22email: {chandra.thapa, chamikara.arachchige, seyit.camtepe}@data61.csiro.au
21>2email: lis221@lehigh.edu
SplitFed:当联邦学习遇上分割学习
摘要
联邦学习(FL)和分割学习(SL)是两种流行的分布式机器学习方法。 两者都遵循模型到数据的场景;客户无需共享原始数据即可训练和测试机器学习模型。 由于客户端和服务器之间的机器学习模型架构分开,SL 比 FL 提供更好的模型隐私。 此外,拆分模型使 SL 成为资源受限环境的更好选择。 然而,由于跨多个客户端的基于中继的训练,SL 的执行速度比 FL 慢。 在这方面,本文提出了一种名为分裂学习(SFL)的新颖方法,它将两种方法合并起来,消除了它们固有的缺点,并结合了差分隐私和 PixelDP 的改进架构配置来增强数据隐私和模型的稳健性。 我们的分析和实证结果表明,(纯)SFL 提供了与 SL 相似的测试精度和通信效率,同时与多个客户端的 SL 相比,显着减少了每个全局历元的计算时间。 此外,与 SL 一样,其相对 FL 的通信效率随着客户端数量的增加而提高。 此外,在扩展的实验设置下进一步评估了 SFL 的隐私和鲁棒性措施的性能。
1简介
分布式协作机器学习 (DCML) 因其默认的数据隐私优势而广受欢迎[12]。 与集中汇集和访问数据的传统方法不同,DCML 无需将数据从数据托管方传输到任何不受信任的方即可实现机器学习。 此外,分析师无法获得原始数据;相反,机器学习 (ML) 模型会传输给数据管理员进行处理。 此外,它还可以在多个系统或服务器和分布式设备上进行计算。
最流行的 DCML 方法是联邦学习 [13, 19] 和分割学习 [9]。 联邦学习 (FL) 使用本地数据在分布式客户端上训练完整的 ML 模型,然后聚合本地训练的完整 ML 模型以在服务器中形成全局模型。 FL 的主要优点是它允许跨多个客户端并行训练,从而高效地训练 ML 模型。
佛罗里达州 ML 训练期间客户端的计算要求和模型隐私。 FL 的主要缺点是每个客户端都需要运行完整的 ML 模型,而资源受限的客户端(例如物联网中的客户端)无法运行完整的模型。 如果 ML 模型是深度学习模型,这种情况很常见。 此外,在训练过程中,从模型的隐私角度来看,存在隐私问题,因为服务器和客户端可以完全访问本地和全局模型。
为了解决这些问题,引入了分割学习(SL)。 SL 将完整的 ML 模型分割成多个较小的网络部分,并在服务器上单独训练它们,并使用本地数据分发客户端。 在客户端仅将网络的一部分分配给训练可以减少处理负载(与 FL 中运行完整网络的处理负载相比),这对于资源受限设备上的 ML 计算非常重要[24]. 此外,客户端无法访问服务器端模型,反之亦然。
SL 中的训练时间开销。 尽管 SL 有很多优点,但仍然存在一个主要问题。 SL 中基于中继的训练使客户端资源闲置,因为在一个实例中只有一个客户端与服务器交互;导致许多客户的训练开销显着增加。
为了解决 FL 和 SL 中的这些问题,本文提出了一种称为分割学习(SFL)的新颖架构。 SFL考虑了FL和SL的优点,同时强调数据隐私和模型的鲁棒性。 请参阅表 1 与 FL 和 SL 的摘要比较。 我们的贡献主要有两个:首先,我们是第一个提出SFL的。 通过基于差异隐私的措施 [1] 和 PixelDP [18] 在 SFL 的架构级别增强了数据隐私和模型的稳健性。 其次,为了证明 SFL 的可行性,我们通过考虑四个标准数据集和四个流行模型来比较 FL、SL 和 SFL 的性能测量。 根据我们的分析和实证结果,SFL 提供了一个优秀的解决方案,它比 FL 提供更好的模型隐私,并且比 SL 更快,在模型精度和通信效率方面与 SL 具有相似的性能。
总体而言,SFL 对于资源受限的环境是有益的,在这种环境中,完整的模型训练和部署不可行,并且需要快速模型时间来基于不断更新的数据集定期更新全局模型(例如 , 数据流)。 这些环境具有不同领域的特征,包括健康,例如,具有多个医疗物联网的网络中的实时异常检测111医疗物联网的例子包括血糖监测设备、开放式人工胰腺系统、可穿戴心电图(ECG)监测设备和智能镜头。 通过网关和金融连接,例如,保护隐私的信用卡欺诈检测。
Learning approach Model aggregation Model privacy advantage by splitted model Client-side training Distributed computing Access to raw data SL No Yes Sequential Yes No FL Yes No Parallel Yes No SFL Yes Yes Parallel Yes No
2 背景及相关作品
联邦学习[13,19,2]在每个客户端在其本地数据上并行训练一个完整的ML网络/算法一定数量的本地epoch,然后将本地更新发送到服务器用于聚合[19]。 这样,服务器就形成了一个全局模型,完成了一个全局的epoch222当一个周期内所有参与客户端的所有可用数据集完成前向传播和反向传播时,称为一个全局纪元。. 然后将全局模型学习到的参数发送回所有客户端以进行下一轮的训练。 这个过程一直持续到算法收敛。 在本文中,我们考虑用于 FL 中模型聚合的联合平均 (FedAvg) 算法[19]。 FedAvg 考虑模型更新梯度的加权平均值。
分割学习[24, 9]将深度学习网络分割成多个部分,这些部分在不同的设备上进行处理和计算。 在简单的设置中,被分成两部分和,分别称为客户端网络和服务器端网络。 数据所在的客户端仅提交到网络的客户端部分,而服务器仅提交到网络的服务器端部分。 通信涉及将客户端网络的分割层(称为切割层)的激活(称为粉碎数据)发送到服务器,并接收粉碎数据的梯度来自服务器端操作的数据。 多个客户端的学习过程同步可以在 SL [9] 中以集中模式或点对点模式完成。
