图指针网络和分层强化学习的组合优化
摘要
在这项工作中,我们引入了使用强化学习(RL)训练的图指针网络(GPN)来解决旅行商问题(TSP)。 GPN 基于指针网络构建,在输入上引入图形嵌入层,捕获节点之间的关系。 此外,为了近似解决约束组合优化问题(例如带时间窗的 TSP),我们使用 RL 训练分层 GPN(HGPN),它学习分层策略以在约束下找到最佳城市排列。 层次结构的每一层都设计有单独的奖励函数,从而实现稳定的训练。 我们的结果表明,针对小规模 TSP50/100 问题训练的 GPN 可以很好地推广到更大规模的 TSP500/1000 问题,并且具有更短的行程长度和更快的计算时间。 我们验证了对于受限 TSP 问题(例如具有时间窗口的 TSP),通过分层 RL 训练找到的可行解决方案优于之前的基线。 本着可重复研究的精神,我们公开我们的数据、模型和代码。
1简介
作为计算机科学和运筹学中的一个基本问题,组合优化问题在过去几十年中受到了广泛的关注。 最重要和最实际的问题之一是旅行商问题(TSP)。 为了介绍 TSP,请考虑一位正在多个城市进行巡回演出的推销员。 推销员必须恰好访问所有城市一次,同时最大限度地缩短总的访问时间。 TSP 被认为是一个 NP 完全问题[21],它抓住了在多项式时间内找到高效精确解的难度。 为了克服这种复杂性障碍,人们提出了几种近似算法和启发式算法,例如 2-opt 启发式 [1]、Christofides 算法 [4]、引导局部搜索 [26] 和 Lin-Kernighan 启发式 (LKH) [8]。
随着机器学习 (ML) 和强化学习 (RL) 的发展,最近越来越多的工作集中于使用 ML 或 RL 方法解决组合优化[25, 2, 20, 16, 10, 12, 13 ,9]。 seq2seq 模型,称为 指针网络 [25],在近似解决多个组合优化问题(例如寻找凸函数)方面具有巨大潜力船体和 TSP。 它使用 LSTM 作为编码器,使用注意力机制 [24] 作为解码器,从城市坐标中提取特征。 然后,它预测一个描述下一个可能行动的策略,以便对访问过的城市的排列进行采样。 提出了指针网络的强化学习框架[2],其中指针网络模型由Actor-Critic算法[18]训练,负游程长度为用作奖励。 事实证明,RL 方法比以前的监督学习方法更有效,并且在最多 100 个节点的 TSP 上优于以前的大多数启发式方法。 作为指针网络的扩展,Nazari等人[20]修改了指针网络的架构,以解决更复杂的组合优化问题,例如车辆路径问题(VRP)。
由于路由问题的特性,上述工作中使用的神经网络架构没有充分考虑问题实体之间的关系,这是路由问题的关键特性,并且在其他几个问题中也发挥着作用。 作为处理非欧几里得数据和捕获图信息的强大工具,图神经网络(GNN)[11, 28]近年来得到了广泛的研究。 基于 GNN,提出了两种新颖的方法[16, 10],它们利用了许多组合优化问题中存在的固有图结构的信息。 Li 等人[16]应用图卷积网络(GCN)模型[11]以及引导树搜索算法来解决基于图的组合优化问题,例如Maximal独立集和最小顶点覆盖问题。 Dai等人[10]提出了一种用深度Q学习训练的图嵌入网络,并发现这可以很好地推广到更大规模的问题。 最近,在 Transformer 架构[24]的推动下,Kool 等人提出了一种注意力模型[12, 13]来解决 TSP、VRP 和定向运动等路由问题问题。 在他们的模型中,图节点之间的关系由多头注意力机制捕获,使用 REINFORCE 算法中的 rollout 基线,这显着改善了小规模 TSP 的结果。 然而,规模仍然是注意力模型的一个问题。
先前的工作在各种组合优化问题上取得了良好的近似结果,但有约束的组合优化问题,例如带时间窗的TSP(TSPTW)尚未得到充分考虑。 为了处理约束问题,Bello等人[2]提出了一种惩罚方法,该方法在奖励函数上添加了针对不可行解的惩罚项。 然而,惩罚方法会导致训练不稳定,并且惩罚项的超参数通常很难调整。 更好的训练选择是使用分层强化学习方法,该方法已广泛应用于解决复杂问题,例如奖励稀疏的视频游戏和机器人迷宫任务[14,19,6]. 分层强化学习的关键动机是将复杂任务分解为几个简单的子问题,并在分层结构中学习。 Haarnoja等人[6]引入了分层强化学习的潜在空间策略,其中层次结构的较低层提供可行的解决方案空间并约束较高层的行为。 然后,较高层根据来自较低层潜在空间的信息做出决策。 在这项工作中,我们探索使用分层强化学习方法来解决带约束的组合优化问题,这些问题被分成不同的子任务。 层次结构的每一层都学习在约束下搜索可行的解决方案,或者学习启发式方法来优化目标函数。
