标题不支持的文档类
使用深度强化学习的基于视觉的导航
摘要
深度强化学习(RL)已成功应用于各种类似游戏的环境。 然而,将深度强化学习应用于现实环境中的视觉导航是一项具有挑战性的任务。 我们提出了一种能够导航代理的新颖学习架构,例如移动机器人,根据图像指定目标。 为了实现这一目标,我们使用旨在提高视觉导航性能的辅助任务扩展了批处理 A2C 算法。 我们提出了三个额外的辅助任务:预测观察图像和目标图像的分割以及预测深度图。 这些任务使得能够使用监督学习来预训练大部分网络并大幅减少训练步骤的数量。 随着时间的推移逐渐增加环境复杂性,训练性能得到进一步提高。 提出了一种高效的神经网络结构,能够在多种环境下学习多个目标。 我们的方法在连续状态空间和 AI2-THOR 环境模拟器上进行导航,其性能优于文献中最先进的面向目标的视觉导航方法。
索引术语:
机器人导航、深度强化学习、演员批评家、辅助任务。我简介
视觉导航是代理导航的问题,例如移动机器人,在仅使用摄像头输入的环境中。 代理会获得目标图像(它将从目标位置看到的图像),其目标是仅基于摄像机观察,通过应用一系列动作从当前位置移动到目标。 我们关注环境最初未知的情况,即没有明确的地图可用。 这样的视觉导航问题可以形式化为强化学习(RL)问题[1]。 强化学习公式中的两个主要挑战是智能体观察空间的维度以及只能从图像中部分观察到实际状态的事实。
可以通过使用手工创建的特征,或使用在训练数据集或完全不同的数据集上学习到的特征(例如,从图像 [3, 4] 中自动提取的 ResNet [2] 特征)来降低观测空间维度。 [5] 中提出了一种不同的方法,使用图像分割和深度图作为代理的输入。 它在 SUNCG 数据集 [6] 的房屋上进行了训练和评估,经过训练的智能体能够找到指定为智能体的单独输入的多个目标。
原始高维输入图像也可以直接用于导航[7, 8]。 这两篇论文通过辅助任务扩展了异步优势演员批评家(A3C)算法,以稳定训练并使其在奖励稀疏时更加高效。 然而,他们使用 DeepMind Lab [9] 游戏模拟器,它比现实模拟器 [10, 5, 6] 简单得多。 在真实的室内场景环境中,唯一依赖于视觉输入的方法是[3]。 然而,它被应用于包含小型单房间环境的AI2-THOR [10],并且动作空间将环境离散成简单的网格世界。
在我们的方法中,代理仅根据观察到的原始图像学习导航,这与使用 ResNet 功能的 [3] 不同。 该学习算法基于advantage actor-critic (A2C)[11]的批处理版本,并通过辅助任务进行扩展,以帮助代理学习在缺乏信息性奖励。 在深度神经网络的训练过程中,我们使用深度图和图像分割作为辅助任务的训练目标。 此外,我们提出了一种在应用强化学习算法之前预训练神经网络的方法。 这是通过从一种环境到另一种环境的迁移学习,逐渐增加环境复杂性来实现的。 最后,为了解决部分可观测性问题,我们提出了一种高效且紧凑的新型神经网络架构。 我们在类似于 [3] 和 [8] 的真实室内场景环境中评估我们的方法。
II 预赛
II-A 正式场合
视觉导航问题是一个部分可观察马尔可夫决策过程(POMDP)。 例如,当智能体面向墙壁时,有许多状态会产生相同或非常相似的图像。 然而,为了便于表示,我们首先将问题作为标准 MDP 的实例引入,使用状态 就好像它对代理可用一样。 稍后,我们将用一系列过去的观察结果 替换状态。
在每个学习阶段开始时,代理从状态 开始,该状态是从所有可能的初始状态 的集合中均匀采样的:。111可以使用除均匀分布之外的其他分布。 在离散时间步,代理执行操作。 每个动作的结果是,代理移动到下一个状态并接收奖励。 代理在单个情节中收集的经验定义为以下序列:
| (1) |
当代理达到目标或在预定义的最大时间步数之后,情节终止。 对于训练,剧集被分成同样长的 rollouts,其中最后一个 rollout 可以更短。 在长度为 的单次推出中收集的经验定义为:
| (2) |
II-B 优势 Actor-Critic 算法 (A2C)
Actor-critic 算法适用于连续状态空间[12]。 批评者是状态值函数 的近似器,由 参数化,而参与者是策略的近似器。 我们使用随机策略 ,它是离散的可能动作集的概率分布,以状态 为条件,并由 参数化。 让引导的 步骤返回 定义为:
| (3) |
其中,如果剧集在推出期间结束,则 为零,否则为 。 Actor 的更新类似于 REINFORCE [13],并根据评论家的优势估计进行更新。 参与者损失函数 从 [14] 的梯度由下式给出:
| (4) |
术语被称为优势函数。 使用步时间差异学习更新批评家:自举步返回与批评家输出之间的均方误差(MSE)计算并应用梯度下降更新。 批评家损失函数的梯度为:
| (5) |
为了确保探索,参与者的负熵被添加到总损失中。 状态 下的负熵定义为:
| (6) |
其在 rollout 数据上的梯度为:
| (7) |
请注意,上述设置与 [1] 中给出的设置不同,后者使用 步进视图来计算返回 。当使用 DNN 来近似参与者和批评者时,在单个批次中对多个时间步进行优化是有益的。 因此,我们使用推出数据一次性优化推出中的所有时间步长。 估计回报是每个状态不同长度的回报的混合,这被证明可以减少离散 RL 设置 [15, 16] 中的误差。
由于评论家和演员可以共享有关环境的知识,因此他们可以共享一些参数,从而提高学习性能。 例如,当使用神经网络进行视觉任务时,演员和批评者中最底层的卷积层需要学习相同的卷积滤波器。 A2C 算法 [17] 已通过引入以下两个修改来适应 DNN 的使用:
-
1.
