混合匹配:
半监督学习的整体方法
摘要
半监督学习已被证明是利用未标记数据来减轻对大型标记数据集的依赖的强大范例。 在这项工作中,我们统一了当前半监督学习的主导方法,以产生一种新算法 ,该算法猜测数据增强的未标记示例的低熵标签,并使用 。 在许多数据集和标记数据量中大幅获得了最先进的结果。 例如,在具有 250 个标签的 CIFAR-10 上,我们将错误率降低了 4 倍(从 到 ),在 STL-10 上将错误率降低了 2 倍。 我们还演示了 如何帮助实现差异隐私的显着更好的准确性与隐私权衡。 最后,我们进行了一项消融研究,以梳理 的哪些组成部分对其成功最重要。 我们发布了实验中使用的所有代码。111https://github.com/google-research/mixmatch
1简介
最近在训练大型深度神经网络方面取得的成功很大程度上要归功于大型标记数据集的存在。 然而,对于许多学习任务来说,收集标记数据的成本很高,因为它必然涉及专业知识。 这也许可以通过医疗任务来最好地说明,其中测量需要昂贵的机器,而标签是多名人类专家耗时分析的结果。 此外,数据标签可能包含私人信息。 相比之下,在许多任务中,获取未标记的数据要容易得多,成本也便宜得多。
半监督学习[6] (SSL) 旨在通过允许模型利用未标记数据来很大程度上减轻对标记数据的需求。 最近的许多半监督学习方法都添加了一个损失项,该损失项是在未标记的数据上计算的,并鼓励模型更好地泛化到未见过的数据。 在最近的许多工作中,该损失项属于三类之一(在部分2中进一步讨论):熵最小化[18 ,28]——鼓励模型对未标记的数据输出可信的预测;一致性正则化——鼓励模型在输入受到扰动时产生相同的输出分布;通用正则化——鼓励模型更好地泛化训练并避免过度拟合数据。
在本文中,我们介绍了 ,这是一种 SSL 算法,它引入了一个单一损失,优雅地统一了半监督学习的这些主要方法。 与以前的方法不同, 一次性定位所有属性,我们发现这会带来以下好处:
-
•
通过实验,我们表明 在所有标准图像基准上获得了最先进的结果(section 4.2 ),并将 CIFAR-10 上的错误率降低 4 倍;
-
•
我们在消融研究中进一步表明 大于其各部分之和;
-
•
我们在部分4.3中证明对于差异化私人学习非常有用,使学生能够使用PATE框架 [36]以获得新的最先进的结果,同时加强隐私保证和准确性。
简而言之,为未标记数据引入了一个统一的损失项,可以无缝地减少熵,同时保持一致性并与传统正则化技术保持兼容。

2相关工作
为了为 做好准备,我们首先介绍 SSL 的现有方法。 我们主要关注当前最先进的以及 构建的那些;关于 SSL 技术有大量文献,我们在此不予讨论(例如,“传导”模型 [14, 22, 21]、基于图的方法 [49, 4, 29] ,生成建模[3,27,41,9,17,23,38,34,42]等)。 [49, 6] 中提供了更全面的概述。 在下文中,我们将引用一个通用模型 ,它为带有参数 的输入 生成类标签 上的分布>。
2.1 一致性正则化
监督学习中常见的正则化技术是数据增强,它应用假设不影响类语义的输入转换。 例如,在图像分类中,通常会对输入图像进行弹性变形或添加噪声,这可以显着改变图像的像素内容,而不改变其标签[7,43,10]。 粗略地说,这可以通过生成近乎无限的新的修改数据流来人为地扩展训练集的大小。 一致性正则化利用这样的思想,即分类器即使在增强后也应该为未标记的示例输出相同的类分布,从而将数据增强应用于半监督学习。 更正式地说,一致性正则化强制将未标记的示例 分类为与 相同的类别,这是其自身的增强。
在最简单的情况下,对于未标记的点 ,先前的工作 [25, 40] 添加了损失项
| (1) |
请注意, 是随机变换,因此 eq. 1 中的两项并不相同。 “Mean Teacher”[44] 将 eq. 1 中的一项替换为模型的输出使用模型参数值的指数移动平均值。 这提供了更稳定的目标,并且根据经验发现可以显着改善结果。 这些方法的缺点是它们使用特定领域的数据增强策略。 “Virtual Adversarial 训练”[31](VAT)通过计算加性扰动来应用于输入,从而最大程度地改变输出类分布来解决这个问题。 MixMatch 通过使用图像的标准数据增强(随机水平翻转和裁剪)来利用一致性正则化的形式。
