视觉表示对比学习的简单框架
摘要
本文介绍了 SimCLR:一个用于视觉表示对比学习的简单框架。 我们简化了最近提出的对比自监督学习算法,而不需要专门的架构或存储库。 为了了解是什么使对比预测任务能够学习有用的表示,我们系统地研究了我们框架的主要组成部分。 我们表明,(1)数据增强的组合在定义有效的预测任务中发挥着关键作用,(2)在表示和对比损失之间引入可学习的非线性变换,大大提高了学习表示的质量,以及(3)对比学习与监督学习相比,受益于更大的批量大小和更多的训练步骤。 通过结合这些发现,我们能够大大优于之前 ImageNet 上的自监督和半监督学习方法。 根据 SimCLR 学习的自监督表示进行训练的线性分类器实现了 76.5% 的 top-1 准确率,比之前最先进的技术相对提高了 7%,与有监督的 ResNet-50 的性能相匹配。 当仅对 1% 的标签进行微调时,我们实现了 85.8% 的 top-5 准确率,比 AlexNet 少了 100 标签。 111代码位于https://github.com/google-research/simclr。
1简介
在没有人类监督的情况下学习有效的视觉表示是一个长期存在的问题。 大多数主流方法属于两类之一:生成式或判别式。 生成方法学习在输入空间中生成像素或以其他方式建模像素(Hinton 等人,2006;Kingma & Welling,2013;Goodfellow 等人,2014)。 然而,像素级生成的计算成本很高,并且对于表示学习来说可能不是必需的。 判别方法使用与监督学习类似的目标函数来学习表示,但训练网络来执行借口任务,其中输入和标签都来自未标记的数据集。 许多此类方法依赖启发式方法来设计借口任务(Doersch 等人,2015;Zhang 等人,2016;Noroozi & Favaro,2016;Gidaris 等人,2018),这可能会限制学到的表示。 基于潜在空间对比学习的判别方法最近显示出巨大的前景,取得了最先进的结果(Hadsell 等人, 2006; Dosovitskiy 等人, 2014; Oord 等人, 2018; Bachman 等人,2019)。
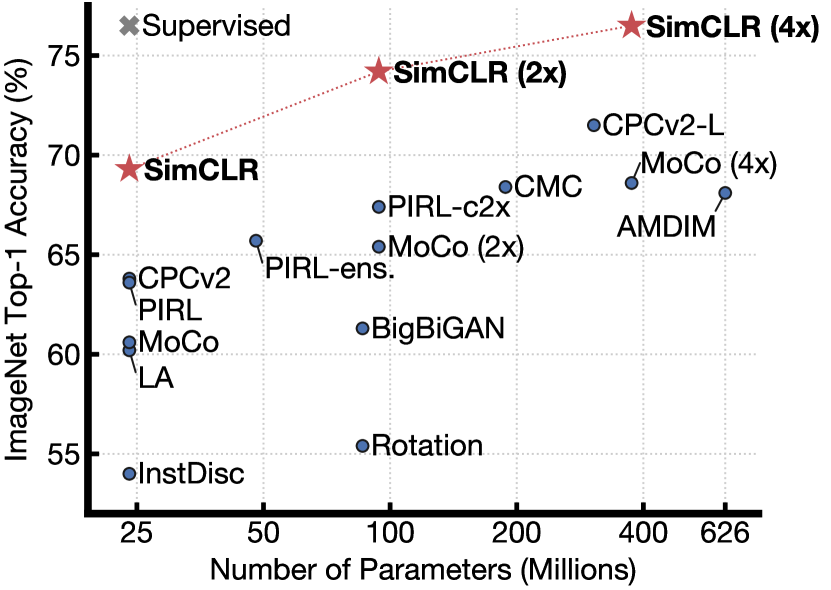
在这项工作中,我们介绍了一个用于视觉表示对比学习的简单框架,我们称之为 SimCLR。 SimCLR 不仅优于之前的工作(图1),而且更简单,既不需要专门的架构(Bachman 等人,2019;Hénaff 等人,2019)也不需要记忆库(Wu 等人, 2018; Tian 等人, 2019; He 等人, 2019; Misra & van der Maaten, 2019)。
为了了解什么能够实现良好的对比表示学习,我们系统地研究了我们框架的主要组成部分,并表明:
-
•
多个数据增强操作的组合对于定义产生有效表示的对比预测任务至关重要。 此外,无监督对比学习比监督学习受益于更强的数据增强。
-
•
在表示和对比损失之间引入可学习的非线性变换,可以显着提高学习表示的质量。
-
•
具有对比交叉熵损失的表示学习受益于归一化嵌入和适当调整的温度参数。
-
•
与监督学习相比,对比学习受益于更大的批量大小和更长的训练。 与监督学习一样,对比学习也受益于更深更广的网络。
我们结合这些发现,在 ImageNet ILSVRC-2012 (Russakovsky 等人,2015)上实现了自监督和半监督学习的新进展。 在线性评估协议下,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的最先进水平(Hénaff 等人,2019)相对提高了 7%。 当仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 的 top-5 准确率达到 85.8%,相对提高了 10%(Hénaff 等人,2019)。 当在其他自然图像分类数据集上进行微调时,SimCLR 在 12 个数据集中的 10 个上的表现与强监督基线(Kornblith 等人,2019)相当或更好。
2方法
2.1 对比学习框架
受最近的对比学习算法(概述请参见第 7 节)的启发,SimCLR 通过潜在空间中的对比损失最大化同一数据示例的不同增强视图之间的一致性来学习表示。 如图2所示,该框架由以下四个主要组件组成。
-
•
随机数据增强模块,随机转换任何给定的数据示例,从而产生同一示例的两个相关视图,表示为和,我们将其视为积极的一对。 在这项工作中,我们依次应用三个简单的增强:随机裁剪,然后将大小调整回原始大小,随机颜色扭曲和随机高斯模糊。 如第 3 节所示,随机裁剪和颜色失真的组合对于实现良好的性能至关重要。
-
•
神经网络基本编码器从增强数据示例中提取表示向量。 我们的框架允许网络架构的各种选择,没有任何限制。 我们选择简单,采用常用的ResNet (He 等人, 2016)来获得,其中是平均池化层之后的输出。
-
•
一个小型神经网络投影头将表示映射到应用对比损失的空间。 我们使用具有一个隐藏层的 MLP 来获得 ,其中 是 ReLU 非线性。 如4节所示,我们发现在而不是上定义对比损失是有益的。
-
•
为对比预测任务定义的对比损失函数。 给定一个集合 包括一对正面示例 和 ,对比预测任务的目的是针对给定的 在 中识别 。
我们随机采样一小批 示例,并在从该小批量派生的一对增强示例上定义对比预测任务,从而产生 数据点。 我们不会明确地对负面例子进行采样。 相反,给定一个正对,类似于 (Chen 等人, 2017),我们将小批量中的其他 增强示例视为负示例。 让 表示 标准化 和 之间的点积(即余弦相似度)。 那么一对正样本 的损失函数定义为
| (1) |
其中 是评估 iff 的指示函数, 表示温度参数。 最终损失是在小批量中计算所有正对( 和 )的。 该损失已在之前的工作中使用过(Sohn, 2016; Wu 等人, 2018; Oord 等人, 2018);为了方便起见,我们将其称为NT-Xent(归一化温度标度交叉熵损失)。
算法1总结了所提出的方法。
2.2 大批量训练
为了简单起见,我们不使用记忆库来训练模型(Wu 等人, 2018; He 等人, 2019)。 相反,我们将训练批量大小 从 256 更改为 8192。 8192 的批量大小为我们提供了来自两个增强视图的每个正对 16382 个负例。 当使用具有线性学习率缩放的标准 SGD/Momentum 时,大批量训练可能会不稳定(Goyal 等人,2017)。 为了稳定训练,我们对所有批量大小使用 LARS 优化器 (You 等人, 2017)。 我们使用 Cloud TPU 训练模型,根据批量大小使用 32 到 128 个核心。222在使用 128 个 TPU v3 内核的情况下,我们的 ResNet-50 在批量大小为 4096 的情况下需要 1.5 个小时来训练 100 个历时。
全球BN。 标准 ResNet 使用批量归一化(Ioffe & Szegedy,2015)。 在具有数据并行性的分布式训练中,BN 均值和方差通常在每个设备本地聚合。 在我们的对比学习中,由于在同一设备中计算正对,因此该模型可以利用局部信息泄漏来提高预测精度,而无需改进表示。 我们通过在训练期间聚合所有设备上的 BN 训练平均值和方差来解决这个问题。 其他方法包括跨设备洗牌数据示例(He等人,2019),或用层范数替换BN(Hénaff等人,2019)。
2.3评估协议
在这里,我们列出了实证研究的协议,旨在了解我们框架中的不同设计选择。
数据集和指标。 我们对无监督预训练(学习无标签的编码器网络 )的大部分研究是使用 ImageNet ILSVRC-2012 数据集 (Russakovsky 等人,2015) 完成的。 CIFAR-10 上的一些额外预训练实验(Krizhevsky & Hinton,2009)可以在附录B.9中找到。 我们还在各种数据集上测试了用于迁移学习的预训练结果。 为了评估学习到的表示,我们遵循广泛使用的线性评估协议(Zhang 等人, 2016; Oord 等人, 2018; Bachman 等人, 2019; Kolesnikov 等人, 2019),其中线性分类器在冻结的基础网络之上进行训练,测试准确性用作表示质量的代理。 除了线性评估之外,我们还与半监督和迁移学习的最新技术进行比较。
默认设置。 除非另有说明,对于数据增强,我们使用随机裁剪和调整大小(随机翻转)、颜色扭曲和高斯模糊(有关详细信息,请参阅附录 A)。 我们使用 ResNet-50 作为基础编码器网络,并使用 2 层 MLP 投影头将表示投影到 128 维潜在空间。 作为损失,我们使用 NT-Xent,使用 LARS 进行优化,学习率为 4.8 (),权重衰减为 。 我们以批量大小 4096 训练 100 个时期。333虽然在 100 个 epoch 中没有达到最大性能,但已经达到了合理的结果,允许公平和高效的消融。 此外,我们在前 10 个 epoch 中使用线性预热,并使用余弦衰减时间表衰减学习率,而无需重新启动(Loshchilov&Hutter,2016)。
3 用于对比表示学习的数据增强










