热身冷启动广告:通过学习 ID 嵌入提高点击率预测
摘要。
点击率(CTR)预测一直是计算广告中最核心的问题之一。 最近,产生广告 ID 低维表示的嵌入技术极大地提高了点击率预测的准确性。 然而,这种学习技术对数据要求很高,并且在记录数据很少的新广告上效果不佳,这被称为冷启动问题。
在本文中,我们的目标是在新广告添加到候选池时改善冷启动阶段和热身阶段的点击率预测。 我们提出了元嵌入,这是一种基于元学习的方法,可以学习为新广告 ID 生成所需的初始嵌入。 所提出的方法通过基于梯度的元学习利用先前学习的广告来训练新广告 ID 的嵌入生成器。 换句话说,我们的方法学习如何学习更好的嵌入。 当新广告出现时,经过训练的生成器通过提供其内容和属性来初始化其 ID 的嵌入。 接下来,与现有的初始化方法相比,当有一些标记示例可用时,生成的嵌入可以在预热阶段加速模型拟合。
在三个真实数据集上的实验结果表明,元嵌入可以显着提高六种现有 CTR 预测模型的冷启动和预热性能,范围从因子分解机等轻量级模型到 PNN 和 DeepFM 等复杂的深度模型。 上述所有内容也适用于转化率 (CVR) 预测。
1. 介绍
网络广告的本质是发布者以社会福利最大化的方式分配广告位。 换句话说,理想的广告拍卖机制为每个用户将最佳时段分配给最佳广告,将第二时段分配给次佳广告,依此类推。 为了确定哪个广告对该用户最有价值,一个关键参数是所谓的点击率,也称为 CTR。 然后,典型的广告拍卖机制根据出价乘以点击率的乘积的降序进行分配。 由于出价是来自广告商的输入,因此发布商的主要工作是估计每个广告用户对的准确点击率,以确保最佳分配。 如果发布商关心这些点击成功转化为商业交易的程度,那么同样的论点也适用于转化率 (CVR)。 因此,学术界和主要互联网公司投入了大量的研究和工程工作来培养优秀的点击率估算器。
预测点击率的一个主导方向是利用深度学习的最新进展(程等人,2016;曲等人,2016;郭等人,2017;潘等人,2018c;周等人,2018)。 这些深度模型通常可以分解为两部分:嵌入和多层感知器(MLP)(Zhou 等人,2018)。 首先,嵌入层将原始输入的每个字段转换为固定长度的实值向量。 嵌入的典型用法是将广告标识符(广告 ID)转换为密集向量,可以将其视为特定广告的潜在表示。 业界众所周知,与没有 ID 输入 的方法相比,对广告 ID 进行良好学习的嵌入可以大大提高预测精度(Cheng 等人,2016;Juan 等人,2017;Qu 等)人,2016;郭等人,2017;周等人,2018)。 接下来,嵌入被输入到复杂的模型中,这些模型可以被视为不同类型的 MLP。 这些模型包括因子分解机 (FM) (Rendle, 2010; Rendle 等人, 2011)、FFM 扩展系列(Juan 等人, 2017) 和 FwFM (Pan 等人, 2018c) 使用嵌入的内积来学习特征交互;更深层次的模型,如 Wide&Deep (Cheng 等人, 2016)、PNN (Qu 等人, 2016) 和 DeepFM (Guo 等人, 2017) 学习特征之间的高阶关系。 这些方法在各种点击率预测任务中都取得了最先进的性能。
尽管这些方法取得了显着的成功,但学习嵌入向量对数据的要求极高。 对于每个广告,都需要大量的标记示例来训练合理的 ID 嵌入。 当将新广告添加到候选池时,使用上述方法不太可能为其 ID 提供良好的嵌入向量。 此外,对于训练样本数量相对较少的“小”广告,很难将其嵌入训练得像“大”广告一样好。 这些困难都可以被视为文献中普遍存在的冷启动问题。
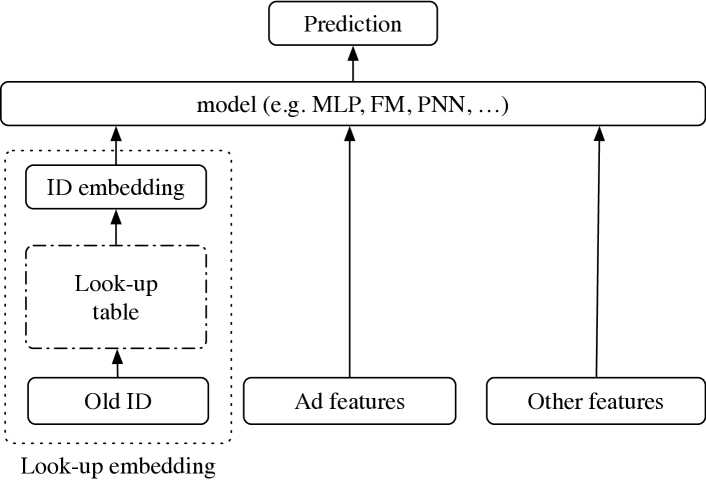
(a) Warm-start: look-up embeddings for old ads
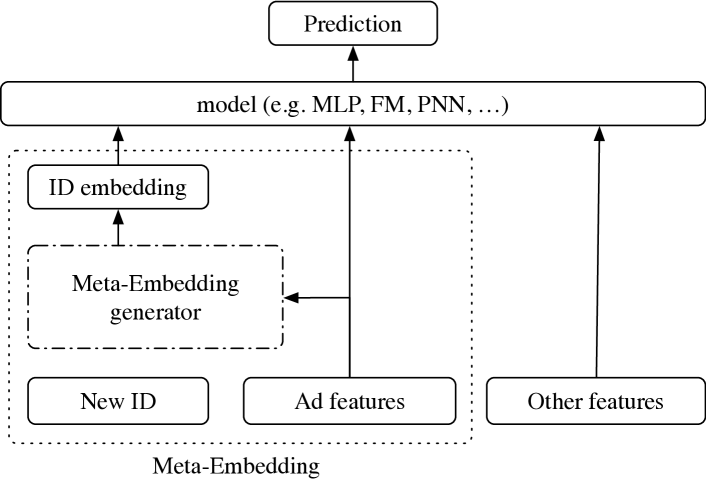
(b) Cold-start: Meta-Embedding for new ads
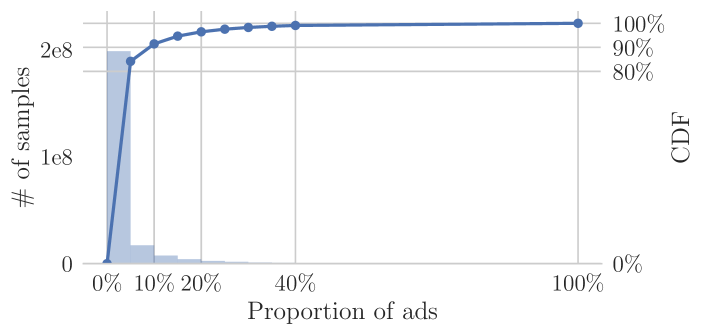
冷启动问题已成为网络广告的一个重要障碍。 例如,图 1 显示在 KDD Cup 2012 数据集中111http://www.kddcup2012.org/c/kddcup2012-track2 的搜索广告, 的广告占样本数超过 ,而其余的 因此,善于冷启动不仅有利于收入,还能提高小广告主的满意度。
根据这些观察结果,我们的目标是开发一种新方法,可以让冰冷的广告升温。 我们的高级想法是为新广告 ID 学习更好的初始嵌入,这可以 1)为冷启动广告产生可接受的预测,2)在获得少量示例后加快模型拟合速度。 我们提出了一种元学习方法,用于学习如何学习此类初始嵌入,在本文中创造了元嵌入。 该方法的主要思想包括利用广告特征的参数化函数作为 ID 嵌入生成器,并对旧 ID 进行两阶段模拟,通过基于梯度的元学习来训练生成器,以改善冷启动和热启动。表演。
首先,我们列出了我们追求的两个重要需求:
-
(1)
更擅长冷启动:在对没有标签数据的新广告进行预测时,应该以较小的损失进行预测;
-
(2)
预热速度更快:观察少量标记样本后,应加快模型拟合速度,以减少后续预测的预测损失。
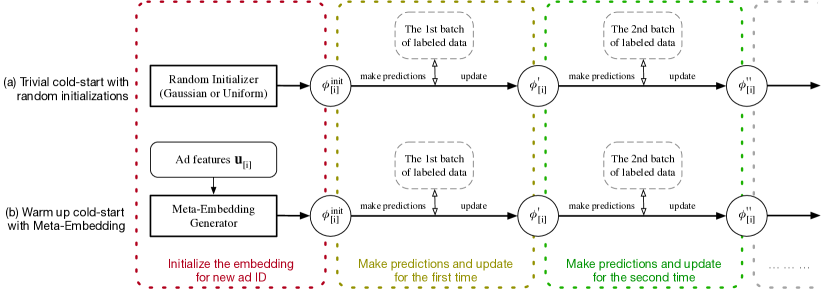
为了实现这两个愿望,我们对手中的“大”广告设计了两阶段模拟。 该模拟由冷启动阶段和预热阶段组成。 在冷启动阶段,我们需要为没有标记数据的 ID 分配初始嵌入。 在预热阶段,当我们可以访问最少数量的标记示例时,我们相应地更新嵌入以模拟模型拟合过程。 这样,我们就能学会如何学习。
