FastDVDnet:实现无需流量估计的实时深度视频去噪
摘要
在本文中,我们提出了一种基于卷积神经网络架构的最先进的视频去噪算法。 直到最近,神经网络视频去噪一直是一个很大程度上未被探索的领域,现有方法无法与最好的基于补丁的方法的性能竞争。 我们在本文中介绍的方法称为 FastDVDnet,与其他最先进的竞争对手相比,显示出相似或更好的性能,但计算时间显着缩短。 与其他现有的神经网络降噪器相比,我们的算法表现出多种理想的特性,例如快速运行时间,以及使用单个网络模型处理各种噪声级别的能力。 其架构的特点使得可以避免使用昂贵的运动补偿级,同时实现卓越的性能。 其去噪性能和较低的计算负载的结合使得该算法对于实际去噪应用具有吸引力。 我们将我们的方法与不同的最先进算法进行比较,无论是视觉上还是客观质量指标。
1简介
尽管近年来摄影传感器取得了巨大进步,但降噪仍然是视频处理中的一个重要步骤,特别是在拍摄条件具有挑战性时(弱光、小型传感器等)。
尽管图像去噪多年来一直是一个非常活跃的研究领域,但致力于数字视频恢复的工作却很少。 然而,应该指出的是,这两个问题的一些关键方面有所不同。 一方面,视频比静态图像包含更多信息,这有助于恢复过程。 另一方面,视频恢复需要良好的时间一致性,这使得恢复过程的要求更高。 此外,由于所有最新的摄像机都会生成高清甚至更大的视频,因此需要非常快速且高效的算法。
在本文中,我们介绍了另一个用于深度视频去噪的网络:FastDVDnet。 该算法建立在 DVDnet [45] 的基础上,但同时相对于其前身引入了许多重要的变化。 最值得注意的是,由于其架构的特点,该算法能够隐式地处理运动,而不是采用显式的运动估计阶段。 这产生了最先进的算法,可以输出高质量的去噪视频,同时具有非常快的运行时间,甚至比其他相关方法快数千倍。
1.1图像去噪
与视频去噪相反,图像去噪在过去几年中一直受到欢迎。 众多基于深度学习技术的新型图像去噪方法因其出色的性能而引起了广泛的关注。 Schmidt和Roth在[38]中提出了级联收缩场方法。 Chen 和 Pock 在[10]中提出的可训练非线性反应扩散模型建立在前者的基础上。 [6]成功地将多层感知器应用于图像去噪。 此类方法的性能可与著名的基于补丁的算法(例如 BM3D [13] 或非局部贝叶斯 (NLB [27]))相媲美。 然而,它们的局限性包括性能仅限于特定形式的先验,或者必须为每个噪声级别训练一组不同的权重。
另一种广泛使用的方法涉及使用卷积神经网络(CNN),例如RBDN [37]、MWCNN [30]、DnCNN [51] 和 FFDNet [52]。 无论是在定量上还是在视觉上,它们的性能都优于其他最先进的图像去噪算法。 这些方法由一系列卷积层组成,层之间具有非线性激活函数。 这些基于 CNN 的方法的一个显着特征是能够仅使用一个经过训练的模型来去除多个级别的噪声。 DnCNN 由Zhang 等人.在[51]中提出,是一种用于图像去噪的端到端可训练深度CNN。 其主要特征之一是它实现了残差学习[22],即估计输入图像中存在的噪声而不是去噪图像。 在随后的论文 [52] 中,Zhang 等人.提出了 FFDNet,它建立在 DnCNN 所做工作的基础上。 最近,[35, 29] 中提出的方法将神经架构与非局部技术相结合。
1.2视频去噪
文献中对视频去噪的探索要少得多。 最近的大多数视频去噪方法都是基于补丁的。 我们特别注意到流行的 BM3D 对视频去噪的扩展,V-BM4D [32] 和视频非局部贝叶斯 (VNLB [3])。 用于视频去噪的神经网络方法比基于补丁的方法更加罕见。 Chen 等人的[9]中的算法是第一个使用循环神经网络解决此问题的算法。 然而,他们的算法仅适用于灰度图像,并且没有达到令人满意的结果,可能是由于与训练循环神经网络[33]相关的困难。 Vogels 等人.在[46]中提出了一种基于内核预测神经网络的架构,能够对蒙特卡洛渲染序列进行去噪。 视频非本地网络 (VNLnet [14]) 将 CNN 与自相似搜索策略融合在一起。 对于每个补丁,网络通过其第一个不可训练层找到最相似的补丁,CNN 随后使用此信息来预测干净图像。 在[45]中,Tassano 等人.提出了DVDnet,它将给定帧的去噪分为两个单独的去噪阶段。 与其他几种方法一样,它依赖于相邻帧的运动估计。 其他最近的盲去噪方法包括 Ehret et al. [16] 和 ViDeNN [11] 的工作。 后者与 DVDnet 共享分两步执行去噪的想法。 然而,与 DVDnet 不同的是,ViDeNN 不采用运动估计。 与 DVDnet 和 ViDeNN 类似,[46, 7] 中也介绍了在恢复任务中使用时空 CNN 块。 如今,最先进的技术由 DVDnet、VNLnet 和 VNLB 定义。 VNLB 和 VNLnet 在小噪声值下表现出最佳性能,而 DVDnet 在较大噪声值下产生更好的结果。 DVDnet 和 VNLnet 的推理时间都比 VNLB 快得多。 正如我们将看到的,我们在本文中介绍的方法的性能与最先进的方法的性能进行了比较,同时具有更快的运行时间。
