GhostNet:廉价运营带来更多功能
摘要
由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难。 特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究。 本文提出了一种新颖的 Ghost 模块,可以通过廉价的操作生成更多的特征图。 基于一组内在特征图,我们以低廉的成本应用一系列线性变换来生成许多鬼特征图,这些特征图可以充分揭示内在特征背后的信息。 所提出的 Ghost 模块可以作为即插即用组件来升级现有的卷积神经网络。 Ghostbottleneck旨在堆叠Ghost模块,然后可以轻松建立轻量级的GhostNet。 在基准测试上进行的实验表明,所提出的 Ghost 模块是基线模型中卷积层的令人印象深刻的替代品,并且我们的 GhostNet 可以实现更高的识别性能(例如。 top-1 准确度)高于 MobileNetV3,在 ImageNet ILSVRC-2012 分类数据集上具有相似的计算成本。 代码可在 https://github.com/huawei-noah/ghostnet 获取。
1简介
深度卷积神经网络在各种计算机视觉任务上表现出了出色的性能,例如图像识别[30, 13]、目标检测[43, 33]和语义分割[4]。 传统的 CNN 通常需要大量参数和浮点运算 (FLOP) 才能达到令人满意的精度,例如。 ResNet-50 [16] 大约有 M 个参数,需要 B 次 FLOP 来处理大小为 的图像。 因此,深度神经网络设计的最新趋势是探索便携式、高效的网络架构,并为移动设备(例如.智能手机和自动驾驶汽车)提供可接受的性能。
多年来,人们提出了一系列方法来研究紧凑型深度神经网络,例如网络剪枝[14, 39]、低位量化[42, 26] 、知识蒸馏[19, 57]、等。 Han 等人. [14]提出剪枝神经网络中不重要的权重。 [31] 利用 -范数正则化来修剪过滤器,以实现高效的 CNN。 [42] 将权重和激活量化为 1 位数据,以实现大压缩比和加速比。 [19]引入了知识蒸馏,用于将知识从较大的模型转移到较小的模型。 然而,这些方法的性能通常受到作为其基线的预训练深度神经网络的上限。
除此之外,高效的神经架构设计在建立参数和计算量较少的高效深度网络方面具有很大的潜力,并且最近取得了相当大的成功。 这种方法还可以为自动搜索方法[62,55,5]提供新的搜索单元。 例如,MobileNet [21, 44, 20] 利用深度卷积和点卷积构建一个单元,用更大的滤波器逼近原始卷积层,并取得了相当的性能。 ShuffleNet [61, 40]进一步探索了通道洗牌操作来增强轻量级模型的性能。
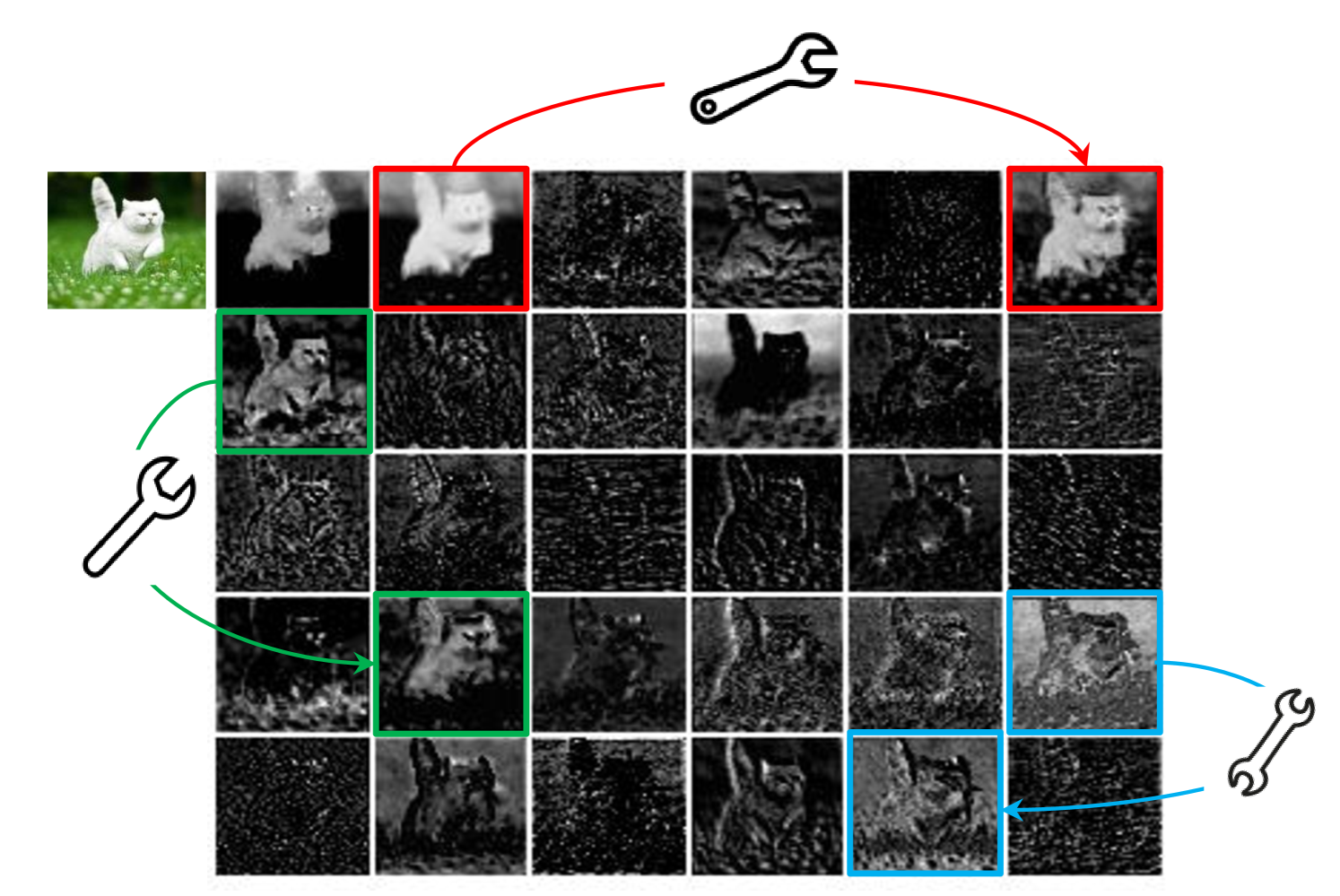
训练有素的深度神经网络的特征图中丰富甚至冗余的信息通常可以保证对输入数据的全面理解。 例如,图1展示了ResNet-50生成的输入图像的一些特征图,并且存在许多相似的特征图对,就像彼此的幽灵。 特征图中的冗余可能是成功的深度神经网络的一个重要特征。 我们倾向于接受它们,而不是避免冗余的特征图,但以一种经济有效的方式。
在本文中,我们介绍了一种新颖的 Ghost 模块,可以使用更少的参数生成更多的特征。 具体来说,深度神经网络中的普通卷积层将被分为两部分。 第一部分涉及普通卷积,但其总数将受到严格控制。 给定第一部分的内在特征图,然后应用一系列简单的线性运算来生成更多特征图。 与普通卷积神经网络相比,在不改变输出特征图大小的情况下,该 Ghost 模块所需的总体参数数量和计算复杂度都降低了。 基于Ghost模块,我们建立了一个高效的神经架构,即GhostNet。 我们首先替换基准神经架构中的原始卷积层,以证明 Ghost 模块的有效性,然后在几个基准视觉数据集上验证 GhostNet 的优越性。 实验结果表明,所提出的 Ghost 模块能够降低通用卷积层的计算成本,同时保持相似的识别性能,并且 GhostNets 可以超越 MobileNetV3 等最先进的高效深度模型[20],在移动设备上进行快速推理的各种任务。
2相关工作
在这里,我们分两部分重新审视现有的减轻神经网络的方法:模型压缩和紧凑模型设计。
2.1模型压缩
