公平主动学习
摘要。
机器学习 (ML) 越来越多地被用于影响社会的重大利益应用中。 因此,至关重要的是 ML 模型不传播歧视。 在社会应用中收集准确的标记数据具有挑战性且成本高昂。 主动学习是一种很有前途的方法,它可以通过在标记预算内交互式地查询预言机来构建准确的分类器。 我们设计了公平主动学习算法,该算法仔细选择要标记的数据点,以平衡模型的准确性和公平性。 我们使用人口统计学一致性和均衡几率公平概念,在广泛使用的基准数据集上证明了我们提出的算法的有效性和效率。
1. 绪论
数据驱动的决策在现代社会中发挥着重要作用,它使明智的决策成为可能,并使社会更加公正、繁荣、包容和安全。 但是,这带来了很多责任,因为数据科学技术的开发不当不仅会失败,还会使情况更糟。 例如,美国法院的法官使用刑事评估算法,该算法基于个人的背景信息来设定保释金或判处罪犯。 虽然这可能潜在地导致更安全的社会,但使用不当会导致对人们生活的有害后果。 例如,为法官提供的累犯分数受到高度批评,因为它们对非裔美国人(Angwin 等人,2016) 的风险评估更高。
机器学习 (ML) 是数据驱动决策的核心,因为它根据现有观察结果提供关于现象的洞察性未知信息。 ML 模型结果不公平的两个主要原因是 训练数据中的偏差 和 代理属性。 前者主要是由于历史数据中固有的偏差(歧视)造成的,这些偏差反映了社会的不公正。 例如,红线区是过去针对特定种族社区的系统性服务拒绝,影响了历史数据记录 (Jan, 2018)。 另一方面,代理属性通常由于标记数据的获取有限而使用,尤其是在涉及社会应用时。 例如,当无法获取个人的实际未来再犯记录时,人们可能会求助于“先前逮捕”等易于收集的信息,并将其用作真实标签的代理,尽管这是一个歧视性的标签。
例子 0。
一家公司有兴趣创建一个预测再犯的模型,供法官在设定保释金时使用;他们希望预测一个人将来犯下罪行的可能性。 假设该公司可以访问一些刑事被告的背景信息 111 在美国,这些信息由各县的警长办公室提供。 例如,对于 COMPAS 数据集,ProPublica 使用了从布劳沃德县警长办公室获得的信息。 https://bit.ly/36CTc2F. 但是,收集到的数据没有标记。 这是因为在审判时没有证据表明一个人将来是否会犯罪。 考虑一个时间窗口,可以通过检查个人在释放后的时间窗口内背景信息来标记数据集中的人。 但是,这很昂贵,因为它可能需要专家来进行数据收集、集成和实体解析。
例子 0。
一家贷款咨询公司希望为金融机构创建一个模型,以识别“有价值的客户”,这些客户将按时偿还贷款。 该公司收集了一个包含过去几年中获得贷款的客户数据集。 该数据集包含诸如人口统计、教育和个人收入水平等信息。 不幸的是,在批准贷款时,无法确定客户是否会按时偿还债务,因此数据未被标记。 然而,该公司已经聘请了专家,他们根据过去批准的申请人的信息,可以核实他们的背景,并评估他们是否按时付款。 当然,考虑到与背景调查相关的成本,自由标记所有客户是不可行的。
以上两个例子都使用有偏差的历史数据来构建他们的模型。 例如,示例 2 中的 收入 众所周知包含性别偏差 (Jones, 1983)。 同样,在示例 1 中使用 先前计数 作为代理属性是有种族偏见的 (Angwin et al., 2016)。 此外,在这两个例子中,数据集都是未标记的。
机器学习中的一种新的 公平性 范式 (Barocas et al., 2019) 已经出现,旨在解决预测结果的不公平问题。 这些工作通常假设有足够数量的(可能是有偏差的) 标记数据。 当这个假设被违反时,它们的性能会下降。 在许多实际的社会应用中,例如示例 1,人们在一个受约束的环境中运作。 获取准确的标记数据成本高昂,并且只能以有限的数量获取。 通过使用(有问题的)代理属性作为真实标签来训练模型 2 22在本文的其余部分,我们将真实标签称为标签。 将会导致一个不公平的模型。
在这项工作中,我们的目标是在获得的标记数据预算有限的环境中,开发用于公平模型的有效算法。 主动学习 (Settles, 2012) 是在这种情况下广泛使用的策略。 它依次选择那些对 ML 模型性能改进最有利的未标记实例进行标记。
在本文中,我们旨在开发一个主动学习框架,该框架将产生更公平的模型。 公平有不同的定义,并且可以通过多种方式衡量。 具体而言,如果模型的结果不依赖于种族或性别等敏感属性,我们认为该模型是公平的。 我们采用人口统计学平等(也称为统计学平等),这是流行的公平性指标之一 (Kusner et al., 2017; Dwork et al., 2012)。
贡献总结。 我们介绍了在有限标记数据的情况下,构建公平模型的 主动学习中的公平性。 我们提出了一个公平主动学习 (FAL) 框架,以平衡模型性能和公平性(§ 4)。 从高级角度来看,FAL 使用准确性-公平性优化器来选择要标记的样本。 我们为优化器提出了三种策略,即 FAL -aggregate(§ 5.1)、FAL Nested(§ 5.2)和 FAL Nested Append(§ 5.3)。 鉴于在 AL 的背景下,样本点是未标记的, 优化器使用 § 4 中提出的 预期不公平性减少。 对于广义线性模型的特殊情况,我们提出了 协方差公平性(§ 6),这是预期不公平性减少的有效替代方案,它将 FAL 的渐近时间复杂度降低到与传统主动学习 相同。 虽然我们对公平性的默认概念基于人口统计学平等,但我们也提供了对其他公平性模型的扩展(§ 7)。 我们对基准数据集进行了全面实验,以评估我们提议的性能(§ 8)。 我们的结果证实,FAL 可以显著减少不公平,同时不会对模型精度产生重大影响。 特别是,我们的优化 FAL Nested Append 在不同的实验和公平模型中表现最佳,证实了针对准确性-公平性权衡提出的改进。
2. 相关工作
