用于求解运动方程的哈密顿神经网络
摘要
人们对应用机器学习来研究动力系统产生了浓厚的兴趣。 我们提出了一个哈密顿神经网络来求解控制动力系统的微分方程。 这是一种方程驱动的机器学习方法,其中网络的优化过程仅取决于预测函数,而不使用任何地面实况数据。 该模型学习的解满足任意小误差的哈密顿方程,因此保留哈密顿不变量。 选择适当的激活函数可以极大地提高网络的可预测性。 此外,还得出了误差分析,并指出数值误差取决于整体网络性能。 然后使用哈密顿网络来求解非线性振子和混沌 Hénon-Heiles 动力系统的方程。 在这两个系统中,辛欧拉积分器需要比哈密顿网络多两个数量级的评估点,以便在预测的相空间轨迹中实现相同数量级的数值误差。
我简介
研究动力系统的演化已成为科学研究的一个重要趋势。 信息时代使存储的数字数据量呈指数级增长,这些数据集中的重要部分描述了动力系统的演变。 其中包括从大规模天体物理学到纳米级量子物理学的广泛系统。 最近,机器学习模型,特别是神经网络(NN),已被用于探索此类数据集并预测复杂动力系统的未来行为[1,2,3],时空混沌行为[4, 5],对时间序列进行分类[6, 7],改进湍流模型[8, 9, 10, 11],发现微分方程(DE) [12, 13, 14, 15],并找到这些方程 [16, 17] 的近似解。 除了数据驱动的研究之外,方程驱动和无数据的无监督神经网络也被用来求解与各种物理系统相关的普通和部分微分方程[18,19,20,21,22]. 方程驱动网络构造满足特定微分结构的分析函数;随后,在此类模型的训练过程中,我们不需要任何地面实况数据。 本质上,损失函数仅取决于神经网络训练获得的解决方案,而神经网络过程完全不需要数据。 这种表述导致了无监督学习方法。 我们强调,所提出的方法不使用传统数值求解器生成的任何数据。 此外,神经网络的万能逼近定理[23]指出,神经网络可以以任意精度逼近任何平滑函数。 这使得神经网络成为解决微分方程控制的复杂问题的合适方法。
受物理启发和基于物理的神经网络已广泛用于求解微分方程,与使用传统积分器相比,提供了一些潜在优势[24]。 这些机器学习求解器的有效性已通过解决具有挑战性的问题得到了证明,在这些问题中,传统的数值方法变得效率低下,例如求解高维偏微分方程 [19, 20]、具有移动边界的系统 [25 ],以及反问题[17,26,27]。 用神经网络求解微分方程是一个快速发展的领域,定期提出新技术来推进和改进这些机器学习求解器,包括蒙特卡罗采样[22]、傅立叶神经算子[28]、课程正规化和顺序学习[29]。 这项工作通过在神经网络框架中引入哈密顿结构来提高非线性哈密顿系统的求解能力,从而为这一努力做出了贡献。 神经网络的计算可以在并行架构上有效地实现,从而显着加速[18]。 事实上,最近的硬件创新,特别是 GPU 的广泛采用和使用,可以以最小的并行化工作极大地加速计算过程。 与传统积分器相比,这是一个巨大的优势,传统积分器的时间并行算法的开发和实现具有挑战性。 [30]总结了并行时间积分方法的优点和挑战,而参考文献。 [31]表明,现代方法已经被发明来并行化时间积分,并且可以在深度网络中用于“层并行训练”,加速网络优化。
数据驱动的哈密顿神经网络已被提议在学习过程中施加物理信息归纳偏差。 这些网络比常规的全连接神经网络训练得更快,泛化能力更好,同时它们学习并遵循精确的保守量,例如能量[32,33,34,35]。 更具体地说,Greydanus 等人[32]引入了嵌入哈密顿形式主义的哈密顿网络,表明神经网络可用于学习描述某些给定时间轨迹的哈密顿量。 通过使用哈密顿方程和自动微分消除时间导数和时间依赖性,从而产生时不变能量。 一旦学习了哈密顿量,就可以通过数值求解哈密顿方程来预测训练范围内外不同初始条件的运动。 最近,这种方法已成功应用于学习哈密顿量、预测混沌行为以及预测向混沌的过渡[34, 36]。 哈密顿神经网络的框架非常通用,可以在不同的机器学习架构中实现,例如水库计算[37]和图网络,并且数值积分器可以嵌入到网络架构中以提供进一步的功能。长期预测的改进[38, 35]。 此外,生成式哈密顿网络已被提出来生成遵循某些基本定律(如能量和动量守恒)的轨迹,随后生成的数据遵循基本物理原理[39]。 标准哈密顿网络的其他扩展考虑在存在外部驱动力和耗散的情况下学习系统的动力学。 采用更通用的公式(例如端口哈密顿量),神经网络能够预测阻尼和驱动时变动力系统的轨迹,并且可以有效地揭示隐藏在数据中的潜在物理量,例如平稳哈密顿量、耗散参数和外部时间依赖力[40]。 这些最近的研究证明,通过在框架中嵌入哈密顿公式可以极大地提高神经网络的学习能力,然而,在神经网络中引入哈密顿方程来求解微分方程的优点尚未被研究。 在这项工作中,我们介绍并研究了用于求解非线性动力系统运动方程的哈密顿神经网络。 这是一种方程驱动的方法,而不是数据驱动的模型,因为假设哈密顿量的形式和系统的初始状态是已知的,而训练过程中不需要地面实况轨迹(数据)。 换句话说,标准哈密顿网络正在从给定数据中学习哈密顿函数,而我们提出的模型发现了近似满足汉密尔顿方程的轨迹。 随后,尽管哈密顿公式都嵌入到两个网络中,但这两种方法在概念上是不同的。
