对抗T恤!
在物理世界中躲避人体探测器
摘要
众所周知,深度神经网络(DNN)很容易受到对抗性攻击。 所谓的物理对抗示例通过将对抗补丁附加到真实对象来欺骗基于 DNN 的决策者。 然而,大多数现有的物理对抗攻击工作都集中在静态物体上,例如玻璃框架、停车标志和附着在纸板上的图像。 在这项工作中,我们提出了对抗性T恤,这是一种强大的物理对抗示例,用于逃避人体检测器,即使它可能由于移动的人的姿势变化而发生非刚性变形。 据我们所知,这是第一个对变形效果进行建模的工作,用于设计 T 恤等非刚性物体的物理对抗示例。 我们表明,所提出的方法在数字世界和物理世界中针对 YOLOv2 的攻击成功率分别为 74% 和 57%。 相比之下,最先进的物理攻击方法来欺骗人体探测器只能达到 18% 的攻击成功率。 此外,通过利用最小-最大优化,我们将我们的方法扩展到同时针对两个目标检测器 YOLO-v2 和 Faster R-CNN 的集成攻击设置。
frame 5
frame 30
frame 60
frame 90
frame 120
frame 150
pattern
Ours (digital)
adversarial T-shirt






 Ours (physical):
Ours (physical):
Adversarial T-shirt






 Affine (non-TPS)
Affine (non-TPS)
adversarial T-shirt






 Baseline physical attack
Baseline physical attack







1简介
从图像分类到语音识别的应用中都发现了深度神经网络 (DNN) 针对对抗性攻击(即扰动输入欺骗 DNN)的脆弱性[18, 33, 35, 6, 32, 2]. 早期的作品仅研究数字空间中的对抗性例子。 最近,一些工作表明,可以在各种现实条件下对物理对象产生对抗性扰动并欺骗基于 DNN 的决策者[28, 13, 1, 14, 25, 7, 30, 5 ,21]。 物理对抗攻击的设计有助于评估现实生活系统(例如自动驾驶车辆和监控系统)中部署的 DNN 的鲁棒性。 然而,大多数研究的物理对抗攻击都遇到两个限制:a)物理对象通常被认为是静态,b)附着在物体上的对抗模式可能变形移动的物体(例如,由于移动的人的姿势变化)通常被忽略。 在本文中,我们提出了一种新型的物理对抗性攻击,即对抗性 T 恤,当一个人穿着对抗性 T 恤时,可以逃避基于 DNN 的人体检测器;请参见图1第二行的说明性示例。
相关工作
大多数现有的物理对抗攻击都是针对图像分类器和对象检测器生成的。 在[28]中,人脸识别系统被在精心设计的对抗模式下设计的真实眼镜框所欺骗。 在[13]中,针对图像分类系统,通过在停车标志上添加黑色或白色贴纸,对停车标志进行了错误分类。 在[21]中,通过在相机镜头上放置精心制作的贴纸来欺骗图像分类器。 在[1]中,提出了一种所谓的期望变换(EoT)框架来合成对一组物理变换(例如旋转、平移、对比度、亮度和随机噪声)具有鲁棒性的对抗性示例。 与攻击图像分类器相比,针对对象检测器生成物理对抗性攻击更加复杂。 例如,攻击者在攻击 YOLOv2 [26] 和 SSD [24] 时需要误导对象的边界框检测器。 此类攻击在物理世界中众所周知的成功案例是生成对抗性停止标志[14],它欺骗了最先进的目标检测器,例如 YOLOv2 和 Faster R-CNN [27]。
与我们最相关的方法是[30]的工作,它证明了一个人可以通过拿着带有对抗性补丁的纸板来逃避检测器。 然而,这种物理攻击限制了对抗性补丁必须附着在刚性载体(即纸板)上,并且与我们这里将生成的对抗性图案直接打印在T恤上的设置不同。 我们证明,当对抗性补丁贴在 T 恤(而不是纸板)上并由移动的人佩戴时,[30] 提出的攻击变得无效(见图 1 的第四行)。 1)。 在技术方面,与[30]不同,我们提出了一种基于薄板样条(TPS)的Transformer来模拟非刚性物体的变形,并开发了一种欺骗物体检测器YOLOv2和Faster的整体物理攻击R-CNN同时进行。 我们强调,我们提出的对抗性 T 恤不仅仅是一件印有时尚服装的对抗性补丁的 T 恤,它还是一种物理对抗性可穿戴设备,旨在躲避现实世界中的人体探测器。
我们的工作还源于人员检测对智能监控的重要性。 基于 DNN 的监视系统极大地推进了目标检测领域[17, 16]。 高效的物体检测器,例如更快的 R-CNN [27]、SSD [24] 和 YOLOv2 [26] 已被部署用于人体检测。 因此,人们可能想知道,智能监控系统是否存在由对抗性人类可穿戴设备(例如对抗性 T 恤)引起的安全风险。 然而,要使物理世界中的人体探测器瘫痪需要更多的挑战,例如低分辨率、姿势变化和遮挡。 我们针对实时人体探测器的对抗性 T 恤的成功为设计实用的物理世界对抗性人类可穿戴设备提供了新的见解。
贡献
我们的贡献总结如下:
-
•
我们开发了一个基于 TPS 的 Transformer 来模拟由移动的人的姿势变化引起的对抗性 T 恤的时间变形。 我们还展示了这种非刚性变换对于确保对抗性 T 恤在物理世界中的有效性的重要性。
-
•
我们提出了一个通用优化框架,用于在单检测器和多检测器设置中设计对抗性 T 恤。
-
•
我们在数字世界和物理世界中进行了实验,结果表明,所提出的对抗性 T 恤在攻击 YOLOv2 时分别实现了 74% 和 57% 的攻击成功率。 相比之下,印在T恤上的物理对抗补丁[30]仅实现了18%的攻击成功率。 我们的一些结果在图 1 中突出显示。 1.
2 通过薄板样条映射对运动物体的变形进行建模
在本节中,我们首先回顾物理对抗示例设计中所需的一些现有转换。 然后,我们详细阐述了在这项工作中采用的薄板样条 (TPS) 映射,以对移动和非刚性物体可能遇到的变形进行建模。
令 为原始图像(或视频帧), 为物理 Transformer。 下变换后的图像 由下式给出
| (1) |
现有的转变。
在[1]中,参数变换器包括缩放、平移、旋转、亮度和加性高斯噪声;详情请参阅[1,附录D]。 在[23]中,通过参数模型研究了几何和光照变换。 [29, 9] 中考虑了其他变换,包括透视变换、亮度调整、重采样(或图像大小调整)、平滑和饱和度。 所有现有的变换都包含在我们的物理变换库中。 然而,它们不足以模拟由移动的人的姿势变化引起的布料变形。 例如,图 1 的第二行和第三行显示,仅针对现有物理变换设计的对抗性 T 恤的攻击成功率较低。



