学习参与者关系图以进行群体活动识别
摘要
对参与者之间的关系进行建模对于识别多人场景中的群体活动非常重要。 本文旨在使用深度模型有效地学习参与者之间的判别关系。 为此,我们建议构建一个灵活高效的演员关系图(ARG)来同时捕获演员之间的外观和位置关系。 借助图卷积网络,ARG中的连接可以以端到端的方式从小组活动视频中自动学习,并且可以通过标准矩阵运算高效地进行ARG的推理。 此外,在实践中,我们提出了两种稀疏 ARG 的变体,以便在视频中进行更有效的建模:空间局部化 ARG 和时间随机 ARG。 我们对两个标准群体活动识别数据集进行了广泛的实验:排球数据集和集体活动数据集,这两个数据集都实现了最先进的性能。 我们还可视化了学习到的演员图和关系特征,这表明所提出的 ARG 能够捕获用于群体活动识别的判别性关系信息。 111The code is available at https://github.com/wjchaoGit/Group-Activity-Recognition
1简介
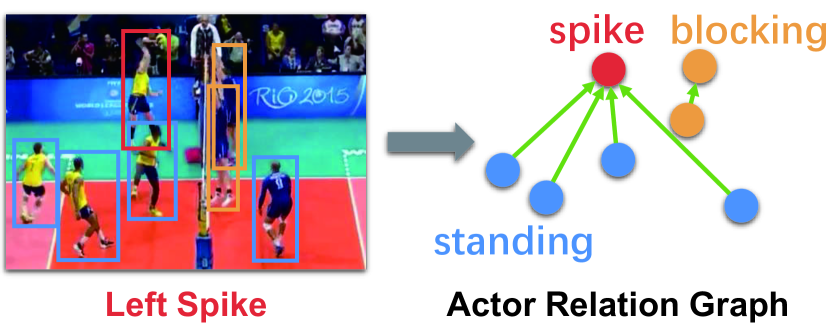
群体活动识别是视频理解中的一个重要问题[56,47,52,14]并且具有许多实际应用,例如监控、体育视频分析和社会行为理解。 为了理解多人的场景,模型不仅需要描述上下文中每个演员的个人行为,还需要推断他们的集体活动。 准确捕获参与者之间的相关关系并进行关系推理对于理解多人的群体活动[30,1,7,23,39,12,24,59]至关重要。 然而,对参与者之间的关系进行建模具有挑战性,因为我们只能访问个体动作标签和集体活动标签,而不了解底层的交互信息。 期望从外观相似性和相对位置等其他方面推断演员之间的关系。 因此,当我们设计有效的群体活动理解深度模型时,需要对这两个重要线索进行建模。
最近的深度学习方法在视频中的群体活动识别方面显示出了良好的结果[3,24,45,12,32,59,23,39]。 通常,这些方法遵循两阶段识别流程。 首先,通过卷积神经网络(CNN)提取人物级特征。 然后,设计一个全局模块来聚合这些人级表示以产生场景级特征。 现有方法使用不灵活的图形模型[23]来建模这些参与者之间的关系,其结构是提前手动指定的,或者使用复杂但不直观的消息传递机制[12, 39][12, 39]. 为了捕获时间动态,通常使用循环神经网络(RNN)对密集采样帧[3, 24]的时间演化进行建模。 这些模型通常计算成本昂贵,有时缺乏处理群体活动变化的灵活性。
在这项工作中,我们解决了捕获参与者之间的外观和位置关系以进行群体活动识别的问题。 我们的基本目标是以更灵活和更有效的方式对演员关系进行建模,其中可以从视频数据中自动学习演员之间的图形连接,并且可以有效地执行群体活动识别的推理。 具体来说,我们建议通过构建演员关系图(ARG)来建模演员-演员关系,如图1所示,其中图中的节点表示演员的特征,边代表两个参与者之间的关系。 ARG 可以轻松放置在任何现有的 2D CNN 之上,形成统一的群体活动识别框架。 得益于图卷积[29]的操作,ARG中的连接可以以端到端的方式自动优化。 因此,我们的模型可以以更灵活的方式发现和学习参与者之间的潜在关系。 经过训练后,我们的网络不仅可以识别多人场景中的个人动作和集体活动,还可以即时生成视频特定的演员关系图,从而有助于进一步了解群体活动。
为了进一步提高 ARG 在视频中进行远程时间建模的效率,我们提出了两种稀疏 ARG 中连接的技术。 具体来说,在空间域中,我们通过强制参与者之间的连接仅在本地邻域内来设计本地化 ARG。 对于时间信息,我们观察到缓慢自然是视频优先的,其中帧被密集捕获,但语义变化非常慢。 我们提出了一个随机 ARG,而不是连接任何对帧,通过随机丢弃几个帧并只保留几个帧。 这种随机丢弃操作不仅能够大大提高建模效率,而且大大增加了训练样本的多样性,降低了ARG的过拟合风险。
在实验中,为了充分利用视觉内容,我们实证研究了根据演员外观特征计算成对关系的不同方法。 然后,我们引入在参与者集上构建多个关系图,以使模型能够关注参与者之间更多样化的关系信息。 我们报告了两个团体活动识别基准的性能:排球数据集 [25] 和集体活动数据集 [7]。 我们的实验结果表明,我们的 ARG 能够获得优于现有最先进方法的性能。
本文的主要贡献总结如下:
-
•
我们构建灵活高效的演员关系图,以同时捕获演员之间的外观和位置关系,以进行群体活动识别。 它提供了一种可解释的机制来明确建模场景中人们之间的相关关系,从而区分不同群体活动的能力。
-
•
我们通过应用具有稀疏时间采样策略的 GCN,在参与者关系图上引入了一种有效的推理方案。 所提出的网络能够对参与者交互进行关系推理,以达到群体活动识别的目的。
-
•
所提出的方法在两个具有挑战性的基准上实现了最先进的结果:排球数据集[25]和集体活动数据集[7]。 学习到的参与者图和关系特征的可视化表明,我们的方法能够处理群体活动识别的关系信息。
2相关工作