批量优势演员评论家 (A2C)。 在批量A2C[11]中,有个不同的环境。 在每个时间步,参与者都会对 动作进行采样,每个动作对应一个环境。 从环境中收集的首次展示用于在单个批次中优化演员和评论家。 该过程可以被视为具有 单独的 A2C 实例,每个实例更新相同的共享参数。 如[17]所示,使用多个环境对训练有稳定作用,类似于使用经验缓冲区[18]。
-
2.
政策外评论家更新。 收集观察结果的成本可能很高,尤其是当环境框架必须模拟物理并渲染 3D 场景时。 为了使算法高效,它需要从迄今为止收集的经验中学习尽可能多的知识。 为了提高数据效率和算法的稳定性,使用了称为经验缓冲区的过去经验的记忆。 它保留最后的体验,即观察、动作、奖励和终端222终端是在特定时间步结束的情节的指示器。. 在每个学习步骤中,都会从缓冲区中采样一系列经验,并用于计算引导的 步骤返回 (3),从而训练批评者。
II-C UNREAL 辅助任务
深度强化学习算法通常通过辅助任务来增强,以提高其学习性能。 例如,在[7]中,A3C算法通过两个辅助任务进行了扩展:奖励预测和像素控制。 前者根据过去的四个观察结果预测奖励的符号,后者使用额外的伪奖励函数来学习最大化绝对像素变化的策略。 批量A2C可以用同样的方式增强; III-C 节中给出了更多详细信息。
III 建议的学习架构
我们的方法通过 UNREAL 辅助任务和用于视觉导航的附加辅助任务扩展了批处理 A2C 算法。 我们将该方法称为 A2CAT-VN,它是 A2C with Auxiliary Tasks for Visual Navigation 的缩写。 我们已经实现了333https://github.com/jkulhanek/a2cat-vn-pytorch 以及实现多种深度强化学习算法的框架444https://github.com/jkulhanek/deep-rl-pytorch 在 GitHub 上公开提供。
III-A 神经网络
我们的方法中使用的深度神经网络由几个模块组成:卷积基、LSTM、演员、评论家和辅助任务,见图1。 在下文中,我们将一一解释各个块。
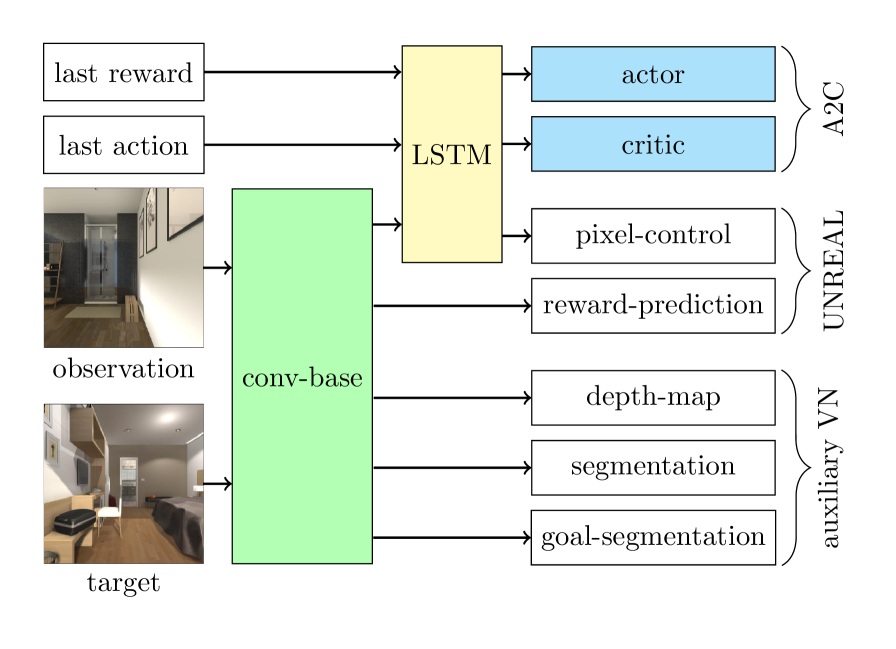
卷积基如图2所示。 它的输入是观察图像和目标图像,每个图像都进入具有共享权重参数的两个卷积层的单独流。 第二层的输出被连接并传递到两个附加的卷积层,然后是一个全连接的线性层。
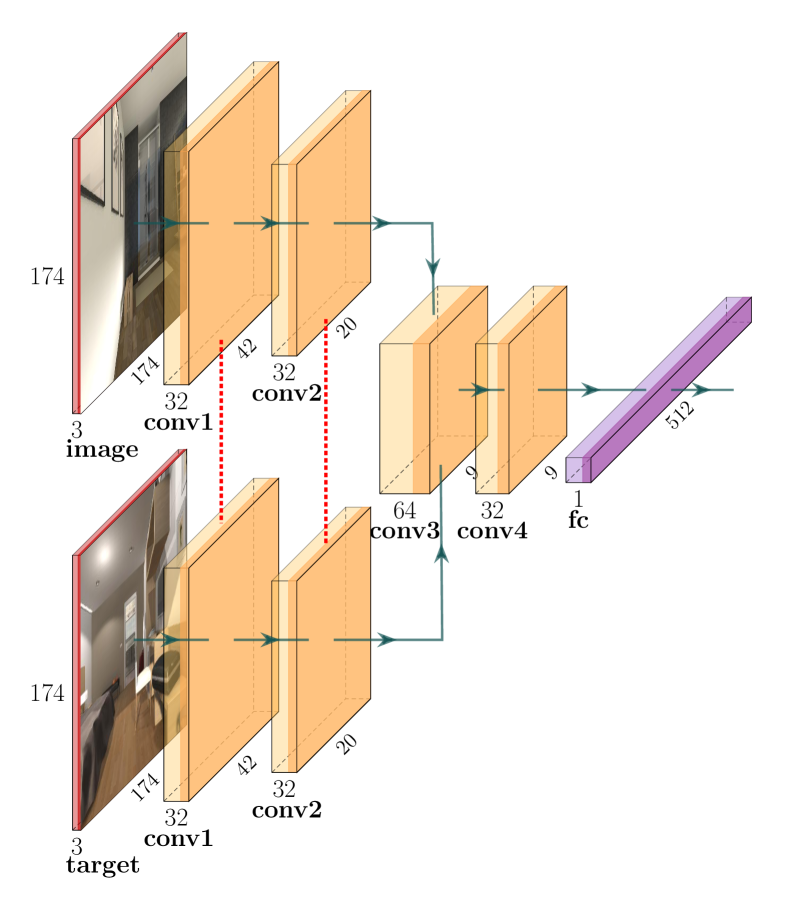
每一层后面都有 ReLU 激活函数。 我们不使用 maxpool 层[2]。 相反,仅按照 [19] 中的建议使用步幅对图像进行下采样。 卷积基本特征与先前的动作和先前的奖励合并,并传递到长短期记忆(LSTM)层[20]。
前一个动作使用 one-hot 编码进行编码,前一个奖励被剪辑到间隔 内。 LSTM 特征用作参与者和评论家的输入,以及像素控制辅助任务的输入。 令 为输入 的 LSTM 特征(LSTM 特征是根据卷积特征计算出来的,因此是输入的函数)。 请注意,输入由图像观察、目标图像、最后一个动作、最后一个奖励以及之前的 LSTM 状态组成。 Critic 是 LSTM 特征的仿射变换,Actor 是 softmax 函数应用于 LSTM 特征的仿射变换的结果。
III-B 解决部分可观察性问题
环境的部分可观察性不允许代理根据单独的观察来唯一区分其所处的状态。 然而,利用之前的观察结果可以极大地提高其在环境中的导航能力。 例如,如果代理面向墙壁,它可以查看之前的观察结果和采取的操作。 [18] 和 [3] 的作者使用了过去的四帧,将其输入网络而不是单个图像输入。 在[7]中,使用了LSTM内存[20]。 我们在我们的方法中使用了后者,因为我们通过实验发现它优于使用过去的四个帧。 过去的四帧不足以捕捉智能体在探索环境时收集的复杂体验,更多的帧会导致参数空间大小和内存需求的难以控制的增加。
