深度强化学习的机会主义视图物化
摘要
精心选择的物化视图可以极大地提高 OLAP 工作负载的性能。 我们研究使用深度强化学习来学习自适应视图物化和驱逐策略。 我们的见解是,可以使用异步强化学习算法有效地训练此类选择策略,该算法在系统空闲时间运行配对的反事实实验,以评估保留某些视图的增量价值。 这种策略消除了对准确基数估计或手工设计的评分启发式的需要。 我们专注于主内存 OLAP 系统中的内连接视图和建模效果。 我们的研究原型系统称为 DQM,是在 SparkSQL 中实现的,我们对多个工作负载进行了实验,包括 Join Order Benchmark 和 TPC-DS 工作负载。 结果表明:(1) 当工作量不满足假设或存在周期维护等时间效应时,DQM 可以优于启发式,(2) 即使考虑到学习成本,DQM 更能适应工作负载的变化,并且 (3) DQM 广泛适用于不同的工作负载和偏差。
1简介
精心选择的物化视图可以极大地提高 OLAP 工作负载的性能。 我们探索机会物化 (OM) [18],其中数据库抢先缓存重要的查询(或子查询)结果以供将来使用。 在理想的情况下,OLAP 系统会积极地保留任何将来可能有用的结果。 然而,实际系统具有不断发展的资源限制和使用模式,当前看似相关的结果将来可能会被废弃。 此外,维护大量视图可能会给查询优化器带来负担,以选择将哪些视图用于给定查询。 因此,OM系统设计的核心技术问题很简单:存储约束下有效的动态视图创建和驱逐策略。
数据库社区广泛研究了视图推荐系统,该系统采用历史查询工作负载、数据库模式以及可能的成本模型来推荐最佳视图来创建 [28, 9, 5, 27, 1, 33]. 这些技术是回顾性的,因为人们隐含地假设未来的查询和数据与过去看到的相似,并且回顾中好的选择在未来也可能是好的。 虽然回顾性方法是有原则的,但从它们优化明确定义的标准的意义上来说,它们受到明显的限制[15]:它们在临时查询、不断变化的工作负载或存储约束方面表现不佳变化。
真正的动态策略通过驱逐和重建行动来适应不断变化的环境。 现有的动态视图选择工作很大程度上是基于启发式的。 他们定义了评分标准来量化保持视图具体化的价值,范围从最简单的最近最少使用或最不经常使用的方法[10,14,30]到更复杂的基于成本模型的方法接近[28, 24]。 然而,由于 LRU 和已知的“顺序洪泛”失败案例,现有的动态策略本质上是脆弱的,并且可能存在微妙的盲点。
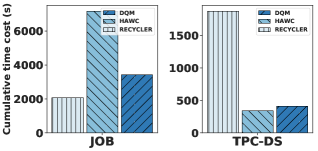
图 1 比较了两种最先进的动态标准,HAWC [28] 和 Recycler [24],在两种不同的工作负载上1000 个查询(源自连接顺序基准和 TPC-DS)。 我们在 SparkSQL 中实现了这两种启发式方法。 HAWC 优先考虑使用频率,而 Recycler 则优先考虑代价高昂的视图(有关我们使用的基线和工作负载的更多详情,请参见第 6.1.1 节中的表 2 和表 3)。 我们观察到各个基准测试之间存在巨大的性能差异。 当 Recycler 可以非常显着地改进少量昂贵的查询时,它会发挥很好的作用,例如在连接顺序基准中,一些查询涉及 方式连接。 TPC-DS 上的情况恰恰相反,它持续存在多余的大视图,实际上会损害性能。
来自实际执行时间的反馈可以改善这种脆弱性。 我们可以观察视图的创建对后续查询延迟是否有净正面或负面影响,而不是依赖启发式方法。 这从根本上来说是一个学习问题,因为有益的决定应该被记住以供将来使用,而不利的决定应该被避免。 这一广泛的想法受到最近查询优化工作的启发,其中实际运行时用于通知/优化未来计划[23,6,22,17]。 为了实现这一目标,我们需要一个能够根据延迟观察自动持续更新其模型的学习框架。
强化学习 (RL) 研究学习如何控制一般状态系统(例如具有持久视图的数据库)的技术[31, 32]。 强化学习的有效定义是“边做边学”;该算法采取行动并通过性能指标(例如查询运行时间)观察反馈。 它根据反馈将功劳或责任归咎于行动,甚至可以解释延迟的影响。 随着观察到的反馈越来越多,学到的行为也越来越有见识。 原则上,强化学习方法可以了解在给定当前系统状态的情况下哪些新视图对于实现是有价值的(当前保留哪些视图)。 这个学习过程可以根据观察到的性能自动适应不断变化的工作负载。 它不需要硬编码的启发式方法,也不需要显式生成预期的工作负载——它的预测模型只是最小化总体查询延迟方面的“手段到目的”。 需要注意的是,必须能够将功劳或归咎于纯粹根据查询执行方式做出的好决策和坏决策。
这是在 OM 系统中应用 RL 的算法挑战的关键——确定视图的净收益很困难。 任何系统在查询优化期间要么选择使用视图,要么不使用视图,并且学习代理仅观察其中一个选择的最终运行时间,并且不知道相对于另一个选择的边际效应。 我们缺乏“配对”实验,即在有视图和没有视图的情况下观察相同的查询,从而量化创建视图[4]的奖励。 如果相同的查询(或类似的查询)不经常重复,那么学习有效且自适应的物化策略所需的时间将是令人望而却步的。
我们的见解是,OM 系统需要一种新型的异步 RL 算法,在后台运行此类配对实验。 对于每个查询,系统都会识别一组可以适时创建的合格视图。 当前工作的范围是集中于内部连接视图,但技术更为通用。 系统使用其查询优化器(可能不使用视图)主动做出它认为当时最好的决策。 反事实的决策(系统未采取的决策)将排队进入实验缓冲区。 我们通过假设内存数据库没有无关的未观察状态(例如,缓冲池状态或缓存效果)来简化实验问题。 因此,我们可以在空闲时间独立安排和运行这些实验,为每个视图生成追溯边际效用指标。 我们的系统可以进一步对视图刷新成本进行建模,但并未针对这些刷新事件可能非常频繁的 OLTP 系统进行优化。
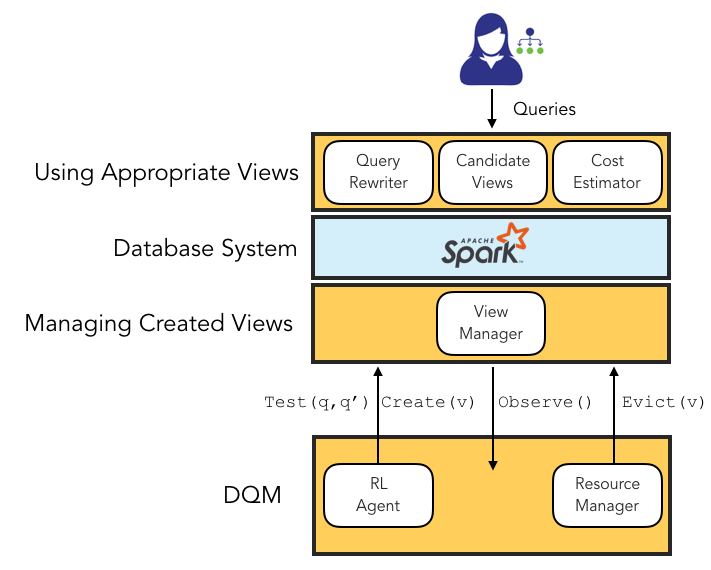
我们在称为 Deep Q-Materialization (DQM) 的原型 OM 系统中实现此模型。 DQM 包含三个主要组件:(1) 在线查询挖掘器,用于分析 SQL 查询的踪迹,以识别当前查询的候选视图以伺机实现,(2) 从集合中进行选择的 RL 代理候选人的数量,以及 (3) 选择要删除的视图的驱逐政策。 DQM 与 SparkSQL 集成。 自适应策略通过 RESTful API 与 Spark 环境交互,并且可以轻松移植到其他基于 SQL 的数据处理系统。