数据增强定义了预测任务。 虽然数据增强已广泛应用于监督和无监督表示学习(Krizhevsky 等人,2012;Hénaff 等人,2019;Bachman 等人,2019),但它尚未被视为一种系统方法定义对比预测任务。 许多现有方法通过改变架构来定义对比预测任务。 例如,Hjelm 等人 (2018); Bachman 等人 (2019) 通过限制网络架构中的感受野实现全局到局部的视图预测,而 Oord 等人 (2018); Hénaff 等人 (2019) 通过固定图像分割过程和上下文聚合网络实现相邻视图预测。 我们证明,可以通过对目标图像执行简单的随机裁剪(调整大小)来避免这种复杂性,这会创建一系列包含上述两项的预测任务,如图 3 这种简单的设计选择可以方便地将预测任务与神经网络架构等其他组件分离。 更广泛的对比预测任务可以通过扩展增强系列并随机组合来定义。
3.1 数据增强操作的组合对于学习良好的表示至关重要
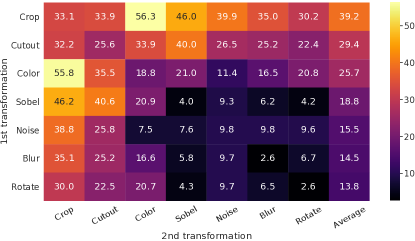
为了系统地研究数据增强的影响,我们在这里考虑几种常见的增强。 一种类型的增强涉及数据的空间/几何变换,例如裁剪和调整大小(水平翻转)、旋转(Gidaris等人,2018)和剪切(DeVries&Taylor,2017) 。 另一种类型的增强涉及外观变换,例如颜色失真(包括颜色下降、亮度、对比度、饱和度、色调)(Howard, 2013; Szegedy 等人, 2015)、高斯模糊和 Sobel过滤。 图4可视化了我们在这项工作中研究的增强功能。
为了了解单个数据增强的效果以及增强组合的重要性,我们研究了单独或成对应用增强时框架的性能。 由于 ImageNet 图像大小不同,我们总是应用裁剪和调整图像大小(Krizhevsky 等人,2012;Szegedy 等人,2015),这使得在没有裁剪的情况下研究其他增强技术变得困难。 为了消除这种混淆,我们考虑针对这种消融采用非对称数据转换设置。 具体来说,我们总是首先随机裁剪图像并将其大小调整为相同的分辨率,然后我们仅将目标变换应用于图2中框架的一个分支,同时保留另一个分支作为标识(即 )。 请注意,这种不对称数据增强会损害性能。 尽管如此,这种设置不应实质性改变单个数据增强或其组成的影响。
图5显示了单独变换和组合变换下的线性评估结果。 我们观察到,尽管模型几乎可以完美地识别对比任务中的正对,但没有任何单一转换足以学习良好的表示。 当组合增强时,对比预测任务变得更加困难,但表示的质量显着提高。 附录B.2提供了关于组成更广泛的增强集的进一步研究。
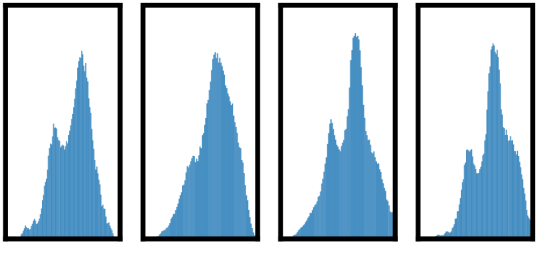
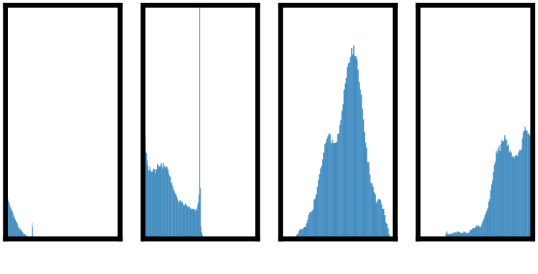
一种突出的增强组合是:随机裁剪和随机颜色失真。 我们推测,仅使用随机裁剪作为数据增强时的一个严重问题是图像中的大多数补丁都具有相似的颜色分布。 图6显示仅颜色直方图就足以区分图像。 神经网络可以利用这个捷径来解决预测任务。 因此,为了学习可概括的特征,将裁剪与颜色失真结合起来至关重要。
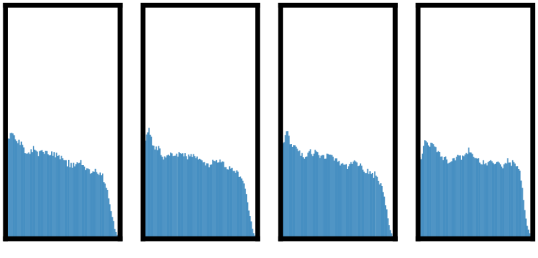
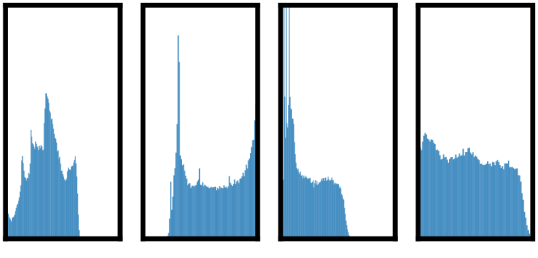
3.2对比学习需要比监督学习更强的数据增强
| Color distortion strength | ||||||
| Methods | 1/8 | 1/4 | 1/2 | 1 | 1 (+Blur) | AutoAug |
| SimCLR | 59.6 | 61.0 | 62.6 | 63.2 | 64.5 | 61.1 |
| Supervised | 77.0 | 76.7 | 76.5 | 75.7 | 75.4 | 77.1 |
为了进一步证明颜色增强的重要性,我们调整颜色增强的强度,如表1所示。 更强的颜色增强显着改善了学习的无监督模型的线性评估。 在这种情况下,AutoAugment (Cubuk 等人, 2019)(一种使用监督学习发现的复杂增强策略)并不比简单的裁剪+(更强的)颜色失真效果更好。 当使用相同的增强集训练监督模型时,我们观察到更强的颜色增强不会提高甚至损害它们的性能。 因此,我们的实验表明,无监督对比学习比监督学习受益于更强的(颜色)数据增强。 尽管之前的工作已经报道数据增强对于自监督学习很有用(Doersch等人,2015;Bachman等人,2019;Hénaff等人,2019;Asano等人,2019),我们表明数据增强虽然不会为监督学习带来准确性优势,但仍然可以对对比学习有很大帮助。
4 编码器和头部的架构
4.1 无监督对比学习从更大的模型中受益(更多)
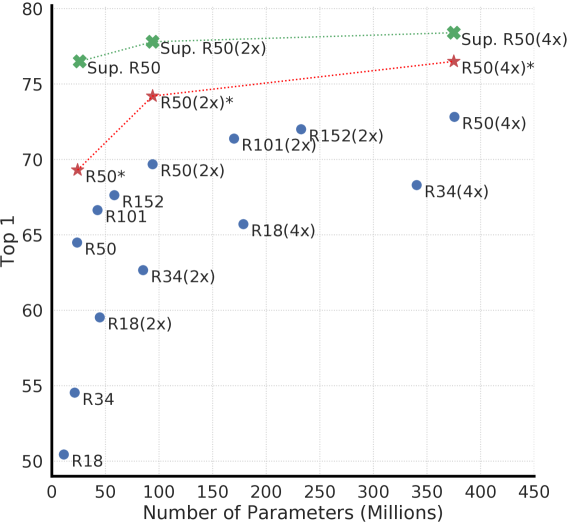
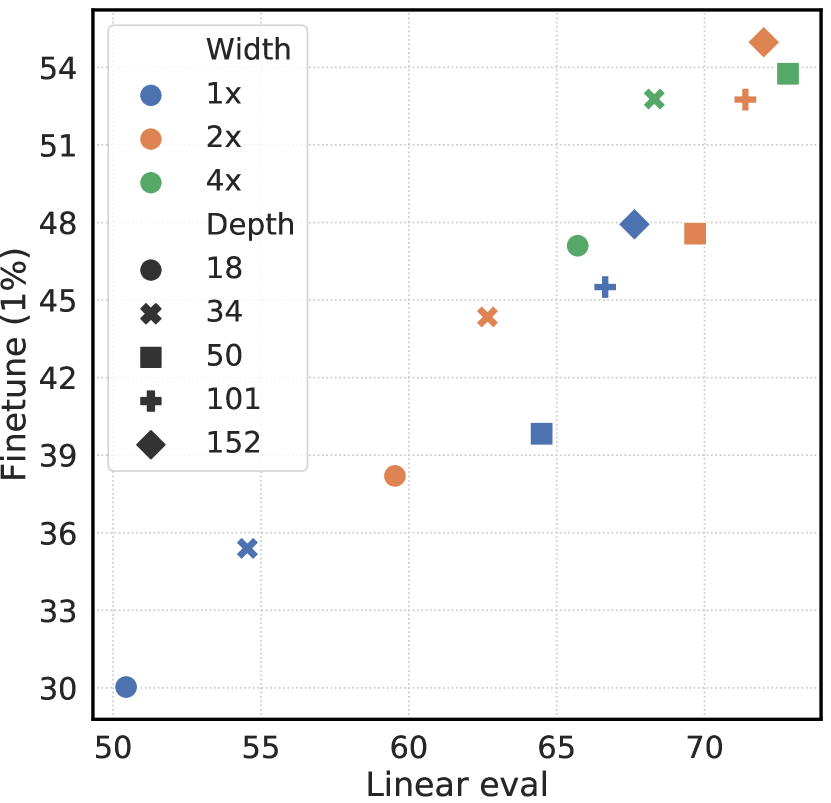
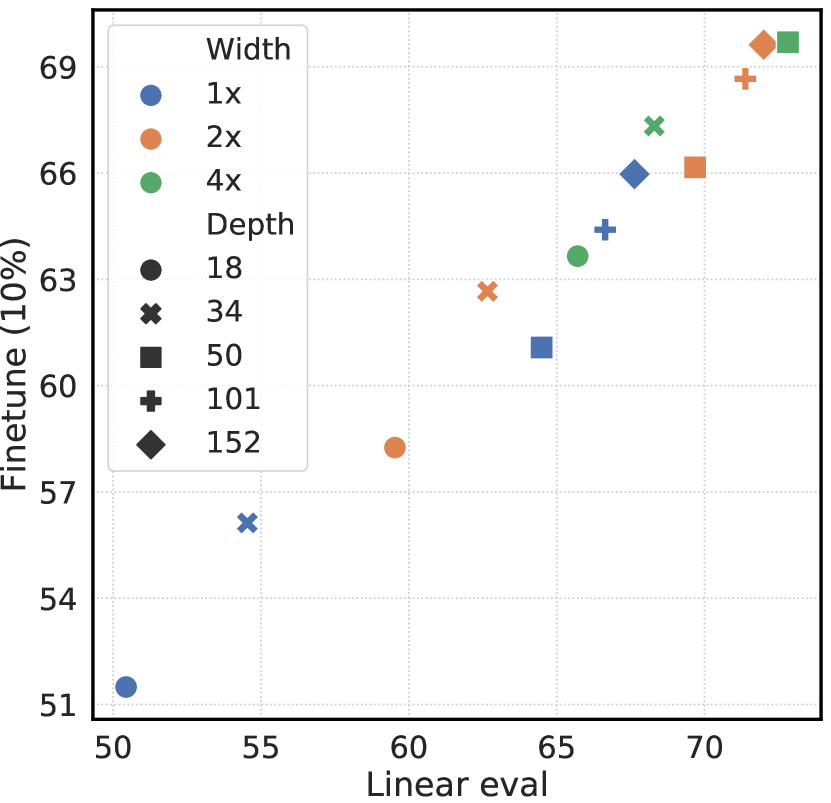
图 7 显示,增加深度和宽度都可以提高性能,这或许并不令人意外。 虽然监督学习也有类似的发现(He等人,2016),但我们发现监督模型和在无监督模型上训练的线性分类器之间的差距随着模型规模的增加而缩小,这表明无监督学习与监督模型相比,从更大的模型中获益更多。
| Name | Negative loss function | Gradient w.r.t. |
| NT-Xent | ||
| NT-Logistic | ||
| Margin Triplet |
4.2 非线性投影头提高了之前层的表示质量
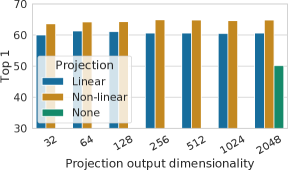
然后我们研究包含投影头的重要性,即。 图8显示了使用三种不同头部架构的线性评估结果:(1)恒等映射; (2)线性投影,如之前的几种方法所使用的(Wu等人,2018); (3) 带有一个额外隐藏层(和 ReLU 激活)的默认非线性投影,类似于 Bachman 等人 (2019)。 我们观察到非线性投影比线性投影好(+3%),并且比没有投影好得多(>10%)。 当使用投影头时,无论输出尺寸如何,都会观察到类似的结果。 此外,即使使用非线性投影,投影头之前的层 仍然比后面的层 好得多(>10%),这表明 投影头之前的隐藏层比投影头之后的层有更好的表示。
我们推测,在非线性投影之前使用表示的重要性是由于对比损失引起的信息损失。 特别是, 被训练为对数据转换不变。 因此,可以删除可能对下游任务有用的信息,例如对象的颜色或方向。 通过利用非线性变换,可以在中形成和维护更多信息。 为了验证这一假设,我们进行了使用 或 进行实验来学习预测预训练期间应用的转换。 这里我们设置,具有相同的输入和输出维度(即2048)。 表 3 显示 包含有关所应用的转换的更多信息,而 丢失了信息。 进一步分析参见附录B.4。
| What to predict? | Random guess | Representation | |
| Color vs grayscale | 80 | 99.3 | 97.4 |
| Rotation | 25 | 67.6 | 25.6 |
| Orig. vs corrupted | 50 | 99.5 | 59.6 |
| Orig. vs Sobel filtered | 50 | 96.6 | 56.3 |
5 损失函数和批量大小
5.1 具有可调温度的归一化交叉熵损失比替代方法效果更好
我们将 NT-Xent 损失与其他常用的对比损失函数进行比较,例如逻辑损失(Mikolov 等人,2013)和边际损失(Schroff 等人,2015)。 表2显示了目标函数以及损失函数输入的梯度。 从梯度来看,我们观察到 1) 归一化(即余弦相似度)和温度有效地对不同示例进行加权,适当的温度可以帮助模型从硬负例中学习; 2)与交叉熵不同,其他目标函数不会通过相对硬度来衡量负数。 因此,必须对这些损失函数应用半硬负挖掘(Schroff等人,2015):可以使用半硬负挖掘来计算梯度,而不是计算所有损失项的梯度。负面项(即,那些在损失裕度内且距离最近但比正面示例更远的项)。
为了使比较公平,我们对所有损失函数使用相同的 归一化,并调整超参数,并报告其最佳结果。888详情请参阅附录B.10。 为简单起见,我们仅考虑一种增强视图的负面影响。 表 4 显示,虽然(半困难)负挖掘有所帮助,但最好的结果仍然比我们默认的 NT-Xent 损失差得多。
接下来,我们测试默认 NT-Xent 损失中 归一化(即余弦相似度与点积)和温度 的重要性。 表 5 显示,如果没有标准化和适当的温标,性能会明显变差。 没有归一化,对比任务精度更高,但在线性评估下得到的表示更差。
| Margin | NT-Logi. | Margin (sh) | NT-Logi.(sh) | NT-Xent |
| 50.9 | 51.6 | 57.5 | 57.9 | 63.9 |
| norm? | Entropy | Contrastive acc. | Top 1 | |
| Yes | 0.05 | 1.0 | 90.5 | 59.7 |
| 0.1 | 4.5 | 87.8 | 64.4 | |
| 0.5 | 8.2 | 68.2 | 60.7 | |
| 1 | 8.3 | 59.1 | 58.0 | |
| No | 10 | 0.5 | 91.7 | 57.2 |
| 100 | 0.5 | 92.1 | 57.0 |
5.2 对比学习从更大的批量大小和更长的时间中受益(更多)
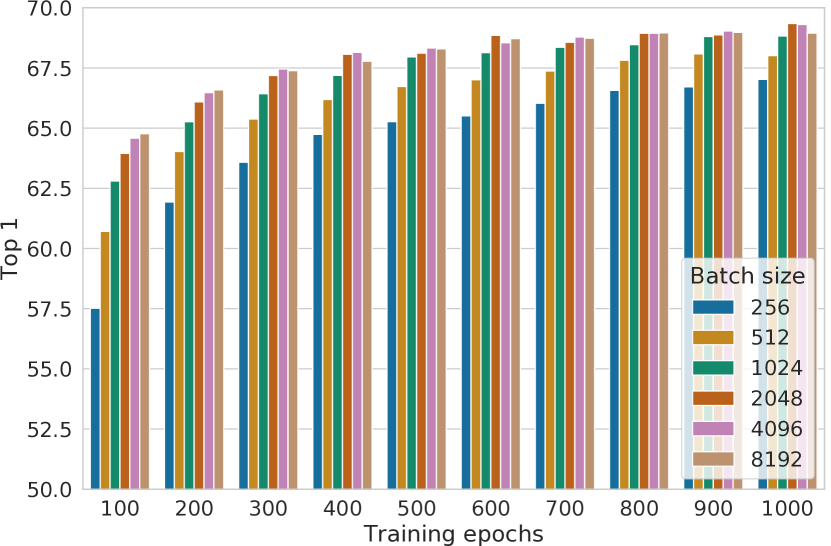
图9显示了模型训练不同时期数时批量大小的影响。 我们发现,当训练 epoch 的数量很小时(例如 100 epoch),较大的批量大小比较小的批量大小具有显着优势。 随着训练步骤/时期的增加,不同批次大小之间的差距会减少或消失,前提是批次是随机重新采样的。 与监督学习(Goyal等人,2017)相比,在对比学习中,较大的批量大小提供更多的反面例子,促进收敛(即在给定的精度下采取更少的时期和步骤)。 更长的训练也会提供更多的反面例子,从而改善结果。 在附录B.1中,提供了更长训练步骤的结果。
