用于行人轨迹预测的时空图变换器网络
摘要
了解人群运动动态对于现实世界的应用至关重要,例如监控系统和自动驾驶。 这是具有挑战性的,因为它需要有效地对具有社会意识的人群空间交互和复杂的时间依赖性进行建模。 我们认为注意力是轨迹预测的最重要因素。 在本文中,我们提出了STAR,一个时空图变换器框架,它仅通过注意机制来处理轨迹预测。 STAR 通过TGConv(一种基于 Transformer 的新型图卷积机制)对图内人群交互进行建模。 图间时间依赖性由单独的时间转换器建模。 STAR 通过空间和时间 Transformer 之间的交错来捕获复杂的时空相互作用。 为了校准行人消失的长期影响的时间预测,我们引入了一个可读写的外部存储模块,由时间 Transformer 持续更新。 我们证明,仅使用注意力机制,STAR 在 5 个常用的现实世界行人预测数据集上实现了最先进的性能。111code available at https://github.com/Majiker/STAR 获取
关键词:
轨迹预测、Transformer、图神经网络1简介
人群轨迹预测对于计算机视觉 [1, 16, 53, 21, 22] 和机器人[34, 33] 社区都至关重要。 这项任务具有挑战性,因为 1)人与人之间的互动是多模式的,并且极难捕捉,例如,陌生人会避免与他人亲密接触,而同伴则倾向于成群结队地行走[53]; 2)复杂的时间预测与空间人与人的交互相结合,例如,人类根据其邻居的历史和未来运动来调节自己的运动[21]。

 |
 |
| (a) Crowd Motion Modeling | (b) STAR Overview |
经典模型通过手工制作的能量函数来捕获人与人的交互[19,18,34],这需要大量的特征工程工作,并且通常无法在拥挤的空间中建立人群交互[21]. 随着深度神经网络的最新进展,循环神经网络(RNN)已广泛应用于轨迹预测并表现出良好的性能[1,16,53,21,22]。 基于 RNN 的方法通过潜在状态捕获行人运动,并通过合并空间邻近行人的潜在状态来建模人与人的交互。 社会池[1, 16]平等对待邻里区域的行人,并通过池机制合并他们的潜在状态。 注意力机制[22,53,21]放宽了这一假设,并根据学习函数对行人进行加权,该函数编码了相邻行人对于轨迹预测的不同重要性。 然而,现有的预测器有两个共同的局限性:1)使用的注意力机制仍然很简单,无法完全建模人与人的交互,2)RNN 通常难以建模复杂的时间依赖性[43] 。
最近,Transformer 网络在自然语言处理 (NLP) 领域取得了突破性进展[43,10,26,52,50]。 Transformer 抛弃了语言序列的顺序性质,仅使用强大的自注意力机制来建模时间依赖性。 与 RNN [43] 相比,Transformer 架构的主要优点是自注意力显着改善了时间建模,特别是对于水平序列。 然而,基于 Transformer 的模型仅限于正常的数据序列,很难将它们推广到更结构化的数据,例如图序列。
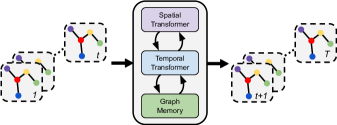
在本文中,我们介绍了时空图变换器(STAR)框架,这是一种纯粹基于自注意力机制的时空轨迹预测的新颖框架。 我们相信学习时间、空间和时空注意力是准确预测人群轨迹的关键,而 Transformers 为这项任务提供了一个简洁有效的解决方案。 STAR 通过新颖的空间图 Transformer 捕捉人与人之间的互动。 我们特别介绍了TGConv,一种基于 Transformer 的图卷积机制。 TGConv 通过 Transformers 的自注意力机制改进了基于注意力的图卷积[44],可以捕获更复杂的社交交互。 具体来说,TGConv 倾向于在行人密度较高的数据集(ZARA1、ZARA2、UNIV)上进行更多改进。 我们使用单独的时间 Transformer 对行人运动进行建模,与 RNN 相比,它可以更好地捕获时间依赖性。 STAR 通过空间 Transformer 和时间 Transformer 的交错来提取行人之间的时空交互,这是一种简单而有效的策略。 此外,由于 Transformer 将序列视为一袋词,因此它们通常在对强制执行强时间一致性的时间序列数据进行建模时遇到问题[29]。 我们引入了一个额外的读写图形内存模块,该模块在预测期间连续对嵌入执行平滑。 图 1 给出了 STAR 的概述。 2.(二)
我们对 5 个常用的现实世界行人轨迹预测数据集进行了实验。 仅通过注意力机制,STAR 在所有 5 个数据集上都达到了最先进的水平。 我们进行广泛的消融研究,以更好地了解每个提议的组件。
2 背景
2.1 自注意力和 Transformer 网络
Transformer 网络在 NLP 领域取得了巨大成功,例如机器翻译、情感分析和文本生成[10]。 Transformer 网络遵循 RNN seq2seq 模型中广泛使用的著名编码器-解码器结构[3, 6]。
Transformer的核心思想是用多头自注意力机制完全替代递归。 对于嵌入,Transformers的自注意力首先学习查询矩阵、键矩阵和相应的值矩阵从 到 的所有嵌入。它通过以下方式计算注意力
| (1) |