III-C UNREAL 辅助任务
III-C1 奖励预测
代理的目标是最大化累积奖励。 事实证明,训练网络来预测给定状态是否会带来积极奖励是有益的,因为它有助于网络构建有用的特征来识别潜在的富有成效的状态。 代理学习根据过去的三个观察来预测下一个奖励 [7, 21]555这里也可以使用 LSTM。 然而,我们更喜欢使用文献中的原始方法。. 首先,从体验重放缓冲区中采样体验序列,使得以零奖励结束的序列与以非零奖励结束的序列之间存在固定比率。 根据过去所有三个观察值计算出的第四卷积层的输出被合并为单个向量。 附加线性层和 softmax 函数应用于奖励为正、负或零的输出概率。 然后使用交叉熵损失来训练这个新网络。
III-C2 像素控制
像素控制任务是通过附加的伪奖励函数定义的,以便最大化绝对像素变化。 使用此奖励,可以训练一个额外的策略,该策略与 A2C 参与者和批评者共享其大部分参数。 该策略必须使用离策略 RL 算法进行训练,因为它使用从参与者生成的体验重播缓冲区中采样的数据。 在[7]中,步Q学习损失[18]用于更新策略。 观察图像被缩小,转换为灰度,计算两个连续观察之间的绝对差,并将其用作 Q-learning [17] 的伪奖励。
LSTM 的输出附加了一个新头。 该头由反卷积层组成——将低维特征上采样回下采样观测值的大小。 对于每个动作,最后一层都有不同的输出来输出每个像素的 Q 函数。 决斗DQN技术[22]用于提高像素控制网络的性能。 我们的方法中使用的像素控制网络如图3所示。
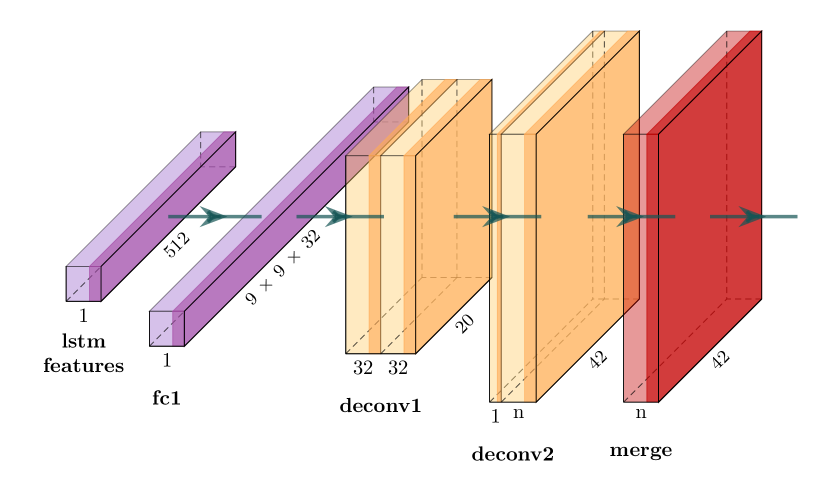
III-D 视觉导航的附加辅助任务

在 [23] 和 [8] 的推动下,我们引入了特定于视觉导航的其他辅助任务。 它们旨在增强训练过程并帮助网络泛化。 我们训练模型来预测深度图、观察的图像分割和目标的图像分割。 对于图像分割,我们将对象类型映射到 RGB 颜色空间,并最大化 HSB 颜色空间中每种颜色之间的距离。 输入以自动编码器的方式通过网络的狭窄部分,以提高网络共享部分的特征质量。 这为演员和评论家提供了最底层的良好特征,以及重建深度图和图像分割所需的所有信息的紧凑表示。 否则,这些最底层将难以训练,因为网络很深,并且由于使用强化学习算法计算的目标值不精确,损失很大。 目标的图像分割确保网络关注目标是什么。 否则,网络将很难在训练开始时考虑目标输入。
对于每个视觉导航辅助任务,都有一个网络附加到由反卷积层组成的最后一个卷积层。 观测图像分割和目标图像分割的网络架构如图4所示。 对于深度图预测,网络结构是相同的,但中间反卷积层只有 32 个滤波器,最后一层只有一个通道。 真实特征(用于观察的图像分割以及目标和深度图)被下采样到较小的尺寸。 MSE 是在网络输出和真实特征之间计算的。
视觉导航的附加辅助任务还允许使用监督学习来初始化网络,使其在网络最底部具有良好的特征,因为这些特征对策略的依赖性最小。 渲染 3D 场景的成本很高,但预先计算从场景中获取的观察数据集并将其用于监督训练的成本很低。
III-E 环境复杂性
智能体的训练可能会很困难,特别是当环境很大并且初始状态与目标相差很远时。 为了使代理的任务更容易,我们首先对更接近目标的初始状态进行采样,并逐渐增加初始状态和目标之间的距离。 令 为环境复杂性。 我们定义环境的最大采样距离如下:
| (8) |
其中 测量给定环境 的任意两个状态之间的距离。可以使用任何距离测量,例如环境中相应代理位置之间的欧几里德距离。
初始状态 是从比 更接近任何目标的一组可能初始状态上的均匀概率分布中采样的:
| (9) |
其中目标状态集由 表示。 环境复杂度 从一个较低的值开始,例如,并在训练过程中逐渐增加到。