差分隐私(DP)是一种根据随机框架[4, 3]定义隐私的隐私模型。 DP 可以正式定义如下:
定义1
如果对于所有相邻数据集 和 ,并且对于所有可能的数据集,机制 被认为是 - 差分私有的结果的子集,机制的,以下内容成立:
实际上,(隐私预算)和(失败概率)的值应保持尽可能小,以保持高水平的隐私。 然而,和的值越小,DP算法施加到输入数据的噪声就越高。
3提议的框架
本节介绍 SFL 框架。 我们首先概述 SFL。 然后我们详细介绍三个关键模块:(1) 差分隐私知识扰动,(2) 用于鲁棒学习的 PixelDP,以及 (3) SFL 的总成本分析。
3.1总体结构
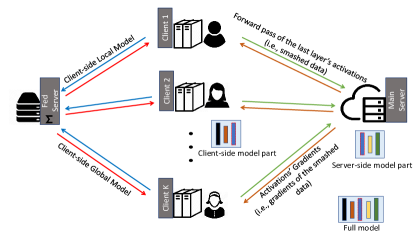
SFL 结合了 FL 的主要优势(分布式客户端之间的并行处理)和 SL 的主要优势(在训练期间将网络分为客户端和服务器端子网络)。 请参阅图 1 了解 SFL 架构的表示。 与 SL 不同,所有客户端并行执行计算并与主服务器和联邦服务器交互。 客户端可以是计算资源较低的医院或医疗物联网,主服务器可以是高性能计算资源的云服务器或研究人员。 引入Fed服务器来对客户端本地更新进行FedAvg。 此外,联邦服务器在每轮网络训练中都会同步客户端全局模型。 fed服务器的计算主要是计算FedAvg,成本并不高。 因此,联邦服务器可以托管在本地边缘边界内。 或者,如果我们在联邦服务器上通过加密信息实现所有操作,即基于同态加密的客户端模型聚合,那么主服务器就可以执行联邦服务器的操作。
SFL 工作流程。 所有客户端都在其客户端模型(包括其噪声层)上并行执行前向传播,并将其粉碎的数据传递到主服务器。 然后,主服务器在其服务器端模型上处理前向传播和反向传播,并以(某种程度上)并行的方式分别处理每个客户端的粉碎数据。 然后,它将粉碎数据的梯度发送到各自的客户端以进行反向传播。 之后,服务器通过 FedAvg 更新其模型,即在每个客户端的粉碎数据的反向传播期间计算的梯度的加权平均。 在客户端,在收到粉碎数据的梯度后,每个客户端对其客户端本地模型执行反向传播并计算其梯度。 使用DP机制将这些梯度设为私有并将它们发送到联邦服务器。 联邦服务器执行客户端本地更新的 FedAvg 并将其发送回所有参与的客户端。
3.1.1 分裂学习的变体。
SFL 可以有多种变体。 我们大致将它们分为以下两类:
基于服务器端聚合。
本文提出了 SFL 的两种变体。 第一个称为 splitfedv1 (SFLV1),在算法 1 和 2 中进行了描述。 下一个算法称为splitfedv2(SFLV2),它的动机是通过删除算法1 在算法1中,所有客户端的服务器端模型分别并行执行,然后聚合以获得每个全局时期的全局服务器端模型。 相比之下,SFLV2 相对于客户端的粉碎数据顺序处理服务器端模型的前向后向传播(没有服务器端模型的 FedAvg)。 在服务器端操作中随机选择客户端顺序,并且模型在每次前向-后向传播中更新。 此外,服务器同步接收来自所有参与客户端的粉碎数据。 客户端操作与SFLV1相同;联邦服务器对客户端本地模型进行 FedAvg 计算,并将聚合模型发送回所有参与的客户端。 这些操作不受客户端订单的影响,因为本地客户端模型是通过加权平均方法(即 FedAvg)聚合的。 文献中还提供了一些其他 SFL 版本,但它们是在我们的方法[10, 7]之后开发并受其影响的。
基于数据标签共享。
由于SFL中的ML模型是分开的,我们可以在两种设置中进行ML; (1) 与服务器共享数据标签;(2) 不与服务器共享任何数据标签。 算法1考虑具有数据标签共享的SFL。 在不共享数据标签的情况下,假设设置简单,SFL 中的 ML 模型可以分为三个部分。 每个客户端将处理两个客户端模型部分;一个包含前几层 ,另一个包含最后几层 和损失计算。 的其余中间层将在服务器端计算。 SL 的所有可能配置,包括垂直分区数据、扩展 vanilla 和多任务 SL [24],都可以在 SFL 中与其变体类似地执行。
3.2隐私保护
SFL固有的隐私保护能力源于两个原因:首先,它采用模型到数据的方法,其次,SFL通过分裂网络进行机器学习。 ML 学习中的网络分割使客户端/馈送服务器和主服务器能够通过不允许主服务器获取客户端模型更新来维护完整的模型隐私,反之亦然。 主服务器只能访问粉碎的数据(即切割层的激活向量)。 好奇的主服务器需要反转所有客户端模型参数,即权重向量,以推断数据和客户端模型。 如果我们为客户端 ML 网络的全连接层配置足够多的节点[9],则推断客户端模型参数和原始数据的可能性极小。 但是,对于较小的客户端网络,出现此问题的可能性可能很高。 这个问题可以通过修改客户端[23]的损失函数来控制。 由于同样的原因,客户端(只能访问来自主服务器的粉碎数据的梯度)和馈送服务器(只能访问客户端更新)无法推断服务器端模型参数。 由于 FL 中的客户端和服务器端没有网络分割和单独的训练,因此与 FL 相比,SFL 提供了卓越的架构配置,可增强 ML 模型在训练期间的隐私性。
3.2.1 客户端隐私保护。
我们在上一节中讨论了所提出模型的固有隐私性。 然而,高级对手可能会利用共享粉碎数据或参数(权重)的底层信息表示来侵犯数据所有者的隐私。 如果任何服务器/客户端变得好奇但仍然诚实,就会发生这种情况。 为了避免这些可能性,我们在研究中采用了两种措施; (i) 客户端模型训练的差分隐私和 (ii) 客户端模型中的 PixelDP 噪声层。
3.2.2 Fed 服务器上的隐私保护。
考虑算法2,我们提出了在客户端实现差异隐私的过程。我们假设如下:表示噪声尺度,表示梯度范数界限。 现在,首先,在时间之后,客户端从服务器接收梯度,并以此计算客户端梯度 对于每个本地样本 ,以及
| (1) |
其次,根据以下等式对每个梯度的范数进行裁剪:
| (2) |
第三,将校准噪声添加到平均梯度中:
| (3) |