| Method | Architecture | Param (M) | Top 1 | Top 5 |
| Methods using ResNet-50: | ||||
| Local Agg. | ResNet-50 | 24 | 60.2 | - |
| MoCo | ResNet-50 | 24 | 60.6 | - |
| PIRL | ResNet-50 | 24 | 63.6 | - |
| CPC v2 | ResNet-50 | 24 | 63.8 | 85.3 |
| SimCLR (ours) | ResNet-50 | 24 | 69.3 | 89.0 |
| Methods using other architectures: | ||||
| Rotation | RevNet-50 () | 86 | 55.4 | - |
| BigBiGAN | RevNet-50 () | 86 | 61.3 | 81.9 |
| AMDIM | Custom-ResNet | 626 | 68.1 | - |
| CMC | ResNet-50 () | 188 | 68.4 | 88.2 |
| MoCo | ResNet-50 () | 375 | 68.6 | - |
| CPC v2 | ResNet-161 () | 305 | 71.5 | 90.1 |
| SimCLR (ours) | ResNet-50 () | 94 | 74.2 | 92.0 |
| SimCLR (ours) | ResNet-50 () | 375 | 76.5 | 93.2 |
| Method | Architecture | Label fraction | |
| 1% | 10% | ||
| Top 5 | |||
| Supervised baseline | ResNet-50 | 48.4 | 80.4 |
| Methods using other label-propagation: | |||
| Pseudo-label | ResNet-50 | 51.6 | 82.4 |
| VAT+Entropy Min. | ResNet-50 | 47.0 | 83.4 |
| UDA (w. RandAug) | ResNet-50 | - | 88.5 |
| FixMatch (w. RandAug) | ResNet-50 | - | 89.1 |
| S4L (Rot+VAT+En. M.) | ResNet-50 (4) | - | 91.2 |
| Methods using representation learning only: | |||
| InstDisc | ResNet-50 | 39.2 | 77.4 |
| BigBiGAN | RevNet-50 () | 55.2 | 78.8 |
| PIRL | ResNet-50 | 57.2 | 83.8 |
| CPC v2 | ResNet-161() | 77.9 | 91.2 |
| SimCLR (ours) | ResNet-50 | 75.5 | 87.8 |
| SimCLR (ours) | ResNet-50 () | 83.0 | 91.2 |
| SimCLR (ours) | ResNet-50 () | 85.8 | 92.6 |
| Food | CIFAR10 | CIFAR100 | Birdsnap | SUN397 | Cars | Aircraft | VOC2007 | DTD | Pets | Caltech-101 | Flowers | |
| Linear evaluation: | ||||||||||||
| SimCLR (ours) | 76.9 | 95.3 | 80.2 | 48.4 | 65.9 | 60.0 | 61.2 | 84.2 | 78.9 | 89.2 | 93.9 | 95.0 |
| Supervised | 75.2 | 95.7 | 81.2 | 56.4 | 64.9 | 68.8 | 63.8 | 83.8 | 78.7 | 92.3 | 94.1 | 94.2 |
| Fine-tuned: | ||||||||||||
| SimCLR (ours) | 89.4 | 98.6 | 89.0 | 78.2 | 68.1 | 92.1 | 87.0 | 86.6 | 77.8 | 92.1 | 94.1 | 97.6 |
| Supervised | 88.7 | 98.3 | 88.7 | 77.8 | 67.0 | 91.4 | 88.0 | 86.5 | 78.8 | 93.2 | 94.2 | 98.0 |
| Random init | 88.3 | 96.0 | 81.9 | 77.0 | 53.7 | 91.3 | 84.8 | 69.4 | 64.1 | 82.7 | 72.5 | 92.5 |
6 与最先进技术的比较
在本小节中,类似于Kolesnikov 等人(2019); He 等人 (2019),我们在 3 种不同的隐藏层宽度中使用 ResNet-50(、 和 的宽度乘数)。 为了更好地收敛,我们的模型训练了 1000 个时期。
线性评估。 表6将我们的结果与之前的方法进行了比较(Zhuang 等人, 2019; He 等人, 2019; Misra & van der Maaten, 2019; Hénaff 等人, 2019; Kolesnikov 等人, 2019 ;Donahue & Simonyan, 2019; Bachman 等人, 2019; Tian 等人, 2019)在线性评估设置中(参见附录B.6)。 表1显示了不同方法之间更多的数值比较。 与以前需要专门设计架构的方法相比,我们能够使用标准网络获得更好的结果。 使用我们的 ResNet-50 () 获得的最佳结果可以与有监督的预训练 ResNet-50 相匹配。
半监督学习。 我们遵循 Zhai 等人 (2019) 并以类平衡的方式对标记的 ILSVRC-12 训练数据集的 1% 或 10% 进行采样(12.8 和 每类分别 128 个图像)。 111111采样和精确子集的详细信息可以在https://www.tensorflow.org/datasets/catalog/imagenet2012_subset中找到。 我们只是简单地在标记数据上影响整个基础网络,而不进行正则化(参见附录B.5)。 表 7 显示了我们的结果与最新方法 的比较(Zhai 等人,2019;Xie 等人,2019;Sohn 等人,2020;Wu 等人,2018;Donahue & Simonyan, 2019;Misra & van der Maaten,2019;Hénaff 等人,2019)。 由于对超参数(包括增强)的深入搜索,(Zhai 等人,2019) 的监督基线非常强大。 同样,我们的方法比使用 1% 和 10% 标签的最先进方法有了显着改进。 有趣的是,在 full ImageNet 上微调我们预训练的 ResNet-50 (2) 也明显优于从头开始训练(高达 2%,请参阅附录 B.2)。
7相关工作
在小变换下使图像的表示彼此一致的想法可以追溯到 Becker & Hinton (1992)。 我们通过利用数据增强、网络架构和对比损失方面的最新进展来扩展它。 类似的一致性想法,但对于类标签预测,已经在其他环境中进行了探索,例如半监督学习(Xie等人,2019;Berthelot等人,2019) 。
手工制作的借口任务。 最近自监督学习的复兴始于人工设计的借口任务,例如相对补丁预测(Doersch等人,2015),解决拼图游戏(Noroozi & Favaro,2016)、着色(Zhang 等人,2016)和旋转预测(Gidaris 等人,2018;Chen 等人,2019)。 尽管通过更大的网络和更长的训练可以获得良好的结果(Kolesnikov等人,2019),但这些借口任务依赖于某种特定的启发式方法,这限制了学习表示的通用性。
对比视觉表征学习。 可以追溯到 Hadsell 等人 (2006),这些方法通过对比正对和负对来学习表示。 沿着这些思路,Dosovitskiy 等人 (2014) 提出将每个实例视为由特征向量(以参数形式)表示的类。 Wu 等人 (2018) 提出使用内存库来存储实例类表示向量,这种方法在最近的几篇论文中被采用和扩展(Zhuang 等人, 2019; Tian 等人, 2019;何等人,2019;Misra & van der Maaten,2019)。 其他工作探索使用批内样本代替记忆库进行负采样(Doersch & Zisserman,2017;Ye 等人,2019;Ji 等人,2019)。
最近的文献试图将其方法的成功与潜在表征之间互信息的最大化联系起来(Oord 等人,2018;Hénaff 等人,2019;Hjelm 等人,2018;Bachman 等人,2019)。 然而,目前尚不清楚对比方法的成功是由互信息决定的,还是由对比损失的具体形式决定的(Tschannen等人,2019)。
我们注意到,我们框架的几乎所有单独组件都出现在之前的工作中,尽管具体的实例可能有所不同。 我们的框架相对于以前的工作的优越性不是通过任何单一的设计选择来解释的,而是通过它们的组合来解释的。 我们在附录C中对我们的设计选择与之前的工作进行了全面的比较。
