联邦学习遇见多目标优化
摘要
联邦学习已成为一种有前途的大规模分布式方式,可以在大量边缘设备上训练联合深度模型,同时将私人用户数据严格保留在设备上。 在这项工作中,出于确保用户之间的公平性和针对恶意对手的稳健性的动机,我们将联邦学习制定为多目标优化,并提出了一种新算法FedMGDA+,保证收敛到帕累托平稳解。 FedMGDA+ 易于实现,需要调整的超参数较少,并且不会牺牲任何参与用户的性能。 我们建立了 FedMGDA+ 的收敛特性,并指出其与现有方法的联系。 对各种数据集的大量实验证实,FedMGDA+ 与最先进的技术相比具有优势。
关键词关键词帕累托优化、分布式算法、联邦学习、边缘计算、机器学习、神经网络。
1简介
深度学习在许多领域应用中取得了令人印象深刻的成功,这主要归功于算法和架构设计的创新,同样重要的是人们可以通过 GPU、计算机集群以及专用软件和硬件来利用巨大的计算能力。 智能手机、平板电脑、路由器、车载设备、家庭传感器等边缘设备因其无处不在和中等计算能力,为深度学习带来了新的机遇和挑战。 一方面,边缘设备可以直接访问用户可能不愿意共享(例如数据中心)的隐私敏感数据,并且它们比前代设备更强大,能够进行大量的设备上计算。 另一方面,边缘设备在容量、功耗、数据、可用性、通信、内存等方面大多是异构的,这给机器学习模型的传统内部训练带来了新的挑战。 因此,最近出现了一种新的范式,称为联邦学习 (FL) (McMahan 等人,, 2017),旨在收获边缘设备的前景。 在边缘设备上开发新的FL算法和系统从此成为机器学习领域的热门研究课题。
从诞生之初,FL就与传统的分布式优化有着密切的联系。 然而,FL 的出现源于解决移动时代新闻挑战的迫切需要,因为现有的分布式优化算法并不是为本身而设计的。 我们提到了与我们的工作最相关的FL的以下特征,并参考了优秀的调查(Li 等人,, 2019; Yang 等人,, 2019; Kairouz 等人, ,2019) 以及其中有关 FL 中更多挑战和应用的参考文献。
-
•
非独立同分布:每个用户的数据可能与其他用户的数据明显不同,这违反了统计学习中的标准独立同分布假设,并且给用精确的数学术语制定目标带来了很大的困难(Mohri 等人,,2019)。 用户数据的分布往往严重不平衡。
-
•
沟通有限: Communication between each user and a central server is constrained by network bandwidth, device status, user participation incentive, etc., demanding a thoughtful balance between computation (on each user device) and communication.
-
•
隐私:保护用户(数据)隐私在FL中至关重要。 因此无法共享用户数据(甚至无法共享给云仲裁者),这为解决前两个挑战增加了另一层难度。
-
•
公平性:正如最近的工作中所强调的那样(例如,Mohri等人,2019;Li等人,2020b),确保用户之间的公平性成为 FL 的另一个重要目标,因为它在很大程度上决定了用户参与的意愿,并确保了一定程度的针对恶意用户操纵的鲁棒性。
-
•
鲁棒性: FL算法最终会在野外部署,因此容易受到恶意攻击。 事实上,最近构建了对抗性攻击(例如、Bagdasaryan 等人,2020;Sun 等人,2019;Bhagoji 等人,2019)来揭示 的漏洞FL系统可防止用户侧的恶意操纵。
在这项工作中,受上述最后两个挑战(即公平性和鲁棒性)的启发,我们提出了一种新算法FedMGDA+,以补充和改进现有的FL系统。 FedMGDA+ 基于多目标优化,并保证收敛到 Pareto 平稳解。 FedMGDA+ 易于实现,需要调整的超参数较少,最重要的是不会牺牲任何参与用户的性能。 我们在包括准确性、公平性和稳健性在内的各种指标下展示了 FedMGDA+ 的卓越性能。
我们的贡献总结如下:
为了促进可重复性,我们已在以下位置发布了代码:https://github.com/watml/Fed-MGDA。
2相关工作
在本节中,我们将简要回顾一些与我们直接相关的近期工作,并将我们的贡献放在背景中。 首先,McMahan 等人 (2017) 提出了第一个 FL 算法,称为“联合平均”(又名,FedAvg),该算法是一种分几轮进行的同步更新方案。 在每一轮中,中央服务器将当前的全局模型发送给用户子集,然后每个用户使用其各自的本地数据来更新接收到的模型。 服务器收到用户更新后的本地模型后,进行聚合(例如简单平均)以更新全局模型。 有关不同平均方案的更多讨论,请参阅 Li 等人, (2020)。 Li 等人,2020a 扩展了 FedAvg 以更好地处理非独立同分布的问题。 通过向局部损失函数添加“近端正则化器”并最小化每个用户的莫罗包络函数来分布数据。 正如第 §3 中所指出的,所得算法 FedProx 是 Yu (2013) 中近端平均算法的随机版本,并减少当正则化减弱时,变为 FedAvg。
由于其灵活的更新方案、部分用户参与以及客户数据的非独立同分布Li等人,2020a,分析FedAvg一直是一项具有挑战性的任务。 针对独立同分布和非独立同分布数据的强凸和平滑问题的 FedAvg 的首次理论分析出现在 Stich, (2019) 和 Li 等人, (2020 ),分别研究了不同采样和平均方案对FedAvg收敛速度的影响,得出这样的结论:当数据集不平衡和非独立同分布。 在Huo等人, (2020)中,FedAvg针对非凸问题进行了分析,其中FedAvg被制定为基于随机梯度的算法具有偏置梯度,并且证明了FedAvg随着步长衰减到驻点的收敛性。 此外,Huo等人,(2020)提出了FedMom,一种基于Nesterov动量的服务器端加速,并再次证明了其收敛于驻点。 最近,Reddi 等人 (2020) 提出并分析了几种流行的自适应优化器的联合版本(例如 ADAM)。 他们通过将FL更新方案解耦为服务器优化器和客户端优化器来概括FedAvg的框架。 有趣的是,和我们一样,Reddi 等人, (2020) 也观察到了客户端和服务器上学习率衰减的重要性。
最近,Pathak 和 Wainwright(2020) 的一项有趣工作从理论上证明了 FedAvg 和 FedProx(如果存在)不需要达到固定点是原始优化问题的驻点,即使在凸设置和确定性更新中也是如此。 为了解决这个问题,他们建议 FedSplit 来恢复正确的不动点。 不过,如果 FedSplit 仍然可以在异步和随机用户更新下收敛到正确的固定点,它仍然保持开放状态,这两种方法在实践中都被广泛采用并在这里进行了研究。
确保用户之间的公平性已成为 FL 的一个重要目标,因为它在很大程度上决定了用户参与训练过程的意愿。 Mohri 等人,(2019) 认为现有的 FL 算法可能会导致偏向不同用户的联合模型。 为了解决这个问题,Mohri 等人,(2019)提出了不可知联邦学习(AFL)来提高用户之间的公平性。 AFL将目标分布视为用户分布的加权组合,并针对最坏情况实现优化集中模型,从而产生鞍点优化问题,并通过快速随机优化算法解决。 另一方面,基于无线网络中公平的资源分配,Li等人,2020b提出了q-fair联邦学习(q-FFL)以实现更统一的测试精度跨用户。 Li等人,2020b进一步提出q-FedAvg作为解决q-FFL的通信高效算法。 然而,AFL 和 q-FedAvg 都没有明确鼓励用户参与,并且它们遭受对抗性攻击,而我们的算法 FedMGDA+ 的设计是公平的在参与者之间并且对加法和乘法攻击具有鲁棒性。
FedAvg 依赖于本地模型的坐标平均来更新全局模型。 根据Wang等人,2020b,在基于神经网络(NN)的模型中,由于神经网络参数的排列不变性,这种坐标平均可能会导致次优结果。 为了解决这个问题,Yurochkin等人,(2019)提出了概率联邦神经匹配(PFNM),它仅适用于全连接的前馈网络。 最近的工作(Wang等人,2020b,)提出了联合匹配平均(FedMA)作为PFNM的分层扩展以适应CNN和 LSTM。 然而,PFNM和FedMA中的贝叶斯非参数机制可能容易受到模型中毒攻击(Bagdasaryan 等人,, 2020; Bhagoji 等人,, 2019 ; Wang 等人, 2020a, ),而Sun 等人, (2019) 中讨论了一些简单的防御,例如规范阈值和差分隐私。 我们注意到这些想法与 FedMGDA+ 是互补的,我们计划在未来的工作中研究它们可能的集成。