通过两阶段模拟,我们提出了一种元学习算法来训练元嵌入生成器。 我们方法的本质是将点击率预测重新定义为一个元学习问题,其中学习每个广告被视为一项任务。 我们提出了一种基于梯度的训练算法,具有模型无关元学习(MAML)的优势(Finn等人,2017)。 MAML 在许多领域的快速适应方面取得了成功,但它为每个任务训练一个模型,因此如果有数百万个任务(广告),它无法用于 CTR 预测。 为此,我们将 MAML 概括为基于内容的嵌入生成器。 我们构建了平衡冷启动和热机性能的统一优化目标。 然后,生成的嵌入不仅可以在没有标记数据的情况下产生可接受的预测,而且可以在可用数据量最少时快速适应。 最后,我们的方法很容易实现,并且可以离线或在线应用静态或流数据。 它还可用于冷启动其他 ID 功能,例如用户 ID 和广告商 ID。
请注意,本文中的所有模型和实验都是在通用在线监督学习框架下进行的,系统被动收集数据。 因此我们不考虑勘探与开发的权衡(Li 等人, 2010; Nguyen 等人, 2014; Tang 等人, 2015; Shah 等人, 2017; Pan 等人, 2018a, b),我们也没有像主动学习那样设计访谈(Park 等人,2006;Zhou 等人,2011;Golbandi 等人,2011;Harpale 和 Yang,2008)。 但我们的方法可以很容易地扩展到这些情况。
总而言之,本文的贡献如下:
-
•
我们提出了元嵌入(Meta-Embedding),它学习如何学习新广告 ID 的嵌入,以解决冷启动问题。 它以广告内容和属性作为输入,为新广告 ID 生成初始嵌入。 据我们所知,这是第一项旨在提高通用监督学习框架下新广告冷启动和热身阶段的各种最先进的点击率预测方法的性能的工作。
-
•
我们提出了一种简单而强大的算法,通过在反向传播时使用二阶导数,使用基于梯度的元学习来训练元嵌入生成器。
-
•
所提出的方法很容易在在线冷启动设置中实现。 一旦嵌入生成器经过训练,它就可以代替新 ID 嵌入的简单随机初始化器,从而为新广告预热冷启动。
-
•
我们在三个大型现实数据集上验证了所提出的方法。 实验结果表明,当利用元嵌入来冷启动新广告和预热小尺寸广告时,现有的六种最先进的点击率预测方法都可以得到显着改进。
2. 背景和配方
CTR 预测是一个有监督的二元分类任务。 每个实例由输入特征和二进制标签组成。 机器学习系统应该近似输入 实例的概率 。
大多数情况下,输入可以分为三部分,即,包括
-
(1)
,广告标识符(ID),一个正整数,用于标识每个广告;
-
(2)
,特定广告的特征和属性,可以有多个字段;
-
(3)
,其他不一定与广告相关的特征可能有多个字段,例如用户特征和上下文信息。
所以我们通过这三个部分的判别函数来预测,
| (1) |
由于 ID 是一个索引,因此必须将其编码为实值才能应用基于梯度的优化方法。 One-hot 编码是一种基本工具,可将其编码为稀疏二进制向量,其中除 分量为 之外,所有分量均为 。 例如,
| (2) |
其中 是总共的 ID 数。 如果接着进行矩阵乘法,我们将得到 ID 的低维表示,即给定一个稠密矩阵 ,然后
| (3) |
是 ID 的结果 维稠密实值向量。 这样,ID就变成了低维稠密向量。
然而,由于 ID 通常有数百万个,one-hot 向量可能会非常大。 因此,如今更常见的是使用查找嵌入作为数学上等效的替代方案。 对于ID ,它直接从中查找行,
| (4) |
其中结果 与 (3) 中的相同。 稠密矩阵通常称为嵌入矩阵或查找表。
Log-loss经常被用作优化目标,即
| (6) |
在离线训练中,每个广告 ID 都有多个样本可用, 和 同时更新,以最大限度地减少随机梯度下降 (SGD) 的对数损失。
如果出现系统以前从未见过的 ID 怎么办? 这意味着我们从未获得广告的标记数据,因此嵌入矩阵中的相应行保持初始状态,例如零附近的随机数。 因此,测试精度会较低。 这被称为广告冷启动问题。
为了解决这个问题,我们的目标是设计一个嵌入生成器。 结构如图2(b)所示。 给定一个看不见的广告 ,生成器输入广告的特征 ,并且可以以某种方式输出“良好”的初始嵌入作为这些特征的函数,
现在我们解释了为什么我们要设计嵌入生成器来解决冷启动问题。 问题是,如何训练这样的嵌入生成器? 我们更新其参数的目的是什么? 为了实现冷启动预热的最终目标,我们提出了一种基于元学习的方法,该方法学习如何学习新的广告 ID 嵌入。 具体来说,嵌入生成器中的参数 是通过基于梯度的元学习利用先前学习的广告来训练的,这将在第 3 节中详细介绍。
3. 学习新广告的 ID 嵌入
在本节中,我们提出了元嵌入(Meta-Embedding),这是一种基于元学习的方法,用于学习新广告的 ID 嵌入,以解决广告冷启动问题。 首先,我们将 CTR 预测问题重新定义为元学习。 然后,我们提出了学习 ID 嵌入的学习框架,并介绍了由预训练模型和元嵌入生成器诱导的元学习器。 最后,我们详细介绍了模型架构和超参数。
3.1. 将点击率预测重塑为元学习
回想一下,(1) 中所示的 CTR 预测的最终目标是学习具有 ID 和两组特征输入的预测函数 。 只有将 ID 转换为实值向量后,我们才能开始学习参数化基础模型 ,如 (5) 所示。 因此,对于给定的广告,ID的嵌入隐含地决定了模型的隐藏结构。
为了从元学习的角度来看,我们引入了一种新的符号来将固定 ID 的预测模型编写为
| (7) |
请注意, 与 完全相同,其参数为 和。
通过这种方式,我们可以将 CTR 预测视为元学习的一个实例,将每个广告 ID 的学习问题视为一项独特的任务。 对于ID ,任务分别是学习特定于任务的模型。 它们共享基本模型中的同一组参数,同时维护其特定于任务的参数。
考虑一下我们可以访问 ID 为 的先前任务 (所有已知 ID 的集合)以及每个任务的多个训练样本。 对这些数据的原始(预)训练为我们提供了一组经过充分学习的共享参数 和所有先前 ID 的特定于任务的参数 。 然而,对于新的 ID ,我们不知道 。 所以我们希望了解如何利用这些旧ID的先前经验来学习。 这就是我们从元学习的角度看待CTR预测的冷启动问题。
