XGNN:实现图
神经网络的模型级解释
摘要。
图神经网络(GNN)通过聚合和组合邻居信息来学习节点特征,这在许多图任务上取得了良好的性能。 然而,GNN 大多数被视为黑匣子,缺乏人类可理解的解释。 因此,如果 GNN 模型无法解释,它们就不能被完全信任并用于某些应用领域。 在这项工作中,我们提出了一种称为 XGNN 的新颖方法,用于在模型级别解释 GNN。 我们的方法可以提供对 GNN 如何工作的高级见解和一般理解。 特别是,我们建议通过训练图生成器来解释 GNN,以便生成的图模式最大化模型的某些预测。 我们将图生成制定为强化学习任务,其中对于每个步骤,图生成器都会预测如何将边添加到当前图中。 图生成器通过基于经过训练的 GNN 的信息的策略梯度方法进行训练。 此外,我们还结合了一些图形规则来鼓励生成的图形有效。 合成数据集和真实数据集的实验结果表明,我们提出的方法有助于理解和验证经过训练的 GNN。 此外,我们的实验结果表明,生成的图可以为如何改进训练后的 GNN 提供指导。
1. 介绍
图神经网络(GNN)已经展示了其有效性,并在不同的图任务上获得了最先进的性能,例如节点分类(Gao和Ji,2019b;Veličković等人,2018) 、图分类(Xu等人,2019;Zhang等人,2018)和链接预测(Zhang和Chen,2018)。 此外,人们还针对不同的图操作做出了广泛的努力,例如图卷积(Kipf and Welling,2017;Gilmer等人,2017;Hamilton等人,2017)、图池化( Yuan和Ji,2020;Lee等人,2019),以及图注意力(Veličković等人,2018;Thekumparampil等人,2018;Gao和Ji,2019a)。 由于图数据广泛存在于不同的现实世界应用中,例如社交网络、化学和生物学,GNN 变得越来越重要和有用。 尽管 GNN 具有出色的性能,但它与其他深度学习模型有着相同的缺点:也就是说,它们通常被视为黑匣子并且缺乏人类可理解的解释。 如果不了解和验证内部工作机制,GNN 就无法被完全信任,这会阻碍其在公平、隐私和安全等关键应用中的使用(Doshi-Velez 和 Kim,2017;Ying 等人,2019). 例如,我们可以训练一个 GNN 模型来预测药物的效果,其中我们将每种药物视为分子图。 如果不探索工作机制,我们不知道分子图中的哪些化学基团导致了预测。 那么我们就无法验证GNN模型的规则是否与现实世界的化学规则一致,因此我们不能完全信任GNN模型。 这就提出了开发 GNN 解释技术的需求。
最近,已经提出了几种解释技术来解释图像和文本数据的深度学习模型。 根据提供的解释类型,现有技术可以分为示例级(Simonyan 等人,2013;Smilkov 等人,2017;Yuan 等人,2019;Selvaraju 等人,2017;Zhou 等人, 2016;Zeiler 和 Fergus,2014;Fong 和 Vedaldi,2017;Dabkowski 和 Gal,2017) 或模型级 (Erhan 等人,2009;Nguyen 等人,2015) 方法。 示例级解释通过模型确定输入中的重要特征或该输入的决策过程来解释给定输入示例的预测。 该类别的常见技术包括基于梯度的方法(Simonyan等人,2013;Smilkov等人,2017;Yuan等人,2019),中间特征图的可视化(Selvaraju等人, 2017;Zhou 等人,2016),以及基于遮挡的方法(Zeiler 和 Fergus,2014;Fong 和 Vedaldi,2017;Dabkowski 和 Gal,2017)。 模型级解释的目的不是提供依赖于输入的解释,而是通过研究哪些输入模式可以导致某种预测来解释模型的一般行为,而不考虑任何特定的输入示例。 输入优化(Erhan等人,2009;Nguyen等人,2017;Nguyen等人,2015;Olah等人,2017)是最流行的模型级解释方法。 这两类解释方法旨在从不同的角度解释深层模型。 由于解释的最终目标是验证和理解深层模型,因此我们需要手动检查解释结果并得出深层模型是否按照我们预期的方式工作的结论。 对于示例级方法,我们可能需要探索大量示例的解释,然后才能信任模型。 然而,这非常耗时并且需要大量专家的努力。 对于模型级方法,解释更加通用和高级,因此需要较少的人工监督。 然而,与示例级解释相比,模型级方法的解释不太精确。 总的来说,模型级和示例级方法对于解释和理解深度模型都很重要。
