图的端到端学习和优化
摘要
现实世界的应用程序通常将图上的学习和优化问题结合起来。 例如,我们的目标可能是对图进行聚类,以检测有意义的社区(或解决其他常见的图优化问题,例如设施位置、maxcut 等)。 然而,图或相关属性通常只能被部分观察到,从而引入了必须在优化之前解决的学习问题,例如链接预测。 标准方法完全分开对待学习和优化,而最近的机器学习工作旨在直接从输入预测最佳解决方案。 在这里,我们提出了一种替代的以决策为中心的学习方法,该方法将常见图优化问题的可微代理集成为学习系统中的一层。 主要思想是学习一种表示,将原始优化问题映射到可以有效区分的更简单的代理问题。 实验结果表明,我们的 ClusterNet 系统优于纯粹的端到端方法(直接预测最优解决方案)和完全分离学习和优化的标准方法。 我们系统的代码可在 https://github.com/bwilder0/clusternet 获取。
1简介
虽然深度学习已被证明在一系列任务中取得了巨大成功,但人们感兴趣的领域正在不断扩大,涉及可以灵活地将学习与优化结合起来的系统。 例子包括最近尝试使用神经架构解决组合优化问题 vinyals2015pointer ; khalil2017学习;贝洛2016神经; kool2019attention ,以及将显式优化算法合并到更大的可微分系统中的工作 amos2017optnet ; donti2017任务;怀尔德2019融合 。 将学习和优化相结合的能力有望提高现实世界问题的性能,这些问题需要通过启用端到端训练来根据机器学习预测做出决策,从而将学习到的模型集中在手头的决策问题上。
我们专注于图优化问题,这是组合优化的一个扩展子类。 虽然图优化在各个领域都很普遍,但完整的应用程序还必须解决机器学习的挑战。 例如,输入图通常是不完整的;某些边可能未被观察到,或者节点可能具有仅部分已知的属性。 最近的工作引入了用于链接预测和半监督分类等任务的复杂方法perozzi2014deepwalk; kipf2017半; schlichtkrull2018建模; Hamilton2017归纳; zhang2018link ,但这些方法是独立于下游优化任务而开发的。 目前大多数解决方案都采用两阶段方法,首先使用标准损失训练模型,然后将模型的预测插入优化算法(yan2012Detecting; burgess2016link; bahulkar2018community; berlusconi2016link; tan2016efficient)。 然而,对于特定的优化任务来说,最小化标准损失函数(例如交叉熵)的预测可能不是最佳的,特别是在即使是最好的模型也不完美的困难环境中。
更好的方法是将下游优化问题纳入机器学习模型的训练中。 最近的大量工作采用了纯粹的端到端方法,其中神经网络被训练为使用监督学习或强化学习来预测优化问题的解决方案vinyals2015pointer; khalil2017学习;贝洛2016神经; kool2019关注 。 然而,这通常需要大量数据并导致性能不佳,因为网络需要完全从头开始发现算法结构。 在完全两阶段方法和纯粹的端到端架构的极端之间,以决策为中心的学习 donti2017task ; wilder2019melding 将优化问题的求解器嵌入为学习系统中的可微层。 这允许模型使用其引起的下游性能作为损失进行训练,同时利用先前的算法知识进行优化。 缺点是这种方法需要手动为每个特定问题开发可微分求解器,并且通常会导致系统变得繁琐,例如每次前向传递都必须调用二次规划求解器。
我们提出了一种两全其美的新方法:将更简单的优化问题的求解器合并为可微层,然后学习将感兴趣的(更难的)问题映射到更简单问题的实例上的表示。 与早期的以决策为中心的学习方法相比,这更加强调系统的表示学习组件并简化了优化组件。 然而,与纯粹的端到端方法相比,我们只需要学习简化问题而不是整个算法。
在这项工作中,我们将更简单的问题实例化为 的可微版本 - 意味着聚类。 聚类的动机是观察到图神经网络将节点嵌入到连续空间中,这使我们能够通过连续嵌入空间中的优化来近似优化离散图。 然后,我们将聚类分配解释为离散问题的解决方案。 我们针对两类优化问题实例化了这种方法:需要对图进行分区的问题(例如,社区检测或最大割),以及需要选择的问题> 节点(设施位置、影响力最大化、免疫等)。 我们并不声称聚类是适合所有任务的正确算法结构,但它足以解决本文所示的许多问题。
简而言之,我们做出了三点贡献。 首先,我们介绍一个集成图学习和优化的通用框架,用连续空间中更简单的优化问题作为更复杂的离散问题的代理。 其次,我们展示如何通过聚类层进行区分,从而使其能够在深度学习系统中使用。 第三,我们展示了对两阶段基线的实验改进以及一系列示例领域的替代端到端方法。
2相关工作
我们以最近关于决策为中心的学习donti2017task 的工作为基础;怀尔德2019融合; demirovicinvestigation ,它将优化问题的求解器包含到训练中,以提高下游决策问题的性能。 相关工作开发并分析有效的替代损失函数,以预测然后优化问题elmachtoub2017smart; balghiti2019概括 . 结构化预测方面的一些工作还集成了离散问题的可微求解器(例如,图像分割djolonga2017 Differentiable或时间序列对齐mensch2018 Differentiable)。 我们的工作有两个不同之处。 首先,我们解决更困难的优化问题。 之前的工作主要集中在凸问题donti2017task或具有近无损凸关系的离散问题wilder2019melding; djolonga2017可微 。 我们专注于高度组合的问题,其中选择的方法是手工设计的离散算法。 其次,为了应对这一困难,我们在方法上有所不同,因为我们不尝试为手头的确切优化问题(或它的紧密松弛)包含一个求解器。 相反,我们包含一个更通用的算法框架,可以自动针对当前的优化问题进行微调。
最近人们对训练神经网络来解决组合优化问题也很感兴趣 vinyals2015pointer ; khalil2017学习;贝洛2016神经; kool2019关注 。 虽然我们主要关注将图学习与优化相结合,但我们的模型也可以经过训练来解决给定输入的完整信息的优化问题。 主要的方法差异在于,我们通过可微分的 表示层包含更多结构,而不是使用更通用的工具(例如前馈或注意层)。 另一个区别是,之前的工作主要通过强化学习进行训练。 相比之下,我们对目标使用可微的近似,从而消除了对策略梯度估计器的需要。 这是我们架构的一个好处,其中最终决策在模型参数方面是完全可微的,而不是需要不可微的选择步骤(如khalil2017learning;bello2016neural;kool2019attention)。 我们通过使用与我们自己的模型相同的可微决策损失来训练它,而不是强迫它使用噪声更大的策略梯度估计,从而为我们的端到端基线(“GCN-e2e”)提供了相同的优势。
