NeRF:以
神经辐射场表示场景,用于视图合成
摘要
我们提出了一种方法,通过使用稀疏的输入视图集优化底层连续体积场景函数,实现合成复杂场景的新颖视图的最先进的结果。 我们的算法使用全连接(非卷积)深度网络表示场景,其输入是单个连续 5D 坐标(空间位置 和观看方向 ),其输出是该空间位置处的体积密度和与视图相关的发射辐射率。 我们通过查询沿相机光线的 5D 坐标来合成视图,并使用经典的体积渲染技术将输出颜色和密度投影到图像中。 由于体积渲染本质上是可微分的,因此优化表示所需的唯一输入是一组具有已知相机姿势的图像。 我们描述了如何有效地优化神经辐射场,以渲染具有复杂几何和外观的场景的逼真新颖视图,并展示了优于神经渲染和视图合成先前工作的结果。 查看合成结果最好以视频形式观看,因此我们敦促读者观看我们的补充视频以获得令人信服的比较。
关键词:
场景表示、视图合成、基于图像的渲染、体渲染、3D 深度学习1简介
在这项工作中,我们通过直接优化连续 5D 场景表示的参数,以一种新的方式解决长期存在的视图合成问题,以最大限度地减少渲染一组捕获图像的错误。
我们将静态场景表示为连续的 5D 函数,该函数输出空间中每个点 处每个方向 发射的辐射亮度,以及每个点的密度,其作用类似于微分不透明度控制穿过 的光线累积的辐射量。 我们的方法优化了没有任何卷积层(通常称为多层感知器或 MLP)的深度全连接神经网络,通过从单个 5D 坐标 回归到单个体积密度和视图来表示该函数依赖 RGB 颜色。 为了从特定视点渲染此神经辐射场 (NeRF),我们:1) 使摄像机光线穿过场景以生成一组采样的 3D 点,2) 使用这些点及其相应的 2D 观看方向作为神经网络的输入以产生一组颜色和密度的输出,以及 3) 使用经典的体积渲染技术将这些颜色和密度累积到 2D 图像中。 因为这个过程自然是可微的,所以我们可以使用梯度下降来优化这个模型,通过最小化每个观察到的图像和从我们的表示呈现的相应视图之间的误差。 在多个视图中尽量减小这一误差,可促使网络预测出一个连贯的场景模型,为包含真实底层场景内容的位置分配较高的体积密度和准确的颜色。 图 2 可视化了整个管道。
我们发现,优化复杂场景的神经辐射场表示的基本实现并不能收敛到足够高分辨率的表示,并且在每条相机光线所需的样本数量方面效率低下。 我们通过使用位置编码来转换输入 5D 坐标来解决这些问题,使 MLP 能够表示更高频率的函数,并且我们提出了一种分层采样过程来减少充分采样这种高频场景表示所需的查询数量。
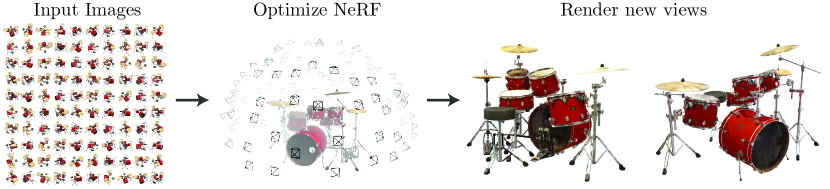
我们的方法继承了体积表示的优点:两者都可以表示复杂的现实世界几何形状和外观,并且非常适合使用投影图像进行基于梯度的优化。 最重要的是,我们的方法克服了离散化体素网格在高分辨率复杂场景建模时令人望而却步的存储成本。 总而言之,我们的技术贡献是:
-
–
一种将具有复杂几何形状和材料的连续场景表示为 5D 神经辐射场的方法,参数化为基本 MLP 网络。
-
–
基于经典体积渲染技术的可微分渲染过程,我们用它来优化标准 RGB 图像的这些表示。 这包括分层采样策略,将 MLP 的容量分配给具有可见场景内容的空间。
-
–
用于将每个输入 5D 坐标映射到更高维度空间的位置编码,这使我们能够成功优化神经辐射场以表示高频场景内容。
我们证明,我们的神经辐射场方法在定量和定性方面都优于最先进的视图合成方法,包括将神经三维表征拟合到场景中的方法,以及训练深度卷积网络来预测采样体积表征的方法。 据我们所知,本文提出了第一个连续神经场景表示,能够从自然环境中捕获的 RGB 图像中渲染真实物体和场景的高分辨率真实感新颖视图。
2相关工作
计算机视觉领域最近一个有前途的方向是在 MLP 的权重中对对象和场景进行编码,该 MLP 直接从 3D 空间位置映射到形状的隐式表示,例如在处的符号距离 [6]那个位置。 然而,到目前为止,这些方法无法以与使用离散表示(例如三角形网格或体素网格)表示场景的技术相同的保真度来再现具有复杂几何形状的现实场景。 在本节中,我们回顾这两条工作,并将它们与我们的方法进行对比,该方法增强了神经场景表示的能力,以产生渲染复杂现实场景的最先进的结果。
使用 MLP 从低维坐标映射到颜色的类似方法也已用于表示其他图形函数,例如图像 [44]、纹理材料 [12, 31, 36, 37] 和间接照明值 [38]。
神经 3D 形状表示
最近的工作通过优化将 坐标映射到有符号距离函数 [15, 32] 或占用字段 的深度网络,研究了连续 3D 形状作为水平集的隐式表示[11, 27]。 然而,这些模型受到访问地面真实 3D 几何形状的限制,这些几何形状通常从合成 3D 形状数据集(例如 ShapeNet [3])获得。 随后的工作通过制定可微分渲染函数来放松对地面实况 3D 形状的要求,该函数允许仅使用 2D 图像来优化神经隐式形状表示。 尼迈耶等人。 [29] 将表面表示为 3D 占用场,并使用数值方法查找每条射线的表面交点,然后使用隐式微分计算精确导数。 每个光线相交位置都作为神经 3D 纹理场的输入提供,该神经 3D 纹理场预测该点的漫反射颜色。 西茨曼等人。 [42] 使用不太直接的神经 3D 表示,仅在每个连续 3D 坐标处输出特征向量和 RGB 颜色,并提出一个可微渲染函数,该函数由沿每条射线行进的循环神经网络组成决定表面的位置。
尽管这些技术可以表示复杂且高分辨率的几何形状,但迄今为止它们仅限于几何复杂度较低的简单形状,从而导致渲染过度平滑。 我们展示了优化网络编码 5D 辐射场(具有 2D 视图相关外观的 3D 体积)的替代策略可以表示更高分辨率的几何和外观,以渲染复杂场景的逼真新颖视图。
视图合成和基于图像的渲染
给定视图的密集采样,可以通过简单的光场样本插值技术[21,5,7]重建逼真的新颖视图。 对于具有稀疏视图采样的新颖视图合成,计算机视觉和图形社区通过从观察到的图像预测传统几何和外观表示取得了重大进展。 一类流行的方法使用基于网格的场景表示,具有漫射 [48] 或依赖于视图的 [2, 8, 49] 外观。 可微分光栅器 [4, 10, 23, 25] 或路径跟踪器 [22, 30] 可以直接优化网格表示,以使用梯度下降再现一组输入图像。 然而,基于图像重投影的基于梯度的网格优化通常很困难,可能是因为局部极小值或损失景观的条件较差。 此外,该策略需要提供具有固定拓扑的模板网格作为优化之前的初始化[22],这通常不适用于无约束的现实世界场景。