机器学习中的算法公平性。 算法公平性是一个广泛关注的议题,(Barocas et al., 2017; Žliobaitė, 2017; Mehrabi et al., 2019) 提供了关于机器学习中的歧视和公平性的调查。 现有工作已将分类中的公平性公式化为约束优化问题 (Zafar et al., 2017; Menon and Williamson, 2018; Celis et al., 2019; Hardt et al., 2016; Huang and Vishnoi, 2019)。 一系列工作专注于修改分类器,在过程中构建公平的分类器 (Fish et al., 2016; Goh et al., 2016; Dwork et al., 2012; Komiyama et al., 2018; Corbett-Davies et al., 2017)。 另一些则通过预处理训练数据来消除不同影响 (Zemel et al., 2013; Kamiran and Calders, 2012; Feldman et al., 2015; Krasanakis et al., 2018; Asudeh et al., 2019),而最后一组则对模型结果进行后处理以实现公平 (Kim et al., 2018; Hardt et al., 2016; Pleiss et al., 2017; Hébert-Johnson et al., 2017)。 我们的提议与公平的 ML 文献是正交的。 虽然本文的目标是选择要标注的样本,但公平的 ML 算法旨在为给定的一组标注样本构建公平模型。
本文是第一个介绍公平主动学习的论文。 除了本文,我们还了解到一项后续工作考虑了主动学习中的公平性 (Sharaf and Daumé III, [n.d.])。 这项工作的设置与标准主动学习设置不同:不是试图最小化标注数据的数量,(Sharaf and Daumé III, [n.d.]) 从预先存在的标注数据开始,并试图通过标注 额外 样本来最小化差异。 相反,我们处理的是没有标注数据的传统主动学习设置。 公平性也已在一些考虑公平性和主动特征获取交叉点的研究中得到研究 (Noriega-Campero et al., 2019; Bakker et al., 2020)。 我们的工作与这项研究无关,因为我们的目标不是特征获取,而是主动学习。
KDD 社区对公平性的各个方面进行了广泛的研究,包括量化和评估 (Speicher 等人,2018;Srivastava 等人,2019;DiCiccio 等人,2020)、 公平性的权衡 (Corbett-Davies 等人,2017) 以及 应用,如排名 (Beutel 等人,2019)、 搜索和推荐器 (Geyik 等人,2019) 和 真相发现 (Li 等人,2020)。
主动学习。 不同的主动学习场景(成员查询合成、基于流的选择性采样、基于池的主动学习)和采样策略(不确定性采样、委员会查询、预期模型变化、方差减少等)已在 (Settles, 2012) 中提出并进行了概述。 不确定性采样是主动学习中最受欢迎的方法之一 (Lewis 和 Catlett,1994;Balcan 等人,2007;Tong 和 Koller,2001),它仅根据信息量的单一目标函数选择数据点。 为了结合多个采样标准,如代表性 (Xu 等人,2003;Donmez 等人,2007;Huang 等人,2010),已经提出了几种主动学习方法。
3. 背景
本节介绍数据模型、具有不确定性采样启发式方法的主动学习框架以及公平性模型。
3.1. 学习模型
给定一个分类器和一个未标记数据的池 , 主动学习 (AL) 识别要标记的数据点,以便 尽快学习到一个准确的模型。 假设 是从底层未知分布中收集的独立同分布 (i.i.d) 样本集。 对于每个数据点 , 我们使用符号 表示 维输入特征向量 并使用 表示 个特征 的值。 每个数据点都与一个非序数分类敏感属性 相关联, 例如 性别 和 种族。 我们使用符号 表示 的敏感属性。 我们还使用 表示点 的标签,它有 个可能的值 。
目标是学习一个分类函数 , 该函数将特征空间 映射到标签 。 令 为 的预测标签。 基于池的主动学习 (Lewis and Gale, 1994),依次从 中选择实例,由 专家预言机 进行标注,并形成一个用于训练的标注集 。 然而,标注成本高昂,通常 标注预算有限 。 挑战在于设计有效的采样策略,明智地利用预算来构建最准确的模型。 不确定性采样 (Lewis and Gale, 1994) 是一种广泛使用的策略,它选择当前模型对其标签最不确定的点 。 分类器 在第 次迭代中选择最大化香农熵 () (Shannon, 1948) 的数据点,该点对应标签概率。
| (1) |
使用公式 1,主动学习算法迭代地从 中选择下一个要标注的点。 它使用前一步训练的分类器来获得标签的概率。 该算法从标注预言机中获取标签,并将该点添加到标注数据集 中,并使用它来训练分类器 。 这个过程持续进行,直到标注预算用完。
3.2. (不)公平模型
我们在 模型独立性 或 人口统计学一致性 (DP) (Barocas et al., 2019; Žliobaitė, 2017; Zafar et al., 2017) 的概念上发展我们的公平模型,也称为统计一致性 (Dwork et al., 2012; Simoiu et al., 2017) 和歧视性影响 (Barocas and Selbst, 2016; Feldman et al., 2015)。 尽管本文重点关注基于模型独立性的公平性,但在 § 7 中,我们将展示如何将我们的框架扩展到基于分离 () 和充分性 () (Barocas et al., 2019) 的其他指标。 给定一个分类器 和一个具有预测标签 的随机点 ,当且仅当 时,DP 成立 (Barocas et al., 2017, 2019)。 对于二元分类器,令 作为“接受”(如获得贷款)。 DP 要求所有 组的接受率相同,在本例中为女性或男性。 对于二元分类器和二元敏感属性,敏感属性与预测标签的统计独立性会导致 DP 的以下概念:
