元学习框架及其零样本时间序列预测的应用
摘要
元学习能否从不同的数据集中发现处理时间序列(TS)的通用方法,从而大大提高来自不同数据集的新 TS 的泛化能力? 这项工作使用广泛的元学习框架为此提供了积极的证据,我们展示了该框架包含许多现有的元学习算法。 我们的理论分析表明,残差连接充当元学习适应机制,根据给定的 TS 输入生成任务特定参数的子集,从而逐渐扩展动态架构的表达能力。 通过线性化分析显示了相同的机制,以解释最终线性层的顺序更新。 我们对广泛数据的实证结果强调了已确定的元学习机制对于成功的零样本单变量预测的重要性,这表明在源 TS 数据集上训练神经网络并将其部署在不同的目标 TS 数据集上是可行的无需重新训练,其性能至少与实际单变量预测模型一样好。
1简介
时间序列(TS)预测既是一个基本的科学问题,又具有重要的实际意义。 它是智能代理行为的核心:计划和控制以及对复杂的部分或完全未知系统的表现做出适当反应的能力通常依赖于根据过去的历史预测相关观察的能力。 此外,对于大多数效用最大化的代理来说,预测准确性的提高广泛地转化为效用收益。因此,预测技术的改进可以产生广泛的影响。 不出所料,预测方法有着悠久的历史,可以追溯到人类文明的起源(Neale 1985)、现代科学(Gauss 1809),并且一直吸引着相当多的研究。研究关注(Yule 1927;Walker 1931;Holt 1957;Winters 1960;Engle 1982;Sezer、Gudelek 和 Ozbayoglu 2019)。 预测的应用涵盖多个领域,包括高频控制(例如车辆和机器人控制(Tang and Salakhutdinov 2019)、数据中心优化(Gao 2014)) 、业务规划(供应链管理(Leung 1995)、劳动力和呼叫中心管理(Chapados 等人 2014;Ibrahim 等人 2016),以及这些至关重要的领域精准农业(Rodrigues Jr 等人 2019)。 具体到商业领域,改进的预测意味着更好的生产规划(减少浪费)和更少的运输(减少排放)(Kahn 2003;Kerkkänen、Korpela 和 Huiskonen 2009;Nguyen、Ni、和罗塞蒂 2010)。 过去四十年单变量预测取得的进展很好地反映在该时期相关竞赛的结果和方法中(Makridakis 等人 1982, 1993; Makridakis 和 Hibon 2000; Athanasopoulos 等人 2011; Makridakis, Spiliotis ,以及阿西马科普洛斯 2018a)。 最近,越来越多的证据开始表明,与一些早期的评估相比,机器学习方法可以改进经典预测方法(Makridakis、Spiliotis 和 Assimakopoulos 2018b)。 例如,2018 年 M4 竞赛(Makridakis、Spiliotis 和 Assimakopoulos 2018a) 的获胜者是 Smyl (2020) 设计的神经网络。
在实践方面,深度神经时间序列模型的部署受到冷启动问题的挑战。 在白板深度神经网络提供有用的预测输出之前,应该在大型特定问题时间序列数据集上对其进行训练。 对于早期采用者来说,这通常意味着数据收集工作、改变数据处理实践,甚至大规模改变现有的 IT 基础设施。 相比之下,高级统计模型的部署工作量要少得多,因为它们一次会在单个时间序列上估计其参数。 在本文中,我们解决了在 TS 预测的工业实践中降低深度神经网络的入门成本的问题。 我们证明,在多样化的源数据集上训练神经网络模型并将其部署在零样本体系的目标数据集上是可行的,即无需对该目标数据进行显式再训练,从而获得以下性能:至少与针对目标数据集定制的高级统计模型一样好。 我们想澄清的是,我们在工作中使用术语“零样本”是因为目标时间序列可用的历史样本数量非常小,以至于训练该时间序列上的深度学习模型不可行。
解决这个实际问题可以为基本问题提供线索。 我们可以学习一些有关预测的一般知识并将这些知识跨数据集转移吗? 如果是这样,什么样的机制可以促进这一点? 通过任务适应来学习和跨任务迁移表示的能力是元学习的一个优势(Raghu 等人 2019)。 我们在这里提出了一个广泛的元学习理论框架,其中包含几种现有的元学习算法。 我们进一步表明,最近的成功模型 N-BEATS (Oreshkin 等人 2020) 适合这个框架。 我们确定了内部元学习适应机制,可以动态生成特定于给定 TS 的新参数,从而迭代扩展架构的表达能力。 我们凭经验证实元学习机制是提高零样本 TS 预测性能的关键,并在广泛的数据集上展示了结果。
1.1背景
离散时间中的单变量点预测问题是在给定长度-预测范围和长度-观察序列历史的情况下制定的>。 任务是预测未来值的向量。 为简单起见,我们稍后将考虑长度为 的 回溯窗口,以最后观察到的值 结尾,作为模型输入,并表示为 。 我们用表示的点预测。 其准确性可以用、对称平均绝对百分比误差(Makridakis、Spiliotis和Assimakopoulos 2018a)来评估,
| (1) |
其他质量指标(例如 、、、)也是可能的,并在附录 A
元学习或学会学习 (Harlow 1949;Schmidhuber 1987;Bengio、Bengio 和 Cloutier 1991) 通常与存在联系在一起能够 (i) 跨任务积累知识(即 迁移学习、多任务学习)以及 (ii) 快速调整积累的知识新任务(任务适应)(Ravi and Larochelle 2016;Bengio 等人 1992)。
N-BEATS算法在多个竞赛基准(Oreshkin等人2020)上表现出了出色的性能。 该模型由使用双残差架构连接的总共 块组成。 块具有输入并产生两个输出:回溯和部分预测。 对于第一个块,我们定义 ,其中 被假定为从现在开始的模型级输入。 我们在第 块中定义第 全连接层;具有非线性、权重、偏差和输入,如。 我们专注于跨块共享所有可学习参数的配置。 通过这种表示法,N-BEATS 的一个块被描述为:
| (2) | ||||
其中 和 是线性运算符。 和线性层中包含的 N-BEATS 参数是通过最小化合适的损失函数(例如 中定义的(1)) 跨多个 TS。 最后,双残差架构由以下递归描述(回想一下 ):
| (3) |
1.2相关工作
从高层次的角度来看,与经典的 TS 建模有很多联系:人类指定的经典模型通常旨在很好地概括未见过的 TS,而我们建议将该过程自动化。 经典模型包括有或没有季节性影响的指数平滑(Holt 1957, 2004;Winters 1960)、多迹指数平滑方法,例如 Theta 及其变体 (Assimakopoulos 和 Nikolopoulos 2000;Fiorucci 等人 2016;Spiliotis、Assimakopoulos 和 Nikolopoulos 2019)。 最后,除了自动 ARIMA 和 GARCH 之外,状态空间建模方法还封装了上述大部分内容(Engle 1982;参见Hyndman 和 Khandakar (2008) 概述)。 状态空间方法也是神经 TS 建模领域大量研究的基础(Salinas 等人 2019;Wang 等人 2019;Rangapuram 等人 2018)。 然而,零样本场景中并未考虑这些模型。 在这项工作中,我们重点研究元学习对于成功的零样本预测的重要性。 Schmidhuber (1987)、Bengio、Bengio 和 Cloutier (1991) 等人提出了元学习的基础。 最近,元学习研究一直在扩展,主要在 TS 预测领域之外(Ravi 和 Larochelle 2016;Finn、Abbeel 和 Levine 2017;Snell、Swersky 和 Zemel 2017;Vinyals 等人 2016;Rusu 等人2019)。 在 TS 领域,元学习通过在 TS 集合上训练的神经模型 (Smyl,2020 年;Oreshkin 等,2020 年) 或通过训练的模型来预测权重,这些权重结合了几种经典预测算法的输出 (Montero-Manso 等,2020 年)。 Hooshmand 和 Sharma (2019) 证明了在源数据集上训练并在目标数据集上进行微调的神经 TS 预测模型的成功应用; Ribeiro 等人 (2018) 以及 Fawaz 等人 (2018) 的 TS 分类。 与这些不同的是,我们专注于零样本场景并解决冷启动问题。
