石头剪刀布游戏††谢谢:H.-J。 周,“石头剪刀布游戏”,当代物理学 57, 151–163 (2016)。 土井:10.1080/00107514.2015.1026556
摘要
剪刀石头布(RPS)是一种循环支配游戏,不仅是一种流行的儿童游戏,也是研究非合作战略交互决策的基本模型系统。
本文针对没有博弈论背景的物理系学生,介绍了纳什均衡和进化稳定策略的概念,并回顾了最近关于迭代RPS非均衡性质的一些理论和实证研究,包括集体循环、条件反应模式以及促进合作的微观机制。 我们还介绍了几个动态过程来说明 RPS 作为生态系统物种竞争和经济市场价格循环的简化模型的应用。
关键词:循环优势;非合作博弈;决策;社交自行车;有条件的回应;非平衡
1简介
统计力学旨在从微观相互作用中理解多粒子系统的集体行为[1]。 如果系统是一个物理系统,则粒子子集之间的每次相互作用都与一种能量相关,并且系统的总能量只是所有这些能量的总和。 该系统更喜欢保持在微观结构中,以最大限度地减少总能量,但它会不断受到环境的干扰。 能量最小化和环境扰动之间的竞争导致了系统宏观特性[1]中非常丰富的非平衡动力学和许多平衡相变。
由自私主体之间的战略互动驱动的各种集体行为也出现在游戏系统中。 作为统计力学的一个新兴研究领域,近年来对此类竞争性社会系统复杂非均衡特性的探索和理解变得相当活跃[2,3,4,5,6,7,8,9]. 然而,与物理系统相比,战略互动的统计机械方法还面临着另外两个主要挑战。
在游戏系统中,每次交互都会给每个参与的智能体带来回报,但与物理系统的根本区别在于,同一交互的不同智能体的回报通常是不同的。 这种不同的收益导致了系统中的所有冲突和竞争[10]。 每个代理人都追求自身收益最大化,但一个代理人收益的增加并不一定意味着所有代理人收益总和的增加。 由于微观动力学不受总收益的指导,因此总收益的平衡玻尔兹曼分布的传统概念没有用处。
另一个主要挑战是决策的微观机制尚不清楚。 在许多游戏系统中,智能体具有一定程度的智能,他们会根据过去的经验和预期的未来事件以复杂的方式做出决策。 此外,决策的微观参数可能会由于学习和适应而及时演变。
文献中对各种游戏进行了研究,其中讨论最广泛的可能是囚徒困境游戏,它是由阿尔伯特·塔克 (Albert Tucker) 于大约 60 年前设计的[11, 12]。 该博弈是研究自私主体合作的范例,也是数千篇研究论文的焦点[13, 14]。 另一方面,剪刀石头布(RPS)游戏是研究循环优势引起的竞争的范例[7],但讨论较少。 在本文中,假设读者没有博弈论背景,我们将回顾面向物理学生的 RPS 博弈的一些方面。
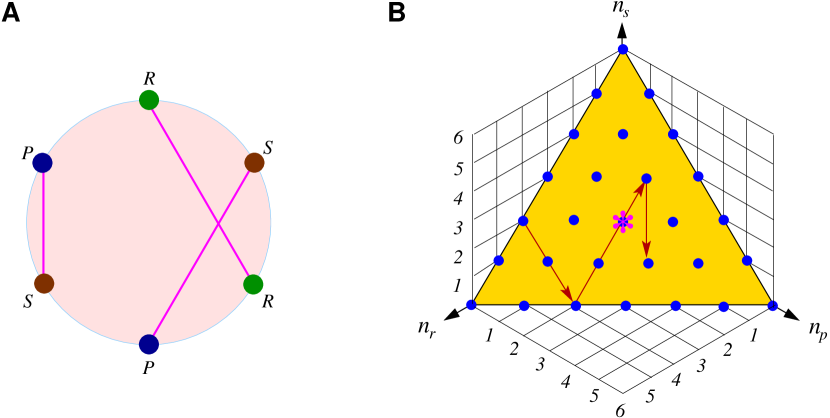
作为一种流行的游戏,RPS 的起源很难追溯,但有一些书面证据表明中国人在两千多年前的汉代就已经玩过它。 这是最简单的竞赛制度,体现了东方道教哲学中古老的轮回观念。 这个游戏给各个年龄段的人带来乐趣,偶尔也可以作为解决朋友或家人之间选择冲突的公平机制。 共有三种可能的动作选择:(石头)、(布)和(剪刀)。 动作优于,而又优于,而又优于(图1A)。 由于这种循环优势,这三种行动都不是绝对获胜的选择。 在最简单的情况下,游戏由两名玩家同时进行。 例如,如果一名玩家 X 选择 ,而另一名玩家 Y 选择 ,则 X 获胜。

RPS博弈不仅仅是一个好玩的游戏,它作为非合作战略交互的基本模型系统实际上具有根本性的重要性。 在理论研究中,循环优势通过收益矩阵更定量地表达。 一种常用的如图1B所示,参数是获胜动作的奖励。 例如,如果玩家 X 选择动作 而她的对手 Y 选择 ,则 X 的收益为 ,而 Y 的收益为 ;如果两个玩家选择相同的动作(例如, 与 ),则出现平局,每个玩家都获得单位收益。 为了确保循环优势的性质,我们需要。 在特定值下,无论输赢还是平局,两个玩家的总收益都是相同的。 如果,输赢提供的总收益高于平局,而则相反。 在更一般的收益矩阵中,三个不同动作的获胜收益是不同的,那么 、 和 之间的旋转对称性被破坏(例如将在第 5 节中给出)。
2 纳什均衡、进化稳定性和合作陷阱策略
研究战略互动有两种通用的理论框架,经典博弈论[16, 10]和进化博弈论[17,18,19]。 经典博弈论基于参与者可以做出完全理性决策的假设,而进化博弈论试图从进化和适应的角度来理解博弈结果。 考虑一个简单的场景,两个玩家 X 和 Y 重复 RPS 无限轮数。 支付矩阵与图 1B 相同,其中 是常数。 关于该系统的长期行为,我们应该观察到什么? 经典博弈论给出了明确的答案,即会达到独特的混合策略纳什均衡,而进化博弈论则更为谨慎,强调决策的实际微观动态也是至关重要的因素。
2.1 纳什均衡混合策略
经典博弈论假设参与者都具有无限理性,纳什均衡(NE)的解概念在这个理论框架中起着基础性的作用。 在两个这样的玩家之间的迭代 RPS 中,如果玩家 X 始终选择相同的操作(例如 ),则另一个玩家 Y 自然会始终选择获胜的操作()以最大化他自己的回报。 如果棋手 X 总是在两个行动(例如 和 )之间做出选择,那么棋手 Y 也会利用这种规律性,总是在行动 和 之间做出选择,从而击败 X。因此,为了避免被利用,棋手 X 应该采取所有正概率的行动。 但如何呢?