2.2 熵最小化
许多半监督学习方法中的一个常见基本假设是分类器的决策边界不应穿过边缘数据分布的高密度区域。 强制执行此操作的一种方法是要求分类器对未标记的数据输出低熵预测。 这是在 [18] 中明确完成的,并使用一个损失项来最小化未标记数据 的 的熵。 这种形式的熵最小化与 [31] 中的 VAT 相结合,以获得更强的结果。 “伪标签”[28] 通过根据未标记数据的高置信度预测构建硬(1-热)标签并将其用作标准交叉熵损失中的训练目标,隐式实现熵最小化。 MixMatch 还通过对未标记数据的目标分布使用“锐化”函数来隐式实现熵最小化,如部分3.2中所述。
2.3 传统正则化
正则化是指对模型施加约束的一般方法,以使其更难记住训练数据,从而希望使其更好地泛化到未见过的数据[19]。 我们使用权重衰减来惩罚模型参数 [30, 46] 的 范数。 我们还在 中使用 [47] 来鼓励示例之间的凸行为。 我们利用 作为正则化器(应用于标记数据点)和半监督学习方法(应用于未标记数据点)。 之前已经应用于半监督学习;特别是,[45] 的并发工作使用 MixMatch 中使用的方法的子集。 我们澄清了消融研究中的差异(部分 4.2.3)。
3混合匹配
在本节中,我们介绍我们提出的半监督学习方法。 是一种“整体”方法,它融合了 部分 2 中讨论的 SSL 主流范例的思想和组件。 给定一批 带有单热目标的标记示例(代表 可能的标签之一)和一批大小相同的 未标记示例, 生成一批经过处理的增强标记示例 和一批带有“猜测”标签 的增强未标记示例。 然后使用 和 计算单独的标记和未标记损失项。 更正式地说,半监督学习的组合损失 定义为
| (2) | ||||
| (3) | ||||
| (4) | ||||
| (5) |
其中 是分布 和 之间的交叉熵,以及 、、和是下面描述的超参数。 algorithm 1中提供了完整的算法,标签猜测过程的图解如图1。 接下来我们对的各个部分进行描述。
3.1 数据增强
3.2 标签猜测
对于 中的每个未标记示例, 使用模型的预测生成示例标签的“猜测”。 这个猜测后来被用在无监督损失术语中。 为此,我们计算 的所有 增强中模型的预测类分布的平均值:
| (6) |
锐化。
3.3混合
我们使用 进行半监督学习,与过去的 SSL 工作不同,我们将带标签的示例和未带标签的示例与标签猜测混合在一起(按照 部分 中所述生成) 3.2)。 为了与我们单独的损失术语兼容,我们定义了稍加修改的版本。 对于具有相应标签概率 的两个示例,我们通过以下方式计算
| (8) | ||||
| (9) | ||||
| (10) | ||||
| (11) |
其中 是超参数。 Vanilla 省略 eq. 9 (即它设置 )。 鉴于标记和未标记的示例在同一批次中连接,我们需要保留批次的顺序以适当地计算各个损失分量。 这是通过 eq. 9 实现的,它确保 比 更接近 。 要应用 ,我们首先将所有增强的标记示例及其标签和所有未标记示例及其猜测的标签收集到
| (12) | ||||
| (13) |
(算法 1,第 10–11 行)。 然后,我们组合这些集合并将结果打乱以形成 ,它将作为 的数据源(算法 1 ,第 12 行)。 对于 中的每个 示例标签对,我们计算 并将结果添加到集合 ( 算法 1,第13行)。 我们计算 的 ,有意使用 的剩余部分,该剩余部分未在 的构造中使用(算法 1,第14行)。 总而言之,将转换为,这是一组经过数据增强的标记示例和(可能与未标记的示例)应用。 类似地, 被转换为 ,即每个未标记示例的多个增强的集合以及相应的标签猜测。
3.4损失函数
3.5超参数