1.3贡献摘要
我们定义了一个带有相关方程的元学习框架,并在其中重新构建了许多现有的元学习算法。 我们证明 N-BEATS 遵循相同的方程。 根据我们的分析,其残差连接实现了元学习内循环,从而在推理时无需梯度步骤即可执行任务适应。
我们定义了一个新颖的零样本单变量 TS 预测任务,并将其数据集加载器和评估代码公开,包括一个具有 290k TS 的新的大规模数据集(fred)。
我们通过经验首次证明,深度学习零样本时间序列预测是可行的,并且元学习组件对于单变量 TS 预测中的零样本泛化非常重要。
2 元学习框架
元学习过程通常可以从两个层面来看待:内循环和外循环。 内部训练循环在单个“元示例”或任务 内运行(快速学习循环比当前 有所改进),外部循环跨任务运行(慢速学习循环)。 任务包括任务训练数据和任务验证数据,两者都可选地涉及输入、目标和特定于任务的损失:,。 因此,元学习设置可以通过假设任务分布、预测器和具有元参数的元学习器来定义>。 我们允许表示为 的预测器参数子集属于元参数 ,因此不具有任务自适应性。 目标是设计一个元学习器,通过在观察 后适当选择预测器的任务自适应参数 ,可以很好地泛化新任务。 元学习器通过暴露于从 采样的数据集 中的许多任务来训练这样做。 对于每个训练任务,元学习器被要求以的形式以为条件产生任务的解决方案。 元参数 在元学习外循环中进行更新,以便在内环 即中获得良好的泛化效果,方法是将映射地面实况和估计输出的预期验证损失 最小化为量化跨任务泛化性能的值。 对多个任务进行训练使元学习器能够生成解决方案 ,该解决方案可以很好地概括从 采样的一组未见过的任务 。
因此,元学习过程具有三个不同的组成部分:(i)元参数,(ii)初始化函数和(iii)更新函数。 元学习器的元参数包括元初始化函数的元参数,,跨模型共享的预测器的元参数任务 和更新函数的元参数 。 元初始化函数根据其元初始化参数为给定任务定义参数的初始值,任务训练数据集和任务元数据。 任务元数据可以具有例如任务ID或文本任务描述的形式。 更新函数通过更新元参数进行参数化。 它根据先前的值和任务训练集 在迭代 时定义对预测参数 的迭代更新。 初始化和更新函数产生一系列预测参数,我们将其简洁地写为。 我们让最终的预测器是整个参数序列的函数,简洁地写为 。 这种通用函数的一种实现可以是贝叶斯集合或加权和,例如:。 如果我们设置,那么我们会得到更常见的情况。 这个元学习框架由以下方程组简洁地描述:
| (4) | ||||
| (5) | ||||
2.1 元学习和时间序列预测
在上一节中,我们提出了元学习的统一框架。 它与 TS 预测任务有何联系? 我们认为,最好回答这个问题,回答“为什么 ARIMA 和 ETS 等经典统计 TS 预测模型不进行元学习?”以及“元学习组件作为预测算法的一部分提供什么?”。 第一个问题可以通过考虑以下事实来回答:经典统计模型通过使用预定义的固定规则集从目标时间序列的历史估计其参数来产生预测,例如,给定模型选择和最大似然参数它的估计器。 因此,就我们的元学习框架而言,经典统计模型仅执行方程(4)中封装的内循环(模型参数估计)。 在这种情况下,外循环是无关紧要的 - 人类分析师根据经验定义方程 (4) 正在做什么(例如,“对于大多数具有趋势的缓慢变化的时间序列,没有季节性和白色残差,带有高斯最大似然估计器的 ETS 可能会很好地工作”)。 考虑到基于元学习的预测算法用可学习的参数估计策略取代了用于模型参数估计的预定义固定规则集,可以回答第二个问题。 可学习参数估计策略使用外环方程 (5) 进行训练,通过调整策略,使其能够生成在多个 TS 上很好地泛化的参数估计。 假设存在一个代表将在推理时处理的预测任务的数据集。 因此,基于元学习的预测方法的主要优点是它们能够学习数据驱动的参数估计器,该估计器可以针对特定的预测任务和预测模型集进行优化。 最重要的是,元学习方法允许在方程 (4) 中使用通用的可学习预测器,可以针对给定的预测任务进行优化。 因此,对于由可用数据表示的预测任务,可以联合学习预测器(模型)及其参数估计器。 根据经验,我们表明,这种优雅的理论概念可以在多个数据集和多个预测任务(例如预测每年、每月或每小时的 TS)中有效地发挥作用,甚至可以在非常松散相关的任务(例如,在每月经济数据训练后预测每小时电力需求)中有效地发挥作用。适当时间尺度标准化后的数据)。
2.2 在提议的框架中表达现有的元学习算法
为了进一步说明所提出的框架的通用性,我们接下来展示如何在转向 N-BEATS 之前在其中使用现有的元学习算法。
MAML 和相关方法 (Finn、Abbeel 和 Levine,2017 年;Li 等人,2017 年;Raghu 等人,2019 年) 可以通过以下方法从 (4) 和 (5) 中导出:(i) 将 设置为将 复制到 的身份映射;(ii) 将 设置为 SGD 梯度更新:,其中 并通过 (iii) 将预测器的元参数设置为空集 。 公式 (5) 无需修改即可应用。 MT-net (Lee and Choi 2018) 是 MAML 的一种变体,其中预测器的元参数集 不为空。 用 参数化的预测器部分是跨任务元学习的,并在任务适应期间固定。
优化作为少样本学习的模型 (Ravi 和 Larochelle 2016) 可以从 (4) 和 (55 导出t4>) 通过以下步骤(除了 MAML 的步骤之外)。 首先,将更新函数 设置为类似 LSTM 单元的更新方程,其形式为( 是 LSTM 更新步骤索引)。 其次,将 设置为 LSTM 忘记门值 (Ravi and Larochelle 2016): 和 作为 LSTM输入门值:。 这里 是 sigmoid 非线性。 最后,将所有 LSTM 参数包含到更新元参数集中:。
原型网络 (PN) (Snell、Swersky 和 Zemel 2017)。 大多数基于度量的元学习方法(包括训练 PN)都依赖于将任务集的嵌入与验证集的嵌入进行比较。 因此,可以方便地考虑由 embedding 函数 和 comparison 函数 组成的复合预测器,。 通过考虑 镜头图像分类任务、卷积网络 ,可以从 (4) 和 (5) 导出 PN > 在 中包含的任务和类原型 之间共享。 带有 的初始化函数 只是将 设置为原型的值。 是一个恒等映射, 和 是一个 softmax 分类器:
| (6) |
这里 是相似性度量,softmax 是标准化的。 所有。 最后,将(5)中的损失定义为(6)中描述的softmax分类器的交叉熵。 有趣的是,只不过是输入到softmax中的最终线性层的动态生成的权重,这在时尤其明显。 事实上,在原型网络场景中,只有最终的线性层权重是根据任务训练集动态生成的,这与 MAML (Raghu 等人 2019) 的最新研究产生了很好的共鸣。 事实证明,仅通过调整内循环中最终线性层的权重就可以恢复 MAML 的大部分增益。
3 N-BEATS 作为元学习算法
现在让我们重点分析由方程 (2)、(3) 描述的 N-BEATS。 我们首先引入以下符号:; ; 。 在原方程中,和是线性的,因此可以用等效矩阵和表示。 在下文中,我们尽可能保持通用的表示法,仅在需要时才过渡到线性情况。 然后,给定网络输入 (),并注意 ,我们可以编写 N-BEATS,如下所示:
| (7) |
N-BEATS 现在源自 Sec 的元学习框架。 2 使用两个观察值:(i) (7) 中 的每个应用都是一个预测器,(ii) N-BEATS 的每个块是内部元学习循环的迭代。 更具体地说,我们有 。 这里 和 是函数 和 的参数,包含在 中并在以下任务中学习外循环。 特定于任务的参数 由输入移位向量序列 组成,其定义使得第 块输入可以写为 。 这会生成预测器任务特定参数的递归表达式,其形式为 ,通过递归展开 eq 获得。 (3)。 这些产生以下初始化和更新函数: 和 将 设置为零; ,与基于生成下一个参数更新:
有趣的是,(i) 元参数 在预测器和更新函数之间共享,(ii) 任务训练集仅限于网络输入 。 请注意,后者是有意义的,因为数据是完整的时间序列,输入 具有与预测目标 相同形式的内部依赖性。 因此,观察 足以推断如何从 预测 ,其方式类似于 不同部分的方式彼此相关。
最后,根据(7),与内循环每次迭代中学习的参数值相对应的预测器输出被组合在最终输出中。 这对应于在 (5) 中选择 形式的预测变量。 外部学习循环 (5) 描述了跨任务 (TS) 的 N-BEATS 训练过程,无需修改。
很明显,该架构的最终输出取决于序列。即使预测器参数 、 跨块共享并固定, 的行为也由参数 的扩展空间控制>。 因此,架构的表达能力预计会随着块数量的增加而增长,与 所跨越的空间的增长成比例,即使 、 跨区块共享。 因此,可以合理地预期,由于表达能力的增加,相同块的添加将提高泛化性能。
3.1线性近似分析
接下来,我们进行更深入的分析,以揭示更复杂的任务适应过程。 使用线性近似分析,我们根据任务输入数据调整网络内部权重来表达 N-BEATS 的元学习操作。 特别是,假设 小,(7) 可以使用 附近的一阶泰勒级数展开来近似:
这里 是 的雅可比行列式。 我们现在考虑线性 和 ,如前所述,在这种情况下 和 由两个适当维度的矩阵表示、 和 ;和。 因此,上面的表达式可以简化为:
连续应用线性近似 直到达到 并回顾 我们得到以下结果:
| (8) |
注意,可以写成迭代更新的形式。 考虑,那么的更新方程可以写成并且(8)变为:
| (9) |
现在让我们讨论如何使用 (9) 将 N-BEATS 重新解释为元学习框架 (4) 和 (5)。 预测器现在可以以解耦形式 表示。 因此,任务适应显然被限制在决策函数 中,而嵌入函数 仅依赖于固定的元参数 。 自适应参数包括投影矩阵序列。 元初始化函数 使用 进行参数化,并且它只是设置 。 更新函数的主要成分是,与之前一样用参数化。 更新函数现在由两个方程组成:
| (10) | ||||
一阶分析结果 (9) 和 (10) 表明,在某些情况下,输入序列的逐块操作在 (7)相当于对(10)中出现的预测器最终线性层权重进行迭代更新,并将块输入设置为相同的固定值。 这与其他元学习算法中识别的最终线性层更新行为非常相似:在 LEO 中,它是通过设计 (Rusu 等人 2019) 呈现的,在 MAML 中,它是由 Raghu 识别的等人 (2019),在 PN 中,它是根据我们在 2.2 节中的分析结果得出的。
| M4, | M3, | tourism, | electr / traff, | fred, | |||||
|---|---|---|---|---|---|---|---|---|---|
| Pure ML | 12.89 | Comb | 13.52 | ETS | 20.88 | MatFact | 0.16 / 0.20 | ETS | 14.16 |
| Best STAT | 11.99 | ForePro | 13.19 | Theta | 20.88 | DeepAR | 0.07 / 0.17 | Naïve | 12.79 |
| ProLogistica | 11.85 | Theta | 13.01 | ForePro | 19.84 | DeepState | 0.08 / 0.17 | SES | 12.70 |
| Best ML/TS | 11.72 | DOTM | 12.90 | Strato | 19.52 | Theta | 0.08 / 0.18 | Theta | 12.20 |
| DL/TS hybrid | 11.37 | EXP | 12.71 | LCBaker | 19.35 | ARIMA | 0.07 / 0.15 | ARIMA | 12.15 |
| N-BEATS | 11.14 | 12.37 | 18.52 | 0.07 / 0.11 | 11.49 | ||||
| DeepAR∗ | 12.25 | 12.67 | 19.27 | 0.09 / 0.19 | n/a | ||||
| DeepAR-M4∗ | n/a | 14.76 | 24.79 | 0.15 / 0.36 | n/a | ||||
| N-BEATS-M4 | n/a | 12.44 | 18.82 | 0.09 / 0.15 | 11.60 | ||||
| N-BEATS-FR | 11.70 | 12.69 | 19.94 | / | n/a | ||||
3.2 的作用
一般来说,从数据中学习到的的形式是很难研究的。 不过,有了第 3.1 节中介绍的线性近似分析结果,我们可以研究双块网络的情况,假设使用 和 之间的 准则损失来训练网络。 此外,如果数据集由 对 的集合组成,则数据集方面的损失 具有以下表达式:
引入,即默认预测与地面实况之间的误差,并扩展 规范我们得到以下结果:
现在,假设网络的其余参数是固定的,我们使用矩阵演算 (Petersen 和 Pedersen 2012) 得到关于 的导数:
使用上面的表达式,我们得出结论,最优 的一阶近似满足以下方程:
虽然这无助于找到 的封闭形式解决方案,但它确实提供了一个相当明显的直觉:当第二个块 创建校正项时,LHS 和 RHS 相等t1>,倾向于补偿默认预测误差。 因此,满足等式的 将趋向于驱动 (10) 中 的更新,从而使 对矩阵 的更新 的投影平均趋向于补偿根据元初始化使用 预测 所产生的误差 。
3.3 支持元学习的因素
现在让我们分析一下使元学习内循环在(10)中变得明显的因素。 首先,如果没有通过残差连接(反馈循环)连接多个块,元学习机制是不可行的:)。 其次,当 是线性时,元学习内循环是不可行的: 的更新是从 在指定点处的曲率中提取的输入 和移位顺序 。事实上,假设是线性的,并用线性运算符表示它。 雅可比行列式 变为常数 。 方程 (8) 简化为(请注意,对于线性 ,(8) 是精确的):
因此,可以被替换为非数据自适应的等效。 有趣的是,恰好是一个截断的诺依曼级数。 将 Moore-Penrose 伪逆表示为 ,假设 有界并完成级数 ,结果为 。 因此,在某些条件下,具有线性 和无限数量块的 N-BEATS 架构可以解释为有色噪声中信号的线性预测器。 这里 部分清除了由投影 创建的中间空间中不需要的预测组件,并 基于初始投影 被 “清理”后。
在本节中,我们确定 N-BEATS 是由方程 (4) 和 (5) 描述的元学习算法的实例。 我们表明,N-BEATS 的每个块都是一个内部元学习循环,可生成特定于输入时间序列的附加移位参数。 因此,即使所有块共享其参数,该架构的表达能力预计也会随着每个附加块的增加而增强。 我们使用线性近似分析来表明,在一定条件下,块中的输入偏移相当于块最终线性层权重的更新。 这个过程中的关键作用似乎封装在 的非线性和残差连接中。
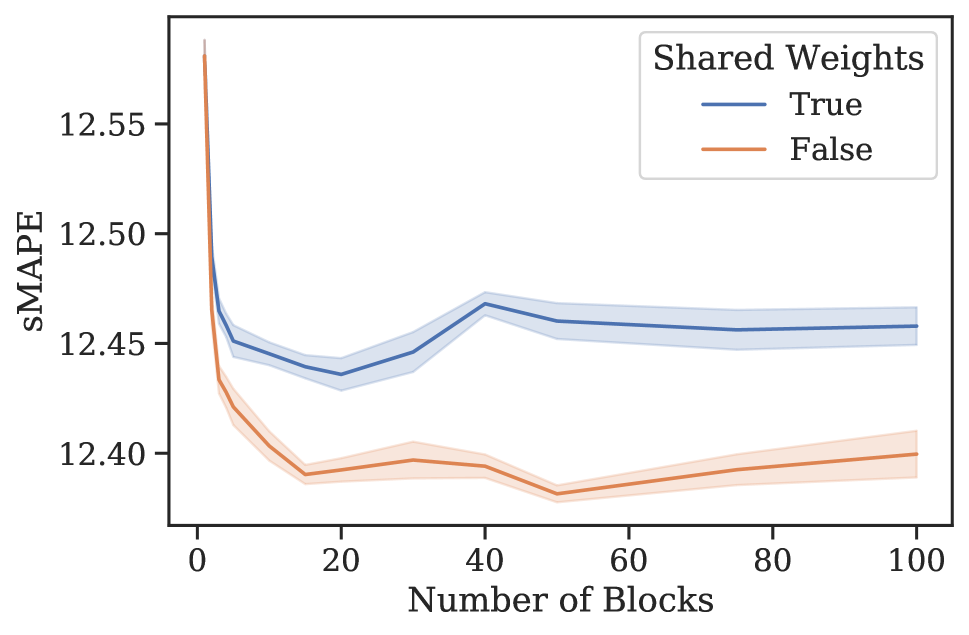
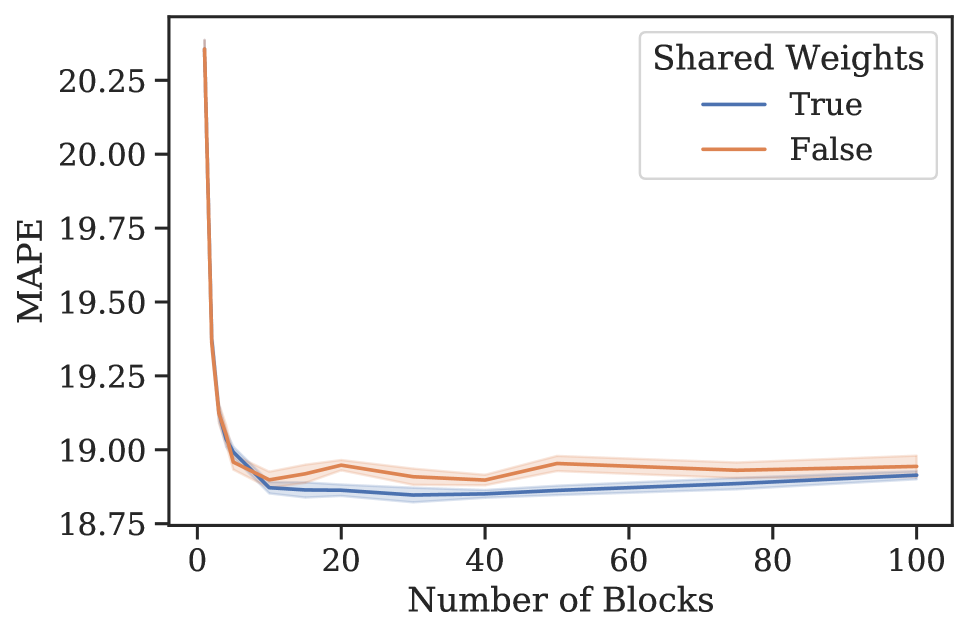
4实证结果
我们评估代表不同单变量时间序列集的多个数据集的性能。 对于每一种方法,我们都将 N-BEATS 的基本性能与已发布的最佳方法进行比较。 我们还评估来自多个源数据集的零样本传输,如下所述。