2FastDVDnet
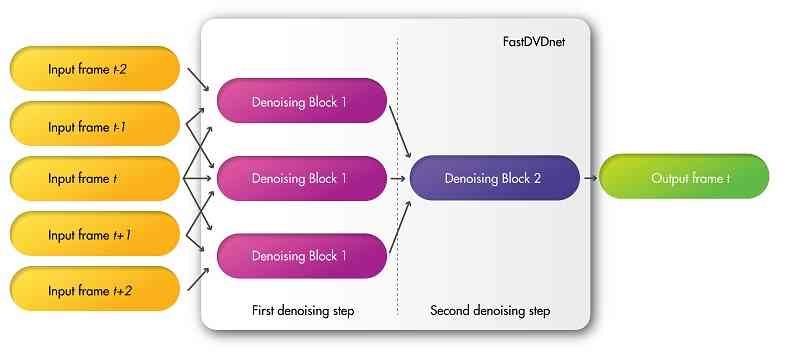
对于视频去噪算法,时间相干性和闪烁消除是结果感知质量的关键方面[40, 39]。 为了实现这些,算法在对图像序列的给定帧进行去噪时必须利用相邻帧中存在的时间信息。 一般来说,之前大多数基于深度学习的方法都未能有效地利用这种时间信息。 成功的最先进算法主要依赖于两个因素来增强结果的时间一致性,即搜索区域从空间邻域到体积邻域的扩展,以及运动估计的使用。
体积(即时空)邻域的使用意味着,当对给定像素(或块)进行去噪时,算法不仅会在参考帧中查找相似的像素(块),还会在序列的相邻帧中查找相似的像素(块) 。 这样做的好处有两个。 首先,时间邻居提供可用于对参考帧进行降噪的附加信息。 其次,使用时间邻居有助于减少闪烁,因为每帧中的残余误差都是相关的。
视频在运动轨迹上具有很强的时间冗余性。 这一事实应该有助于视频去噪图像的去噪。 然而,时间维度上增加的信息也造成了额外的复杂性,可能难以解决。 在这种情况下,运动估计和/或补偿已被应用于许多视频去噪算法中,以帮助提高去噪性能和时间一致性[28,45,3,32,5]。
因此,我们将这两个元素合并到我们的架构中。 然而,我们的算法不包括显式的运动估计/补偿阶段。 处理物体运动的能力本质上嵌入到所提出的架构中。 事实上,我们的架构由许多修改后的 U-Net [36] 块组成(参见部分 2.1有关这些块的更多详细信息)。 多尺度、类似 U-Net 的架构已被证明具有学习错位的能力[50, 15]。 我们的级联架构进一步提高了处理运动的能力。 与[45]相比,我们的架构是在没有光流对齐的情况下进行端到端训练的,这避免了由于错误流而导致的扭曲和伪影。 因此,我们能够在不牺牲性能的情况下消除昂贵的专用运动补偿级。 这导致运行时间显着减少:我们的算法运行速度比 VNLB 快三个数量级,比 DVDnet 和 VNLnet 快一个数量级。
图 1a显示了我们方法的架构图。 当在时间、对给定帧进行去噪时,其相邻帧也被视为输入。 也就是说,算法的输入将为。 该模型由不同的时空去噪块组成,组装在级联的两步架构中。 这些去噪块都很相似,并且由修改后的 U-Net 模型组成,该模型以三个帧作为输入。 第一个去噪步骤中的三个块共享相同的权重,这导致模型的内存需求减少并有利于网络的训练。 与 [52, 18] 类似,噪声图也作为输入包含在内,它允许处理空间变化的噪声 [44]。 特别是,噪声图是一个单独的输入,它向网络提供有关输入处噪声分布的信息。 该信息被编码为该噪声的预期每像素标准偏差。 例如,当对高斯噪声进行去噪时,噪声图将是恒定的;当对泊松噪声进行去噪时,噪声图将取决于图像的强度。 事实上,噪声图可以用作用户输入参数来控制噪声消除与细节保留之间的权衡(例如,参见[44]中的在线演示)。 在其他情况下,例如 JPEG 去噪,可以通过附加的 CNN [20] 来估计噪声图。 噪声图的使用已被证明可以提高去噪性能,特别是在处理空间变异噪声[4]时。 与其他去噪算法相反,除了图像序列和输入噪声的估计之外,我们的去噪器不采用其他参数作为输入。
观察本文中提出的实验重点关注加性高斯白噪声 (AWGN) 的情况。 尽管如此,该算法可以扩展到其他类型的噪声,例如空间变化的噪声(例如泊松噪声)。 假设 是无噪声图像,而 是被标准偏差为 的零均值白高斯噪声 实现所破坏的噪声版本,则
| (1) |
2.1 去噪块
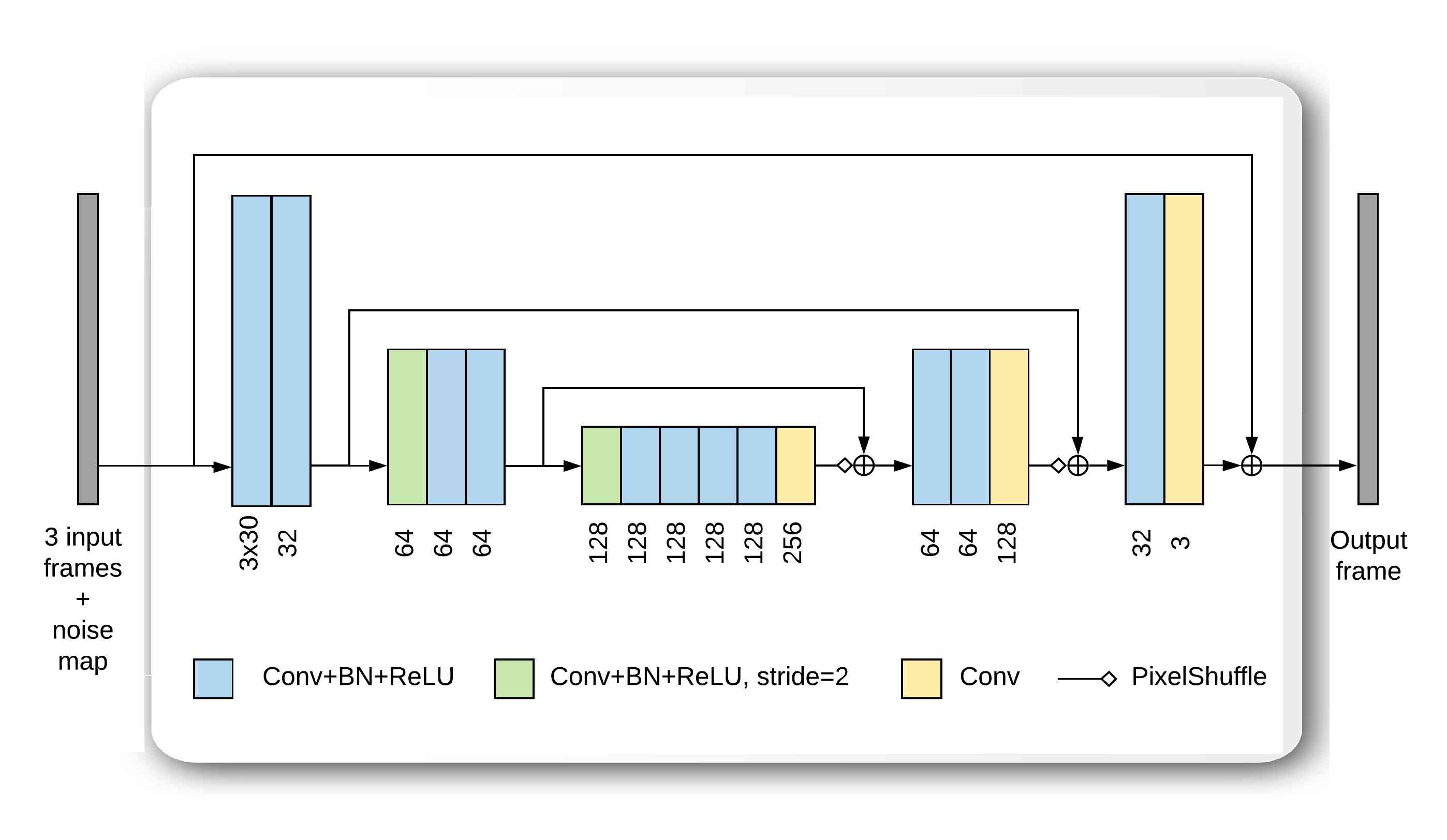
图1a、去噪块1和去噪块2中显示的两个去噪块>,由修改后的 U-Net 架构组成。 去噪块 1 的所有实例共享相同的权重。 U-Net 本质上是一种多尺度编码器-解码器架构,具有跳跃连接[22],将每个编码器层的输出直接转发到相应解码器层的输入。 这些块的更详细图表如图图1b所示。 我们的去噪块与标准 U-Net 存在一些差异:
-
•
编码器已调整为将三个帧和一个噪声图作为输入
-
•
解码器中的上采样是通过 PixelShuffle 层 [41] 执行的,这有助于减少网格伪影。 有关该层的更多信息,请参阅补充材料。
-
•
编码器特征与解码器特征的合并是通过逐像素加法操作而不是逐通道串联来完成的。 这会减少内存需求
-
•
块实现残差学习——在中心噪声输入帧和输出之间有残差连接——据观察,这可以简化训练过程[44]
