实例感知、上下文聚焦和内存高效
弱监督对象检测
摘要
通过减少训练过程中对强监督的需求,弱监督学习已成为一种引人注目的目标检测工具。 然而,主要挑战仍然存在:(1)对象实例的区分可能不明确; (2) 检测器倾向于关注有区别的部分而不是整个物体; (3)如果没有基本事实,目标建议对于高召回率来说必须是冗余的,从而导致大量的内存消耗。 应对这些挑战很困难,因为通常需要消除不确定性和琐碎的解决方案。 为了解决这些问题,我们开发了一个实例感知和以上下文为中心的统一框架。 它采用实例感知的自训练算法和可学习的 Concrete DropBlock,同时设计内存高效的顺序批量反向传播。 我们提出的方法在 COCO (12.1% AP, 24.8% )、VOC 2007 (54.9% AP) 和 VOC 2012 (52.1% AP) 上取得了最先进的结果,将基线提高了巨大的利润。 此外,所提出的方法是第一个对基于 ResNet 的模型和弱监督视频对象检测进行基准测试的方法。 代码、模型和更多详细信息将在以下网址提供:https://github.com/NVlabs/wetectron。
1简介
最近的物体检测工作[18,36,35,27]取得了令人印象深刻的成果。 然而,训练过程通常需要对精确边界框进行强有力的监督。 大规模获得此类注释可能成本高昂、耗时,甚至不可行。 这激发了弱监督对象检测(WSOD)方法[5,46,23],其中检测器使用较弱的监督形式(例如图像级类别标签)进行训练。 这些工作通常将 WSOD 表述为多实例学习任务,将每个图像中的对象建议集视为一个包。 真正覆盖对象的提案的选择是使用可学习的潜在变量进行建模的。

在减轻对精确标注的需求的同时,现有的弱监督目标检测方法[5,46,51,41,61]由于不确定性和不适定性而经常面临三大挑战,如图1所示:
(1) 实例模糊性。 这可以说是最大的挑战,其中包含两种常见类型的问题:(a) 缺失实例: 背景中具有罕见姿势和较小尺度的不太显着的物体通常被忽略(图 1 中的顶行)。 (二) 分组实例: 当空间相邻时,同一类别的多个实例将被分组到一个边界框中(图 1 中的中间行)。 这两个问题都是由于较大或较显着的框比较小或较不显着的框获得更高的分数而引起的。
(2) 部分统治。 预测往往以对象最具辨别力的部分为主(图 1 底部)。 对于班内差异较大的班级,这个问题尤其明显。 例如,在动物和人等类别上,模型通常会变成“面部检测器”,因为面部是最一致的外观信号。
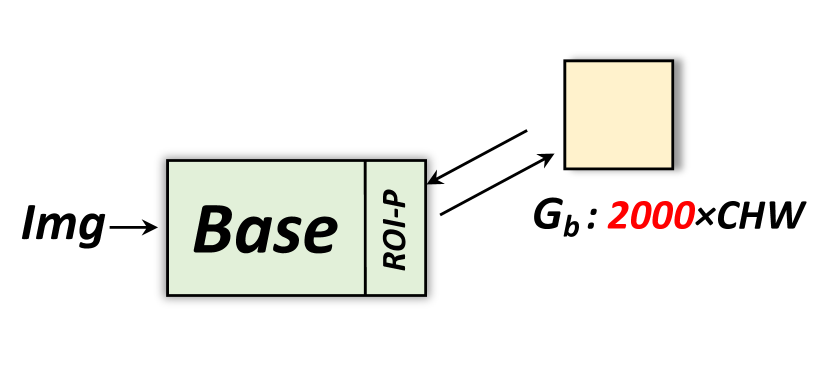
(3)内存消耗。 现有的提案生成方法[50, 65]通常会产生密集的提案。 如果没有真实的本地化,就需要维护大量的提案才能获得合理的召回率和良好的性能。 这需要大量内存,特别是对于视频对象检测。 由于提案数量较多,大部分内存消耗在 ROI-Pooling 之后的中间层。
为了解决上述三个挑战,我们提出了一个统一的弱监督学习框架,该框架是实例感知和上下文关注的。 所提出的方法通过引入先进的自训练算法来解决实例模糊性,其中通过考虑更多实例关联的空间多样化约束来计算以类别标签和回归目标形式存在的实例级伪地面实况(第4.1)。 所提出的方法还通过引入称为 "Concrete DropBlock "的参数空间剔除来解决 Part Domination 问题。该模块通过端到端学习,以逆向方式最大化检测目标,从而鼓励整个框架考虑上下文,而不是专注于最具辨别力的部分(4.2节)。 最后,为了缓解内存消耗问题,我们的方法采用了顺序批量反向传播算法,该算法在内存最密集的阶段批量处理数据。 这允许评估更大的深度模型,例如 WSOD 中的 ResNet [19],以及弱监督视频对象检测的探索(第 4.3 节)。
通过我们提出的框架解决上述三个挑战,可以在几个流行的数据集上实现最先进的性能,包括 COCO [30]、VOC 2007 和 2012 [11]。 每个提出的模块的有效性和稳健性都在详细的消融研究中得到证明,并通过定性结果进一步验证。 最后,我们对视频进行了额外的实验,并给出了 ImageNet VID [8] 上弱监督视频对象检测的第一个基准。
2相关工作
弱监督目标检测(WSOD)。
目标检测是计算机视觉中最基本的问题之一。 最近的监督方法[17,16,36,18,35,31,27]在准确性和速度方面都表现出了出色的性能。 对于 WSOD,大多数方法都会制定多实例学习问题,其中输入图像包含一袋实例(对象建议)。 该模型通过分类损失进行训练,以选择最有信心的积极建议。 修改w.r.t. 初始化 [44, 43]、正则化 [7, 3, 55] 和表示 [7, 4, 28] 已被证明改善结果。 例如,Bilen 和 Vedaldi [5] 为此任务提出了一种端到端的可训练架构。 后续工作通过利用空间关系[46,45,23]、更好的优化[62,22,2,51]以及弱监督分割的多任务来进一步改进[13,38,12,41]。
WSOD 自我训练。
在上述方向中,自我训练[67, 66]已被证明具有开创性。 自训练使用实例级伪标签来增强训练,并且可以以离线方式实现[63,42,28,63]:首先训练WSOD模型使用上述任何方法;然后将置信预测用作伪标签来训练最终的监督检测器。 这种迭代知识蒸馏过程是有益的,因为额外的监督模型从噪声较少的数据中学习,并且通常具有更好的架构,而训练非常耗时。 许多作品[46,45,51,12,61,47]研究了自训练的端到端实现:WSOD模型在训练过程中同时计算和使用伪标签,这通常是称为在线解决方案。 然而,这些方法通常只考虑伪标签最可信的预测。 因此,他们往往会出现过度拟合的问题,而困难的部分和实例会被忽略。
空间辍学。
为了解决上述问题,一种有效的正则化策略是在训练过程中丢弃部分空间特征图。 空间丢失的变体已被广泛设计用于监督任务,例如分类[14]、对象检测[54]和人体关节定位[49]. 类似的方法也被应用于弱监督任务中,以更好地定位检测[40]和语义分割[56]。 然而,这些方法是非参数的,不能以数据驱动的方式适应不同的数据集。 作为进一步的改进,Kingma et al. [24] 设计了变分 dropout,其中 dropout 率是在训练过程中学习的。 Wang 等人. [54]提出了一种用REINFORCE训练的参数但不可微的空间丢失[58]。 相比之下,所提出的“Concrete DropBlock”模块具有参数化和可微分的结构化新颖形式。
内存高效的反向传播。
内存一直是一个问题,因为更深的模型 [19, 39] 和更大的批量大小 [33] 通常会产生更好的结果。 缓解这种担忧的一种方法是通过修改反向传播 (BP) 算法[37],以计算时间换取内存消耗。 合适的技术[25,34,6]是在前向传播期间不存储一些中间深度网络表示。 人们可以通过在反向传播期间注入小的前向传播来恢复这些。 因此,一阶段反向传播被分为几个逐步过程。 然而,这种方法不能直接应用于我们的模型,因为少数中间层消耗了大部分内存。 为了解决这个问题,我们建议对内存较多的中间层进行批处理操作。
3背景
Bilen 和 Vedaldi [5] 是最早开发基于多实例学习思想的端到端深度 WSOD 框架的人之一。 具体来说,给定输入图像 和相应的预计算 [50, 65] 建议 集,使用 ImageNet [8] 预训练神经网络为每个对象类别 和每个区域 生成分类对数 和检测对数 。 向量 包含所有可训练参数。 两个分数矩阵,即。、的区域被分类为类别,类别的检测区域的通过以下方式获得
| (1) |
将类别 分配给区域 的最终得分 通过元素乘积计算:。 训练过程中,对所有区域进行求和以获得图像证据。 然后通过以下方式计算损失:
| (2) |
其中 是真实值 (GT) 类标签,指示类别 的图像级存在。对于推理, 用于预测,然后是标准非极大值抑制 (NMS) 和阈值处理。
为了集成在线自我训练,区域得分通常用作教师,为每个区域生成实例级伪类别标签 [45、51、12、61、47]。 这是通过将得分最高的区域及其高度重叠的邻居视为类 的正面示例来完成的。然后通过以下方式训练额外的学生层以进行区域分类:
| (3) |
其中 是该层的输出。 在测试期间,将使用学生预测 而不是 。 我们在此基础上开发了两个额外的新颖模块,如下所述。
4方法
图像级标签是挖掘图像中常见模式的有效监督形式。 然而,不精确的监管往往会导致定位模糊。 为了解决由这种模糊性引起的上述三个挑战,我们开发了图2中概述的实例感知和上下文为中心的框架。 它包含一种新颖的在线自训练算法,具有 ROI 回归功能,可减少实例模糊性并更好地利用自训练监督(第 4.1 节)。 它还通过一种新颖的端到端可学习的 "Concrete DropBlock"(4.2节),减少了具有较大类内差异的类的部分异化,而且它对内存更加友好(4.3节)。
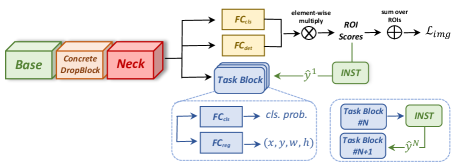
4.1 多实例自训练(MIST)
通过在线或离线生成的伪标签[45,42,63],自训练有助于消除本地化歧义,主要受益于两个方面:(1)伪标签允许对提案级别进行建模监督和提案间关系; (2)自我训练可以广泛地视为师生的升华过程,人们发现它有助于提高学生的代表性。 我们在设计框架时考虑以下维度:
实例关联:对象检测通常是“实例关联”:高度重叠的提案应该分配相似的标签。 大多数 WSOD 自我训练方法都会忽略这一点,而是独立处理提案。 相反,我们将显式实例关联约束强加到伪框生成中。
代表性:每个提案的得分一般可以很好地代表其代表性。 它并不完美,尤其是在一开始,人们倾向于关注物体的部分。 然而,该分数提供了至少位于正确物体上的高召回率。
空间多样性:对选定的伪标签施加空间多样性可能是一种有用的自训练归纳偏差。 它可以更好地覆盖困难的(例如。、罕见的外观、姿势或遮挡)对象,并提高多个实例的召回率(例如。 ,不同的比例和大小)。
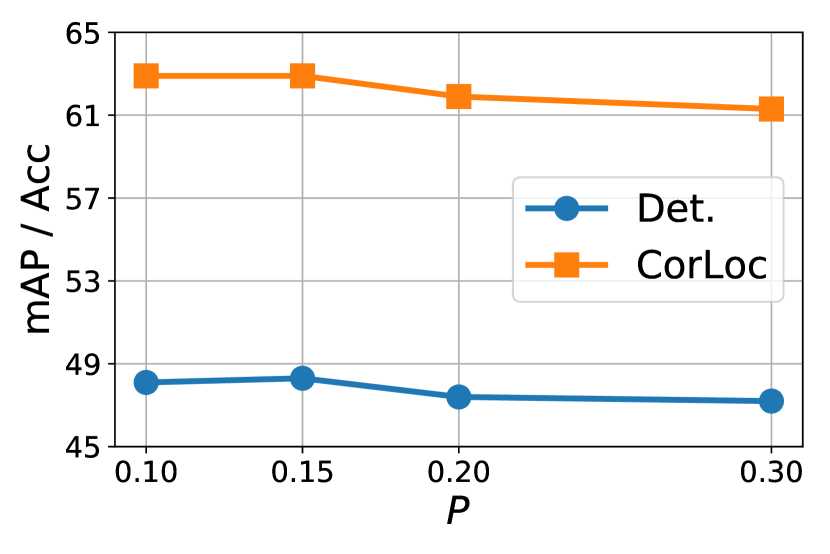
上述约束和标准激发了一种新颖的算法来生成与实例关联的多样化但具有代表性的伪框。 Alg 中提供了详细信息。 1. 具体来说,我们首先对类别标签中出现的每个类 的集合 中的所有分数进行排序。 然后,我们选择排名最高的 区域来形成初始候选池 。 请注意,候选池的大小,即。,是图像自适应和内容相关的与成正比。 直观上, 对于输入图像的整体对象性来说是有意义的先验。 然后使用非极大值抑制从 中挑选一组不同的高分非重叠区域作为伪框 。 尽管很简单,但这种有效的算法可以显着提高性能,如第 2 节所示。 5。
通过回归进行自我训练。
边界框回归是另一个在监督目标检测中发挥重要作用但在在线自训练方法中缺失的模块。 为了缩小差距,我们将分类层和回归层封装到“学生块”中,如图2中的蓝色框所示。 我们使用伪标签 联合优化它们。 对于所有区域 ,通过 引用来自回归层的预测边界框。 对于每个区域 ,如果它与真实类别 的伪框 高度重叠,我们会生成回归目标 通过使用 的坐标并标记分类标签 。 训练学生块的完整区域级损失是:
| (4) | ||||
其中 是 [16] 中使用的 Smooth-L1 目标, 是 [46]< 中使用的标量每区域权重/t3>.
在实践中,当我们强制 成为 one-hot 向量时,就会发生冲突,因为可以选择同一区域对于不同的真实类别为正,特别是在训练的早期阶段。 我们的解决方案是将该类用于伪标签 ,它具有更高的预测分数 。 此外,获得的伪标签和提案不可避免地存在噪声。 施加边界框回归能够通过捕获其中最一致的模式来正确地从噪声标签中学习,并相应地细化噪声建议坐标。 我们在第 2 节中凭经验进行验证。 5.3 边界框回归提高了鲁棒性和泛化性。
自集成。
我们按照[46, 45]堆叠多个学生块以提高性能。 如图2所示,第一个伪标签是从教师分支生成的,然后学生块生成伪标签 用于下一个学生块。 该技术类似于自集成方法[26]。
4.2 混凝土掉落块
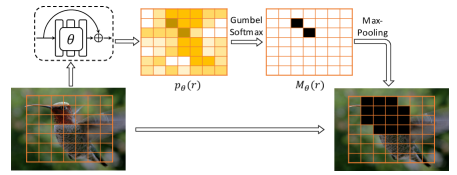
update ‘Head’. saved.
accumulated.
由于类别内的变化,现有的 WSOD 方法经常错误地只检测对象的有区别的部分,而不是其全部范围。 这个问题的一个自然解决方案是鼓励网络专注于上下文,这可以通过删除最具辨别力的部分来实现。 因此,空间丢失是一种直观的拟合。
由于物体的区别部分的位置和大小不同,朴素空间丢失对检测有限制。 提出了一种更结构化的 DropBlock [14],其中 ROI 特征图上的空间点被随机采样为 blob 中心,然后将这些大小为 的中心周围的方形区域丢弃到ROI 特征图上的所有通道。 最后,通过整个 ROI 的面积与未丢弃区域的面积的比例来重新缩放特征值,以便在没有丢弃区域时不必应用归一化来进行推理。
DropBlock 是一种非参数正则化技术。 虽然它能够提高模型的鲁棒性并减轻部分支配,但它基本上平等地对待区域。 我们考虑以对抗性方式更频繁地在有区别的部分掉落。 为此,我们开发了Concrete DropBlock:DropBlock 的数据驱动和参数化变体,它通过端到端学习来删除最相关的区域,如图3. 给定输入图像,使用 ROI 池化之前的各层计算每个区域 的特征图 。 是 ROI-Pooling 输出维度。 然后,我们将 输入卷积残差块以生成概率图 ,其中 包含该模块的可训练参数。 的每个元素被视为独立的伯努利变量,并且该概率图通过空间 Gumbel-Softmax [21, 32] 转换为硬掩模 . 此操作是采样的可微近似。 为了避免琐碎的解决方案(例如。,所有内容都将被丢弃或某个区域被一致丢弃),我们应用一个阈值,使得。 这保证了计算出的掩码是稀疏的。 我们按照 DropBlock 最终生成结构化掩码并对特征进行归一化。 在训练过程中,我们以以下最小最大目标联合优化原始网络参数和残差块参数:
| (5) |
通过最大化原始损失 Concrete DropBlock 参数,Concrete DropBlock 将学习丢弃对象中最具辨别力的部分,因为这是增加训练损失的最简单方法。 这迫使对象检测器也查看上下文区域。 我们发现这种策略可以提高性能,特别是对于非刚性对象类别,这些类别通常具有较大的类内差异。
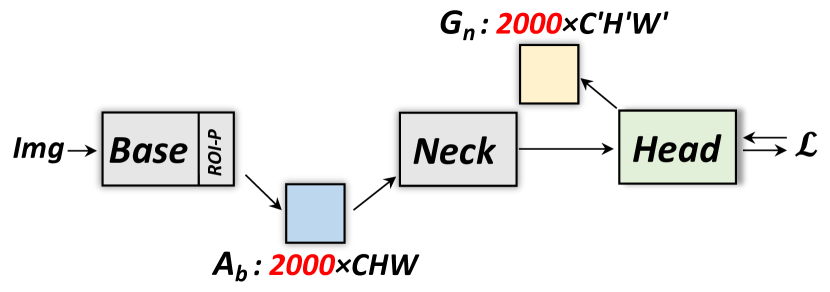
4.3 顺序批量反向传播
在本节中,我们将讨论如何处理内存限制,特别是在训练期间,这成为阻止以前的 WSOD 方法使用最先进的深度网络的主要瓶颈。 我们介绍专为 WSOD 模型量身定制的内存高效顺序批量前向和后向计算。
Vanilla 通过反向传播训练 [37] 存储前向传播过程中的所有中间激活,这些激活在计算网络参数的梯度时会被重用。 由于记忆化,这种方法在计算上是高效的,但由于同样的原因,对内存的要求也很高。 已经提出了更高效的版本[25, 6],其中在关键层的前向传递过程中仅保存中间激活的子集。 整个模型在这些关键层被分割成更小的子网络。 当计算子网络的梯度时,首先应用前向传递来获取该子网络的中间表示,从子网络的输入关键层处存储的激活开始。 结合从早期子网络传播的梯度,计算子网络权重的梯度,并将梯度传播到早期子网络的输出。
该算法专为极深的网络而设计,其中内存成本沿层大致均匀分布。 然而,当这些深度网络适用于检测时,激活(ROI池化后)从(图像特征)增长到(ROI特征),其中 对于弱监督模型有数千个。 如果没有ground-truth box,所有这些提案都需要保持高召回率,从而获得良好的性能(参见附录F中的证据)。
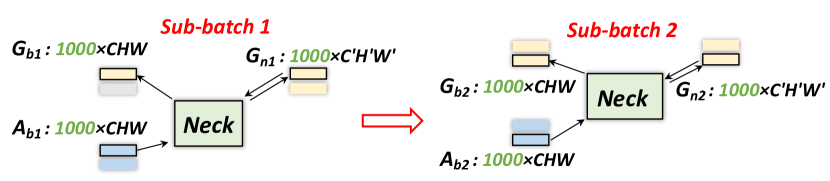
为了解决这个训练挑战,我们建议在“Neck”子模块中进行顺序计算,如图7所示。 在前向传递过程中,输入图像首先通过“Base”和“Neck”,仅存储“Base”之后的激活。 然后“Neck”的输出进入“Head”进行第一次向前和向后传递,以更新“Head”的权重和梯度,如图7 (a)。 为了更新“Neck”的参数,我们将 ROI 特征分成“子批次”,并按顺序对每个小子批次运行反向传播。 因此,我们避免在“Neck”内存储消耗内存的特征图及其梯度。图 7 (b) 显示了这种顺序方法的示例,其中我们将 2000 个提案分成两个子提案每批 1000 个提案。 梯度被累积并用于通过定期反向传播更新“Base”网络的参数,如图7(c)所示。 对于测试,如果 ROI 数量或“颈部”尺寸太大,则可以应用相同的策略。
5实验
在详细介绍数据集、评估指标和实施之后,我们随后评估了我们提出的方法。
| Methods | Val-AP | Val-AP50 | Test-AP | Test-AP50 |
|---|---|---|---|---|
| Fast R-CNN | 18.9 | 38.6 | 19.3 | 39.3 |
| Faster R-CNN | 21.2 | 41.5 | 21.5 | 42.1 |
| WSDDN [5] | - | - | - | 11.5 |
| WCCN [9] | - | - | - | 12.3 |
| PCL [45] | 8.5 | 19.4 | ||
| C-MIDN [12] | 9.6 | 21.4 | - | - |
| WSOD2 [61] | 10.8 | 22.7 | - | - |
| Diba et al. [10]+SSD | - | - | - | 13.6 |
| OICR [46]+Ens+FRCNN | 7.7 | 17.4 | - | - |
| Ge et al. [13]+FRCNN | 8.9 | 19.3 | - | - |
| PCL [45]+Ens.+FRCNN | 9.2 | 19.6 | - | - |
| Ours (single-model) | 11.4 | 24.3 | 12.1 | 24.8 |
| Methods | Proposal | Backbone | AP | AP50 |
|---|---|---|---|---|
| Faster R-CNN | RPN | R101-C4 | 27.2 | 48.4 |
| Ours | MCG | VGG16 | 11.4 | 24.3 |
| Ours | MCG | R50-C4 | 12.6 | 26.1 |
| Ours | MCG | R101-C4 | 13.0 | 26.3 |
数据集和评估指标。