当前的工作提出了一种用于求解 DE 系统的无数据哈密顿神经网络架构。 尽管受物理启发的神经网络在求解微分方程方面取得了成功,但哈密顿神经网络求解器尚未得到探索。 随后,所提出的哈密顿神经网络是先前使用的无数据神经网络的演变,用于近似相同满足边界和初始条件的DE的解。 我们通过加速网络向解决方案的收敛,同时获得底层物理属性的好处,对其他 NN DE 求解器进行了改进。 我们提出了一种神经网络架构,其灵感来自于具有与时间无关的哈密顿量的哈密顿系统。 一旦优化,神经网络在整个时域上满足哈密顿方程,直接意味着每个不变量在各自的哈密顿流下的守恒。 正如[20]中所讨论的,使用自动微分计算二阶导数比计算一阶导数要昂贵得多。 在这里,我们通过求解一阶微分方程组(即哈密顿方程组)而不是二阶方程组来避免这一瓶颈。 神经网络求解器在概念上与传统数值求解器不同。 辛积分器旨在长期保存能量。 作为迭代求解器,这些传统方法会及时累积误差,并且还需要先前时间点的计算值才能构建近似解。 传统积分器保存的哈密顿量(能量)与真正的哈密顿量略有不同。 另一方面,建议的哈密顿神经网络独立评估每个时间点,并同时满足系统的所有微分方程。 因此,哈密顿量网络保留了原始哈密顿量,并导致任何累积数值误差的显着减少。 另一个独特的机器学习方向是神经网络积分器的发展[19, 16]。 这些混合模型将传统积分器与神经网络相结合,提高了求解微分方程的性能。 我们的神经网络求解器不属于此类机器学习方法,因为它不需要结构化网格或嵌入任何迭代算法。 另一方面,所提出的模型提出了一种使用神经网络求解 ODE 的替代方法,而无需嵌入传统积分器。 与标准半隐式方案(例如辛欧拉积分器)相比,所提出的哈密顿神经网络包含一种数值更精确、更稳健的动态方程求解方法。 通过共享网络权重、选择三角激活函数、惩罚违反能量守恒定律的行为以及使用有效的参数化解形式,我们展示了优化过程中收敛行为的加速,以及随后的改进网络的可预测性。 此外,我们还表明,在训练之后,所提出的神经网络架构可以被认为是一个真正的全局辛单元,因此是一个时不变单元。
在本研究的其余部分中,我们描述了用于近似哈密顿轨迹的哈密顿神经网络架构。 执行误差分析并表明可以在优化网络之前预定义预测解决方案的准确性。 然后,应用所提出的辛神经网络来求解描述非线性振荡器和二维混沌系统运动的方程。 我们指出哈密顿神经网络求解器优于半隐式欧拉数值方法(一阶辛积分器)的情况。 然而,这项工作中没有提出与高阶辛积分器的比较。 通过不同的参数解决方案和激活函数探索不同的架构来展示网络性能。 通过使用正则化项来获得准确的长期解决方案,以鼓励发现节省总能量的解决方案。 本手稿中提出的实验是使用 PyTorch [41] 进行的,代码发布在 github 上111https://github.com/mariosmat/hamiltonianNNetODEs。 我们总结了本研究中引入的关键思想、使用哈密顿神经网络求解微分方程的优点,并讨论了未来的计划。
II 哈密尔顿神经网络
II.1网络架构
经典力学的一个基石思想是,可以通过研究系统的基本对称性和约束来研究系统的演化。 到了 20 世纪,拉格朗日、汉密尔顿和其他人已经证明,系统的动力学与简单的标量函数、拉格朗日函数和哈密顿函数有关,具有多个守恒定律及其与这些函数预先包装的基本对称性。 然后使用这些标量函数导出控制系统运动的微分方程。 特别是,从拉格朗日(动能和势能之间的差异)出发,引用汉密尔顿原理(运动遵循最小化作用积分的轨迹),并采用变分法技术,系统的运动由下式描述:欧拉-拉格朗日 (E-L) 方程。 另一方面,在哈密顿量公式中,我们从哈密顿量开始,它是拉格朗日量的变换,并且是一个保守量,即它不随时间变化。 这个公式产生了 Hamilton 方程,它相当于 E-L 方程,因此可以最小化相同的作用。 汉密尔顿方程是一组耦合的一阶微分方程,而拉格朗日形式主义提供了一组二阶微分方程。 与拉格朗日方程相比,哈密顿方程具有固有的优势,因为一组耦合的一阶微分方程在数值上比一组二阶微分方程更稳定且更容易求解。 然而,由此产生的微分方程在分析上往往难以处理,因此工程师和科学家求助于离散化技术来获得解决方案。 然而,求解微分方程的离散化过程可能会导致违反基本的守恒定律。 这个问题可以通过使用神经网络求解器来解决,该求解器能够提供尊重基本原则的分析解决方案。 事实上,任何类型的半隐式方法,例如辛欧拉积分器,都允许误差随时间累积。 特别是混沌系统对此类问题高度敏感,因此是测试所提出的哈密顿神经网络性能的理想基础。
我们考虑一个由许多在太空中移动的物体组成的物理系统。 这些对象的运动可以在维配置空间中描述,该空间由系统中所有对象的位置规范定义为时间的函数。 更准确地说, 被定义为系统中物体的数量与允许这些物体移动的空间维度数量的乘积。 在拉格朗日公式中,我们研究的是构型空间,而哈密顿形式主义是在相空间中定义的,相空间由物体的位置和动量组成。 随后,配置空间中的每个维度与相空间中的两个自由度相关联。 在这项工作中,我们对哈密顿框架感兴趣,因此我们考虑 维的相空间。 许多经典系统,从简单的摆到太阳系,都可以用可分离的哈密顿形式来描述,其中势能项仅取决于广义空间坐标 ,动力学项仅取决于广义动量 。 由于这种哈密顿形式不直接依赖于时间,因此它描述的系统将节省能量。 其他动力学不变量也可能是内置的,具体取决于各个相空间变量的具体选择及其相应的连续对称性[43]。 例如,当哈密顿量不直接依赖于坐标 时,相关动量 守恒,反之亦然。 对于此类哈密顿函数,动力学由以下耦合 DE 控制,称为哈密顿方程或规范方程:
| (1) |
其中点表示时间导数。 表达汉密尔顿方程的一种优雅方式是辛符号。 令 和 J 为 矩阵
| (2) |
其中 和 分别表示 零矩阵和单位矩阵。 那么,哈密顿方程可以写成紧向量形式
| (3) |
其中 评估方程的数值方法。 (3) 称为辛方法,已广泛用于计算混沌系统的长期演化[44]。 在这项工作中,我们提出了一种基于神经网络的替代方法来解决方程。 (3)。 正如我们将在下面讨论的,辛积分器守恒哈密顿量,该哈密顿量与原始哈密顿量略有扰动,而辛神经网络则守恒原始哈密顿量。 这是所提出的神经网络相对于辛积分器的一个巨大优势。