Since combines multiple mechanisms for leveraging unlabeled data, it introduces various hyperparameters – specifically, the sharpening temperature , number of unlabeled augmentations , parameter for in , and the unsupervised loss weight . 在实践中,具有许多超参数的半监督学习方法可能会出现问题,因为小验证集[35,39,35]很难进行交叉验证。 然而,我们在实践中发现,大多数 的超参数都是可以固定的,不需要在每个实验或每个数据集的基础上进行调整。 具体来说,对于所有实验,我们设置 和 。 此外,我们仅针对每个数据集更改 和 ;我们发现 和 是调整的良好起点。 在所有实验中,我们在训练的前 步中将 线性提升至最大值,这是常见的做法 [44]。
4实验
4.1实现细节
除非另有说明,在所有实验中我们都使用[35]中的“Wide ResNet-28”模型。 我们的模型和训练过程的实现与 [35] 的实现非常匹配(包括使用 5000 个示例来选择超参数),但存在以下差异:首先,我们评估的不是衰减学习率,而是评估模型使用其参数的指数移动平均值,衰减率为 。 其次,我们在 Wide ResNet-28 模型的每次更新时应用 的权重衰减。 最后,我们对每个 个训练样本进行检查,并报告最后 20 个检查点的中位错误率。 这简化了分析,但可能会降低准确性,例如,对检查点 [2] 进行平均或选择验证误差最低的检查点。
4.2半监督学习
首先,我们在四个标准基准数据集上评估 的有效性:CIFAR-10 和 CIFAR-100 [24]、SVHN [32]、和 STL-10 [8]。 在前三个数据集上评估半监督学习的标准做法是将大部分数据集视为未标记数据,并使用一小部分作为标记数据。 STL-10是专门为SSL设计的数据集,包含5,000张标记图像和100,000张未标记图像,这些图像的分布与标记数据的分布略有不同。
4.2.1 基线方法
作为基线,我们考虑 [35] 中考虑的四种方法(-模型 [25, 40]、Mean Teacher [44 ]、虚拟对抗训练[31]和伪标签[28]),在部分中进行了描述2。 我们还使用 [47] 本身作为基线。 被设计为监督学习的正则化器,因此我们通过将其应用于增强的标记示例和增强的未标记示例及其相应的预测来针对 SSL 对其进行修改。 根据的标准用法,我们在生成的猜测标签和模型的预测之间使用交叉熵损失。 正如[35]所提倡的,我们在同一代码库中重新实现了这些方法,并将它们应用于同一模型(在部分中描述4.1)以确保公平比较。 我们重新调整了每种基线方法的超参数,与[35]相比,这通常会带来边际精度的提高,从而为测试提供更具竞争力的实验设置>。
![[Uncaptioned image]](x2.png)
![[Uncaptioned image]](x3.png)
4.2.2结果
CIFAR-10
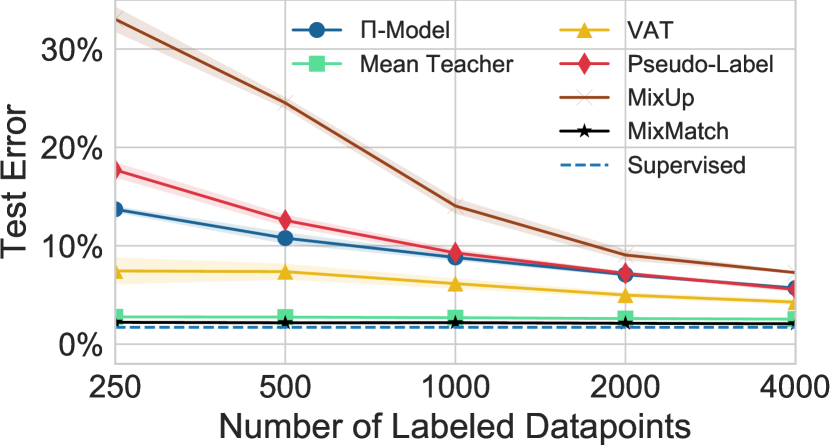
对于 CIFAR-10,我们使用从 到 的不同数量的标记示例来评估每种方法的准确性(这是标准做法)。 结果如图图2所示。 我们对 CIFAR-10 使用 。 我们为每个标记点数量创建了 5 个分割,每个分割都有不同的随机种子。 每个模型都在每次分割上进行训练,并通过分割之间的平均值和方差来报告错误率。 我们发现 明显优于所有其他方法,例如使用 标签达到 的错误率。 作为参考,在同一模型上,所有 样本上的完全监督训练实现了 的错误率。 此外,仅使用 标签时 的错误率为 。 为了进行比较,在 标签处,表现次佳的方法 (VAT [31]) 的错误率达到 ,超过 高于 考虑到 是我们在完全监督学习的模型上获得的错误极限。 此外,在 标签处,下一个表现最好的方法(Mean Teacher [44])获得的错误率为 ,这表明 只需使用 数量的标签即可实现类似的性能。 我们认为,最有趣的比较是与很少的标记数据点的比较,因为它揭示了该方法的样本效率,而这对于 SSL 至关重要。
CIFAR-10 和 CIFAR-100 以及更大的型号
一些先前的工作[44, 2]也考虑使用更大的百万参数模型。 [35] 中使用的基本模型只有 万个参数,这使得与这些结果的比较变得混乱。 为了与这些结果进行更合理的比较,我们测量了增加基础 ResNet 模型宽度的效果,并评估 在具有 的 28 层 Wide Resnet 模型上的性能> 每层进行过滤,产生 万个参数。 我们还在带有 标签的 CIFAR-100 上的更大模型上评估 ,以与 [2] 的相应结果进行比较。 结果如表2所示。 一般来说, 匹配或优于 [2] 的最佳结果,但我们注意到,由于 [44 中的模型, 2] 还使用了更复杂的“摇动”正则化[15]。 对于此模型,我们使用了 的权重衰减。 我们对 CIFAR-10 使用 ,对 CIFAR-100 使用 。