由于任何选择的规律性都可能被理性(且聪明)的玩家 Y 发现并利用,因此玩家 X 在每轮游戏中做出完全独立于她在前几轮中的选择的行动选择是安全的。 让我们用、和分别表示、和 在一轮游戏中被玩家 X 选择 ()。 概率向量在博弈论文献[10]中被称为混合策略。 (如果其中两个动作概率严格为零,则混合策略会简化为纯策略。) 在给定的 X 混合策略下,如果玩家 Y 采取行动 ,那么他每轮游戏的预期收益 就是 。 类似地,和的预期收益和是和。
请注意,如果玩家 X 选择特定的混合策略
| (1) |
玩家 Y 的预期收益与他的行为无关,并且
| (2) |
换句话说,如果 X 的行动选择完全随机,Y 就不可能利用 X。 类似地,如果玩家 Y 将其混合策略设置为 ,则玩家 X 的预期收益等于 ,并且无论 X 如何努力调整,都无法进一步增加她的混合策略。 也就是说,玩家X占Y便宜的机会也被消除了。
方程(1)是两人迭代RPS的NE混合策略。 一般来说,对于具有两个或多个动作选择并涉及两个或多个玩家的游戏,我们将玩家的动作概率向量定义为该玩家的NE混合策略,如果 当所有其他玩家都保持自己的混合策略时,无法通过更改为任何其他混合策略来增加其预期收益。 如果群体中的每个参与者都采取这种混合策略,则整个系统被称为纳什均衡[10]。
可以很容易地看出,两人迭代的RPS在任何处都只有一个唯一的NE,并且概率向量是唯一的NE混合策略。 我们可以将讨论扩展到两个以上玩家的场景。 在每一轮游戏中,每个玩家都与所有其他玩家竞争或仅与随机选择的一个玩家竞争。 如果我们只考虑严格混合的概率向量(满足),那么相对容易证明也是唯一的严格混合的NE策略[20]。
策略是最大程度随机的。 当个参与者的系统达到纳什均衡时,所有种可能的微观配置都同样可能被观察到,系统的熵达到全局最大值。 由于每个玩家的决策都独立于其他玩家和之前的决策,因此系统的动态特性是完全微不足道的。
混合策略纳什均衡虽然对于迭代 RPS 博弈来说是独特的,但在小扰动下可能不一定稳定。 由于不同的行动选择会给玩家带来相同的预期收益,因此该玩家的策略可能会偏离(1),从而导致触发其他玩家的策略调整。 面对这些引起的偏差,如果玩家的最佳反应是进一步偏离(1),那么纳什均衡是不稳定的。 为了研究这种类型的局部稳定性,人们通常需要指定个体玩家如何更新他们的行动选择。 [21]对战略互动的人口动态进行了全面回顾。
在下一小节中,我们介绍另一种类型的稳定性标准,它独立于特定的微观竞争动态。
2.2 进化稳定性
混合策略的稳定性也可以从突变和选择的角度来定义[17,18,19]。 让我们考虑一群 代理与混合策略交互,例如 。 假设现在代理的子群发生突变,使得这些代理采用不同的策略(例如)。 对于这个混合系统,如果未受扰动子群中智能体的预期收益高于变异子群中智能体的预期收益,则原始策略视为进化稳定策略,否则为进化不稳定策略[22]。 进化稳定性的概念是进化博弈论的基础,对于理解生物进化非常有用[18, 23]。
对于迭代的RPS博弈,我们假设成员的变异策略为,而其余成员采用NE混合策略,见图2。 在每一轮游戏中,每个玩家都与整个群体中随机选择的成员进行竞争。 未受干扰子群体中玩家的预期收益仅为 ,而突变子群体中玩家的预期收益为
| (3) |
如果我们有,采用NE策略的玩家比采用变异策略的玩家有更高的预期收益。 通过自然选择,突变亚群的规模应该缩小 (),从而使 NE 策略在进化上保持稳定。 另一方面,如果我们有,那么NE策略在进化上不稳定并且不能在策略突变下持续存在。 在后一个参数区域中,系统实际上没有进化稳定的策略。
为什么策略在时进化稳定,但在时不稳定? 原因在于突变亚群内的相互作用。 考虑两个玩家采用变异策略。 如果他们相遇,平局的概率是
它大于 。 由于仅对于 ,输赢输出的平均收益 小于平局输出的平均收益,因此变异策略仅在此参数区域中有益。
在上面的讨论中,混合策略是在个体玩家的层面上定义的。 我们还可以在人口层面定义混合策略。 在后一种观点中,每个个体可能采取固定的行动(纯策略),然后混合策略描述了采取不同行动的个体的比例,这更适合研究某些生物系统中的策略相互作用。 同样的进化稳定性分析可以在种群层面进行,以回答自然选择下种群组成稳定的问题[18, 23]。

2.3 合作陷阱策略
如果迭代 RPS 系统处于混合策略纳什均衡,则每个玩家都处于安全位置,不会被其他玩家利用。 就规避风险而言,这当然很好,但另一方面,由于所有参与者都在非合作地互动,他们可能会错过获得更高累积收益的机会。 是否有可能在这种本质上非合作的博弈中维持高度合作并打破纳什均衡? 对于两人迭代的 RPS,[15] 证明,确实存在对双方都最大程度公平且利润最大化的简单策略。 此类策略被称为合作陷阱策略[15],因为它们可以诱导对手玩家完全合作。 在这里,我们提供了一种合作陷阱策略的实现,该策略改进了[15]中建议的原始协议。
当奖励参数时,玩家从输赢中获得的平均收益高于平局的收益。 因此,聪明而理性的玩家(比如 X)有动力去寻找一种策略,以最大化获胜的机会,同时最小化平局的机会。 简单的合作陷阱策略的秘诀如下:
-
1.
