用于视觉和场景文本联合推理
的多模态图神经网络
摘要
对于当前的模型来说,回答需要阅读图像中的文本的问题具有挑战性。 这项任务的一个关键困难是图像中经常出现罕见的、多义的和歧义的单词,例如.地点、产品和运动队的名称。 为了克服这个困难,仅仅依靠预先训练的词嵌入模型是远远不够的。 理想的模型应利用图像多种模式中的丰富信息来帮助理解场景文本的含义,例如。瓶子上的突出文本最有可能是品牌。 遵循这个想法,我们提出了一种新颖的 VQA 方法,多模态图神经网络(MM-GNN)。 它首先将图像表示为由三个子图组成的图,分别描述视觉、语义和数字模态。 然后,我们引入三个聚合器,引导消息从一个图传递到另一个图,以利用各种模式的上下文,从而细化节点的特征。 更新后的节点为下游问答模块提供了更好的功能。 实验评估表明,我们的 MM-GNN 更好地表示了场景文本,并且明显促进了两个需要阅读场景文本的 VQA 任务的性能。
1简介
场景中的文本传达了丰富的信息,这对于执行日常任务(例如寻找地点、获取产品信息等)至关重要。能够对场景文本和其他视觉内容进行推理的高级视觉问答 (VQA) 模型可以在实践中具有广泛的应用,例如帮助视障用户和儿童教育。 本文的重点是赋予 VQA 模型更好地表示包含场景文本的图像的能力,以促进回答需要读取图像的 VQA 任务[44, 8]的性能。

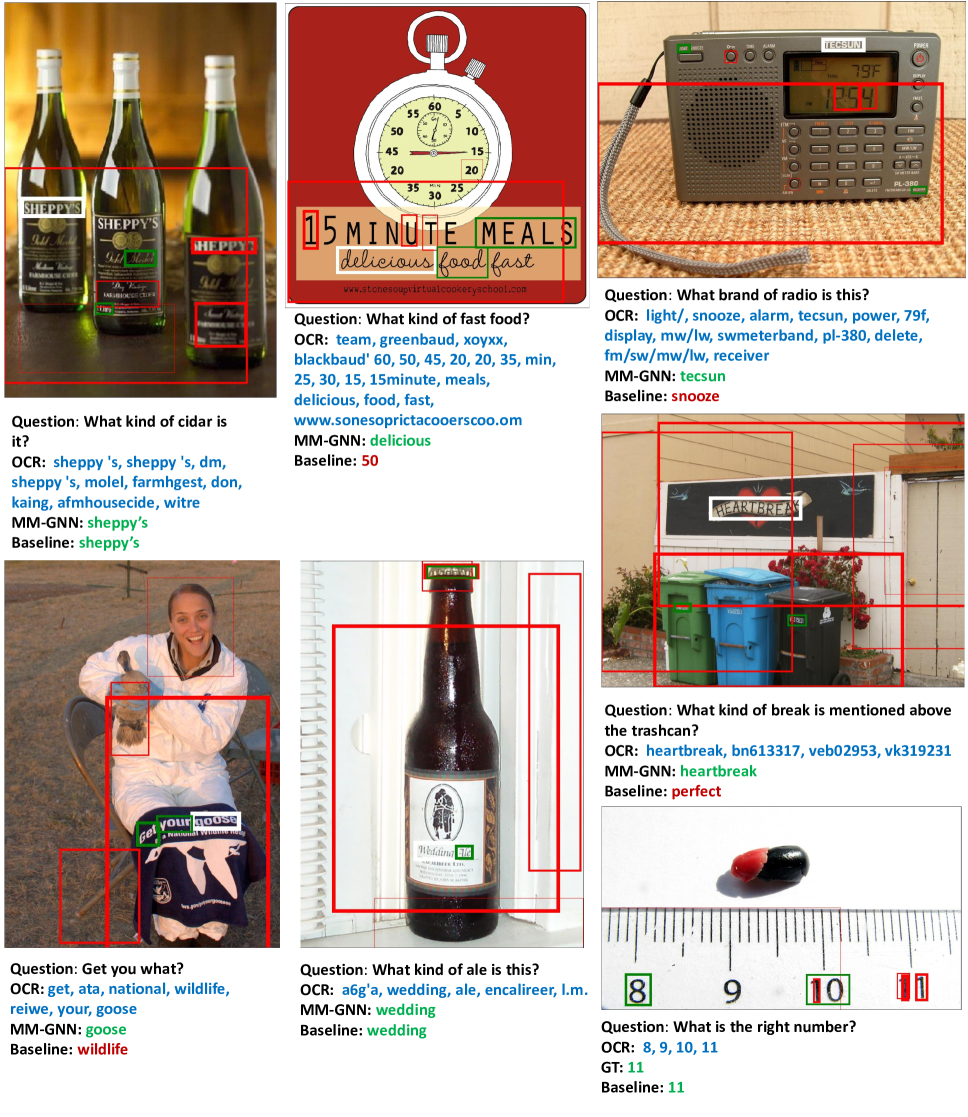
与纯视觉实体(例如对象和场景)和自然语言文本(句子或短语)相比,场景文本建模有哪些独特的挑战? 场景文本本质上包含多种形式的信息,视觉信息,包括颜色、形状和语义信息,例如。“New York”是城市名称,数字信息表示数字,例如。“65”大于“50” ”。 这些类型的信息经常用于回答日常问题。 例如图1中,Q2要求模型通过视觉信息找到目标场景文本; Q3需要模型理解“65”的语义,表示金额; Q4 需要理解数字之间的数字关系。 因此,要正确回答涉及场景文本的问题,必须清楚地描述场景文本的每种情态。 此外,在这三种模态中,确定场景文本的语义更加困难,因为日常环境中遇到的场景文本很有可能是未知的、罕见的或多义词,例如例如。 ,产品名称“STP”,如图1所示。 为了解决这个问题,模型应该能够确定这些文本的语义,而不仅仅是使用在文本语料库上预训练的词嵌入 [38, 26] 。 在本文中,我们建议教会模型如何像人类一样利用单词周围不同形式的上下文来确定它们的含义,即1)视觉上下文:瓶子上突出的单词最有可能是其品牌,如图1中的Q1和图2中的Q1,2)语义上下文:罕见或模棱两可的单词周围的文本可能有助于推断其含义,例如。Q2如图2所示>。 此外,利用数字语义还可以描述数字之间更丰富的数字关系,如图2所示的Q3。

根据上述想法,我们提出了一种新方法,多模态图神经网络(MM-GNN),以获得图像中多模态内容的更好表示并促进问题回答。 我们提出的 MM-GNN 包含三个子图,用于表示图像中的三种模态,即视觉实体(包括文本和对象)的视觉模态、场景文本的语义模态和数字相关文本的数字模态,如图所示图3。 三个图中节点的初始表示是从先验中获得的,例如从语料库和 Faster R-CNN 特征中学习的词嵌入。 然后,MM-GNN 通过三个基于注意力的聚合器动态更新节点的表示,对应于利用图 2 中三种典型的上下文类型。 这些聚合器考虑两个节点的视觉外观和图像中的布局信息以及问题来计算两个节点的相关性分数。 除了节点之间的相关性之外,通过关注布局信息,我们实际上将文本链接到它们的物理载体(文本被打印或雕刻的对象);在给定语言提示的情况下,注意力模型可以通过考虑问题暗示的指令来更准确地传递信息。 三个不同的聚合器引导消息从一种模态传递到另一种模态(或自身),以利用不同类型的上下文以特定顺序细化节点特征。 更新后的表示包含更丰富、更精确的信息,有助于回答模型注意正确答案。
最后,我们在最近提出的两个数据集 TextVQA [44] 和 ST-VQA [8] 上使用我们提出的 MM-GNN 及其变体进行实验。 结果表明,我们的 MM-GNN 与新设计的聚合器可以有效地学习场景文本的表示,并促进需要阅读文本的 VQA 任务的执行。
2相关工作