最后,一些工作使用深度架构作为聚类算法的一部分tian2014learning;法律2017深; guo2017改进; shaham2018光谱网; nazi2019gap ,或包含聚类步骤作为深度网络 greff2016tagger 的组件; greff2017神经; ying2018分层 . 虽然有些技术是相似的,但我们解决的总体任务和我们提出的框架是完全不同的。 我们的目标不是对欧几里得数据集进行聚类(如 tian2014learning ; law2017deep ; guo2017improved ; shaham2018spectralnet ),或解决感知分组问题(如 greff2016tagger ; greff2017neural )。 相反,我们提出了一种解决图优化问题的方法。 也许最接近这项工作的是 Neural EM greff2017neural ,它使用展开的 EM 算法来学习视觉对象的表示。 我们没有使用 EM 来推断对象的表示,而是使用图嵌入空间中的 -means 来解决优化问题。 还有一些使用深度网络进行图聚类的工作 xie2016unsupervised ; yang2016模块化 . 然而,这些工作都没有在网络中包含显式的聚类算法,也没有考虑我们集成图学习和优化的目标。
3设置
我们考虑将学习和优化相结合的设置。 输入是一个图,它以某种方式被部分观察。 我们将以链接预测为例来形式化我们的问题,但我们的框架适用于其他常见的图学习问题(例如,半监督分类)。 在链接预测中,图并不完全已知;相反,我们只观察训练边缘。 令 表示图的邻接矩阵, 表示仅包含训练边的邻接矩阵。 学习任务是根据预测。 在我们考虑的领域中,执行链接预测的动机是解决目标取决于完整图的决策问题。 具体来说,我们有一个决策变量、目标函数和一个可行集。 我们的目标是解决优化问题
| (1) |
然而, 未被观察到。 我们还可以考虑一种归纳设置,其中我们观察图 作为训练示例,然后寻求预测来自相同分布的部分观察到的图的边缘。 这两种设置的最常见方法是训练一个模型,使用标准损失函数(例如交叉熵)从 重建 ,产生估计 。 两阶段方法将插入到问题1的优化算法中,最大化。
我们提出了从直接映射到可行决策的端到端模型。 该模型将被训练以最大化,即根据训练数据评估其决策的质量(而不是测量纯粹预测准确性的损失)。 一种方法是通过训练标准模型(例如 GCN)直接从 映射到 来“学习”问题。 然而,这迫使模型完全重新发现算法概念,而两阶段方法能够利用高度复杂的优化方法。 我们提出了一种替代方案,将算法结构嵌入到学习模型中,从而两全其美。
4方法:ClusterNet
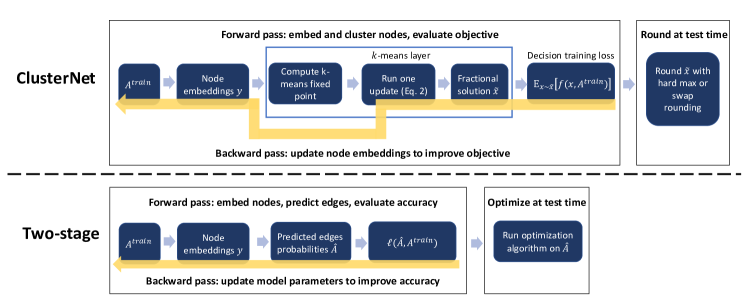
我们提出的 ClusterNet 系统(图 1)将两个可微组件合并到一个经过端到端训练的系统中。 首先,图嵌入层使用和任何节点特征将图的节点嵌入到中。 在我们的实验中,我们使用 GCN kipf2017semi 。 其次,执行可微分优化的层。 该层将连续空间嵌入作为输入,并使用它们生成图优化问题的解决方案。 具体来说,我们建议使用一个实现可微版本的 均值聚类的层。 该层产生节点到簇的软分配,以及嵌入空间中的簇中心。
直觉上,聚类分配可以解释为许多常见图优化问题的解决方案。 例如,在社区检测中,我们可以将集群分配解释为将节点分配给社区。 或者,在 maxcut 中,我们可以使用两个簇将节点分配到切割的任一侧。 另一个例子是最大覆盖和相关问题,我们尝试选择一组 节点来覆盖尽可能多的其他节点(与其相邻)。 这个问题可以通过将节点聚类为 组件并选择嵌入靠近每个聚类中心的节点来近似。 我们并不声称这些问题中的任何一个都可以完全简化为 均值。 相反,这个想法是,将 包含为网络中的一层可以提供有用的归纳偏差。 这种算法结构可以通过训练第一个组件(产生嵌入)来针对特定问题进行微调,以便学习到的表示为底层下游优化任务带来具有高目标价值的聚类。 我们现在更详细地解释我们系统的优化层。 我们首先详细说明聚类过程的前向和后向传递,然后解释如何将聚类分配解释为图优化问题的解决方案。
4.1 前向传递
令表示节点的嵌入,表示簇的中心。 表示节点分配给集群的程度。在传统的 中,这是一个二进制量,但我们将其放宽为小数值,使得所有 都为 。 具体来说,我们采用,它是每个点根据距离到聚类中心的软最小分配。 虽然我们的架构可以与任何范数 一起使用,但由于其强大的经验性能,我们使用负余弦相似度。 是反温度超参数;采用 恢复标准 均值分配。 我们可以通过类似于典型的 的迭代过程来优化聚类中心 - 通过交替设置来更新
| (2) |
这些迭代收敛到一个固定点,其中 在连续更新 mackay2003information 之间保持不变。 前向传递的输出是最后对。
4.2 向后传递
我们将利用隐函数定理,通过前向传递-means迭代收敛到的不动点进行解析微分,得到和的表达式。 之前的工作 donti2017task ; wilder2019melding利用隐函数定理通过优化问题的KKT条件进行微分;在这里,我们采用更直接的方法来描述更新过程本身。 这样做允许我们将决策损失的梯度反向传播到生成嵌入 的组件。 定义函数 为
| (3) |
现在,是迭代的固定点。 应用隐函数定理可以得到,通过链式法则可以很容易地得到。
精确向后传递: 我们现在检查计算的过程。 和 都可以很容易地以封闭形式计算(参见附录)。 计算前者需要时间。 计算后者需要 时间,之后必须对其求逆(否则必须使用迭代方法来计算其逆的乘积)。 这需要时间 ,因为它是大小为 的矩阵。 虽然精确的向后传递对于某些问题可能是可行的,但对于大型实例来说它很快就会变得很麻烦。 我们现在提出一种快速近似。
近似向后传递: 我们从观察到 通常由其对角项(单位矩阵)主导。 非对角线条目捕获对 的一个条目的更新通过对簇分配 的更改间接影响其他条目的程度。然而,当聚类分配相对固定时,不会对聚类中心的微小变化高度敏感。 我们发现这在经验上是典型的,特别是因为参数(控制聚类分配的难度)的最佳选择通常相当高。 在这些条件下,我们可以用 的对角线 来近似。 这又给出了。
当簇相对平衡且分离良好时,我们可以正式证明这种近似的合理性。 更准确地说,将 定义为距点 最近的簇。 命题 1(在附录中证明)表明,对角线近似的质量在两项的乘积中呈指数级快速提高:(聚类分配的难度)和 ,它衡量集群的分离程度。 (定义如下)测量簇大小的平衡。 为了方便起见,我们假设输入被缩放为 。
Proposition 1。