对于给定的神经网络,模型压缩旨在减少计算、能量和存储成本[14,48,11,54]。 修剪连接[15,14,50]剪掉神经元之间不重要的连接。 通道修剪[51,18,31,39,59,23,35]进一步致力于删除无用的通道,以便在实践中更容易加速。 模型量化[42,24,26]表示神经网络中的权重或激活,具有用于压缩和计算加速的离散值。 具体来说,仅具有 1 位值的二值化方法 [24, 42, 38, 45] 可以通过高效的二元运算极大地加速模型。 张量分解[27, 9]通过利用权重的冗余和低秩特性来减少参数或计算量。 知识蒸馏[19,12,3]利用较大的模型来教导较小的模型,从而提高较小模型的性能。 这些方法的性能通常取决于给定的预训练模型。 基础操作和架构上的改进会让他们走得更远。
2.2紧凑模型设计
随着在嵌入式设备上部署神经网络的需求,近年来提出了一系列紧凑模型[7,21,44,20,61,40,53,56]。 Xception [7] 利用深度卷积运算来更有效地使用模型参数。 MobileNets [21] 是一系列基于深度可分离卷积的轻量级深度神经网络。 MobileNetV2 [44]提出了反向残差块,MobileNetV3 [20]进一步利用AutoML技术[62,55,10]以更少的资源实现更好的性能失败。 ShuffleNet[61]引入通道洗牌操作来改善通道组之间的信息流交换。 ShuffleNetV2 [40]进一步考虑了目标硬件上的实际速度,以实现紧凑的模型设计。 尽管这些模型以很少的 FLOP 获得了出色的性能,但特征图之间的相关性和冗余从未得到很好的利用。
3方法
在本节中,我们将首先介绍 Ghost 模块,利用几个小过滤器从原始卷积层生成更多特征图,然后开发一个具有极其高效架构和高性能的新 GhostNet。
3.1 Ghost 模块提供更多功能
深度卷积神经网络[30,46,16]通常由大量卷积组成,这会导致巨大的计算成本。 尽管 MobileNet [21, 44] 和 ShuffleNet [40] 等最近的工作引入了深度卷积或洗牌操作,以使用较小的卷积滤波器(浮点数运算)构建高效的 CNN ),剩余的卷积层仍然会占用相当大的内存和FLOPs。
鉴于主流CNN计算的中间特征图中广泛存在冗余,如图1所示,我们建议减少所需的资源,即。用于生成它们的卷积滤波器。 实际上,给定输入数据,其中是输入通道的数量,和是高度和宽度分别为输入数据的任意卷积层用于生成特征图的操作可以表示为
| (1) |
其中 是卷积运算, 是偏差项, 是具有 个通道的输出特征图,是该层的卷积滤波器。 另外,和是输出数据的高度和宽度,是卷积滤波器的内核大小 , 分别。 在这个卷积过程中,所需的 FLOP 数量可以计算为 ,由于滤波器数量 和通道数量 通常非常大(例如。 256 或 512)。
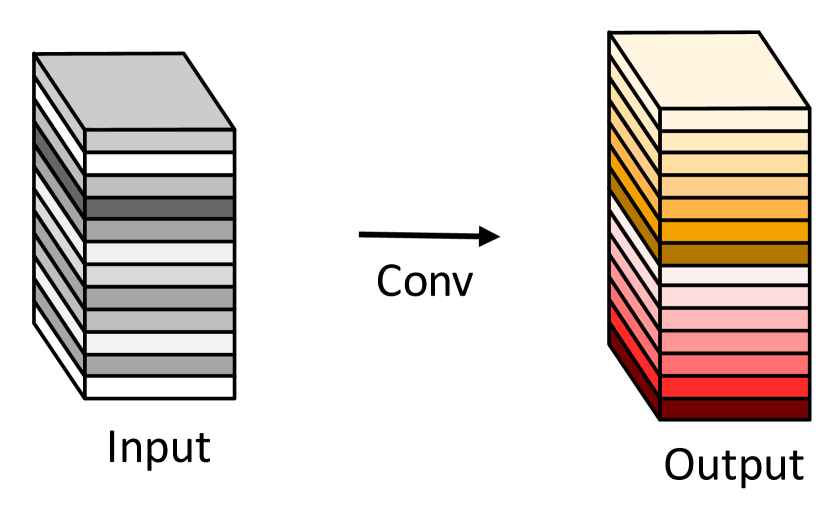
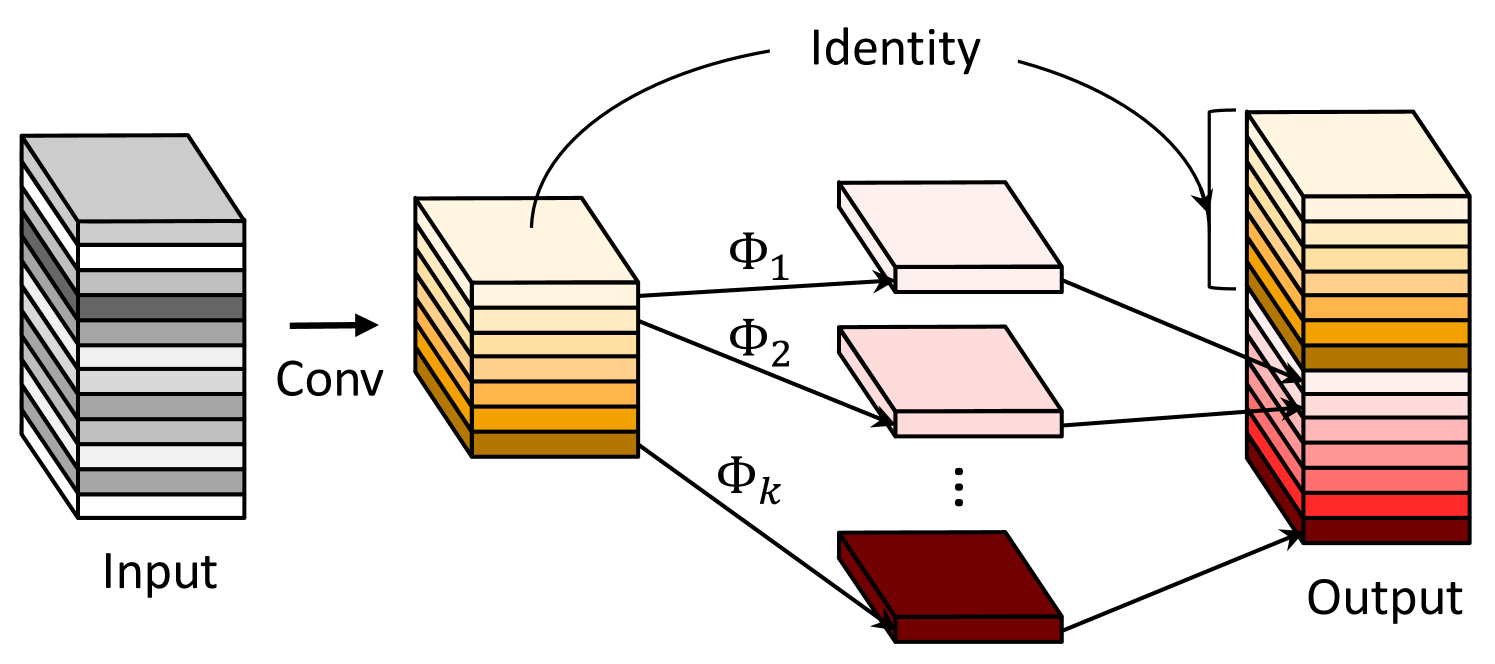
根据方程。 1,要优化的参数数量(在和中)由输入和输出特征图的维度明确确定。 如图1所示,卷积层的输出特征图通常包含大量冗余,并且其中一些可能彼此相似。 我们指出,没有必要用大量的 FLOP 和参数来一一生成这些冗余特征图。 假设输出特征图是一些带有一些廉价变换的内在特征图的“幽灵”。 这些内在特征图通常尺寸较小,由普通卷积滤波器产生。 具体来说,内在特征图是使用主卷积生成的:
| (2) |
其中 是所使用的滤波器, 并且为了简单起见,省略了偏置项。 过滤器大小、步长、填充等超参数与普通卷积中的超参数(等式1)相同,以保持空间大小(即。和)的输出特征图一致。 为了进一步获得所需的 特征图,我们建议对 中的每个内在特征应用一系列廉价的线性操作,以根据以下条件生成 鬼特征:以下功能:
| (3) |
其中 是 中的第 个内在特征图,上述函数中的 是 -th(除了最后一个)生成第个鬼特征图的线性操作,也就是说可以有一个或更多鬼特征图。 最后一个是用于保留内在特征图的恒等映射,如图2(b)所示。 通过利用方程。 3,我们可以得到特征图作为Ghost模块的输出数据,如图2(b )。 请注意,线性运算在每个通道上进行操作,其计算成本远低于普通卷积。 实际上,Ghost 模块中可能有多种不同的线性操作,例如、、和线性内核,它们将在实验部分进行分析。
与现有方法的区别。 所提出的 Ghost 模块与现有的高效卷积方案有重大区别。 i) 与广泛使用逐点卷积的[21, 61]中的单元相比,Ghost模块中的主卷积可以具有定制的内核大小。 ii)现有方法[21,44,61,40]采用逐点卷积处理跨通道的特征,然后采用深度卷积处理空间信息。 相比之下,Ghost 模块采用普通卷积首先生成一些固有特征图,然后利用廉价的线性运算来增强特征并增加通道。 iii) 之前的高效架构[21,61,53,28]中处理每个特征图的操作仅限于深度卷积或移位操作,而Ghost模块中的线性操作可以具有很大的多样性。 iv) 此外,恒等映射与 Ghost 模块中的线性变换并行,以保留内在特征图。