在这项工作中,我们的目标是近似解决更大规模的 TSP 问题并解决约束组合优化问题。 这项工作的贡献有三个方面:首先,我们提出了一个图指针网络(GPN)来解决普通的 TSP。 GPN 通过图嵌入层扩展了指针网络,并实现了更快的收敛。 其次,我们将向量上下文添加到 GPN 架构中,并使用提前停止进行训练,以便泛化我们的模型来处理更大规模的 TSP 实例,例如TSP1000,来自在更小的 TSP50 实例上训练的模型。 第三,我们采用分层 RL 框架和 GPN 架构来有效地解决具有时间窗口约束的 TSP。 对于每项任务,我们都会进行实验,将我们的模型性能与现有基线和之前的工作进行比较。
这项工作的结构如下。 在预备部分,我们制定了 TSP 及其相应的强化学习框架。 分层强化学习部分介绍了分层强化学习框架以及分层策略梯度方法。 图指针网络部分描述了所提出的 GPN 的架构及其分层版本。 然后,在实验部分,我们分析了我们在小规模 TSP 问题上的方法、它们对大规模 TSP 问题的泛化能力,以及它们在带有时间窗口的 TSP 问题上的性能。
2 预备知识
2.1 旅行商问题
在这项工作中,我们专注于解决对称二维欧几里得旅行商问题(TSP)[15]。 对称 TSP 的图是完备且无向的。 给定 个城市坐标列表 ,问题是找到一条最优路线,使得每个城市都被恰好访问一次,并且所覆盖的总距离在路线被最小化。 换句话说,我们希望在城市上找到一个最佳排列,从而最小化游览长度[2]:
| (1) |
其中,,对于任何 、and 是一个由所有城市坐标 组成的矩阵。 此外,在我们的工作中,我们考虑了带有附加约束的 TSP。 通常,约束TSP被写为以下优化问题:
| (2) |
其中 是排列,和
2.2 TSP的强化学习
我们首先介绍用于将 TSP 表述为强化学习问题的符号。 令 为状态空间, 为动作空间。 每个状态 均已定义作为所有之前访问过的城市的集合,即 。 定义了动作 作为下一个选定的城市,即 。 自 ,因此
将策略表示为 、是给定一组访问过的城市的候选城市分布。 给定一组访问过的城市,该策略将返回下一个尚未选择的候选城市的概率分布。 在我们的例子中,策略由神经网络表示,参数 表示神经网络的可训练权重。 此外,奖励函数被定义为从状态 开始采取行动 所产生的负成本,即. 那么期望奖励[23]定义如下:
| (3) |
其中 是城市集合的空间, 是 上所有可能的排列 的空间、和 是神经网络预测的 上的分布。 为了最大化上述奖励函数,网络必须学习一种策略来最小化预期的旅行长度。 我们采用策略梯度算法[23]来学习最大化奖励函数,如下所述。
3 分层强化学习
3.1 TSP 的分层强化学习
我们工作的一个关键方面是解决有限制的 TSP。 用惩罚项增强传统的强化学习奖励函数可以鼓励解决方案位于可行集[2]中;然而,我们发现这种方法会导致训练不稳定。 相反,我们提出了一个分层强化学习框架来更有效地处理有约束的 TSP。
受 Haarnoja 等人[6, 7]工作的启发,我们采用概率图形模型框架进行控制,如图1所示。 层次结构的每一层都定义一个策略,我们可以从中采样操作。 在给定层 ,当前操作是从策略中采样的,where 是层次结构中上一层的潜变量,是其对应的潜空间。 图 1(b)所示的最底层是一个简单的马尔可夫决策过程 (MDP),其中的行动 是从策略中采样的。,这为高层提供了一个潜向量 。 中间层不仅依赖于潜在变量 来自 层,还提供了一个潜在变量 为方便记述,在 层,我们对策略进行了扩展,既对操作进行了采样,又提供了潜在变量,即.
每层对应一个不同的强化学习任务,因此每层的奖励函数都是手工设计的不同。 有两种自然的方法可以以分层方式制定约束 TSP 优化问题。 首先,我们将较低层的奖励函数设置为简单地将解偏置到约束优化问题的可行集中,并将较高层的奖励函数设置为原始优化目标。 相反,我们对奖励函数进行排序,以增加优化的难度:第一层尝试解决普通 TSP,第二层给出具有一个约束的 TSP 实例,依此类推。 在我们的实验中,我们使用第一种配方,因为我们发现这会产生更好的结果。