前馈神经网络[18,20,24]提供了另一种数值求解微分方程的方法。 与传统数值方法相比,此类神经网络的一个关键优势是它们寻求学习满足 DE 的实际函数,而不是创建实际解的近似值。 此外,神经网络的解决方案采用封闭、可微分和分析的形式[18],并且可以在并行架构上有效地实现计算,从而显着提高速度[18]. 使用我们提出的神经网络架构的优点是它提供了同时满足汉密尔顿方程的解决方案。 因此,与迭代求解器中不可避免的误差累积相比,特定哈密顿量的动态不变量被尊重到所需的精度。 为了进行比较,我们提出了半隐式欧拉方法,它是求解汉密尔顿方程的最简单但使用最广泛的辛积分器。 辛欧拉方法将能量守恒到波动误差,因为它守恒的哈密顿量与原始方法略有不同。 对于可分离哈密顿量形式 ,求解系统 (1) 的辛欧拉方案为
| (4) | ||||
| (5) |
这里,是两个连续时间点之间的时间步,表示评估的时间点,和 。 由于辛欧拉方法的迭代性质,我们在方程中读到。 (4), (5) 需要两个连续时间点的解来计算任意点的 Hamilton 方程,从而导致能量计算中出现数值误差,即与成比例。 类似地,高阶迭代辛积分器会累积数值误差,但是,这项工作仅对所提出的 NN 求解器和一阶辛欧拉积分器获得的解进行比较。
本研究的目标是利用神经网络在一定的时间间隔内求解哈密顿方程(3)。 让我们考虑参数解的一般形式
| (6) |
其中 是神经网络发现的解向量, 是初始状态向量, 是 输出的向量前馈全连接神经网络。 参数函数 在参数解中强制执行初始条件,即 当 时。 网络将时间点 作为单个输入,其中 表示第 个连续点;不失一般性,我们考虑初始时间。 我们通过根据网络的学习参数最小化由 Hamilton 方程 (3) 定义的均方误差 (MSE) 来训练神经网络,如下所示:
| (7) |
其中和是用于网络优化的输入时间点的总数。 项 可以是任何正则化项,其中 是正则化参数。 我们发现,对于长时间的预测,使用正则化项来惩罚违反能量守恒定律的行为是有效的。 给定系统的初始状态和相应的能量 ,一个方便的正则化项是
| (8) |
对于长时间预测,使用正则化损失 (8) 可将预测轨迹稳定在正确的能量水平,并可以导致更快的网络收敛。 在本工作中,除非另有说明,否则显示 的结果。
时间导数是通过使用自动微分获得的,自动微分在计算上需要通过整个网络[41]进行一次反向传播。 我们首先在时间间隔内生成等距时间点训练。 然后,我们在每个时期随机扰动这些点:,其中是通过正态分布[20]获得的随机项。 该技巧提高了网络的可预测性,因为它在连续的时间间隔内进行了有效的训练。 此外,扰动每个时期的训练点采用随机梯度下降(SGD)方法,从而帮助优化器逃离损失函数中的局部极小值。 扰动每个时期的点意味着我们扰动损失函数,随后局部最小值会动态移动。 在 SGD 的背景下,每个时期都被视为一个小批量,而所有时期都包含训练集的整个批次。 最小化方程中的损失函数。 (7) 产生的解同样遵循方程的辛结构。 (3) 因此,哈密顿流的每个动力学不变量也受到尊重。 我们指出,当在训练间隔 内评估神经网络时,神经网络解决方案具有很高的准确性,但在训练间隔之外误差会迅速增加。 所提出的哈密顿神经网络架构如图 1 所示。 值得注意的是,图 1 中提出的网络具有与标准哈密顿神经网络 [32] 中使用的架构不同的架构。 我们的网络以 作为输入并返回 ,而标准哈密顿网络中的输入为 ,输出为 。
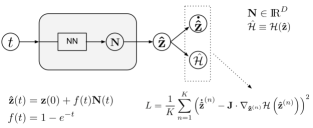
对神经网络的性能起着至关重要的作用。 执行初始条件的标准选择是 ,它满足 [18] 。 然而,这是一个无界函数,当 变大时会增加进一步的难度。 具体来说,对于足够时期后的 NN 输出,方程: (6) 指出。 随着 的增加, 趋于零,这会对大时间尺度的网络可预测性产生负面影响。 为了弥补这种低效率,我们提出了参数函数
| (9) |
这是一个平滑的有界函数,带有 。 后来,我们证明参数函数的具体选择极大地提高了神经网络求解器的可预测性。 有趣的是, 迅速趋于 的事实意味着所提出的架构由辛神经网络组成。 特别是,对于 和极限 方程。 (7) 产生 ,作为 ,我们有 。 考虑上述两个限制并执行线性变换,我们得到:
| (10) |
这表明所提出的架构包含一个辛神经网络,该神经网络声明函数 是时不变的。
我们的方法表明的一个重大进步是方程的能量正则化。 (8)。 由于缺乏迭代学习,神经网络求解器不会使用先前步骤的预测来构建解决方案。 结果,它往往会忘记系统的初始状态,因此,在长时间的解决方案中,可能会观察到能量泄漏,从而导致误差累积。 这个问题在长期解决方案中变得至关重要,降低了求解非线性常微分方程尤其是混沌系统的能力。 方程的正则化损失。 (8) 将预测轨迹稳定在正确的能量上,从而产生强大的求解器。 这项工作的另一个重要创新是激活函数的选择。 事实证明,具有三角激活函数的神经网络可以从数据中学习周期性行为,其性能优于使用 Relu 和 Sigmoid [45] 等常见激活的网络。 我们采用这种方法并选择三角作为激活函数。 随后通过数值实验得出的经验结果表明, 激活在求解哈密顿系统的 ODE 方面优于 sigmoid。
II.2错误分析
我们寻求根据损失函数的最大值提供解中误差的粗略界限。 首先,请注意方程式。 (7) 可以写成
| (11) |
在哪里
| (12) | ||||
| (13) |