视觉问答任务。 近年来,许多作品提出了各种 VQA 任务[39,34,4,16,48,42,53,24,23]来评估回答视觉问题的不同类型的核心技能。 一行数据集[39,34,4,16],例如COCO-QA和VQA,研究有关查询图像视觉信息的问题。 相关工作[33,14,41,1,6,35,50]提出了各种注意机制和多模态融合技术,以更好地定位给定问题的图像区域,以促进回答过程。 另一系列作品,例如 CLEVR 和 GQA,引入了需要复杂和组合空间推理技能的问题。 这些任务的相关工作引入了模块化网络 [2, 3, 20, 25, 22] 和神经符号模型 [43, 51],它们可以通过执行来稳健地生成答案对图像进行显式多步骤推理。
在本文中,我们重点关注 TextVQA [44] 和 ST-VQA [8] 最近提出的一种新型问题。 与其他 VQA 任务相比,这两个任务的独特之处在于引入了有关包含多模态内容的图像的问题,包括视觉对象和不同的场景文本。 为了解决这些任务,本文重点讨论如何制定多模态内容并获得场景文本和对象的更好表示。
VQA 中的表征学习。 一些鼓舞人心的作品研究了图像的表示,以提高 VQA 任务的性能。 早期的VQA模型[33,14,41,35,50]主要使用在ImageNet上预训练的VGG或ResNet特征来表示图像。 然而,这种类型的网格级特征仅限于执行对象级注意。 因此,[1]建议将一幅图像表示为检测到的对象特征的列表。 此外,为了解决复杂的构图问题,[43, 51]提出了合成图像的一些符号结构表示(例如。提取的场景图CLEVR 中的图像)允许 VQA 系统对它们执行显式符号推理。 最近,[36,32,21]将自然图像表示为完全连接的图(可以视为隐式场景图,其中对象之间的关系没有明确表示)。 这种类型的图允许模型预测动态边缘权重,以关注与问题相关的子图,并广泛应用于自然图像 QA 中。
上述方法均侧重于视觉对象的表示,而本文将其扩展到表示具有多模态内容的图像。 我们将一幅图像表示为由三个子图组成的图,以分别描述每种模态中的实体并建立不同模态中实体之间的连接。
图神经网络。 图神经网络(GNN)[40,10,29,46,49]是一个用于表示图结构数据的强大框架。 GNN 遵循一种聚合方案,该方案控制节点的相邻节点计算的表示向量如何捕获图的特定模式。 最近,人们提出了许多 GNN 变体来捕获许多任务中不同类型的图模式。 对于图分类任务,许多关于文本分类[40,46,11]和蛋白质界面预测[13]的工作利用GNN迭代地组合邻近的信息节点来捕获图的结构信息。
此外,许多有趣的作品[45,36,32,21,47]引入了GNN用于接地相关任务,例如引用表达式[27]和视觉问答[54,16,23]。 这些作品[45,36,32,21,47]提出了带有语言条件聚合器的 GNN 来动态定位给定查询(例如引用表达式或问题)的场景子图,然后GNN更新子图中节点的特征来编码对象之间的关系。 更新后的节点对于后面的接地相关任务具有更好的功能。
与之前用于接地相关任务的 GNN [45,36,32,21,47] 类似,我们利用 GNN 来获得更好的特征。 但这篇论文将 GNN 从对单模态图执行推理扩展到多模态图。 此外,我们提出的新聚合方案可以显式捕获不同类型的多模态上下文来更新节点的表示。
3方法
在本节中,我们将详细介绍所提出的多模态图神经网络(MM-GNN),用于回答需要阅读的视觉问题。 给定一个包含视觉对象和场景文本的图像和一个问题,目标是生成答案。 我们的模型分三个步骤回答了这个问题:(1)提取图像的多模态内容并构建三层图,(2)在不同模态之间执行多步消息传递以细化节点的表示,以及(3)根据图像的图形表示来预测答案。
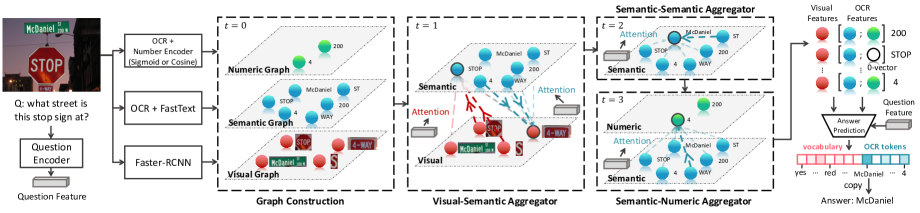
3.1 多模态图构建
如图3所示,给定一幅图像,我们首先构造一个由三个子图组成的多模态图,即视觉图、语义图和数字图,用于以三种模态表示信息。 视觉图 是一个完全连接的图,其中每个节点编码实体(即对象和场景文本)的纯视觉信息和是提取器生成的候选对象的数量。 的初始表示是通过使用图像特征提取器例如获得的。 更快的 R-CNN [15] 检测器。
语义图 也是一个全连接图,每个节点代表场景文本的语义,例如.“New York”是城市名称,“Sunday”是一周中的某一天,是提取的 Token 数量。 具体来说,为了获得语义图,我们首先使用光学字符识别(OCR)模型来提取图像中的单词标记。 然后,通过预训练的词嵌入模型将第词符嵌入作为节点的初始表示。