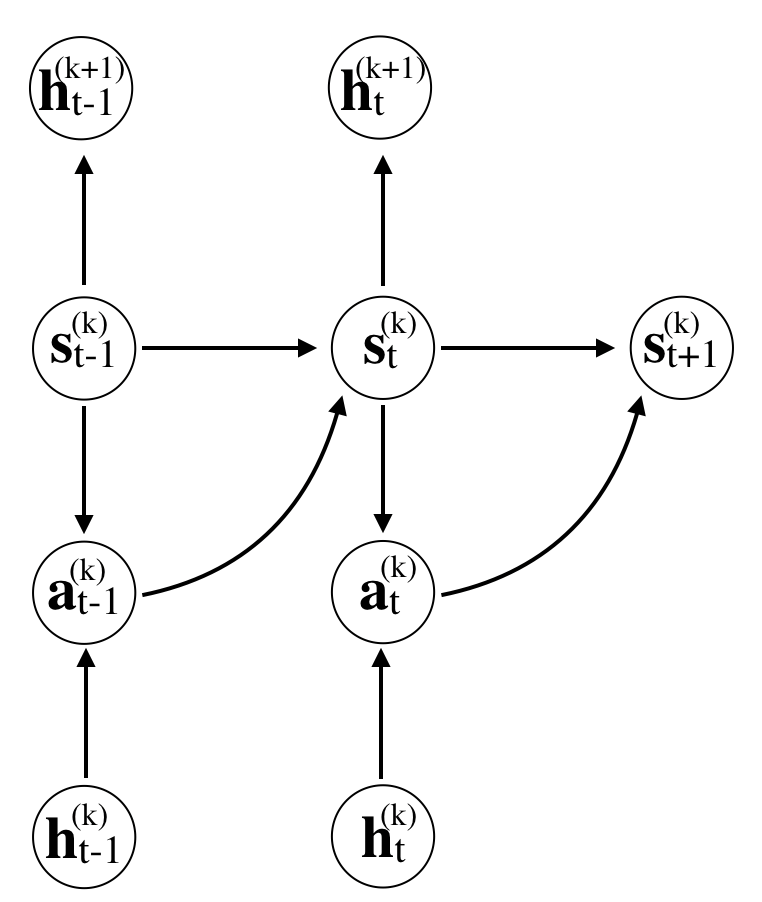
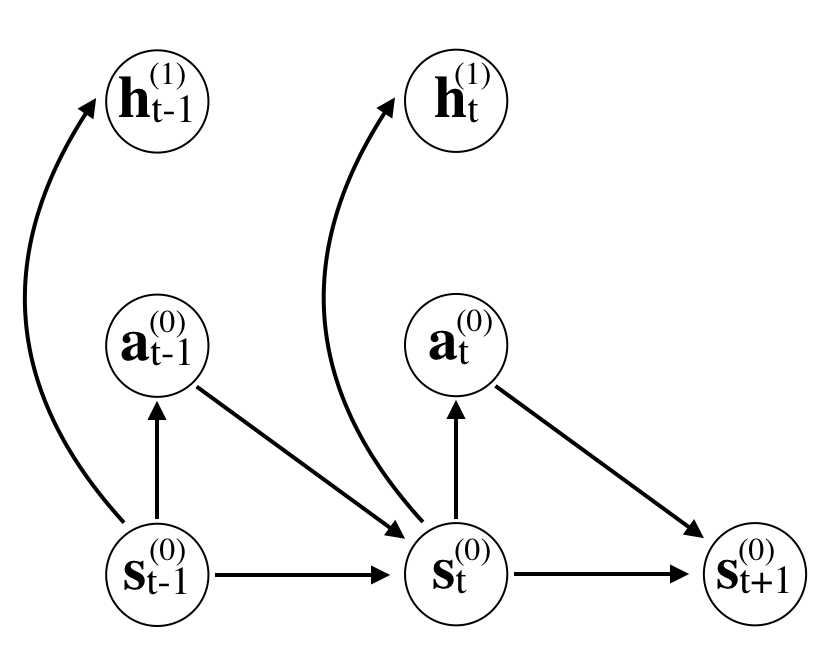

3.2 分层策略梯度
我们使用策略梯度方法来学习分层策略。 Considering a hierarchical policy, the objective function of the -th layer is . 基于REINFORCE算法,第层策略的梯度表示为[2, 27]:
| (4) |
其中,为批量大小,为第 层策略、 是第 层的奖励函数、是第 层的基线,是下层的潜变量。 根据公式 4、参数 通过更新规则使用梯度下降法进行优化.
3.2.1中央自我批评
我们引入中心自我批评基线,类似于注意力模型中的自我批评基线[22]和rollout基线[12]0>。 中心自我批评基线 表示为:
| (5) |
其中动作 is from the greedy policy ,i.即动作是贪婪采样的,是相应的状态。 方程5的第二项是采样方法和贪婪方法之间的奖励差距,旨在将REINFORCE算法[27]中的优势项居中。 与使用奖励的指数移动平均值相比,使用中央自我批评基线可以加快收敛速度。
由于层次结构的最低层是马尔可夫决策过程(MDP),因此最低层的策略是直接学习的,并为高层提供潜在变量。 换句话说,我们使用自下而上的方法来学习分层策略和训练神经网络。
3.2.2 分层策略优化
假设我们需要学习 层分层策略、which includes ,,…,. 每个策略都由一个 GPN 表示。 为了学习策略,我们首先需要训练所有下层 对于 然后,对于层 , we sample based on ,并为下一层提供潜变量 。 最后,我们可以从 中学习到策略 。 算法1提供了详细的伪代码。
4 图形指针网络
4.1GPN架构
我们提出了一种基于指针网络[2]的图指针网络(GPN)来近似求解TSP。 GPN架构如图2所示,由编码器和解码器组件组成。
编码器
编码器包括两部分:点编码器和图编码器。 对于点编码器,每个城市坐标 嵌入到更高维向量 ,其中 此线性变换在所有城市 之间共享权重。 然后,LSTM 对当前城市 的向量 进行编码。 LSTM 的隐藏变量 被传递到当前步骤中的解码器和编码器在下一个时间步中。 对于图编码器,我们使用图嵌入层对所有城市坐标进行编码 ,并将其传递给解码器。
图嵌入层
在TSP中,城市节点的上下文信息包括该城市的邻居信息。 在 GPN 中,上下文信息是通过图神经网络 (GNN) [11, 28] 对所有城市坐标 进行编码来获得的。 GNN的每一层表示为:
| (6) |
其中 是 -是第 , , 是一个可训练参数,用于规范权重矩阵的特征值、是一个可训练的权重矩阵、是节点 的邻接集,是聚合函数 [11]、在本文中用神经网络表示。 此外,由于我们只考虑对称TSP,因此TSP的图是完全图。 因此,图嵌入层进一步表示为:
| (7) |
其中 ,和
矢量上下文
在以前的工作中,[2, 12] 是根据所有城市的二维坐标计算上下文的,即 。 我们将此上下文称为点上下文。 相比之下,在这项工作中,我们没有直接使用坐标特征,而是使用从当前城市指向所有其他城市的向量作为上下文,我们将其称为向量上下文。 对于当前城市,假设 是一个矩阵,具有相同的行 我们定义 作为向量上下文。 的 行是从节点 指向节点 的向量。 然后 被传递到图嵌入层中。 图嵌入层被重写为 。 在实践中,使用向量上下文的 GPN 会产生更多可转移的表示,这使得模型能够在更大规模的 TSP 上表现良好。
解码器
解码器基于注意力机制并输出指针向量,然后将其传递到softmax层以生成分布下一个候选城市。 与指针网络[2]类似,注意力机制和指针向量定义为:
| (8) |
其中 是向量 的 项、 和 是可训练矩阵、 是来自 LSTM 隐藏变量的查询向量, 是包含所有城市上下文信息的参考向量。 准确地说,我们使用点编码器中的隐藏变量 作为查询向量 ,并使用图嵌入层中的上下文 作为参照,即e. and .
