GPipe:通过微批量管道并行性轻松扩展
摘要
扩展深度神经网络容量被认为是提高多种不同机器学习任务模型质量的有效方法。 在许多情况下,将模型容量提高到超出单个加速器的内存限制需要开发特殊的算法或基础设施。 这些解决方案通常是特定于体系结构的,并且不会转移到其他任务。 为了满足高效且独立于任务的模型并行性的需求,我们引入了 GPipe,这是一个管道并行库,它允许扩展任何可以表示为层序列的网络。 通过在单独的加速器上管道化不同的层子序列,GPipe 提供了有效地将各种不同网络扩展到巨大尺寸的灵活性。 此外,GPipe 采用了一种新颖的批量分割流水线算法,当模型跨多个加速器进行分区时,几乎可以实现线性加速。 我们通过在具有不同网络架构的两个不同任务上训练大规模神经网络来展示 GPipe 的优势:(i)图像分类:我们训练了一个 5.57 亿参数的 AmoebaNet 模型并获得了最佳性能1 ImageNet-2012 上的准确率达到 84.4%,(ii) 多语言神经机器翻译:我们在涵盖 100 多种语言的语料库上训练单个 60 亿参数、128 层 Transformer 模型,并取得更好的成绩质量优于所有双语模型。
1简介
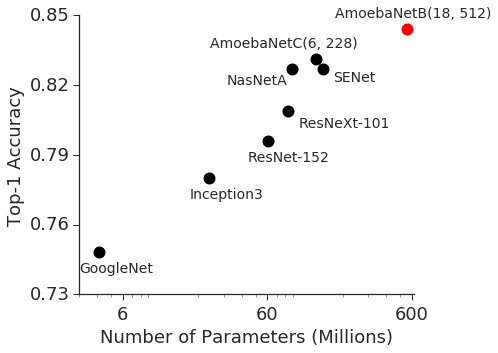
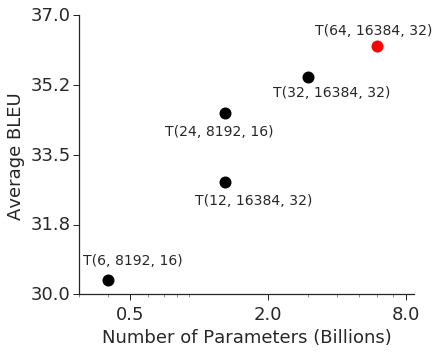
深度学习在过去十年中取得了巨大进步,部分归功于促进扩展神经网络有效能力的方法的发展。 这种趋势在图像分类中最为明显,随着模型容量的增加,ImageNet 的准确性得到了提高(图1a)。 在自然语言处理的背景下也可以观察到类似的现象(图 1b),其中简单的浅层句子表示模型 [1, 2] 的性能优于其更深层次的模型和更大的对应物[3, 4]。
虽然较大的模型为多个领域带来了显着的质量改进,但扩展神经网络却带来了重大的实际挑战。 硬件限制,包括加速器(GPU 或 TPU)上的内存限制和通信带宽,迫使用户将较大的模型划分为多个分区,并将不同的分区分配给不同的加速器。 然而,高效的模型并行算法极其难以设计和实现,这通常要求从业者在扩展能力、灵活性(或特定任务和架构的特异性)和训练效率之间做出艰难的选择。 因此,最有效的模型并行算法是特定于架构和任务的。 随着深度学习应用的不断增加,对可靠且灵活的基础设施的需求不断增加,使研究人员能够轻松扩展神经网络以执行各种机器学习任务。
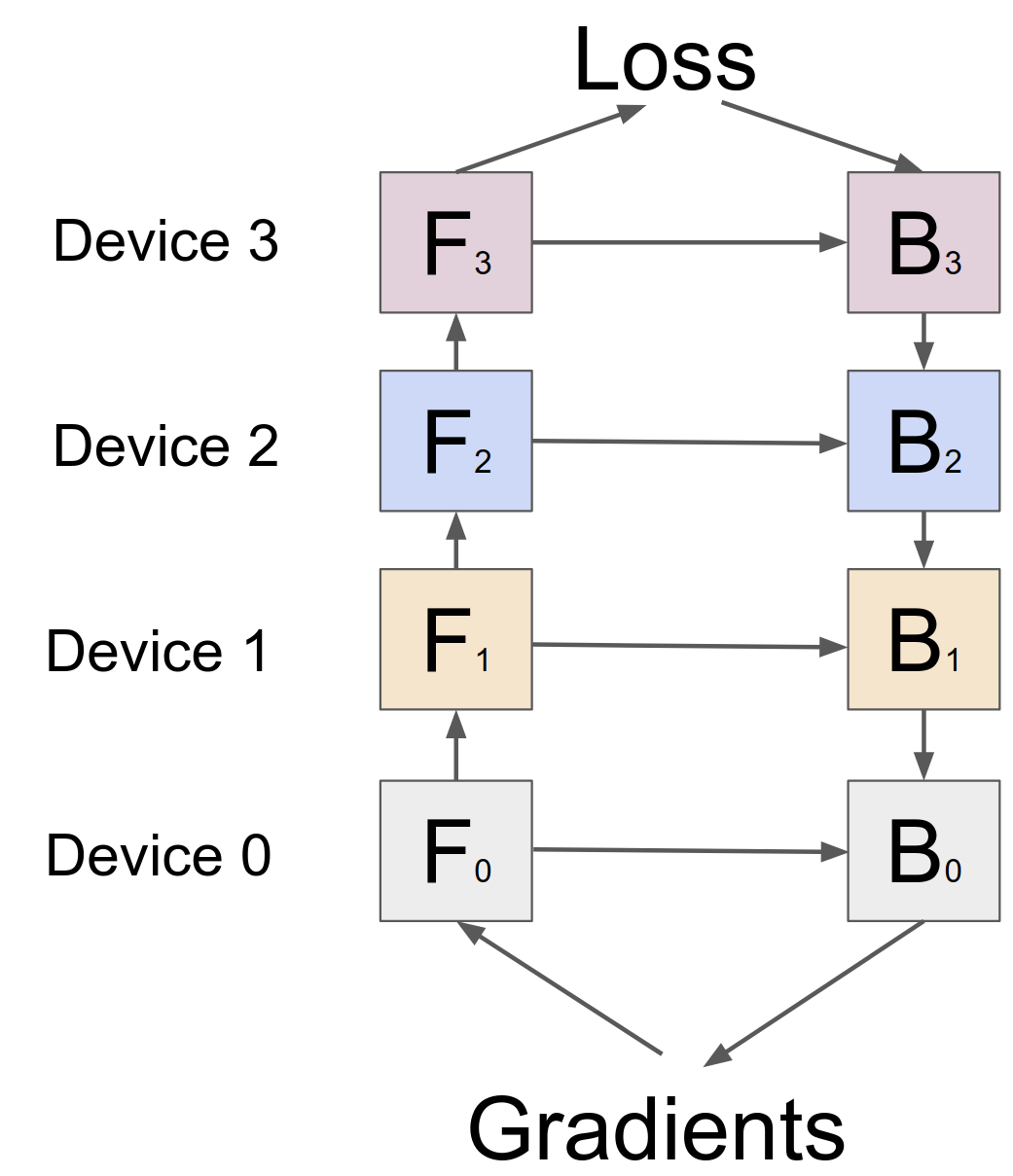
为了应对这些挑战,我们引入了 GPipe,这是一个灵活的库,可以实现大型神经网络的高效训练。 GPipe 允许将任意深度神经网络架构扩展到单个加速器的内存限制之外,方法是将模型划分到不同的加速器上并支持每个加速器上的重新实现[13, 14]。 使用 GPipe,可以将每个模型指定为一系列层,并且可以将连续的层组划分为单元。 然后将每个细胞放置在单独的加速器上。 基于这种分区设置,我们提出了一种具有批量分割的新型管道并行算法。 我们首先将训练示例的小批量分成更小的微批次,然后在单元上管道化执行每组微批次。 我们在训练中应用同步小批量梯度下降,其中梯度在小批量中的所有微批量中累积,并在小批量结束时应用。 因此,无论分区数量如何,使用 GPipe 的梯度更新都是一致的,从而使研究人员能够通过部署更多加速器轻松训练越来越大的模型。 GPipe 还可以通过数据并行性进行补充,以进一步扩展训练。
我们展示了 GPipe 在图像分类和机器翻译方面的灵活性和效率。 对于图像分类,我们在 ImageNet 2012 数据集的 输入上训练 AmoebaNet 模型。 通过增加模型宽度,我们将参数数量扩大到 万个,并实现了 84.4% 的 top-1 验证准确度。 在机器翻译方面,我们针对 103 种语言(102 种语言到英语)训练了一个 128 层、60 亿参数的多语言 Transformer 模型。 我们证明,该模型能够在 100 个语言对上优于单独训练的 3.5 亿参数双语 Transformer Big [15] 模型。
