自适应通用广义 PageRank 图神经网络
摘要
在许多重要的图数据处理应用中,获取的信息包括节点特征和图拓扑的观察。 图神经网络(GNN)旨在利用这两种证据来源,但它们并没有以最佳方式权衡其效用并以通用的方式整合它们。 这里,普遍性是指对同质或异质图假设的独立性。 我们通过引入一种新的广义 PageRank (GPR) GNN 架构来解决这些问题,该架构自适应地学习 GPR 权重,从而联合优化节点特征和拓扑信息提取,无论节点标签同质或异质的程度如何。 学习到的 GPR 权重会自动调整到节点标签模式,与初始化类型无关,从而保证通常难以处理的标签模式的出色学习性能。 此外,它们还可以避免特征过度平滑,这一过程使特征信息变得无差别,而不需要网络变浅。 由所谓的上下文随机块模型生成的新颖的综合基准数据集促进了我们对 GPR-GNN 方法的伴随理论分析。 我们还使用众所周知的基准同质和异质数据集,将我们的 GNN 架构与几种最先进的 GNN 在节点分类问题上的性能进行了比较。 结果表明,与现有技术相比,GPR-GNN 在合成数据和基准数据上都提供了显着的性能改进。 我们的实现可在线获取。111https://github.com/jianhao2016/GPRGNN
1简介
近年来,以图为中心的机器学习受到了广泛关注,这是因为图结构数据无处不在,而且它在解决半监督节点分类和图分类等众多实际问题方面具有重要意义(Zhu,2005;Shervashidze 等人,2011;Lü & Zhou,2011)。 通常,手头的数据包含两个信息源:节点特征和图拓扑。 例如,在社交网络中,节点代表具有由其相应特征向量捕获的不同兴趣和属性组合的用户;另一方面,边记录了可观察的友谊和协作关系,这些关系可能取决于也可能不取决于节点特征。 因此,非常需要能够同时自适应地利用节点特征和图拓扑的学习方法,因为它们利用它们的潜在连接,从而改进图的学习。
图神经网络 (GNN) 在解决上述应用领域时利用其表征能力提供最先进的性能。 许多 GNN 使用消息传递(Gilmer 等人,2017;Battaglia 等人,2018) 来操纵节点特征和图拓扑。 它们是通过堆叠(图)神经网络层构建的,这些神经网络层本质上是在给定的图拓扑上传播和转换节点特征。 不同类型的层已经被提出并在实践中使用,包括图卷积层(GCN)(Bruna等人,2014;Kipf&Welling,2017),图注意力层(GAT)( Velickovic 等人, 2018) 和许多其他人(Hamilton 等人, 2017; Wijesinghe & Wang, 2019; Zeng 等人, 2020; Abu-El-Haija 等人, 2019)。
然而,大多数现有的 GNN 架构都有两个根本弱点,限制了它们对一般图结构数据的学习能力。 首先,它们中的大多数似乎都是为同质(关联)图而量身定制的。 节点分类上下文中的同质原则(McPherson等人,2001)断言来自同一类的节点倾向于形成边。 同质性也是图聚类中的常见假设(Von Luxburg,2007;Tsourakakis,2015;Dau & Milenkovic,2017)和许多 GNN 设计(Klicpera 等人,2018)。 为同亲图开发的方法是非通用的,因为它们无法正确解决异亲(不协调)图的学习问题 (Pei 等人,2019;Bojchevski 等人,2019;2020). 在异性图中,具有不同标签的节点更有可能连接在一起(例如,许多人倾向于在约会图中优先与异性连接,不同类别的氨基酸更有可能在许多蛋白质结构中连接(朱等人,2020)等)。 GNN 通过聚合图邻域内的节点特征来建模同质原理。 为此,他们使用不同的机制,例如在每个网络层中进行平均。 邻域聚合是有问题的,并且对于异嗜图来说要困难得多(Jia & Benson,2020)。
其次,大多数现有的 GNN 都不够“深度”。 尽管原则上可以堆叠任意数量的层,但实际模型通常是浅层的(包括 - 层),因为已知这些架构比深层网络能够实现更好的经验性能。 随着深度的增加,GNN 性能下降,一个广为接受的解释是 特征过度平滑,可以直观地解释如下。 GNN 特征传播的过程代表了“特征图”上的一种随机游走形式,在适当的条件下,这种随机游走以指数速率收敛到其驻点。 这本质上平衡了特征的表达能力并使它们具有非歧视性。 这种直观推理首先在 Li 等人 (2018) 中针对线性设置进行了描述,最近在 Oono & Suzuki (2020) 中针对涉及非线性整流器的设置进行了研究。
我们通过在名为 GPR-GNN 的新模型中将 GNN 与通用 PageRank 技术 (GPR) 相结合来解决这两个弱点。 GPR-GNN 架构旨在首先学习隐藏特征,然后通过 GPR 技术传播它们。 网络的核心组件是 GPR 过程,它将特征传播的每个步骤与 可学习的重量。 权重取决于信息传播过程中不同步骤的贡献,可以是正值,也可以是负值。 这偏离了常见的非负性假设(Klicpera等人,2018)允许权重的符号适应基础图的同质/异质结构。 权重的幅值权衡节点特征的平滑程度和拓扑特征的聚合能力。 这些特征不会随着初始化过程的选择而改变,并阐明了用于组合节点特征和图结构的过程,以实现(接近)最优的预测。 总之,GPR-GNN 方法可以同时学习不同类图的节点标签模式并防止特征过度平滑。
GPR-GNN 的优异性能在现实世界数据集上得到了实证证明,并通过许多理论研究结果得到了进一步支持。 在后一种设置中,我们表明探地雷达过程与一般多项式图滤波相关,它可以自然地处理图信号的高频部分和低频部分。 相比之下,最近使用具有固定权重的个性化PageRank(PPR)的GNN模型(Wu等人,2019;Klicpera等人,2018;2019)不可避免地充当低通滤波器。 因此,他们无法学习异性图的标签。 我们还证明,即使在大步传播之后(即在大量传播步骤之后),GPR-GNN 也可以以自适应方式缓解特征过度平滑问题。 因此,该方法能够利用信息丰富的大步传播。
为了测试 GPR-GNN 在同质和异质节点标签模式上的性能并确定节点和拓扑特征探索之间的权衡,我们首先描述最近提出的上下文随机块模型(cSBM)(Deshpande等人,2018)。 cSBM 允许平滑地控制节点特征和图拓扑之间的“信息比率”,其中图可以从高度同质到高度异质变化。 我们表明,在 cSBM 上从强同质到强异质的半监督节点分类任务中,GPR-GNN 的表现优于所有其他基线方法。 然后,我们继续证明 GPR-GNN 在包含同质图和异质图的节点分类基准真实世界数据集上提供了最先进的性能。 由于篇幅限制,我们将所有证明、形式定理陈述和结论部分放在补充中。
2 预赛
令 为具有节点 和边 的无向图。让 表示节点数,假设属于 类之一。 节点与节点特征矩阵 相关联,其中 表示每个节点的特征数量。 在整篇论文中,我们使用 分别表示矩阵的行和表示列。 符号 是为 Kronecker delta 函数保留的。 图由邻接矩阵描述,而代表添加了自循环的图的邻接矩阵。 我们令为的对角度矩阵,表示具有自环的对称归一化邻接矩阵。
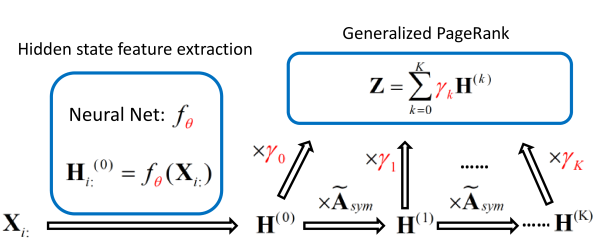
3 GPR-GNN:动机和贡献
广义 PageRank。 广义 PageRank (GPR) 方法首先在无监督图聚类的背景下使用,与个性化 PageRank 相比,它们表现出显着的性能改进(Kloumann 等人,2017;Li 等人,2019)。 探地雷达的工作原理可以简洁地描述如下。 给定图中某个簇中的种子节点 ,根据以下公式初始化一维特征向量 . GPR 得分定义为 ,其中参数 称为 GPR 权重。 通过对 GPR 分数进行阈值化,在本地执行图的聚类。 某些 PangRank 方法,例如个性化 PageRank 或热内核 PageRank (Chung,2007),与 GPR 权重的特定选择相关联(Li 等人,2019)。 有关 PageRank 方法的精彩深入讨论,感兴趣的读者可以参考(Gleich,2015)。 Li 等人 (2019) 的工作最近介绍并理论上分析了一种特殊形式的探地雷达,称为逆 PR (IPR),并表明长随机游走路径更有利于如果正确选择了 GPR 权重,则可以进行先前假设的聚类(请注意,IPR 是针对同性图开发的,目前尚不清楚异性图的最佳 GPR 权重)。