我们首先在 COCO [30] 上进行实验,这是用于监督目标检测的最流行的数据集,但在 WSOD 中很少研究。 我们使用 COCO 2014 训练/验证/测试分割并报告标准 COCO 指标,包括 AP(超过 IoU 阈值的平均值)和 AP50(IoU 阈值为 50%)。
然后,我们对 VOC 2007 和 2012 [11] 进行评估,它们通常用于评估 WSOD 性能。 IoU阈值为50%的平均精度(AP)用于评估目标检测(Det.)的准确性 关于测试数据。 我们还评估正确的定位精度(CorLoc.),它测量一类训练图像的百分比,其中最置信度的预测框与至少一个真实框的 IoU 至少为 50%。
实施细节。
5.1整体表现
VGG16-COCO。 我们在表 1 中与 COCO 上最先进的 WSOD 方法进行了比较。 2. 我们的单一模型没有任何后处理,其性能远远优于以前的所有方法(带有花哨的功能)。 在私有 Test-dev 基准测试中,我们将 AP50 提高了 11.2 (+82.3%)。 对于 2014 年验证集,我们将 AP 和 AP50 分别增加了 0.6 (+5.6%) 和 1.6 (+7.1%)。 完整的结果在附录B中提供。 请注意,与前两行所示的监督模型相比,性能差距仍然较大:我们的平均是 Faster R-CNN 的 56.9%。 此外,我们的模型在 COCO 2017 分裂上实现了 12.4 AP 和 25.8 AP50,如表 1 所示。 4,在监督论文中更常见。


ResNet-COCO。 ResNet 模型之前从未针对 WSOD 进行过训练和评估。 尽管如此,它们是监督方法中最受欢迎的骨干网络。 部分原因是ResNet的内存消耗较大。 没有第二节中介绍的训练技巧。 4.3,不可能使用所有建议在标准 GPU 上进行训练。 在选项卡中。 2 我们使用 ResNet-50 和 ResNet-101 为 COCO 数据集提供了第一个基准测试。 正如预期的那样,我们观察到 ResNet 模型的性能优于 VGG16 模型。 此外,我们注意到 ResNet-50 和 ResNet-101 之间的差异相对较小。
VGG16-VOC。 为了与大多数以前的 WSOD 作品进行公平比较,我们还在 VOC 数据集[11]上评估了我们的方法。 与最近作品的比较见表 1。 3. 该表中的所有条目均为单一模型结果。 对于对象检测,我们的单模型结果在公开的 2007 年测试集 (+1.3 AP50) 和私有 2012 测试集 (+1.9 AP50 此外,我们的单一模型也比之前所有具有附加功能的方法表现得更好(例如.、“+FRCNN”:监督再训练、“+Ens.”) :模型合奏)。 结合 2007 年和 2012 年的训练集,我们的模型在 2007 年的测试集上达到了 58.1% (+2.1 AP50),如表 1 所示。 4. 附录 C 中提供了训练集的 CorLoc 结果和每个类别的结果。由于 VOC 比 COCO 更容易,因此与监督方法的性能差距更小:我们的平均是 Faster R-CNN 的 78.1%。
| Methods | Proposal | 07-AP50 | 12-AP50 |
|---|---|---|---|
| Fast R-CNN | SS | 66.9 | 65.7 |
| Faster R-CNN | RPN | 69.9 | 67.0 |
| WSDDN [5] | EB | 34.8 | - |
| OICR [46] | SS | 41.2 | 37.9 |
| PCL [45] | SS | 43.5 | 40.6 |
| SDCN [29] | SS | 50.2 | 43.5 |
| Yang et al. [60] | SS | 51.5 | 45.6 |
| C-MIL [51] | SS | 50.5 | 46.7 |
| WSOD2 [61] | SS | 53.6 | 47.2 |
| Pred Net [2] | SS | 52.9 | 48.4 |
| C-MIDN [12] | SS | 52.6 | 50.2 |
| C-MIL [51]+FRCNN | SS | 53.1 | - |
| SDCN [29]+FRCNN | SS | 53.7 | 46.7 |
| Pred Net [2]+Ens.+FRCNN | SS | 53.6 | 49.5 |
| Yang et al. [60]+Ens.+FRCNN | SS | 54.5 | 49.5 |
| C-MIDN [12]+FRCNN | SS | 53.6 | 50.3 |
| Ours (single) | SS | 54.9 | 52.1***http://host.robots.ox.ac.uk:8080/anonymous/DCJ5GA.html |
附加训练数据。 WSOD 方法的最大优点是可以获得更多数据。 因此,我们有兴趣研究更多的训练数据是否可以改善结果。 我们分别在 VOC 2007 trainval(5011 张图像)、2012 trainval(11540 张图像)以及两者的组合(16555 张图像)上训练我们的模型,并在 VOC 2007 测试集上进行评估。 如表所示。 4(上),性能随着训练数据量的增加而不断提高。 我们在 COCO 上验证了这一点,其中 2014-train(82783 张图像)和 2017-train(128287 张图像)用于训练,2017-val(又称为 2017-val)用于训练。 最小)用于测试。 观察到类似的结果,如表 1 所示。 4(底部)。
| Data-Split | 07-Trainval | 12-Trainval | 07-Test |
|---|---|---|---|
| Metrics | CorLoc | CorLoc | Det |
| Ours-07 | 68.8 | - | 54.9 |
| Ours-12 | - | 70.9 | 56.3 |
| WSOD2(07+12) [61] | 71.4 | 72.2 | 56.0 |
| Ours-(07+12) | 71.8 | 72.9 | 58.1 |
| Metrics | 17-Val-AP | 17-Val-AP50 | 17-Val-AP75 |
| Ours-Train2014 | 11.4 | 24.3 | 9.4 |
| Ours-Train2017 | 12.4 | 25.8 | 10.5 |
5.2定性结果
5.3分析
每个模块有多少帮助? 我们研究了表中每个模块的有效性。 6. 我们首先重现 Tang et al. [46] 的方法,获得类似的结果(前两行)。 应用开发的 MIST 模块可显着改善结果。 这与我们的观察一致,即实例模糊性是 WSOD 的最大瓶颈。 我们概念上简单的解决方案也优于改进版本[45] (PCL),它基于计算成本昂贵且经过仔细调整的聚类。
设计的 Concrete DropBlock 在使用 MIST 作为基础时进一步提高了性能。 该模块超越了几个变体,包括:(1)(Img Spa.-Dropout):应用于图像级特征的空间丢失; (2) (ROI-Spa.-Dropout):应用于每个 ROI 的空间丢失,其中每个特征点被独立处理。 该设置与[40, 54]类似; (3) (DropBlock):[14] 中报告的性能最佳的 DropBlock 设置。
| Data-Split | 07 trainval | 07 test | 12 trainval | 12 test |
|---|---|---|---|---|
| Metrics | CorLoc | Det. | CorLoc | Det. |
| Baseline [46]* | 60.8 | 42.5 | - | - |
| PCL [45] | 62.7 | 43.5 | 63.2 | 40.6 |
| MIST w/o Reg. | 62.9 | 48.3 | 65.1 | - |
| MIST | 64.9 | 51.4 | 66.7 | - |
| Img Spa.-Dropout | 64.3 | 51.1 | 65.9 | - |
| ROI Spa.-Dropout | 66.8 | 52.4 | 67.3 | - |
| DropBlock [14] | 67.1 | 52.9 | 68.4 | - |
| Concrete DropBlock | 68.8 | 54.9 | 70.9 | 52.1 |
| Metrics | ||||||
|---|---|---|---|---|---|---|
| w/o MIST | 18.6 | 30.6 | 32.5 | 8.8 | 25.8 | 38.9 |
| w/ MIST | 20.5 | 37.8 | 43.9 | 15.0 | 34.8 | 51.7 |
实例歧义是否得到解决?
为了验证实例模糊性是否得到缓解,我们报告了多个 IoU 值 () 的平均召回率 (AR),每个图像有 1、10、100 次检测(、、)以及 VOC 2007 上的小型、中型和大型对象(、、) 。 我们在表 1 中比较了有 MIST 和没有 MIST 的模型。 6 我们的方法增加了所有召回指标。
部分支配问题得到解决了吗?