3.2. 元嵌入
在本节中,我们提出了元嵌入,它捕获通过元学习学习新广告的 ID 嵌入的技能。
在上一节中,我们介绍了旧项目的共享参数和任务特定参数。 由于 通常是之前使用大量历史数据进行训练的,因此我们对其有效性充满信心。 因此,在训练元嵌入时,我们冻结 并且在整个过程中不更新它。 本文中的冷启动问题唯一重要的是如何学习新 ID 的嵌入。
回想一下,对于任何未见过的 ID,特定于任务的参数 都是未知的。 因此我们需要使用共享函数嵌入生成器来代替它。 对于 ID 为 的新广告,我们让
| (8) |
作为生成的初始嵌入,以简化符号。 那么由生成的嵌入导出的模型是
| (9) |
所以这里 是一个模型(元学习器),它输入特征并输出预测,不涉及嵌入矩阵。 它的可训练参数是来自 的元参数 。
现在我们描述使用旧 ID 模拟冷启动的详细过程,就像它们是新 ID 一样。 考虑到对于每个带有旧 ID 的任务 ,我们已经获得了训练样本 ,其中 是训练样本的数量给定 ID 的样本。
首先,我们随机选择两个不相交的小批量标记数据 和 ,每个小批量都有 样本。 假设小批量大小相对较小,即。
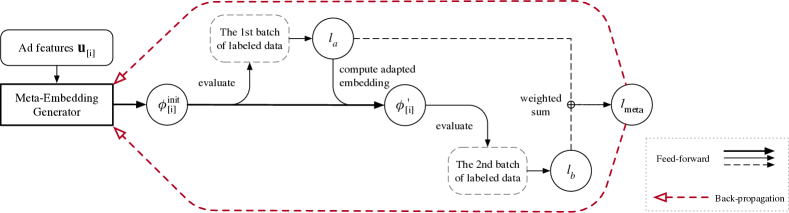
3.2.1. 冷启动阶段
我们首先使用 对第一个小批量 进行预测,如下所示
| (10) |
其中下标“”代表批次中的样本。 然后我们计算这些样本的平均损失
| (11) |
到目前为止,我们已经完成了冷启动阶段:我们通过生成器 生成嵌入 ,并在第一批数据上对其进行评估以获得损失 。
3.2.2. 热身阶段
接下来,我们用第二批数据模拟预热阶段的学习过程。
通过计算 相对于初始嵌入 的梯度并采取梯度下降步骤,我们得到了一个新的适应嵌入
| (12) |
其中是梯度下降的步长。
现在我们有了一个用最少数据训练的新嵌入,我们可以在第二批数据上测试它。 与前一部分类似,我们进行预测
| (13) |
并计算平均损失
| (14) |
3.2.3. 统一的优化目标
我们建议从两个方面评估初始嵌入的好坏:
-
(1)
新广告的CTR预测误差应该很小;
-
(2)
收集少量标记示例后,一些梯度更新应该可以实现快速学习。
令人惊讶的是,我们发现两个损失和分别可以完美地满足这两个方面。 在第一批中,由于我们使用生成的初始嵌入进行预测,因此 是在冷启动阶段评估生成器的自然指标。 对于第二批,由于嵌入已更新一次,因此 可以直接评估预热阶段的样本效率。
为了统一这两个损失,我们提出元嵌入的最终损失函数作为 和 的加权和,
| (15) |
其中是平衡两相的系数。
由于 是初始嵌入的函数,我们可以通过链式法则反向传播元参数 的梯度:
| (16) |
在哪里
| (17) |
虽然它涉及二阶导数,即 Hessian 向量,但它可以通过现有的允许自动微分的深度学习库有效地实现,例如 TensorFlow (Abadi 等人, 2016)。
请注意,元嵌入不仅可以使用离线数据集进行训练,还可以通过使用新兴的新 ID 作为训练示例,进行少量修改进行在线训练。
3.3. 架构和超参数
最后,我们讨论如何选择嵌入生成器的架构以及超参数。
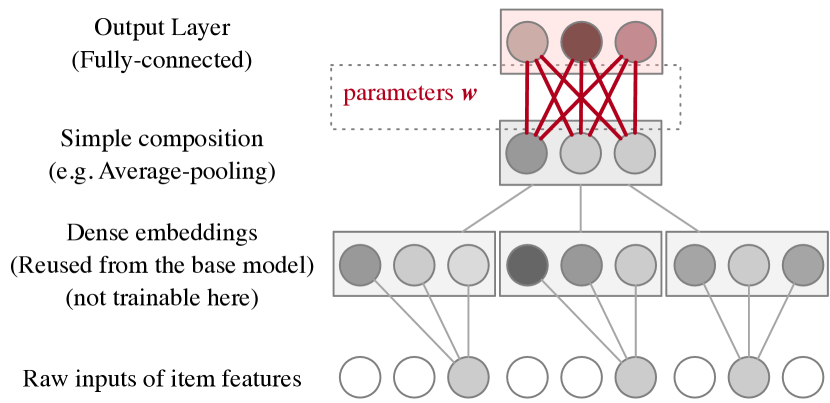
3.3.1. 的架构
原则上,我们希望嵌入生成器既简单又强大。 所以我们建议使用神经网络作为参数化函数。 任何常见的网络架构都可以用于元嵌入。
在这里,我们想展示一个生成器的实例,其有效性在我们的实验中进行了测试,见图5。 它简单且轻量级,因此如果有人想开始使用元嵌入,它可以是一个基本选择。
生成器网络的输入是广告特征。 但是,我们不需要从头开始训练生成器。 回想一下,在基础模型中,已经有广告特征的嵌入层,因此我们可以直接重用这些层。 我们建议冻结重用层的权重,以减少可训练参数的数量。 来自不同字段的嵌入可以通过平均池化、最大池化或连接来聚合。 最后,我们使用密集层来获取输出,这是生成器唯一可训练的部分。 我们可以通过在最后一层使用三个技巧来获得数值稳定的输出:1)使用 tanh 激活,2)不添加偏差项,3)使用 L2 正则化来惩罚权重。
3.3.2. 超参数
系数平衡冷启动损失和暖机损失。 由于实践中热身阶段通常比冷启动阶段涉及更多的时间步,因此我们建议将其设置为较小的值,以便元学习器更加关注热身阶段以实现快速适应。 根据经验,我们发现我们的算法对超参数具有鲁棒性。 对于所有实验,我们只需将 设置为 即可。
4. 实验
4.1. 数据集
我们在三个数据集上评估元嵌入:
MovieLens-1M222http://www.grouplens.org/datasets/movielens/:最著名的基准数据之一。 该数据由数千部电影和用户的 100 万个电影排名实例组成。 在我们的论文中,每部电影都可以被视为一则广告,其特征包括片名、发行年份和类型。 标题和流派是标记列表。 其他特征包括用户的 ID、年龄、性别和职业。 我们首先对评分进行二值化来模拟 CTR 预测任务,这通常用于测试二元分类方法(Kozma 等人,2009;Volkovs 和 Yu,2015)。 评分至少为 4 的变为 1,其他变为 0。 虽然这个数据集不是用于 CTR 预测的数据集,但它的小规模使我们能够轻松验证我们提出的方法的有效性。
腾讯App推荐CVR预测数据集: 2018年腾讯社交广告大赛公开数据集333http://algo.qq.com/ 点击次数超过 5000 万次。 每个实例都由广告、用户和二进制标签(转化)组成。 每个广告都有 6 个分类属性:广告商 ID、广告类别、营销活动 ID、应用 ID、应用大小和应用类型。 其他特征是用户属性,包括用户的性别、年龄、职业、消费能力、受教育程度、城市等。
