具有簇大小约束的可微深度聚类
Aude Genevay Gabriel Dulac-Arnold Jean-Philippe Vert
CSAIL, MIT Google Brain Google Brain
摘要
聚类是一种基本的无监督学习方法。 许多聚类算法(例如 -means)依赖欧氏距离作为相似性度量,这通常不是高维数据(例如图像)最相关的度量。 因此,学习可以更好地反映数据集几何形状的低维嵌入对于性能很有帮助。 我们针对此任务提出了一种新方法,其中嵌入由可微模型(例如深度神经网络)执行。 通过将-均值聚类算法重写为最佳传输任务,并添加熵正则化,我们得出了一个完全可微的损失函数,该函数可以通过随机函数最小化嵌入参数和聚类参数梯度下降。 我们表明,这种新的公式通过添加对簇大小的约束,概括了最近提出的基于软-means的最先进方法。 对图像分类基准的实证评估表明,与最先进的方法相比,我们基于传输的最佳方法提供了更好的无监督准确性,并且不需要预训练阶段。
1简介
聚类是一项基本的无监督学习任务,其中,给定一组训练数据和许多类,我们的目标是将训练数据划分为 对应于不同类点的非重叠簇。 我们考虑这个问题的扩展,我们另外想要对不在训练集中的样本外数据进行分类,即我们想要推断一个函数 将数据空间中的给定点映射到一类。 存在许多聚类技术,例如当被赋予度量时的凝聚聚类,或者当被赋予度量时的-means。 然而,这些方法在应用于复杂的高维数据时通常会失败,因为数据空间上的常用度量(例如 中的欧几里德)没有意义。
对于图像或字符串等复杂数据,近年来在学习表示 方面取得了重大进展,其中 通常是参数为 的深度神经网络 (DNN),而 是一个低维空间,意在捕捉数据的底层结构 (Bengio 等人,2013 年)。 表示 通常经过优化,可以解决监督任务,例如使用一组标记图像进行图像分类,或者在没有标签的情况下,可以用于总结数据,例如,通过使用(变分)自动编码器或 GAN (Kingma 等人,2014;Goodfellow 等人,2014)。
任何此类学习的表示 都可以与任何聚类算法结合使用,以对映射到表示空间 的训练集进行聚类。 但是,如果表示 已针对其他任务进行了优化,则不能保证表示 对于该聚类任务“良好”。 在这项工作中,我们提出了一种新方法来学习表示,该表示非常适合在没有标签的情况下解决聚类任务。 最近有几位作者考虑了这种设置,通常以“深度聚类”的名义,在回顾现有方法之前,让我们修复一些符号。
设置和注释。
我们考虑 点 的数据集,其中 是输入数据的空间(例如, 表示 3 通道 图片)。 我们的目标是将数据聚类到 簇中,这可能对应于监督设置中的类数量。 对于数据集 ,我们用 表示嵌入的数据集 ,其中 是一个深度神经网络,参数为 和 。