团体活动认可。 研究界对群体活动识别进行了广泛的研究。 早期的方法主要基于手工制作的视觉特征与概率图形模型 [1, 31, 30, 43, 6, 8, 17] 或 AND-OR 语法模型 的组合[2, 46]。 最近,深度卷积神经网络 (CNN) 的广泛采用已证明在群体活动识别方面取得了显着的性能提升[3,24,41,45,12,32,59,23,39]。 Ibrahim 等人。 [24]设计了一个两阶段深度时间模型,构建了一个LSTM模型来表示个体的动作动态,另一个用于聚合个人信息的 LSTM 模型。 Bagautdinov 等人。 [3]提出了一种用于多人联合检测和活动识别的统一框架。 Ibrahim 等人。 [23]提出了一种分层关系网络,为每个人构建关系表示。 还有一些努力探索通过结构化循环神经网络[12,59,39]对场景上下文进行建模或生成字幕[32]。 我们的工作与这些方法的不同之处在于,它通过构建灵活且可解释的 ARG 来明确地建模交互信息。 此外,我们没有使用 RNN 进行信息融合,而是采用具有稀疏时间采样策略的 GCN,从而能够有效地进行关系推理。
视觉关系。 建模或学习对象或实体之间的关系是计算机视觉中的一个重要问题[35,9,22,68,57]。 最近的几项工作专注于检测和识别人与物体交互(HOI)[66,16,67,5,40],这通常需要对交互进行额外的注释。 在场景理解中,人们在场景图生成的成对关系建模方面做出了很多努力[26,34,63,65,33,62]。 Santoro 等人. [44]提出了一种用于对象之间关系推理的关系网络模块,在视觉问答方面实现了超人类的表现。 Hu 等. [21]将对象关系模块应用于对象检测,并验证了基于CNN的检测中对象关系建模的有效性。 此外,许多工作表明,建模交互信息可以帮助动作识别[60,36,15,37,50]。 我们表明,明确利用关系信息可以显着提高群体活动识别的准确性。
图上的神经网络。 近年来,将图模型与深度神经网络相结合是深度学习研究中的一个新兴课题。 为了在各种任务中对图结构数据进行推理,已经出现了大量的模型,例如图的分类[13,10,38,11,27],图中的节点分类 [29,18,55],并对多主体交互物理系统进行建模[28,49,4,20]。 在我们的工作中,我们应用了图卷积网络(GCN)[29],它最初是为半监督学习而提出的,用于解决图中节点的分类问题。 GCN 也应用于单人动作识别问题[64, 61]。 然而,计算所有视频帧中的所有成对关系以将视频构建为全连接图的效率很低。 因此,我们根据相对位置将多人场景构建为稀疏图。 同时,我们建议将 GCN 与稀疏时间采样策略相结合[58]以实现更高效的学习。
3方法
我们的目标是通过显式利用关系信息来识别多人场景中的群体活动。 为此,我们构建演员关系图(ARG)来表示多人场景,并对其进行关系推理以进行群体活动识别。 在本节中,我们将详细描述我们的方法。 首先,我们概述了我们的框架。 然后,我们介绍如何构建ARG。 最后,我们描述了 ARG 的高效训练和推理算法。
3.1群体活动识别框架
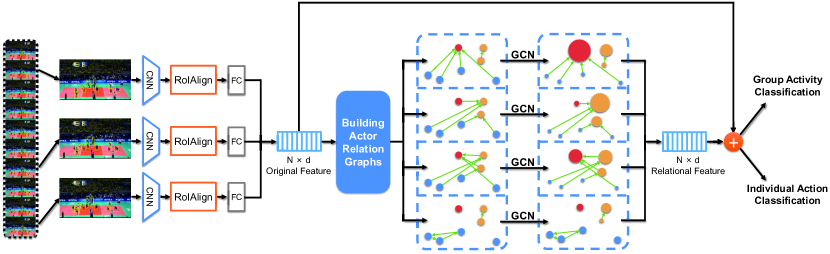
整体网络框架如图2所示。 给定视频序列和场景中演员的边界框,我们的框架需要三个关键步骤。 首先,我们从视频中统一采样一组 帧,并从采样帧中提取演员的特征向量。 我们遵循[3]中使用的特征提取策略,采用Inception-v3 [51]为每一帧提取多尺度特征图。 除此之外,我们还在其他骨干模型上进行了实验,以验证我们方法的通用性和有效性。 我们应用 RoIAlign [19] 从帧特征图中提取每个演员边界框的特征。 之后,对对齐的特征执行 fc 层,以获得每个演员的 维外观特征向量。 帧中的边界框总数表示为 。我们使用 矩阵 来表示演员的特征向量。
然后,根据演员的这些原始特征,我们构建演员关系图,其中每个节点表示一个演员。 图中的每条边都是一个标量权重,它是根据两个演员的外观特征及其相对位置计算的。 为了表示不同的关系信息,我们从同一组参与者特征构建多个关系图。
最后,我们进行学习和推理以识别个人行为和群体活动。 我们应用GCN来进行基于ARG的关系推理。 经过图卷积后,ARG 被融合在一起以生成参与者的关系表示,这也是 维度。 然后,分别用于识别个体行为和群体活动的两个分类器将应用于池化参与者的关系表示和原始表示。 我们在个体表示上应用全连接层以进行个体动作分类。 演员表示最大池化在一起以生成场景级表示,该表示用于通过另一个全连接层进行群体活动分类。
3.2 构建参与者关系图
如上所述,ARG 是我们框架中的关键组件。 我们利用图结构来显式地建模成对关系信息,以实现群体活动的理解。 我们的设计灵感来自最近成功的关系推理和图神经网络[44, 29]。
图定义。 形式上,图中的节点对应于一组参与者,其中是参与者的数量,是参与者 的外观特征, 是演员 边界框的中心坐标。 我们构造图来表示参与者之间的成对关系,其中关系值表示参与者的特征对参与者