最后,客户端的客户端模型参数更新如下; 。
我们迭代地应用校准噪声,直到模型收敛或达到指定的迭代次数。 随着迭代的进行,最终的收敛将表现出 的隐私级别 - 差分隐私,其中 是客户端模型的总体隐私成本。
基于Abadi等人的方法[1],使用差分隐私对客户端模型训练算法实施严格的隐私保护。 方程2(范数裁剪)保证在时被保留。 此步骤还保证 在 时缩小为 。 此步骤还有助于消除方程 5 对梯度的影响。 因此,范数裁剪步骤允许在保证差异隐私的过程中限制每个单独示例对的影响。 结果表明,相应的噪声加法(参见方程3)为的每一步提供了-DP(),如果我们选择(噪声等级)为[5]。 因此,在 步骤结束时,这将导致 -DP。 如Abadi等人所示,对于任何和,通过选择,可以将隐私保持在-DP [1]。 朋友圈会计师(隐私会计师)用于跟踪和维护。 因此,在 末尾,客户端模型保证 -DP。 严格假设所有客户端都处理 IID 数据,我们可以确认所有客户端在客户端模型训练和同步时都维护并保证 -DP。
3.2.3 主服务器上的隐私保护。
上述 DP 措施虽然对第一个全局 epoch 之后的粉碎数据有一定影响,但并不能阻止粉碎数据到主服务器的潜在泄漏。 因此,为了避免隐私泄露并进一步增强数据隐私和模型针对潜在对抗性机器学习设置的鲁棒性,我们基于 PixelDP [18] 的概念在客户端模型中集成了噪声层。
这种扩展措施利用差分隐私中涉及的噪声应用机制来将校准噪声添加到客户端模型的层的输出(例如,激活向量),同时保持实用性。 在这个过程中,我们首先计算过程的灵敏度。 函数 的灵敏度定义为输入变化可产生的最大输出变化,给定输入和输出的一些距离度量(分别为 p 范数和 q 范数) ):
| (4) |
其次,应用尺度 的拉普拉斯噪声来随机化任何数据,如下所示:
| (5) |
其中,表示的私有版本,是用于拉普拉斯噪声的隐私预算。 该方法可以将粉碎数据的私有版本转发到主服务器;因此,保护了粉碎数据的隐私。 被粉碎数据的私有版本是由于客户端模型中噪声层应用的DP机制的后处理免疫性。 由于校准噪声,噪声粉碎数据比原始数据更私密。 此外,PixelDP不仅可以为粉碎数据提供隐私,还可以提高模型针对对抗样本的鲁棒性。 然而,为未来的工作保留了详细的分析和数学保证,以保留拟议工作的主要焦点。
通过 PixelDP 实现稳健性。
使用随机 DP 机制来针对对抗性示例增强 ML 的主要直觉是创建 DP 评分函数。 例如,通过 DP 评分函数馈送任何数据样本,输出是关于输入特征的 DP。 然后,DP 函数的预期输出的稳定性界限由以下引理 [18] 给出:
引理1
假设随机函数 具有有界输出 ,满足 ()-DP。 那么其输出的期望值满足以下性质:
| (6) |
其中 是 -范数球,并且期望取代 中的随机性。
与方程 相结合,该界限为对抗性示例的稳健性提供了严格的认证。
3.3总成本分析
本节分析了统一数据分布下 FL、SL 和 SFL 的总通信成本和模型训练时间。 假设为客户端数量,为总数据大小,为粉碎层大小,为通信速率, 是在数据集大小为 的完整模型上进行一次前向和反向传播所需的时间(对于任何架构), 是执行完整模型聚合所需的时间(令 为单个服务器的聚合时间), 为完整模型的大小, > 是 SL/SFL 客户端中可用的完整模型大小的一部分,即 每个客户端通信中的术语 是由于客户端分别在训练之前和之后下载和上传客户端模型更新。 结果如表2所示。 如表所示,当存在大量客户端时,SL 可能会变得低效。 此外,我们看到,当增加时,总训练时间成本按SFLV2SFLV1SL的顺序增加。 此外,我们在实证结果中也观察到了这一点。
Method Comms. per client Total comms. Total model training time FL SL SFLV1 SFLV2
4实验
在客户端之间均匀分布和水平划分的图像数据集上进行了实验。 所有程序均使用 PyTorch 库 (PyTorch 1.2.0) 用 python 3.7.2 编写。 为了更快地进行实验和开发,我们使用基于 Dell EMC PowerEdge 平台构建的高性能计算 (HPC) 平台,并配有合作伙伴 GPU 用于计算和 InfiniBand 网络。 我们在 HPC 提供的集群的不同计算节点上运行客户端和服务器。 我们为 HPC 上的一项 slurm 作业请求以下资源:10GB RAM、1 个 GPU (Tesla P100-SXM2-16GB)、1 个计算节点,每个节点最多执行一项任务。 节点的架构是x86_64。 在我们的设置中,我们认为所有参与者都会在每个全局时期更新模型(即训练期间的 )。 我们根据机器学习网络架构和数据集的性能以及按比例参与我们的研究的需要来选择机器学习网络架构和数据集。 对于其余网络架构(AlexNet、ResNet 和 VGG16),LeNet 的学习率保持在 0.004 和 0.0001。 我们根据初始观察期间模型的性能选择学习率。 例如,对于 FMNIST 上的 LeNet,我们在 200 个全局 epoch 中观察到,学习率为 0.004 时,训练和测试准确率分别为 94.8% 和 92.1%,而学习率为 0.0001 时,训练和测试准确率分别为 87.8% 和 87.3%。 我们搭建了一个类似的计算环境进行比较分析。
我们在实验中使用了四个公共图像数据集,这些数据集总结在表3中。 HAM10000 数据集是一个医学数据集,即具有 10000 个训练图像的人类对抗机器[22]。 它由色素性皮肤病变的彩色图像组成,并具有通过不同方式获取和存储的不同人群的皮肤镜图像。 它有七个重要诊断类别的病变类别:Akiec、bcc、bkl、df、mel、nv 和 vasc。 MNIST、Fashion MNIST 和 CIFAR10 是标准数据集,均包含 10 个类别。