其中 是每个查询的维度。 实现了缩放点积项,以实现注意力的数值稳定性。 通过计算不同时间步长的嵌入之间的自注意力,自注意力机制能够学习长时间范围内的时间依赖性,这与使用有限内存的单个向量记住历史的 RNN 形成鲜明对比。 此外,将注意力解耦到查询、键和值元组中允许自注意力机制捕获更复杂的时间依赖性。
多头注意力机制在计算注意力时学会结合多个假设。 它允许模型共同关注来自不同位置的不同表示的信息。 有了 头,我们有
| (2) |
其中 是一个全连接层,合并了 个头的输出, 表示第 个头的自注意力。 附加位置编码用于将位置信息添加到 Transformer 嵌入中。 最后,Transformer 通过具有两个跳跃连接的全连接层输出更新的嵌入。
然而,当前基于 Transformer 的模型的一个主要限制是它们仅适用于非结构化数据序列,例如单词序列。 STAR 将 Transformer 扩展到更结构化的数据序列,作为第一步,绘制序列图,并将其应用于轨迹预测。
2.2相关作品
2.2.1 图神经网络
图神经网络 (GNN) 是用于图结构数据的强大深度学习架构。 图卷积 [27, 24, 9, 15, 47] 在图机器学习任务上表现出显着的改进,例如物理系统建模[4, 28]、药物预测[31]和社交推荐系统[11]。 特别是,图注意力网络(GAT)[44]实现了节点之间高效的加权消息传递,并在多个领域取得了最先进的结果。 从序列预测的角度来看,时间图 RNN 允许学习图序列 [8, 17] 中的时空关系。 我们的 STAR 通过 TGConv(一种 Transformer 增强注意力机制)改进了 GAT,并通过 Transformer 架构解决了图时空建模问题。
2.2.2 序列预测
RNN 及其变体,例如 LSTM [20] 和 GRU [7],在序列预测任务中取得了巨大成功,例如语音识别 [46, 39]、机器人定位[14, 36]、机器人决策[23, 37]等。RNN也已成功应用于建模行人的时间运动模式[1,16,21,53,22]。 基于 RNN 的预测器使用 Seq2Seq 结构[41]进行预测。 附加结构,例如社交池 [1, 16]、注意力机制 [48, 45, 22] 和图神经网络 [21, 53],用于通过社交交互建模改进轨迹预测。
近年来,Transformer 网络在自然语言处理领域占据主导地位[43,10,26,52,50]。 Transformer 模型完全抛弃了递归,而是专注于跨时间步长的注意力。 该架构允许长期依赖建模和大批量并行训练。 Transformer 架构也已成功应用于其他领域,例如股票预测[30]、机器人决策[12]等。STAR 将 Transformer 的思想应用于图序列。 我们在具有挑战性的人群轨迹预测任务中演示了它,其中我们将人群交互视为图表。 STAR 是一个通用框架,可以应用于其他图序列预测任务,例如社交网络中的事件预测[35]和物理系统建模[28]。 我们将其留待将来研究。
2.2.3 人群交互建模
作为开创性的工作,社会力模型[19, 32]已在各种应用中被证明是有效的,例如人群分析[18]和机器人[13 ]。 他们假设行人由虚拟力驱动,以实现目标导航和避免碰撞。 社会力模型在交互建模方面表现良好,但在轨迹预测方面表现不佳[25]。 基于几何的方法,例如 ORCA [42] 和 PORCA [34],考虑代理的几何形状并将交互建模转换为优化问题。 经典方法的一个主要限制是它们依赖于手工制作的特征,而这些特征调整起来并不容易,而且很难泛化。
基于深度学习的模型通过直接从数据中学习模型来实现自动特征工程。 行为 CNN [51] 通过 CNN 捕获人群交互。 社交池[1, 16]通过近似人群交互的池机制进一步编码最近的行人状态。 最近的工作将人群视为一个图,并将空间邻近行人的信息与注意机制合并[48,45,22]。 与池化方法相比,注意力机制对行人进行重要性建模。 图神经网络也应用于解决人群建模[21, 53]。 显式消息传递允许网络模拟更复杂的社交行为。
3方法
3.1概述
在本节中,我们介绍了所提出的基于时空图 Transformer 的轨迹预测框架 STAR。 我们相信注意力是有效且高效的轨迹预测的最重要因素。
STAR将时空注意力模型分解为时间模型和空间模型。 对于时间建模,STAR 独立考虑每个行人,并应用标准时间 Transformer 网络来提取时间依赖性。 与 RNN 相比,时间 Transformer 提供了更好的时间依赖性建模协议,我们在消融研究中对此进行了验证。 对于空间建模,我们引入了TGConv,一种基于 Transformer 的消息传递图卷积机制。 TGConv 通过更好的注意力机制改进了最先进的图卷积方法,并为复杂的空间交互提供了更好的模型。 特别是,TGConv 倾向于在行人密度较高(ZARA1、ZARA2、UNIV)和复杂交互的数据集上进行更多改进。 我们构建了两个编码器模块,每个模块包括一对空间和时间 Transformer,并将它们堆叠起来以提取时空交互。
3.2问题设置
我们感兴趣的是,考虑到一段时间内观察到的历史,预测场景中涉及的总 行人从时间步 到 的未来轨迹的问题步骤到。 在每个时间步,我们有一组行人,其中表示行人在顶部的位置-向下查看地图。 我们假设距离小于 的行人对 将具有无向边 。 这会在每个时间步骤 生成一个交互图:,其中 和 。 对于时间的每个节点,我们将其邻居集定义为,其中对于每个节点,.