2 GPipe 库
现在我们描述 GPipe 的界面和主要设计特点。 该开源库是在 Lingvo [16] 框架下实现的。 GPipe 的核心设计特性是普遍适用的,并且可以为其他框架[17,18,19]实现。
2.1接口
任何深度神经网络都可以定义为一系列 层。 每层由前向计算函数和相应的参数集组成。 GPipe 另外还允许用户指定可选的计算成本估计函数。 通过给定数量的分区 , 层序列可以划分为 复合层或单元。 让 由层 和 之间的连续层组成。 对应的参数集相当于、、…、的并集,其forward函数为为。 可以使用自动符号微分从 计算相应的反向传播函数 。 成本估算器 设置为 。
GPipe 界面极其简单直观,要求用户指定:(i) 模型分区的数量 ,(ii) 微批次的数量 ,以及 ( iii) 定义模型的层的顺序和定义。 请参阅补充材料中的示例。
2.2算法
一旦用户根据模型参数 、前向计算函数 和成本估计函数 定义网络中的层序列,GPipe 就会进行分区将网络划分为 个单元,并将第 个单元放置在第 个加速器上。 通信原语自动插入到分区边界,以允许相邻分区之间的数据传输。 分区算法最小化所有单元估计成本的方差,以便通过同步所有分区的计算时间来最大化管道的效率。
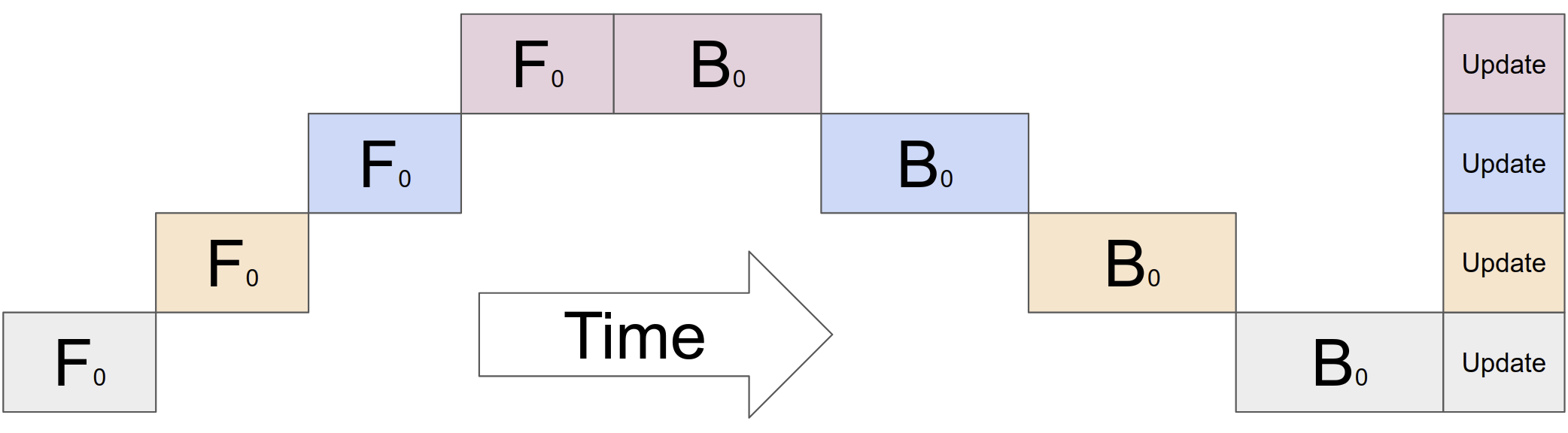
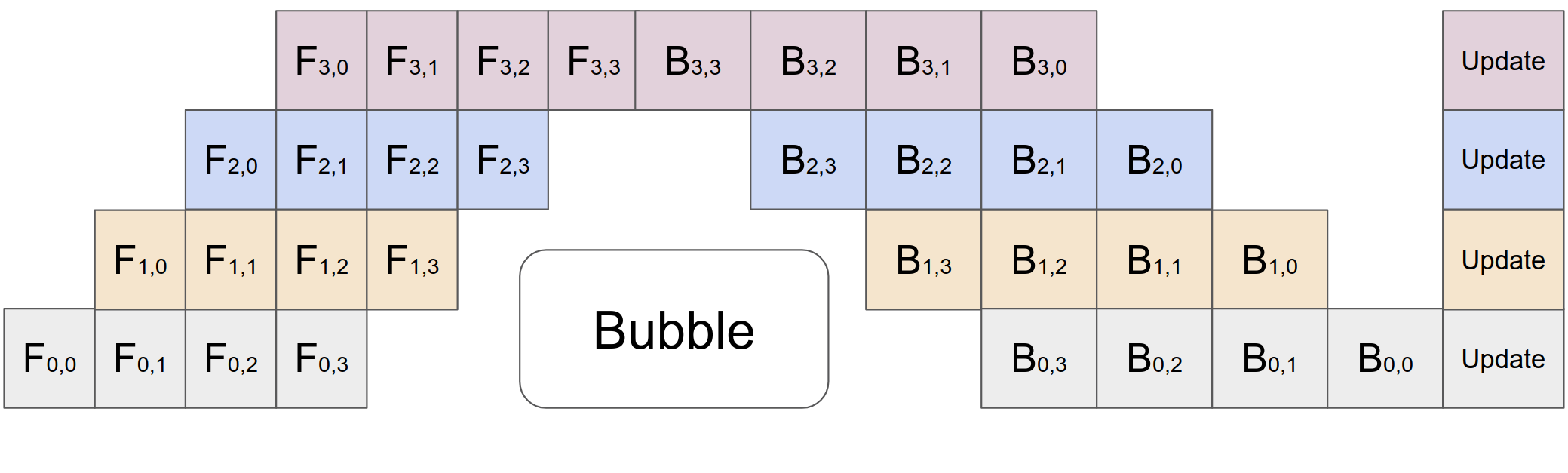
在前向传递过程中,GPipe 首先将每个大小为 的小批量划分为 个相等的微批量,这些微批量通过 加速器进行管道传输。 在向后传递过程中,每个微批次的梯度是根据用于向前传递的相同模型参数计算的。 在每个小批量结束时,所有 微批量的梯度都会被累积并应用于更新所有加速器上的模型参数。 此操作序列如图2c 所示。
如果在网络中使用批量归一化[20],则训练期间输入的足够统计数据将在每个微批次上计算,并在必要时在副本上计算[21 ]。 我们还跟踪评估期间使用的整个小批量的足够统计数据的移动平均值。
2.3性能优化
为了减少激活内存需求,GPipe 支持重新物化[14]。 在前向计算期间,每个加速器仅存储分区边界处的输出激活。 在向后传递期间,第加速器重新计算复合前向函数。 因此,峰值激活内存需求减少到 ,其中 是微批量大小, 是每个分区的层数。 相比之下,没有重新物化和分区的内存需求将为,因为计算梯度需要上层梯度和缓存的激活。
如图2(c)所示,分区会给每个加速器带来一些空闲时间,我们将其称为气泡开销。 该冒泡时间按微步数分摊。在我们的实验中,我们发现当 时,气泡开销可以忽略不计。 这也部分是因为可以更早地安排向后传递期间的重新计算,而无需等待来自较早层的梯度。
GPipe 还引入了较低的通信开销,因为我们只需要在加速器之间的分区边界传递激活张量。 因此,即使在没有高速互连的加速器上,我们也可以实现高效的扩展性能。
图2(c)假设分区是均匀平衡的。 然而,不同层的内存需求和计算失败通常非常不平衡。 在这种情况下,不完善的分区算法可能会导致负载不平衡。 更好的分区算法可能会比我们的启发式方法提高性能。
3 性能分析
| NVIDIA GPUs (8GB each) | Naive-1 | Pipeline-1 | Pipeline-2 | Pipeline-4 | Pipeline-8 |
|---|---|---|---|---|---|
| AmoebaNet-D (L, D) | (18, 208) | (18, 416) | (18, 544) | (36, 544) | (72, 512) |
| # of Model Parameters | 82M | 318M | 542M | 1.05B | 1.8B |
| Total Model Parameter Memory | 1.05GB | 3.8GB | 6.45GB | 12.53GB | 24.62GB |
| Peak Activation Memory | 6.26GB | 3.46GB | 8.11GB | 15.21GB | 26.24GB |