假设对于所有点,对于所有,,对于所有簇,。 此外,假设。 然后,,其中 是运算符 1-范数。
我们现在表明,通过采用 获得的近似梯度可以通过在收敛时展开方程 2 的前向更新的单次迭代来计算。 检查方程 3,我们发现第一项 () 相对于 是常数,因为这里 是一个固定值。 因此,
这只是 的更新方程。 由于前向传递更新完全是根据可微函数编写的,因此我们可以自动计算相对于 的近似后向传递(即,用我们对 的近似计算乘积,并且)通过将标准自微分工具应用于前向传递的最终更新。 与计算精确的解析梯度相比,这避免了显式推理或反转 的需要。 最终迭代(通过微分的迭代)需要时间,与数据大小线性。
与通过在计算图中展开整个更新序列进行区分(正如针对其他问题 domke2012generic ; andrychowicz2016learning ; zheng2015conditional 所建议的那样),我们的方法有两个关键优势。 首先,它避免存储更新的整个历史记录并通过所有更新进行反向传播。 我们的近似的运行时间与达到收敛所需的更新数量无关。 其次,我们实际上可以使用完全不可微的操作来达到固定点,例如,均值问题的启发式方法,仅检查子集的随机方法数据等 这允许前向传递扩展到更大的数据集,因为我们可以使用可用的最佳算法工具,而不仅仅是那些可以在自动微分工具的计算图中显式编码的算法工具。
4.3 获取优化问题的解
以可微分的方式获得聚类分配 以及中心 后,我们需要一种方法 (1) 可微分地将聚类解释为优化问题的软解,(2)根据该解区分图优化问题的目标值的松弛,然后(3)舍入为测试时的离散解。 我们针对两大类问题提供了完成这三个步骤的通用方法:涉及将图划分为不相交组件的问题,以及涉及选择的问题 节点的子集。
分区: (1) 我们可以自然地将簇分配解释为图的软分区。 (2) 一个通用的连续目标函数(在软分区上定义)源自将每个节点 分配给分区的随机过程,概率为 ,在所有节点上独立重复此过程。 这给出了预期的训练决策 ,其中 表示此随机分配。 现在可以根据 进行微分,并且可以通过标准自微分工具以封闭形式计算许多感兴趣的问题(请参阅第 5 节)。 我们注意到,当期望无法以封闭形式获得时,我们的方法仍然可以通过重复采样 并使用策略梯度估计器来计算结果目标的梯度来应用。 (3) 在测试时,我们只需对 应用硬最大值即可获取每个节点的分配。
子集选择: (1) 这里,如何从集群分配中获取 节点的子集不太明显。 我们的连续解将是一个向量 、,其中 。 直观上, 是解中包含 的概率。 我们的方法通过在靠近聚类中心的节点上放置更大的概率质量来获得。 具体来说,每个中心被赋予一个概率质量单位,并将其分配给点作为。 分配给节点的总概率为。 由于我们可能有 ,因此我们将 通过 sigmoid 函数传递,以将条目限制为 1;具体来说,我们采用 ,其中 是一个可调参数。 如果生成的 超出预算约束 (),我们将输出 以确保可行的解决方案。
(2) 我们按照与上面类似的目标来解释这个解决方案。 具体来说,我们考虑绘制离散解 的结果,其中每个节点 都以独立的概率 包含(即设置为 1)。步骤(1)。 那么训练目标就是。 对于许多问题,这可以再次通过封闭形式进行计算和微分(参见第 5 节)。
(3) 在测试时,我们需要一个可行的离散向量;请注意,独立舍入各个条目可能会产生一个具有多个 个的向量。 在这里,我们应用了一种基于 pipage 舍入 ageev2004pipage 的相当通用的方法,这是一种随机舍入方案,已应用于许多问题(特别是具有子模块目标的问题)。 可以实现管道舍入以在时间 karimi2017stochastic 内产生随机可行解;在实践中,我们进行多次舍入,并在观察到的边缘上采用最佳决策损失的解决方案。 虽然管道舍入仅对特定类别的函数具有理论上的保证,但我们发现它甚至在其他领域(例如设施位置)也能很好地工作。 但是,如果可用,可以应用更多特定于域的舍入方法。
| Learning + optimization | Optimization | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| cora | cite. | prot. | adol | fb | cora | cite. | prot. | adol | fb | ||
| ClusterNet | 0.54 | 0.55 | 0.29 | 0.49 | 0.30 | 0.72 | 0.73 | 0.52 | 0.58 | 0.76 | |
| GCN-e2e | 0.16 | 0.02 | 0.13 | 0.12 | 0.13 | 0.19 | 0.03 | 0.16 | 0.20 | 0.23 | |
| Train-CNM | 0.20 | 0.42 | 0.09 | 0.01 | 0.14 | 0.08 | 0.34 | 0.05 | 0.57 | 0.77 | |
| Train-Newman | 0.09 | 0.15 | 0.15 | 0.15 | 0.08 | 0.20 | 0.23 | 0.29 | 0.30 | 0.55 | |
| Train-SC | 0.03 | 0.02 | 0.03 | 0.23 | 0.19 | 0.09 | 0.05 | 0.06 | 0.49 | 0.61 | |
| GCN-2stage-CNM | 0.17 | 0.21 | 0.18 | 0.28 | 0.13 | - | - | - | - | - | |
| GCN-2stage-Newman | 0.00 | 0.00 | 0.00 | 0.14 | 0.02 | - | - | - | - | - | |
| GCN-2stage-SC | 0.14 | 0.16 | 0.04 | 0.31 | 0.25 | - | - | - | - | - | |
| Learning + optimization | Optimization | ||||||||||
| cora | cite. | prot. | adol | fb | cora | cite. | prot. | adol | fb | ||
| ClusterNet | 10 | 14 | 6 | 6 | 4 | 9 | 14 | 6 | 5 | 3 | |
| GCN-e2e | 12 | 15 | 8 | 6 | 5 | 11 | 14 | 7 | 6 | 5 | |
| Train-greedy | 14 | 16 | 8 | 8 | 6 | 9 | 14 | 7 | 6 | 5 | |
| Train-gonzalez | 12 | 17 | 8 | 6 | 6 | 10 | 15 | 7 | 7 | 3 | |