 |
 |
| (a) Temporal Transformer | (b) Spatial Transformer |
3.3时间转换器
STAR 中的时间 Transformer 块使用一组行人轨迹嵌入 作为输入,并输出一组具有时间依赖性的更新嵌入 作为输出,独立考虑每个行人。
图 1 给出了时间 Transformer 块的结构。 3.(a)。 自注意力模块首先学习给定输入的查询矩阵 、键矩阵 和值矩阵 。 对于第 个行人,我们有
| (3) |
其中、和是行人共享的相应查询、键和值函数。 得益于 GPU 加速,我们可以对所有行人进行并行计算。
我们按照等式分别计算每个行人的注意力。 1。 类似地,行人 的多头注意力(头)表示为
| (4) | ||||
| (5) | ||||
| (6) |
其中 是一个完全连接的层,它合并 头, 索引 头。 最终的嵌入由两个跳跃连接和最终的全连接层生成,如图 2 所示。 3.(A)。
时间 Transformer 是 Transformer 网络到数据序列集的简单概括。 我们在实验中证明,基于 Transformer 的架构提供了更好的时间建模。
3.4空间变换器
空间 Transformer 块提取行人之间的空间交互。 我们提出了一种新颖的基于 Transformer 的图卷积 TGConv,用于在图上传递消息。
我们的主要观察是,自注意力机制可以被视为在无向全连接图上传递消息。 对于特征集的特征向量,我们可以将其对应的查询向量表示为,键向量表示为,值表示向量为。 我们将全连接图中从节点 到 的消息定义为
| (7) |
注意力函数(方程1)可以重写为
| (8) |
基于上述见解,我们引入了基于 Transformer 的图卷积(TGConv)。 TGConv 本质上是一种基于注意力的图卷积机制,类似于 GATConv [44],但具有更好的由 Transformers 支持的注意力机制。 对于任意图,其中是节点集,。 假设每个节点与嵌入和邻居集相关联。 节点的图卷积运算写为
| (9) | ||||
| (10) |
其中 是输出函数,在我们的例子中是全连接层, 是 TGConv 更新的节点 的嵌入。 我们通过总结节点的TGConv函数。 在 Transformer 结构中,我们通常会在上述方程中的每个跳跃连接之后应用层归一化 [2]。 为了简洁的符号,我们在方程中忽略了它们。
空间Transformer,如图所示。 3.(b),可以通过TGConv轻松实现。 具有共享权重的 TGConv 分别应用于每个图 。 我们相信 TGConv 是通用的,可以应用于其他任务,我们将其留待将来研究。
3.5 时空图转换器
在本节中,我们介绍用于行人轨迹预测的时空图变换器(STAR)框架。
Temporal Transformer 可以单独对每个行人的运动动力学进行建模,但无法纳入空间交互;空间 Transformer 解决了与 TGConv 的人群交互问题,但很难推广到时间序列。 行人预测的一大挑战是对耦合时空交互进行建模。 行人的空间和时间动态相互紧密依赖。 例如,当一个人决定下一步行动时,他会首先预测邻居未来的动作,并选择在时间间隔内避免与他人发生碰撞的行动。
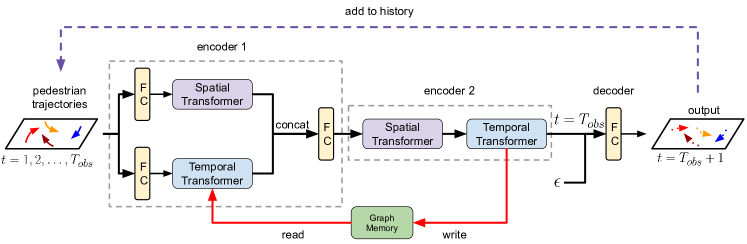
STAR 通过在单一框架中交错空间和时间 Transformer 来解决耦合时空建模问题。 图4展示了STAR的网络结构。 STAR 有两个编码器模块和一个简单的解码器模块。 网络的输入是从到的行人位置序列,其中时间步的行人位置由表示> 与 。 在第一个编码器中,我们通过两个独立的全连接层嵌入位置,并将嵌入传递给空间变换器和时间变换器,以从行人历史中提取独立的空间和时间信息。 然后,空间和时间特征由全连接层合并,从而给出一组具有时空编码的新特征。 为了进一步模拟特征空间中的时空交互,我们使用第二个编码器模块对特征进行后处理。 在编码器2中,空间Transformer对空间与时间信息的交互进行建模;时间 Transformer 通过时间注意力增强输出空间嵌入。 STAR 使用简单的全连接层来预测 处的行人位置,其中来自第二个时间 Transformer 的 嵌入作为输入,与随机高斯噪声连接以生成各种未来预测 [21]。 我们根据预测的位置连接距离小于的节点来构造。 该预测将添加到历史记录中以供下一步预测。
与简单地组合空间和时间 Transformer 相比,STAR 架构显着提高了时空建模能力。
3.6外部图形内存
虽然 Transformer 网络通过自注意力机制改进了长范围序列建模,但它在处理需要强时间一致性的连续时间序列数据时可能会遇到困难[29]。 然而,时间一致性是轨迹预测的严格要求,因为行人位置通常不会在短时间内发生急剧变化。
我们引入了一个简单的外部图形内存来解决这个困境。 图存储器是可读写和可学习的,其中与具有相同的大小,并记住行人的嵌入。 在时间步 ,在编码器 1 中,时间 Transformer 首先从内存中读取 使用函数 的过去的图嵌入,并将其与当前的图嵌入连接起来。 这允许时间转换器根据先前的嵌入来调整当前的嵌入,以实现一致的预测。 在编码器2中,我们通过函数将Temporal Transformer的输出写入图存储器,该函数对时间序列数据进行平滑。 对于任何 ,嵌入将通过来自 的信息进行更新,这会提供时间上更平滑的嵌入,以获得更一致的轨迹。
为了实现和,可以采用许多潜在的函数形式。 在本文中,我们只考虑一个非常简单的策略
| (11) | |||
| (12) |
也就是说,我们直接用嵌入替换内存并复制内存以生成输出。 这个简单的策略在实践中效果很好。 可以考虑更复杂的 和 函数形式,例如全连接层或 RNN。 我们将其留待将来研究。
4实验
在本节中,我们首先报告五个行人轨迹数据集的结果,这些数据集作为轨迹预测任务的主要基准:ETH(ETH和HOTEL)和UCY(ZARA1、ZARA2和UNIV)数据集。 我们将 STAR 与 9 个轨迹预测器进行比较,包括 SOTA 模型、SR-LSTM [53]。 我们遵循以前的工作中普遍采用的留一法交叉验证评估策略。 我们还进行了广泛的消融研究,以了解每个提出的组件的效果,并尝试为轨迹预测任务中的模型设计提供更深入的见解。
作为一个简短的结论,我们表明:1)STAR 在 5 个数据集中的 4 个上优于 SOTA 模型,并且在其他数据集上具有与 SOTA 模型相当的性能; 2)与现有的图卷积方法相比,空间 Transformer 改进了人群交互建模; 3)时间Transformer普遍改进了LSTM; 4)图存储器提供了更平滑的时间预测和更好的性能。