| Cloud TPUv3 (16GB each) | Naive-1 | Pipeline-1 | Pipeline-8 | Pipeline-32 | Pipeline-128 |
| Transformer-L | 3 | 13 | 103 | 415 | 1663 |
| # of Model Parameters | 282.2M | 785.8M | 5.3B | 21.0B | 83.9B |
| Total Model Parameter Memory | 11.7G | 8.8G | 59.5G | 235.1G | 937.9G |
| Peak Activation Memory | 3.15G | 6.4G | 50.9G | 199.9G | 796.1G |
我们使用两种截然不同类型的模型架构来评估 GPipe 性能:AmoebaNet [12] 卷积模型和 Transformer [15] 序列到序列模型。 我们进行了实验来研究它们的可扩展性、效率和通信成本。
我们预计重新物化和管道并行都会有利于内存利用率,从而使拟合巨型模型变得可行。 我们在表 1 中报告了 GPipe 在相当大的输入大小下可以支持的最大模型大小。 对于 AmoebaNet,我们在每个加速器具有 8GB 内存的 Cloud TPUv2 上运行了实验。 我们使用固定输入图像大小 和小批量大小 。 如果没有 GPipe,单个加速器最多可以训练 82M 参数的 AmoebaNet,但受设备内存限制。 由于反向传播和批次分割中的重新实现,GPipe 将中间激活内存需求从 6.26GB 降低到 3.46GB,从而在单个加速器上实现 318M 参数模型。 借助模型并行性,我们能够在 8 个加速器上将 AmoebaNet 扩展到 18 亿个参数,比没有 GPipe 的情况下多出 25 倍。 在这种情况下,由于 AmoebaNet 中模型参数在不同层上的不平衡分布,最大模型尺寸无法完美线性缩放。
接下来,我们使用 Cloud TPUv3 训练 Transformer 模型,每个加速器核心具有 16GB 内存。 我们使用固定词汇量 32k、序列长度 1024 和批量大小 32。 每个 Transformer 层有 2048 个模型维度、8192 个前馈隐藏维度和 32 个注意力头。 我们通过改变层数来缩放模型。 重新物化允许在单个加速器上训练更大的模型。 GPipe 具有 128 个分区,允许将 Transformer 扩展至高达 83.9B 参数,比单个加速器上可能的参数增加。 与 AmoebaNet 不同的是,最大模型大小与 Transformer 的加速器数量成线性比例,因为每一层都有相同数量的参数和输入大小。
| TPU | AmoebaNet | Transformer | ||||
|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 2 | 4 | 8 | |
| 1 | 1.13 | 1.38 | 1 | 1.07 | 1.3 | |
| 1.07 | 1.26 | 1.72 | 1.7 | 3.2 | 4.8 | |
| 1.21 | 1.84 | 3.48 | 1.8 | 3.4 | 6.3 | |
为了评估效率,我们在表 2 中报告了 AmoebaNet-D (18, 256) 和 Transformer-48 使用具有不同分区数量和不同微批次数量的 GPipe 的归一化训练吞吐量。 每个分区都分配给一个单独的加速器。 我们观察到,当微批次数量 至少为 分区数量时,气泡开销几乎可以忽略不计。 对于 Transformer 模型,当它被划分到四倍以上的加速器上时,会有 加速。 此外,由于计算均匀分布在 Transformer 层上,训练吞吐量几乎与设备数量成线性关系。 相比之下,AmoebaNet 模型由于其不平衡的计算分布而实现了亚线性加速。 当相对较小时,气泡开销就不能再忽略不计了。 当为时,实际上不存在管道并行性。 无论使用多少加速器,我们都观察到相对恒定的吞吐量,这表明在任何给定时间只有一台设备正在主动计算。