此外,我们用 表示概率单纯形。 对于任何整数 ,令 为 维向量。 给定两个向量 ,其中 代表 ,我们用 表示具有条目 的向量。 对于任何向量或矩阵,我们用表示通过逐项应用操作获得的矩阵,例如,并用表示> 的转置。
一种有区别的聚类方法。
聚类任务可以改写为分类问题,不依赖于数据的表示,直接关注聚类函数。 这仅在班级分隔良好的情况下才有意义。 在这种情况下,训练集的标签 是已知的,然后可以通过最小化 形式的经验风险来训练监督模型
由于我们正在考虑无监督设置,因此 不可用。 因此,解决方案是在 和 上联合优化上述标准,以学习类分配和分类器:
| (1) |
一个明显的计算困难是这个问题涉及到离散变量。 此外,在这个双重优化任务中需要某种正则化,以防止出现平凡的解决方案;在 上添加约束对于防止空集群或集群过度填充至关重要。 Joulin 等人(2010 年)针对二元问题(),提出了线性回归情况下 (1) 的凸松弛与平方损失 。 在这种情况下,目标函数在 中是二次的,并且它们使用矩阵 的标准半定规划 (SDP) 松弛来逼近最小值。
Chang 等人 (2017) 使用了一种不同的方法,他将聚类问题重新定义为二元分类问题:给定两个数据点,它们是否属于同一个聚类? 由此产生的算法,深度自适应聚类(DAC)可以总结如下:由于,每个数据点都映射到单位球中的向量,它代表其概率属于每个阶级。 然后将这些概率与余弦距离进行比较,余弦距离定义了两点的相似度。 如果相似度高于某个阈值,则假定这些点属于同一类。 然后更新参数以增加相似点之间的相似性。
学习“聚类友好”的表示。
然而,表示在聚类任务之外很有用,例如,提取特征或减少数据集的维度,这就是为什么文献中的许多方法宁愿学习表示 ,使得 变得容易聚类。 在大多数情况下,问题在于最小化由两项组成的组合损失:(i)“表示损失”,以确保表示空间不退化(ii)“聚类损失” 强制学习的表示 与聚类任务相关。 这会产生以下优化问题:
| () |
而自动编码器的重建损失的选择(编码器和解码器)
| (2) |
是表示损失的标准,这些方法主要在聚类损失、自动编码器模型和优化策略(特别是防止平凡解决方案)的选择上有所不同。
Song 等人 (2013) 是最早通过调整标准自动编码器的目标函数来学习聚类表示的人之一。 他们将问题表述为最小化组合损失 (),目标为 - 意味着聚类损失:
| (3) |
为了优化编码器参数 、解码器参数 和聚类中心 的目标函数,它们在 ,对聚类中心和分配进行了一次更新。
虽然大多数最先进的方法依赖于与均值密切相关的聚类目标,但联合无监督学习(JULE)(Yang等人,2016)使用基于“凝聚聚类”的聚类损失。 从由数据点组成的集群开始,训练在凝聚聚类的几个步骤(即合并相似的集群)和向后传递(在向后传递期间更新网络参数以最小化聚类损失)之间交替进行。 尽管该方法具有更灵活的几何结构,但它需要在每次更新后构建数据集的亲和图,因此计算量很大。