| GCN-2Stage-greedy | 14 | 17 | 8 | 7 | 6 | - | - | - | - | - | |
| GCN-2Stage-gonzalez | 13 | 17 | 8 | 6 | 6 | - | - | - | - | - | |
5实验结果
我们现在展示将链接预测与优化相结合的领域的实验。
学习问题: 在链接预测中,我们观察部分图并旨在推断存在哪些未观察到的边缘。 在每个实验中,我们都保留了图中的边 ,并在训练期间观察到 。 我们使用未包含在结果中的图形数据集来设置方法的超参数,这些超参数在数据集中保持不变(详细信息请参阅附录)。 学习任务是使用训练边来预测剩余边是否存在,之后我们将在预测图上解决优化问题。 目标是找到在整个图上测量的具有高目标值的解决方案,而不仅仅是训练边缘。
优化问题: 我们考虑两项优化任务,其中一项来自上面介绍的大类。 首先,社区检测旨在将图的节点划分为不同的子组,这些子组内部密集,但组间边缘很少。 形式上,目标是找到一个最大化模块化 newman2006modularity 的分区,定义为
这里, 是节点 的度,如果节点 被分配到社区 ,则 为 1,否则为 0。 如果边缘随机放置,这将测量社区内边缘的数量与预期数量的比较。 我们的集群模块为每个 社区提供一个集群。 将 定义为具有 条目的模块化矩阵,我们的训练目标(根据 采样的分区的期望值)为 .
其次,minmax 设施位置,其中问题是从图中选择节点的子集,最小化从任何节点到设施(选定节点)的最大距离。 令为从顶点到一组顶点的最短路径长度,目标为。 为了获得训练损失,我们采取两个步骤。 首先,我们将 替换为 ,其中 表示从乘积分布中绘制一个带有边际 的集合。 这可以很容易地以封闭形式 karimi2017stochastic 计算。 其次,我们用 softmin 替换 。
基线学习方法: 我们使用 2 层 GCN 进行节点嵌入来实例化 ClusterNet,后面是一个聚类层。 我们与三个基线系列进行比较。 首先,GCN-2stage,这是一种两阶段方法,首先训练链路预测模型,然后将预测图输入优化算法。 对于链接预测,我们使用基于 GCN 的 schlichtkrull2018modeling 系统(我们也采用他们的训练程序,包括负采样和边缘 dropout)。 对于优化算法,我们对每个领域使用标准方法,如下所述。 第二,“训练”,仅在观察到的训练子图上运行每个优化算法(不尝试任何链接预测)。 第三,GCN-e2e,一种不包含显式算法结构的端到端方法。 我们使用与我们自己的模型相同的训练目标来训练基于 GCN 的网络来直接预测最终决策变量( 或 )。 根据经验,我们观察到 2 层 GCN 的最佳性能。 该基线使我们能够分离出包含算法结构的好处。
基线优化方法:在每个领域,我们都会与文献中找到的专家设计的优化算法进行比较。 在社区检测中,我们将“CNM”clauset2004finding(一种凝聚方法)、“Newman”(一种递归划分图的方法newman2006finding)和“SC”(执行模块化矩阵上的谱聚类von2007tutorial。 在设施选址中,我们比较了“贪婪”(迭代选择目标值边际改进最大的点的常见启发式)和“冈萨雷斯”gonzalez1985clustering(一种迭代选择距离设施最远节点的算法)。当前设置。 “gonzalez”获得了该问题的最佳 2 近似(请注意,最小最大设施位置目标是非子模的,排除了通常的 近似)。
数据集:我们使用几个标准图形数据集:cora sen2008collective(具有 2,708 个节点的引文网络)、citeseer sen2008collective(具有 3,327 个节点的引文网络) )、蛋白质 koblenz Protein (具有 3,133 个节点的蛋白质相互作用网络)、adol koblenzadhealth (具有 2,539 个顶点的青少年社交网络)和 fb koblenzfb ; leskovec2012learning(一个拥有 2,888 个节点的在线社交网络)。 对于设施位置,我们使用图中最大的连通分量(因为否则距离可能是无限的)。 Cora 和 citeseer 具有节点特征(基于文档的词袋表示),这些特征被赋予所有基于 GCN 的方法。 对于其他数据集,我们使用训练边生成无监督的 node2vec 特征 grover2016node2vec。
5.1 单个图表的结果
我们从组合链接预测和优化问题的结果开始。 表1显示了每种方法在社区检测的完整图表上获得的目标值,表2显示了设施位置。 我们首先关注“学习+优化”列,它显示了组合的链接预测/优化任务。 我们使用簇; 非常相似,可以在附录中找到。 ClusterNet 在几乎所有情况下都优于基线,而且通常是大幅优于基线。 GCN-e2e 学习产生重要的解决方案,通常可以与其他基线方法相媲美。 然而,我们的方法 ClusterNet 使用的显式结构带来了更高的性能。
有趣的是,两阶段方法有时比仅训练基线表现更差,后者仅根据训练边缘(不尝试学习)进行优化。 这表明尝试准确重建图形的方法有时可能会错过对优化很重要的质量,并且在最坏的情况下可能只是添加噪声,从而压倒训练边缘中的信号。 为了确认两阶段方法学会了做出有意义的预测,在附录中我们给出了每个数据集的 AUC 值。 平均 AUC 值为 0.7584,表明两阶段模型确实学会了做出重要的预测。 然而,少量的训练数据(仅观察到 40% 的边)使其无法完美地重建真实图。 这说明了这样一个观点:当即使对于复杂的学习方法也无法实现高度准确的预测时,ClusterNet 等以决策为中心的学习方法可以提供巨大的好处。
接下来我们检查一个仅优化的任务,其中整个图可作为输入(表 1 和表 2 的“优化”列)。 与专家设计的算法相比,这测试了 ClusterNet 学习解决组合优化问题的能力,即使不存在部分信息或学习问题。 我们发现 ClusterNet 具有很强的竞争力,达到并经常超过基线。 它对于社区检测特别有效,我们观察到与某些数据集的最佳基线相比有很大(> 3 倍)的改进。 在设施位置,我们的方法至少总是与基线联系在一起,并经常对其进行改进。 这些实验提供的证据表明,我们的方法在训练过程中自动专门化以在给定的图上进行优化,可以与文献中手工设计的算法相媲美并超越。 另一种学习方法 GCN-e2e 是一种端到端方法,试图学习直接从节点特征预测优化解决方案,最多只能与基线挂钩,并且通常表现不佳。 这强调了将算法结构作为端到端架构的一部分的好处。
| Community detection | Facility location | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| synthetic | pubmed | synthetic | pubmed | |||||||||