降噪模块的设计特性在性能和快速运行时间之间取得了良好的折衷。 这些去噪块总共由 个卷积层组成。 在大多数层中,除了最后一层之外,其卷积层的输出后面跟着逐点 ReLU [26] 激活函数 。 批量归一化层 (BN [23]) 放置在卷积层和 ReLU 层之间。
3讨论
FastDVDnet 中避免了显式流量估计。 然而,为了保持性能,我们需要引入多种技术来处理运动并有效地利用时间信息。 本节将进一步讨论这些技术。 有关消融研究的更多详细信息,请参阅补充材料。
3.1两步去噪
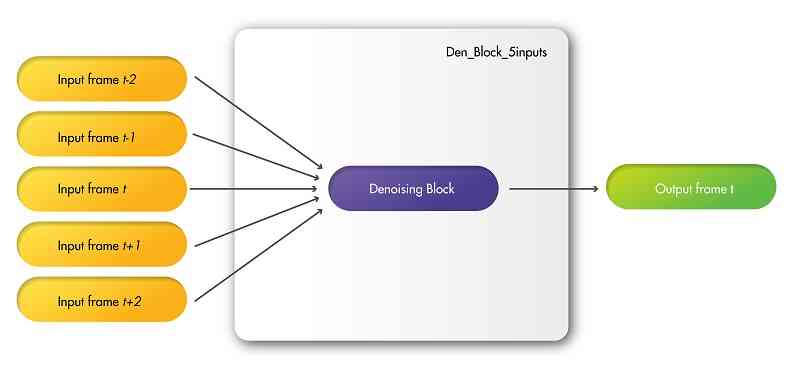
与 DVDnet 和 ViDeNN 类似,FastDVDnet 采用两步级联架构。 其背后的动机是有效地利用时间邻居中存在的信息,并加强输出帧中剩余噪声的时间相关性。 为了证明两步去噪是一个必要的功能,我们进行了以下实验:我们修改了FastDVDnet的一个去噪块(参见图 1b)将五个帧而不是三个帧作为输入,我们将其称为 Den_Block_5inputs。 通过这种方式,这种新的降噪器会考虑相同数量的时间相邻帧,并处理与 FastDVDnet 中相同的信息。 该模型的架构图如图图2所示。 然后,我们训练了这个新模型,并将序列去噪的结果与 FastDVDnet 的结果进行了比较(有关训练的更多详细信息,请参阅部分4)过程)。
据观察,FastDVDnet 的级联架构在 Den_Block_5inputs 上呈现出明显的优势,PSNR 差异高达 。 更多详情请参阅补充材料。 此外,Den_Block_5inputs 的结果显示时间伪影(闪烁)急剧增加。 尽管它是一个多尺度架构,Den_Block_5inputs 无法像 FastDVDnet 的两步架构那样处理序列中对象的运动。 总体而言,两步架构相对于一步架构表现出更优越的性能。
3.2 多尺度架构和端到端训练
为了研究在我们的架构中使用多尺度去噪块的重要性,我们进行了以下实验:我们修改了 FastDVDnet 架构,用 DVDnet 的去噪块替换其去噪块。 这导致了两步级联架构,具有单尺度去噪块,经过端到端训练,并且场景中没有运动补偿。 在我们的测试中,观察到使用多尺度去噪块可以显着改善去噪结果。 更多详情请参阅补充材料。
我们还在 FastDVDnet 的每个步骤中分别训练了多尺度去噪块——就像在 DVDnet 中所做的那样。 尽管这种情况下的结果相对于上述单尺度去噪块的情况确实有所改善,但输出中仍然存在明显的闪烁。 从这种单独的训练切换到端到端训练有助于大大减少时间伪影。
3.3 运动处理
除了减少运行时间之外,避免通过光流方式使用运动补偿还有一个额外的好处。 明确依赖于运动估计技术的视频去噪算法通常会因在具有挑战性的情况下(例如遮挡或强噪声)中的错误流而出现伪影。 本节讨论的不同技术,即多尺度去噪块、级联两步去噪架构和端到端训练,不仅为 FastDVDnet 提供了处理运动的能力,而且还有助于避免相关的伪影。导致错误的流量估计。 此外,与[51,45,44]类似,FastDVDnet的去噪块实现了残差学习,这有助于进一步提高结果的质量。 图3显示了由于三个连续帧上的错误流而导致的伪影的示例,以及 FastDVDnet 的多尺度架构如何避免他们。












4培训详情
训练数据集由输入输出对组成
其中 是在连续帧中同一位置裁剪的 空间块的集合, 是序列的干净中心块。 这些是通过将 的 AWGN 添加到给定序列的干净补丁中生成的,并且在这种情况下构建相应的噪声图 常量,其所有元素等于 .时空补丁是从训练数据集的随机采样序列中随机裁剪的。
从DAVIS数据库[24]集合中提取了总共个训练样本。 补丁的空间大小为,而时间大小为。 选择补丁的空间大小,使得去噪块的较粗尺度中的结果补丁大小为。 损失函数为
| (2) |
其中是网络的输出,是所有可学习参数的集合。
该架构已在流行的机器学习库 PyTorch [34] 中实现。 ADAM 算法[25] 用于最小化损失函数,并将其所有超参数设置为默认值。 纪元数设置为,小批量大小为。 学习率的调度对于这两种情况也是通用的。 它从第一个 时期的 开始,然后在接下来的 时期更改为 ,最后切换到 剩下的训练。 换句话说,学习率步进衰减与 ADAM 结合使用。 学习率衰减和自适应率方法的组合也已应用于其他深度学习项目[43, 49],通常会取得积极的结果。 通过引入不同比例因子和随机翻转的重新缩放来增强数据。 在第一个 时期,卷积核的正交化被用作正则化的一种手段。 据观察,使用正交化初始化训练可能有利于性能[52, 44]。
5结果
