探地雷达方法和多项式图过滤的等价性。 如果我们将 GPR 定义中的无限和截断为某个自然数 ,则 对应于阶数为 的多项式图滤波器。因此,学习最优 GPR 权重相当于学习最优多项式图滤波器。 请注意,我们可以使用多项式图过滤器(Shuman等人,2013)来近似任何图过滤器,因此GPR方法能够处理大量不同的节点标签模式。 此外,增加 可以更好地近似底层最佳图形过滤器。 这再次表明大步长传播是有益的。
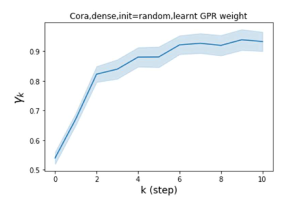
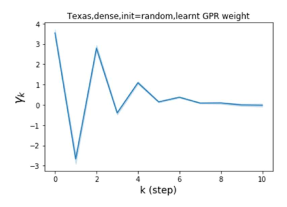
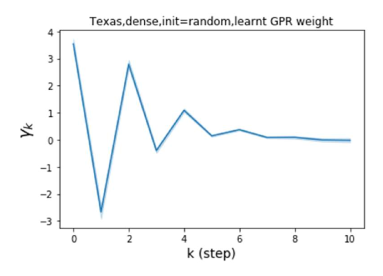
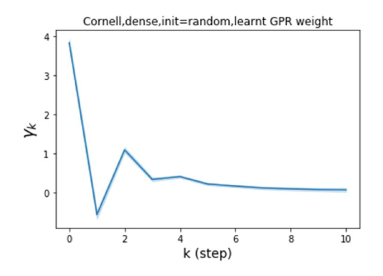
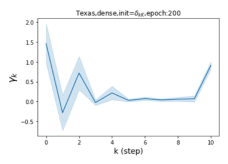
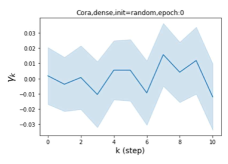
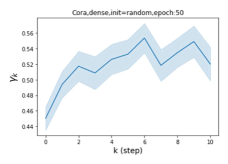
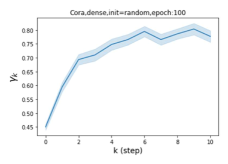
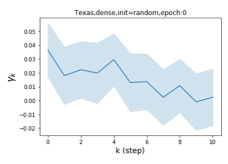
节点标签模式的普遍性:同质与异质。 Pei 等人 (2019) 在他们最近的工作中提出了一个指标来衡量图中节点的同质性水平。请注意, 对应于强同质性,而 表示强异质性。 图 1 (b) 和 (c) 绘制了我们的 GPR-GNN 方法在同性 (Cora) 和异性 (Texas) 数据集上学习到的 GPR 权重。 从 Cora 中学习到的 GPR 权重与 IPR (Li 等人, 2019) 的行为相匹配,这验证了大步传播对于同亲图确实非常重要。 从德克萨斯州学到的 GPR 权重的表现与所有已知的 PR 变体显着不同,具有许多负值。 这些权重模式的差异是在随机初始化下观察到的,表明权重实际上是由网络学习的,而不是由特定初始化强制的。 此外,这两个图模型的 GPR 权重的巨大差异说明了 GPR-GNN 的学习能力及其普遍适应性。
过度平滑问题。 大多数 GNN 模型的关键组件之一是图卷积层,描述为
其中 和 表示 层的可训练权重矩阵。 限制多层堆叠的关键问题是过度平滑现象:如果要删除上面表达式中的 ReLU,则 其中 的每一行> 仅取决于相应节点的度,前提是该图是不可约且非周期的。 这表明随着层数的增加,模型会丢失节点特征提供的判别信息。
使用 GPR-GNN 模型缓解图异质性和过度平滑问题。 GPR-GNN 首先提取每个节点的隐藏状态特征,然后使用 GPR 传播它们。 GPR-GNN 过程可以在数学上描述为:
| (1) |
其中 表示具有参数集 的神经网络,可生成隐藏状态特征 。 GPR 权重 与 以端到端方式一起训练。 GPR-GNN 模型很容易解释:正如已经指出的,GPR-GNN 具有自适应控制每个传播步骤的贡献并将其调整为节点标签模式的能力。 检查学习到的 GPR 权重还有助于阐明图的拓扑信息的属性(即确定最佳多项式图滤波器),如图 1 (b) 和 (c) 所示。
将 GPR-GNN 置于相关先前工作的背景下。 在与重复堆叠 GCN 层不同的方法中,APPNP (Klicpera 等人, 2018) 代表了与我们的 GPR-GNN 方法相关的最先进的 GNN 之一。 很容易看出,APPNP 和 SGC (Wu 等人,2019) 是我们模型的特例,因为 APPNP 修复了 、,而SGC 分别用 消除所有非线性。 这两个权重选择对应于个性化 PageRank (PPR)(Jeh & Widom, 2003),众所周知,当应用于同亲节点分类时,与 IPR 框架相比,其不是最优的(Li 等人,2019)。 固定 GPR 权重使得模型无法自适应地学习最优传播规则,这一点至关重要:正如我们将在第 4 节中展示的,固定的 PPR 权重对应于低通图滤波器,这使得它们不足以学习异嗜图。 最近的工作(Klicpera等人,2018)表明固定PPR权重(APPNP)也可以证明解决过度平滑问题。 然而,APPNP防止过度平滑的方式与节点标签信息无关。 相比之下,GPR-GNN 避免过度平滑是由节点标签信息引导的(定理 4.2)。 对这一现象的详细讨论以及说明性例子委托给了补充材料。
在类 GCN 模型中,JK-Net (Xu 等人, 2018) 与 GPR-GNN 表现出一些相似之处。 它还聚合不同 GCN 层的输出以得出最终输出。 另一方面,GCN-Cheby 方法(Defferrard 等人, 2016; Kipf & Welling, 2017) 与多项式图过滤相关,其中每个卷积层传播多个步骤,图过滤器相关为切比雪夫多项式。 在这两种情况下,模型的深度在实践中都受到限制(Klicpera等人,2018)并且它们不容易解释为我们的GPR-GNN方法。 一些先前的工作还强调自适应学习不同步骤的重要性(Abu-El-Haija 等人,2018;Berberidis 等人,2018)。 然而,上述工作均不适用于 GNN 的半监督学习并考虑异嗜图。
4 GPR-GNN 的理论特性
GPR-GNN 的图过滤方面。 正如3节中提到的,网络的GPR组件可以被视为多项式图滤波器。 令为的特征值分解。 然后,相应的多项式图过滤器等于,其中按元素应用,。 我们得出以下结果。
Theorem 4.1 (非正式).
假设图是连通的。 如果、和使得,则是低通图滤波器。 此外,如果 和 足够大,则 是高通图滤波器。
根据定理4.1以及我们在3节中的讨论,我们知道APPNP和SGC都会不可避免地抑制高频分量。 因此,它们不足以用于异嗜图。 相反,如果允许 为负并自适应学习,图滤波器将通过相关的高频。 这就是 GPR-GNN 在异性图上表现异常出色的原因(见图 1)。
GPR-GNN 可以避免过度平滑。 正如已经强调的,GPR-GNN 方法的一项关键创新是使 GPR 权重自适应可学习,这使得 GPR-GNN 能够避免过度平滑并交换节点和拓扑特征信息。 直观上,当大步传播没有好处时,它会增加训练损失。 因此,相应的探地雷达权重应该在幅度上衰减。 这一观察结果由以下结果体现,由于篇幅限制,其更正式的陈述和证明委托给补充材料。
Theorem 4.2 (非正式).
假设图 已连接,并且训练集包含每个类的节点。 还假设 足够大,以便 发生过度平滑效应,这主导了对最终输出 的贡献。 那么,对于所有, 和 的梯度符号相同。
定理4.2表明,只要发生过度平滑,当我们使用这样的优化器时,对于所有,都会接近作为随机梯度下降(SGD),它具有合适的学习率衰减。 这减少了相应步骤在最终输出中的贡献。 当权重足够小,使得不再主导最终输出的值时,过度平滑效应就会被消除。
5 新 cSBM 合成数据集和真实数据集的结果
综合数据。 为了测试 GNN 在具有任意同质和异质水平的图上的标签学习能力,我们建议使用 cSBM (Deshpande 等人,2018) 来生成合成图。 我们考虑两个大小相等的类的情况。 在 cSBM 中,节点特征是高斯随机向量,其中高斯的均值取决于社区分配。 均值的差异由参数控制,而社区内和社区之间的边缘密度的差异由参数控制。 因此 和 分别捕获节点特征和图拓扑的“相对信息性”。 此外,正对应同性图,负对应异性图。 Deshpande 等人 (2018) 描述了 cSBM 重建的信息论限制。 结果表明,渐进地需要来保证误分类节点与节点总数的消失率,其中和与之前一样表示节点特征向量的维度。