另一类方法使用体积表示来解决从一组输入 RGB 图像合成高质量照片级真实感视图的任务。 体积方法能够真实地表示复杂的形状和材料,非常适合基于梯度的优化,并且与基于网格的方法相比,往往会产生更少的视觉干扰伪影。 早期的体积方法使用观察到的图像直接对体素网格进行着色[19,40,45]。 最近,几种方法[9, 13, 17, 28, 33, 43, 46, 52]使用多个场景的大型数据集来训练深度网络,从一组数据中预测采样的体积表示输入图像,然后使用 alpha 合成 [34] 或学习沿光线合成在测试时渲染新颖的视图。 其他工作针对每个特定场景优化了卷积网络(CNN)和采样体素网格的组合,使得 CNN 可以补偿低分辨率体素网格[41]的离散化伪影,或者允许预测体素网格根据输入时间或动画控件[24]而变化。 虽然这些体积技术在新颖的视图合成方面取得了令人印象深刻的结果,但由于其离散采样,它们扩展到更高分辨率图像的能力从根本上受到较差的时间和空间复杂性的限制——渲染更高分辨率的图像需要对 3D 空间进行更精细的采样。 我们通过在深度全连接神经网络的参数内编码连续体积来规避这个问题,这不仅比之前的体积方法产生更高质量的渲染,而且只需要一小部分这些采样体积表示的存储成本。

3 神经辐射场场景表示
我们将连续场景表示为 5D 矢量值函数,其输入是 3D 位置 和 2D 观看方向 ,其输出是发射颜色 和体积密度。 在实践中,我们将方向表示为 3D 笛卡尔单位向量 。 我们使用 MLP 网络 来近似这种连续的 5D 场景表示,并优化其权重 ,以从每个输入 5D 坐标映射到其相应的体积密度和定向发射颜色。
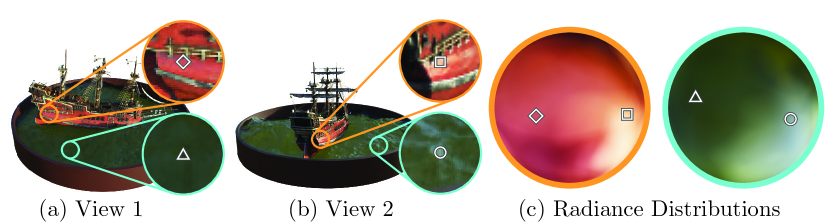
我们通过限制网络将体积密度 预测为仅位置 的函数,同时允许 RGB 颜色 ,鼓励多视图一致的表示> 根据位置和观察方向进行预测。 为了实现这一点,MLP 首先使用 8 个全连接层(使用 ReLU 激活和每层 256 个通道)处理输入 3D 坐标 ,并输出 和256维特征向量。 然后,该特征向量与相机光线的观看方向连接,并传递到一个额外的全连接层(使用 ReLU 激活和 128 个通道),该层输出与视图相关的 RGB 颜色。
4 使用辐射场进行体积渲染
我们的 5D 神经辐射场将场景表示为空间中任意点的体积密度和定向发射辐射度。 我们使用经典体积渲染[16]的原理来渲染穿过场景的任何光线的颜色。 体积密度可以解释为射线终止于位置处的无穷小粒子的微分概率。 具有近边界和远边界 和 的相机光线 的预期颜色 为:
| (1) |
函数表示沿光线从到的累积透射率,i.e .,光线从 传播到 而不撞击任何其他粒子的概率。 从我们的连续神经辐射场渲染视图需要估计通过所需虚拟相机的每个像素追踪的相机光线的积分。
我们使用求积法对这个连续积分进行数值估计。 确定性求积通常用于渲染离散体素网格,它会有效地限制我们表示的分辨率,因为 MLP 只能在一组固定的离散位置进行查询。 相反,我们使用分层抽样方法,将 划分为 均匀间隔的箱,然后从每个箱内均匀随机抽取一个样本:
| (2) |
尽管我们使用一组离散样本来估计积分,但分层采样使我们能够表示连续的场景表示,因为它会导致在优化过程中在连续位置评估 MLP。 我们使用这些样本通过 Max [26] 的体积渲染评论中讨论的正交规则来估计 :
| (3) |
其中是相邻样本之间的距离。 此用于根据 值集合计算 的函数是微可微的,并且可简化为使用 alpha 值 的传统 alpha 合成。
5 优化神经辐射场
在上一节中,我们描述了将场景建模为神经辐射场并根据该表示渲染新视图所需的核心组件。 然而,我们发现这些组件不足以实现最先进的质量,如第 6.4 节所示)。 我们引入了两项改进来能够表示高分辨率的复杂场景。 第一个是输入坐标的位置编码,帮助 MLP 表示高频函数;第二个是分层采样过程,使我们能够有效地对这种高频表示进行采样。
|
|
|
|
|
| Ground Truth | Complete Model | No View Dependence | No Positional Encoding |
5.1 位置编码
尽管神经网络是通用函数逼近器[14],但我们发现让网络直接对输入坐标进行操作会导致渲染结果在表示颜色和几何形状的高频变化方面表现不佳。 这与 Rahaman 等人最近的工作是一致的。 [35],这表明深度网络偏向于学习低频函数。 他们还表明,在将输入传递到网络之前使用高频函数将输入映射到更高维度的空间可以更好地拟合包含高频变化的数据。
我们在神经场景表示的背景下利用这些发现,并表明将 重新表述为两个函数 的组合(一个是学习的,一个是未学习的),可以显着提高性能(见图 4 和表 2)。 这里是从到更高维空间的映射,而仍然只是一个常规的MLP。 形式上,我们使用的编码函数是:
| (4) |
此函数 分别应用于 中的三个坐标值(它们被标准化为位于 中)以及笛卡尔坐标系的三个分量观察方向单位向量(通过构造位于中)。 在我们的实验中,我们为 设置 ,为 设置 。
流行的 Transformer 架构 [47] 中使用了类似的映射,称为位置编码。 然而,Transformers 将其用于不同的目标,即提供序列中 Token 的离散位置作为不包含任何顺序概念的架构的输入。 相反,我们使用这些函数将连续输入坐标映射到更高维度的空间,以使我们的 MLP 能够更轻松地逼近更高频率的函数。 针对从投影 [51] 建模 3D 蛋白质结构的相关问题的并行工作也利用了类似的输入坐标映射。
5.2分层体积采样
我们的渲染策略是沿着每条相机射线在查询点处密集评估神经辐射场网络,效率很低:对渲染图像没有贡献的自由空间和遮挡区域仍然被重复采样。 我们从体积渲染的早期工作中汲取灵感[20],并提出了一种分层表示,通过根据最终渲染的预期效果按比例分配样本来提高渲染效率。
我们不只是使用单个网络来表示场景,而是同时优化两个网络:一个“粗略”网络和一个“精细”网络。 我们首先使用分层采样对一组 位置进行采样,并评估这些位置处的“粗略”网络,如方程式 2 和 3所述。 给定这个“粗略”网络的输出,我们然后对每条射线上的点进行更明智的采样,其中样本偏向体积的相关部分。 为此,我们首先重写方程式中粗略网络 的 alpha 合成颜色 (在方程式3中的),作为沿光线的所有采样颜色 的加权和:
| (5) |
将这些权重标准化为 会产生沿光线的分段常数 PDF。 我们使用逆变换采样从该分布中采样第二组 位置,在第一组和第二组样本的并集处评估我们的“精细”网络,并计算光线的最终渲染颜色 使用方程式。 3 但使用所有 样本。 此过程将更多样本分配给我们期望包含可见内容的区域。 这解决了与重要性采样类似的目标,但我们使用采样值作为整个积分域的非均匀离散化,而不是将每个样本视为整个积分的独立概率估计。
5.3实施细节
我们为每个场景优化单独的神经连续体积表示网络。 这仅需要捕获的场景 RGB 图像、相应的相机姿态和内在参数以及场景边界的数据集(我们使用地面实况相机姿态、内在参数和合成数据的边界,并使用 COLMAP 结构从运动包[39] 估计真实数据的这些参数)。 在每次优化迭代中,我们从数据集中的所有像素集中随机采样一批相机光线,然后遵循第 2 节中描述的分层采样。 5.2 用于查询来自粗略网络的 个样本和来自精细网络的 个样本。 然后我们使用第 2 节中描述的体积渲染过程。 4 渲染两组样本中每条光线的颜色。 我们的损失只是粗略渲染和精细渲染的渲染像素颜色和真实像素颜色之间的总平方误差:
| (6) |
其中 是每个批次中的光线集,、 和 是地面实况、粗略体积预测和精细体积分别预测光线 的 RGB 颜色。 请注意,即使最终渲染来自,我们也会最小化的损失,以便粗网络的权重分布可以用于在精细网络中分配样本。
在我们的实验中,我们使用 4096 条光线的批量大小,每条光线在粗略体积中的 坐标和精细体积中的 附加坐标处采样。 我们使用 Adam 优化器 [18],其学习率从 开始,并在优化过程中以指数方式衰减到 (其他 Adam 超参数是保留默认值 、 和 )。 单个场景的优化通常需要大约 100-300k 迭代才能在单个 NVIDIA V100 GPU 上收敛(大约 1-2 天)。
6结果
我们定量(表 1)和定性(图 1-2)。 8 和 6)表明我们的方法优于之前的工作,并提供广泛的消融研究来验证我们的设计选择(表2)。 我们敦促读者观看我们的补充视频,以更好地欣赏我们的方法在渲染新视图的平滑路径时相对于基线方法的显着改进。
6.1数据集
物体的合成渲染
我们首先展示了两个对象合成渲染数据集的实验结果(表1,“漫反射合成”和“真实合成”)。 DeepVoxels [41] 数据集包含四个具有简单几何形状的朗伯对象。 每个对象都从上半球采样的视点以 像素渲染(479 作为输入,1000 用于测试)。 我们还生成了自己的数据集,其中包含八个物体的路径追踪图像,这些物体表现出复杂的几何形状和真实的非朗伯材料。 六个是从上半球采样的视点渲染的,两个是从整个球体采样的视点渲染的。 我们渲染每个场景的 100 个视图作为输入,并渲染 200 个用于测试,所有视图均位于 像素。
 Ship
Ship
|

|
|
|


|
|
|
|
|
|
|


|
|
 Microphone
Microphone
|
|
|
|


|
|
 Materials
Materials
|
|
|
|


|
|
| Ground Truth | NeRF (ours) | LLFF [28] | SRN [42] | NV [24] |
复杂场景真实图像
我们展示了使用大致前向图像捕获的复杂现实场景的结果(表1,“真实前向”)。 该数据集由手持手机捕获的 8 个场景组成(5 个取自 LLFF 论文,3 个是我们捕获的),用 20 到 62 张图像捕获,并将其中的 用于测试集。 所有图像都是 像素。
 Fern
Fern
|
|
|
|
|
 T-Rex
T-Rex
|
|
|
|
|
 Orchid
Orchid
|
|
|
|
|
| Ground Truth | NeRF (ours) | LLFF [28] | SRN [42] |
| Diffuse Synthetic [41] | Realistic Synthetic | Real Forward-Facing [28] | |||||||
| Method | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| SRN [42] | |||||||||
| NV [24] | - | - | - | ||||||
| LLFF [28] | |||||||||
| Ours | |||||||||
6.2比较
为了评估我们的模型,我们将其与当前性能最佳的视图合成技术进行比较,详细信息如下。 所有方法都使用相同的输入视图集为每个场景训练一个单独的网络,局部光场融合 [28] 除外,它在大型数据集上训练单个 3D 卷积网络,然后使用相同的训练数据网络在测试时处理新场景的输入图像。
神经卷 (NV) [24]
合成完全位于不同背景前面的有限体积内的物体的新颖视图(必须在没有感兴趣物体的情况下单独捕获)。 它优化了深度 3D 卷积网络,以预测具有 样本的离散 RGB 体素网格以及具有 样本的 3D 扭曲网格。 该算法通过使相机光线穿过扭曲的体素网格来渲染新颖的视图。
场景表示网络 (SRN) [42]
将连续场景表示为不透明表面,由将每个 坐标映射到特征向量的 MLP 隐式定义。 他们训练循环神经网络,通过使用任意 3D 坐标处的特征向量来预测沿光线的下一步大小,从而沿着光线行进穿过场景表示。 最后一步的特征向量被解码为表面上该点的单一颜色。 请注意,SRN 是同一作者的 DeepVoxels [41] 的性能更好的后续产品,这就是为什么我们不包括与 DeepVoxels 的比较。
局部光场融合(LLFF) [28]
LLFF 旨在为采样良好的前向场景生成逼真的新颖视图。 它使用训练有素的 3D 卷积网络直接预测每个输入视图的离散平截头体采样 RGB 网格(多平面图像或 MPI [52]),然后通过以下方式渲染新颖的视图将附近的 MPI 进行 alpha 合成和混合到新颖的视点中。
6.3讨论
我们完全优于这两个基线,这两个基线还在所有场景中优化了每个场景(NV 和 SRN)的单独网络。 此外,与 LLFF(除一项指标外的所有指标)相比,我们在仅使用其输入图像作为我们的整个训练集时,生成了质量和数量上更出色的渲染。