4.1 实验设置
我们的方法遵循与 SR-LSTM[53] 相同的数据预处理策略。 所有输入的原点都转移到最后一个观察帧。 采用随机旋转进行数据增强。
-
•
平均位移误差(ADE):预测轨迹和地面实况轨迹中的总体估计位置的均方误差(MSE)。
-
•
最终位移误差(FDE):预测最终目的地与地面真实最终目的地之间的距离。
我们以8帧(3.2s)作为一个序列,12帧(4.8s)作为目标序列进行预测,以便与所有现有作品进行公平的比较。
4.2实现细节
作为输入的坐标首先由全连接层编码为大小为 32 的向量,然后进行 ReLU 激活。 处理输入数据时应用 0.1 的丢失率。 所有 Transformer 层都接受特征大小为 32 的输入。 空间 Transformer 和时间 Transformer 均由 8 个头的编码层组成。 我们在较小的网络上对学习率进行了超参数搜索,从 0.0001 到 0.004,间隔为 0.0001,并选择性能最佳的学习率 (0.0015) 来训练所有其他模型。 因此,我们使用 Adam 优化器对网络进行 300 个周期的训练,学习率为 0.0015,批量大小为 16。 每批次包含大约 256 名处于不同时间窗口的行人,由注意掩模指示,以加速训练和推理过程。
4.3基线
我们将 STAR 与各种基线进行比较,包括:1)LR:一个简单的时间线性回归器; 2)LSTM:普通的时间 LSTM; 3)S-LSTM [1]:每个行人都用一个LSTM建模,并且在每个时间步将隐藏状态与邻居池化; 4)社会注意力[45]:它将人群建模为时空图,并使用两个LSTM来捕获时空动态; 5) CIDNN [49]:一种使用 LSTM 进行时空人群轨迹预测的模块化方法; 6) SGAN [16]:GAN 的随机轨迹预测器; 7) SoPhie [40]:具有 LSTM 的 SOTA 随机轨迹预测器之一。 8) TrafficPredict [38]:用于异构交通代理的基于 LSTM 的运动预测器。 请注意,[38] 中的 TrafficPredict 报告等距标准化结果。 我们将它们缩小以进行一致的比较; 9) SR-LSTM:具有运动门和成对注意力的 SOTA 轨迹预测器,用于细化 LSTM 编码的隐藏状态以获得社交互动。
4.4定量结果和分析
我们将 STAR 与 4.3 节中提到的最先进的方法进行比较。 所有随机方法都会采样 20 次并报告性能最佳的样本。
主要结果如表1所示。 我们观察到 STAR-D 在整体性能上优于 SOTA 确定性模型,并且随机 STAR 大幅优于所有 SOTA 模型。
一个有趣的发现是,在酒店场景中,简单模型 LR 显着优于许多深度学习方法,包括 SOTA 模型、SR-LSTM,该场景主要包含直线轨迹并且相对不那么拥挤。 这表明这些复杂的模型可能会过度拟合像 UNIV 这样的复杂场景。 另一个例子是,STAR在ETH和HOTEL上显着优于SR-LSTM,但在人群密度较高的UNIV上只能与SR-LSTM相当。 这可能是因为 SR-LSTM 具有精心设计的用于在图上传递消息的门控结构,但具有相对较弱的时间模型(单个 LSTM)。 SR-LSTM 的设计可能会改进空间建模,但也可能导致过度拟合。 相比之下,我们的方法在简单和复杂的场景中都表现良好。 然后我们将在Sect.中进一步演示这一点。 4.5 具有可视化结果。
| Performance (ADE/FDE) | ||||||
| Deterministic | ETH | HOTEL | ZARA1 | ZARA2 | UNIV | AVERAGE |
| LR | 1.33/2.94 | 0.39/0.72 | 0.62/1.21 | 0.77/1.48 | 0.82/1.59 | 0.79/1.59 |
| LSTM | 1.13/2.39 | 0.69/1.47 | 0.64/1.43 | 0.54/1.21 | 0.73/1.60 | 0.75/1.62 |
| S-LSTM[1] | 0.77/1.60 | 0.38/0.80 | 0.51/1.19 | 0.39/0.89 | 0.58/1.28 | 0.53/1.15 |
| CIDNN[49] | 1.25/2.32 | 1.31/1.86 | 0.90/1.28 | 0.50/1.04 | 0.51/1.07 | 0.89/1.73 |
| SocialAttention [45] | 1.39/2.39 | 2.51/2.91 | 1.25/2.54 | 1.01/2.17 | 0.88/1.75 | 1.41/2.35 |
| TrafficPredict [38] | 5.46/9.73 | 2.55/3.57 | 4.32/8.00 | 3.76/7.20 | 3.31/6.37 | 3.88/6.97 |
| SR-LSTM [53] | 0.63/1.25 | 0.37/0.74 | 0.41/0.90 | 0.32/0.70 | 0.51/1.10 | 0.45/0.94 |
| STAR-D | 0.56/1.11 | 0.26/0.50 | 0.41/0.90 | 0.31/0.71 | 0.52/1.15 | 0.41/0.87 |
| Stochastic | ETH | HOTEL | ZARA1 | ZARA2 | UNIV | AVERAGE |
| SGAN† [16] | 0.81/1.52 | 0.72/1.61 | 0.34/0.69 | 0.42/0.84 | 0.60/1.26 | 0.58/1.18 |
| SoPhie*† [40] | 0.70/1.43 | 0.76/1.67 | 0.30/0.63 | 0.38/0.78 | 0.54/1.24 | 0.54/1.15 |
| STGAT† [21] | 0.65/1.12 | 0.35/0.66 | 0.34/0.69 | 0.29/0.60 | 0.52/1.10 | 0.43/0.83 |
| STAR† | 0.36/0.65 | 0.17/0.36 | 0.26/0.55 | 0.22/0.46 | 0.31/0.62 | 0.26/0.53 |
4.5定性结果和分析
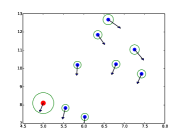 |