请注意,给定公差值,是椭圆体的弧,其中和。 为了公平、持续地控制节点特征和图拓扑所承载的信息范围,我们引入了参数。 设置表示仅节点特征提供信息,而表示仅图拓扑提供信息。 此外,对应于强同性图,而对应于强异性图。 请注意,值 和 传达有关图拓扑的相同数量的信息。 这是由于。 理想情况下,能够在同性图和异性图上进行最佳学习的 GNN 对于 和 应该具有相似的性能。 由于篇幅限制,我们建议感兴趣的读者参考(Deshpande等人,2018)来回顾所有正式的理论结果,并仅概述我们分析所需的cSBM属性。 补充材料中还提供了更多信息。
我们的实验设置检查了传导设置中的半监督节点分类任务。 我们考虑两种不同的选择,将随机分割为训练/验证/测试样本,分别称为稀疏分割()和密集分割()。 稀疏 splittnig 更类似于 Kipf & Welling (2017) 中考虑的原始半监督设置,而密集设置则在 Pei 等人 (2019) 中考虑进行研究异嗜图。 我们使用多个随机分割和不同的初始化来运行每个实验 次。
用于比较的方法。 我们将 GPR-GNN 与 基线模型进行比较:MLP、GCN (Kipf & Welling, 2017)、GAT (Velickovic 等人, 2018)、 JK-Net (Xu 等人, 2018)、GCN-Cheby (Defferrard 等人, 2016)、APPNP (Klicpera 等人, 2018)、SGC (Wu 等人, 2019)、SAGE (Hamilton 等人, 2017) 和 Geom-GCN (Pei 等人, 2019)。 对于所有架构,我们使用相应的 Pytorch Geometric 库实现(Fey & Lenssen,2019)。 对于Geom-GCN,我们直接使用作者提供的代码222https://github.com/graphdml-uiuc-jlu/geom-gcn。 由于预处理子例程未公开,我们无法在 cSBM 和其他最初在论文中测试的数据集上测试 Geom-GCN (Pei 等人,2019)。
GPR-GNN 模型设置和超参数调整。 我们选择带有 的随机游走路径长度,并使用带有 隐藏单元的 层(MLP)作为神经网络组件。 对于 GPR 权重,我们使用不同的初始化,包括带有 、 或 的 PPR 以及 pytorch 中的默认随机初始化。 类似地,对于 APPNP,我们在 内搜索最佳 。 对于其他超参数调整,我们优化了所有模型的学习率 和权重衰减 。 对于 Geom-GCN,我们对每个数据集使用原始论文中的最佳变体。 最后,我们使用 GPR-GNN(rand) 来描述 GPR 权重随机初始化所获得的结果。 补充材料中讨论了进一步的实验设置。
结果。 我们使用 cSBM 生成的数据和 检查所有基线方法和 GPR-GNN 的稳健性,其中包括跨异质/同质频谱的图表。 结果总结在图2中。 对于稀疏和密集设置,每当 (异嗜图)时,GPR-GNN 都显着优于所有其他基线模型。 另一方面,当图信息较弱时(),所有基线 GNN 都可能比简单的 MLP 更差。 这表明现有的 GNN 无法应用于任意图,而 GPR-GNN 显然更加鲁棒。 APPNP 方法在强异嗜图上的性能最差。 这与定理 4.1 的结果一致,该定理断言 APPNP 本质上充当低通滤波器,因此不适用于强异性设置。 JKNet、GCN-Cheby 和 SAGE 是仅有的三个能够在密集分裂下学习强异亲图的基线模型。 这也是意料之中的,因为 JKNet 是唯一一个结合了最后一层不同步骤结果的基线模型,这与 GPR-GNN 中的做法类似。 GCN-Cheby 在每一层中使用多个步骤,这使得它能够部分适应异嗜性设置,因为每一层都与比 GCN 更高阶的多项式图滤波器相关。 SAGE 以不同的方式对待自我嵌入和来自相邻节点的嵌入,而不是简单地对它们进行平均。 这使得 SAGE 能够适应异性情况,因为自我嵌入可以防止节点被邻居的信息淹没。 尽管如此,JKNet、GCN-Cheby 和 SAGE 的实践并不深入。
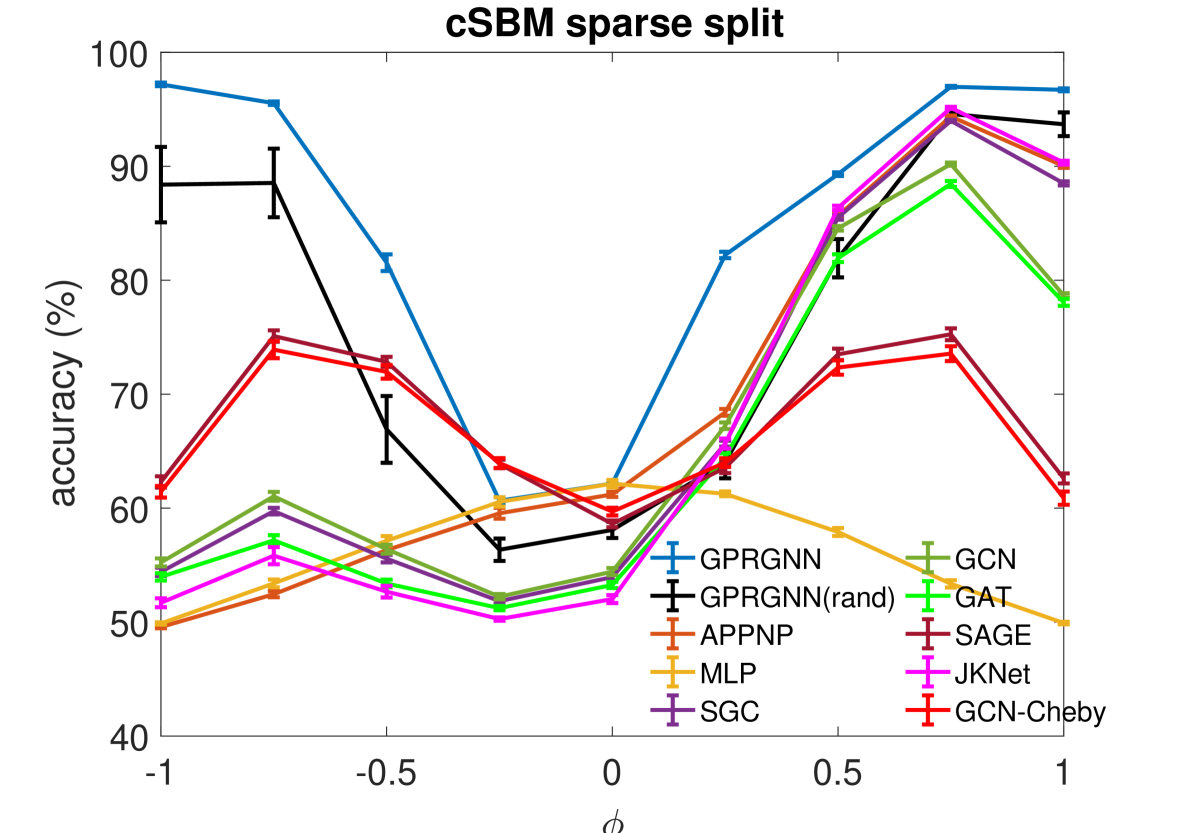
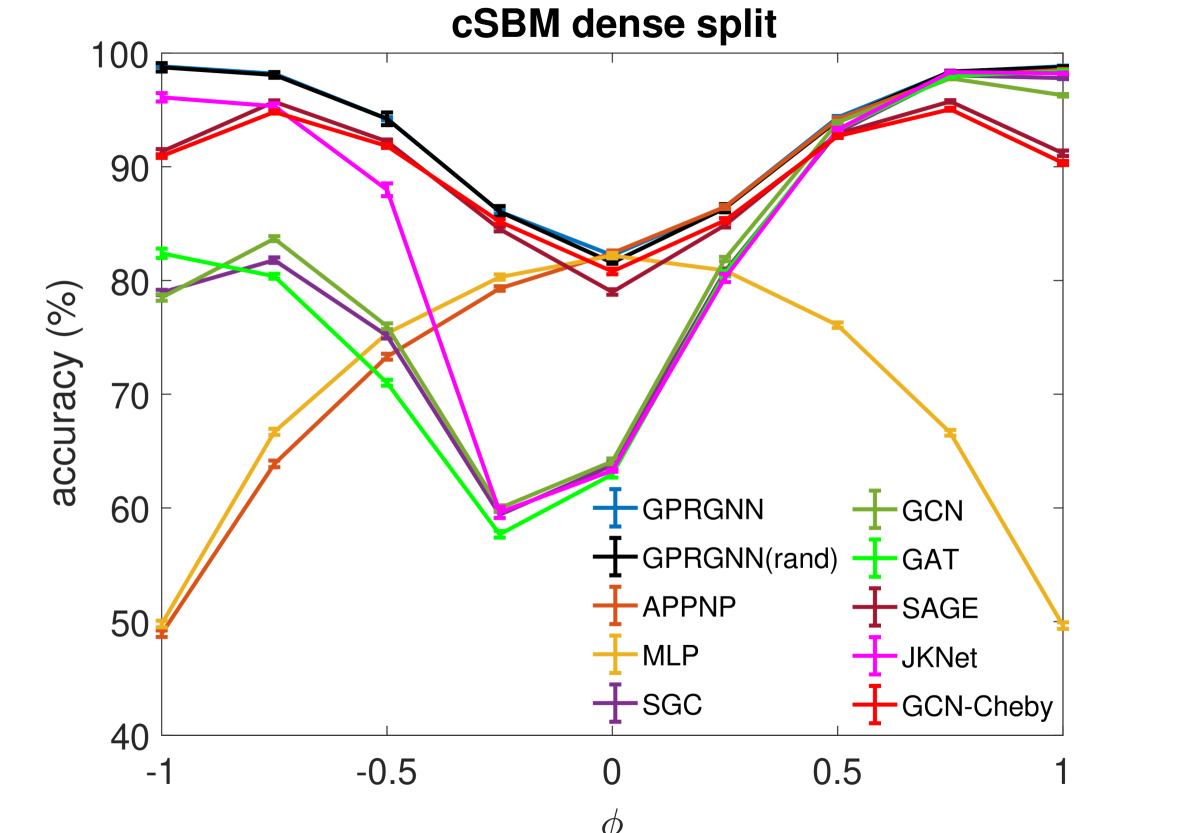
此外,JKNet 在稀疏分裂模型下无法学习,而 GCN-Cheby 和 SAGE 在图信息较强时()也无法在稀疏分裂模型下很好地学习。
此外,我们观察到 GPR 权重的随机初始化只会导致密集分裂下轻微的性能下降。 对于稀疏分割设置,下降更为明显,但对于强异嗜图,我们的方法仍然大大优于基线模型。 这也是意料之中的,因为我们在稀疏分割设置中拥有较少的标签信息,而良好的 GPR 初始化提供的隐式偏差是有帮助的。 由于标签信息足够丰富,隐式偏差与密集分割设置无关。
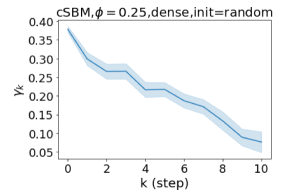
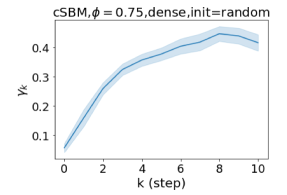
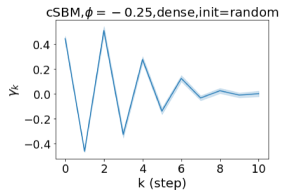
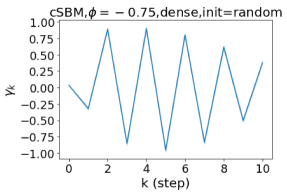
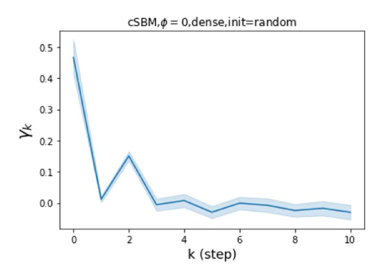
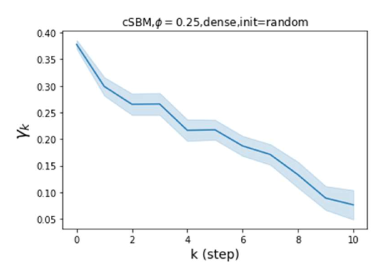
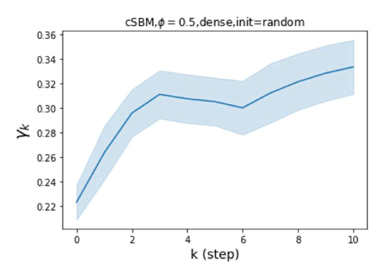
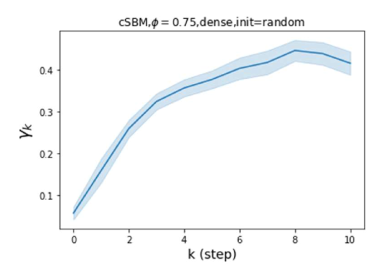
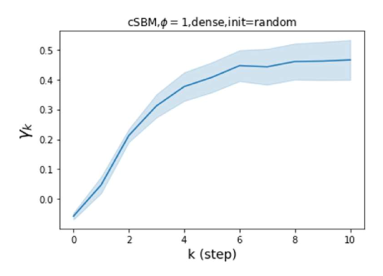
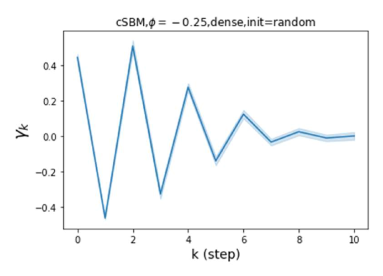
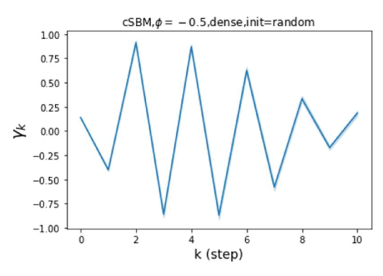
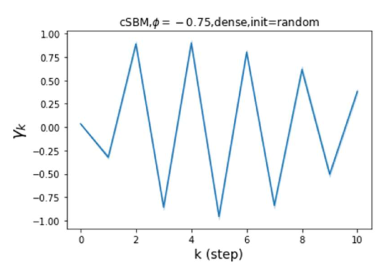
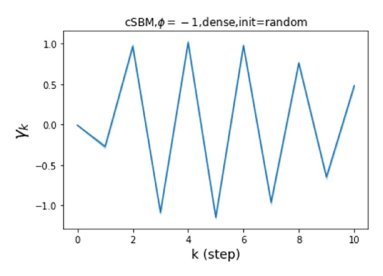
GPR-GNN 除了强大的性能之外,另一个好处是它的可解释性。 在图 3 中,我们展示了通过随机初始化的 cSBM 上的 GPR-GNN 学习到的 GPR 权重。 当图是弱同性()时,学习到的 GPR 权重正在减少。 这与 APPNP 中使用的 PPR 权重类似,尽管衰减速度不同。 当图具有强同性()时,学习到的 GPR 权重会增加,这与 PPR 权重显着不同。 这一结果与 Li 等人 (2019) 中的最新发现相匹配,并且与作者提出的知识产权相似。 另一方面,当图是异性的时,学习到的 GPR 权重具有锯齿形状。 这再次验证了定理 4.1,因为具有交替符号的 GPR 权重对应于高通滤波器。 有趣的是,当 时,学习到的 GPR 权重的大小正在减小。 这是因为在这种情况下图信息较弱而节点特征信息更重要。 学习到的 GPR 权重集中在前几步是有道理的。 因此,我们验证了 GPR-GNN 的可解释性。 在实践中,人们可以使用学习到的 GPR 权重来更好地理解手头的图结构化数据。 我们在现实世界基准数据集的结果中展示了这一优势。
()
()
()
()
真实世界基准数据集。 我们使用 Pytorch Geometric 库中提供的同质基准数据集,包括引用图 Cora、CiteSeer、PubMed (Sen 等人,2008;Yang 等人,2016) 和亚马逊共同购买图表计算机和照片(McAuley 等人,2015;Shchur 等人,2018)。 我们还使用 Pei 等人 (2019) 中测试的 异性基准数据集,包括维基百科图 Chameleon 和 Squirrel (Rozemberczki 等人, 2021),演员共现图,以及来自 WebKB333http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb。 我们在表1中总结了数据集统计数据。