Dataset Training samples Testing samples Image size HAM10000 [22] MNIST [16] FMNIST [25] CIFAR10 [14]
关于机器学习模型,我们在实验中考虑了四种流行的架构。 这四种架构属于卷积神经网络 (CNN) 架构,并在表 4 中进行了总结。 我们将实验限制在 CNN 架构上,以保持本文提出的工作的凝聚力。 我们将在未来的工作中对循环神经网络等其他架构进行进一步的实验评估。
对于 SL、SFLV1 和 SFLV2 中的所有实验,网络层在以下层分割:LeNet 第二层(在 2D MaxPool 层之后)、AlexNet 第二层(在 2D MaxPool 层之后)、VGG16 第四层(在 2D MaxPool 层之后) MaxPool 层)和 ResNet18 的第三层(在 2D BatchNormalization 层之后)。 为了公平比较,在对 SFLV1 和 SFLV2 与 FL 和 SL 进行比较评估时,我们不考虑在 SFLV1 和 SFLV2 中添加基于差分隐私的措施和 PixelDP。
4.1FL、SL、SFLV1 和 SFLV2 的性能
我们以正常学习(集中学习)下的结果作为基准。 表 5 总结了我们的第一个结果,其中观察窗口为 200 个全局时期和一个局部时期,批量大小为 1024,DCML 有 5 个客户端。 该表显示了 200 个全球时期观察到的最佳准确度。 此外,测试准确性是在每个全局时期的 DCML 设置中的所有客户端上进行平均的。
Architecture No. of parameters Layers Kernel size LeNet [17] thousands , AlexNet [15] million , , VGG16 [20] million ResNet18 [11] 11.7 million ,
Dataset Architecture Normal FL SL SFLV1 SFLV2 HAM10000 ResNet18 79.3% 77.5% 79.1% 79% 79.2% HAM10000 AlexNet 80.1% 75 % 73.8% 70.5% 74.9% FMNIST LeNet 92.7% 91.9 % 90.4% 89.6% 90.4% FMNIST AlexNet 90.5% 89.7% 84.7% 86% 81% CIFAR10 LeNet 72.1% 69.4 % 62.7% 62.6% 63.8% MNIST AlexNet 98.8% 98.7 % 95.1% 96.9% 92% MNIST ResNet18 99.3% 99.2 % 99.2% 99% 99.2%
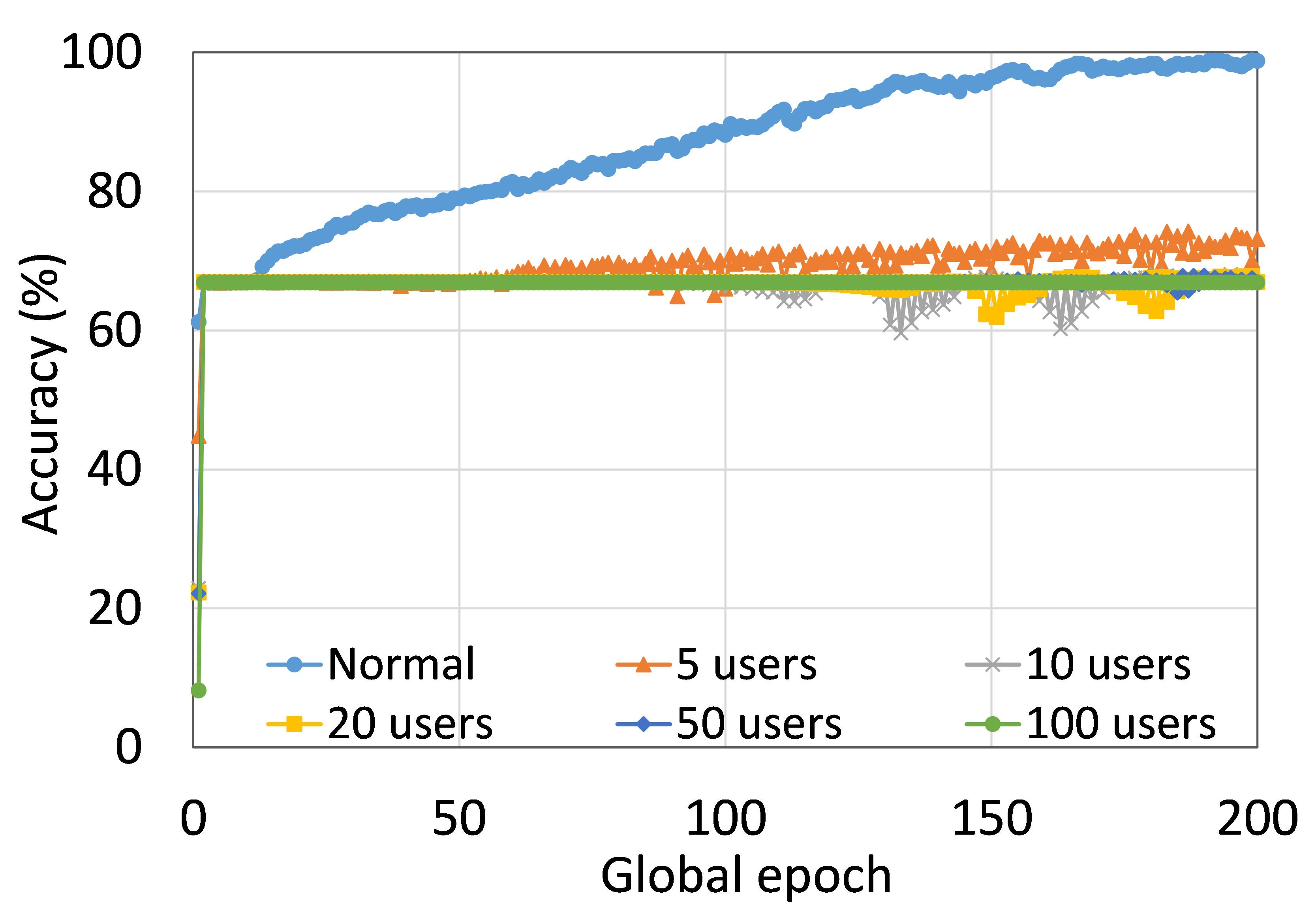
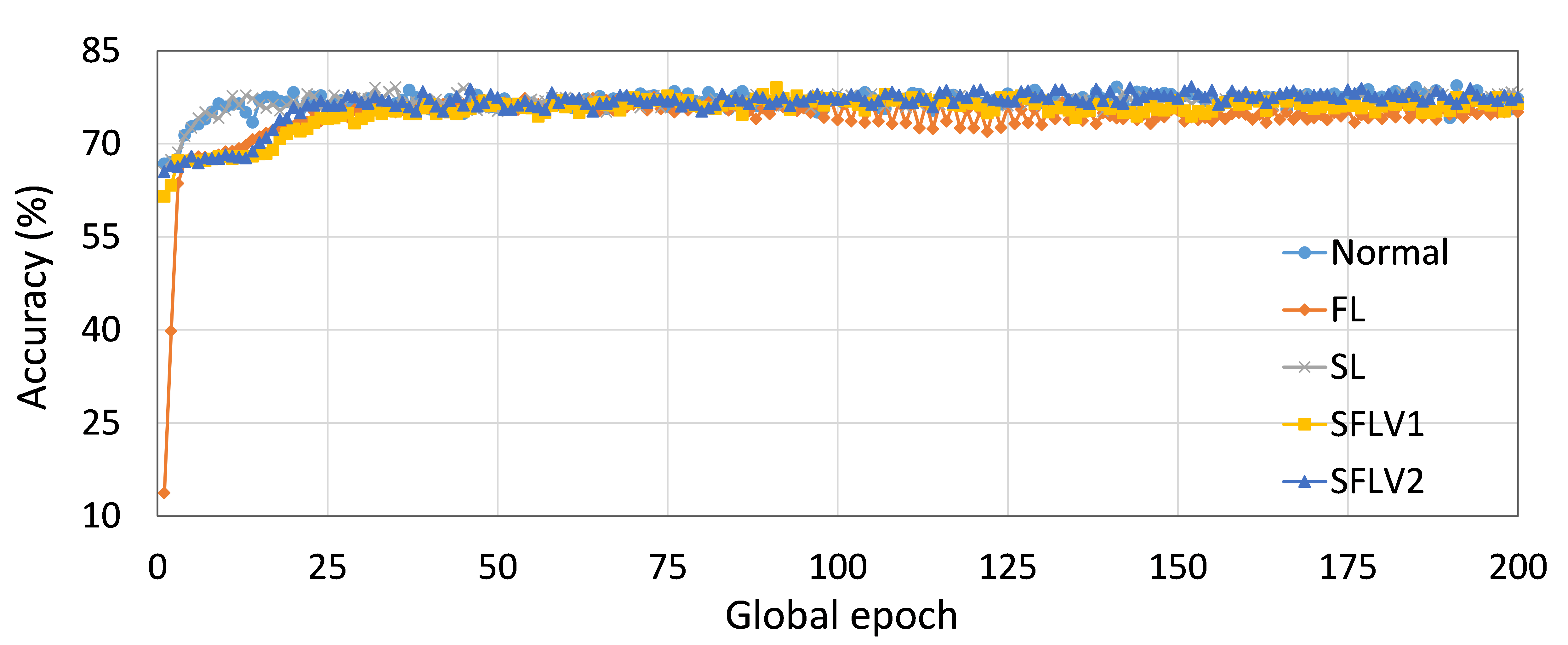
如表 5 所示,SL 和 SFL(两个版本)在建议的实验设置下表现良好。 然而,我们还观察到,在 DCML 中,FL 在大多数情况下表现出更好的学习性能,这可能是由于每个全局时期的完整模型的 FedAvg。 根据结果,我们可以观察到SFLV1和SFLV2继承了SL的特征。 在另一个实验中,我们注意到 CIFAR10 上的 VGG16 在 SL 中没有收敛,这对于两个版本的 splitfed 学习都是一样的,尽管 FL 的训练和测试准确率分别约为 66% 和 67%。 我们假设这是因为某些其他因素不可用,例如超参数调整或数据分布的变化或损失函数中的附加正则化项,这些超出了本文的范围。
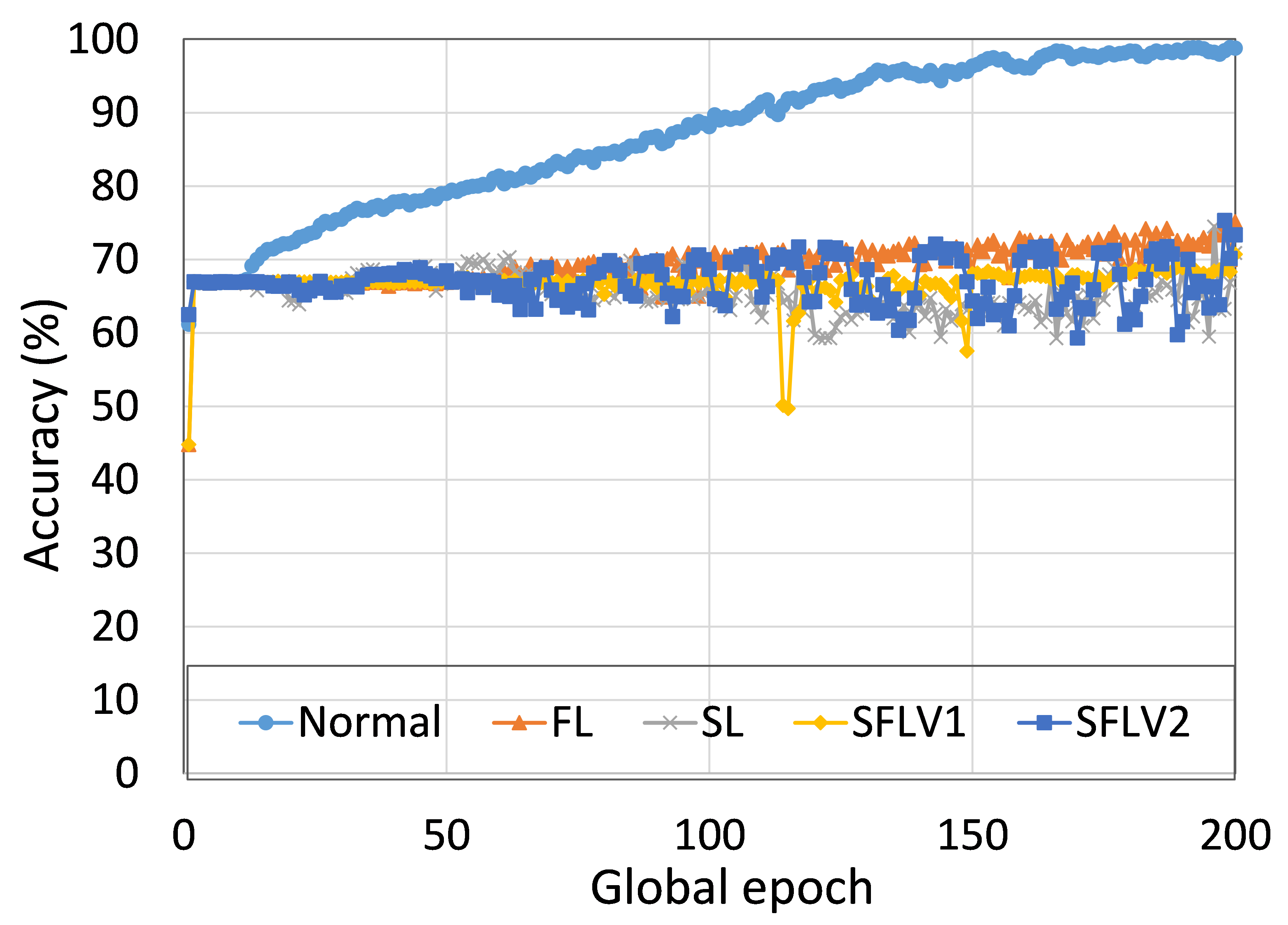
进一步深入研究个别案例,作为示例,我们展示了在类似设置下 ResNet18 在正常(集中学习)、FL、SL、SFLV1 和 SFLV2 数据集上的 ResNet18 的性能。 对于HAM10000上的ResNet18,FL、SL、SFLV1和SFLV2的测试精度收敛性几乎相同,并且在200个全局epoch的观察窗口中达到了76%左右(参见图2 )。 然而,如果 SL 无法收敛,SFLV1 和 SFLV2 就会难以收敛。 在我们单独的实验中,我们在 CIFAR10 上的 VGG16 的情况下观察到了这一点。
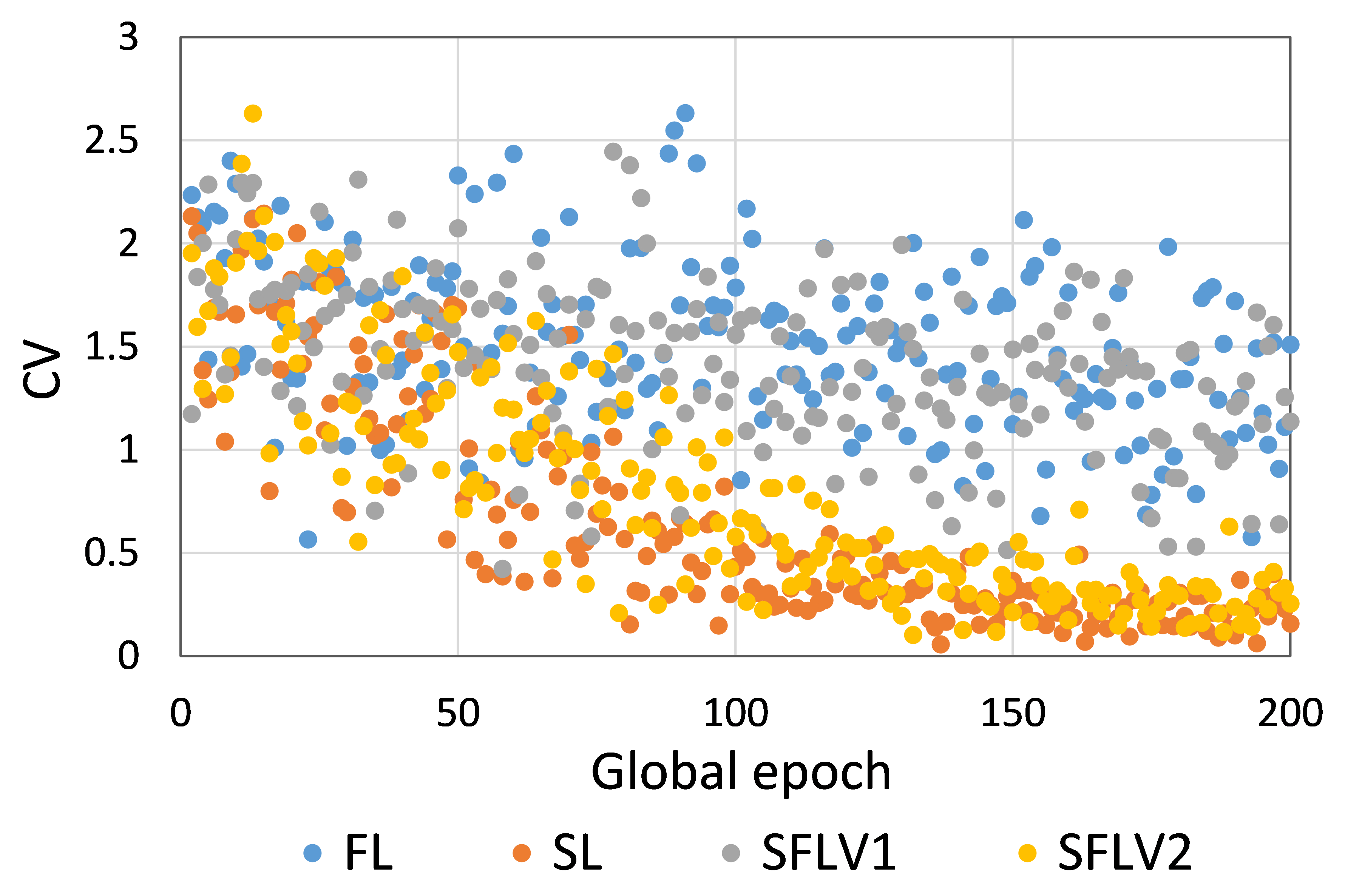
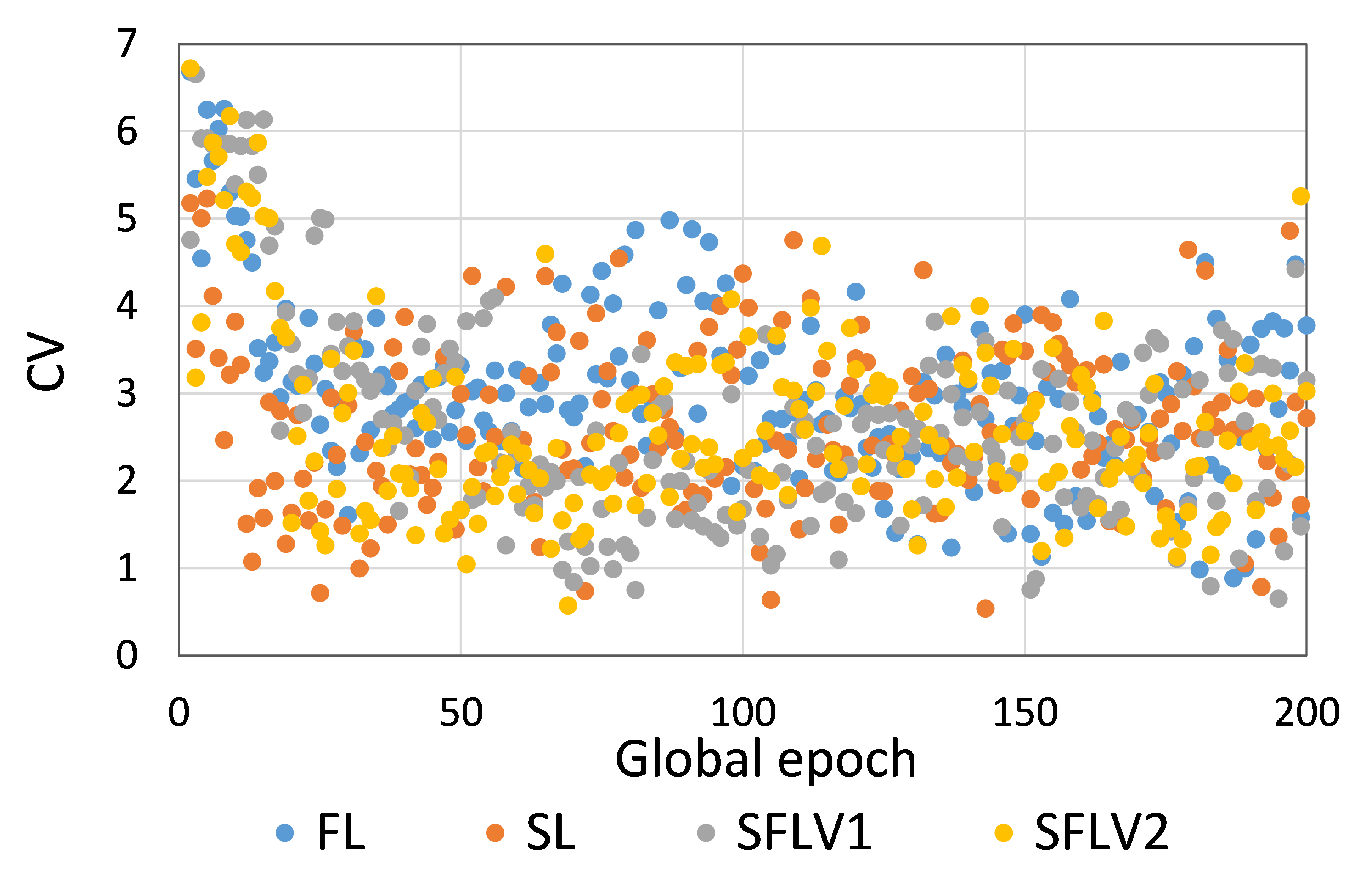
到目前为止,我们考虑了结果中的测试平均准确性。 图4说明了每个全球时期五个客户端的性能(即准确性)变化。 在这方面,我们计算变异系数(CV),它是标准差与平均值的比值,它衡量离散度。 此外,我们还计算了五个客户端在每个全球时期生成的五个准确度的 CV。 根据我们在 HAM10000 上的 ResNet18 的结果,训练时 SL、FL、SFLV1 和 SFLV2 的 CV 在 0.06 和 2.63 之间,在 epoch 2 后测试时在 0.54 和 6.72 之间;在第 1 轮,CV 略高。 结果表明,各个客户的个人客户水平表现一致,因为文献中低于 10 的 CV 系数值被认为是一个良好的范围。
在某些数据集和架构中,模型的训练/测试准确性仍在提高,并在高于 200 的全局 epoch 上表现出更好的性能。 例如,从 200 个 epoch 到 400 个 epoch,我们注意到对于 100 个用户的 FMNIST 上的 LeNet FL,训练和测试准确率从大约 83% 增加到大约 86%。 然而,我们将观察窗口限制为 100 或 200 个全局 epoch,因为某些网络架构(例如佛罗里达州 HAM10000 上的 AlexNet)在 HPC(共享资源)上花费了大量训练时间。
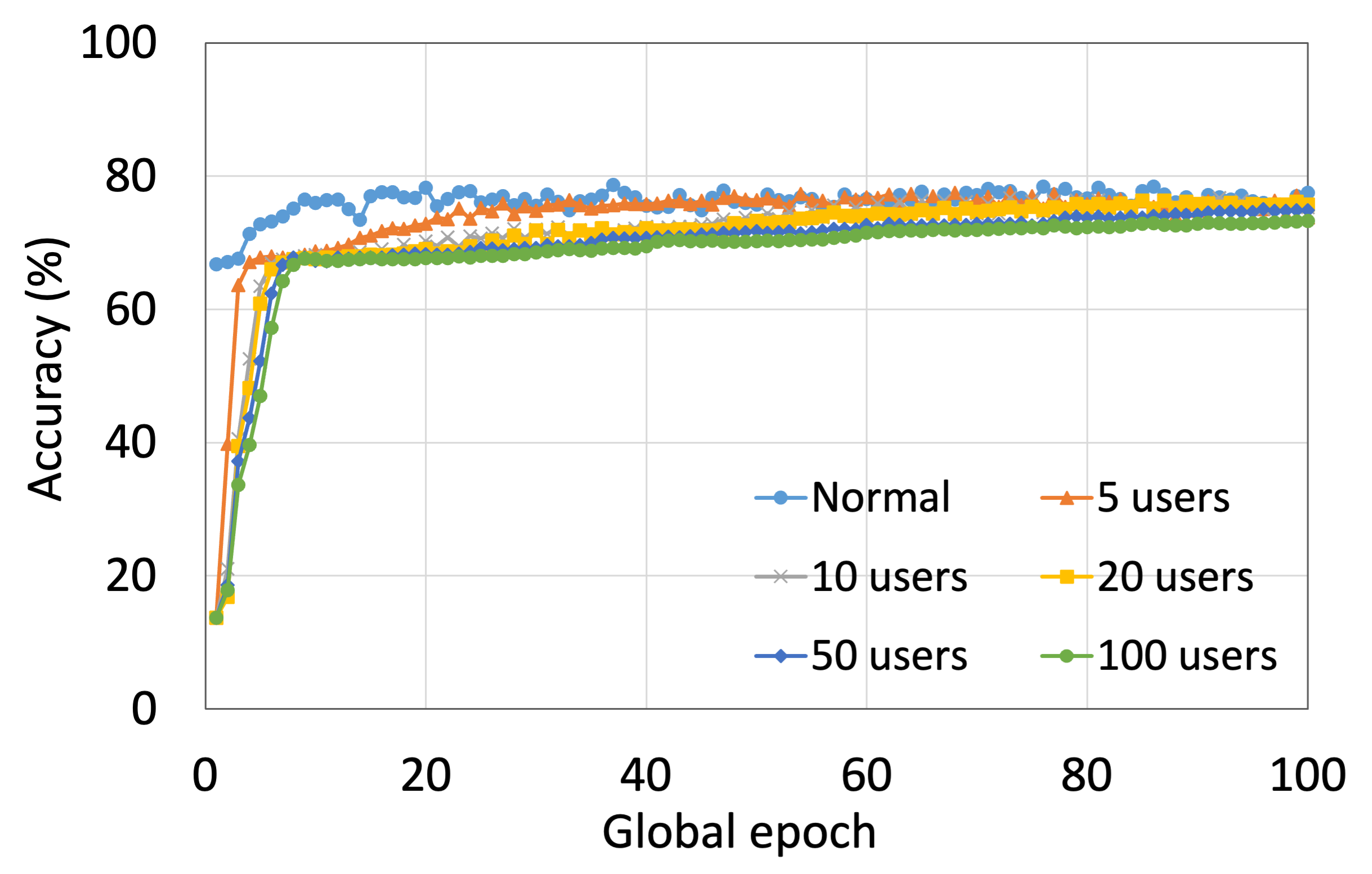
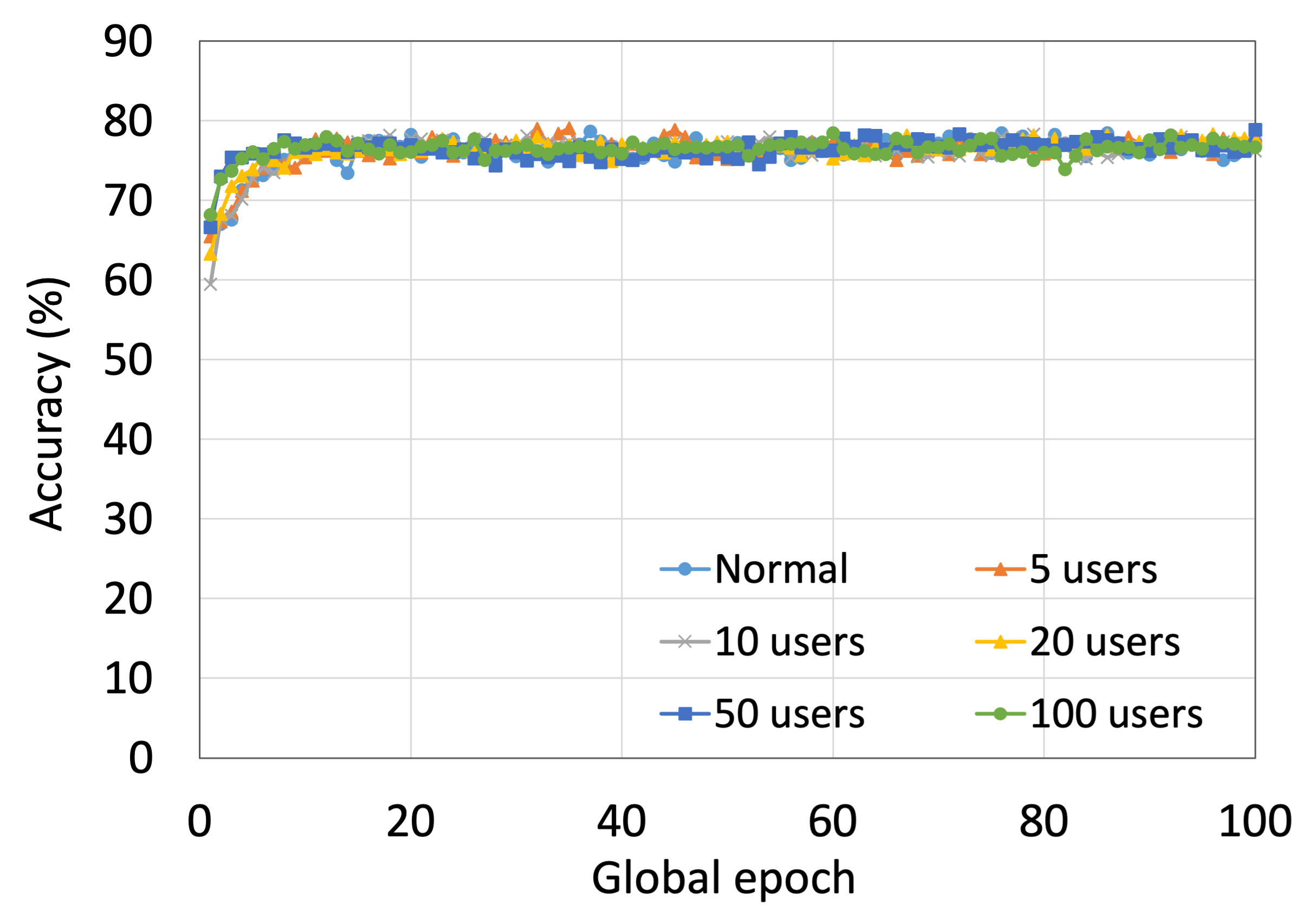
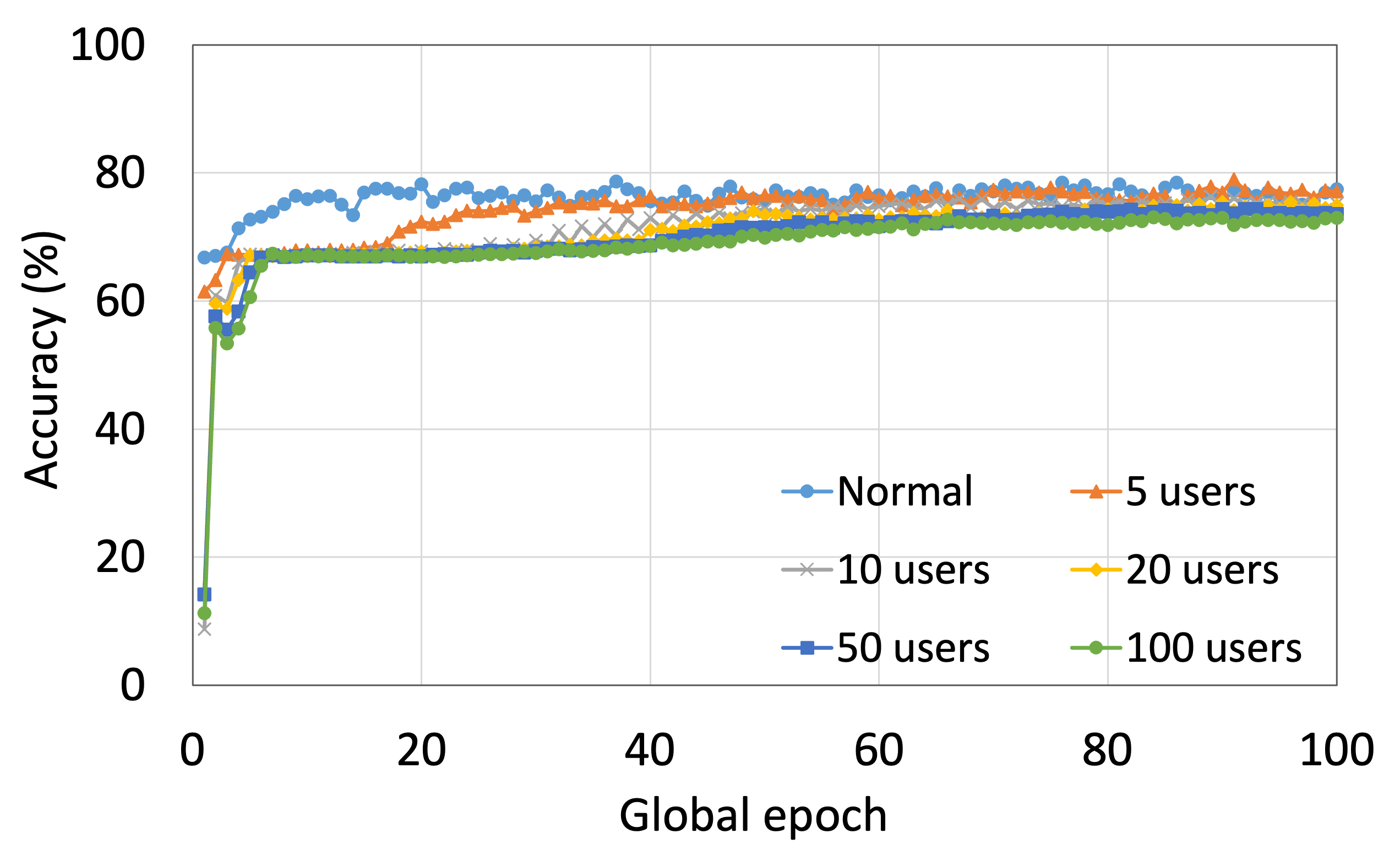