SRN 方法会生成高度平滑的几何图形和纹理,并且其视图合成的表示能力因每条相机光线仅选择单一深度和颜色而受到限制。 NV 基线能够捕获相当详细的体积几何形状和外观,但其使用底层显式 体素网格使其无法缩放以表示高分辨率的精细细节。 LLFF 特别提供了“采样准则”,要求输入视图之间的差异不超过 64 像素,因此它经常无法估计合成数据集中的正确几何图形,这些数据集中包含视图之间最多 400-500 像素的差异。 此外,LLFF 会混合不同的场景表示以渲染不同的视图,从而导致感知上分散注意力的不一致,如我们的补充视频中所示。
这些方法之间最大的实际权衡是时间与空间。 所有比较的单场景方法每个场景至少需要 12 小时的训练时间。 相比之下,LLFF 可以在 10 分钟内处理小型输入数据集。 然而,LLFF 为每个输入图像生成一个大型 3D 体素网格,从而导致巨大的存储需求(一个“真实合成”场景超过 15GB)。 我们的方法仅需要 5 MB 的网络权重(与 LLFF 相比, 的相对压缩),这甚至比来自任何场景的单个场景的单独输入图像的内存还要少。我们的数据集。
6.4消融研究
| Input | #Im. | PSNR | SSIM | LPIPS | ||||
| 1) | No PE, VD, H | 100 | - | (256, - ) | ||||
| 2) | No Pos. Encoding | 100 | - | (64, 128) | ||||
| 3) | No View Dependence | 100 | 10 | (64, 128) | ||||
| 4) | No Hierarchical | 100 | 10 | (256, - ) | ||||
| 5) | Far Fewer Images | 25 | 10 | (64, 128) | ||||
| 6) | Fewer Images | 50 | 10 | (64, 128) | ||||
| 7) | Fewer Frequencies | 100 | 5 | (64, 128) | ||||
| 8) | More Frequencies | 100 | 15 | (64, 128) | ||||
| 9) | Complete Model | 100 | 10 | (64, 128) |
我们通过表 2 中的广泛消融研究来验证算法的设计选择和参数。 我们展示了“真实合成”场景的结果。 第 9 行显示了我们的完整模型作为参考。 第 1 行显示了我们模型的极简版本,没有位置编码 (PE)、视图相关性 (VD) 或分层采样 (H)。 在第 2-4 行中,我们从完整模型中一次删除这三个组件,观察到位置编码(第 2 行)和视图依赖性(第 3 行)提供了最大的定量收益,其次是分层采样(第 4 行)。 第 5-6 行显示了随着输入图像数量的减少,我们的性能如何下降。 请注意,当提供 100 个图像时,我们的方法仅使用 25 个输入图像,在所有指标上的性能仍然超过 NV、SRN 和 LLFF(请参阅补充材料)。 在第 7-8 行中,我们验证了 位置编码中使用的最大频率 的选择(用于 的最大频率按比例缩放) 。 仅使用 5 个频率会降低性能,但将频率数量从 10 个增加到 15 个并不会提高性能。 我们认为,一旦 超过采样输入图像中存在的最大频率(我们的数据中大约为 1024),增加 的好处就会受到限制。
7结论
我们的工作直接解决了先前使用 MLP 将对象和场景表示为连续函数的工作的缺陷。 我们证明,将场景表示为 5D 神经辐射场(一种 MLP,输出体积密度和与视图相关的发射辐射作为 3D 位置和 2D 观看方向的函数)可以比之前训练深度卷积网络输出的主导方法产生更好的渲染效果离散体素表示。
尽管我们提出了一种分层采样策略来提高渲染的样本效率(对于训练和测试),但在研究有效优化和渲染神经辐射场的技术方面仍有很多进展。 未来工作的另一个方向是可解释性:体素网格和网格等采样表示承认对渲染视图和故障模式的预期质量进行推理,但尚不清楚当我们以深度神经网络的权重对场景进行编码时如何分析这些问题。 我们相信这项工作在基于现实世界图像的图形管道方面取得了进展,其中复杂的场景可以由根据实际物体和场景的图像优化的神经辐射场组成。
致谢 我们感谢 Kevin Cao、Guowei Frank Yang 和 Nithin Raghavan 的评论和讨论。 RR 感谢 ONR 拨款 N000141712687 和 N000142012529 以及 Ronald L. Graham 主席的资助。 BM 由赫兹基金会奖学金资助,MT 由 NSF 研究生奖学金资助。 Google 通过 BAIR Commons 计划慷慨捐赠了云计算积分。 我们感谢以下 Blend Swap 用户在我们的真实合成数据集中使用的模型:gregzaal(船)、1DInc(椅子)、bryanajones(鼓)、Herberhold(榕树)、erickfree(热狗)、Heinzelnisse(乐高)、elbrujodelatribu(材料) )和 up3d.de(麦克风)。
参考
- [1] Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G.S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Mané, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viégas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., Zheng, X.: TensorFlow: Large-scale machine learning on heterogeneous systems (2015)
- [2] Buehler, C., Bosse, M., McMillan, L., Gortler, S., Cohen, M.: Unstructured lumigraph rendering. In: SIGGRAPH (2001)
- [3] Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv:1512.03012 (2015)