复杂性分析。 因为我们可以利用方程式中提出的 Ghost 模块。 3 为了生成与普通卷积层相同数量的特征图,我们可以轻松地将 Ghost 模块集成到现有精心设计的神经架构中,以降低计算成本。 这里我们进一步分析使用Ghost模块对内存使用和理论加速的好处。 例如,有恒等映射和线性操作,并且每个线性操作的平均内核大小等于。 理想情况下,线性运算可以具有不同的形状和参数,但是在线推理将受到阻碍,特别是考虑到CPU或GPU卡的效用。 因此,我们建议在一个 Ghost 模块中采用相同大小的线性操作(例如. 或 )高效实施。 用Ghost模块升级普通卷积的理论加速比为
| (4) | ||||
其中 的大小与 和 的大小相似。 类似地,压缩比可以计算为
| (5) |
这等于利用建议的 Ghost 模块的加速比。
| Input | Operator | #exp | #out | SE | Stride |
|---|---|---|---|---|---|
| Conv2d 33 | - | 16 | - | 2 | |
| G-bneck | 16 | 16 | - | 1 | |
| G-bneck | 48 | 24 | - | 2 | |
| G-bneck | 72 | 24 | - | 1 | |
| G-bneck | 72 | 40 | 1 | 2 | |
| G-bneck | 120 | 40 | 1 | 1 | |
| G-bneck | 240 | 80 | - | 2 | |
| G-bneck | 200 | 80 | - | 1 | |
| G-bneck | 184 | 80 | - | 1 | |
| G-bneck | 184 | 80 | - | 1 | |
| G-bneck | 480 | 112 | 1 | 1 | |
| G-bneck | 672 | 112 | 1 | 1 | |
| G-bneck | 672 | 160 | 1 | 2 | |
| G-bneck | 960 | 160 | - | 1 | |
| G-bneck | 960 | 160 | 1 | 1 | |
| G-bneck | 960 | 160 | - | 1 | |
| G-bneck | 960 | 160 | 1 | 1 | |
| Conv2d 11 | - | 960 | - | 1 | |
| AvgPool 77 | - | - | - | - | |
| Conv2d 11 | - | 1280 | - | 1 | |
| FC | - | 1000 | - | - |
3.2构建高效的 CNN
幽灵瓶颈。
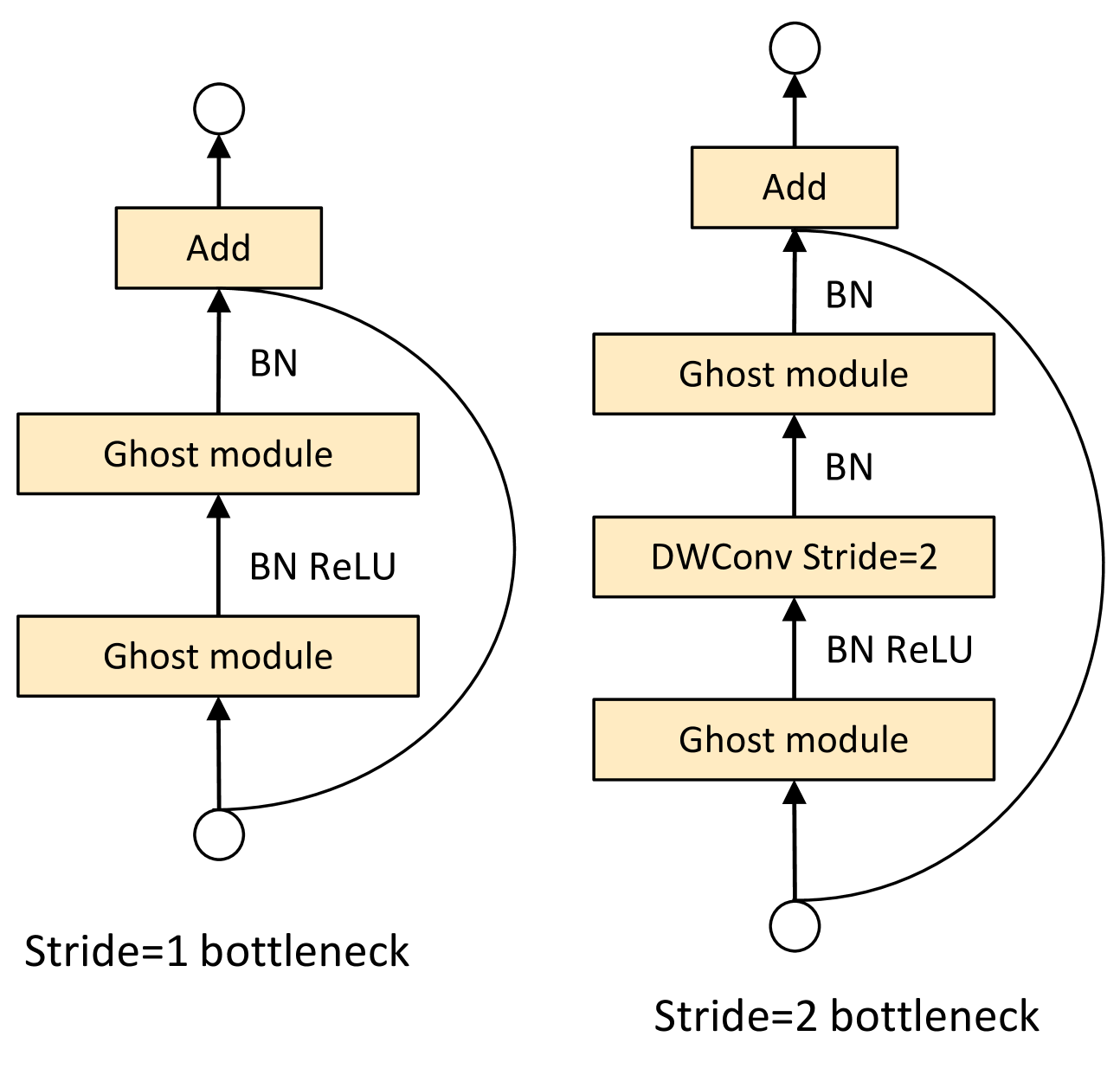
利用 Ghost 模块的优点,我们引入了专为小型 CNN 设计的 Ghost 瓶颈(G-bneck)。 如图3所示,Ghost瓶颈似乎类似于ResNet [16]中的基本残差块,其中集成了多个卷积层和快捷方式。 所提出的 Ghost 瓶颈主要由两个堆叠的 Ghost 模块组成。 第一个 Ghost 模块充当扩展层,增加通道数量。 我们将输出通道数与输入通道数之间的比率称为扩展比。 第二个 Ghost 模块减少了通道数量以匹配快捷路径。 然后将快捷方式连接在这两个 Ghost 模块的输入和输出之间。 批量归一化 (BN) [25] 和 ReLU 非线性在每一层之后应用,但按照 MobileNetV2 [44] 的建议,在第二个 Ghost 模块之后不使用 ReLU 。 上述 Ghost 瓶颈是针对 stride=1 的情况。 对于stride=2的情况,捷径由下采样层实现,并在两个Ghost模块之间插入stride=2的深度卷积。 实际上,这里的 Ghost 模块中的主要卷积是逐点卷积,以提高其效率。
幽灵网。
基于 Ghost 瓶颈,我们提出了 GhostNet,如表 7 所示。 我们基本上遵循 MobileNetV3 [20] 的架构的优越性,并用我们的 Ghost 瓶颈替换 MobileNetV3 中的瓶颈块。 GhostNet主要由一堆Ghost瓶颈组成,以Ghost模块为构建块。 第一层是具有 16 个滤波器的标准卷积层,然后是一系列通道逐渐增加的 Ghost 瓶颈。 这些 Ghost 瓶颈根据其输入特征图的大小分为不同的阶段。 所有 Ghost 瓶颈均采用 stride=1,但每个阶段的最后一个瓶颈均采用 stride=2。 最后利用全局平均池化和卷积层将特征图转换为1280维特征向量以进行最终分类。 挤压和激励(SE)模块[22]也应用于一些幽灵瓶颈中的残留层,如表7所示。 与 MobileNetV3 相比,我们不使用 Hard-swish 非线性函数,因为它的延迟较大。 所提出的架构提供了一个基本设计可供参考,尽管进一步的超参数调整或基于ghost模块的自动架构搜索将进一步提高性能。