最后,我们注意到人们对标准化 FL 中的基准、协议和评估非常感兴趣,例如参见 (Caldas 等人,, 2018; He 等人,, 2020). 我们花费了大量精力来遵守建议的规则,通过报告通用数据集、开源我们的代码并包括所有实验细节。
3问题设置
我们回顾了 McMahan 等人 (2017) 的联邦学习 (FL) 框架,并指出了一个看似统一了不同实现的简单解释。 我们考虑 FL 与 用户(边缘设备),其中 用户对最小化函数 感兴趣,在共享模型参数 上定义。 通常,每个用户函数还取决于相应用户的本地(私有)数据。 FL 的主要目标是集体有效优化个人目标,同时应对诸如在简介(§1):用户数据的非独立同分布、有限通信、用户隐私、公平性、鲁棒性等等。
McMahan 等人, (2017)提出FedAvg来优化单个用户函数的算术平均值:
| (1) |
权重需要事先指定。 典型的选择包括每个用户的数据集大小、每个用户的“重要性”,或者简单地统一,即。 FedAvg 的工作原理如下:在每一轮中,选择一个(随机)用户子集,每个用户执行 次局部(完整或小批量)梯度下降:
| (2) |
然后在服务器端对权重进行平均:
| (3) |
最终在下一轮广播给用户。 本地纪元 的数量是一个关键因素。 设置相当于通过通常的梯度下降算法求解(1),同时设置(并假设每个局部函数收敛) 相当于(重复)对 的各个最小值进行平均。 现在,我们对 FedAvg 进行了新的解释,从而深入了解它通过中间 来优化的内容。
我们的解释基于最近平均值(Bauschke等人,2008)。 回想一下,莫罗包络线和凸函数的近端映射111对于非凸函数,一旦我们解决近端映射的多值性,类似的结果就会成立,参见Yu等人,(2015)。 函数分别定义为:
| (4) | ||||
| (5) |
给定一组凸函数和总和为1的正权重,我们将近端平均值定义为唯一函数 这样 换句话说,邻近平均值的邻近图是邻近图的平均值。 更具体地说,Bauschke 等人,(2008) 给出了以下明确但复杂的近端平均值公式:
| (6) | ||||
| (7) |
从上面的公式我们很容易得出
有趣的是,我们现在可以在两种极端设置下将 FedAvg 解释为最小化近端平均值:
-
•
具有 局部步长的 FedAvg 与使用 最小化近端平均值 完全相同。 这从 FedAvg 的目标 (1) 中可以清楚地看出(正如我们的符号已经表明的那样)。
-
•
具有 局部步骤的 FedAvg 与使用 最小化近端平均值 完全相同。 的确,
(8) 其中右侧解耦,因此最优时的 是 的最小值(回想一下 )。
因此,我们可以将带有中间 的 FedAvg 解释为带有中间 的最小化 。 更有趣的是,如果我们应用 PA-PG 算法 余,(2013,算法。 222) 为了最小化,我们得到简单的更新规则
| (9) |
其中近端图是在用户端并行计算的。 我们注意到,最近的 FedProx 算法 (Li 等人, 2020a, ) 本质上是 (9) 的随机版本。 至关重要的是,我们不需要评估复杂的公式 (6),因为更新 (9) 仅需要其近端图,根据定义,它是各个近端图的平均值地图(由每个用户单独计算)。 此外,近端平均值 和算术平均值 之间的差异可以使用每个函数 的 Lipschitz 常数均匀地限制> (余,2013)。 因此,对于小步长,FedAvg(对于任何有限的)和FedProx都最小化一些近似值 形式的算术平均值 (1)。