和 是包含任意时间点 各自损失分量的向量。 由于 是 NN 的损失函数,是时间上的平均值,因此 可视为 时间点上的瞬时损失,当 时。 令 为真实解与 NN 解之间的误差。 在关于 的泰勒级数中展开哈密顿量 并保持二次项,得到:
| (14) |
其中 是 Hessian 矩阵。 取方程的梯度。 (14) 对于 和重新排列项给出,
| (15) |
我们注意到,对于二次依赖于 的哈密顿量,二次展开式 (14) 是精确的,因为高阶项消失了。 此外, 中的第二个订单是仍然足够大的最小订单,当我们移动到替换方程式时不会被取消。 (15) 代入等式。 (12)。 然而,推导可以以简单的方式扩展到包括更高阶项。 为了表述清楚,在下文中,我们删除了上标 。 将泰勒级数展开式 (15) 代入 (12) 并调用 (3) 结果,
| (16) |
检查向量 DE (16),我们观察到它的分量组成了每个预测轨迹 中误差 的闭微分系统。 用初始条件 求解该微分系统,因为它由参数化 (6) 决定,我们可以计算误差如何及时传播。 然而,这需要了解的损失成分,因此,只有在我们训练了网络之后才能进行这样的分析。
另一方面,我们可以通过构建最坏的情况来导出 大小的界限,而无需准确了解 。 我们希望在 和 之间建立关系,以便它确定何时停止网络训练,以获得比一定精度更好的解决方案。 令表示神经网络训练后将产生的最大瞬时损失。 在下面的分析中,我们用来表示范数。 我们有,
| (17) |
其中 是 的最小奇异值。 上述表达式中的最后一行 (17) 可以通过考虑数量 并使用 上的奇异值分解来获得,表明 。 重新排列术语会导致,
| (18) |
求解 的二次不等式 (18) 得到,
| (19) |
现在考虑错误的单个组成部分,。 可以取的最大值出现在 的 和 时。 也就是说,对于固定误差,所有误差都集中在单个分量中。 在本例中为。 如果 在值 处最大化,则 在 处最大化。 因此,。 在 (19) 中使用它可以提供:
| (20) |
我们指出,在边界 处,误差及其导数恰好为零,因为通过方程(1)的参数化可以相同地满足初始条件。 (6)。 此外,假设所有误差都集中在单个分量 上,这意味着 和 是 的零函数。 这个强有力的假设简化了方程。 (19) 产生方程的误差上限。 (20)。
如果对神经网络进行训练,使得损失函数的最大值为 ,则解决方案的任何组件可以承受的最大误差以 (20) 为界。 换句话说,我们可以提前选择解决方案的精度,并使用关系 (20) 来计算 ,从而确定我们何时必须停止训练网络以确保所需的准确性。 可以根据训练过程进行计算,因为在最一般的情况下,它是解的函数。 此外,表达式 (16) 和 (20) 表明 取决于总体网络性能,而不仅仅是时间点的数量在训练过程中使用,这是数值积分器的情况。 发生这种情况是因为训练点数并不是决定损失函数值的唯一参数。 例如,固定训练点的数量,同时增加隐藏层或神经元的数量,会产生更好的性能,对应于较小的 。 总之,一旦哈密顿神经网络被优化,方程: (16) 可用于计算误差传播。 另一方面,我们可以使用式(1)来确定优化前解的准确性。 (20) 定义确定何时停止网络训练的 。
III实验
III.1 非线性振荡器
作为一个具体的例子,我们考虑具有哈密顿量的一维非线性(非谐波)振荡器
| (21) |
其中固有频率和振荡器的质量被认为是统一的。 哈密顿量 (21) 对应于系统的总能量 ,相关运动方程为 (Eq. 1):
| (22) |
接下来,我们使用辛神经网络架构来求解上述非线性哈密顿系统,并将神经网络解与辛欧拉积分器获得的解进行比较。 结果表明,辛欧拉方法需要比神经网络多两个数量级的评估时间点才能达到相同的数值误差。 我们还探索了不同激活和参数函数的网络效率。
振荡器的相空间由两个自由度组成。因此,我们利用具有两个输出 的前馈神经网络,用于根据方程式对近似解 进行参数化。 (6)。 损失函数由等式定义。 (22) 并根据等式: (7) 为:
| (23) |
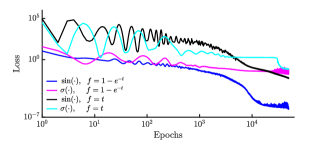
我们初始化一个网格,其中 个时间点在时间间隔 中均匀分布。 在每个时期的开始,我们使用均值为零、标准差为 的正态分布获得的随机项来扰动所有时间点。 初始状态选择为,对应总初始能量;在这种能量下,运动偏离简谐振子的行为。 该神经网络由两个隐藏层组成,每个隐藏层都有 个神经元,并且通过使用 Adam 优化器 [46] 和学习来训练 个周期。 的比率。 我们进行了四个独立的数值实验,分别对应于不同的神经网络设计,即 sigmoid 和三角函数 激活函数的组合,以及参数函数 和。 图2以对数尺度展示了训练过程中的损失函数(23);每种颜色代表传说中的四种杰出建筑案例之一。 我们强调,我们提出的设计(蓝线)的损失函数比其他模型收敛得更快。
哈密顿神经网络训练后的性能如图(3)中的蓝色曲线所示。 此外,我们使用scipy python包[47]的DE求解器odeint来求解系统(22) 并将获得的数值解视为基本事实。 我们注意到,scipy 提供的求解器具有堪称典范的误差控制和自适应性,可带来出色的求解轨迹。 出于比较的目的,我们还利用等式中描述的辛欧拉方法。 (4),(5) 来求解 DE (22),并将解与我们提出的辛神经网络获得的解进行比较。 我们指出,真实数据和辛欧拉方法获得的解仅用于评估神经网络预测的性能,而从未用于神经网络优化。 本质上,哈密顿神经网络不使用传统数值求解器生成的任何数据。 在图 3 中,我们展示了求解器(绿线)、神经网络(蓝线)和辛欧拉积分器(黑色和红色)获得的结果。 网络优化后我们得到。 哈密顿量的 Hessian 矩阵 (21) 的最小奇异值为 。 