宽度乘数。
虽然表7中给定的架构已经可以提供低延迟和有保证的准确性,但在某些场景下,我们可能需要更小、更快的模型或特定任务的更高准确性。 为了根据所需需求定制网络,我们可以简单地在每层统一的通道数量上乘以一个因子 。 这个因子被称为宽度乘数,因为它可以改变整个网络的宽度。 我们将宽度乘数 的 GhostNet 表示为 GhostNet-。 宽度乘数可以以大约的二次方方式控制模型大小和计算成本。 通常较小的 会导致较低的延迟和较低的性能,反之亦然。
4实验
在本节中,我们首先用提出的 Ghost 模块替换原始卷积层以验证其有效性。 然后,使用新模块构建的 GhostNet 架构将在图像分类和目标检测基准上进行进一步测试。
数据集和设置。
为了验证所提出的 Ghost 模块和 GhostNet 架构的有效性,我们在几个基准视觉数据集上进行了实验,包括 CIFAR-10 [29]、ImageNet ILSVRC 2012 数据集 [8] 和 MS COCO 对象检测基准[34]。
CIFAR-10数据集用于分析所提出方法的属性,该数据集由10个类别的60,000张彩色图像组成,其中50,000张训练图像和10,000张测试图像。 采用常见的数据增强方案,包括随机裁剪和镜像[16, 18]。 ImageNet 是一个大规模图像数据集,包含超过 1.2 个训练图像和 50 个验证图像,属于 1,000 个类别。 期间应用了常见的数据预处理策略,包括随机裁剪和翻转训练[16]。 我们还在 MS COCO 数据集[34]上进行了对象检测实验。 遵循常见做法 [32, 33],我们在 COCO trainval35k 分割上训练模型(80 图像和随机 35 验证集中的图像子集),并使用 5 图像对 minival 分割进行评估。
4.1 Ghost模块效率
4.1.1玩具实验。
我们在图1中展示了一个图表来指出存在一些相似的特征图对,可以使用一些高效的线性运算来有效地生成这些特征图对。 在这里,我们首先进行一个玩具实验来观察原始特征图和生成的鬼特征图之间的重建误差。 以图1中的三对(即.红色、贪婪和蓝色)为例,使用ResNet的第一个残差块提取特征-50 [16]。 将左边的特征作为输入,另一个作为输出,我们利用一个小的深度卷积滤波器来学习映射,即。线性运算 他们之间。 卷积滤波器的大小范围为到,每对具有不同的MSE(均方误差)值>如表2所示。
| MSE () | =1 | =3 | =5 | =7 |
|---|---|---|---|---|
| red pair | ||||
| green pair | ||||
| blue pair |
从表2中可以发现,所有的MSE值都非常小,这表明深度神经网络中的特征图之间存在很强的相关性,并且这些冗余特征图可以由多个内在特征图生成。 除了上述实验中使用的卷积之外,我们还可以探索一些其他低成本的线性运算来构造 Ghost 模块,例如仿射变换和小波变换。 然而,卷积是当前硬件已经很好支持的高效运算,它可以涵盖许多广泛使用的线性运算,例如平滑、模糊、运动等等。 此外,尽管我们还可以了解每个过滤器的大小。 线性运算、不规则模块会降低计算单元(例如.CPU和GPU)的效率。 因此,我们建议让 Ghost 模块中的 为固定值,并利用深度卷积来实现式(1)。 3 用于在后续实验中构建高效的深度神经网络。
| Weights (M) | FLOPs (M) | Acc. (%) | |
|---|---|---|---|
| VGG-16 | 15.0 | 313 | 93.6 |
| 1 | 7.6 | 157 | 93.5 |
| 3 | 7.7 | 158 | 93.7 |
| 5 | 7.7 | 160 | 93.4 |
| 7 | 7.7 | 163 | 93.1 |
| Weights (M) | FLOPs (M) | Acc. (%) | |
|---|---|---|---|
| VGG-16 | 15.0 | 313 | 93.6 |
| 2 | 7.7 | 158 | 93.7 |
| 3 | 5.2 | 107 | 93.4 |
| 4 | 4.0 | 80 | 93.0 |
| 5 | 3.3 | 65 | 92.9 |
4.1.2CIFAR-10。