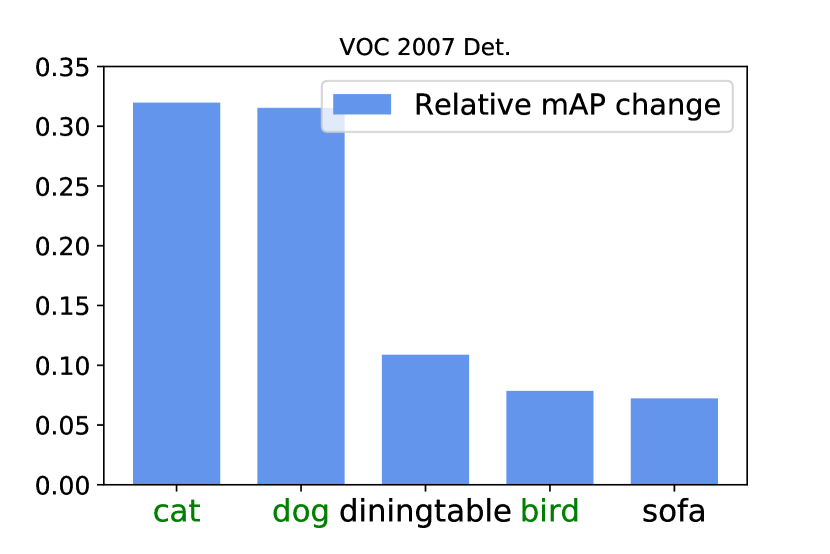
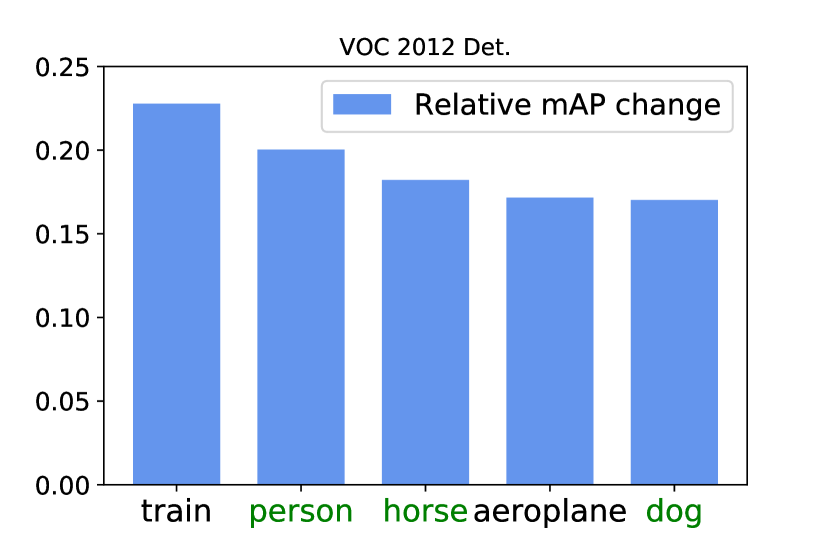
在图11中,我们展示了应用Concrete DropBlock后在VOC 2007和VOC 2012数据集上相对性能提升最大的5个类别。 包括“人”在内的动物类别的表现增加最多,这符合我们在第 2 节中提到的直觉。 1:对于具有僵化和歧视性部件的铰接类,部件支配问题最为突出。 在这两个数据集中,前五个类别中的三个是哺乳动物。
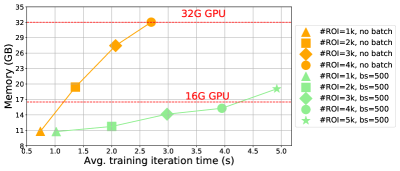
连续批量BP的时空分析?
我们还研究了顺序批量反向传播的效果。 我们将输入图像的大小固定为 ,并运行两种方法(普通反向传播方法和我们使用 ResNet-101 的子批次大小为 500 的方法进行比较。 我们以 1k 为增量将提案数量从 1k 更改为 5k,并在图 11 中报告平均训练迭代时间和内存消耗。 我们观察到:(1) 在标准 16GB GPU 上,普通反向传播甚至无法承受 2k 个提案([16,5,46] 中广泛使用的 ROI 平均数量),但我们的 GPU 可以轻松处理到 4k 盒子; (2) 训练过程并没有大幅减慢,我们的训练时间比普通版本多 1-2 时间。 在实践中,输入分辨率和提案总数可以更大。
| Methods | Backbone | Det. (AP) | Backbone | Det. (AP) |
|---|---|---|---|---|
| Supervised | VGG16 | 61.7 [59] | R-101 | 80.5 [59] |
| [5] | VGG16 | 24.2 | R-101 | 21.9 |
| [46] | VGG16 | 34.8 | R-101 | 40.5 |
| Ours (MIST only) | VGG16 | 35.7 | R-101 | 44.0 |
| Ours | VGG16 | 36.6 | R-101 | 45.7 |
| Ours+flow | VGG16 | 38.3 | R-101 | 46.9 |
MIST 的稳健性?
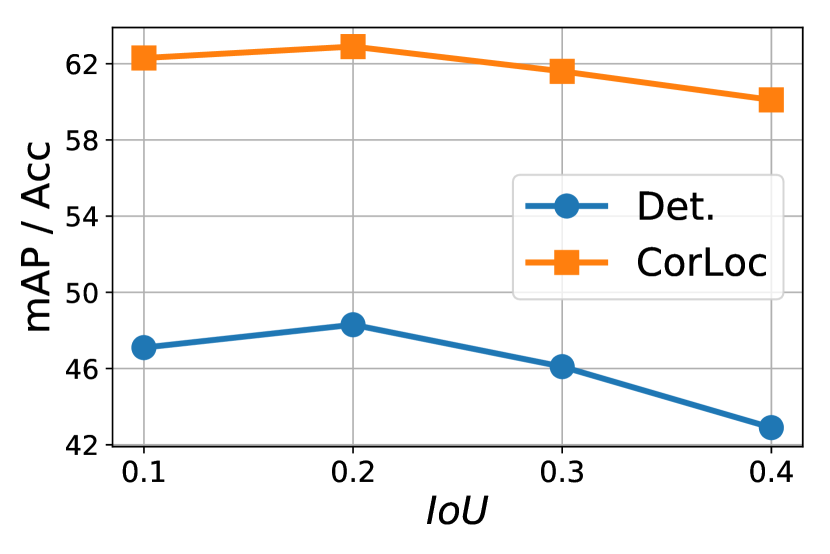
为了评估鲁棒性,我们在 VOC 2007 数据集上仅使用不同的最高百分比 和拒绝 IoU 来测试基线模型和该算法。 结果如图12所示。 最好的结果是使用 和 实现的,我们将其用于所有其他模型和数据集。 重要的是,我们注意到,总体而言,最终结果对 值的敏感性很小,并且对于 IoU 来说仅稍大一些。
5.4 扩展:视频对象检测
6结论
在本文中,我们解决了 WSOD 的三个主要问题。 对于每个问题,我们都提出了一个解决方案,并通过大量的实验证明了其有效性。 我们在流行数据集(COCO、VOC 07 和 12)上取得了最先进的结果,并且是第一个对 ResNet 主干和弱监督视频对象检测进行基准测试的人。
致谢:ZR 得到云妮和包美欣纪念奖学金的支持。 这项工作得到了美国国家科学基金会 (NSF) 的部分支持,授权号为: 1718221 和编号 1751206.
参考
- [1] P. Arbeláez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In Proc. CVPR, 2014.
- [2] Aditya Arun, C. V. Jawahar, and M. Pawan Kumar. Dissimilarity coefficient based weakly supervised object detection. In Proc. CVPR, 2019.
- [3] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with posterior regularization. In Proc. BMVC, 2014.
- [4] Hakan Bilen, Marco Pedersoli, and Tinne Tuytelaars. Weakly supervised object detection with convex clustering. In Proc. CVPR, 2015.
- [5] H. Bilen and A. Vedaldi. Weakly supervised deep detection networks. In Proc. CVPR, 2016.
- [6] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. CoRR, abs/1604.06174, 2016.
- [7] Ramazan Gokberk Cinbis, Jakob J. Verbeek, and Cordelia Schmid. Multi-fold MIL training for weakly supervised object localization. In Proc. CVPR, 2014.
- [8] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In Proc. CVPR, 2009.
- [9] Ali Diba, Vivek Sharma, Ali Mohammad Pazandeh, Hamed Pirsiavash, and Luc Van Gool. Weakly supervised cascaded convolutional networks. In Proc. CVPR, 2017.
- [10] Ali Diba, Vivek Sharma, Rainer Stiefelhagen, and Luc Van Gool. Object discovery by generative adversarial & ranking networks. 2017.
- [11] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. In Proc. IJCV, 2010.
- [12] Yan Gao, Boxiao Liu, Nan Guo, Xiaochun Ye, Fang Wan, Haihang You, and Dongrui Fan. C-midn: Coupled multiple instance detection network with segmentation guidance for weakly supervised object detection. In Proc. ICCV, 2019.
- [13] Weifeng Ge, Sibei Yang, and Yizhou Yu. Multi-evidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning. In Proc. CVPR, 2018.
- [14] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V. Le. Dropblock: A regularization method for convolutional networks. In Proc. NIPS, 2018.
- [15] Ross Girshick, Ilija Radosavovic, Georgia Gkioxari, Piotr Dollár, and Kaiming He. Detectron. https://github.com/facebookresearch/detectron, 2018.
- [16] Ross B. Girshick. Fast R-CNN. In Proc. ICCV, 2015.
- [17] Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proc. CVPR, 2014.
- [18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proc. ICCV, 2017.
- [19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proc. CVPR, 2016.
- [20] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proc. CVPR, 2017.
- [21] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In Proc. ICLR, 2017.
- [22] Zequn Jie, Yunchao Wei, Xiaojie Jin, Jiashi Feng, and Wei Liu. Deep self-taught learning for weakly supervised object localization. In Proc. CVPR, 2017.
- [23] Vadim Kantorov, Maxime Oquab, Minsu Cho, and Ivan Laptev. Contextlocnet: Context-aware deep network models for weakly supervised localization. In Proc. ECCV, 2016.
- [24] Durk P Kingma, Tim Salimans, and Max Welling. Variational dropout and the local reparameterization trick. In Proc. NIPS. 2015.
- [25] Iasonas Kokkinos. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. In Proc. CVPR, 2017.
- [26] Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In Proc. ICLR, 2017.
- [27] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proc. ECCV, 2018.
- [28] Dong Li, Jia-Bin Huang, Yali Li, Shengjin Wang, and Ming-Hsuan Yang. Weakly supervised object localization with progressive domain adaptation. In Proc. CVPR, 2016.
- [29] Xiaoyan Li, Meina Kan, Shiguang Shan, and Xilin Chen. Weakly supervised object detection with segmentation collaboration. In Proc. ICCV, 2019.
- [30] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In Proc. ECCV, 2014.
- [31] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. Ssd: Single shot multibox detector. In ECCV, 2016.
- [32] Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. In Proc. ICLR, 2017.
- [33] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu Zhang, Kai Jia, Gang Yu, and Jian Sun. Megdet: A large mini-batch object detector. In Proc. CVPR, 2018.
- [34] Geoff Pleiss, Danlu Chen, Gao Huang, Tongcheng Li, Laurens van der Maaten, and Kilian Q. Weinberger. Memory-efficient implementation of densenets. CoRR, abs/1707.06990, 2017.
- [35] Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proc. CVPR, 2016.
- [36] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. TPAMI, 2016.
- [37] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Parallel distributed processing: Explorations in the microstructure of cognition. chapter Learning Internal Representations by Error Propagation. MIT Press, 1986.
- [38] Yunhang Shen, Rongrong Ji, Yan Wang, Yongjian Wu, and Liujuan Cao. Cyclic guidance for weakly supervised joint detection and segmentation. In Proc. CVPR, 2019.
- [39] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Proc. ICLR, 2015.
- [40] Krishna Kumar Singh and Yong Jae Lee. Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization. In Proc. ICCV, 2017.