8结论
在这项工作中,我们提出了一个简单的框架及其用于对比视觉表示学习的实例。 我们仔细研究其组件,并展示不同设计选择的效果。 通过结合我们的研究结果,我们比以前的自监督、半监督和迁移学习方法有了很大的改进。
我们的方法与 ImageNet 上的标准监督学习的不同之处仅在于数据增强的选择、网络末端非线性头的使用以及损失函数。 这个简单框架的优势表明,尽管最近人们的兴趣激增,但自我监督学习的价值仍然被低估。
致谢
我们要感谢翟晓华、Rafael Müller 和 Yani Ioannou 对草案的反馈。 我们还感谢多伦多和其他地方的 Google 研究团队的大力支持。
参考
- Asano et al. (2019) Asano, Y. M., Rupprecht, C., and Vedaldi, A. A critical analysis of self-supervision, or what we can learn from a single image. arXiv preprint arXiv:1904.13132, 2019.
- Bachman et al. (2019) Bachman, P., Hjelm, R. D., and Buchwalter, W. Learning representations by maximizing mutual information across views. In Advances in Neural Information Processing Systems, pp. 15509–15519, 2019.
- Becker & Hinton (1992) Becker, S. and Hinton, G. E. Self-organizing neural network that discovers surfaces in random-dot stereograms. Nature, 355(6356):161–163, 1992.
- Berg et al. (2014) Berg, T., Liu, J., Lee, S. W., Alexander, M. L., Jacobs, D. W., and Belhumeur, P. N. Birdsnap: Large-scale fine-grained visual categorization of birds. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2019–2026. IEEE, 2014.
- Berthelot et al. (2019) Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., and Raffel, C. A. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pp. 5050–5060, 2019.
- Bossard et al. (2014) Bossard, L., Guillaumin, M., and Van Gool, L. Food-101–mining discriminative components with random forests. In European conference on computer vision, pp. 446–461. Springer, 2014.
- Chen et al. (2017) Chen, T., Sun, Y., Shi, Y., and Hong, L. On sampling strategies for neural network-based collaborative filtering. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 767–776, 2017.
- Chen et al. (2019) Chen, T., Zhai, X., Ritter, M., Lucic, M., and Houlsby, N. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12154–12163, 2019.
- Cimpoi et al. (2014) Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., and Vedaldi, A. Describing textures in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3606–3613. IEEE, 2014.
- Cubuk et al. (2019) Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 113–123, 2019.
- DeVries & Taylor (2017) DeVries, T. and Taylor, G. W. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- Doersch & Zisserman (2017) Doersch, C. and Zisserman, A. Multi-task self-supervised visual learning. In Proceedings of the IEEE International Conference on Computer Vision, pp. 2051–2060, 2017.
- Doersch et al. (2015) Doersch, C., Gupta, A., and Efros, A. A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1422–1430, 2015.
- Donahue & Simonyan (2019) Donahue, J. and Simonyan, K. Large scale adversarial representation learning. In Advances in Neural Information Processing Systems, pp. 10541–10551, 2019.
- Donahue et al. (2014) Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., and Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In International Conference on Machine Learning, pp. 647–655, 2014.
- Dosovitskiy et al. (2014) Dosovitskiy, A., Springenberg, J. T., Riedmiller, M., and Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. In Advances in neural information processing systems, pp. 766–774, 2014.
- Everingham et al. (2010) Everingham, M., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A. The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2):303–338, 2010.
- Fei-Fei et al. (2004) Fei-Fei, L., Fergus, R., and Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshop on Generative-Model Based Vision, 2004.
- Gidaris et al. (2018) Gidaris, S., Singh, P., and Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728, 2018.
- Goodfellow et al. (2014) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680, 2014.
- Goyal et al. (2017) Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., and He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- Hadsell et al. (2006) Hadsell, R., Chopra, S., and LeCun, Y. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pp. 1735–1742. IEEE, 2006.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2019) He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722, 2019.