所有候选城市的分配政策由下式给出:
| (9) |
我们预测下一个访问的城市,通过从策略
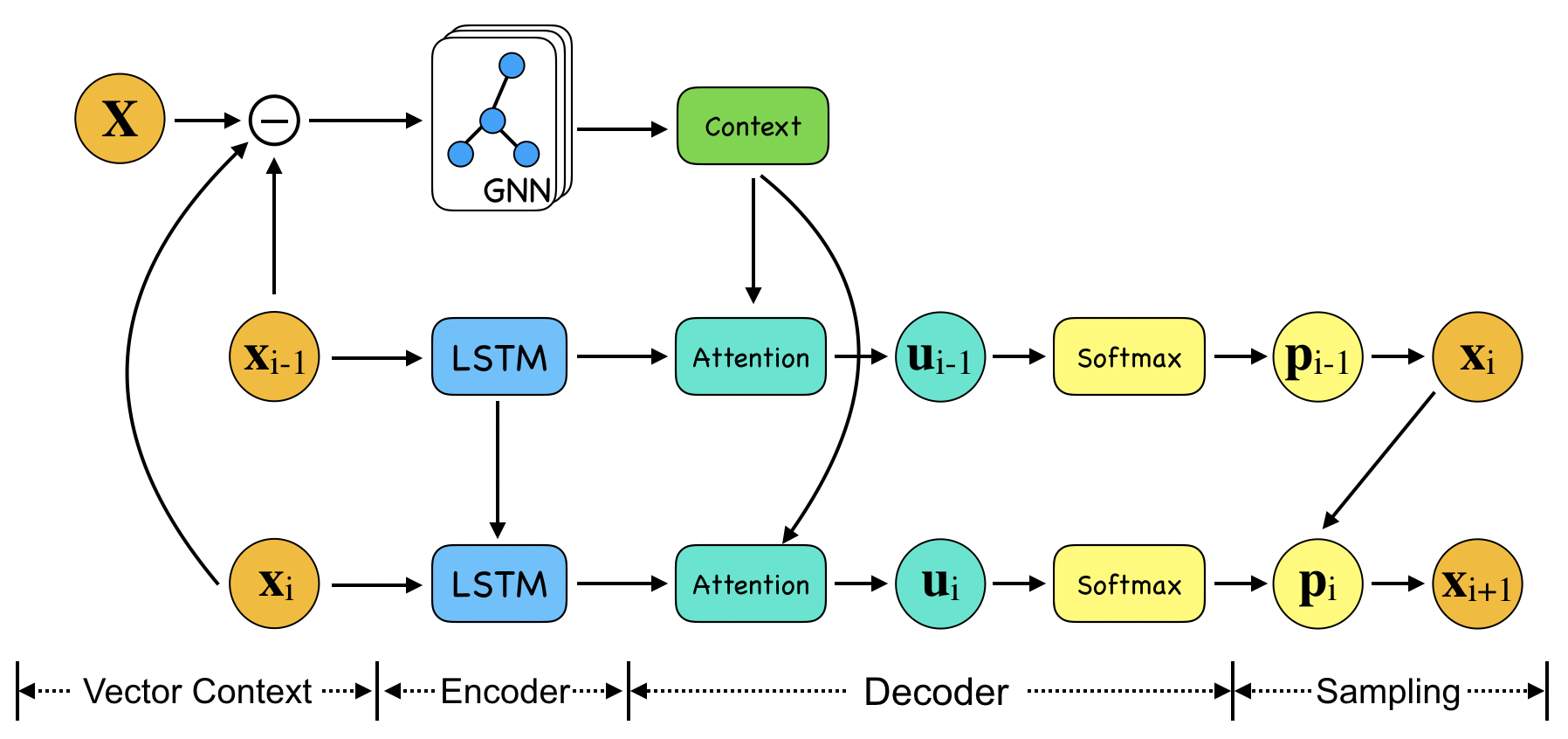
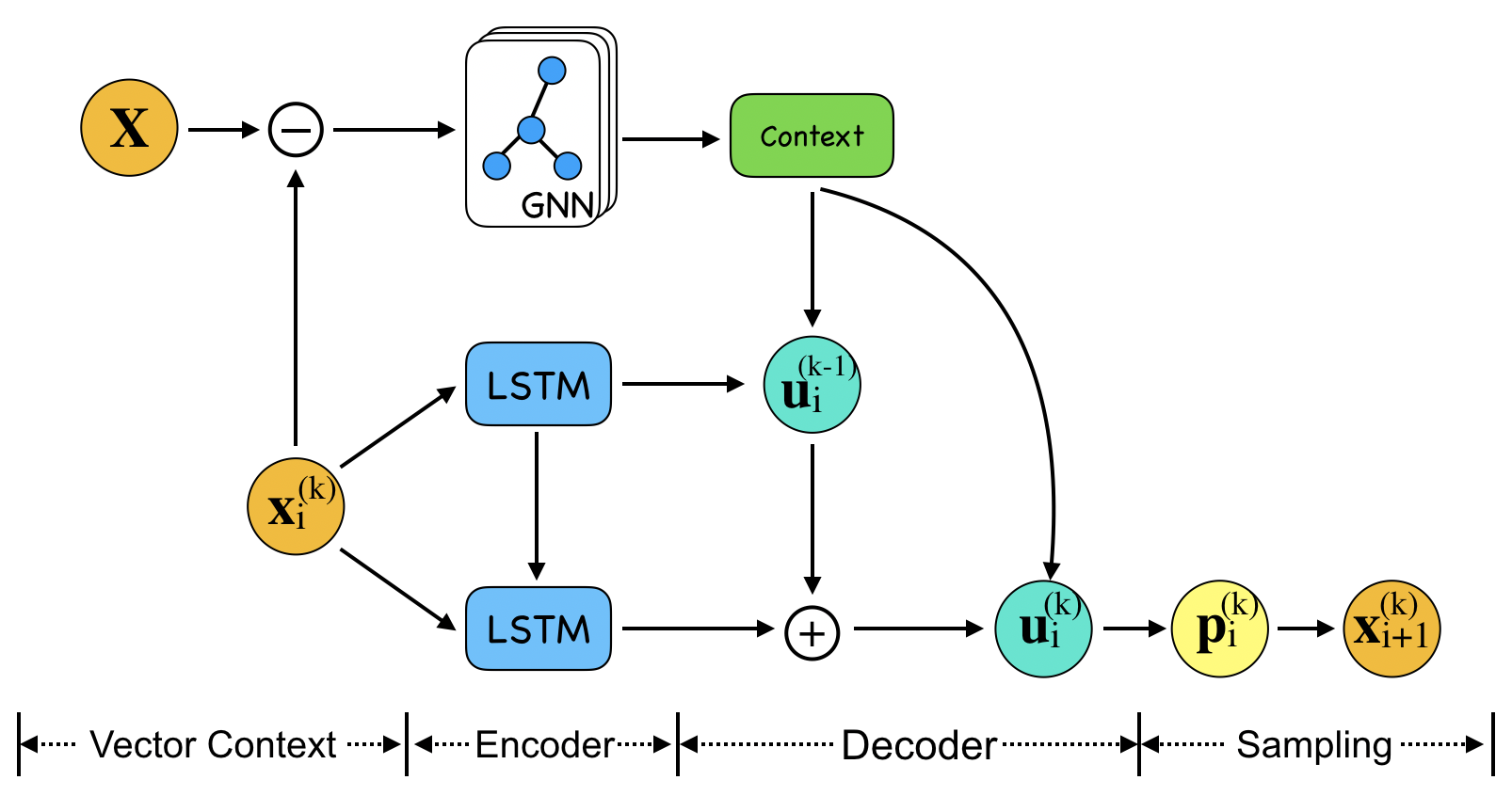
4.2分层GPN架构
在本节中,我们使用所提出的 GPN 来设计分层架构。 两层分层GPN(HGPN)的架构如图3所示。 与单层 GPN 相比,坐标 在第 层首先作为输入传递给较低层的神经网络,网络输出一个指针向量 那么被添加到的指针向量、i.e.,其中 为可训练参数。 这起着重要作用,因为 包含较低层信息,提供输出城市的先验分布。 输出采样自,其中是下层的潜变量。
5 实验
在我们的实验中,我们使用 图嵌入层对 GPN 中的上下文进行编码。 使用的聚合函数是单层全连接神经网络。 图嵌入层表示为
| (10) |
其中 是 ReLU 激活函数、and 是可训练的权重和偏差,其中 为 . 我们对 TSP20/50 等小规模问题使用点上下文,对 TSP500 等大规模问题使用向量上下文。 训练数据是从 均匀分布。 在每个时期,训练数据都是动态生成的。 强化学习训练期间使用中心自我批评基线。 除非另有说明,以下实验均使用表1所示的超参数。
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Epoch | 100 | Optimizer | Adam |
| Batch size | 512 | Learning rate | 1e-3 |
| Training steps (per epoch) | 2500 | Learning rate decay | 0.96 |
OR-工具设置
我们使用 OR-Tools [5] 作为与我们的结果进行比较的基线之一。 为了与更大规模的 TSP 实例进行比较,OR-Tools 选择 Savings 和 Christofides 算法作为第一个解决策略。 每个TSP实例的搜索时间限制设置为5秒。 运行 OR-Tools 时,我们选择引导本地搜索作为元启发式方法。 对于带有时间窗的 TSP (TSPTW),Savings 算法被选为 OR-Tools 中的第一个解决策略。 我们使用其搜索限制和元启发法的默认设置。
5.1 小规模TSP实验
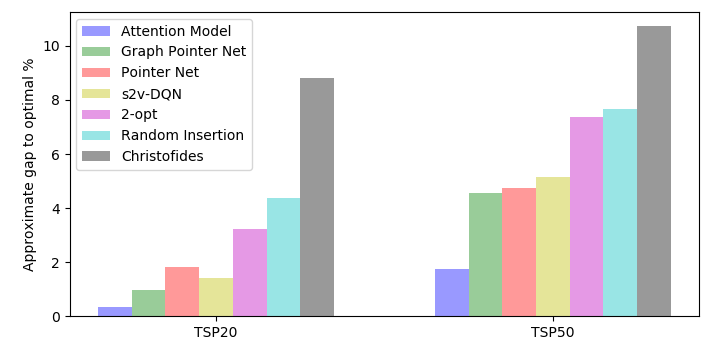
我们使用 TSP20 和 TSP50 实例训练 GPN 模型。 使用一个 NVIDIA Tesla P100 GPU,每个 epoch 的训练时间对于 TSP20 为 7 分钟,对于 TSP50 为 30 分钟。 我们将我们的模型在小规模 TSP 上的性能与之前的工作进行了比较,例如注意力模型 [12]、s2v-DQN [10]、Pointer Network [2],以及其他启发式方法,例如2-opt 启发式、Christofides 算法和随机插入。 结果如图4所示,它比较了近似差距与最优解。 间隙越小表示结果越好。 通过LKH算法得到最优解。 我们观察到,对于小规模 TSP 实例,GPN 优于指针网络,这证明了图嵌入的有用性,但产生的近似值比注意力模型差。
5.2大规模TSP实验
| TSP 250 | TSP 500 | TSP 750 | TSP 1000 | |||||
|---|---|---|---|---|---|---|---|---|
| Method | Tour Len. | Time | Tour Len. | Time | Tour Len. | Time | Tour Len. | Time |