默认情况下,玩家 X 处于合作模式。 在这种默认模式下,X 会避免使用三个行动中的一个(例如 ),并在每个博弈回合中以相等的概率 采用其余两个行动( 和 )。 如果玩家 Y 通过采取行动 合作响应 X,则双方每轮都会获得相等的预期收益 ,这是一个公平的结果,并且高于值 NE混合策略。
-
2.
然而,如果玩家 Y 通过采取行动 来利用 X 的合作模式,从而为 Y 返回更高的预期收益 ,则玩家 X 会切换到惩罚模式 在接下来的 游戏轮次中。 在这种惩罚模式中,X采用NE混合策略,并以相同的概率采取动作、和。 然后,双方玩家每轮的预期收益都会减少到 。 玩家 X 是可原谅的,她在每次长度为 的惩罚模式后切换回默认合作模式。
如果玩家X采用这种合作陷阱策略,则有利于玩家Y放弃动作;此外,如果惩罚模式持续时间等于或大于最小值,则Y在每个时间点将其动作固定为是最佳的。游戏回合。 当时,我们有,表明最低惩罚水平足以维持完全合作(图3A)。
当时,输赢的平均收益小于平局收益。 在该区域中,玩家X的默认合作模式被修改为促进平局而不是输赢。 默认情况下,只要玩家 Y 也用动作 做出响应,玩家 X 在每个游戏回合中都会采取相同的动作(例如 )。如果Y在一轮游戏中通过采取动作来利用X,则X在接下来的轮中切换到惩罚模式,然后切换回合作模式。 也很容易验证两个玩家之间是否可以实现完全合作(图3A)。
为了实现高度的合作,我们需要一个主动的玩家X来初始化合作。 对方玩家Y是否也需要足够聪明才能弄清楚X的意图? 这可能没有必要。 让我们考虑一个完全短视的玩家 Y,他采用混合策略 并及时改变该策略以最大化他的收益。 由于当面对采用合作陷阱策略的玩家 X 时,动作 优于 ,因此 将演化为零,然后 Y 的混合策略变为。 玩家Y每轮的预期收益与玩家X相应的以及图3中的NE收益进行比较B 表示 和 的情况。 我们注意到是的严格递增函数,表明完全合作()是玩家Y的任何渐进学习过程的唯一固定点。
图3B还表明,除非达成完全合作,否则参与者X的预期收益小于Y的预期收益。 事实上,如果玩家 Y 不充分合作, 甚至小于 NE 收益 。 玩家 X 可以通过进一步改进合作陷阱策略来克服这个缺点。 这个问题以及合作陷阱策略的实证评估将得到进一步系统的研究。
3人类受试者的条件反应模式
上一节的一个方便的假设是,玩家具有无限的理性(他们必须拥有出色的随机数生成器!) 基于某种混合策略做出决策,并根据迭代RPS的反馈信息修改该策略。 然而,这样的假设在涉及人类受试者的竞争过程中通常是不现实的。 一个人可能没有很好地意识到混合策略,而是决策是启发式的,很容易受到环境和心理因素的干扰(例如,自动模仿对手的行为[24])。 即使人脑可能有能力实施混合策略,但遵循该策略生成随机动作序列本身要求很高(人脑在随机化任务中表现不佳[25, 26]) 。
人们如何在迭代 RPS 中选择操作? 作为回答这个难题的第一步,多个研究团队在过去几年中进行了实证研究[27,28,29,20]。 其中两个实验 [27, 29] 采用了全对所有人协议,每个人同时与群体中的所有其他玩家进行游戏,而 [28, 20] 采用更传统的随机配对协议,每个人只与另一个玩家竞争。 在这里,我们重点关注后者的结果,因为实验设置模拟了不确定性下的决策。
共有名大学生参与了王和徐[28, 20]的实验。 这些人类受试者组成组,每组(群体)包含六人。 如图4A所示,在每个游戏轮中,每个群体的六名玩家被随机配对,他们与配对的对手玩一次(在不同的情况下可能会有所不同)轮),根据图1B的支付规则,然后每个玩家都会收到关于她/他自己在本轮中的支付、她/他的累积支付以及对手在本轮中的行动的反馈信息。
在实验中,每个群体都使用固定的奖励参数,其值范围从到。 实证结果表明,的精确值不会影响该有限总体系统[20, 30]的定性动力学行为。
3.1个体惯性效应与集体循环
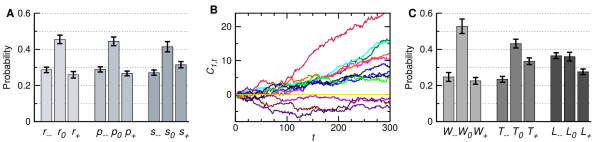
在轮迭代期间,每个玩家留下一个动作序列,,,其中 是第 轮的动作。 然后,我们获取该玩家对三个动作 的偏好向量,其中 只是动作 的回合分数(与 和 和 )。 我们发现,与纳什均衡理论一致,参与者的向量接近于混合策略。 例如 处的 、 和 (平均值和标准差,通过对 求平均值获得主题)[20]。 考虑到三个动作之间的旋转对称性,这种观察当然是最自然的。
纳什均衡理论还预测,玩家在连续两轮游戏中的选择是完全相互独立的。 但这并不是游戏中实际发生的情况。 相反,每个动作序列内都存在相当程度的时间相关性。 特别是,如图5A所示,每一轮中的玩家更有可能重复上一轮的动作,而不是逆时针方向移动动作(或或)方向或顺时针(或或)方向。 这种惯性效应在处最强,随着的增加略有减弱,即使在[20]处仍然非常显着t3>. 另一方面,如果玩家确实做出了改变,那么这种改变是对称的,即逆时针方向移动动作的概率几乎与顺时针方向移动的概率相同。