| Method | CIFAR-10 | CIFAR-100 |
|---|---|---|
| Mean Teacher [44] | - | |
| SWA [2] | ||
| Method | labels | labels |
| CutOut [12] | - | |
| IIC [20] | - | |
| SWWAE [48] | - | |
| CC-GAN2 [11] | - | |
| 5.59 |
SVHN 和 SVHN+Extra
与 CIFAR-10 一样,我们使用从 到 不同数量的标签来评估每种 SSL 方法在 SVHN 上的性能。 按照标准做法,我们首先考虑将 -example 训练集分为标记数据和未标记数据的设置。 结果如图图3所示。 我们使用了。 在这里,模型再次针对每个标记点数量进行 5 次分割评估,每个分割具有不同的随机种子。 我们发现 在所有标记数据量中的性能相对稳定(并且优于所有其他方法)。 令人惊讶的是,经过额外的调整,我们能够从 Mean Teacher [44] 获得非常好的性能,尽管它的错误率始终略高于 。
请注意,SVHN 有两个训练集:训练 和extra。 在完全监督学习中,两个集合连接起来形成完整的训练集( 样本)。 在 SSL 中,由于历史原因,额外集被搁置,仅使用训练(样本)。 我们认为,同时利用 训练 和 extra 来处理未标记的数据更有趣,因为它表现出未标记样本比标记样本的比例更高。 我们在表3中报告了 SVHN 和 SVHN+Extra 的错误率。 对于 SVHN+Extra,由于可用数据量较大,我们使用 和较低的权重衰减 。 我们发现,在这两个训练集上,几乎可以立即与同一训练集上的完全监督性能相匹配--例如,在 SVHN+Extra 上仅使用 250 个标签就能达到的错误率,而完全监督性能为。 有趣的是,对于所考虑的每个标记数据量,在 SVHN+Extra 训练中 的表现优于完全监督的 SVHN,而没有 extra( 错误)。 为了强调这一点的重要性,请考虑以下场景:您有来自 SVHN 的 个示例,其中标记有 个示例,并且有一个选择:您可以获取 更多未标记数据并使用或获取更多标记数据并使用完全监督学习。 我们的结果表明,获取额外的未标记数据并使用 更有效,这可能比获取 更多标签便宜得多。
| Labels | All | |||||
|---|---|---|---|---|---|---|
| SVHN | ||||||
| SVHN+Extra |
STL-10
STL-10 包含 训练示例,旨在与 预定义折叠一起使用(我们仅使用前 5 个),每个示例都有 示例。 然而,一些先前的工作对所有 示例进行了训练。 因此,我们在两种实验设置中进行比较。 使用 示例 超越了 示例的最新技术以及使用所有 标记的示例。 请注意,table2中的基线均未使用相同的实验设置(即模型),因此很难直接比较结果;然而,由于 获得了两倍的最低误差,因此我们认为这是对我们的方法的信任投票。 我们使用了。
4.2.3 消融研究
由于结合了各种半监督学习机制,因此它与文献中现有的方法有很多共同点。 因此,我们研究了删除或添加组件的影响,以便进一步深入了解 的性能。 具体来说,我们衡量的效果
-
•
使用 增强的平均类分布或使用单个增强的类分布(即设置 )
-
•
移除温度锐化(即设置 )
-
•
在生成猜测标签时使用模型参数的指数移动平均值 (EMA),如 Mean Teacher [44] 所做的那样
-
•
仅在标记示例和未标记示例之间执行 ,并且不混合标记和未标记示例
-
•
使用插值一致性训练[45],这可以看作是这种消融研究的一个特例,其中仅使用未标记的混合,不应用锐化,并且使用EMA参数进行标签猜测。
