重新审视图神经网络:
我们拥有的只是低通滤波器
摘要
图神经网络已成为解决图结构数据机器学习问题的最重要技术之一。 最近关于顶点分类的工作提出了深度和分布式学习模型,以实现高性能和可扩展性。 然而,我们发现基准数据集的特征向量对于分类任务来说已经提供了相当丰富的信息,而图结构仅提供了一种对数据进行去噪的方法。 在本文中,我们开发了一个基于图信号处理的理论框架来分析图神经网络。 我们的结果表明,图神经网络仅对特征向量进行低通滤波,不具有非线性流形学习特性。 我们进一步研究了它们对特征噪声的适应能力,并提出了一些关于基于 GCN 的图神经网络设计的见解。
1简介
图神经网络(GNN)属于一类可以从图结构数据中学习的神经网络。 最近,用于顶点分类和图同构测试的图神经网络在多个基准数据集上取得了优异的成绩,并不断创下新的最先进性能Abu-El-Haija 等人 (2019);基普夫和威灵(2017); Veličković 等人 (2017);徐等人(2019). 从 ChebNet Defferrard 等人 (2016) 和 GCN Kipf and Welling (2017) 在顶点分类方面的早期成功开始,GNN 的许多变体被提出来解决以下问题:社交网络 Hamilton 等人 (2017);张等人 (2018a),生物学 Veličković 等人 (2017, 2019),化学 Fout 等人 (2017); Gilmer 等人 (2017),自然语言处理 Bastings 等人 (2017);张等人 (2018b)、计算机视觉 Santoro 等人 (2017) 以及弱监督学习 Garcia 和 Bruna (2017)。
在半监督顶点分类中,我们观察到图卷积网络 (GCN) Kipf 和 Welling (2017) 中图卷积层的参数只会导致过度拟合。 在 SGC Wu 等人 (2019) 等简单架构和 DGI Veličković 等人 (2019) 等更复杂的架构中都报告了类似的观察结果。 基于这一现象,Wu等人(2019)提出将图神经网络简单地视为特征传播,并提出一种极其高效的模型,在许多基准数据集上具有最先进的性能。 Kawamoto等人(2018)对图分区设置下未经训练的类GCN GNN做出了相关的理论评论。 从这些先前的研究中,自然会出现一个问题: 为什么以及何时图神经网络可以很好地进行顶点分类? 换句话说,即使没有训练,图神经网络模型的顶点特征向量是否也能正常工作? 因此,我们能否找到基线图神经网络(例如 SGC 或 GCN)无法执行的现实反例?
在本研究中,我们从图信号处理的角度为上述问题提供了答案Ortega等人(2018)。 形式上,我们考虑图上的半监督学习问题。 给定一个图 ,每个顶点 都有一个特征 和标签 ,其中 是维欧几里得空间和用于回归,用于分类。 任务是学习一个假设,以根据特征 预测标签 。 然后,我们描述了该问题的图神经网络解决方案,并深入了解最常用的基线模型 GCN Kipf 和 Welling (2017) 及其简化变体 SGC Wu 等人(2019)。
![[Uncaptioned image]](x2.png) 图2: gfNN的简单实现
图2: gfNN的简单实现