- Hénaff et al. (2019) Hénaff, O. J., Razavi, A., Doersch, C., Eslami, S., and Oord, A. v. d. Data-efficient image recognition with contrastive predictive coding. arXiv preprint arXiv:1905.09272, 2019.
- Hinton et al. (2006) Hinton, G. E., Osindero, S., and Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554, 2006.
- Hjelm et al. (2018) Hjelm, R. D., Fedorov, A., Lavoie-Marchildon, S., Grewal, K., Bachman, P., Trischler, A., and Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670, 2018.
- Howard (2013) Howard, A. G. Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:1312.5402, 2013.
- Ioffe & Szegedy (2015) Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
- Ji et al. (2019) Ji, X., Henriques, J. F., and Vedaldi, A. Invariant information clustering for unsupervised image classification and segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pp. 9865–9874, 2019.
- Kingma & Welling (2013) Kingma, D. P. and Welling, M. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Kolesnikov et al. (2019) Kolesnikov, A., Zhai, X., and Beyer, L. Revisiting self-supervised visual representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1920–1929, 2019.
- Kornblith et al. (2019) Kornblith, S., Shlens, J., and Le, Q. V. Do better ImageNet models transfer better? In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2661–2671, 2019.
- Krause et al. (2013) Krause, J., Deng, J., Stark, M., and Fei-Fei, L. Collecting a large-scale dataset of fine-grained cars. In Second Workshop on Fine-Grained Visual Categorization, 2013.
- Krizhevsky & Hinton (2009) Krizhevsky, A. and Hinton, G. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. URL https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
- Loshchilov & Hutter (2016) Loshchilov, I. and Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Maaten & Hinton (2008) Maaten, L. v. d. and Hinton, G. Visualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605, 2008.
- Maji et al. (2013) Maji, S., Kannala, J., Rahtu, E., Blaschko, M., and Vedaldi, A. Fine-grained visual classification of aircraft. Technical report, 2013.
- Mikolov et al. (2013) Mikolov, T., Chen, K., Corrado, G., and Dean, J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- Misra & van der Maaten (2019) Misra, I. and van der Maaten, L. Self-supervised learning of pretext-invariant representations. arXiv preprint arXiv:1912.01991, 2019.
- Nilsback & Zisserman (2008) Nilsback, M.-E. and Zisserman, A. Automated flower classification over a large number of classes. In Computer Vision, Graphics & Image Processing, 2008. ICVGIP’08. Sixth Indian Conference on, pp. 722–729. IEEE, 2008.
- Noroozi & Favaro (2016) Noroozi, M. and Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision, pp. 69–84. Springer, 2016.
- Oord et al. (2018) Oord, A. v. d., Li, Y., and Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Parkhi et al. (2012) Parkhi, O. M., Vedaldi, A., Zisserman, A., and Jawahar, C. Cats and dogs. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3498–3505. IEEE, 2012.
- Russakovsky et al. (2015) Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- Schroff et al. (2015) Schroff, F., Kalenichenko, D., and Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 815–823, 2015.
- Simonyan & Zisserman (2014) Simonyan, K. and Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Sohn (2016) Sohn, K. Improved deep metric learning with multi-class n-pair loss objective. In Advances in neural information processing systems, pp. 1857–1865, 2016.
- Sohn et al. (2020) Sohn, K., Berthelot, D., Li, C.-L., Zhang, Z., Carlini, N., Cubuk, E. D., Kurakin, A., Zhang, H., and Raffel, C. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020.
- Szegedy et al. (2015) Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015.
- Tian et al. (2019) Tian, Y., Krishnan, D., and Isola, P. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
- Tschannen et al. (2019) Tschannen, M., Djolonga, J., Rubenstein, P. K., Gelly, S., and Lucic, M. On mutual information maximization for representation learning. arXiv preprint arXiv:1907.13625, 2019.
- Wu et al. (2018) Wu, Z., Xiong, Y., Yu, S. X., and Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3733–3742, 2018.
- Xiao et al. (2010) Xiao, J., Hays, J., Ehinger, K. A., Oliva, A., and Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3485–3492. IEEE, 2010.
- Xie et al. (2019) Xie, Q., Dai, Z., Hovy, E., Luong, M.-T., and Le, Q. V. Unsupervised data augmentation. arXiv preprint arXiv:1904.12848, 2019.
- Ye et al. (2019) Ye, M., Zhang, X., Yuen, P. C., and Chang, S.-F. Unsupervised embedding learning via invariant and spreading instance feature. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6210–6219, 2019.
- You et al. (2017) You, Y., Gitman, I., and Ginsburg, B. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017.
- Zhai et al. (2019) Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. S4l: Self-supervised semi-supervised learning. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
- Zhang et al. (2016) Zhang, R., Isola, P., and Efros, A. A. Colorful image colorization. In European conference on computer vision, pp. 649–666. Springer, 2016.
- Zhuang et al. (2019) Zhuang, C., Zhai, A. L., and Yamins, D. Local aggregation for unsupervised learning of visual embeddings. In Proceedings of the IEEE International Conference on Computer Vision, pp. 6002–6012, 2019.
附录 A数据增强详细信息
在我们默认的预训练设置(用于训练我们最好的模型)中,我们利用随机裁剪(调整大小和随机翻转)、随机颜色失真和随机高斯模糊作为数据增强。 下面提供了这三个增强的详细信息。
随机裁剪并调整大小至 224x224
我们使用标准的 Inception 风格的随机裁剪(Szegedy 等人,2015)。 进行原始大小的随机大小(面积统一从 0.08 到 1.0)和原始宽高比的随机宽高比(默认:3/4 到 4/3)的裁剪。 该作物最终被调整为原始大小。 这在 Tensorflow 中被实现为“”,或者在 Pytorch 中被实现为“”。 此外,随机裁剪(带调整大小)后始终跟随 概率的随机水平/从左到右翻转。 这很有帮助,但不是必需的。 通过从我们的默认增强策略中删除这一点,经过 100 个 epoch 训练的 ResNet-50 模型的 top-1 线性评估从 64.5% 下降到 63.4%。
色彩失真
颜色失真由颜色抖动和颜色下降组成。 我们发现更强的颜色抖动通常会有所帮助,因此我们设置了一个强度参数。
使用 TensorFlow 进行颜色失真的伪代码如下。
import tensorflow as tf def color_distortion(image, s=1.0): # image is a tensor with value range in [0, 1]. # s is the strength of color distortion. def color_jitter(x): # one can also shuffle the order of following augmentations # each time they are applied. x = tf.image.random_brightness(x, max_delta=0.8*s) x = tf.image.random_contrast(x, lower=1-0.8*s, upper=1+0.8*s) x = tf.image.random_saturation(x, lower=1-0.8*s, upper=1+0.8*s) x = tf.image.random_hue(x, max_delta=0.2*s) x = tf.clip_by_value(x, 0, 1) return x def color_drop(x): image = tf.image.rgb_to_grayscale(image) image = tf.tile(image, [1, 1, 3]) # randomly apply transformation with probability p. image = random_apply(color_jitter, image, p=0.8) image = random_apply(color_drop, image, p=0.2) return image
使用Pytorch进行颜色失真的伪代码如下 121212我们的代码和结果基于Tensorflow,这里的Pytorch代码仅供参考。.