在图数据上解释深度学习模型变得越来越重要,但探索仍然较少。 据我们所知,目前还没有在模型级别解释 GNN 的研究。 现有研究(Ying等人,2019;Baldassarre and Azizpour,2019)仅提供了图模型的示例级解释。 作为与现有工作的根本不同,我们提出了一种称为 XGNN 的新颖解释技术,用于在模型级别解释深度图模型。 我们建议研究哪些图形模式可以最大化某个预测。 具体来说,我们建议训练一个图生成器,以便生成的图模式可以用于解释深度图模型。 我们将其表述为强化学习问题,在每一步,图生成器都会预测如何向给定图添加边并形成新图。 然后使用策略梯度(Sutton等人,2000)根据训练后的图模型的反馈来训练生成器。 我们还结合了一些图表规则来鼓励生成的图表有效。 请注意,我们的 XGNN 框架中的图生成部分可以推广到任何合适的图生成方法,这由手头的数据集和要解释的 GNN 决定。 最后,我们在现实世界和合成数据集上训练了 GNN 模型,这可以产生良好的性能。 然后我们使用我们提出的 XGNN 来解释这些经过训练的模型。 实验结果表明,我们提出的 XGNN 可以找到所需的图形模式并解释这些模型。 通过生成的图形模式,我们可以验证、理解甚至改进经过训练的 GNN 模型。
2. 相关工作
2.1. 图神经网络
图被广泛用于表示不同现实世界领域中的数据,图神经网络在这些数据上显示出了有希望的性能。 与图像和文本数据不同,图由特征矩阵和邻接矩阵表示。 形式上,具有 个节点的图 由其特征矩阵 及其邻接矩阵 表示。 请注意,我们假设每个节点都有一个 维向量来表示其特征。 图神经网络根据这些矩阵学习节点特征。 尽管 GNN 有多种变体,例如图卷积网络(GCN)(Kipf 和 Welling,2017)、图注意力网络(GAT)(Veličković 等人,2018) t1>和图同构网络(GIN)(Xu等人,2019),它们共享相似的特征学习策略。 对于每个节点,GNN 通过聚合其邻居的特征并将其与自己的特征相结合来更新其节点特征。 我们以 GCN 为例来说明邻域信息聚合方案。 GCN 的操作定义为
| (1) |
其中和是图卷积层的输入和输出特征矩阵。 另外,用于向邻接矩阵添加自循环,表示对角节点度矩阵,用于归一化。 矩阵是层的可训练矩阵,用于执行线性特征变换,表示非线性激活函数。 通过堆叠图卷积层,可以聚合跳邻域信息。 由于其优越的性能,我们将方程(1)中的图卷积作为我们的图神经网络算子。
2.2. 模型级解释
接下来,我们简要讨论图像数据深度学习模型的流行模型级解释技术,称为输入优化方法(Erhan等人,2009;Nguyen等人,2017;Nguyen等人,2015;Olah等人, 2017)。 这些方法通常会生成优化的输入,可以最大化深度模型的某些行为。 他们随机初始化输入并迭代更新输入以实现目标,例如最大化班级分数。 那么这样的优化输入就可以看作是对目标行为的解释。 这样的过程称为优化,类似于训练深度神经网络。 主要区别在于,在这种输入优化技术中,所有网络参数都是固定的,而输入被视为可训练变量。 虽然这些方法可以为图像上的深度模型提供有意义的模型级解释,但由于三个挑战,它们不能直接应用于解释 GNN。 首先,图的结构信息由离散邻接矩阵表示,无法通过反向传播直接优化。 其次,对于图像,优化的输入是摘要图像,可视化显示高级模式和含义。 就图而言,摘要图没有意义并且难以可视化。 第三,所获得的图对于化学或生物规则可能无效,因为不可微图规则不能直接纳入优化中。 例如,原子的节点度不应超过其最大化学价。
2.3. 图模型解释
据我们所知,现有的研究专注于深度图模型的可解释性(Ying等人,2019;Baldassarre and Azizpour,2019)。 最近的 GNN 解释工具 GNNExplainer(Ying 等人, 2019) 提出通过学习软掩模来解释示例级别的深度图模型。 对于给定的示例,它将软掩码应用于图形边缘和节点特征并更新掩码,以使预测保持与原始预测相同。 然后通过对掩模进行阈值化来选择一些图的边和节点特征,并将它们视为重要的边和特征来对给定的示例进行预测。
另一项工作(Baldassarre 和 Azizpour,2019) 也专注于深度图模型的示例级解释。 它将几种著名的图像解释方法应用于图模型,如敏感性分析(SA)(Gevrey等人,2003)、引导反向传播(GBP)(Springenberg等人,2014) ,以及逐层相关性传播(LRP)(Bach 等人,2015)。 SA 和 GBP 方法基于梯度,而 LRP 方法通过将输出预测分解为其输入的组合来计算显着性图。 此外,这两项研究都为个别示例生成了依赖于输入的解释。 为了验证和理解深度模型,人类需要检查所有示例的解释,这是耗时的甚至不可行的。
虽然依赖于输入的解释对于理解深层模型很重要,但模型级别的解释不应被忽视。 然而,现有的工作都没有研究深度图模型的模型级解释。 在这项工作中,我们认为模型级解释可以提供更高层次的见解和对深度学习模型如何工作的更普遍的理解。 因此,我们的目标是为 GNN 提供模型级解释。 我们提出了一种称为 XGNN 的新方法,通过图生成来解释 GNN,以便生成的图可以最大化某种行为。
3. XGNN:可解释的图神经网络
3.1. 模型级 GNN 解释