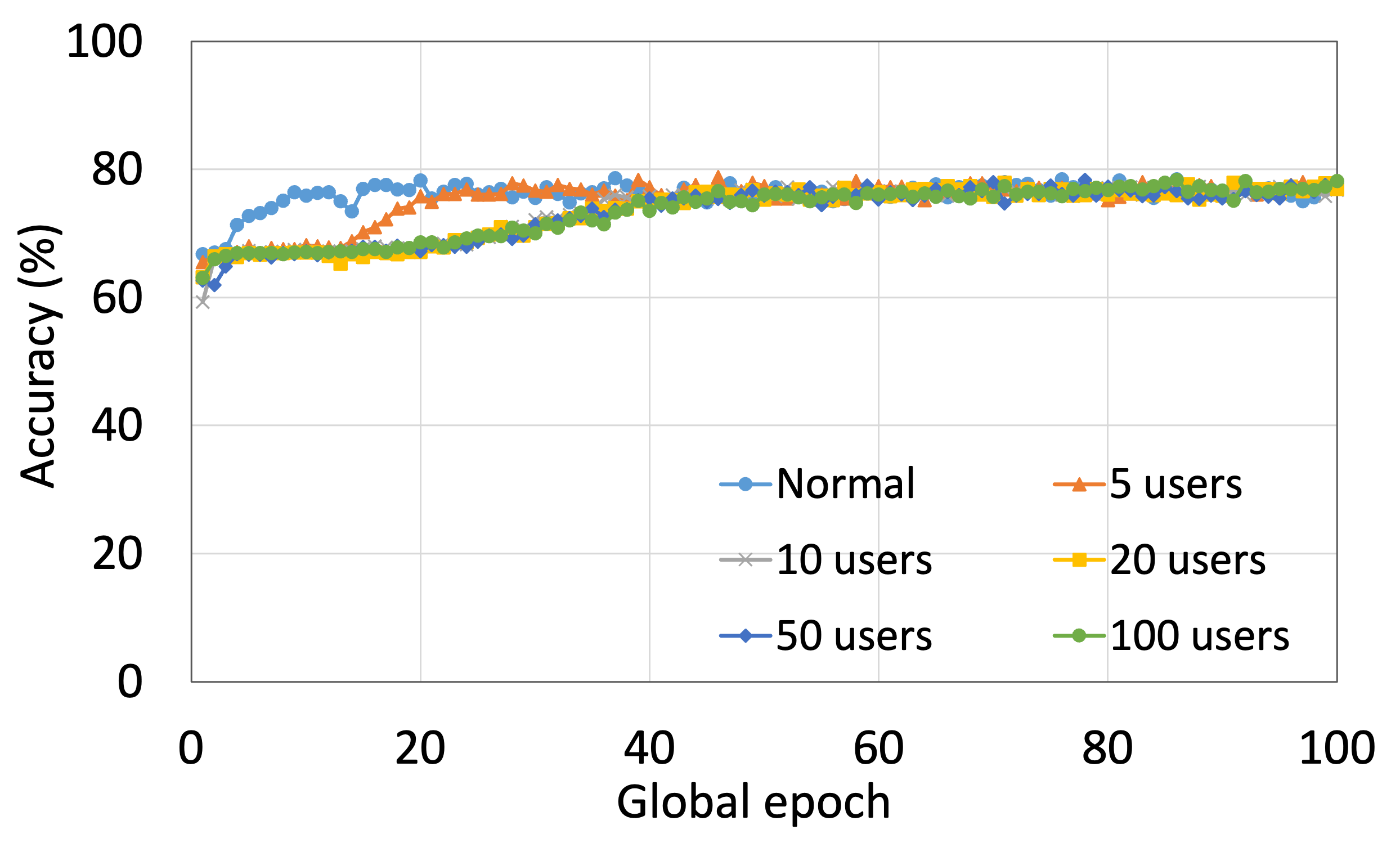
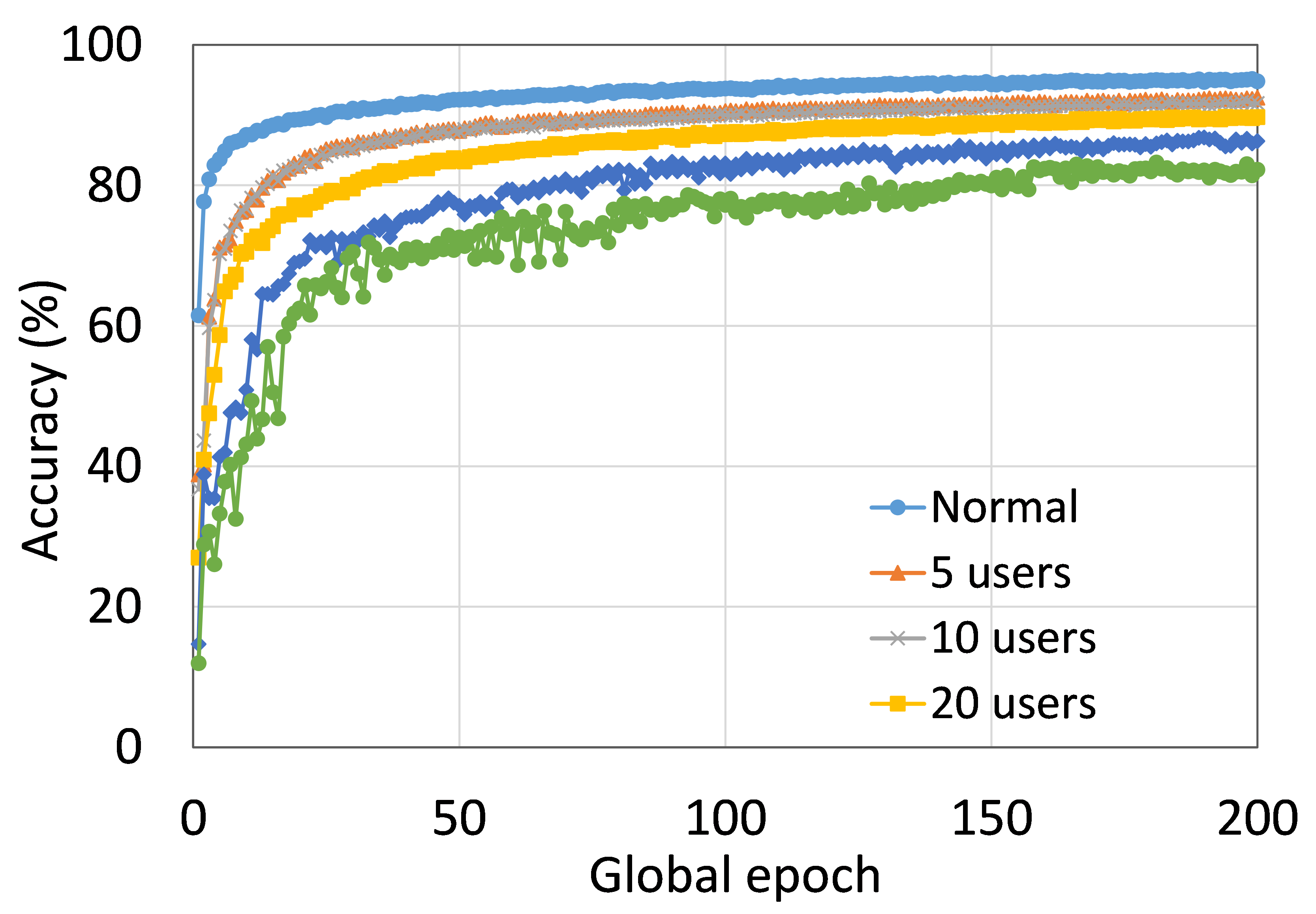
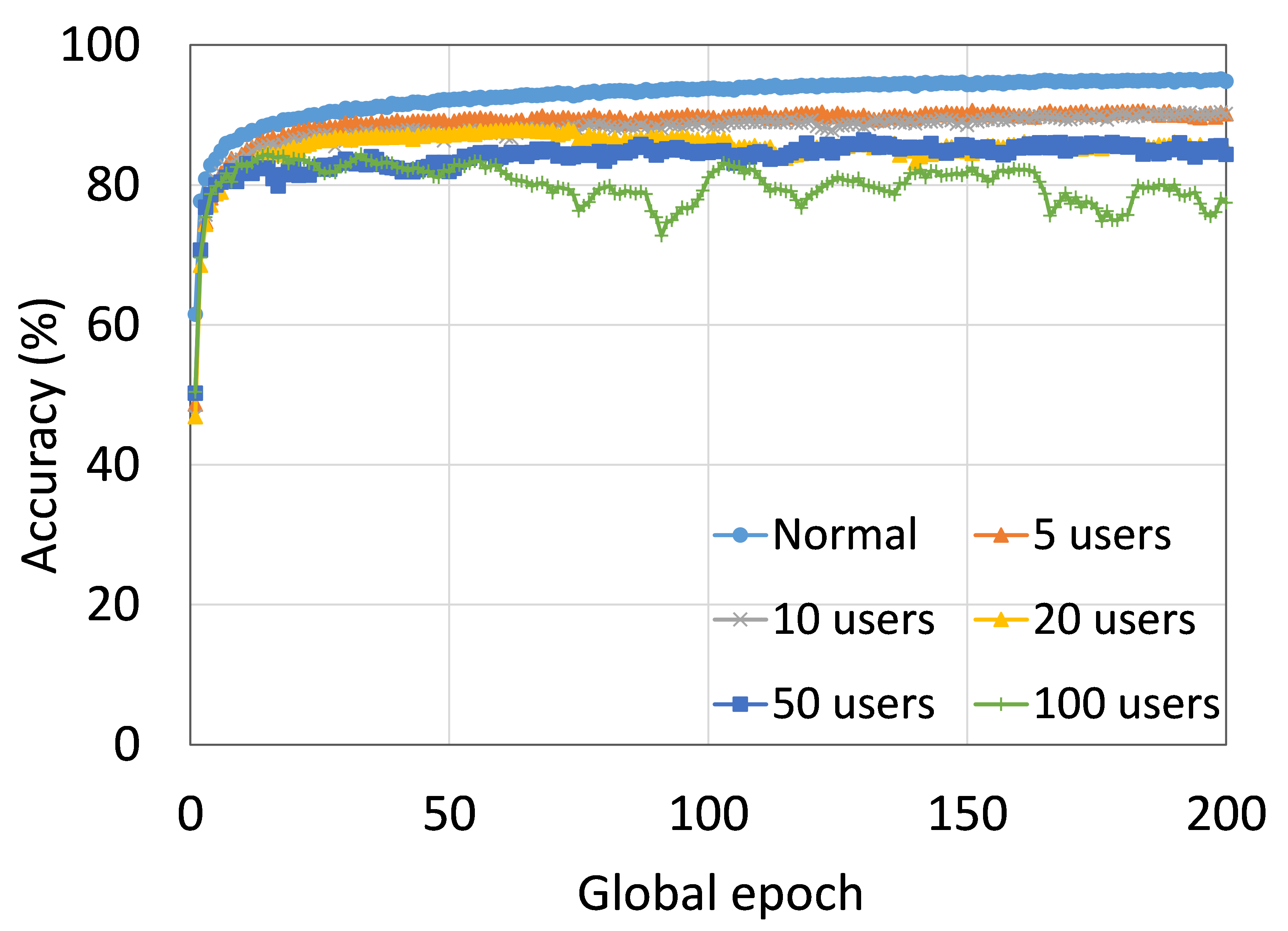
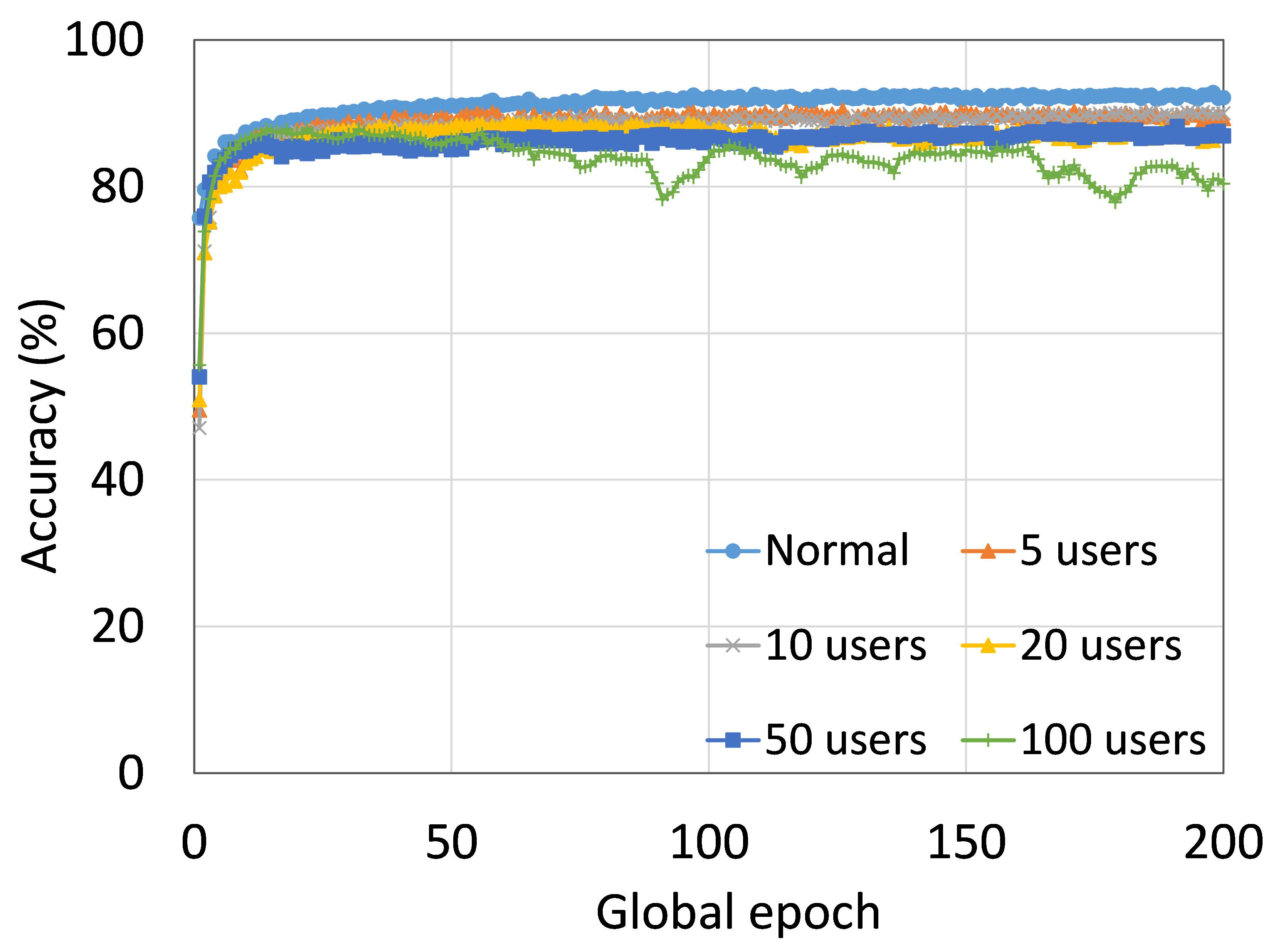
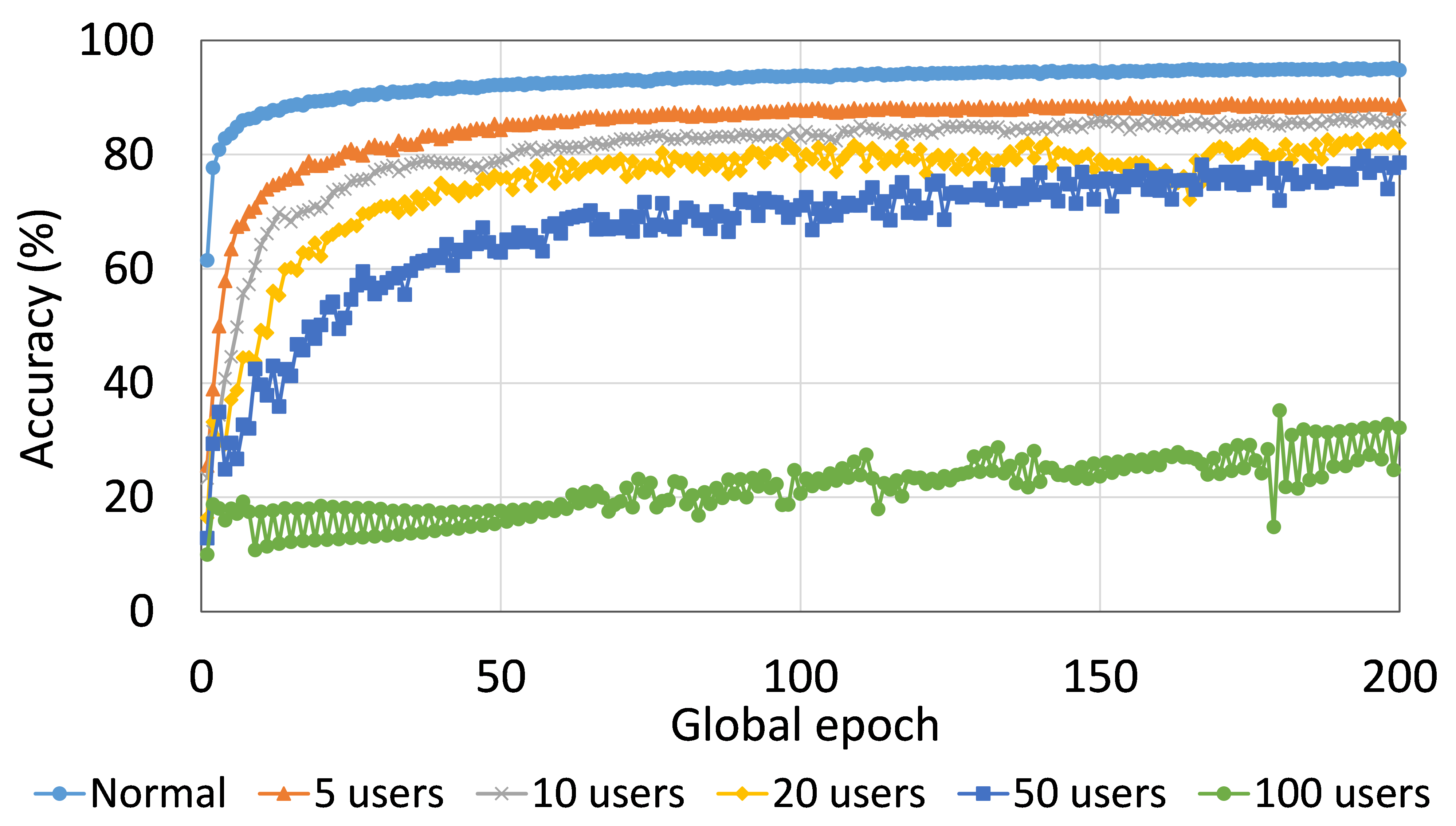
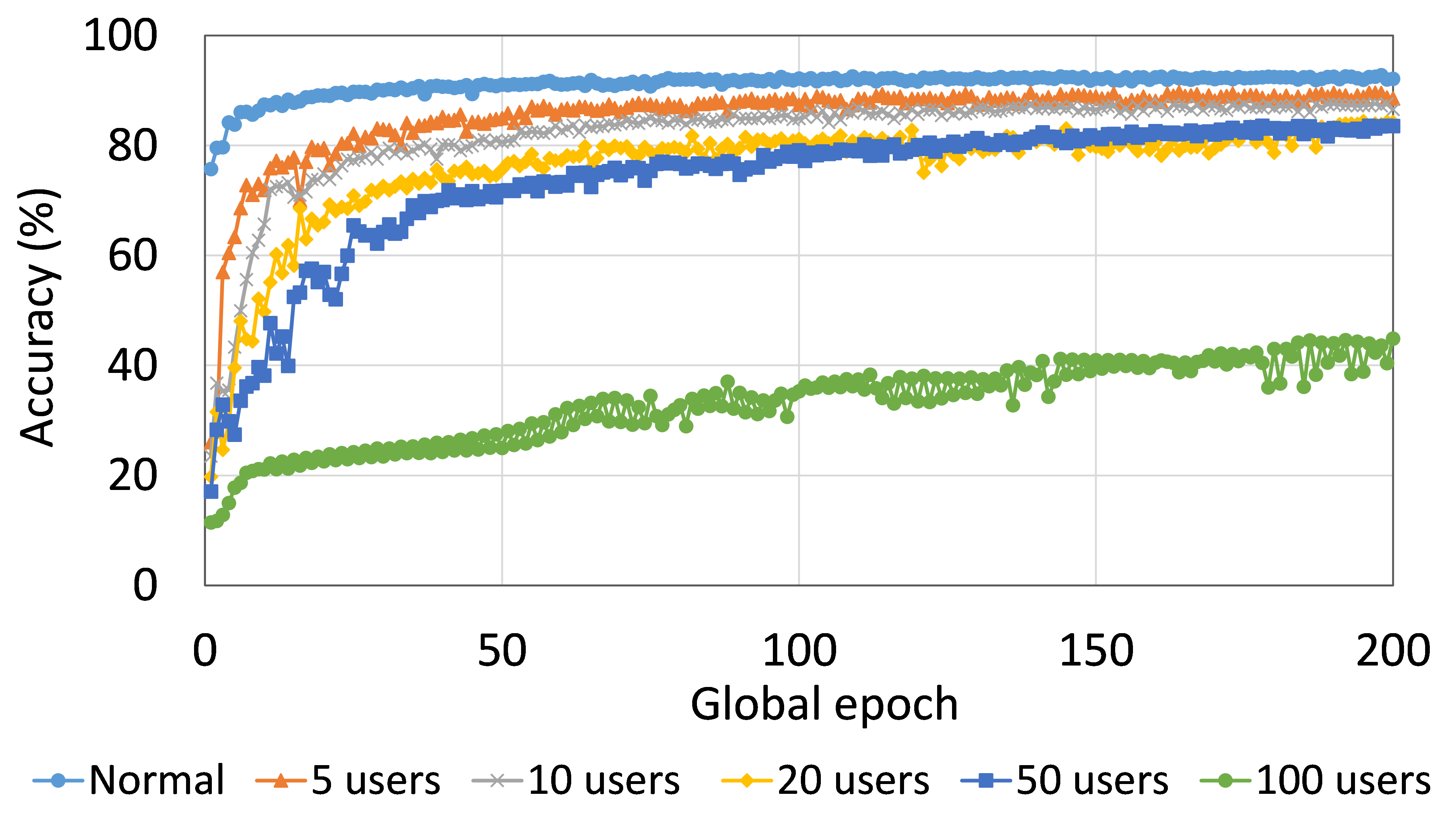
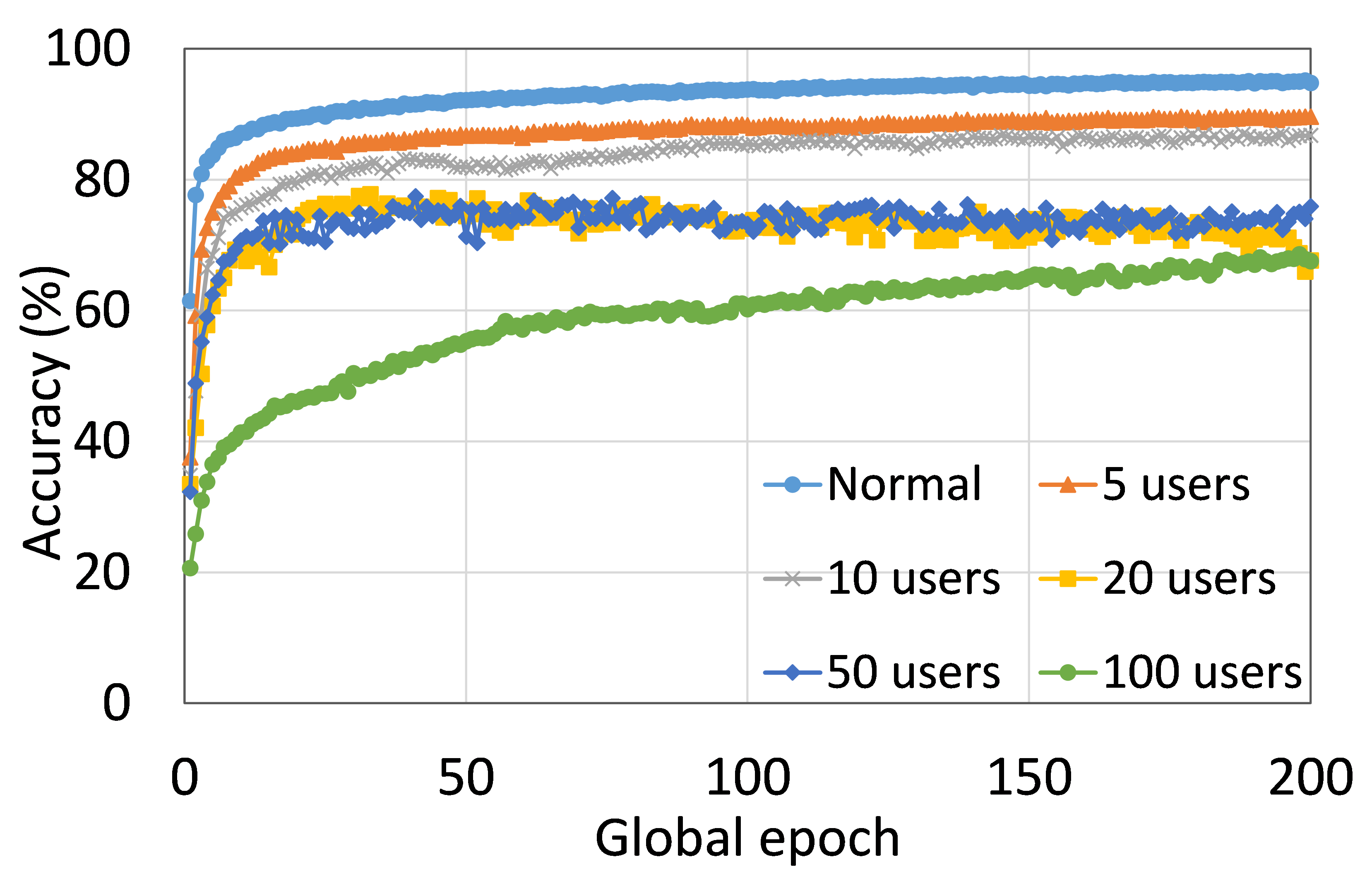
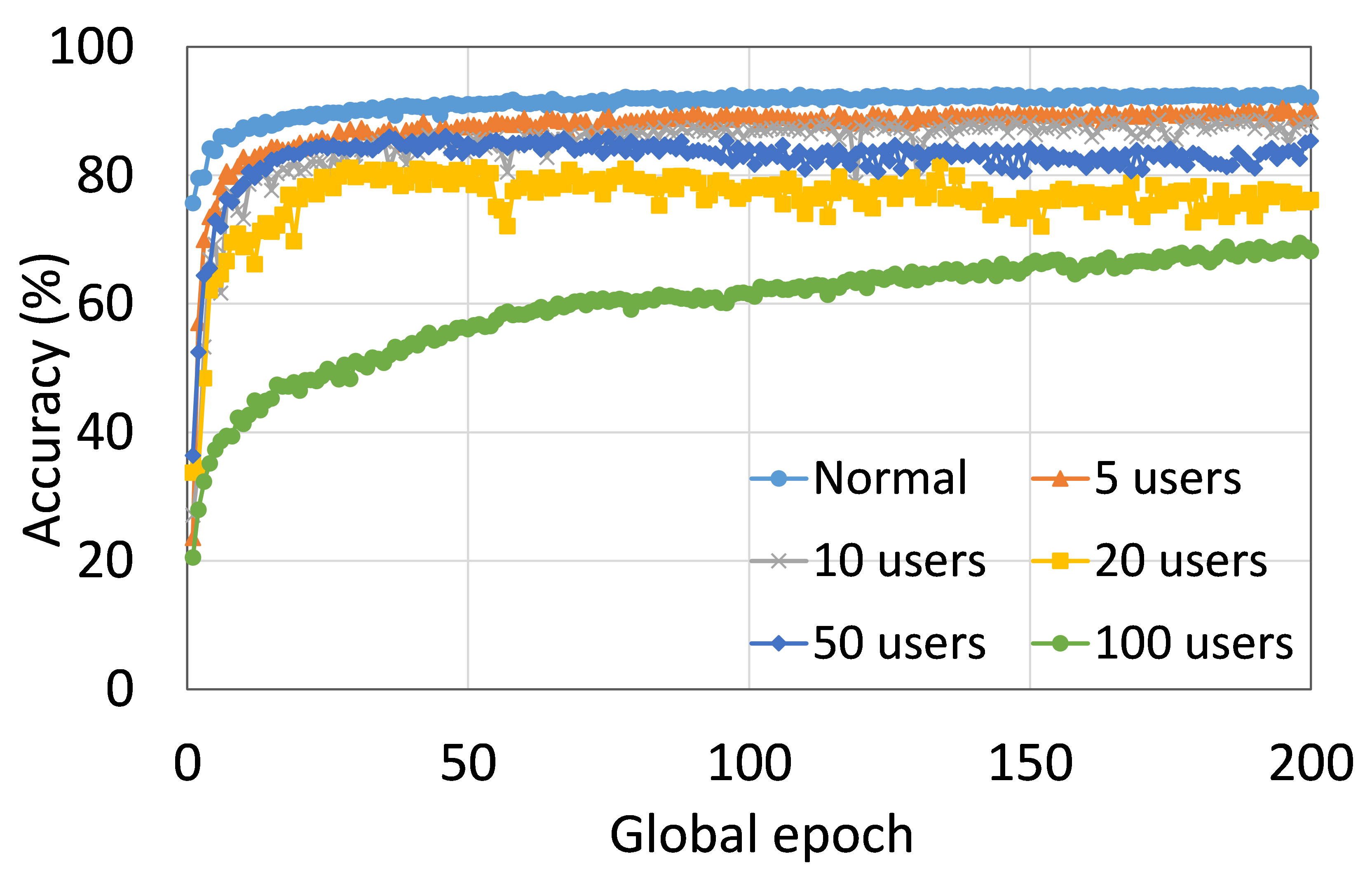
4.2 用户数量对性能的影响
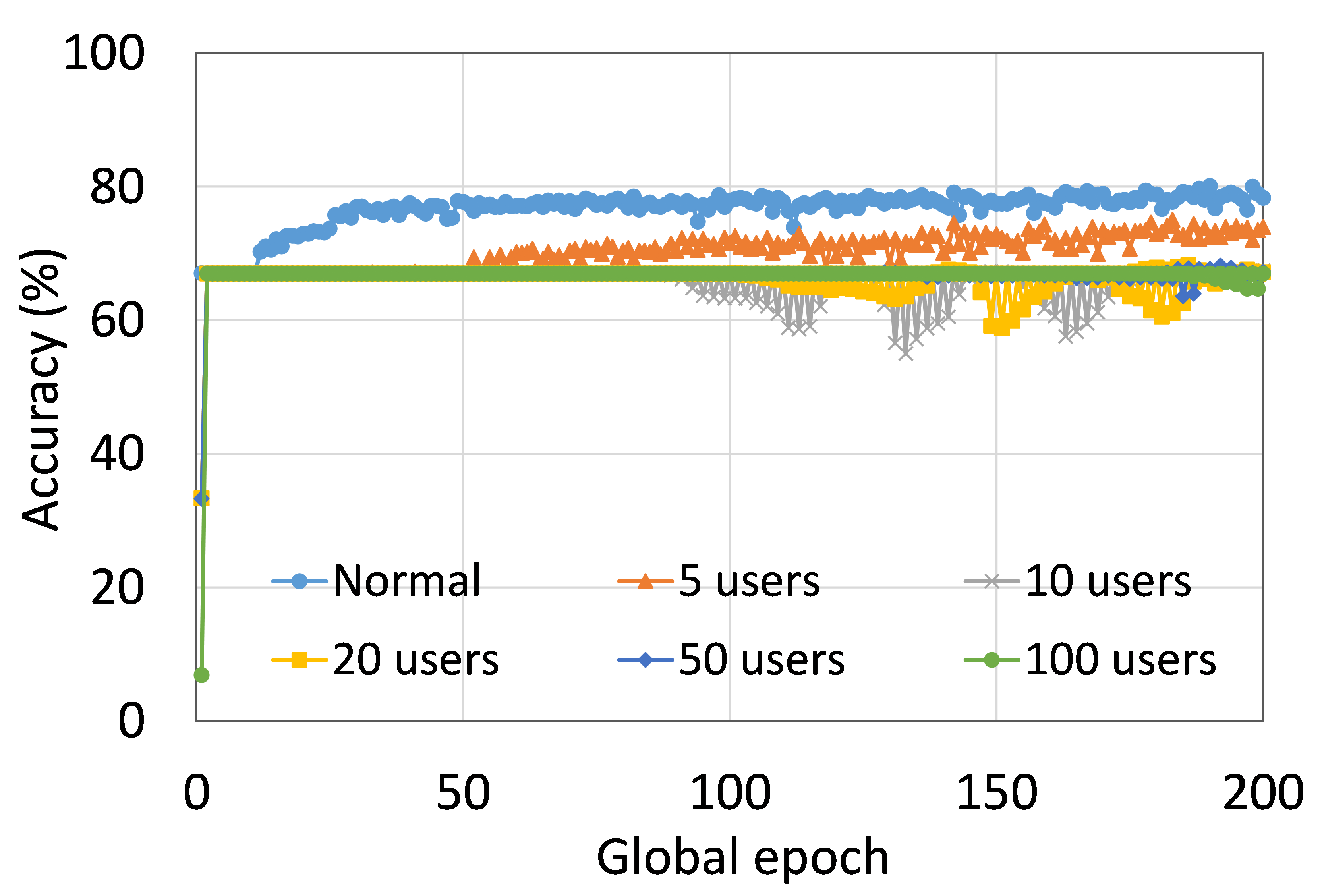
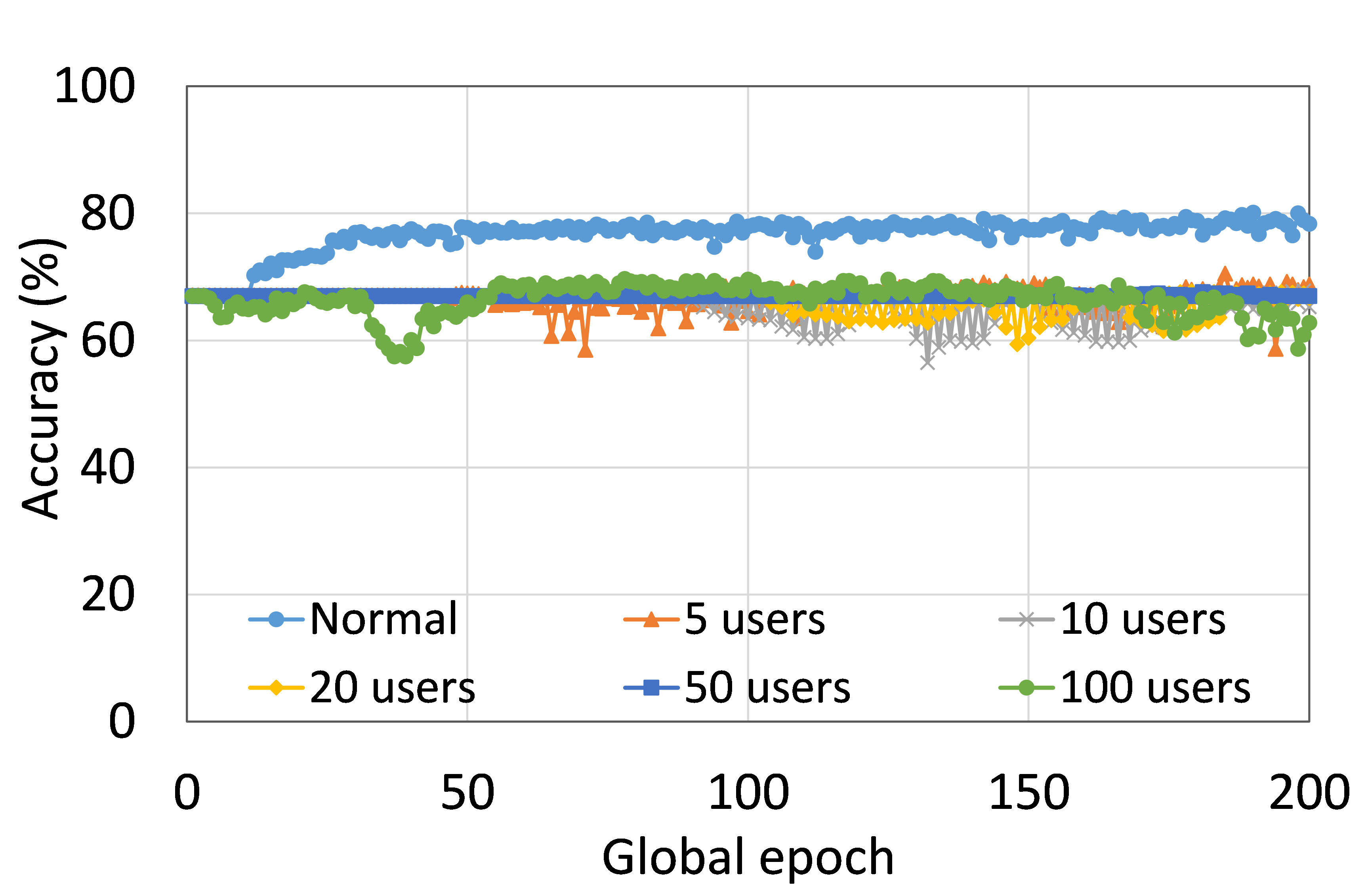
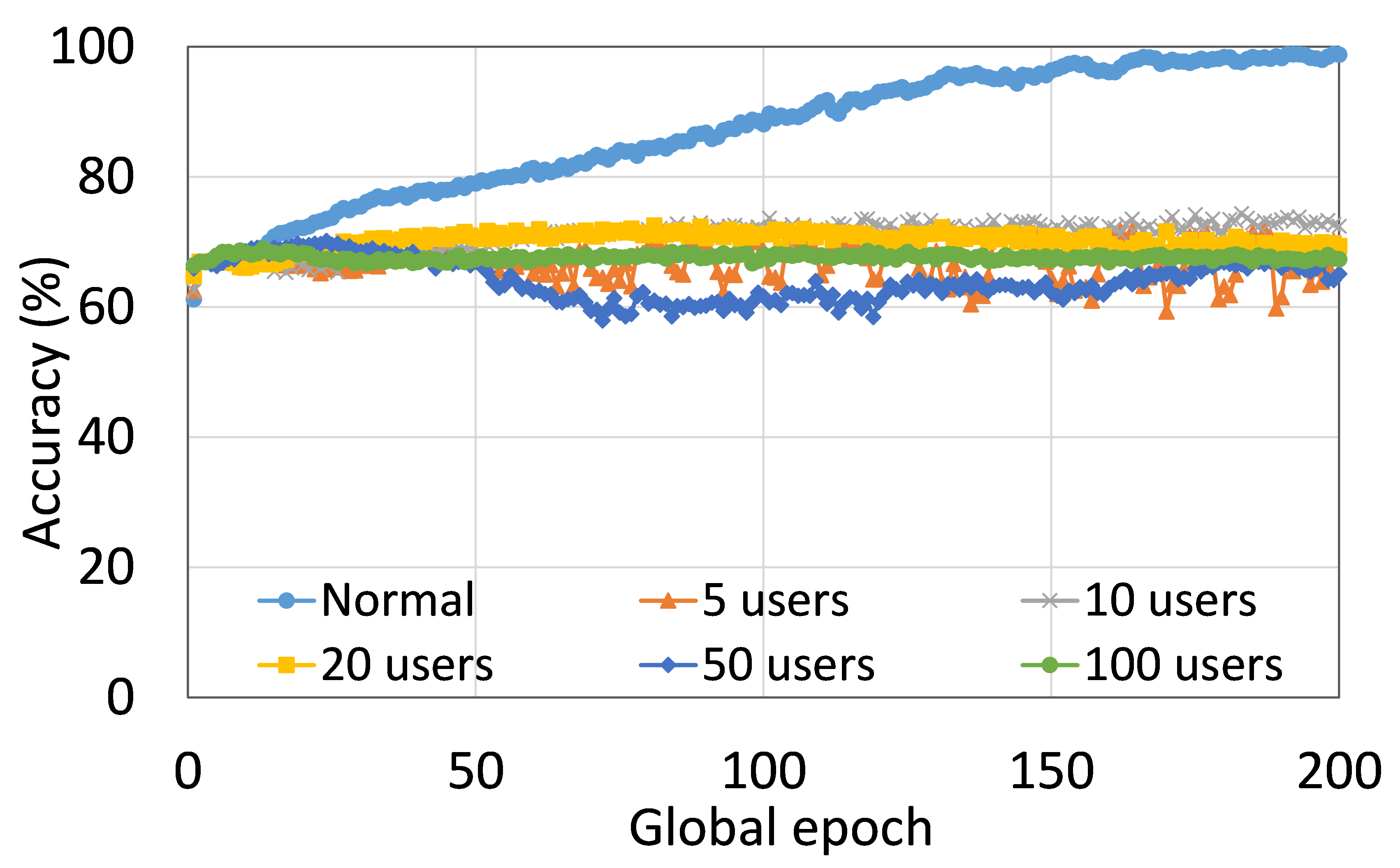
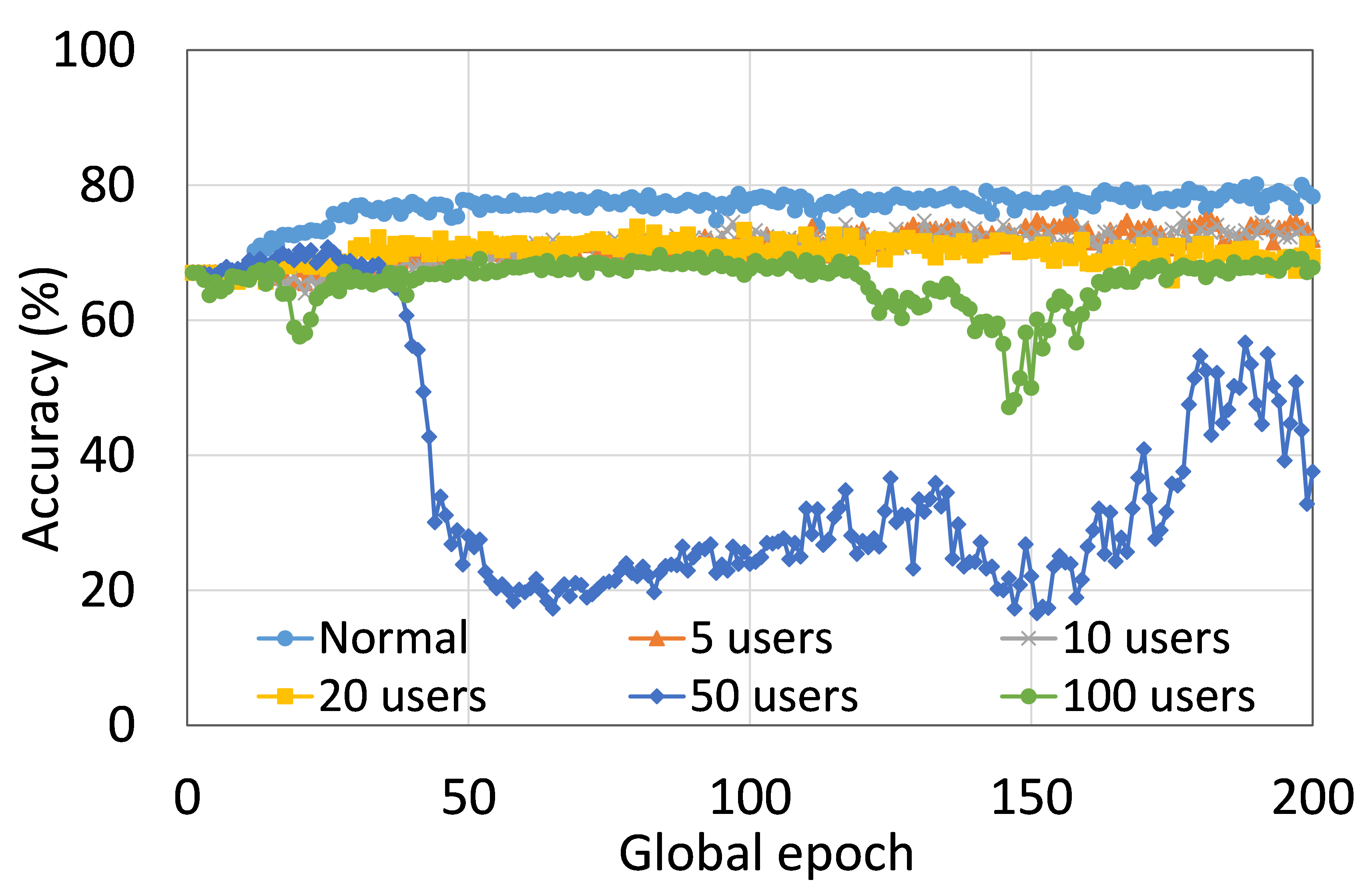
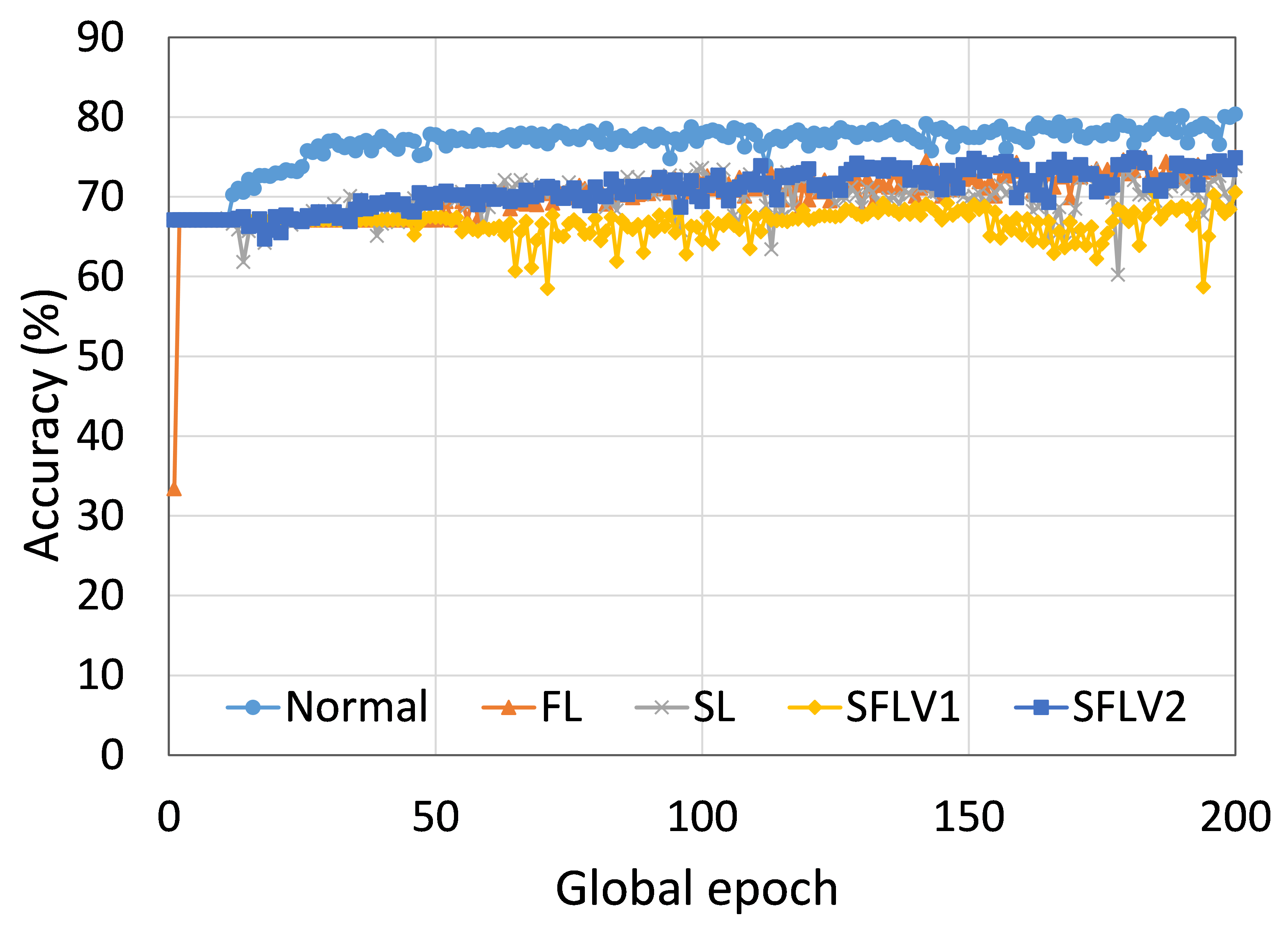
本节介绍ResNet18用户数量对HAM10000的影响分析。 我们观察到多达 100 个客户端(客户端范围从 5 到 100 个),所有数量的客户端的训练和测试曲线在每个图中都遵循类似的模式。 此外,他们在我们的每个 DCML 中都达到了相似的准确性水平。 我们在 100 个全局 epoch 中获得了约 74% (FL)、77% (SL)、75% (SFLV1) 和 77% (SFLV2) 的相对平均测试准确度。 在训练时,只有 SL 和 SFLV2 在大约 100 个全局 epoch 时达到了集中训练(正常学习)的准确性。 相比之下,FL和SFLV1即使在200个全局时期也无法达到这个结果。 从5到100个客户端的实验结果表明,由于FL、SL、SFLV1和SFLV2中客户端数量的增加,对性能的影响可以忽略不计(例如,参见图3) >)。 然而,这一观察结果并非如此。 对于 FMNIST 上客户端较少的 LeNet,FL 和 SL 的测试性能接近正常学习。 此外,对于 HAM10000 上使用 AlexNet 的 SL,随着客户端数量的增加,性能下降,甚至无法收敛,我们在 SFLV2 上看到了类似的效果。 总体而言,由于资源限制和其他约束(例如客户端之间数据分布的变化),随着客户端数量(在我们的 DCML 技术中)的增加,学习和性能的收敛速度减慢(有时无法进展)随着其数量的增加,并定期进行全局模型聚合以在多个客户端之间同步模型。
4.3 在具有 PixelDP 噪声层的客户端模型上具有差异隐私的 SFL
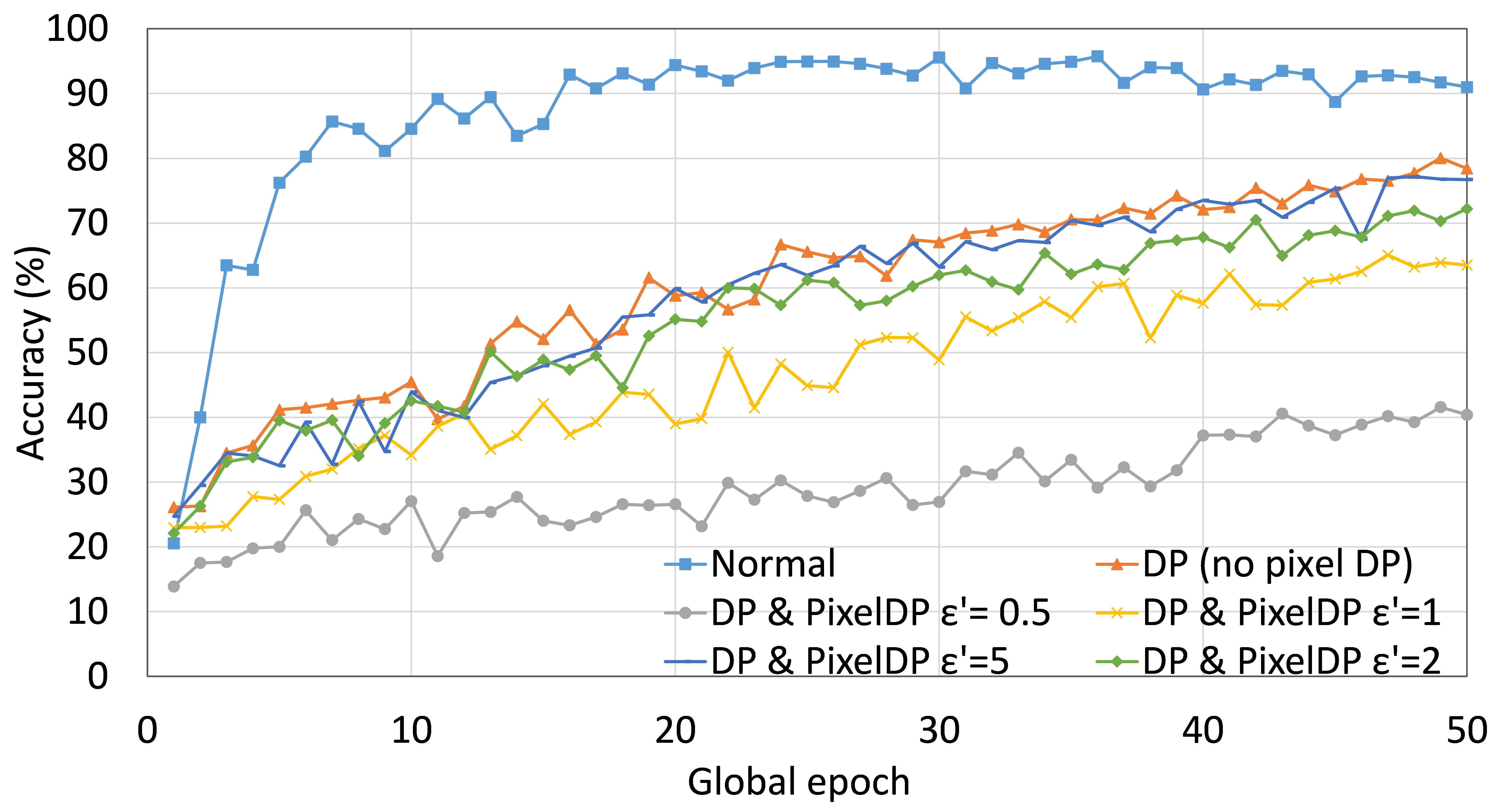
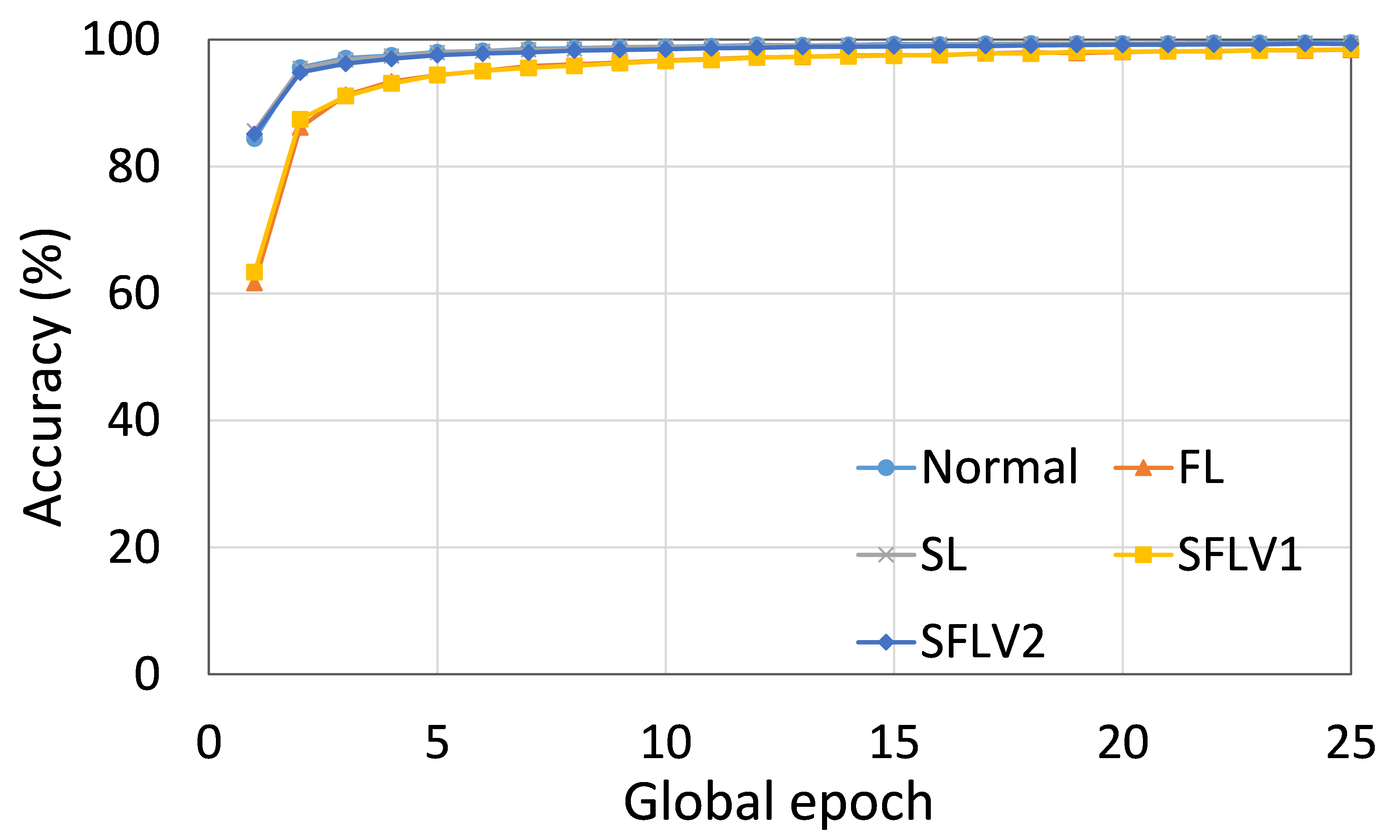
我们实施了“隐私保护”部分中所述的差异隐私措施。为了便于说明,我们使用 AlexNet 在分布于五个客户端的 MNIST 数据上对 SFLV1 进行了实验。 对于 50 个全局 epoch,每个全局 epoch 每个客户端有 5 个本地 epoch,测试精度曲线收敛,如图 5 所示。 此外,为了便于说明,我们更改了的值,这是放置在AlexNet第一个卷积层之后的PixelDP噪声层使用的隐私预算,以查看对整体性能的影响。 此外,我们在所有实验中将 训练保持在 0.5(客户端模型的隐私预算),以检查 SFLV1 在严格的客户端模型隐私下的行为。 正如预期的那样,与非差分私人训练相比,DP 测量的准确率曲线的收敛是渐进且缓慢的。 此外,在全局 epoch 50 上,对于 等于 和没有 PixelDP 的情况,测试准确率分别约为 40%、64%、73%、77% 和 78% 。 显然,准确性随着隐私预算(即 )的增加而增加。 总体而言,效用随着隐私预算的减少而降低。 由于SFLV2中的客户端架构与SFLV1中的相同,因此SFLV2中差分隐私的应用可以按照与SFLV1中相同的方式来完成。
5结论
通过将联邦学习(FL)和分裂学习(SL)结合在一起,我们提出了一种新颖的分布式机器学习方法,称为分裂学习(SFL)。 SFL 通过网络分裂和差分私有客户端模型更新来提供模型隐私。 通过跨客户端执行并行处理,它比 SL 更快。 我们的结果表明,与 SL 相比,SFL 在模型精度方面提供了相似的性能。 因此,作为一种混合方法,它支持使用资源受限设备(如 SL 中的网络拆分启用)和快速训练(如 FL 中的并行处理客户端启用)的机器学习。 进一步分析了基于差分隐私和 PixelDP 的具有隐私和鲁棒性措施的 SFL 的性能,以研究其在数据隐私和模型鲁棒性方面的可行性。 与隐私和实用性的详细权衡分析以及同态加密[8]的集成以保证数据隐私相关的研究留待未来的工作。
参考
- [1] Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with differential privacy. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. pp. 308–318 (2016)
- [2] Bonawitz, K., Eichner, H., Grieskamp, W., Huba, D., Ingerman, A., Ivanov, V., Kiddon, C., Konecný, J., Mazzocchi, S., McMahan, H.B., Overveldt, T.V., Petrou, D., Ramage, D., Roselander, J.: Towards federated learning at scale: System design. In: Proc. SysML Conference. pp. 1–15 (2019), https://mlsys.org/Conferences/2019/doc/2019/193.pdf