- [4] Chen, W., Gao, J., Ling, H., Smith, E.J., Lehtinen, J., Jacobson, A., Fidler, S.: Learning to predict 3D objects with an interpolation-based differentiable renderer. In: NeurIPS (2019)
- [5] Cohen, M., Gortler, S.J., Szeliski, R., Grzeszczuk, R., Szeliski, R.: The lumigraph. In: SIGGRAPH (1996)
- [6] Curless, B., Levoy, M.: A volumetric method for building complex models from range images. In: SIGGRAPH (1996)
- [7] Davis, A., Levoy, M., Durand, F.: Unstructured light fields. In: Eurographics (2012)
- [8] Debevec, P., Taylor, C.J., Malik, J.: Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In: SIGGRAPH (1996)
- [9] Flynn, J., Broxton, M., Debevec, P., DuVall, M., Fyffe, G., Overbeck, R., Snavely, N., Tucker, R.: DeepView: view synthesis with learned gradient descent. In: CVPR (2019)
- [10] Genova, K., Cole, F., Maschinot, A., Sarna, A., Vlasic, D., , Freeman, W.T.: Unsupervised training for 3D morphable model regression. In: CVPR (2018)
- [11] Genova, K., Cole, F., Sud, A., Sarna, A., Funkhouser, T.: Local deep implicit functions for 3d shape. In: CVPR (2020)
- [12] Henzler, P., Mitra, N.J., Ritschel, T.: Learning a neural 3d texture space from 2d exemplars. In: CVPR (2020)
- [13] Henzler, P., Rasche, V., Ropinski, T., Ritschel, T.: Single-image tomography: 3d volumes from 2d cranial x-rays. In: Eurographics (2018)
- [14] Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Networks (1989)
- [15] Jiang, C., Sud, A., Makadia, A., Huang, J., Nießner, M., Funkhouser, T.: Local implicit grid representations for 3d scenes. In: CVPR (2020)
- [16] Kajiya, J.T., Herzen, B.P.V.: Ray tracing volume densities. Computer Graphics (SIGGRAPH) (1984)
- [17] Kar, A., Häne, C., Malik, J.: Learning a multi-view stereo machine. In: NeurIPS (2017)
- [18] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2015)
- [19] Kutulakos, K.N., Seitz, S.M.: A theory of shape by space carving. International Journal of Computer Vision (2000)
- [20] Levoy, M.: Efficient ray tracing of volume data. ACM Transactions on Graphics (1990)
- [21] Levoy, M., Hanrahan, P.: Light field rendering. In: SIGGRAPH (1996)
- [22] Li, T.M., Aittala, M., Durand, F., Lehtinen, J.: Differentiable monte carlo ray tracing through edge sampling. ACM Transactions on Graphics (SIGGRAPH Asia) (2018)
- [23] Liu, S., Li, T., Chen, W., Li, H.: Soft rasterizer: A differentiable renderer for image-based 3D reasoning. In: ICCV (2019)
- [24] Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: Learning dynamic renderable volumes from images. ACM Transactions on Graphics (SIGGRAPH) (2019)
- [25] Loper, M.M., Black, M.J.: OpenDR: An approximate differentiable renderer. In: ECCV (2014)
- [26] Max, N.: Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics (1995)
- [27] Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A.: Occupancy networks: Learning 3D reconstruction in function space. In: CVPR (2019)