使用两个不同的测试集对我们的方法进行基准测试:DAVIS-test 测试集和 Set8,它由来自 Derf 测试媒体集合1 的 颜色序列组成t3>11https://media.xiph.org/video/derf 和 DAVIS 集包含分辨率 的 颜色序列。 Set8 的序列已缩小至分辨率 。 在所有情况下,序列都限制为最大 帧。 我们使用 DeepFlow 算法[48]来计算 DVDnet 和 VNLB 的流图。 VNLnet 需要针对特定噪声级别进行训练的模型。 由于没有为 提供模型,因此两个表中均未显示此噪声级别的结果。 我们还将我们的方法与商业盲降噪软件 Neat Video (NV [1]) 进行比较。 对于 NV,其自动噪声分析设置用于手动对 Set8 的序列进行去噪。 请注意,显示的值是测试集中所有序列的平均值,序列的 PNSR 计算为每帧 PSNR 的平均值。
一般来说,DVDnet 和 FastDVDnet 的输出序列都具有显着的时间一致性。 我们的方法渲染的闪烁特别小,特别是在平坦区域,基于补丁的算法通常会留下低频残留噪声。 可以在图4中观察到一个示例(最好以数字格式查看)。 平坦区域中的时间去相关低频噪声对于观看者来说显得特别麻烦。 更多视频示例可以在补充材料和算法网站上找到。 我们鼓励读者观看这些示例,以比较我们方法结果的视觉质量。
基于补丁的方法很容易在具有大量重复结构的序列中超越 DVDnet 和 FastDVDnet,因为这些方法利用了非局部相似性先验。 另一方面,我们的算法可以很好地处理非重复纹理,请参见图5中去噪文本和植被的清晰度。
表 1分别显示了 Set8 和 DAVIS 数据集上 PSNR 和 ST-RRED 的比较。 时空缩减参考熵差 (ST-RRED) 是一种高性能缩减参考视频质量评估指标[42]。 该指标不仅考虑图像质量,还考虑视频中的时间失真。 我们使用 scikit-video 库222http://www.scikit-video.org。
可以看出,对于较小的噪声值,VNLB 在 Set8 上表现更好。 事实上,在某些情况下,DVDnet 往往会过度降噪。 FastDVDnet 和 VNLnet 分别是 DAVIS 上针对小西格玛 (PSNR 和 ST-RRED) 性能最佳的算法。 然而,对于较大的噪声值,DVDnet 超过了 VNLB。 FastDVDnet 在所有情况下都始终表现良好,这是一项了不起的壮举,因为它的运行速度比 DVDnet 快 倍,比 VNLnet 快 倍,并且比 快> 比 VNLB 快 1 倍(参见部分6)。 与其他基于 CNN 的降噪器相反,例如 VNLnet——我们的算法能够仅使用一种经过训练的模型对不同的噪声级别进行去噪。 最重要的是,方法的使用不涉及手动调整参数,因为它们仅将图像序列和输入噪声的估计作为输入。 表 2 显示与 ViDeNN 的比较。 该算法实际上并未针对 AWGN 进行训练,而是针对削波 AWGN 进行训练。 然后,针对这种情况训练了一个 FastDVDnet 模型来对削波的 AWGN 进行去噪,我们将其称为 FastDVDnet_clipped。 可以看出,FastDVDnet_clipped 的性能大幅优于 ViDeNN 的性能。
| Set8 | VNLB | V-BM4D | NV | VNLnet | DVDnet | FastDVDnet |
|---|---|---|---|---|---|---|
| / 2.86 | / | / | / | / | / | |
| / 6.28 | / | / | / | / | / | |
| / 11.53 | / | / | - | / | / | |
| / | / | / | / | / | / 18.45 | |
| / | / | / | / | / | / 26.75 |
| DAVIS | VNLB | V-BM4D | VNLnet | DVDnet | FastDVDnet |
|---|---|---|---|---|---|
| / | / | / 2.81 | / | / | |
| / | / | / 6.11 | / | / | |
| / | / | - | / | / | |
| / | / | / | / 18.16 | / | |
| / | / | / | / 25.63 | / |
| DAVIS | ViDeNN | FastDVDnet_clipped |
|---|---|---|
| 38.45 | ||
| 33.52 | ||
| 31.23 |
6 运行时间
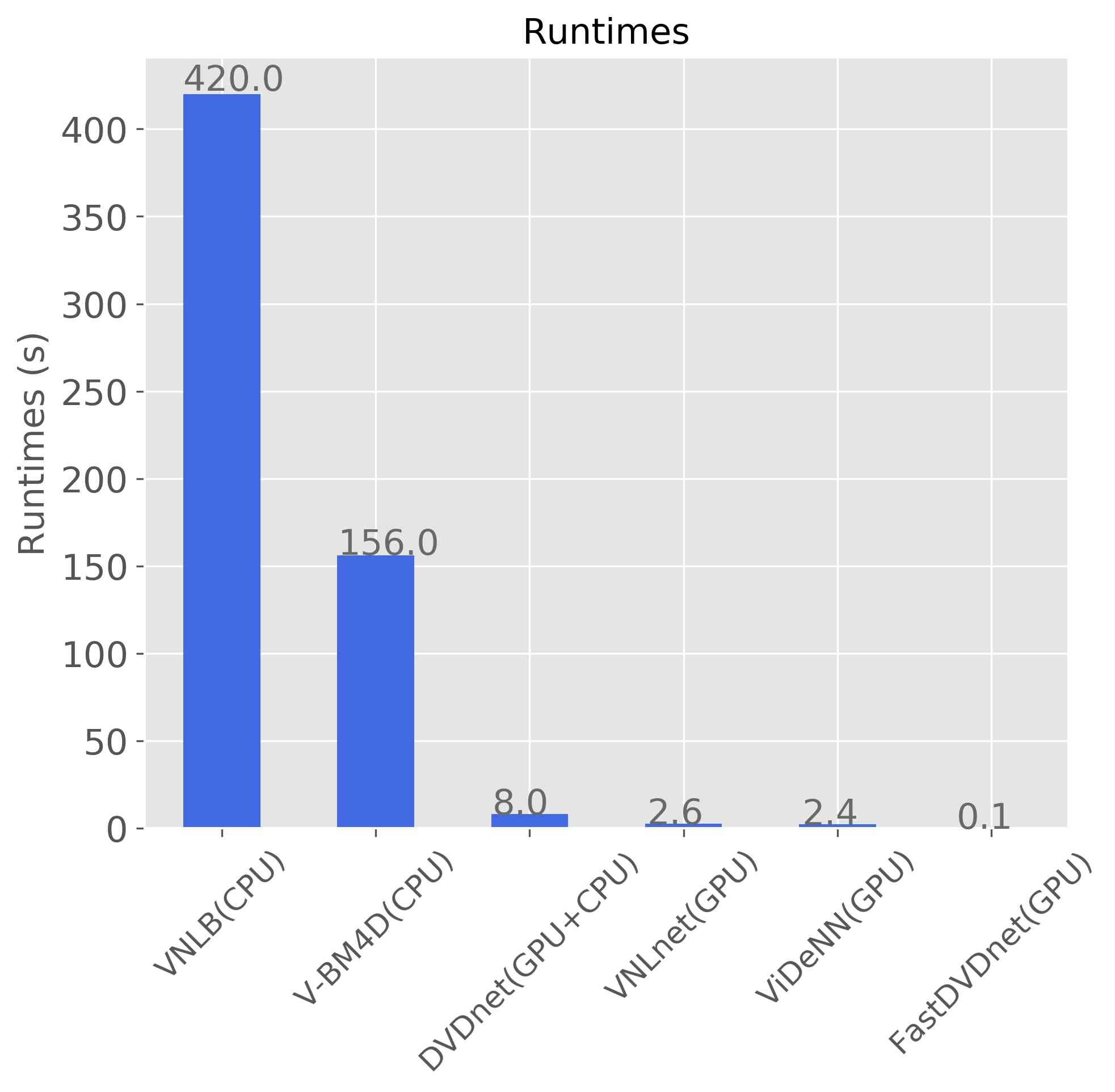
由于其设计特点和简单的架构,我们的方法实现了快速的推理时间。 我们的算法只需要 即可对 彩色帧进行去噪,比 V-BM4D 和 VNLB 快 个数量级,并且比比在 GPU、DVDnet 和 VNLnet 上运行的其他 CNN 算法快一个数量级。 这些算法在配备 Titan Xp NVIDIA GPU 卡的服务器上进行了测试。 图 6比较了不同最先进算法的运行时间。