KDD Cup 2012 搜索广告点击率预测数据集444https://www.kaggle.com/c/kddcup2012-track2:该数据集包含约 2 亿个源自腾讯专有搜索引擎 soso 会话日志的实例。 com。 每个广告都具有三个特征:关键字、标题和说明。 这些功能是从自然语言散列的匿名标记列表。 其他功能包括查询(也是 Token 列表)、两个会话功能以及用户的性别和年龄。
4.2. 基础型号
因为我们的元嵌入与模型无关,所以它可以应用于嵌入和 MLP 范式中的各种现有模型。 为了证明我们方法的有效性,我们对以下代表性模型进行了实验:
-
•
FM:2 路分解机(Rendle,2010)。 最初它使用 one-hot 编码和矩阵乘法来获取嵌入向量,而在我们的实现中我们直接使用查找嵌入。 为了提高效率,我们对一阶和二阶分量使用相同的嵌入向量。
-
•
Wide & Deep:由 Google 在 (Cheng 等人,2016) 中提出,它对低阶和高阶特征交互进行建模。 Wide 组件是一种 Logistic 回归,它将 one-hot 向量作为输入。 深层组件具有嵌入层和三个带有 ReLU 激活的密集隐藏层。
-
•
PNN:基于产品的神经网络(曲等人,2016)。 它首先将密集嵌入输入密集层和产品层,然后将它们连接在一起并使用另外两个密集层来获得预测。 正如他们的论文所建议的,我们使用三种变体:IPNN、OPNN 和 PNN*。 IPNN是具有内积层的PNN,OPNN是具有外积层的PNN,PNN*同时具有内积和外积。
-
•
DeepFM (Guo 等人,2017):一种最新的最先进的方法,可以学习领域之间的低级和高级交互。 它将密集嵌入输入到 FM 和深度组件中,然后连接它们的输出并通过密集层获得最终预测。 对于深层组件,我们按照(Guo等人,2017)中的建议使用三个ReLU层。
这些基础模型共享共同的嵌入和 MLP 结构。 对于我们所有的实验,每个输入字段的嵌入向量的维数都固定为 256。 对于MovieLens和KDD Cup数据集中的自然语言特征,我们首先将每个词符(单词)嵌入到256维的单词嵌入中,然后使用AveragePooling获得字段(句子)级别的表示。 换句话说,在嵌入层之后,每个字段分别嵌入到一个256维的向量中。
4.3. 实验设置
| Dataset | Minibatch size | Old ads | New ads | ||||
|---|---|---|---|---|---|---|---|
| # of IDs | # of samples | # of samples used to | # of IDs | # of samples | # of samples in | ||
| train Meta-Embedding | the hold-out set | ||||||
| MovieLens-1M | 20 | 1127 | 0.76 M | 0.09 M | 1058 | 0.19 M | 0.12 M |
| Tencent CVR data | 200 | 572 | 49.33 M | 0.45 M | 443 | 5.00 M | 4.74 M |
| KDD Cup 2012 | 200 | 6534 | 148.55 M | 5.22 M | 9299 | 28.71 M | 23.13 M |
4.3.1. 数据集分割
为了评估冷启动广告在两个阶段的性能,我们通过分割数据集进行实验。 首先,我们按大小对广告进行分组:
-
•
旧广告:标记实例数大于阈值的广告。由于三个数据集的数据量不同,我们对MovieLens-1M、腾讯使用了、和中的分别是 CVR 数据和 KDD Cup 数据。
-
•
新广告:标记实例数小于但大于的广告,其中是第3节中提到的小批量大小。 之所以设置最小样本数,是为了保证在预热阶段切割个样本后,仍然剩余一定数量的样本进行测试。 对于三个数据集, 分别设置为 、 和 。
数据分割的摘要可以在表1中看到。 我们设置阈值,使新广告的数量接近旧广告的数量,尽管新广告的数据量要小得多。
4.3.2. 实验管线
首先,我们使用旧广告来预训练基本模型。 然后我们用它们进行元嵌入的离线训练。 用于训练Meta-Embedding的样本数量也可以在表1中找到。 训练后,它会在新广告上进行测试。 对于每个新广告,我们在 3 个小批量上一一进行训练,就像它们是热身数据一样,命名为批量 a、-b 和 -c,每个批量都有 实例。 新广告的其他实例正在等待测试。
实验按以下步骤完成:
-
0.
使用旧广告的数据(1 个时期)预训练基本模型。
-
1.
使用训练数据训练元嵌入(2 个时期)。
-
2.
使用(随机初始化或元嵌入)生成新广告 ID 的初始嵌入。
-
3.
评估保持集的冷启动性能;
-
4.
使用batch-a更新新广告ID的嵌入,并计算保留集的评估指标;
-
5.
使用batch-b更新新广告ID的嵌入,并计算保留集上的评估指标;
-
6.
使用batch-c更新新广告ID的嵌入并计算保留集的评估指标;
与预训练步骤相比,元嵌入的训练工作量非常小。 我们在每个时期/广告中使用 个样本对其进行训练,因此涉及的样本数量仅为(旧 ID 数)。 实际数量见表1。
4.3.3. 评估指标
我们采用两个常用指标来评估结果,即对数损失和 AUC 分数(接收器操作员特征曲线下的面积)。 所有指标仅在保留集上进行评估。
为了提高可读性,我们将显示相对于基线冷启动分数的相对改进百分比:
| LogLoss_precentage | |||
| AUC_precentage |
其中“base-cold”是指由基础模型生成的冷启动分数,其中随机初始化了未见过的 ID 的嵌入。 因此,对于 LogLoss,百分比越负越好。 对于AUC来说,百分比是正数,越大越好。 请注意,这个“base-cold”是一个强基线,因为它具有所有可用的温暖内容,并且是工业界常用的。
4.4. 实验结果