我们在两种流行的网络架构上评估了所提出的 Ghost 模块,即。 VGG-16 [46] 和 ResNet-56 [16 ],在 CIFAR-10 数据集上。 由于VGG-16最初是为ImageNet设计的,因此我们使用其在文献中广泛使用的变体[60]来进行以下实验。 这两个模型中的所有卷积层都被所提出的 Ghost 模块取代,新模型分别表示为 Ghost-VGG-16 和 Ghost-ResNet-56。 我们的训练策略严格遵循[16]中的设置,包括动量、学习率、等。我们首先分析 Ghost 模块中两个超参数 和 的影响,然后将 Ghost 模型与最先进的方法进行比较。
超参数分析。
如方程式中所述。 3,提出的用于高效深度神经网络的 Ghost 模块有两个超参数,即. ,用于生成 内在特征图,以及用于计算鬼影的线性运算的内核大小(即。深度卷积滤波器的大小)特征图。 在VGG-16架构上测试了这两个参数的影响。
首先,我们修复并调整中的,并在表3中列出CIFAR-10验证集上的结果。 我们可以看到,建议的带有 的 Ghost 模块比更小或更大的模块性能更好。 这是因为 大小的核无法在特征图上引入空间信息,而 或 等更大的核会导致过度拟合和更多计算。 因此,为了有效性和效率,我们在接下来的实验中采用。
在研究了提议的 Ghost 模块中使用的内核大小后,我们保留 并将另一个超参数 调整在 范围内。 事实上,与最终网络的计算成本直接相关,即较大的会导致较大的压缩比和加速比,如式(1)所示。 5 和等式。 4。 从表4的结果来看,当我们增加时,FLOPs显着减少,并且准确率逐渐下降,这与预期一致。 特别是当(即通过压缩VGG-16)时,我们的方法的性能甚至比原始模型稍好,表明所提出的Ghost模块的优越性。
| Model | Weights | FLOPs | Acc. (%) |
|---|---|---|---|
| VGG-16 | 15M | 313M | 93.6 |
| -VGG-16 [31, 37] | 5.4M | 206M | 93.4 |
| SBP-VGG-16 [18] | - | 136M | 92.5 |
| Ghost-VGG-16 (=2) | 7.7M | 158M | 93.7 |
| ResNet-56 | 0.85M | 125M | 93.0 |
| CP-ResNet-56 [18] | - | 63M | 92.0 |
| -ResNet-56 [31, 37] | 0.73M | 91M | 92.5 |
| AMC-ResNet-56 [17] | - | 63M | 91.9 |
| Ghost-ResNet-56 (=2) | 0.43M | 63M | 92.7 |
| Model | Weights (M) | FLOPs (B) | Top-1 Acc. (%) | Top-5 Acc. (%) |
|---|---|---|---|---|
| ResNet-50 [16] | 25.6 | 4.1 | 75.3 | 92.2 |
| Thinet-ResNet-50 [39] | 16.9 | 2.6 | 72.1 | 90.3 |
| NISP-ResNet-50-B [59] | 14.4 | 2.3 | - | 90.8 |
| Versatile-ResNet-50 [49] | 11.0 | 3.0 | 74.5 | 91.8 |
| SSS-ResNet-50 [23] | - | 2.8 | 74.2 | 91.9 |
| Ghost-ResNet-50 (=2) | 13.0 | 2.2 | 75.0 | 92.3 |
| Shift-ResNet-50 [53] | 6.0 | - | 70.6 | 90.1 |
| Taylor-FO-BN-ResNet-50 [41] | 7.9 | 1.3 | 71.7 | - |
| Slimmable-ResNet-50 0.5 [58] | 6.9 | 1.1 | 72.1 | - |
| MetaPruning-ResNet-50 [36] | - | 1.0 | 73.4 | - |
| Ghost-ResNet-50 (=4) | 6.5 | 1.2 | 74.1 | 91.9 |
与最先进的技术比较。
我们将 Ghost-Net 与 VGG-16 和 ResNet-56 架构上的几个代表性的最先进模型进行比较。 比较的方法包括不同类型的模型压缩方法,剪枝[31, 37]、SBP [18]、通道剪枝(CP)[18] 和 AMC [17]。 对于VGG-16,我们的模型可以在2加速度下获得比原始模型略高的精度,这表明VGG模型中存在相当大的冗余。 我们的 Ghost-VGG-16 () 的性能优于竞争对手,性能最高 (),但 FLOP 数显着减少。 对于已经比 VGG-16 小得多的 ResNet-56,我们的模型可以以 2 加速实现与基线相当的精度。 我们还可以看到,具有相似或更大计算成本的其他最先进模型的准确性低于我们的模型。