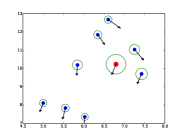 |
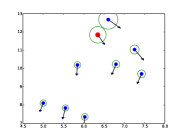 |
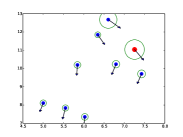 |
| (a) | (b) | (c) | (d) |
-
•
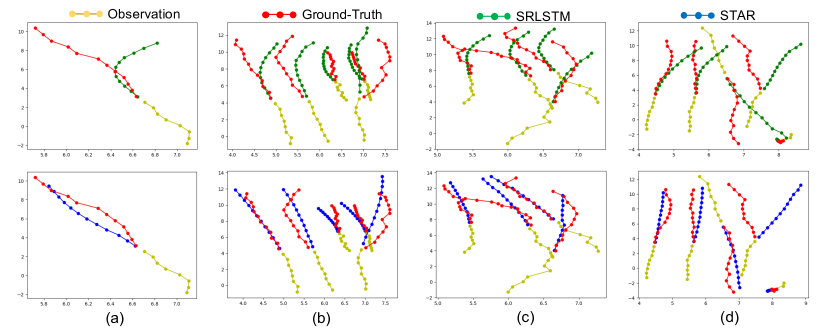
STAR 能够预测时间一致的轨迹。 在图中。 5.(a),在不存在社交互动的情况下,STAR 成功捕获了单个行人的意图和速度。
- •
-
•
STAR能够捕捉人群的时空互动。 在图中。 5.(b),我们可以看到行人的预测考虑了其邻居的未来运动。 此外,与 SR-LSTM 相比,STAR 更好地平衡了空间建模和时间建模。 SR-LSTM 可能会过度拟合空间模型,并且即使在行人笔直行走时也往往会预测曲线。 这也与我们在定量分析部分的发现相对应,即深度预测器过度拟合复杂的数据集。 STAR 通过时空 Transformer 结构更好地缓解了这个问题。
-
•
更准确的轨迹预测需要辅助信息。 尽管STAR达到了SOTA结果,但预测有时仍然不准确,例如图1。 5.(d)。 行人急转弯,这使得无法纯粹根据位置的历史来预测未来的轨迹。 对于未来的工作,应使用附加信息(例如环境设置或地图)来为预测提供额外信息。
4.6消融研究
我们对所有 5 个数据集进行了广泛的消融研究,以了解每个 STAR 组件的影响。 具体来说,我们选择确定性 STAR 来消除随机样本的影响,并专注于所提出组件的效果。 结果如表2所示。
| Components | Performance (ADE/FDE) | ||||||||
| SP | TP | GM | ETH | HOTEL | ZARA1 | ZARA2 | UNIV | AVG | |
| (1) | GCN | STAR | ✓ | 3.06/5.57 | 0.99/1.80 | 2.49/4.58 | 1.37/2.52 | 1.38/2.47 | 1.86 /3.34 |
| (2) | GAT | STAR | ✓ | 0.64/1.25 | 0.34/0.72 | 0.47/1.09 | 0.37/0.86 | 0.55/1.19 | 0.48/1.02 |
| (3) | MHA | STAR | ✓ | 0.58/1.15 | 0.25/0.48 | 0.50/0.98 | 0.35/0.76 | 0.60/1.24 | 0.56/0.92 |
| (4) | STAR | LSTM | - | 0.66/1.29 | 0.34/0.68 | 0.45/0.96 | 0.34/0.74 | 0.60/1.29 | 0.48/0.99 |
| (5) | STAR | STAR | 0.60/1.18 | 0.28/0.60 | 0.53/1.13 | 0.36/0.76 | 0.57/1.20 | 0.47/0.97 | |
| (6) | VSTAR | VSTAR | ✓ | 0.61/1.18 | 0.29/0.56 | 0.48/1.00 | 0.36/0.76 | 0.58/1.24 | 0.46/0.95 |
| (7) | STAR | STAR | ✓ | 0.56/1.11 | 0.26/0.50 | 0.41/0.90 | 0.31/0.71 | 0.52/1.15 | 0.41/0.87 |
-
•
与 RNN 相比,时间 Transformer 改进了行人动力学的时间建模。 在(4)和(5)中,我们删除了图存储器并修复了用于空间编码的STAR。 这两个模型的时间预测能力仅取决于它们的时间编码器,即(4)的 LSTM 和(5)的 STAR。 我们观察到,使用时间 Transformer 编码的模型在整体性能上优于 LSTM,这表明与 RNN 相比,Transformer 提供了更好的时间建模能力。
-
•
TGConv 在人群运动建模方面优于其他图卷积方法。 在(1)、(2)、(3)和(7)中,我们改变了空间编码器,并将TGConv (7)的空间Transformer与GCN [24]、GATConv 进行比较[44]和多头加法图卷积[5]。 我们观察到,与其他两种基于注意力的图卷积相比,TGConv 在人群建模场景下实现了更高的性能增益。
-
•
交错空间和时间 Transformer 能够更好地提取时空相关性。 在(6)和(7)中,我们观察到 STAR 框架(7)中提出的两个编码器结构通常优于单个编码器结构(6)。 这种经验性能增益可能表明,交错空间和时间 Transformer 能够提取更复杂的行人时空交互。
-
•
图存储器提供更平滑的时间嵌入并提高性能。 在(5)和(7)中,我们验证了图内存模块的嵌入平滑能力,其中(5)是没有GM的STAR变体。 我们首先注意到图内存提高了 STAR 在所有数据集上的性能。 此外,我们注意到在 ZARA1 上,空间交互很简单,时间一致性预测更重要,图内存最大程度地从 (6) 提高到 (7)。 根据经验证据,我们可以得出结论,图内存的嵌入平滑能够改善 STAR 的整体时间建模。
5结论
我们引入了 STAR,一个仅使用注意力机制的时空人群轨迹预测框架。 STAR由两个编码器模块组成,分别由空间Transformers和时间Transformers组成。 我们还引入了 TGConv,一种基于 Transformer 的新颖强大的图卷积机制。 STAR 仅使用注意力机制,在 5 个常用数据集上实现了 SOTA 性能。
STAR仅根据过去的轨迹进行预测,可能无法检测到不可预测的急转弯。 可以将附加信息(例如环境配置)合并到框架中来解决此问题。
STAR框架和TGConv不限于轨迹预测。 它们可以应用于任何图学习任务。 我们将其留待将来研究。
参考
- [1] Alahi, A., Goel, K., Ramanathan, V., Robicquet, A., Fei-Fei, L., Savarese, S.: Social lstm: Human trajectory prediction in crowded spaces. In: CVPR (2016)
- [2] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
- [3] Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