为了获得足够的表征能力来捕捉两个演员之间的潜在关系,需要考虑外观特征和位置信息。 此外,我们注意到外观关系和位置关系具有不同的语义属性。 为此,我们以单独且显式的方式对外观关系和位置关系进行建模。 关系值定义为以下复合函数:
| (1) |
其中表示两个演员之间的外观关系,位置关系由计算。 函数 将外观和位置关系与标量权重融合。
在我们的实验中,我们采用以下函数来计算关系值:
| (2) |
我们使用softmax函数对每个actor节点进行归一化,使得一个actor节点的所有关系值的总和将为。
外观关系。 这里我们讨论计算演员之间的外观关系值的不同选择:
-
(1)
点积:外观特征的点积相似度可以被认为是关系值的简单形式。 其计算公式为:
(3) 其中 充当标准化因子。
-
(2)
嵌入式点积:受缩放点积注意力机制[54]的启发,我们可以扩展点积运算来计算嵌入空间中的相似度,并且相应的函数可以表示为:
(4) 其中 和 是两个可学习的线性变换。 和是权重矩阵,和是权重向量。 通过原始特征的可学习变换,我们可以学习子空间中两个参与者之间的关系值。
-
(3)
关系网络:我们还评估了[44]中提出的关系网络模块。 可以写成:
(5) 其中 是串联操作, 和 是将串联向量投影到标量的可学习权重,后跟 ReLU 非线性。
位置关系。 为了向参与者图添加空间结构信息,需要考虑参与者之间的位置关系。 为此,我们研究了在工作中使用空间特征的两种方法:
-
(1)
Distance Mask:通常,来自本地实体的信号比来自远处实体的信号更重要。 对于群体活动建模来说,局部范围内的关系信息比全局关系更重要。 基于这些观察,我们可以将距离超过特定阈值的两个参与者的 设置为零。 我们将生成的 ARG 称为本地化 ARG。 的构成如下:
(6) 其中是指示函数,表示两个演员边界框中心点之间的欧几里德距离,充当距离阈值,它是超参数。
-
(2)
距离编码:或者,我们可以使用最近的方法[54]来学习位置关系。 具体来说,位置关系值计算为
(7) 使用不同波长的余弦和正弦函数,将两个参与者之间的相对距离嵌入到 的高维表示中。 嵌入后的特征维度为。 然后,我们通过权重向量 和 将嵌入特征转换为标量,然后进行 ReLU 激活。
多个图表。 单个 ARG 通常关注参与者之间的特定关系信号,因此丢弃大量上下文信息。 为了捕获不同类型的关系信号,我们可以将单个参与者关系图扩展到多个图。 也就是说,我们在同一参与者集上构建一组图,其中是图的数量。 每个图 都根据等式以相同的方式计算。 (2),但权重不共享。 构建多个关系图允许模型共同关注参与者之间不同类型的关系。 因此,该模型可以对图进行更稳健的关系推理。
时间建模。 时间上下文信息是活动识别的关键线索。 与之前使用循环神经网络聚合密集帧上的时间信息的工作不同,我们的模型通过稀疏时间采样策略[58]合并时域中的信息。 在训练过程中,我们从整个视频中随机采样一组 帧,并根据这些帧中的演员构建时间图。 我们将结果 ARG 称为随机 ARG。 在测试时,我们可以使用滑动窗口方法,对所有窗口的活动分数进行均值池化以形成全局活动预测。
根据经验,我们发现训练时稀疏采样帧可以显着提高识别精度。 一个关键原因是,现有的群体活动识别数据集(例如集体活动数据集和排球数据集)在规模和多样性方面仍然有限。 因此,对视频帧进行随机采样会在训练过程中带来更多的多样性,并降低过度拟合的风险。 此外,这种稀疏采样策略以极低的成本保留时间信息,从而在时间和计算资源的合理预算下实现端到端学习。
3.3 图推理与训练
一旦 ARG 构建完成,我们就可以对它们进行关系推理,以识别个人行为和群体活动。 我们首先回顾一个图推理模块,称为图卷积网络(GCN)[29]。 GCN 将图作为输入,对结构进行计算,并返回图作为输出,可以将其视为“图到图”块。 对于图中的目标节点,它根据所有邻居节点之间的边权重聚合来自所有邻居节点的特征。 形式上,一层 GCN 可以写成:
| (8) |
其中 是图的矩阵表示。 是层中节点的特征表示,。 是特定于层的可学习权重矩阵。 表示激活函数,我们在本工作中采用ReLU。 这种逐层传播可以堆叠成多层。 为了简单起见,我们在这项工作中只使用了一层 GCN。
最初的 GCN 在单个图结构上运行。 GCN 之后,如何将一组图融合在一起仍然是一个悬而未决的问题。 在这项工作中,我们采用了后期融合方案,即在GCN之后融合不同图中同一参与者的特征:
| (9) |
我们使用逐元素求和作为融合函数。 我们还将串联作为融合函数进行评估。 或者,也可以通过早期融合来融合一组图,即在 GCN 之前通过求和融合到一个图。 我们在实验中比较了融合一组图的不同方法。
最后,GCN 的输出关系特征通过求和与原始特征融合,形成场景表示。 如图2所示,场景表示被馈送到两个分类器以生成个体动作和群体活动预测。
整个模型可以通过反向传播以端到端的方式进行训练。 结合标准交叉熵损失,最终损失函数为