7结论
在本文中,我们提出了 FastDVDnet,一种最先进的视频去噪算法。 FastDVDnet 的去噪结果具有显着的时间一致性、极低的闪烁和出色的细节保留。 即使没有流量估计步骤,也能达到这种性能水平。 该算法的运行速度比其他最先进的竞争对手快一到三个数量级。 从这个意义上说,我们的方法向高质量实时深度视频降噪迈出了重要一步。 尽管本文提出的结果适用于高斯噪声,但我们的方法可以扩展到对其他类型的噪声进行降噪。
致谢
Julie Delon 衷心感谢 NVIDIA 公司的支持,为我们提供了本研究中使用的 Titan Xp GPU。 我们感谢安娜·默里和何塞·莱扎马做出的宝贵贡献。 这项工作得到了法国国家研究和技术局 (ANRT) 和 GoPro Technology France 的部分资助。
参考
- [1] ABSoft. Neat Video. https://www.neatvideo.com, 1999–2019.
- [2] Miika Aittala and Frédo Durand. Burst image deblurring using permutation invariant convolutional neural networks. In European Conference on Computer Vision, pages 748–764. Springer International Publishing, 2018.
- [3] Pablo Arias and Jean-Michel Morel. Video denoising via empirical bayesian estimation of space-time patches. Journal of Mathematical Imaging and Vision, 60(1):70–93, Jan 2018.
- [4] Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, and Jonathan T. Barron. Unprocessing Images for Learned Raw Denoising. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [5] Antoni Buades, Jose-Luis Lisani, and Marko Miladinovic. Patch-based video denoising with optical flow estimation. IEEE Transactions on Image Processing, 25(6):2573–2586, Jun 2016.
- [6] H.C. Burger, C.J. Schuler, and S. Harmeling. Image denoising: Can plain neural networks compete with BM3D? In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2392–2399, 2012.
- [7] Jose Caballero, Christian Ledig, Andrew Aitken, Alejandro Acosta, Johannes Totz, Zehan Wang, and Wenzhe Shi. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4778–4787, 2017.
- [8] C. Chen, Q. Chen, M. Do, and V. Koltun. Seeing motion in the dark. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3184–3193, 2019.
- [9] Xinyuan Chen, Li Song, and Xiaokang Yang. Deep rnns for video denoising. volume 9971 of SPIE Proceedings, page 99711T. SPIE, Sep 2016.
- [10] Yunjin Chen and Thomas Pock. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1256–1272, Jun 2017.