IV 实验
我们使用平均剧集长度和平均剧集未贴现回报作为性能指标,通过实验评估了我们的方法 A2CAT-VN 的性能。 平均值是基于 100 次展示的蒙特卡罗估计值计算得出的。 随机性来自初始状态、环境的非确定性行为以及参与者的随机性。
IV-A 环境
我们采用了三种不同的适合视觉导航任务的 3D 环境模拟器。
1) DeepMind Lab [9] 是一个 3D 框架,允许代理在合成环境中移动和收集对象。 它针对训练人工智能代理进行了快速且高度优化,并且允许的操作集是可定制的。 图5显示了来自该环境的图像示例。 我们用它来将所提出的算法与文献中的替代算法进行比较,并针对其他环境预训练代理网络,从而加快了训练过程。


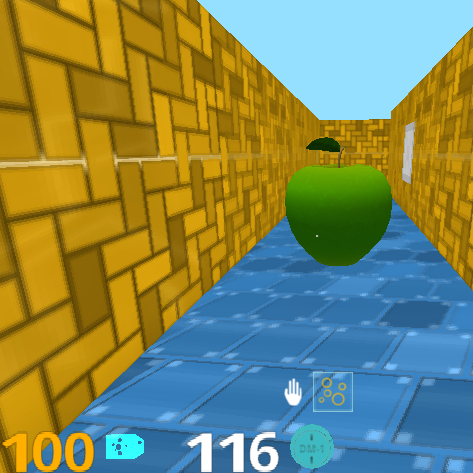
2) AI2-THOR [10]是一个具有高质量室内图像的逼真交互框架(见图6)。 大多数环境都是一个房间并且是动态的,即在剧集开始时,各种物体可以放置在随机位置。 代理在网格上移动:一个动作将代理移动到网格上的相邻点或将代理旋转。 这不允许良好的概括,因为代理可以记住它可以接收的有限(且少量)数量的观察结果。 因此,我们修改了AI2-THOR 3D模拟器的实现以使用连续空间。 我们通过添加任意角度的旋转和任意距离的移动来扩展可能的动作集。 我们还实现了碰撞物理学。




3) House3D with SUNCG [5] 是一个 3D 框架,允许使用 SUNCG 数据集 [6] 中的环境。 SUNCG 数据集包含超过 45,000 个室内环境,其中大多数是两层房屋和工作室。 House3D 针对 AI 代理训练进行了高度优化,并在 GPU 上快速运行。 除了RGB输出渲染外,还支持深度图和图像分割渲染。 来自该环境的说明性图像如图7所示。 可以按照与 DeepMind 实验室环境中类似的方式自定义这组操作。
 |
 |
 |
 |
IV-B 行动空间
在我们的每个实验中,我们都使用以下一组动作:向前、向后、向左、向右、向左旋转、向右旋转、向上倾斜、向下倾斜。 向前和向后的动作使代理朝当前面对的方向移动。 左右动作使代理沿与其面对的方向垂直的方向移动。 向左旋转和向右旋转操作将代理旋转 度666一个实验使用 角度。 分别逆时针和顺时针方向,向上倾斜和向下倾斜动作使代理的相机向上或向下倾斜 度。
在现实环境中,执行器很少能够精确地移动代理。 为了模拟这样的设置,在采取行动后,将高斯噪声添加到代理的位置和旋转中。 更具体地说,让 为代理在添加噪声之前采取动作后的位置、水平旋转和相机倾斜。 那么智能体的最终位置和旋转是,以及、和。
IV-C 训练
可以使用不同的方案将奖励分配给代理。 在我们的工作中,如果智能体达到目标,我们将奖励 1,否则奖励为零。 在训练阶段,我们将总梯度计算为所有部分梯度的加权和:参与者、批评家、熵损失、离策略批评家和辅助任务。 梯度被剪裁,因此其范数不超过,并且RMSprop优化器用于优化权重。 在所有实验中,我们使用了两个 Tesla K40 GPU(每个 10GB)——一个 GPU 专用于环境,另一个用于代理。 我们的方法中使用的参数在表I中给出,其中表示到目前为止处理的帧数,是要处理的最大帧数。训练时进行处理。 一些参数被选择为与[7, 11]中的相同,其他参数通过实验进行调整。
| name | value |
|---|---|
| discount factor () | |
| maximum episode length | 900 |
| maximum rollout length | 20 |
| maximum number of frames () | |
| number of environment instances | 16 |
| replay buffer size | |