图信号处理(GSP)将顶点上的数据视为信号,并应用信号处理技术来理解信号特征。 通过将信号(特征向量)和图结构(邻接矩阵或其变换)结合起来,GSP 启发了图结构数据学习算法的发展S human 等人(2012)。 在标准信号处理问题中,通常假设观测值包含一些噪声,并且潜在的“真实信号”具有低频 Rabiner 和 Gold (1975)。 在这里,我们对我们的问题提出了类似的假设。
Assumption 1。
输入特征由低频真实特征和噪声组成。 真实特征为机器学习任务提供了足够的信息。
我们的第一个贡献是在常用数据集上验证假设1(第3部分)。 图 1 显示了在具有不同频率分量的特征上训练的 2 层感知器 (MLP) 的性能。 在所有基准数据集中,我们看到只有少量频率成分有助于学习。 向特征向量添加更多频率分量只会降低性能。 反过来,当我们向特征中添加高斯噪声 时,分类精度会变得更差。
最近的许多 GNN 都是基于图信号处理的结果构建的。 最常见的做法是将(增强的)归一化邻接矩阵与特征矩阵相乘。 产品被理解为特征平均和传播Hamilton等人(2017);基普夫和威灵(2017);吴等人(2019)。 在图信号处理文献中,这种操作在图上过滤信号,而不对归一化拉普拉斯矩阵显式执行特征分解,这需要时间Vaseghi (2008)。 在这里,我们将这种增强归一化邻接矩阵及其变体可互换地称为图过滤器和传播矩阵。
我们的第二个贡献表明,将图形信号与传播矩阵相乘对应于低通滤波(第4节,特别是定理3)。 此外,我们还表明观测信号和低通滤波器之间的矩阵乘积是真实信号优化问题的解析解。 对比近期图神经网络的设计原理Abu-El-Haija 等人 (2019);基普夫和威灵(2017); Xu等人(2019),我们的结果表明图卷积层只是低通滤波。 因此,学习图卷积层的参数是没有必要的。 Wu 等人 (2019, Theorem 1) 也通过分析增强归一化邻接矩阵的频谱截断效应提出了类似的主张。 我们扩展这个结果来表明所有特征值单调收缩,这进一步解释了频谱截断效应的含义。
基于我们的理论理解,我们提出了一个名为gfNN(图过滤神经网络)的新基线框架来对顶点分类问题进行实证分析。 gfNN 包含两个步骤: 1. 通过与图过滤矩阵相乘来过滤特征; 2. 通过机器学习模型学习顶点标签。 我们使用图2中的简单实现模型展示了我们框架的有效性。
我们的第三个贡献是以下定理:
定理 7 意味着,在假设 1 下,gfNN 和 GCN Kipf and Welling (2017) 具有相似的高性能。 由于 gfNN 在学习阶段不需要邻接矩阵的乘法,因此它比 GCN 快得多。 此外,gfNN 还具有更强的噪声容忍度。
最后,我们将 gfNN 与 SGC 模型 Wu 等人 (2019) 进行比较。 虽然 SGC 在基准数据集上计算速度也快且准确,但我们的分析表明,当特征输入是非线性可分离时,它会失败,因为图卷积部分对非线性流形学习没有贡献。 我们创建了一个人工数据集来凭经验证明这一说法。
2 图形信号处理
在本节中,我们介绍图信号处理的基本概念。 我们采用了最新的不规则图上的图傅立叶变换公式Girault等人(2018)。
令 是一个简单的无向图,其中 是 顶点的集合, 是边的集合。111我们只考虑未加权的边缘,但它很容易应用于正加权的边缘。 设为的邻接矩阵,为的度矩阵,其中为顶点的度数。 为的组合拉普拉斯矢量,为的归一化拉普拉斯矢量,其中为身份矩阵,为的随机漫步拉普拉斯矢量。另外,对于带有 的 ,让 成为 附加邻接矩阵,它是通过在 中加入 自循环得到的、是相应的增强度矩阵,、、是相应的增强组合矩阵、归一化矩阵和随机漫步拉普拉斯矩阵。