为了测量 GPipe 通信开销的影响,我们在具有多个 NVIDIA P100 GPU 但没有 NVLink 的单个主机上运行了实验。 然后,跨 GPU 的数据传输必须涉及通过 PCI-E 进行的相对较慢的设备到主机和主机到设备的传输。 微批次的数量固定为 32。 如表 3 所示,当我们将分区数从 增加到 时,我们观察到 AmoebaNet-D (18, 128) 的速度提高了 。 对于层Transformer,
| GPU | AmoebaNet | Transformer | ||||
|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 2 | 4 | 8 | |
| 1 | 1.7 | 2.7 | 1 | 1.8 | 3.3 | |
加速比为。 与我们在配备高速互连的 TPU 上观察到的线性加速类似。 设备之间的通信带宽不再是模型并行性的瓶颈,因为 GPipe 仅在分区边界传输激活张量。
4图像分类
作为概念证明,我们首先使用 GPipe 来扩展 AmoebaNet。 我们增加了 AmoebaNet 中的通道数量,并将输入图像大小缩放至 。 我们使用 [12] 中描述的相同超参数在 ImageNet 2012 数据集上训练了这个包含 5.57 亿参数的 AmoebaNet-B(18, 512)。 网络被分为 4 个分区。 该单一模型通过单一裁剪实现了 top-1 和 top-5 验证精度。
我们通过迁移学习[22, 23]进一步证明了巨型卷积网络在其他图像数据集上的有效性。 具体来说,我们使用预训练的 ImageNet 模型对从一般分类到细粒度分类的各种目标数据集进行了调整。 我们将最后一个 softmax 分类层中的输出单元数量更改为目标数据集中的类数量,并随机初始化新的 softmax 层。 所有其他层都是从 ImageNet 预训练中初始化的。 训练期间网络的输入图像被调整为 大小,随机水平翻转并使用切口 [24] 进行增强。 训练超参数与 ImageNet 使用的超参数相同(补充材料中提供了我们训练设置的详细描述)。 在表 4 中,我们报告了每个数据集 5 次微调运行的平均单作物测试精度。 我们的巨型模型在所有目标数据集上都获得了有竞争力的结果。 例如,CIFAR-10 错误率降低至 ,CIFAR-100 错误率降低至 。 这些结果证实了 Kornblith 等人的发现。 [25],即更好的 ImageNet 模型传输效果更好。
| Dataset | # Train | # Test | # Classes | Accuracy () | Previous Best () |
|---|---|---|---|---|---|
| ImageNet-2012 | 1,281,167 | 50,000 | 1000 | [12] ([27]) | |
| CIFAR-10 | 50,000 | 10,000 | 10 | [26] | |
| CIFAR-100 | 50,000 | 10,000 | 100 | [26] | |
| Stanford Cars | 8,144 | 8,041 | 196 | [26] | |
| Oxford Pets | 3,680 | 3,369 | 37 | [29] | |
| Food-101 | 75,750 | 25,250 | 101 | [30] | |
| FGVC Aircraft | 6,667 | 3,333 | 100 | [31] | |
| Birdsnap | 47,386 | 2,443 | 500 | [32] |
5 大规模多语言机器翻译