随后,方程。 (20) 为 和 产生上限误差。 有趣的是,辛欧拉方法需要个时间点来接近这个最大误差。 在欧拉方法的情况下,我们在图3中提出了两个数值解:一个具有与NN训练中使用的相同时间点(黑色),第二个具有相同的时间点。 100 倍以上的点(红色)。 图 3 中的左图展示了数值误差的相空间,我们观察到 NN 解中的误差与辛欧拉在 100 倍以上时间时获得的误差处于同一数量级。点被使用。 在图 3 的右图中,我们展示了 和 以及通过使用中的数值解计算出的总能量作为时间的函数哈密顿量 (21)。 这一探索的一个重要结果是,与欧拉积分器相比,神经网络的解决方案在局部保存了总能量。 这是因为辛神经网络获得的解保留了正确的哈密顿量,而不是辛积分器的扰动量。 因此,在能量守恒任务的背景下,哈密顿神经网络优于辛欧拉积分器。
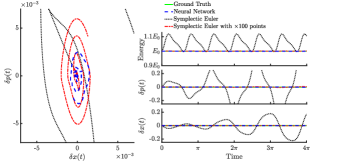
我们通过求解较长时间段内的 DE 来验证哈密顿神经网络的长期预测的可预测性。 特别是,方程式系统。 (22) 使用与先前模拟相同的初始条件(即 )针对延长时间间隔 进行求解。 尽管之前使用的架构提供了高精度的解决方案,但我们发现每个隐藏层使用 80 个神经元可以在神经网络优化中产生更快的收敛速度。 而且,由于时间间隔扩大,训练点数相应地增加到时间点。 对于这种情况下的长时间预测,我们使用正则化损失(7)和,它会惩罚违反能量守恒的行为。 将 NN 预测与使用 点通过辛欧拉方法获得的解进行比较。 这比用于网络优化的点多了 100 倍。 长时间求解的结果如图4所示。 训练过程中的损失函数如图4左上图所示。 下图表示真实能量(绿色实线)、哈密顿神经网络获得的能量(蓝色虚线)以及辛欧拉方法(红色虚线)计算的能量。 我们观察到神经网络比数值积分器稍微更好地保存能量。 图4右图是相空间误差,与图3类似,我们观察到辛欧拉(红色点划线)得到的误差)随时间不断增加的速度远远快于我们从 NN 解决方案中获得的误差。 有趣的是,我们观察到,尽管两种方法的能量守恒相当好,但哈密顿神经网络在预测解的准确性方面优于辛欧拉方法。 发生这种情况的原因是,NN 求解器同时满足 DE 系统的所有方程并保留原始哈密顿量,而积分器保留了随时间累积误差的扰动哈密顿量。
III.2 混沌系统
我们通过求解混沌二维动力系统的方程进一步证明了所提出的辛神经网络的效率。 特别是,我们求解了 Hénon-Heiles (HH) 系统 [48] 的正则方程,该系统描述了恒星围绕银河系中心的非线性运动,且该运动仅限于平面。 HH 系统在相空间中有四个自由度,其中。该系统的哈密顿量和总能量为
| (24) |
Hamilton 方程得出非线性 DE 系统:
| (25) | ||||||
| (26) |
对于 HH 系统,我们正在寻求近似解。 因此,我们采用具有四个输出 的全连接前馈神经网络,用于根据通用公式 (6) 参数化 。 数值实验的初始条件为,对应能量。 这组初始条件的最大李亚普诺夫指数为,并且由于为正,因此运动是混沌[49]。 该网络由两个隐藏层组成,每个隐藏层有 50 个神经元。 的等距网格在相当于 1.3 Lyapunov 时间的时间间隔 内初始化。 这些点用作训练集,并在每个时期的开始时通过使用由零均值和标准差 的正态分布获得的随机项进行扰动。 损失函数由等式定义。 (25), (26),并根据等式: (7),如
| (27) |
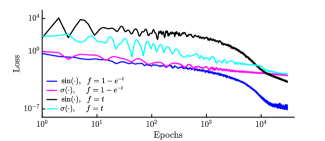
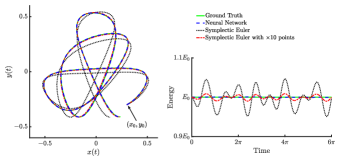
我们研究了类似于非线性振荡器系统的四种不同的网络架构,即不同的激活和参数函数。 使用学习率为 的 Adam 优化器对网络进行 纪元的训练。 经过足够长的训练以确保损失函数收敛后,我们发现这个时期数足以优化网络。 在图5中,我们展示了训练中的损失函数(III.2),其中根据图中的图例,每种颜色对应于不同的架构。 同样,选择 激活和 会产生最佳网络性能。 在图 6 中,我们比较了辛 NN(蓝线)和辛欧拉积分器获得的近似轨迹和能量,该积分器在 和 时间点(分别用黑线和红线表示)。 求解器获得的解被视为基本事实(绿色曲线)。 图 6 中的左图显示了 平面中的轨道,其中哈密顿神经网络解与地面实况无法区分。 右图表示时间上的总能量,其中 NN 解比辛欧拉方法获得的解更好地保存能量。 辛欧拉必须使用比神经网络高一个数量级的分辨率才能捕获正确的轨道图像,但是能量仍然不守恒。
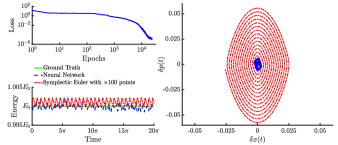
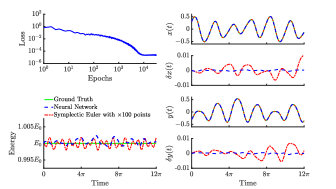
我们将 HH 系统的积分时间延长至 ,相当于 Lyapunov 时间。 对于长时间预测,我们采用等式的正则化项。 (7) 和 网络架构由两个隐藏层组成,每层有 80 个神经元。 网络优化使用500个时间点。 对于该模型的训练,我们发现使用顺序学习[29]效率更高。 首先,我们在 的短积分时间范围内训练模型并保存网络参数;网络以 周期进行训练,学习率为 。 然后,我们加载之前保存的参数,并在更大的域 ] 中训练模型,持续 个周期,学习率为 。 这种迁移学习应用程序增强了学习能力,因此,与从随机初始化参数开始训练相比,网络更快地收敛到解决方案。 结果如图7所示,其中左上图表示哈密顿网络训练期间的损失函数。 为了进行比较,我们以蓝色显示 NN 结果以及通过使用比训练点多 点评估的辛欧拉获得的解。 左图中的下图显示了能量,我们观察到神经网络(蓝色)和辛欧拉(红色)都保存了正确的(绿色)能量,误差大约相同。 图7的右图表示位置状态和的预测以及由表示的相关数值误差> 和 分别。 正如我们在非线性振荡器系统中观察到的那样,尽管两种方法都很好地保存了能量,但通过神经网络获得的解呈现出比辛积分器更低的数值误差。
