3, no. 3, pp. 553–567, Sep. 2017.
- [4] P. Mercado, A. Gautier, F. Tudisco, and M. Hein, “The power mean laplacian for multilayer graph clustering,” in International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, Spain, Apr. 2018, pp. 1828–1838.
- [5] X. Wang, W. Bian, and D. Tao, “Grassmannian regularized structured multi-view embedding for image classification,” IEEE Transactions on Image Processing, vol. 22, no. 7, pp. 2646–2660, Jul. 2013.
- [6] S. Bickel and T. Scheffer, “Multi-view clustering,” in Fourth IEEE International Conference on Data Mining, Washington, DC, USA, Nov. 2004, pp. 19–26.
- [7] A. Kumar and H. Daumé, “A co-training approach for multi-view spectral clustering,” in Proceedings of International Conference on Machine Learning, Bellevue, Washington, USA, Jun. 2011, pp. 393–400.
- [8] A. Blum and T. Mitchell, “Combining labeled and unlabeled data with co-training,” in Proceedings of the eleventh annual conference on Computational learning theory, New York, NY, USA, 1998, pp. 92–100.
- [9] V. Sindhwani and P. Niyogi, “A co-regularization approach to semi-supervised learning with multiple views,” in Proceedings of the ICML Workshop on Learning with Multiple Views, Bonn, Germany, Aug. 2005.
- [10] H. Wang, Y. Yang, and B. Liu, “GMC: Graph-based multi-view clustering,” IEEE Transactions on Knowledge and Data Engineering (to appear), 2019.
- [11] X. Dong, P. Frossard, P. Vandergheynst, and N. Nefedov, “Clustering on multi-layer graphs via subspace analysis on grassmann manifolds,” IEEE Transactions on Signal Processing, vol. 62, no. 4, pp. 905–918, Feb. 2014.
- [12] A. Clauset, C. Moore, and M. E. J. Newman, “Hierarchical structure and the prediction of missing links in networks,” Nature, vol. 453, no. 7191, p. 98, 2008.
- [13] S. Fortunato, “Community detection in graphs,” Physics Reports, vol. 486, no. 3, pp. 75–174, Feb. 2010.
- [14] J. Kim and J.-G. Lee, “Community detection in multi-layer graphs: A survey,” ACM SIGMOD Record, vol. 44, no. 3, pp. 37–48, Dec. 2015.
- [15] C. W. Loe and H. J. Jensen, “Comparison of communities detection algorithms for multiplex,” Physica A: Statistical Mechanics and its Applications, vol. 431, p. 29–45, 2015.
- [16] E. Schaeffer, “Survey: Graph clustering,” Computer Science Review, vol. 1, no. 1, pp. 27 – 64, Aug. 2007.
- [17] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22, no. 8, pp. 888–905, Aug. 2000.
- [18] A. Y. Ng, M. I. Jordan, and W. Yair, “On spectral clustering: Analysis and an algorithm,” Advances in Neural Information Processing Systems 14, pp. 849–856, 2002.
- [19] J. B. MacQueen, “Some methods for classification and analysis of multivariate observations,” Berkeley Symposium on Mathematical Statistics and Probability, 1967.
- [20] Q. Xu, M. Desjardins, and K. Wagstaff, “Constrained spectral clustering under a local proximty structure,” Proceedings of the 18th International Florida Artificial Intelligence Research Society, May 2005.
- [21] X. Wang and I. Davidson, “Flexible constrained spectral clustering,” in International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM, Oct. 2010, pp. 563–572.
- [22] M. E. J. Newman, “Finding community structure in networks using the eigenvectors of ma- trices,” Physical Review E, vol. 74, no. 3, Sep. 2006.
- [23] ——, “Modularity and community structure in networks,” Proceedings of the National Academy of Sciences of the United States of America, vol. 103, no. 23, pp. 8577–8582, Jun. 2006.
- [24] M. Saerens, F. Fouss, L. Yen, and P. Dupont, “The principal components analysis of a graph, and its relationships to spectral clustering,” in Proceedings of European Conference on Machine Learning, Berlin, Heidelberg, 2004, pp. 371–383.
- [25] J. B. Kruskal and M. Wish, “Multidimensional scaling,” in Sage Publications, Beverely Hills,California, 1978.
- [26] M. Belkin and N. Partha, “Laplacian eigenmaps and spectral techniques for embedding and clustering,” in Advances in Neural Information Processing Systems 14, T. G. Dietterich, S. Becker, and Z. Ghahramani, Eds. Vancouver CANADA: MIT Press, Dec. 2002, pp. 585–591.
- [27] J. B. Tenenbaum, V. De Silva, and J. C. Langford, “A global geometric framework for nonlinear dimensionality reduction,” Science, vol. 290, no. 5500, pp. 2319–2323, 2000.
- [28] S. T. Roweis and L. K. Saul, “Nonlinear dimensionality reduction by locally linear embedding,” Science, vol. 290, no. 5500, pp. 2323–2326, Dec. 2000.
- [29] H. Yang, S. Pan, P. Zhang, L. Chen, D. Lian, and C. Zhang, “Binarized attributed network embedding,” in IEEE International Conference on Data Mining, Singapore, Nov. 2018, pp. 1476–1481.