Xie 等人 (2016) 提出深度嵌入聚类(DEC),它从仅使用重建损失 的预训练阶段开始,然后通过以下方式提高表示的聚类能力以自我监督的方式优化。 它们的聚类损失是每个点到每个簇的软分配与软分配的平方之间的Kullback-Leibler散度,这应该会推动嵌入有利于更困难的任务。 DEC 有多种使用更复杂的自动编码器和训练技术的变体,例如 Guo 等人 (2017)。 DEPICT 算法 (Dizaji 等人, 2017) 类似地最小化 KL 散度以锐化其分配,但也引入了分类器 ,输出 概率 类上的分布(通常是最后一层具有 softmax 激活的神经网络)。 因此,聚类损失对应于区分 不同类中的数据的可能性。
深度聚类网络(DCN)中的聚类损失(Yang等人,2017)是表示空间中均值的目标。 然而,最小化(聚类中心)和(聚类分配)的总损失是具有挑战性的。 因此,Yang 等人 (2017) 在 中替代优化固定 ,成为 AE 训练的变体,在 用于固定。 Deep -means (DKM) (Fard 等人, 2018) 算法使用与 DCN 相同的损失,但通过用软分配替换簇分配来放松分配问题 - 表示目标。 这导致可以使用随机梯度下降 (SGD) 在 和 上共同最小化聚类损失,并在深度聚类中实现最先进的性能(Fard等人,2018)。 后者是最接近我们的方法,因为我们还提出了基于 均值的完全可微目标。
聚类和最优传输
-均值聚类和最优传输之间存在联系,这一点在 Pollard (1982) 中首次被注意到,并在 Canas 和 Rosasco (2012) 中进行了更详细的研究。 粗略地说,最佳传输相当于 的约束公式,其中规定了簇大小。 在已知数据集中每个类别的比例但在个体级别上没有可用信息的情况下,该框架是有意义的。 Cuturi 和 Doucet (2014) 引入了该问题的熵正则化,可以实现高效的求解器。
贡献
2 具有最佳传输的集群
集群分配作为最优传输问题
考虑通过 嵌入表示空间中的 个样本点 ,以及 在该表示空间中以中心 我们希望将样本分配给集群,以便:
-
(我)
每个样本都被分配到一个簇,
-
(二)
每个簇 恰好包含 点,
-
(三)
聚类中心与其分配的样本之间的总距离(在表示空间中)最小。
上述问题的数学表述如下:
| () | ||||||
| s.t. | () | |||||
| () | ||||||
其中 是簇比例的向量。
最优传输的熵正则化
解决最佳传输的计算成本很高,因为它需要解决大型线性程序,文献中常见的解决方法是使用熵(Cuturi,2013)对问题进行正则化。 正则化问题如下:
| () | ||||||
| s.t. | () | |||||
| () | ||||||