可以使用上述任何概念来定义差异(或不公平)度量。 子弹 1 或 2 中的绝对差值或概率比提供四种差异测量。 互信息和协方差(或相关性)提供两种自然度量,因为这两者绝对值越大,差异越大。 在本文中,我们不会局限于任何不公平措施(人口统计差异),并赋予用户提供定制措施的自由。 我们将不公平的(用户提供的)度量表示为 。 当 在上下文中明确时,我们将其简化为 。
4. 公平主动学习 (FAL) 框架
通过仔细选择要标注的样本, AL 有可能通过将公平性度量纳入其采样过程来缓解算法偏差。 尽管如此,在构建模型时不考虑公平性会导致模型不公平。 作为一种简单的解决方案,可以决定从训练数据中删除敏感属性。 然而,这并不充分,因为特征中的偏差可能会导致模型不公平 (Buolamwini 和 Gebru,2018;Zou 和 Schiebinger,2018)。 因此,需要一种智能采样策略来缓解偏差。 盲目地优化公平性可能会导致模型不准确。 例如,在示例 1 中,考虑一个随机将个人分类为高风险的模型。 该模型确实满足了人口统计一致性,因为结果的概率是(随机的,因此)与 无关的。 然而,这种模型没有提供有关个人风险程度的任何信息。
我们提出了公平主动学习 (FAL) 框架来平衡准确性和公平性。 FAL 是一种迭代方法,类似于标准主动学习方法。 如图 1 所示,FAL 的核心组成部分是样本选择单元 (SSU),它从 中选择一个未标记点 并从预言机获取标签。 标注点 被移动到 ,即用于训练 的标注点集。 在下一轮迭代中,,SSU 使用 并选择下一个要标记的点。 这个过程持续进行,直到标注预算用尽。
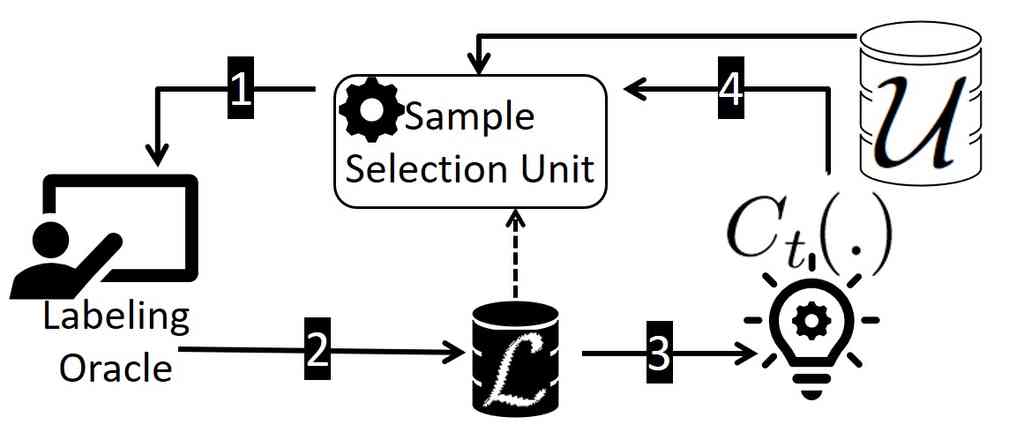
从高层面上来看,SSU 可以被看作是两个计算块堆叠在一起。 上面的块是公平性-准确性优化器,它从 中选择下一个要标记的点,以使准确性(误分类减少)和公平性(不公平性减少)的组合最大化。 我们将在 § 5 中提供此块的详细信息。
准确性-公平性优化器依赖于下面的块来估计不公平性值。 令 为当前模型,在之前的迭代 中创建。 为了评估标记样本点 后的不公平性减少,优化器块需要计算当前模型 的不公平性,以及标记样本点 后模型的不公平性。 计算 证明是有问题的,因为在评估 中的候选点时,我们仍然不知道它们的标签。 另一方面,要评估 ,我们需要知道在标记点 并将其添加到 后模型参数将是什么。 换句话说,为了评估一个点是否应该被标记,我们需要提前知道它的标签! 这与 未标记的事实相矛盾。
为了解决这个问题,使用决策理论方法 (Settles, 2012),我们考虑 预期不公平性减少:选择预计会对当前模型不公平性产生最大减少的点,在获取其标签后。 因此,在公式 3 中,我们用预期公平性 代替 。 这样,我们使用当前模型下所有可能标签来近似模型的预期未来公平性。 考虑一个点,并让是将添加到后的模型(如果其真实标签是)。 不可避免地,SSU事先不知道标签。 因此,它必须改为计算不公平性作为对可能标签的期望。 等式2表示SSU使用的预期(不)公平性计算:
| (2) |
使用图4进行解释,对于未标记池中的每个点,SSU将的不同值视为的可能标签。 对于每个可能的标签,它使用将模型参数更新到中间模型。
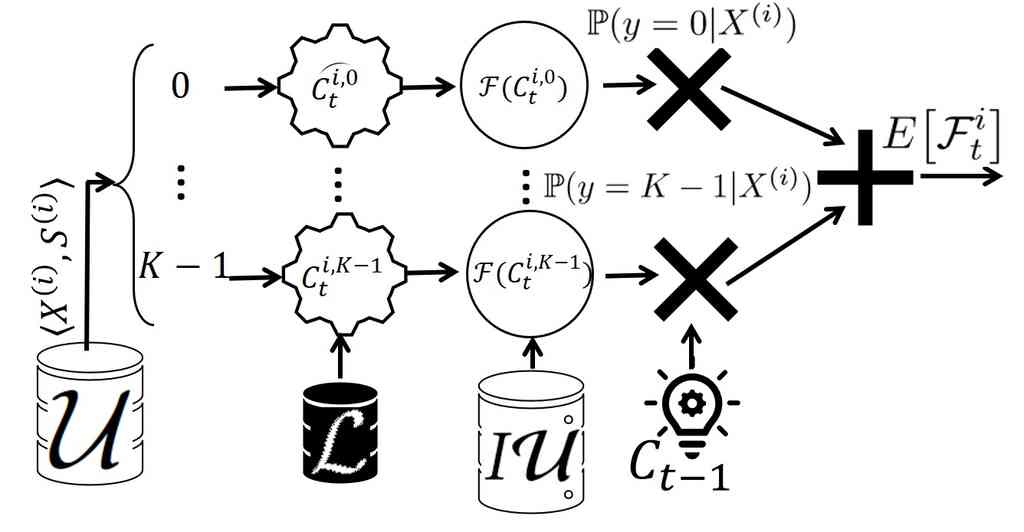
由于要标记的点是从 中选取的样本,并且从 移动到 ,因此在处理开始后,既不能将 视为实际潜在分布的独立同分布 (i.i.d.) 样本,也不能将 视为实际潜在分布的独立同分布 (i.i.d.) 样本,因此,不能用它们来估计公平性。 然而,最初遵循底层分布。 因此,为了创建一个数据集来评估模型在样本选择方面的公平性,我们利用了最初的未标注池 (称为 )并在不同的FAL迭代中使用它。 遵循标准AL,在每次迭代中,对于点 的每个可能的标签,SSU 使用当前模型 来计算 。 算法 1 展示了计算预期不公平性的伪代码。 为了计算预期不公平性,算法 1 需要训练 个模型,每个模型对应于点 的一个可能标签,这使得它效率低下。 在第 6 节中,我们提出了一种 常数时间 近似替代方法,它使 相同 的渐近时间复杂度与传统的主动学习相同。 然后,我们将提供在第 7 节中扩展公平性模块以涵盖除DP以外的其他公平性度量的详细信息。
在讨论了FAL框架和不公平性估计模块之后,我们将接下来描述SSU 用于选择下一个要标记的样本的准确性-公平性优化模块。
5. 准确性-公平性优化
5.1. FAL -聚合
与AL类似,FAL也是一个迭代过程,它从未标注池 中选择一个样本进行标注,并将它添加到已标注池 中。 然而,FAL -聚合将不公平性和误分类误差降低的组合视为采样步骤的优化目标。 具体来说,对于一个样本点 ,我们考虑香农熵度量 来表示误分类误差,同时考虑人口统计差异 来表示不公平性 - 是在迭代 中对 进行训练的分类器,在标记点 之后,而 是基于当前模型 的 的熵。 该公式可以被视为公平性和误分类误差的多目标优化。 另一个观点是将公平性视为优化的正则化项。 公式 3 与这两种观点一致,因此在我们框架中得到考虑。
| (3) |
是减少不公平性(公平性改进)项,系数 是用户提供的参数,用于确定模型公平性和模型性能之间的权衡。 更接近 的值更强调模型性能,而更小的 值更重视公平性。 正如我们将在第 8 节中详细阐述的那样,在方程式 3 中组合之前,熵和公平性值会标准化为相同的尺度。
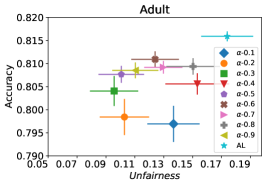
虽然 控制着准确性(熵)和公平性项之间的权衡,但对于用户来说,选择合适的 值可能并不明确。 更重要的是,FAL 可能会发现很难基于 在不同的迭代中使用固定的学习策略。 为了避免在主动学习中进行参数调整,而不是对所有迭代使用固定的 ,可以使用一个 衰减函数,该函数从 的较大值开始,从而提高模型的准确性。 随着模型变得更加稳定, 的值会下降,从而更加重视提高公平性。 该概念应用于不同的环境,例如分配学习率 (Schaul et al., 2013),其中最初使用较大的值,随着时间的推移逐渐减小。 我们的方法对所使用的衰减函数是不可知的。 在实验中,我们使用一个函数,该函数在 [0,1] 范围内进行线性插值。 具有 -聚合的 FAL 的伪代码在算法 2 中给出。