直观上,给定一个经过训练的 GNN 模型,其模型级解释应该解释哪些图模式或子图模式会导致某种预测。 例如,一种可能的模式类型被称为网络图案,它代表复杂网络(图)的简单构建块,广泛存在于生物化学、神经生物学、生态学和工程学的图中(Milo等人,2002;Alon) ,2006,2007;Shen-Orr等人,2002)。 不同功能的图中可以找到不同的motif集合(Milo等人, 2002; Alon, 2006),这意味着不同的motif可能与图的功能直接相关。 然而,目前尚不清楚 GNN 是否基于此类主题或其他图形信息进行预测。 通过识别图模式和 GNN 预测之间的关系,我们可以更好地理解模型并验证模型是否按预期工作。 因此,我们提出了 XGNN,它解释了使用此类图模式的 GNN。 具体来说,在这项工作中,我们研究了 GNN 对于图分类任务的模型级解释,并且图模式是通过图生成获得的。
形式上,让 表示经过训练的 GNN 分类模型, 表示分类预测。 给定 和选定的类 、,我们的目标是研究哪些输入图模式可以最大化该类的预测概率。 获得的模式可以被视为关于的模型级解释。 形式上,任务可以定义为
| (2) |
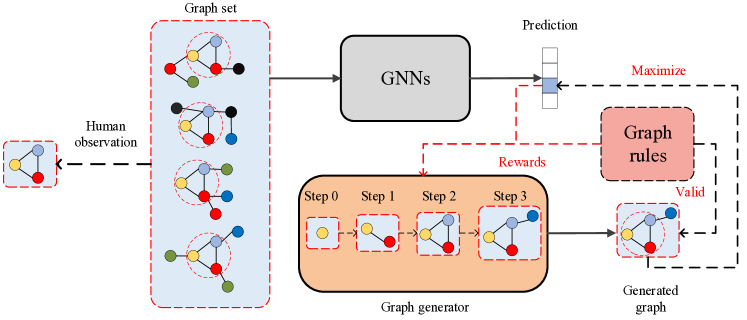
其中 是我们需要的优化输入图。 获得这种用于解释图像和文本模型的优化输入的流行方法被称为输入优化(Yuan 等人,2019;Erhan 等人,2009;Nguyen 等人,2017;Nguyen 等人,2015;Olah 等人,2017)。 然而,正如2.2节中所讨论的,由于图数据的特殊表示,这种优化方法不能应用于解释图模型。 相反,我们建议通过图生成来获得优化的图。 我们提出的方法的总体说明如图1所示。 给定一个预先训练的图分类模型,我们通过为其第三类提供解释来解释它。 我们可以从图形数据集中手动总结图形模式。 通过评估数据集中的所有图示例,我们可以获得预测为第三类的图。 然后我们可以手动检查这些图中有哪些常见的图形模式。 例如,图1的左侧部分显示一组四个图被分类为第三类。 根据人类观察,我们知道导致预测的重要图形模式是由红色节点、黄色节点和蓝色节点组成的三角形模式。 然而,这种手动分析非常耗时,并且不适用于大规模和复杂的图数据集。 如右部分所示,我们建议训练一个图生成器来生成可以最大化第三类预测分数的图模式。 此外,我们还结合了图形规则,例如化学价检查,以鼓励有效且人类可理解的解释。 最后,我们可以分析生成的图以获得第三类的模型级解释。 与直接对原始数据集进行手动分析相比,我们提出的方法生成小规模且不太复杂的图,这可以显着降低进一步手动分析的成本。
3.2. 通过图生成解释 GNN
图生成领域的最新进展催生了许多成功的图生成模型,例如 GraphGAN (Wang 等人, 2018)、ORGAN (Guimaraes 等人, 2017)、Junction Tree VAE (Jin 等人, 2018)、DGMG (Li 等人, 2018)、图卷积策略网络 (GCPN) (You 等人, 2018). 受这些方法的启发,我们建议训练一个图形生成器,逐步生成。 对于每个步骤,图生成器都会根据当前图生成一个新图。 形式上,我们将步骤 中部分生成的图定义为 ,其中包含 节点。 它被表示为特征矩阵和邻接矩阵,假设每个节点都有一个维特征向量。 然后我们将 参数化图形生成器定义为 ,它将 作为输入,并输出一个新图形
| (3) |
然后在预训练的 GNN 的指导下训练生成器。 由于从 生成新图 是不可微分的,因此我们将生成过程表述为强化学习问题。 具体来说,假设数据集中有类型的节点,我们定义一个候选集来表示这些可能的节点类型。 例如,在化学分子数据集中,候选集可以是。 在节点未标记的社交网络数据集中,候选集仅包含单个节点类型。 然后在每一步,根据部分生成的图,生成器通过预测如何添加边来生成到当前图表。 请注意,生成器可能会在当前图 中的两个节点之间添加边,或者将候选集 中的节点添加到当前图 并连接它与 中的现有节点一起使用。 形式上,我们将其表述为强化学习问题,由四个要素组成:状态、行动、策略和奖励。
状态:步骤处强化学习环境的状态是部分生成的图。 第一步的初始图可以是候选集中中的随机节点,也可以是基于先验领域知识手动设计的。 例如,对于描述有机分子的数据集,我们可以将初始图设置为用碳原子标记的单个节点,因为任何有机化合物通常都含有碳(Seager and Slabaugh,2013)。
操作:步骤 的操作(表示为 )是根据当前图形 生成新图形 。 具体来说,给定当前状态,动作就是通过确定边的起始节点和结束节点来向添加一条边。 请注意,起始节点 可以是当前图 中的任何节点,而结束节点 是从当前图 和排除所选起始节点的候选集,记为。 请注意,通过预定义的最大操作步骤和最大节点数,我们可以控制图生成的终止。
策略:我们采用图神经网络作为策略。 该策略根据状态确定操作。 具体来说,该策略是图生成器,它以和作为输入并输出可能动作的概率。 有了奖励函数,生成器可以通过策略梯度(Sutton等人,2000)进行训练。
Reward:步骤的奖励,表示为,用于评估步骤的动作,其中包括两部分。 第一部分是经过训练的 GNN 的指导,它鼓励生成的图最大化类 的类分数。 通过将生成的图输入到 ,我们可以获得类 的预测概率,并将其用作更新 的反馈。 第二部分鼓励生成的图在某些图规则方面是有效的。 例如,对于社交网络数据集,可能不允许在两个节点之间添加多条边。 此外,对于化学分子数据集,原子的程度不能超过其化学价。 请注意,对于每个步骤,我们都包含中间奖励和总体奖励来评估操作。