| Dataset | Metrics | Cold-Start phase | Warm-Up phase: a | Warm-Up phase: b | Warm-Up phase: c | ||||
|---|---|---|---|---|---|---|---|---|---|
| baseline | Meta | baseline | Meta | baseline | Meta | baseline | Meta | ||
| MovieLens-1M | AUC percentage | 0.0% | +3.36% | +7.02% | +8.66% | +9.25% | +10.40% | +10.27% | +11.15% |
| Logloss percentage | 0.0% | -10.23% | -7.83% | -16.42% | -11.45% | -18.93% | -13.53% | -20.20% | |
| Tencent CVR data | AUC percentage | 0.0% | +0.50% | +0.60% | +0.99% | +1.16% | +1.47% | +1.57% | +1.83% |
| LogLoss percentage | 0.0% | -0.19% | -0.30% | -0.44% | -0.55% | -0.65% | -0.71% | -0.79% | |
| KDD Cup 2012 | AUC percentage | 0.0% | +0.73% | +2.34% | +2.76% | +3.56% | +3.87% | +4.36% | +4.61% |
| Search Ads CTR | LogLoss percentage | 0.0% | -1.52% | -1.97% | -2.99% | -3.06% | -3.82% | -3.79% | -4.40% |
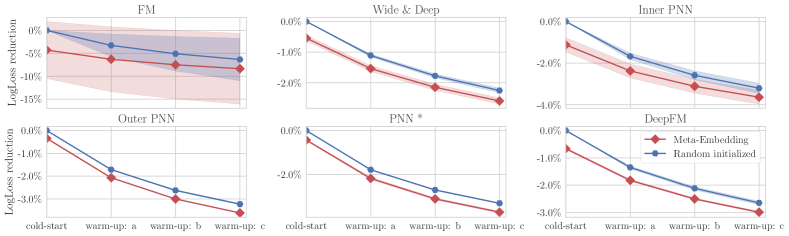
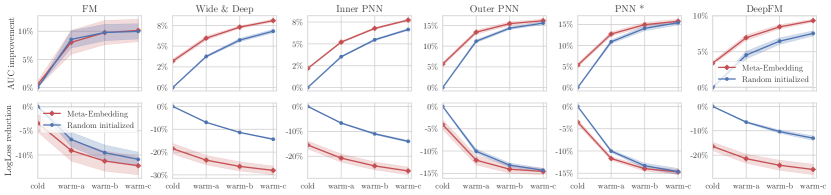
对于每个实验,我们进行了三次运行并报告了平均性能。 主要实验结果如表2所示。
我们首先在 MovieLens-1M 上看到结果。 图6展示了每个测试模型的详细性能。 我们观察到,使用元嵌入时,与随机初始化基线相比,大多数模型产生了更好的 AUC 和 LogLoss 结果。 虽然系数的超参数设置为0.1,因此主要关注的是预热损失,但它在冷启动阶段仍然表现得很好。 例如,当使用 Wide&Deep、IPNN 和 DeepFM 作为基础模型时,Meta-Embedding 在冷启动阶段提供了超过 15% 的 LogLoss 降低。 经过三次预热更新后,Meta-Embedding 仍然优于基线,因此我们有信心 Meta-Embedding 可以提高新广告的样本效率。
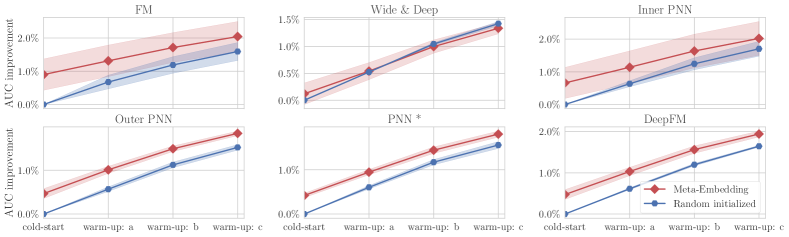
在两个较大的数据集上,Meta-Embedding 也取得了相当大的改进,如表2所示。 由于篇幅限制,我们只展示了部分详细结果:图7展示了在腾讯CVR预测数据集上的AUC改进,图8展示了在腾讯CVR预测数据集上的LogLoss KDD Cup 搜索广告数据集。
一个有趣的发现是,较小数据集 (MovieLens) 上的相对改进比较大数据集更显着。 为了解释一下,请记住,MovieLens 中的训练示例数量要少得多,因此共享的预训练模型参数 可能不够好。 因此,在这种情况下,冷启动广告可能会有更大的改进空间,例如,Meta-Embedding有时可以比随机初始化基线提高一倍。
对于大多数实验,通过用元嵌入代替随机初始化,分数得到了极大的提高。 但也有一些表现参差不齐的情况。 例如,对于以 FM 作为基础模型的 MovieLens,Meta-Embedding 具有与基线相似的 AUC。 但是Meta-Embedding的LogLoss更小,所以我们仍然可以肯定Meta-Embedding可以帮助FM。 对于腾讯CVR数据中的Wide & Deep(见图7),在第三次预热更新后,基线有超过Meta-Embedding的趋势。 不过,这种情况仅发生在腾讯CVR数据上。 我们认为这是由于“Wide”组件直接使用原始输入造成的。 我们推测这主要是因为该数据集仅具有分类输入。 在另外两个数据集中,存在顺序输入,因此“Wide”组件不能主导性能。
总的来说,我们观察到元嵌入能够显着提高冷启动广告的点击率和转化率预测,并且可以适用于我们比较中几乎所有测试的基础模型和数据集。
5. 相关工作
A. 解决冷启动问题的方法
有两种方法。 第一类通过设计决策策略主动解决冷启动问题,例如使用上下文老虎机(Li等人,2010;Caron和Bhagat,2013;Nguyen等人,2014;Tang等人,2015;Shah等人, 2017; Pan 等人, 2018a),或者设计访谈来收集冷项或用户的信息(Park 等人, 2006; Zhou 等人, 2011; Golbandi 等人, 2011; Harpale 和 Yang,2008)。
本文属于第二种类型,在在线监督学习框架内处理冷启动。 冷启动阶段通常使用辅助信息,例如使用用户属性(Seroussi等人,2011;Zhang等人,2014;Roy和Guntuku,2016;Volkovs等人,2017),项目属性 (Zhang 等人,2014;Saveski 等人,2014;Schein 等人,2002;Gu 等人,2010;Mo 等人,2015;Volkovs 等人,2017;Vartak 等人,2017) ,或关系数据(姚等人,2014;林等人,2013;赵等人,2016)。 这些方法可以被视为我们的“基础冷”基线,具有不同的输入和模型结构,而不使用广告 ID。 与不使用这些功能的经典方法相比,它们当然可以提高冷启动性能。 但他们并没有考虑广告 ID 是否会优化以改善预热阶段。 相反,我们的方法不仅使用所有可用的功能,而且旨在提高冷启动和预热性能。