在图的顶点上定义的向量称为图信号。 为了引入图傅立叶变换,我们需要在图信号空间上定义两个运算:变分和内积。 在这里,我们通过以下方式定义变体 和 内积:
| (1) |
我们用 表示由 导出的范数。 直观上,变化和内积分别指定如何测量信号的平滑度和重要性。 特别是,我们的内积更加重视高度顶点,其中较大的 使重要性更加均匀。 然后我们考虑广义特征值问题(变分形式):找到,使得对于每个,是一个解决方案如下优化问题:
| (2) |
解称为第个广义特征向量,对应的目标值称为第个广义特征值。 广义特征值和特征向量也是以下广义特征值问题(方程形式)的解:
| (3) |
因此,如果 是广义特征对,则 是 的特征对。 广义特征值越小,广义特征向量在变化方面越平滑。 因此,广义特征值被称为图的频率。
图傅里叶变换是广义特征向量的基展开。 令 为矩阵,其列为广义特征向量。 然后,图傅立叶变换由定义,逆图傅立叶变换 由 定义。 请注意,这些实际上是自 以来的逆变换。
Parseval 恒等式 将数据范数及其傅立叶变换联系起来:
| (4) |
令 为解析函数。 指定的图过滤器是由频域中的关系定义的映射。 在空间域中,上式等价于。其中 是通过 的泰勒展开式定义的;有关矩阵函数的详细信息,请参阅 Higham (2008)。
在图上的机器学习问题中,每个顶点 都有一个 维特征 。 我们将特征视为图信号,并通过每个信号的图傅里叶变换来定义特征的图傅里叶变换。 令 为特征矩阵。 然后,图傅里叶变换用表示,逆变换用表示。 我们将表示为的频率分量。
3 假设的经验证据1
本文的结果很大程度上依赖于假设1。 因此,我们首先在现实世界的数据集中验证这一假设:Cora、Citeseer 和 Pubmed Sen 等人 (2008)。 这些是引文网络,其中顶点是科学论文,边是引文。 我们考虑以下实验设置:1。 根据计算图傅里叶基; 2。 对输入特征添加高斯噪声: for ; 3。 计算第一个频率分量:; 4。 重构特征:; 5。 训练并报告测试 2 层感知器在重建特征 上的准确性。
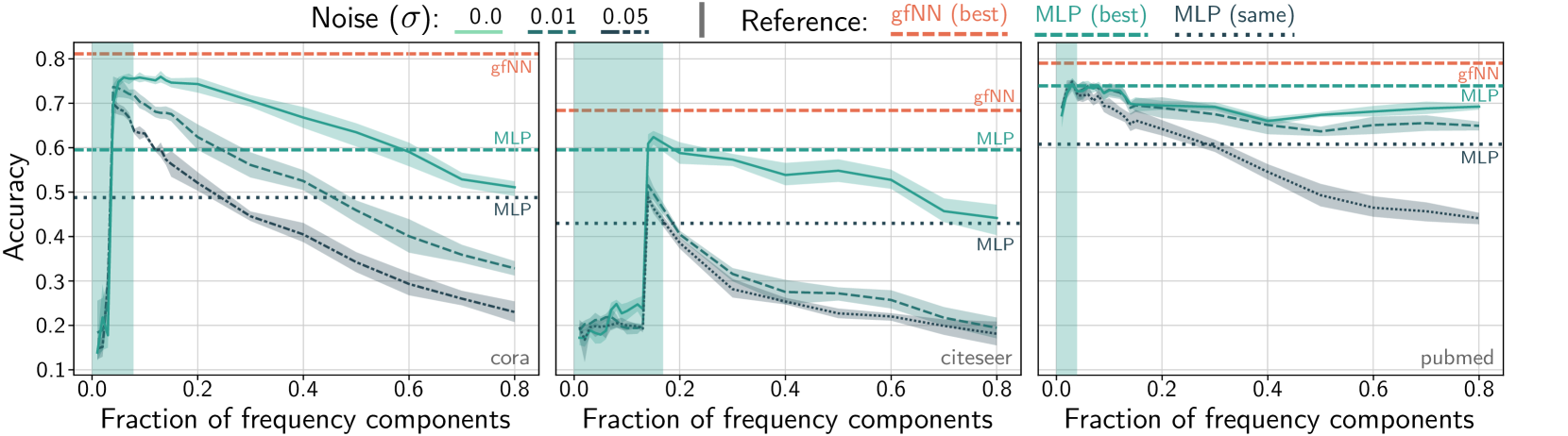
在图3中,我们逐步添加归一化拉普拉斯频率分量来重建特征向量并训练2层MLP。 我们看到所有三个数据集都表现出低频性质。 2 层 MLP 的分类精度往往在光谱的前 20% 内达到峰值(绿色框)。 通过添加人工高斯噪声,我们观察到低频区域的性能相对稳健,这意味着很强的去噪效果。
有趣的是,当高频分量不包含对分类有用的信息时,图神经网络和简单 MLP 之间的性能差距要大得多。 在 Cora 数据集中,高频成分只会降低分类精度。 因此,我们的 gfNN 优于简单的 MLP。 Citeseer 和 Pubmed 具有类似的低频性质。 然而,这里的性能差距并不那么大。 由于 Citeseer 和 Pubmed 的添加噪声性能系列通常与原始 Cora 性能系列相似,因此我们预计原始 Citeseer 和 Pubmed 包含的噪声比 Cora 少得多。 因此,我们可以预期图过滤度在 Citeseer 和 Pubmed 案例中影响不大。
4 邻接矩阵相乘就是低通滤波