- [4] Battaglia, P., Pascanu, R., Lai, M., Rezende, D.J., et al.: Interaction networks for learning about objects, relations and physics. In: Advances in neural information processing systems (2016)
- [5] Chen, B., Barzilay, R., Jaakkola, T.: Path-augmented graph transformer network (2019). https://doi.org/10.26434/chemrxiv.8214422
- [6] Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y.: Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (2014)
- [7] Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014)
- [8] Cui, Z., Henrickson, K., Ke, R., Wang, Y.: Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. IEEE Transactions on Intelligent Transportation Systems (2019)
- [9] Defferrard, M., Bresson, X., Vandergheynst, P.: Convolutional neural networks on graphs with fast localized spectral filtering. In: Advances in neural information processing systems (2016)
- [10] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
- [11] Fan, W., Ma, Y., Li, Q., He, Y., Zhao, E., Tang, J., Yin, D.: Graph neural networks for social recommendation. In: WWW (2019)
- [12] Fang, K., Toshev, A., Fei-Fei, L., Savarese, S.: Scene memory transformer for embodied agents in long-horizon tasks. In: CVPR (2019)
- [13] Ferrer, G., Garrell, A., Sanfeliu, A.: Robot companion: A social-force based approach with human awareness-navigation in crowded environments. In: IROS (2013)
- [14] Förster, A., Graves, A., Schmidhuber, J.: Rnn-based learning of compact maps for efficient robot localization. In: ESANN (2007)
- [15] Gilmer, J., Schoenholz, S.S., Riley, P.F., Vinyals, O., Dahl, G.E.: Neural message passing for quantum chemistry. In: ICML (2017)
- [16] Gupta, A., Johnson, J., Fei-Fei, L., Savarese, S., Alahi, A.: Social gan: Socially acceptable trajectories with generative adversarial networks. In: CVPR (2018)
- [17] Hajiramezanali, E., Hasanzadeh, A., Narayanan, K., Duffield, N., Zhou, M., Qian, X.: Variational graph recurrent neural networks. In: Advances in Neural Information Processing Systems (2019)
- [18] Helbing, D., Buzna, L., Johansson, A., Werner, T.: Self-organized pedestrian crowd dynamics: Experiments, simulations, and design solutions. Transportation science (2005)
- [19] Helbing, D., Molnar, P.: Social force model for pedestrian dynamics. Physical review E (1995)
- [20] Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation (1997)
- [21] Huang, Y., Bi, H., Li, Z., Mao, T., Wang, Z.: Stgat: Modeling spatial-temporal interactions for human trajectory prediction. In: ICCV (2019)
- [22] Ivanovic, B., Pavone, M.: The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. In: ICCV (2019)
- [23] Karkus, P., Ma, X., Hsu, D., Kaelbling, L.P., Lee, W.S., Lozano-Pérez, T.: Differentiable algorithm networks for composable robot learning. arXiv preprint arXiv:1905.11602 (2019)