- [11] Michele Claus and Jan van Gemert. Videnn: Deep blind video denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- [12] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016.
- [13] K Dabov, A Foi, and V Katkovnik. Image denoising by sparse 3D transformation-domain collaborative filtering. IEEE Transactions on Image Processing (TIP), 16(8):1–16, 2007.
- [14] Axel Davy, Thibaud Ehret, Gabriele Facciolo, Jean-Michel Morel, and Pablo Arias. Non-local video denoising by cnn. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [15] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. pages 2758–2766. IEEE, Dec 2015.
- [16] Thibaud Ehret, Axel Davy, Jean-Michel Morel, Gabriele Facciolo, and Pablo Arias. Model-blind video denoising via frame-to-frame training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11369–11378, 2019.
- [17] T. Ehret, J. Morel, and P. Arias. Non-local kalman: A recursive video denoising algorithm. In 2018 25th IEEE International Conference on Image Processing (ICIP), pages 3204–3208, 2018.
- [18] Michaël Gharbi, Gaurav Chaurasia, Sylvain Paris, and Frédo Durand. Deep joint demosaicking and denoising. ACM Transactions on Graphics, 35(6):1–12, Nov 2016.
- [19] Ross Girshick. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, 2015.
- [20] Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, and Lei Zhang. Toward Convolutional Blind Denoising of Real Photographs. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1712–1722, jul 2019.
- [21] Samuel W. Hasinoff, Dillon Sharlet, Ryan Geiss, Andrew Adams, Jonathan T. Barron, Florian Kainz, Jiawen Chen, and Marc Levoy. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Trans. Graph., 35(6), Nov. 2016.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- [23] Sergey Ioffe and Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In International Conference on Machine Learning (ICML), pages 448–456. JMLR.org, 2015.
- [24] Anna Khoreva, Anna Rohrbach, and Bernt Schiele. Video object segmentation with language referring expressions. In ACCV, 2018.