尽管任何行动的个体行动变化都没有方向性偏好,但经验数据揭示了总体集体行为中持续的逆时针循环。 每个游戏轮 的群体集体状态可以用向量 来描述,其中 是采取行动 的玩家总数> (对于 和 类似)。 这种所谓的社会状态随着的演化,在社会状态平面上画出了一条高度随机的轨迹(图4B)。 为了检测表示偏离平衡的方向运动,为每个社会状态转换 [20] 分配一个旋转角度 。 如果转变与围绕社会状态平面质心的逆时针旋转相关,则 为正;如果它与绕质心顺时针旋转相关,则 为负;在所有其他情况下(图4B)。 从第一轮到第 轮游戏,轨迹围绕社会状态平面质心循环的净转数 可以通过将旋转角度相加得到。 如图5B中的所示,累积循环次数随呈线性增加趋势,揭示了持续集体沿方向骑行。 平均循环频率为(大约轮游戏中逆时针循环一个循环),并且该值不会随支付参数显着变化[20]。
3.2 条件响应机制
这个明显的矛盾在[20]中得到了解决,主要观察是玩家有不同程度的做出改变的意愿,具体取决于之前的比赛是赢、平还是输。 考虑一个人在连续两轮中选择相同动作的倾向 、 和 ,如果前一轮获胜 (W)、a分别为平局 (T) 或失败 (L)。 经验数据表明,即重复某个动作的倾向随着前一轮的收益而增加(图5C)。 这种微观模式在本质上类似于囚徒困境迭代博弈中的“赢-留-输-移”策略,其有效性已被理论计算[31, 32]和广泛的计算机模拟所证实。 [33, 34]。 顺时针方向移动动作的趋势(、和)和趋势(、和)逆时针方向移位也很大程度上取决于上一轮[20]的输出。
受这些经验条件响应模式的启发,[20]中提出了一个简单的决策模型来理解迭代 RPS 中的相互作用。 该模型假设每轮游戏中的动作转移概率仅取决于前一轮的游戏输出。 例如,如果玩家赢得了比赛,那么在下一轮中,她/他有概率坚持相同的动作,有概率沿顺时针方向转移动作,并且逆时针方向移动动作的概率。 这种条件响应微观规则的特征是六个独立的参数,这些参数可以根据经验固定,并且完全忽略了决策过程中所有可能的高阶复杂性。 然而令人鼓舞的是,这个简单的模型定量地再现了所有主要实验结果,包括在不同群体中测量的循环频率和惯性效应(更多详细信息请参见[20]) 。
用如此简单的条件反应机制来统计描述人类受试者复杂的决策过程,真是有趣又出乎意料。 但我们也应该指出,条件反应模型目前还只是一个现象学模型。 一个具有基本意义的缺失环节是六个独立的条件响应参数如何随着学习的结果而及时演变。 条件响应机制可能只是某些较低级别学习动态的结果。 这些问题都需要从神经生物学方面进一步研究[35, 36]。
条件反应模型的一个反直觉理论预测是,社会状态循环并不需要条件反应的微观不对称性:只要、和不完全相等[20],即使、和也会持续存在。 这一预测已被计算机模拟所验证,证实社会循环确实是一种新兴现象。
3.3 人口规模影响的讨论
在随机配对协议下,每个玩家在连续两轮游戏中遇到相同对手的概率。 这种概率随着人口规模而迅速下降,因此随着的增加,不同玩家的行动选择相关性越来越小。 由于主动决策是一个代价高昂的心理过程,随着动作相关性随着而降低,玩家改变动作的动机应该越来越弱,特别是如果玩家赢得了上一轮。 因此我们预计,在人口较多的情况下,参与者的积极性会降低,决策的惯性效应会更强;此外,获胜概率也会随着而增加。
迭代的RPS是特殊的。 由于双方玩家都知道对手的行动历史,因此这是一个完整的信息系统。 为了避免在这个两人游戏中成为失败者,双方都应该非常积极,并且让他们的行动选择最难以预测。 因此,我们预计,(i) 个体玩家的惯性效应将最弱,(ii) 条件响应概率只会微弱地偏离,并且玩家可能不喜欢重复获胜动作。
将通过实验室实验系统地探讨人口规模的影响。 这些实证研究可能会启发迭代 RPS 的精细学习模型的构建。
4物种竞赛中的石头剪刀布
循环优势是生态系统中普遍存在的现象。 例如,欧洲蜜蜂传入日本后入侵了当地蜜蜂,但它们对日本黄蜂的攻击毫无防备,而日本蜜蜂则通过共同进化适应,形成了针对黄蜂的集体热防御机制[37 ]。 另一个更定量的例子是雄性侧斑蜥蜴的颜色多态性[38]。 现场测量表明,三种周期性优势雄性蜥蜴的频率振荡周期约为六年,相互相移约为两年[38]。 生态学家认为循环优势是导致生态系统复杂性的关键因素,他们将RPS博弈作为物种竞争与共存的基本模型[39,40,7]。 在本节中,我们简要回顾两个简单的微观生态过程:碰撞动力学和复制动力学。
4.1 碰撞动力学
我们可以考虑由三个不同物种、和形成的生态系统。系统中的个体总数是一个固定整数。其中属于物种,属于物种,其余属于物种 ( 在每个时间间隔,随机选择的一对相邻个体之间都会发生竞争。 如果这种竞争是在同一物种的两个个体之间进行的,那么两个个体都会生存。 如果它位于物种 的个体和物种 之一之间,则 的概率将 个体替换为个体的后代。 参数量化了物种相对于物种的优势程度。 类似地,另外两个优势度分别表示为和。 请注意,一个物种的扩张与另一物种的缩小相关(常和博弈)。
许多作者已经研究了这种简单的碰撞模型及其各种扩展(例如,参见评论[39,5,7])。 在种群混合良好的情况下,每个个体都有相同的机会遇到另一个个体,那么对于,物种频率、、 作为时间的函数 受 [41, 42] 控制
| (4a) | ||||
| (4b) | ||||
| (4c) | ||||
方程(4)作为三个物种之间循环优势的简单理论,可以看作是关于两个物种之间非线性捕食者-猎物相互作用的校准Lotka-Volterra方程的扩展[ 43]。 该演化方程的定点解为
| (5a) | ||||
| (5b) | ||||