接下来,我们通过扩展用于自然语言处理 (NLP) 的模型来展示 GPipe 的灵活性。 由于可用的并行语料库丰富,神经机器翻译 (NMT) 已成为任何用于 NLP 的架构的基准任务[33,15,34,35,36]。 因此,我们继续在大规模多语言 NMT 任务上进行 GPipe 实验。 我们使用超过 102 种语言和英语的并行文档语料库,总共包含 250 亿个训练示例,每种语言的范围从 到 [37]。 该数据集通过跨越从数据稀缺(低资源)到数据丰富(高资源)的多种语言,为可扩展性实验创建了一个现实的测试平台。 我们首次在机器翻译领域证明,足够大的 NMT 模型可以同时学习 100 多个语言对之间的映射,同时对所有语言实现优于双语模型的性能。 这进一步凸显了拥有高效、灵活的模型并行工具的重要性。
我们的比较基于在此语料库中所有语言对上训练的单个 Transformer [15] 的性能。 我们沿两个维度缩放架构以强调 GPipe 的灵活性:(i) 通过增加模型中的层数沿深度,以及 (ii) 通过增加前馈层中的隐藏维度和数量沿宽度类似于 Shazeer et al 的多头注意力层中的注意力头(以及 # 个注意力通道)。 [34]。 请参阅补充材料,了解我们的数据集、训练基线、配置和优化超参数的详细描述。
我们从标准的 400M 参数 Transformer Big 模型开始,111 是一个具有 编码器层和 解码器层的 Transformer 模型,一个 feed -和注意力头的前向隐藏维度。 模型尺寸固定为。,如 Chen等人所述。 [35],词汇量为64k。 在图 3 中,我们将其性能与 1.3B 参数深度模型 、1.3B 参数宽模型、、3B 模型进行了比较。 -参数模型,和6B参数模型,。 所有模型都同时在所有语言对上进行训练,使用多语言 BERT222https://github.com/google-research/bert/blob/master/multilingual.md[3]。 、、 和 划分为 、,分别是 和 加速器。
从图3中,我们可以观察到将模型容量从400M参数增加到1.3B参数显着提高了所有语言的性能。 将模型从 1.3B 参数扩展到 6B 参数显示出进一步的改进,特别是对于高资源语言,尽管将模型从 1.3B 扩展到 3B 和 6B 参数时可以观察到收益递减。
下面我们讨论基于这些大规模实验的一些实证研究结果。
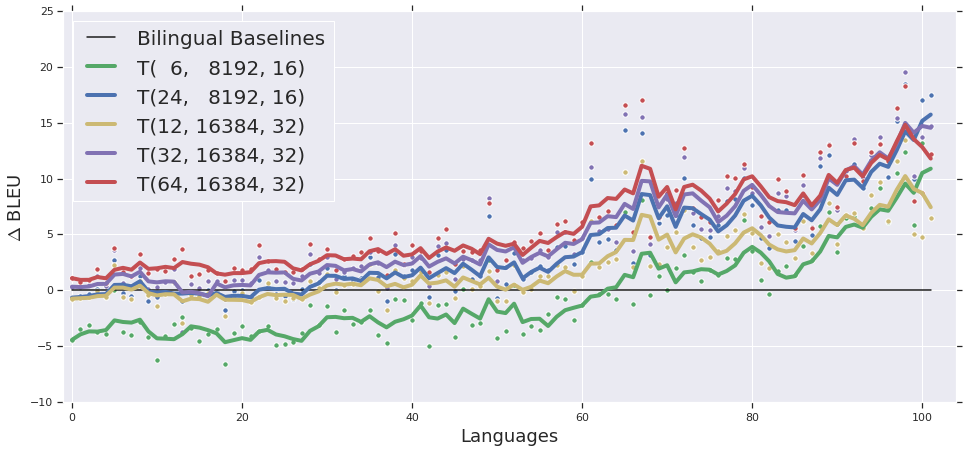
深度与宽度的权衡: 我们研究了多语言设置中深度和宽度之间的权衡,并比较了 1.3B 宽模型 和 1.3B 深模型 的性能。 虽然这两个模型在高资源语言上的质量(图 3 左侧)非常相似,但更深的模型在低资源语言上的表现要好得多,这表明增加模型深度可能会更好为了概括。 此外,当将 1.3B 深度模型与 400M 模型进行比较时,低资源语言的质量改进(图3右侧)几乎与高资源语言的改进一样大,表明增加深度可能会增加向低资源任务转移的程度。
深度模型的可训练性挑战: 虽然深度增加了神经网络的表示能力,但它也使优化问题变得复杂。 在我们的大规模实验中,我们遇到了由于尖锐激活(正峰度)和数据集噪声的组合而引起的严重可训练性问题。 我们观察到,训练几千步后,模型预测将变得极其峰值并且容易受到噪声的影响,这经常导致非有限或大的梯度,最终破坏学习进度。 为了解决这些问题,我们采用了两种方法:(i)遵循张等人。 [38],我们按层数缩小所有 Transformer 前馈层的初始化。 (ii) 每当 logit 预测(softmax 预激活)的大小超过某个值时,我们就会对其进行剪辑。
| Batch Size | 260K | 1M | 4M |
|---|---|---|---|
| BLEU | 30.92 | 31.86 | 32.71 |
| Loss (NLL) | 2.58 | 2.51 | 2.46 |
这两种方法的结合使我们能够减轻因缩放模型深度而带来的训练不稳定性。
大批量: 由于其简单性,数据并行性是扩展神经网络训练[39, 40]的主要方法。 我们通过显着增加用于标准 Transformer Big 训练的批量大小来测试大批量训练的极限。 从每批 260K Token 开始,我们将有效批量大小增加到 4M,并观察高资源语言对德语-英语的验证损失和 BLEU 分数(其他语言对也可以观察到类似的趋势)。 这里使用的优化参数与之前实验的参数相同。 据我们所知,每批训练 4M 个 Token 是迄今为止文献中用于 NMT 模型[41]的最大批量大小。 表 5 显示,随着我们增加批量大小,这两个指标都会显着改善。 我们相信,进一步增加批量大小可能会带来更多改进。