图1显示了DQM的潜在优势。 超过 1000 个查询的工作负载 DQM 在累积查询延迟方面可与每个工作负载上的最佳启发式方法相媲美。 这甚至包括学习选择模型所需的时间。 进一步的实验发现,DQM 可以在两种不同工作负载上的 5 种不同时间查询模式中匹配或优于标准启发式策略。 DQM 最大限度地利用给定工作负载和查询处理引擎的可用存储。
综上所述,本文做出以下贡献:
-
•
我们将机会物化系统中的在线视图选择形式化为马尔可夫决策过程(MDP)。
-
•
我们提出了一种基于 Double DQN 模型的新异步强化学习算法,以在线优化此 MDP 目标。
-
•
我们提出了一种新的基于信用的驱逐模型,可以对学习选择策略创建的视图实施硬存储约束。
-
•
我们将我们的方法与经典和最先进的基线进行比较,以证明 DQM 的适应性、延迟和鲁棒性。
本文的其余部分的结构如下。 第 2 节概述了相关工作。 第三部分介绍了我们的问题设置和系统架构。 在第 4 节中,我们讨论强化学习方法的技术细节。 第 5 节描述了我们驱逐政策的设计。 第 6 节介绍了我们系统的实验评估。 最后,第七节通过讨论总结了本文。
2 背景
在这里,我们概述了先前的 OM 方法,讨论了相关的反应性和预测性策略,并回顾了强化学习。
2.1 动机和应用
我们借用术语“机会主义物化”[18]来描述 Hive 和 Pig 等大规模数据处理系统中的自动持久性。 虽然与我们的工作大相径庭(上述持久化是为了任务内优化),但我们使用术语 opportunistic 来描述任何物化,这些物化是执行的产物,并非由人类数据库管理员明确定义。
跨查询重复使用之前计算的中间结果可以显着提高整体吞吐量和延迟。 虽然之前已经研究过总体思路,但我们相信有几个趋势鼓励我们重新审视这个问题。 首先,由于自然语言处理和计算机视觉的进步,用于机器学习推理的计算绑定 UDF 越来越普遍。 避免对先前计算的值进行额外的重新计算可以极大地改进查询处理。 其次,基于云的数据库产品的增长为个人用户提供了更大的存储限制和更大的灵活性来实现大量视图。 最后,像 SparkSQL 这样的批处理数据处理系统对于即席查询处理的速度越来越快,并且用于快速连续执行许多相关查询的数据探索上下文中。
尽管有这种新的需求,现有的基于启发式的方法仍然有限。 如图 1 中的示例所示,不存在“一刀切”的启发式方法。 先验决定基于启发式的方法是否适用于工作负载是具有挑战性的。 更微妙的是,这些启发式方法可能会受到 DBMS 成本估算和查询优化器的支配,实际上会损害性能。 我们相信,这是使用实际观察到的查询延迟作为反馈的自适应在线方法(例如 DQM)的机会。
2.2 追溯政策
静态视图选择的经典方法是在存储和/或维护约束下从给定输入候选视图集中选择最佳物化视图,这是 OM 设计空间的一种极端。 这些方法根据查询工作负载和存储约束来推荐要创建的最佳视图[28,9,5,27,1,33]。
在这些方法中,“最优性”是明确定义的。 他们找到满足存储约束并且最大程度地改善整个工作负载的估计查询执行成本的最佳视图集。 缺点是只能搜索“静态”策略,其中视图是预先创建的。 这些系统很难推理驱逐和重新创建视图。 即使我们定期运行此类视图推荐工具,我们也会遇到许多困难的、未解决的问题:如何窗口化工作负载、如何惩罚视图创建成本以及重新运行推荐工具的频率。
2.3 反应性和预测性策略
动态策略表面上可以解决这些问题。 DynaMat [14] 和 WATCHMAN [30] 是动态物化视图管理领域的开创性项目。 我们将这些方法称为“响应式”,因为它们不是纯粹依赖于历史工作负载,而是对瞬态使用模式做出反应。 该领域的系统必须解决多个问题:具体化哪些视图[21, 29]、何时逐出视图[10]以及如何选择要使用的视图[7]。 较旧的系统借鉴了数据库分页(例如 LRU)的策略,而最先进的系统则应用更复杂的评分启发式方法来考虑创建和使用成本。 HAWC [28] 基于成本模型对视图进行评分,并维护持久视图的此类分数表。 分数高于表中分数的新视图会强制执行驱逐事件。 表中的分数是窗口化的,仅考虑最新的 查询,以确保适应性。 RECYCLER [25] 优先考虑最昂贵的视图(就创建成本而言)。 原因是,如果这些观点被驱逐,就更难重新创建。 这些想法的一个有趣的变体是形成一个预测模型,该模型可以预测可能遇到的查询的类型和分布[20]。 据我们所知,这种预测方法尚未真正应用于物化视图选择(马等人只研究索引创建),并推迟对未来工作量预测的详细探索。
2.4强化学习
强化学习 (RL) 研究学习如何控制有状态系统的算法。 在强化学习中,假设的学习代理做出影响系统状态的决策。 在每个决策之后,系统都会更新其状态(可能是非确定性的),然后,代理会观察到“奖励”,或者该决策的好坏程度的分数。 代理的目标是学习策略,该函数根据当前状态自动做出决策,并获得最大的长期奖励。
从数学上讲,智能体和系统之间的交互由马尔可夫决策过程(MDP)描述,它是一个六元组,其中表示状态空间(集合所有可能的状态), 动作空间(所有可能的决策的集合), 初始状态分布(系统如何开始),状态转换分布(给定决策时状态如何变化), 是奖励函数, 折扣因子(折扣未来奖励的权重)。 MDP 的目标是找到决策策略,即操作 的概率分布。 策略 导致轨迹 上的分布:
策略的价值是其在轨迹上的预期总折扣奖励
目标是在一类允许的策略 中找到一个策略来最大化回报:
| (1) |
当 和 的分析模型未知时,RL 算法是 MDP 的经验解决方案。 在最纯粹的形式中,代理一开始并不知道如何控制系统。 代理做出随机决策(探索,并收集对访问的状态、采取的操作以及观察到的效果的时间序列观察:
不同的算法以不同的方式利用这些观察结果,但本质是建立一个预测模型,找到能够带来最长长期利益的行动(即使瞬时奖励很小)。
2.5缺少什么?