| Dataset | Cora | Citeseer | PubMed | Computers | Photo | Chameleon | Squirrel | Actor | Texas | Cornell |
|---|---|---|---|---|---|---|---|---|---|---|
| Classes | 7 | 6 | 5 | 10 | 8 | 5 | 5 | 5 | 5 | 5 |
| Features | 1433 | 3703 | 500 | 767 | 745 | 2325 | 2089 | 932 | 1703 | 1703 |
| Nodes | 2708 | 3327 | 19717 | 13752 | 7650 | 2277 | 5201 | 7600 | 183 | 183 |
| Edges | 5278 | 4552 | 44324 | 245861 | 119081 | 31371 | 198353 | 26659 | 279 | 277 |
| 0.825 | 0.718 | 0.792 | 0.802 | 0.849 | 0.247 | 0.217 | 0.215 | 0.057 | 0.301 |
真实世界数据集的结果。
| Cora | Citeseer | PubMed | Computers | Photo | Chameleon | Actor | Squirrel | Texas | Cornell | |
|---|---|---|---|---|---|---|---|---|---|---|
| GPRGNN | 79.510.36 | 67.630.38 | 85.070.09 | 82.900.37 | 91.930.26 | 67.480.40 | 39.300.27 | 49.930.53 | 92.920.61 | 91.360.70 |
| APPNP | 79.410.38 | 68.590.30 | 85.020.09 | 81.990.26 | 91.110.26 | 51.910.56 | 38.860.24 | 34.770.34 | 91.180.70 | 91.800.63 |
| MLP | 50.340.48 | 52.880.51 | 80.570.12 | 70.480.28 | 78.690.30 | 46.720.46 | 38.580.25 | 31.280.27 | 92.260.71 | 91.360.70 |
| SGC | 70.810.67 | 58.980.47 | 82.090.11 | 76.270.36 | 83.800.46 | 63.020.43 | 29.390.20 | 43.140.28 | 55.181.17 | 47.801.50 |
| GCN | 75.210.38 | 67.300.35 | 84.270.01 | 82.520.32 | 90.540.21 | 60.960.78 | 30.590.23 | 45.660.39 | 75.160.96 | 66.721.37 |
| GAT | 76.700.42 | 67.200.46 | 83.280.12 | 81.950.38 | 90.090.27 | 63.90.46 | 35.980.23 | 42.720.33 | 78.870.86 | 76.001.01 |
| SAGE | 70.890.54 | 61.520.44 | 81.300.10 | 83.110.23 | 90.510.25 | 62.150.42 | 36.370.21 | 41.260.26 | 79.031.20 | 71.411.24 |
| JKNet | 73.220.64 | 60.850.76 | 82.910.11 | 77.800.97 | 87.700.70 | 62.920.49 | 33.410.25 | 44.720.48 | 75.531.16 | 66.731.73 |
| GCN-Cheby | 71.390.51 | 65.670.38 | 83.830.12 | 82.410.28 | 90.090.28 | 59.960.51 | 38.020.23 | 40.670.31 | 86.080.96 | 85.331.04 |
| GeomGCN | 20.371.13 | 20.300.90 | 58.201.23 | NA | NA | 61.060.49 | 31.810.24 | 38.280.27 | 58.561.77 | 55.591.59 |
我们使用准确性(micro-F1 分数)以及 置信区间作为评估指标。 相关结果总结于表2中。 对于同质数据集,我们提供了稀疏分割的结果,这与 Kipf & Welling (2017) 中使用的原始设置更加一致; Shchur 等人 (2018). 对于异性数据集,我们采用Pei等人(2019)中使用的密集分裂。
表2显示,总的来说,GPR-GNN 优于所有测试方法。 在同质数据集上,GPR-GNN 实现了最先进的性能。 在异质数据集上,GPR-GNN 显着优于所有其他基线模型。 需要指出的是,在异嗜性数据集中观察到两种不同的模式。 在 Chameleon 和 Squirrel 上,MLP 和 APPNP 的表现比其他基线方法(例如 GCN 和 JKNet)更差。 相比之下,MLP 和 APPNP 在 Actor、Texas 和 Cornell 上的表现优于其他基线方法。 我们推测这是由于图拓扑信息分别强和弱造成的。 请注意,这两种模式分别与 接近 和 的 cSBM 实验结果相匹配(图 2) 。 此外,Pei等人(2019)提出的同质性度量无法表征异质数据集中的这种差异。 我们将对该主题的更详细讨论以及说明性示例放在补充中。为了公平起见,我们还使用密集分割在同质数据集上重复了涉及 GeomGCN 的实验 - 观察到的性能模式往往是相似的,这可以在补充中找到。
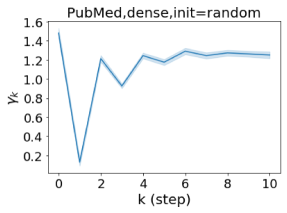
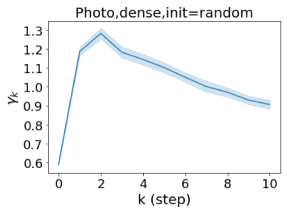
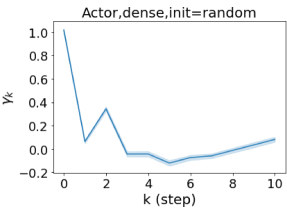
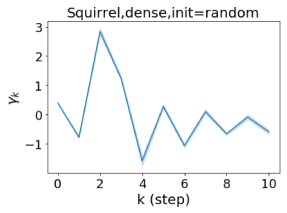
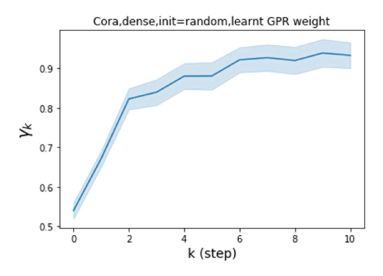
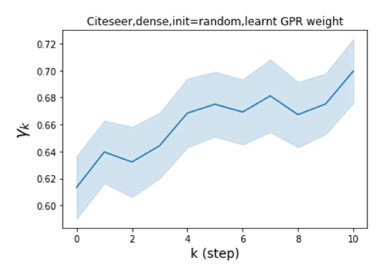
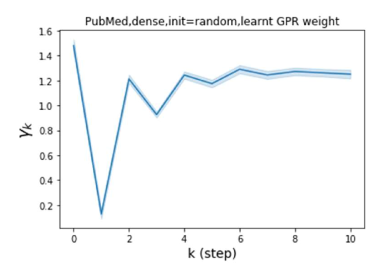
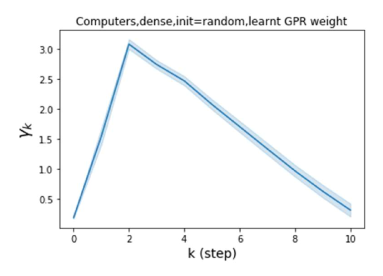
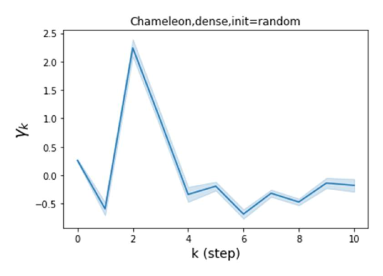
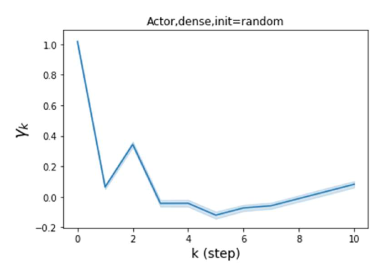
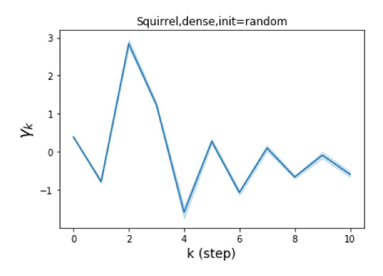
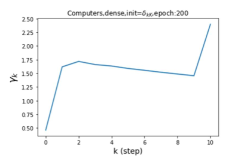
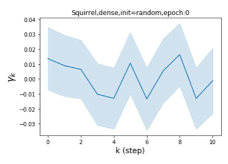
我们还在图 4 中检查了真实数据集上学习到的 GPR 权重。 由于篇幅限制,对其他数据集进行更全面的 GPR 权重分析将推迟到补编中。 我们可以看到,学习到的 GPR 权重对于同质数据集(PubMed 和 Photo)都是正值。 相反,从异性数据集(Actor 和 Squirrel)学习到的一些 GPR 权重是负的。 这些结果与 cSBM 上观察到的模式一致。 有趣的是,学习到的权重 对于 Actor 数据集具有最大的量级。 这表明大部分信息都包含在节点特征中。 从表2中我们还可以看到MLP确实优于大多数基线GNN(这与cSBM的情况类似)。 另一方面,从 Squirrel 学到的 GPR 权重具有锯齿形图案。 这意味着与 Actor 相比,Squirrel 的图拓扑信息更丰富。 从表2中我们还看到基线 GNN 在 Squirrel 上也优于 MLP。