| (10) |
其中和是交叉熵损失,和表示群体活动和个人行为的真实标签、 和 是对群体活动和个人行为的预测。 第一项对应于群体活动分类损失,第二项对应于个人行为分类损失。 权重用于平衡这两个任务。
| Method | Accuracy |
|---|---|
| base model | 89.8% |
| dot-product | 91.3% |
| embedded dot-product | 91.3% |
| relation network | 90.7% |
| Method | Accuracy |
|---|---|
| no position relation | 91.3% |
| distance mask | 91.6% |
| distance encoding | 91.5% |
| Number | 1 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|
| Accuracy | 91.6% | 92.0% | 92.0% | 92.1% | 92.0% |
| Method | Accuracy |
|---|---|
| early fusion | 90.8% |
| late fusion (summation) | 92.1% |
| late fusion (concatenation) | 91.9% |
| Method | Accuracy |
|---|---|
| single frame | 92.1% |
| TSN (3 frames) | 92.3% |
| temporal-graphs (3 frames) | 92.5% |
4实验
在本节中,我们首先介绍两个广泛采用的数据集以及我们方法的实现细节。 然后,我们进行了一些消融研究,以了解模型中建议组件的效果。 我们还将我们的模型的性能与最先进的方法进行比较。 最后,我们将学习到的演员关系图和特征可视化。
4.1 数据集和实现细节
数据集。 我们在两个公开的群体活动识别数据集(即排球数据集和集体活动数据集)上进行了实验。
排球数据集[25]由从55场排球比赛中收集的4830个片段组成,其中3493个训练片段和1337个用于测试的片段。 每个剪辑都标有 8 个组活动标签之一(右组、右扣球、右传球、右获胜点、左组、左扣球、左传球和左获胜点)。 只有每个剪辑的中间帧标注有玩家的边界框以及来自 9 个个人动作标签的个人动作(等待、设置、挖掘、失败、扣球、阻挡、跳跃、移动和站立)。 在[24]之后,我们使用10帧来训练和测试我们的模型,这对应于带注释的帧之前的5帧和之后的4帧。 为了获取未注释帧的真实边界框,我们使用 [3] 提供的轨迹数据。
集体活动数据集[7]包含 44 个短视频序列(约 2500 帧),来自 5 个团体活动(过路、等待、排队、行走和说话)和 6 个个人动作(NA、过路、等待、排队、步行和交谈)。 框架的组活动标签由大多数人参与的活动定义。 我们遵循与[39]相同的评估方案,并选择视频序列中的进行测试,其余部分进行训练。
实施细节。 我们使用 3.1 节中提到的方法为每个参与者提取具有真实边界框的 1024 维特征向量。 在消融研究中,我们采用 Inception-v3 作为骨干网络。 我们还使用 VGG [48] 网络进行实验,以便与之前的方法进行公平比较。 由于内存限制,我们分两个阶段训练模型:首先,我们在从每个视频中随机选择的单帧上对 ImageNet 预训练模型进行训练,而不使用 GCN。 在整个实验中,我们将上述微调模型称为我们的基本模型。 基础模型对参与者的原始特征进行群体活动和个人行为分类,无需进行关系推理。 然后我们固定网络特征提取部分的权重,并进一步用 GCN 训练网络。
我们采用 ADAM 的随机梯度下降来学习具有固定超参数 的网络参数。 对于排球数据集,我们使用 32 的小批量大小和范围从 到 的学习率在 150 个时期内训练网络。 对于 Collective Activity 数据集,我们使用 16 的小批量,学习率为 ,并在 80 个 epoch 中训练网络。 使用单独的动作损失权重。 此外,GCN的参数设置为,我们采用图像宽度的作为距离掩模阈值。
我们的实现基于 PyTorch 深度学习框架。 在单个 TITAN-XP GPU 上,推断视频的运行时间约为 0.2 秒。
4.2消融研究
在本小节中,我们对排球数据集进行详细的消融研究,以了解所提出的模型组件对使用群体活动识别准确性作为评估指标的关系建模的贡献。 结果如表1所示。
外观关系。 我们通过研究对演员和不同功能之间的外观关系进行建模来计算外观关系值的效果来开始我们的实验。 基于单帧,我们构建单个ARG,不使用位置关系。 结果列于表1(a)中。 我们首先观察到显式建模参与者之间的关系带来了显着的性能提升。 所有具有 GCN 的模型都优于基本模型。 结果表明,点积和嵌入点积的识别精度相同,均为,并且比关系网络表现更好。 我们推测点积运算对于表示关系信息更稳定。 在下面的实验中,使用嵌入点积来计算外观关系值。