| optimizer | RMSprop |
| RMSprop alpha | |
| RMSprop epsilon | |
| learning rate | |
| max. gradient norm | 0.5 |
| entropy gradient weight | 0.001 |
| actor weight | 1.0 |
| critic weight | 0.5 |
| off-policy critic weight | 1.0 |
| pixel control weight | 0.05 |
| reward prediction weight | 1.0 |
| depth-map prediction weight | 0.1 |
| observation image segmentation prediction weight | 0.1 |
| target segmentation prediction weight | 0.1 |
| pixel control discount factor | 0.9 |
| pixel control downsize factor | 4 |
| auxiliary VN downsize factor | 4 |
| pre-training optimizer | Adam |
| pre-training total epochs | 30 |
| pre-training dataset size |
IV-D 部分可观察性
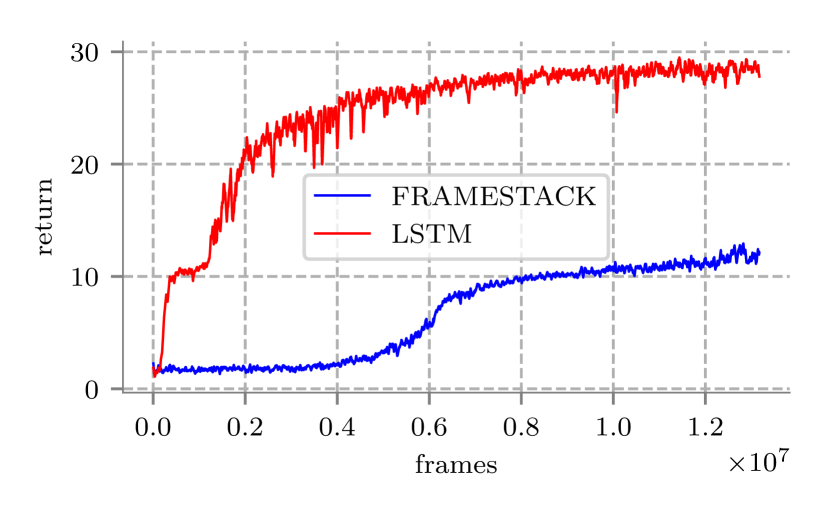
我们比较了解决部分可观测性问题的两种不同方法。 [3, 18] 使用的一种方法将过去的四帧连接起来作为代理的输入。 另一种方法[7]使用LSTM网络[20]。 我们在 DeepMind 实验室环境中测试了这两种方法,因为它速度快且相对简单。 允许的操作包括向前、向后、向左、向右、向左旋转、向右旋转。 我们没有使用任何噪音,并且向前、向后、向左、向右的动作移动代理的距离为 米。 代理的输入是分辨率为 像素的单个 RGB 图像。 基于[7]的网络结构在两种情况下都是相似的,除了在帧串联版本中,LSTM被线性层取代。 两个网络都使用了 UNREAL 辅助任务[7]。 这些算法在 DeepMind Lab SeekAvoid 环境中进行训练。 结果如图8所示。 实验清楚地表明 LSTM 优于帧连接方法。
IV-E AI2雷神
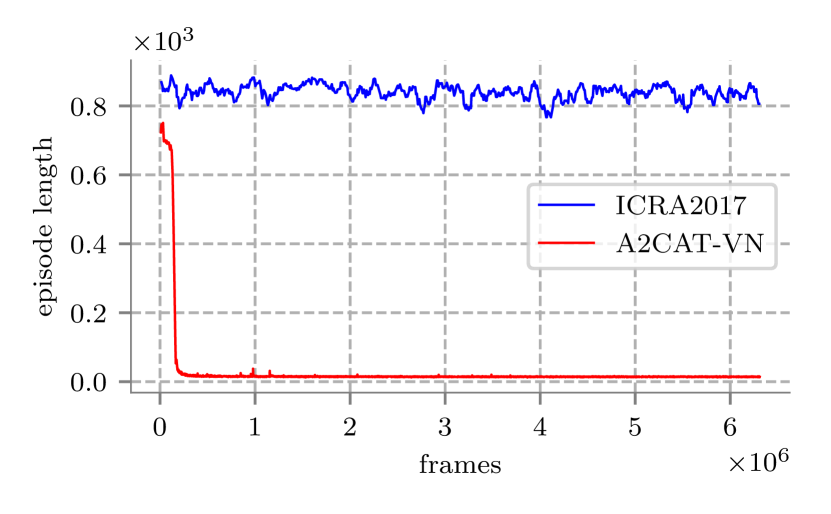
我们在具有多个目标的 AI2-THOR 环境中的四个环境中训练了我们的算法。 我们使用了与 [3] 相同的操作集 - 向左旋转、向右旋转、向前和向后。 向前和向后的动作使代理沿着米或米所面对的方向移动。操作“rotate-left”和“rotate-right”使代理旋转 。 没有施加噪音。 这使我们能够将我们的方法与 [3] 进行比较,并缓存观察结果,因为它将问题转化为网格世界的实例。 输入图像的分辨率为 像素。 我们的算法并行使用了 16 个环境,每个环境使用不同的场景或不同的目标。 我们没有使用任何预训练,也没有增加环境复杂性。 我们的方法与[3]进行比较。 我们为此实验选择的环境比 [3] 中使用的环境更大且更难导航,但来自相同的 AI2-THOR 模拟器。 使用我们的算法进行训练大约需要一天的时间,而使用[3]中描述的算法训练网络则需要三天的时间。 结果如图9所示。 我们的方法 A2CAT-VN 在大约 帧后找到了最佳解决方案,而 [3] 中描述的方法即使在 步中也无法收敛。
IV-F 连续AI2-雷神
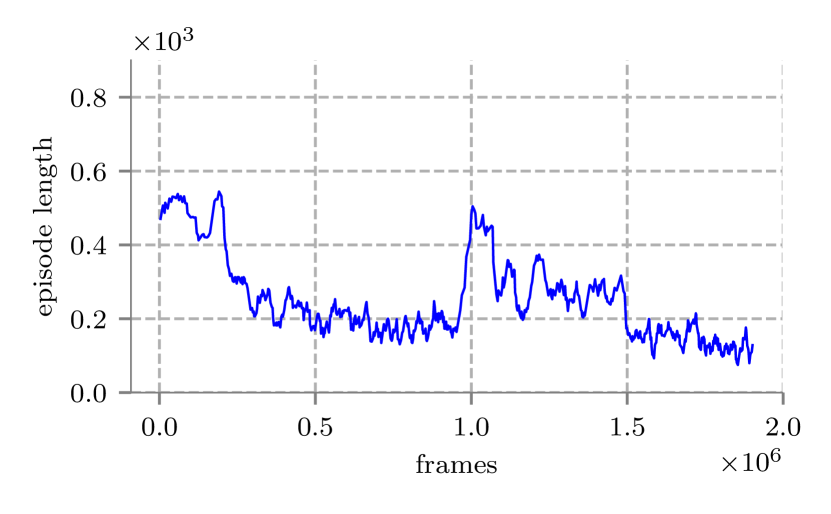