| (5c) | ||||
请注意,降低物种的优势度对其定点频率有增强作用。 这是因为减少 会间接抑制捕食物种 的物种 的生长。
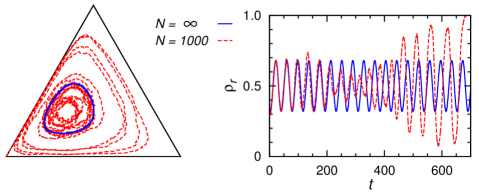
如果三个物种的初始频率偏离固定点,则系统不会演化为该固定点,而是沿周期轨道绕其运动,见图6。 方程(4)有无限多个这样的极限环解,每个解都由一个不变量[42, 41]来表征。 在固定点处,并且随着极限环到固定点的距离的增加而不断减小到零。
由于人口状态沿着极限循环演化,这样一个无限的生态系统只是边际稳定的。 这对于有限的生态系统来说具有非常重大的后果,即物种灭绝是不可避免的命运。 图6说明了具有个个体的种群的单一进化轨迹。 从初始状态开始,布居状态最初遵循周期轨道,然后由于碰撞过程固有的随机性,它越来越偏离该轨道。 在后期,物种频率的振荡幅度变得越来越明显,最终种群中只剩下一个物种。 最终生存的物种取决于整个进化过程,但优势度值最低的物种生存机会最高(“弱者生存”[42])。
这种物种灭绝的预测与经验观察不符。 不同的物种确实共存于仅包含有限数量个体的各种现实世界生态系统中。 关于这个问题已经有很多理论和实验研究。 现实世界系统的一个核心方面是其空间结构[44]。 不同的物种在二维或三维空间中聚集成不同的局部区域,并且不同物种之间的相互作用仅发生在这些区域之间的边界处。 模拟结果和理论计算表明,在这样的空间系统中,即使经过无限的进化时间,所有物种也有很高的生存概率。 物种形成非常有趣的纠缠图案,物种的每个区域都是螺旋形状,区域的边界随时间移动[45, 46]。
在现实世界的生态系统中,个体动物也在空间中积极移动。 流动性的增加意味着与其他物种的互动增加,并使种群更加混合。 [47]一个有趣的理论观察是,石头剪刀布生态系统中的生物多样性存在急剧的“相变”:如果物种流动性超过某个临界值,物种共存的概率对于足够大的系统,从 下降到 。 因此,RPS生态系统可以容忍一定程度的物种流动,但不能过多。
4.2 复制器动态
在许多生态系统中,物种冲突不是由直接的捕食者与猎物相互作用引起的,而是争夺相同资源的结果。 例如,不同菌株的芽殖酵母细胞可以在相同的环境中生长和繁殖。 一个母细胞在其体型超过一定临界值后分裂成两个子细胞,因此在良好的营养条件下,酵母细胞的数量呈指数级增殖。 如果酵母细胞的一种菌株比另一种菌株具有更高的生长速率,那么它就会具有更高的繁殖率,并且其种群规模将比竞争对手菌株[45, 48]以指数速度增长。
在[45]实验体系中研究了三种类型酵母细胞之间的相互作用,观察到了生长速率优势的循环显性。 类似的循环优势现象也存在于其他工程或自然存在的微生物生态系统中。 对于这样的生态系统,特定物种的繁殖率在很大程度上取决于所有物种的相对丰度。 作为一个简单的模型,我们可以再次考虑由三个物种、和形成的生态系统。假设三个物种的繁殖率、和与物种频率、 和 :
| (6a) | ||||
| (6b) | ||||
| (6c) | ||||
其中参数表示不存在物种竞争时的零繁殖率(为简单起见,我们假设所有三个物种都是相同的),这通常取决于种群中的个体总数。 请注意,增加物种的频率会对物种的繁殖率产生负面影响,同时增加当 时, 物种的数量对 具有积极影响。
个体的预期数量 根据 随着时间 变化,对于其他两个值 和 。 总人口规模按照演变,平均繁殖率为。 如果 始终为正,则总人口将随时间而发散。 由于 以及类似的 和 ,我们有
| (7a) | ||||
| (7b) | ||||
| (7c) | ||||
方程(7)与零再现率无关。 这种进化动态通常被称为复制动态[22, 19]。
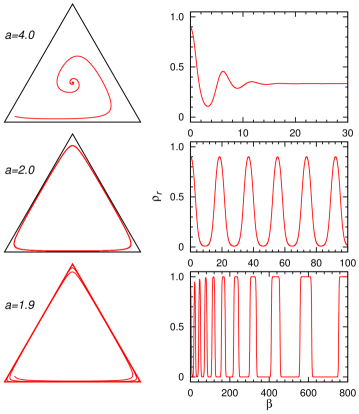
确定性动力学 (7) 很容易通过数值求解。 该方程有一个定点解。 如果,则种群状态从任何满足的初始条件开始向固定点演化,因此该固定点为所有三个物种的全球稳定状态和共存对于扰动是稳定的(图7,顶部面板)。 然而,在处,演化收敛到极限环(图7的中图)。 与前一小节的碰撞模型类似,生态系统仅处于边缘稳定状态,最终将导致物种灭绝。 为了保持生物多样性,我们需要再次考虑物种竞争的空间结构。
当时,演化不会收敛到一个固定点,也不会收敛到一个极限循环,而是以越来越长的周期不断循环。 最后一个非周期振荡现象首先在[49]中讨论。 如图7右下图所示,每个物种(例如)的频率在濒临灭绝状态()之间来回跳跃)和压倒性占据状态()。 这两种情况之间的跳跃发生得非常快,而每种状态的停留时间却越来越长。 一个物种之所以能够从濒临灭绝的状态恢复到优势地位,主要是基于后代呈指数级增殖的假设。 在种群数量有限的实际情况下,其中两个物种将不可避免地灭绝。
复制动力学已广泛应用于博弈论研究[4]。 它是讨论进化稳定策略的定量模型系统[17, 18]。 这种动态也可以解释为通过模仿进行社会学习的简单模型[19]。
5市场价格竞争中的剪刀石头布
常见的情况是,市场上的不同商店以不同的价格出售相同的商品,而且,每个商店的价格不是恒定的,而是随时间非单调变化(例如,参见 [50, 51 ])。 御剑首先预测了持续价格周期的存在[52],认为在激烈的竞争下,商店会小幅降低价格以吸引更多顾客,但如果价格触底,他们会突然抬高价格达到一个更高的水平。 RPS博弈已在理论经济学领域用于定性描述价格动态[53]。