from torchvision import transforms def get_color_distortion(s=1.0): # s is the strength of color distortion. color_jitter = transforms.ColorJitter(0.8*s, 0.8*s, 0.8*s, 0.2*s) rnd_color_jitter = transforms.RandomApply([color_jitter], p=0.8) rnd_gray = transforms.RandomGrayscale(p=0.2) color_distort = transforms.Compose([ rnd_color_jitter, rnd_gray]) return color_distort
高斯模糊
这种增强是我们的默认策略。 我们发现它很有帮助,因为它将训练 100 个 epoch 的 ResNet-50 从 63.2% 提高到 64.5%。 我们使用高斯核在 50% 的时间里模糊图像。 我们随机采样 ,内核大小设置为图像高度/宽度的 10%。
附录 B其他实验结果
B.1 批量大小和训练步骤
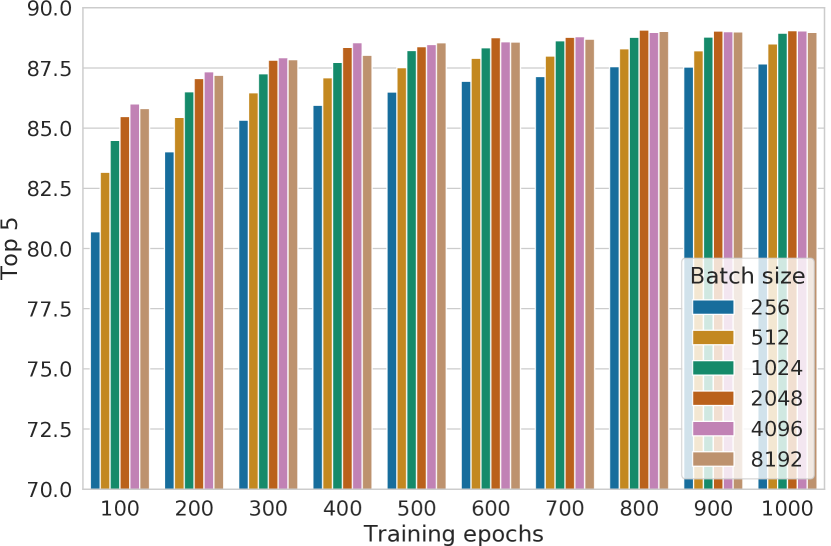
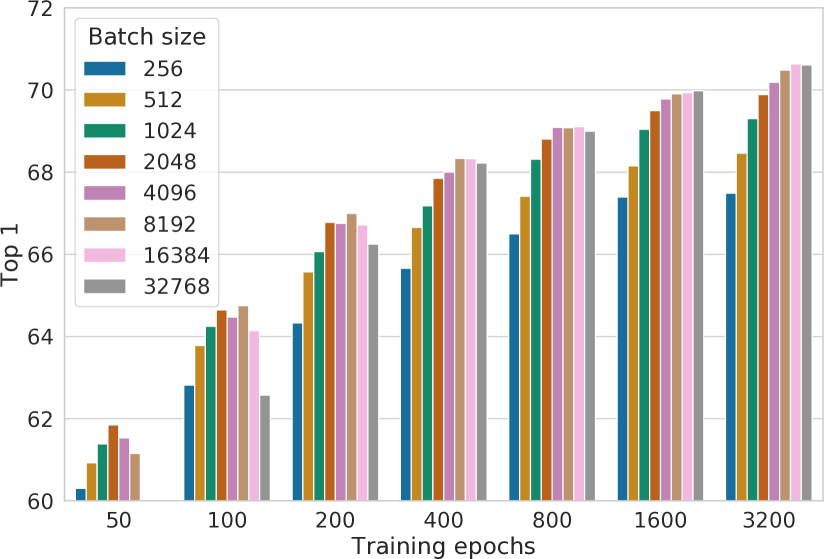
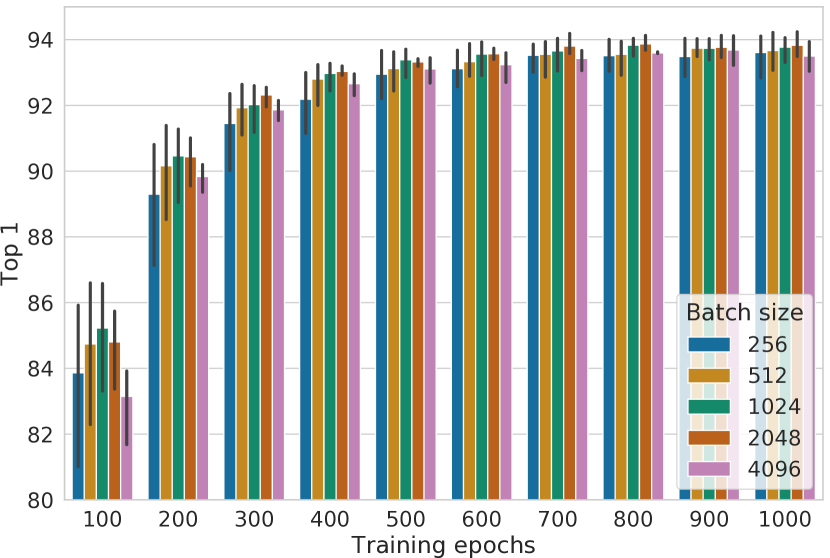
图 B.2 显示了使用不同批量大小和训练周期进行训练时线性评估的前 5 名准确率。 结论与之前显示的 top-1 准确率非常相似,只是不同批量大小和训练步骤之间的差异在这里似乎稍微小一些。
在图9和图B.2中,我们在训练时使用类似于(Goyal等人,2017)的学习率线性缩放具有不同的批量大小。 尽管线性学习率缩放在 SGD/Momentum 优化器中很流行,但我们发现平方根学习率缩放在 LARS 优化器中更受欢迎。 使用平方根学习率缩放,我们有 ,而不是线性缩放情况下的 ,但是当批量大小为 4096(我们的默认批量大小)。 表 B.1 中进行了比较,我们观察到平方根学习率缩放提高了小批量和较少周期数训练的模型的性能。
| Batch size \ Epochs | 100 | 200 | 400 | 800 |
| 256 | 57.5 / 62.8 | 61.9 / 64.3 | 64.7 / 65.7 | 66.6 / 66.5 |
| 512 | 60.7 / 63.8 | 64.0 / 65.6 | 66.2 / 66.7 | 67.8 / 67.4 |
| 1024 | 62.8 / 64.3 | 65.3 / 66.1 | 67.2 / 67.2 | 68.5 / 68.3 |
| 2048 | 64.0 / 64.7 | 66.1 / 66.8 | 68.1 / 67.9 | 68.9 / 68.8 |
| 4096 | 64.6 / 64.5 | 66.5 / 66.8 | 68.2 / 68.0 | 68.9 / 69.1 |
| 8192 | 64.8 / 64.8 | 66.6 / 67.0 | 67.8 / 68.3 | 69.0 / 69.1 |
我们还使用更大的批量大小(高达 32K)和更长的批量(高达 3200 epoch)进行训练,并使用平方根学习率缩放。 如图B.2所示,批量大小为8192时,性能似乎已经饱和,而更长的训练仍然可以显着提高性能。
B.2 更广泛的数据增强组合进一步提高了性能
当扩展默认增强策略以包括以下内容时,我们在正文中的最佳结果(表6和7)可以进一步改进:(1)Sobel过滤,(2 ) 额外的颜色失真(均衡、曝光),以及 (3) 运动模糊。 对于线性评估协议,使用更广泛的数据增强训练的 ResNet-50 模型 () 分别达到 70.0 (+0.7)、74.4 (+0.2)、76.8 (+0.3)。
表B.2显示了通过微调SimCLR模型获得的ImageNet精度(微调过程的详细信息参见附录B.5)。 有趣的是,当在完整 (100%) ImageNet 训练集上进行微调时,我们的 ResNet (4) 模型实现了 80.4% top-1 / 95.4% top-5 131313对于预训练 SimCLR,在没有更广泛增强的情况下,top-1 的概率为 80.1% / top-5 的概率为 95.2%。,这明显优于使用相同一组增强(即随机裁剪和水平翻转)从头开始训练的(78.4% top-1 / 94.2% top-5)。 对于 ResNet-50 (2),微调我们预训练的 ResNet-50 (2) 也比从头开始训练要好 (77.8% top-1 / 93.9 % 前5)。 ResNet-50 的微调没有任何改进。
| Architecture | Label fraction | |||||
| 1% | 10% | 100% | ||||
| Top 1 | Top 5 | Top 1 | Top 5 | Top 1 | Top 5 | |
| ResNet-50 | 49.4 | 76.6 | 66.1 | 88.1 | 76.0 | 93.1 |
| ResNet-50 (2) | 59.4 | 83.7 | 71.8 | 91.2 | 79.1 | 94.8 |
| ResNet-50 (4) | 64.1 | 86.6 | 74.8 | 92.8 | 80.4 | 95.4 |
B.3 更长的训练对监督模型的影响
在这里,我们进行实验,看看训练步骤和更强的数据增强如何影响监督训练。 我们在无监督模型中使用的同一组数据增强(随机裁剪、颜色失真、50% 高斯模糊)下测试 ResNet-50 和 ResNet-50 (4)。 图B.3显示了top-1精度。 我们观察到,在 ImageNet 上训练更长的监督模型并没有显着的好处。 更强的数据增强稍微提高了 ResNet-50 的准确性 (4),但对 ResNet-50 没有帮助。 当应用更强的数据增强时,ResNet-50 通常需要更长的训练(例如 500 epoch) 141414使用 AutoAugment (Cubuk 等人, 2019),可以在 900 到 500 epoch 之间实现最佳测试精度。)以获得最佳结果,而 ResNet-50 (4) 并不能从较长的训练中受益。
| Model | Training epochs | Top 1 | ||
| Crop | +Color | +Color+Blur | ||
| ResNet-50 | 90 | 76.5 | 75.6 | 75.3 |
| 500 | 76.2 | 76.5 | 76.7 | |
| 1000 | 75.8 | 75.2 | 76.4 | |
| ResNet-50 (4) | 90 | 78.4 | 78.9 | 78.7 |
| 500 | 78.3 | 78.4 | 78.5 | |
| 1000 | 77.9 | 78.2 | 78.3 | |
B.4 了解非线性投影头

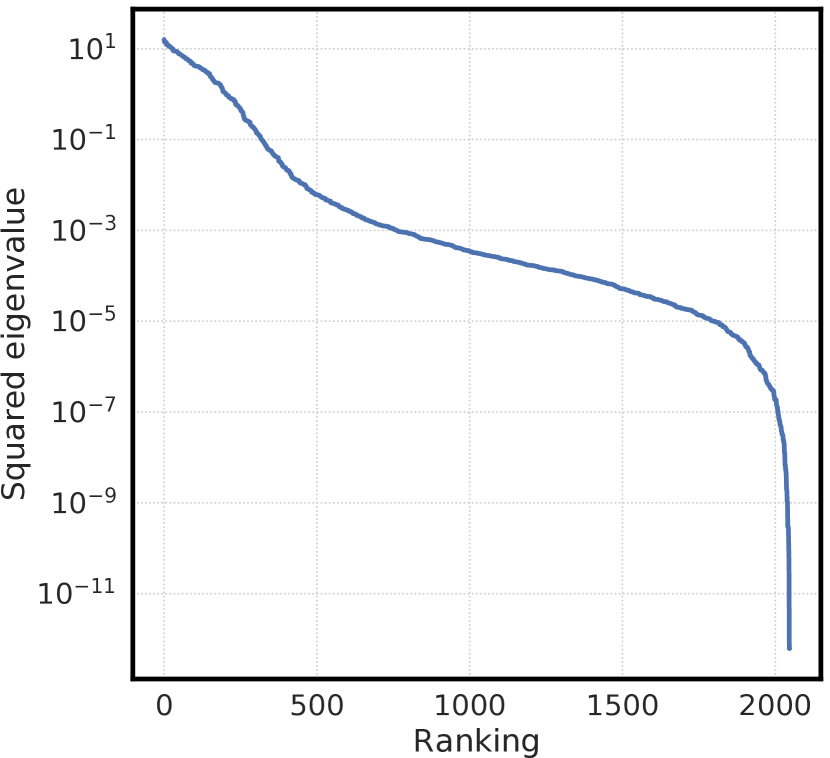


图B.4显示了用于计算的线性投影矩阵的特征值分布。 该矩阵具有相对较少的大特征值,表明它近似低秩。
图 B.4 显示随机选择的 10 个对象的 和 的 t-SNE (Maaten & Hinton,2008) 可视化由我们最好的 ResNet-50 进行分类(top-1 线性评估 69.3%)。 与 相比, 表示的类可以更好地分离。
B.5 通过微调进行半监督学习
微调程序
我们使用 Nesterov 动量优化器,批量大小为 4096,动量为 0.9,学习率为 0.8(遵循 ),无需预热。 仅使用随机裁剪(随机从左到右翻转并将大小调整为 224x224)进行预处理。 我们不使用任何正则化(包括权重衰减)。 对于 1% 的标记数据,我们调整 60 个时期,对于 10% 的标记数据,我们调整 30 个时期。 为了进行推理,我们将给定图像的大小调整为 256x256,并采用 224x224 的单个中心裁剪。
表B.4显示了不同半监督学习方法的top-1准确率比较。 我们的模型显着提高了最先进的水平。
| Method | Architecture | Label fraction | |
| 1% | 10% | ||
| Top 1 | |||
| Supervised baseline | ResNet-50 | 25.4 | 56.4 |
| Methods using label-propagation: | |||
| UDA (w. RandAug) | ResNet-50 | - | 68.8 |
| FixMatch (w. RandAug) | ResNet-50 | - | 71.5 |