我们对带有和标签的CIFAR-10进行了消融;结果如表4所示。 我们发现每个组件都会对 的性能做出贡献,其中 标签设置的差异最为显着。 尽管 Mean Teacher 对 SVHN 很有效(图 3),但我们发现使用类似的 EMA 参数值会损害 的表现略有不同。
| Ablation | labels | labels |
|---|---|---|
| without distribution averaging () | ||
| with | ||
| with | ||
| without temperature sharpening () | ||
| with parameter EMA | ||
| without | ||
| with on labeled only | ||
| with on unlabeled only | ||
| with on separate labeled and unlabeled | ||
| Interpolation Consistency Training [45] |
4.3 隐私保护学习和泛化
隐私学习使我们能够衡量我们方法的泛化能力。 事实上,保护训练数据的隐私相当于证明模型不会过度拟合:如果添加、修改或删除任何训练样本,则该学习算法被称为差分隐私(最广泛接受的隐私技术定义)。保证不会导致学习到的模型参数出现统计上的显着差异[13]。 因此,在实践中,差分隐私学习是正则化的一种形式[33]。 每个训练数据访问都构成潜在的隐私泄露,编码为输入及其标签对。 因此,从私人训练数据进行深度学习的方法,例如 DP-SGD [1] 和 PATE [36],受益于访问尽可能少的标记私人训练点当计算模型参数的更新时。 半监督学习非常适合这种环境。
我们使用 PATE 框架进行隐私学习。 学生通过公共未标记数据以半监督方式进行训练,其中部分数据由一组可以访问私人标记训练数据的教师进行标记。 学生达到固定准确度所需的标签越少,其提供的隐私保证就越强。 教师使用嘈杂的投票机制来回应学生的标签查询,当他们无法达成足够强烈的共识时,他们可以选择不提供标签。 因此,如果 提高了 PATE 的性能,它也将说明 从每个类的少数规范示例中改进了泛化能力。
我们将 实现的准确性与隐私权衡与 SVHN 上的增值税 [31] 基线进行比较。 VAT 达到了之前最先进的 测试精度,但隐私损失为 [37]。 由于 在标记点较少的情况下表现良好,因此能够在 的隐私损失小得多的情况下实现 测试精度。 由于使用来衡量隐私程度,因此改进程度约为,这是一个显着的改进。 低于 1 的隐私损失 对应于更强的隐私保证。 请注意,在私人训练设置中,学生模型总共仅使用 10,000 个示例。
5结论
我们引入了,这是一种半监督学习方法,它结合了当前 SSL 主流范式的思想和组件。 通过对半监督和隐私保护学习的大量实验,我们发现与我们研究的所有设置中的其他方法相比, 表现出显着提高的性能,通常可以将错误率降低两倍或更多。 在未来的工作中,我们有兴趣将半监督学习文献中的其他想法融入混合方法中,并继续探索哪些组件可以产生有效的算法。 另外,大多数现代半监督学习算法的工作都是在图像基准上进行评估的;我们有兴趣探索 在其他领域的有效性。
致谢
我们要感谢 Balaji Lakshminarayanan 提供的有益的理论见解。
参考
- [1] Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 308–318. ACM, 2016.
- [2] Ben Athiwaratkun, Marc Finzi, Pavel Izmailov, and Andrew Gordon Wilson. Improving consistency-based semi-supervised learning with weight averaging. arXiv preprint arXiv:1806.05594, 2018.
- [3] Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps and spectral techniques for embedding and clustering. In Advances in Neural Information Processing Systems, 2002.