假设一种简化的情况,每天都有 个新的懒惰买家和 个新的勤奋买家在寻找特定商品。 懒惰的买家会进入他找到的第一家商店并购买该商品,而勤奋的买家会检查市场上的所有商店并在价格最低的商店购买该商品。 我们进一步假设只有两家商店出售该商品,这两家商店可以选择以三种不同的价格水平出售,即高价 、中价 和低价。
最初,两家商店都可以以高价 出售该商品,每个商店的预期利润或回报为 。 如果一家商店(比如 X)现在把价格降到 ,它的预期收益会变为 ,如果 ,它的预期收益会高于 ,但另一家商店(Y)的预期收益会降到 。 如果,商店Y的最佳反应是将价格从转移到低值,这将导致预期收益 本身以及商店 X 的降低值 。 但如果,商店X将再次做出反应,转向高价,这将其预期收益增加到,...,导致持续的价格振荡[54]。 上述分析表明,在和参数范围内,存在中等价格击败高价,低价击败中等价格,高价击败低价。
如果这个简单的市场系统处于混合策略纳什均衡,则每个店铺选择低、中、高价格的混合策略为
| (8) |
注意,意思是每个商店应该以最高的概率选择低价,以最低的概率选择高价。 对于代表性参数集、和,我们有、和。 每天的预期收益(通过 标准化)为 ,它始终大于 但小于 。
但实际上不同商店的价格是高度纠缠的[50, 51]。 对于我们的两店玩具模型,模拟相关决策的简单微观过程是具有单个参数 [55] 的噪声最佳响应动态。 知道商店 X 在第 天的价格 但不确定第二天 的价格,商店 Y 选择其价格 在天根据条件概率分布
| (9) |
其中 是商店 Y 在状态 下的收益(通过 标准化),而其他商店 X 选择价格 ,例如 、 和 。
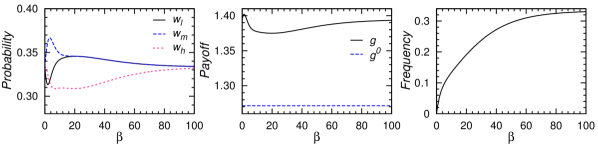
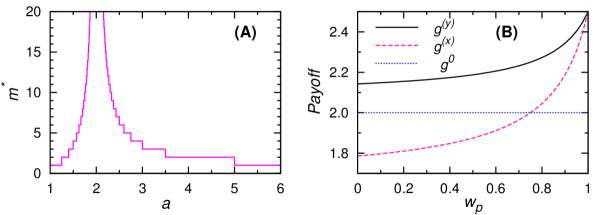
如果两个商店都受相同的随机变量控制,则选择三个价格的稳态边际概率(、 和 )很容易计算动态 (9)。 这种稳态分布与NE混合策略有很大不同(见图8,左)。 如果,则没有选择,,每天的预期收益为。 随着 的增加,预期收益以非单调的方式变化,并且存在 的最优值,在该值处预期收益达到远高于 NE 值的全局最大值(图8,中间)。
我们可以按照3.1节的相同方法来研究这个两店玩具模型的集体行为。 当时,系统中存在持续循环(图8,右),这与Edgeworth价格周期[53, 52]一致。 循环频率是的增函数(正循环方向是高价中价低价高价) 。
现实世界的市场当然比这里讨论的模型复杂得多。 我们要强调的关键点是(i)实际市场中确实存在不同价格水平之间的循环主导[50, 51],以及(ii)做出直觉引导的决策更有利而不是在价格竞争中遵循纳什均衡混合策略。 第二点确实与争论中的合理性问题密切相关(更多讨论读者可查阅[56])。
6展望
剪刀石头布游戏是一个简单的游戏,有助于提高我们对许多复杂竞争问题(物种分歧、价格循环、人类决策、理性与合作等)的理解。 该博弈是研究非合作战略互动的非平衡统计力学最简单的模型系统,可以作为进入统计物理与博弈论交叉学科领域的起点。
在这篇简短的回顾中,我们没有触及可能的相变问题。 如果石头剪刀布游戏在无限格子或复杂网络上进行,是否存在竞争驱动的临界现象以及如何定量描述这些行为? 目前,参与者如何调整决策参数仍然很不清楚,并且在理论研究中很大程度上被忽视。 在这些方向上需要大量的经验和理论努力。
致谢
我感谢徐斌教授和王志坚博士的合作,并感谢徐斌教授对手稿的批判性阅读。 这项工作得到了国家基础研究计划(批准号2013CB932804)和国家自然科学基金(批准号11121403和11225526)的部分支持。
周海军于2000年获得中国科学院博士学位。 他的论文是关于生物聚合物的结构转变。 2005年起任中国科学院理论物理研究所研究员。 目前,他正在研究统计物理学及其跨学科应用,包括自旋玻璃和组合优化、复杂网络中的渗流过程以及游戏系统中的集体动力学。
参考
- [1] Huang, K. Statistical Mechanics (John Wiley, New York, 1987), second edn.
- [2] Szabó, G. & Fáth, G. Evolutionary games on graphs. Phys. Rep. 446, 97–216 (2007).
- [3] Castellano, C., Fortunato, S. & Loreto, V. Statistical physics of social dynamics. Rev. Mod. Phys. 81, 591–646 (2009).
- [4] Roca, C. P., Cuesta, J. A. & Sánchez, A. Evolutionary game theory: Temporal and spatial effects beyond replicator dynamics. Phys. Life Rev. 6, 208–249 (2009).