基础数据集。 M4 (M4 Team 2018),包含100k个TS,代表人口、金融、行业、宏观和微观指标。 采样频率包括每年、每季度、每月、每周、每天和每小时。 M3 (Makridakis 和 Hibon 2000) 包含来自域的 3003 个 TS,采样频率与 M4 类似。 fred是本文介绍的数据集,包含来自89个来源的29万个美国和国际经济TS,是圣路易斯联邦储备银行(Federal Reserve Bank of St.路易斯2019)。 旅游业 (Athanasopoulos等人2011)包括与旅游活动相关的月度、季度和年度系列指标。 电力 (Dua 和 Graff 2017 年;Yu、Rao 和 Dhillon 2016 年) 代表 370 个客户每小时的用电量。 交通 (Dua 和 Graff 2017;Yu、Rao 和 Dhillon 2016) 跟踪湾区高速公路 963 条车道的每小时占用率。 所有数据集的其他详细信息请参见附录 E。
零样本 TS 预测任务定义。 基础数据集之一(源数据集)用于训练机器学习模型。 然后,经过训练的模型会预测目标数据集中的 TS。 源数据集和目标数据集是不同的:它们不包含其值是彼此线性变换的 TS。 预测的 TS 分为两个不重叠的部分:历史和测试。 历史记录用作模型输入,测试用于计算预测误差指标。 除非另有明确说明,否则我们使用与其原始出版物一致的基本数据集的历史记录和测试分割。 为了生成预测,模型可以一次访问目标数据集中的 TS。 这是为了避免模型根据目标数据集中包含的除预测 TS 历史之外的任何信息隐式学习/适应。 如果需要调整模型参数或超参数,则只能使用预测 TS 的历史数据。
训练设置。 DeepAR (Salinas 等人 2019) 使用其作者 (Alexandrov 等人 2019) 的 GluonTS 实现进行训练。 N-BEATS 是按照 Oreshkin 等人 (2020) 的原始训练设置进行训练的。 N-BEATS 和 DeepAR 都通过将所有输入/输出值除/乘以每个目标时间序列计算的输入窗口的最大值来对架构输入/输出进行缩放/去缩放进行训练。 这不会影响模型在通常训练/测试场景中的准确性。 在零样本制度中,此操作旨在防止当目标时间序列的规模与源数据集的规模显着不同时发生灾难性故障。 附录 D 中提供了其他训练设置详细信息。
关键结果。 对于每个数据集,我们根据特定数据集的指标(M4, fred, M3:;旅游:;电力,交通:)。 我们还训练了流行的机器学习 TS 模型 DeepAR 并在零样本体系中对其进行评估。 我们的主要结果见表1,附录F中提供了更多详细信息。在零样本预测体系(底部三行)中,N-BEATS 始终优于针对这些数据集定制的大多数统计模型以及在 M4 上训练并在其他数据集上的零样本体系中进行评估的 DeepAR。 N-BEATS 在 fred 上进行训练,并应用于 M4 的零样本体系,其性能优于根据其在 M4 上的性能而选择的最佳统计模型,并且在与比赛的第二个参赛作品(增强树木)相当。 在M3和旅游业上,N-BEATS的零样本预测性能优于M3获胜者Theta(Assimakopoulos和尼科洛普洛斯 2000)。 在电力和交通方面,N-BEATS 的表现接近或优于在这些数据集上训练的其他神经模型。 结果表明,神经模型能够提取有关 TS 预测的一般知识,然后成功地将其应用于对不可见的 TS 的预测。 我们的研究首次成功应用神经模型来解决各种数据集的单变量零样本 TS 点预测,并表明预先训练的 N-BEATS 模型可以为该任务构成强大的基线。
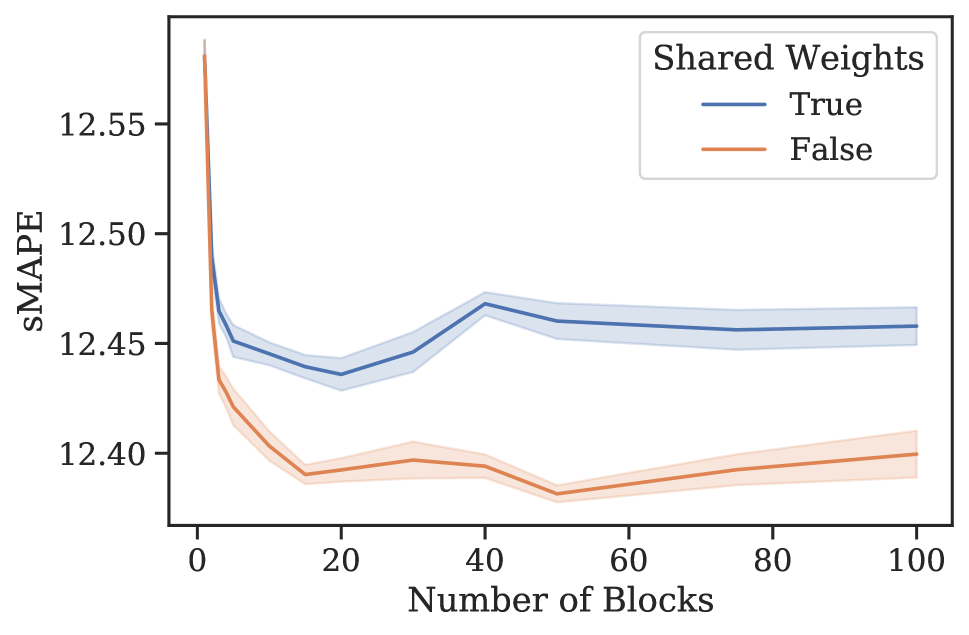
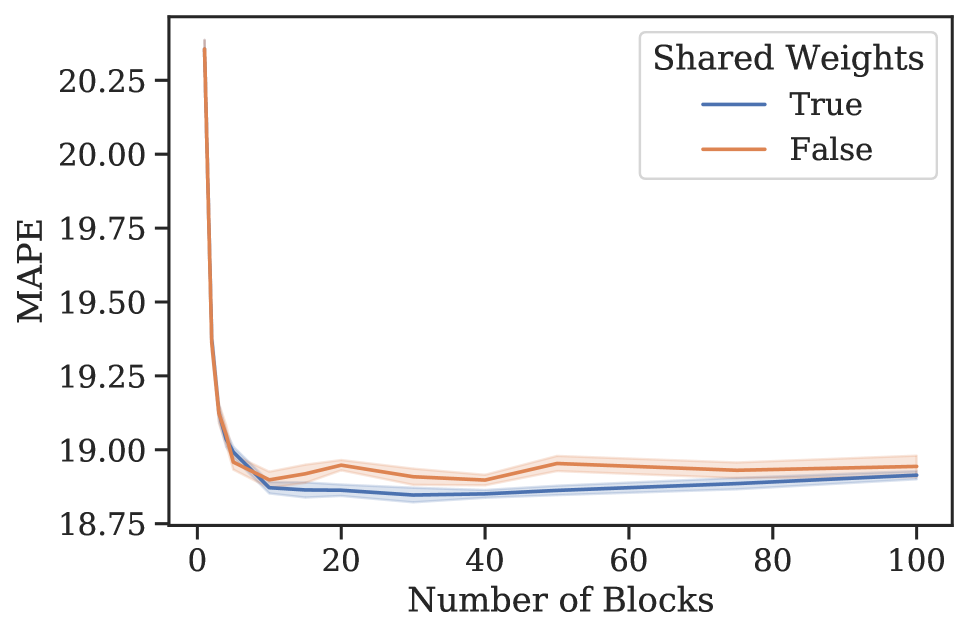
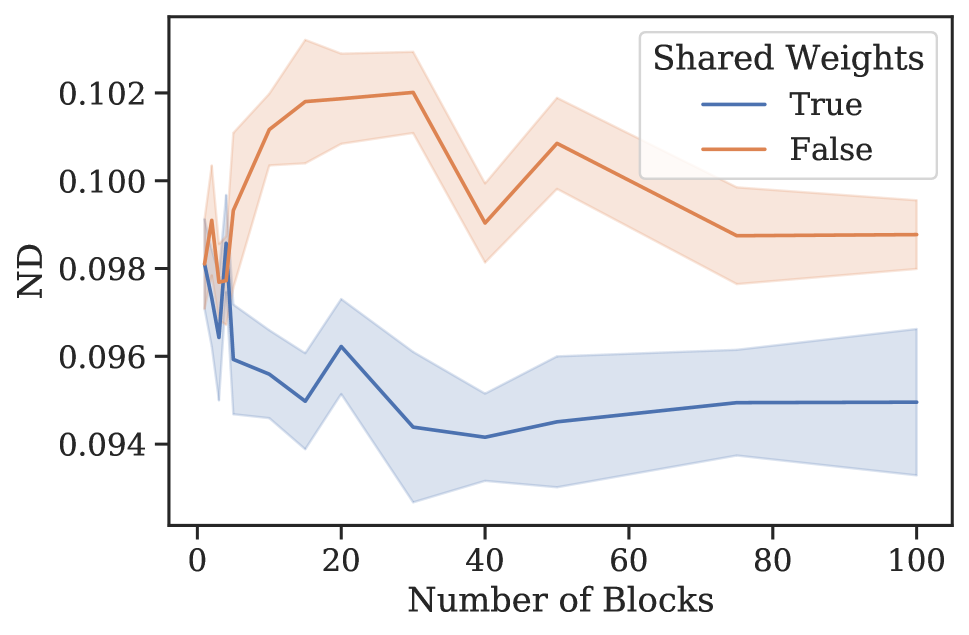
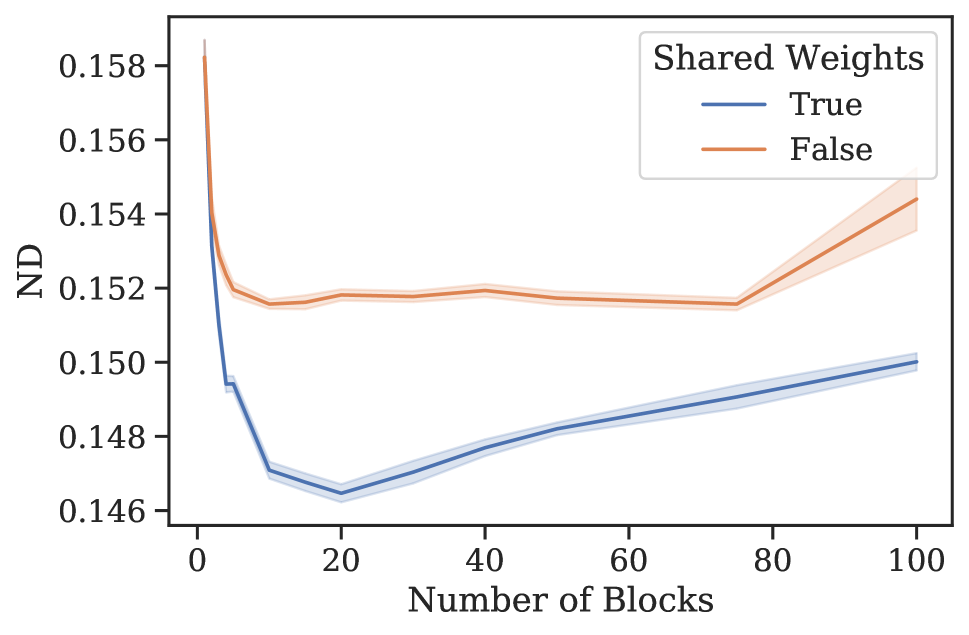
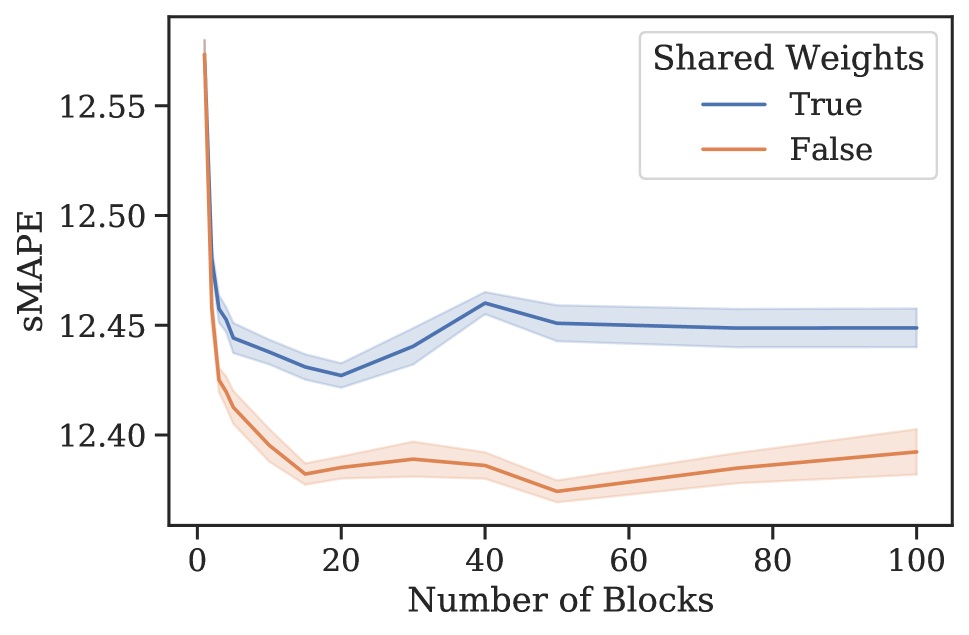
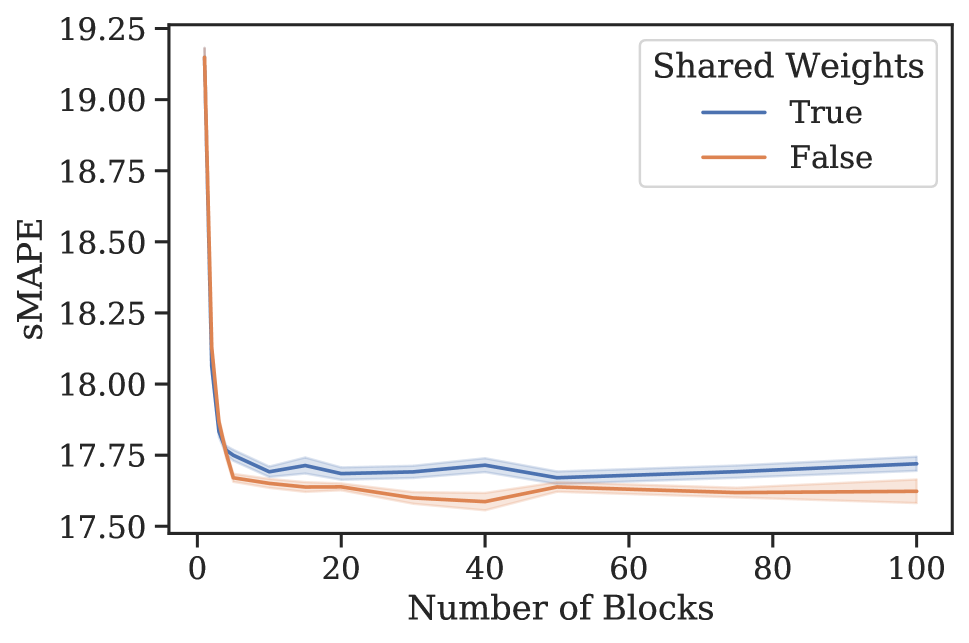
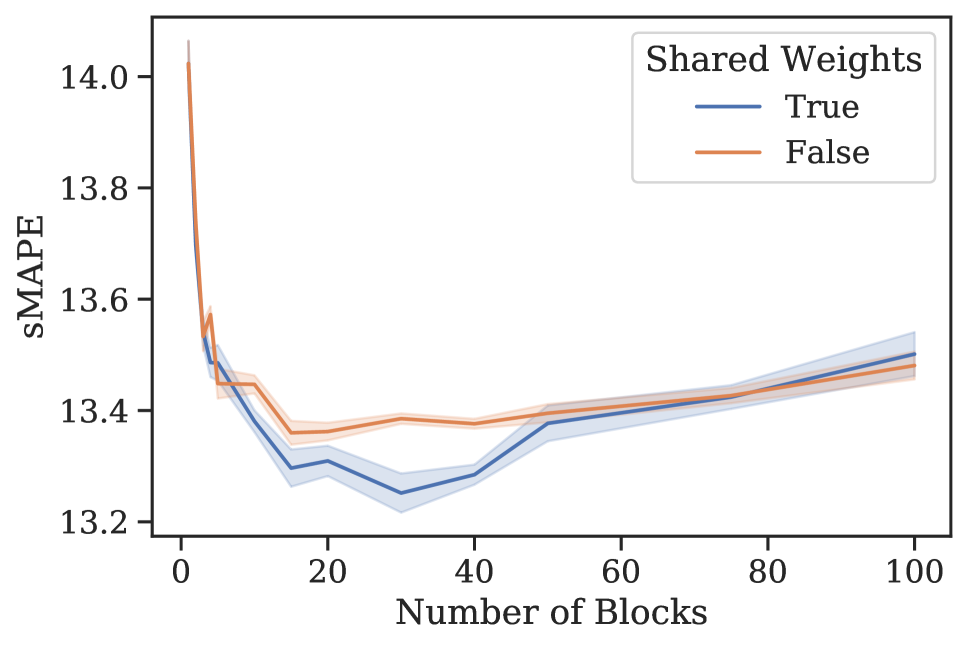
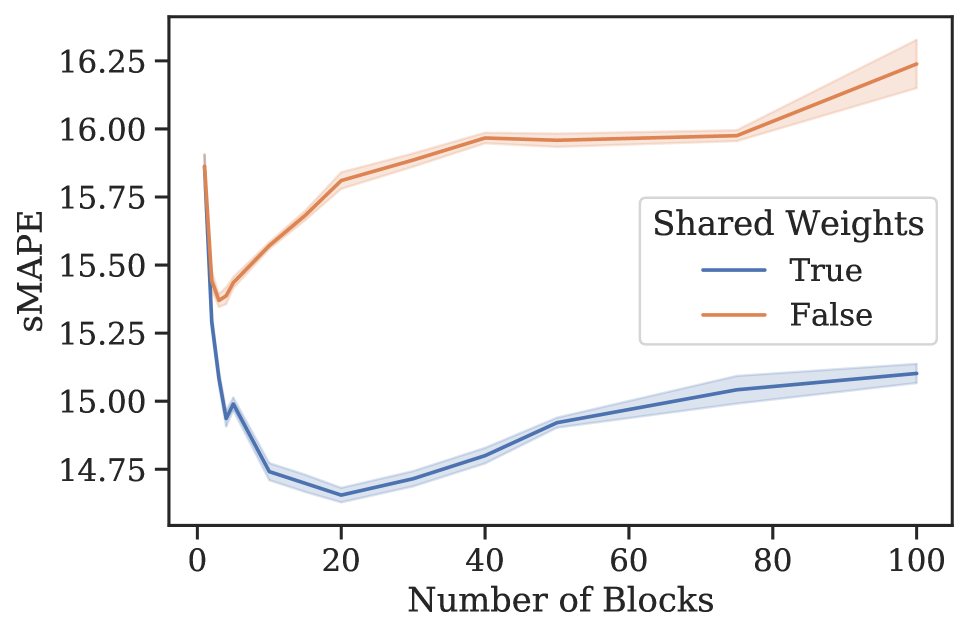
元学习效果。 3 节中的分析表明,N-BEATS 在内部生成一系列参数,这些参数可以通过每个新添加的块动态扩展架构的表达能力,即使这些块是相同的。 为了验证这一假设,我们进行了一项实验,研究 N-BEATS 随着块数量的增加、有或没有参数共享的零样本预测性能。 该架构在 M4 上进行训练,并在目标数据集 M3 和 tourism 上测量性能。 结果如图1所示。 在这两个数据集和共享权重配置中,当块数量增加到大约 30 个块时,我们一致看到性能有所提高。 在相同的场景中,将块数量增加到超过 30 会导致性能出现小幅但持续的下降。 人们可以将这些结果视为支持 N-BEATS 元学习解释的证据,并可能将这种现象解释为元学习内循环中的过度拟合。 否则,如何解释图 1 中的泛化动态就不那么明显了。 此外,对于 M3 和 旅游,仅元学习(共享权重、多区块与单区块)带来的性能提升分别为 12.60 到 12.44(1.2%)和 20.40 到 18.82(7.8%)(见图 1)。 元学习和独特权重带来的性能提升111直观上,具有唯一块权重的网络包括具有相同权重的网络作为特例。 因此,可以根据其训练损失自由地将元学习的效果与独特块权重的效果结合起来。 (独特权重,多个块与单个块)为 12.60 至 12.40 (1.6%) 和 20.40 至 18.91 (7.4%)。 显然,大部分收益都归功于元学习。 引入独特的块权重有时会带来边际增益,但通常会导致损失(更多结果参见附录G)。
在本节中,我们提出了经验证据,表明神经网络能够对看不见的 TS 提供高质量的零样本预测。 我们进一步根据经验支持了以下假设:第 3 节中 N-BEATS 中确定的元学习适应机制有助于实现令人印象深刻的零样本预测准确性结果。
5讨论与结论
零样本迁移学习。 我们提出了一个广泛的元学习框架,并解释了促进零样本预测的机制。 我们的结果表明,神经网络可以提取有关预测的通用知识并将其应用于零样本传输。 一般而言,第 2 节的分析涵盖了剩余架构。 3,这可能解释了残差架构的一些成功,尽管它们的更深入研究应该取决于未来的工作。 我们的理论表明,残差连接通过为相同的块生成一系列输入移位来生成动态的、紧凑的特定于任务的参数更新。 秒。 3.1 重新解释了我们的结果,表明作为一阶近似残差连接会产生对预测器最终线性层的迭代更新。 记忆效率和知识压缩。 我们的实证结果表明,N-BEATS 能够将给定数据集的所有相关知识压缩到单个块中,而不是压缩到具有单独权重的 10 或 30 个块中。 从实际角度来看,这可用于获得 10-30 倍的神经网络权重压缩,并且与高效存储神经网络很重要的应用相关。
参考
- Alexandrov et al. (2019) Alexandrov, A.; Benidis, K.; Bohlke-Schneider, M.; Flunkert, V.; Gasthaus, J.; Januschowski, T.; Maddix, D. C.; Rangapuram, S.; Salinas, D.; Schulz, J.; Stella, L.; Türkmen, A. C.; and Wang, Y. 2019. GluonTS: Probabilistic Time Series Modeling in Python. arXiv preprint arXiv:1906.05264 .