- [41] Krishna Kumar Singh and Yong Jae Lee. You reap what you sow: Using videos to generate high precision object proposals for weakly-supervised object detection. In Proc. CVPR, 2019.
- [42] Krishna Kumar Singh, Fanyi Xiao, and Yong Jae Lee. Track and transfer: Watching videos to simulate strong human supervision for weakly-supervised object detection. In Proc. CVPR, 2016.
- [43] P. Siva and T. Xiang. Weakly supervised object detector learning with model drift detection. In Proc. ICCV, 2013.
- [44] Hyun Oh Song, Yong Jae Lee, Stefanie Jegelka, and Trevor Darrell. Weakly-supervised discovery of visual pattern configurations. In Proc. NIPS, 2014.
- [45] Peng Tang, Xinggang Wang, Song Bai, Wei Shen, Xiang Bai, Wenyu Liu, and Alan Yuille. PCL: Proposal cluster learning for weakly supervised object detection. TPAMI, 2018.
- [46] Peng Tang, Xinggang Wang, Xiang Bai, and Wenyu Liu. Multiple instance detection network with online instance classifier refinement. In Proc. CVPR, 2017.
- [47] Peng Tang, Xinggang Wang, Angtian Wang, Yongluan Yan, Wenyu Liu, Junzhou Huang, and Alan L. Yuille. Weakly supervised region proposal network and object detection. In Proc. ECCV, 2018.
- [48] Eu Wern Teh, Mrigank Rochan, and Yang Wang. Attention networks for weakly supervised object localization. In Proc. BMVC, 2016.
- [49] Jonathan Tompson, Ross Goroshin, Arjun Jain, Yann LeCun, and Christoph Bregler. Efficient object localization using convolutional networks. In Proc. CVPR, 2015.
- [50] J.R.R. Uijlings, K.E.A. van de Sande, T. Gevers, and A.W.M.Smeulders. Selective search for object recognition. IJCV, 2013.
- [51] Fang Wan, Chang Liu, Wei Ke, Xiangyang Ji, Jianbin Jiao, and Qixiang Ye. C-MIL: continuation multiple instance learning for weakly supervised object detection. In Proc. CVPR, 2019.
- [52] Fang Wan, Pengxu Wei, Jianbin Jiao, Zhenjun Han, and Qixiang Ye. Min-entropy latent model for weakly supervised object detection. In Proc. CVPR, 2018.
- [53] Chong Wang, Weiqiang Ren, Kaiqi Huang, and Tieniu Tan. Weakly supervised object localization with latent category learning. In Proc. ECCV, 2014.
- [54] Xiaolong Wang, Abhinav Shrivastava, and Abhinav Gupta. A-fast-rcnn: Hard positive generation via adversary for object detection. In Proc. CVPR, 2017.
- [55] Xinggang Wang, Zhuotun Zhu, Cong Yao, and Xiang Bai. Relaxed multiple-instance SVM with application to object discovery. In Proc. ICCV, 2015.
- [56] Yunchao Wei, Jiashi Feng, Xiaodan Liang, Ming-Ming Cheng, Yao Zhao, and Shuicheng Yan. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proc. CVPR, 2017.
- [57] Yunchao Wei, Zhiqiang Shen, Bowen Cheng, Honghui Shi, Jinjun Xiong, Jiashi Feng, and Thomas S. Huang. TS2C: tight box mining with surrounding segmentation context for weakly supervised object detection. In Proc. ECCV, 2018.
- [58] Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 1992.
- [59] Fanyi Xiao and Yong Jae Lee. Video object detection with an aligned spatial-temporal memory. In Proc. ECCV, 2018.
- [60] Ke Yang, Dongsheng Li, and Yong Dou. Towards precise end-to-end weakly supervised object detection network. In Proc. ICCV, 2019.
- [61] Zhaoyang Zeng, Bei Liu, Jianlong Fu, Hongyang Chao, and Lei Zhang. WSOD2: Learning bottom-up and top-down objectness distillation for weakly-supervised object detection. In Proc. ICCV, 2019.
- [62] Xiaopeng Zhang, Jiashi Feng, Hongkai Xiong, and Qi Tian. Zigzag learning for weakly supervised object detection. In Proc. CVPR, 2018.
- [63] Yongqiang Zhang, Yancheng Bai, Mingli Ding, Yongqiang Li, and Bernard Ghanem. W2f: A weakly-supervised to fully-supervised framework for object detection. In Proc. CVPR, 2018.
- [64] Xizhou Zhu, Yujie Wang, Jifeng Dai, Lu Yuan, and Yichen Wei. Flow-guided feature aggregation for video object detection. In Proc. ICCV, 2017.
- [65] C. Lawrence Zitnick and Piotr Dollár. Edge boxes: Locating object proposals from edges. In Proc. ECCV, 2014.
- [66] Yang Zou, Zhiding Yu, Xiaofeng Liu, B.V.K. Vijaya Kumar, and Jinsong Wang. Confidence regularized self-training. In Proc. ICCV, 2019.
- [67] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proc. ECCV, 2018.
附录
在本节中,我们提供:(1)COCO 的额外定量结果; (2) VOC上的每类检测(AP)和正确定位(CorLoc)结果; (3) 额外的定性结果; (四)提案统计; (五)提案数量消减研究; (6)弱监督视频目标检测的实现细节和视频演示。 具体来说,我们表明我们的方法在 COCO 上产生了最先进的结果(见表 1)。 8),在 VOC 2007 和 2012 上优于所有竞争模型(参见表 1)。 10 和选项卡。 10)。 我们还在选项卡中提供了正确的本地化结果。 11 和选项卡。 12 为了完整性,并说明表 1 中顺序批量反向传播的必要性(在主论文的 4.3 节中介绍)。 13 和选项卡。 14. 还提供了全面的可视化(图13至图16)。
附录A实施细节
在本节中,为了完整性,我们提供了额外的实现细节。
A.1 骨干
VGG-16
我们使用标准 VGG-16(没有批量归一化)作为主干。 如图2所示,“Base”网络包含全连接层之前的所有卷积层。 在[46]之后,我们删除了最后一个最大池化层,并用扩张卷积(dilation=2)层替换倒数第二个最大池化层和后续卷积层,以提高特征图分辨率。 标准 RoI 池化用于计算区域级特征。 我们使用 VGG-16 的全连接层,除了最后一个分类器层作为“颈部”。 在“Neck”之后,RoI 特征使用 4 个单全连接层投影到 。
残差网络
我们使用 Detectron 代码存储库 [15] 中的 ResNet-50/101-C4 变体。 前 4 个 ResNet 阶段 (C1-C4) 的卷积层用作“Base”,最后一个阶段 (C5) 用作“Neck”。 使用标准 RoI 池化,并使用线性层投影 RoI 特征。
A.2 混凝土 DropBlock
Concrete DropBlock 是作为 ResNet 中的标准残差块实现的。 它将 RoI 特征作为输入并输出 1 通道热图 。 在跳跃连接上,我们使用卷积来减少特征通道。 然后,我们使用 Gumbel-softmax 生成硬掩模 ,以及 DropBlock [14] 中的结构化 dropout 区域。
A.3 学生块
在[46]之后,我们堆叠了 3 个学生块。 在训练期间,学生块为下一个学生块生成伪标签。 在测试过程中,我们将所有学生块的预测平均作为最终结果。
A.4培训
我们的代码在 PyTorch 中实现,所有实验都在单 8-GPU (NVIDIA V100) 机器上进行。 SGD 用于优化,权重衰减为 0.0001,动量为 0.9。 VOC 2007上批量大小和初始学习率设置为8和0.01; VOC 2012 为 16 和 0.02。 在这两个数据集上,我们对模型进行 30k 次迭代训练,并在 20k 和 26k 步时将学习率衰减 0.1。 在 COCO 上,我们训练模型总共 130k 次迭代,并在 90k 和 120k 步时衰减学习率,批量大小为 8,初始学习率为 0.01。 我们对 VOC 数据集使用选择性搜索 (SS) [50],对 COCO 使用 MCG [1]。