5.2. FAL 嵌套
准确地估计预期不公平性减少对于 FAL 的性能至关重要。 观察方程 2,计算预期公平性直接依赖于当前模型 对不同类别标签 的概率估计。这些概率的错误计算会导致对公平性的估计不准确。 在先前步骤中牺牲准确性以换取公平性将影响后续步骤中对预期公平性的估计。 这种错误估计预期不公平改进的结果,导致选择了不支持(甚至可能恶化)模型公平性的点,并且可能不利于模型准确性。 为了防止这种现象,有必要始终维护一个准确的中间模型,即确保所选的待标记点不会对模型的准确性产生负面影响。
幸运的是,我们在实践中观察到一个现象,有助于我们在实现公平性的同时保持中间模型的准确性。 正如我们将在后面进一步解释的那样,我们的观察结果也有助于我们通过只关注的子集,而不是全部集,来降低模型的计算成本。
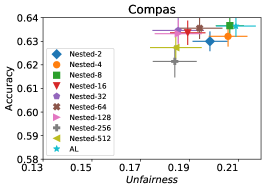
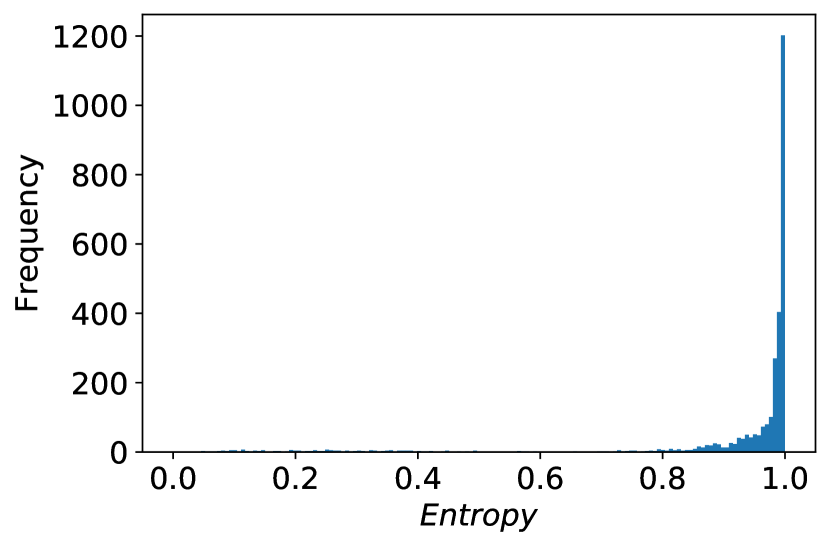
事实证明,在实践中,中数据点熵的分布是右偏的,即有大量点其熵接近于1,即从准确性角度来看,所有这些点都是几乎同样好的候选点。 我们在实际实验中观察到这一点,包括图4中显示的 COMPAS 数据集上的实验。
考虑熵接近于一的右侧桶中的点集。 该集合中的任何点都是主动学习(公式1)中确保中间模型高质量的良好候选点。 另一方面,该集合的相对较大尺寸(如在图4中观察到的)增加了它包含一个点具有很高的减少不公平性的潜力的可能性。
我们利用上述观察结果来设计一个用于准确性和公平性的嵌套优化。 特别地,我们不是通过线性组合这两个项(公式3)来计算分数,而是应用嵌套优化,其中在第一层,我们选择中前个点的子集 3 33除了固定集合基数之外,还可以考虑选择其值接近最大值(例如,距离小于 0.001)的点。 这些点使用当前分类器最大化熵:
| (4) |
其中函数-argmax 返回具有最大值的个样本。 第一层优化只针对准确性进行优化,以确保为中间模型保持高准确性。 接下来,将优化标准更改为第二层中的公平性,SSU 从中选择一个点,该点最大化不公平性改进(公式5),并将其传递给标记预言机。
| (5) |
5.3. FAL 嵌套追加
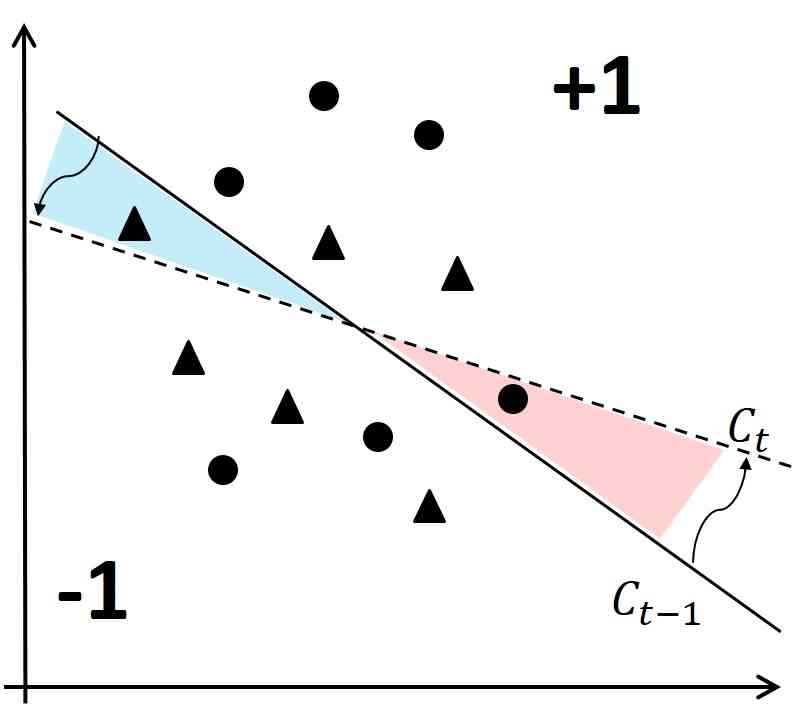
由于 中的样本点未标记,FAL 只能根据其获取每个可能标签的可能性,在标记一个点后估计预期的不公平减少。 但不公平是否减少取决于将该点添加到 后的实际标签。 为了进一步说明这一点,让我们考虑图 4 中突出显示的一个玩具示例。 为了简化说明,我们使用 6 个三角形和 6 个圆形点,每个点代表一个人口统计群体,来评估线性二元分类器的公平性。 假设当前分类器 () 的决策边界是图中实线所示,线右上角的点被分类为 +1。 将三分之二(6 个中的 4 个)圆形点分类为 +1,但只将三分之一(6 个中的 2 个)三角形点分类为 +1,因此根据 DP 来说不公平。
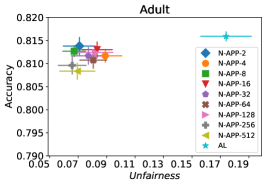
观察图,为了使分类器公平,FAL 需要将边界旋转到虚线的方向。 考虑图中两条线交点处突出显示的两个角度。 为了进行旋转,FAL 需要在 中找到具有真实 +1 标签且属于左上角角度的点,或具有真实 -1 标签且属于右下角角度的点。 请注意,这些点被当前分类器错误分类。 因此,不太可能找到具有适当标签的点,这些点对于减少不公平性是必需的。 另一方面,如果标签不像预期的那样,添加新点将无助于减少不公平性。 因此,为了提升 FAL 以改善公平性,我们的下一个优化 FAL Nested-Append 复制了以减少不公平性的方式被标记的点。 令 为使用 FAL Nested 选择的点。 令 为收集 的真实标签并将其添加到 后模型的不公平性。 如果 ,则算法在 中复制 ,进一步增强其对减少不公平性的影响。 特别地,由于 FAL Nested 更重视准确性,FAL Nested-Append 有助于更多地考虑公平性。 正如我们将在 § 8 中展示的那样,通过提升 FAL Nested 对公平性的性能,FAL Nested-Append 在不同的实验中都具有 最佳性能。
6. 通过协方差实现高效 FAL
我们提出的 FAL 框架与分类器 的选择无关。 在本节中,我们展示了为广义线性模型的特殊情况设计高效算法是可能的。 我们算法的一个吸引人的特性是,使用附录 A 中提供的有效计算,它具有与传统主动学习 相同 的渐近时间复杂度。 我们通过避免在算法 1 中重新训练模型来计算未标记样本的预期公平性,从而实现了这一点。
考虑形式为 的广义线性模型。 4 44分类器的决策边界被视为 上的阈值,该阈值使用例如符号函数将不同的类分开。 在模型独立性(人口统计公平性)下,模型和敏感属性 之间的协方差应为零。 我们在引理 1 中做出了一个关键的观察结果,该结果表明这种协方差 仅取决于 和 。
根据引理 1,模型与敏感属性的协方差(导致不公平)仅取决于权重向量 和特征 与 的底层协方差。 我们可以通过确保模型不会为有问题的特征分配高权重(与 具有高协方差的特征)来减少模型的不公平。 此观察结果使我们能够通过协方差来间接优化公平性,而不是计算预期的不公平性减少。
考虑一个与敏感属性高度相关的特征 (即, 很高),并且在当前模型中也具有高权重 。 我们的目标是减少分配给此类特征的权重。 模型将较大权重分配给 的原因是 在 中高度预测 . 因此,为了减少权重 ,我们需要在标记池 中减少 ,使其在 中对 的预测能力降低。 现在,考虑一个点 及其在特征 上的值 。 取决于 及其标签 (标记后),点 会影响 中的 。 事实上,我们在样本选择步骤期间不知道 。 尽管如此,类似于第 5 节,我们可以考虑 上的概率分布,并计算协方差的预期改进。 令 为 和 在 中的协方差, 并且 为 和 在将 添加到 后的协方差。 将 添加到 后, 的预期协方差改进为