| S4L (Rot+VAT+Ent. Min.) | ResNet-50 (4) | - | 73.2 |
| Methods using self-supervised representation learning only: | |||
| CPC v2 | ResNet-161() | 52.7 | 73.1 |
| SimCLR (ours) | ResNet-50 | 48.3 | 65.6 |
| SimCLR (ours) | ResNet-50 () | 58.5 | 71.7 |
| SimCLR (ours) | ResNet-50 () | 63.0 | 74.4 |
B.6线性评估
对于线性评估,我们遵循与微调类似的程序(在附录B.5中描述),除了更大的学习率1.6(遵循)和更长的训练90 个纪元。 或者,使用 LARS 优化器和预训练超参数也能产生类似的结果。 此外,我们发现将线性分类器附加在基本编码器的顶部(在线性分类器的输入上使用 以防止标签信息影响编码器)并在预训练期间同时进行类似的表现。
B.7线性评估与微调之间的相关性
在这里,我们研究了不同训练步骤和网络架构设置下线性评估和微调之间的相关性。
图 B.5 显示了当 ResNet-50 的训练周期(使用批量大小 4096)从 50 变化到 3200 时的线性评估与微调,如图 B.2。 虽然它们几乎是线性相关的,但对一小部分标签进行微调似乎可以从更长的训练中获益更多。

图 B.6 显示了针对不同所选架构的线性评估与微调。
B.8 迁移学习
我们在两种设置中评估了用于迁移学习的自监督表示的性能:线性评估,其中逻辑回归分类器被训练以基于在 ImageNet 上学习的自监督表示对新数据集进行分类,以及微调,其中我们允许训练期间所有重量发生变化。 在这两种情况下,我们都遵循 Kornblith 等人 (2019) 描述的方法,尽管我们的预处理略有不同。
B.8.1方法
数据集
We investigated transfer learning performance on the Food-101 dataset (Bossard et al., 2014), CIFAR-10 and CIFAR-100 (Krizhevsky & Hinton, 2009), Birdsnap (Berg et al., 2014), the SUN397 scene dataset (Xiao et al., 2010), Stanford Cars (Krause et al., 2013), FGVC Aircraft (Maji et al., 2013), the PASCAL VOC 2007 classification task (Everingham et al., 2010), the Describable Textures Dataset (DTD) (Cimpoi et al., 2014), Oxford-IIIT Pets (Parkhi et al., 2012), Caltech-101 (Fei-Fei et al., 2004), and Oxford 102 Flowers (Nilsback & Zisserman, 2008). 我们遵循介绍这些数据集的论文中的评估协议,即,我们报告了 Food-101、CIFAR-10、CIFAR-100、Birdsnap、SUN397、Stanford Cars 和 DTD 的 top-1 准确度; FGVC Aircraft、Oxford-IIIT Pets、Caltech-101 和 Oxford 102 Flowers 的平均每类准确度;以及 Everingham 等人 (2010) 中为 PASCAL VOC 2007 定义的 11 点 mAP 度量。 对于 DTD 和 SUN397,数据集创建者定义了多个训练/测试拆分;我们仅报告第一次分组的结果。 Caltech-101 没有定义训练/测试分割,因此我们为每个类随机选择 30 张图像并对其余图像进行测试,以便与之前的工作进行公平比较(Donahue 等人,2014;Simonyan & Zisserman,2014) 。
我们使用数据集创建者指定的验证集来选择 FGVC Aircraft、PASCAL VOC 2007、DTD 和 Oxford 102 Flowers 的超参数。 对于其他数据集,我们在执行超参数调整时提供了训练集的子集进行验证。 在验证集上选择最佳超参数后,我们使用所有训练和验证图像使用所选参数重新训练模型。 我们报告测试集的准确性。
通过线性分类器进行迁移学习
我们根据从冻结的预训练网络中提取的特征训练了正则化多项逻辑回归分类器。 我们使用 L-BFGS 来优化 softmax 交叉熵目标,并且没有应用数据增强。 作为预处理,所有图像都使用双三次重采样沿短边调整为 224 像素,之后我们进行了 中心裁剪。 我们从 和 之间的 45 个对数间隔值范围中选择了 正则化参数。
通过微调进行迁移学习
我们使用预训练网络的权重作为初始化来微调整个网络。 我们使用带有 Nesterov 动量(动量参数为 0.9)的 SGD,以 256 的批量大小训练了 20,000 步。 我们将批量归一化统计数据的动量参数设置为 ,其中 是每个时期的步数。 作为微调过程中的数据增强,我们仅执行随机裁剪并调整大小和翻转;与预训练相反,我们没有进行颜色增强或模糊。 在测试时,我们将图像的短边尺寸调整为 256 像素,并进行了 中心裁剪。 (通过进一步优化数据增强,可能会进一步提高准确性,特别是在 CIFAR-10 和 CIFAR-100 数据集上。) 我们选择了学习率和权重衰减,网格由 0.0001 和 0.1 之间的 7 个对数间隔的学习率以及 和 之间的 7 个对数间隔的权重衰减值组成,以及没有重量衰减。 我们将这些权重衰减值除以学习率。
从随机初始化训练
我们使用与微调相同的程序从随机初始化来训练网络,但时间更长,并且使用更改的超参数网格。 我们从 0.001 到 1.0 之间的 7 个对数间隔的学习率以及 和 之间的 8 个对数间隔的权重衰减值的网格中选择超参数。 重要的是,我们的随机初始化基线经过了 40,000 个步骤的训练,这足以实现接近最大的精度,如 Kornblith 等人 (2019) 的图 8 所示。
在 Birdsnap 上,方法之间的训练训练没有统计学上的显着差异,而在 Food-101、Stanford Cars 和 FGVC Aircraft 数据集上,微调仅比随机初始化提供很小的优势。 然而,在其余8个数据集上,预训练具有明显的优势。
监督基线
我们与在 ImageNet 上训练的具有标准交叉熵损失的架构相同的 ResNet 模型进行比较。 这些模型使用与我们的自监督模型相同的数据增强(裁剪、强颜色增强和模糊)进行训练,并且还训练了 1000 个时期。 我们发现,虽然更强的数据增强和更长的训练时间并不利于 ImageNet 的准确性,但这些模型的表现明显优于训练 90 个 epoch 的监督基线和在传输数据集子集上进行线性评估的普通数据增强。 有监督的 ResNet-50 基线在 ImageNet 上实现了 76.3% 的 top-1 准确率,而自监督对应的准确率则为 69.3%,而 ResNet-50 () 基线则达到了 78.3%,而自监督的准确率则为 76.5%对于自监督模型。
统计显着性检验
我们通过排列测试来测试模型之间差异的显着性。 给定两个模型的预测,我们通过随机交换每个示例的预测并计算执行此随机化后的准确性差异,从零分布中生成 100,000 个样本。 然后,我们计算零分布中比观察到的预测差异更极端的样本百分比。 对于 top-1 精度,此过程产生与精确 McNemar 测试相同的结果。 原假设下的可交换性假设对于平均每类精度也有效,但在计算平均精度曲线时则不然。 因此,我们对 VOC 2007 上的准确度差异而不是 mAP 上的差异进行显着性测试。 此过程的一个警告是,它在模型时不考虑训练运行之间的变异性,只考虑使用有限图像样本进行评估所产生的变异性。
B.8.2 标准 ResNet 的结果
| Food | CIFAR10 | CIFAR100 | Birdsnap | SUN397 | Cars | Aircraft | VOC2007 | DTD | Pets | Caltech-101 | Flowers | |
| Linear evaluation: | ||||||||||||
| SimCLR (ours) | 68.4 | 90.6 | 71.6 | 37.4 | 58.8 | 50.3 | 50.3 | 80.5 | 74.5 | 83.6 | 90.3 | 91.2 |