A.5 数据增强和推理
在[46, 23]之后的训练和测试过程中使用多尺度输入(480, 576, 688, 864, 1000, 1200),并将最长图像边设置为小于2000。 在测试时,分数是所有量表及其水平翻转的平均值。
附录 B COCO 的其他定量结果
在选项卡中。 8,我们报告了不同模型在 COCO 上不同阈值和尺度的定量结果。 报告的指标包括: 多个 IoU 阈值 (.50 : .05 : .95) 的平均预测 (),在 IoU 阈值 50% 和 75% 时(、),以及小型、中型和大型对象(、、);以及多个 IoU 值 (.50 : .05 : .95) 上的平均召回率 (),每个图像有 1、10 和 100 次检测 ();以及小型、中型和大型对象(、、 结果如表所示。 8表明物体尺寸是影响检测精度的重要因素。 探测器在大物体上的表现往往比在小物体上的表现更好。
| Train | Test | Model | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2014 Train | 2014 Val | VGG16 | 11.4 | 24.3 | 9.4 | 3.6 | 12.2 | 17.6 | 13.5 | 22.6 | 23.9 | 8.5 | 25.4 | 38.3 |
| 2014 Train | 2014 Val | R50-C4 | 12.6 | 26.1 | 10.8 | 3.7 | 13.3 | 19.9 | 14.8 | 23.7 | 24.7 | 8.4 | 25.1 | 41.8 |
| 2014 Train | 2014 Val | R101-C4 | 13.0 | 26.3 | 11.4 | 3.5 | 13.7 | 20.4 | 15.4 | 23.4 | 24.6 | 8.5 | 24.6 | 40.9 |
| 2017 Train | minival | VGG16 | 12.4 | 25.8 | 10.5 | 3.9 | 13.8 | 19.9 | 14.3 | 23.3 | 24.6 | 9.7 | 26.6 | 39.6 |
| 2014 Train | Test-Dev | VGG16 | 12.1 | 24.8 | 10.2 | 4.1 | 13.0 | 18.3 | 13.5 | 25.5 | 29.0 | 9.6 | 30.0 | 46.7 |
附录 CVOC 的其他结果
C.1 每类检测结果
| Methods | Proposal | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Motor | Person | Plant | Sheep | Sofa | Train | TV | AP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN | SS | 73.4 | 77.0 | 63.4 | 45.4 | 44.6 | 75.1 | 78.1 | 79.8 | 40.5 | 73.7 | 62.2 | 79.4 | 78.1 | 73.1 | 64.2 | 35.6 | 66.8 | 67.2 | 70.4 | 71.1 | 66.0 |
| Faster R-CNN | RPN | 70.0 | 80.6 | 70.1 | 57.3 | 49.9 | 78.2 | 80.4 | 82.0 | 52.2 | 75.3 | 67.2 | 80.3 | 79.8 | 75.0 | 76.3 | 39.1 | 68.3 | 67.3 | 81.1 | 67.6 | 69.9 |
| Cinbis [7] | SS | 35.8 | 40.6 | 8.1 | 7.6 | 3.1 | 35.9 | 41.8 | 16.8 | 1.4 | 23.0 | 4.9 | 14.1 | 31.9 | 41.9 | 19.3 | 11.1 | 27.6 | 12.1 | 31.0 | 40.6 | 22.4 |
| Bilen [4] | SS | 46.2 | 46.9 | 24.1 | 16.4 | 12.2 | 42.2 | 47.1 | 35.2 | 7.8 | 28.3 | 12.7 | 21.5 | 30.1 | 42.4 | 7.8 | 20.0 | 26.8 | 20.8 | 35.8 | 29.6 | 27.7 |
| Wang [53] | SS | 48.8 | 41.0 | 23.6 | 12.1 | 11.1 | 42.7 | 40.9 | 35.5 | 11.1 | 36.6 | 18.4 | 35.3 | 34.8 | 51.3 | 17.2 | 17.4 | 26.8 | 32.8 | 35.1 | 45.6 | 30.9 |
| Li [28] | EB | 54.5 | 47.4 | 41.3 | 20.8 | 17.7 | 51.9 | 63.5 | 46.1 | 21.8 | 57.1 | 22.1 | 34.4 | 50.5 | 61.8 | 16.2 | 29.9 | 40.7 | 15.9 | 55.3 | 40.2 | 39.5 |
| WSDDN [5] | EB | 39.4 | 50.1 | 31.5 | 16.3 | 12.6 | 64.5 | 42.8 | 42.6 | 10.1 | 35.7 | 24.9 | 38.2 | 34.4 | 55.6 | 9.4 | 14.7 | 30.2 | 40.7 | 54.7 | 46.9 | 34.8 |
| Teh [48] | EB | 48.8 | 45.9 | 37.4 | 26.9 | 9.2 | 50.7 | 43.4 | 43.6 | 10.6 | 35.9 | 27.0 | 38.6 | 48.5 | 43.8 | 24.7 | 12.1 | 29.0 | 23.2 | 48.8 | 41.9 | 34.5 |
| ContextLocNet [23] | SS | 57.1 | 52.0 | 31.5 | 7.6 | 11.5 | 55.0 | 53.1 | 34.1 | 1.7 | 33.1 | 49.2 | 42.0 | 47.3 | 56.6 | 15.3 | 12.8 | 24.8 | 48.9 | 44.4 | 47.8 | 36.3 |
| OICR [46] | SS | 58.0 | 62.4 | 31.1 | 19.4 | 13.0 | 65.1 | 62.2 | 28.4 | 24.8 | 44.7 | 30.6 | 25.3 | 37.8 | 65.5 | 15.7 | 24.1 | 41.7 | 46.9 | 64.3 | 62.6 | 41.2 |
| Jie [22] | ? | 52.2 | 47.1 | 35.0 | 26.7 | 15.4 | 61.3 | 66.0 | 54.3 | 3.0 | 53.6 | 24.7 | 43.6 | 48.4 | 65.8 | 6.6 | 18.8 | 51.9 | 43.6 | 53.6 | 62.4 | 41.7 |
| Diba [9] | EB | 49.5 | 60.6 | 38.6 | 29.2 | 16.2 | 70.8 | 56.9 | 42.5 | 10.9 | 44.1 | 29.9 | 42.2 | 47.9 | 64.1 | 13.8 | 23.5 | 45.9 | 54.1 | 60.8 | 54.5 | 42.8 |
| PCL [45] | SS | 54.4 | 69.0 | 39.3 | 19.2 | 15.7 | 62.9 | 64.4 | 30.0 | 25.1 | 52.5 | 44.4 | 19.6 | 39.3 | 67.7 | 17.8 | 22.9 | 46.6 | 57.5 | 58.6 | 63.0 | 43.5 |
| Wei [57] | SS | 59.3 | 57.5 | 43.7 | 27.3 | 13.5 | 63.9 | 61.7 | 59.9 | 24.1 | 46.9 | 36.7 | 45.6 | 39.9 | 62.6 | 10.3 | 23.6 | 41.7 | 52.4 | 58.7 | 56.6 | 44.3 |
| Tang [47] | SS | 57.9 | 70.5 | 37.8 | 5.7 | 21.0 | 66.1 | 69.2 | 59.4 | 3.4 | 57.1 | 57.3 | 35.2 | 64.2 | 68.6 | 32.8 | 28.6 | 50.8 | 49.5 | 41.1 | 30.0 | 45.3 |
| Shen [38] | SS | 52.0 | 64.5 | 45.5 | 26.7 | 27.9 | 60.5 | 47.8 | 59.7 | 13.0 | 50.4 | 46.4 | 56.3 | 49.6 | 60.7 | 25.4 | 28.2 | 50.0 | 51.4 | 66.5 | 29.7 | 45.6 |
| Wan [52] | SS | 55.6 | 66.9 | 34.2 | 29.1 | 16.4 | 68.8 | 68.1 | 43.0 | 25.0 | 65.6 | 45.3 | 53.2 | 49.6 | 68.6 | 2.0 | 25.4 | 52.5 | 56.8 | 62.1 | 57.1 | 47.3 |
| SDCN [29] | SS | 59.4 | 71.5 | 38.9 | 32.2 | 21.5 | 67.7 | 64.5 | 68.9 | 20.4 | 49.2 | 47.6 | 60.9 | 55.9 | 67.4 | 31.2 | 22.9 | 45.0 | 53.2 | 60.9 | 64.4 | 50.2 |
| C-MIL [51] | SS | 62.5 | 58.4 | 49.5 | 32.1 | 19.8 | 70.5 | 66.1 | 63.4 | 20.0 | 60.5 | 52.9 | 53.5 | 57.4 | 68.9 | 8.4 | 24.6 | 51.8 | 58.7 | 66.7 | 63.6 | 50.5 |
| Yang [60] | SS | 57.6 | 70.8 | 50.7 | 28.3 | 27.2 | 72.5 | 69.1 | 65.0 | 26.9 | 64.5 | 47.4 | 47.7 | 53.5 | 66.9 | 13.7 | 29.3 | 56.0 | 54.9 | 63.4 | 65.2 | 51.5 |
| C-MIDN [12] | SS | 53.3 | 71.5 | 49.8 | 26.1 | 20.3 | 70.3 | 69.9 | 68.3 | 28.7 | 65.3 | 45.1 | 64.6 | 58.0 | 71.2 | 20.0 | 27.5 | 54.9 | 54.9 | 69.4 | 63.5 | 52.6 |
| Arun [2] | SS | 66.7 | 69.5 | 52.8 | 31.4 | 24.7 | 74.5 | 74.1 | 67.3 | 14.6 | 53.0 | 46.1 | 52.9 | 69.9 | 70.8 | 18.5 | 28.4 | 54.6 | 60.7 | 67.1 | 60.4 | 52.9 |
| WSOD2 [61] | SS | 65.1 | 64.8 | 57.2 | 39.2 | 24.3 | 69.8 | 66.2 | 61.0 | 29.8 | 64.6 | 42.5 | 60.1 | 71.2 | 70.7 | 21.9 | 28.1 | 58.6 | 59.7 | 52.2 | 64.8 | 53.6 |
| Ours | SS | 68.8 | 77.7 | 57.0 | 27.7 | 28.9 | 69.1 | 74.5 | 67.0 | 32.1 | 73.2 | 48.1 | 45.2 | 54.4 | 73.7 | 35.0 | 29.3 | 64.1 | 53.8 | 65.3 | 65.2 | 54.9 |
| Methods | Proposal | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Motor | Person | Plant | Sheep | Sofa | Train | TV | AP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN | SS | 80.3 | 74.7 | 66.9 | 46.9 | 37.7 | 73.9 | 68.6 | 87.7 | 41.7 | 71.1 | 51.1 | 86.0 | 77.8 | 79.8 | 69.8 | 32.1 | 65.5 | 63.8 | 76.4 | 61.7 | 65.7 |