- [28] Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Transactions on Graphics (SIGGRAPH) (2019)
- [29] Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.: Differentiable volumetric rendering: Learning implicit 3D representations without 3D supervision. In: CVPR (2019)
- [30] Nimier-David, M., Vicini, D., Zeltner, T., Jakob, W.: Mitsuba 2: A retargetable forward and inverse renderer. ACM Transactions on Graphics (SIGGRAPH Asia) (2019)
- [31] Oechsle, M., Mescheder, L., Niemeyer, M., Strauss, T., Geiger, A.: Texture fields: Learning texture representations in function space. In: ICCV (2019)
- [32] Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: DeepSDF: Learning continuous signed distance functions for shape representation. In: CVPR (2019)
- [33] Penner, E., Zhang, L.: Soft 3D reconstruction for view synthesis. ACM Transactions on Graphics (SIGGRAPH Asia) (2017)
- [34] Porter, T., Duff, T.: Compositing digital images. Computer Graphics (SIGGRAPH) (1984)
- [35] Rahaman, N., Baratin, A., Arpit, D., Dräxler, F., Lin, M., Hamprecht, F.A., Bengio, Y., Courville, A.C.: On the spectral bias of neural networks. In: ICML (2018)
- [36] Rainer, G., Ghosh, A., Jakob, W., Weyrich, T.: Unified neural encoding of BTFs. Computer Graphics Forum (Eurographics) (2020)
- [37] Rainer, G., Jakob, W., Ghosh, A., Weyrich, T.: Neural BTF compression and interpolation. Computer Graphics Forum (Eurographics) (2019)
- [38] Ren, P., Wang, J., Gong, M., Lin, S., Tong, X., Guo, B.: Global illumination with radiance regression functions. ACM Transactions on Graphics (2013)
- [39] Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016)
- [40] Seitz, S.M., Dyer, C.R.: Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision (1999)
- [41] Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhöfer, M.: Deepvoxels: Learning persistent 3D feature embeddings. In: CVPR (2019)
- [42] Sitzmann, V., Zollhoefer, M., Wetzstein, G.: Scene representation networks: Continuous 3D-structure-aware neural scene representations. In: NeurIPS (2019)
- [43] Srinivasan, P.P., Tucker, R., Barron, J.T., Ramamoorthi, R., Ng, R., Snavely, N.: Pushing the boundaries of view extrapolation with multiplane images. In: CVPR (2019)
- [44] Stanley, K.O.: Compositional pattern producing networks: A novel abstraction of development. Genetic programming and evolvable machines (2007)
- [45] Szeliski, R., Golland, P.: Stereo matching with transparency and matting. In: ICCV (1998)
- [46] Tulsiani, S., Zhou, T., Efros, A.A., Malik, J.: Multi-view supervision for single-view reconstruction via differentiable ray consistency. In: CVPR (2017)
- [47] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