虽然我们将图生成表述为强化学习问题,但值得注意的是,我们提出的 XGNN 是一种新颖且通用的框架,用于在模型级别解释 GNN。 该框架中的图生成部分可以推广到任何合适的图生成方法,由手头的数据集和要解释的 GNN 决定。
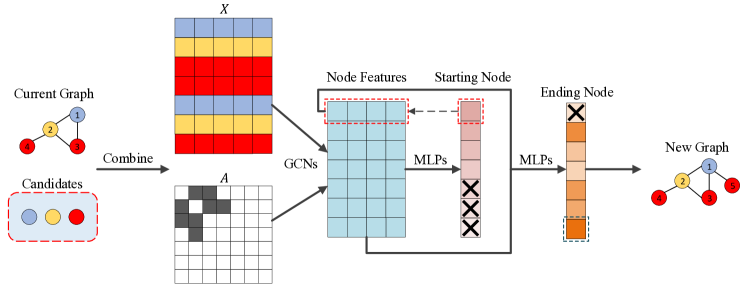
3.3. 图形生成器
对于步骤,图生成器结合部分生成的图和候选集来预测不同动作的概率,表示为和。 假设中有节点,中有节点,则和 具有 维度。 然后从概率 中对动作 进行采样。 接下来,我们可以根据动作获取新的图。 具体来说,在我们的生成器中,我们首先使用几个图卷积层来聚合邻域信息并学习节点特征。 从数学上来说,它可以写成
| (4) |
其中表示学习到的节点特征。 请注意,图 和候选集 组合作为 GCN 的输入。 我们将中的所有节点合并到中,不添加任何边,然后得到新的节点特征矩阵和邻接矩阵。 然后使用多层感知器 (MLP) 来预测起始节点 的概率,并从此概率分布中对动作 进行采样。 从数学上来说,它可以写成
| (5) | |||||
| (6) |
其中表示逐元素乘积,表示屏蔽掉所有候选节点,因为起始节点只能从当前图中中选择。 让表示由启动操作选择的节点的特征。 然后以所选节点为条件,我们使用第二个 MLP 来计算结束节点 的概率分布,从中我们对结束节点动作 进行采样。 请注意,由于起始节点和结束节点不能相同,因此我们应用掩码 来屏蔽 选择的节点。 从数学上来说,它可以写成
| (7) | |||||
| (8) |
其中表示广播和级联。 另外,是除了指示的位置之外全1组成的掩码。 请注意,相同的图形生成器 由不同的时间步共享,并且我们的生成器能够合并具有可变大小的图形。
我们在图 2 中说明了我们的图形生成器,其中显示了一步的图形生成过程。 当前图由4个节点组成,候选集有3个可用节点。 它们组合在一起作为图形生成器的输入。 候选节点的嵌入被连接到的特征矩阵,而的邻接矩阵相应地扩展。 然后采用多个图卷积层来学习所有节点的特征。 通过第一个 MLP,我们获得选择不同节点作为起始节点的概率,并从中采样节点 1 作为起始节点。 然后根据节点 1 的特征和所有节点特征,第二个 MLP 预测结束节点。 我们从概率中进行采样,并选择节点 7 作为结束节点,它对应于候选集中的红色节点。 最后,包含一个红色节点并将其与节点 1 连接,得到一个新图。
3.4. 训练图形生成器
图生成器经过训练,生成特定的图,可以最大化类 的类分数,并且对图规则有效。 由于这种指导是不可微的,我们采用策略梯度 (Sutton 等人, 2000) 来训练生成器。 根据(Lei 等人, 2016; Yu 等人, 2017),步骤动作的损失函数可以在数学上写为
| (9) |
其中表示交叉熵损失,表示步骤的奖励函数。直观上,奖励表示是否有很大机会生成类得分高且有效的图。 因此,奖励由两部分组成。 第一部分 是来自训练模型 的反馈,第二部分 来自图规则。 具体来说,对于步骤 ,奖励 包含图 的中间奖励和最终图奖励:
| (10) |
其中 是超参数,第一项是中间奖励,可以通过将 馈送到经过训练的 GNN 并检查预测来获得类 的概率。 在数学上,它可以计算为
| (11) |
其中 表示 可能的类数。 另外,式(10)中的第二项是的最终图奖励,可以通过执行Rollout获得(Yu等人, 2017)中间图 上的 t3> 次。 每次,都会基于 生成最终图表,直到终止,然后使用方程 (11) 通过 进行评估。 然后对最终图的评估进行平均,作为最终的图奖励。 总体而言,当获得的图倾向于为类 产生高分时, 为正,反之亦然。
此外,奖励是从图规则中获得的,用于鼓励生成的图有效且易于理解。 我们采用的第一条规则是任意两个节点之间只允许添加一条边。 其次,生成的图包含的节点数不能多于预定义的最大节点数。 此外,我们还结合了数据集特定的规则来指导图形生成。 例如,在化学数据集中,每个节点代表一个原子,因此其度数不能超过相应原子的化合价。 当违反任何这些规则时,将获得负奖励。 最后,通过组合和,我们可以获得步骤的奖励:
| (12) |
其中 和 是超参数。 我们在算法1中说明了训练过程。 请注意,当操作 被评估为不承诺 时,我们会将图表 回滚到 。
4. 实验研究
4.1. 数据集和实验设置
我们在合成数据集和真实数据集上评估了我们提出的 XGNN。 我们在表 1 中报告了这些数据集的汇总统计数据。 由于没有现有的工作研究 GNN 的模型级解释,因此我们没有可比较的基线。 请注意,现有研究(Ying等人,2019;Baldassarre和Azizpour,2019)仅关注示例级别的GNN解释,而忽略模型级别的解释。 不需要与它们进行比较,因为这些示例级别和模型级别是两个完全不同的解释方向。
合成数据集:由于我们的 XGNN 为 Deep GNN 生成模型级解释,因此我们构建了一个名为 Is_Acircy 的合成数据集,其中提供了基本事实解释。 根据图中是否存在循环来对图进行标记。 这些图是使用 Networkx 软件包(Hagberg 等人,2008)获得的。