位置关系。 我们进一步向 ARG 添加空间结构信息。 在3.2节中,我们提出了两种使用空间特征的方法:距离掩模和距离编码。 表1(b)报告了这两种方法的性能比较结果。 我们可以看到,这两种方法都比不使用空间特征的方法获得了更好的性能,证明了建模位置关系的有效性。 距离掩模的精度比距离编码稍好。 在本文的其余部分,我们选择距离掩模来表示位置关系。
多个图表。 我们还研究了构建一组图来捕获不同类型的关系信息的有效性。 首先,我们比较使用不同数量的图的性能。 如表1(c)所示,我们观察到与仅构建单个图相比,构建多个图会带来一致且显着的增益,并且能够进一步提高的准确性到。 然后我们评估三种融合一组图的方法:(1)早期融合,(2)通过求和进行后期融合,(3)通过串联进行后期融合。 使用16张图的实验结果总结在表1(d)中。 我们看到通过求和进行的后期融合实现了最佳性能。 我们注意到,早期的融合方案在 GCN 之前通过求和来聚合一组图,导致性能急剧下降。 这一观察表明,不同图学习到的关系值编码不同的语义信息,如果在图卷积之前融合它们,将会导致关系推理的混乱。 在接下来的实验中我们采用并通过求和进行后期融合。
时间建模。 设置好所有设计选择后,我们现在将模型扩展到时域。 正如3.2节中提到的,我们采用稀疏时间采样策略[58],并在训练期间从整个视频中均匀采样一组帧。 在最简单的设置中,我们可以单独处理输入帧,然后将不同帧的预测分数融合为时间段网络(TSN)[58]。 或者,我们可以在输入帧中的参与者上构建时间图,并通过 GCN 融合时间信息。 我们在表1(e)中报告了这两种时间建模方法的准确性。 我们看到 TSN 建模有助于提高我们模型的性能。 此外,构建时间图进一步将准确性提高到 ,这表明时间推理有助于区分群体活动类别。
| Method | Backbone | Group | Individual |
|---|---|---|---|
| activity | action | ||
| HDTM [24] | AlexNet | 81.9% | - |
| CERN [45] | VGG16 | 83.3% | - |
| stagNet (GT) [39] | VGG16 | 89.3% | - |
| stagNet (PRO) [39] | VGG16 | 87.6% | - |
| HRN [23] | VGG19 | 89.5% | - |
| SSU (GT) [3] | Inception-v3 | 90.6% | 81.8% |
| SSU (PRO) [3] | Inception-v3 | 86.2% | 77.4% |
| OURS (GT) | Inception-v3 | 92.5% | 83.0% |
| OURS (PRO) | Inception-v3 | 91.5% | - |
| OURS (GT) | VGG16 | 91.9% | 83.1% |
| OURS (GT) | VGG19 | 92.6% | 82.6% |
| Method | Backbone | Group activity |
|---|---|---|
| SIM [12] | AlexNet | 81.2% |
| HDTM [24] | AlexNet | 81.5% |
| Cardinality Kernel [17] | None | 83.4% |
| SBGAR [32] | Inception-v3 | 86.1% |
| CERN [45] | VGG16 | 87.2% |
| stagNet (GT) [39] | VGG16 | 89.1% |
| stagNet (PRO) [39] | VGG16 | 87.9% |
| OURS (GT) | Inception-v3 | 91.0% |
| OURS (PRO) | Inception-v3 | 90.2% |
| OURS (GT) | VGG16 | 90.1% |

4.3与现有技术的比较
现在,我们将我们的最佳模型与表2中最先进的方法进行比较。 为了与之前的方法进行公平比较,我们报告了 Inception-v3 和 VGG 主干网络的结果。 同时,我们进行基于提案的实验。 我们使用训练数据训练 Faster-RCNN [42]。 在测试时使用 Faster-RCNN 的边界框,我们的模型仍然可以达到有希望的准确性。
表2(a)显示了与先前在排球数据集上的团体活动和个人动作识别结果的比较。 我们的方法远远超过了所有现有的方法,建立了新的最先进方法。 我们的 Inception-v3 模型采用与 [3] 相同的特征提取策略,并且在群体活动识别准确性方面优于它约 ,因为我们的模型可以捕获和利用参与者之间的关系信息。 而且,我们在个人动作识别任务上也取得了更好的表现。 同时,我们的方法优于最近使用分层关系网络[23]或语义RNN[39]的方法,主要是因为我们显式地对外观和位置关系图进行建模,并采用更有效的时间建模方法。