我们相信强化学习是 OM 系统中重要的缺失部分,可以促进智能创建和驱逐策略。 物化与分页不同:即时效果(使用)和长期效果(存储视图的机会成本)之间存在复杂的相互作用。 即使忽略 DBMS 中的其他不确定性,例如查询优化器成本估计中的错误,这些影响从根本上来说很难编码为固定启发式。
因此,我们提倡基于真实运行时的强化学习方法。 我们当然不是第一个在查询优化器中考虑“学习”(或更广泛的统计估计)的人[23,6,13,26,22,17];然而,我们认为本文描述的问题设置是新颖的。 实现实用 OM 系统的第一步是开发一个通过实验学习此类策略的框架。
不幸的是,直接应用强化学习是行不通的。 自然奖励函数将是创建视图后未来查询的时间改进。 除非使用成本模型(第6.6节解释了为什么成本模型可能非常不准确),我们无法直接观察到这个数量。 我们的查询优化器将选择使用或不使用视图,因此,有一个未知的“控制”实验来准确评估创建视图的好处。 我们对算法的关键见解是,强化学习算法可以通过一系列配对的反事实实验进行有效训练;具有特定视图的系统的效率如何更高? 这些实验可以排队异步运行。 当然,这需要假设数据库的完整运行时状态很容易推理。 使用不同缓冲池状态运行的查询可能具有截然不同的运行时间。 因此,我们假设不存在此类问题(例如,在内存数据库中)。 实验结果确定了可以输入强化学习算法的奖励信号。
3系统架构
在本节中,我们将概述我们的决策模型以及与 SparkSQL 集成的系统架构。
3.1决策模型
每个数据库都是基本关系(表)和派生关系(物化视图)的集合。 令 为只读查询的无限序列。 这些查询按照到达的顺序发送给 。 随着视图的具体化和删除,数据库状态 发生变化。 系统会根据具体化的视图自动选择重写查询。 因此,在给定数据库的当前状态的情况下,每个查询都有与之相关的延迟,并且工作负载的总体运行时间定义为:
对于某些查询,不存在合适的重写计划。 因此,与每个查询 关联的是一组新视图 ,可以在将来机会性地(在执行查询时)保留这些视图。 为了简化查询规划和选择,我们最多选择在每个决策点保留一个视图。 当我们选择持久化视图时,查询的整体延迟在逻辑上分解为两部分:
即,创建视图 的成本和使用视图 回答查询的增量成本。我们假设 是无状态的,即,如果使用完全相同的视图,针对不同数据库状态运行查询不会影响运行时。 这意味着没有缓存效应或缓冲池效应。
保存此类视图会产生存储成本,这是当前数据库状态的函数:
并且在任何给定时间使用的存储量还有一个上限:
因此,我们的系统可能需要驱逐一个视图:
在每个时间步长,数据库的状态根据策略 所采取的视图创建和逐出操作而递增:
Problem 1(机会实现)
给定一个数据库实例 和一个查询流 ,规划一组视图创建和逐出操作:
3.2架构
我们在 SparkSQL 中实现了DQM,并概述了图3中的架构。 我们发现在 Spark 之外的单独进程中运行 OM 系统来发出创建和删除操作是很方便的。 所有模型训练均与另一个进程异步进行,并且是 Python 的。 系统通过RESTful API与Spark环境交互。
当前范围: DQM 目前主要关注内连接谓词视图,其中系统中的每个视图都可以用以下形式表示:
这不是 DQM 中基于深度强化学习的方法的基本限制,但允许更简单的查询重写以使用视图和更简单的视图特征化(每个视图只是根据其条件范围进行特征化) 。 我们计划在未来的工作中探索更复杂的观点。
查询重写器: 给定一组物化视图 和一个查询 ,查询重写器会更改查询以使用视图。 如果查询中包含其谓词条件,则视图 是合格的。 查询重写器可以重写查询,以便可以使用任何符合条件的视图。 我们的系统搜索所有符合条件的视图并选择成本最低的计划(可能根本不使用视图)。
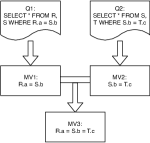
查看候选矿工: 假设查询 没有找到任何有用的、符合条件的视图。 它可以实现自己的中间结果之一以供将来使用。 虽然原则上系统可以搜索在执行任何查询计划时可能机会实现的所有可能视图,但搜索空间将非常大。 作为启发式,我们只选择其谓词之前在工作负载中见过的候选视图。 我们计算等式谓词的传递闭包(图2)。
查看创建政策: 我们需要系统来决定实现哪个候选视图。 视图创建者决定是否以及何时从候选视图中创建视图:
查看驱逐政策: 每当有空间来实现另一个视图时,充分利用可用的存储空间就很有意义。 但是一旦达到存储限制,我们需要决定驱逐哪个视图以为新视图腾出空间。 View Evictor 删除数据库中已创建的视图:
4学习物化
在本节中,我们讨论本文的核心技术贡献:用于自适应视图创建的强化学习方法。
4.1 单一视图问题
近年来,强化学习引起了人们强烈的研究兴趣[31, 32]。 我们从一个简化的问题开始,讨论使其实用化所面临的挑战。 考虑是否实现单个视图的决定(忽略机会选择)。 让我们假设有一个自动化的黑盒系统进程,当旧视图不再使用时,它会对其进行垃圾收集。 因此,我们的数据库有一位状态 - 当前是否已实现。 如果视图当前尚未具体化,我们的系统必须简单地决定何时应用一元操作来创建视图。
虽然看起来很简单,但这个决定实际上必须权衡具体化视图在潜在查询运行时改进方面的好处。 工作负载 的创建成本:
不经常使用的视图没有创建价值。
4.1.1 机会主义环境
人们可能想知道为什么 与机会主义设置相关,在这种情况下,视图是作为查询执行的工件创建的。 回想一下上一节,这些具体化事件之一期间的查询延迟可分解为两个术语:视图成本和使用该视图的增量查询成本:
通过以这种方式显式分解问题,我们可以考虑以下场景:创建视图可能会强制执行即时次优查询计划,但创建的视图从长远来看有利于其他查询组。
在我们的系统中,“时间步长”与查询工作负载同步,因为我们仅在查询数据库时观察到效果。 因此每个查询定义了是否创建视图的离散时间决策点。 然而,为了能够应用强化学习,我们需要每个时间步(每个查询)的奖励来量化特定状态下某个动作的瞬时收益或危害。 不是一个适定的奖励函数,因为创建成本 Cost 分摊到整个工作负载,并且不容易分解为每个查询的值。 我们可以应用以下技巧来产生一致的奖励函数:
其中是一个指示函数,用于确定是否使用该视图,是该视图过去被使用的次数。 这意味着每个相关查询都会产生部分创建成本。 可以很容易地验证111在实践中,我们近似计算摊销因子,而不是回顾性地修改奖励。 此外,我们可以通过超参数缩放 来调整单位差异。:
每个查询的成本函数允许我们将决策过程建模为 MDP:
我们的目标是找到一个视图创建策略:给定当前系统状态(即视图是否物化以及当前点之前的查询工作负载),决定创建视图的正确时间。 RL 是一个通过反复试验(探索随机创建策略)来学习此策略的框架,以优化累积奖励,或者在我们的例子中为 。
4.1.2 反事实运行时实验
如今,所有强化学习算法都假设能够即时、神妙地访问奖励函数。 在我们的环境中情况并非如此。 评估 Improvement() 函数需要运行系统通常不会运行的查询,即不使用视图的反事实查询。 此实验可能会使用大量的系统资源。 一个关键的挑战是隐藏这种开销。
反事实情景是与实际发生的情况相反的情景。 假设,我们决定具体化视图。然后,假设 用于回答未来的查询 (具有观察到的运行时间 )。 有一个假设的(反事实)世界,其中 未创建,并且 在不使用 的情况下得到回答(反事实运行时间为 )。 我们真正感兴趣的是 ,这是我们在系统中采取的操作引起的边际改进:
但是,我们无法实时运行这两个查询(带视图和不带视图),因为这会给用户带来额外的延迟。 我们的系统维护着要运行的配对实验的运行缓冲区。 在空闲时间,它执行这些实验并存储每个查询的边际改进。
4.1.3 异步强化学习算法
强化学习算法的典型结构是从随机初始化的策略开始,并做出影响系统的决策。 它观察其决策的结果。 它根据这些结果定期重新训练模型,使政策更加明智。 我们现在重点介绍算法框架的不同部分。
推出(数据收集): 强化学习算法的核心组成部分是“推出”过程。 给定策略(无论是随机的还是知情的),DQM需要通过将其应用到系统来评估其效果。 这些观察结果必须采用以下形式:
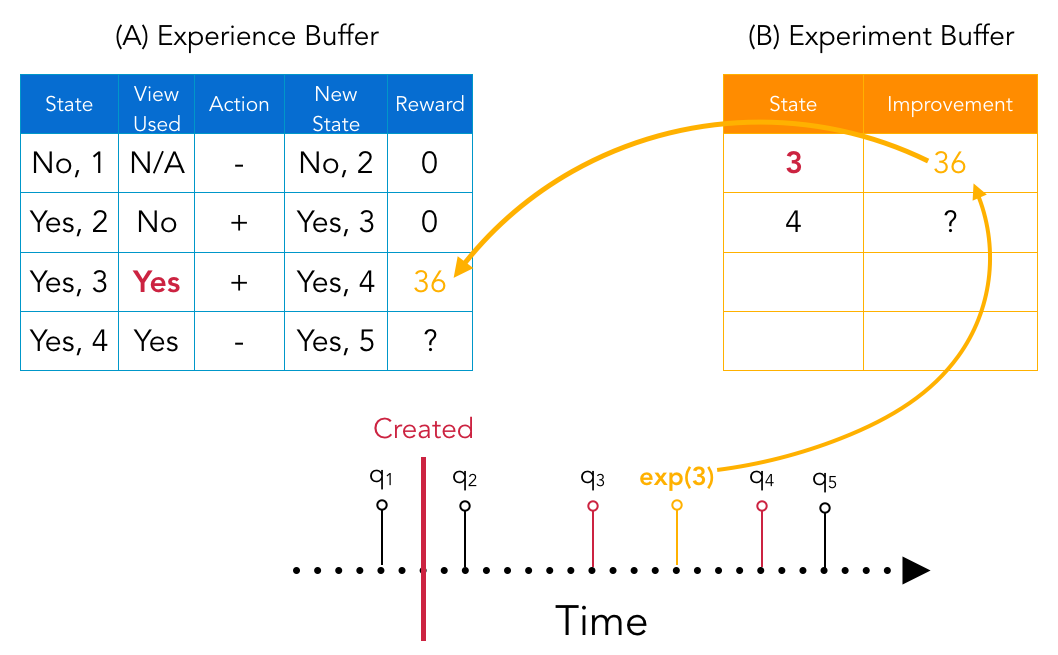
正如上一节中提到的,DQM 通过维护两个缓冲区以异步方式收集这些数据:经验缓冲区和实验缓冲区。 图4描绘了这个过程。 在每个时间步,DQM 决定是否创建视图。 如果使用创建的视图并且它会提高查询运行时间,则会收到奖励。 每次使用创建的视图时,它都会在(B)中排队一个反事实实验,以便在系统空闲时运行;使用和不使用视图运行查询。 实验运行后,观察到的改进将置于 (A) 中,并可用于改进策略。 简而言之,经验缓冲区维护了一组完整的观察结果。
还有一些额外的簿记值得一提。 因为我们只在视图被点击时(分配奖励时)收集这样的经验,即使算法的目标是选择最佳视图来创建,我们在视图点击时收集的经验并不直接相关查看创作。 因此,视图的创建和使用之间存在差距,例如我们在时间步 T 创建一个视图,但它只在时间步 T+10 时使用。 为了缩小两个事件之间的差距,我们将 的体验调整为 ,其中 和 。 新体验代表了创建视图并立即被点击的情况,这意味着创建视图的操作会立即分配奖励,从而缩小视图创建和视图点击之间的差距。
政策更新: 我们的系统不断收集数据并定期更新政策。 我们的 RL 算法基于 Deep Q 神经网络 (DQN);作为一种离策略算法,对于异步数据收集具有鲁棒性。 DQN 算法定义了一个Q 函数(类似于 cost-to-go 函数):
| (2) |
给定当前状态和行动,假设未来的最佳行为,该行动的价值是多少。 当然,这个函数是假设的,因为拥有这个函数就意味着拥有一个最优策略。 DQN 根据数据迭代逼近该函数。 令 为参数化函数(例如,由神经网络表示):
其中是表示状态的特征向量,是表示创建决策的特征向量。 是代表该函数的模型参数,在开始时随机初始化。 对于经验缓冲区中的每个训练元组 ,可以计算以下标签,或“估计”Q 值:
然后, 可以用作回归问题中的标签。 如果 是真正的 Q 函数,则以下递归式成立:
因此,学习过程或Q-learning定义了每次迭代的损失:
然后可以通过梯度下降来优化 Q 函数的参数,直到收敛。
上面的描述概述了 Q-Learning 背后的主要理论。 我们还应用了实践中常用的技巧,例如体验回放和双 DQN [12]。 经验回放通过维护过去观察的缓冲区(而不是真正在线学习)来稳定 DQN 训练。 每次模型更新时都会从缓冲区中采样数据。 我们用来改进 RL 算法的另一种优化技术称为双 DQN。 该技术用于处理 Q 值的噪声估计。 如方程2所示,我们通过结合即时奖励和由DQN本身确定的折扣最大长期价值来近似Q函数,这意味着我们不断地使用DQN来寻找最佳动作更新时采取。 问题是 DQN 在更新过程中给出的最佳动作可能会有噪音,因此可能会使学习过程变得复杂。 为了解决这个问题,双 DQN 技术建议使用两个参数化神经网络:一个网络用于评估,另一个网络用于更新。 然后,每次更新过程(例如 10 个时期)完成时,我们都会同步两个网络。 因此,学习过程变得更加稳定。
特征化:DQN 要求对每个状态和动作元组进行特征化。 在单视图问题中,特征化是微不足道的。 它只是一个 1 位二进制向量,指示是否创建视图,另一个位表示创建视图或不执行任何操作。
| View Featurization | State Action Featurization | ||||
|---|---|---|---|---|---|
| View | Tables | Encoding | Action | State | Encoding |
| MV1 | A, B | [1, 1, 0, 0, 0, 0, 0] | MV1 | MV2, MV3 | [1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0] |
| MV2 | B, C | [0, 1, 1, 0, 0, 0, 0] | MV2 | MV1 | [0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0] |
| MV3 | A, D, E | [1, 0, 0, 1, 1, 0, 0] | MV3 | MV2, MV4 | [1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0] |
| MV4 | C, D, E | [0, 0, 1, 1, 1, 0, 0] | MV4 | MV1, MV2, MV3 | [0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0] |
4.2 推广到 N 个视图
为了简单起见,我们引入了使用单个视图来创建的算法。 当有一组可能的视图可供创建时,多视图情况并没有那么困难。 原则上,我们可以将其视为上述算法的N个独立版本。
然而,有一些主要的警告。 首先,视图集可能无法提前获知,甚至可能随着工作负载的变化而变化。 其次,视图可能彼此高度相关,甚至相互排斥(创建两个非常相似且相互排斥的视图是没有意义的)。 因此,强化学习问题的 N 视图版本的关键变化是额外记录视图的上下文,即它们考虑的关系和谓词。
我们采用类似于[17]的特征化方法,即我们关注每个视图中涉及的关系(表),并使用one-hot编码对其进行编码。 表征一个动作很简单,因为一个动作只是一种视图。 对于包含多个视图的状态,我们对所有活动视图中涉及的关系的并集执行 one-hot 编码。 最后,我们连接动作向量和状态向量。 表 1 展示了我们在包含 7 个关系的工作负载上的特征化过程。
5 查看驱逐
在纯 RL 设置中,很难使用学习模型强制实施硬约束,例如存储限制。 因此,我们必须将创建策略与驱逐策略分离,后者独立地强制执行此约束。
5.1 顺从驱逐
我们的驱逐策略“服从”强化学习算法,因为它的目标是让强化学习算法在执行存储约束的同时尽可能发挥最佳性能。 每当有空间实现所需视图时,强化学习算法就可以做出决定。 但是,如果某个决策超出了分配的空间,它会尝试释放空间,以便可以强制执行约束。
由于这种对视图成本及其观察到的收益的固有依赖性,我们认为它无法通过传统的逐出策略来解决:(1) 像 LRU 这样的新近度指标不能考虑视图的有益程度,(2) 大多数其他启发式方法没有考虑重新实现视图的潜在成本。 换句话说,如果我们已经为实现昂贵的视图付出了代价,那么即使两种视图带来相同的好处,我们也应该驱逐更便宜的视图。 我们需要一种与之前的 RL 算法相反的算法;它保留了对驱逐视图的负面影响的估计。