- [4] Yoshua Bengio, Olivier Delalleau, and Nicolas Le Roux. Label Propagation and Quadratic Criterion, chapter 11. MIT Press, 2006.
- [5] Glenn W. Brier. Verification of forecasts expressed in terms of probability. Monthey Weather Review, 78(1):1–3, 1950.
- [6] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-Supervised Learning. MIT Press, 2006.
- [7] Dan Claudiu Cireşan, Ueli Meier, Luca Maria Gambardella, and Jürgen Schmidhuber. Deep, big, simple neural nets for handwritten digit recognition. Neural computation, 22(12):3207–3220, 2010.
- [8] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223, 2011.
- [9] Adam Coates and Andrew Y. Ng. The importance of encoding versus training with sparse coding and vector quantization. In International Conference on Machine Learning, 2011.
- [10] Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
- [11] Emily Denton, Sam Gross, and Rob Fergus. Semi-supervised learning with context-conditional generative adversarial networks. arXiv preprint arXiv:1611.06430, 2016.
- [12] Terrance DeVries and Graham W. Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- [13] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. Journal of Privacy and Confidentiality, 7(3):17–51, 2016.
- [14] Alexander Gammerman, Volodya Vovk, and Vladimir Vapnik. Learning by transduction. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, 1998.
- [15] Xavier Gastaldi. Shake-shake regularization. Fifth International Conference on Learning Representations (Workshop Track), 2017.
- [16] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016.
- [17] Ian J. Goodfellow, Aaron Courville, and Yoshua Bengio. Spike-and-slab sparse coding for unsupervised feature discovery. In NIPS Workshop on Challenges in Learning Hierarchical Models, 2011.
- [18] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in Neural Information Processing Systems, 2005.
- [19] Geoffrey Hinton and Drew van Camp. Keeping neural networks simple by minimizing the description length of the weights. In Proceedings of the 6th Annual ACM Conference on Computational Learning Theory, 1993.
- [20] Xu Ji, Joao F Henriques, and Andrea Vedaldi. Invariant information distillation for unsupervised image segmentation and clustering. arXiv preprint arXiv:1807.06653, 2018.
- [21] Thorsten Joachims. Transductive inference for text classification using support vector machines. In International Conference on Machine Learning, 1999.
- [22] Thorsten Joachims. Transductive learning via spectral graph partitioning. In International Conference on Machine Learning, 2003.
- [23] Diederik P. Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems, 2014.
- [24] Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- [25] Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In Fifth International Conference on Learning Representations, 2017.
- [26] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems, 2017.
- [27] Julia A. Lasserre, Christopher M. Bishop, and Thomas P. Minka. Principled hybrids of generative and discriminative models. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2006.
- [28] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML Workshop on Challenges in Representation Learning, 2013.
- [29] Bin Liu, Zhirong Wu, Han Hu, and Stephen Lin. Deep metric transfer for label propagation with limited annotated data. arXiv preprint arXiv:1812.08781, 2018.
- [30] Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in Adam. arXiv preprint arXiv:1711.05101, 2017.
- [31] Takeru Miyato, Shin-ichi Maeda, Shin Ishii, and Masanori Koyama. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 2018.
- [32] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- [33] Kobbi Nissim and Uri Stemmer. On the generalization properties of differential privacy. CoRR, abs/1504.05800, 2015.
- [34] Augustus Odena. Semi-supervised learning with generative adversarial networks. arXiv preprint arXiv:1606.01583, 2016.
- [35] Avital Oliver, Augustus Odena, Colin Raffel, Ekin Dogus Cubuk, and Ian Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. In Advances in Neural Information Processing Systems, pages 3235–3246, 2018.
- [36] Nicolas Papernot, Martín Abadi, Ulfar Erlingsson, Ian Goodfellow, and Kunal Talwar. Semi-supervised knowledge transfer for deep learning from private training data. arXiv preprint arXiv:1610.05755, 2016.
- [37] Nicolas Papernot, Shuang Song, Ilya Mironov, Ananth Raghunathan, Kunal Talwar, and Úlfar Erlingsson. Scalable private learning with pate. arXiv preprint arXiv:1802.08908, 2018.
- [38] Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, and Lawrence Carin. Variational autoencoder for deep learning of images, labels and captions. In Advances in Neural Information Processing Systems, 2016.