- Assimakopoulos and Nikolopoulos (2000) Assimakopoulos, V.; and Nikolopoulos, K. 2000. The theta model: a decomposition approach to forecasting. International Journal of Forecasting 16(4): 521–530.
- Athanasopoulos and Hyndman (2011) Athanasopoulos, G.; and Hyndman, R. J. 2011. The value of feedback in forecasting competitions. International Journal of Forecasting 27(3): 845–849.
- Athanasopoulos et al. (2011) Athanasopoulos, G.; Hyndman, R. J.; Song, H.; and Wu, D. C. 2011. The tourism forecasting competition. International Journal of Forecasting 27(3): 822–844.
- Baker and Howard (2011) Baker, L. C.; and Howard, J. 2011. Winning methods for forecasting tourism time series. International Journal of Forecasting 27(3): 850–852.
- Bengio et al. (1992) Bengio, S.; Bengio, Y.; Cloutier, J.; and Gecsei, J. 1992. On the optimization of a synaptic learning rule. In Optimality in Artificial and Biological Neural Networks.
- Bengio, Bengio, and Cloutier (1991) Bengio, Y.; Bengio, S.; and Cloutier, J. 1991. Learning a Synaptic Learning Rule. In Proceedings of the International Joint Conference on Neural Networks, II–A969. Seattle, USA.
- Bergmeir, Hyndman, and Benítez (2016) Bergmeir, C.; Hyndman, R. J.; and Benítez, J. M. 2016. Bagging exponential smoothing methods using STL decomposition and Box–Cox transformation. International Journal of Forecasting 32(2): 303–312.
- Chapados et al. (2014) Chapados, N.; Joliveau, M.; L’Écuyer, P.; and Rousseau, L.-M. 2014. Retail store scheduling for profit. European Journal of Operational Research 239(3): 609 – 624.
- Dua and Graff (2017) Dua, D.; and Graff, C. 2017. UCI Machine Learning Repository. URL http://archive.ics.uci.edu/ml.
- Engle (1982) Engle, R. F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50(4): 987–1007.
- Fawaz et al. (2018) Fawaz, H. I.; Forestier, G.; Weber, J.; Idoumghar, L.; and Muller, P.-A. 2018. Transfer learning for time series classification. 2018 IEEE International Conference on Big Data (Big Data) .
- Federal Reserve Bank of St. Louis (2019) Federal Reserve Bank of St. Louis. 2019. FRED Economic Data. Data retrieved from https://fred.stlouisfed.org/ Accessed: 2019-11-01.
- Finn, Abbeel, and Levine (2017) Finn, C.; Abbeel, P.; and Levine, S. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In ICML, 1126–1135.
- Fiorucci et al. (2016) Fiorucci, J. A.; Pellegrini, T. R.; Louzada, F.; Petropoulos, F.; and Koehler, A. B. 2016. Models for optimising the theta method and their relationship to state space models. International Journal of Forecasting 32(4): 1151–1161.
- Flunkert, Salinas, and Gasthaus (2017) Flunkert, V.; Salinas, D.; and Gasthaus, J. 2017. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. CoRR abs/1704.04110.
- Gao (2014) Gao, J. 2014. Machine learning applications for data center optimization. Technical report, Google.
- Gauss (1809) Gauss, C. F. 1809. Theoria motus corporum coelestium in sectionibus conicis solem ambientium. Hamburg: Frid. Perthes and I. H. Besser.
- Harlow (1949) Harlow, H. F. 1949. The Formation of Learning Sets. Psychological Review 56(1): 51–65. doi:10.1037/h0062474.
- Holt (1957) Holt, C. C. 1957. Forecasting trends and seasonals by exponentially weighted averages. Technical Report ONR memorandum no. 5, Carnegie Institute of Technology, Pittsburgh, PA.
- Holt (2004) Holt, C. C. 2004. Forecasting seasonals and trends by exponentially weighted moving averages. International Journal of Forecasting 20(1): 5–10.
- Hooshmand and Sharma (2019) Hooshmand, A.; and Sharma, R. 2019. Energy Predictive Models with Limited Data Using Transfer Learning. In Proceedings of the Tenth ACM International Conference on Future Energy Systems, e-Energy’19, 12–16.
- Hyndman and Koehler (2006) Hyndman, R.; and Koehler, A. B. 2006. Another look at measures of forecast accuracy. International Journal of Forecasting 22(4): 679–688.
- Hyndman and Khandakar (2008) Hyndman, R. J.; and Khandakar, Y. 2008. Automatic time series forecasting: the forecast package for R. Journal of Statistical Software 26(3): 1–22.
- Ibrahim et al. (2016) Ibrahim, R.; Ye, H.; L’Ecuyer, P.; and Shen, H. 2016. Modeling and forecasting call center arrivals: A literature survey and a case study. International Journal of Forecasting 32(3): 865–874.
- Kahn (2003) Kahn, K. B. 2003. How to Measure the Impact of a Forecast Error on an Enterprise? The Journal of Business Forecasting Methods & Systems 22(1).
- Kerkkänen, Korpela, and Huiskonen (2009) Kerkkänen, A.; Korpela, J.; and Huiskonen, J. 2009. Demand forecasting errors in industrial context: Measurement and impacts. International Journal of Production Economics 118(1): 43–48.
- Lee and Choi (2018) Lee, Y.; and Choi, S. 2018. Gradient-based meta-learning with learned layerwise metric and subspace. In ICML, 2933–2942.
- Leung (1995) Leung, H. C. 1995. Neural networks in supply chain management. In Proceedings for Operating Research and the Management Sciences, 347–352.
- Li et al. (2017) Li, Z.; Zhou, F.; Chen, F.; and Li, H. 2017. Meta-SGD: Learning to Learn Quickly for Few Shot Learning. CoRR abs/1707.09835.
- M4 Team (2018) M4 Team. 2018. M4 competitor’s guide: prizes and rules. URL www.m4.unic.ac.cy/wp-content/uploads/2018/03/M4-CompetitorsGuide.pdf.
- Makridakis et al. (1982) Makridakis, S.; Andersen, A.; Carbone, R.; Fildes, R.; Hibon, M.; Lewandowski, R.; Newton, J.; Parzen, E.; and Winkler, R. 1982. The accuracy of extrapolation (time series) methods: Results of a forecasting competition. Journal of forecasting 1(2): 111–153.
- Makridakis et al. (1993) Makridakis, S.; Chatfield, C.; Hibon, M.; Lawrence, M.; Mills, T.; Ord, K.; and Simmons, L. F. 1993. The M2-competition: A real-time judgmentally based forecasting study. International Journal of Forecasting 9(1): 5–22.
- Makridakis and Hibon (2000) Makridakis, S.; and Hibon, M. 2000. The M3-Competition: results, conclusions and implications. International Journal of Forecasting 16(4): 451–476.
- Makridakis, Spiliotis, and Assimakopoulos (2018a) Makridakis, S.; Spiliotis, E.; and Assimakopoulos, V. 2018a. The M4-Competition: Results, findings, conclusion and way forward. International Journal of Forecasting 34(4): 802–808.
- Makridakis, Spiliotis, and Assimakopoulos (2018b) Makridakis, S.; Spiliotis, E.; and Assimakopoulos, V. 2018b. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 13(3).
- Montero-Manso et al. (2020) Montero-Manso, P.; Athanasopoulos, G.; Hyndman, R. J.; and Talagala, T. S. 2020. FFORMA: Feature-based forecast model averaging. International Journal of Forecasting 36(1): 86–92.
- Neale (1985) Neale, A. A. 1985. Weather Forecasting: Magic, Art, Science and Hypnosis. Weather and Climate 5(1): 2–5.
- Nguyen, Ni, and Rossetti (2010) Nguyen, H.-N.; Ni, Q.; and Rossetti, M. D. 2010. Exploring the cost of forecast error in inventory systems. In Proceedings of the 2010 Industrial Engineering Research Conference.
- Oreshkin et al. (2020) Oreshkin, B. N.; Carpov, D.; Chapados, N.; and Bengio, Y. 2020. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. In ICLR.
- Oreshkin, Rodríguez López, and Lacoste (2018) Oreshkin, B. N.; Rodríguez López, P.; and Lacoste, A. 2018. TADAM: Task dependent adaptive metric for improved few-shot learning. In NeurIPS, 721–731.
- Perez et al. (2018) Perez, E.; Strub, F.; De Vries, H.; Dumoulin, V.; and Courville, A. 2018. FiLM: Visual reasoning with a general conditioning layer. In AAAI.
- Petersen and Pedersen (2012) Petersen, K. B.; and Pedersen, M. S. 2012. The Matrix Cookbook. Version 20121115.
- Raghu et al. (2019) Raghu, A.; Raghu, M.; Bengio, S.; and Vinyals, O. 2019. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML.
- Rangapuram et al. (2018) Rangapuram, S. S.; Seeger, M.; Gasthaus, J.; Stella, L.; Wang, Y.; and Januschowski, T. 2018. Deep State Space Models for Time Series Forecasting. In NeurIPS.
- Ravi and Larochelle (2016) Ravi, S.; and Larochelle, H. 2016. Optimization as a model for few-shot learning. In ICLR.
- Ribeiro et al. (2018) Ribeiro, M.; Grolinger, K.; ElYamany, H. F.; Higashino, W. A.; and Capretz, M. A. 2018. Transfer learning with seasonal and trend adjustment for cross-building energy forecasting. Energy and Buildings 165: 352–363.
- Rodrigues Jr et al. (2019) Rodrigues Jr, F. A.; Jabloun, M.; Ortiz-Monasterio, J. I.; Crout, N. M. J.; Gurusamy, S.; and Green, S. 2019. Mexican Crop Observation, Management and Production Analysis Services System — COMPASS. In Poster Proceedings of the 12th European Conference on Precision Agriculture.
- Rusu et al. (2019) Rusu, A. A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; and Hadsell, R. 2019. Meta-Learning with Latent Embedding Optimization. In ICLR.
- Salinas et al. (2019) Salinas, D.; Flunkert, V.; Gasthaus, J.; and Januschowski, T. 2019. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. International Journal of Forecasting .