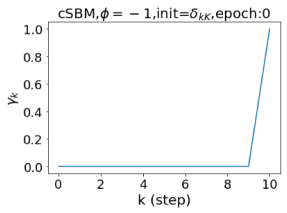
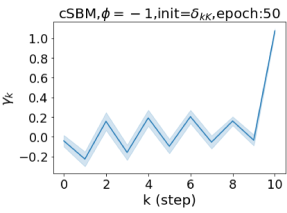
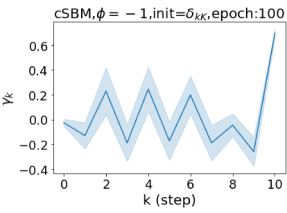
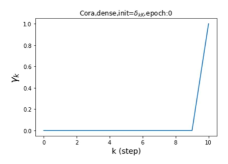
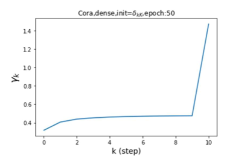
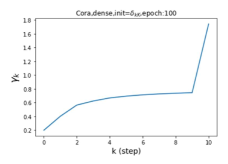
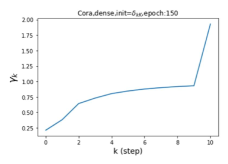
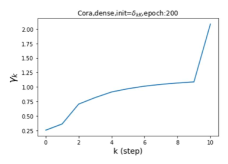
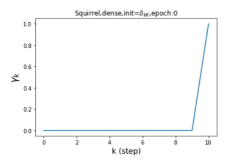
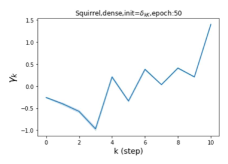
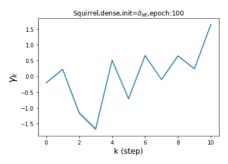
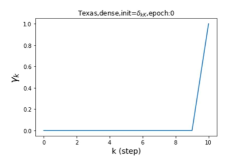
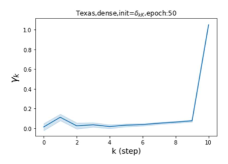
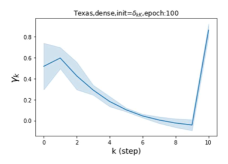
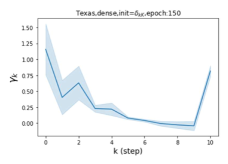
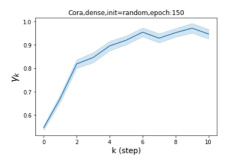
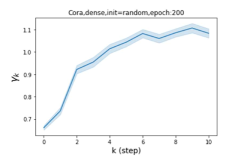
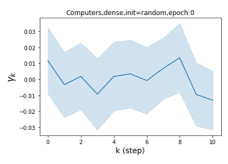
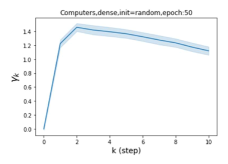
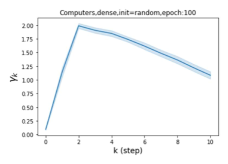
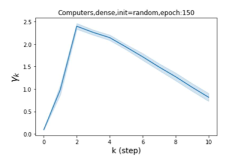
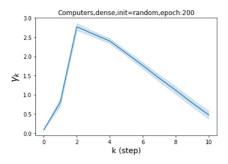
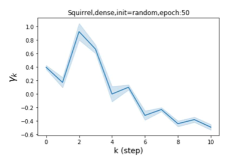
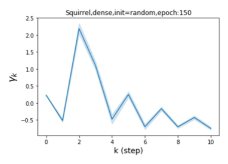
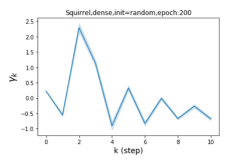
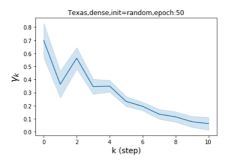
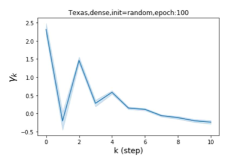
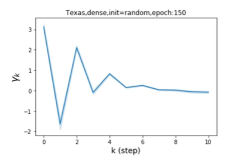
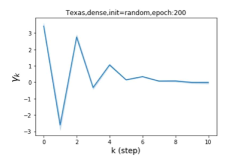
摆脱学习 GPR 权重的过度平滑和动态。 为了证明 GPR-GNN 避免过度平滑的能力,我们选择初始 GPR 权重为 。 这确保了在学习过程的一开始就很可能出现过度平滑效果。 在具有密集分割的 cSBM 上,我们发现对于 次运行中的 次运行,GPR-GNN 在 epoch ,这意味着过度平滑确实立即发生。 最终预测的准确度是,远高于在时期的初始准确度。 对于其他数据集也可以观察到类似的结果,这验证了我们的理论发现。 我们在图4(e)-(h)中绘制了学习到的 GPR 权重的动态,这表明最后一步的峰值确实减少了,而其他步骤的 GPR 权重在幅度上显着增加。 有关学习 GPR 权重的动态的更多结果可以在补充中找到。
| Cora | Pubmed | Computers | Chameleon | Actor | Squirrel | Texas | |
|---|---|---|---|---|---|---|---|
| GPRGNN | 17.62ms / 3.74s | 20.19ms / 5.53s | 39.93ms / 11.40s | 16.74ms / 3.40s | 19.31ms / 4.49s | 25.28ms / 5.12s | 17.56ms / 3.55s |
| APPNP | 17.16ms / 4.00s | 18.47ms / 6.29s | 39.59ms / 20.00s | 17.01ms / 3.44s | 16.32ms / 4.04s | 22.93ms / 4.63s | 15.96ms / 3.24s |
| MLP | 4.14ms / 0.92s | 5.43ms / 2.86s | 5.33ms / 2.77s | 3.41ms / 0.69s | 4.84ms / 0.98s | 5.19ms / 1.05s | 3.81ms / 1.04s |
| SGC | 3.31ms / 3.31s | 3.81ms / 3.81s | 4.36ms / 4.36s | 3.13ms / 3.13s | 3.98ms / 1.00s | 4.79ms / 4.79s | 2.86ms / 2.09s |
| GCN | 9.25ms / 1.97s | 14.11ms / 4.17s | 32.45ms / 16.29s | 13.83ms / 2.79s | 12.39ms / 2.50s | 27.11ms / 5.56s | 10.22ms / 2.06s |
| GAT | 14.78ms / 3.42s | 21.52ms / 6.70s | 61.45ms / 24.28s | 16.63ms / 3.63s | 18.91ms / 3.86s | 47.46ms / 10.05s | 15.50ms / 3.13s |
| SAGE | 12.06ms / 2.44s | 28.82ms / 6.32s | 171.36ms / 71.94s | 64.43ms / 13.02s | 27.95ms / 5.65s | 343.47ms / 69.38s | 6.08ms / 1.28s |
| JKNet | 18.97ms / 4.41s | 24.48ms / 6.61s | 35.02ms / 14.96s | 20.03ms / 5.15s | 23.52ms / 4.75s | 29.89ms / 6.67s | 19.67ms / 4.01s |
| GCN-cheby | 22.96ms / 4.75s | 45.76ms / 12.02s | 218.82ms / 96.58s | 89.41ms / 18.06s | 43.94ms / 8.88s | 440.55ms / 88.99s | 12.34ms / 3.08s |
6 结论
我们解决了现有 GNN 的两个基本弱点:无法泛化到异嗜图并利用大量传播步骤,从而无法充当通用学习者。 我们开发了一种新颖的 GPR-GNN 架构,它将自适应广义 PageRank (GPR) 方案与 GNN 相结合。 我们从理论上证明,我们的方法不仅可以减轻特征过度平滑,而且还适用于高度多样化的节点标签模式。 我们还在同性和异性节点标签模式上测试了 GPR-GNN,并提出了一种由上下文随机块模型生成的新颖的综合基准数据集。 我们对现实世界基准数据集的实验表明,GPR-GNN 相对于最先进的方法有明显的性能提升。 此外,我们表明 GPR-GNN 具有独立兴趣的理想可解释性。
致谢
这项工作得到了 NSF 信息科学新兴前沿拨款 0939370 和 NSF CIF 1618366 拨款的部分支持。 作者感谢 Mohamad Bairakdar 对本文早期版本的有益评论。
参考
- Abbe (2017) Emmanuel Abbe. Community detection and stochastic block models: recent developments. The Journal of Machine Learning Research, 18(1):6446–6531, 2017.