计算低频分量的成本很高,因为计算拉普拉斯矩阵的特征值分解需要 时间。 因此,合理的替代方案是使用低通滤波器。 许多关于图神经网络的论文迭代地乘以(增强的)邻接矩阵 (或 )来传播信息。 在本节中,我们看到此操作对应于低通滤波器。
乘以归一化邻接矩阵对应于应用图过滤器。 由于归一化拉普拉斯算子的特征值位于区间上,因此该操作类似于去除中频分量的带阻滤波器。 然而,由于归一化拉普拉斯算子的最大特征值是 当且仅当该图包含非平凡二分图作为连通分量 (Chung,1997,引理 1.7) 。 因此,对于其他图,乘以归一化(非增广)邻接矩阵充当低通滤波器(即,高频分量必须减少)。
我们可以通过添加自循环(即考虑增强邻接矩阵)来增加低通滤波效果,因为它将特征值缩小到零,如下所示。222最大特征值的收缩已在(吴等人, 2019, 定理1)中得到证明。 我们的定理比他们的定理更强,因为我们展示了“所有”特征值的“单调收缩”。 此外,我们的证明更简单、更短。
Theorem 3.
令 为 的第 广义特征值。 那么,是一个非负数,并且在中单调非递增。 此外,如果,则严格单调递减。
请注意, 不能太大。 否则,所有特征值将集中在零附近,即所有数据将被视为“低频”;因此,我们无法从低频分量中提取有用的信息。
图过滤器也可以从拉普拉斯正则化最小二乘法Belkin and Niyogi (2004)的一阶近似导出。 让我们考虑从观察 估计低频真实特征 的问题。 然后,自然优化问题由下式给出
| (5) |
其中。 请注意,从 开始,它是先验分布为 的最大后验估计。 该问题的最优解由给出。 相应的滤波器是,因此是它的一阶泰勒近似。
5 低通滤波器的偏差-方差权衡
在本文的其余部分中,我们在假设1下建立了理论结果。 具体来说,我们提出一个更精确的假设如下。
Assumption 4 (假设1第一部分的精确版本)。
观察到的特征由真实特征和噪声组成。 真实特征的频率最多为,噪声遵循高斯白噪声,即 独立地相同地遵循正态分布。
使用这个假设,我们可以如下评估低通滤波器的效果。
Lemma 5.
(6) 右侧的第一项和第二项是应用滤波器产生的偏差项和产生的方差项分别来自过滤后的噪声。 在此假设下,偏差会增加一点,例如 。 方差项会在 中减小,其中 是图形的典型度数,因为 在小 中通常表现为 。333这恰好适用于一类局部树状图Dembo等人(2013),其中包括Erdos-Renyi随机图和配置型号。 因此,如果的最大频率远小于信噪比,我们可以通过乘以邻接矩阵,从噪声观测中获得对真实数据更准确的估计。 t1>。
该定理还建议选择。通过将右侧最小化,我们得到:
Corollary 6。
假设 对应于某些 。 令由定义,并假设存在常量和,使得为。 然后,通过选择,(6)的右侧是。444 抑制对数依赖性。 ∎
由此得出的结论是,我们可以通过多次乘以 来获得准确度 的真实特征估计。
6 图过滤神经网络
在上一节中,我们看到低通滤波特征 是对真实特征的高概率准确估计。 在本节中,我们分析该操作的性能。
令多层(两层)感知器为
| (7) |
其中是entry-wise ReLU函数,是softmax函数。 请注意, 和 都是收缩图,即 。
现在,我们考虑将图过滤器应用于特征,然后使用多层感知器进行学习,即。 使用引理5,我们得到以下结果。
这意味着如果真实数据的最大频率很小,我们会得到类似于最优解的解。
与GCN的比较
在同样的假设下,我们可以分析两层GCN的性能。 GCN 由下式给出
| (10) |
Theorem 8.