| (6) |
遵循引理 1,特征 的协方差降低对公平性的贡献与 成正比。 因此,对于与敏感属性高度相关且在模型中具有较高权重 的特征,降低 至关重要。 因此,协方差对点 的(间接)公平性改进可以计算如下:
| (7) |
7. 扩展到其他公平性模型
到目前为止,在本文中,我们考虑了独立性 () 以实现公平性。 接下来,我们讨论如何将我们的发现扩展到其他基于分离和充分性 (Barocas et al., 2019) 的度量,例如均衡几率 (Hardt et al., 2016),其中预测结果 在给定真实标签 的情况下独立于敏感特征 ,即 。
FAL 的公平性-准确性优化器并不局限于特定类型的公平性,用于平衡准确性和公平性。 同样,预期不公平性降低的概念并不依赖于特定的公平性概念,因为 在公式 2 中可以使用任何公平性度量来计算,除了人口统计学奇偶性。 因此,从高层次来看,FAL 框架应该对其他公平性概念也能照常工作。 但是,正如我们将在下面解释的那样,计算 将需要额外的信息,这些信息需要以随机标记数据子集的代价为代价。
看看图 4,回想一下,我们使用初始未标记集 来估计模型的公平性。 遵循底层数据分布,因此,可以用于评估人口统计差异。 但是,该集合不能用于根据分离或充分性估计公平性,因为它的实例没有被标记。 另一方面,标记数据的池子并不能代表底层数据分布。
我们的解决方案是使用一小部分 进行公平计算,接受与集合大小相关的估计误差。 在开始 FAL 过程之前,我们需要标记 。 一旦标记完成, 将被用于计算 。 基于其他公平概念,FAL 可以按原样执行。 在 § 8 中,我们进行实验以展示 FAL 对均衡几率的扩展。
8. 实验
实验在一台配备 Core I9 CPU 和 128GB 内存的 Linux 机器上进行。 这些算法使用 Python 3.7 666Our codes are publicly available: https://github.com/anahideh/FAL--Fair-Active-Learning 实现。
8.1. 数据集
COMPAS777ProPublica, https://bit.ly/35pzGFj:由 ProPublica 发布 (Angwin 等,2016),该数据集包含少年重罪的信息,例如 婚姻状况、种族、年龄、先前定罪 以及当前逮捕的 指控等级。 我们对数据进行了标准化,使其具有零均值和单位方差。 我们将 种族 视为敏感属性,并对数据集进行了过滤,仅保留黑人和白人被告。 在过滤后,该数据集包含 5,875 条记录。 遵循标准实践 (Corbett-Davies 等,2017;Mehrabi 等,2019),我们使用两年暴力再犯记录作为再犯的真实标签: 如果再犯时间超过一年,则为 否则。
成人数据集888UCI repository, https://bit.ly/2GTWz9Z:包含从 1994 年人口普查数据中提取的 45,222 个人的收入,其中包含诸如 年龄、职业、教育程度、种族、性别、婚姻状况、每周工作时间、 原籍国 等属性。 我们使用 收入(一个具有值 美元和 美元的二元属性)作为真实标签。 我们将 性别 视为敏感属性。 我们对数据进行了归一化,使其具有零均值和单位方差。
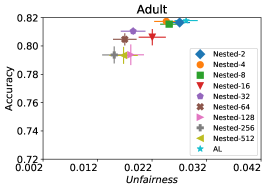
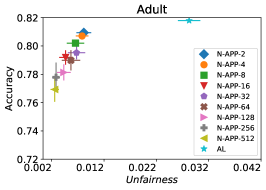
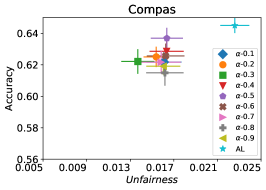
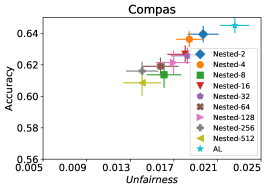
8.2. 评估的算法
我们提出的所有方法都使用正则化 范数逻辑回归分类器进行评估,正则化强度为 1。 我们使用 liblinear 优化器训练逻辑回归,最大迭代次数为 100。 我们的发现可以转移到其他分类器。 我们首先将我们提出的方法与各种代表性基线进行比较。 然后,我们专注于了解我们提出的方法在不同设置下的有效性和性能。
基线: 为了在数据有限的环境中构建一个公平的分类器,我们考虑了四个基线。 我们首先开始评估被动方法,RandL 和 R-FLR,它们一次性随机选择所有样本以形成训练集,并分别拟合一个常规且公平的逻辑回归(由 (Zafar 等人,2017) 提出)。 然后,我们评估主动方法,AL 和 AL-FLR,它们根据样本点的信息量(公式 1)迭代地选择一个样本点,并在每次迭代中分别拟合一个常规且公平的逻辑回归 (Zafar 等人,2017)。
8.3. 性能评估
我们使用数据集的 30 个随机拆分进行实验,将数据集拆分为训练 ( 例子)和测试( 例子)。 我们考虑 30 个随机拆分的平均值和方差。 我们将最大标注预算指定为 200,在此之后性能趋于平稳。 在每个 FAL 和 AL 场景中,我们从六个标记点开始,依次选择点进行标记,直到预算耗尽。 互信息是我们的人口统计公平度的默认度量。
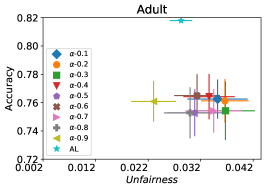
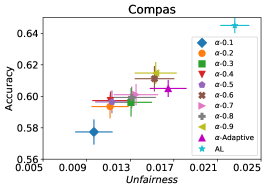
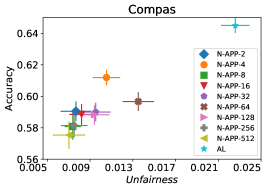
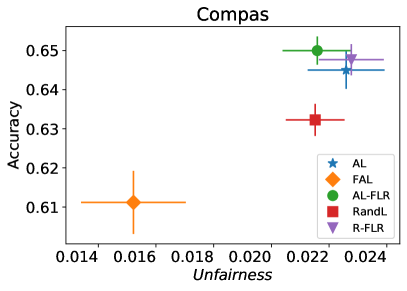
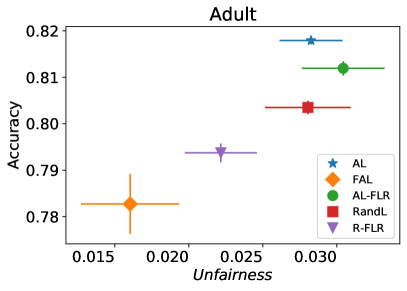
我们首先评估 FAL- 的性能与被动和主动基线 RandL,R-FLR,AL 和 AL-FLR 相比,使用准确性和公平度量来展示这些方法在构建最终公平分类器方面的不足。 图 8 说明了基线和 FAL- 的性能,其中 用于 COMPAS 和 Adult 数据集。 条形图表示数据 30 个随机拆分的标准差。 我们观察到基线在公平性方面具有相似的性能。 即使应用公平分类器(FLR)也无法改善公平性。 另一方面,FAL- 显著降低了不公平性,同时保持了相当的准确性。
