44email: {angus.dempster1,francois.petitjean,geoff.webb}@monash.edu
ROCKET:使用随机卷积核进行异常快速且准确的时间序列分类
摘要
大多数达到最先进精度的时间序列分类方法都具有很高的计算复杂性,即使对于较小的数据集也需要大量的训练时间,并且对于较大的数据集来说也很棘手。 此外,许多现有方法专注于单一类型的特征,例如形状或频率。 基于最近用于时间序列分类的卷积神经网络的成功,我们表明使用随机卷积核的简单线性分类器可以实现最先进的精度,而计算费用仅为现有方法的一小部分。
关键词:
可扩展时间序列分类随机卷积1简介

大多数达到最先进精度的时间序列分类方法都具有很高的计算复杂性,即使对于较小的数据集也需要大量的训练时间,并且根本无法扩展到大型数据集。 这推动了更可扩展的方法的开发,例如邻近森林(Lucas等人,2019)、TS-CHIEF(Shifaz等人,2019)和InceptionTime(Ismail Fawaz 等人,2019c)。
我们证明,通过使用随机卷积核转换时间序列,并使用转换后的特征来训练线性分类器,即使是这些最近的、更具可扩展性的方法所需的时间也只需一小部分即可实现最先进的分类精度。 我们将此方法称为 Rocket(对于 R 和 Om Convolutional KErnel T变换)。
现有的时间序列分类方法通常侧重于单一表示,例如形状、频率或方差。 卷积核构成了一个单一的机制,可以捕获许多以前需要各自专门技术的特征,并且已被证明在用于时间序列分类的卷积神经网络中有效,例如 ResNet (Wang 等人,2017 ; Ismail Fawaz 等人,2019a),以及 InceptionTime。
与典型卷积神经网络中使用的学习卷积核相比,我们证明生成大量随机卷积核是有效的,这些随机卷积核结合在一起捕获与时间序列分类相关的特征(即使单独地,单个卷积核)随机卷积核可能只能非常近似地捕获给定时间序列中的相关特征)。
Rocket 在 UCR 档案 (Dau 等人, 2019) 中的数据集上实现了最先进的分类精度,但只需要训练时间的一小部分现有的方法。 图 1 显示了 Rocket 与几种最先进的时间序列分类方法在 UCR 档案中的 85 个“bake off”数据集上的平均排名 (Dau 等人, 2019; Bagnall 等人, 2017)。 限于单个CPU核心,Rocket的总训练时间为:
-
•
具有最大训练集的“bake off”数据集(ElectricDevices,包含 8,926 个训练示例)需要 6 分钟,而 Proximity Forest 需要 1 小时 35 分钟,TS-CHIEF 需要 2 小时 24 分钟,而InceptionTime 为 7 小时 46 分钟(在 GPU 上训练);和
-
•
时间序列最长的“bake off”数据集(HandOutlines,时间序列长度为 2,709)需要 4 分 52 秒,而 InceptionTime(在 GPU 上训练)需要 8 小时 10 分钟,几乎Proximity Forest 需要 3 天,TS-CHIEF 需要 4 天以上。
Rocket 在所有 85 个“bake off”数据集上的总计算时间(训练和测试)为 1 小时 50 分钟,而 InceptionTime 的总计算时间(使用 GPU 进行训练和测试)则超过 6 天,等等Proximity Forest 和 TS-CHIEF 各超过 11 天。 (Rocket 的计时是 10 次运行的平均值,在混合使用 Intel Xeon E5-2680 v3 和 Intel Xeon Gold 6150 处理器的集群上执行,每次运行每个数据集仅限一个 CPU 核心。)
Rocket对于大型数据集的可扩展性也更强,其训练复杂度与时间序列长度和训练示例数量成线性关系。 Rocket 可以在 1 小时 15 分钟内学习 100 万个时间序列,其准确度与 Proximity Forest 类似,后者需要超过 16 个小时才能训练相同数量的数据。 Rocket 的受限变体可以在不到 1 分钟的时间内从相同的 100 万个时间序列中学习,或者说速度再次提高了大约 100 倍,尽管精度稍低。 Rocket 本质上是并行的,并且可以通过使用多个 CPU 核心(我们的实现自动在可用的多个 CPU 核心之间并行化转换)或 GPU 来加快速度。
2相关工作
2.1 最先进的方法
时间序列分类的任务可以被认为涉及学习或检测与相关类别相关的时间序列内的信号或模式。 “[D]不同的问题需要不同的表示”(Bagnall 等人, 2017, p. 647),并且类可以通过多种类型的模式来区分:“多个领域中的歧视性特征” (Bagnall等人,2017,第645页)。
不同的时间序列分类方法代表了从时间序列中提取有用特征的不同方法(Bagnall等人,2017)。 现有方法通常关注单一类型的特征,例如信号的频率或方差,或判别性子系列(shapelet)的存在。 Bagnall 等人 (2017) 识别了 COTE(已被 HIVE-COTE 取代)、Shapelet 变换(Hills 等人,2014;Bostrom 和 Bagnall,2015) 和 BOSS (Schäfer,2015) 作为 UCR 档案中三个最准确的分类器。
BOSS 是几种基于字典的方法之一,它使用基于时间序列中模式出现频率的表示(Bagnall 等人,2017)。 BOSS 的训练复杂度在训练示例数量和时间序列长度上都是二次方的,。 BOSS-VS 是 BOSS 的可扩展性更强的变体,但准确性较低(Schäfer,2016)。 另一种相关方法 WEASEL 比 BOSS 更准确,但具有相似的训练复杂度和较高的内存复杂度(Schäfer 和 Leser 2017;另见 Lucas 等人 2019)。
Shapelet 变换是基于查找判别性子系列的几种方法之一,即所谓的“shapelet”(Bagnall 等人,2017)。 Shapelet 变换的训练复杂度是训练示例数量的二次方,时间序列长度的四次方,。 还有其他更具可扩展性的 shapelet 方法,但这些方法不太准确(Bagnall 等人,2017)。
HIVE-COTE 是其他分类器的大型集合,包括 BOSS 和 Shapelet Transform,以及基于弹性距离度量和频率表示的分类器(Lines 等人,2018)。 自Lines等人(2018)以来,HIVE-COTE被认为是最准确的时间序列分类方法。 HIVE-COTE 的训练复杂度受到 Shapelet Transform 复杂度的限制,但其其他组件也具有很高的计算复杂度,例如具有 的 Elastic Ensemble (Lines等人,2018)。
2.2 更多可扩展的方法
现有最先进的时间序列分类方法的高计算复杂性使得这些方法即使对于较小的数据集也很慢,并且对于大型数据集来说也很棘手。 这推动了更具可扩展性的方法的开发,包括 Proximity Forest、TS-CHIEF 和 InceptionTime。
邻近森林是一个决策树的集合,使用弹性距离度量作为分割标准(Lucas等人,2019),其复杂度与训练示例的数量呈拟线性关系,但与时间序列长度呈二次方关系。
TS-CHIEF 建立在邻近森林的基础上,结合了基于字典和基于区间的分割标准(Shifaz 等人,2019)。 与邻近森林一样,TS-CHIEF 的训练复杂度与示例数量呈拟线性关系,但与时间序列长度呈二次关系。
已经提出了几种使用卷积神经网络进行时间序列分类的方法(一般参见 Ismail Fawaz 等人,2019a)。 最近,基于 Inception 架构的五个深度卷积神经网络的集成 InceptionTime (Ismail Fawaz 等人,2019c) 已被证明在 UCR 档案上与 HIVE-COTE 具有竞争力。