在与定理 7 相同的假设下,我们有
| (11) |
这个定理意味着GCN对于真实特征也具有类似于MLP的性能。 因此,在和的限制下,所有MLP、GCN和gfNN都具有相同的性能。
在实践中,gfNN 相对于 GCN 有两个优势。 首先,gfNN 比 GCN 更快,因为它在训练期间不使用图。 其次,GCN 存在对噪声过度拟合的风险。 当噪声太大而无法通过一阶低通滤波器降低时,使用噪声特征训练内部权重,这会过度拟合噪音。 我们在7.2节中验证了这一点。
与SGC比较
回想一下,2 度 SGC 由下式给出
| (12) |
即,它是一个具有单层感知器的 gfNN。 因此,通过同样的讨论,SGC 具有与应用于真实特征的感知器(而不是 MLP)类似的性能。 这就澄清了SGC的一个问题:如果真实特征是不可分离的,SGC就无法解决问题。 我们在实验E2(第7.3节)中验证了这个问题。
7实验
为了验证我们在前几节中的主张,我们设计了两个实验。 在实验E1中,我们向真实数据集的特征向量添加不同级别的白噪声,并报告基线模型之间的分类准确性。 实验E2研究了一个具有复杂特征空间的人工数据集,用于演示SGC等简单模型何时无法分类。
有两种类型的数据集:通常用于图神经网络基准测试的现实世界数据(引用网络、社交网络和生物网络)Sen 等人(2008);杨等人(2016); Zitnik 和 Leskovec (2017) 以及从两个圆圈数据集人工合成的随机图。 我们通过将每个数据点变成一个顶点并连接欧氏距离中最近的 5 个顶点来创建两个圆数据集的图结构。 表 1 概述了每个数据集。
| Dataset | Nodes | Edges | Features | Classes | Train/Val/Test Nodes |
|---|---|---|---|---|---|
| Cora | 2,708 | 5,278 | 1,433 | 7 | 140/500/1,000 |
| Citeseer | 3,327 | 4,732 | 3,703 | 6 | 120/500/1,000 |
| Pubmed | 19,717 | 44,338 | 500 | 3 | 60/500/1,000 |
| 231,443 | 11,606,919 | 602 | 41 | 151,708/23,699/55,334 | |
| PPI | 56,944 | 818,716 | 50 | 121 | 44,906/6,514/5,524 |
| Two Circles | 4,000 | 10,000 | 2 | 2 | 80/80/3,840 |
7.1神经网络
我们将我们的结果与基准数据集上的一些最先进的图神经网络进行比较。 我们使用 Adam 优化器 Kingma 和 Ba (2015) (lr=0.2, epochs=50) 训练每个模型。 我们使用 32 个隐藏单元作为 GCN、MLP 和 gfNN 的隐藏层。 其他超参数设置与SGC Wu 等人(2019)类似。
gfNN 我们的简单模型有三个图形过滤器:左范数 ()、增强归一化邻接 ()和双边 ()。
SGC Wu 等人 (2019) 简单图卷积 () 通过消除神经网络中的非线性并仅求平均来简化图卷积神经网络模型特征。
GCN Kipf 和 Welling (2017) 图卷积神经网络 (✖) 是最常用的基线。
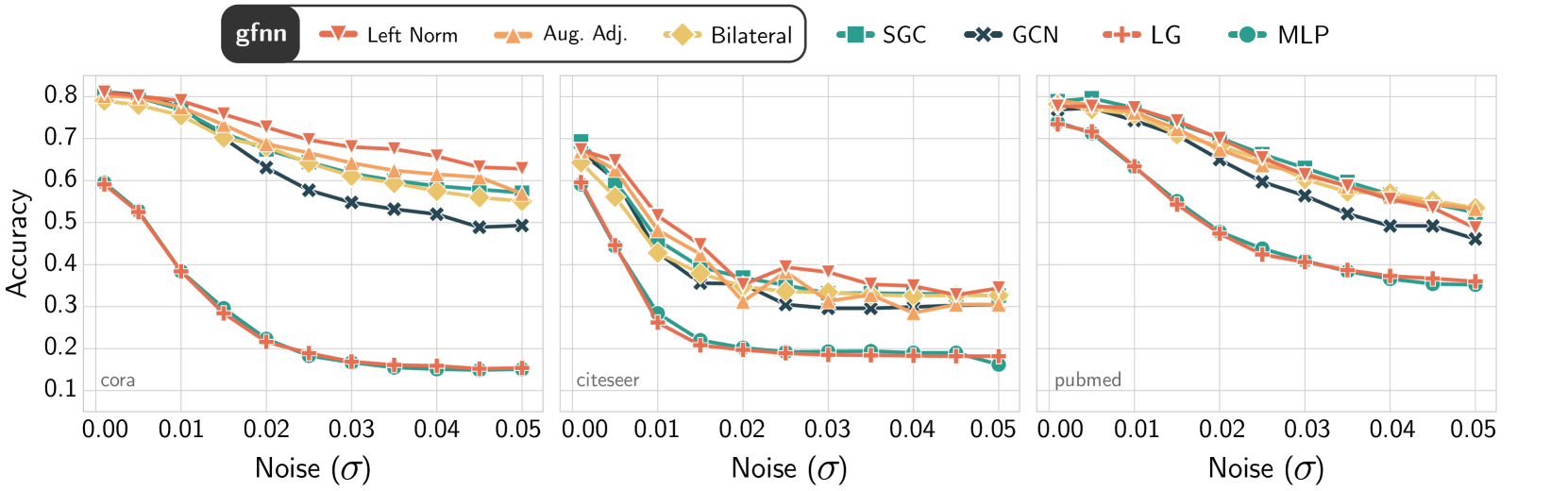
7.2 图滤波器的去噪效果
7.3 图过滤器的表现力
由于图卷积只是去噪,我们预计它对非线性学习几乎没有贡献。 因此,我们实现一个简单的二维两圆数据集来看看图过滤是否可以具有非线性流形学习效果。 基于数据点之间的欧几里得距离,我们构造一个 -nn 图作为底层图结构。 在这个特定的实验中,我们将每个数据点连接到 5 个最近的邻居。 图 5 演示了 SGC 如何无法对简单的 500 个数据点集进行直观分类。