- [39] Antti Rasmus, Mathias Berglund, Mikko Honkala, Harri Valpola, and Tapani Raiko. Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems, 2015.
- [40] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in Neural Information Processing Systems, 2016.
- [41] Ruslan Salakhutdinov and Geoffrey E. Hinton. Using deep belief nets to learn covariance kernels for Gaussian processes. In Advances in Neural Information Processing Systems, 2007.
- [42] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. In Advances in Neural Information Processing Systems, 2016.
- [43] Patrice Y. Simard, David Steinkraus, and John C. Platt. Best practice for convolutional neural networks applied to visual document analysis. In Proceedings of the International Conference on Document Analysis and Recognition, 2003.
- [44] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in Neural Information Processing Systems, 2017.
- [45] Vikas Verma, Alex Lamb, Juho Kannala, Yoshua Bengio, and David Lopez-Paz. Interpolation consistency training for semi-supervised learning. arXiv preprint arXiv:1903.03825, 2019.
- [46] Guodong Zhang, Chaoqi Wang, Bowen Xu, and Roger Grosse. Three mechanisms of weight decay regularization. arXiv preprint arXiv:1810.12281, 2018.
- [47] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- [48] Junbo Zhao, Michael Mathieu, Ross Goroshin, and Yann Lecun. Stacked what-where auto-encoders. arXiv preprint arXiv:1506.02351, 2015.
- [49] Xiaojin Zhu, Zoubin Ghahramani, and John D Lafferty. Semi-supervised learning using gaussian fields and harmonic functions. In International Conference on Machine Learning, 2003.
附录 A 符号和定义
| Notation | Definition |
|---|---|
| Cross-entropy between “target” distribution and “predicted” distribution | |
| A labeled example, used as input to a model | |
| A (one-hot) label | |
| The number of possible label classes (the dimensionality of ) | |
| A batch of labeled examples and their labels | |
| A batch of processed labeled examples produced by | |
| An unlabeled example, used as input to a model | |
| A guessed label distribution for an unlabeled example | |
| A batch of unlabeled examples | |
| A batch of processed unlabeled examples with their label guesses produced by | |
| The model’s parameters | |
| The model’s predicted distribution over classes | |
| A stochastic data augmentation function that returns a modified version of . For example, could implement randomly shifting an input image, or implement adding a perturbation sampled from a Gaussian distribution to . | |
| A hyper-parameter weighting the contribution of the unlabeled examples to the training loss | |
| Hyperparameter for the distribution used in | |
| Temperature parameter for sharpening used in | |
| Number of augmentations used when guessing labels in |
附录 B表格结果
B.1 CIFAR-10
在整个 -示例训练集上使用监督学习训练相同的模型,实现了 的错误率。
| Methods/Labels | 250 | 500 | 1000 | 2000 | 4000 |
|---|---|---|---|---|---|
| PiModel | |||||
| PseudoLabel | |||||
| Mixup | |||||
| VAT | |||||
| MeanTeacher | |||||
| MixMatch |
B.2SVHN
在整个 -示例训练集上使用监督学习训练相同的模型,实现了 的错误率。
| Methods/Labels | 250 | 500 | 1000 | 2000 | 4000 |
|---|---|---|---|---|---|
| PiModel | |||||
| PseudoLabel | |||||
| Mixup | |||||
| VAT | |||||
| MeanTeacher | |||||
| MixMatch |
B.3SVHN+额外
在整个 -示例训练集上使用监督学习训练相同的模型,实现了 的错误率。
| Methods/Labels | 250 | 500 | 1000 | 2000 | 4000 |
|---|---|---|---|---|---|
| PiModel | |||||
| PseudoLabel | |||||
| Mixup | |||||
| VAT | |||||
| MeanTeacher | |||||
| MixMatch |
附录C13层ConvNet结果
半监督学习的早期工作使用 13 层卷积网络架构[31,44,25]。 在 table 8 中,我们展示了类似架构的结果。 我们警告不要将这些数字直接与以前的工作进行比较,因为我们使用不同的实现和训练过程[35]。
| Method | CIFAR-10 | SVHN | ||
|---|---|---|---|---|
| 250 | 4000 | 250 | 1000 | |
| Mean Teacher | 46.34 | 88.57 | 94.00 | 96.00 |
| MixMatch | 85.69 | 93.16 | 96.41 | 96.61 |