对于在线推荐,许多研究有助于改善在线学习并加速增量数据的模型拟合。 例如,(Sarwar等人,2002;Takács等人,2008)用增量数据调整矩阵分解因子; (Xu 等人, 2017) 使用评分比较策略来学习潜在特征。 这些方法可以用少量数据更快地学习,但如果没有新广告的样本,则无法直接应用。 此外,这些方法大多是为矩阵分解而设计的,因此将它们应用于深度前馈模型并不直接。 与这些方法不同,Meta-Embedding 改进了冷启动和预热阶段的 CTR 预测,并且专为具有 Embedding 和 MLP 结构的深度模型而设计。
Dropout-Net (Volkovs 等人, 2017) 通过将 Dropout 应用于深度协同过滤模型来处理丢失的输入,这可以被视为预训练基础模型的成功方法。 但由于本文关注的是一般点击率预测而不是协同过滤,因此我们没有将其包含在我们的实验中。
B.元学习
它学习如何利用相关任务的先前经验来学习新任务(Vilalta 和 Drissi,2002;Finn 等人,2017;Vanschoren,2018)。 它引发了人们对许多领域的兴趣,例如推荐(Vartak等人,2017)、自然语言处理(Xu等人,2018;Kiela等人,2018)和计算机视觉(Choi 等人,2017;Finn 等人,2017)。
我们研究如何预热冷启动广告。 在元学习文献中,这个问题涉及少样本学习(Lake等人,2015)和快速适应(Finn等人,2017;Grant等人,2018) 。 具体来说,我们遵循 MAML (Finn 等人,2017) 的类似精神,这是一种基于梯度的元学习方法,可以学习跨任务的共享模型参数并实现对新任务的快速适应。 然而,MAML 不能直接应用于 CTR 预测,因为它被设计为每个任务学习一个模型,如果有数百万个任务(广告),这是不可接受的。
Vartak 等人(Vartak 等人, 2017) 最近的一项工作也利用了元学习来进行项目冷启动。 它通过用户之前标记的项目的平均表示来表示每个用户。 我们的方法不会对用户活动进行建模,而只专注于学习项目(广告)的 ID 嵌入。
在自然语言处理中,还有另一种所谓的“元嵌入”,它通过聚合来自先前域 的预训练词向量来学习新语料库的词嵌入(Yin 和 Schütze,2016;Xu 等人,2018) ; Kiela 等人, 2018). 它是专门针对NLP的,与我们的没有共同点。
6. 结论与讨论
在本文中,我们提出了一种元学习方法来解决点击率预测的冷启动问题。 我们提出了 Meta-Embedding,其重点是学习如何学习新广告的 ID 嵌入,以便应用于 CTR 预测的最先进的深度模型。 基于预训练的基本模型,我们建议对之前学习的广告进行两阶段模拟来训练元嵌入生成器。 我们寻求通过利用统一的训练损失函数来提高冷启动和热身性能。 之后,在测试时,经过训练的生成器可以初始化新广告的 ID 嵌入,这在冷启动和预热阶段都产生了显着的改进。 据我们所知,这是第一项旨在改善通用在线监督学习框架下新广告冷启动和热身阶段点击率预测的工作。 我们在六个最先进的点击率预测模型的三个现实数据集上验证了元嵌入。 实验表明,通过用元嵌入代替简单的随机初始化,可以显着提高冷启动和预热性能。
这是一项有趣的工作,它将表征学习与学习学习联系起来,特别是对于包括广告和推荐在内的在线学习任务。 本文重点关注学习广告 ID 的嵌入,这是在线 CTR/CVR 预测的知识表示的特定组成部分。 对于未来的工作,这种洞察力还可以扩展到其他任务,例如,学习当特征和标签的分布随时间演变时学习模型,或者学习调整特定子任务的超参数。
7. 致谢
该工作得到了国家重点研发计划项目的部分支持,批准号为: 2017YFB1002104,国家自然科学基金项目,批准号: U1811461, 61602438, 91846113, 61573335, CCF-腾讯犀牛鸟青年教师开放科研基金编号 RAGR20180111。 这项工作也由蚂蚁金服通过蚂蚁金服安全研究科学基金提供部分资助。 翔翱还得到了中国科学院青年创新促进会的支持。
唐平中的研究得到了国家自然科学基金项目61561146398、中国青年千人计划和阿里巴巴创新研究计划的部分支持。
参考
- (1)
- Abadi et al. (2016) Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation. 265–283.
- Caron and Bhagat (2013) Stéphane Caron and Smriti Bhagat. 2013. Mixing bandits: A recipe for improved cold-start recommendations in a social network. In Proceedings of the 7th Workshop on Social Network Mining and Analysis. ACM, 11.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 7–10.
- Choi et al. (2017) Janghoon Choi, Junseok Kwon, and Kyoung Mu Lee. 2017. Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space. arXiv preprint arXiv:1712.09153 (2017).