- Schmidhuber (1987) Schmidhuber, J. 1987. Evolutionary principles in self-referential learning. Master’s thesis, Institut f. Informatik, Tech. Univ. Munich.
- Sezer, Gudelek, and Ozbayoglu (2019) Sezer, O. B.; Gudelek, M. U.; and Ozbayoglu, A. M. 2019. Financial Time Series Forecasting with Deep Learning : A Systematic Literature Review: 2005-2019.
- Smyl (2020) Smyl, S. 2020. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. International Journal of Forecasting 36(1): 75 – 85.
- Smyl and Kuber (2016) Smyl, S.; and Kuber, K. 2016. Data Preprocessing and Augmentation for Multiple Short Time Series Forecasting with Recurrent Neural Networks. In 36th International Symposium on Forecasting.
- Snell, Swersky, and Zemel (2017) Snell, J.; Swersky, K.; and Zemel, R. S. 2017. Prototypical Networks for Few-shot Learning. In NIPS, 4080–4090.
- Spiliotis, Assimakopoulos, and Nikolopoulos (2019) Spiliotis, E.; Assimakopoulos, V.; and Nikolopoulos, K. 2019. Forecasting with a hybrid method utilizing data smoothing, a variation of the Theta method and shrinkage of seasonal factors. International Journal of Production Economics 209: 92–102.
- Syntetos, Boylan, and Croston (2005) Syntetos, A. A.; Boylan, J. E.; and Croston, J. D. 2005. On the categorization of demand patterns. Journal of the Operational Research Society 56(5): 495–503.
- Tang and Salakhutdinov (2019) Tang, C.; and Salakhutdinov, R. R. 2019. Multiple Futures Prediction. In NeurIPS 32, 15398–15408.
- Velkoski (2016) Velkoski, A. 2016. Python Client for FRED API. URL https://github.com/avelkoski/FRB.
- Vinyals et al. (2016) Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; and Wierstra, D. 2016. Matching Networks for One Shot Learning. In NIPS, 3630–3638.
- Walker (1931) Walker, G. 1931. On Periodicity in Series of Related Terms. Proc. R. Soc. Lond. A 131: 518–532.
- Wang et al. (2019) Wang, Y.; Smola, A.; Maddix, D. C.; Gasthaus, J.; Foster, D.; and Januschowski, T. 2019. Deep Factors for Forecasting. In ICML.
- Winters (1960) Winters, P. R. 1960. Forecasting Sales by Exponentially Weighted Moving Averages. Management Science 6(3): 324–342.
- Yu, Rao, and Dhillon (2016) Yu, H.-F.; Rao, N.; and Dhillon, I. S. 2016. Temporal Regularized Matrix Factorization for High-dimensional Time Series Prediction. In NIPS.
- Yule (1927) Yule, G. U. 1927. On a Method of Investigating Periodicities in Disturbed Series, with Special Reference to Wolfer’s Sunspot Numbers. Phil. Trans. the R. Soc. Lond. A 226: 267–298.
用于零样本时间序列预测的强大元学习基线的补充材料
附录 A TS 预测准确性指标
以下指标是点预测绩效评估实践中的标准无标度指标(Hyndman 和 Koehler 2006;Makridakis 和 Hibon 2000;Makridakis、Spiliotis 和 Assimakopoulos 2018a;Athanasopoulos 等人 2011):(平均绝对百分比误差)、(对称)和(平均绝对比例误差)。 按预测与真实值之间的平均值缩放误差,而 按朴素预测器的平均误差缩放,该预测器仅复制测量的观测值 过去的时期,从而解释季节性。 这里 是数据的周期性(例如,每月系列为 12)。 (总体加权平均值)是M4特定的指标,用于对参赛作品进行排名(M4 Team 2018),其中 和 指标被标准化,以便季节性调整的朴素预测获得 。 归一化偏差 在传统 TS 预测文献中是一个不太标准的指标,但在机器学习 TS 预测论文 中相当流行(Yu、Rao 和 Dhillon 2016;Fluunkert、Salinas, Gasthaus 2017;Wang 等人 2019;Rangapuram 等人 2018)。
在这些表达式中, 指的是观察到的时间序列(基本事实), 指的是点预测。 在最后一个等式中, 指的是索引为 的 TS 中的样本 ,总和 对所有 TS 索引进行计算和 TS 样本。
附录 BN-BEATS 详细信息
B.1架构详细信息
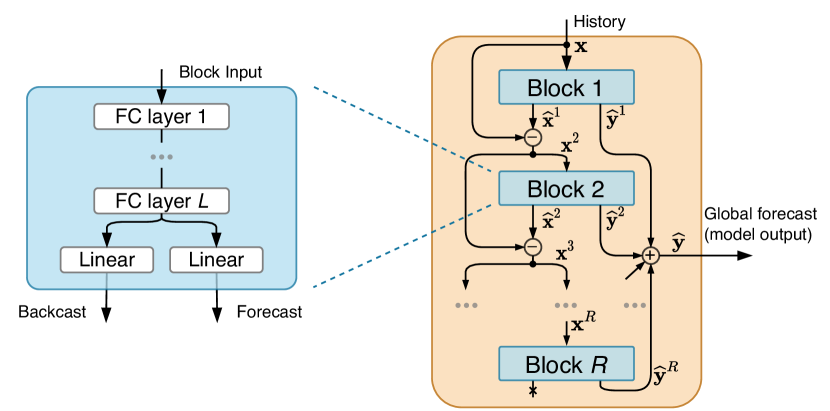
N-BEATS 最初由 (Oreshkin 等人 2020) 提出,可选地具有由多个堆栈组成的可解释的层次结构。 在这项工作中,为了不失一般性,我们专注于与输出分区无关的通用模型。 这如图2所示,根据Oreshkin等人(2020)中的图1进行相应修改。 最终的预测是根据区块产生的各个预测的总和获得的;这些块使用双残差架构链接在一起。
附录C其他现有元学习算法的分析
匹配网络 (Vinyals 等人 2016) 与 PN 类似,但做了一些调整。 在 vanilla 匹配网络架构中,定义了 ,假设单热编码 和 作为软最近邻:
softmax 是标准化的。 。 由 动态生成的预测器参数包括嵌入/标签对:。 在 FCE 匹配网络中,验证和训练嵌入还通过注意力 LSTM (Vinyals 等人 2016) 与任务训练集进行交互。 为了反映这一点,更新函数 通过 LSTM 方程更新原始嵌入:。 LSTM 参数包含在 中。 其次,使用附加关系模块 增强预测器,例如 ,并相应扩展预测器元参数集:。 关系模块再次通过 LSTM 实现:。
TADAM (Oreshkin、Rodríguez López 和 Lacoste 2018) 通过 FiLM 层动态调节任务训练数据上的嵌入函数来扩展 PNs (Perez 等人 2018) 。 TADAM 的预测器具有以下形式:; 。 比较函数参数与之前一样,。 嵌入函数参数 包括每个卷积层的 FiLM 层 (缩放/移位)向量,由任务嵌入中的单独 FC 网络生成。 初始化函数将设置为全零,嵌入任务训练数据,并将任务嵌入设置为类原型的平均值。 更新函数 的元参数包括 FC 网络的系数 ,从任务嵌入生成对 的更新。 然后,它使用以更新的 为条件的 生成类原型 的更新。
LEO (Rusu 等人 2019) 使用固定的预训练嵌入函数。 中间低维潜在空间经过优化,用于生成预测器的任务自适应最终层权重。 LEO 的预测器 具有最终层和潜在空间参数 ,并且没有元参数 。 初始化函数、使用任务编码器和具有元参数和的关系网络。 它根据任务训练数据对潜在空间参数 进行元初始化。 更新函数 、 使用具有元参数 的解码器将 迭代解码为最终层权重,。 它通过在内循环中执行梯度下降来优化。
附录 D 培训设置详细信息
大多数时候,在源数据集的给定频率分割上训练的模型用于预测目标数据集上的相同频率分割。 此规则有一些例外。 首先,当从 M4 转移到 M3 时,使用在 M4< 的季度分割上训练的模型来预测 M3 的其他分割。 /t3>. 这是因为 (i) M4 Quarterly 的默认水平长度为 8,与 M3 Others 相同,并且 (ii) M4 Others 为异构,包含周、日、小时数据,范围长度为 13、14、48。 因此,从实施的角度来看,M4季度向M3其他转移提供了更自然的基础。 其次,从M4到电力和交通数据集的传输是基于在M4每小时训练的模型完成的。 这是因为电力和交通包含每小时的时间序列,具有明显的24小时季节性模式。 值得注意的是,M4每小时仅包含414个时间序列,我们可以在表1中清楚地看到在这个相当小的数据集上训练的模型的正零样本传输。 第三,从fred到电力和交通的转移是通过在fred每月分割上训练模型来完成的,使用双线性插值进行双倍上采样。 这是因为 fred 没有每小时的数据。 月度数据自然会提供季节性周期 12 的模式。 使用两倍的上采样和双线性插值提供自然季节性周期为 24 的数据,最常在每小时数据中观察到,例如电力和交通。
D.1 N-BEATS 训练设置
我们使用与 Oreshkin 等人 (2020) 定义的相同的整体训练框架,包括对源数据集中的 TS 进行分层均匀采样来训练模型。 根据数据集的频率划分(例如M4数据集中的每年、每季度、每月、每周、每日和每小时频率)训练一个模型。 所有报告的准确性结果均基于 30 个模型的集合(5 个不同的初始化和 6 个不同的回溯期)。 我们发现零样本训练体系中与原始设置不同的一个重要方面是输入/输出的缩放/除缩放。 我们通过将所有输入/输出值除/乘以输入窗口的最大值来缩放/缩小架构输入/输出。 我们发现这不会以统计上显着的方式影响在同一数据集上训练和测试的模型的准确性。 在零样本制度中,当目标数据集规模(边际分布)与源数据集规模显着不同时,此操作可以防止灾难性失败。
D.2 DeepAR 训练设置
DeepAR 实验使用 GluonTS (Alexandrov 等人 2019) 1.6 版提供的模型实现。 我们优化了 DeepAR 的超参数,因为 GluonTS 中提供的默认值通常会导致许多数据集上的性能明显次优。 表2中描述了每个数据集的训练参数。 除电力数据集为 0.1 外,所有实验的权重衰减为 0.0,Dropout 率为 0.0。 默认缩放比例被 MaxAbs 取代,这改进并稳定了结果。 所有其他参数均为 gluonts.model.deepar.DeepAREstimator 的默认值。 为了减少实验之间的性能差异,我们使用 30 次独立运行的中值集合。 DeepAR 实验的代码可以在 https://github.com/timeseries-zeroshot/deepar_evaluation 找到。