| Faster R-CNN | RPN | 82.3 | 76.4 | 71.0 | 48.4 | 45.2 | 72.1 | 72.3 | 87.3 | 42.2 | 73.7 | 50.0 | 86.8 | 78.7 | 78.4 | 77.4 | 34.5 | 70.1 | 57.1 | 77.1 | 58.9 | 67.0 |
| Li [28] | EB | 62.9 | 55.5 | 43.7 | 14.9 | 13.6 | 57.7 | 52.4 | 50.9 | 13.3 | 45.4 | 4.0 | 30.2 | 55.6 | 67.0 | 3.8 | 23.1 | 39.4 | 5.5 | 50.7 | 29.3 | 35.9 |
| ContextLocNet [23] | SS | 64.0 | 54.9 | 36.4 | 8.1 | 12.6 | 53.1 | 40.5 | 28.4 | 6.6 | 35.3 | 34.4 | 49.1 | 42.6 | 62.4 | 19.8 | 15.2 | 27.0 | 33.1 | 33.0 | 50.0 | 35.3 |
| OICR [46] | SS | 67.7 | 61.2 | 41.5 | 25.6 | 22.2 | 54.6 | 49.7 | 25.4 | 19.9 | 47.0 | 18.1 | 26.0 | 38.9 | 67.7 | 2.0 | 22.6 | 41.1 | 34.3 | 37.9 | 55.3 | 37.9 |
| Jie [22] | ? | 60.8 | 54.2 | 34.1 | 14.9 | 13.1 | 54.3 | 53.4 | 58.6 | 3.7 | 53.1 | 8.3 | 43.4 | 49.8 | 69.2 | 4.1 | 17.5 | 43.8 | 25.6 | 55.0 | 50.1 | 38.3 |
| Diba [9] | EB | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 37.9 |
| Shen [38] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 39.1 |
| PCL [45] | SS | 58.2 | 66.0 | 41.8 | 24.8 | 27.2 | 55.7 | 55.2 | 28.5 | 16.6 | 51.0 | 17.5 | 28.6 | 49.7 | 70.5 | 7.1 | 25.7 | 47.5 | 36.6 | 44.1 | 59.2 | 40.6 |
| Wei [57] | SS | 67.4 | 57.0 | 37.7 | 23.7 | 15.2 | 56.9 | 49.1 | 64.8 | 15.1 | 39.4 | 19.3 | 48.4 | 44.5 | 67.2 | 2.1 | 23.3 | 35.1 | 40.2 | 46.6 | 45.8 | 40.0 |
| Tang [47] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 40.8 |
| Wan [52] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 42.4 |
| SDCN [29] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 43.5 |
| Yang [60] | SS | 64.7 | 66.3 | 46.8 | 28.5 | 28.4 | 59.8 | 58.6 | 70.9 | 13.8 | 55.0 | 15.7 | 60.5 | 63.9 | 69.2 | 8.7 | 23.8 | 44.7 | 52.7 | 41.5 | 62.6 | 46.8 |
| C-MIL [51] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 46.7 |
| WSOD2 [61] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 47.2 |
| Arun [2] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 48.4 |
| C-MIDN [12] | SS | 72.9 | 68.9 | 53.9 | 25.3 | 29.7 | 60.9 | 56.0 | 78.3 | 23.0 | 57.8 | 25.7 | 73.0 | 63.5 | 73.7 | 13.1 | 28.7 | 51.5 | 35.0 | 56.1 | 57.5 | 50.2 |
| Ours†††http://host.robots.ox.ac.uk:8080/anonymous/DCJ5GA.html | SS | 78.3 | 73.9 | 56.5 | 30.4 | 37.4 | 64.2 | 59.3 | 60.3 | 26.6 | 66.8 | 25.0 | 55.0 | 61.8 | 79.3 | 14.5 | 30.3 | 61.5 | 40.7 | 56.4 | 63.5 | 52.1 |
在选项卡中。 10 和选项卡。 10,我们报告了 VOC 2007 和 2012 测试集上的每类检测 AP。 与我们观察到的其他 WSOD 方法相比:(1) 我们的方法在大多数类别上都优于所有其他方法(VOC 2007 上有 10 个类别,VOC 2012 上有 14 个类别)。 (2) 对于我们的方法来说很难的类(例如.、船、植物和椅子)对于其他方法来说也具有挑战性。 这表明这些类别本质上是 WSOD 方法的硬示例,可能仍然需要一定程度的强有力的监督。
与监督模型(Fast R-CNN、Faster R-CNN)相比,我们注意到:(1)我们的弱监督模型在飞机、自行车、公共汽车、汽车、牛、摩托车、羊、电视监视器、其中性能差距通常小于 10% AP。 我们的模型有时甚至在那些被认为相对简单、类内差异较小的类别上表现优于监督模型(VOC 2007 中的自行车和摩托车,VOC 2012 中的摩托车和电视显示器)。 (2) 对于船、椅子、餐桌、人等类,所有 WSOD 方法都明显比监督方法差。 这可能是由于类内差异较大造成的。 WSOD 方法无法捕获这些类的一致模式。
C.2 每类正确的定位结果
| Methods | Proposal | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Motor | Person | Plant | Sheep | Sofa | Train | TV | CorLoc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cinbis [7] | SS | 56.6 | 58.3 | 28.4 | 20.7 | 6.8 | 54.9 | 69.1 | 20.8 | 9.2 | 50.5 | 10.2 | 29.0 | 58.0 | 64.9 | 36.7 | 18.7 | 56.5 | 13.2 | 54.9 | 59.4 | 38.8 |
| Bilen [4] | SS | 66.4 | 59.3 | 42.7 | 20.4 | 21.3 | 63.4 | 74.3 | 59.6 | 21.1 | 58.2 | 14.0 | 38.5 | 49.5 | 60.0 | 19.8 | 39.2 | 41.7 | 30.1 | 50.2 | 44.1 | 43.7 |
| Wang [53] | SS | 80.1 | 63.9 | 51.5 | 14.9 | 21.0 | 55.7 | 74.2 | 43.5 | 26.2 | 53.4 | 16.3 | 56.7 | 58.3 | 69.5 | 14.1 | 38.3 | 58.8 | 47.2 | 49.1 | 60.9 | 48.5 |
| Li [28] | EB | 78.2 | 67.1 | 61.8 | 38.1 | 36.1 | 61.8 | 78.8 | 55.2 | 28.5 | 68.8 | 18.5 | 49.2 | 64.1 | 73.5 | 21.4 | 47.4 | 64.6 | 22.3 | 60.9 | 52.3 | 52.4 |
| WSDDN [5] | EB | 65.1 | 58.8 | 58.5 | 33.1 | 39.8 | 68.3 | 60.2 | 59.6 | 34.8 | 64.5 | 30.5 | 43.0 | 56.8 | 82.4 | 25.5 | 41.6 | 61.5 | 55.9 | 65.9 | 63.7 | 53.5 |
| Teh [48] | EB | 84.0 | 64.6 | 70.0 | 62.4 | 25.8 | 80.6 | 73.9 | 71.5 | 35.7 | 81.6 | 46.5 | 71.3 | 79.1 | 78.8 | 56.7 | 34.3 | 69.8 | 56.7 | 77.0 | 72.7 | 64.6 |
| ContextLocNet [23] | SS | 83.3 | 68.6 | 54.7 | 23.4 | 18.3 | 73.6 | 74.1 | 54.1 | 8.6 | 65.1 | 47.1 | 59.5 | 67.0 | 83.5 | 35.3 | 39.9 | 67.0 | 49.7 | 63.5 | 65.2 | 55.1 |
| OICR [46] | SS | 81.7 | 80.4 | 48.7 | 49.5 | 32.8 | 81.7 | 85.4 | 40.1 | 40.6 | 79.5 | 35.7 | 33.7 | 60.5 | 88.8 | 21.8 | 57.9 | 76.3 | 59.9 | 75.3 | 81.4 | 60.6 |
| Jie [22] | ? | 72.7 | 55.3 | 53.0 | 27.8 | 35.2 | 68.6 | 81.9 | 60.7 | 11.6 | 71.6 | 29.7 | 54.3 | 64.3 | 88.2 | 22.2 | 53.7 | 72.2 | 52.6 | 68.9 | 75.5 | 56.1 |
| Diba [9] | EB | 83.9 | 72.8 | 64.5 | 44.1 | 40.1 | 65.7 | 82.5 | 58.9 | 33.7 | 72.5 | 25.6 | 53.7 | 67.4 | 77.4 | 26.8 | 49.1 | 68.1 | 27.9 | 64.5 | 55.7 | 56.7 |
| Wei [57] | SS | 84.2 | 74.1 | 61.3 | 52.1 | 32.1 | 76.7 | 82.9 | 66.6 | 42.3 | 70.6 | 39.5 | 57.0 | 61.2 | 88.4 | 9.3 | 54.6 | 72.2 | 60.0 | 65.0 | 70.3 | 61.0 |
| Wan [52] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 61.4 |
| PCL [45] | SS | 79.6 | 85.5 | 62.2 | 47.9 | 37.0 | 83.8 | 83.4 | 43.0 | 38.3 | 80.1 | 50.6 | 30.9 | 57.8 | 90.8 | 27.0 | 58.2 | 75.3 | 68.5 | 75.7 | 78.9 | 62.7 |
| Tang [47] | SS | 77.5 | 81.2 | 55.3 | 19.7 | 44.3 | 80.2 | 86.6 | 69.5 | 10.1 | 87.7 | 68.4 | 52.1 | 84.4 | 91.6 | 57.4 | 63.4 | 77.3 | 58.1 | 57.0 | 53.8 | 63.8 |