- [3] Dwork, C., McSherry, F., Nissim, K., Smith, A.D.: Calibrating noise to sensitivity in private data analysis. J. Priv. Confidentiality 7(3), 17–51 (2016). https://doi.org/10.29012/jpc.v7i3.405, https://doi.org/10.29012/jpc.v7i3.405
- [4] Dwork, C., Roth, A.: The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 9(3-4), 211–407 (2014)
- [5] Dwork, C., Roth, A., et al.: The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 9(3-4), 211–407 (2014)
- [6] Gao, Y., Kim, M., Abuadbba, S., Kim, Y., Thapa, C., Kim, K., Camtepe, S.A., Kim, H., Nepal, S.: End-to-end evaluation of federated learning and split learning for internet of things. In: Proc. SRDS (2020), https://arxiv.org/pdf/2003.13376.pdf
- [7] Gao, Y., Kim, M., Thapa, C., Abuadbba, S., Zhang, Z., Camtepe, S., Kim, H., Nepal, S.: Evaluation and optimization of distributed machine learning techniques for internet of things. CoRR abs/2103.02762 (2021), https://arxiv.org/abs/2103.02762
- [8] Gentry, C.: A fully homomorphic encryption scheme. Ph.D. thesis, Stanford University, Stanford, California (Sept 2009)
- [9] Gupta, O., Raskar, R.: Distributed learning of deep neural network over multiple agents. J. Network and Computer Applications 116, 1–8 (2018). https://doi.org/10.1016/j.jnca.2018.05.003
- [10] Han, D.J., amd Jungmoon Lee, H.I.B., Moon, J.: Accelerating federated learning with split learning on locally generated losses. In: Proc. FL-ICML (2021)
- [11] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proc. IEEE CVPR. pp. 770–778 (June 2016). https://doi.org/10.1109/CVPR.2016.90
- [12] Kairouz, P., McMahan, H.B., et al.: Advances and open problems in federated learning. CoRR abs/1912.04977 (2019), http://arxiv.org/abs/1912.04977
- [13] Konecný, J., McMahan, B., Ramage, D.: Federated optimization: Distributed optimization beyond the datacenter. arxiv (2015), https://arxiv.org/pdf/1511.03575.pdf
- [14] Krizhevsky, A., Nair, V., Hinton, G.: Cifar-10 (canadian institute for advanced research) Http://www.cs.toronto.edu/ kriz/cifar.html
- [15] Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Proc. NIPS’12 - Vol. 1. pp. 1097–1105. USA (2012)
- [16] Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. In: Proc. of the IEEE. vol. 86, pp. 2278–2324 (Nov 1998). https://doi.org/10.1109/5.726791
- [17] Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. of the IEEE 86(11), 2278–2324 (Nov 1998)