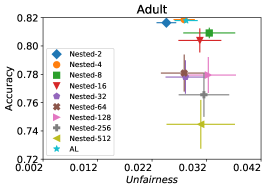
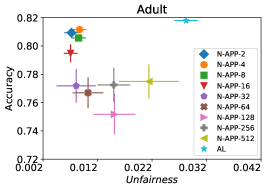
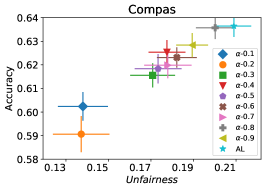
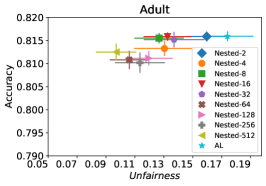
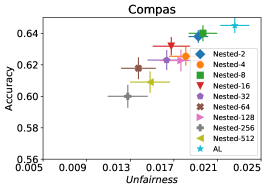
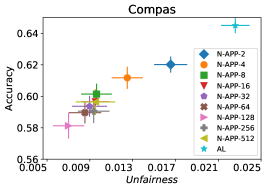
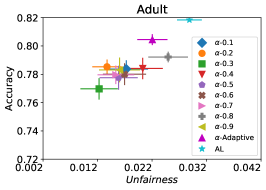
在我们的下一个实验中,如图 5 所示,我们评估了三种不同优化器的平均性能 FAL-, Nested 和 N-App,这些是在 §5 中提出的有效算法,并将其与 AL 进行比较。 图 5(a) 展示了 FAL 与不同用户定义的 和自适应 alpha 相比在 COMPAS 数据集上的综合比较。 我们可以观察到 FAL- 在不同的 值上实现了良好的公平性。 图 5(b) 对应于 Nested 的性能,它侧重于熵分布的上百分位数,以确保所选点提高准确性,而不仅仅是公平性。 正如预期的那样,结果表明这种方法提高了 FAL- 的准确性。 最后,在图 5(c) 中,我们评估了 N-App 在 COMPAS 数据集上的平均性能。 与 FAL- 和 Nested 相比,当模型在每次迭代中真正提高公平性水平时,通过将点追加两次,模型的公平性水平显着提高。 同样,我们复制了成人数据集的结果,如图 5(d)、5(e) 和 5(f) 所示。 可以看出,有效的 N-App 方法在保持模型准确性的同时,显着提高了模型的公平性水平。
我们还评估了在 §6 中提出的 FBC 方法的平均性能。 图 6 包含 FBC 在 COMPAS 数据集上使用三个提出的优化器的结果(成人数据集的结果在附录 C 中提供)。 结果与我们在图 5 中观察到的 COMPAS 数据集的结果相当一致。 请注意,FBC 是预期公平性减少的近似值,在计算上更有效,可以在 FAL 算法中使用(图 10)。 正如我们在 §7 中所讨论的,我们提出的方法可以扩展到使用其他公平性度量。 图 8 对应于实验设置,其中在 (Hardt et al., 2016) 中提出的公平性的均衡几率概念在 FAL- 中用于衡量公平性。 结果表明,与使用不同 值的 AL 相比,FAL 的有效性。 成人数据集的相同设置结果在附录中的图 13(a) 中提供。
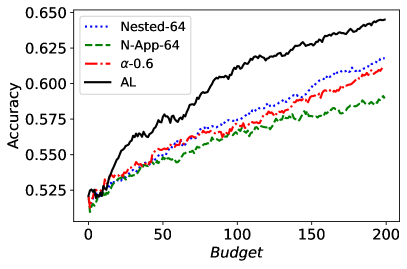
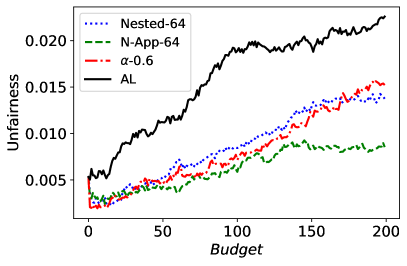
图 10 对应于 30 次随机运行的平均(不)公平性和平均准确性得分。 从图中可以看出,Nested-64 在样本选择中考虑了公平性,同时保证了准确性。 因此,它以更高的准确性和更低的非公平性优于 FAL--0.6。 请注意,N-App-64 的性能优于 FAL--0.6 和 Nested-64,这与预期一致。
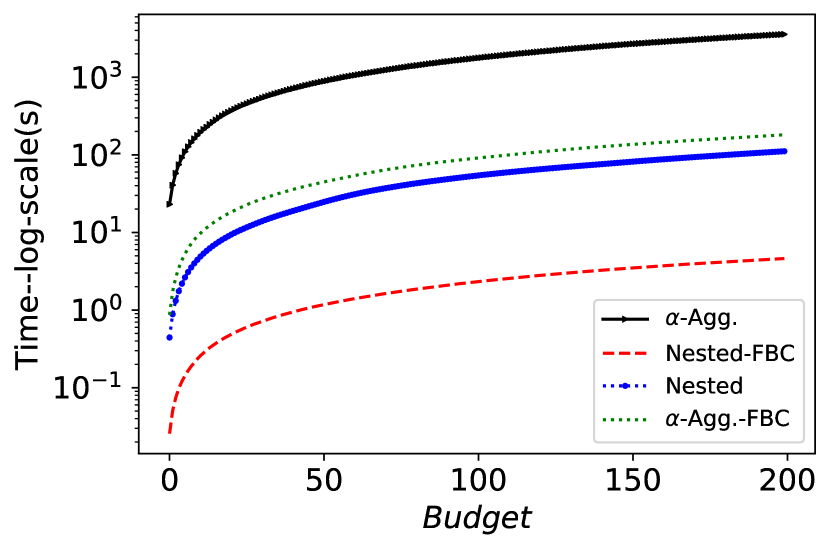
图 10 展示了不同准确性-公平性优化器与原始 FAL 相比,每个采样迭代的计算时间。 FBC 比 FAL 快几个数量级,因为它避免了计算预期公平性的需要。 另一方面,由于它间接地优化了公平性,FAL 在公平性方面优于它。
9. 总结
以前关于公平分类的研究假设有足够标记的数据可用。 在许多社会应用中,例如再犯预测,标记数据不可用,收集数据既昂贵又耗时。 传统的主动学习方法侧重于准确性,往往以公平性为代价。 在本文中,我们提出了一个用于主动学习中公平性的框架,该框架通过从未标记池中选择样本(最大限度地提高误分类错误减少和预期公平性改进的线性组合)来平衡公平性和准确性。 我们描述了各种优化方法,以提高准确性、公平性和运行时间。 具体来说,FAL Nested-Append 成功地实现了准确性和公平性之间的巧妙平衡。 我们对真实数据集的广泛实验表明,我们提出的方法能够产生更公平的模型,而不会显著牺牲准确性。 我们希望我们提出的方法能够通过提高许多现实场景中的模型公平性,产生积极的影响。
参考文献
- (1)
- Angwin et al. (2016) J. Angwin, J. Larson, S. Mattu, and L. Kirchner. 2016. Machine Bias: Risk Assessments in Criminal Sentencing. ProPublica (2016). https://bit.ly/2s0UMfA
- Asudeh et al. (2019) Abolfazl Asudeh, Zhongjun Jin, and HV Jagadish. 2019. Assessing and remedying coverage for a given dataset. In ICDE. IEEE, 554–565.
- Bakker et al. (2020) M. A Bakker, H. R. Valdés, D. P. Tu, K. P Gummadi, K. R Varshney, A. Weller, and A. Pentland. 2020. Fair Enough: Improving Fairness in Budget-Constrained Decision Making Using Confidence Thresholds.. In SafeAI@ AAAI.
- Balcan et al. (2007) Maria-Florina Balcan, Andrei Broder, and Tong Zhang. 2007. Margin based active learning. In COLT. Springer, 35–50.