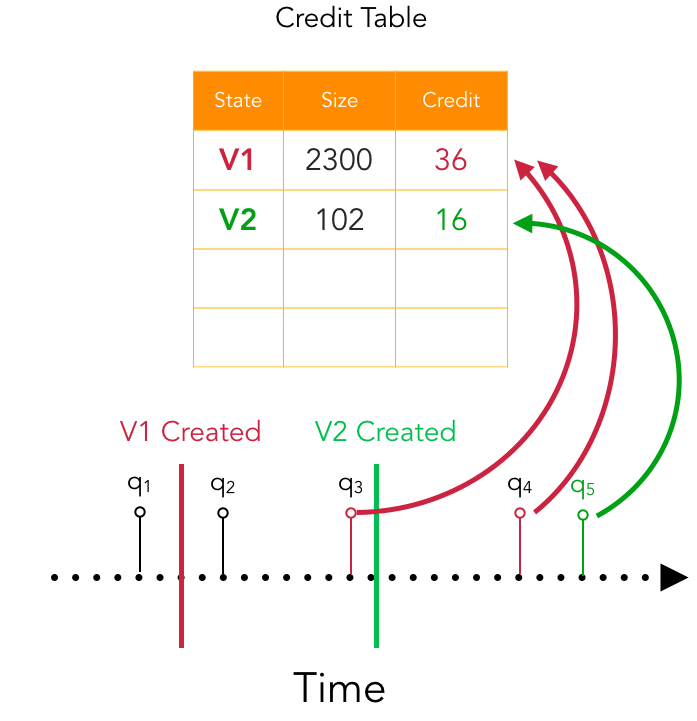
5.2算法
对于每个创建的视图,保持其物化的观察值是:
或者到目前为止的累积改进加上重新实现视图的成本。 与创建期间不同,Cost 对每个查询进行摊销,但不存在这样的摊销。 如果我们删除视图,则重新创建它总是需要固定的成本。 每次查询使用视图时,我们都会将其当前值作为表的成员进行维护(图5):
同样,与视图创建策略一样,我们可能必须调整超参数来缩放总和以考虑不同的单位或不同的偏好。
一项挑战是对动态工作负载进行建模。 如果某个视图在工作负载的早期阶段非常有价值,但随后就不再使用,那么信用表的分数可能会过高。 在实践中,我们以 的速率衰减每个视图的信用222在实践中,视图可能会导致负面改进,我们不会衰减负面信用,并且我们用于缩放成本的超参数也会为负数,这样成本就变成了一种惩罚,而不是对其信用的奖励。:
给定信用表,我们的驱逐政策是简单地驱逐最低信用的视图,直到为新视图腾出足够的空间。
5.3 通过驱逐查看维护
我们考虑不经常维护物化视图的 OLAP 设置。 在这个问题设置中,将视图维护视为自动驱逐事件就足够了。 对于当前具体化的每个视图,如果其基表之一已更新,我们会将其从池中逐出。 驱逐后,我们还必须刷新使用该视图的任何排队实验的实验缓冲区,因为配对的实验结果现在已经过时了。 由于我们明确地对 及其摊销方式进行建模,因此我们的奖励函数在维护事件下是一致的,因为创建反复驱逐的视图将迫使视图产生无法很好摊销的高创建成本。 该模型足以通过重新计算来捕获维护,而不是增量视图维护。 我们希望在未来的工作中更详细地探索建模增量视图维护。
6实验
我们探讨以下问题:(1) DQM 与传统启发式方法以及最新最先进的方法相比如何,(2) DQM 的速度有多快了解创建有效的策略,以及 (3) 不同的超参数设置如何影响DQM。
6.1设置
我们在 SparkSQL 中实现了DQM。 我们的强化学习算法与 Spark 环境解耦,并使用 Keras 框架[8]实现。 所有实验均在一组机器上运行,每台机器配备 2 个 Intel E5-2680 2.40 GHz CPU 和 64G 内存,运行 Scientific Linux 7.2。 我们将每个实验运行 5 次并给出 5 次运行的平均值。
6.1.1 工作负载
查询和数据源自连接顺序基准 (JOB) 和 TPC-DS。 JOB 基于 IMDB 数据集,由 113 个聚合查询组成,最多可连接 16 个表。 TPC-DS 基于合成数据集和查询生成器,该生成器生成带有聚合、连接和子查询的查询。 我们的 TPC-DS 数据以比例因子 1 生成。
我们根据这两个基准生成不同的场景。 我们的默认工作负载称为para。 para 是稳态工作负载(不随时间变化),不包含特定查询的频率偏差。 来自两个基准的查询都使用随机单属性谓词进行增强,因此完全相同的查询永远不会出现两次。 工作负载包含一系列 1000 个此类查询,并且查询以顺序方式提交和服务。 查询定期到达,并且异步实验可以在单个时间步长中运行(我们稍后会明确评估这些效果)。
然后,在后续实验中,我们超越para,应用幂律来扭曲查询频率,就像之前的工作[11, 19]所做的那样。 dzipf 使两个查询生成器都偏向以更高的频率运行更昂贵的查询,而 azipf 偏向查询生成器以更高的频率运行最便宜的查询。 然而,对于这两种工作负载,查询频率在 1000 个查询中是固定的,尽管存在偏差。 接下来,我们考虑动态工作负载。 dablend 是一个 1000 查询工作负载,它开始执行最昂贵的查询,然后切换到执行最便宜的查询,而 adblend 则执行相反的操作。
我们对所有实验的存储约束进行标准化。 机会物化的可用存储设置为 200MB(大约是实验中最大基表大小的 20%)。 这使我们能够以同类方式比较不同工作负载的结果。
| Name | Description |
|---|---|
| azipf | Rank the queries by latency in ascending order then apply the zipf distribution. |
| dzipf | Rank the queries by latency in descending order then apply zipf distribution. |
| rzipf | Shuffle the queries then apply zipf distribution. |
| adblend | Concatenate the first 500 queries from the workload with the first 500 queries from the workload. |
| dablend | Concatenate the first 500 queries from the workload with the first 500 queries from the workload. |
| para | Parameterize the queries with unique random parameters. |
6.1.2 基线
我们实现了表 3 中所示的许多基线,范围从传统的缓存算法(例如最近最少使用 (LRU))到以前工作中基于启发式的复杂方法。 所有基线都受益于 DQM 的其他组件,例如候选视图挖掘器。 DQM 提出可以由当前查询机会生成且与过去工作负载相关的相关视图。 基线必须选择要保留哪些视图,并在必要时逐出现有视图。
| Baselines | |
| Eviction Only | |
| LRU | Randomly select one of the candidates, evict the least recently used view in the cache. |
| LFU | Randomly select one of the candidates, evict the least frequently used view in the cache. |
| FIFO | Randomly select one of the candidates, evict the earliest view inserted into the cache. |
| Selection and Eviction | |
| HAWC [28] | Select the best view from the candidates based on the Spark query optimizer cost model. For each materialized view, maintain a “credit table” based on subsequent query cost that uses the view (cost difference of using vs. not using the view). The credit table is windowed to take the latest queries. HAWC evicts the lowest credit view. |