 (a)
(b)
(c)
(d)
(a)
(b)
(c)
(d)
布料变形的 TPS 变换。
人的运动可能会导致衣服上出现明显且不断变化的皱纹(又称变形)。 这使得在现实世界中有效开发对抗性 T 恤变得具有挑战性。 为了规避这一挑战,我们采用TPS映射[4]来模拟人体运动引起的布料变形。 TPS 作为非刚性变换模型已广泛应用于图像对齐和形状匹配[19]。 它由仿射分量和非仿射扭曲分量组成。 我们将证明,TPS 中的非线性变形部分可以为布料变形建模提供有效的手段,以学习非刚性物体的对抗模式。
TPS 通过一组给定位置的控制点学习从原始图像 到目标图像 的参数变形映射。 让 表示图像像素的 2D 位置。 然后,从 到 的形变由每个像素的 位移来表征,即图像 上 处的像素如何变化为图像 上 处的像素、其中,和、和分别表示图像上的像素沿方向和方向的位移。
给定一组控制点,其位置位于图像上,TPS在将映射到 [8]
| (2) |
其中和是TPS参数,表示沿或方向的位移。
TPS 的重要应用
对抗性T恤设计实现TPS的困难来自两个方面:1)如何确定控制点集合? 2)如何获得一对视频帧和之间对齐的控制点的位置和?
为了解决第一个问题,我们在T恤上打印一个棋盘,并使用相机校准算法[15, 34]来检测每两个棋盘之间的交叉点网格区域。 这些成功检测到的点被视为一帧的控制点。 图2-(a)显示了棋盘印刷的T恤以及检测到的交点。 由于 TPS 需要在两个帧之间对齐一组控制点,因此出现了关于点匹配的第二个问题。 挑战在于,在一个视频帧上检测到的控制点与在另一视频帧上检测到的控制点不同(例如,由于丢失检测)。 图2-(a) vs. (b) 提供了点不匹配的示例。 为了解决这个问题,我们采用了一个两阶段的过程,坐标系对齐,然后是点对齐,其中前者是指进行从一个框架到另一个框架的透视变换,后者通过最近邻法找到两帧处的匹配点。 我们在图2-(c)中提供了一个说明性示例。 我们建议读者参阅附录A,了解有关我们方法的更多详细信息。
3 对抗性 T 恤的生成:优化视角
在本节中,我们首先将对抗性 T 恤问题形式化并介绍我们设置中使用的符号。 然后,我们建议设计一种用于对抗性 T 恤的通用扰动,以欺骗单个目标检测器。 最后,我们提出了一个最小-最大(鲁棒)优化框架来设计针对多个对象检测器的通用对抗补丁。