| LKH | 11.893 | 9792s | 16.542 | 23070s | 20.129 | 36840s | 23.130 | 50680s |
| Concorde | 1894s | 13902s | 32993s | 47804s | ||||
| Nearest Neighbor | 14.928 | 25s | 20.791 | 60s | 25.219 | 115s | 28.973 | 136s |
| 2-opt | 13.253 | 303s | 18.600 | 1363s | 22.668 | 3296s | 26.111 | 6153s |
| Farthest Insertion | 13.026 | 33s | 18.288 | 160s | 22.342 | 454s | 25.741 | 945s |
| OR-Tools (Savings) | 12.652 | 5000s | 17.653 | 5000s | 22.933 | 5000s | 28.332 | 5000s |
| OR-Tools (Christofides) | 12.289 | 5000s | 17.449 | 5000s | 22.395 | 5000s | 26.477 | 5000s |
| s2v-DQN | 13.079 | 476s | 18.428 | 1508s | 22.550 | 3182s | 26.046 | 5600s |
| Pointer Net | 14.249 | 29s | 21.409 | 280s | 27.382 | 782s | 32.714 | 3133s |
| Attention Model | 14.032 | 2s | 24.789 | 14s | 28.281 | 42s | 34.055 | 136s |
| GPN (ours) | 13.679 | 32s | 19.605 | 111s | 24.337 | 232s | 28.471 | 393s |
| GPN+2opt (ours) | 12.942 | 214s | 18.358 | 974s | 22.541 | 2278s | 26.129 | 4410s |
在现实世界的应用中,大多数实际的 TSP 实例都有数百或数千个节点,并且最优解无法有效计算。 我们发现所提出的 GPN 模型可以很好地概括从小规模的 TSP 问题到更大规模的问题。 泛化能力提高了一个数量级。
在表2中,我们在具有10个epoch的TSP50数据上训练了带有向量上下文的GPN模型,并使用该模型来预测TSP250/500/750/1000上的路线。 此外,我们使用本地搜索算法 2-opt [1] 来改进预测后的结果。 指针网络 (PN) [2]、s2v-DQN [10] 和注意力模型 (AM) [12] 也经过训练TSP50 数据,我们还检查了这些模型对更大规模问题的可迁移性。 结果是 1000 个 TSP 实例的平均值。 由于内存限制,我们在所有模型的推理过程中设置批量大小 。 结果还与 LKH、最近邻、2-opt、最远插入和 Google OR-Tools [5] 进行了比较。
表 2 显示,当我们使用 TSP50 实例并推广到更大规模的问题时,我们的 GPN 模型优于 PN 和 AM。 添加本地搜索后,GPN+2opt 的行程长度与 s2v-DQN 相似,但可节省 运行时间。 与2-opt启发式相比,GPN+2opt使用运行时间较少,这意味着GPN模型可以被视为一种很好的初始化方法。 GPN+2opt 在 TSP1000 上的性能也优于 OR-Tools。 在表 2 上,GPN 的性能并不优于最先进的 TSP 求解器,例如LKH 和最远插入。 然而,它仍然有可能成为一种有效的初始化方法,因为 GPN 显示出良好的泛化能力并且可以并行解决 TSP 实例。 一些示例游览如图5所示。