我们进一步评估集体活动数据集上提出的模型。 结果以及与之前方法的比较列于表2(b)。 我们的时间多重图模型再次实现了最先进的性能,具有 群体活动识别精度。 这一出色的性能表明了所提出的 ARG 在捕获多人场景中的关系信息方面的有效性和通用性。
4.4模型可视化
参与者关系图可视化我们在图3中可视化了我们的模型生成的关系图的几个示例。 我们在单帧上使用单图模型,因为它更容易可视化。 可视化结果有助于我们理解 ARG 的工作原理。 我们可以看到,我们的模型能够捕获群体活动识别的关系信息,并且生成的 ARG 可以自动发现关键角色来确定场景中的群体活动。
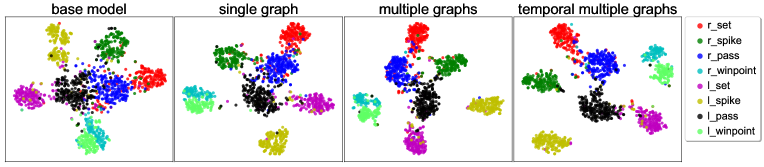
学习表示的 t-SNE 可视化。 图 4 显示了 t-SNE [53] 可视化,用于嵌入通过不同模型变体学习的视频表示。 具体来说,我们使用 t-SNE 将排球数据集验证集上的视频表示投影到二维空间中。 我们可以观察到,使用 ARG 学习到的场景级表示分离得更好。 此外,构建多个图表并聚合时间信息可以更好地区分群体活动。 这些可视化结果表明我们的 ARG 模型对于群体活动识别更有效。
5结论
本文提出了一种灵活有效的方法来确定多人场景中演员之间的相关关系。 我们学习演员关系图(ARG)来对图进行关系推理以进行群体活动识别。 我们还在两个数据集上评估了所提出的模型,并建立了新的最先进的结果。 全面的消融实验和可视化结果表明,我们的模型能够学习关系信息以理解群体活动。 未来,我们计划进一步了解ARG的工作原理,并融入更多的全局场景信息来进行群体活动识别。
致谢
该工作得到了国家自然科学基金委(No.61321491)和软件新技术及产业化协同创新中心的资助。
参考
- [1] Mohamed Rabie Amer, Peng Lei, and Sinisa Todorovic. Hirf: Hierarchical random field for collective activity recognition in videos. In ECCV, pages 572–585, 2014.
- [2] Mohamed R. Amer, Dan Xie, Mingtian Zhao, Sinisa Todorovic, and Song Chun Zhu. Cost-sensitive top-down/bottom-up inference for multiscale activity recognition. In ECCV, pages 187–200, 2012.
- [3] Timur M. Bagautdinov, Alexandre Alahi, François Fleuret, Pascal Fua, and Silvio Savarese. Social scene understanding: End-to-end multi-person action localization and collective activity recognition. In CVPR, pages 3425–3434, 2017.
- [4] Peter W. Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and Koray Kavukcuoglu. Interaction networks for learning about objects, relations and physics. In NIPS, pages 4502–4510, 2016.
- [5] Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, and Jia Deng. Learning to detect human-object interactions. In WACV, pages 381–389, 2018.
- [6] Wongun Choi and Silvio Savarese. Understanding collective activitiesof people from videos. IEEE Trans. Pattern Anal. Mach. Intell., 36(6):1242–1257, 2014.
- [7] Wongun Choi, Khuram Shahid, and Silvio Savarese. What are they doing? : Collective activity classification using spatio-temporal relationship among people. In ICCV Workshops, pages 1282–1289, 2009.