让 表示从一个或多个给定视频中提取的 个视频帧,其中 表示第 帧。 让 表示应用于 的通用对抗性扰动。 然后,对抗性 T 恤的特征为 ,其中 是一个边界框,编码在第 帧处要扰动的布料区域的位置, 表示逐元素乘积。 对抗性T恤的目标是设计,使得的扰动帧被对象检测器误检测到。
欺骗单个物体检测器。
我们在[3]中推广了期望优于变换(EoT)方法来设计对抗性T恤。 请注意,与传统的 EoT 不同,生成对抗性 T 恤需要 Transformer 的组合。 例如,T 恤边界框上的透视变换与应用于布料区域的 TPS 变换相合成。
让我们首先考虑两个视频帧,一个锚定图像 (例如视频中的第一帧)和 的目标图像 111表示整数集合。. 给定 处人物 () 和 T 恤 () 的边界框,我们应用 的透视变换t3> 到 以获得图像 处的边界框 和 。 在缺乏物理变换的情况下,扰动图像相对于(w.r.t.) 由下式给出
| (4) |
其中术语表示人物边界框外部的背景区域,术语是人物边界区域,术语擦除像素T 恤边界框内的值,术语 是新引入的加性扰动。 在(4)中,和的先验知识分别通过人体检测器和手动标注获得。 在不考虑物理变换的情况下,方程。 (4) 简单地简化为对抗性示例 的常规表述。
接下来,我们考虑物理变换的三种主要类型:a) TPS变换应用于对抗性扰动以对布料变形的效果进行建模,b) 物理颜色变换,将数字颜色转换为物理世界中打印和可视化的颜色, 和 c) 应用于区域内的传统物理变换人的边界框,即 。 这里 表示可能的非刚性变换的集合, 由从数字空间中的色谱与其印刷对应物中学习的回归模型给出,和表示一组常用的物理变换,例如缩放、平移、旋转、亮度、模糊和对比度。 在不同变换源下对 (4) 的修改由下式给出
| (5) |
对于 、 和 。 在(5)中, 术语 A、B 和 C 已在 (4) 中定义, 表示对环境亮度条件进行建模的亮度变换。 在(5)中,是允许像素值变化的加性高斯噪声,其中是给定的平滑参数,我们将其设置为 在我们的实验中,噪声实现落入 范围内。 随机噪声注入也称为高斯平滑[11],它使最终的目标函数更加平滑,有利于优化时的梯度计算。
先前的工作,例如[28, 12],建立了不可打印分数(NPS)来测量设计的扰动向量与从物理世界获取的可打印颜色库之间的距离。 常用的方法是通过正则化将NPS纳入攻击损失中。 然而,找到合适的正则化参数变得非常困难,并且 NPS 的不平滑性使得对抗性 T 恤的优化变得困难。 为了规避这些挑战,我们建议使用二次多项式回归对颜色 Transformer 进行建模。 详细的颜色映射见附录B。
用于愚弄多个物体检测器的最小-最大优化。
与数字空间不同,对抗性攻击的可转移性在物理环境中大幅下降,因此我们考虑针对多个对象检测器的物理集成攻击。 最近[31]表明,集成攻击可以从最小-最大优化的角度进行设计,并且比多个模型的平均策略产生更高的最坏情况攻击成功率。 给定与攻击损失函数相关联的对象检测器,物理集合攻击被转换为
| (9) |
其中 被称为域权重,在攻击生成期间调整每个对象检测器的重要性, 是由 给出的概率单纯形, 是正则化参数, 后面跟着 (7)。 在(9)中,如果,则对抗性扰动是针对最大攻击损失(最坏情况)设计的攻击场景)自开始,其中位于固定的。 此外,如果,那么问题的内部最大化(9)意味着,即对攻击的平均方案损失。 因此,(9)中的正则化参数在最大策略和平均策略之间取得了平衡。