| Supervised | 72.3 | 93.6 | 78.3 | 53.7 | 61.9 | 66.7 | 61.0 | 82.8 | 74.9 | 91.5 | 94.5 | 94.7 |
| Fine-tuned: | ||||||||||||
| SimCLR (ours) | 88.2 | 97.7 | 85.9 | 75.9 | 63.5 | 91.3 | 88.1 | 84.1 | 73.2 | 89.2 | 92.1 | 97.0 |
| Supervised | 88.3 | 97.5 | 86.4 | 75.8 | 64.3 | 92.1 | 86.0 | 85.0 | 74.6 | 92.1 | 93.3 | 97.6 |
| Random init | 86.9 | 95.9 | 80.2 | 76.1 | 53.6 | 91.4 | 85.9 | 67.3 | 64.8 | 81.5 | 72.6 | 92.0 |
文中表 8 中显示的 ResNet-50 () 结果显示,监督或自监督模型没有明显的优势。 然而,由于 ResNet-50 架构较窄,监督学习相对于自监督学习保持着明显的优势。 在所有具有线性评估的数据集以及大多数(12 个中的 10 个)微调数据集上,有监督的 ResNet-50 模型都优于自监督模型。 与 ResNet () 模型相比,ResNet 模型的性能较弱可能与 ImageNet 上监督模型和自监督模型之间的准确率差距有关。 自监督 ResNet 的 top-1 准确率达到 69.3%,绝对比监督模型差 6.8%,而自监督 ResNet 模型的准确率达到 76.5%,仅比监督模型差 1.8%。监督模型。
B.9CIFAR-10
虽然我们专注于使用 ImageNet 作为预训练无监督模型的主要数据集,但我们的方法也适用于其他数据集。 我们通过在 CIFAR-10 上进行测试来演示它,如下所示。
设置
由于我们的目标不是优化 CIFAR-10 性能,而是为了进一步证实我们在 ImageNet 上的观察结果,因此我们对 CIFAR-10 实验使用相同的架构 (ResNet-50)。 由于 CIFAR-10 图像比 ImageNet 图像小得多,因此我们将步幅 2 的第一个 7x7 卷积替换为步幅 1 的 3x3 卷积,并且还删除了第一个最大池化操作。 对于数据增强,我们使用与 ImageNet 相同的 Inception 裁剪(翻转并调整大小至 32x32),151515值得注意的是,虽然 CIFAR-10 图像比 ImageNet 图像小得多,并且图像大小在示例之间没有差异,但调整大小的裁剪仍然是一种非常有效的方法增强对比学习。 和颜色失真(强度=0.5),忽略高斯模糊。 我们预训练学习率为 ,温度为 ,批量大小为 。 其余的设置(包括优化器、权重衰减等)与我们的 ImageNet 训练相同。
我们使用批量大小 1024 训练的最佳模型可以实现 94.0% 的线性评估精度,而使用相同架构和批量大小的监督基线的线性评估精度为 95.1%。 在 CIFAR-10 上报告线性评估结果的最佳自监督模型是 AMDIM (Bachman 等人, 2019),它的模型 比我们的模型大,达到了 91.2%。 我们注意到,我们的模型可以通过合并额外的数据增强以及使用更合适的基础网络来改进。
不同批量大小和训练步骤下的性能
图B.7显示了不同批量大小和训练步骤下的线性评估性能。 结果与我们在 ImageNet 上的观察结果一致,尽管最大批量大小 4096 似乎会导致 CIFAR-10 上的性能略有下降。
不同批量下的最佳温度
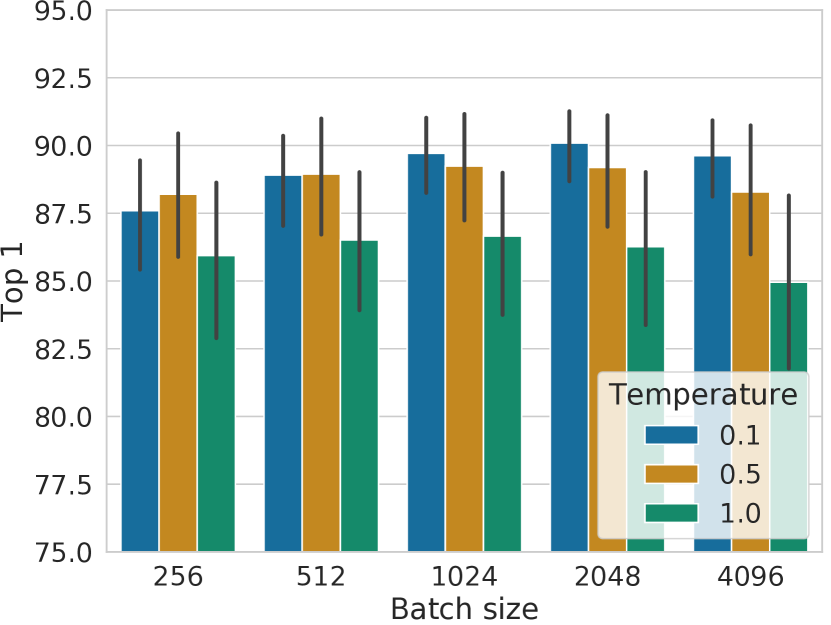
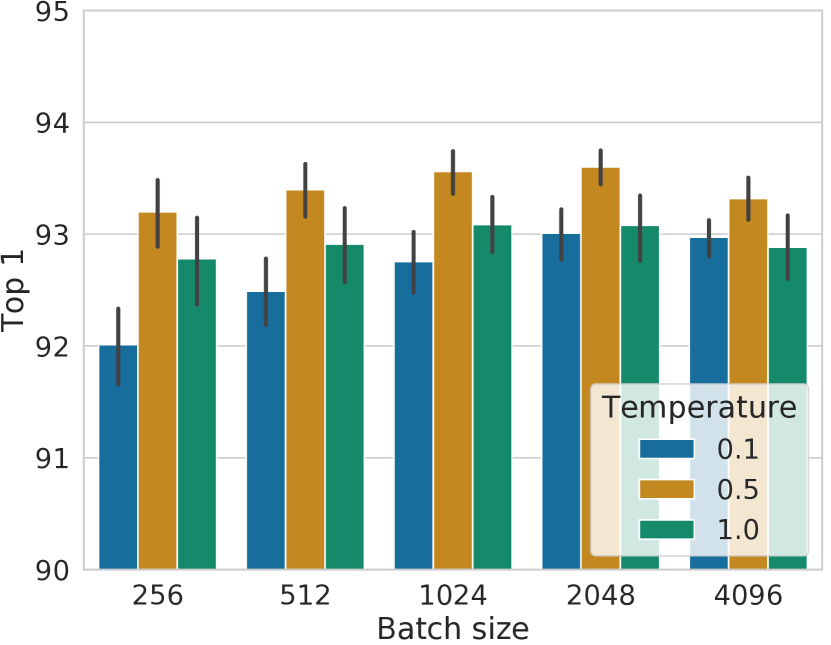
图B.8显示了在不同批量大小下使用三种不同温度训练的模型的线性评估。 我们发现,当训练收敛时(例如训练时期 > 300), 中的最佳温度为 0.5,并且无论批量大小如何,似乎都是一致的。 然而, 的性能随着批量大小的增加而提高,这可能表明最佳温度向 0.1 小幅移动。
B.10 调整其他损失函数
对于 NT-Xent 损失最有效的学习率对于其他损失函数可能不是一个好的学习率。 为了确保公平比较,我们还调整了边际损失和逻辑损失的超参数。 具体来说,我们调整两个损失函数的学习率 。 我们进一步调整 中的裕度来表示裕度损失,调整 中的温度来表示逻辑损失。 为简单起见,我们只考虑一个增强视图(而不是两侧)的负面影响,这会稍微影响性能,但确保公平比较。
附录C与相关方法的进一步比较
正如我们在正文中指出的,SimCLR 的大多数单独组件都出现在之前的工作中,性能的提高是这些设计选择组合的结果。 表C.1提供了我们的方法与以前方法的设计选择的高级比较。 与以前的工作相比,我们的设计选择通常更简单。
| Model | Data Augmentation | Base Encoder | Projection Head | Loss | Batch Size | Train Epochs |
| CPC v2 | Custom | ResNet-161 (modified) | PixelCNN | Xent | 512# | 200 |
| AMDIM | Fast AutoAug. | Custom ResNet | Non-linear MLP | Xent w/ clip,reg | 1008# | 150 |
| CMC | Fast AutoAug. | ResNet-50 (, L+ab) | Linear layer | Xent w/ | 156∗ | 280 |
| MoCo | Crop+color | ResNet-50 (4) | Linear layer | Xent w/ | 256∗ | 200 |
| PIRL | Crop+color | ResNet-50 (2) | Linear layer | Xent w/ | 1024∗ | 800 |
| SimCLR | Crop+color+blur | ResNet-50 () | Non-linear MLP | Xent w/ | 4096 | 1000 |
下面,我们将我们的方法与最近提出的对比表示学习方法进行深入比较:
-
•
DIM/AMDIM (Hjelm 等人, 2018; Bachman 等人, 2019) 通过预测 ConvNet 的中间层实现全局到局部/局部到邻居的预测。 ConvNet 是一个 ResNet,经过修改,对网络的感受野施加了重大限制(例如,用 1x1 Conv 替换许多 3x3 Conv)。 在我们的框架中,我们通过随机裁剪(调整大小)并使用两个增强视图的最终表示进行预测来解耦预测任务和编码器架构,因此我们可以使用标准且更强大的 ResNet。 我们的 NT-Xent 损失函数利用归一化和温度来限制相似性分数的范围,而他们使用带有正则化的 tanh 函数。 我们使用更简单的数据增强策略,而他们使用 FastAutoAugment 以获得最佳结果。
-
•
CPC v1 和 v2 (Oord 等人, 2018; Hénaff 等人, 2019) 使用确定性策略定义上下文预测任务,将示例分割为补丁,并使用上下文聚合网络(PixelCNN)进行聚合这些补丁。 基础编码器网络只能看到比原始图像小得多的补丁。 我们将预测任务和编码器架构解耦,因此我们不需要上下文聚合网络,并且我们的编码器可以查看更广泛分辨率的图像。 此外,我们使用 NT-Xent 损失函数,该函数利用归一化和温度,而他们使用非归一化的基于交叉熵的目标。 我们使用更简单的数据增强。
-
•
InstDisc、MoCo、PIRL (Wu 等人, 2018; He 等人, 2019; Misra & van der Maaten, 2019) 概括了 Dosovitskiy 等人 (2014)< 最初提出的 Exemplar 方法 并利用显式内存库。 我们不使用记忆库;我们发现,在批量大小较大的情况下,批量内的负例采样就足够了。 我们还利用非线性投影头,并使用投影头之前的表示。 尽管我们使用类似类型的增强(例如随机裁剪和颜色失真),但我们预计具体参数可能会有所不同。
-
•
CMC (Tian 等人, 2019) 对每个视图使用单独的网络,而我们只是对所有随机增强的视图使用共享的单个网络。 数据增强、投影头和损失函数也不同。 我们使用更大的批量大小而不是存储体。
-
•
尽管 Ye 等人 (2019) 最大化了同一图像的增强副本和未增强副本之间的相似性,但我们将数据增强对称地应用于框架的两个分支(图 2)。 我们还在基础特征网络的输出上应用了非线性投影,并使用投影网络之前的表示,而Ye等人(2019)使用线性投影的最终隐藏向量作为表示。 当使用多个加速器进行大批量训练时,我们使用全局 BN 来避免可能大大降低表示质量的捷径。