- Barocas et al. (2017) Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2017. Fairness in machine learning. NIPS Tutorial (2017).
- Barocas et al. (2019) Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2019. Fairness and machine learning: Limitations and opportunities. fairmlbook.org.
- Barocas and Selbst (2016) Solon Barocas and Andrew D Selbst. 2016. Big data’s disparate impact. Calif. L. Rev. 104 (2016), 671.
- Beutel et al. (2019) Alex Beutel, Jilin Chen, Tulsee Doshi, Hai Qian, Li Wei, Yi Wu, Lukasz Heldt, Zhe Zhao, Lichan Hong, Ed H Chi, et al. 2019. Fairness in recommendation ranking through pairwise comparisons. In SIGKDD. 2212–2220.
- Buolamwini and Gebru (2018) Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In FAccT. 77–91.
- Celis et al. (2019) L Elisa Celis, Lingxiao Huang, Vijay Keswani, and Nisheeth K Vishnoi. 2019. Classification with fairness constraints: A meta-algorithm with provable guarantees. In FAccT. ACM, 319–328.
- Corbett-Davies et al. (2017) Sam Corbett-Davies, Emma Pierson, Avi Feller, Sharad Goel, and Aziz Huq. 2017. Algorithmic decision making and the cost of fairness. In SIGKDD. ACM, 797–806.
- DiCiccio et al. (2020) Cyrus DiCiccio, Sriram Vasudevan, Kinjal Basu, Krishnaram Kenthapadi, and Deepak Agarwal. 2020. Evaluating fairness using permutation tests. In SIGKDD.
- Donmez et al. (2007) Pinar Donmez, Jaime G Carbonell, and Paul N Bennett. 2007. Dual strategy active learning. In ECIR.
- Dwork et al. (2012) Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. 2012. Fairness through awareness. In ITCS. ACM, 214–226.
- Feldman et al. (2015) Michael Feldman, Sorelle A Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. 2015. Certifying and removing disparate impact. In SIGKDD.
- Fish et al. (2016) Benjamin Fish, Jeremy Kun, and Ádám D Lelkes. 2016. A confidence-based approach for balancing fairness and accuracy. In SDM. SIAM, 144–152.
- Geyik et al. (2019) Sahin Cem Geyik, Stuart Ambler, and Krishnaram Kenthapadi. 2019. Fairness-aware ranking in search & recommendation systems with application to linkedin talent search. In SIGKDD. 2221–2231.
- Goh et al. (2016) Gabriel Goh, Andrew Cotter, Maya Gupta, and Michael P Friedlander. 2016. Satisfying real-world goals with dataset constraints. In NeurIPS. 2415–2423.
- Hardt et al. (2016) Moritz Hardt, Eric Price, Nati Srebro, et al. 2016. Equality of opportunity in supervised learning. In NeurIPS. 3315–3323.
- Hébert-Johnson et al. (2017) Ursula Hébert-Johnson, Michael P Kim, Omer Reingold, and Guy N Rothblum. 2017. Calibration for the (computationally-identifiable) masses. arXiv preprint arXiv:1711.08513 (2017).