4实验
在本节中,我们通过与 攻击基线方法进行比较,展示了我们的方法(我们称为 advT-TPS)用于设计对抗性 T 恤的有效性,a) [30]中提出的欺骗YOLOv2的对抗性补丁及其在T恤上的印刷版本(我们称之为 高级补丁222为了公平比较,我们将扰动大小修改为与我们相同,并在训练数据集下执行 [30] 中提供的代码。),b)我们的方法在没有TPS转换的情况下的变体,即(5)中的(我们称之为advT-Affine )。 我们检查所提出算法的收敛行为及其攻击成功率333ASR由成功攻击的测试帧占测试帧总数的比率给出。 (ASR)在数字世界和物理世界中。 我们在附录D中阐明了我们的算法参数设置。
在详细说明之前,我们简要总结了我们提出的对抗性 T 恤的攻击性能。 当攻击 YOLOv2 时,我们的方法在数字世界中实现了 74%的 ASR,在物理世界中实现了 57%的 ASR,其中后者是通过对表中列出的所有不同场景(即室内、室外和不可预见的场景)成功攻击的视频帧进行平均来计算的。表 2. 当攻击 Faster R-CNN 时,我们的方法在数字世界和物理世界中分别实现了 61% 和 47% 的 ASR。 相比之下,在所有数字和物理场景中,与 YOLOv2 或 Faster R-CNN 相比,基线 advPatch 在最佳情况下仅实现了约 25% 的 ASR(例如,在物理情况下,与 YOLOv2 相比,ASR 为 18%)。
4.1 实验设置
数据采集。
我们收集两个数据集,用于在数字世界和物理世界中学习和测试我们提出的攻击算法。 训练数据集包含来自 个不同场景的 视频( 视频帧):一个室外场景和三个室内场景。 每个视频持续 - 秒,由穿着印有棋盘格 T 恤的移动人物拍摄。 然后从训练数据集中学习所需的对抗模式。 数字空间中的测试数据集包含在与训练数据集相同的场景下捕获的 视频。 该数据集用于评估数字世界中学习的对抗模式的攻击性能。 在现实世界中,我们定制了一件 T 恤,上面印有从我们的算法中学到的对抗图案。 然后在不同时间收集另一个 测试视频(第 4.3 节),捕捉两个或三个人(其中一个穿着对抗性 T 恤)a)并排行走或 b)以不同距离行走。 进行了一项额外的控制实验,其中穿着对抗性 T 恤的演员以夸张的方式行走,以在测试数据中引入较大的姿势变化。 此外,我们还通过不可预见的场景来测试我们的对抗性 T 恤,其中测试视频涉及训练数据集中从未涵盖的不同地点和不同人员。 所有视频均使用 iPhone X 拍摄,大小调整为 416 416。 在附录F的表A2中,我们总结了所有情况下收集的数据集。
物体探测器。
4.2 数字世界中的对抗性T恤
我们提出的攻击算法的收敛性能。
在图 4 中,我们显示了 ASR 与我们提出的算法用来解决问题的纪元数 (7) 的关系。 这里,我们在一个测试框架上的成功攻击需要满足两个条件:a)误检测到穿着对抗性 T 恤的人,b)成功检测到穿着普通衣服的人。 正如我们所看到的,所提出的攻击方法可以很好地攻击 YOLOv2 和 Faster R-CNN。 我们还注意到,攻击 Faster R-CNN 比攻击 YOLOv2 更困难。 此外,如果在训练期间不应用 TPS,那么与我们利用 TPS 的方法相比,ASR 会下降 左右。