此外,对于数字类型的字符串,例如.“2000”,它们不仅包含表示字符串类型的语义,例如. 年(或美元),也可以是数字含义,表示其他数字类型字符串之间的数字关系,例如。“2000”大于“1900” ”。 因此,我们构建了一个全连接的数字图来表示数字类型文本的此类信息。 我们将常见的数字文本分为几种类型,例如.数字、时间等。然后将数字类型的文本嵌入到-1到1中,表示为,根据类别使用 sigmoid 函数(对于单调数,如“12”)或余弦函数(对于周期数,如“10:00”),其中 是数字的个数- 键入文本。 有关数字编码器的更多详细信息,请参阅补充材料。 此外,由三个子图组成的整个图整体上是全连接的,但在一个聚合器中仅使用节点和边的特定部分。
3.2聚合方案
在构建图并初始化每个节点的表示之后,我们提出了三个聚合器,它们引导一个子图到另一个子图或其本身之间的信息流,以利用不同类型的上下文来细化节点的表示,如图 1 所示。 3。
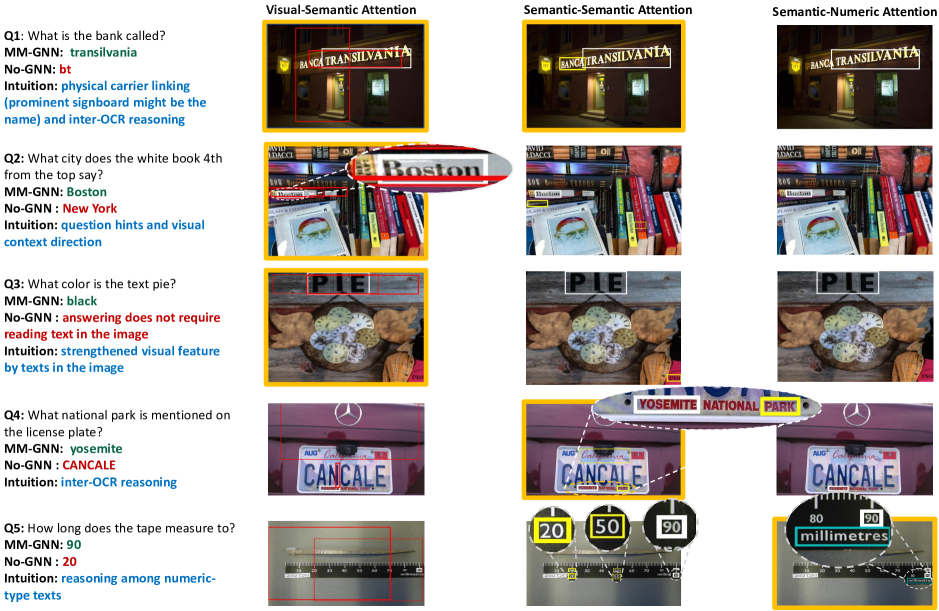
视觉语义聚合器。 第一个聚合器是视觉-语义聚合器,其目标有两个:1)利用视觉上下文来完善语义节点(用于解决图 2 中的 Q1 等问题);2)利用语义上下文来完善视觉节点,使文本的物理载体的视觉表示意识到文本(用于解决图 5 中的 Q3 等问题)。 这里,我们首先说明第一个目标的实现。 对于语义图 中的每个节点 ,聚合器通过首先关注可视图 中的相关邻居节点来更新 的表示>,然后聚合参与节点的信息来更新的表示。 具体来说,我们首先根据节点 及其相邻节点 的可视化表示及其位置特征 和 (即边界框坐标),以及通过嵌入问题单词并经过 LSTM [19] 获得的问题特征 ,计算出它们之间的相关性得分 ,计算公式如下、
| (1) |
其中 、、 和 是用于编码语义节点、视觉节点、边界框特征和问题的 MLP分别是特征,表示连接两个向量,是逐元素乘法。 这里,我们在计算注意力分数时也考虑了问题信息,因为我们希望模型能够考虑问题中的信息来聚合相关节点。 然后,我们聚合参与节点的信息,并将聚合的特征附加到描述该节点的附加信息的 中,以获得更新的语义表示,公式为:
| (2) |
其中 是 = 处更新的节点表示(如图 3 所示),是对相邻节点的特征进行编码的MLP。
与细化语义节点的方案类似,我们通过以下方式获得中节点的更新表示:
| (3) | ||||
| (4) |
其中是对进行编码的MLP,表示语义图中的邻居节点。 请注意,在所有聚合器中,附加信息都附加在原始特征之后;具体来说,在视觉语义聚合之后,语义和视觉特征的维度都乘以2。
语义-语义聚合器。 然后,该聚合器通过考虑其语义上下文来细化每个语义节点的表示(用于解决图 2 中的 Q2 等问题)。 对于每个节点,聚合器通过注意力机制在语义图中找到合适的邻居节点和,然后聚合参与节点的信息。
更具体地说,节点及其邻居节点的相关性得分是通过它们的语义表示和位置特征计算的图像中的 > 和 公式为,
| (5) |
其中 、、 和 是用于编码节点特征(前两个)、边界框特征的 MLP和问题特征。 然后,我们聚合参与节点的信息,并将聚合的特征附加到 中,如下所示:
| (6) |
其中 是 = 处更新的节点表示, 是对相邻节点的特征进行编码的 MLP。
语义数字聚合器。 该聚合器的目标是利用语义上下文来细化值节点,以描述数字之间信息更丰富的数字关系(用于解决图 2 中的 Q3 等问题)。 语义数字聚合器的机制类似于视觉语义聚合器中实现第一个目标的机制。 我们首先计算节点和之间的相关性得分,然后将语义节点的信息聚合到数字节点,公式为:
| (7) |
其中 用于编码语义节点, 用于编码。 最后,我们将数字节点附加到其相应的语义节点作为 OCR 标记的表示,表示为 。 对于非数字类型的 OCR 标记,我们连接一个元素全为 0 的向量。
3.3答案预测
答案预测模块以更新后的视觉特征和OCR特征作为输入,并通过复制机制[17]输出答案。 具体来说,首先将输出空间的大小扩展为词汇量+OCR个数,其中输出空间中的一些索引表示复制对应的OCR作为答案,如图3所示。 然后,我们计算两种模态特征的注意力分数,并使用注意特征生成每个答案的分数,公式为:
| (8) |
其中 和 是 [1] 中的自上而下的注意力网络, 是一个 MLP,用于输出所有分数候选人回答。 最后,我们优化二元交叉熵损失来训练整个网络。 这使我们能够处理答案同时位于预定义答案空间和 OCR 标记中的情况,而不会因为预测其中任何一个而受到惩罚。
4实验
4.1 实验设置
数据集。 我们使用 TextVQA 数据集和场景文本 VQA (ST-VQA) 数据集评估我们的模型。