卷积神经网络通常使用随机梯度下降或密切相关的算法进行训练,例如 Adam (Kingma 和 Ba,2015)。 随机梯度下降的训练复杂度基本上与训练示例的数量成线性关系,并且可以使用 GPU 并行训练(Goodfellow 等人 2016, pp. 147–149; Bottou等人2018)。
2.3卷积神经网络和卷积核
Ismail Fawaz 等人 (2019c, pp. 2–3) 观察到卷积神经网络在图像分类中的成功表明,它们对于时间序列分类也应该有效,因为时间序列与图像具有本质上相同的拓扑结构,但少一个维度 (另请参阅 Bengio 等人,2013 ,第 1820–1821 页)。
卷积神经网络代表了一种与许多其他方法不同的时间序列分类方法。 卷积神经网络不是使用预先设想的表示来解决问题,而是使用卷积核来检测输入中的模式。 在学习核的权重时,卷积神经网络学习与不同类别相关的时间序列特征(Ismail Fawaz等人,2019a)。
内核通过滑动点积运算与输入时间序列进行卷积,生成特征图,进而用作分类的基础(参见 Ismail Fawaz 等人,2019a)。 内核的基本参数是其大小(长度)、权重和偏差、膨胀和填充 (一般参见 Goodfellow 等人,2016 年,第 1 章) 9). 内核与输入具有相同的结构,但通常要小得多。 对于时间序列,核是一个权重向量,带有一个偏置项,该偏置项被添加到输入时间序列与给定核的权重之间的卷积运算的结果中。 膨胀将内核“扩展”到输入上,例如,膨胀为 2 时,内核中的权重与输入时间序列的每隔一个元素 进行卷积(参见 Bai 等人,2018)。 填充涉及将值(通常为零)附加到输入时间序列的开头和结尾,通常使给定内核的“中间”权重与卷积运算开始时输入时间序列的第一个元素对齐。
卷积核可以捕获其他方法中使用的许多类型的特征。 内核可以捕获时间序列中的基本模式或形状,类似于 shapelet:卷积运算将在内核与输入匹配的情况下产生较大的输出值。 此外,膨胀允许内核在不同尺度捕获相同的模式(Yu 和 Koltun,2016)。 多个内核的组合可以捕获复杂的模式。
将内核应用于时间序列时生成的特征图反映了内核表示的模式在时间序列中存在的程度。 从某种意义上说,这与字典方法没有什么不同,字典方法基于时间序列中模式的出现频率。
卷积神经网络中学习的内核通常包括频率滤波器(例如,参见 Krizhevsky 等人,2012;Yosinski 等人,2014;Zeiler 和 Fergus,2014)。 Saxe 等人 (2011) 证明即使是随机核也是频率选择性的。 频率信息也可以通过膨胀来捕获:较大的膨胀对应于较低的频率,较小的膨胀对应于较高的频率。
尽管存在扭曲,内核仍可以检测时间序列中的模式。 池化机制使内核对于时间序列中模式的位置保持不变。 膨胀允许具有相似权重的内核捕获不同尺度的模式,即尽管重新缩放。 尽管存在复杂的扭曲,但具有不同膨胀的多个内核可以组合起来捕获有区别的模式。
卷积神经网络用于时间序列分类的成功,例如ResNet和InceptionTime,证明了卷积核作为时间序列分类基础的有效性。
2.4随机卷积核
卷积核的权重通常是学习的。 然而,众所周知,随机卷积核是有效的(Jarrett 等人,2009;Pinto 等人,2009;Saxe 等人,2011;Cox 和 Pinto,2011)。
Ismail Fawaz 等人 (2019c) 观察到,单个卷积神经网络在 UCR 档案上的分类精度方面表现出很大的差异,从而激发了使用具有大量和多种内核的此类架构的集成 (参见 Ismail Fawaz 等人,2019b)。 在小数据集上学习“好的”内核可能很困难。 随机卷积核在这种情况下可能具有优势(参见 Jarrett 等人,2009;Yosinski 等人,2014)。
使用卷积核作为变换,并使用变换后的特征作为另一个分类器的输入的想法已经很成熟了(参见,例如,Bengio等人,2013,1803)。 Franceschi 等人 (2019) 提出了一种用于时间序列输入特征变换的卷积核无监督学习方法,该方法基于多层卷积架构,在每个连续层中扩张呈指数级增长。 使用输出特征作为支持向量机的输入来演示该方法。
随机卷积核已被用作特征转换的基础。 在 Saxe 等人 (2011) 中,随机卷积层用作特征变换(对于图像)的基础,用作支持向量机的输入。
在这里,使用随机卷积核作为时间序列的变换和与核方法的随机变换相关的工作之间存在联系(如在支持向量机中,不要与卷积核混淆)。 Rahimi 和 Recht (2008) 提出了一种用于核方法的近似核的随机变换(另请参见 Rahimi 和 Recht,2009)。 Morrow 等人 (2017) 基于 Rahimi 和 Recht (2008) 提出了一种近似 DNA 序列字符串内核的方法,该方法涉及使用随机卷积内核转换输入序列,并使用得到的特征来训练线性分类器。 Morrow 等人 (2017, p. 1) 将他们的方法描述为“单层随机卷积神经网络”。 同样继Rahimi and Recht (2008)之后,Jimenez and Raj (2019)提出了一种类似的方法来近似互相关核,以测量时间序列之间的相似性,涉及卷积输入时间序列与相同长度的随机时间序列产生所谓的“随机卷积特征”,可用于训练线性分类器。 Jimenez 和 Raj (2019) 在 UCR 档案中选择的二元分类数据集上评估他们的方法。 (在这两种情况下,与典型卷积神经网络中使用的卷积运算存在一些差异。) Farahmand 等人 (2017) 提出了一种基于随机自回归滤波器卷积输入时间序列的特征转换。
Rocket 与典型卷积神经网络中使用的卷积层以及使用与时间序列相关的卷积核(包括随机卷积核)的其他方法有很多区别,详细信息请参见 3。 我们证明,利用内核架构的各个方面——最重要的是,利用各种随机长度、膨胀和填充(以及权重和偏差),并从卷积的输出中提取一组有效的特征——提供了状态-具有最先进的精度,而计算费用仅为现有最先进方法的一小部分。
3方法
Rocket 使用大量随机卷积核(即具有随机长度、权重、偏差、膨胀和填充的核)来转换时间序列。 转换后的特征用于训练线性分类器。 Rocket 和逻辑回归的组合实际上形成了一个具有随机核权重的单层卷积神经网络,其中变换后的特征构成了训练有素的 softmax 层的输入。 然而,在实践中,对于除最大数据集之外的所有数据集,我们都使用岭回归分类器,它具有对正则化超参数(并且没有其他超参数)进行快速交叉验证的优点。 尽管如此,由于使用随机梯度下降训练的逻辑回归对于非常大的数据集来说更具可扩展性,因此当训练示例的数量远远大于特征的数量时,我们使用逻辑回归。
Rocket与典型卷积神经网络中使用的卷积层以及以前使用卷积核(包括随机核)处理时间序列的工作有四点不同:
-
1.
Rocket 使用了大量的内核。 由于只有一个“层”内核,并且由于不需要学习内核权重,因此计算卷积的计算成本较低,并且可以使用相对较少的计算费用使用大量内核。
-
2.
Rocket 使用大量不同的内核。 与典型的卷积网络相反,在典型的卷积网络中,内核组通常共享相同的大小、膨胀和填充,对于 Rocket,每个内核具有随机长度、膨胀和填充,以及随机的权重和偏差。
-
3.
特别是,Rocket 重点利用了内核扩张。 与卷积神经网络中扩张的典型使用相反,扩张随着深度呈指数增加(例如,Yu and Koltun, 2016; Bai 等人, 2018; Franceschi 等人, 2019),我们采样对每个内核进行随机膨胀,产生各种各样的内核膨胀,捕获不同频率和尺度的模式,这对于该方法的性能至关重要(请参见下面的 4.3.4 节)。
-
4.