我们使用 IV-B 节中描述的全套动作,在 AI2-THOR 环境的修改版本上训练我们的代理:向前、向后、向左、向右、向左旋转、向左旋转向右、向上倾斜、向下倾斜。 向前和向后动作分别将代理移动 和 米,向左和向右动作将代理移动 米。 然而,由于性能问题,噪声仅施加在运动方向上,并且在向上倾斜和向下倾斜动作的情况下不施加噪声。 该代理接受了单卧室场景的训练,其中包含图像指定的多个目标。 我们并行使用了 16 个环境,每个环境都有不同的目标。 目标物体被随机放置在环境中的不同位置,并且训练智能体以接近目标物体(1米)。 输入图像的分辨率为 像素。 我们没有使用预训练,也没有增加环境复杂性。 结果如图10所示。 训练历时4天。 AI2-THOR 3D 环境模拟器速度太慢,无法进行进一步的实验。 结果显示了代理在非静态环境中导航并识别场景中不同物体的能力。
IV-G 辅助任务
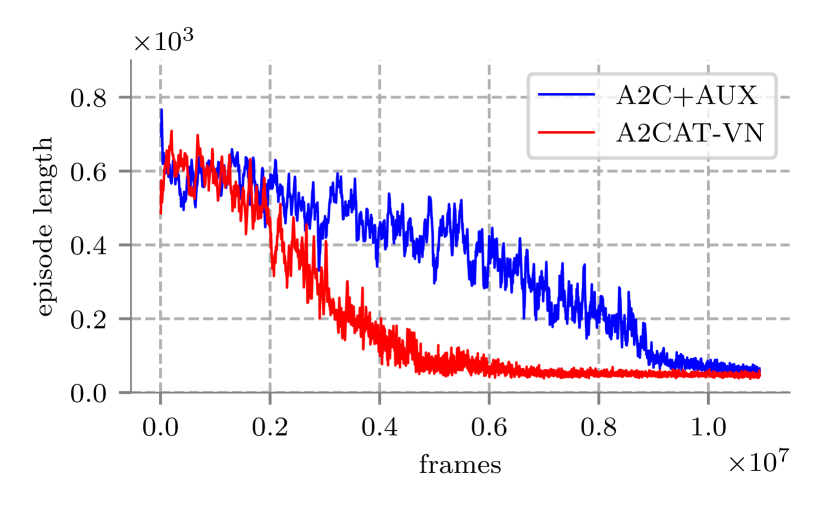
我们将我们的方法 (A2CAT-VN) 与使用原始两个 UNREAL 辅助任务扩展的批处理 A2C 进行了比较。 使用 House3D 环境模拟器对从 SUNCG 数据集 [6] 的子集中随机选择的 16 个房屋进行训练。 除了向上倾斜和向下倾斜动作之外,我们使用了与第IV-F节中描述的相同的动作。 受[5]的启发,智能体被训练寻找房屋中选定的房间。 该房间以在相同类型的房间中进行的观察的形式提供给代理。 例如,如果目标房间是卧室,则代理应该找到任何卧室。 输入图像的分辨率为 像素。 我们使用从 SUNCG 数据集中所有房屋的子集收集的数据来预训练我们的神经网络。 我们用于预训练的图像数量约为 ,并且我们使用 Adam 优化器将网络训练了 30 个时期。 对于完整的训练,我们将环境复杂度从时间步长 5M 的 0.3 线性增加到时间步长 10M 的 1.0。 训练大约花了两天时间。 平均剧集长度的训练曲线如图11所示。 在启用视觉导航的附加辅助任务的情况下,我们的算法 A2CAT-VN 收敛得更快,在 帧中达到 200 的平均剧集长度,而没有附加任务时,训练需要 帧达到相同的水平。
V 结论与未来工作
我们提出了一种新颖的学习架构 A2CAT-VN,用于室内环境中的视觉导航。 它基于紧凑的深度神经网络,能够在多个现实环境中快速学习,使用通过新颖的辅助任务扩展的批处理 A2C 算法。 通过使用目标图像作为输入,我们的方法使代理能够定位任意目标,只要它们的图像在训练阶段使用过即可。
该方法在 AI2-THOR 和 House3D 环境中进行了演示。 首先,我们证明了基本批处理 A2C 算法受益于添加 UNREAL 辅助任务[7]。 通过采用专为视觉导航设计的附加辅助任务,进一步提高了性能。
当应用于 AI2-THOR 环境时,我们的方法能够比替代的最先进方法[3]快至少一个数量级,该方法还允许使用与我们的方法类似,多个目标并在室内环境中进行了演示。 引入的辅助任务被证明可以将训练代理所需的帧数减少两倍,并且允许使用监督学习来预训练网络的一部分。
未来的研究可以集中于使用额外辅助任务的监督预训练进行视觉导航对训练表现的潜在影响,以及通过消融研究个别额外辅助任务的影响。 我们还想探索我们的方法在更多 3D 环境(也许是室外环境)中的应用,并有可能将其应用于在现实环境中移动的移动机器人。 需要对该方法推广到看不见的目标的能力进行另一方面的研究。 此外,我们相信智能体处理看不见的环境的能力可能会成为未来研究的一个重要领域。
参考
- [1] R. S. Sutton and A. G. Barto, Introduction to Reinforcement Learning, 2nd ed. Cambridge, MA, USA: MIT Press, 2017.