| Li [29] | SS | 85.0 | 83.9 | 58.9 | 59.6 | 43.1 | 79.7 | 85.2 | 77.9 | 31.3 | 78.1 | 50.6 | 75.6 | 76.2 | 88.4 | 49.7 | 56.4 | 73.2 | 62.6 | 77.2 | 79.9 | 68.6 |
| Shen [38] | SS | 82.9 | 74.0 | 73.4 | 47.1 | 60.9 | 80.4 | 77.5 | 78.8 | 18.6 | 70.0 | 56.7 | 67.0 | 64.5 | 84.0 | 47.0 | 50.1 | 71.9 | 57.6 | 83.3 | 43.5 | 64.5 |
| C-MIL [51] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 65.0 |
| Yang [60] | SS | 80.0 | 83.9 | 74.2 | 53.2 | 48.5 | 82.7 | 86.2 | 69.5 | 39.3 | 82.9 | 53.6 | 61.4 | 72.4 | 91.2 | 22.4 | 57.5 | 83.5 | 64.8 | 75.7 | 77.1 | 68.0 |
| WSOD2 [61] | SS | 87.1 | 80.0 | 74.8 | 60.1 | 36.6 | 79.2 | 83.8 | 70.6 | 43.5 | 88.4 | 46.0 | 74.7 | 87.4 | 90.8 | 44.2 | 52.4 | 81.4 | 61.8 | 67.7 | 79.9 | 69.5 |
| Arun [2] | SS | 88.6 | 86.3 | 71.8 | 53.4 | 51.2 | 87.6 | 89.0 | 65.3 | 33.2 | 86.6 | 58.8 | 65.9 | 87.7 | 93.3 | 30.9 | 58.9 | 83.4 | 67.8 | 78.7 | 80.2 | 70.9 |
| Ours | SS | 87.5 | 82.4 | 76.0 | 58.0 | 44.7 | 82.2 | 87.5 | 71.2 | 49.1 | 81.5 | 51.7 | 53.3 | 71.4 | 92.8 | 38.2 | 52.8 | 79.4 | 61.0 | 78.3 | 76.0 | 68.8 |
| Methods | Proposal | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Motor | Person | Plant | Sheep | Sofa | Train | TV | CorLoc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Li [28] | EB | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 29.1 |
| ContextLocNet [23] | SS | 78.3 | 70.8 | 52.5 | 34.7 | 36.6 | 80.0 | 58.7 | 38.6 | 27.7 | 71.2 | 32.3 | 48.7 | 76.2 | 77.4 | 16.0 | 48.4 | 69.9 | 47.5 | 66.9 | 62.9 | 54.8 |
| OICR [46] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 62.1 |
| Jie [22] | ? | 82.4 | 68.1 | 54.5 | 38.9 | 35.9 | 84.7 | 73.1 | 64.8 | 17.1 | 78.3 | 22.5 | 57.0 | 70.8 | 86.6 | 18.7 | 49.7 | 80.7 | 45.3 | 70.1 | 77.3 | 58.8 |
| PCL [45] | SS | 77.2 | 83.0 | 62.1 | 55.0 | 49.3 | 83.0 | 75.8 | 37.7 | 43.2 | 81.6 | 46.8 | 42.9 | 73.3 | 90.3 | 21.4 | 56.7 | 84.4 | 55.0 | 62.9 | 82.5 | 63.2 |
| Wei [57] | SS | 79.1 | 83.9 | 64.6 | 50.6 | 37.8 | 87.4 | 74.0 | 74.1 | 40.4 | 80.6 | 42.6 | 53.6 | 66.5 | 88.8 | 18.8 | 54.9 | 80.4 | 60.4 | 70.7 | 79.3 | 64.4 |
| Shen [38] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 63.5 |
| Tang [47] | SS | 85.5 | 60.8 | 62.5 | 36.6 | 53.8 | 82.1 | 80.1 | 48.2 | 14.9 | 87.7 | 68.5 | 60.7 | 85.7 | 89.2 | 62.9 | 62.1 | 87.1 | 54.0 | 45.1 | 70.6 | 64.9 |
| Li [29] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 67.9 |
| C-MIL [51] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 67.4 |
| Yang [60] | SS | 82.4 | 83.7 | 72.4 | 57.9 | 52.9 | 86.5 | 78.2 | 78.6 | 40.1 | 86.4 | 37.9 | 67.9 | 87.6 | 90.5 | 25.6 | 53.9 | 85.0 | 71.9 | 66.2 | 84.7 | 69.5 |
| Arun [2] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 69.5 |
| WSOD2 [61] | SS | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 71.9 |
| Ours | SS | 91.7 | 85.6 | 71.7 | 56.6 | 55.6 | 88.6 | 77.3 | 63.4 | 53.6 | 90.0 | 51.6 | 62.6 | 79.3 | 94.2 | 32.7 | 58.8 | 90.5 | 57.7 | 70.9 | 85.7 | 70.9 |
在选项卡中。 11 和选项卡。 12,我们报告了 VOC 2007 和 VOC 2012 的训练集上的每类正确定位(CorLoc)结果。 与之前的工作[5, 46, 51, 61, 63, 2]一致,该指标是在训练集上计算的。 因此它不能反映检测模型的真实性能,并且尚未被监督方法[16,36,18]广泛采用。 对于 WSOD 方法,它充当“过度拟合”行为的指标。 与之前的最先进方法相比,我们的方法在 VOC 2007 上取得了第三好的成绩,在 2 个类别中获胜。 我们还在 VOC 2012 上取得了第二好的成绩,并在 19 个类别中获胜。 我们发现:(1)我们的模型对于飞机、自行车、瓶子、公共汽车、摩托车、羊、电视显示器等类别表现良好。 这一观察结果与检测结果非常吻合。 (2) 表现最好的方法因类别而异,这表明方法有可能被集成以进一步改进。
附录 D 其他定性结果
D.1 静态图像数据集的结果
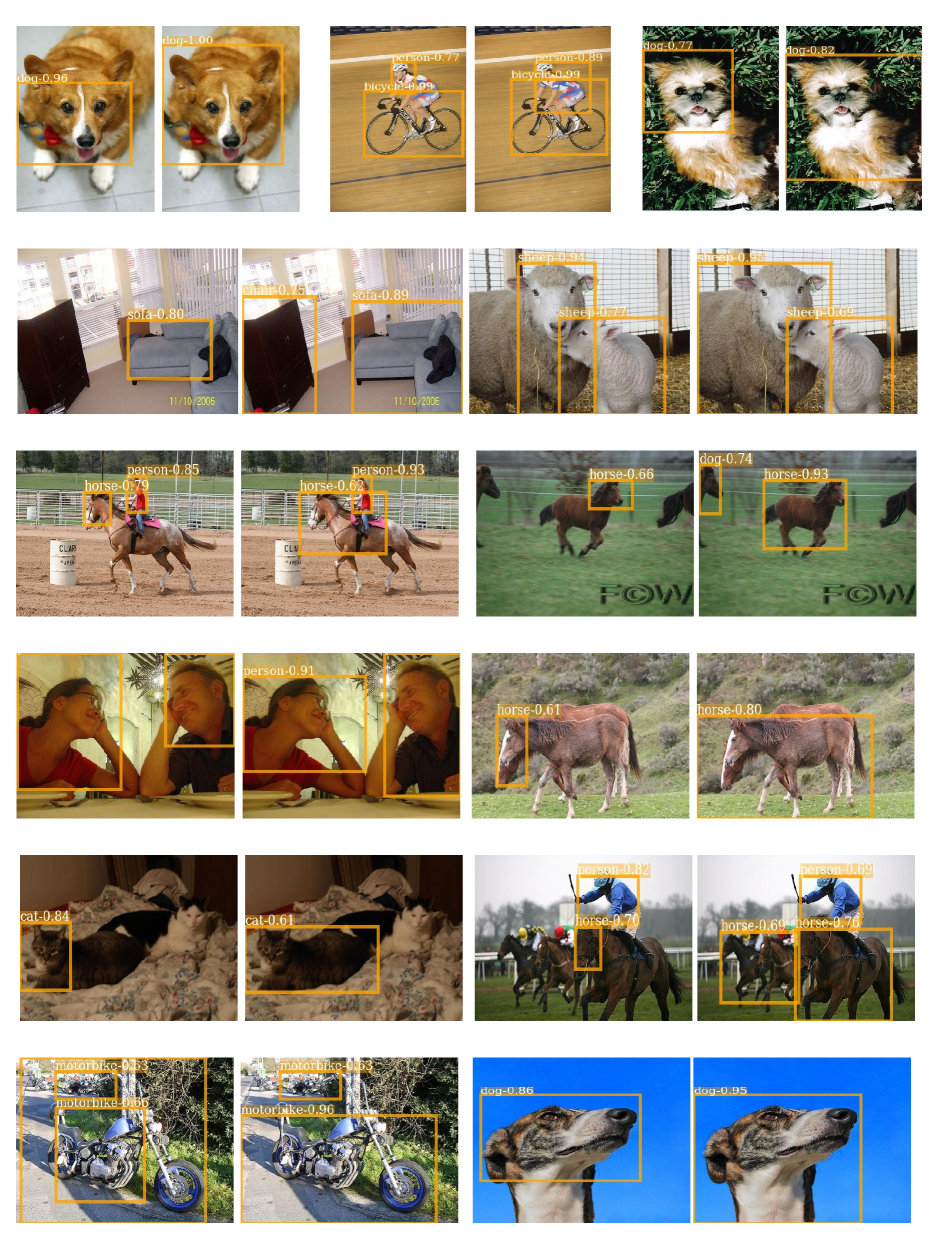
我们在图 13 和图 14 中分别展示了强调 "实例模糊性" 和 "部分支配" 的其他结果。 在主要论文之后,我们将最终模型与没有第 2 节中提出的模块的基线进行比较。 4.1 和 Sec。主论文的4.2直观地展示了这两个模块的有效性。 我们并排展示一组两张图片,左边是基线,右边是我们的基线。 从结果中,我们观察到:(1) 我们已经解决了“丢失实例”问题,并且以前忽略的对象被检测到并具有良好的召回率(例如。、图13中的监视器、羊、汽车、人); (2) 我们已经解决了“分组实例”问题,因为我们的模型预测多个实例的紧密且精确的框,而不是一个大实例(例如。,图13中的公共汽车、机动船、船、汽车); (3) 我们还缓解了狗、猫、羊、人、马和沙发等物体的“部分支配”0>问题(见图14
我们还在图 15 中提供了 COCO 结果的附加可视化。 我们通过在 COCO 2014 验证集上运行基于 VGG16 的模型来获得这些结果。 我们的模型能够在相对复杂的场景中检测同一类别的不同实例(例如。、汽车、大象、披萨、牛、雨伞)以及不同类别的各种对象,并且获得的框可以很好地覆盖整个对象,而不是简单地关注有区别的部分。
D.2 ImageNet VID 数据集的结果
我们在 ImageNet VID 上获得的结果的附加可视化如图 16 所示,其中同一视频的帧显示在同一行中。 这些结果是使用基于 ResNet-101 的模型获得的。 我们观察到:我们的模型能够处理视频中不同姿势、尺度和视点的对象。



附录E提案统计
为了与之前的文献保持一致,我们对 VOC 使用选择性搜索 (SS) [50],对 COCO 使用 MCG [1]。 两种方法平均生成大约 2K 个提案,如表 1 所示。 13,但某些图像有时会产生超过 5K 的结果。 即使使用 ResNet-101,我们的顺序批量反向传播也可以轻松处理这些情况,而其他方法很快就会耗尽内存(主论文中的图 11)。
| Data | voc07-train | voc07-val | voc07-test | voc12-train | voc12-val | voc12-test |
|---|---|---|---|---|---|---|
| Avg/Max | 2001 / 4663 | 2001 / 5236 | 2002 / 5398 | 2014 / 5254 | 2010 / 5563 | 2020/5660 |
| Data | coco14-train | coco14-val | coco17-train | coco17-val | coco-test | - |
| Avg/Max | 1957 / 5143 | 1958 / 6234 | 1957 / 6234 | 1961 / 3774 | 1947 / 4411 | - |
附录F需要冗余提案
在 WSOD 中,由于缺少真实框,因此为了获得高召回率,对象建议必须是冗余的,从而消耗大量内存。 为了研究对大量提案的需求,我们随机抽取所有提案的 %。 使用基于 VOC 2007 的 VGG16 模型。 结果总结在表中。 14. 即使减少少量提案数量也会显着降低准确性:使用 95% 的提案会导致 AP 下降 2.8%。 这表明所有建议都应用于获得最佳性能。
| 60% | 80% | 90% | 95% | 100% | |
|---|---|---|---|---|---|
| AP | 48.4 | 49.7 | 50.8 | 52.1 | 54.9 |
附录 G有关视频实验的其他详细信息
在本节中,我们提供了 Sec 的更多详细信息。 5.4。 按照视频对象检测的监督方法[64, 59],我们在最流行的数据集:ImageNet VID [8] 上进行实验。 训练期间可以使用帧级类别标签。 对于每个视频,我们使用 [64] 中均匀采样的 15 个关键帧进行训练。 为了进行评估,我们在标准验证集上进行测试,其中对所有视频的每帧空间对象检测结果进行评估。
“我们的”和“我们的(仅限 MIST)”这两个模型是带有或不带有 Concrete DropBlock 的两个单帧基线(主要论文第 4.2 节)。 此外,内存高效的顺序批量反向传播(主要论文第 4.3 节)允许利用短期运动模式(即。,光流)以进一步提高性能。 对于“Ours+flow”,我们首先使用 FlowNet2 [20] 来计算相邻帧和参考帧之间的光流。 然后使用估计的流图来扭曲附近帧的特征图,以与参考帧线性求和以增强表示。 然后将累积的特征输入到建议的任务头(主论文图2中“Base”之后的模块)中,以进行弱监督训练。 该方法结合了[64]中讨论的流引导特征扭曲方法来利用时间一致性和所提出的 WSOD 任务头来处理帧级弱监督。 因此,它比使用 VGG16 和 ResNet-101 的上述两个基线(“我们的”和“我们的(仅 MIST)”)取得了更好的结果,如表 1 所示。 7.