特征图的可视化。
我们还可视化了 Ghost 模块的特征图,如图 4 所示。 尽管生成的特征图来自主特征图,但它们确实具有显着差异,这意味着生成的特征足够灵活,可以满足特定任务的需要。


4.1.3 ImageNet 上的大型模型
接下来我们将 Ghost 模块嵌入到标准 ResNet-50 [16] 中,并在大规模 ImageNet 数据集上进行实验。 ResNet-50 有大约 25.6M 参数和 4.1B FLOP,top-5 错误为 。 我们使用 Ghost 模块替换 ResNet-50 中的所有卷积层以获得紧凑的模型,并将结果与几种最先进的方法进行比较,如表 6 所示。 为了公平比较,优化器、学习率和批量大小等训练设置与[16]中的设置完全相同。
从表6的结果可以看出,我们的Ghost-ResNet-50(=2)获得了大约2的加速和压缩比,同时保持原始 ResNet-50 的精度。 与最近最先进的方法相比,包括 Thinet [39]、NISP [59]、Versatile 过滤器 [49] 和稀疏结构选择(SSS)[23],我们的方法在2加速度设置下可以获得明显更好的性能。 当我们进一步将 增加到 4 时,基于 Ghost 的模型仅出现 精度下降,计算加速比约为 4。 相反,具有相似权重或 FLOP 的比较方法 [53, 58] 的性能比我们的方法低得多。
4.2 视觉基准上的 GhostNet
在证明了所提出的 Ghost 模块在有效生成特征图方面的优越性后,我们分别使用图像分类和目标检测任务上的 Ghost 瓶颈来评估精心设计的 GhostNet 架构,如表 7 所示。
4.2.1 ImageNet分类
为了验证所提出的 GhostNet 的优越性,我们在 ImageNet 分类任务上进行了实验。 我们遵循 [61] 中使用的大部分训练设置,不同之处在于,当 8 个 GPU 上的批量大小为 1,024 时,初始学习率设置为 0.4。 所有结果均在 ImageNet 验证集上以单一作物 top-1 性能报告。 对于 GhostNet,为了简单起见,我们在主卷积中设置内核大小 ,在所有 Ghost 模块中设置 和 。
选取几种现代小型网络架构作为参赛者,包括MobileNet系列[21, 44, 20]、ShuffleNet系列[61, 40]、ProxylessNAS[2] 、FBNet [52]、MnasNet [47]、等。 结果总结于表7中。 这些模型通常分为移动应用程序的三个计算复杂度级别,即。50、150 和200-300 MFLOP。 从结果中我们可以看到,通常较大的 FLOP 会导致这些小型网络的准确性更高,这表明了它们的有效性。 我们的 GhostNet 在各种计算复杂度级别上始终优于其他竞争对手,因为 GhostNet 在利用计算资源生成特征图方面更加高效。
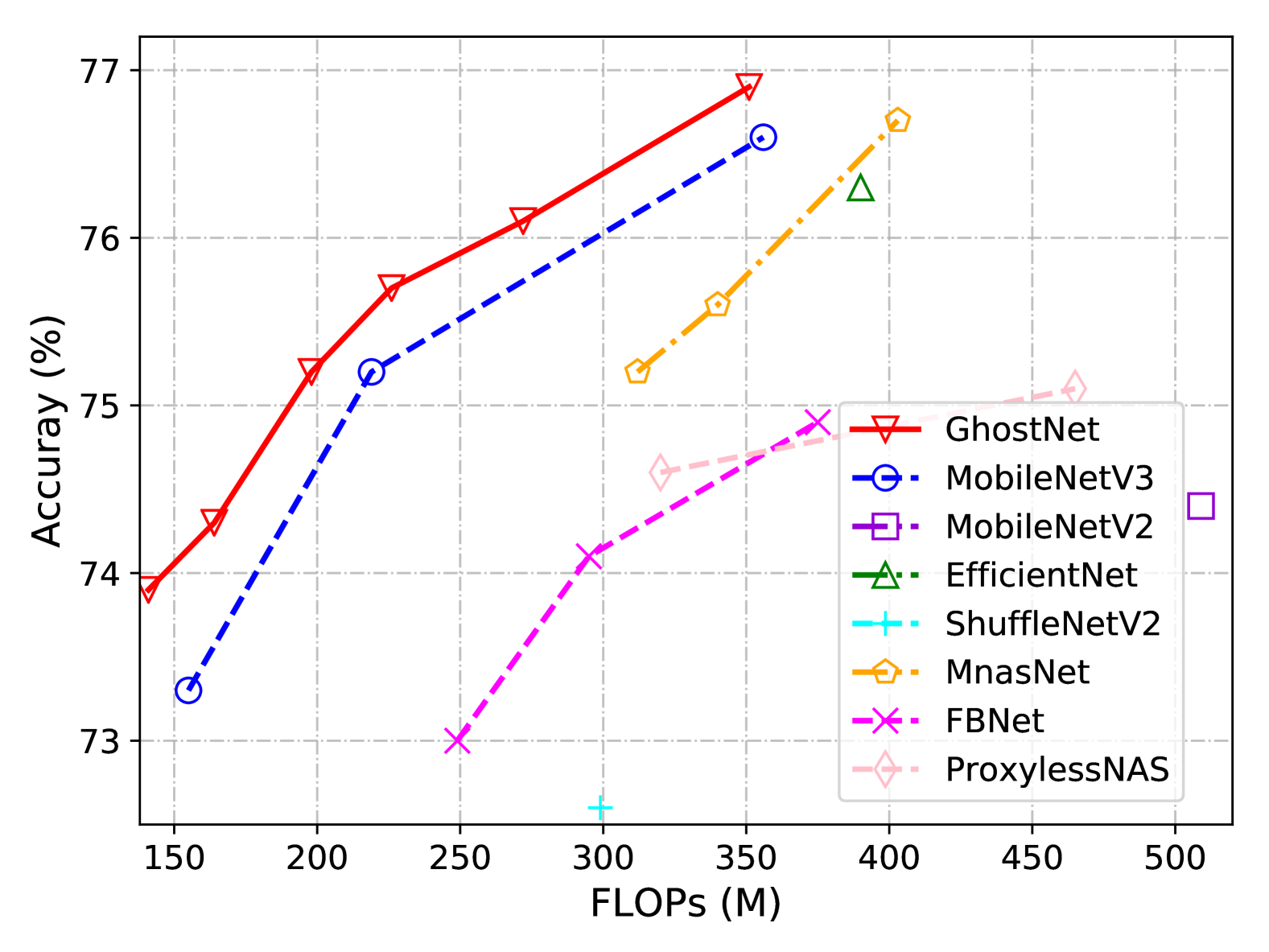
| Model | Weights (M) | FLOPs (M) | Top-1 Acc. (%) | Top-5 Acc. (%) |
|---|---|---|---|---|
| ShuffleNetV1 0.5 (g=8) [61] | 1.0 | 40 | 58.8 | 81.0 |
| MobileNetV2 0.35 [44] | 1.7 | 59 | 60.3 | 82.9 |
| ShuffleNetV2 0.5 [40] | 1.4 | 41 | 61.1 | 82.6 |
| MobileNetV3 Small 0.75 [20] | 2.4 | 44 | 65.4 | - |
| GhostNet 0.5 | 2.6 | 42 | 66.2 | 86.6 |
| MobileNetV1 0.5 [21] | 1.3 | 150 | 63.3 | 84.9 |
| MobileNetV2 0.6 [44, 40] | 2.2 | 141 | 66.7 | - |
| ShuffleNetV1 1.0 (g=3) [61] | 1.9 | 138 | 67.8 | 87.7 |
| ShuffleNetV2 1.0 [40] | 2.3 | 146 | 69.4 | 88.9 |
| MobileNetV3 Large 0.75 [20] | 4.0 | 155 | 73.3 | - |
| GhostNet 1.0 | 5.2 | 141 | 73.9 | 91.4 |