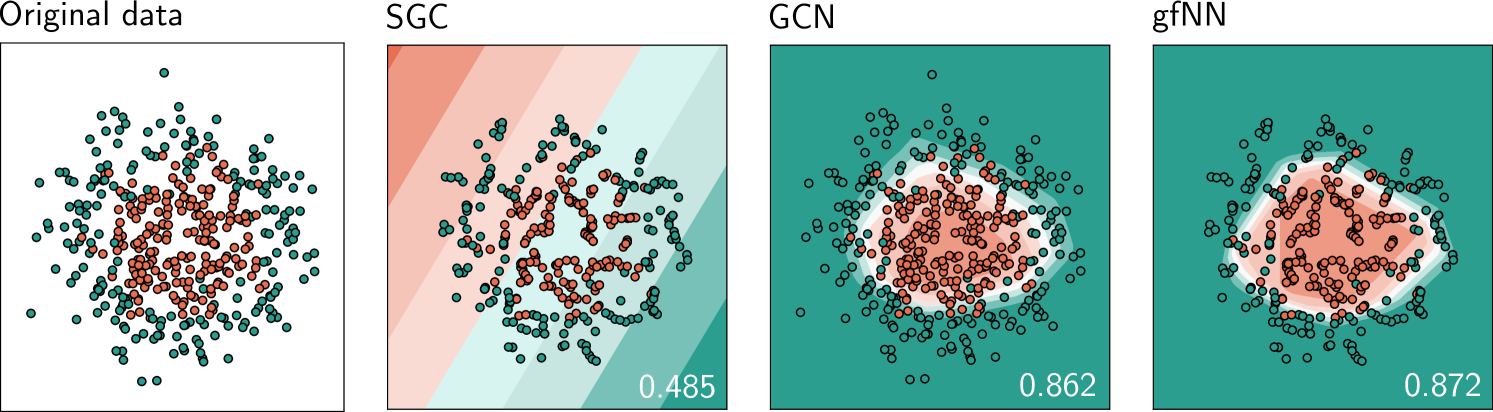
另一方面,SGC、GCN 和我们的模型 gfNN 在大多数基准图数据集上的表现相当。 表 2 比较了随机/测试集的训练精度(Reddit 的 f1-micro)。 我们看到所有这些图神经网络都具有相似的性能(一些小的改进可能会受到超参数调整的影响)。 因此,我们认为当前图神经网络的基准数据集具有相当“简单”的特征空间。
在实践中,我们的分析和实验结果都表明图卷积层应该被简单地视为一个去噪滤波器。 与最近涉及 GCN Abu-El-Haija 等人 (2019) 的设计趋势相反; Valsesia 等人 (2019),我们的结果表明,简单地堆叠 GCN 层可能只会使模型更容易出现特征噪声,同时具有与简单 MLP 相同的表达能力。
| Denoise | Classifier | Cora | Citeseer | Pubmed | PPI | Two Circles | ||
|---|---|---|---|---|---|---|---|---|
| GCN | 1st order | Non-linear | OOM | OOM | ||||
| SGC | 2nd order | Linear | ||||||
| gfNN | 2nd order | Non-linear |
8讨论
很少有工作能够解决 GCN 架构的局限性。 Kawamoto等人(2018)采用平均场方法分析统计物理的简单GCN模型。 他们得出的结论是,反向传播既不能提高基于 GCN 的 GNN 模型的准确性,也不能提高可检测性。 Li等人(2018)实证分析了有限标记数据设置下的多层GCN模型,并指出GCN在标记数据太少或堆叠层太多的情况下效果不佳。 虽然这些结果为 GCN 提供了富有洞察力的观点,但它们并没有充分回答以下问题: 我们什么时候应该使用 GNN?.
我们的结果表明,如果假设 1 成立,我们应该使用 GNN 方法来解决给定问题。 从我们的角度来看,源自 GCN 的 GNN 只是执行噪声过滤并从去噪数据中学习。 根据我们的分析,我们提出了 GCN 和 SGC 可能无法执行的两种情况:噪声特征和非线性特征空间。 反过来,我们提出了一种在这两种情况下都能很好地发挥作用的简单方法。
最近,基于 GCN 的 GNN 已应用于许多重要应用,例如点云分析 Valsesia 等人 (2019) 或弱监督学习 Garcia 和 Bruna (2017)。 随着输入特征空间变得复杂,我们主张重新审视当前基于 GCN 的 GNN 设计。 我们不应该将 GCN 层视为计算机视觉中的卷积层,而需要将其简单地视为一种去噪机制。 因此,简单地堆叠 GCN 层只会给神经网络设计带来过度拟合和复杂性。
参考
- Abu-El-Haija et al. [2019] Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Hrayr Harutyunyan, Nazanin Alipourfard, Kristina Lerman, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolution architectures via sparsified neighborhood mixing. In Proceedings of the 36th International Conference on International Conference on Machine Learning, volume 97. JMLR, 2019.