- Abu-El-Haija et al. (2018) Sami Abu-El-Haija, Bryan Perozzi, Rami Al-Rfou, and Alexander A Alemi. Watch your step: Learning node embeddings via graph attention. In Advances in Neural Information Processing Systems, pp. 9180–9190, 2018.
- Abu-El-Haija et al. (2019) Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In International Conference on Machine Learning, pp. 21–29, 2019.
- Battaglia et al. (2018) Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- Berberidis et al. (2018) Dimitris Berberidis, Athanasios Nikolakopoulos, and Georgios B Giannakis. Adaptive diffusions for scalable learning over graphs. In Mining and Learning with Graphs Workshop @ ACM KDD 2018, pp. 1, 8 2018.
- Bojchevski et al. (2019) Aleksandar Bojchevski, Johannes Klicpera, Bryan Perozzi, Martin Blais, Amol Kapoor, Michal Lukasik, and Stephan Günnemann. Is pagerank all you need for scalable graph neural networks? In ACM KDD, MLG Workshop, 2019.
- Bojchevski et al. (2020) Aleksandar Bojchevski, Johannes Klicpera, Bryan Perozzi, Amol Kapoor, Martin Blais, Benedek Rózemberczki, Michal Lukasik, and Stephan Günnemann. Scaling graph neural networks with approximate pagerank. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2464–2473, 2020.
- Bruna et al. (2014) Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann Lecun. Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations (ICLR2014), CBLS, April 2014, pp. http–openreview, 2014.
- Chung (2007) Fan Chung. The heat kernel as the pagerank of a graph. Proceedings of the National Academy of Sciences, 104(50):19735–19740, 2007.
- Dau & Milenkovic (2017) Hoang Dau and Olgica Milenkovic. Latent network features and overlapping community discovery via boolean intersection representations. IEEE/ACM Transactions on Networking, 25(5):3219–3234, 2017.
- Defferrard et al. (2016) Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, pp. 3844–3852, 2016.
- Deshpande et al. (2018) Yash Deshpande, Subhabrata Sen, Andrea Montanari, and Elchanan Mossel. Contextual stochastic block models. In Advances in Neural Information Processing Systems, pp. 8581–8593, 2018.
- Fey & Lenssen (2019) Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1263–1272. JMLR. org, 2017.
- Gleich (2015) David F Gleich. Pagerank beyond the web. Siam Review, 57(3):321–363, 2015.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pp. 1024–1034, 2017.
- Jeh & Widom (2003) Glen Jeh and Jennifer Widom. Scaling personalized web search. In Proceedings of the 12th international conference on World Wide Web, pp. 271–279, 2003.
- Jia & Benson (2020) Junteng Jia and Austin Benson. Outcome correlation in graph neural network regression. arXiv preprint arXiv:2002.08274, 2020.
- Kingma & Ba (2014) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kipf & Welling (2017) Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
- Klicpera et al. (2018) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In International Conference on Learning Representations, 2018.
- Klicpera et al. (2019) Johannes Klicpera, Stefan Weißenberger, and Stephan Günnemann. Diffusion improves graph learning. In Advances in Neural Information Processing Systems, pp. 13333–13345, 2019.
- Kloumann et al. (2017) Isabel M Kloumann, Johan Ugander, and Jon Kleinberg. Block models and personalized pagerank. Proceedings of the National Academy of Sciences, 114(1):33–38, 2017.
- Li et al. (2019) Pan Li, I Chien, and Olgica Milenkovic. Optimizing generalized pagerank methods for seed-expansion community detection. In Advances in Neural Information Processing Systems, pp. 11705–11716, 2019.
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Lü & Zhou (2011) Linyuan Lü and Tao Zhou. Link prediction in complex networks: A survey. Physica A: statistical mechanics and its applications, 390(6):1150–1170, 2011.
- McAuley et al. (2015) Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 43–52, 2015.
- McPherson et al. (2001) Miller McPherson, Lynn Smith-Lovin, and James M Cook. Birds of a feather: Homophily in social networks. Annual review of sociology, 27(1):415–444, 2001.
- Oono & Suzuki (2020) Kenta Oono and Taiji Suzuki. Graph neural networks exponentially lose expressive power for node classification. In International Conference on Learning Representations, 2020.
- Pei et al. (2019) Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, 2019.
- Rozemberczki et al. (2021) Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-Scale Attributed Node Embedding. Journal of Complex Networks, 9(2), 2021.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shchur et al. (2018) Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868, 2018.
- Shervashidze et al. (2011) Nino Shervashidze, Pascal Schweitzer, Erik Jan Van Leeuwen, Kurt Mehlhorn, and Karsten M Borgwardt. Weisfeiler-lehman graph kernels. Journal of Machine Learning Research, 12(77):2539–2561, 2011.
- Shuman et al. (2013) D. I. Shuman, S. K. Narang, P. Frossard, A. Ortega, and P. Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Processing Magazine, 30(3):83–98, 2013.
- Tsourakakis (2015) Charalampos Tsourakakis. Provably fast inference of latent features from networks: With applications to learning social circles and multilabel classification. In Proceedings of the 24th International Conference on World Wide Web, pp. 1111–1121, 2015.
- Velickovic et al. (2018) Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lia, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rJXMpikCZ.
- Von Luxburg (2007) Ulrike Von Luxburg. A tutorial on spectral clustering. Statistics and computing, 17(4):395–416, 2007.
- Wijesinghe & Wang (2019) WOK Asiri Suranga Wijesinghe and Qing Wang. Dfnets: Spectral cnns for graphs with feedback-looped filters. In Advances in Neural Information Processing Systems, pp. 6007–6018, 2019.
- Wu et al. (2019) Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International Conference on Machine Learning, pp. 6861–6871, 2019.
- Xu et al. (2018) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning, pp. 5453–5462, 2018.
- Yang et al. (2016) Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. In Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48, pp. 40–48, 2016.
- Zeng et al. (2020) Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. GraphSAINT: Graph sampling based inductive learning method. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=BJe8pkHFwS.
- Zhu et al. (2020) Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Generalizing graph neural networks beyond homophily. arXiv preprint arXiv:2006.11468, 2020.
- Zhu (2005) Xiaojin Jerry Zhu. Semi-supervised learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2005.