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In International Conference on Machine Learning. 1126–1135.
- Golbandi et al. (2011) Nadav Golbandi, Yehuda Koren, and Ronny Lempel. 2011. Adaptive bootstrapping of recommender systems using decision trees. In Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 595–604.
- Grant et al. (2018) Erin Grant, Chelsea Finn, Sergey Levine, Trevor Darrell, and Thomas Griffiths. 2018. Recasting gradient-based meta-learning as hierarchical bayes. arXiv preprint arXiv:1801.08930 (2018).
- Gu et al. (2010) Quanquan Gu, Jie Zhou, and Chris Ding. 2010. Collaborative filtering: Weighted nonnegative matrix factorization incorporating user and item graphs. In Proceedings of the 2010 SIAM international conference on data mining. SIAM, 199–210.
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. AAAI Press, 1725–1731.
- Harpale and Yang (2008) Abhay S Harpale and Yiming Yang. 2008. Personalized active learning for collaborative filtering. In Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 91–98.
- Juan et al. (2017) Yuchin Juan, Damien Lefortier, and Olivier Chapelle. 2017. Field-aware factorization machines in a real-world online advertising system. In Proceedings of the 26th International Conference on World Wide Web Companion. International World Wide Web Conferences Steering Committee, 680–688.
- Kiela et al. (2018) Douwe Kiela, Changhan Wang, and Kyunghyun Cho. 2018. Dynamic Meta-Embeddings for Improved Sentence Representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 1466–1477.
- Kozma et al. (2009) László Kozma, Alexander Ilin, and Tapani Raiko. 2009. Binary principal component analysis in the Netflix collaborative filtering task. In IEEE International Workshop on Machine Learning for Signal Processing, 2009. IEEE, 1–6.
- Lake et al. (2015) Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. 2015. Human-level concept learning through probabilistic program induction. Science 350, 6266 (2015), 1332–1338.
- Li et al. (2010) Lihong Li, Wei Chu, John Langford, and Robert E Schapire. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web. ACM, 661–670.
- Lin et al. (2013) Jovian Lin, Kazunari Sugiyama, Min-Yen Kan, and Tat-Seng Chua. 2013. Addressing cold-start in app recommendation: latent user models constructed from twitter followers. In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. ACM, 283–292.
- Mo et al. (2015) Kaixiang Mo, Bo Liu, Lei Xiao, Yong Li, and Jie Jiang. 2015. Image Feature Learning for Cold Start Problem in Display Advertising.. In IJCAI. 3728–3734.