四结论
近年来,机器学习在传统科学和工程领域取得了进展。 神经网络因其在回归、分类和预测任务中的出色能力而引起了科学家的兴趣。 由于这些方法对于物理学来说相对较新,因此有许多物理概念尚未嵌入神经网络的结构中。 在这项工作中,我们提出了一种受物理启发的无监督神经网络,用于求解描述动态系统时间运动的微分方程。 哈密顿公式通过损失函数嵌入到神经网络中,因此,预测的解决方案可以节省能量。 损失函数仅由网络预测构建,不使用任何地面实况数据。 所提出的方法不使用传统数值求解器生成的任何数据。 因此,所提出的哈密顿网络提供了一种无数据的无监督学习方法。 尽管当前工作中提出的哈密顿网络是一个无监督模型,但对所提出的网络的概括可以以半监督的方式合并数据。 尽管如此,在本研究中,我们专注于对基线无监督模型的探索,并将半监督案例留给未来的工作。
本研究引入了一种平滑且有界的参数形式的解决方案,使所提出的架构成为辛网络,进而成为时不变单元。 通过适当选择激活函数,可以提供更好的领域知识,从而极大地提高网络性能。 此外,所提出的哈密顿架构允许网络输出共享其权重。 共享学习参数有助于神经网络发现潜在的相互依赖性,从而提高满足差分方程非线性系统的学习解决方案中的网络可预测性。 所提出的神经网络的哈密顿结构允许使用正则化项来惩罚违反能量守恒定律的行为。 这种惩罚极大地提高了网络性能,特别是对于长时间的解决方案。 这项工作中提出的实验表明,为了获得更大积分时间的准确解决方案,需要更多的隐藏神经元和时间点,从而增加了网络复杂性和计算成本。 由于每个时间点都是独立处理的,因此通过并行计算可以潜在地降低这种成本,但是,本研究中没有提出这样的实现。 在很长的集成时间的限制下,我们预计需要非常大的网络复杂性和批量的时间点,因此并行实现至关重要。 这项工作中开发了一种误差分析,可用于分析预测解中的误差如何及时传播。 此外,这种误差分析在损失函数中提供了一个阈值,当达到一定的精度时,我们可以提前停止训练网络,即确保预测解中的误差较低。
使用神经网络求解器代替传统的辛数值积分器来求解微分方程有几个优点。 神经网络获得的解是连续的、平滑的并且是解析形式的。 由于许多输出具有可共享的权重,哈密顿神经网络发现同时且一致地满足哈密顿方程的解。 随后,神经网络求解器保留了正确的哈密顿量,而辛积分器保留了稍微扰动的哈密顿量。 我们概述了神经网络获得的解在所有时间点上都局部守恒能量,并且优于用波动误差项预测能量的辛欧拉积分器。 除了一阶欧拉方法外,还有更高阶的辛积分器,其累积误差比半隐式欧拉方法小,但计算成本较大。 本研究中没有对所提出的神经网络求解器和高阶积分器进行比较。 在能量守恒至关重要的问题中,哈密顿神经网络将表现出比辛积分器更好的性能。 此外,神经网络求解器可能比最先进的集成器(例如 scipy Python 包中的 odeint)拥有优势。 正如[18]所指出的,神经网络的计算可以在并行架构上有效地实现,从而显着加速。 这是可能的,因为神经网络求解器独立评估时间点。 自从 [18] 的原创作品出现以来,GPU 等硬件创新使得神经网络的并行化变得更加容易。 相反,传统数值积分器的时间并行算法的开发和实现具有挑战性,因为某个时间点的计算需要先前时间点的解。 此外,随着系统中微分方程数量的增加,会出现“维数灾难”的问题,由于计算成本的迅速增加,导致数值积分器效率低下。 另一方面,[19, 20]表明,神经网络微分方程求解器不会出现“维数灾难”问题。 随后,在许多身体问题等高维问题中,我们预计哈密顿神经网络的性能优于常规辛积分器。 考虑到哈密顿公式为物理许多领域(例如微扰方法和混沌理论以及统计和量子力学)的理论扩展提供了坚实的框架,所提出的哈密顿神经网络为处理现代研究问题提供了肥沃的土壤。
致谢。
这项研究没有获得公共、商业或非营利部门资助机构的任何具体资助。 作者要感谢与 E. Lagaris 教授、G. P. Tsironis 教授和 E. Kaxiras 教授进行的富有成效的讨论。参考
- [1] Bethany Lusch, J. Nathan Kutz, and Steven L. Brunton. Deep learning for universal linear embeddings of nonlinear dynamics. Nature Communications, 9, 2018.
- [2] Pantelis R. Vlachas, Wonmin Byeon, Zhong Y. Wan, Themistoklis P. Sapsis, and Petros Koumoutsakos. Data-driven forecasting of high-dimensional chaotic systems with long short-term memory networks. Proceeding of the Royal Sociaty A- Mathematical Physical and Engineering Sciences, 474(2213), 2018.
- [3] George Neofotistos, Marios Mattheakis, Georgios D. Barmparis, Johanne Hizanidis, Giorgos P. Tsironis, and Efthimios Kaxiras. Machine Learning With Observers Predicts Complex Spatiotemporal Behavior. Frontiers in Physics, 7, 2019.