附录A附录
A.1关于防止过度平滑的详细讨论。
正如 4 节中提到的,另一种方法 - APPNP - 也可以证明可以防止过度平滑 Klicpera 等人 (2018)。 本研究的作者利用了 PPR 传播将收敛于 的事实,其中 独立于训练数据中提供的节点标签信息。 的每一行仍然依赖于 ,因此 APPNP 不会受到过度平滑的影响。 但是,由于 独立于标签信息,因此它可能会导致我们在下面讨论的不良后果。
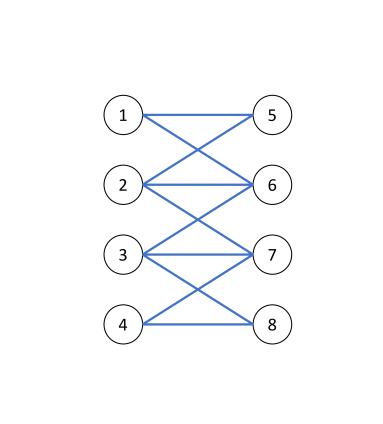
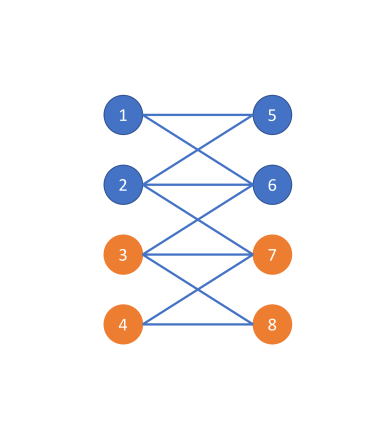
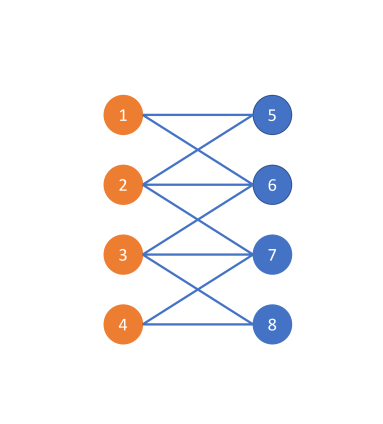
让我们考虑一个如图 5 所示的简单示例,涉及一个连通无向图 (图 5 (a))。 考虑图 5 (b) 和图 5 (c) 中所示的两种不同的节点标签分配。 显然,图5(b)和(c)中描述的图拓扑是相同的,唯一的区别是类标签分配。 在图5(b)中,图是同质的,因此最佳图滤波器应该强调图信号的低频部分。 相反,在图5(c)中,该图是异性的,因为该图相对于标签是二分的。 因此,最佳的图滤波器应该强调图信号的高频部分。 此示例说明最佳图过滤器应取决于图拓扑和节点标签信息。 回想一下,APPNP 在渐进机制中使用的等效图过滤器是 ,它独立于节点标签信息。 此外,定理 4.1 确定 APPNP 本质上利用低通滤波器。 相比之下,GPR-GNN 学习由节点标签信息引导的 GPR 权重,这使得它能够解释所示的两种情况(同性和异性)。
A.2 同质性测度不足的讨论
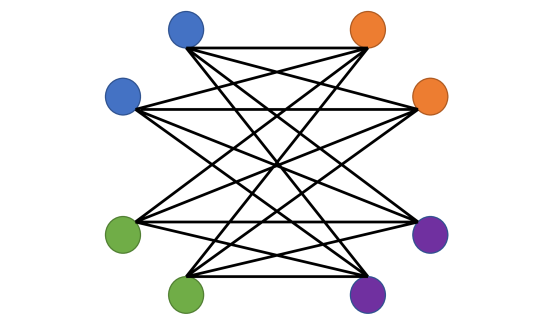
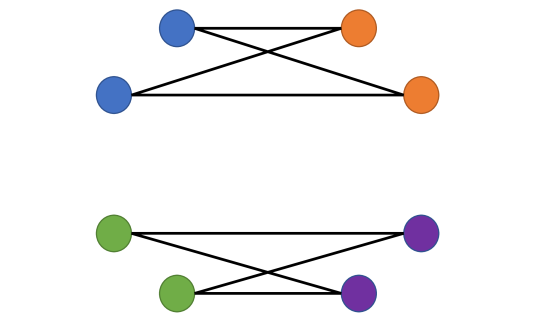
正如5节中提到的,同质性度量不足以表征异亲图拓扑是否提供信息。 考虑图 6 中描述的两个简单示例,其中节点的颜色表示它们的标签。 在情况 1 中,蓝色和绿色节点链接到所有橙色和紫色节点。 在情况 2 中,蓝色节点仅链接到橙色节点,绿色节点仅链接到紫色节点。 从的定义可以看出,这两种情况都有,因为在这两种情况下,节点都不会链接到同一标签的其他节点。 然而,很明显,与情况 1 相比,情况 2 中的图拓扑携带了更多的节点标签信息。 事实上,对于情况 1,仅从图拓扑中无法区分蓝色和绿色节点(橙色和紫色节点也是如此)。 同质性度量的一种可能替代方案是经验边缘概率矩阵 的 Chernoff-Hellinger 散度 Abbe (2017);这里 是一条边的经验概率,其中一个末端节点标记为 ,另一个末端节点标记为 。 我们的建议背后的直觉在于 Chernoff-Hellinger 散度表征了 SBM 的基本极限。 然而,由于许多实际的图生成过程可能与 SBM 显着不同,因此研究替代同质/异质度量是另一个有趣的开放问题。
A.3 定理证明4.1
我们首先陈述定理4.1的正式版本。
Theorem A.1 (定理 4.1 的正式版本)。
假设图 已连接。 令 为 的特征值。 如果、和使得,则。 另外,如果 和 ,则 。
请注意, 意味着在应用图形过滤器 后,最低频率分量(对应于)进一步占主导地位。 回想一下,在未过滤的情况下,我们不与 相乘。 它也可以被视为乘以单位矩阵,其中特征值比为。 因此,在这种情况下 的作用就像一个低通滤波器。 相反, 意味着应用图形过滤器后,最低频率分量(对应于 )不再占主导地位。 这对应于高通滤波器的情况。
证明。
我们从低通滤波器结果开始。 从基本频谱分析(Von Luxburg,2007)我们知道和。 人们还可以在补充中的引理A.2的证明中找到分析。 然后通过假设我们知道
因此,证明定理A.1相当于证明
这是显而易见的,因为 是具有非负系数的 阶多项式。 很容易检查。 结合所有 都是非负的事实,我们有
最后,请注意,自 以来,(a) 中的等式成立的唯一可能性是 。 然而,通过假设和使得我们知道这是不可能的。 因此(a)是一个严格的不等式。 我们一起完成低通滤波部分的证明。
对于高通滤波器的结果,不难看出
其中最后一步是由于 和 的事实。 因此我们有
严格的不等式(b)来自于这一事实。 值得注意的是,发生在边界处,它对应于二部图。 它进一步表明,关于选择 的图形滤波器强调高频分量,因此它确实充当高通滤波器。 ∎
A.4 定理证明4.2
在我们继续定理 4.2 的正式陈述之前,我们首先介绍一些附加的符号、引理和定义。 标签矩阵用表示,其中每一行都是一个one-hot向量。 我们使用 来表示向量 的 argmax:当且仅当 时我们才有 (关系均匀断开) ,否则 。 让我们用softmax替换softmax,其中我们让 代表具有平滑参数 的 softmax。 请注意,对于 ,我们恢复标准 softmax。 稍微滥用了符号,对于向量 ,我们编写 来表示按元素取幂。 我们使用 来表示标准欧几里得内积。 我们还使用 来表示交叉熵损失,其中
Lemma A.2.
假设无向连通图中的节点 具有 标签之一。 然后,对于足够大的 ,我们有
| (2) |
对于任何和足够大的,如果标签预测以为主,所有节点将具有与成比例的表示。 因此,我们将为所有节点得出相同的标签。 这就是我们所说的过度平滑现象。
Definition A.3 (过度平滑现象).
首先,回想一下。 如果在 足够大的情况下,GPR-GNN 中出现过度平滑,那么在 的情况下,对于某个 就会出现 ,而在 的情况下,对于某个 就会出现 。
Lemma A.4.
让 为交叉熵损失,令 为训练集。 在与引理 A.2 中给出的相同假设下, 足够大的 的梯度为
Lemma A.5.
对于任何足够大的实向量 和 ,我们有 。
现在我们准备好陈述定理4.2的正式版本。
Theorem A.6 (定理 4.2 的正式版本)。
在与引理A.2中列出的假设相同的情况下,如果集合包含每个类的节点,那么GPR-GNN方法总是可以避免过度平滑。 更具体地说,对于足够大的 我们有
| (3) | |||
| (4) |
A.5 cSBM 详细信息
cSBM 在经典 SBM 之上添加高斯随机向量作为节点特征。 为简单起见,我们假设 大小相同的社区,在 中具有节点标签 。 每个节点 都与一个 维高斯向量 关联,其中 是节点数,和有独立的标准正常条目。 cSBM 中的(无向)图由邻接矩阵 描述,定义为
与经典的 SBM 类似,给定节点标签,边是独立的。 符号代表图的平均度。 另外,请记住 和 分别控制节点特征和图结构携带的信息强度。
使用 cSBM 生成合成数据的原因之一是模型的信息论极限已在 Deshpande 等人 (2018) 中得到表征。 该结果总结如下。
Theorem A.7 (Deshpande 等人 (2018) 中的非正式主要结果)。
假设、和。 然后存在一个估计器,使得当且仅当时远离。
在我们的实验中,我们设置了 ,因此有 。 对于某些,我们沿着弧线改变和,以确保我们处于可实现的参数范围内。 我们还为所有实验选择 。
A.6 引理证明A.2
请注意,引理 A.2 的证明简化为图上随机游走的标准分析。 为了完整起见,我们将其包含在内,并请感兴趣的读者参考教程 Von Luxburg (2007)。
我们首先证明对称图拉普拉斯
| (13) |
是半正定的。 令 为单位范数和 的任意实数向量,则我们有
| (14) | |||
| (15) | |||
| (16) |
其中最后一步来自度的定义。
接下来我们证明 确实是与单位特征向量 相关的 特征值,其中 。
令 为全一个向量。 那么直接计算可知
| (17) | |||
| (18) | |||
| (19) |
将此结果与拉普拉斯算子的正半定性质相结合表明 确实是与特征向量 相关的 的最小特征值。 而且,从(16)和图连通的假设,不难看出特征值的重数恰好为1(见命题2和命题4)参见 Von Luxburg (2007) 了解更多详情)。 最后,从(13)可以明显看出的最大特征值是,对应特征向量 。 因此 的所有其他特征值。
接下来我们证明。 这也可以直接从 (16) 显示。 注意
| (20) | |||
| (21) | |||
| (22) |
该不等式源自柯西-施瓦茨不等式的应用。 因此, 的最大特征值以 为界,这意味着 。 请注意,当且仅当底层图是二分图时,相等才成立。 然而,这在我们的设置中是不可能的,因为我们已经向每个节点添加了一个自循环。 因此。 这意味着
| (23) |
因此,对于任何 我们有
| (24) |
请注意,这也可以用 项写成
| (25) |
这样就完成了证明。
A.7 引理证明A.4
A.8 引理证明A.5
让。 然后根据 的 softmax 的定义,我们有
| (34) |
请注意, 时为 , 时为 。 不失一般性,我们假设 中有 最大值,其中 并让 表示这些最大值的索引集最大值。 然后,取限制 我们有
| (35) |
这意味着对于足够大的 有
| (36) |
以上结果完成了证明。
A.9其他实验细节
| 0.039 | 0.073 | 0.170 | 0.328 | 0.500 | 0.673 | 0.829 | 0.928 | 0.960 |
所有实验均在具有 个内核、GB RAM 以及具有 GB GPU 内存的 NVIDIA Tesla P100 GPU 的 Linux 计算机上执行。 对于训练集,我们确保每个类的节点数量大致相同,并使训练节点总数接近 。 对于验证集,我们随机抽取节点 并将其余节点放入测试集中。
对于所有基线模型,我们直接使用 Pytorch 几何库 Fey & Lenssen (2019) 中提供的实现。我们使用提前停止 和最大时期数等于 对于真实基准数据集和我们的 cSBM 合成数据集。 所有模型均使用 Adam 优化器Kingma & Ba (2014)。 请注意,早期停止标准与 Pytorch Geometric 中的完全相同 - 当历元大于最大历元的一半时,我们检查当前验证损失是否低于过去 历元的平均值。 如果不低于,我们停止训练过程。
对于 GCN,我们使用带有 隐藏单元的 GCN 层。 对于 GAT,我们使用 GAT 卷积层,其中第一层有 个注意力头,每个头有 个隐藏单元;第二层有 注意力头和 隐藏单元。 对于 GCN-Cheby,我们对具有 隐藏单元的每一层使用 步骤传播。 请注意,在这种情况下,每层的等效隐藏单元数量为。 对于 JK-Net,我们使用基于 GCN 的模型,每层都有 层和 隐藏单元。 至于层聚合部分,我们使用具有 通道和 层的 LSTM。 对于 MLP,我们选择具有 4 个隐藏单元的 层全连接网络。 对于 APPNP,我们使用相同的 层 MLP 和 传播步骤。 除了GPR-GNN之外,我们将NN部分的dropout率固定为作为APPNP,并优化中GPR部分的dropout率。 对于 Geom-GCN,我们选择论文中已经测试过的数据集,该数据集首次描述了该方法(Pei 等人,2019)。 对于SGC,我们在之间测试后使用默认的层。 对于 SAGE,我们使用 SAGE 卷积层和 隐藏单元。
(裴等人,2019)中使用的异嗜性数据集。 图 Chameleon、Actor、Squirrel、Texas 和 Cornell 的原始形式是有向图(参见 (Pei 等人, 2019) 的 github 存储库)。 由于半监督节点分类的通常设置涉及无向图,因此我们将图转换为无向图,以在所有先前描述的基准方法上对其进行测试。 我们保留针对 Geom-GCN 的输入图,因为该方法使用固定的预处理方案,不幸的是作者没有公开该方案。 表1中的同质性度量值均基于无向图,因此与(Pei等人,2019)中报告的数字不同>。
A.10附加实验结果
| GPRGNN | 97.190.16 | 95.540.15 | 81.540.73 | 60.650.31 | 62.160.23 | 68.830.28 | 89.310.16 | 96.980.08 | 96.710.13 |