- [8] Wongun Choi, Khuram Shahid, and Silvio Savarese. Learning context for collective activity recognition. In CVPR, pages 3273–3280, 2011.
- [9] Bo Dai, Yuqi Zhang, and Dahua Lin. Detecting visual relationships with deep relational networks. In CVPR, pages 3298–3308, 2017.
- [10] Hanjun Dai, Bo Dai, and Le Song. Discriminative embeddings of latent variable models for structured data. In ICML, pages 2702–2711, 2016.
- [11] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, pages 3837–3845, 2016.
- [12] Zhiwei Deng, Arash Vahdat, Hexiang Hu, and Greg Mori. Structure inference machines: Recurrent neural networks for analyzing relations in group activity recognition. In CVPR, pages 4772–4781, 2016.
- [13] David K. Duvenaud, Dougal Maclaurin, Jorge Aguilera-Iparraguirre, Rafael Gómez-Bombarelli, Timothy Hirzel, Alán Aspuru-Guzik, and Ryan P. Adams. Convolutional networks on graphs for learning molecular fingerprints. In NIPS, pages 2224–2232, 2015.
- [14] Chuang Gan, Naiyan Wang, Yi Yang, Dit-Yan Yeung, and Alex G Hauptmann. Devnet: A deep event network for multimedia event detection and evidence recounting. In CVPR, pages 2568–2577, 2015.
- [15] Georgia Gkioxari, Ross B. Girshick, and Jitendra Malik. Actions and attributes from wholes and parts. In ICCV, pages 2470–2478, 2015.
- [16] Abhinav Gupta, Aniruddha Kembhavi, and Larry S. Davis. Observing human-object interactions: Using spatial and functional compatibility for recognition. IEEE Trans. Pattern Anal. Mach. Intell., 31(10):1775–1789, 2009.
- [17] Hossein Hajimirsadeghi, Wang Yan, Arash Vahdat, and Greg Mori. Visual recognition by counting instances: A multi-instance cardinality potential kernel. In CVPR, pages 2596–2605, 2015.
- [18] William L. Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NIPS, pages 1025–1035, 2017.
- [19] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross B. Girshick. Mask R-CNN. In ICCV, pages 2980–2988, 2017.
- [20] Yedid Hoshen. VAIN: attentional multi-agent predictive modeling. In NIPS, pages 2698–2708, 2017.
- [21] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen Wei. Relation networks for object detection. In CVPR, pages 3588–3597, 2018.
- [22] Ronghang Hu, Marcus Rohrbach, Jacob Andreas, Trevor Darrell, and Kate Saenko. Modeling relationships in referential expressions with compositional modular networks. In CVPR, pages 4418–4427, 2017.
- [23] Mostafa S. Ibrahim and Greg Mori. Hierarchical relational networks for group activity recognition and retrieval. In ECCV, pages 742–758, 2018.
- [24] Mostafa S. Ibrahim, Srikanth Muralidharan, Zhiwei Deng, Arash Vahdat, and Greg Mori. A hierarchical deep temporal model for group activity recognition. In CVPR, pages 1971–1980, 2016.
- [25] Mostafa S. Ibrahim, Srikanth Muralidharan, Zhiwei Deng, Arash Vahdat, and Greg Mori. A hierarchical deep temporal model for group activity recognition. In CVPR, pages 1971–1980, 2016.
- [26] Justin Johnson, Ranjay Krishna, Michael Stark, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Image retrieval using scene graphs. In CVPR, pages 3668–3678, 2015.
- [27] Steven M. Kearnes, Kevin McCloskey, Marc Berndl, Vijay S. Pande, and Patrick Riley. Molecular graph convolutions: moving beyond fingerprints. Journal of Computer-Aided Molecular Design, 30(8):595–608, 2016.
- [28] Thomas N. Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard S. Zemel. Neural relational inference for interacting systems. In ICML, pages 2693–2702, 2018.
- [29] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. CoRR, abs/1609.02907, 2016.
- [30] Tian Lan, Leonid Sigal, and Greg Mori. Social roles in hierarchical models for human activity recognition. In CVPR, pages 1354–1361, 2012.
- [31] Tian Lan, Yang Wang, Weilong Yang, Stephen N. Robinovitch, and Greg Mori. Discriminative latent models for recognizing contextual group activities. IEEE Trans. Pattern Anal. Mach. Intell., 34(8):1549–1562, 2012.
- [32] Xin Li and Mooi Choo Chuah. SBGAR: semantics based group activity recognition. In ICCV, pages 2895–2904, 2017.
- [33] Yikang Li, Wanli Ouyang, Bolei Zhou, Jianping Shi, Chao Zhang, and Xiaogang Wang. Factorizable net: An efficient subgraph-based framework for scene graph generation. In ECCV, pages 346–363, 2018.
- [34] Yikang Li, Wanli Ouyang, Bolei Zhou, Kun Wang, and Xiaogang Wang. Scene graph generation from objects, phrases and caption regions. CoRR, abs/1707.09700, 2017.