| RECYCLER [25] | Select the most expensive view (in terms of creation cost). Materialize a new view if its cost is higher than existing views. Evict the lowest cost view otherwise. For views in the cache, the cost is scaled up when used, scaled down when not used. Our default implementation of Recycler makes use of the true costs of views, we further study a more practical alternative using cost model estimated view costs in Section 6.6. |
| Hypothetical | |
| BELADY∗ | Select the optimal view to use based on complete, accurate foresight and use Belady’s algorithm[3] to evict old views. |
6.2 基准性能
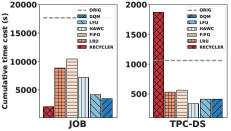
我们首先评估DQM和para的基线(图6)。 我们测量整个 1000 个查询工作负载的累积运行时间。 DQM的神经网络是随机初始化的,并且必须在线学习创建和删除策略。 DQM 的探索时间包含在整体运行时间中。
正如简介中所述,当 Recycler 的创建成本启发式与运行时的改进相关时,它会很好地工作。 Recycler 将 JOB 中的查询延迟速度加快了 10 倍以上。 这些结果存在很大的细微差别。 我们为 Recycler 提供视图大小的精确基数估计。 虽然在创建视图后事后可以知道这一点,以便确定删除的优先级;在创建期间不可能准确地知道这一点(即连接基数估计问题)。 尽管如此,我们对 Recycler 很慷慨,因为未来的实验表明,错误的基数估计会非常显着地影响结果。
该实验的下一个有趣的见解是,所有“仅驱逐”策略在两个基准上都表现得相当好。 具有合理逐出启发式的随机选择可在两个基准上实现高达 3 倍的改进。 HAWC 使用基于 Spark 查询优化器的知情选择策略,但其在两种工作负载上的性能发生了急剧变化,这表明基于优化器的选择策略并不可靠,我们将在第 6.6 节中进一步讨论这种低成本估计将如何影响 DQM。
DQM 即使在需要学习的情况下,在两个基准测试中也能与所有基线竞争。 通过利用真实的运行时观察,它对于查询优化器中的成本估计问题具有鲁棒性。 对我们来说,这是一个非常令人惊讶的见解。 探索过程中存在开销,因为系统必须从次优操作中学习。 即便如此,该系统在这个学习阶段仍然可以与最好的基线竞争。 我们还将看到 para 是 DQM 的最坏情况。
6.3 偏差性能
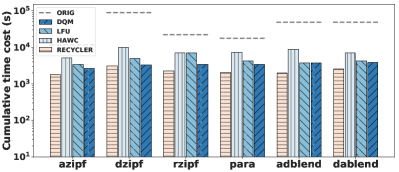
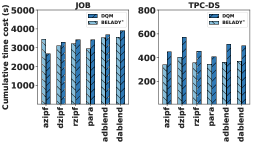
我们更深入地研究这些基线,并考虑不同的查询偏差和查询分布。 我们使用所有 12 种不同的工作负载评估 DQM、LFU 和两种基于启发式的方法。 基于 JOB 的工作负载和基于 TPCDS 的工作负载的结果分别如图 8 A 和图 8 B 所示。 我们发现之前实验的结果广泛适用于所有不同的偏差。
Recycler 在基于 JOB 的工作负载上运行得非常好,在基于 JOB 的工作负载上它的性能优于 DQM。 对于所有这些工作负载,Recycler 在处理前 100 个查询后将停止接纳新视图。 然而,这种启发式方法对 TPC-DS 工作负载存在重大问题。 当我们深入研究 TPC-DS 结果时,我们发现视图挖掘器重复生成了一个非常大的候选视图,并且对查询优化器来说足够混乱,以至于在某些查询使用时会损害性能。
我们发现HAWC的性能在JOB和TPCDS上也发生了巨大的变化。 这是因为它的视图选择是基于 Spark 优化器的不准确估计,我们也在 6.6 节中进行了演示。
6.4维护性能
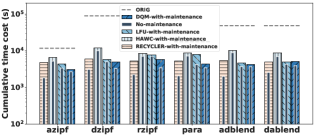
当存在无法建模或预测的成本时,启发式方法就会失效。 OLAP 系统的维护成本并不常见,但也很大。 在此实验中,我们研究视图维护如何影响 DQM 和基线。 由于 Spark 不支持视图的增量更新,因此每次修改基表时,我们都必须重新计算并重新具体化受影响的视图。 为了模拟定期维护,我们的系统将随机选择工作负载的基表并逐出使用该表的所有视图。
出于比较目的,我们每 100 个查询执行一次驱逐,并且这是受控制的,因此所有方法都具有相同的维护例程。 即使维护例程相同,但不同的方法会因为具体化的视图不同而带来不同的维护成本。
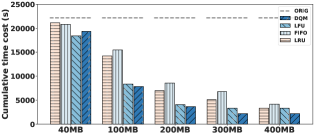
JOB 基准测试中 para 工作负载的结果如图 7 所示。 维护无疑会增加所有技术的开销,但结果表明 DQM 的维护效率更高、更稳健。 在之前的实验中,我们发现Recycler对于这个工作负载非常有效。 但维护后,我们发现 DQM 现在在 6 个基于 JOB 的工作负载中的 4 个上明显优于 Recycler,因为 DQM。 Recycler 的启发式方法倾向于昂贵的视图,因此会选择比 DQM 产生更高维护开销的视图。 同样,DQM 的好处是直接优化观察到的查询延迟。 由于需要维护而必须不断重新创建的视图很快就会不受学习算法的青睐。
6.5探索与探索 开发
我们在纯在线环境中评估DQM。 在每个工作负载开始时,DQM 必须处理冷启动问题。 DQM 从随机选择开始探索,直到经验数量达到,并且随着观察的到来,它会定期重新训练其模型。 随着我们收集更多的观察结果,我们对DQM变得更加有信心,然后我们开始用随机动作探索更少的东西。 探索参数为; 代表探索率, 代表利用我们所学知识的概率。
另一方面,我们必须始终具有某种程度的随机创建,以确保 DQM 能够适应变化。 我们的系统从 开始(始终采取随机操作),并将该值衰减到 。 我们使用不同的来评估DQM。
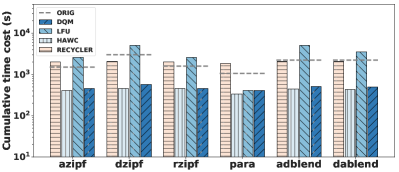
我们将设置为0.1、0.2、0.3、0.4、0.5,结果如图9所示333其他实验使用固定的 0.1。. 正如预期的那样,尽管 DQM 需要进行探索以避免陷入局部最优,但随着我们了解更多,我们应该更喜欢更多的利用,而高 会损害性能。 然而,即使 高达 0.5,DQM 的性能仍可与 LFU 竞争。 奇怪的是,较高的探索项在工作负载的早期阶段(例如 0.2)有利于 DQM。
6.6 成本估算问题
在我们之前的结果中,我们实际上对我们的基线非常慷慨。 我们为基线提供了精确的视图基数估计(DQM 不使用它,因为它纯粹从观察到的运行时学习)。