- [18] Lecuyer, M., Atlidakis, V., Geambasu, R., Hsu, D., Jana, S.: Certified robustness to adversarial examples with differential privacy. In: 2019 IEEE Symposium on Security and Privacy (SP). pp. 656–672. IEEE (2019)
- [19] McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Proc. AISTATS. pp. 1273–1282 (2017)
- [20] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Proc. 3rd ICLR (2015), http://arxiv.org/abs/1409.1556
- [21] Singh, A., Vepakomma, P., Gupta, O., Raskar, R.: Detailed comparison of communication efficiency of split learning and federated learning. arxiv (2019), https://arxiv.org/abs/1909.09145
- [22] Tschandl, P.: The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions (2018), doi:10.7910/DVN/DBW86T
- [23] Vepakomma, P., Gupta, O., Dubey, A., Raskar, R.: Reducing leakage in distributed deep learning for sensitive health data. In: Proc. ICLR (2019)
- [24] Vepakomma, P., Gupta, O., Swedish, T., Raskar, R.: Split learning for health: Distributed deep learning without sharing raw patient data. arxiv (2018), http://arxiv.org/abs/1812.00564
- [25] Xiao, H., Rasul, K., Vollgraf, R.: Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arxiv (2017), http://arxiv.org/abs/1708.07747
附录
附录0.A威胁模型
在这项工作中,对于联邦学习(FL)、分割学习(SL)和分割学习(SFL),我们认为系统模型的联邦服务器和主服务器是诚实但好奇的对手。 他们按照指定执行任务,但可能对客户端的本地私有数据和完整模型感到好奇。 此外,这里考虑的服务器的攻击场景是被动的,它们仅观察更新并可能进行一些计算来获取信息,但它们不会为了攻击目的而恶意修改自己的输入或参数。 此外,服务器和客户端彼此不串通。 对于客户来说,他们被视为好奇的对手;在训练时诚实行事,但只能在推理(测试)期间输入对抗性输入。
我们假设我们的方法 splitfedv1 (SFLV1) 和 splitfedv2 (SFLV2) 遵循标准的客户端-服务器安全模型,其中客户端和服务器在开始网络模型训练之前建立一定程度的信任。 例如,在健康领域,医院(客户端)只允许具有一定信任度的平台(服务器)和研究人员(模型所有者)。 如果相应平台存在恶意客户端或服务器,医院会选择退出。 此外,我们假设参与实体之间的所有通信(例如,客户端和主服务器之间的粉碎数据和梯度的交换)都是以加密形式执行的。 与 FL 的威胁模型相比,SFL 在客户端多了一个诚实但好奇且非共谋的联邦服务器(类似于中心化模式下的 SL 的情况)。 SFL 中的馈送服务器和客户端只能访问客户端模型部分的梯度/权重。 在 FL 中,主服务器可以访问整个模型。 相比之下,主服务器只能访问模型的服务器端部分以及来自 SL 和 SFL 中客户端的粉碎数据(即剪切层的激活向量)。
附录0.B总成本衡量
除了对 FL、SL、SFLV1 和 SFLV2 学习的通信成本和模型训练时间成本进行理论分析之外,我们还对通信和训练时间进行了实证测试。 这些结果补充了我们在“总成本分析”部分中的分析。
0.B.1 通信测量
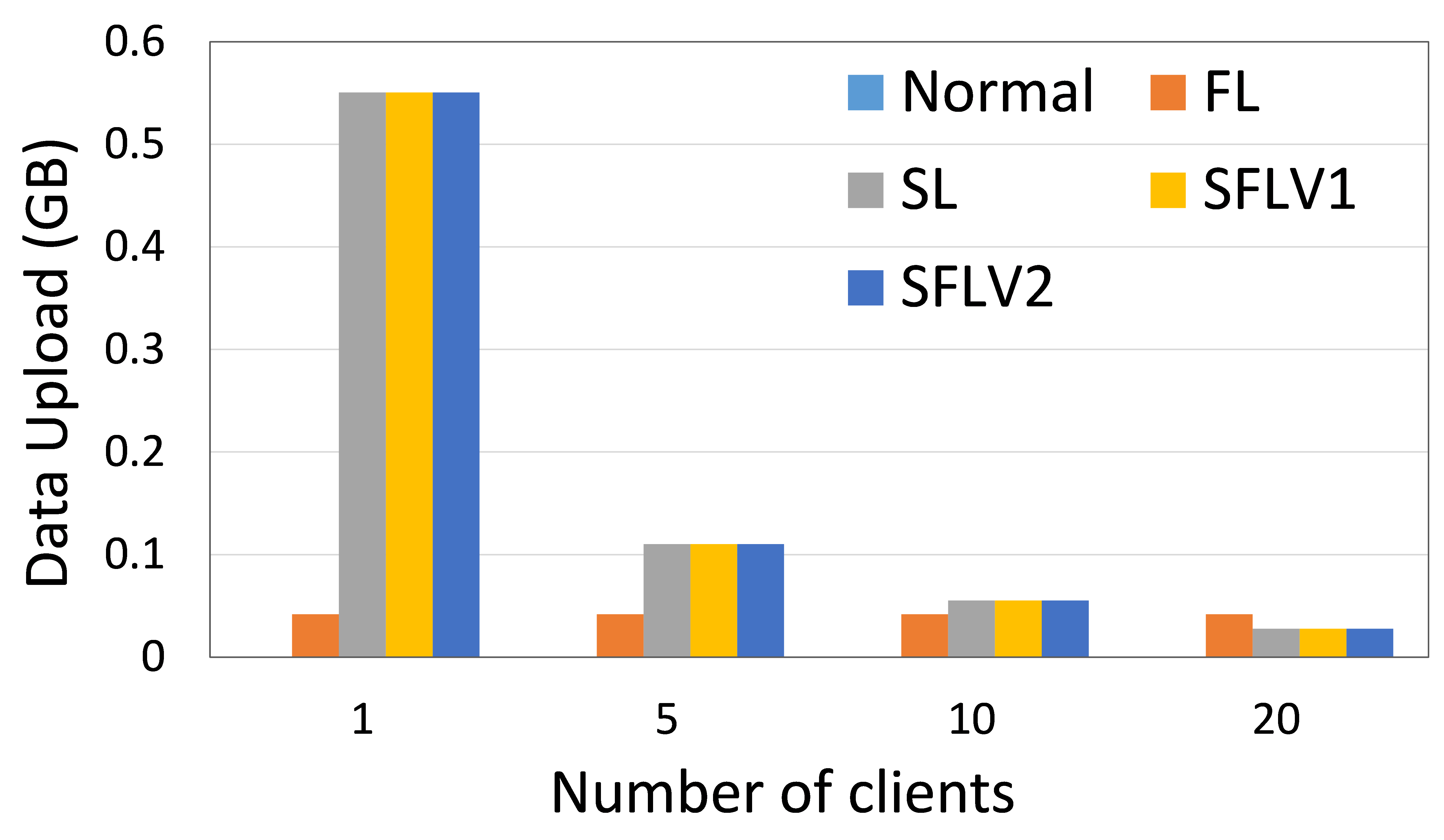
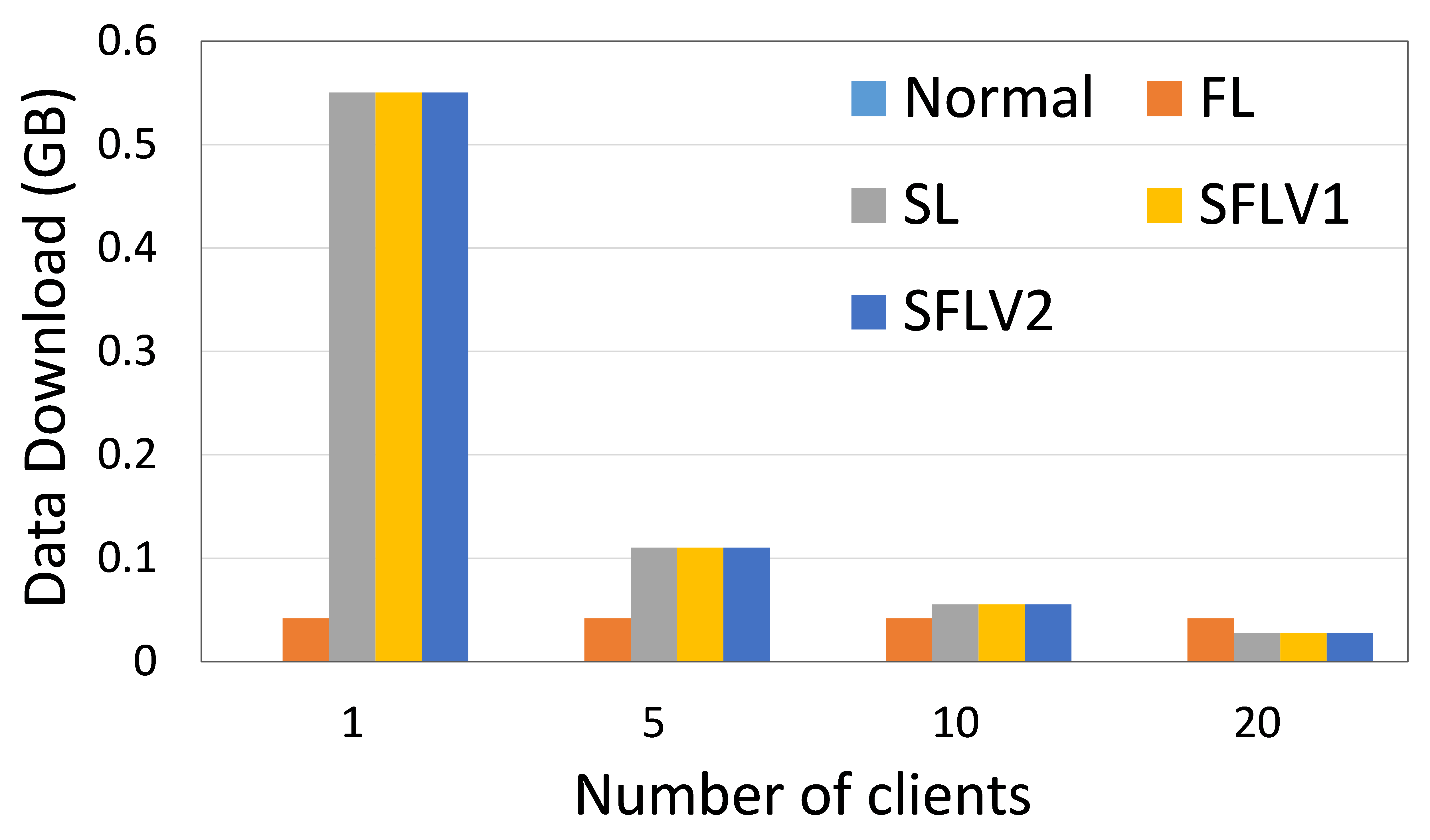
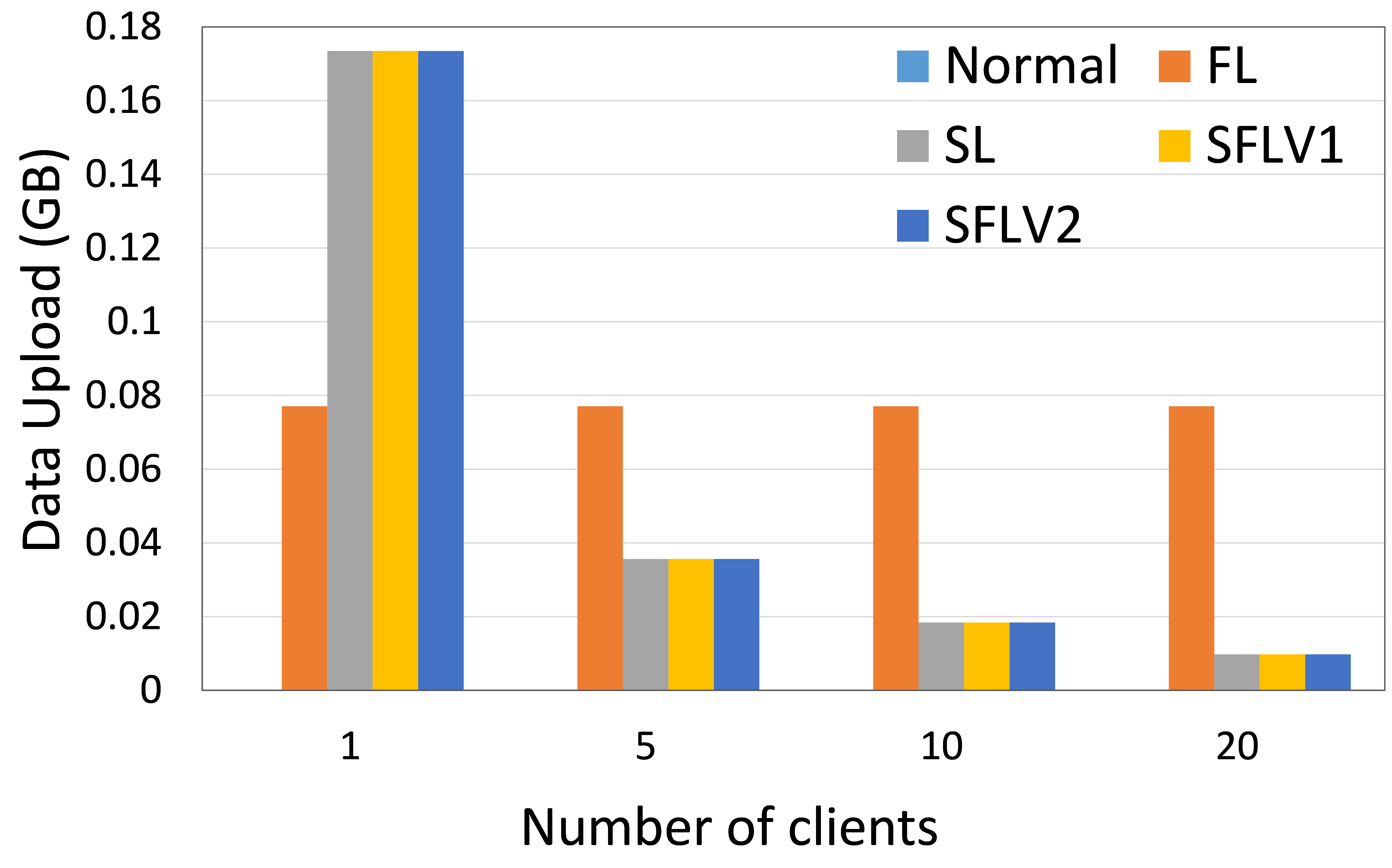
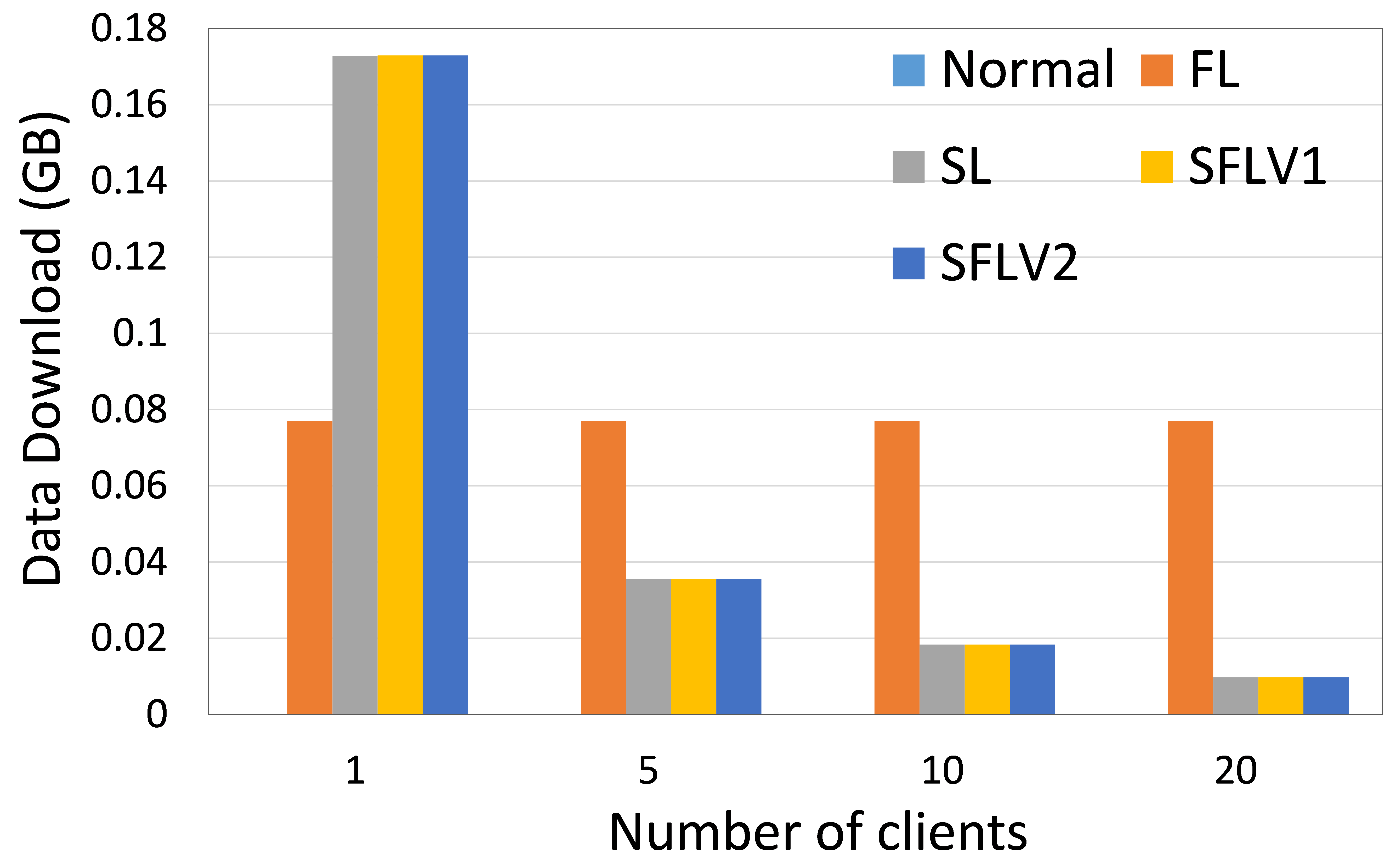
客户端上传和下载的数据量表明分布式协作机器学习(DCML)方法在资源受限的环境中的可操作性。 高数据通信会减慢机器学习(ML)训练和测试过程,客户需要有足够的资源来处理高通信成本。 在这方面,我们在实验中测量了数据通信量,并展示了四种 DCML 技术的相对性能。 为了使实验设置针对不同数量的客户端进行标准化,我们在以下配置下运行我们的程序:主服务器和联邦服务器的程序在两个不同的 HPC 节点中运行,客户端的程序在五个单独的节点中运行(除了一个实验)客户)。 每个客户端 HPC 节点针对 5 个、10 个和 20 个客户端案例运行 1 个、2 个和 4 个客户端(客户端程序)。 我们记录了 11 个全局 epoch 和 1 个局部 epoch 的观察窗口的总通信量,批量大小为 256。 然后对所有全球时期和客户端的结果进行平均,以获得每个全球时期每个客户端的通信成本。 HAM10000 上的 ResNet18 和 MNIST 上的 AlexNet 的通信负载见图6。