第一类是循环图,包括网格图、循环图、轮图、循环梯图。 第二类表示非循环图,包括星形图、二叉树图、路径图和满散列树图(Storer,2012)。 请注意,该数据集中的所有节点均未标记,我们重点研究 GNN 捕获图结构的能力。
真实世界数据集:我们在真实世界数据集MUTAG上进行实验。 MUTAG 数据集包含表示化合物的图表,其中节点表示不同的原子,边表示化学键。 这些图根据其对细菌的诱变作用被标记为两个不同的类别(Debnath 等人,1991)。 每个节点根据其原子类型进行标记,有七种可能的原子类型:碳、氮、氧、氟、碘、氯、溴。 请注意,为了简单起见,边缘标签被忽略。 对于这个数据集,我们研究了 GNN 捕获图结构和节点标签的能力。
图分类模型:我们使用这些数据集训练图分类模型,然后尝试解释这些模型。 这些模型共享相似的流程,首先使用多层 GCN 学习节点特征,然后通过平均所有节点特征来获得图级嵌入,最后使用全连接层来执行图分类。 对于合成数据集 Is_Acycl,我们使用节点度作为所有节点的初始特征。 然后我们应用输出维度分别等于 8、16 的两层 GCN,并执行全局平均以获得图表示。 最后,我们采用一个全连接层作为分类器。 同时,对于现实世界的数据集 MUTAG,由于所有节点都被标记,因此我们采用相应的 one-hot 表示作为初始节点特征。 然后我们采用输出维度分别等于 32、48、64 的三层 GCN,并对所有节点特征进行平均。 最终分类器包含两个全连接层,其中隐藏维度设置为 32。 请注意,对于所有 GCN 层,我们应用公式 (1) 中所示的 GCN 版本。 此外,我们在数据集 Is_Acycl 中使用 Sigmoid 作为 GCN 中的非线性函数,而在数据集 MUTAG 中使用 Relu。 这些模型使用 Pytorch (Paszke 等人,2017) 实现,并使用 Adam 优化器 (Kingma 和 Ba,2014) 进行训练。
这些模型的训练精度如表1所示,这表明我们尝试解释的模型是具有合理性能的模型。
| Dataset | Classes | # of Edges | # of Nodes | Accuracy |
|---|---|---|---|---|
| Is_Acyclic | 2 | 30.04 | 28.46 | 0.978 |
| MUTAG | 2 | 19.79 | 17.93 | 0.963 |
图生成器:对于这两个数据集,我们的图生成器共享相同的结构。 我们的生成器首先采用全连接层将节点特征映射到 8 维。 然后采用三层 GCN,输出维度分别等于 16、24、32。 第一个 MLP 由两个隐藏维度等于 16 的全连接层和一个 ReLU6 非线性函数组成。 第二个 MLP 也有两个全连接层,隐藏维度设置为 24,并应用 ReLU6。 输入图的初始特征与上面提到的相同。 对于数据集 Is_Acycl,如果生成的图违反任何图规则,我们将设置 、 和 。 对于数据集 MUTAG,如果生成的图违反任何图规则,我们会设置 、 和总奖励 。 此外,我们每一步执行 rollout 次以获得最终的图表奖励。 这些模型使用 Pytorch (Paszke 等人,2017) 实现,并使用 Adam 优化器 (Kingma 和 Ba,2014) 以及 和 。 图形生成器训练的学习率设置为 0.01。
4.2. 合成数据的实验结果
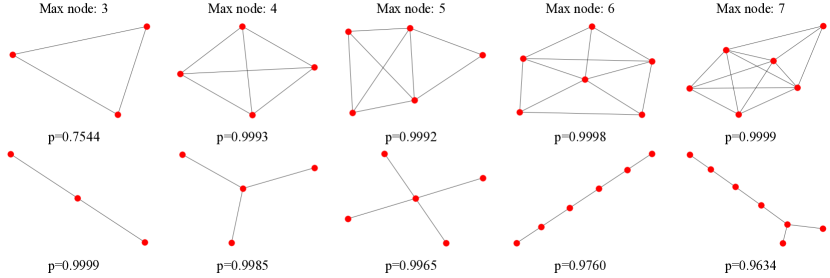
我们首先在可以获得基本事实的合成数据集 Is_Acircy 上进行实验。 如表1所示,经过训练的GNN分类器可以达到令人鼓舞的性能。 由于数据集是根据图形是否包含圆圈手动综合构建的,因此我们可以检查训练后的 GNN 分类器是否以这种方式进行预测。 我们用我们提出的 XGNN 解释模型,并在图 3 中报告生成的解释。 我们在第一行中显示“循环”类的解释,在第二行中显示“非循环”类的结果。 此外,我们还通过设置不同的最大图节点限制来报告不同的生成解释。
首先,通过比较不同类生成的图,我们可以很容易地得出结论:“循环”类的解释总是包含圆圈,而“非循环”类的结果根本没有圆圈。 其次,为了验证我们的解释是否可以最大化某个类的类概率,如方程 (2) 所示,我们将每个生成的图提供给经过训练的 GNN 分类器,并报告相应类的预测概率。班级。 结果表明,我们生成的图形模式可以一致地产生高预测概率。 请注意,即使为最大节点数等于 3 的“循环”类获得的图仅导致 ,但它仍然是具有 3 个节点的所有可能图的最高概率。 最后,根据这些结果,我们可以了解哪些模式可以最大化不同类别的预测概率。 在我们的结果中,我们知道经过训练的 GNN 分类器很可能通过检测圆形结构来区分不同的类别,这与我们的预期一致。 因此,这样的解释有助于理解和信任该模型,并提高该模型用作圆形图检测器的可信度。 此外,值得注意的是,与数据集中的图表相比,我们生成的图表更容易分析。 我们生成的图的节点数量明显更少,结构更简单,并且产生更高的预测概率,而数据集中的图平均有 28 个节点和 30 条边,如表 1 所示。