| GPRGNN(random) | 88.393.31 | 88.543.01 | 66.912.93 | 56.350.98 | 58.090.71 | 64.011.39 | 81.931.68 | 94.590.29 | 93.691.04 |
| APPNP | 49.570.11 | 52.450.27 | 56.320.40 | 59.550.48 | 61.210.23 | 68.410.30 | 85.660.22 | 94.370.09 | 90.020.16 |
| MLP | 49.880.10 | 53.400.34 | 57.140.41 | 60.550.41 | 62.150.33 | 61.260.21 | 57.910.35 | 53.360.32 | 49.920.11 |
| SGC | 54.410.37 | 59.740.29 | 55.570.33 | 51.840.23 | 53.950.28 | 65.650.27 | 85.510.20 | 93.990.10 | 88.500.18 |
| GCN | 55.240.35 | 61.040.39 | 56.400.39 | 52.230.24 | 54.430.32 | 67.230.29 | 84.560.20 | 90.190.14 | 78.670.19 |
| GAT | 53.970.32 | 57.180.45 | 53.390.34 | 51.230.19 | 53.260.27 | 64.450.36 | 81.940.34 | 88.450.26 | 78.060.30 |
| SAGE | 62.300.50 | 75.100.50 | 72.840.44 | 63.880.37 | 58.620.30 | 63.550.47 | 73.500.50 | 75.260.52 | 62.610.44 |
| JKNet | 51.700.39 | 55.830.75 | 52.670.51 | 50.270.15 | 52.020.35 | 65.670.44 | 86.350.19 | 95.130.09 | 90.320.17 |
| GCN-Cheby | 61.440.51 | 73.910.75 | 71.960.6 | 63.960.43 | 59.700.34 | 64.000.38 | 72.340.63 | 73.560.65 | 60.880.58 |
| GPRGNN | 98.830.06 | 98.190.08 | 94.230.14 | 86.060.20 | 82.220.20 | 86.480.20 | 94.340.13 | 98.460.08 | 98.840.06 |
| GPRGNN(random) | 98.750.05 | 98.080.08 | 94.220.14 | 86.060.20 | 81.570.23 | 86.360.20 | 94.090.14 | 98.380.08 | 98.770.07 |
| APPNP | 48.940.29 | 63.870.29 | 73.300.26 | 79.300.20 | 82.410.23 | 86.470.18 | 94.200.14 | 97.960.10 | 98.530.08 |
| MLP | 49.790.29 | 66.690.27 | 75.360.26 | 80.300.24 | 82.190.24 | 80.880.22 | 76.070.24 | 66.610.25 | 49.650.29 |
| SGC | 78.950.23 | 81.790.24 | 75.150.25 | 59.400.28 | 63.750.26 | 80.810.22 | 93.040.15 | 98.050.08 | 97.800.09 |
| GCN | 78.500.28 | 83.680.22 | 75.980.25 | 59.980.25 | 64.090.26 | 81.890.19 | 93.910.12 | 97.780.08 | 96.290.11 |
| GAT | 82.390.41 | 80.370.22 | 71.010.26 | 57.680.29 | 62.950.28 | 80.610.24 | 93.260.14 | 97.990.08 | 98.400.09 |
| SAGE | 91.330.23 | 95.720.12 | 93.230.17 | 84.520.20 | 78.990.24 | 84.870.20 | 92.900.15 | 95.750.11 | 91.190.24 |
| JKNet | 96.110.37 | 95.330.25 | 87.980.56 | 59.610.49 | 63.280.10 | 80.230.36 | 93.280.15 | 98.330.07 | 98.220.07 |
| GCN-Cheby | 90.940.16 | 94.820.13 | 91.830.17 | 85.180.21 | 80.800.25 | 85.280.21 | 92.700.16 | 95.060.13 | 90.340.18 |
| Cora | Citeseer | PubMed | |
|---|---|---|---|
| GPRGNN | 88.650.28 | 80.010.28 | 89.180.15 |
| APPNP | 88.10.23 | 80.50.26 | 89.150.13 |
| MLP | 76.440.30 | 76.250.28 | 86.430.13 |
| SGC | 86.580.26 | 76.230.29 | 83.520.10 |
| GCN | 86.870.25 | 79.280.25 | 86.970.12 |
| GAT | 87.520.24 | 80.560.31 | 86.640.11 |
| SAGE | 86.580.26 | 78.240.30 | 86.850.11 |
| JKNet | 86.970.27 | 77.690.35 | 87.380.13 |
| GCN-Cheby | 86.460.26 | 78.660.26 | 88.20.09 |
| GeomGCN | 85.40.26 | 76.420.37 | 88.510.08 |
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
()
| Accuracy at epoch (%) | Accuracy at the final epoch(%) | Over-smoothing ratio(%) | |
|---|---|---|---|
| Cora | 12.75 | 88.25 | 84 |
| Computers | 9.41 | 85.93 | 89 |
| Squirrel | 19.87 | 52.06 | 97 |
| Texas | 21.05 | 90.05 | 100 |
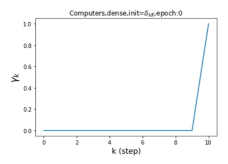
纪元
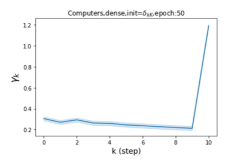
纪元
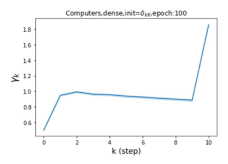
纪元
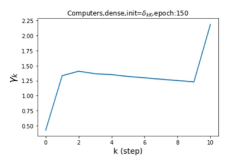
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
纪元
| Cora | Citeseer | Pubmed | Computers | Photo | |
|---|---|---|---|---|---|
| GPRGNN | 17.62ms / 3.74s | 19.28ms / 3.89s | 20.19ms / 5.53s | 39.93ms / 11.40s | 21.61ms / 6.18s |
| APPNP | 17.16ms / 4.00s | 15.97ms / 3.26s | 18.47ms / 6.29s | 39.59ms / 20.00s | 20.10ms / 10.93s |
| MLP | 4.14ms / 0.92s | 5.30ms / 1.13s | 5.43ms / 2.86s | 5.33ms / 2.77s | 4.63ms / 2.72s |
| SGC | 3.31ms / 3.31s | 11.45ms / 2.31s | 3.81ms / 3.81s | 4.36ms / 4.36s | 19.12ms / 8.75s |
| GCN | 9.25ms / 1.97s | 17.46ms / 3.53s | 14.11ms / 4.17s | 32.45ms / 16.29s | 32.56ms / 11.33s |
| GAT | 14.78ms / 3.42s | 19.94ms / 4.47s | 21.52ms / 6.70s | 61.45ms / 24.28s | 24.57ms / 11.61s |
| SAGE | 12.06ms / 2.44s | 41.40ms / 8.36s | 28.82ms / 6.32s | 171.36ms / 71.94s | 108.88ms / 42.18s |
| JKNet | 18.97ms / 4.41s | 3.99ms / 3.99s | 24.48ms / 6.61s | 35.02ms / 14.96s | 3.66ms / 3.66s |
| GCN-cheby | 22.96ms / 4.75s | 23.16ms / 4.68s | 45.76ms / 12.02s | 218.82ms / 96.58s | 82.38ms / 30.48s |
| Chameleon | Squirrel | Actor | Texas | Cornell | |
|---|---|---|---|---|---|
| GPRGNN | 16.74ms / 3.40s | 25.28ms / 5.12s | 19.31ms / 4.49s | 17.56ms / 3.55s | 18.42ms / 3.72s |
| APPNP | 17.01ms / 3.44s | 22.93ms / 4.63s | 16.32ms / 4.04s | 15.96ms / 3.24s | 14.66ms / 3.09s |
| MLP | 3.41ms / 0.69s | 5.19ms / 1.05s | 4.84ms / 0.98s | 3.81ms / 1.04s | 3.46ms / 0.89s |
| SGC | 13.83ms / 2.79s | 27.11ms / 5.56s | 12.39ms / 2.50s | 10.22ms / 2.06s | 10.38ms / 2.10s |
| GCN | 16.63ms / 3.63s | 47.46ms / 10.05s | 18.91ms / 3.86s | 15.50ms / 3.13s | 13.67ms / 2.76s |
| GAT | 20.03ms / 5.15s | 29.89ms / 6.67s | 23.52ms / 4.75s | 19.67ms / 4.01s | 19.35ms / 3.91s |
| SAGE | 89.41ms / 18.06s | 440.55ms / 88.99s | 43.94ms / 8.88s | 12.34ms / 3.08s | 12.15ms / 2.69s |
| JKNet | 3.13ms / 3.13s | 4.79ms / 4.79s | 3.98ms / 1.00s | 2.86ms / 2.09s | 2.81ms / 1.18s |
| GCN-cheby | 64.43ms / 13.02s | 343.47ms / 69.38s | 27.95ms / 5.65s | 6.08ms / 1.28s | 6.05ms / 1.44s |