| Batch | ||||
|---|---|---|---|---|
| Layers | Cells | Epochs | Size | |
| Yearly (M3, M4, Tourism) | 3 | 40 | 300 | 32 |
| Quarterly (M3, M4, Tourism) | 2 | 20 | 100 | 32 |
| Monthly (M3, M4, Tourism) | 2 | 40 | 500 | 32 |
| Others (M3) | 2 | 40 | 100 | 32 |
| M4 (weekly, daily) | 3 | 20 | 100 | 32 |
| M4 Hourly | 2 | 20 | 50 | 32 |
| Electricity (all splits) | 2 | 40 | 50 | 64 |
| Traffic (2008-01-14) | 1 | 20 | 5 | 64 |
| Traffic (other splits) | 4 | 40 | 50 | 64 |
附录 E数据集详细信息
E.1 M4数据集详细信息
| Frequency / Horizon | |||||||
| Type | Yearly/6 | Qtly/8 | Monthly/18 | Wkly/13 | Daily/14 | Hrly/48 | Total |
| Demographic | 1,088 | 1,858 | 5,728 | 24 | 10 | 0 | 8,708 |
| Finance | 6,519 | 5,305 | 10,987 | 164 | 1,559 | 0 | 24,534 |
| Industry | 3,716 | 4,637 | 10,017 | 6 | 422 | 0 | 18,798 |
| Macro | 3,903 | 5,315 | 10,016 | 41 | 127 | 0 | 19,402 |
| Micro | 6,538 | 6,020 | 10,975 | 112 | 1,476 | 0 | 25,121 |
| Other | 1,236 | 865 | 277 | 12 | 633 | 414 | 3,437 |
| Total | 23,000 | 24,000 | 48,000 | 359 | 4,227 | 414 | 100,000 |
| Min. Length | 19 | 24 | 60 | 93 | 107 | 748 | |
| Max. Length | 841 | 874 | 2812 | 2610 | 9933 | 1008 | |
| Mean Length | 37.3 | 100.2 | 234.3 | 1035.0 | 2371.4 | 901.9 | |
| SD Length | 24.5 | 51.1 | 137.4 | 707.1 | 1756.6 | 127.9 | |
| % Smooth | 82% | 89% | 94% | 84% | 98% | 83% | |
| % Erratic | 18% | 11% | 6% | 16% | 2% | 17% | |
表 3 概述了跨领域和预测范围的 M4 数据集的组成,根据频率和类型列出了 TS 的数量(M4 Team 2018). M4 数据集庞大且多样化:所有预测范围均由商业、金融和经济预测中经常遇到的异构 TS 类型(每小时除外)组成。 还列出了系列长度的汇总统计数据,显示其中的广泛变化,以及遵循 Syntetos、Boylan 和 Croston 的特征(平滑 与 不稳定)( 2005),并且基于序列的变异系数的平方。 所有系列在所有时间步长都有正观测值;因此,根据Syntetos、Boylan 和 Croston (2005),没有一个可以被视为间歇性或块状。
E.2 fred 数据集详细信息
fred 是本文引入的一个大规模数据集,包含来自 89 个来源的约 29 万个美国和国际经济 TS,是美联储经济数据的子集 (圣路易斯联邦储备银行 2019) 。 fred 是使用基于高级 FRED python API (Velkoski 2016) 的自定义下载脚本下载的。 这是基于低级 Web FRED API 的 Python 包装器。 对于时间序列中的每个点,都会下载首次发布时发布的原始数据。 所有包含 NaN 条目的时间序列均已被过滤掉。 我们重点关注年度、季度、每月、每周和每日频率数据。 还有其他频率可供选择,例如每两周一次和五年一次。 它们被跳过,因为只存在少量。 这些因素解释了这样一个事实:我们为本研究收集的数据集大小为 290k,而原则上可用的总时间序列为 672k(圣路易斯联邦储备银行,2019 年)。 此数据集中没有每小时数据。 对于fred数据集中包含的数据频率,我们使用与M4数据集相同的预测范围:每年:6,每季度:8,每月:18,每周:13和每日:14。 由于低级 FRED API 施加的带宽限制,数据集下载大约需要 7-10 天。 测试、验证和训练子集以通常的方式定义。 测试集是通过在每个时间序列最后一个水平线的左边界分割完整的 fred 数据集而得出的。 类似地,验证集是从每个时间序列的倒数第二个水平线得出的。
E.3 M3数据集详细信息
表 4 概述了跨领域和预测范围的 M3 数据集的组成,根据频率和类型列出了 TS 的数量(Makridakis 和 Hibon 2000). M3 比 M4 小,但它仍然很大且多样化:所有预测范围都由商业、金融和经济预测中经常遇到的异构 TS 类型组成。 在过去的 20 年里,该数据集支持了高级统计模型设计的重大努力,例如Theta 及其变体(Assimakopoulos 和 Nikolopoulos 2000;Fiorucci 等人 2016;Spiliotis、Assimakopoulos 和 Nikolopoulos 2019)。 还列出了系列长度的汇总统计数据,显示了长度的广泛变化,以及遵循 Syntetos、Boylan 和 Croston 的特征(平滑 与 不稳定) (2005),并且基于序列的变异系数的平方。 所有系列在所有时间步长都有正观测值;因此,根据Syntetos、Boylan 和 Croston (2005),没有一个可以被视为间歇性或块状。
| Frequency / Horizon | |||||
| Type | Yearly/6 | Quarterly/8 | Monthly/18 | Other/8 | Total |
| Demographic | 245 | 57 | 111 | 0 | 413 |
| Finance | 58 | 76 | 145 | 29 | 308 |
| Industry | 102 | 83 | 334 | 0 | 519 |
| Macro | 83 | 336 | 312 | 0 | 731 |
| Micro | 146 | 204 | 474 | 4 | 828 |
| Other | 11 | 0 | 52 | 141 | 204 |
| Total | 645 | 756 | 1,428 | 174 | 3,003 |
| Min. Length | 20 | 24 | 66 | 71 | |
| Max. Length | 47 | 72 | 144 | 104 | |
| Mean Length | 28.4 | 48.9 | 117.3 | 76.6 | |
| SD Length | 9.9 | 10.6 | 28.5 | 10.9 | |
| % Smooth | 90% | 99% | 98% | 100% | |
| % Erratic | 10% | 1% | 2% | 0% | |
E.4 旅游数据集详细信息
表 5 通过根据频率列出 TS 数量,概述了整个预测范围内旅游数据集的组成。 列出了系列长度的汇总统计数据,显示长度的广泛变化。 所有系列在所有时间步长都有正观测值。 与 M4 和 M3 数据集相比,tourism 包含更高比例的不稳定序列。
| Frequency / Horizon | ||||
| Yearly/4 | Quarterly/8 | Monthly/24 | Total | |
| 518 | 427 | 366 | 1,311 | |
| Min. Length | 11 | 30 | 91 | |
| Max. Length | 47 | 130 | 333 | |
| Mean Length | 24.4 | 99.6 | 298 | |
| SD Length | 5.5 | 20.3 | 55.7 | |
| % Smooth | 77% | 61% | 49% | |
| % Erratic | 23% | 39% | 51% | |
E.5 电力和交通数据集详细信息
电力222https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014 和 流量31>33https://archive.ics.uci.edu/ml/datasets/PEMS-SF 数据集(Dua 和Graff 2017;Yu、Rao 和 Dhillon 2016)8> 都是 UCI 存储库的一部分。 电力代表了三年来370个客户每小时的用电量监测。 traffic 数据集跟踪旧金山湾区高速公路 963 条车道在一年多的时间里按 (0,1) 范围缩放的每小时占用率。 这两个数据集都表现出强烈的每小时和每日季节性模式。
两个数据集均聚合为每小时数据,但使用不同的聚合操作:电力求和,交通均值。 进行每小时聚合,以便将 小时内的所有可用点聚合到 小时,因此,如果原始数据集于 2011-01-01 00:15 开始,则第一次聚合后的点将为 2011-01-01 01:00。 对于electricity训练数据集,我们根据下载的聚合数据集从集合中删除了第一年,以匹配(Yu,Rao和Dhillon 2016)中使用的集合来自推测作者的 Github 存储库444https://github.com/rofuyu/exp-trmf-nips16/blob/master/python/exp-scripts/datasets/download-data.sh。 我们还确保聚合后电力和交通数据集的数据点与(Yu、Rao和Dhillon 2016)中使用的数据点匹配。 MatFact 模型的作者使用最近 7 天的数据集作为测试集,但来自 Amazon DeepAR (Flunkert、Salinas 和 Gasthaus 2017)、Deep State (Rangapuram 等人 2018)的论文),Deep Factors (Wang 等人 2019) 使用不同的分割,其中分割点由日期提供。 在没有充分理由的情况下更改分割点会增加模型性能的可比性的不确定性,并对结果的可重复性造成挑战,因此我们试图在实验中匹配所有不同的分割。 在 traffic 数据集上尤其具有挑战性,我们必须使用一些启发式方法来查找记录日期;数据集作者指出:“测量范围涵盖 2008 年 1 月 1 日至 3 月。 2009 年 3 月 30 日”和“我们从数据集中删除了公共假期,以及有异常的两天(2009 年 3 月 8 日和 2008 年 3 月 9 日),所有传感器在凌晨 2:00 到 3:00 之间都被静音。”尽管如此,我们还是未能将所提供的工作日标签的一部分与实际日期相匹配。 因此,我们必须假设实际的间隙列表(包括假期和异常日期)如下:
-
1.
2008年1月1日(元旦)
-
2.
2008 年 1 月 21 日(马丁·路德·金纪念日)
-
3.
2008年2月18日(华盛顿诞辰)
-
4.
2008年3月9日(异常日)
-
5.
2008 年 5 月 26 日(阵亡将士纪念日)
-
6.
2008 年 7 月 4 日(独立日)
-
7.
2008年9月1日(劳动节)
-
8.
2008 年 10 月 13 日(哥伦布日)
-
9.
2008 年 11 月 11 日(退伍军人节)
-
10.
2008 年 11 月 27 日(感恩节)
-
11.
2008年12月25日(圣诞节)
-
12.
2009年1月1日(元旦)
-
13.
2009 年 1 月 19 日(马丁·路德·金纪念日)
-
14.
2009年2月16日(华盛顿诞辰)
-
15.