- [5] Frey, E. Evolutionary game theory: Theoretical concepts and applications to microbial communities. Physica A 389, 4265–4298 (2010).
- [6] Perc, M., Gómez-Gardeñes, J., Szolnoki, A., Floría, L. M. & Moreno, Y. Evolutionary dynamics of group interactions on structured populations: a review. J. R. Soc. Interface 10, 20120997 (2013).
- [7] Szolnoki, A., Mobilia, M., Jiang, L.-L., Szczesny, B., Rucklidge, A. M. & Perc, M. Cyclic dominance in evolutionary games: a review. J. R. Soc. Interface 11, 20140735 (2014).
- [8] Chakraborti, A., Challet, D., Chatterjee, A., Marsili, M., & Chakraborti, A. et al. Statistical mechanics of competitive resource allocation using agent-based models. Phys. Rep. 552, 1–26 (2015).
- [9] Huang, J.-P. Experimental Econophysics (Springer, Berlin, 2015).
- [10] Osborne, M. J. & Rubinstein, A. A Course in Game Theory (MIT Press, New York, 1994).
- [11] Rapoport, A. & Chammah, A. M. Prisoner’s Dilemma: A Study in Conflict and Cooperation (University of Michigan Press, Ann Arbor, Michigan, 1965).
- [12] Fisher, L. Rock, Paper, Scissors: Game Theory in Everyday Life (Basic Books, New York, 2008).
- [13] Axelrod, R. The Evolution of Cooperation (Basic Books, New York, 1984).
- [14] Hauert, C. & Szabó, G. Game theory and physics. Am. J. Phys. 73, 405–414 (2005).
- [15] Bi, Z. & Zhou, H.-J. Optimal cooperation-trap strategies for the iterated rock-paper-scissors game. PLOS One 9, e111278 (2014).
- [16] Nash, J. F. Equilibrium points in -person games. Proc. Natl. Acad. Sci. USA 36, 48–49 (1950).
- [17] Maynard Smith, J. & Price, G. R. The logic of animal conflict. Nature 246, 15–18 (1973).
- [18] Maynard Smith, J. Evolution and the Theory of Games (Cambridge University Press, Cambridge, 1982).
- [19] Weibull, J. M. Evolutionary Game Theory (MIT Press, Cambridge, MA, 1995).
- [20] Wang, Z., Xu, B. & Zhou, H.-J. Social cycling and conditional responses in the rock-paper-scissors game. Sci. Rep. 4, 5830 (2014).
- [21] Sandholm, W. M. Population Games and Evolutionary Dynamics (MIT Press, New York, 2010).
- [22] Taylor, P. D. & Jonker, L. B. Evolutionarily stable strategies and game dynamics. Mathematical Biosciences 40, 145–156 (1978).
- [23] Dawkins, R. The Selfish Gene (Oxford University Press, Oxford, UK, 2006), 30th anniversary edition.