- [4] Zhixin Lu, Jaideep Pathak, Brian Hunt, Michelle Girvan, Roger Brockett, and Edward Ott. Reservoir observers: Model-free inference of unmeasured variables in chaotic systems. Chaos, 27(4), 2017.
- [5] Jaideep Pathak, Brian Hunt, Michelle Girvan, Zhixin Lu, and Edward Ott. Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach. Phys. Rev. Lett., 120:024102, 2018.
- [6] Gouhei Tanaka, Toshiyuki Yamane, Jean Benoit Héroux, Ryosho Nakane, Naoki Kanazawa, Seiji Takeda, Hidetoshi Numata, Daiju Nakano, and Akira Hirose. Recent advances in physical reservoir computing: A review. Neural Networks, 115:100 – 123, 2019.
- [7] Fazle Karim, Somshubra Majumdar, Houshang Darabi, and Samuel Harford. Multivariate lstm-fcns for time series classification. Neural Networks, 116:237 – 245, 2019.
- [8] Julia Ling, Reese Jones, and Jeremy Templeton. Machine learning strategies for systems with invariance properties. Journal of Computational Physics, 318:22–35, 2016.
- [9] Julia Ling, Andrew Kurzawski, and Jeremy Templeton. Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. Journal of Fluid Mechanics, 807:155–166, 2016.
- [10] Rui Fang, David Sondak, Pavlos Protopapas, and Sauro Succi. Neural network models for the anisotropic reynolds stress tensor in turbulent channel flow. Journal of Turbulence, 0(0):1–19, 2019.
- [11] Karthik Duraisamy, Gianluca Iaccarino, and Heng Xiao. Turbulence Modeling in the Age of Data. Annual Review of Fluid Mechanics, 51:357–377, 2019.
- [12] Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Inferring solutions of differential equations using noisy multi-fidelity data. Journal of Computational Physics, 335:736–746, 2017.
- [13] Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Machine learning of linear differential equations using Gaussian processes. Journal of Computational Physics, 348:683–693, 2017.
- [14] Samuel H. Rudy, Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. Data-driven discovery of partial differential equations. Science Advances, 3(4), 2017.
- [15] J. Nathan Kutz, Samuel H. Rudy, Alessandro Alla, and Steven L. Brunton. Data-driven discovery of governing physical laws and their parametric dependencies in engineering, physics and biology. 2017 IEEE 7th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pages 1–5, 2017.