对于 TextVQA 数据集,它包含来自开放图像数据集 [30] 的 28,408 张图像的总共 45,336 个人工提出的问题。 每个问答对都附带由对象字符识别 (OCR) 模型 Rosetta [9] 提取的标记列表。 这些问题通过 VQA 准确性指标[16]进行评估。
对于 ST-VQA 数据集,它由 23,038 张图像组成,搭配 31,791 个人工注释的问题。 在ST-VQA的弱语境化任务中,为该任务中的所有问题提供了30,000个单词的词典;开放词典任务是open-lexicon。 这些问题通过两个指标进行评估:平均标准化编辑相似度 (ANLS) [31] 和准确性。
实施细节。 对于 TextVQA 训练 数据集的实验,我们使用在该集中至少出现两次的答案作为我们的词汇表。 因此,我们的输出空间的大小是词汇大小和OCR数量的总和,即。 对于问题特征,我们使用在 VQA 模型中广泛使用的 GloVe [38] 来嵌入单词,然后将单词嵌入输入到具有 self 的 LSTM [19] -attention [52] 生成问题嵌入。 对于编码 OCR 标记,GloVe 只能将词汇外 (OOV) 单词表示为 0 向量,不适合对其进行初始化,因此我们使用 fastText [26],它可以表示 OOV 单词作为不同的向量,以初始化 OCR 标记。 对于图像特征,我们对 TextVQA 数据集提供的每张图像使用两种预提取的视觉特征,1)从预训练的 ResNet-152 中获得的 196 个基于网格的特征,以及 2)从预训练的 ResNet-152 中提取的 100 个基于区域的特征。 -训练的 Faster R-CNN 模型,如 [1]。 两个视觉特征都是 2048 维的。 请注意,Faster R-CNN 提供了对象和场景文本的视觉特征,因为检测器产生过多的边界框,其中一些边界框将约束场景文本。
首先将对象和 OCR 标记的边界框坐标标准化为 区间。 然后我们将其中心点、左下角和右上角的坐标、宽度、高度、面积和长宽比连接成一个10维特征。 我们使用AdaMax优化器[28]进行优化。 除用于微调的 fc7 层外,所有参数均应用 1e-2 的学习率,这些参数均使用 5e-3 进行训练。
对于ST-VQA数据集的实验,由于没有提供可用的OCR结果,我们使用TextSpotter [18]提取图像中的场景文本。 对于问题和 OCR 词符嵌入,我们使用与 TextVQA 中相同的模型;对于图像特征,我们只使用 Faster R-CNN 特征。 此外,我们交换预测词汇以适应数据集的变化。 对于开放词典任务,我们收集至少出现两次的答案以及在训练集中出现一次的单个单词答案作为我们的词汇。 对于弱语境化任务,直接使用给定的 30,000 个词汇量。 另外,源码是用PyTorch实现的[37] 111我们的源代码可在http://vipl.ict.ac.cn/resources/codes获取。.
| Method | Val | Test |
|---|---|---|
| Pythia | 13.04 | 14.01 |
| LoRRA (BAN) | 18.41 | - |
| LoRRA (Pythia) | 26.56 | 27.63 |
| BERT + MFH | 28.96 | - |
| MM-GNN (ours) | 31.44 | 31.10 |
| BERT + MFH (ensemble) | 31.50 | 31.44 |
| MM-GNN (ensemble) (ours) | 32.92 | 32.46 |
| LA+OCR UB | 67.56 | 68.24 |
4.2结果
与最先进的技术比较。 表 1 显示了我们的方法与 TextVQA 数据集的验证和测试集上最先进的方法之间的比较。 表中,LoRRA (Pythia) 是 TextVQA 数据集[44]提供的基线。 BERT + MFH 是 CVPR 2019 TextVQA 挑战赛的获胜者,该挑战赛被认为是最先进的,其结果引用自其挑战赛获胜者演讲。 LA+OCR UB 是指使用当前 OCR 结果和 TextVQA 数据集[44]提供的 LoRRA Large Vocabulary 的模型可实现的最大准确度。 LoRRA 和 BERT+MFH 利用先进的融合技术来处理由预训练的 FastText [26] 编码的 OCR Token 。 BERT+MFH 还在回答模型中引入了强大的问题编码器 BERT [12]。 我们的方法优于上述主要依赖于预训练词嵌入的方法,并取得了最先进的结果。 表2比较了我们在场景文本VQA数据集的弱上下文化和开放词典任务上的方法和最先进的方法,其中VTA是ICDAR 2019 STVQA竞赛的获胜者模型,它扩展了自下而上的 VQA 模型 [1] 使用 BERT 对问题和文本进行编码。 从结果中,我们可以看到 MM-GNN 比基线方法获得了明显的改进,例如SAN(CNN)+STR,达到与VTA相当的精度。