6 设计特性和权衡
已经提出了几种方法来实现高效的大规模模型并行性。 然而,每种方法都会选择自己的一套权衡,使其适合在特定硬件限制下扩展特定架构。 在这里,我们重点介绍几种模型并行方法涉及的各种设计选择和权衡,以及它们在各种硬件限制和架构变体下的灵活性、可扩展性和效率方面与 GPipe 的比较。
模型并行的核心思想是将网络划分为不同的计算单元,然后将其放置在不同的设备上[42,43,44,45]。 从概念上讲,这支持将大量模型扩展到巨大的容量。 然而,这些方法通常会遇到硬件利用率低和设备通信瓶颈的问题。 单程序多数据(SPMD)和管道并行性已被提出作为应对这些挑战的解决方案。
Mesh-Tensorflow [34] 遵循 SPMD 范例,它将用于数据并行的单指令多数据 (SIMD) 方法扩展到其他张量维度。 SPMD 允许将每个计算拆分到多个设备上,从而允许用户根据加速器的数量线性缩放各个矩阵乘法的大小(以及各个层的模型参数)。 然而,由于大量类似 AllReduce 的操作用于组合每个并行矩阵乘法的输出,这也会在加速器之间引入较高的通信开销。 这限制了该方法对加速器与高速互连连接的场景的适用性。 此外,SPMD 限制了可以有效扩展的操作类型,将其使用限制在一组特定的网络架构和机器学习任务上。 例如,考虑到通道有效地完全连接,在此范式下沿卷积层的通道维度进行分割并不高效,而沿空间维度进行分割则需要针对光环区域的复杂技术。 虽然 SPMD 允许通过缩小每个操作来扩展模型深度,但它需要将每一层拆分到更多数量的加速器上,这反过来又进一步增加了设备之间的通信开销。
其他方法尝试利用基于管道并行性的方法来扩展神经网络[46, 47]。 应用于神经网络训练的管道并行性的最新迭代是 PipeDream [48],其目标是减少参数服务器 [49] 的通信开销。 PipeDream 将前向传递的执行进行管道化,并将其与后向传递进行散布,以最大限度地提高硬件利用率。 这种设计受到异步向后更新引入的权重过时的困扰。 为了避免因权重过时而导致的优化问题,PipeDream 需要在每个加速器上维护模型参数的多个版本副本,以便准确计算梯度更新,从而防止用户扩展到更大的模型。
GPipe 引入了一种新的管道并行性,可以在对整个小批量应用单个同步梯度更新之前对微批量的执行进行管道化。 我们新颖的批量分割管道并行算法与重新物化相结合,可以扩展到大量微批量。 这可以最大限度地减少 bubble 开销,而无需异步梯度更新。 GPipe 使用户能够根据所使用的加速器数量线性缩放模型大小。 与 SPMD 不同,管道并行在扩展模型时几乎不会带来额外的通信开销。 设备间通信仅发生在每个微批次的分区边界,并且引入的通信开销很小,从而将 GPipe 的实用性扩展到高速设备互连不可用的情况。 然而,GPipe 目前假设单个层适合单个加速器的内存要求333解决此限制的一种可能方法是将单个矩阵乘法拆分为较小的矩阵乘法,并将它们按顺序分布在多个层上。 . 此外,微批次分割需要复杂的策略来支持需要跨批次计算的层(例如,BatchNorm 在训练期间使用微批次的统计数据,但会累积小批量统计数据以进行评估)。
7结论
在这项工作中,我们引入了 GPipe,一个用于训练巨型神经网络的可扩展模型并行库。 我们提出并实现了一种新颖的批量分割管道并行算法,该算法使用同步梯度更新,允许具有高硬件利用率和训练稳定性的模型并行性。 我们利用 GPipe 来训练大规模卷积和基于 Transformer 的模型,并在图像分类和多语言机器翻译方面展示了强大的实证结果。 我们重点介绍 GPipe 库的三个关键属性: 1) 效率:使用新颖的批量分割流水线算法,GPipe 实现了与设备数量几乎线性的加速。 2) 灵活性:GPipe 支持任何可以表示为层序列的深层网络。 3)可靠性:GPipe利用同步梯度下降并保证训练的一致性,无论分区数量如何。