如何设置FedAvg中的权重一直是一个重大挑战。 在FL中,数据以高度非独立同分布和不平衡的方式分布,因此不清楚(1)中选择的某些算术平均值是否真的满足人们的实际意图。 (1) 中算术平均值的第二个问题是其众所周知的针对恶意操作的非鲁棒性,这一点已在最近的对抗性攻击中被利用(Bhagoji 等人,, 2019). 相反,Agnostic FL (AFL (Mohri 等人,, 2019)) 旨在优化最坏情况的损失:
| (10) |
其中集合 可能比任何特定的 更好地覆盖现实,并为所有用户提供一些最低限度的保证(从而实现温和的公平)。 另一方面,(10) 中最坏情况的损失对于对抗性攻击可能更加不稳健。 例如,为某些损失添加正常数可以使其主导整个优化过程。 最近的工作 q-FedAvg (Li 等人, 2020b, ) 提出了 FedAvg 之间的 范数插值(本质上是 规范)和 AFL(本质上是 规范)。 通过调整,q-FedAvg可以实现比FedAvg或AFL更好的折衷。
4 多目标最小化 (MoM)
多目标最小化 (MoM) 是指需要同时最小化多个标量目标函数(可能彼此不兼容)的设置。 它也称为向量优化 (Jahn,, 2009),因为目标函数可以组合成单个向量值函数。 用数学术语来说,MoM 可以写成
| (11) |
其中最小值是根据 partial 排序定义的:
| (12) |
(我们提醒一下,当将诸如 和 之类的代数运算应用于具有另一个向量 或标量 的向量时,始终按分量执行。) 与单目标优化不同,多目标优化可能会
| (13) |
在这种情况下,我们说 和 不具有可比性。
如果 的目标值 是一个最小元素(相对于 (12) 中的部分排序),我们称 为 (11) 的帕累托最优解,或者等价于任何 , 意味着 。 换句话说,在不损害其他目标的情况下,不可能改进中的任何组件目标。 类似地,如果不存在任何使得,即,我们将称为弱帕累托最优解,不可能改进中的所有组件目标。 显然,任何帕累托最优解也是弱帕累托最优解,但反之则可能不成立。
我们指出MoM中的最优解通常是一个集合(一般是无限基数)(Mukai,1980),并且在没有额外的主观偏好信息的情况下,所有Pareto最佳解决方案被认为同样好(因为它们彼此之间没有可比性)。 这与单一目标案例根本上不同。
从现在开始,为了简单起见,我们假设所有目标函数都是连续可微的,但不一定是凸的(以适应深度模型)。 在这种情况下找到(弱)帕累托最优解非常具有挑战性(在单一目标情况下已经如此)。 相反,我们将面对帕累托平稳解,即满足直观的一阶必要条件的解:
Definition 1 (帕累托平稳性,Mukai,1980)。
我们称帕累托平稳当且仅当一些梯度的凸组合消失,即存在一些使得 和 。
Lemma 1 (向井,1980)。
任何帕累托最优解都是帕累托平稳的。 相反,如果所有函数都是凸函数,则任何帕累托平稳解都是弱帕累托最优。
不用说,对于单一目标情况(),上述结果简化为熟悉的结果。
存在许多用于寻找帕累托平稳解的算法。 我们简要回顾了与我们相关的三个流行的内容,并建议读者参阅优秀的专着(Miettinen,1998)以了解更多详细信息。
加权方法。 令 (单纯形)并考虑以下单一加权目标:
| (14) |
这本质上是 FedAvg 所采用的方法,任何 (14) 的(全局)最小化器都是弱帕累托最优(事实上,如果所有权重 从 定义 1 可以清楚地看出,加权标量问题 (14) 的任何平稳解都是帕累托平稳原始 MoM (11) 的解决方案。 请注意,标量化权重一旦选择,就始终是固定的。 不同的 会导致不同的 Pareto 平稳解。
-约束。 令 、 并考虑以下约束标量问题:
| (15) | ||||
| (16) |
假设约束条件可满足,则 (15) 的任何(全局)最小化器同样是弱帕累托最优。 -约束方法通过通常的拉格朗日重构与上面的加权方法密切相关。 不过,两者都需要提前固定 尺寸参数( 与 )。
切比雪夫方法。 让 并考虑极小极大问题(其中 是单纯形约束):
| (17) |
同样,任何(全局)最小化器都是弱帕累托最优。 这里 是一个固定向量,理想情况下是 的下限。 这本质上是 AFL (Mohri 等人,, 2019) 与 采取的方法。