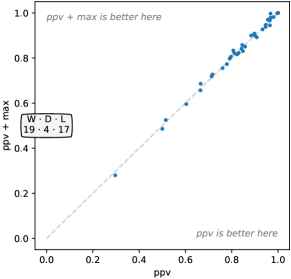
除了使用生成的特征图的最大值(广义上讲,类似于全局最大池化)之外,Rocket还使用了一个额外的、据我们所知新颖的特征:正值的比例(或ppv)。 这使得分类器能够对时间序列内给定模式的流行程度进行加权。 这是 Rocket 架构的单个元素,对其出色的准确性至关重要(请参阅第 4.3.6 节)。
实际上,Rocket 的唯一超参数是内核数量 。在设置时,需要在分类精度和计算时间之间进行权衡。 一般来说, 值越大,分类精度越高(参见4.3.1 节),但代价是计算时间相应较长。 (变换的复杂度与 成线性关系。)但是,即使有大量内核(我们默认使用 10,000 个),Rocket 也非常快。
我们在 Python 中实现了 Rocket,通过 Numba (Lam 等人,2015) 使用即时编译。 对于 UCR 存档中的数据集的实验,我们使用 scikit-learn (Pedregosa 等人, 2011) 中的岭回归分类器。 对于研究可扩展性的实验,我们将 Rocket 与逻辑回归和 Adam 集成,并使用 PyTorch (Paszke 等人,2017) 实现。 我们的代码将在 https://github.com/angus924/rocket 上提供。
在开发 Rocket 时,我们努力不让整个 UCR 档案过拟合(参见 Bagnall 等人,2017,第 608 页)。 同时,为了开发该方法,我们需要有代表性的时间序列数据集。 因此,我们选择在 85 个“烘焙”数据集中随机选择的 40 个数据集的子集上开发该方法。 我们将这些称为“开发”数据集。 我们在附录 B 中对“开发”数据集和其余“保留”数据集上的 Rocket 性能进行了单独评估。
3.1内核
Rocket 使用卷积核转换时间序列,如典型的卷积神经网络中所示。 本质上,内核的所有方面都是随机的:长度、权重、偏差、膨胀和填充。 对于每个内核,这些值设置如下(通过实验确定,以在“开发”数据集上产生最高的分类精度):
-
•
长度。 长度以等概率从 中随机选择,使得内核在大多数情况下比输入时间序列短得多。
-
•
权重。 权重从正态分布中采样,、,设置后以均值为中心,。 因此,大多数权重相对较小,但可以具有更大的量级。
-
•
偏差。 偏差是从均匀分布 中采样的。 仅使用特征图中的正值(参见3.2部分)。 因此,偏差的效果是,两个相似的内核但具有不同的偏差,可以通过将特征图中的值移至高于或低于零固定的量来“突出”结果特征图的不同方面。
-
•
膨胀。 膨胀以指数尺度进行采样,其中,这确保了内核的有效长度(包括膨胀)达到输入时间序列的长度。 膨胀允许相似的内核但具有不同的膨胀来匹配不同频率和尺度的相同或相似模式。
-
•
填充。 当生成每个内核时,会(随机地、以相等的概率)决定在应用内核时是否使用填充。 如果使用填充,则在应用内核时,将在每个时间序列的开头和结尾附加一定量的零填充,以便内核的“中间”元素以时间序列中的每个点为中心,即 。 如果没有填充,内核不会以时间序列的第一个和最后一个 点为中心,并且“关注”时间序列中心区域的模式,而使用填充时,内核还会匹配开始或结束处的模式。时间序列结束(另请参见 3.4.1 节)。
步幅永远是一。 我们不会将诸如 ReLU 之类的非线性应用于生成的特征图(实际上 ppv 和 max 与 ReLU 无关)。 请注意,权重和偏差的参数是基于以下假设设置的:按照标准做法,输入时间序列已标准化为均值为零,标准差为 1 (一般参见 Dau 等人,2019)。
如上所述,确定这些参数是为了在“开发”数据集上产生最高的分类精度。 然而,如下面 4.3 节所示,有几种替代配置可以产生相似的分类精度。 总的来说,这表明我们的方法可能很好地推广到新问题,并且从贝叶斯意义上来说,内核参数相对“无信息”。
3.2转换
每个内核应用于每个输入时间序列,生成一个特征图。 卷积运算涉及内核和输入时间序列之间的滑动点积。 将内核 与膨胀 应用于给定时间序列 的结果,从位置 ,由 给出(例如,参见 Bai 等人,2018):
Rocket 从每个特征映射中计算两个聚合特征,生成两个实数值作为每个内核的特征,并组成我们的变换:
-
•
最大值(广义上来说,相当于全局最大池化);和
-
•
正值的比例(或ppv)。
池化,包括全局平均池化(Lin等人,2014)和全局最大池化(Oquab等人,2015),在卷积神经网络中用于降维和空间(或时间)不变性(Boureau 等人, 2010)。
Rocket 在每个特征图上计算的另一个特征是 ppv。 ppv 直接捕获与给定模式匹配的输入比例。 我们发现 ppv 比其他特征(包括平均值(大致相当于全局平均池化))产生更高的分类准确率。
对于 内核,Rocket 为每个时间序列生成 个特征(即 ppv 和 max)。 对于 10,000 个内核(默认),Rocket 会生成 20,000 个特征。 因此,对于较小的数据集(事实上,对于 UCR 存档中的所有数据集),特征数量可能远大于数据集中的示例数量或每个时间序列中的元素数量。
尽管如此,我们发现,当用作线性分类器的输入时,Rocket 生成的特征提供了很高的分类精度,即使对于特征数量使示例数量和长度都相形见绌的数据集也是如此。时间序列。
3.3分类器
转换后的特征用于训练线性分类器。 Rocket原则上可与任何分类器一起使用。 我们发现,Rocket 与线性分类器(能够利用大量特征中每个特征的少量信息)结合使用时非常有效。
逻辑回归。
Rocket 可与逻辑回归和随机梯度下降一起使用。 这特别适合非常大的数据集,因为它提供了具有固定内存成本(由每个小批量的大小固定)的快速训练。 可以在每个小批量上执行转换,也可以在数据集的较大部分上执行转换,然后将其进一步划分为用于训练的小批量。
岭回归。
然而,对于 UCR 档案中的所有数据集,我们使用岭回归分类器。 (岭回归模型以“一个与休息”的方式为每个类别进行训练,并进行 正则化。)
当特征数量明显大于训练示例数量时,正则化至关重要,可以优化线性模型,并防止迭代优化中的病态行为,例如逻辑回归 (参见 Goodfellow 等人,2016 年,第 17 页) 232–233). 岭回归分类器可以利用广义交叉验证来快速确定适当的正则化参数(参见 Rifkin 和 Lippert,2007)。 我们发现,对于较小的数据集,岭回归分类器在实践中比逻辑回归要快得多,同时仍能实现较高的分类精度。
3.4复杂度分析
Rocket的计算复杂度有两个方面:(1)变换本身的复杂度; (2)使用变换后的特征训练的线性分类器的复杂性。
3.4.1 转换
变换本身与以下两个因素呈线性关系:(a) 示例的数量; (b) 给定数据集中时间序列的长度。 形式上,变换的计算复杂度为 ,其中 是内核数量, 是示例数量, 是时间序列的长度。 该变换必须应用于训练集和测试集。
卷积运算可以通过多种方式实现,包括作为卷积神经网络实现中典型的矩阵乘法,以及使用快速傅立叶变换 (参见 Goodfellow 等人, 2016, ch. 9). 我们简单地实现了Rocket,沿着每个时间序列“滑动”每个内核并计算每个位置的点积。 这涉及重复的元素乘法和求和,其复杂性由时间序列的长度和内核的长度(即内核中的权重数量)决定。 Rocket 的内核长度最多限制为 11。 因此,出于本分析的目的,内核长度是一个恒定因素。
膨胀增加了内核的有效大小。 因此,在不使用填充的情况下,膨胀降低了计算复杂度。 如果没有填充,卷积将从时间序列的第一个元素开始使用内核的第一个元素进行计算,并在内核的最后一个元素到达时间序列的最后一个元素时结束。 在极端情况下,对于最大的膨胀值,内核将“填充”整个时间序列,计算次数将是内核中权重的数量。 然而,填充是以等概率随机应用的,因此复杂性的降低是一个常数因子。
在使用填充的情况下,膨胀对复杂性没有影响:无论膨胀或内核的有效大小如何,都需要相同数量的计算。 无论扩张如何,内核都以时间序列的第一个元素为中心,并沿着时间序列“滑动”相同数量的元素。
因此,对于内核和时间序列,每个长度为,变换的复杂度为。 对于具有不同长度的时间序列的数据集,这可以表示平均长度 的平均复杂度,或最大长度 的最坏情况复杂度。
3.4.2 分类器
逻辑回归和随机梯度下降。
随机梯度下降的复杂度与参数数量成正比(由特征数量和类数量决定),但与训练示例的数量成线性关系 (Bottou 等人, 2018). 此外,收敛速度并不由训练示例的数量决定。 对于大型数据集,收敛可能发生在单次数据传递中,或者甚至不使用所有训练数据(Goodfellow 等人 2016, pp. 286–288; Bottou等人2018)。
岭回归。
实际上,在较小的数据集上,岭回归分类器比逻辑回归要快得多,因为它可以利用所谓的广义交叉验证来确定适当的正则化。 这里使用的实现采用特征分解,其中特征比训练示例更多,否则采用奇异值分解,有效复杂度分别为 和 (参见 Dongarra 等人, 2018),其中 是示例数量, 是特征数量。
这使得岭回归分类器对于大型数据集的可扩展性较差。 这也需要彻底的改造,而不是增量的。 实际上,这些限制不会影响 UCR 档案中的任何数据集。 对于较大的数据集,正则化的重要性降低,并且适合增量执行变换,使用岭回归分类器的好处减弱,并且使用随机梯度下降进行训练更有意义。
4实验
我们在 UCR 存档(4.1 节)上评估 Rocket,证明 Rocket 与当前最先进的方法具有竞争力,获得85 个“烘焙”数据集的最佳平均排名。
我们根据训练集大小和时间序列长度(第 4.2 节)评估可扩展性,证明 Rocket 比当前方法快几个数量级。 我们还评估了不同内核参数的效果(4.3 节),表明 Rocket 的几种替代配置表现相似,这很好地表明了该想法的力量,而不是对其进行微调。 除非另有说明,所有实验均使用 10,000 个内核。
UCR 档案中数据集的实验是使用 Rocket 与岭回归分类器结合进行的,与训练集大小相关的实验是使用 Rocket 与逻辑回归。 UCR 存档上的实验是在集群上进行的(但每个实验使用单个 CPU 核心,为了速度而没有并行化)。 与可扩展性(时间序列长度和训练集大小)相关的实验是使用 Intel Core i5-5200U 双核处理器在本地执行的。
4.1UCR
4.1.1 “Bake Off”数据集
我们在 UCR 档案中的 85 个“bake off”数据集(每个数据集的原始训练/测试分割)上评估了 Rocket。 Rocket 呈现的结果是 10 次运行的平均结果(每次运行使用一组不同的随机内核)。