| Method | Weakly Contextualized | Open Dictionary | ||
|---|---|---|---|---|
| ANLS | Acc. | ANLS | Acc. | |
| SAAA | 0.085 | 6.36 | 0.085 | 6.36 |
| SAAA+STR | 0.096 | 7.41 | 0.096 | 7.41 |
| SAN(LSTM)+STR | 0.136 | 10.34 | 0.136 | 10.34 |
| SAN(CNN)+STR | 0.135 | 10.46 | 0.135 | 10.46 |
| VTA [7] | 0.279 | 17.77 | 0.282 | 18.13 |
| MM-GNN (ours) | 0.203 | 15.69 | 0.207 | 16.00 |
多模态 GNN 的有效性。 我们模型的优势在于引入了多模态图和不同子图之间精心设计的消息传递策略,以捕获不同类型的上下文。 因此,我们提出了模型的几种变体,其中每种变体都消除了一些聚合器以显示它们的不可或缺性。
-
•
No-GNN:该变体直接使用从预训练模型中提取的对象和 OCR 词符特征来回答问题,而不经过多模态 GNN。 其他模块(输出、嵌入)与 MM-GNN 保持相同。
-
•
Vanilla GNN:此变体将对象和 OCR 词符特征放在单个图中。 然后,它执行类似于语义-语义聚合器的聚合来更新节点的表示。 其他模块与MM-GNN相同。
-
•
VS、SS 和 SN 的组合:这些变体像 MM-GNN 一样构建多模态图,但仅使用一两个聚合器来更新表示。 VS、SS 和 SN 分别代表视觉-语义、语义-语义和语义-数字聚合器。
此外,为了更好地详细比较结果,我们将 TextVQA 中的问题分为三种类型。 第一类问题是无法回答,包括对于 TextVQA 数据集中当前提供的给定 OCR 标记无法回答的问题。 我们通过检查预定义答案词汇表中是否缺少真实答案并提供 OCR 标记来获得此类问题。 第二类问题的答案只能在预定义的答案词汇中找到,例如“red”、“bus”,并且不在 OCR Token 中,表示为 Vocab。 第三类问题是与 OCR 相关的问题,其答案源自 OCR Token 。 由于无法回答类型的问题无法有效评估不同变体的能力,我们报告了Vocab和OCR的分数,这些分数属于可回答,以及总体准确性(包括无法回答)。
我们评估了 TextVQA 数据集验证集上的变体,并报告了它们在每种类型问题上的准确性,如表 3 所示。 将完整模型 MM-GNN 与基线 No-GNN 的性能进行比较,我们可以看到 MM-GNN 的整体准确率优于 NO-GNN,约为 4%,在 OCR 相关问题上的准确率超过 8%,这是 TextVQA 的主要关注点。 这表明将图表示引入TextVQA模型可以有效帮助答题过程。 比较 Vanilla GNN 和 MM-GNN 系列的结果,我们发现如果 GNN 中的消息传递设计不完善,直接将 GNN 应用于 TextVQA 任务没有什么帮助。 通过比较 SS、SN 和 VS 的结果,我们发现视觉语义聚合器对 OCR 相关问题和整体准确性贡献了最大的性能提升。 这证明了我们的想法,即多模态上下文可以有效提高场景文本表示的质量。
然而,我们发现数字语义聚合器的贡献小于其他两个聚合器,可能是因为查询数字之间关系的问题部分(例如“图像中最大的数字是多少?”)相对较小。 因此,它限制了展示该聚合器有效性的空间。
| Method | Answerable | Overall | |
|---|---|---|---|
| Vocab | OCR | ||
| No-GNN | 28.88 | 35.38 | 27.55 |
| Vanilla GNN | 28.29 | 37.70 | 28.58 |
| VS | 27.54 | 41.38 | 30.14 |
| SS | 29.75 | 38.89 | 29.71 |
| SN | 25.67 | 40.30 | 28.82 |