- [16] Yohai Bar-Sinai, Stephan Hoyer, Jason Hickey, and Michael P. Brenner. Learning data-driven discretizations for partial differential equations. Proceedings of the National Academy of Sciences of the United States of America, 116(31):15344–15349, 2019.
- [17] M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019.
- [18] Isaac E. Lagaris, Aristidis Likas, and Dimitrios I. Fotiadis. Artificial neural networks for solving ordinary and partial differential equations. IEEE transactions on neural networks, 9:987–1000, 1998.
- [19] Jiequn Han, Arnulf Jentzen, and E Weinan. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences of the United States of America, 115 34:8505–8510, 2017.
- [20] Justin A. Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics, 375:1339–1364, 2018.
- [21] Martin Magill, Faisal Qureshi, and Hendrick W. de Haan. Neural networks trained to solve differential equations learn general representations. In NeurIPS, 2018.
- [22] Hong Li, Qilong Zhai, and Jeff Z. Y. Chen. Neural-network-based multistate solver for a static schrödinger equation. Phys. Rev. A, 103:032405, Mar 2021.
- [23] Kurt Hornik. Approximation capabilities of multilayer feedforward networks. Neural Networks, 4:251–257, 1991.
- [24] George Em Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning. Nature Review Physics, 2021.
- [25] Sifan Wang and Paris Perdikaris. Deep learning of free boundary and stefan problems. Journal of Computational Physics, 428:109914, 2021.
- [26] Ehsan Kharazmi, Min Cai, Xiaoning Zheng, Zhen Zhang, Guang Lin, and George Em Karniadakis. Identifiability and predictability of integer- and fractional-order epidemiological models using physics-informed neural networks. Nature Computational Science, 1:744, 2018.
- [27] Modeling the effect of the vaccination campaign on the covid-19 pandemic. Chaos, Solitons Fractals, 154:111621, 2022.
- [28] Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In ICLR, 2021.
- [29] Aditi S. Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M. Kirby, and Michael W. Mahoney. Characterizing possible failure modes in physics-informed neural networks. In NeurIPS, 2021.
- [30] Martin J. Gander. 50 years of time parallel time integration. In in Multiple Shooting and Time Domain Decomposition, pages 69–114. Springer, 2015.
- [31] Stefanie Gunther, Lars Ruthotto, Jacob B. Schroder, Eric C. Cyr, and Nicolas R. Gauger. Layer-parallel training of deep residual neural networks. SIAM Journal on Mathematics of Data Science, 2:1–23, 2020.
- [32] Sam Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks. In Advances in Neural Information Processing Systems 32, pages 15379–15389. Curran Associates, Inc., 2019.
- [33] Tom Bertalan, Felix Dietrich, Igor Mezic, and Ioannis G. Kevrekidis. On learning hamiltonian systems from data. Chaos: An Interdisciplinary Journal of Nonlinear Science, 29(12):121107, 2019.
- [34] Anshul Choudhary, John F. Lindner, Elliott G. Holliday, Scott T. Miller, Sudeshna Sinha, and William L. Ditto. Physics-enhanced neural networks learn order and chaos. Phys. Rev. E, 101:062207, Jun 2020.
- [35] Shaan A. Desai, Marios Mattheakis, and Stephen J. Roberts. Variational integrator graph networks for learning energy-conserving dynamical systems. Phys. Rev. E, 104:035310, 2021.
- [36] Chen-Di Han, Bryan Glaz, Mulugeta Haile, and Ying-Cheng Lai. Adaptable hamiltonian neural networks. Phys. Rev. Research, 3:023156, 2021.
- [37] Han Zhang, Huawei Fan, Liang Wang, and Xingang Wang. Learning hamiltonian dynamics with reservoir computing. Phys. Rev. E, 104:024205, 2021.
- [38] Alvaro Sanchez-Gonzalez, Victor Bapst, Kyle Cranmer, and Peter Battaglia. Hamiltonian Graph Networks with ODE Integrators. arXiv:1909.12790 [physics], 2019. arXiv: 1909.12790.
- [39] Peter Toth, Danilo Jimenez Rezende, Andrew Jaegle, Sebastien Racaniere, Aleksandar Botev, and Irina Higgins. Hamiltonian generative networks. In International Conference on Learning Representations, 2020.
- [40] Shaan A. Desai, Marios Mattheakis, David Sondak, Pavlos Protopapas, and Stephen J. Roberts. Port-hamiltonian neural networks for learning explicit time-dependent dynamical systems. Phys. Rev. E, 104:034312, 2021.
- [41] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary Devito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. In NeurIPS, 2017.
- [42] https://github.com/mariosmat/hamiltonianNNetODEs.
- [43] Emmy Noether. Invariante variationsprobleme. Math. Phys. Klasse, 2:235 – 257, 1918.
- [44] Benedict J Leimkuhler and Robert D Skeel. Symplectic numerical integrators in constrained hamiltonian systems. Journal of Computational Physics, 112(1):117–125, 1994.
- [45] Liu Ziyin, Tilman Hartwig, and Masahito Ueda. Neural networks fail to learn periodic functions and how to fix it. ArXiv, 2006.08195, 2020.
- [46] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014.
- [47] Travis E. Oliphant. Python for scientific computing. Computing in Science & Engineering, 9, 2007.
- [48] Michel Hénon and Carl Heiles. The applicability of the third integral of motion: Some numerical experiments. The Astronomical Journal, 69:73–79, 1964.
- [49] I. I. Shevchenko and A. V. Mel’Nikov. Lyapunov exponents in the hénon-heiles problem. JETP Letters, 77(12):642–646, 12 2003.