- [48] Waechter, M., Moehrle, N., Goesele, M.: Let there be color! Large-scale texturing of 3D reconstructions. In: ECCV (2014)
- [49] Wood, D.N., Azuma, D.I., Aldinger, K., Curless, B., Duchamp, T., Salesin, D.H., Stuetzle, W.: Surface light fields for 3D photography. In: SIGGRAPH (2000)
- [50] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
- [51] Zhong, E.D., Bepler, T., Davis, J.H., Berger, B.: Reconstructing continuous distributions of 3D protein structure from cryo-EM images. In: ICLR (2020)
- [52] Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learning view synthesis using multiplane images. ACM Transactions on Graphics (SIGGRAPH) (2018)
附录 0.A 其他实施细节
网络架构
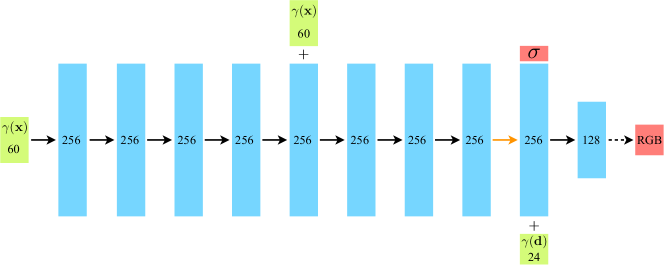
图7详细介绍了我们简单的全连接架构。
体积界限
我们的方法通过查询沿相机光线的连续 5D 坐标处的神经辐射场表示来渲染视图。 对于合成图像的实验,我们缩放场景,使其位于以原点为中心、边长为 2 的立方体内,并且仅查询此包围盒内的表示。 我们的真实图像数据集包含可能存在于最近点和无穷大之间任何位置的内容,因此我们使用标准化设备坐标将这些点的深度范围映射到 中。 这会将所有光线原点移动到场景的近平面,将相机的透视光线映射到变换体积中的平行光线,并使用视差(逆深度)而不是公制深度,因此所有坐标现在都是有界的。
训练详情
对于真实场景数据,我们通过在优化过程中向输出 值(在将它们传递给 ReLU 之前)添加具有零均值和单位方差的随机高斯噪声来规范我们的网络,发现这稍微提高了视觉性能呈现新颖的观点。 我们在 Tensorflow [1] 中实现我们的模型。
渲染细节
为了在测试时渲染新视图,我们通过粗略网络对每条光线采样 点,通过精细网络对每条光线采样 点,总共 每条射线的网络查询。 我们的真实合成数据集每张图像需要 640k 光线,而我们的真实场景每张图像需要 762k 光线,导致每个渲染图像需要 150 到 2 亿次网络查询。 在 NVIDIA V100 上,每帧大约需要 30 秒。
附录 0.B 其他基线方法详细信息
神经卷 (NV) [24]
我们使用作者在 https://github.com/facebookresearch/neuralvolumes 开源的 NV 代码,并按照他们的程序在单个场景上进行训练,而不依赖于时间。
场景表示网络 (SRN) [42]
我们使用作者在 https://github.com/vsitzmann/scene-representation-networks 上开源的 SRN 代码,并按照他们的程序在单个场景上进行训练。
局部光场融合(LLFF) [28]
我们使用作者在 https://github.com/Fyusion/LLFF 开源的预训练 LLFF 模型。
定量比较
作者发布的 SRN 实现需要大量 GPU 内存,并且即使在 4 个 NVIDIA V100 GPU 上并行时,图像分辨率也仅限于 像素。 与 和 相比,我们在合成数据集的 像素和真实数据集的 像素处计算 SRN 的定量指标> 分别适用于可以在更高分辨率下运行的其他方法。
附录0.CNDC光线空间推导
我们在标准化设备坐标(NDC)空间中使用“前向”捕获来重建真实场景,该空间通常用作三角形光栅化管道的一部分。 这个空间很方便,因为它保留了平行线,同时将 轴(相机轴)转换为线性视差。
在这里,我们导出应用于光线的变换,将它们从相机空间映射到 NDC 空间。 齐次坐标的标准 3D 透视投影矩阵为:
| (7) |
其中 是近剪裁平面和远剪裁平面, 和 是近剪裁平面处场景的右边界和上边界。 (请注意,这是按照惯例,相机朝 方向看。) 为了投影齐次点 ,我们左乘 M,然后除以第四个坐标:
| (8) | ||||
| project | (9) |
投影点现在位于标准化设备坐标 (NDC) 空间中,其中原始视锥体已映射到立方体 。
我们的目标是获取一条射线 并计算 NDC 空间中的射线原点 和方向 ,这样对于每个 ,存在一个新的 ,其中 (其中 是使用上述矩阵的投影)。 换句话说,原始光线和 NDC 空间光线的投影追踪出相同的点(但不一定以相同的速率)。
让我们重写方程中的投影点。 9 为 。 新原点 和方向 的分量必须满足:
| (10) |
为了消除自由度,我们决定 和 应映射到同一点。 代入 和 等式。 10直接给出了我们的NDC空间原点:
| (11) |
这正是原始光线原点的投影 。 通过将其代回方程。 10对于任意,我们可以确定和的值:
| (12) | ||||
| (13) | ||||
| (14) |
分解出仅依赖于 的通用表达式,得出:
| (15) | ||||
| (16) |
请注意,根据需要, 当 时。 此外,我们将 视为 。 回到原来的投影矩阵,我们的常数是:
| (17) | ||||
| (18) | ||||
| (19) | ||||
| (20) |
使用标准针孔相机模型,我们可以重新参数化为:
| (21) | ||||
| (22) |
其中 和 是图像的宽度和高度(以像素为单位), 是相机的焦距。
在我们真实的前向捕捉中,我们假设远场景边界是无穷大(这花费我们很少,因为 NDC 使用 维度来表示逆深度,即视差) 。 在此限制下, 常量简化为:
| (23) | ||||
| (24) |
将所有内容组合在一起:
| (25) | ||||
| (26) |