| VS + SS | 28.81 | 42.16 | 30.99 |
| VS + SN | 28.61 | 41.30 | 30.44 |
| SS + SN | 25.69 | 41.99 | 29.78 |
| VS + SS + SN (ours) | 27.85 | 43.36 | 31.21 |
不同组合方法的影响。 选择控制源节点与其相邻节点的聚合特征融合的组合方案是图神经网络设计的关键部分之一。 最初的 MM-GNN 旨在逐渐向每个节点附加附加信息,作为区分 OCR 词符的提示,并方便回答模型找到正确的 OCR 词符。 在这里,我们用其他 GNN 中广泛使用的几种变体替换串联更新器:
-
•
Sum:该变体通过求和运算将源节点及其邻居节点的特征结合起来,在现有的GNN作品中广泛使用,例如[5]。
-
•
产品:此变体通过计算节点特征与其相邻节点的聚合特征的逐元素乘法来更新每个节点。
-
•
Concat + MLP:该变体通过连接节点特征和其相邻节点的聚合特征来更新每个节点,然后使用 MLP 对连接的特征进行编码,这在之前的视觉语言相关方法中使用[21].
| Method | Answerable | Overall | |
|---|---|---|---|
| Vocab | OCR | ||
| Sum | 27.40 | 40.40 | 29.59 |
| Product | 27.89 | 32.18 | 25.79 |
| Concat+MLP | 28.11 | 38.44 | 28.73 |
| Concat (ours) | 27.85 | 43.36 | 31.21 |

我们在TextVQA数据集的验证集上评估它们的性能,性能如表4所示。 我们可以看到,这三种方案都或多或少地损害了性能。 从经验上看,这是因为节点及其邻域之间的信息被压缩,逐渐平均化了节点特征之间的差异,从而使回答模块在尝试定位与问题相关的OCR词符时感到困惑。 需要注意的是,以上三种组合方案都具有不通过迭代改变节点特征尺寸的优越性;而我们的串联方案则放松了这一限制,以便在组合阶段保留更多信息。
4.3定性分析
为了直观地了解聚合器中的注意力分布,我们在图 4 中将它们可视化。 这表明我们的模型可以产生非常敏锐的注意力来对图进行推理,并且注意力具有良好的可解释性。 在Q1中,当问题询问带球的球员时,OCR Token 在注意力模块的引导下融入更多与篮球相关的信息;除了问题提示之外,《WDOVER》自然也关注玩家的领域。 在Q2中,OCR词符“Panera”根据问题融合了“BREAD”中的位置和语义信息,并且可以在回答模块中选择,因为模型了解到“BREAD”上面的单词是很可能是这个名字。
为了更好地说明 MM-GNN 的回答过程,我们可视化每个聚合器在回答问题时的注意力结果,并比较 MM-GNN 和基线 No-GNN 的最终答案。 在图5中,我们展示了几个典型问题的结果:Q1要求模型利用视觉上下文“建筑物招牌上的显着文字”来推断未知 OCR 词符“transilvania”的语义。 此外,OCR 上下文“banca”也有助于找出“transilvania”是一家银行的名称。 Q2需要将文本“Boston”链接到其物理载体“白皮书”并复制OCR词符作为答案,Q3需要将文本“PIE”链接到其物理载体“包含黑色字母的区域”,Q4需要从其周围的OCR标记推断OCR词符的语义,Q5 评估找到最大数的能力。
5结论
在本文中,我们介绍了一种用于场景文本 VQA 的新颖框架多模态图神经网络 (MM-GNN)。 MM-GNN 将具有多模态内容的图像表示为三个图的组合,其中每个图代表一种模态。 此外,MM-GNN 中设计的多模态聚合器利用多模态上下文来获得图像中元素的更精细表示,特别是对于未知、罕见或多义词。 通过实验,我们证明了新的图像表示和消息传递方案极大地提高了场景文本 VQA 的性能,并提供可解释的中间结果。
致谢。 该工作得到了国家自然科学基金委的部分支持,合同号为: 61922080、U19B2036、61772500、中国科学院前沿科学重点研究项目编号 QYZDJ-SSWJSC009。
参考
- [1] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and vqa. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6077–6086, 2018.