| No finetune | Avg. | % | Avg. | % | No finetune | Avg. | % | Avg. | % | |||
| ClusterNet | 0.57 | 26/30 | 0.30 | 7/8 | ClusterNet | 7.90 | 25/30 | 7.88 | 3/8 | |||
| GCN-e2e | 0.26 | 0/30 | 0.01 | 0/8 | GCN-e2e | 8.63 | 11/30 | 8.62 | 1/8 | |||
| Train-CNM | 0.14 | 0/30 | 0.16 | 1/8 | Train-greedy | 14.00 | 0/30 | 9.50 | 1/8 | |||
| Train-Newman | 0.24 | 0/30 | 0.17 | 0/8 | Train-gonzalez | 10.30 | 2/30 | 9.38 | 1/8 | |||
| Train-SC | 0.16 | 0/30 | 0.04 | 0/8 | 2Stage-greedy | 9.60 | 3/30 | 10.00 | 0/8 | |||
| 2Stage-CNM | 0.51 | 0/30 | 0.24 | 0/8 | 2Stage-gonz. | 10.00 | 2/30 | 6.88 | 5/8 | |||
| 2Stage-Newman | 0.01 | 0/30 | 0.01 | 0/8 | ClstrNet-1train | 7.93 | 12/30 | 7.88 | 2/8 | |||
| 2Stage-SC | 0.52 | 4/30 | 0.15 | 0/8 | ||||||||
| ClstrNet-1train | 0.55 | 0/30 | 0.25 | 0/8 | ||||||||
| Finetune | Finetune | |||||||||||
| ClstrNet-ft | 0.60 | 20/30 | 0.40 | 2/8 | ClstrNet-ft | 8.08 | 12/30 | 8.01 | 3/8 | |||
| ClstrNet-ft-only | 0.60 | 10/30 | 0.42 | 6/8 | ClstrNet-ft-only | 7.84 | 16/30 | 7.76 | 4/8 | |||
5.2 跨图概括
接下来,我们研究我们的方法是否可以学习通用的优化策略:我们可以在从某个分布绘制的一组图上训练模型,然后将其应用于看不见的图吗? 我们考虑两个图分布。 首先是 wilder2018optimizing 引入的合成生成器,它基于空间优先依恋模型 barthelemy2011spatial(详情见附录)。 我们使用 20 个训练图、10 个验证和 30 个测试。 其次,使用 metis karypis1998fast 将 pubmed 图拆分为 20 个组件而获得的数据集。 我们修复了 10 个训练图、2 个验证和 8 个测试。 在测试时,每个图中仅显示 40% 的边,与上面的“学习 + 优化”设置相匹配。
表3显示了结果。 首先,我们不对测试图进行任何微调,而是完全评估所学习的表示的普遍性。 ClusterNet 在所有任务上都优于所有基线方法,但 pubmed 上的设施位置除外,它位居第二。 我们得出的结论是,学习的模型成功地推广到完全看不见的图。 接下来我们研究(在表 3 的“微调”部分)是否可以通过微调每个节点 40% 的观察到的边缘来进一步提高 ClusterNet 的性能。测试图(将每个测试图视为第 5.1 节中的链接预测问题的实例,但使用通过训练图学习的模型参数进行初始化)。 我们看到ClusterNet的性能通常会提高,这表明如果有额外的训练时间,微调可以让我们获得额外的收益。
有趣的是,仅微调(根本不使用训练图)会产生相似的性能(“ClstrNet-ft-only”行)。 虽然我们早期的结果表明 ClusterNet 可以学习通用策略,但当有机会进行调整时,可能没有必要这样做。 这允许在质量和运行时间之间进行权衡:无需微调,在测试时应用我们的方法只需要一次前向传递,这是非常高效的。 如果测试时的额外计算成本可以接受,则可以使用微调来提高性能。 附录中显示了所有方法的完整运行时间。 ClusterNet 的前向传递(即无需微调)非常高效,在最大的网络上最多需要 0.23 秒,并且始终比基线更快(在相同的硬件)。 微调需要更长的时间,与最慢的基线相当。
最后,我们调查了预训练相对于微调几乎没有改进的原因。 本质上,我们发现 训练 ClusterNet 的样本效率极高:仅使用单个图即可获得几乎与完整训练集一样好的性能(并且仍然优于所有基线),如表 3 的“ClstrNet-1train”行。 也就是说,ClusterNet能够学习优化策略,在仅观察单个训练示例后,可以以强大的性能泛化到完全看不见的图。 这强调了将算法结构作为架构一部分的好处,它可以指导模型学习有意义的策略。
6结论
当机器学习用于指导决策时,通常需要将下游优化问题纳入训练中。 在这里,我们提出了一种解决这个以决策为中心的学习问题的新方法:包括一个可微分求解器,用于真实、困难的优化问题的简单代理,并学习将困难问题映射到更简单问题的表示。 该表示以完全自动的方式进行训练,使用真正下游问题的解决方案质量作为损失函数。 我们发现,这种在学习中包含算法结构的“中间路径”比完全分离学习和优化的两阶段方法和使用学习直接预测最优解决方案的纯粹端到端方法都有所改进。 在这里,我们针对一类图优化问题实例化了这个框架。 我们希望未来的工作能够为其他问题系列探索这样的想法,为深度学习中灵活高效的基于优化的结构铺平道路。
致谢
这项工作得到了陆军研究办公室 (MURI W911NF1810208) 的支持。 怀尔德得到了美国国家科学基金会研究生研究奖学金的支持。 Dilkina 得到了 NSF 奖项 # 1914522 和美国国土安全部授予的部分资助,奖项编号为 1914522。 2015-ST-061-CIRC01。 本文件中包含的观点和结论属于作者的观点和结论,不应被解释为必然代表美国国土安全部明示或暗示的官方政策。
参考
- (1) Alexander A Ageev and Maxim I Sviridenko. Pipage rounding: A new method of constructing algorithms with proven performance guarantee. Journal of Combinatorial Optimization, 8(3):307–328, 2004.