我们实现过程中的最后一个细节:我们将 移动到射线与 近平面的交点(在 NDC 转换之前),将 作为 的位置。 一旦我们转换为 NDC 射线,我们就可以简单地从 到 对 进行线性采样,以便从 到在原来的空间。
附录 0.D 其他结果
按场景细分
表 3、4、5 和 6 将主论文中提出的定量结果细分为每个场景的指标。 每个场景的细分与论文中提出的聚合定量指标一致,我们的方法在定量上优于所有基线。 尽管 LLFF 实现了稍微更好的 LPIPS 指标,但我们强烈建议读者观看我们的补充视频,其中我们的方法实现了更好的多视图一致性,并且比所有基线产生的伪影更少。
 Pedestal
Pedestal
|
|
|
|
|
|
 Cube
Cube
|
|
|
|
|
|
| Ground Truth | NeRF (ours) | LLFF [28] | SRN [42] | NV [24] |
| PSNR | SSIM | LPIPS | ||||||||||
| Chair | Pedestal | Cube | Vase | Chair | Pedestal | Cube | Vase | Chair | Pedestal | Cube | Vase | |
| DeepVoxels [41] | ||||||||||||
| SRN [42] | ||||||||||||
| NV [24] | ||||||||||||
| LLFF [28] | ||||||||||||
| Ours | ||||||||||||
| PSNR | ||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | |
| SRN [42] | ||||||||
| NV [24] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| SSIM | ||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | |
| SRN [42] | ||||||||
| NV [24] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| LPIPS | ||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | |
| SRN [42] | ||||||||
| NV [24] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| PSNR | ||||||||
| Room | Fern | Leaves | Fortress | Orchids | Flower | T-Rex | Horns | |
| SRN [42] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| SSIM | ||||||||
| Room | Fern | Leaves | Fortress | Orchids | Flower | T-Rex | Horns | |
| SRN [42] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| LPIPS | ||||||||
| Room | Fern | Leaves | Fortress | Orchids | Flower | T-Rex | Horns | |
| SRN [42] | ||||||||
| LLFF [28] | ||||||||
| Ours | ||||||||
| PSNR | |||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | ||
| 1) | No PE, VD, H | ||||||||
| 2) | No Pos. Encoding | ||||||||
| 3) | No View Dependence | ||||||||
| 4) | No Hierarchical | ||||||||
| 5) | Far Fewer Images | ||||||||
| 6) | Fewer Images | ||||||||
| 7) | Fewer Frequencies | ||||||||
| 8) | More Frequencies | ||||||||
| 9) | Complete Model | ||||||||
| SSIM | |||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | ||
| 1) | No PE, VD, H | ||||||||
| 2) | No Pos. Encoding | ||||||||
| 3) | No View Dependence | ||||||||
| 4) | No Hierarchical | ||||||||
| 5) | Far Fewer Images | ||||||||
| 6) | Fewer Images | ||||||||
| 7) | Fewer Frequencies | ||||||||
| 8) | More Frequencies | ||||||||
| 9) | Complete Model | ||||||||
| LPIPS | |||||||||
| Chair | Drums | Ficus | Hotdog | Lego | Materials | Mic | Ship | ||
| 1) | No PE, VD, H | ||||||||
| 2) | No Pos. Encoding | ||||||||
| 3) | No View Dependence | ||||||||
| 4) | No Hierarchical | ||||||||
| 5) | Far Fewer Images | ||||||||
| 6) | Fewer Images | ||||||||
| 7) | Fewer Frequencies | ||||||||
| 8) | More Frequencies | ||||||||
| 9) | Complete Model | ||||||||