我们将 Rocket 与现有最先进的时间序列分类方法(即 BOSS、Shapelet Transformer、Proximity Forest、ResNet 和 HIVE-COTE)进行了比较。 我们还将 Rocket 与两种最新方法(论文发表在 arXiv 上)InceptionTime 和 TS-CHIEF 进行了比较,这两种方法已被证明与 HIVE-COTE 相比具有竞争力,同时扩展性更强。 BOSS、Shapelet Transform 和 HIVE-COTE 的结果取自 Bagnall 等人 (2019)。
为了与其他已发布的结果进行比较,我们将 Rocket 与所有 85 个“bake off”数据集上的其他方法进行比较。 然而,如上所述,Rocket 是使用 40 个随机选择的数据集的子集开发的,以确保我们不会过度拟合 UCR 存档。 附录 B 中提供了 40 个“开发”数据集以及其余 45 个“保留”数据集的单独排名。
4.1.2 额外的 2018 年数据集
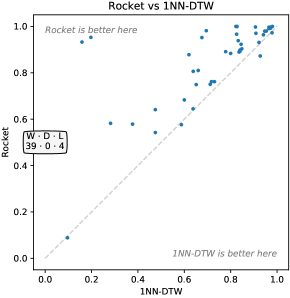
截至 2018 年,我们还在 UCR 档案中的另外 43 个数据集上对 Rocket 进行了评估,以便:(1) 显示我们的方法能够处理不同长度的数据集;(2) 为未来的论文提供参考结果:(1) 表明我们的方法能够处理不同长度的数据集;以及 (2) 为未来的研究论文提供参考结果。
这些数据集上最先进的方法尚未公布结果。 使这些方法适用于可变长度时间序列并非易事,因为处理可变长度的最合适方法 (1) 取决于可变长度是否表示子采样或可变采样频率,并且 (2) 取决于分类器 (谭等人,2019)。 因此,我们将比较限制于 1NN-DTW (Dau 等人,2019) 的可用结果,其中可变长度时间序列已用“低幅度随机[噪声]”填充到相同长度作为最长时间序列(Dau 等人, 2018, p. 16)。 图2显示了Rocket和1NN-DTW在43个附加数据集上的相对准确度。 Rocket 在除四个数据集之外的所有数据集上都更准确,并且在大多数数据集上都更准确。
继Dau等人(2018)之后,我们对每个时间序列进行了归一化并插入了缺失值。 根据 10 倍交叉验证确定,可变长度时间序列已重新调整或“按原样”使用(以其原始长度)。
4.2可扩展性
4.2.1 训练集大小
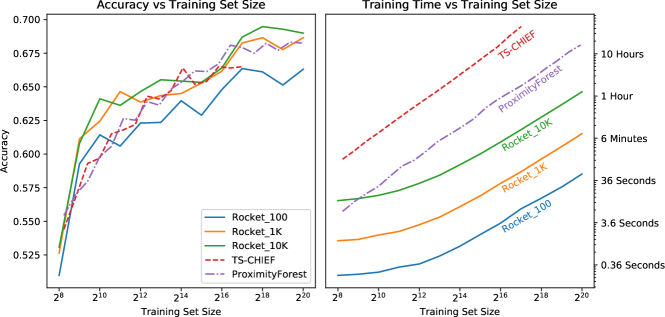
继 Lucas 等人 (2019)、Shifaz 等人 (2019) 和 Ismail Fawaz 等人 (2019c) 之后,我们从以下方面评估可扩展性卫星图像时间序列数据集(参见 Petitjean 等人,2012)越来越大的子集(最多大约 100 万个时间序列)上的训练集大小。 该数据集中的时间序列代表植被指数,根据福卫二号卫星获取的光谱数据计算得出,类别代表不同的土地覆盖类型。 对这些时间序列进行分类的目的是将不同的植被剖面映射到不同类型的农作物和森林地区。 每个时间序列的长度为 46。
为此,我们将 Rocket 与逻辑回归集成。 转换是分批执行的,并进一步分为训练的小批量。 每个时间序列都被标准化为具有零均值和单位标准差。
我们为每个子集大小至少训练一个时期的模型。 为了防止过度拟合,如果验证损失在 20 次更新后未能改善,我们将停止训练(在第一个 epoch 之后)。 在实践中,虽然对于较小的子集大小,训练可能会持续 40 或 50 个时期,但对于超过大约 16,000 个训练示例,训练会在单遍内收敛。 验证损失是在单独的验证集(所有子集大小的同一组 2,048 个示例)上计算的。
使用 Adam (Kingma 和 Ba,2015) 执行优化。 我们对初始学习率进行最小搜索,以确保训练损失不会发散。 如果训练损失在 100 次更新后未能改善,则学习率减半(仅与较大的子集大小相关)。
我们以三种形式运行 Rocket:使用 100、1,000 和 10,000 个内核(默认)。 我们将 Rocket 与 Proximity Forest 和 TS-CHIEF 进行比较,后者已被证明比 HIVE-COTE 从根本上更具可扩展性(Lucas 等人,2019;Shifaz 等人,2019). (InceptionTime 尚无法获得大量数据的结果。)
图 3 显示了 Rocket、Proximity Forest 和 TS-CHIEF 的分类精度和训练时间与训练集大小的关系。 正如预期的那样,Rocket 相对于训练示例的数量和内核的数量呈线性缩放(请参阅3.4部分)。 通过 1,000 或 10,000 个内核,Rocket 实现了与 Proximity Forest 和 TS-CHIEF 相似的分类精度。 使用 100 个内核时,Rocket 的分类精度较低,但从超过 100 万个时间序列中学习只需不到一分钟。 即使有 10,000 个内核,Rocket 也比邻近森林快一个数量级。 (Rocket 的较小子集大小的训练时间主要由验证集的转换成本决定,这就是为什么较小子集大小的训练时间是“平坦”的。)
4.2.2 时间序列长度
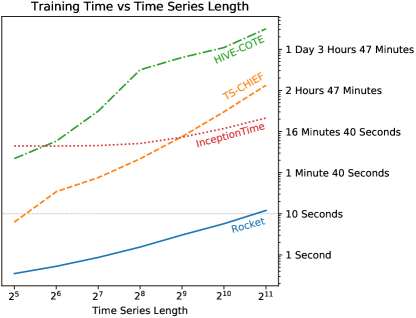
继 Shifaz 等人 (2019) 和 Ismail Fawaz 等人 (2019c) 之后,我们使用 InlineSkate 数据集评估时间序列长度方面的可扩展性来自加州大学河滨分校档案馆。 我们在与 UCR 存档中其他数据集相同的配置中使用 Rocket(即使用岭回归分类器和 10,000 个内核)。 HIVE-COTE 和 TS-CHIEF 的结果取自 Shifaz 等人 (2019)。
图 4 显示了 Rocket、TS-CHIEF、HIVE-COTE 和 InceptionTime 的训练时间与时间序列长度的关系。 Rocket 和 TS-CHIEF 之间的训练时间差异很大。 Rocket 在长度为 2,048 的时间序列上进行训练所花费的时间大约与 TS-CHIEF 在长度为 32 的时间序列上所花费的时间一样长,并且对于最长的时间序列长度来说,大约要快三个数量级。
Rocket 也比 InceptionTime 快得多。 不过,鉴于 InceptionTime 和 Rocket 都基于卷积架构,基本的可扩展性可能是相似的。
4.3敏感性分析
我们探讨不同核参数对分类精度的影响。 我们将默认配置(即使用 3 中指定的参数)的准确性与内核数量、长度、权重和偏差、膨胀、填充和输出特征的不同选择进行比较。 在每种情况下,只有给定参数(例如长度)发生变化,所有其他参数保持固定为其默认值。 比较是在“开发”数据集上进行的。 结果是 10 次运行的平均结果(每次运行使用一组不同的随机内核)。
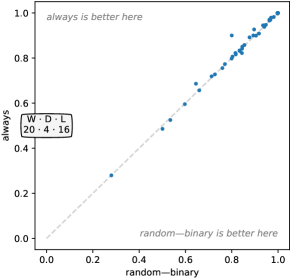
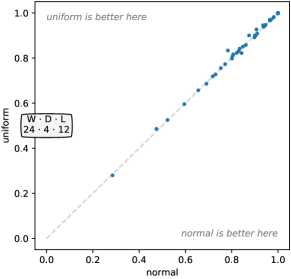
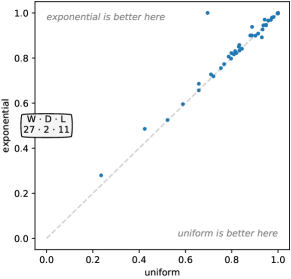
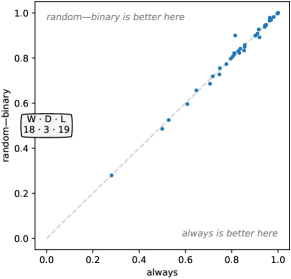
在大多数情况下,替代配置代表相对于默认配置的相对微妙的变化。 因此,毫不奇怪,在许多情况下,相关参数的一种或多种替代选择会产生与基线配置相似的精度。 换句话说,Rocket对于许多参数的不同选择都相对稳健。 然而,很明显,膨胀和 ppv 尤其是该方法性能的两个关键方面。
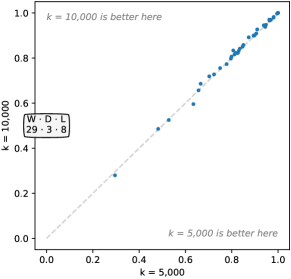
4.3.1 内核数量


我们评估了 10 到 100,000 之间不断增加的内核数量。 图5显示了内核数量对准确性的影响。 显然,增加内核数量可以提高准确性。 然而,例如 和 之间的实际准确度差异相对较小,即使具有统计显着性也是如此。 事实上, 在某些数据集上产生了更高的准确性(图16,附录C)。 尽管如此, 在胜/平/负方面明显领先(29/3/8)。 、 和 之间的差异不具有统计显着性。
尽管 Rocket 是不确定的,但对于大量内核来说,准确性的变化相当低。 不出所料,标准差随着 的增加而减小。 40 个“开发”数据集的中位标准差对于 为 0.0038,对于 为 0.0021。
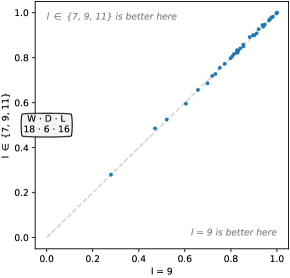
4.3.2 内核长度
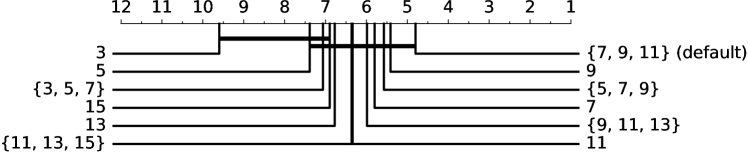
我们改变内核长度,将基线(从 中随机选择长度)与以下内容进行比较:
-
•
固定长度为 3、5、7、9、11、13 和 15;和
-
•
从、、和中随机选择长度。
4.3.3 权重(包括居中)和偏差
重量。

我们改变权重采样的分布,将基线(从正态分布采样)与:
-
•
从均匀分布中采样,,;和
-
•
从统一采样整数权重。
定心。

我们改变居中方式,将基线(始终居中)与:
-
•
永远不要将内核权重居中;和
-
•
以等概率随机居中或不居中。
偏见。

我们改变偏差,将基线(使用均匀分布)与:
-
•
使用零偏差;和
-
•
从正态分布中采样偏差,。
4.3.4 膨胀

我们改变扩张,将基线(以指数规模采样扩张)与:
-
•
无扩张(即固定扩张为 1);和
-
•
均匀采样膨胀,,。
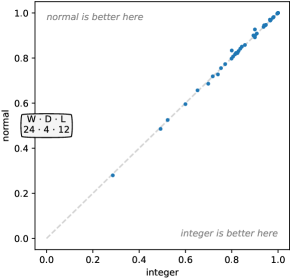
4.3.5填充

我们改变填充,将基线(随机应用填充)与:
-
•
总是填充,使得给定内核的“中间”元素以时间序列的第一个元素 为中心;
-
•
均匀采样填充,;和
-
•
从不填充。
4.3.6功能

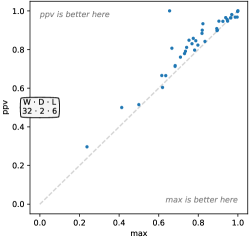
5结论
卷积核是一种强大的单一工具,可以捕获现有时间序列分类方法所使用的许多特征。 我们表明,与学习内核权重不同,大量随机内核(虽然孤立地仅近似相关模式)组合起来对于捕获时间序列中的判别模式非常有效。
此外,随机内核的计算要求非常低,使得学习和分类速度非常快。 我们提出的方法利用随机卷积核来转换和分类时间序列,Rocket,以现有方法的一小部分计算成本实现了最先进的精度。 Rocket 还可以扩展到数百万个时间序列。
Rocket 关键利用正值的比例(或 ppv)来总结特征图的输出,允许分类器对给定时间内模式的流行程度进行加权系列。 据我们所知,ppv以前没有以这种方式使用过。 我们发现这比传统最大池操作中应用的简单最大值要有效得多。 可信的是,ppv 对于其他数据类型(例如图像)也有效。
在未来的工作中,我们建议探索Rocket的特征选择、Rocket在多元时间序列中的应用、Rocket在时间序列数据之外的应用,以及使用学习内核的 Rocket 的各个方面。
致谢。