参考
- [1] Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. Learned in translation: Contextualized word vectors. CoRR, abs/1708.00107, 2017.
- [2] Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In ACL, 2018.
- [3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [4] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- [5] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR. IEEE, 2009.
- [6] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, and et al. Going deeper with convolutions. In CVPR, pages 1–9, 2015.
- [7] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, pages 2818–2826, 2016.
- [8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European conference on computer vision, pages 630–645. Springer, 2016.
- [9] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.
- [10] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. CVPR, 2018.
- [11] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. CVPR, 2018.
- [12] Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. arXiv preprint arXiv:1802.01548, 2018.
- [13] Andreas Griewank and Andrea Walther. Algorithm 799: revolve: an implementation of checkpointing for the reverse or adjoint mode of computational differentiation. ACM Transactions on Mathematical Software (TOMS), 26(1):19–45, 2000.
- [14] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- [15] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Neurips, pages 5998–6008, 2017.
- [16] Jonathan Shen, Patrick Nguyen, Yonghui Wu, Zhifeng Chen, Mia Xu Chen, Ye Jia, Anjuli Kannan, Tara Sainath, Yuan Cao, Chung-Cheng Chiu, et al. Lingvo: a modular and scalable framework for sequence-to-sequence modeling. arXiv preprint arXiv:1902.08295, 2019.