熵的添加允许使用更快的迭代算法解决问题,称为 Sinkhorn 算法,其迭代总结在算法 1 中。 尽管这种快速求解器是正则化最优传输在机器学习任务中常规使用的主要原因,但最近的论文利用了这样一个事实,即它也会导致可微分损失,其梯度可以通过 Sinkhorn 迭代通过反向传播轻松计算(日内瓦等人,2018;萨利曼斯等人,2018)。
众所周知,线性规划在顶点上达到最大值,这就是为什么最优传输问题等价于其对单纯形的松弛。 熵的添加将使解决方案远离最佳顶点,移向约束多面体的中心,从而产生更平滑的分配(Peyré等人,2019)。 这在下面的提议中得到了形式化:
证明。
该命题是 (Genevay 等人, 2018) 中定理 1 的改编,以适应我们的聚类设置。 ∎
的选择是一个关键问题:当 epsilon 变小时,即当我们接近“真正的”最优传输时,Sinkhorn 算法需要更多迭代才能收敛(参见例如 (Peyré 等人, 2019)),这意味着更好地近似最优传输需要付出大量的计算代价。 然而,最近已经证明,从样本中近似最佳传输(机器学习中的典型情况),使用不太小的 实际上是有益的,以避免最佳传输遭受的维度灾难(日内瓦等人,2019)。
与 中的软分配链接-means
最佳传输公式包括两个边际约束,一个是每个样本恰好分配给一个簇,另一个是簇大小。 可以省略后一个约束以获得 -means 的目标。 当仅用一个边际约束对最优传输问题进行正则化时,我们得到了一个可微的均值目标。
Proposition 2。
考虑只有一个边际约束的熵正则化最优传输的变体(即,没有先验的簇大小):
| s.t. | |||||
那么最优分配由下式给出
| (7) |
证明。
该问题的解决方案与 Fard 等人 (2018) 引入的可微 均值损失完全对应,作者通过替换 来激发该损失在 中 - 表示带有 softmin 函数的目标 (3)。 因此,命题2提供了对DKM的新解释,并表明我们下面提出的方法通过添加对簇大小的约束来推广DKM。


解决聚类问题
3实验
我们在图像分类的两个经典基准数据集 MNIST 和 CIFAR10 上评估了基于传输的最佳聚类损失的效率。 我们将其与一个简单的基线进行比较,该基线包括使用自动编码器学习嵌入,然后在嵌入数据上运行 -means,以及与最先进的 DKM 方法 Fard等人(2018)基于软-意味着损失,已经证明了其相对于现有方法的优越性。
实验设置
对于 MNIST 数据集,我们使用具有 500-250-10-250-500 结构和 ReLu 激活的全连接自动编码器,遵循文献中的多个示例。 对于 CIFAR 数据集,我们使用使用 ReLu 激活的标准卷积网络作为编码器,具有三个卷积层,深度分别为 32、64、128,内核大小分别为 5、5、3,公共步幅为 2,然后是完全卷积层。连接层到维度 10 的潜在空间。 在这两种情况下,我们都使用大小为 的批次。 