- [24] Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
- [25] Kuderer, M., Kretzschmar, H., Sprunk, C., Burgard, W.: Feature-based prediction of trajectories for socially compliant navigation. In: RSS (2012)
- [26] Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., Soricut, R.: Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 (2019)
- [27] Li, Y., Tarlow, D., Brockschmidt, M., Zemel, R.: Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493 (2015)
- [28] Li, Y., Wu, J., Tedrake, R., Tenenbaum, J.B., Torralba, A.: Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. arXiv preprint arXiv:1810.01566 (2018)
- [29] Lim, B., Arik, S.O., Loeff, N., Pfister, T.: Temporal fusion transformers for interpretable multi-horizon time series forecasting. arXiv preprint arXiv:1912.09363 (2019)
- [30] Liu, J., Lin, H., Liu, X., Xu, B., Ren, Y., Diao, Y., Yang, L.: Transformer-based capsule network for stock movement prediction. In: Proceedings of the First Workshop on Financial Technology and Natural Language Processing (2019)
- [31] Liu, K., Sun, X., Jia, L., Ma, J., Xing, H., Wu, J., Gao, H., Sun, Y., Boulnois, F., Fan, J.: Chemi-net: a molecular graph convolutional network for accurate drug property prediction. International journal of molecular sciences (2019)
- [32] Löhner, R.: On the modeling of pedestrian motion. Applied Mathematical Modelling (2010)
- [33] Luo, Y., Cai, P.: Gamma: A general agent motion prediction model for autonomous driving. arXiv preprint arXiv:1906.01566 (2019)
- [34] Luo, Y., Cai, P., Bera, A., Hsu, D., Lee, W.S., Manocha, D.: Porca: Modeling and planning for autonomous driving among many pedestrians. IEEE Robotics and Automation Letters (2018)
- [35] Ma, X., Gao, X., Chen, G.: Beep: A bayesian perspective early stage event prediction model for online social networks. In: ICDM (2017)
- [36] Ma, X., Karkus, P., Hsu, D., Lee, W.S.: Particle filter recurrent neural networks. arXiv preprint arXiv:1905.12885 (2019)
- [37] Ma, X., Karkus, P., Hsu, D., Lee, W.S., Ye, N.: Discriminative particle filter reinforcement learning for complex partial observations. arXiv preprint arXiv:2002.09884 (2020)
- [38] Ma, Y., Zhu, X., Zhang, S., Yang, R., Wang, W., Manocha, D.: Trafficpredict: Trajectory prediction for heterogeneous traffic-agents. AAAI (2019)
- [39] Miao, Y., Gowayyed, M., Metze, F.: Eesen: End-to-end speech recognition using deep rnn models and wfst-based decoding. In: ASRU (2015)
- [40] Sadeghian, A., Kosaraju, V., Sadeghian, A., Hirose, N., Rezatofighi, H., Savarese, S.: Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In: CVPR (2019)
- [41] Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in neural information processing systems (2014)