| MobileNetV2 1.0 [44] | 3.5 | 300 | 71.8 | 91.0 |
| ShuffleNetV2 1.5 [40] | 3.5 | 299 | 72.6 | 90.6 |
| FE-Net 1.0 [6] | 3.7 | 301 | 72.9 | - |
| FBNet-B [52] | 4.5 | 295 | 74.1 | - |
| ProxylessNAS [2] | 4.1 | 320 | 74.6 | 92.2 |
| MnasNet-A1 [47] | 3.9 | 312 | 75.2 | 92.5 |
| MobileNetV3 Large 1.0 [20] | 5.4 | 219 | 75.2 | - |
| GhostNet 1.3 | 7.3 | 226 | 75.7 | 92.7 |
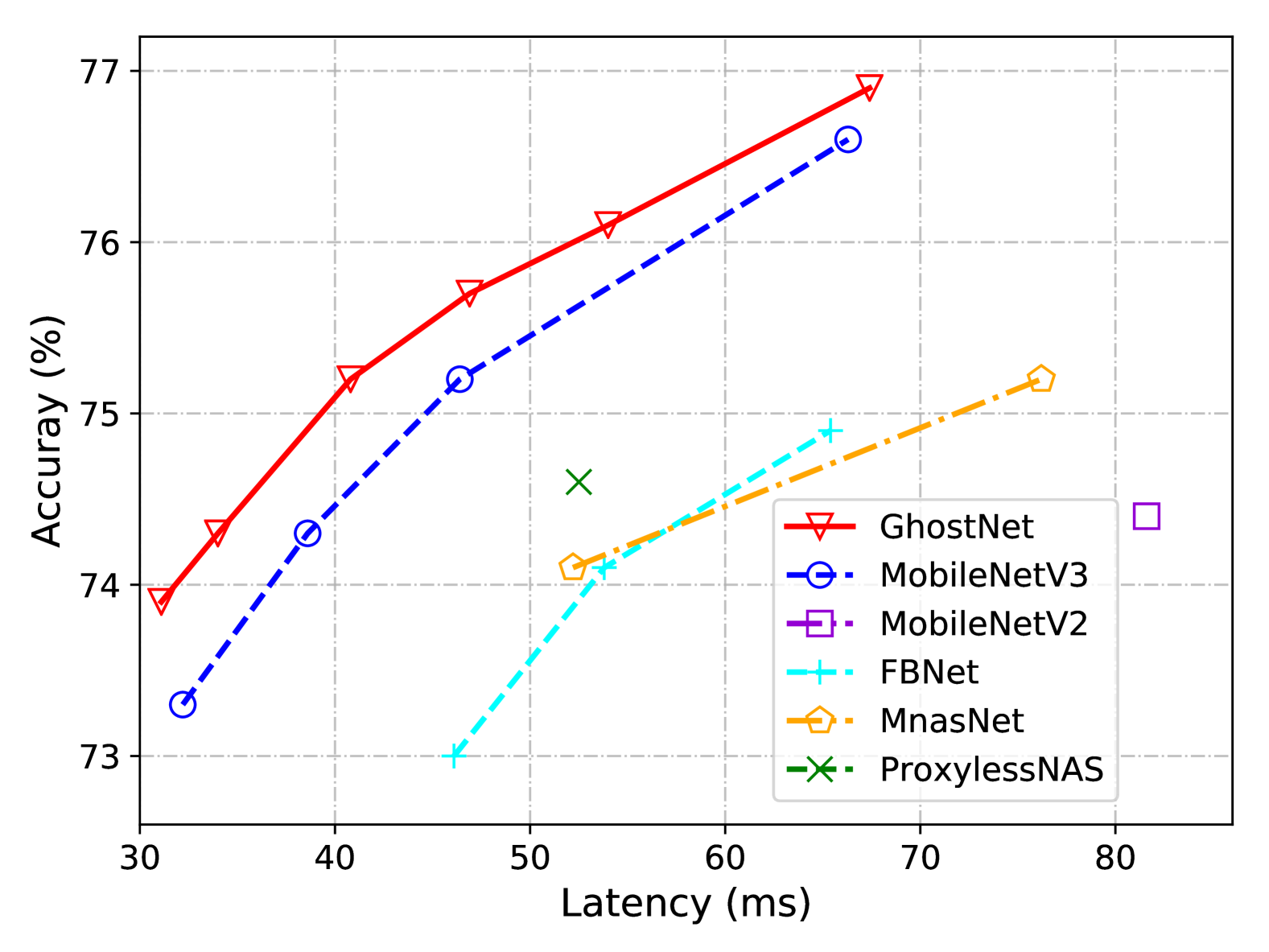
实际推理速度。
由于所提出的 GhostNet 是为移动应用程序设计的,因此我们使用 TFLite 工具[1]进一步测量了 GhostNet 在基于 ARM 的手机上的实际推理速度。 遵循[21, 44]中的常见设置,我们使用批量大小为1的单线程模式。 从图7的结果中,我们可以看到,在相同延迟的情况下,GhostNet比MobileNetV3获得了约0.5%的top-1准确率,并且GhostNet需要更少的运行时间来实现相似的性能。 例如,精度为 75.0% 的 GhostNet 仅具有 40 毫秒的延迟,而具有相似精度的 MobileNetV3 处理一张图像大约需要 45 毫秒。 总体而言,我们的模型通常优于著名的最先进模型,即。 MobileNet 系列[21, 44, 20],ProxylessNAS [2]、FBNet [52] 和 MnasNet [47]。
4.2.2 物体检测
为了进一步评估GhostNet的泛化能力,我们在MS COCO数据集上进行了目标检测实验。 我们使用 trainval35k 训练 分割作为数据,并按照 [32, 33] 在 minival 分割上以平均精度 (mAP) 报告结果。 带有特征金字塔网络 (FPN) [43, 32] 的两阶段 Faster R-CNN 和单阶段 RetinaNet [33] 都用作我们的框架GhostNet 充当主干特征提取器的直接替代品。 我们使用 SGD 从 ImageNet 预训练权重中使用 SGD 训练所有模型,并使用 [32, 33] 中建议的超参数。 输入图像的大小调整为短边不超过800,长边不超过1333。 表 8 显示了检测结果,其中 FLOP 是使用 图像作为常见做法计算的。 GhostNet 凭借显着降低的计算成本,在一级 RetinaNet 和两级 Faster R-CNN 框架上实现了与 MobileNetV2 和 MobileNetV3 类似的 mAP。
| Backbone |
|
|
mAP | ||||
|---|---|---|---|---|---|---|---|
| MobileNetV2 1.0 [44] | RetinaNet | 300M | 26.7% | ||||
| MobileNetV3 1.0 [20] | 219M | 26.4% | |||||
| GhostNet 1.1 | 164M | 26.6% | |||||
| MobileNetV2 1.0 [44] | Faster R-CNN | 300M | 27.5% | ||||
| MobileNetV3 1.0 [20] | 219M | 26.9% | |||||
| GhostNet 1.1 | 164M | 26.9% |
5结论
为了降低近期深度神经网络的计算成本,本文提出了一种新颖的 Ghost 模块,用于构建高效的神经架构。 基本的 Ghost 模块将原始卷积层分成两部分,并利用更少的滤波器来生成几个内在特征图。 然后,将进一步应用一定数量的廉价变换操作来有效地生成鬼特征图。 在基准模型和数据集上进行的实验表明,所提出的方法是一个即插即用的模块,用于将原始模型转换为紧凑模型,同时保持可比较的性能。 此外,使用所提出的新模块构建的 GhostNet 在效率和准确性方面都优于最先进的便携式神经架构。
致谢
我们感谢匿名审稿人的有益评论。 Chang Xu 得到了澳大利亚研究委员会 DE180101438 项目的支持。
参考
- [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- [2] Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. In ICLR, 2019.