如上所述,GPN 模型的泛化能力大约比模型训练实例的大小大一个数量级。 更具体地说,我们在 TSP20/50/100 上训练 GPN 模型,并使用这些模型在 TSP500/1000 上进行预测。 结果如表 3 所示,这表明如果我们增加用于训练的 TSP 实例的大小,结果会有所改善。
| TSP 500 | TSP 1000 | |||
|---|---|---|---|---|
| Model | Tour Len. | Time | Tour Len. | Time |
| GPN (TSP20) | 22.320 | 107s | 33.649 | 391s |
| GPN (TSP50) | 19.605 | 111s | 28.471 | 393s |
| GPN (TSP100) | 19.527 | 109s | 28.036 | 408s |
5.3 带时间窗口的 TSP 实验
最后,我们考虑一个众所周知的约束 TSP 问题,即带有时间窗的 TSP (TSPTW)。 在 TSPTW 中,每个节点 都有自己的服务时间间隔 、其中,为进入时间,为离开时间。 一座城市在离开时间之后就无法再被访问。 如果该节点被访问早于进入时间,则业务员必须等待直到服务开始,即直到进入时间。 在本实验中,我们考虑以下带有时间窗问题的 TSP 形式化:
| (11) |
其中 是第 个城市的时间成本。 在这个问题中,并不总是存在可行的解决方案。 为了确保训练和测试数据的存在,我们首先从 均匀分布。 然后对生成的实例使用2-opt局部搜索,我们求解近似解对于。 我们设定 and,where and . 因此,,这意味着训练数据和测试数据中始终存在可行解。 数据集是通过对上述实例中的所有城市进行混洗而获得的。 RL 训练期间使用指数移动平均批评基线 [12]。
在带有时间窗的 TSP(TSPTW)实验中,我们构建了一个两层分层 GPN(HGPN)。 首先我们定义:
| (12) |
作为到达时间超过离开时间的惩罚,其中是离开时间, 是到达时间。 那么下层的奖励函数就是违反离开时间约束的惩罚 ,其中 较高层的奖励是TSPTW的总时间成本加上惩罚:
| (13) |
对于推理阶段,我们使用 来衡量准确性,即成功解决的实例数。 对于任何实例,如果 ,则至少存在一个城市到达时间超过离开时间,说明该解不可行。
下层使用 TSPTW20 数据的 epoch 进行训练,高层使用 epoch 进行训练。 对于 TSPTW 数据,每个节点 都是一个元组 ,其中,是二维坐标,是进入和离开时间。 我们对 个问题实例的结果进行平均,以将我们的结果与 OR-Tools 和蚁群优化 (ACO) 算法 [3] 进行比较。
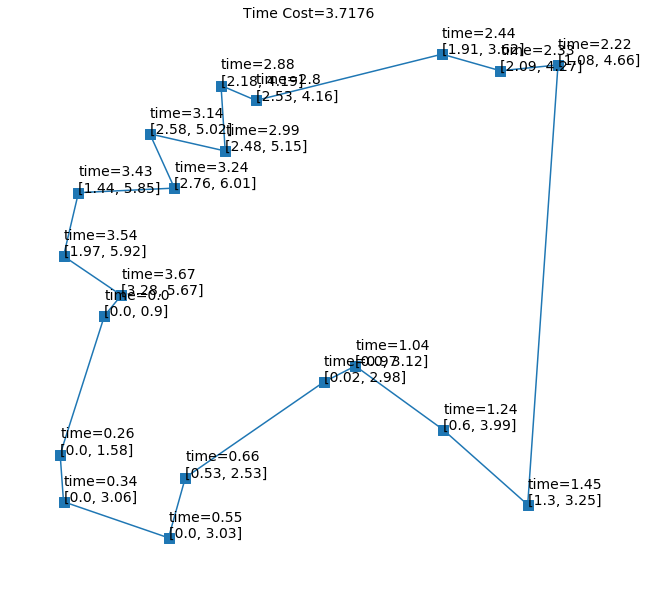
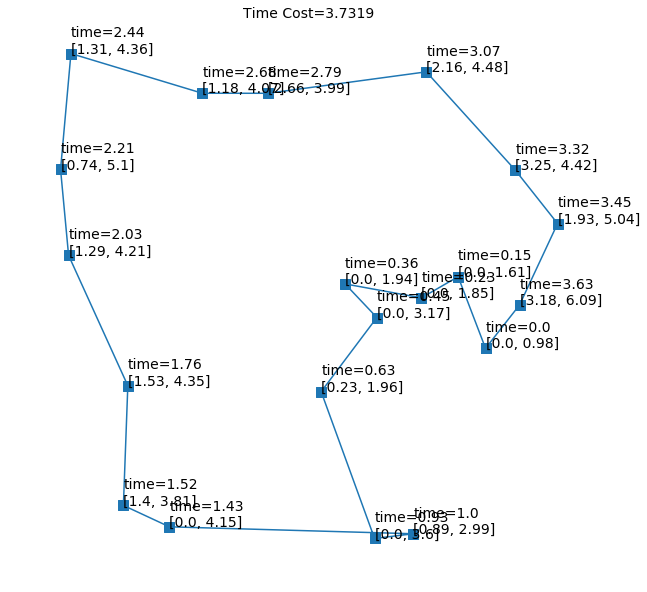
在预测时,我们同时使用贪婪方法和采样方法。 通过采样 100 或 500 次,结果会得到改善。 表4表明我们的HGPN框架优于TSPTW上的所有其他基线,包括单层GPN。 尽管根据我们的训练设置,所有实例都有可行的解决方案,但有时算法将无法找到可行的解决方案。 为了捕捉这一点,我们使用可行解决方案的百分比作为评估指标。 与基线相比,HGPN 实现了更高比例的可行解决方案。 一些示例游览如图6所示。
| Method | Cost | Time | Feasible % |
|---|---|---|---|