2009年3月8日(异常日)
前 6 个差距是通过标签上的差距得到证实的,但其余的距离旧金山、加利福尼亚州和美国 2008 年和 2009 年的任何公共假期都超过一天。 此外,我们在数据集作者提供的标签中发现的空白数量为 10,而 2008 年 1 月 1 日到 3 月 1 日之间的天数为 10 个。 2009 年 30 日是 455,假设从值和标签中跳过 2008 年 1 月 1 日,我们最终应该得到 而不是 440 天或不同的结束日期。 用于评估数据集性能的指标是(Yu、Rao和Dhillon 2016),它等于DeepAR中使用的损失, Deep State 和 Deep Factors 论文。
E.6 数据集之间的重叠
实验中使用的一些数据集由来自不同领域的时间序列组成。 因此,建议用于迁移学习性能评估的目标数据集可以包含源数据集的时间序列是合理的。 为了验证模型性能不会受到这些数据集可能共享部分时间序列这一事实的影响,我们在训练集和测试集之间进行了序列到序列的比较。 搜索序列是根据输入的最后一个层构建的,在测试期间提供给模型,以及目标数据集的测试部分,形成两个层长度的块。 然后将搜索到的序列与源数据集的每个序列进行比较。 此方法允许发现训练情况,其中输入的最后部分与输出与目标数据集中的时间序列的最后两个水平完全匹配,用于性能评估。 我们发现唯一具有共同序列的数据集是 M4 和 fred:每年 3 个,季度 34 个,每月 195 个。 考虑到这些数据集中时间序列的总数,重叠的影响可以被认为是微不足道的。
附录 F实证结果详细信息
在所有数据集上,我们考虑原始的 N-BEATS (Oreshkin 等人 2020),即在给定数据集上训练并应用于同一数据集的模型。 提供此目的是为了评估零样本 N-BEATS 的泛化差距。 我们考虑零样本 N-BEATS 的四种变体:NB-SH-M4、NB-NSH-M4、NB-SH-FR、NB-NSH-FR。 -SH/-NSH 选项表示块权重共享开/关。 -M4/-FR 选项表示 M4/fred 源数据集。 目标数据集和源数据集的季节模式之间的映射如表6所示。 模型架构和训练过程不依赖于源数据集,即我们使用相同的参数来训练 M4 和 fred 的模型。 参数值可以在表7中找到。 结果是基于 90 个模型的集合计算的:6 个回溯视野、3 个损失函数和 5 个重复。 使用源数据集的训练部分来训练模型。
| M4 | fred | |
| fred | ||
| Yearly | Yearly | – |
| Quarterly | Quarterly | – |
| Monthly | Monthly | – |
| Weekly | Weekly | – |
| Daily | Daily | – |
| M4 | ||
| Yearly | – | Yearly |
| Quarterly | – | Quarterly |
| Monthly | – | Monthly |
| Weekly | – | Monthly |
| Daily | – | Monthly |
| Hourly | – | |
| M3 | ||
| Yearly | Yearly | Yearly |
| Quarterly | Quarterly | Quarterly |
| Monthly | Monthly | Monthly |
| Others | Quarterly | Quarterly |
| tourism | ||
| Yearly | Yearly | Yearly |
| Quarterly | Quarterly | Quarterly |
| Monthly | Monthly | Monthly |
| electricity | Hourly | |
| traffic | Hourly |
| Source Datasets | M4, fred |
|---|---|
| Loss Functions | , , |
| Number of Blocks | 30 |
| Layers in Block | 4 |
| Layer Size | 512 |
| Iterations | 15 000 |
| Lookback Horizons | 2, 3, 4, 5, 6, 7 |
| History size | 10 horizons |
| Learning rate | |
| Batch size | 1024 |
| Repeats | 5 |
F.1 详细的M4结果
在 M4 上,我们与五个 M4 竞赛参赛作品进行比较,每个参赛作品都代表了广泛的模型类别。 最佳纯 ML 是 B. Trotta 提交的,是 6 个纯 ML 模型中最好的参赛作品。 最佳统计是 N.Z. 的最佳纯统计模型。 莱加基和 K. 库苏里。 ProLogistica 是一种统计方法的加权集成,是排名第三的M4参与者。 最佳 ML/TS 组合是 (Montero-Manso 等人 2020) 的模型,第二佳条目,在一些统计时间序列模型上的梯度提升树。 最后,DL/TS Hybrid 成为 M4 竞赛(Smyl 2020) 的获胜者。 结果如表8所示。
| Yearly | Quarterly | Monthly | Others | Average | |
| (23k) | (24k) | (48k) | (5k) | (100k) | |
| Best pure ML | 14.397 | 11.031 | 13.973 | 4.566 | 12.894 |
| Best statistical | 13.366 | 10.155 | 13.002 | 4.682 | 11.986 |
| ProLogistica | 13.943 | 9.796 | 12.747 | 3.365 | 11.845 |
| Best ML/TS combination | 13.528 | 9.733 | 12.639 | 4.118 | 11.720 |
| DL/TS hybrid, M4 winner | 13.176 | 9.679 | 12.126 | 4.014 | 11.374 |
| DeepAR∗ | 12.362 | 10.822 | 13.705 | 4.668 | 12.253 |
| N-BEATS | 12.913 | 9.213 | 12.024 | 3.643 | 11.135 |
| NB-SH-FR | 13.267 | 9.634 | 12.694 | 4.892 | 11.701 |
| NB-NSH-FR | 13.272 | 9.596 | 12.676 | 4.696 | 11.675 |
F.2 详细的fred结果
我们与 R 预测包(Hyndman 和 Khandakar 2008) 中提供的完善的现成统计模型进行比较。 其中包括 Naïve(重复最后一个值)、ARIMA、Theta、SES 和 ETS。 质量指标是 (1) 中定义的常规 。
| Yearly | Quarterly | Monthly | Weekly | Daily | Average | |
| (133,554) | (57,569) | (99,558) | (1,348) | (17) | (292,046) | |
| Theta | 16.50 | 14.24 | 5.35 | 6.29 | 10.57 | 12.20 |
| ARIMA | 16.21 | 14.25 | 5.58 | 5.51 | 9.88 | 12.15 |
| SES | 16.61 | 14.58 | 6.45 | 5.38 | 7.75 | 12.70 |
| ETS | 16.46 | 19.34 | 8.18 | 5.44 | 8.07 | 14.52 |
| Naïve | 16.59 | 14.86 | 6.59 | 5.41 | 8.65 | 12.79 |
| N-BEATS | 15.79 | 13.27 | 4.79 | 4.63 | 8.86 | 11.49 |
| NB-SH-M4 | 15.00 | 13.36 | 6.10 | 5.67 | 8.57 | 11.60 |
| NB-NSH-M4 | 15.06 | 13.48 | 6.24 | 5.71 | 9.21 | 11.70 |
F.3 详细的M3结果
在 M3 数据集(Makridakis 和 Hibon 2000) 上,我们与 Theta 方法(Assimakopoulos 和 Nikolopoulos 2000) 进行比较,M3的获胜者; DOTA,动态优化的 Theta 模型(Fiorucci 等人 2016); EXP,最新的统计方法,也是 M3 上最先进的方法(Spiliotis、Assimakopoulos 和 Nikolopoulos 2019);以及ForecastPro0>,一款现成的预测软件,基于指数平滑、ARIMA 和移动平均之间的模型选择(Athanasopoulos 等人 2011;Assimakopoulos 和 Nikolopoulos 2000)1>. 我们还包括在 M3 上训练的 DeepAR 模型(表示为“DeepAR”),以及在 M4 上训练并在 M3 上以零样本传输模式进行测试的 DeepAR 模型t2>,表示“DeepAR-M4”。 其他模型的详细信息请参见(Makridakis 和 Hibon 2000)。
| Yearly | Quarterly | Monthly | Others | Average | |
| (645) | (756) | (1428) | (174) | (3003) | |
| Naïve2 | 17.88 | 9.95 | 16.91 | 6.30 | 15.47 |
| ARIMA (B–J automatic) | 17.73 | 10.26 | 14.81 | 5.06 | 14.01 |
| Comb S-H-D | 17.07 | 9.22 | 14.48 | 4.56 | 13.52 |
| ForecastPro | 17.14 | 9.77 | 13.86 | 4.60 | 13.19 |
| Theta | 16.90 | 8.96 | 13.85 | 4.41 | 13.01 |
| DOTM (Fiorucci et al. 2016) | 15.94 | 9.28 | 13.74 | 4.58 | 12.90 |
| EXP (Spiliotis, Assimakopoulos, and Nikolopoulos 2019) | 16.39 | 8.98 | 13.43 | 5.46 | |
| LGT (Smyl and Kuber 2016) | 15.23 | n/a | n/a | 4.26 | n/a |
| BaggedETS.BC (Bergmeir, Hyndman, and Benítez 2016) | 17.49 | 9.89 | 13.74 | n/a | n/a |
| DeepAR∗ | 13.33 | 9.07 | 13.72 | 7.11 | 12.67 |
| N-BEATS | 15.93 | 8.84 | 13.11 | 4.24 | 12.37 |
| NB-SH-M4 | 15.25 | 9.07 | 13.25 | 4.34 | 12.44 |
| NB-NSH-M4 | 15.07 | 9.10 | 13.19 | 4.29 | 12.38 |
| NB-SH-FR | 16.43 | 9.05 | 13.42 | 4.67 | 12.69 |
| NB-NSH-FR | 16.48 | 9.07 | 13.30 | 4.51 | 12.61 |
| DeepAR-M4∗ | 14.76 | 9.28 | 16.15 | 13.09 | 14.76 |
F.4 详细旅游结果
在旅游数据集(Athanasopoulos等人2011)上,我们与三个统计基准进行比较:ETS,使用交叉验证的加法/乘法的指数平滑模型; Theta方法; ForePro,与M3中的ForecastPro相同;以及旅游 Kaggle 竞赛(Athanasopoulos 和 Hyndman 2011) 的前 2 名参赛作品:Stratometrics,一种未知的技术; LeeCBaker0> (Baker and Howard 2011)1>,Naïve、线性趋势模型和指数加权最小二乘回归趋势的加权组合。 我们还包括在旅游上训练的DeepAR模型,表示为“DeepAR”,以及在M4上训练并在旅游零样本传输模式下进行测试的DeepAR模型t2>,表示“DeepAR-M4”。 其他模型详情请参见(Athanasopoulos 等人 2011)。
| Yearly | Quarterly | Monthly | Average | |
| (518) | (427) | (366) | (1311) | |
| Statistical benchmarks | ||||
| SNaïve | 23.61 | 16.46 | 22.56 | 21.25 |
| Theta | 23.45 | 16.15 | 22.11 | 20.88 |
| ForePro | 26.36 | 15.72 | 19.91 | 19.84 |
| ETS | 27.68 | 16.05 | 21.15 | 20.88 |
| Damped | 28.15 | 15.56 | 23.47 | 22.26 |
| ARIMA | 28.03 | 16.23 | 21.13 | 20.96 |
| Kaggle competitors | ||||
| SaliMali | n/a | 14.83 | 19.64 | n/a |
| LeeCBaker | 22.73 | 15.14 | 20.19 | 19.35 |
| Stratometrics | 23.15 | 15.14 | 20.37 | 19.52 |
| Robert | n/a | 14.96 | 20.28 | n/a |
| Idalgo | n/a | 15.07 | 20.55 | n/a |
| DeepAR∗ | 21.14 | 15.82 | 20.18 | 19.27 |
| N-BEATS | 21.44 | 14.78 | 19.29 | 18.52 |
| NB-SH-M4 | 23.57 | 14.66 | 19.33 | 18.82 |
| NB-NSH-M4 | 24.04 | 14.78 | 19.32 | 18.92 |
| NB-SH-FR | 23.53 | 14.47 | 21.23 | 19.94 |
| NB-NSH-FR | 23.43 | 14.45 | 20.47 | 19.46 |
| DeepAR-M4∗ | 21.51 | 22.01 | 26.64 | 24.79 |
F.5 详细电力结果
在电力方面,我们与 MatFact (Yu、Rao 和 Dhillon 2016)、DeepAR (Flunkert、Salinas 和 Gasthaus 2017)、Deep 进行比较状态(Rangapuram 等人 2018),深层因素(Wang 等人 2019)。 我们使用这些论文中使用的 指标。 结果如表12所示。 我们展示了 3 个不同分组的结果,如附录 E.5 中所述。
| 2014-09-01 (DeepAR split) | 2014-03-31 (Deep Factors split) | last 7 days (MatFact split) | |
| MatFact | 0.160† | n/a | 0.255 |
| DeepAR | 0.070 | 0.272 | n/a |
| Deep State | 0.083 | n/a | n/a |
| Deep Factors | n/a | 0.112 | n/a |
| Theta | 0.079 | 0.080 | 0.191 |
| ARIMA | 0.067 | 0.068 | 0.225 |
| ETS | 0.083 | 0.075 | 0.190 |
| SES | 0.372 | 0.320 | 0.365 |
| DeepAR∗ | 0.094 | 0.089 | 0.765 |
| N-BEATS | 0.067 | 0.067 | 0.178 |
| NB-SH-M4 | 0.094 | 0.092 | 0.178 |
| NB-NSH-M4 | 0.102 | 0.095 | 0.180 |
| NB-SH-FR | 0.091 | 0.084 | 0.205 |
| NB-NSH-FR | 0.085 | 0.080 | 0.207 |
| DeepAR-M4∗ | 0.151 | 0.081 | 0.532 |
F.6 详细流量结果
在流量上,我们与 MatFact (Yu、Rao 和 Dhillon 2016)、DeepAR (Flunkert、Salinas 和 Gasthaus 2017)、Deep 进行比较状态(Rangapuram 等人 2018),深层因素(Wang 等人 2019)。 我们使用这些论文中使用的 指标。 结果如表13所示。 我们展示了 3 个不同分组的结果,如附录 E.5 中所述。
| 2008-06-15 (DeepAR split) | 2008-01-14 (Deep Factors split) | last 7 days (MatFact split) | |
| MatFact | 0.200† | n/a | 0.187 |
| DeepAR | 0.170 | 0.296 | n/a |
| Deep State | 0.167 | n/a | n/a |
| Deep Factors | n/a | 0.225 | n/a |
| Theta | 0.178 | 0.841 | 0.170 |
| ARIMA | 0.145 | 0.500 | 0.153 |
| ETS | 0.701 | 1.330 | 0.720 |
| SES | 0.634 | 1.110 | 0.637 |
| DeepAR∗ | 0.191 | 0.478 | 0.136 |
| N-BEATS | 0.114 | 0.230 | 0.111 |
| NB-SH-M4 | 0.147 | 0.245 | 0.156 |
| NB-NSH-M4 | 0.152 | 0.250 | 0.160 |
| NB-SH-FR | 0.260 | 0.355 | 0.265 |
| NB-NSH-FR | 0.259 | 0.348 | 0.265 |
| DeepAR-M4∗ | 0.355 | 0.410 | 0.363 |
附录G元学习效果研究细节