- [3] Hanting Chen, Yunhe Wang, Chang Xu, Zhaohui Yang, Chuanjian Liu, Boxin Shi, Chunjing Xu, Chao Xu, and Qi Tian. Data-free learning of student networks. In ICCV, 2019.
- [4] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2016.
- [5] Wuyang Chen, Xinyu Gong, Xianming Liu, Qian Zhang, Yuan Li, and Zhangyang Wang. Fasterseg: Searching for faster real-time semantic segmentation. In ICLR, 2020.
- [6] Weijie Chen, Di Xie, Yuan Zhang, and Shiliang Pu. All you need is a few shifts: Designing efficient convolutional neural networks for image classification. In CVPR, 2019.
- [7] François Chollet. Xception: Deep learning with depthwise separable convolutions. In CVPR, pages 1251–1258, 2017.
- [8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009.
- [9] Emily L Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Exploiting linear structure within convolutional networks for efficient evaluation. In NeurIPS, pages 1269–1277, 2014.
- [10] Xinyu Gong, Shiyu Chang, Yifan Jiang, and Zhangyang Wang. Autogan: Neural architecture search for generative adversarial networks. In ICCV, 2019.
- [11] Shupeng Gui, Haotao N Wang, Haichuan Yang, Chen Yu, Zhangyang Wang, and Ji Liu. Model compression with adversarial robustness: A unified optimization framework. In NeurIPS, 2019.
- [12] Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In NeurIPS, 2018.
- [13] Kai Han, Jianyuan Guo, Chao Zhang, and Mingjian Zhu. Attribute-aware attention model for fine-grained representation learning. In ACM MM, 2018.
- [14] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In ICLR, 2016.
- [15] Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. In NeurIPS, pages 1135–1143, 2015.
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- [17] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. Amc: Automl for model compression and acceleration on mobile devices. In ECCV, 2018.
- [18] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks. In ICCV, 2017.
- [19] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [20] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In ICCV, 2019.
- [21] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [22] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018.
- [23] Zehao Huang and Naiyan Wang. Data-driven sparse structure selection for deep neural networks. In ECCV, pages 304–320, 2018.
- [24] Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks. In NeurIPS, pages 4107–4115, 2016.
- [25] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
- [26] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In CVPR, pages 2704–2713, 2018.
- [27] Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. Speeding up convolutional neural networks with low rank expansions. In BMVC, 2014.
- [28] Yunho Jeon and Junmo Kim. Constructing fast network through deconstruction of convolution. In NeurIPS, 2018.
- [29] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009.
- [30] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, pages 1097–1105, 2012.
- [31] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. In ICLR, 2017.
- [32] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
- [33] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, 2017.
- [34] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV. Springer, 2014.
- [35] Chuanjian Liu, Yunhe Wang, Kai Han, Chunjing Xu, and Chang Xu. Learning instance-wise sparsity for accelerating deep models. In IJCAI, 2019.
- [36] Zechun Liu, Haoyuan Mu, Xiangyu Zhang, Zichao Guo, Xin Yang, Tim Kwang-Ting Cheng, and Jian Sun. Metapruning: Meta learning for automatic neural network channel pruning. In ICCV, 2019.
- [37] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. In ICLR, 2019.
- [38] Zechun Liu, Baoyuan Wu, Wenhan Luo, Xin Yang, Wei Liu, and Kwang-Ting Cheng. Bi-real net: Enhancing the performance of 1-bit cnns with improved representational capability and advanced training algorithm. In ECCV, 2018.
- [39] Jian-Hao Luo, Jianxin Wu, and Weiyao Lin. Thinet: A filter level pruning method for deep neural network compression. In ICCV, pages 5058–5066, 2017.
- [40] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In ECCV, 2018.
- [41] Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruning. In CVPR, 2019.
- [42] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. In ECCV, pages 525–542. Springer, 2016.
- [43] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
- [44] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, pages 4510–4520, 2018.
- [45] Mingzhu Shen, Kai Han, Chunjing Xu, and Yunhe Wang. Searching for accurate binary neural architectures. In ICCV Workshops, 2019.
- [46] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
- [47] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. In CVPR, pages 2820–2828, 2019.
- [48] Yue Wang, Ziyu Jiang, Xiaohan Chen, Pengfei Xu, Yang Zhao, Yingyan Lin, and Zhangyang Wang. E2-train: Training state-of-the-art cnns with over 80% energy savings. In NeurIPS, 2019.
- [49] Yunhe Wang, Chang Xu, Chunjing XU, Chao Xu, and Dacheng Tao. Learning versatile filters for efficient convolutional neural networks. In NeurIPS, 2018.
- [50] Yunhe Wang, Chang Xu, Shan You, Dacheng Tao, and Chao Xu. Cnnpack: packing convolutional neural networks in the frequency domain. In NeurIPS, pages 253–261, 2016.
- [51] Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks. In NeurIPS, pages 2074–2082, 2016.
- [52] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In CVPR, pages 10734–10742, 2019.
- [53] Bichen Wu, Alvin Wan, Xiangyu Yue, Peter Jin, Sicheng Zhao, Noah Golmant, Amir Gholaminejad, Joseph Gonzalez, and Kurt Keutzer. Shift: A zero flop, zero parameter alternative to spatial convolutions. In CVPR, 2018.
- [54] Yixing Xu, Yunhe Wang, Hanting Chen, Kai Han, XU Chunjing, Dacheng Tao, and Chang Xu. Positive-unlabeled compression on the cloud. In NeurIPS, 2019.
- [55] Zhaohui Yang, Yunhe Wang, Xinghao Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, and Chang Xu. Cars: Continuous evolution for efficient neural architecture search. arXiv preprint arXiv:1909.04977, 2019.
- [56] Zhaohui Yang, Yunhe Wang, Chuanjian Liu, Hanting Chen, Chunjing Xu, Boxin Shi, Chao Xu, and Chang Xu. Legonet: Efficient convolutional neural networks with lego filters. In ICML, 2019.
- [57] Shan You, Chang Xu, Chao Xu, and Dacheng Tao. Learning from multiple teacher networks. In SIGKDD, 2017.
- [58] Jiahui Yu, Linjie Yang, Ning Xu, Jianchao Yang, and Thomas Huang. Slimmable neural networks. In ICLR, 2019.
- [59] Ruichi Yu, Ang Li, Chun-Fu Chen, Jui-Hsin Lai, Vlad I Morariu, Xintong Han, Mingfei Gao, Ching-Yung Lin, and Larry S Davis. Nisp: Pruning networks using neuron importance score propagation. In CVPR, 2018.
- [60] Sergey Zagoruyko. 92.45 on cifar-10 in torch, 2015. URL http://torch.ch/blog/2015/07/30/cifar. html.
- [61] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. CVPR, 2018.
- [62] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V Le. Learning transferable architectures for scalable image recognition. In CVPR, pages 8697–8710, 2018.