| OR-Tools (Savings) | 4.045 | 121s | 72.06% |
| ACO | 4.655 | 204s | 62.10% |
| GPN-greedy | 4.209 | 1s | 99.87% |
| HGPN-greedy | 4.178 | 1s | 99.88% |
| HGPN-sampling-100 | 4.013 | 99s | 100% |
| HGPN-sampling-500 | 3.991 | 494s | 100% |
5.4 真实世界 TSP 实例
我们使用节点数少于 1500 个的实例在现实世界的 TSPLIB 数据集上评估了我们的模型。 我们报告结果与最佳解决方案之间的平均差距,如表 5 所示。
| Method | Concorde | GPN+2opt |
|---|---|---|
| Optimality Gap | ||
| Running Time | 1377s | 200s |
6讨论
6.1 概括
矢量上下文
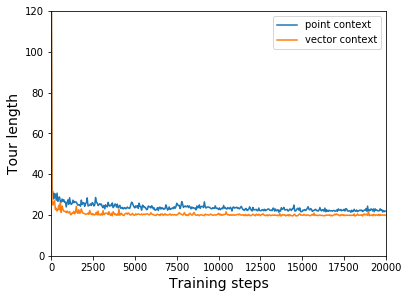
在我们的 GPN 模型中,我们在编码之前使用向量上下文。 矢量上下文有助于获取城市之间的成对信息。 因此,在每一步中,我们的模型都知道当前城市与所有其他城市之间的相对位置,这有助于良好的泛化。 在实验中,在较大规模的 TSP 上,带有向量上下文的 GPN 比带有点上下文的 GPN 表现更好,如图7所示。
提前停止
为了很好地泛化到更大规模的训练实例并避免对小规模问题的过度拟合,我们在 期间使用提前停止,并使用训练了 10 个时期的模型来解决更大规模的 TSP。 不同提前停止级别的性能比较结果如表6所示。 根据性能,我们仍然训练 PN、s2v-DQN、AM 100 个 epoch。
| Epoch | 1 | 5 | 10 | 100 |
|---|---|---|---|---|
| TSP500 | 20.26 | 19.69 | 19.58 | 20.19 |
| TSP1000 | 29.23 | 28.52 | 28.48 | 29.28 |
剪辑范围
在我们的模型中,我们将指针向量 的范围裁剪为 。 代替之前工作中使用的 [2] ,我们选择 来做出更好的探索-利用权衡。
6.2分层架构
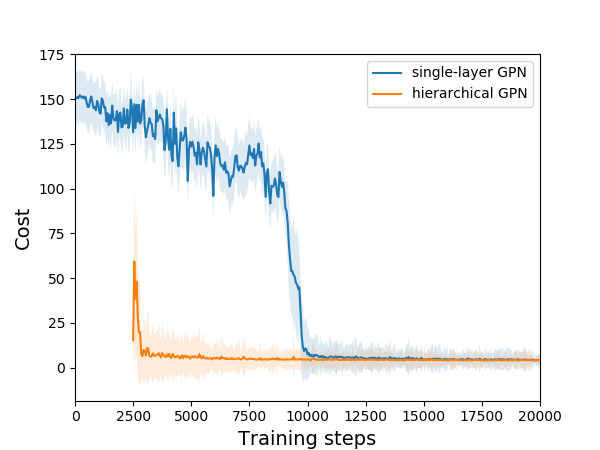
在 TPTTW 问题中,分层 GPN (HGPN) 的性能优于单层 GPN。 HGPN和单层GPN的训练曲线如图8所示。 对于单层GPN,奖励函数既包含了惩罚,又包含了TSPTW的目标,导致前期不稳定,如图8中蓝色曲线所示。 相比之下,我们训练 HGPN 的下层来最小化惩罚项,这样学习起来很简单,并且在一个 epoch 内快速收敛。 然后,较低层为较高层提供可能可行解的先验分布。 给定可行解的潜在信息,更高层的 HGPN 比单层 GPN 收敛得更快,并产生更好的解。
7 结论
在这项工作中,我们提出了一种图指针网络(GPN)框架,它通过使用图嵌入层有效地解决更大规模的 TSP。 训练分层强化学习模型使我们的方法能够额外解决约束组合优化问题,例如具有时间窗口的 TSP。 我们的实验结果表明,GPN 能够很好地概括从小规模问题到大规模问题,优于之前的 RL 方法。 我们公开我们的数据、模型和代码[17]。
参考
- [1] Emile Aarts, Emile HL Aarts, and Jan Karel Lenstra, Local search in combinatorial optimization, Princeton University Press, 2003.