|
各种攻击环境下对抗性 T 恤的 ASR。
我们通过数字模拟对我们的方法进行更全面的评估。 表 1 比较了在 4 种攻击设置中使用或不使用 TPS 转换生成的对抗性 T 恤的 ASR:a) 针对对抗性 T 恤的单检测器攻击使用相同的目标检测器设计和评估,b)转移单检测器攻击指使用不同的目标检测器设计和评估的对抗性T恤,c)整体攻击(平均) 由 (9) 给出,但使用各个模型的攻击损失平均值,并且 d) 整体攻击(最小-最大) 由 (9)。 正如我们所看到的,将TPS变换纳入对抗性T恤的设计中至关重要:没有TPS,攻击更快的R-CNN时,ASR从61%下降到34%,攻击YOLOv2时,ASR从74%下降到48%在单探测器攻击设置中。 我们还注意到,单检测器攻击的可转移性在所有设置中都很弱。 Faster R-CNN 始终比 YOLOv2 更稳健,与图 4 中的结果类似。 与我们的方法和 advT-Affine 相比,基线方法 advPatch 在攻击单个检测器时会产生最差的 ASR。 此外,我们评估了所提出的最小-最大集成攻击(9)的有效性。 正如我们所看到的,当攻击更快的 R-CNN 时,最小-最大集成攻击明显优于使用平均策略的对应攻击,从而导致 ASR 的 改进。 这一改进是以攻击 YOLOv2 时 性能下降为代价的。
method model target transfer ensemble(average) ensemble(min-max) advPatch[30] 22% 10% N/A N/A advT-Affine Faster R-CNN 34% 11% 16% 32% advT-TPS(ours) 61% 10% 32% 47% advPatch[30] 24% 10% N/A N/A advT-Affine YOLOv2 48% 13% 31% 27% advT-TPS(ours) 74% 13% 60% 53%
4.3 物理世界中的对抗性T恤
接下来我们在物理世界中评估我们的方法。 首先,我们按照 4.2 节,通过针对 YOLOv2 和 Faster R-CNN 解决问题 (7) 来生成对抗模式。 然后我们将对抗性图案打印在白色 T 恤上,从而得到对抗性 T 恤。 为了公平比较,我们还打印了 4.2 节中的 advPatch [30] 和 advT-Affine 生成的对抗模式> 同样款式的白色T恤。 值得注意的是,与通过拍摄物理对抗样本的静态照片进行评估不同,我们的评估是在更实际和更具挑战性的环境中进行的。 这是因为我们录制视频来跟踪穿着对抗性T恤的移动人,这可能会遇到多种环境影响,例如距离、T恤的变形、移动人的姿势和角度。
在表2中,我们将我们的方法与advPatch和advT-Affine在指定场景(包括室内、户外和不可预见的场景444不可预见的场景是指涉及不同地点和演员的测试视频,在训练数据集中从未见过。,以及所有场景的整体情况。 我们观察到,我们的方法实现了 64% 的 ASR(相对于 YOLOv2),远高于室内场景中的 advT-Affine (39%) 和 advPatch (19%) 。 与室内场景相比,室外场景中躲避人体探测器变得更具挑战性。 我们方法的 ASR 降低至 47%,但优于 advT-Affine (36%) 和 advPatch (17%)。 这并不奇怪,因为室外场景会遭受更多的环境变化,例如照明变化。 即使考虑到不可预见的情况,我们发现我们的对抗性 T 恤对于人和位置的变化具有鲁棒性,导致针对 Faster R-CNN 的 ASR 为 48%,针对 YOLOv2 的 ASR 为 59%。 与数字结果相比,我们的对抗 T 恤的 ASR 在所有测试的物理世界场景中下降了 左右;具体视频帧见图A5。
method model indoor outdoor new scenes average ASR advPatch[30] 15% 16% 12% 14% advT-Affine Faster R-CNN 27% 25% 25% 26% advT-TPS(ours) 50% 42% 48% 47% advPatch[30] 19% 17% 17% 18% advT-Affine YOLOv2 39% 36% 34% 37% advT-TPS(ours) 64% 47% 59% 57%
4.4消融研究
在本节中,我们进行了更多实验,以更好地了解对抗性 T 恤在各种条件下的鲁棒性,包括与相机的角度和距离、相机视图、人的姿势以及包括人群和遮挡在内的复杂场景。 由于基线方法 (advPatch) 在大多数情况下表现不佳,因此我们专注于根据 advT-Affine 评估我们的方法 (advT-TPS) > 使用 YOLOv2。 我们建议读者参阅附录E,了解有关我们消融研究设置的详细信息。
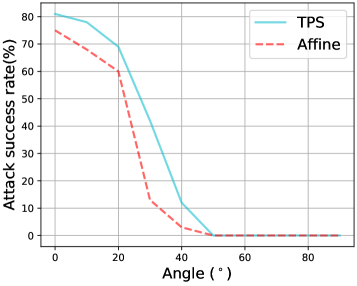
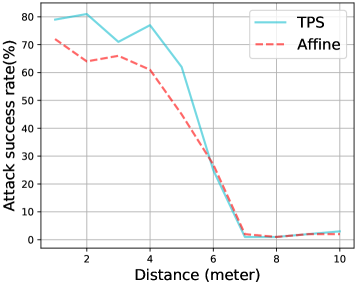
到相机的角度和距离。
在图5中,我们展示了当演员以不同角度穿着对抗性T-shit时的advT-TPS和advT-Affine的ASR以及到相机的距离。 正如我们所看到的,advT-TPS 在角度 和距离 m 内效果良好。而且 advT-TPS 始终优于 advT-Affine。 我们还注意到,ASR 在角度 处显着下降,因为它会导致对抗模式的遮挡。 此外,如果距离大于米,则无法从相机清楚地看到图案。
|
人体姿势。
复杂的场景。
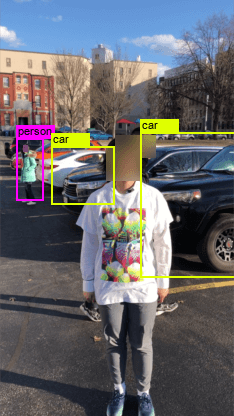
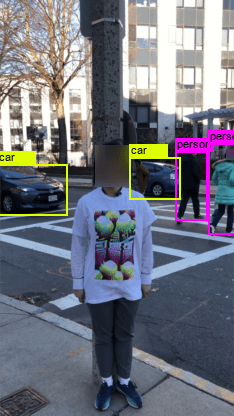
在表3(右)中,我们在几个背景杂乱的复杂场景中测试了我们的对抗性T恤,包括a)有多个物体和人员走动的办公室; b) 有车辆和行人的停车场; c) 交通繁忙、人群拥挤的十字路口。 我们观察到,与 advT-Affine 相比,advT-TPS 在复杂场景中相当有效,并且不会遭受 ASR 的重大损失。 与相机角度和遮挡等其他因素相比,杂乱的背景甚至人群可能是我们方法中最不关心的。 这是可以解释的,因为我们的方法直接作用于对象建议来抑制分类器。
crouching
sitting
running
advT-Affine