- [2] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2016.
- [3] Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), May 2017, pp. 3357–3364.
- [4] J. Bruce, N. Suenderhauf, P. Mirowski, R. Hadsell, and M. Milford, “One-shot reinforcement learning for robot navigation with interactive replay,” 2017.
- [5] Y. Wu, Y. Wu, G. Gkioxari, and Y. Tian, “Building generalizable agents with a realistic and rich 3d environment,” 2018.
- [6] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic scene completion from a single depth image,” Proceedings of 29th IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- [7] M. Jaderberg, V. Mnih, W. M. Czarnecki, T. Schaul, J. Z. Leibo, D. Silver, and K. Kavukcuoglu, “Reinforcement learning with unsupervised auxiliary tasks,” 2016.
- [8] P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. J. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuoglu, D. Kumaran, and R. Hadsell, “Learning to navigate in complex environments,” 2016.
- [9] C. Beattie, J. Z. Leibo, D. Teplyashin, T. Ward, M. Wainwright, H. Küttler, A. Lefrancq, S. Green, V. Valdés, A. Sadik, J. Schrittwieser, K. Anderson, S. York, M. Cant, A. Cain, A. Bolton, S. Gaffney, H. King, D. Hassabis, S. Legg, and S. Petersen, “Deepmind lab,” 2016.
- [10] E. Kolve, R. Mottaghi, D. Gordon, Y. Zhu, A. Gupta, and A. Farhadi, “AI2-THOR: An Interactive 3D Environment for Visual AI,” arXiv, Dec 2017.
- [11] Y. Wu, E. Mansimov, S. Liao, R. B. Grosse, and J. Ba, “Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation,” CoRR, vol. abs/1708.05144, 2017.