本材料基于澳大利亚政府研究训练计划奖学金支持的工作;空军科学研究办公室、亚洲航空航天研究与发展办公室 (AOARD),奖项编号为 FA2386-18-1-4030;和澳大利亚研究委员会授予 DE170100037 和 DP190100017 奖项。 作者要感谢 Eamonn Keogh 教授以及所有为 UCR 时间序列分类档案做出贡献的人们。 显示 Rocket 不同分类器和变体排名的图表是使用 Ismail Fawaz 等人 (2019a) 的代码生成的。参考
- Bagnall et al. (2017) Bagnall A, Lines J, Bostrom A, Large J, Keogh E (2017) The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Mining and Knowledge Discovery 31(3):606–660
- Bagnall et al. (2019) Bagnall A, Lines J, Vickers W, Keogh E (2019) The UEA & UCR time series classification repository. http://www.timeseriesclassification.com
- Bai et al. (2018) Bai S, Kolter JZ, Koltun V (2018) An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv:180301271
- Benavoli et al. (2016) Benavoli A, Corani G, Mangili F (2016) Should we really use post-hoc tests based on mean-ranks? Journal of Machine Learning Research 17(5):1–10
- Bengio et al. (2013) Bengio Y, Courville A, Vincent P (2013) Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence 35(8):1798–1828
- Bostrom and Bagnall (2015) Bostrom A, Bagnall A (2015) Binary shapelet transform for multiclass time series classification. In: Madria S, Hara T (eds) Big Data Analytics and Knowledge Discovery, Springer, Cham, pp 257–269
- Bottou et al. (2018) Bottou L, Curtis FE, Nocedal J (2018) Optimization methods for large-scale machine learning. SIAM Review 60(2):223–311
- Boureau et al. (2010) Boureau YL, Ponce J, LeCun Y (2010) A theoretical analysis of feature pooling in visual recognition. In: Fürnkranz J, Joachims T (eds) Proceedings of the 27th International Conference on Machine Learning, Omnipress, USA, pp 111–118
- Cox and Pinto (2011) Cox D, Pinto N (2011) Beyond simple features: A large-scale feature search approach to unconstrained face recognition. In: Face and Gesture 2011, pp 8–15
- Dau et al. (2018) Dau HA, Keogh E, Kamgar K, et al. (2018) UCR time series classification archive (briefing document). https://www.cs.ucr.edu/~eamonn/time_series_data_2018/
- Dau et al. (2019) Dau HA, Bagnall A, Kamgar K, Yeh CCM, Zhu Y, Gharghabi S, Ratanamahatana CA, Keogh E (2019) The UCR time series archive. arXiv:181007758
- Demšar (2006) Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. Journal of Machine Learning Research 7:1–30
- Dongarra et al. (2018) Dongarra J, Gates M, Haidar A, Kurzak J, Luszczek P, Tomov S, Yamazaki I (2018) The singular value decomposition: Anatomy of optimizing an algorithm for extreme scale. SIAM Review 60(4):808–865
- Farahmand et al. (2017) Farahmand A, Pourazarm S, Nikovski D (2017) Random projection filter bank for time series data. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in Neural Information Processing Systems 30, pp 6562–6572
- Franceschi et al. (2019) Franceschi J, Dieuleveut A, Jaggi M (2019) Unsupervised scalable representation learning for multivariate time series. In: Seventh International Conference on Learning Representations, Learning from Limited Labeled Data Workshop
- García and Herrera (2008) García S, Herrera F (2008) An extension on “statistical comparisons of classifiers over multiple data sets” for all pairwise comparisons. Journal of Machine Learning Research 9:2677–2694
- Goodfellow et al. (2016) Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT Press, Cambridge, MA
- Hills et al. (2014) Hills J, Lines J, Baranauskas E, Mapp J, Bagnall A (2014) Classification of time series by shapelet transformation. Data Mining and Knowledge Discovery 28(4):851–881
- Ismail Fawaz et al. (2019a) Ismail Fawaz H, Forestier G, Weber J, Idoumghar L, Muller P (2019a) Deep learning for time series classification: a review. Data Mining and Knowledge Discovery 33(4):917–963
- Ismail Fawaz et al. (2019b) Ismail Fawaz H, Forestier G, Weber J, Idoumghar L, Muller P (2019b) Deep neural network ensembles for time series classification. arXiv:190306602
- Ismail Fawaz et al. (2019c) Ismail Fawaz H, Lucas B, Forestier G, Pelletier C, Schmidt DF, Weber J, Webb GI, Idoumghar L, Muller P, Petitjean F (2019c) InceptionTime: Finding AlexNet for time series classification. arXiv:190904939
- Jarrett et al. (2009) Jarrett K, Kavukcuoglu K, Ranzato M, LeCun Y (2009) What is the best multi-stage architecture for object recognition? In: 2009 IEEE 12th International Conference on Computer Vision, pp 2146–2153
- Jimenez and Raj (2019) Jimenez A, Raj B (2019) Time signal classification using random convolutional features. In: 2019 IEEE International Conference on Acoustics, Speech and Signal Processing
- Kingma and Ba (2015) Kingma DP, Ba JL (2015) Adam: A method for stochastic optimization. In: Third International Conference on Learning Representations, arXiv:1412.6980