梯度更新是使用 Adam 算法和 TensorFlow 的标准学习率 (0.001) 进行逐步衰减,因为在无监督设置中不应进行参数调整。 用于训练的算法总结在算法2中。 我们还在原始像素上运行 -means,以了解嵌入 在数据中引入了多少结构。 遵循有关最佳传输正则化的通常准则,我们设置 ,它给出了最佳传输的足够好的近似值,而不需要太多的 Sinkhorn 迭代。 我们在图2中表明,只要的选择不是太大,最终的性能就很稳健。
| -means | AE + -means | soft -means | soft -means (p) | OT | OT (p) | |
|---|---|---|---|---|---|---|
| MNIST | 0.513 | |||||
| CIFAR10 | 0.206 | |||||
评估
在每个时期之后,我们通过以下公式计算将集群与类匹配所给出的准确度来评估不同的方法:
其中 和 分别是与 关联的类标签和簇索引, 是 。 对于“AE + -means”方法,通过在嵌入数据上运行 -means 来进行聚类分配,而对于“soft ” -means' 和 'OT',因为这些方法还学习聚类中心 ,我们将点 分配给聚类 ,这样 . 如文献中所示,簇和类之间的最佳匹配是通过匈牙利算法完成的。
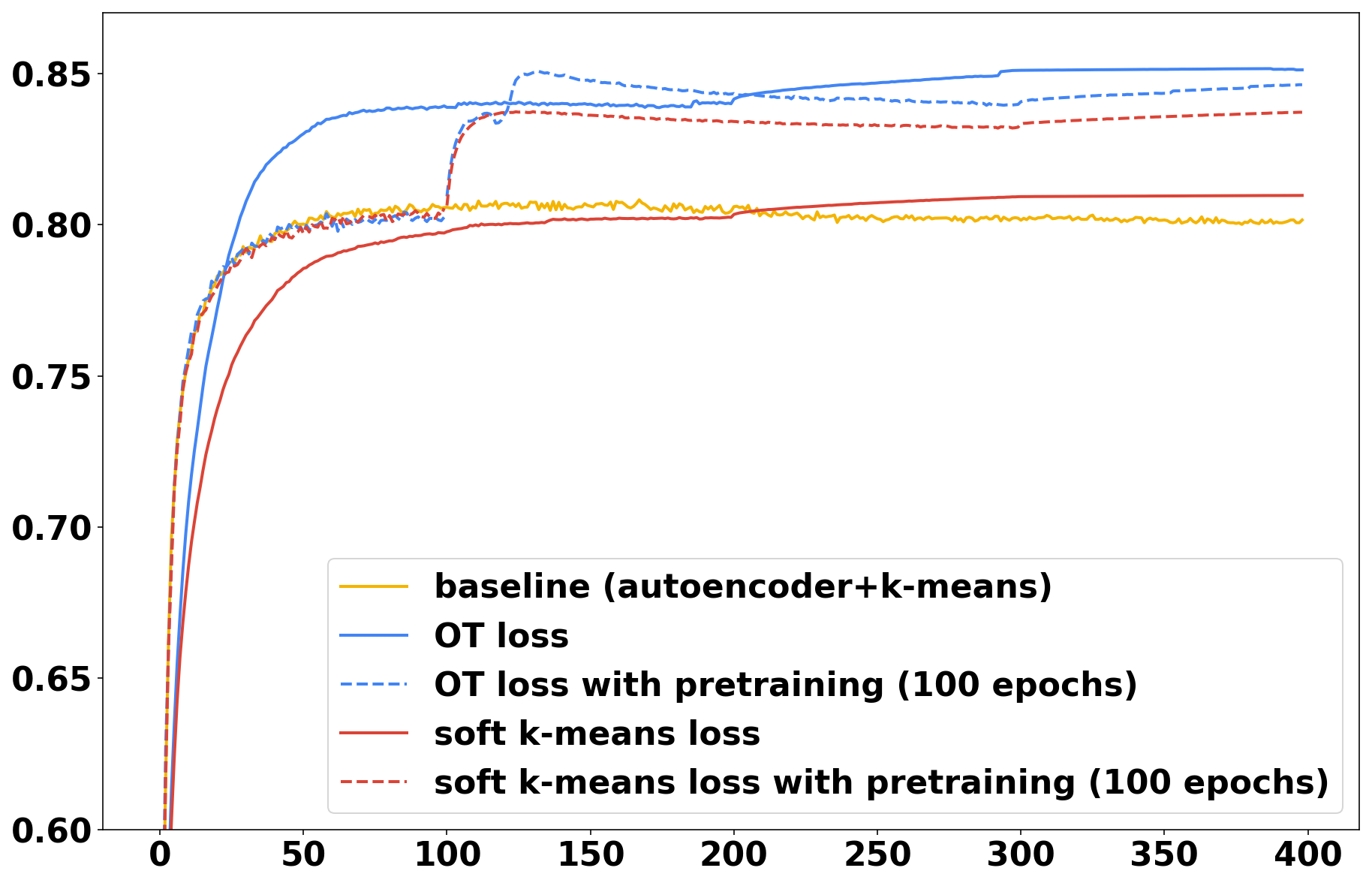
所有三种方法(自动编码器 + kmeans、软 -means、最佳传输)在训练期间的准确度演变如图 1 所示。 曲线是 50 次运行的平均值。 最终精度以及标准差列于表 1 中。 我们可以看到,最优的传输损失实现了较高的精度,但大多数不需要依赖预训练来获得良好的性能,与软-means相反,其性能仅略高于基线无需预训练。 为了断言该框架中最佳传输优越性的统计显着性,我们进一步对 50 次运行的最终精度进行 Welch t 检验。 在没有预训练的情况下,我们发现最佳传输明显优于软 均值(CIFAR10 的 p 值 和 MNIST 的 的 p 值) 。 通过预训练,MNIST 在 10% 水平(p 值为 0.10)时,最佳传输仍显着优于软 均值,但 CIFAR10 的情况并非如此(p 值为 0.33) 。 请注意,对于这两个数据集,预训练并未产生显着更好的最佳传输性能(p 值 ),但它显着改善了软 均值(p 值 )。
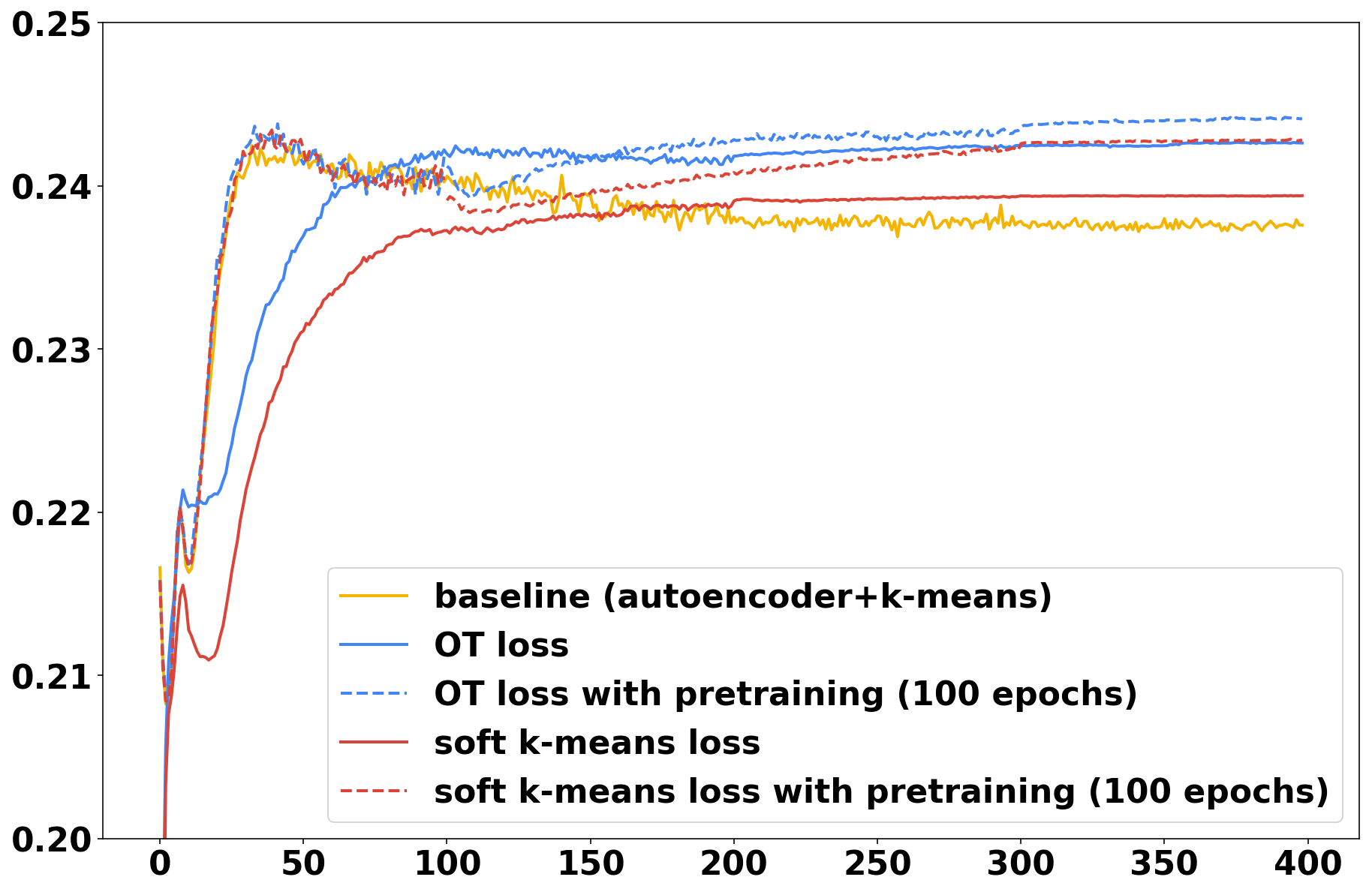
图 2 显示了每种方法 200 个 epoch 后的准确度,作为 的函数。 我们看到,只要 不是太大,OT 相对于软 手段的竞争优势对于 的选择是稳健的。 顺便说一句,经过预训练的方法对于 的大值更加稳健。 请注意,这些曲线仅在 5 次运行中取平均值,因此不能被视为具有统计显着性,它们仅作为该方法对所选参数的稳健性的证明。