- (2) Nesreen K Ahmed, Ryan Rossi, John Boaz Lee, Theodore L Willke, Rong Zhou, Xiangnan Kong, and Hoda Eldardiry. Learning role-based graph embeddings. arXiv preprint arXiv:1802.02896, 2018.
- (3) Brandon Amos and J. Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. In ICML, 2017.
- (4) Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Processing Systems, pages 3981–3989, 2016.
- (5) Ashwin Bahulkar, Boleslaw K Szymanski, N Orkun Baycik, and Thomas C Sharkey. Community detection with edge augmentation in criminal networks. In 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), 2018.
- (6) Othman El Balghiti, Adam N Elmachtoub, Paul Grigas, and Ambuj Tewari. Generalization bounds in the predict-then-optimize framework. arXiv preprint arXiv:1905.11488, 2019.
- (7) Marc Barthélemy. Spatial networks. Physics Reports, 499(1-3):1–101, 2011.
- (8) Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning. arXiv preprint arXiv:1611.09940, 2016.
- (9) Giulia Berlusconi, Francesco Calderoni, Nicola Parolini, Marco Verani, and Carlo Piccardi. Link prediction in criminal networks: A tool for criminal intelligence analysis. PloS one, 11(4):e0154244, 2016.
- (10) Matthew Burgess, Eytan Adar, and Michael Cafarella. Link-prediction enhanced consensus clustering for complex networks. PloS one, 11(5):e0153384, 2016.
- (11) Aaron Clauset, Mark EJ Newman, and Cristopher Moore. Finding community structure in very large networks. Physical review E, 70(6):066111, 2004.
- (12) Koblenz Network Collection. Adolescent health. http://konect.uni-koblenz.de/networks/moreno_health, 2017.
- (13) Koblenz Network Collection. Facebook (nips). http://konect.uni-koblenz.de/networks/ego-facebook, 2017.
- (14) Koblenz Network Collection. Human protein (vidal). http://konect.uni-koblenz.de/networks/maayan-vidal, 2017.
- (15) Emir Demirovic, Peter J Stuckey, James Bailey, Jeffrey Chan, Chris Leckie, Kotagiri Ramamohanarao, and Tias Guns. Prediction + optimisation for the knapsack problem. In CPAIOR, 2019.
- (16) Josip Djolonga and Andreas Krause. Differentiable learning of submodular models. In NeurIPS, 2017.
- (17) Justin Domke. Generic methods for optimization-based modeling. In Artificial Intelligence and Statistics, pages 318–326, 2012.
- (18) Priya Donti, Brandon Amos, and J Zico Kolter. Task-based end-to-end model learning in stochastic optimization. In Advances in Neural Information Processing Systems, pages 5484–5494, 2017.
- (19) Adam N Elmachtoub and Paul Grigas. Smart" predict, then optimize". arXiv preprint arXiv:1710.08005, 2017.
- (20) Teofilo F Gonzalez. Clustering to minimize the maximum intercluster distance. Theoretical Computer Science, 38:293–306, 1985.
- (21) Klaus Greff, Antti Rasmus, Mathias Berglund, Tele Hao, Harri Valpola, and Jürgen Schmidhuber. Tagger: Deep unsupervised perceptual grouping. In NeurIPS, 2016.
- (22) Klaus Greff, Sjoerd van Steenkiste, and Jürgen Schmidhuber. Neural expectation maximization. In NeurIPS, 2017.
- (23) Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864. ACM, 2016.
- (24) Xifeng Guo, Long Gao, Xinwang Liu, and Jianping Yin. Improved deep embedded clustering with local structure preservation. In IJCAI, 2017.
- (25) Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NIPS, 2017.
- (26) Mohammad Karimi, Mario Lucic, Hamed Hassani, and Andreas Krause. Stochastic submodular maximization: The case of coverage functions. In Advances in Neural Information Processing Systems, 2017.
- (27) George Karypis and Vipin Kumar. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM Journal on scientific Computing, 20(1):359–392, 1998.
- (28) Elias Khalil, Hanjun Dai, Yuyu Zhang, Bistra Dilkina, and Le Song. Learning combinatorial optimization algorithms over graphs. In NIPS, 2017.
- (29) Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2017.
- (30) Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems! In ICLR, 2019.
- (31) Marc T Law, Raquel Urtasun, and Richard S Zemel. Deep spectral clustering learning. In ICML, 2017.
- (32) Jure Leskovec and Julian J Mcauley. Learning to discover social circles in ego networks. In Advances in neural information processing systems, pages 539–547, 2012.
- (33) David JC MacKay. Information theory, inference and learning algorithms. Cambridge university press, 2003.
- (34) Arthur Mensch and Mathieu Blondel. Differentiable dynamic programming for structured prediction and attention. In ICML, 2018.