- Krizhevsky et al. (2012) Krizhevsky A, Sutskever I, Hinton G (2012) Imagenet classification with deep convolutional neural networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ (eds) Advances in Neural Information Processing Systems 25, pp 1097–1105
- Lam et al. (2015) Lam SK, Pitrou A, Seibert S (2015) Numba: A LLVM-based python JIT compiler. In: Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, pp 1–6
- Lin et al. (2014) Lin M, Chen Q, Yan S (2014) Network in network. In: Second International Conference on Learning Representations, arXiv:1312.4400
- Lines et al. (2018) Lines J, Taylor S, Bagnall A (2018) Time series classification with HIVE-COTE: The hierarchical vote collective of transformation-based ensembles. ACM Transactions on Knowledge Discovery from Data 12(5):52:1–52:35
- Lucas et al. (2019) Lucas B, Shifaz A, Pelletier C, O’Neill L, Zaidi N, Goethals B, Petitjean F, Webb GI (2019) Proximity Forest: an effective and scalable distance-based classifier for time series. Data Mining and Knowledge Discovery 33(3):607–635
- Morrow et al. (2017) Morrow A, Shankar V, Petersohn D, Joseph A, Recht B, Yosef N (2017) Convolutional kitchen sinks for transcription factor binding site prediction. arXiv:170600125
- Oquab et al. (2015) Oquab M, Bottou L, Laptev I, Sivic J (2015) Is object localization for free? weakly-supervised learning with convolutional neural networks. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition, pp 685–694
- Paszke et al. (2017) Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, Lin Z, Desmaison A, Antiga L, Lerer A (2017) Automatic differentiation in PyTorch. In: NIPS Autodiff Workshop
- Pedregosa et al. (2011) Pedregosa F, Varoquaux G, Gramfort A, et al. (2011) Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12:2825–2830
- Petitjean et al. (2012) Petitjean F, Inglada J, Gancarski P (2012) Satellite image time series analysis under time warping. IEEE Transactions on Geoscience and Remote Sensing 50(8):3081–3095
- Pinto et al. (2009) Pinto N, Doukhan D, DiCarlo JJ, Cox DD (2009) A high-throughput screening approach to discovering good forms of biologically inspired visual representation. PLOS Computational Biology 5(11):1–12
- Rahimi and Recht (2008) Rahimi A, Recht B (2008) Random features for large-scale kernel machines. In: Platt JC, Koller D, Singer Y, Roweis ST (eds) Advances in Neural Information Processing Systems 20, pp 1177–1184
- Rahimi and Recht (2009) Rahimi A, Recht B (2009) Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning. In: Koller D, Schuurmans D, Bengio Y, Bottou L (eds) Advances in Neural Information Processing Systems 21, pp 1313–1320
- Rifkin and Lippert (2007) Rifkin RM, Lippert RA (2007) Notes on regularized least squares. Tech. rep., MIT
- Saxe et al. (2011) Saxe A, Koh PW, Chen Z, Bhand M, Suresh B, Ng A (2011) On random weights and unsupervised feature learning. In: Getoor L, Scheffer T (eds) Proceedings of the 28th International Conference on Machine Learning, Omnipress, USA, pp 1089–1096
- Schäfer (2015) Schäfer P (2015) The BOSS is concerned with time series classification in the presence of noise. Data Mining and Knowledge Discovery 29(6):1505–1530
- Schäfer (2016) Schäfer P (2016) Scalable time series classification. Data Mining and Knowledge Discovery 30(5):1273–1298
- Schäfer and Leser (2017) Schäfer P, Leser U (2017) Fast and accurate time series classification with WEASEL. In: Proceedings of the 2017 ACM Conference on Information and Knowledge Management, pp 637–646
- Shifaz et al. (2019) Shifaz A, Pelletier C, Petitjean F, Webb GI (2019) TS-CHIEF: A scalable and accurate forest algorithm for time series classification. arXiv:190610329
- Tan et al. (2019) Tan CW, Petitjean F, Keogh E, Webb GI (2019) Time series classification for varying length series. arXiv:191004341
- Wang et al. (2017) Wang Z, Yan W, Oates T (2017) Time series classification from scratch with deep neural networks: A strong baseline. In: 2017 International Joint Conference on Neural Networks, pp 1578–1585
- Yosinski et al. (2014) Yosinski J, Clune J, Bengio Y, Lipson H (2014) How transferable are features in deep neural networks? In: Ghahramani Z, Welling M, Cortes C, Lawrence ND, Weinberger KQ (eds) Advances in Neural Information Processing Systems 27, pp 3320–3328
- Yu and Koltun (2016) Yu F, Koltun V (2016) Multi-scale context aggregation by dilated convolutions. In: Fourth International Conference on Learning Representations, arXiv:1511.07122
- Zeiler and Fergus (2014) Zeiler MD, Fergus R (2014) Visualizing and understanding convolutional networks. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T (eds) European Conference on Computer Vision, Springer, Cham, pp 818–833