- [25] D.P. Kingma and J.L. Ba. ADAM: a Method for Stochastic Optimization. Proc. ICLR, pages 1–15, 2015.
- [26] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems (NIPS), pages 1–9, 2012.
- [27] M. Lebrun, A. Buades, and J. M. Morel. A nonlocal bayesian image denoising algorithm. SIAM Journal on Imaging Sciences, 6(3):1665–1688, Jan 2013.
- [28] Ce Liu and William Freeman. A high-quality video denoising algorithm based on reliable motion estimation. In European Conference on Computer Vision (ECCV), pages 706–719. Springer, 2015.
- [29] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. In Advances in Neural Information Processing Systems, pages 1680–1689, 2018.
- [30] Pengju Liu, Hongzhi Zhang, Kai Zhang, Liang Lin, and Wangmeng Zuo. Multi-level wavelet-CNN for image restoration. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2018.
- [31] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rectifier nonlinearities improve neural network acoustic models. In in ICML Workshop on Deep Learning for Audio, Speech and Language Processing, 2013.
- [32] Matteo Maggioni, Giacomo Boracchi, Alessandro Foi, and Karen Egiazarian. Video denoising, deblocking, and enhancement through separable 4-d nonlocal spatiotemporal transforms. IEEE Transactions on Image Processing, 21(9):3952–3966, Sep 2012.
- [33] Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In ICML, pages 1310–1318, 2013.
- [34] Adam Paszke, Gregory Chanan, Zeming Lin, Sam Gross, Edward Yang, Luca Antiga, and Zachary Devito. Automatic differentiation in PyTorch. Advances in Neural Information Processing Systems 30, pages 1–4, 2017.
- [35] Tobias Plötz and Stefan Roth. Neural nearest neighbors networks. In Advances in Neural Information Processing Systems (NIPS), pages 1087–1098, 2018.
- [36] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation, volume 9351 of Lecture Notes in Computer Science, chapter chapter 28, pages 234–241. Springer International Publishing, 2015.
- [37] V. Santhanam, V.I. Morariu, and L.S. Davis. Generalized Deep Image to Image Regression. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [38] U. Schmidt and S. Roth. Shrinkage fields for effective image restoration. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), number 8, pages 2774–2781, 2014.
- [39] K. Seshadrinathan and A.C. Bovik. Motion tuned spatio-temporal quality assessment of natural videos. IEEE Transactions on Image Processing, 19(2):335–350, Feb 2010.
- [40] Tamara Seybold. Noise Characteristics and Noise Perception, pages 235–265. Springer International Publishing, 2018.
- [41] Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1874–1883. IEEE, Jun 2016.
- [42] Rajiv Soundararajan and Alan C. Bovik. Video quality assessment by reduced reference spatio-temporal entropic differencing. IEEE Transactions on Circuits and Systems for Video Technology, 2013.
- [43] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the Inception Architecture for Computer Vision. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, dec 2015.
- [44] Matias Tassano, Julie Delon, and Thomas Veit. An analysis and implementation of the ffdnet image denoising method. Image Processing On Line, 9:1–25, Jan 2019.
- [45] Matias Tassano, Julie Delon, and Thomas Veit. DVDnet: A fast network for deep video denoising. In IEEE International Conference on Image Processing, Sep 2019.
- [46] Thijs Vogels, Fabrice Rousselle, Brian Mcwilliams, Gerhard Röthlin, Alex Harvill, David Adler, Mark Meyer, and Jan Novák. Denoising with kernel prediction and asymmetric loss functions. ACM Transactions on Graphics, 37(4):1–15, Jul 2018.
- [47] Wei Wang, Xin Chen, Cheng Yang, Xiang Li, Xuemei Hu, and Tao Yue. Enhancing low light videos by exploring high sensitivity camera noise. pages 4110–4118, 10 2019.
- [48] Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. DeepFlow: Large displacement optical flow with deep matching. In IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, Dec. 2013.
- [49] Ashia C Wilson, Rebecca Roelofs, Mitchell Stern, Nati Srebro, and Benjamin Recht. The marginal value of adaptive gradient methods in machine learning. In Advances in Neural Information Processing Systems (NIPS), pages 4148–4158, 2017.
- [50] Shangzhe Wu, Jiarui Xu, Yu-Wing Tai, and Chi-Keung Tang. Deep High Dynamic Range Imaging with Large Foreground Motions. In European Conference on Computer Vision (ECCV), pages 117–132, 2018.
- [51] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Transactions on Image Processing, 26(7):3142–3155, Jul 2017.
- [52] Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622, Sep 2018.