- [2] Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio, ‘Neural combinatorial optimization with reinforcement learning’, International Conference on Learning Representations Workshop, (2017).
- [3] Chi-Bin Cheng and Chun-Pin Mao, ‘A modified ant colony system for solving the travelling salesman problem with time windows’, Mathematical and Computer Modelling, 46(9-10), 1225–1235, (2007).
- [4] Nicos Christofides, ‘Worst-case analysis of a new heuristic for the travelling salesman problem’, Technical report, Carnegie-Mellon University, Pittsburgh Management Sciences Research Group, (1976).
- [5] Google, ‘Or-tools, Google optimization tools’, https://developers.google.com/optimization/routing, (2016).
- [6] Tuomas Haarnoja, Kristian Hartikainen, Pieter Abbeel, and Sergey Levine, ‘Latent space policies for hierarchical reinforcement learning’, in International Conference on Machine Learning, pp. 1846–1855, (2018).
- [7] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine, ‘Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor’, in International Conference on Machine Learning, pp. 1856–1865, (2018).
- [8] Keld Helsgaun, ‘An effective implementation of the lin–kernighan traveling salesman heuristic’, European Journal of Operational Research, 126(1), 106–130, (2000).
- [9] Chaitanya K Joshi, Thomas Laurent, and Xavier Bresson, ‘An efficient graph convolutional network technique for the travelling salesman problem’, arXiv preprint arXiv:1906.01227, (2019).
- [10] Elias Khalil, Hanjun Dai, Yuyu Zhang, Bistra Dilkina, and Le Song, ‘Learning combinatorial optimization algorithms over graphs’, in Advances in Neural Information Processing Systems, pp. 6348–6358, (2017).
- [11] Thomas N Kipf and Max Welling, ‘Semi-supervised classification with graph convolutional networks’, International Conference on Learning Representations, (2016).
- [12] Wouter Kool, Herke van Hoof, and Max Welling, ‘Attention, learn to solve routing problems!’, International Conference on Learning Representations, (2019).
- [13] Wouter Kool, Herke van Hoof, and Max Welling, ‘Buy 4 reinforce samples, get a baseline for free!’, International Conference on Learning Representations, (2019).
- [14] Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum, ‘Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation’, in Advances in Neural Information Processing Systems, pp. 3675–3683, (2016).
- [15] Eugene L Lawler, Jan Karel Lenstra, AHG Rinnooy Kan, David Bernard Shmoys, et al., The traveling salesman problem: a guided tour of combinatorial optimization, volume 3, Wiley New York, 1985.
- [16] Zhuwen Li, Qifeng Chen, and Vladlen Koltun, ‘Combinatorial optimization with graph convolutional networks and guided tree search’, in Advances in Neural Information Processing Systems, pp. 537–546, (2018).
- [17] Quiang Ma, Suwen Ge, Danyang He, Darshan Thaker, and Iddo Drori, ‘GitHub Repository for Combinatorial Optimization by Graph Pointer Networksand Hierarchical Reinforcement Learning’, https://github.com/qiang-ma/graph-pointer-network, (2019).
- [18] Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu, ‘Asynchronous methods for deep reinforcement learning’, in International Conference on Machine Learning, pp. 1928–1937, (2016).
- [19] Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine, ‘Data-efficient hierarchical reinforcement learning’, in Advances in Neural Information Processing Systems, pp. 3303–3313, (2018).
- [20] Mohammadreza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takác, ‘Reinforcement learning for solving the vehicle routing problem’, in Advances in Neural Information Processing Systems, pp. 9839–9849, (2018).
- [21] Christos H Papadimitriou, ‘The euclidean travelling salesman problem is np-complete’, Theoretical Computer Science, 4(3), 237–244, (1977).
- [22] Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel, ‘Self-critical sequence training for image captioning’, in IEEE Conference on Computer Vision and Pattern Recognition, pp. 7008–7024, (2017).
- [23] Richard S Sutton and Andrew G Barto, Reinforcement learning: An introduction, MIT Press, 2018.
- [24] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin, ‘Attention is all you need’, in Advances in neural information processing systems, pp. 5998–6008, (2017).
- [25] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly, ‘Pointer networks’, in Advances in Neural Information Processing Systems, pp. 2692–2700, (2015).
- [26] Christos Voudouris and Edward Tsang, ‘Guided local search and its application to the traveling salesman problem’, European Journal of Operational Research, 113(2), 469–499, (1999).
- [27] Ronald J Williams, ‘Simple statistical gradient-following algorithms for connectionist reinforcement learning’, Machine Learning, 8(3-4), 229–256, (1992).
- [28] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka, ‘How powerful are graph neural networks?’, International Conference on Learning Representations, (2019).