5 FL 作为多目标最小化
介绍了FL和MoM,并观察了两者之间的一些联系,在FL中处理每个用户函数是非常自然的 作为 MoM 中的一个单独目标,并旨在同时优化它们,如 (11) 中所示。 这将是我们下面遵循的主要方法,据我们所知,以前尚未正式探讨过这种方法(尽管我们在上一节中看到了明显的联系,也许是回顾性的)。 特别是,我们将MoM中的多重梯度下降算法(Mukai,1980)扩展到FL,与现有的建立连接FL 算法,并证明我们的扩展算法 FedMGDA+ 的收敛特性。 非常重要的是,帕累托最优性和平稳性的概念立即增强了用户之间的公平性,因为我们不鼓励通过牺牲其他用户来改善某些用户。
为了进一步激励我们的发展,让我们与AFL (Mohri 等人,, 2019)中的目标进行比较:
| (18) |
其中 表示单纯形222准确地说,AFL将限制为的子集。 我们简单地设置 来简化讨论。. 通过优化FedAvg中最差损失而不是平均损失,AFL为所有用户提供了一些保证,从而实现了一些公平的形式。 但请注意,AFL 的目标 (18) 对于对抗性攻击并不稳健。 事实上,如果恶意用户人为地“夸大”其损失(例如,甚至通过添加/乘以一个常数),它可以完全控制和误导AFL 仅专注于优化其性能。 同样的问题也适用于 q-FedAvg (Li 等人, 2020b, ),尽管如果 很小,效果就不那么引人注目。
AFL 的目标 (18) 与 MoM 中的切比雪夫方法非常相似(参见部分 4),这启发我们提出以下迭代算法来求解(11):
| (19) |
我们使用上一次迭代中的函数值自适应“居中”用户函数。 当函数光滑时,我们应用二次界得到:
| (20) |
其中 是雅可比矩阵, 是步长。 至关重要的是,请注意 不会出现在上述边界 (20) 中,因为我们在 (19) 中减去了它。 由于 (20) 在 中是凸的,在 中是凹的,我们可以将 min 与 max 交换并获得对偶:
| (21) |
通过将其导数设置为 来求解 ,我们得到:
| (22) | |||
| (23) |
请注意, 正是雅可比行列式 中列(即,梯度)的凸包中的最小范数元素,并找到 相当于求解一个简单的二次规划。 (22) 中产生的迭代算法称为多重梯度下降算法 (MGDA),它已在 Mukai (1980) 中(重新)发现; Fliege 和 Svaiter,(2000); Désidéri,(2012),最近在 Sener 和 Koltun,(2018)中应用于多任务学习; Lin 等人,(2019) 以及在 Albuquerque 等人,(2019) 训练 GAN。 我们在这里的简洁推导揭示了关于 MGDA 的一些新见解,特别是它与 AFL 的联系。
为了使 MGDA 适应联邦学习环境,我们提出了以下扩展。
平衡用户平均性能和公平性。 我们观察到 (22) 中的 MGDA 更新类似于 FedAvg,其关键区别在于 MGDA 自动 调整双权重变量 在每个步骤中,而 FedAvg 根据有关用户功能的先验信息(或在缺乏此类信息时简单统一)预设 )。 重要的是,在 MGDA 中找到的方向 是所有参与目标的共同下降方向:
| (24) |
其中第一个不等式源自 上熟悉的平滑度假设,而第二个不等式则简单地源自将 插入 (20) 并注意到 根据定义只能进一步减少 (20)。 很明显,当且仅当 、即、 是帕累托平稳时(参见部分 4)。 换句话说,MGDA 绝不会牺牲任何参与目标来换取比其他目标更大的改进,而具有固定权重 的 FedAvg 可能会尝试这样做。 另一方面,具有固定权重的FedAvg可以在权重下实现更高的平均性能。 很自然地在平均性能和公平性之间引入以下权衡:
| (25) |
显然,设置会恢复FedAvg,并具有先验权重,而设置会恢复MGDA,其中权重变量在没有任何限制的情况下进行调整,以实现最大的公平性。 在实践中,通过中间的,我们可以在两个(有时)相互冲突的目标之间取得理想的平衡。 此外,即使使用无信息权重,使用中间也允许我们将每个用户函数对共同方向的贡献设定上限,从而实现一些针对恶意操纵的鲁棒性形式。