4.3. 真实世界数据的实验结果
我们还使用真实世界数据评估我们提出的 XGNN。 对于数据集 MUTAG,解释没有基本事实。 由于所有节点都被标记为不同类型的原子,因此我们研究训练后的 GNN 分类器是否可以捕获图结构和节点标签。 我们用我们提出的方法解释训练后的 GNN,并在图 4 和图 5 中报告选定的结果。 请注意,生成的图表可能不代表真正的化合物,因为为了简单起见,我们仅结合了一个简单的化学规则,即原子的程度不能超过其最大化学价。 此外,由于节点被标记,我们可以将初始图设置为不同类型的原子。
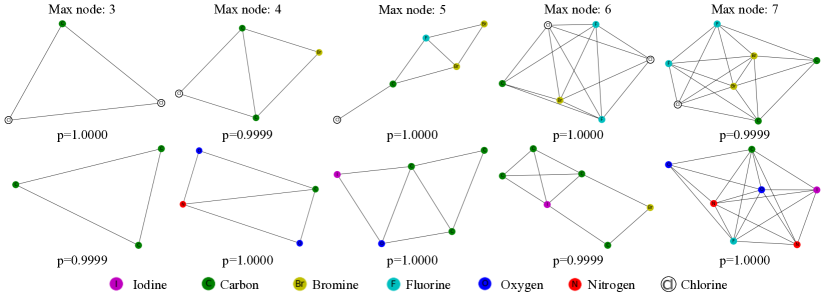

我们首先将初始图设置为单个碳原子,并在图 4 中报告结果,因为通常任何有机化合物都含有碳(Seager 和 Slabaugh,2013)。 第一行报告“非诱变”类别的解释,而第二行显示“诱变”类别的结果。 我们报告具有不同节点限制的生成图和 GNN 预测概率。 对于“致突变”类,我们可以观察到碳环和是一些常见的模式,这与碳环和化学基团具有致突变性的化学事实是一致的(Debnath等人,1991)。 这些观察结果表明,经过训练的 GNN 分类器可以捕获这些关键图形模式来进行预测。 此外,对于“非致突变”类别,我们观察到原子氯广泛存在于生成的图中,并且氯、溴和氟的组合总是导致“非致突变”预测。 通过分析这些解释,我们可以更好地理解训练好的 GNN 模型。
我们还探索了不同的初始图并在图 5 中报告了结果。 我们将最大节点限制固定为 5,并生成“致突变”类的解释。 首先,无论我们如何设置初始图,我们提出的方法总能找到使“致突变”类的预测概率最大化的图模式。 对于前 5 个图,这意味着初始图设置为碳、氮、氧、碘或氟的单个节点,一些生成的图仍然具有常见的模式,如碳环和 化学基团。 我们的观察进一步证实这些关键模式是由经过训练的 GNN 捕获的。 此外,我们注意到生成器仍然可以生成含有氯的图表,这些图表被预测为“致突变”,这与我们上面的结论相反。 如果所有含有氯的图都应被识别为“非致突变”,那么这种解释就显示了经过训练的 GNN 的局限性。 然后,这些生成的解释可以为改进训练的 GNN 提供指导,例如,我们在训练 GNN 时可能会更加重视氯图。 此外,生成的解释还可以用于重新训练和改进 GNN 模型,以正确捕获我们想要的模式。 总的来说,实验结果表明,我们提出的解释方法 XGNN 可以帮助验证、理解、甚至帮助改进训练好的 GNN 模型。
5. 结论
图神经网络最近得到了广泛的研究,并且在多个图任务上表现出了出色的性能。 然而,图模型仍然被视为黑匣子,因此不能完全可信。 它提出了研究图神经网络解释技术的需要。 这仍然是一个较少探索的领域,现有方法仅关注图模型的示例级解释。 然而,现有的工作还没有研究更通用和更高层次的图模型的模型级解释。 因此,在这项工作中,我们提出了一种新方法 XGNN,在模型级别解释图模型。 具体来说,我们建议找到可以通过图生成最大化某些预测的图模式。 我们将其表述为强化学习问题并迭代生成图模式。 我们训练一个图生成器,对于每个步骤,它都会预测如何将边添加到当前图中。 此外,我们还结合了一些图形规则,以鼓励生成的图形有效且易于理解。 最后,我们对合成数据集和真实数据集进行实验,以证明我们提出的 XGNN 的有效性。 实验结果表明,生成的图有助于发现哪些模式可以最大化训练后的 GNN 的某些预测。 生成的解释有助于验证和更好地理解经过训练的 GNN 是否以我们预期的方式做出预测。 此外,我们的结果还表明,生成的解释可以帮助改进训练的模型。
致谢
这项工作得到了国家科学基金会拨款 DBI-2028361、IIS-1714741、IIS-1715940、IIS-1845081、IIS-1900990 和国防高级研究项目局拨款 N66001-17-2-4031 的部分支持。
参考
- (1)
- Alon (2006) Uri Alon. 2006. An introduction to systems biology: design principles of biological circuits. Chapman and Hall/CRC.
- Alon (2007) Uri Alon. 2007. Network motifs: theory and experimental approaches. Nature Reviews Genetics 8, 6 (2007), 450.
- Bach et al. (2015) Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one 10, 7 (2015).
- Baldassarre and Azizpour (2019) Federico Baldassarre and Hossein Azizpour. 2019. Explainability Techniques for Graph Convolutional Networks. In International Conference on Machine Learning (ICML) Workshops, 2019 Workshop on Learning and Reasoning with Graph-Structured Representations.