附录
附录 A相对准确度

附录 B“开发”和“保留”数据集


附录 C 其他绘图
附录 D“Bake Off”数据集的结果
“开发”数据集标有星号。
| Rocket | BOSS | ST | HCTE | ResNet | PF | CHIEF | ITime | |
|---|---|---|---|---|---|---|---|---|
| Adiac | 0.7847 | 0.7647 | 0.7826 | 0.8107 | 0.8289 | 0.7340 | 0.7980 | 0.8363 |
| ArrowHead | 0.8051 | 0.8343 | 0.7371 | 0.8629 | 0.8446 | 0.8754 | 0.8229 | 0.8286 |
| Beef | 0.8333 | 0.8000 | 0.9000 | 0.9333 | 0.7533 | 0.7200 | 0.7333 | 0.7000 |
| BeetleFly | 0.9000 | 0.9000 | 0.9000 | 0.9500 | 0.8500 | 0.8750 | 0.9500 | 0.8500 |
| BirdChicken | 0.9000 | 0.9500 | 0.8000 | 0.8500 | 0.8850 | 0.8650 | 0.9000 | 0.9500 |
| CBF | 0.9999 | 0.9978 | 0.9744 | 0.9989 | 0.9950 | 0.9933 | 0.9978 | 0.9989 |
| Car | 0.8917 | 0.8333 | 0.9167 | 0.8667 | 0.9250 | 0.8467 | 0.8500 | 0.9000 |
| ChlCon | 0.8130 | 0.6609 | 0.6997 | 0.7120 | 0.8436 | 0.6339 | 0.7206 | 0.8753 |
| CinCECGTorso | 0.8349 | 0.8870 | 0.9543 | 0.9964 | 0.8261 | 0.9343 | 0.9826 | 0.8514 |
| Coffee | 1.0000 | 1.0000 | 0.9643 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Computers | 0.7600 | 0.7560 | 0.7360 | 0.7600 | 0.8148 | 0.6444 | 0.7120 | 0.8120 |
| CricketX | 0.8223 | 0.7359 | 0.7718 | 0.8231 | 0.7913 | 0.8021 | 0.7974 | 0.8667 |
| CricketY | 0.8503 | 0.7538 | 0.7795 | 0.8487 | 0.8033 | 0.7938 | 0.8026 | 0.8513 |
| CricketZ | 0.8577 | 0.7462 | 0.7872 | 0.8308 | 0.8115 | 0.8010 | 0.8359 | 0.8590 |
| DiaSizRed | 0.9703 | 0.9314 | 0.9248 | 0.9412 | 0.3013 | 0.9657 | 0.9771 | 0.9314 |
| DisPhaOutAgeGro | 0.7547 | 0.7482 | 0.7698 | 0.7626 | 0.7165 | 0.7309 | 0.7410 | 0.7266 |
| DisPhaOutCor | 0.7678 | 0.7283 | 0.7754 | 0.7717 | 0.7710 | 0.7928 | 0.7862 | 0.7935 |
| DisPhaTW | 0.7187 | 0.6763 | 0.6619 | 0.6835 | 0.6647 | 0.6597 | 0.6835 | 0.6763 |
| ECG200 | 0.9060 | 0.8700 | 0.8300 | 0.8500 | 0.8740 | 0.9090 | 0.8600 | 0.9100 |
| ECG5000 | 0.9470 | 0.9413 | 0.9438 | 0.9462 | 0.9342 | 0.9365 | 0.9458 | 0.9409 |
| ECGFiveDays | 1.0000 | 1.0000 | 0.9837 | 1.0000 | 0.9748 | 0.8492 | 1.0000 | 1.0000 |
| Earthquakes | 0.7482 | 0.7482 | 0.7410 | 0.7482 | 0.7115 | 0.7540 | 0.7482 | 0.7410 |
| ElectricDevices | 0.7305 | 0.7992 | 0.7470 | 0.7703 | 0.7291 | 0.7060 | 0.7524 | 0.7227 |
| FaceAll | 0.9475 | 0.7817 | 0.7787 | 0.8030 | 0.8388 | 0.8938 | 0.8426 | 0.8041 |
| FaceFour | 0.9750 | 1.0000 | 0.8523 | 0.9545 | 0.9545 | 0.9739 | 1.0000 | 0.9659 |
| FacesUCR | 0.9616 | 0.9571 | 0.9059 | 0.9629 | 0.9547 | 0.9459 | 0.9649 | 0.9732 |
| FiftyWords | 0.8305 | 0.7055 | 0.7055 | 0.8088 | 0.7396 | 0.8314 | 0.8462 | 0.8418 |
| Fish | 0.9789 | 0.9886 | 0.9886 | 0.9886 | 0.9794 | 0.9349 | 0.9943 | 0.9829 |
| FordA | 0.9449 | 0.9295 | 0.9712 | 0.9644 | 0.9205 | 0.8546 | 0.9470 | 0.9483 |
| FordB | 0.8063 | 0.7111 | 0.8074 | 0.8235 | 0.9131 | 0.7149 | 0.8321 | 0.9365 |
| GunPoint | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9907 | 0.9973 | 1.0000 | 1.0000 |
| Ham | 0.7257 | 0.6667 | 0.6857 | 0.6667 | 0.7571 | 0.6600 | 0.7143 | 0.7143 |
| HandOutlines | 0.9416 | 0.9027 | 0.9324 | 0.9324 | 0.9111 | 0.9214 | 0.9297 | 0.9595 |
| Haptics | 0.5250 | 0.4610 | 0.5227 | 0.5195 | 0.5188 | 0.4445 | 0.5162 | 0.5682 |
| Herring | 0.6859 | 0.5469 | 0.6719 | 0.6875 | 0.6188 | 0.5797 | 0.5781 | 0.7031 |
| InlineSkate | 0.4582 | 0.5164 | 0.3727 | 0.5000 | 0.3731 | 0.5418 | 0.5364 | 0.4855 |
| InsWinSou | 0.6566 | 0.5232 | 0.6268 | 0.6551 | 0.5065 | 0.6187 | 0.6465 | 0.6348 |
| ItaPowDem | 0.9691 | 0.9086 | 0.9475 | 0.9631 | 0.9630 | 0.9671 | 0.9718 | 0.9679 |
| LarKitApp | 0.9000 | 0.7653 | 0.8587 | 0.8640 | 0.8997 | 0.7819 | 0.7893 | 0.9067 |
| Lightning2 | 0.7639 | 0.8361 | 0.7377 | 0.8197 | 0.7705 | 0.8656 | 0.7705 | 0.8033 |
| Lightning7 | 0.8219 | 0.6849 | 0.7260 | 0.7397 | 0.8452 | 0.8219 | 0.7534 | 0.8082 |
| Mallat | 0.9560 | 0.9382 | 0.9642 | 0.9620 | 0.9716 | 0.9576 | 0.9774 | 0.9629 |
| Meat | 0.9450 | 0.9000 | 0.8500 | 0.9333 | 0.9683 | 0.9333 | 0.9000 | 0.9500 |
| MedicalImages | 0.7975 | 0.7184 | 0.6697 | 0.7776 | 0.7703 | 0.7582 | 0.7974 | 0.7987 |
| MidPhaOutAgeGro | 0.5955 | 0.5455 | 0.6429 | 0.5974 | 0.5688 | 0.5623 | 0.5909 | 0.5325 |
| MidPhaOutCor | 0.8412 | 0.7801 | 0.7938 | 0.8316 | 0.8089 | 0.8364 | 0.8522 | 0.8351 |
| MiddlePhalanxTW | 0.5558 | 0.5455 | 0.5195 | 0.5714 | 0.4844 | 0.5292 | 0.5584 | 0.5130 |
| MoteStrain | 0.9142 | 0.8786 | 0.8970 | 0.9329 | 0.9276 | 0.9024 | 0.9441 | 0.9034 |
| NonInvFetECGTho1 | 0.9514 | 0.8382 | 0.9496 | 0.9303 | 0.9454 | 0.9066 | 0.9074 | 0.9623 |
| NonInvFetECGTho2 | 0.9688 | 0.9008 | 0.9511 | 0.9445 | 0.9461 | 0.9399 | 0.9445 | 0.9674 |