- [24] Cook, R., Bird, G., Lünser, G., Huck, S. & Heyes, C. Automatic imitation in a strategic context: players of rock-paper-scissors imitate opponents’ gestures. Proc. R. Soc. B 279, 780–786 (2012).
- [25] Wagenaar, W. A. Generation of random sequences by human subjects: A critical survey of literature. Psychological Bulletin 77, 65–72 (1972).
- [26] Jahanshahi, M., Saleem, T., Ho, A. K., Dirnberger, G. & Fuller, R. Random number generation as an index of controlled processing. Neuropsychology 20, 391–399 (2006).
- [27] Hoffman, M., Suetens, S., Nowak, M. A. & Gneezy, U. An experimental test of Nash equilibrium versus evolutionary stability. In Proceedings of the Fourth World Congress of the Game Theory Society (GAMES 2012), session 145, paper 1 (Istanbul, Turkey, 2012). URL http://games2012.bilgi.edu.tr/.
- [28] Xu, B., Zhou, H.-J. & Wang, Z. Cycle frequency in standard rock-paper-scissors games: Evidence from experimental economics. Physica A 392, 4997–5005 (2013).
- [29] Cason, T. N., Friedman, D. & Hopkins, E. Cycles and instability in a rock-paper-scissors population game: A continuous time experiment. Review of Economic Studies 81, 112–136 (2014).
- [30] Wang, Z. & Xu, B. Incentive and stability in the rock-paper-scissors game: An experimental investigation. arXiv:1407.1170v1 (2014).
- [31] Grofman, B. & Pool, J. How to make cooperation the optimizing strategy in a two-person game. J. Math. Sociol. 5, 173–186 (1977).
- [32] Kraines, D. & Kraines, V. Pavlov and the prisoner’s dilemma. Theory and Decision 26, 47–79 (1989).
- [33] Kraines, D. & Kraines, V. Learning to cooperate with Pavlov: an adaptive strategy for the iterated prisoner’s dilemma with noise. Theory and Decision 35, 107–150 (1993).
- [34] Nowak, M. & Sigmund, K. A strategy of win-stay, lose-shift that outperforms tit-for-tat in the prisoner’s dilemma game. Nature 364, 56–58 (1993).
- [35] Glimcher, P. W., Camerer, C. F., Fehr, E. & Poldrack, R. A. (eds.). Neuroeconomics: Decision Making and the Brain (Academic Press, London, 2009).
- [36] Janacsek, K. & Nemeth, D. Predicting the future: From implicit learning to consolidation. Int. J. Psychophysiology 83, 213–221 (2012).
- [37] Ono, M., Igarashi, T., Ohno, E. & Sasaki, M. Unusual thermal defence by a honeybee against mass attack by hornets. Nature 377, 334–336 (1995).
- [38] Sinervo, B. & Lively, C. The rock-paper-scissors game and the evolution of alternative male strategies. Nature 380, 240–243 (1996).
- [39] Tainaka, K. Physics and ecology of rock-paper-scissors game. Lect. Notes Comput. Sci. 2063, 384–395 (2001).
- [40] Claussen, J. C. & Traulsen, A. Cyclic dominance and biodiversity in well-mixed populations. Phys. Rev. Lett. 100, 058104 (2008).
- [41] Itoh, Y. Integrals of a Lotka-Volterra system of odd number of variables. Prog. Theor. Phys. 78, 507–510 (1987).
- [42] Frean, M. & Abraham, E. R. Rock-scissors-paper and the survival of the weakest. Proc. R. Soc. Lond. B 268, 1323–1327 (2001).
- [43] Kot, M. Elements of Mathematical Ecology (Cambridge Univ. Press, Cambridge, UK, 2001).
- [44] Durrett, R. & Levin, S. A. Stochastic spatial models: a user’s guide to ecological applications. Phil. Trans. R. Soc. Lond. B 343, 329–350 (1994).
- [45] Kerr, B., Riley, M. A., Feldman, M. W. & Bohannan, B. J. M. Local dispersal promotes biodiversity in a real-life game of rock-paper-scissors. Nature 418, 171–174 (2002).
- [46] Laird, R. A. Population interaction structure and the coexistence of bacterial strains playing ’rock-paper-scissors’. Oikos 123, 472–480 (2014).
- [47] Reichenbach, T., Mobilia, M. & Frey, E. Mobility promotes and jeopardizes biodiversity in rock-paper-scissors games. Nature 448, 1046–1049 (2007).
- [48] Waite, A. J. & Shou, W. Adaptation to a new environment allows cooperators to purge cheaters stochastically. Proc. Natl. Acad. Sci. USA 109, 19079–19086 (2012).
- [49] May, R. M. & Leonard, W. J. Nonlinear aspects of competition between three species. SIAM J. Appl. Math. 29, 243–253 (1975).
- [50] Lach, S. Existence and persistence of price dispersion: An empirical analysis. Review of Economics and Statistics 84, 433–444 (2002).
- [51] Noel, M. D. Edgeworth price cycles: Evidence from the Toronto gasoline market. Journal of Industrial Economics 55, 69–92 (2007).
- [52] Edgeworth, F. Y. The pure theory of monopoly. In Papers Relating to Political Economy, 111–142 (Macmillan, London, 1925).
- [53] Hopkins, E. & Seymour, R. M. The stability of price dispersion under seller and consumer learning. International Economic Review 43, 1157–1190 (2002).
- [54] Cason, T. N., Friedman, D. & Wagener, F. The dynamics of price dispersion, or Edgeworth variations. J. Economic Dynamics and Control 29, 801–822 (2005).
- [55] Blume, L. E. The statistical mechanics of strategic interation. Games Econ. Behavior 5, 387–424 (1993).
- [56] Basu, K. The traveler’s dilemma. Scientific American 296 (6), 90–95 (2007).