4结论与讨论
在本文中,我们提出了一种基于正则化最优传输的新的深度聚类完全可微框架,该框架概括了最近提出的基于软的Fard等人(2018)方法>-意思是。 与竞争方法相比,它的主要优点是能够自然地强制执行类别比例的先验。 这显着提高了具有良好平衡类的数据集的性能,而无需依赖嵌入的预训练。
在我们的实验中,我们观察到在类别平衡的情况下比软-手段有优势。 一个有趣的探索方向是当簇大小的先验知识不统一时扩展我们的方法的应用。 这可能与某些情况相关,例如,当专家提供不同类别的比例的粗略估计时,例如组织病理学图像中癌细胞的比例。 虽然我们的方法可以自然地适用于不均匀的聚类比例,但我们在预备知识实验中发现,如果不注意确保聚类大小约束(算法 2 中的 )与聚类中心集(算法 2 中的向量 )的一致性,我们的方法就会表现不佳。 我们特别发现,通过-means(算法2中的步骤4)初始化中心通常很难实现这一点。 例如,考虑一下我们有两个集群的情况——比如一个人的图像和两个人的图像——我们知道我们应该有 20% 的前者和 80% 的后者。 但是,如果中心的 -means 初始化将第一个中心放在 2 的中间,第二个中心放在 1 的中间,则算法将尝试强制 1 和 20 的比例为 80%两人比例%。 一般来说,为了确保我们正确执行聚类比例,必须在学习阶段之前在聚类索引和类索引之间进行某种匹配。 这可以通过使用每个类的示例来初始化中心,以监督的方式完成。 这一扩展属于一次性学习的框架,并增加了有关班级比例的知识。
我们方法的另一个扩展是将簇比例的严格约束放宽为软约束,例如使用不平衡的最优传输和 Sinkhorn 算法的宽松版本,该算法惩罚边际约束而不是强烈强制执行它们(Chizat 等人,2018)。 当考虑小批量时,这可能特别相关,因为人们不会期望每批的成分能够完美地反映整体成分。
最后,我们注意到,我们对具有最佳传输的聚类问题的表述与 Dulac-Arnold 等人 (2019) 的表述密切相关,后者提出了一种算法,可以根据微型中的标签比例来学习分类器。批次。 主要区别在于,作者没有使用 来参数化嵌入,而是直接使用它来预测属于类 的概率。 的最后一层是 softmax,因此项 被 替换。此外,他们通过使用不平衡的最优传输来放松规定簇比例的边际约束。 后者也可以在我们提出的方法中实现,因为它包括使用 Sinkhorn 算法的变体(Chizat 等人,2018)。 然而,他们报告的大批量大小的性能低于我们在实验中报告的完全无监督任务的性能。 这将使我们的最佳传输方法成为比例问题学习的良好候选者。
参考
- Bengio et al. (2013) Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, August 2013.