补充材料
1 两步去噪
FastDVDnet 采用两步级联架构。 其背后的动机是有效地利用时间邻居中存在的信息,并加强输出帧中剩余噪声的时间相关性。 为了证明两步去噪是一个必要的功能,我们进行了以下实验:我们修改了FastDVDnet的去噪块(参见相关论文),以五帧而不是三帧作为输入,这我们将其称为 Den_Block_5inputs。 通过这种方式,这种新的降噪器会考虑相同数量的时间相邻帧,并处理与 FastDVDnet 中相同的信息。 该模型的架构图如图图S1所示。 然后我们训练了这个新模型,并将序列去噪的结果与 FastDVDnet 的结果进行了比较。
表 1 显示两种降噪器在四种 颜色序列上的 PSNR。 可以看出,FastDVDnet 的级联架构在 Den_Block_5inputs 上呈现出明显的优势,PSNR 的平均差异为 。 此外,Den_Block_5inputs 的结果显示时间伪影(闪烁)急剧增加。 尽管它是一个多尺度架构,Den_Block_5inputs 无法像 FastDVDnet 的两步架构那样处理序列中对象的运动。 总体而言,两步架构相对于一步架构表现出更优越的性能。
| FastDVDnet | Den_Block_5inputs | ||
|---|---|---|---|
| hypersmooth | 37.34 | 35.64 | |
| motorbike | 34.86 | 34.00 | |
| rafting | 36.20 | 34.61 | |
| snowboard | 36.50 | 34.27 | |
| hypersmooth | 32.17 | 31.21 | |
| motorbike | 29.16 | 28.77 | |
| rafting | 30.73 | 30.03 | |
| snowboard | 30.59 | 29.67 | |
| hypersmooth | 29.77 | 28.92 | |
| motorbike | 26.51 | 26.19 | |
| rafting | 28.45 | 27.88 | |
| snowboard | 28.08 | 27.37 |
2 多尺度架构和端到端训练
为了研究在我们的架构中使用多尺度去噪块的重要性,我们进行了以下实验:我们修改了 FastDVDnet 架构,用 DVDnet 的去噪块替换其去噪块。 这导致了两步级联架构,具有单尺度去噪块,经过端到端训练,并且场景中没有运动补偿。 我们将这种新架构称为 FastDVDnet_Single。 表2显示了FastDVDnet和FastDVDnet_Single在四种颜色序列上的PSNR。 可以看出,多尺度去噪块的使用显着改善了去噪效果。 特别是,PSNR 的平均差异为,有利于多尺度架构。
| FastDVDnet | FastDVDnet_Single | ||
|---|---|---|---|
| hypersmooth | 37.34 | 36.61 | |
| motorbike | 34.86 | 34.30 | |
| rafting | 36.20 | 35.54 | |
| snowboard | 36.50 | 35.50 | |
| hypersmooth | 32.17 | 31.54 | |
| motorbike | 29.16 | 28.82 | |
| rafting | 30.73 | 30.36 | |
| snowboard | 30.59 | 30.04 | |
| hypersmooth | 29.77 | 29.14 | |
| motorbike | 26.51 | 26.22 | |
| rafting | 28.45 | 28.11 | |
| snowboard | 28.08 | 27.56 |
3消融研究
相关论文中讨论的有关基线架构的许多修改已经过测试,即:
-
•
使用Leaky ReLU [31]或ELU[12]而不是ReLU。 在这两种情况下,都没有观察到性能的显着变化,所有序列的 PSNR 平均差异均小于 ,并且考虑了噪声的标准偏差。
-
•
根据 Huber [19] 而不是 规范进行优化。 没有观察到性能的显着变化。 所有序列的 PSNR 平均差异和所考虑的噪声标准差为 ,有利于 正常情况。
-
•
删除批量归一化层。 在这种情况下,观察到性能平均下降。
-
•
获取更多输入帧。 基线模型被修改为采用 7 和 9 个输入帧,而不是 5 个。 在这两种情况下都没有观察到性能改善。 还观察到这些具有更多参数的模型在训练过程中相对于 5 个输入帧的情况收敛的难度增加。
4 放大图层
在多尺度去噪块中,解码器中的上采样是通过 PixelShuffle 层[41]执行的。 该层将其尺寸为 的输入重新打包为尺寸为 的输出,其中 分别是通道数、高度和宽度。 换句话说,该层将其输出的所有非重叠块与输入的不同通道的像素构造在一起,如图图 S2
5高斯噪声模型
最近,人们提出了许多用于低光条件下视频和突发去噪的算法,例如[8,47,21]。 更重要的是,其中一些研究认为,真实的噪声无法用简单的高斯模型精确建模。 然而,我们在这里提出的算法是为高斯去噪而开发的,因为尽管高斯 i.i.d. 噪声并不完全现实,它简化了与可比较数据集上的其他方法的比较——这是我们的主要目标之一。 我们相信高斯去噪是一个中间立场,可以公平地比较不同的去噪架构。 考虑到所述数据集的图像处理管道,一些被提议对特定低光数据集进行去噪的网络被设计并过度拟合。 在某些情况下,与尚未为给定数据集设计的其他方法进行比较,例如 我们方法的当前版本可能不准确。 尽管如此,低光去噪并不是我们提交的主要目标。 相反,它是为了表明一个简单但精心设计的架构可以胜过其他更复杂的方法。 我们认为去噪算法的主要挑战是输入信噪比。 在这方面,所呈现的结果与低光视频具有相似的特征。
6 排列不变性
[2]中提出的突发去模糊和去噪算法具有对其输入帧排序排列不变的特点。 人们可能会想在像我们这样的架构中复制其特征,以从排列不变性的优势中受益。 然而,我们的算法的应用是视频去噪——这与突发去噪不同。 实际上,输入帧中的顺序是我们的算法利用的先验,以强制输出序列中的时间一致性。 换句话说,在我们的例子中,排列不变性不一定是理想的。
7递归处理
如前所述,实际上,我们的算法的处理仅限于五个输入帧。 考虑到这一限制,人们会想知道理论性能界限是否可能低于基于递归处理的其他解决方案(即使用时间 中的输出帧作为时间 )。 然而,我们对视频递归过滤的经验是,后一种方法很难与采用多个帧作为输入的方法相媲美。 尽管从理论上讲,递归方法在去噪方面比多帧方法渐近更强大,但实际上,递归方法的性能由于时间伪影而受到影响。 在给定时间输出帧中可能出现的任何未对准或运动补偿伪影很可能出现在所有后续输出中。 说明这一点的一个有趣的例子是 [17] 中的方法与视频非局部贝叶斯降噪器 (VNLB [3]) 的比较。 前者实现了 VNLB 的递归版本,这导致算法复杂度较低,但性能相对于后者非常差。