- [2] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Learning to compose neural networks for question answering. In Proceedings of NAACL-HLT, pages 1545–1554, 2016.
- [3] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 39–48, 2016.
- [4] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2425–2433, 2015.
- [5] James Atwood and Don Towsley. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems (NIPS), pages 1993–2001, 2016.
- [6] Hedi Ben-Younes, Rémi Cadene, Matthieu Cord, and Nicolas Thome. Mutan: Multimodal tucker fusion for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2612–2620, 2017.
- [7] Ali Furkan Biten, Rubèn Tito, Andrés Mafla, Lluís Gómez, Marçal Rusiñol, Minesh Mathew, C. V. Jawahar, Ernest Valveny, and Dimosthenis Karatzas. Icdar 2019 competition on scene text visual question answering. CoRR, abs/1907.00490, 2019.
- [8] Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusiñol, Ernest Valveny, C. V. Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 4291–4301, 2019.
- [9] Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79, 2018.
- [10] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann Lecun. Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations (ICLR), 2014.
- [11] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems (NIPS), pages 3844–3852, 2016.
- [12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019.
- [13] Alex Fout, Jonathon Byrd, Basir Shariat, and Asa Ben-Hur. Protein interface prediction using graph convolutional networks. In Advances in Neural Information Processing Systems (NIPS), pages 6530–6539, 2017.
- [14] Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. In Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 457–468, 2016.
- [15] Ross Girshick. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1440–1448, 2015.
- [16] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6904–6913, 2017.
- [17] Jiatao Gu, Zhengdong Lu, Hang Li, and Victor O.K. Li. Incorporating copying mechanism in sequence-to-sequence learning. In In Annual Meeting of the Association for Computational Linguistics (ACL), pages 1631–1640, 2016.
- [18] Tong He, Zhi Tian, Weilin Huang, Chunhua Shen, Yu Qiao, and Changming Sun. An end-to-end textspotter with explicit alignment and attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5020–5029, 2018.
- [19] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [20] Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Kate Saenko. Learning to reason: End-to-end module networks for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 804–813, 2017.
- [21] Ronghang Hu, Anna Rohrbach, Trevor Darrell, and Kate Saenko. Language-conditioned graph networks for relational reasoning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 10294–10303, 2019.
- [22] Drew A. Hudson and Christopher D. Manning. Compositional attention networks for machine reasoning. International Conference on Learning Representations (ICLR), 2018.
- [23] Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6700–6709, 2019.
- [24] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1988–1997, 2017.
- [25] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Judy Hoffman, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. Inferring and executing programs for visual reasoning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2989–2998, 2017.
- [26] Armand Joulin, Édouard Grave, Piotr Bojanowski, and Tomáš Mikolov. Bag of tricks for efficient text classification. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics (EACL), pages 427–431, 2017.
- [27] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- [28] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
- [29] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
- [30] Ivan Krasin, Tom Duerig, Neil Alldrin, Vittorio Ferrari, Sami Abu-El-Haija, Alina Kuznetsova, Hassan Rom, Jasper Uijlings, Stefan Popov, Andreas Veit, Serge Belongie, Victor Gomes, Abhinav Gupta, Chen Sun, Gal Chechik, David Cai, Zheyun Feng, Dhyanesh Narayanan, and Kevin Murphy. Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages, 2017.
- [31] Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet Physics Doklady, volume 10, pages 707–710, 1966.
- [32] Linjie Li, Zhe Gan, Yu Cheng, and Jingjing Liu. Relation-aware graph attention network for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 10313–10322, 2019.
- [33] Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. Hierarchical question-image co-attention for visual question answering. In Advances in Neural Information Processing Systems (NIPS), pages 289–297, 2016.
- [34] Mateusz Malinowski and Mario Fritz. A multi-world approach to question answering about real-world scenes based on uncertain input. In Advances in Neural Information Processing Systems (NIPS), pages 1682–1690, 2014.