- [35] Xiaodan Liang, Lisa Lee, and Eric P. Xing. Deep variation-structured reinforcement learning for visual relationship and attribute detection. In CVPR, pages 4408–4417, 2017.
- [36] Chih-Yao Ma, Asim Kadav, Iain Melvin, Zsolt Kira, Ghassan AlRegib, and Hans Peter Graf. Attend and interact: Higher-order object interactions for video understanding. In CVPR, pages 6790–6800, 2018.
- [37] Bingbing Ni, Xiaokang Yang, and Shenghua Gao. Progressively parsing interactional objects for fine grained action detection. In CVPR, pages 1020–1028, 2016.
- [38] Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. Learning convolutional neural networks for graphs. In ICML, pages 2014–2023, 2016.
- [39] Mengshi Qi, Jie Qin, Annan Li, Yunhong Wang, Jiebo Luo, and Luc Van Gool. stagnet: An attentive semantic RNN for group activity recognition. In ECCV, pages 104–120, 2018.
- [40] Siyuan Qi, Wenguan Wang, Baoxiong Jia, Jianbing Shen, and Song-Chun Zhu. Learning human-object interactions by graph parsing neural networks. In ECCV, pages 407–423, 2018.
- [41] Vignesh Ramanathan, Jonathan Huang, Sami Abu-El-Haija, Alexander N. Gorban, Kevin Murphy, and Li Fei-Fei. Detecting events and key actors in multi-person videos. In CVPR, pages 3043–3053, 2016.
- [42] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, pages 91–99, 2015.
- [43] Michael S. Ryoo and Jake K. Aggarwal. Stochastic representation and recognition of high-level group activities: Describing structural uncertainties in human activities. In CVPR Workshops, page 11, 2009.
- [44] Adam Santoro, David Raposo, David G. T. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Tim Lillicrap. A simple neural network module for relational reasoning. In NIPS, pages 4974–4983, 2017.
- [45] Tianmin Shu, Sinisa Todorovic, and Song-Chun Zhu. CERN: confidence-energy recurrent network for group activity recognition. In CVPR, pages 4255–4263, 2017.
- [46] Tianmin Shu, Dan Xie, Brandon Rothrock, Sinisa Todorovic, and Song-Chun Zhu. Joint inference of groups, events and human roles in aerial videos. In CVPR, pages 4576–4584, 2015.
- [47] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, pages 568–576, 2014.
- [48] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
- [49] Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus. Learning multiagent communication with backpropagation. In NIPS, pages 2244–2252, 2016.
- [50] Chen Sun, Abhinav Shrivastava, Carl Vondrick, Kevin Murphy, Rahul Sukthankar, and Cordelia Schmid. Actor-centric relation network. In ECCV, pages 335–351, 2018.
- [51] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, pages 2818–2826, 2016.
- [52] Du Tran, Lubomir D. Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In ICCV, pages 4489–4497, 2015.
- [53] Laurens van der Maaten and Geoffrey E. Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(2):2579–2605, 2008.
- [54] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 6000–6010, 2017.
- [55] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. CoRR, abs/1710.10903, 2017.
- [56] Limin Wang, Wei Li, Wen Li, and Luc Van Gool. Appearance-and-relation networks for video classification. In CVPR, pages 1430–1439, 2018.
- [57] Limin Wang, Yu Qiao, and Xiaoou Tang. MoFAP: A multi-level representation for action recognition. International Journal of Computer Vision, 119(3):254–271, 2016.
- [58] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, pages 20–36, 2016.
- [59] Minsi Wang, Bingbing Ni, and Xiaokang Yang. Recurrent modeling of interaction context for collective activity recognition. In CVPR, pages 7408–7416, 2017.
- [60] Xiaolong Wang, Ross B. Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, pages 7794–7803, 2018.
- [61] Xiaolong Wang and Abhinav Gupta. Videos as space-time region graphs. In ECCV, pages 413–431, 2018.
- [62] Sanghyun Woo, Dahun Kim, Donghyeon Cho, and In So Kweon. Linknet: Relational embedding for scene graph. In NIPS, pages 558–568, 2018.
- [63] Danfei Xu, Yuke Zhu, Christopher B. Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. In CVPR, pages 3097–3106, 2017.
- [64] Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In AAAI, pages 7444–7452, 2018.
- [65] Jianwei Yang, Jiasen Lu, Stefan Lee, Dhruv Batra, and Devi Parikh. Graph R-CNN for scene graph generation. In ECCV, pages 690–706, 2018.
- [66] Bangpeng Yao and Fei-Fei Li. Modeling mutual context of object and human pose in human-object interaction activities. In CVPR, pages 17–24, 2010.
- [67] Bangpeng Yao and Fei-Fei Li. Recognizing human-object interactions in still images by modeling the mutual context of objects and human poses. IEEE Trans. Pattern Anal. Mach. Intell., 34(9):1691–1703, 2012.
- [68] Hanwang Zhang, Zawlin Kyaw, Shih-Fu Chang, and Tat-Seng Chua. Visual translation embedding network for visual relation detection. In CVPR, pages 3107–3115, 2017.