- Dabkowski and Gal (2017) Piotr Dabkowski and Yarin Gal. 2017. Real time image saliency for black box classifiers. In Advances in Neural Information Processing Systems. 6967–6976.
- Debnath et al. (1991) Asim Kumar Debnath, Rosa L Lopez de Compadre, Gargi Debnath, Alan J Shusterman, and Corwin Hansch. 1991. Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity. Journal of medicinal chemistry 34, 2 (1991), 786–797.
- Doshi-Velez and Kim (2017) Finale Doshi-Velez and Been Kim. 2017. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608 (2017).
- Erhan et al. (2009) Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2009. Visualizing higher-layer features of a deep network. Technical Report, University of Montreal 1341, 3 (2009), 1.
- Fong and Vedaldi (2017) Ruth C Fong and Andrea Vedaldi. 2017. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision. 3429–3437.
- Gao and Ji (2019a) Hongyang Gao and Shuiwang Ji. 2019a. Graph representation learning via hard and channel-wise attention networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 741–749.
- Gao and Ji (2019b) Hongyang Gao and Shuiwang Ji. 2019b. Graph U-Net. In International conference on machine learning. 2083–2092.
- Gevrey et al. (2003) Muriel Gevrey, Ioannis Dimopoulos, and Sovan Lek. 2003. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecological modelling 160, 3 (2003), 249–264.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 1263–1272.
- Guimaraes et al. (2017) Gabriel Lima Guimaraes, Benjamin Sanchez-Lengeling, Carlos Outeiral, Pedro Luis Cunha Farias, and Alán Aspuru-Guzik. 2017. Objective-reinforced generative adversarial networks (ORGAN) for sequence generation models. arXiv preprint arXiv:1705.10843 (2017).
- Hagberg et al. (2008) Aric Hagberg, Pieter Swart, and Daniel S Chult. 2008. Exploring network structure, dynamics, and function using NetworkX. Technical Report. Los Alamos National Lab.(LANL), Los Alamos, NM (United States).
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In Advances in neural information processing systems. 1024–1034.