通过规范化增强抵御恶意用户的鲁棒性。 现有工作(例如,Bhagoji 等人,, 2019; Xie 等人,, 2019) 已经证明,FedAvg 中的平均梯度可以是即使是单个恶意用户也很容易操纵。 虽然最近研究了更稳健的聚合策略(例如,参见 Blanchard 等人,, 2017; Yin 等人,, 2018; Diakonikolas 等人,, 2019),但它们不一定能保持FedMGDA+(例如找到共同的下降方向并收敛到帕累托平稳解)。 相反,我们建议基于以下考虑将每个用户的梯度简单地归一化为单位长度: (a) 归一化(子)梯度对于非平滑和随机优化专家来说很常见(Anstreicher 和 Wolsey,2009 ),有时可以简化步长调整。 (b) 用归一化梯度求解(22)中的权重仍然保证公平性,即,结果方向对于所有参与目标都是递减的(通过与 (5) 之后的评论完全相似的推理)。 (c) 归一化恢复了针对任何恶意用户的乘法“通货膨胀”的鲁棒性,这与 MGDA 针对加性“通货膨胀”的内置鲁棒性相结合(参见方程 19),提供针对对抗性攻击的合理稳健性保证。
平衡通信和设备上计算。 由于§3中提到的各种原因,用户设备和中央服务器之间的通信在FL中受到严重限制。 另一方面,现代边缘设备能够执行合理数量的设备内计算。 因此,我们允许每个用户设备在将其更新(即初始和最终之间的差异)传达给中央服务器。 然后服务器调用(扩展的)MGDA执行全局更新,该更新将广播到下一轮用户设备。 我们注意到,许多现有的FL系统已经采用了类似的策略(例如,McMahan 等人,2017;Li 等人,2020b,;Li 等人,2020a,)。
二次采样可减轻非独立同分布并提高吞吐量。 由于FL中的边缘设备数量巨大,期望大多数设备参与每一轮甚至大多数轮次是不现实的。 因此,FL 中的当前做法是选择用户设备的(不同)子集来参与每一轮(McMahan 等人,, 2017)。 此外,对用户设备进行随机二次采样还可以帮助对抗用户特定数据的非独立同分布(例如,McMahan 等人,, 2017;Li 等人,, 2020)。 在这里,我们指出基于 MGDA 的算法的一个重要优势:它的更新是沿着共同的下降方向(参见 (5)),这意味着任何参与的目标用户只能减少。 我们相信 MGDA 的这一独特属性为用户参与FL提供了强大的动力。 据我们所知,现有的FL算法不提供类似的算法激励。 最后但并非最不重要的一点是,子采样还解决了 MGDA 中的简并问题:当参与用户的数量超过维度 时,雅可比行列式 具有完整的行秩(22)在单次迭代中实现帕累托平稳并停止进展。 子采样消除了这种不良影响,并允许不断优化不同的用户子集。
Theorem 1a.
令每个用户函数为-Lipschitz平滑且-Lipschitz连续,并选择步长使得 和 ,其中 与
| (26) | ||||
| (27) |
然后,对于 我们有:
| (28) |
这里 是本地更新的数量, 是每个本地更新中的小批量的数量。 收敛速度取决于随机共同下降方向 的“方差”项 减小的速度(如果有的话),而这又取决于我们对用户进行二次采样或用户的异质性如何。
对于确定性梯度更新,即使有更多的局部更新,我们也可以证明收敛性(即):
Theorem 1b。
令每个用户函数为-Lipschitz平滑且-Lipschitz连续。 对于任意数量的局部更新,如果全局步长与、局部学习率和,那么我们有:
| (29) |
该定理的精确表述及其证明请参见附录A。 我们注意到,限制偏差 的一种自然方法是应用 FedMGDA 的 约束版本。 例如,如果 和 是有界的,则 也是有界的。 因此,当 时 。 而且,当时,我们不需要局部学习率衰减来收敛;此外,如果(例如在FedAvg中),那么我们的收敛保证减少到通常的梯度下降,这是预期的,因为我们知道FedAvg 与 与集中梯度下降相同。 最后,我们注意到,当时,局部学习率必须消失才能获得收敛。 Reddi 等人, (2020) 中也指出了局部学习率衰减的重要性。
当函数是凸函数时,我们可以得到更好的结果:
Theorem 2.