- [42] Van Den Berg, J., Guy, S.J., Lin, M., Manocha, D.: Reciprocal n-body collision avoidance. In: Robotics research (2011)
- [43] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems (2017)
- [44] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y.: Graph attention networks. arXiv preprint arXiv:1710.10903 (2017)
- [45] Vemula, A., Muelling, K., Oh, J.: Social attention: Modeling attention in human crowds. In: ICRA (2018)
- [46] Xiong, W., Wu, L., Alleva, F., Droppo, J., Huang, X., Stolcke, A.: The Microsoft 2017 conversational speech recognition system. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (2018)
- [47] Xu, K., Hu, W., Leskovec, J., Jegelka, S.: How powerful are graph neural networks? arXiv preprint arXiv:1810.00826 (2018)
- [48] Xu, Y., Piao, Z., Gao, S.: Encoding crowd interaction with deep neural network for pedestrian trajectory prediction. In: CVPR (2018)
- [49] Xu, Y., Piao, Z., Gao, S.: Encoding crowd interaction with deep neural network for pedestrian trajectory prediction. In: CVPR (2018)
- [50] Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R.R., Le, Q.V.: Xlnet: Generalized autoregressive pretraining for language understanding. In: Advances in neural information processing systems (2019)
- [51] Yi, S., Li, H., Wang, X.: Pedestrian behavior understanding and prediction with deep neural networks. In: ECCV (2016)
- [52] Young, T., Hazarika, D., Poria, S., Cambria, E.: Recent trends in deep learning based natural language processing. ieee Computational intelligenCe magazine (2018)
- [53] Zhang, P., Ouyang, W., Zhang, P., Xue, J., Zheng, N.: Sr-lstm: State refinement for lstm towards pedestrian trajectory prediction. In: CVPR (2019)
额外的注意力可视化
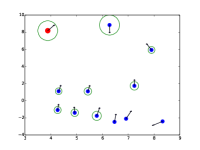 |
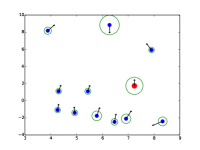 |
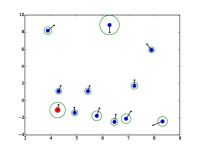 |
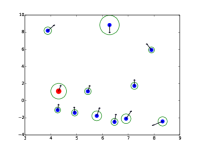 |
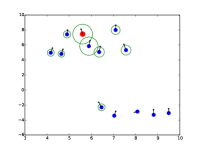 |
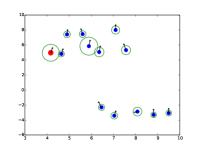 |
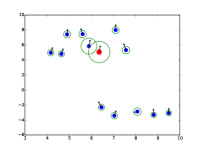 |
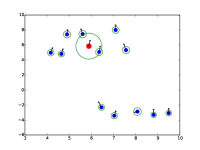 |
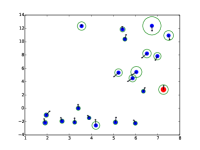 |
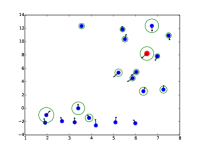 |
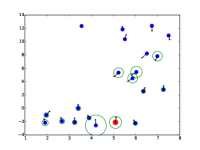 |
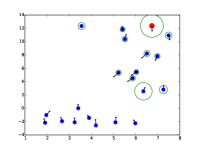 |
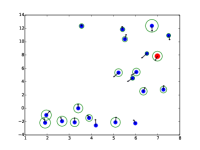 |
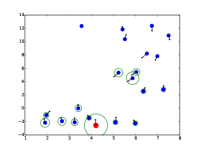 |
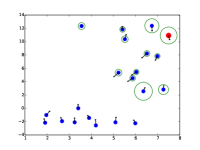 |
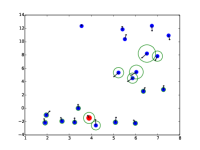 |
消融轨迹预测可视化
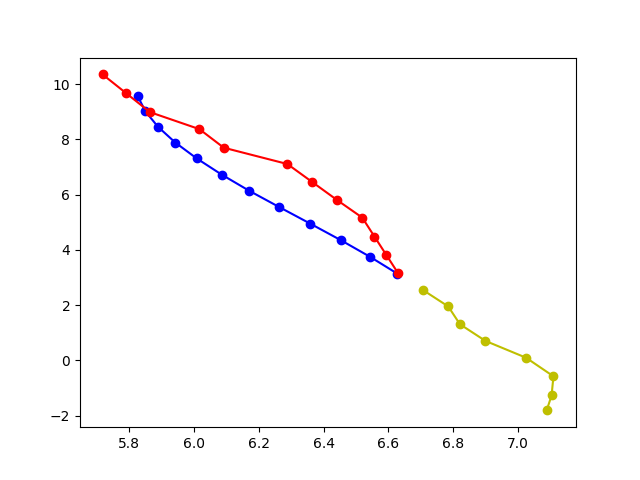 |
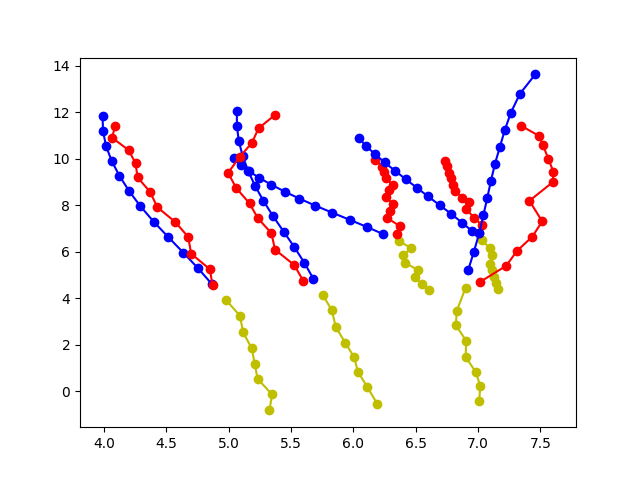 |
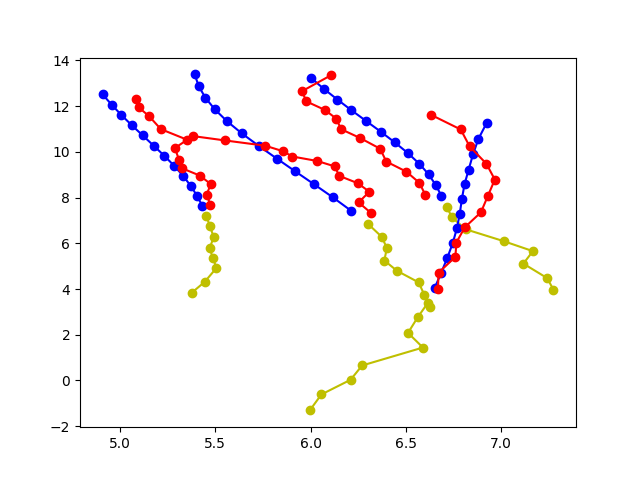 |
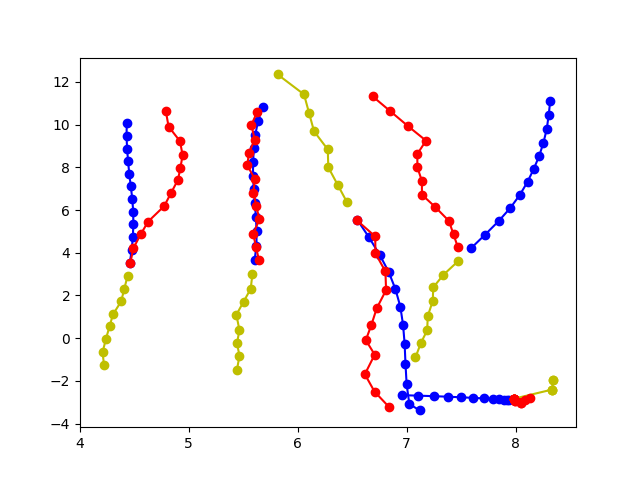 |
| (a) GAT + STAR | |||
|
|
|
|
| (b) MHA + STAR | |||
|
|
|
|
| (c) STAR + LSTM | |||
|
|
|
|
| (d) STAR without Graph Memory | |||
|
|
|
|
| (e) Simplified STAR without Encoder 2 | |||
|
|
|
|
| (f) STAR | |||