- Nguyen et al. (2014) Hai Thanh Nguyen, Jérémie Mary, and Philippe Preux. 2014. Cold-start problems in recommendation systems via contextual-bandit algorithms. arXiv preprint arXiv:1405.7544 (2014).
- Pan et al. (2018a) Feiyang Pan, Qingpeng Cai, Pingzhong Tang, Fuzhen Zhuang, and Qing He. 2018a. Policy Gradients for Contextual Recommendations. arXiv preprint arXiv:1802.04162v3 (2018).
- Pan et al. (2018b) Feiyang Pan, Qingpeng Cai, An-Xiang Zeng, Chun-Xiang Pan, Qing Da, Hualin He, Qing He, and Pingzhong Tang. 2018b. Policy Optimization with Model-based Explorations. arXiv preprint arXiv:1811.07350 (2018).
- Pan et al. (2018c) Junwei Pan, Jian Xu, Alfonso Lobos Ruiz, Wenliang Zhao, Shengjun Pan, Yu Sun, and Quan Lu. 2018c. Field-weighted factorization machines for click-through rate prediction in display advertising. In Proceedings of the 2018 World Wide Web Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 1349–1357.
- Park et al. (2006) Seung-Taek Park, David Pennock, Omid Madani, Nathan Good, and Dennis DeCoste. 2006. Naïve filterbots for robust cold-start recommendations. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 699–705.
- Qu et al. (2016) Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying Wen, and Jun Wang. 2016. Product-based neural networks for user response prediction. In IEEE 16th International Conference on Data Mining (ICDM). IEEE, 1149–1154.
- Rendle (2010) Steffen Rendle. 2010. Factorization machines. In IEEE 10th International Conference on Data Mining (ICDM). IEEE, 995–1000.
- Rendle et al. (2011) Steffen Rendle, Zeno Gantner, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2011. Fast context-aware recommendations with factorization machines. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 635–644.
- Roy and Guntuku (2016) Sujoy Roy and Sharath Chandra Guntuku. 2016. Latent factor representations for cold-start video recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 99–106.
- Sarwar et al. (2002) Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2002. Incremental singular value decomposition algorithms for highly scalable recommender systems. In Fifth International Conference on Computer and Information Science. Citeseer, 27–28.
- Saveski and Mantrach (2014) Martin Saveski and Amin Mantrach. 2014. Item cold-start recommendations: learning local collective embeddings. In Proceedings of the 8th ACM Conference on Recommender systems. ACM, 89–96.
- Schein et al. (2002) Andrew I Schein, Alexandrin Popescul, Lyle H Ungar, and David M Pennock. 2002. Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 253–260.
- Seroussi et al. (2011) Yanir Seroussi, Fabian Bohnert, and Ingrid Zukerman. 2011. Personalised rating prediction for new users using latent factor models. In Proceedings of the 22nd ACM conference on Hypertext and hypermedia. ACM, 47–56.
- Shah et al. (2017) Parikshit Shah, Ming Yang, Sachidanand Alle, Adwait Ratnaparkhi, Ben Shahshahani, and Rohit Chandra. 2017. A practical exploration system for search advertising. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1625–1631.
- Takács et al. (2008) Gábor Takács, István Pilászy, Bottyán Németh, and Domonkos Tikk. 2008. Investigation of various matrix factorization methods for large recommender systems. In IEEE International Conference on Data Mining Workshops, 2008. IEEE, 553–562.
- Tang et al. (2015) Liang Tang, Yexi Jiang, Lei Li, Chunqiu Zeng, and Tao Li. 2015. Personalized recommendation via parameter-free contextual bandits. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 323–332.
- Vanschoren (2018) Joaquin Vanschoren. 2018. Meta-Learning: A Survey. arXiv preprint arXiv:1810.03548 (2018).
- Vartak et al. (2017) Manasi Vartak, Arvind Thiagarajan, Conrado Miranda, Jeshua Bratman, and Hugo Larochelle. 2017. A Meta-Learning Perspective on Cold-Start Recommendations for Items. In Advances in Neural Information Processing Systems. 6904–6914.
- Vilalta and Drissi (2002) Ricardo Vilalta and Youssef Drissi. 2002. A perspective view and survey of meta-learning. Artificial Intelligence Review 18, 2 (2002), 77–95.
- Volkovs et al. (2017) Maksims Volkovs, Guangwei Yu, and Tomi Poutanen. 2017. DropoutNet: Addressing Cold Start in Recommender Systems. In Advances in Neural Information Processing Systems. 4957–4966.
- Volkovs and Yu (2015) Maksims Volkovs and Guang Wei Yu. 2015. Effective latent models for binary feedback in recommender systems. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 313–322.
- Xu et al. (2018) Hu Xu, Bing Liu, Lei Shu, and Philip S Yu. 2018. Lifelong Domain Word Embedding via Meta-Learning. arXiv preprint arXiv:1805.09991 (2018).
- Xu et al. (2017) Jingwei Xu, Yuan Yao, Hanghang Tong, Xianping Tao, and Jian Lu. 2017. R a P are: A Generic Strategy for Cold-Start Rating Prediction Problem. IEEE Transactions on Knowledge and Data Engineering 29, 6 (2017), 1296–1309.
- Yao et al. (2014) Yuan Yao, Hanghang Tong, Guo Yan, Feng Xu, Xiang Zhang, Boleslaw K Szymanski, and Jian Lu. 2014. Dual-regularized one-class collaborative filtering. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management. ACM, 759–768.
- Yin and Schütze (2016) Wenpeng Yin and Hinrich Schütze. 2016. Learning Word Meta-Embeddings. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Vol. 1. 1351–1360.
- Zhang et al. (2014) Mi Zhang, Jie Tang, Xuchen Zhang, and Xiangyang Xue. 2014. Addressing cold start in recommender systems: A semi-supervised co-training algorithm. In Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval. ACM, 73–82.
- Zhao et al. (2016) Wayne Xin Zhao, Sui Li, Yulan He, Edward Y Chang, Ji-Rong Wen, and Xiaoming Li. 2016. Connecting social media to e-commerce: Cold-start product recommendation using microblogging information. IEEE Transactions on Knowledge and Data Engineering 28, 5 (2016), 1147–1159.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 1059–1068.
- Zhou et al. (2011) Ke Zhou, Shuang-Hong Yang, and Hongyuan Zha. 2011. Functional matrix factorizations for cold-start recommendation. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 315–324.