假设每个用户函数 是凸函数并且 -Lipschitz 连续。 假设每轮 FedMGDA+ 都包含一个强凸用户函数,其权重远离 0。 然后,通过选择 和 ,我们有
| (30) |
和 几乎可以肯定,其中 是 最接近的 Pareto 平稳解, 是某个常数。
在附录A中可以找到稍微更强的结果,我们还允许一些用户函数是非凸的。 如果梯度归一化远离 0,则相同的结果成立(否则我们已经接近帕累托平稳性)。 对于,使用与§3中类似的参数,我们期望FedMGDA+优化一些代理问题(例如近端平均值),我们将彻底的理论分析留给未来的工作。
我们注意到,即使仅限于确定性情况,MGDA 的收敛速度也是最近在 Fliege 等人,(2019) 中得出的。 随机情况(我们在这里考虑)更具挑战性,我们的定理为 FedMGDA+ 提供了第一个收敛保证。 我们希望强调,FedMGDA+ 不仅仅是 FL 从业者的替代算法;它可以用作后处理步骤来增强现有的 FL 系统或与现有的 FL 算法(例如 FedProx 或 q-FedAvg)。 这对于非凸用户函数特别有吸引力,因为 MGDA 能够收敛到所有 Pareto 驻点,而诸如 FedAvg 之类的方法即使在我们枚举权重时也不一定享有此属性 (米耶蒂宁,1998)。 此外,还可以找到多个甚至枚举所有帕累托最优解(即帕累托前沿)。 例如,我们可以使用不同的随机种子或初始化多次运行FedMGDA+。 正如 Lin 等人 (2019) 所示,我们还可以在 (22) 中加入额外的线性约束来编码一个人的偏好并鼓励更多样化的解决方案。 不过,在维度较高(即用户数量较多时)和通信受限的情况下,这些技术的效果会大打折扣。 实际上,服务器可以动态调整(22)中的线性约束,以将算法引导至更理想的帕累托平稳解。
最后,我们提到寻找共同的下降方向(即算法1的第6行)是一个标准的二次方程仅在服务器端解决的编程(QP)问题。 对于中等数量的(采样)用户,使用通用 QP 求解器就足够了,而对于大量用户,我们也可以使用条件梯度算法 (Sener 和 Koltun,2018 年) 等方法高效求解 ,每一步的复杂度与模型维度和参与用户数量成正比。 在下面的实验中,我们使用了通用 QP 解析器,并且我们观察到这种开销可以忽略不计,因此 FedAvg 和 FedMGDA 的总体运行时间几乎相同。
6实验
6.1 实验设置
| Dataset | Train Clients | Train samples | Test clients | Test samples | Batch size |
|---|---|---|---|---|---|
| CIFAR-10 (Krizhevsky,, 2009) | |||||
| F-MNIST (Xiao et al.,, 2017) | |||||
| FEMNIST (Caldas et al.,, 2018) | |||||
| Shakespeare (Li et al., 2020a, ) | |||||
| Adult (Dua and Graff,, 2017) |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| LocalResponseNorm | size= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| LocalResponseNorm | size= | |||
| MaxPool2d | pool size= | |||
| Flatten | ||||
| Dense | ReLU | |||
| Dense | ReLU | |||
| Dense | softmax | |||
| Total |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Dropout2d | ||||
| Flatten | ||||
| Dense | ReLU | |||
| Dropout | ||||
| Dense | softmax | |||
| Total |
| Layer | Output Shape | of Trainable Parameters | Activation | Hyper-parameters |