- Bastings et al. [2017] Joost Bastings, Ivan Titov, Wilker Aziz, Diego Marcheggiani, and Khalil Sima’an. Graph convolutional encoders for syntax-aware neural machine translation. Empirical Methods in Natural Language Processing, 2017.
- Belkin and Niyogi [2004] Mikhail Belkin and Partha Niyogi. Semi-supervised learning on riemannian manifolds. Machine Learning, 56(1-3):209–239, 2004.
- Bhatia [2013] Rajendra Bhatia. Matrix analysis, volume 169. Springer Science & Business Media, 2013.
- Chung [1997] Fan R.K. Chung. Spectral graph theory. American Mathematical Society, 1997.
- Defferrard et al. [2016] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in neural information processing systems, pages 3844–3852, 2016.
- Dembo et al. [2013] Amir Dembo, Andrea Montanari, and Nike Sun. Factor models on locally tree-like graphs. The Annals of Probability, 41(6):4162–4213, 2013.
- Fout et al. [2017] Alex Fout, Jonathon Byrd, Basir Shariat, and Asa Ben-Hur. Protein interface prediction using graph convolutional networks. In Advances in Neural Information Processing Systems, pages 6530–6539, 2017.
- Garcia and Bruna [2017] Victor Garcia and Joan Bruna. Few-shot learning with graph neural networks. International Conference on Learning Representations, 2017.
- Gilmer et al. [2017] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, volume 70, pages 1263–1272. JMLR, 2017.
- Girault et al. [2018] Benjamin Girault, Antonio Ortega, and Shrikanth S. Narayanan. Irregularity-aware graph fourier transforms. IEEE Transactions on Signal Processing, 66(21):5746–5761, 2018.