 advT-TPS
advT-TPS








crouching siting running advT-Affine 27% 26% 52% advT-TPS 53% 32% 63% office parking lot crossroad advT-Affine 69% 53% 51% advT-TPS 73% 65% 54%

|
5结论
在本文中,我们提出了对抗性 T 恤,这是第一个成功逃避移动人员检测的对抗性可穿戴设备。 由于 T 恤是非刚性物体,因此在生成对抗性扰动时会考虑由人的姿势变化引起的变形。 我们还提出了一种最小-最大集成攻击算法来同时欺骗多个对象检测器。 我们表明,我们对 YOLOv2 的攻击在数字世界和物理世界中分别可以实现 74% 和 57% 的攻击成功率。 相比之下,advPatch方法只能实现24%和18%的ASR。 根据我们的研究,我们希望对如何在物理世界中实施对抗性扰动提供一些启示。
参考
- [1] Athalye, A., Engstrom, L., Ilyas, A., Kwok, K.: Synthesizing robust adversarial examples. In: Dy, J., Krause, A. (eds.) Proceedings of the 35th International Conference on Machine Learning. vol. 80, pp. 284–293 (10–15 Jul 2018)
- [2] Athalye, A., Carlini, N., Wagner, D.: Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv:1802.00420 (2018)
- [3] Athalye, A., Engstrom, L., Ilyas, A., Kwok, K.: Synthesizing robust adversarial examples. In: International Conference on Machine Learning. pp. 284–293 (2018)
- [4] Bookstein, F.L.: Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Transactions on pattern analysis and machine intelligence 11(6), 567–585 (1989)
- [5] Cao, Y., Xiao, C., Yang, D., Fang, J., Yang, R., Liu, M., Li, B.: Adversarial objects against lidar-based autonomous driving systems. arXiv preprint arXiv:1907.05418 (2019)
- [6] Carlini, N., Wagner, D.: Audio adversarial examples: Targeted attacks on speech-to-text. In: 2018 IEEE Security and Privacy Workshops (SPW). pp. 1–7. IEEE (2018)
- [7] Chen, S.T., Cornelius, C., Martin, J., Chau, D.H.P.: Shapeshifter: Robust physical adversarial attack on faster r-cnn object detector. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases. pp. 52–68. Springer (2018)
- [8] Chui, H.: Non-rigid point matching: algorithms, extensions and applications. Citeseer (2001)
- [9] Ding, G.W., Lui, K.Y.C., Jin, X., Wang, L., Huang, R.: On the sensitivity of adversarial robustness to input data distributions. In: International Conference on Learning Representations (2019)
- [10] Donato, G., Belongie, S.: Approximate thin plate spline mappings. In: European conference on computer vision. pp. 21–31. Springer (2002)
- [11] Duchi, J.C., Bartlett, P.L., Wainwright, M.J.: Randomized smoothing for stochastic optimization. SIAM Journal on Optimization 22(2), 674–701 (2012)
- [12] Evtimov, I., Eykholt, K., Fernandes, E., Kohno, T., Li, B., Prakash, A., Rahmati, A., Song, D.: Robust physical-world attacks on machine learning models. arXiv preprint arXiv:1707.08945 (2017)
- [13] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., Song, D.: Robust physical-world attacks on deep learning visual classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1625–1634 (2018)
- [14] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Tramer, F., Prakash, A., Kohno, T., Song, D.: Physical adversarial examples for object detectors. In: 12th USENIX Workshop on Offensive Technologies (WOOT 18) (2018)
- [15] Geiger, A., Moosmann, F., Car, Ö., Schuster, B.: Automatic camera and range sensor calibration using a single shot. In: 2012 IEEE International Conference on Robotics and Automation. pp. 3936–3943. IEEE (2012)