- (35) Azade Nazi, Will Hang, Anna Goldie, Sujith Ravi, and Azalia Mirhoseini. Gap: Generalizable approximate graph partitioning framework. arXiv preprint arXiv:1903.00614, 2019.
- (36) Mark EJ Newman. Finding community structure in networks using the eigenvectors of matrices. Physical review E, 74(3):036104, 2006.
- (37) Mark EJ Newman. Modularity and community structure in networks. Proceedings of the National Academy of Sciences, 103(23):8577–8582, 2006.
- (38) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701–710. ACM, 2014.
- (39) M. Schlichtkrull, T. Kipf, P. Bloem, R. Van Den Berg, I. Titov, and M. Welling. Modeling relational data with graph convolutional networks. In European Semantic Web Conference, 2018.
- (40) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- (41) Uri Shaham, Kelly Stanton, Henry Li, Boaz Nadler, Ronen Basri, and Yuval Kluger. Spectralnet: Spectral clustering using deep neural networks. In ICLR, 2018.
- (42) Suo-Yi Tan, Jun Wu, Linyuan Lü, Meng-Jun Li, and Xin Lu. Efficient network disintegration under incomplete information: the comic effect of link prediction. Scientific reports, 6:22916, 2016.
- (43) Fei Tian, Bin Gao, Qing Cui, Enhong Chen, and Tie-Yan Liu. Learning deep representations for graph clustering. In Twenty-Eighth AAAI Conference on Artificial Intelligence, 2014.
- (44) Michalis Titsias. One-vs-each approximation to softmax for scalable estimation of probabilities. In NeurIPS, 2016.
- (45) Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In NIPS, 2015.
- (46) Ulrike Von Luxburg. A tutorial on spectral clustering. Statistics and computing, 17(4):395–416, 2007.
- (47) Bryan Wilder, Bistra Dilkina, and Milind Tambe. Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. In AAAI, 2019.
- (48) Bryan Wilder, Han Ching Ou, Kayla de la Haye, and Milind Tambe. Optimizing network structure for preventative health. In AAMAS, 2018.
- (49) Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. In International conference on machine learning, pages 478–487, 2016.
- (50) Bowen Yan and Steve Gregory. Detecting community structure in networks using edge prediction methods. Journal of Statistical Mechanics: Theory and Experiment, 2012(09):P09008, 2012.
- (51) Liang Yang, Xiaochun Cao, Dongxiao He, Chuan Wang, Xiao Wang, and Weixiong Zhang. Modularity based community detection with deep learning. In IJCAI, volume 16, pages 2252–2258, 2016.
- (52) Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical graph representation learning with differentiable pooling. In Advances in Neural Information Processing Systems, pages 4800–4810, 2018.
- (53) Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks. In NIPS, 2018.
- (54) Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, and Philip HS Torr. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE international conference on computer vision, pages 1529–1537, 2015.
附录A证明
A.1 梯度的精确表达式
定义和。 我们将使用 作为列向量。 对于固定的,我们有
其中 表示 维单位矩阵。 类似地,固定 给出
A.2 保证近似梯度
Proposition 2。
假设对于所有点,对于所有,,对于所有簇,。 此外,假设。 然后,,其中 是运算符 1-范数。
我们关注 的非对角线分量,由下式给出
这里的关键术语是。 让 因为 是通过 softmax 函数定义的,所以我们有
在哪里
现在请注意,通过引理1,在这两种情况下我们都有
定义 并注意我们有 ,因为我们根据余弦相似度定义了 并假设输入已标准化。 把这些放在一起,我们有
所以
由于通过假设 ,我们知道 并应用引理 2 来完成证明。
Lemma 1.
考虑一个点并让。 然后,,相应地,。
证明。
[44] 的方程 4 给出
由于假设我们有 ,我们得到
这证明了引理。 ∎
Lemma 2.
假设对于矩阵 、 对于某些 和运算符范数 。 然后,。
证明。
让。 我们有
所以。 我们有
∎
附录 B实验设置详细信息
B.1 超参数
所有方法均使用 Adam 优化器进行训练。 对于单图实验,我们在 pubmed 图上测试了以下设置(在我们的单图实验中未使用):
-
•
= 1, 10, 30, 50
-
•
学习率 = 0.01, 0.001
-
•
训练迭代次数 = 100, 200, …, 1000
-
•
前向传递次数-表示更新:1、3
-
•
是否增加训练次数——表示500次迭代后更新为5。
-
•
GCN 隐藏层大小:20、50、100
-
•
嵌入尺寸:20、50、100
对于所有单图实验,我们使用 作为设施位置目标,使用 进行社区检测,,GCN 隐藏层 = 嵌入维度 = 50, 1 -表示在前向传递中更新,学习率 = 0.01,训练迭代 1000 次,-表示在 500 次迭代后更新增加到 5。
我们在每个图分布的验证集上测试了以下一组超参数
-
•
= 30, 50, 70, 100
-
•
学习率 = 0.01, 0.001
-
•
辍学率 = 0.5, 0.2
-
•
训练迭代次数 = 10, 20…300
-
•
前向传递次数-表示更新:1、5、10、15
-
•
隐藏层大小:20、50、100
-
•
嵌入尺寸:20、50、100
我们为所有实验选择,学习率 = 0.001,dropout = 0.2,隐藏层 = 嵌入维度 = 50。 在合成图上,我们使用了 70 次训练迭代和 10 次前向传递 均值更新。 对于 pubmed,我们分别使用 220 和 1。
B.2 合成图生成