- [35] Hyeonwoo Noh, Paul Hongsuck Seo, and Bohyung Han. Image question answering using convolutional neural network with dynamic parameter prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 30–38, 2016.
- [36] Will Norcliffe-Brown, Stathis Vafeias, and Sarah Parisot. Learning conditioned graph structures for interpretable visual question answering. In Advances in Neural Information Processing Systems (NIPS), pages 8334–8343, 2018.
- [37] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. pages 8024–8035, 2019.
- [38] Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- [39] Mengye Ren, Ryan Kiros, and Richard Zemel. Exploring models and data for image question answering. In Advances in Neural Information Processing Systems (NIPS), pages 2953–2961, 2015.
- [40] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1):61–80, 2008.
- [41] Idan Schwartz, Alexander Schwing, and Tamir Hazan. High-order attention models for visual question answering. In Advances in Neural Information Processing Systems (NIPS), pages 3667–3677, 2017.
- [42] Sanket Shah, Anand Mishra, Naganand Yadati, and Partha Pratim Talukdar. Kvqa: Knowledge-aware visual question answering. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 8876–8884, 2019.
- [43] Jiaxin Shi, Hanwang Zhang, and Juanzi Li. Explainable and explicit visual reasoning over scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8376–8384, 2019.
- [44] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8317–8326, 2019.
- [45] Damien Teney, Lingqiao Liu, and Anton van den Hengel. Graph-structured representations for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 804–813, 2017.
- [46] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations (ICLR), 2017.
- [47] Peng Wang, Qi Wu, Jiewei Cao, Chunhua Shen, Lianli Gao, and Anton van den Hengel. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1960–1968, 2019.
- [48] Peng Wang, Qi Wu, Chunhua Shen, Anthony Dick, and Anton van den Hengel. Fvqa: Fact-based visual question answering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(10):2413–2427, 2018.
- [49] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations (ICLR), 2019.
- [50] Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 21–29, 2016.
- [51] Kexin Yi, Jiajun Wu, Chuang Gan, Antonio Torralba, Pushmeet Kohli, and Josh Tenenbaum. Neural-symbolic vqa: Disentangling reasoning from vision and language understanding. In Advances in Neural Information Processing Systems (NIPS), pages 1039–1050, 2018.
- [52] Zhou Yu, Jun Yu, Chenchao Xiang, Jianping Fan, and Dacheng Tao. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Transactions on Neural Networks and Learning Systems, 29(12):5947–5959, 2018.
- [53] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6720–6731, 2019.
- [54] Peng Zhang, Yash Goyal, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Yin and yang: Balancing and answering binary visual questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5014–5022, 2016.
补充材料
概述
6 数字编码器
在 MM-GNN 中,数字和星期几类似于包含周期性信息的时间相关字符串,例如“Sunday”被视为数字类型字符串。 此外,对于周期数,例如10:00,我们首先将其标准化为,然后应用余弦嵌入函数。 请注意,如何对数字字符串进行编码仍然是一个悬而未决的问题,不同的编码器可以捕获数字之间的不同关系,例如使用极坐标系的另一种表示法,即使用余弦和正弦两个函数对数字进行编码,可以更好地表示周期数。
7定量分析
聚合器顺序的影响。 在多模态图神经网络(MM-GNN)中,更新不同子图中节点表示的三个聚合器按特定顺序执行,即首先执行视觉语义聚合器(VS),然后执行语义聚合器-语义聚合器(SS),最后是语义数字聚合器(SN)。 在这一部分中,我们评估所有不同顺序的聚合器的影响。 结果如表5所示。
从结果中,我们可以看到不同变体的性能彼此相似,这表明我们提出的 MM-GNN 对于顺序的变化具有鲁棒性。 这可能要归功于三个聚合器的功能相互之间的依赖性相对较低。
| Method | Answerable | Overall | |
|---|---|---|---|
| Vocab | OCR | ||
| SS-VS-SN | 26.71 | 42.99 | 30.54 |
| SS-SN-VS | 26.88 | 43.11 | 30.65 |
| VS-SN-SS | 25.80 | 43.08 | 30.27 |
| SN-SS-VS | 26.58 | 42.97 | 30.46 |
| SN-VS-SS | 27.66 | 41.63 | 30.33 |
| VS-SS-SN (ours) | 27.85 | 43.36 | 31.21 |
不同问题类型的结果。 与 VQA 数据集[4]类似,我们根据问题类型将 TextVQA 中的问题分为三组,即是/否、数字和其他。 MM-GNN 和基线 No-GNN 在不同问题类型上的表现如表6所示。 我们可以看到,我们的方法主要在其他类型的问题上优于预期的基线,因为这些问题主要与理解不同的场景文本有关。
| Model | yes/no | number | others | Final |
|---|---|---|---|---|
| No-GNN | 88.79 | 35.14 | 22.65 | 27.55 |
| MM-GNN | 88.93 | 36.13 | 27.36 | 31.21 |
8定性分析
在图6中,我们展示了我们的MM-GNN模型在TextVQA数据集上的更多成功案例。 我们表明,MM-GNN 在利用多模态上下文时获得了正确的答案以及合理的注意力结果。 在图7中,我们展示了MM-GNN的一些失败案例,并分析了图像中每个示例的可能原因。