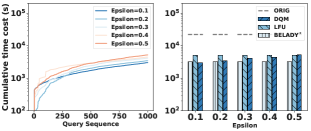
Recycler 基线对此最为敏感。 我们实现了一个更现实的 Recycler 替代方案,称为 SORecycler。 两者之间唯一的区别是 SORecycler 使用 SparkSQL 的查询优化器来估计视图的成本,而不是使用真实的成本。 正如我们在图10中看到的,这种变化显着影响了Recycler的性能,因为视图的成本在Recycler的启发式中起着重要的作用:它假设更昂贵的视图会带来更多的好处。 因此,当视图成本不准确时,dzipf 工作负载的性能会下降多达 25 倍。
我们可以用DQM做相反的事情;如果我们使用 Spark 的优化器进行廉价的成本估算而不是反事实实验,会产生什么效果? 使用或不使用视图的查询成本的差异可用于确定改进。 在本实验中,我们修改 DQM 以使用 SparkSQL 查询优化器的估计奖励来研究它将如何影响 DQM 的性能。 我们将基于 Spark 优化器的版本称为 DQM,结果如图 10 所示。 正如前面提到的,奖励函数在强化学习系统中发挥着重要作用,它旨在引导模型朝着最高长期价值的方向发展。 因此,当奖励函数不准确甚至错误时,强化学习系统表现不佳也就不足为奇了。 实际上,这个差距在 adblend 工作负载中高达 2 倍。 DQM 其性能仍然合理,但我们相信 RL 的力量在于反馈真实的执行时间。 直接优化真实奖励函数解释了 DQM 的大部分功能。
6.7 存储限制
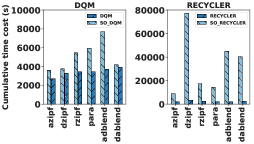
为了研究 DQM 如何响应存储约束的变化,我们使用与之前实验相同的 JOB-rzipf 工作负载。 结果如图 11 所示,其中存储约束通过可能实现的候选视图的一部分进行标准化。
当系统中有大量空闲存储时,OM 最有价值。 OM 的强大之处在于用此备用存储来换取未来的查询延迟。 正如预期的那样,随着我们增加存储约束,DQM 和基线的性能会提高。 我们注意到最显着的增长是在 40MB 到 100MB 之间444作为参考,200MB 数据点是用于 DQM 和之前实验中所有基线的级别。.
6.8延迟奖励
在此实验中,我们探讨了异步实验中的延迟如何影响 DQM。 DQM依赖系统空闲时间来执行配对实验,如果这个空闲时间发生争用怎么办? 我们通过以下方式进行模拟:给定 的延迟,在时间步 生成的经验将仅可供 DQM 进行学习在时间步。 作为一个极端的示例,如果 等于 1000,DQM 将为我们的 1000 个查询工作负载完全随机选择视图。
这是延迟奖励的最坏情况模拟。 实际上,系统空闲时间可能会更加随机分布,并且某些查询可能会得到更早的观察结果。 然而,通过将所有体验推到流程的最后,我们正在模拟延迟奖励的最坏情况。 IE。如果丢弃相同数量的经验,但系统空闲时间分布更加随机,那么代理将更早地获得更多经验来学习,从而使系统受益。
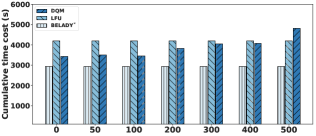
我们在此实验中使用 JOB 中的 para 工作负载,并测试延迟为 50、100、200、300、400 和 500。 结果如图12所示。 我们看到,DQM 的性能在延迟 500 时发生了巨大变化,因为一半的体验被丢弃了。 低于 200 的延迟不会对 DQM 的性能产生太大影响,它仍然明显优于 LFU。
6.9 DQM 与 Belady*
接下来,我们想要了解 DQM 的绝对表现如何。 Belady* 是一个假设的基线,其驱逐策略基于 Belady 的算法[3],这是假设的,因为它依赖于事后诸葛亮来驱逐不需要的视图在未来最长的一段时间内。 Belady* 也是假设的,因为它总是有远见地选择最佳视图(来自预言机)。 因此,Belady*的准入策略是最优的,但它的驱逐策略不是最优的,因为它没有考虑视图的成本和收益。 我们认为,优化所有可能的最佳创建和删除策略的成本将非常昂贵。
我们在所有 12 个工作负载上评估 Belady*。 通过学习直接优化运行时间改进的预测模型,DQM 在基于作业的工作负载和 TPC-DS 工作负载上实际上与 Belady* 具有竞争优势,如图 13。 DQM 学习一种有状态的创建策略,该策略考虑哪些视图已经具体化,以及由这些改进实验通知的成本感知驱逐策略。 在本节的其余部分中,我们将在一组微基准上评估 DQM,以了解不同设置如何影响 DQM 的性能。
6.10开销
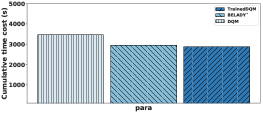
在我们之前的所有实验中,我们将学习和探索的开销包含在累积运行时间中。 接下来,我们尝试了解学习后的系统性能(当然假设未来的工作负载是固定的)。 我们首先使用 0.1 的 来训练 DQM,其中包含来自 para 工作负载的 1000 个查询,然后将 更改为 0(以避免探索),然后使用经过训练的模型为另外 1000 个查询选择视图(无需额外探索)。
结果如图14所示。 整体性能提升约 15。 这表明DQM是一种非常高效的数据学习方法。 配对实验给出了非常强的学习信号,DQM 能够快速从该信号中学习。
这也表明,对于真实的系统来说,持续学习并不算太繁重。 总是进行一定程度的探索(一些看似次优的决策)是有利的。 如果工作负载或执行环境发生变化,这允许系统从局部最小值“反弹”。 然而,话虽如此,我们确实认为过度拟合可能是一个问题 - 如果是这种情况,则 DQM 和经过训练的DQM 之间的差异会更加显着,如果经过训练DQM 错误地记住了工作负载的模式(如果有)。 当我们在实际场景中构建和部署 DQM 时,我们将对此进行进一步研究。
7 讨论和未来的工作
我们认为我们当前工作的一个限制是查询特征化的复杂方法。 更好的查询特征肯定会帮助代理更好地学习并做出更好的决策,例如捕获工作负载中的潜在模式。 这个问题与 Ortiz 等人在查询优化方面研究的工作相关[26]。 我们还相信,研究相对动态工作负载可以做更多的工作。 我们正在积极寻找模拟即席查询的基准工作负载。 我们相信这样的工作负载对于构建和评估更实用的方法是必要的。
OLAP 工作负载中还有大量重用计算和中间查询状态的机会,我们相信机器学习将成为未来 OLAP 系统的重要组成部分。 机器学习在数据库内部的应用仍然是备受争议的话题,并且在未来几年仍将是一个有争议的问题[2,16,20]。 一个重要的问题是哪些问题适合机器学习解决方案。 我们认为物化就是这样一个子领域。
我们将DQM视为迈向面向视图的数据库的第一步,该数据库积极预测未来的查询并具体化任何可能有用的内容。 这种架构将查询优化负担从规划查询转移到有效地重用过去的计算。 必须开发新的算法和理论来理解新的问题设置。 我们相信机器学习将成为本次讨论的重要组成部分。 从短期来看,扩展DQM以考虑OLTP设置和更复杂的奖励函数无疑是一个优先事项。 我们还想探索动态或周期性工作负载。
参考
- [1] S. Agrawal, S. Chaudhuri, and V. R. Narasayya. Automated selection of materialized views and indexes in sql databases. In VLDB, volume 2000, pages 496–505, 2000.