- Jin et al. (2018) Wengong Jin, Regina Barzilay, and Tommi Jaakkola. 2018. Junction Tree Variational Autoencoder for Molecular Graph Generation. In Proceedings of the 35th International Conference on Machine Learning. 2323–2332.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations.
- Lee et al. (2019) Junhyun Lee, Inyeop Lee, and Jaewoo Kang. 2019. Self-Attention Graph Pooling. In International Conference on Machine Learning. 3734–3743.
- Lei et al. (2016) Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016. Rationalizing Neural Predictions. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 107–117.
- Li et al. (2018) Yujia Li, Oriol Vinyals, Chris Dyer, Razvan Pascanu, and Peter Battaglia. 2018. Learning deep generative models of graphs. arXiv preprint arXiv:1803.03324 (2018).
- Milo et al. (2002) Ron Milo, Shai Shen-Orr, Shalev Itzkovitz, Nadav Kashtan, Dmitri Chklovskii, and Uri Alon. 2002. Network motifs: simple building blocks of complex networks. Science 298, 5594 (2002), 824–827.
- Nguyen et al. (2017) Anh Nguyen, Jeff Clune, Yoshua Bengio, Alexey Dosovitskiy, and Jason Yosinski. 2017. Plug & play generative networks: Conditional iterative generation of images in latent space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4467–4477.
- Nguyen et al. (2015) Anh Nguyen, Jason Yosinski, and Jeff Clune. 2015. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 427–436.
- Olah et al. (2017) Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. 2017. Feature visualization. Distill 2, 11 (2017), e7.
- Paszke et al. (2017) Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in PyTorch. In Proceedings of the International Conference on Learning Representations.
- Seager and Slabaugh (2013) Spencer L Seager and Michael R Slabaugh. 2013. Chemistry for today: General, organic, and biochemistry. Cengage learning.
- Selvaraju et al. (2017) Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision. 618–626.
- Shen-Orr et al. (2002) Shai S Shen-Orr, Ron Milo, Shmoolik Mangan, and Uri Alon. 2002. Network motifs in the transcriptional regulation network of Escherichia coli. Nature genetics 31, 1 (2002), 64.
- Simonyan et al. (2013) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2013. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 (2013).
- Smilkov et al. (2017) Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. 2017. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825 (2017).
- Springenberg et al. (2014) Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller. 2014. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806 (2014).
- Storer (2012) James Andrew Storer. 2012. An introduction to data structures and algorithms. Springer Science & Business Media.
- Sutton et al. (2000) Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. 2000. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems. 1057–1063.
- Thekumparampil et al. (2018) Kiran K Thekumparampil, Chong Wang, Sewoong Oh, and Li-Jia Li. 2018. Attention-based graph neural network for semi-supervised learning. arXiv preprint arXiv:1803.03735 (2018).
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph Attention Networks. In International Conference on Learning Representations. https://openreview.net/forum?id=rJXMpikCZ
- Wang et al. (2018) Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. GraphGAN: Graph representation learning with generative adversarial nets. In Thirty-Second AAAI Conference on Artificial Intelligence. 2508–2515.
- Xu et al. (2019) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How Powerful are Graph Neural Networks?. In International Conference on Learning Representations. https://openreview.net/forum?id=ryGs6iA5Km
- Ying et al. (2019) Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec. 2019. GNNExplainer: Generating Explanations for Graph Neural Networks. In Advances in Neural Information Processing Systems 32. 9244–9255.
- You et al. (2018) Jiaxuan You, Bowen Liu, Zhitao Ying, Vijay Pande, and Jure Leskovec. 2018. Graph convolutional policy network for goal-directed molecular graph generation. In Advances in Neural Information Processing Systems. 6410–6421.
- Yu et al. (2017) L Yu, W Zhang, J Wang, and Y Yu. 2017. Seqgan: sequence generative adversarial nets with policy gradient. In AAAI-17: Thirty-First AAAI Conference on Artificial Intelligence, Vol. 31. Association for the Advancement of Artificial Intelligence (AAAI), 2852–2858.
- Yuan et al. (2019) Hao Yuan, Yongjun Chen, Xia Hu, and Shuiwang Ji. 2019. Interpreting Deep Models for Text Analysis via Optimization and Regularization Methods. In Thirty-Third AAAI Conference on Artificial Intelligence. 5717–5724.
- Yuan and Ji (2020) Hao Yuan and Shuiwang Ji. 2020. StructPool: Structured Graph Pooling via Conditional Random Fields. In International Conference on Learning Representations. https://openreview.net/forum?id=BJxg_hVtwH
- Zeiler and Fergus (2014) Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolutional networks. In European Conference on Computer Vision. Springer, 818–833.
- Zhang and Chen (2018) Muhan Zhang and Yixin Chen. 2018. Link prediction based on graph neural networks. In Advances in Neural Information Processing Systems. 5165–5175.
- Zhang et al. (2018) Muhan Zhang, Zhicheng Cui, Marion Neumann, and Yixin Chen. 2018. An end-to-end deep learning architecture for graph classification. In Thirty-Second AAAI Conference on Artificial Intelligence. 4438–4445.
- Zhou et al. (2016) Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. 2016. Learning deep features for discriminative localization. In Proceedings of the IEEE International Conference on Computer Vision. 2921–2929.