- Canas and Rosasco (2012) Guillermo Canas and Lorenzo Rosasco. Learning probability measures with respect to optimal transport metrics. In Advances in Neural Information Processing Systems, pages 2492–2500, 2012.
- Chang et al. (2017) Jianlong Chang, Lingfeng Wang, Gaofeng Meng, Shiming Xiang, and Chunhong Pan. Deep adaptive image clustering. In Proceedings of the IEEE International Conference on Computer Vision, pages 5879–5887, 2017.
- Chizat et al. (2018) Lenaic Chizat, Gabriel Peyré, Bernhard Schmitzer, and François-Xavier Vialard. Scaling algorithms for unbalanced optimal transport problems. Mathematics of Computation, 87(314):2563–2609, 2018.
- Cuturi (2013) Marco Cuturi. Sorn distances: Lightspeed computation of optimal transport. In Advances in neural information processing systems, pages 2292–2300, 2013.
- Cuturi and Doucet (2014) Marco Cuturi and Arnaud Doucet. Fast computation of Wasserstein barycenters. In International Conference on Machine Learning, pages 685–693, 2014.
- Dizaji et al. (2017) K. G. Dizaji, A. Herandi, C. Deng, W. Cai, and H. Huang. Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 5747–5756, Oct 2017. doi: 10.1109/ICCV.2017.612.
- Dulac-Arnold et al. (2019) G. Dulac-Arnold, N. Zeghidour, M. Cuturi, L. Beyer, and J.-P. Vert. Deep multi-class learning from label proportions. Technical Report 1905.12909, arXiv, 2019.
- Fard et al. (2018) Maziar Moradi Fard, Thibaut Thonet, and Eric Gaussier. Deep -means: Jointly clustering with -means and learning representations. arXiv preprint arXiv:1806.10069, 2018.
- Genevay et al. (2018) Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with Sinkhorn divergences. In International Conference on Artificial Intelligence and Statistics, 2018.
- Genevay et al. (2019) Aude Genevay, Lénaic Chizat, Francis Bach, Marco Cuturi, and Gabriel Peyré. Sample complexity of Sinkhorn divergences. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), Naha, Okinawa, Japan, 2019.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014.
- Guo et al. (2017) Xifeng Guo, Long Gao, Xinwang Liu, and Jianping Yin. Improved deep embedded clustering with local structure preservation. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI’17, pages 1753–1759. AAAI Press, 2017. ISBN 978-0-9992411-0-3.
- Joulin et al. (2010) A. Joulin, F. Bach, and J. Ponce. Discriminative clustering for image co-segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
- Kingma et al. (2014) Diederik P. Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 3581–3589, 2014.
- Peyré et al. (2019) Gabriel Peyré, Marco Cuturi, et al. Computational optimal transport. Foundations and Trends® in Machine Learning, 11(5-6):355–607, 2019.
- Pollard (1982) David Pollard. Quantization and the method of k-means. IEEE Transactions on Information theory, 28(2):199–205, 1982.
- Salimans et al. (2018) Tim Salimans, Han Zhang, Alec Radford, and Dimitris Metaxas. Improving gans using optimal transport. arXiv preprint arXiv:1803.05573, 2018.
- Song et al. (2013) Chunfeng Song, Feng Liu, Yongzhen Huang, Liang Wang, and Tieniu Tan. Auto-encoder based data clustering. In José Ruiz-Shulcloper and Gabriella Sanniti di Baja, editors, Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, pages 117–124, Berlin, Heidelberg, 2013. Springer Berlin Heidelberg.
- Xie et al. (2016) Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, pages 478–487. JMLR.org, 2016.
- Yang et al. (2017) Bo Yang, Xiao Fu, Nicholas D. Sidiropoulos, and Mingyi Hong. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3861–3870, International Convention Centre, Sydney, Australia, 06–11 Aug 2017. PMLR.
- Yang et al. (2016) Jianwei Yang, Devi Parikh, and Dhruv Batra. Joint unsupervised learning of deep representations and image clusters. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016. doi: 10.1109/cvpr.2016.556.