- [12] I. Grondman, L. Buşoniu, G. Lopes, and R. Babuška, “A survey of actor-critic reinforcement learning: Standard and natural policy gradients,” IEEE Transactions on Systems, Man, and Cybernetics. Part C: Applications and Reviews, vol. 42, no. 6, pp. 1291–1307, 2012.
- [13] R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, no. 3, pp. 229–256, May 1992. [Online]. Available: https://doi.org/10.1007/BF00992696
- [14] R. S. Sutton, D. A. McAllester, S. P. Singh, and Y. Mansour, “Policy gradient methods for reinforcement learning with function approximation,” in Advances in neural information processing systems, 2000, pp. 1057–1063.
- [15] C. J. C. H. Watkins and P. Dayan, “Q-learning,” in Machine Learning, 1992, pp. 279–292.
- [16] L. Gurvits, L. Lin, and S. Hanson, “Incremental learning of evaluation functions for absorbing markov chains: New methods and theorems,” preprint, 1994.
- [17] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in International conference on machine learning, 2016, pp. 1928–1937.
- [18] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” 2013.
- [19] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, “Striving for simplicity: The all convolutional net,” 2014.
- [20] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
- [21] J. Munk, J. Kober, and R. Babuska, “Learning state representation for deep actor-critic control,” 12 2016.
- [22] Z. Wang, T. Schaul, M. Hessel, H. van Hasselt, M. Lanctot, and N. de Freitas, “Dueling network architectures for deep reinforcement learning,” 2015.
- [23] S. Lange and M. Riedmiller, “Deep auto-encoder neural networks in reinforcement learning,” in The 2010 International Joint Conference on Neural Networks (IJCNN), July 2010, pp. 1–8.