| OSULeaf | 0.9380 | 0.9545 | 0.9669 | 0.9793 | 0.9785 | 0.8273 | 0.9876 | 0.9339 |
| OliveOil | 0.9267 | 0.8667 | 0.9000 | 0.9000 | 0.8300 | 0.8667 | 0.9000 | 0.8667 |
| PhaOutCor | 0.8300 | 0.7716 | 0.7634 | 0.8065 | 0.8390 | 0.8235 | 0.8485 | 0.8543 |
| Phoneme | 0.2796 | 0.2648 | 0.3207 | 0.3824 | 0.3343 | 0.3201 | 0.3608 | 0.3354 |
| Plane | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| ProPhaOutAgeGro | 0.8551 | 0.8341 | 0.8439 | 0.8585 | 0.8532 | 0.8463 | 0.8488 | 0.8537 |
| ProPhaOutCor | 0.8990 | 0.8488 | 0.8832 | 0.8797 | 0.9213 | 0.8732 | 0.8969 | 0.9313 |
| ProPhaTW | 0.8161 | 0.8000 | 0.8049 | 0.8146 | 0.7805 | 0.7790 | 0.8146 | 0.7756 |
| RefDev | 0.5347 | 0.4987 | 0.5813 | 0.5573 | 0.5253 | 0.5323 | 0.5387 | 0.5093 |
| ScreenType | 0.4856 | 0.4640 | 0.5200 | 0.5893 | 0.6216 | 0.4552 | 0.5040 | 0.5760 |
| ShapeletSim | 1.0000 | 1.0000 | 0.9556 | 1.0000 | 0.7794 | 0.7761 | 1.0000 | 0.9889 |
| ShapesAll | 0.9082 | 0.9083 | 0.8417 | 0.9050 | 0.9213 | 0.8858 | 0.9300 | 0.9250 |
| SmaKitApp | 0.8213 | 0.7253 | 0.7920 | 0.8533 | 0.7861 | 0.7443 | 0.8160 | 0.7787 |
| SonAIBORobSur1 | 0.9241 | 0.6323 | 0.8436 | 0.7654 | 0.9581 | 0.8458 | 0.8270 | 0.8835 |
| SonAIBORobSur2 | 0.9164 | 0.8594 | 0.9339 | 0.9276 | 0.9778 | 0.8963 | 0.9286 | 0.9528 |
| StarLightCurves | 0.9811 | 0.9778 | 0.9785 | 0.9815 | 0.9718 | 0.9813 | 0.9820 | 0.9792 |
| Strawberry | 0.9819 | 0.9757 | 0.9622 | 0.9703 | 0.9805 | 0.9684 | 0.9676 | 0.9838 |
| SwedishLeaf | 0.9659 | 0.9216 | 0.9280 | 0.9536 | 0.9563 | 0.9466 | 0.9664 | 0.9712 |
| Symbols | 0.9746 | 0.9668 | 0.8824 | 0.9739 | 0.9064 | 0.9616 | 0.9799 | 0.9819 |
| SynCon | 0.9970 | 0.9667 | 0.9833 | 0.9967 | 0.9983 | 0.9953 | 1.0000 | 0.9967 |
| ToeSeg1 | 0.9702 | 0.9386 | 0.9649 | 0.9825 | 0.9627 | 0.9246 | 0.9693 | 0.9693 |
| ToeSeg2 | 0.9262 | 0.9615 | 0.9077 | 0.9538 | 0.9062 | 0.8623 | 0.9538 | 0.9385 |
| Trace | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| TwoLeadECG | 0.9991 | 0.9807 | 0.9974 | 0.9965 | 1.0000 | 0.9886 | 0.9965 | 0.9956 |
| TwoPatterns | 1.0000 | 0.9930 | 0.9550 | 1.0000 | 0.9999 | 0.9996 | 1.0000 | 1.0000 |
| UWavGesLibAll | 0.9757 | 0.9389 | 0.9422 | 0.9685 | 0.8595 | 0.9723 | 0.9687 | 0.9545 |
| UWavGesLibX | 0.8546 | 0.7621 | 0.8029 | 0.8398 | 0.7805 | 0.8286 | 0.8417 | 0.8247 |
| UWavGesLibY | 0.7729 | 0.6851 | 0.7303 | 0.7655 | 0.6701 | 0.7615 | 0.7716 | 0.7688 |
| UWavGesLibZ | 0.7917 | 0.6949 | 0.7485 | 0.7831 | 0.7501 | 0.7640 | 0.7797 | 0.7697 |
| Wafer | 0.9983 | 0.9948 | 1.0000 | 0.9994 | 0.9986 | 0.9955 | 0.9989 | 0.9987 |
| Wine | 0.8074 | 0.7407 | 0.7963 | 0.7778 | 0.7444 | 0.5685 | 0.8889 | 0.6667 |
| WordSynonyms | 0.7552 | 0.6379 | 0.5705 | 0.7382 | 0.6224 | 0.7787 | 0.7868 | 0.7555 |
| Worms | 0.7273 | 0.5584 | 0.7403 | 0.5584 | 0.7909 | 0.7182 | 0.7922 | 0.8052 |
| WormsTwoClass | 0.7987 | 0.8312 | 0.8312 | 0.7792 | 0.7468 | 0.7844 | 0.8182 | 0.7922 |
| Yoga | 0.9085 | 0.9183 | 0.8177 | 0.9177 | 0.8702 | 0.8786 | 0.8483 | 0.9057 |
附录 E其他 2018 年数据集的结果
| Rocket | DTW | |
|---|---|---|
| ACSF1 | 0.8780 | 0.6200 |
| AllGestureWiimoteX | 0.7619 | 0.7171 |
| AllGestureWiimoteY | 0.7617 | 0.7300 |
| AllGestureWiimoteZ | 0.7491 | 0.6514 |
| BME | 1.0000 | 0.9800 |
| Chinatown | 0.9802 | 0.9536 |
| Crop | 0.7502 | 0.7117 |
| DodgerLoopDay | 0.5762 | 0.5875 |
| DodgerLoopGame | 0.8725 | 0.9275 |
| DodgerLoopWeekend | 0.9725 | 0.9783 |
| EOGHorizontalSignal | 0.6409 | 0.4751 |
| EOGVerticalSignal | 0.5423 | 0.4751 |
| EthanolLevel | 0.5820 | 0.2820 |
| FreezerRegularTrain | 0.9976 | 0.9070 |
| FreezerSmallTrain | 0.9519 | 0.6758 |
| Fungi | 1.0000 | 0.8226 |
| GestureMidAirD1 | 0.8062 | 0.6385 |
| GestureMidAirD2 | 0.6831 | 0.6000 |
| GestureMidAirD3 | 0.5785 | 0.3769 |
| GesturePebbleZ1 | 0.9663 | 0.8256 |
| GesturePebbleZ2 | 0.8911 | 0.7785 |
| GunPointAgeSpan | 0.9968 | 0.9652 |
| GunPointMaleVersusFemale | 0.9978 | 0.9747 |
| GunPointOldVersusYoung | 0.9905 | 0.9651 |
| HouseTwenty | 0.9639 | 0.9412 |
| InsectEPGRegularTrain | 0.9996 | 0.8273 |
| InsectEPGSmallTrain | 0.9815 | 0.6948 |
| MelbournePedestrian | 0.9035 | 0.8482 |
| MixedShapesRegularTrain | 0.9704 | 0.9089 |
| MixedShapesSmallTrain | 0.9386 | 0.8326 |
| PLAID | 0.8896 | 0.8361 |
| PickupGestureWiimoteZ | 0.8100 | 0.6600 |
| PigAirwayPressure | 0.0885 | 0.0962 |
| PigArtPressure | 0.9529 | 0.1971 |
| PigCVP | 0.9327 | 0.1587 |
| PowerCons | 0.9311 | 0.9222 |
| Rock | 0.8980 | 0.8400 |
| SemgHandGenderCh2 | 0.9230 | 0.8450 |
| SemgHandMovementCh2 | 0.6444 | 0.6378 |
| SemgHandSubjectCh2 | 0.8836 | 0.8000 |
| ShakeGestureWiimoteZ | 0.8920 | 0.8400 |
| SmoothSubspace | 0.9793 | 0.9467 |
| UMD | 0.9924 | 0.9722 |