- [16] Girshick, R.: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 1440–1448 (2015)
- [17] Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 580–587 (2014)
- [18] Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014)
- [19] Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in neural information processing systems. pp. 2017–2025 (2015)
- [20] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [21] Li, J., Schmidt, F., Kolter, Z.: Adversarial camera stickers: A physical camera-based attack on deep learning systems. In: International Conference on Machine Learning. pp. 3896–3904 (2019)
- [22] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
- [23] Liu, H.T.D., Tao, M., Li, C.L., Nowrouzezahrai, D., Jacobson, A.: Beyond pixel norm-balls: Parametric adversaries using an analytically differentiable renderer. In: International Conference on Learning Representations (2019), https://openreview.net/forum?id=SJl2niR9KQ
- [24] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: European conference on computer vision. pp. 21–37. Springer (2016)
- [25] Lu, J., Sibai, H., Fabry, E.: Adversarial examples that fool detectors. arXiv preprint arXiv:1712.02494 (2017)
- [26] Redmon, J., Farhadi, A.: Yolo9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7263–7271 (2017)
- [27] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems. pp. 91–99 (2015)
- [28] Sharif, M., Bhagavatula, S., Bauer, L., Reiter, M.K.: Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. pp. 1528–1540. ACM (2016)
- [29] Sitawarin, C., Bhagoji, A.N., Mosenia, A., Mittal, P., Chiang, M.: Rogue signs: Deceiving traffic sign recognition with malicious ads and logos. arXiv preprint arXiv:1801.02780 (2018)
- [30] Thys, S., Van Ranst, W., Goedemé, T.: Fooling automated surveillance cameras: adversarial patches to attack person detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 0–0 (2019)
- [31] Wang, J., Zhang, T., Liu, S., Chen, P.Y., Xu, J., Fardad, M., Li, B.: Beyond adversarial training: Min-max optimization in adversarial attack and defense. arXiv preprint arXiv:1906.03563 (2019)
- [32] Xu, K., Chen, H., Liu, S., Chen, P.Y., Weng, T.W., Hong, M., Lin, X.: Topology attack and defense for graph neural networks: An optimization perspective. In: International Joint Conference on Artificial Intelligence (IJCAI) (2019)
- [33] Xu, K., Liu, S., Zhao, P., Chen, P.Y., Zhang, H., Fan, Q., Erdogmus, D., Wang, Y., Lin, X.: Structured adversarial attack: Towards general implementation and better interpretability. In: International Conference on Learning Representations (2019)
- [34] Zhang, Z.: A flexible new technique for camera calibration. IEEE Transactions on pattern analysis and machine intelligence 22 (2000)
- [35] Zhao, P., Xu, K., Liu, S., Wang, Y., Lin, X.: Admm attack: an enhanced adversarial attack for deep neural networks with undetectable distortions. In: Proceedings of the 24th Asia and South Pacific Design Automation Conference. pp. 499–505. ACM (2019)
附录
在补充中,我们提供了有关薄板样条(TPS)变换、攻击损失的制定、算法参数的设置以及物理世界中对抗性T恤的附加实验的详细信息。
附录A如何构建TPS转换?