- Huang and Vishnoi (2019) Lingxiao Huang and Nisheeth K Vishnoi. 2019. Stable and Fair Classification. arXiv preprint arXiv:1902.07823 (2019).
- Huang et al. (2010) Sheng-Jun Huang, Rong Jin, and Zhi-Hua Zhou. 2010. Active learning by querying informative and representative examples. In NeurIPS. 892–900.
- Jan (2018) Tracy Jan. 2018. Redlining was banned 50 years ago. It’s still hurting minorities today. Washington Post.
- Jones (1983) Frank L Jones. 1983. Sources of gender inequality in income: what the Australian Census says. Social Forces 62, 1 (1983), 134–152.
- Kamiran and Calders (2012) Faisal Kamiran and Toon Calders. 2012. Data preprocessing techniques for classification without discrimination. KAIS 33, 1 (2012), 1–33.
- Kim et al. (2018) Michael P Kim, Amirata Ghorbani, and James Zou. 2018. Multiaccuracy: Black-box post-processing for fairness in classification. arXiv preprint arXiv:1805.12317 (2018).
- Komiyama et al. (2018) Junpei Komiyama, Akiko Takeda, Junya Honda, and Hajime Shimao. 2018. Nonconvex optimization for regression with fairness constraints. In ICML.
- Krasanakis et al. (2018) Emmanouil Krasanakis, Eleftherios Spyromitros-Xioufis, Symeon Papadopoulos, and Yiannis Kompatsiaris. 2018. Adaptive sensitive reweighting to mitigate bias in fairness-aware classification. In WWW. 853–862.
- Kusner et al. (2017) Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. Counterfactual fairness. In NeurIPS. 4066–4076.
- Lewis and Catlett (1994) David D Lewis and Jason Catlett. 1994. Heterogeneous uncertainty sampling for supervised learning. In Machine learning proceedings 1994. Elsevier, 148–156.
- Lewis and Gale (1994) David D Lewis and William A Gale. 1994. A sequential algorithm for training text classifiers. In SIGIR’94. Springer, 3–12.
- Li et al. (2020) Yanying Li, Haipei Sun, and Wendy Hui Wang. 2020. Towards Fair Truth Discovery from Biased Crowdsourced Answers. In SIGKDD. 599–607.
- Mehrabi et al. (2019) Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2019. A survey on bias and fairness in machine learning. arXiv preprint arXiv:1908.09635 (2019).
- Menon and Williamson (2018) Aditya Krishna Menon and Robert C Williamson. 2018. The cost of fairness in binary classification. In FAccT. 107–118.
- Noriega-Campero et al. (2019) Alejandro Noriega-Campero, Michiel A Bakker, Bernardo Garcia-Bulle, and Alex’Sandy’ Pentland. 2019. Active fairness in algorithmic decision making. In AIES. 77–83.
- Pleiss et al. (2017) Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q Weinberger. 2017. On fairness and calibration. In NeurIPS. 5680–5689.
- Schaul et al. (2013) Tom Schaul, Sixin Zhang, and Yann LeCun. 2013. No more pesky learning rates. In ICML. 343–351.
- Settles (2012) Burr Settles. 2012. Active Learning. In Synthesis Lectures on Artificial Intelligence and Machine Learning 18. 1–111.
- Shannon (1948) Claude Elwood Shannon. 1948. A mathematical theory of communication. Bell system technical journal 27, 3 (1948), 379–423.
- Sharaf and Daumé III ([n.d.]) Amr Sharaf and Hal Daumé III. [n.d.]. Promoting Fairness in Learned Models by Learning to Active Learn under Parity Constraints. ([n. d.]).
- Simoiu et al. (2017) Camelia Simoiu, Sam Corbett-Davies, Sharad Goel, et al. 2017. The problem of infra-marginality in outcome tests for discrimination. The Annals of Applied Statistics 11, 3 (2017), 1193–1216.
- Speicher et al. (2018) Till Speicher, Hoda Heidari, Nina Grgic-Hlaca, Krishna P Gummadi, Adish Singla, Adrian Weller, and Muhammad Bilal Zafar. 2018. A unified approach to quantifying algorithmic unfairness: Measuring individual &group unfairness via inequality indices. In SIGKDD. 2239–2248.
- Srivastava et al. (2019) Megha Srivastava, Hoda Heidari, and Andreas Krause. 2019. Mathematical notions vs. human perception of fairness: A descriptive approach to fairness for machine learning. In SIGKDD. 2459–2468.
- Tong and Koller (2001) Simon Tong and Daphne Koller. 2001. Support vector machine active learning with applications to text classification. JMLR 2, Nov (2001), 45–66.
- Xu et al. (2003) Zhao Xu, Kai Yu, Volker Tresp, Xiaowei Xu, and Jizhi Wang. 2003. Representative sampling for text classification using support vector machines. In European conference on information retrieval. Springer, 393–407.
- Zafar et al. (2017) Muhammad Bilal Zafar, Isabel Valera, Manuel Gomez Rodriguez, and Krishna P Gummadi. 2017. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In WWW. 1171–1180.
- Zemel et al. (2013) Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. 2013. Learning fair representations. In ICML. 325–333.
- Žliobaitė (2017) Indrė Žliobaitė. 2017. Measuring discrimination in algorithmic decision making. Data Mining and Knowledge Discovery 31, 4 (2017), 1060–1089.
- Zou and Schiebinger (2018) James Zou and Londa Schiebinger. 2018. AI can be sexist and racist—it’s time to make it fair.
附录
附录 A 在 中有效地计算 和 的协方差
当特征数量 为常数时,可以通过维护先前步骤的聚合来在 恒定时间 内计算 ,从而进一步提高效率。 因此,公平主动学习框架的时间复杂度(不考虑标记成本)从 降至 ,与传统的主动学习相同。
首先,我们注意到 ,即每个特征 与 的协方差,不依赖于 ,并且可以使用 中的未标记样本提前计算。 它在过程开始时为每个特征计算一次,并且相同的数字将在不同的迭代中使用。 但是,等式 6 中的 和 的值取决于标记数据的集合,并且应该在不同的迭代和不同的点 上重新计算。 我们维护以下聚合以有效地计算这些值:
请注意,在每次迭代中,上述每个聚合都可以通过将来自新点的对应值添加到它来在恒定时间内更新。 现在,使用这些聚合:
同样,对于点 和标签 :
附录 B 引理 1 的证明
附录 C 补充实验结果
在本节中,我们提供了使用 FBC 和均衡几率对我们提出的算法性能进行的额外实验结果。
图 11 展示了使用三种不同的优化器 FAL-、嵌套 和 N-App 在 Adult 数据集上使用 FBC 方法的结果。 可以看出,当我们使用高效的 FBC 方法进行公平性近似时,我们理想的 N-App 方法优于其他优化器。
最后,图 13 展示了在成人数据集上使用三种不同优化器获得的 FAL 关于均衡几率的结果。 结果表明,我们高效且有效的 N-App 方法在保持精度的情况下,在减少不公平方面优于其他优化器。