每个节点都有一组属性(在本例中,是根据真实人口数据模拟的人口统计特征);节点 与节点 形成连接,概率与 成正比,其中 是节点 的度数>。 该模型模拟了现实世界网络中的同质性和重尾度分布。 我们取来获得高度的同质性,从而存在有意义的社区结构。 为了使问题变得更加困难,我们的方法没有观察特征;相反,我们使用 role2vec [2] 仅从图结构生成无监督特征(它根据跨图有意义的主题计数生成归纳表示)。 每个图有 500 个节点。
B.3代码
有关用于运行实验的代码和数据,请参阅 https://github.com/bwilder0/clusternet。
B.4硬件
所有方法均在具有 14 个 i9 3.1 GHz 内核和 128 GB RAM 的计算机上运行。 为了与基线进行公平的运行时比较,所有方法都在 CPU 上运行。
附录 C 的结果
| Learning + optimization | Optimization | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| cora | cite. | prot. | adol | fb | cora | cite. | prot. | adol | fb | ||
| ClusterNet | 0.56 | 0.53 | 0.28 | 0.47 | 0.28 | 0.71 | 0.76 | 0.52 | 0.55 | 0.80 | |
| GCN-e2e | 0.01 | 0.01 | 0.06 | 0.08 | 0.00 | 0.07 | 0.08 | 0.14 | 0.15 | 0.15 | |
| Train-CNM | 0.20 | 0.44 | 0.09 | 0.01 | 0.17 | 0.08 | 0.34 | 0.05 | 0.60 | 0.80 | |
| Train-Newman | 0.08 | 0.15 | 0.15 | 0.14 | 0.07 | 0.20 | 0.22 | 0.29 | 0.30 | 0.47 | |
| Train-SC | 0.06 | 0.04 | 0.05 | 0.22 | 0.21 | 0.15 | 0.08 | 0.07 | 0.46 | 0.79 | |
| GCN-2stage-CNM | 0.20 | 0.23 | 0.18 | 0.32 | 0.08 | - | - | - | - | - | |
| GCN-2stage-Newman | 0.01 | 0.00 | 0.00 | - | 0.00 | - | - | - | - | - | |
| GCN-2stage-SC | 0.13 | 0.18 | 0.10 | 0.29 | 0.18 | - | - | - | - | - | |
| Learning + optimization | Optimization | ||||||||||
| cora | cite. | prot. | adol | fb | cora | cite. | prot. | adol | fb | ||
| ClusterNet | 9 | 14 | 7 | 5 | 2 | 8 | 13 | 6 | 5 | 2 | |
| GCN-e2e | 12 | 15 | 8 | 6 | 4 | 10 | 14 | 7 | 5 | 4 | |
| Train-greedy | 14 | 16 | 8 | 8 | 6 | 9 | 14 | 7 | 6 | 5 | |
| Train-gonzalez | 11 | 15 | 8 | 7 | 6 | 9 | 13 | 7 | 6 | 2 | |
| GCN-2Stage-greedy | 14 | 16 | 8 | 7 | 6 | - | - | - | - | - | |
| GCN-2Stage-gonzalez | 12 | 16 | 8 | 6 | 5 | - | - | - | - | - | |
附录 D时序结果
我们在具有 128 GB RAM 的 Intel i9 7940X @ 3.1 GHz 上运行实验。 我们以秒为单位报告运行时间。 对于具有学习模型的算法,我们报告训练时间和完成单次前向传递的时间。
| cora | cite. | prot. | adol | fb | |
|---|---|---|---|---|---|
| ClusterNet - Training Time | 59.48 | 149.73 | 129.63 | 56.68 | 54.33 |
| ClusterNet - Forward Pass | 0.04 | 0.12 | 0.11 | 0.04 | 0.05 |
| GCN-e2e - Training Time | 36.83 | 54.99 | 34.60 | 29.04 | 28.17 |
| GCN-e2e - Forward Pass | 0.002 | 0.005 | 0.002 | 0.003 | 0.001 |
| Train-CNM | 1.31 | 1.28 | 1.02 | 1.03 | 2.94 |
| Train-Newman | 9.99 | 15.89 | 15.19 | 11.45 | 7.25 |
| Train-SC | 0.41 | 0.62 | 0.55 | 0.38 | 0.48 |
| GCN-2Stage - Training Time | 68.79 | 72.20 | 75.69 | 103.56 | 57.62 |
| GCN-2Stage-CNM | 119.34 | 178.39 | 159.64 | 101.64 | 142.02 |
| GCN-2Stage-New. | 37.96 | 58.26 | 51.70 | 33.14 | 43.88 |
| GCN-2Stage-SC | 0.40 | 0.61 | 0.50 | 0.33 | 0.36 |
| cora | cite. | prot. | adol | fb | |
|---|---|---|---|---|---|
| ClusterNet - Training Time | 264.14 | 555.84 | 488.37 | 244.74 | 246.57 |
| ClusterNet - Forward Pass | 0.10 | 0.23 | 0.20 | 0.09 | 0.11 |
| GCN-e2e - Training Time | 237.68 | 511.23 | 446.76 | 229.49 | 221.28 |
| GCN-e2e - Forward Pass | 0.003 | 0.006 | .005 | 0.004 | .003 |
| Train-Greedy | 1029.18 | 2387 | 1966 | 619.06 | 1244.09 |
| Train-Gonzalez | 0.082 | 0.14 | 0.12 | 0.07 | .066 |
| GCN-2Stage - Training Time | 73.82 | 70.21 | 103.98 | 75.48 | 104.66 |
| GCN-2Stage-Greedy | 1189.15 | 2367 | 2017 | 621.59 | 1237.871 |
| GCN-2Stage-Gonzalez | 0.18 | 0.28 | 0.25 | 0.13 | 0.13 |
| synthetic | pubmed | |
|---|---|---|
| ClusterNet - Training time | 6.57 | 13.74 |
| ClusterNet - Forward Pass | 0.003 | 0.008 |
| GCN-e2e - Training time | 11.40 | 15.86 |
| GCN-e2e - Forward Pass | 0.04 | 0.03 |
| Train-CNM | 0.08 | 0.17 |
| Train-Newman | 0.65 | 1.83 |
| Train-SC | 0.03 | 0.04 |
| 2Stage - Train | 10.98 | 15.86 |
| 2Stage-CNM | 3.23 | 13.73 |
| 2Stage-New. | 1.12 | 4.29 |
| 2Stage-SC | 0.04 | 0.10 |
| synthetic | pubmed | |
|---|---|---|
| ClusterNet - Training Time | 14.36 | 43.06 |
| ClusterNet - Forward Pass | 0.005 | 0.02 |
| GCN-e2e - Training Time | 9.49 | 33.73 |
| GCN-e2e - Forward Pass | 0.01 | 0.02 |
| Train-Gonzalez | 0.07 | 0.49 |
| Train-Greedy | 4.99 | 32.7 |
| 2Stage - Train | 11.00 | 15.78 |
| 2Stage-Gonzalez | 0.07 | 0.07 |
| 2Stage-Greedy | 5.31 | 16.16 |