| frame 1 in Fig.2a | frame 2 in Fig.2b |
|---|---|
 |
|
我们首先手动标注四个角点(见图A1中的蓝色标记),以在不同时刻的两帧之间进行透视变换。 此透视变换用于对齐用于两帧之间的 TPS 变换的锚点的坐标系。
理想情况下,棋盘检测工具 [15, 34] 始终输出检测到的角点网格。 大多数情况下,它可以完美地定位棋盘上的所有点,因此不需要额外的努力来建立两个图像之间的点对应关系。 当检测中存在角点缺失的情况下,我们使用以下方法来匹配两幅图像。 我们执行点匹配过程(参见算法1)来对齐棋盘检测工具检测到的锚点(参见图A1中的红色标记)。 数据匹配过程选择用于构建TPS变换的匹配锚点集。
附录B颜色变换
如图 A2 所示,我们生成训练数据集,将数字调色板映射到 T 恤上打印的相同调色板。 借助 颜色单元对。 我们通过最小化预测物理颜色(以图A2(a)中的数字颜色作为输入)和中提供的真实物理颜色的均方误差来学习二次多项式回归的权重。图A2(b)。 一旦学习了颜色转换器 ,我们就会将其合并到 (5) 中。
 |
 |
 |
| (a) | (b) | (c) |
附录C攻击损失的表述
有两种可能的选择来制定攻击损失以欺骗人员检测器。 首先,被指定为错误分类损失,在大多数先前的工作中常用。 目标是将“人”类错误分类为任何其他不正确的类。 然而,我们的工作考虑了一种更先进的消失攻击,它强制检测器甚至不绘制对象“人”的边界框。 对于 YOLOv2,我们最小化与“person”类对应的所有边界框的置信度得分。 对于 Faster R-CNN,我们攻击类“背景”的所有边界框。 令 为受扰动的视频帧,则 (6) 中的攻击损失由下式给出
| (11) |
其中, 表示 YOLOv2 的 th 边界框的置信度分数,或 Faster R-CNN 的 th 边界框中 "人 "类的概率、 是置信度阈值,使用 会强制优化器最小化高概率(大于 )的边界框, 是第 个边界框、 是编码该人区域的已知边界框,数量 表示 和 之间的交集, 是卡方函数, 是指示函数,如果 与 至少有 重叠,则返回 ,否则返回 。 在方程(11)中,数量表征了我们感兴趣的边界框,与具有高概率和大重叠。 方程(11)中的最终损失给出了检测对象“人”的边界框的最大概率。
附录D超参数设置
求解方程时(7),我们使用 Adam 优化器 [20] 以初始学习率 训练 5,000 轮。 当损失停止减少时,该比率就会衰减。 总变异范数的正则化参数设置为。 在等式中。 (9),我们将设置为1,并以初始学习率解决6000个epochs的最小-最大问题。 在等式中。 (5),转换的详细信息如表A1所示。
| Transformation | Minimum | Maximum |
|---|---|---|
| Scale | 0.5 | 2 |
| Brightness | -0.1 | 0.1 |
| Contrast | 0.8 | 1.2 |
| Random uniform noise | -0.1 | 0.1 |
| Blurring | average pooling/filter size = 5 | |
在实验中,我们发现超参数在精细增益扰动模式与其平滑度之间取得了平衡。 如图A3所示,当最小(即)时,扰动可以达到相对于YOLOv2的最佳ASR(82%)在数字空间中,然而,当我们在物理世界中测试数字模式时,攻击性能下降至 51%(比 的情况更差),因为非平滑(尖锐)扰动模式可能不会被现实世界的相机很好地捕捉到。 在我们的实验中,我们选择 来实现数字结果和物理结果之间的最佳权衡。
| 1 | 3 | 5 | |
 |
|
 |
|
| digital | 82% | 74% | 69% |
| physical | 51% | 57% | 55% |
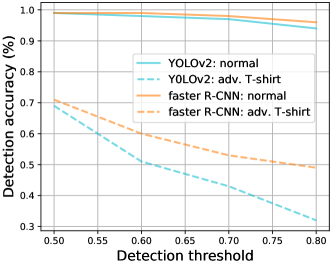
对于人体探测器的实际部署,需要根据经验确定最小检测阈值,以便在检测精度和误报率之间获得良好的权衡。 在我们的物理词测试中,我们将 Faster R-CNN 和 YOLOv2 的阈值设置为 0.7,此时它们对穿着正常衣服的人的检测准确率都达到了 97% 以上。 图A4提供了该阈值的敏感性分析。
 |
附录 E数据集详细信息
| videos (frames) | indoor | outdoor | overall | |||
| office | elevator | hallway | street1 | street2 | ||
| single-person | 4 (177) | 4 (135) | 4 (230) | 4 (225) | 4 (240) | 20 (1007) |
| multi-persons | 4 (162) | 4 (132) | 4 (245) | 4 (230) | 4 (227) | 20 (996) |
| train | 6 (245) | 6 (180) | 6 (335) | 6 (344) | 6 (365) | 30 (1469) |
| test (digital) | 2 (94) | 2 (87) | 2 (140) | 2 (111) | 2 (102) | 10 (534) |
| unseen | elevator | hallway | street3 | |||
| test (physical) | 6 (236) | 6 (184) | 6 (220) | 6 (288) | 24 (928) | |
在4.4节中关于参数敏感性的消融研究以及对更复杂测试场景的泛化,我们进一步收集了一些新的测试数据。 具体来说,我们考虑了五个人(两名女性和三名男性)进行消融研究的场景,但他们都没有出现在原始训练和测试数据集中。 我们使用两台摄像头(一台 iPhone X 和一台 iPhone XI)录制了多个视频,并报告了生成的平均 ASR。
附录F更多实验结果
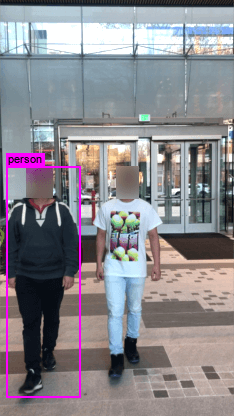
在图A5中,我们展示了两种场景下的物理世界攻击结果:a)由advT-TPS、advT-Affine生成的对抗性T恤t3>和advPatch在室外场景(前三行),b)由advT-TPS和advT-Affine生成的对抗性T恤> 在一个看不见的场景中(在训练数据集中从未见过的位置)。 正如我们所看到的,我们的方法优于仿射和基线。 在没有 TPS 的情况下,通过仿射和基线生成的对抗性 T 恤在大多数情况下都会失败,这意味着 TPS 对 T 恤变形建模的重要性。 正如预期的那样,当穿着对抗性 T 恤的人走向摄像机时,探测器也变得更容易受到攻击。
advT-TPS






 advT-Affine
advT-Affine






 advPatch
advPatch






 advT-TPS
advT-TPS





 advT-Affine
advT-Affine







| advT-Affine | advT-TPS | ||||
|---|---|---|---|---|---|

|

|

|

|

|

|