- [17] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, pages 675–678. ACM, 2014.
- [18] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv preprint arXiv:1512.01274, 2015.
- [19] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- [20] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ICML, 2015.
- [21] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu Zhang, Kai Jia, Gang Yu, and Jian Sun. Megdet: A large mini-batch object detector. CVPR, 7, 2017.
- [22] Ali Sharif Razavian, Hossein Azizpour, Josephine Sullivan, and Stefan Carlsson. Cnn features off-the-shelf: An astounding baseline for recognition. In CVPR Workshops, pages 512–519, 2014.
- [23] Evan Shelhamer, Jonathan Long, and Trevor Darrell. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell., 39(4):640–651, 2017.
- [24] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- [25] Simon Kornblith, Jonathon Shlens, and Quoc V. Le. Do better imagenet models transfer better? CoRR, abs/1805.08974, 2018.
- [26] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
- [27] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. Exploring the limits of weakly supervised pretraining. ECCV, 2018.
- [28] Jiquan Ngiam, Daiyi Peng, Vijay Vasudevan, Simon Kornblith, Quoc Le, and Ruoming Pang. Domain adaptive transfer learning. 2018.
- [29] Yuxin Peng, Xiangteng He, and Junjie Zhao. Object-part attention model for fine-grained image classification. IEEE Transactions on Image Processing, 27(3):1487–1500, 2018.
- [30] Yin Cui, Yang Song, Chen Sun, Andrew Howard, and Serge Belongie. Large scale fine-grained categorization and domain-specific transfer learning. In CVPR, 2018.
- [31] Fisher Yu, Dequan Wang, and Trevor Darrell. Deep layer aggregation. In CVPR, 2018.
- [32] Xiu-Shen Wei, Chen-Wei Xie, Jianxin Wu, and Chunhua Shen. Mask-cnn: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognition, 76:704–714, 2018.
- [33] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. CoRR, abs/1705.03122, 2017.
- [34] Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, et al. Mesh-tensorflow: Deep learning for supercomputers. In Neurips, pages 10414–10423, 2018.
- [35] Mia Xu Chen, Orhan Firat, Ankur Bapna, Melvin Johnson, Wolfgang Macherey, George Foster, Llion Jones, Niki Parmar, Mike Schuster, Zhifeng Chen, Yonghui Wu, and Macduff Hughes. The best of both worlds: Combining recent advances in neural machine translation. CoRR, abs/1804.09849, 2018.
- [36] Felix Wu, Angela Fan, Alexei Baevski, Yann N. Dauphin, and Michael Auli. Pay less attention with lightweight and dynamic convolutions. CoRR, abs/1901.10430, 2019.
- [37] Naveen Arivazhagan, Ankur Bapna, Orhan Firat, Dmitry Lepikhin, Melvin Johnson, Maxim Krikun, Mia Xu Chen, Yuan Cao, George Foster, Colin Cherry, et al. Massively multilingual neural machine translation in the wild: Findings and challenges. arXiv preprint arXiv:1907.05019, 2019.
- [38] Hongyi Zhang, Yann N Dauphin, and Tengyu Ma. Fixup initialization: Residual learning without normalization. arXiv preprint arXiv:1901.09321, 2019.
- [39] Nitish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping T.P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima. CoRR, abs/1609.04836, 2016.
- [40] Samuel L. Smith, Pieter-Jan Kindermans, and Quoc V. Le. Don’t decay the learning rate, increase the batch size. CoRR, abs/1711.00489, 2017.
- [41] Myle Ott, Sergey Edunov, David Grangier, and Michael Auli. Scaling neural machine translation. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 1–9, Belgium, Brussels, October 2018. Association for Computational Linguistics.
- [42] Alex Krizhevsky. One weird trick for parallelizing convolutional neural networks. arXiv preprint arXiv:1404.5997, 2014.
- [43] Seunghak Lee, Jin Kyu Kim, Xun Zheng, Qirong Ho, Garth A Gibson, and Eric P Xing. On model parallelization and scheduling strategies for distributed machine learning. In Neurips, pages 2834–2842, 2014.
- [44] Azalia Mirhoseini, Hieu Pham, Quoc V Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou, Naveen Kumar, Mohammad Norouzi, Samy Bengio, and Jeff Dean. Device placement optimization with reinforcement learning. arXiv preprint arXiv:1706.04972, 2017.
- [45] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, Quoc V. Le, and Andrew Y. Ng. Large scale distributed deep networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Neurips 25, pages 1223–1231. Curran Associates, Inc., 2012.
- [46] A. Petrowski, G. Dreyfus, and C. Girault. Performance analysis of a pipelined backpropagation parallel algorithm. IEEE Transactions on Neural Networks, 4(6):970–981, Nov 1993.
- [47] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. Transactions of the Association for Computational Linguistics,, 2017.
- [48] Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training. arXiv preprint arXiv:1806.03377, 2018.
- [49] Mu Li, David G Andersen, Jun Woo Park, Alexander J Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J Shekita, and Bor-Yiing Su. Scaling distributed machine learning with the parameter server. In OSDI, volume 14, pages 583–598, 2014.