- [2] P. Bailis, K. S. Tai, P. Thaker, and M. Zaharia. Don’t throw out your algorithms book just yet: Classical data structures that can outperform learned indexes. https://dawn.cs.stanford.edu/2018/01/11/index-baselines/, 2017.
- [3] L. A. Belady, R. A. Nelson, and G. S. Shedler. An anomaly in space-time characteristics of certain programs running in a paging machine. Commun. ACM, 12(6):349–353, June 1969.
- [4] G. E. Box, W. G. Hunter, J. S. Hunter, et al. Statistics for experimenters. 1978.
- [5] N. Bruno and S. Chaudhuri. Automatic physical database tuning: a relaxation-based approach. In Proceedings of the 2005 ACM SIGMOD international conference on Management of data, pages 227–238. ACM, 2005.
- [6] S. Chaudhuri, V. Narasayya, and R. Ramamurthy. A pay-as-you-go framework for query execution feedback. Proceedings of the VLDB Endowment, 1(1):1141–1152, 2008.
- [7] C. M. Chen and N. Roussopoulos. The implementation and performance evaluation of the adms query optimizer: Integrating query result caching and matching. In International Conference on Extending Database Technology, pages 323–336. Springer, 1994.
- [8] F. Chollet et al. Keras. https://keras.io, 2015.
- [9] B. Dageville, D. Das, K. Dias, K. Yagoub, M. Zait, and M. Ziauddin. Automatic sql tuning in oracle 10g. In Proceedings of the Thirtieth international conference on Very large data bases-Volume 30, pages 1098–1109. VLDB Endowment, 2004.
- [10] P. M. Deshpande, K. Ramasamy, A. Shukla, and J. F. Naughton. Caching multidimensional queries using chunks. In ACM SIGMOD Record, volume 27, pages 259–270. ACM, 1998.
- [11] A. L. Drapeau, D. A. Patterson, and R. H. Katz. Toward workload characterization of video server and digital library applications. ACM SIGMETRICS Performance Evaluation Review, 22(1):274–275, 1994.
- [12] H. V. Hasselt. Double q-learning. In J. D. Lafferty, C. K. I. Williams, J. Shawe-Taylor, R. S. Zemel, and A. Culotta, editors, Advances in Neural Information Processing Systems 23, pages 2613–2621. Curran Associates, Inc., 2010.
- [13] A. Kipf, T. Kipf, B. Radke, V. Leis, P. Boncz, and A. Kemper. Learned cardinalities: Estimating correlated joins with deep learning. arXiv preprint arXiv:1809.00677, 2018.
- [14] Y. Kotidis and N. Roussopoulos. Dynamat: a dynamic view management system for data warehouses. In ACM Sigmod record, volume 28, pages 371–382. ACM, 1999.
- [15] Y. Kotidis and N. Roussopoulos. A case for dynamic view management. ACM Transactions on Database Systems (TODS), 26(4):388–423, 2001.
- [16] T. Kraska, A. Beutel, E. H. Chi, J. Dean, and N. Polyzotis. The case for learned index structures. In Proceedings of the 2018 International Conference on Management of Data, pages 489–504. ACM, 2018.
- [17] S. Krishnan, Z. Yang, K. Goldberg, J. Hellerstein, and I. Stoica. Learning to optimize join queries with deep reinforcement learning. arXiv preprint arXiv:1808.03196, 2018.
- [18] J. LeFevre, J. Sankaranarayanan, H. Hacigumus, J. Tatemura, N. Polyzotis, and M. J. Carey. Opportunistic physical design for big data analytics. In Proceedings of the 2014 ACM SIGMOD international conference on Management of data, pages 851–862. ACM, 2014.
- [19] E. Lo, N. Cheng, and W.-K. Hon. Generating databases for query workloads. Proceedings of the VLDB Endowment, 3(1-2):848–859, 2010.
- [20] L. Ma, D. Van Aken, A. Hefny, G. Mezerhane, A. Pavlo, and G. J. Gordon. Query-based workload forecasting for self-driving database management systems. In Proceedings of the 2018 International Conference on Management of Data, pages 631–645. ACM, 2018.
- [21] I. Mami and Z. Bellahsene. A survey of view selection methods. ACM SIGMOD Record, 41(1):20–29, 2012.
- [22] R. Marcus and O. Papaemmanouil. Deep reinforcement learning for join order enumeration. arXiv preprint arXiv:1803.00055, 2018.
- [23] V. Markl, G. M. Lohman, and V. Raman. LEO: An autonomic query optimizer for DB2. IBM Systems Journal, 42(1):98–106, 2003.
- [24] F. Nagel. Recycling intermediate results in pipelined query evaluation. PhD thesis, Citeseer.
- [25] F. Nagel, P. Boncz, and S. D. Viglas. Recycling in pipelined query evaluation. In 2013 IEEE 29th International Conference on Data Engineering (ICDE), pages 338–349, April 2013.
- [26] J. Ortiz, M. Balazinska, J. Gehrke, and S. S. Keerthi. Learning state representations for query optimization with deep reinforcement learning. In Proceedings of the Second Workshop on Data Management for End-To-End Machine Learning, DEEM’18, pages 4:1–4:4, New York, NY, USA, 2018. ACM.
- [27] S. Papadomanolakis, D. Dash, and A. Ailamaki. Efficient use of the query optimizer for automated physical design. In Proceedings of the 33rd international conference on Very large data bases, pages 1093–1104. VLDB Endowment, 2007.
- [28] L. L. Perez and C. M. Jermaine. History-aware query optimization with materialized intermediate views. In Data Engineering (ICDE), 2014 IEEE 30th International Conference on, pages 520–531. IEEE, 2014.
- [29] T. Phan and W.-S. Li. Dynamic materialization of query views for data warehouse workloads. In Data Engineering, 2008. ICDE 2008. IEEE 24th International Conference on, pages 436–445. IEEE, 2008.
- [30] P. Scheuermann, J. Shim, and R. Vingralek. Watchman: A data warehouse intelligent cache manager. 1996.
- [31] R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- [32] R. S. Sutton, A. G. Barto, and R. J. Williams. Reinforcement learning is direct adaptive optimal control. IEEE Control Systems, 12(2):19–22, 1992.
- [33] D. C. Zilio, C. Zuzarte, S. Lightstone, W. Ma, G. M. Lohman, R. J. Cochrane, H. Pirahesh, L. Colby, J. Gryz, E. Alton, et al. Recommending materialized views and indexes with the ibm db2 design advisor. In Autonomic Computing, 2004. Proceedings. International Conference on, pages 180–187. IEEE, 2004.