最近的研究表明,在增加客户端数量或模型大小的同时,SL 比 FL 的通信效率更高[21]。 相反,如果通过保持较低的客户端数量或模型大小来增加数据样本量[21, 6],那么 FL 是首选。
0.B.2 时间测量
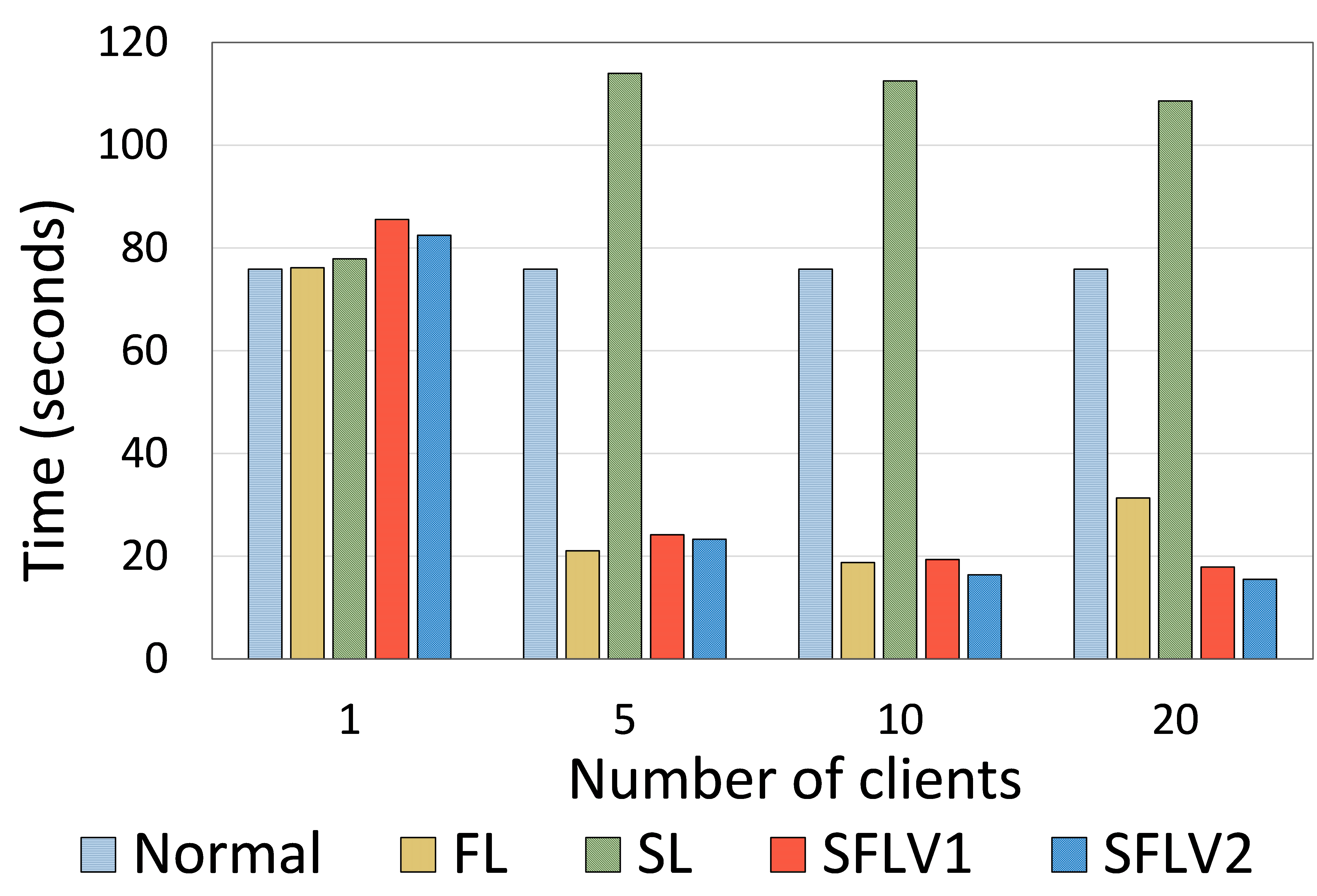
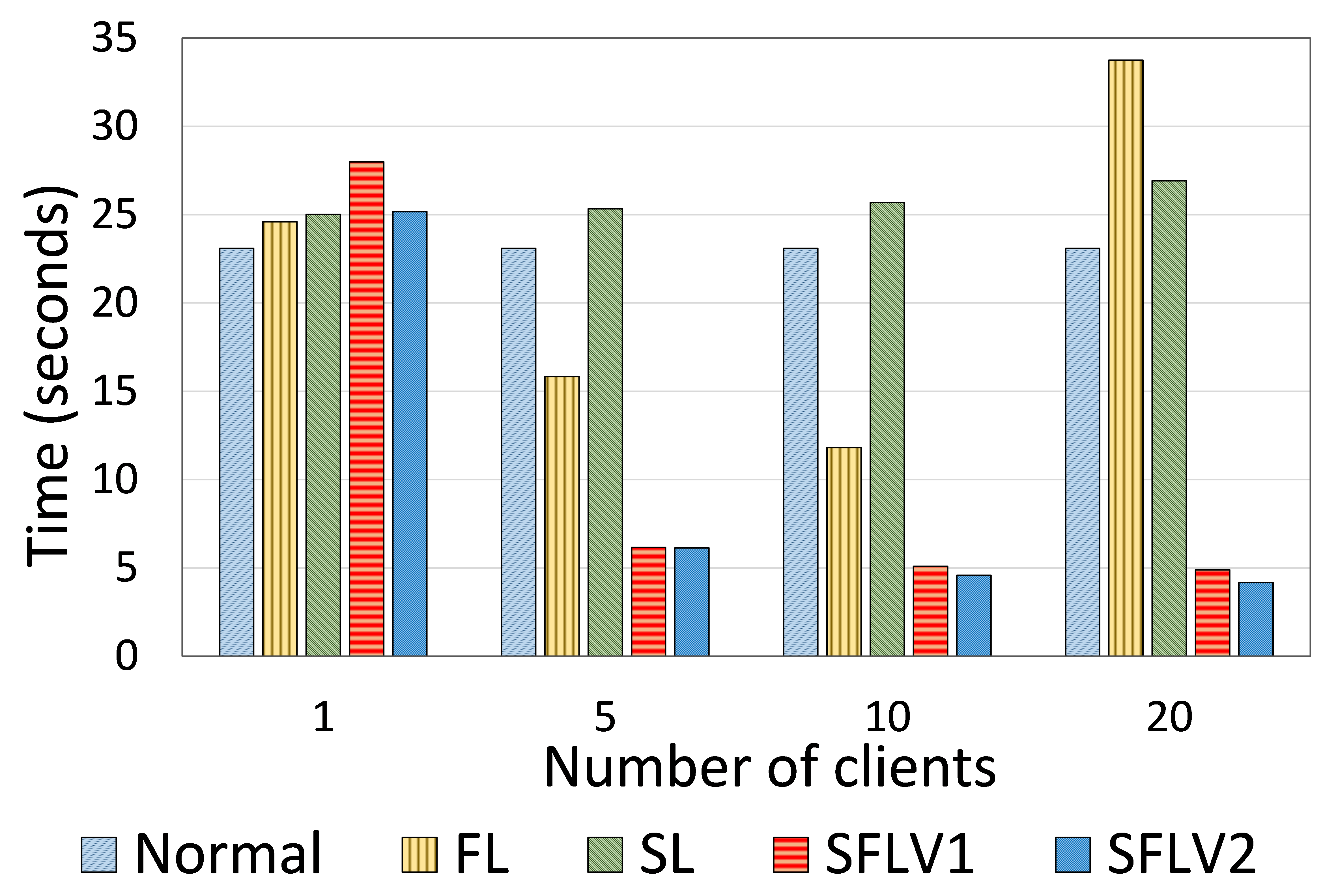
为了显示 SFLV1 和 SFLV2 与 SL 相比的时间效率,我们分析了一个全局 epoch 所需的训练时间。 考虑到“总成本分析”一节的算法1和算法2,不难看出以下几点:对于SL,主要开销是由于每个客户端的客户端模型上传和下载,而对于全局epoch,是客户端总数 () 的倍数。 相反,在计算 SFLV1 和 SFLV2 中的时间时,不存在此类乘积项,因为服务器可以是超级计算资源并并行处理所有客户端。 因此,对于多个客户端,SFL(两个版本)比 SL 更快。 此外,这也表明训练时间的测量不仅取决于实现,还取决于算法。 对于 SFL 中的实验,我们为主服务器实现了一个多线程 python 程序。 使用相同的实验设置(用于测量通信成本),我们运行了十一个全局时期的每个实验,并记录了每个全局时期的时间。 与通信测量设置不同,训练时间是通过考虑运行每个实验十次后所有客户端从第二个全局纪元开始的时间来平均的。 第一个全局纪元的时间被排除在外,因为它包括客户端连接到服务器所花费的时间,即初始连接开销(在我们的设置中,所有客户端首先连接到服务器并在实验期间保持连接) )。 我们将每个实验运行了十次——每个实例中都有不同的 HPC slurm 作业——以排除每次运行中计算环境变化的影响。
根据我们对 HAM10000 上的 ResNet18 和 MNIST 上的 AlexNet 的观察,多客户端案例的时间统计表明,SFLV1 和 SFLV2 明显比 SL 快 - 四到六倍。 它的速度与FL相似甚至更好(参见图7)。 对于单个客户端的情况,SL 和 FL 方法花费的时间相似; SFLV1 和 SFLV2 花费的时间略多于另一个。
附录 0.C 其他经验结果
0.C.1 FL、SL、SFLV1 和 SFLV2 的性能
本节介绍正常(集中)学习、FL、SL、SFLV1 和 SFLV2 的训练和测试收敛图。 实验考虑五个客户端,并在 HAM10000 上使用 AlexNet、MNIST 上的 ResNet18、MNIST 上的 AlexNet、FMNIST 上的 LeNet5、FMNIST 上的 AlexNet、CIFAR10 上的 LeNet5 和 CIFAR10 上的 VGG16。 我们提供训练和测试结果来展示训练和测试实例的图片。
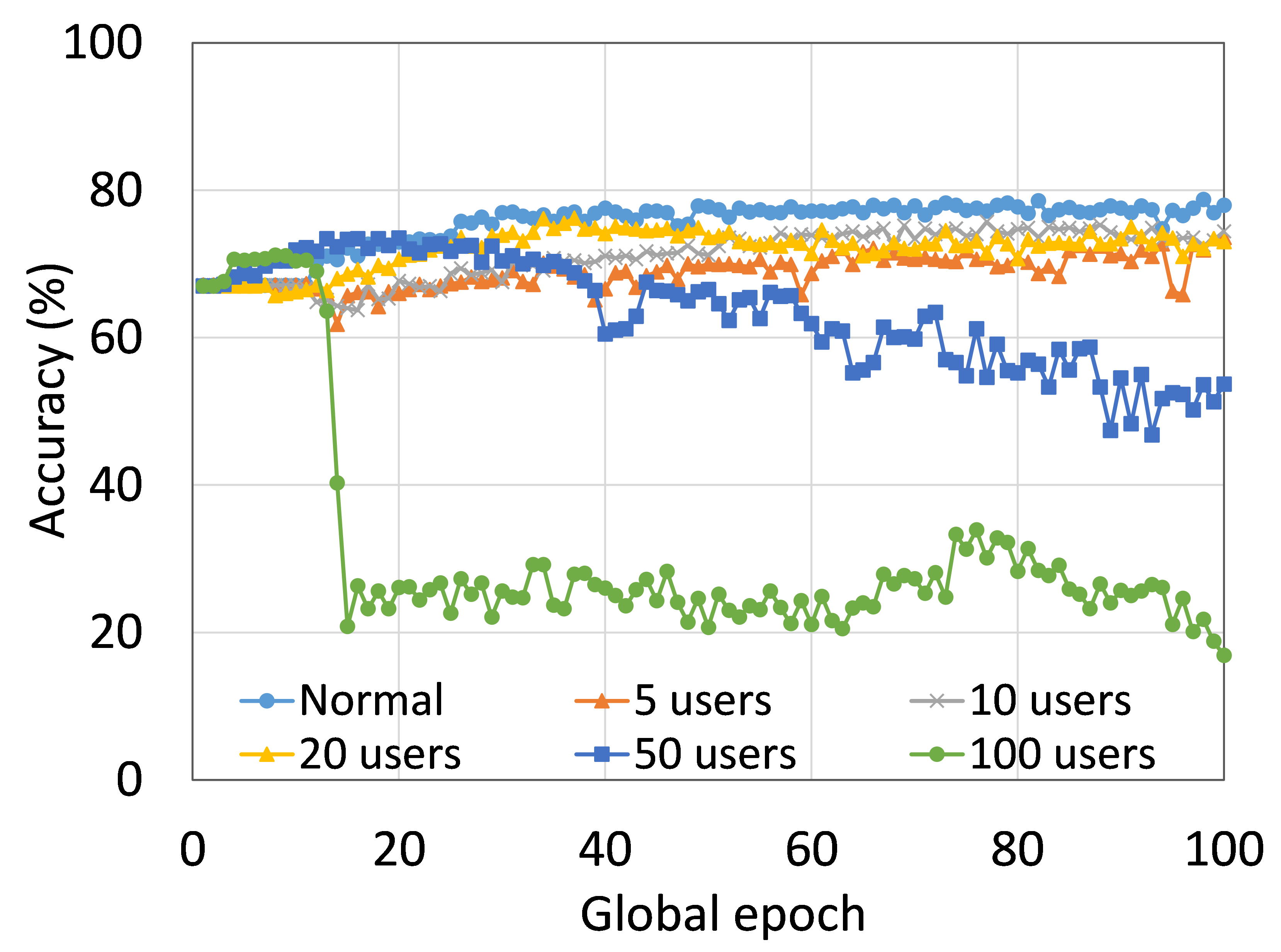
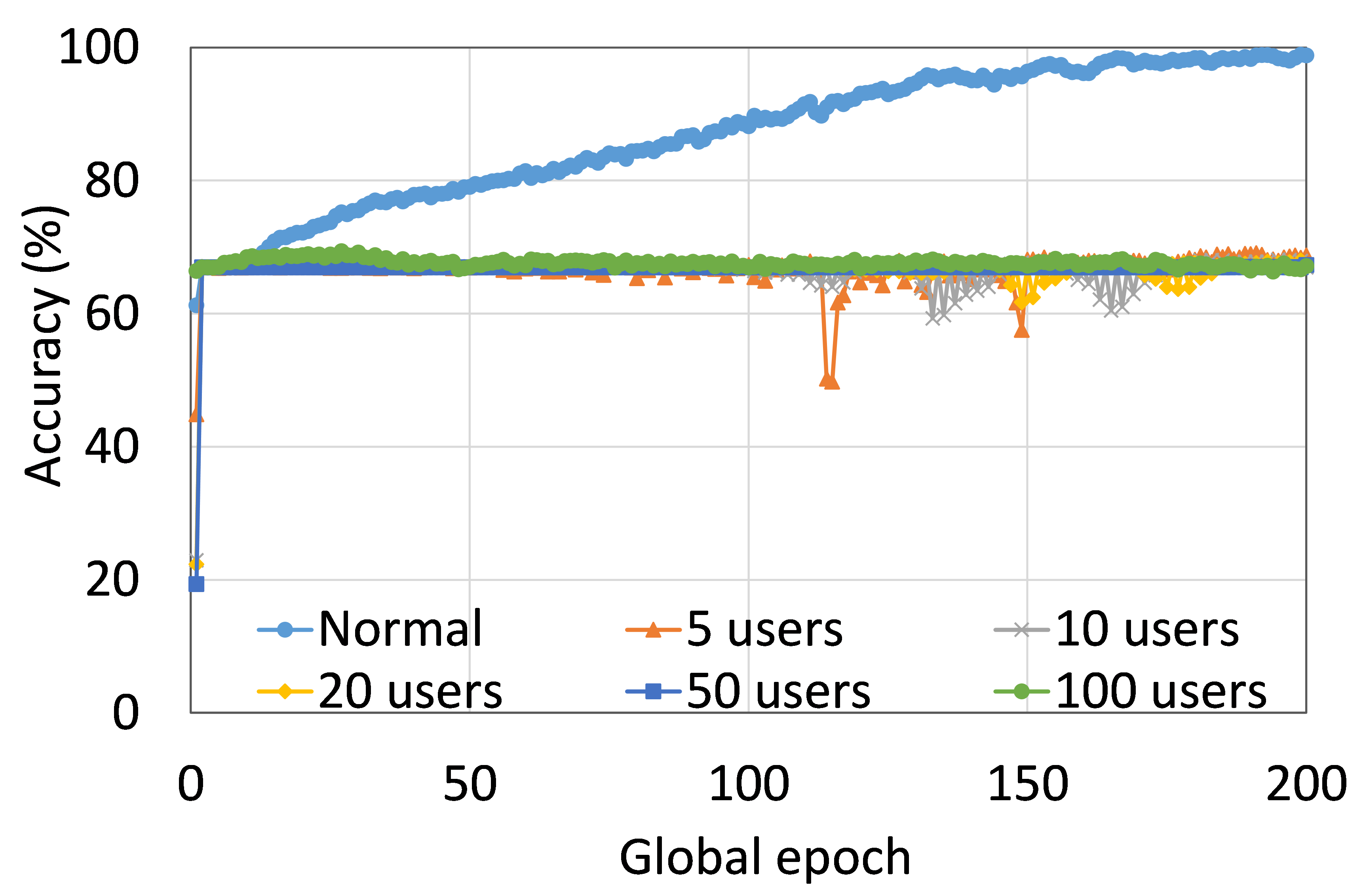
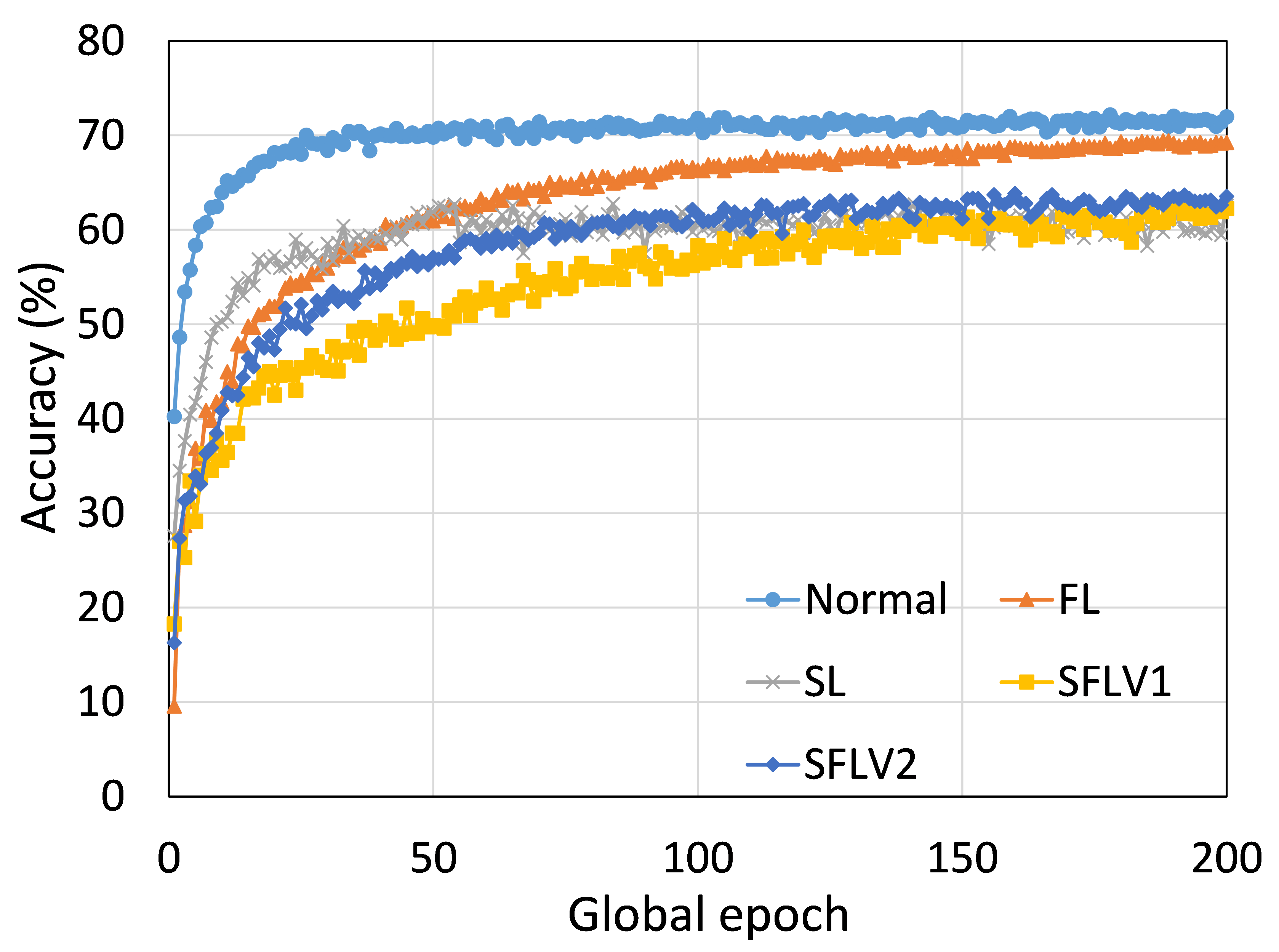
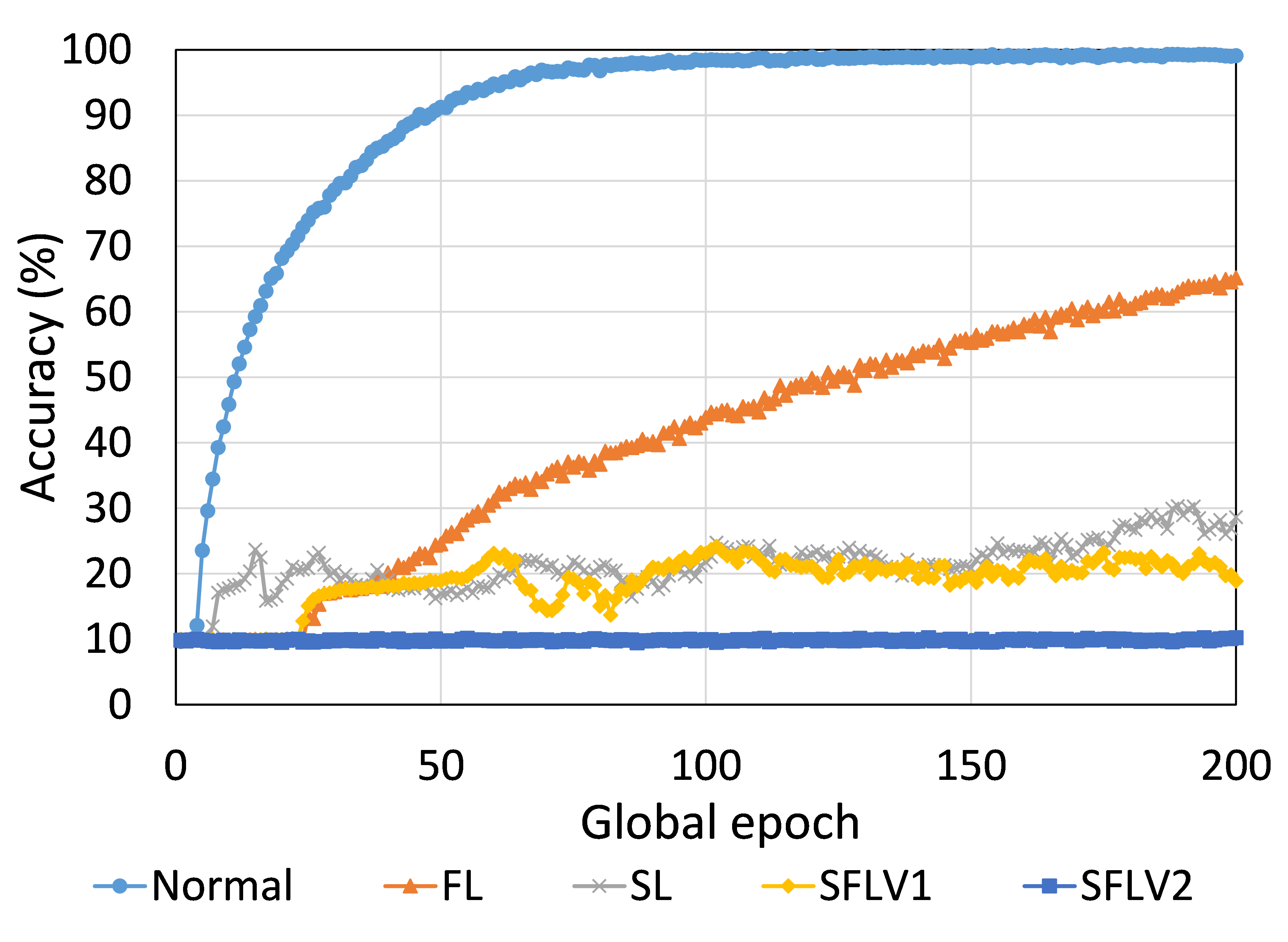
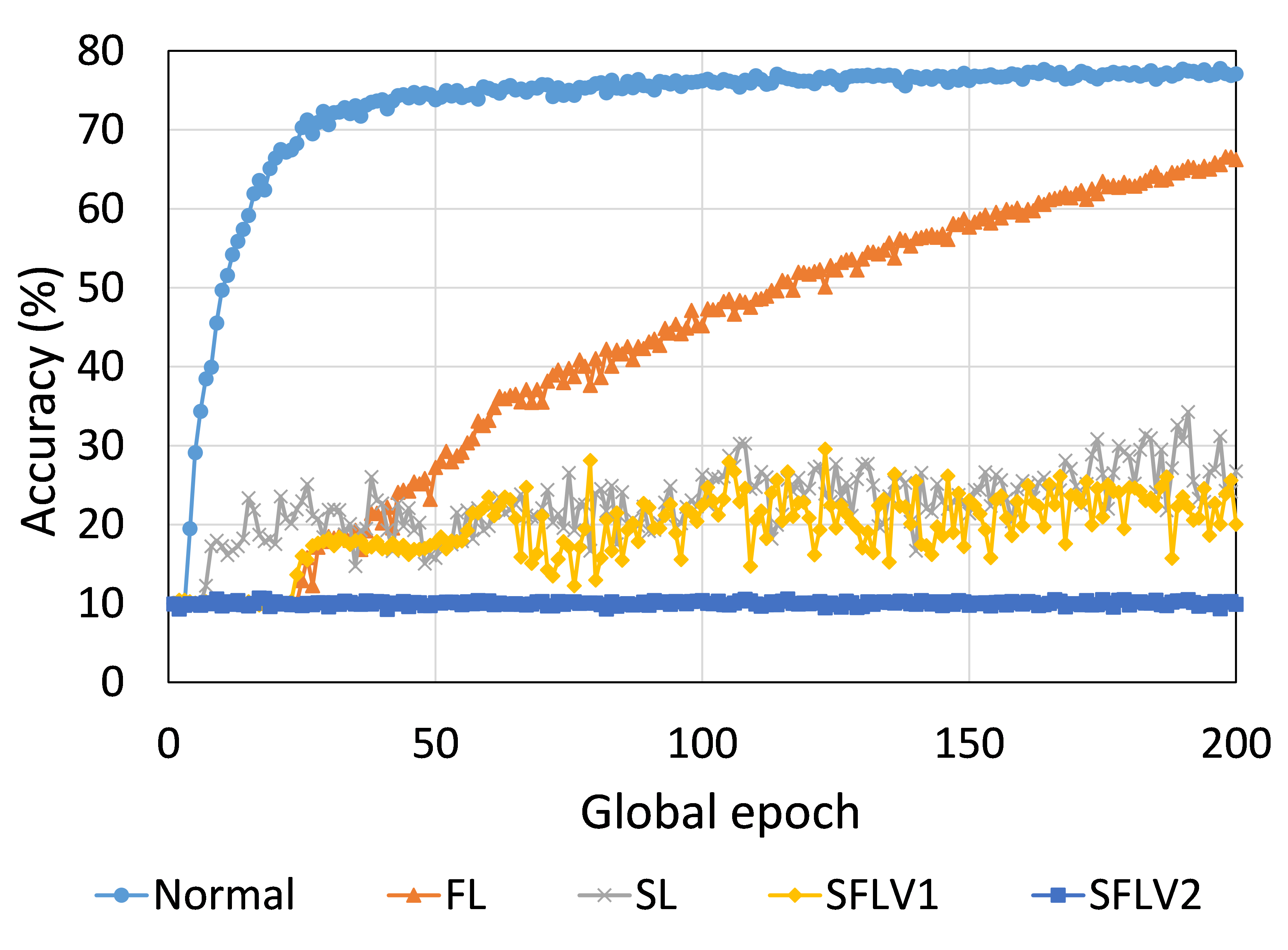
从这些结果中可以看出,在大多数情况下,FL、SL、SFLV1 和 SFLV2 在训练和测试时表现出相似的特征。 此外,单个方法的最佳性能取决于数据集。 可能存在最坏的情况,在某些情况下,某些方法可能无法在简单的实现中学习。 例如,SL、SFLV1 和 SFLV2 可能会因 CIFAR10 上的 VGG16 无法学习而受到影响(参见图 8(m) 和 8(n))。 这需要进一步调查。 在其他情况下,我们的 DCML 方法以预期的方式学习。 对于某些数据集(例如 CIFAR10),与类似设置中的其他数据集相比,FL 表现良好;然而,与 FL 相比,SL、SFLV1 和 SFLV2 由于分离网络架构而具有优势,例如客户端计算要求低和模型隐私。 此外,在SFLV1和SFLV2中,服务器端网络的FedAvg并不总是有效的;例如,HAM10000 上的 AlexNet(参见图 8(b));大多数情况下,FedAvg(在 FL 和 SFLV1 中)正在为有希望的结果做出贡献。
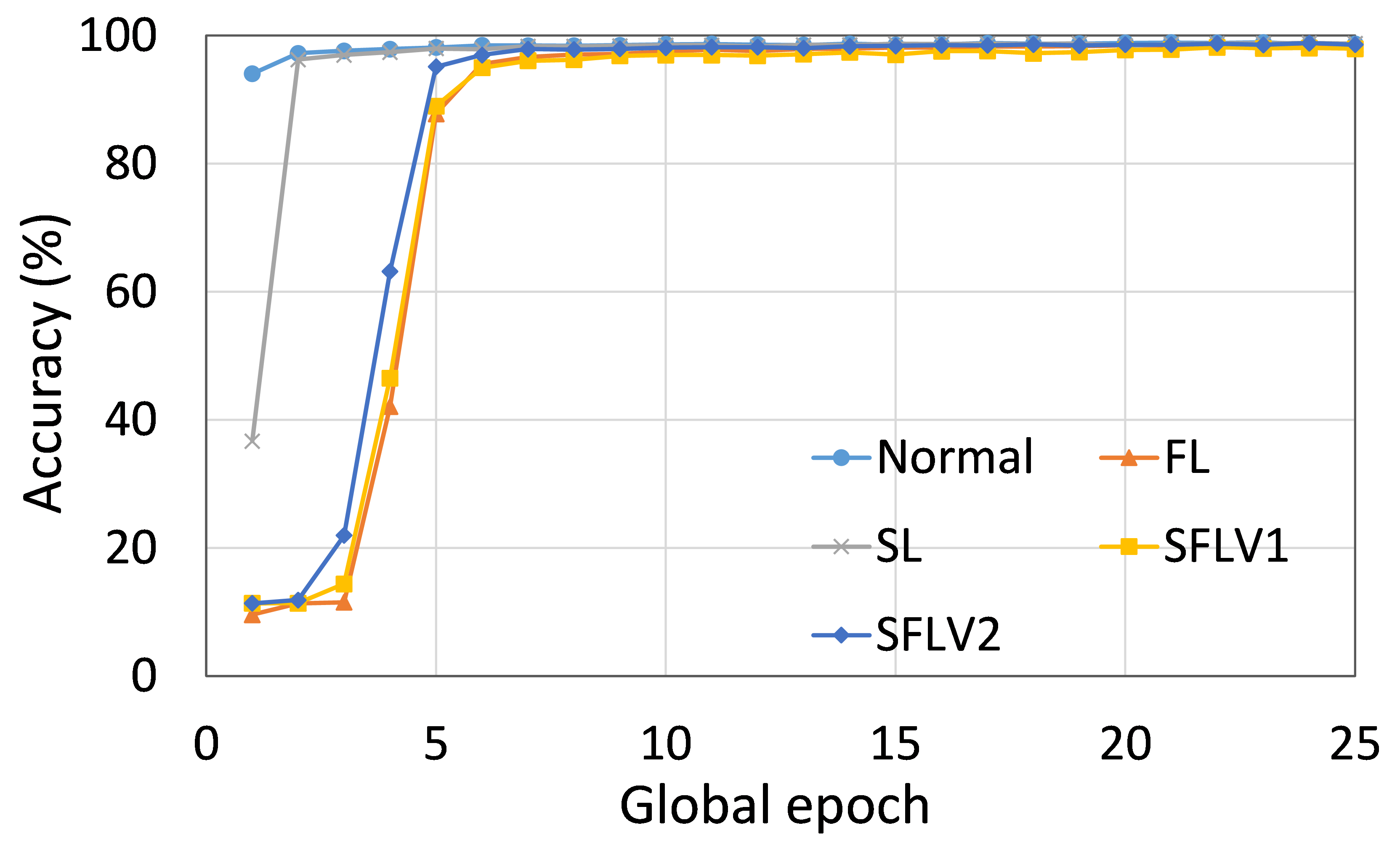
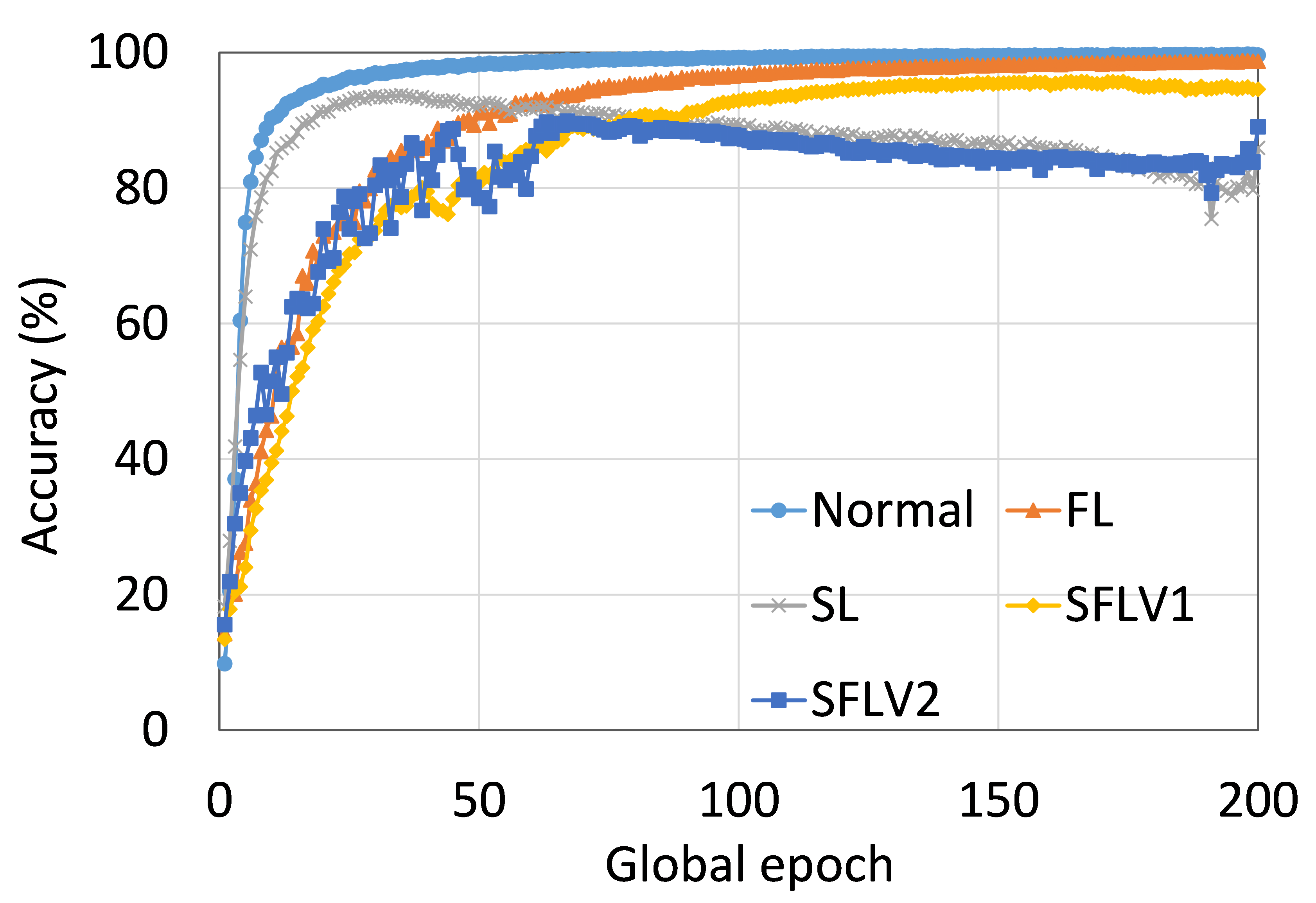
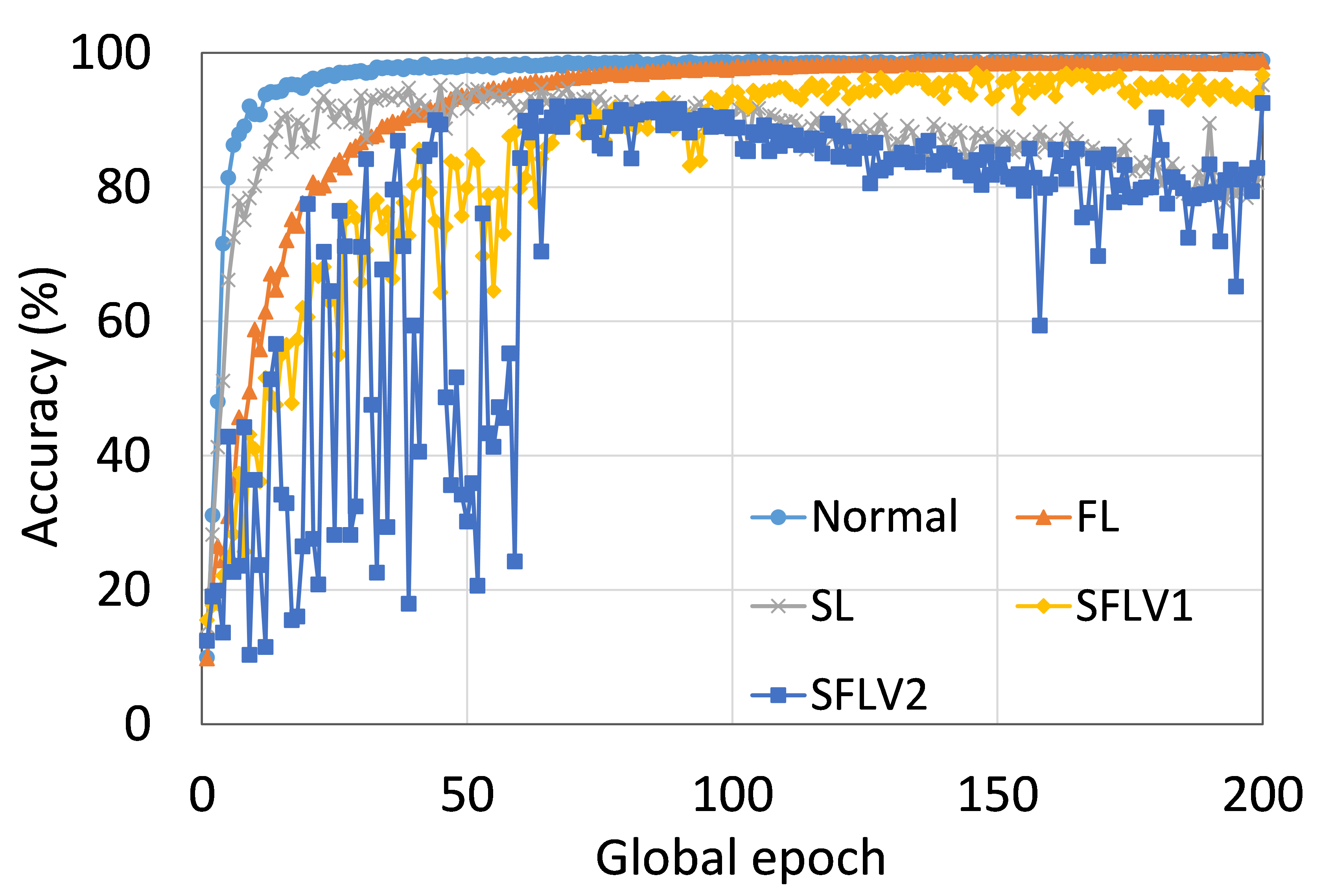
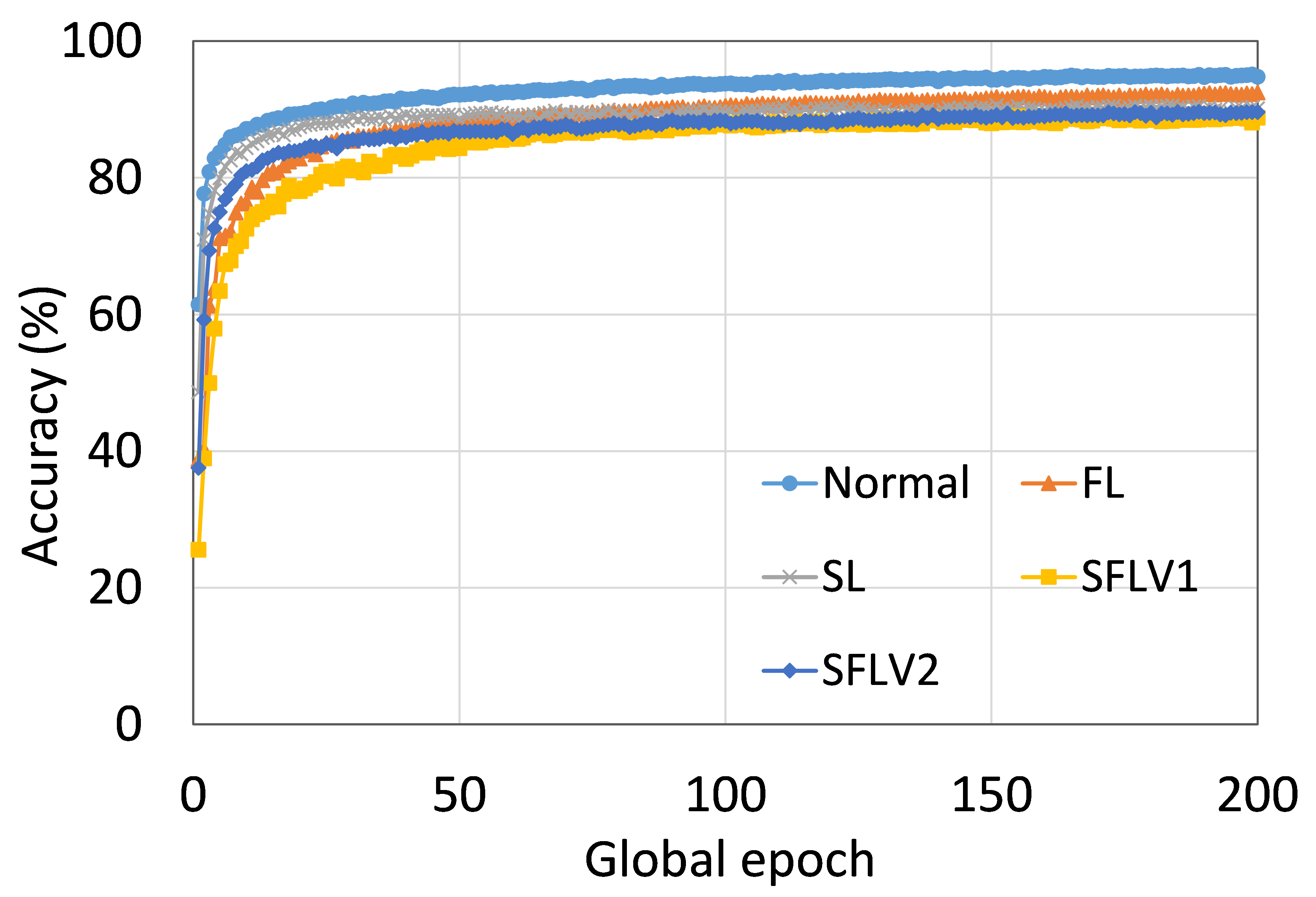
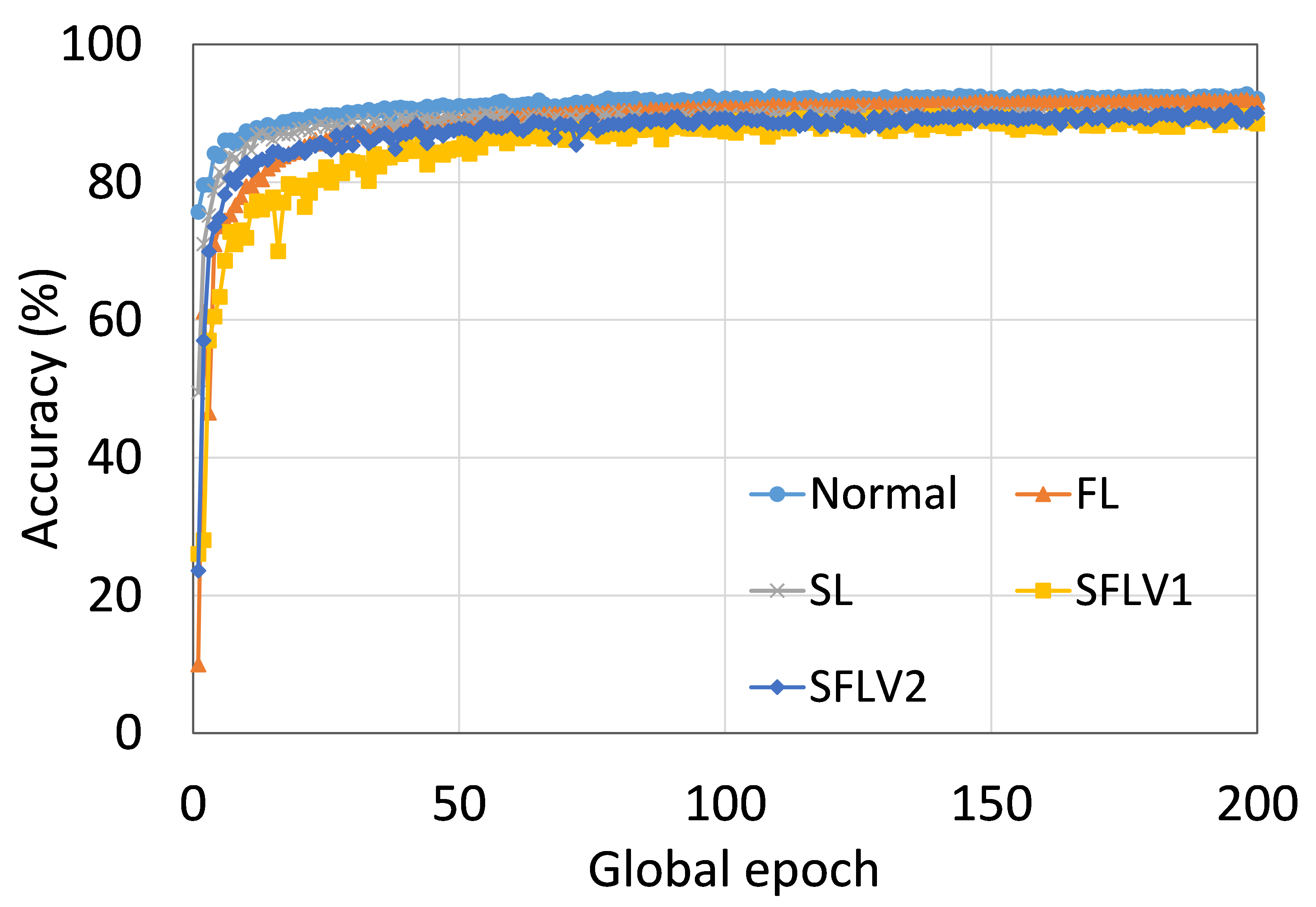
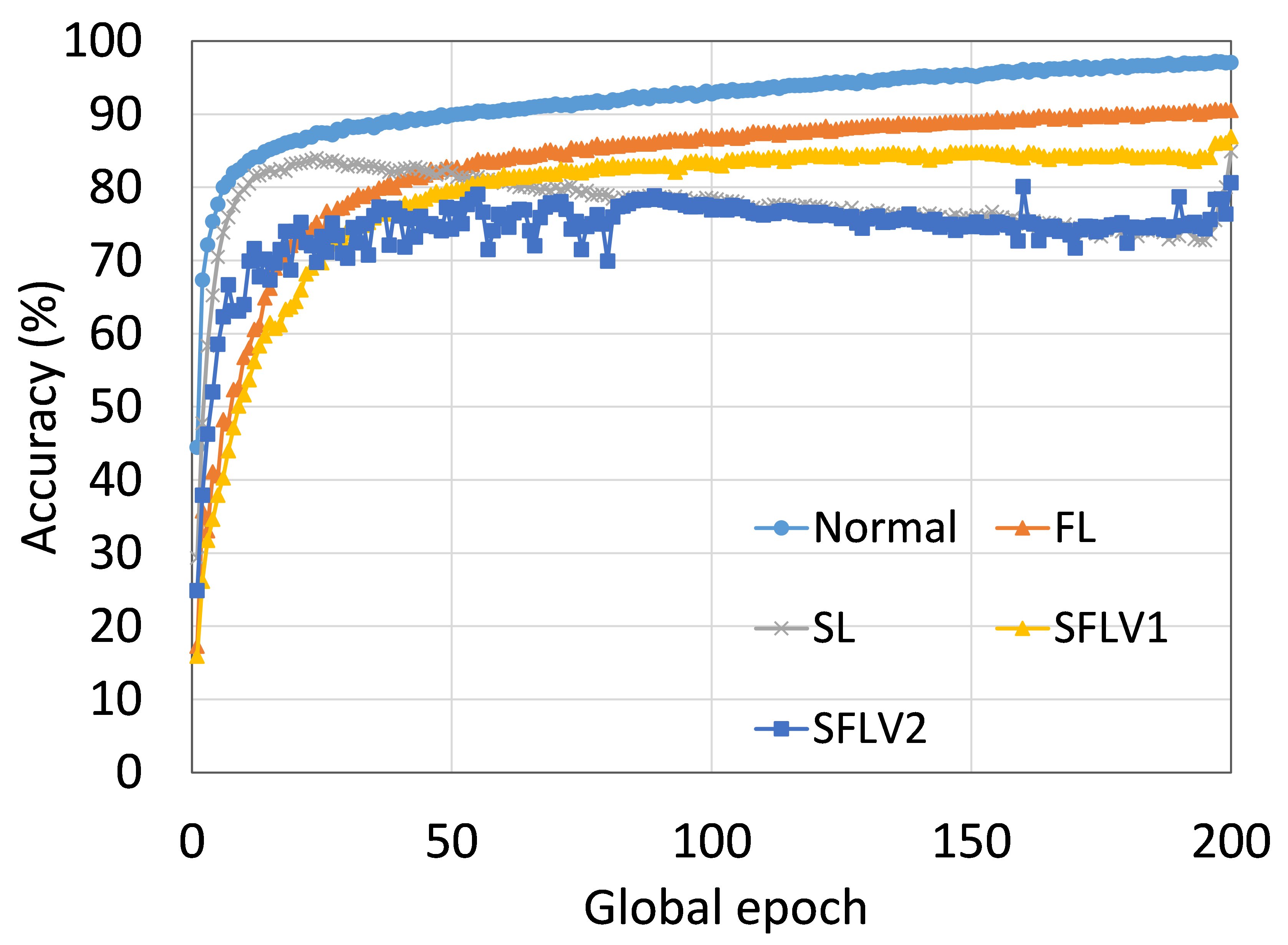
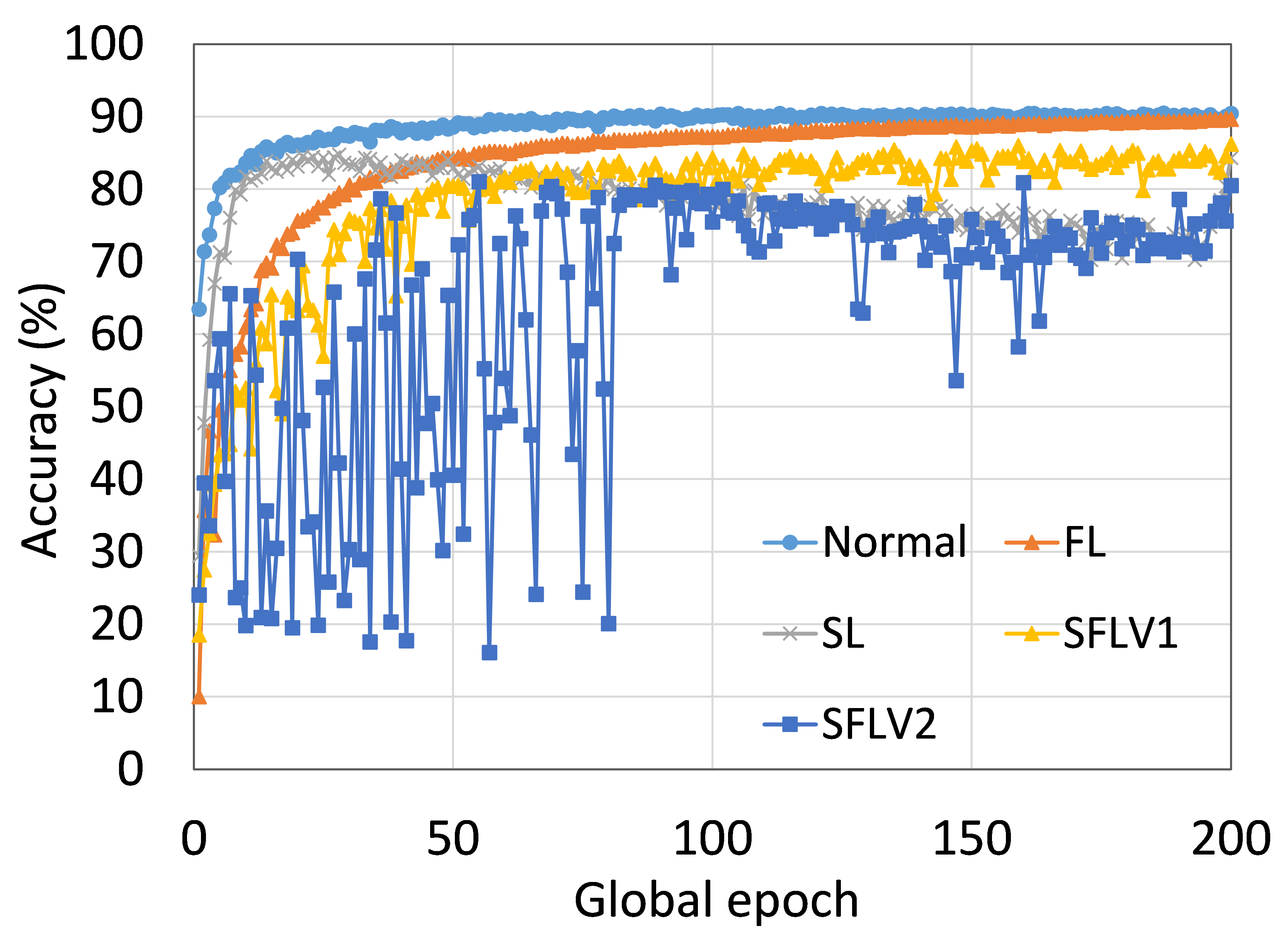
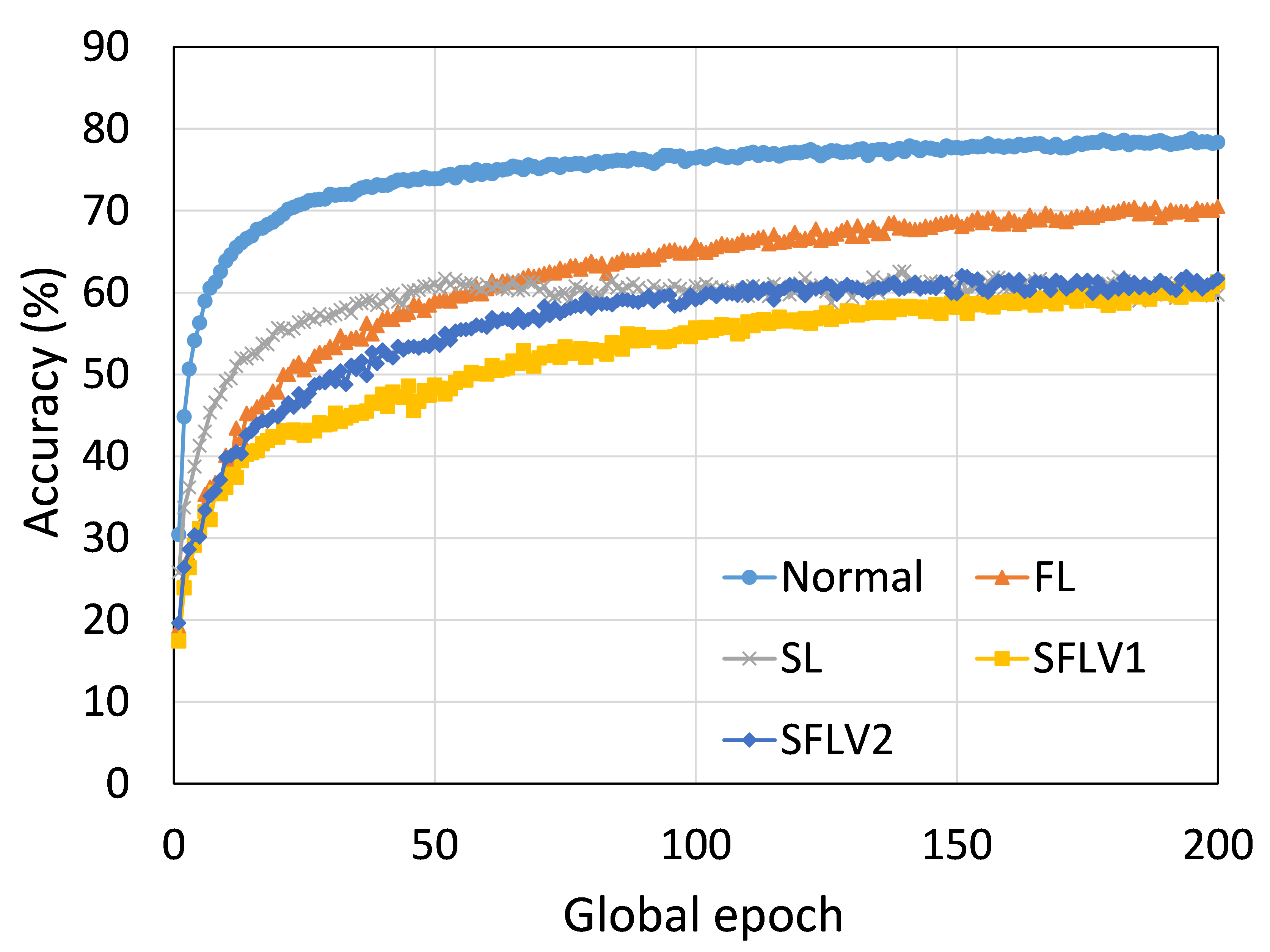
0.C.2 用户数量对性能的影响
本节介绍正常(集中)学习、SL、FL、SFLV1 和 SFLV2 的训练和测试收敛图。 进行实验时考虑了从 5 到 100 不等的不同数量的客户端。 此外,我们考虑 FMNIST 上的 LeNet5 和 HAM10000 上的 AlexNet。
我们的主要观察是,通常情况下,随着用户数量的增加,收敛速度减慢,性能下降(见图9(b),(d),(f)和(h) )) 在全球历元的观察窗口内。 此外,我们所有的 DCML 方法在不同数量的用户(客户端)上都表现出相似的行为。 然而,在 SL 的某些情况下,尽管训练期间模型学习得很好,但测试性能却急剧下降,例如,在 100 个用户的 HAM10000 上使用 AlexNet 的 SL(见图 9 (l))。 同样,在服务器端操作方面与 SL 类似的 SFLV2 也显示出类似的下降,但针对的是 50 个用户。 这个特殊案例需要进一步调查。