- [30] X. Shen, S. Pan, W. Liu, Y.-S. Ong, and Q.-S. Sun, “Discrete network embedding,” in International Joint Conference on Artificial Intelligence, vol. 7, Stockholm, Sweden, Jul. 2018, pp. 3549–3555.
- [31] B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepwalk: Online learning of social representations,” in ACM SIGKD Dinternational conference on Knowledge discovery and data mining, New York, New York, USA, Aug. 2014, pp. 701–710.
- [32] W. L. Hamilton, R. Ying, and J. Leskovec, “Representation learning on graphs: Methods and applications,” IEEE Data Engineering Bulletin, 2017. [Online]. Available: http://arxiv.org/abs/1709.05584
- [33] U. Shaham, K. Stanton, H. Li, B. Nadler, R. Basri, and Y. Kluger, “Spectralnet: Spectral clustering using deep neural networks,” in International Conference on Learning Representations, Vancouver, Canada, May 2018.
- [34] A. Bojchevski and S. Günnemann, “Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking,” in International Conference on Learning Representations, Vancouver, Canada, Apr. 2018.
- [35] D. Pfau, S. Petersen, A. Agarwal, D. Barrett, and K. Stachenfeld, “Spectral inference networks: Unifying deep and spectral learning,” in Proc. of ICLR, 2019.
- [36] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, and M. Welling, “Modeling relational data with graph convolutional networks,” in The Semantic Web, Heraklion, Crete, Greece, Jun. 2018, pp. 593–607.
- [37] G. Chierchia, N. Pustelnik, B. Pesquet-Popescu, and J.-C. Pesquet, “A nonlocal structure tensor based approach for multicomponent image recovery problems,” IEEE Trans. Image Proces., vol. 23, no. 12, pp. 5531–5544, Dec. 2014.
- [38] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in Proc. CVPR, June 2018.
- [39] Y. Tao, Q. Sun, Q. Du, and W. Liu, “Nonlocal neural networks, nonlocal diffusion and nonlocal modeling,” in Advances in Neural Information Processing Systems 31, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., 2018, pp. 496–506.
- [40] Y. Lim and M. Pálfia, “Matrix power means and the karcher mean,” Journal of Functional Analysis, vol. 262, no. 4, pp. 1498–1514, 2012.
- [41] P. Zadeh, R. Hosseini, and S. Sra, “Geometric mean metric learning,” in Proc. ICML, M. F. Balcan and K. Q. Weinberger, Eds., vol. 48, New York, New York, USA, 20–22 Jun 2016, pp. 2464–2471.
- [42] P. Mercado, F. Tudisco, and M. Hein, “Clustering signed networks with the geometric mean of laplacians,” in Advances in Neural Information Processing Systems 29, D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, Eds., 2016, pp. 4421–4429.
- [43] H. Karcher, “Riemannian center of mass and mollifier smoothing,” Communications on pure and applied mathematics, vol. 30, no. 5, pp. 509–541, Sep. 1977.
- [44] H. Zhang and S. Sra, “First-order methods for geodesically convex optimization,” Journal of Machine Learning Research, vol. 49, pp. 1–22, 2016.
- [45] U. V. Luxburg, “A tutorial on spectral clustering,” Statistics and Computing, vol. 17, no. 4, pp. 395–416, Dec. 2007.
- [46] S. Chopra, R. Hadsell, and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” in IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, Jun. 2005, pp. 539–546.
- [47] K. Q. Weinberger and L. K. Saul, “Distance metric learning for large margin nearest neighbor classification,” J. Mach. Learn. Res., vol. 10, pp. 207–244, Jun. 2009.
- [48] E. Hoffer and N. Ailon, “Deep metric learning using triplet network,” in International Workshop on Similarity-Based Pattern Recognition, A. Feragen, M. Pelillo, and M. Loog, Eds., 2015, vol. 9370, pp. 84–92.
- [49] F. Schroff, D. Kalenichenko, and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” in IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
- [50] M. Bontonou, C. Lassance, G. B. Hacene, V. Gripon, J. Tang, and J. Tang, “Introducing graph smoothness loss for training deep learning architectures,” in IEEE Data Science Workshop, Jun. 2019, pp. 160–164.
- [51] R. Lai and S. Osher, “A splitting method for orthogonality constrained problems,” J. Sci. Comput., vol. 58, no. 2, pp. 431–449, Feb. 2014.
- [52] M. El Gheche, G. Chierchia, and P. Frossard, “Stochastic gradient descent for spectral embedding with implicit orthogonality constraint,” in IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, May 2019, pp. 3567–3571. [Online]. Available: https://arxiv.org/abs/1812.05721
- [53] S. J. Reddi, S. Kale, and S. Kumar, “On the convergence of adam and beyond,” in International Conference on Learning Representations, Vancouver, Canada, May 2018.
- [54] A. Edelman, T. A. Arias, and S. T. Smith, “The geometry of algorithms with orthogonality constraints,” SIAM J. Matrix Anal. Appl., vol. 20, no. 2, pp. 303–353, Apr. 1999.
- [55] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proc. ICCV, Washington, DC, USA, 2015, pp. 1026–1034.
- [56] M. Giles, “An extended collection of matrix derivative results for forward and reverse mode automatic differentiation,” Numerical Analysis Report, Oxford University Computing Laboratory, vol. 08, no. 01, 2008.
- [57] I. Murray, “Differentiation of the Cholesky decomposition,” Eprint arXiv:1602.07527, 2016.