- Hamilton et al. [2017] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pages 1024–1034, 2017.
- Higham [2008] Nicholas J. Higham. Functions of matrices: theory and computation, volume 104. SIAM, 2008.
- Kawamoto et al. [2018] Tatsuro Kawamoto, Masashi Tsubaki, and Tomoyuki Obuchi. Mean-field theory of graph neural networks in graph partitioning. In Advances in Neural Information Processing Systems, pages 4361–4371, 2018.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. International Conference on Learning Representations, 2015.
- Kipf and Welling [2017] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- Laurent and Massart [2000] Beatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selection. Annals of Statistics, pages 1302–1338, 2000.
- Li et al. [2018] Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Ortega et al. [2018] Antonio Ortega, Pascal Frossard, Jelena Kovačević, José MF Moura, and Pierre Vandergheynst. Graph signal processing: Overview, challenges, and applications. Proceedings of the IEEE, 106(5):808–828, 2018.
- Rabiner and Gold [1975] Lawrence R. Rabiner and Bernard Gold. Theory and application of digital signal processing. Englewood Cliffs, NJ, Prentice-Hall, Inc., 1975.
- Santoro et al. [2017] Adam Santoro, David Raposo, David G. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational reasoning. In Advances in Neural Information Processing Systems, pages 4967–4976, 2017.
- Sen et al. [2008] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shuman et al. [2012] David I. Shuman, Sunil K. Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. arXiv preprint arXiv:1211.0053, 2012.
- Valsesia et al. [2019] Diego Valsesia, Giulia Fracastoro, and Enrico Magli. Learning localized generative models for 3d point clouds via graph convolution. International Conference on Learning Representations, 2019.
- Vaseghi [2008] Saeed V. Vaseghi. Advanced digital signal processing and noise reduction. John Wiley & Sons, 2008.
- Veličković et al. [2017] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. International Conference on Learning Representations, 2017.
- Veličković et al. [2019] Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R. Devon Hjelm. Deep graph infomax. International Conference on Learning Representations, 2019.
- Wu et al. [2019] Felix Wu, Tianyi Zhang, Amauri Holanda de Souza Jr., Christopher Fifty, Tao Yu, and Kilian Q. Weinberger. Simplifying graph convolutional networks. In Proceedings of the 36th International Conference on International Conference on Machine Learning, volume 97. JMLR, 2019.
- Xu et al. [2019] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? International Conference on Learning Representations, 2019.
- Yang et al. [2016] Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, volume 48. JMLR, 2016.
- Zhang et al. [2018a] Jiani Zhang, Xingjian Shi, Junyuan Xie, Hao Ma, Irwin King, and Dit-Yan Yeung. Gaan: Gated attention networks for learning on large and spatiotemporal graphs. In Proceedings of the Thirty Fourth Conference on Uncertainty in Artificial Intelligence (UAI), 2018a.
- Zhang et al. [2018b] Yuhao Zhang, Peng Qi, and Christopher D. Manning. Graph convolution over pruned dependency trees improves relation extraction. Empirical Methods in Natural Language Processing, 2018b.
- Zitnik and Leskovec [2017] Marinka Zitnik and Jure Leskovec. Predicting multicellular function through multi-layer tissue networks. Bioinformatics, 33(14):i190–i198, 2017.
附录A证明
定理证明3。
由于 的广义特征值是正半定矩阵 的特征值,因此它们是非负实数。 为了获得收缩结果,我们使用 Courant-Fisher-Weyl 的最小-最大原理 [Bhatia,2013,推论 III。 1.2]:对于任何,
| (13) | ||||
| (14) | ||||
| (15) |
这里,第二个不等式如下,因为 对于所有 因此,如果 即 ,则不等式是严格的。 ∎
Lemma 9.
如果的频率最多为,则为。
证明。
根据帕塞瓦尔恒等式,
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
∎
引理5的证明。
Lemma 10.
如果的频率最多为,则存在,使得的频率最多为 和。
证明。
我们通过截断大于的频率分量来选择。 然后,
| (27) | ||||
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) | ||||
| (32) | ||||
| (33) |
∎
定理证明8。
| (34) | |||
| (35) | |||
| (36) | |||
| (37) |
∎