|---|---|---|---|---|
| Input | ||||
| Conv2d | kernel size =; strides= | |||
| Conv2d | ReLU | kernel size =; strides= | ||
| MaxPool2d | pool size= | |||
| Dropout | ||||
| Flatten | ||||
| Dense | ||||
| Dropout | ||||
| Dense | softmax | |||
| Total |
| Name | Parameters |
|---|---|
| AFL | |
| q-FedAvg | , |
| FedMGDA+ | , and |
| FedAvg-n | , and |
| FedProx | |
| MGDA-Prox | , , and |
在本小节中,我们提供实验细节,包括数据集描述、采样方案、模型配置和超参数设置。 我们使用的数据集的快速摘要可以在 Table 1 中找到。 我们在FedMGDA+中有两个参数来控制每轮通信中本地更新的总数:,本地epoch的数量,以及,每个本地时期的更新数量。 这里 是每个用户的样本数量(为简单起见,假设相同),而 是每个本地更新的小批量大小。 正如 例如、McMahan 等人,(2017)(表 2)所观察到的,具有较大的 与具有较小的 (或等效的更大的),就本地更新总数而言。 此外,具有合适的 的 通常会带来令人满意的性能,而非常大的 可能会导致稳定或发散。 因此,在我们的实验中,我们修复,同时改变以减少超参数的总数。 这对应于每个通信轮中每个用户的本地数据的单次传递。
6.1.1 CIFAR-10 (Krizhevsky,, 2009) 和 Fashion MNIST (Xiao 等人,, 2017) 数据集
为了创建一个非 i.i.d. 数据集,我们遵循与 McMahan 等人,(2017) 中类似的采样过程:首先,我们根据类别对所有数据点进行排序。 然后,它们被分成 分片,每个用户被随机分配 数据分片。 通过考虑个用户,该过程保证没有用户从超过个类接收数据,并且每个用户的数据分布彼此不同。 本地数据集是平衡的——所有用户都有相同数量的训练样本。 本地数据分为训练集、验证集和测试集,百分比分别为 %、% 和 %。 这样,每个用户都有用于训练的 数据点、用于测试的 数据点和用于验证的 数据点。 我们使用的 CNN 模型类似于 McMahan 等人 (2017) 中的模型,具有两个卷积层,后跟三个全连接层。 详细信息包含在 CIFAR-10 的表2和表3<中/t5> 代表 Fashin MNIST。 为了使用本地数据更新每个用户的本地模型,我们应用具有本地批量大小 、本地历元 和本地学习率 或 、 和 。 为了模拟并非所有用户都可以参与每轮通信的事实,我们使用参数 来控制参与用户的比例: 是默认设置,这意味着只有 % 的用户参与每轮沟通。
6.1.2 联合 EMNIST 数据集(Caldas 等人,2018)
对于此实验设置,我们使用与 Reddi 等人 (2020) 相同的数据集、模型和超参数。 我们使用 Caldas 等人 (2018) 的联合 EMNIST 数据集。 该数据集由数字图像和英文字符(包括小写和大写)组成,总共 62 个类别。 作者对图像进行分区的方式自然会导致数据集异构且不平衡。 我们使用Table4中描述的模型和以下超参数:局部学习率并选择 每轮沟通客户数(按照建议)。 我们的设置与 (Reddi 等人,, 2020) 中的设置之间的唯一区别是我们对所有算法都使用本地纪元 。
6.1.3 莎士比亚数据集(李等人, 2020a, )
对于莎士比亚数据集的实验,我们使用与 q-FedAvg 论文 (Li 等人, 2020b, ) 中相同的模型、数据预处理和采样程序。 该数据集基于莎士比亚全集构建,其中剧中的每个角色代表一个用户。 在 Li 等人, 2020a 之后,我们对 用户进行二次采样,以训练用于下一个字符预测的神经语言模型。 每个字符嵌入在维空间中,序列长度为个字符。 我们使用的模型是一个两层 LSTM(隐藏大小 ),后面跟着一个密集层 (McMahan 等人,, 2017; Li 等人, 2020a, )。 所有算法共享的联合超参数包括:总通信轮次、本地批量大小、本地历元以及本地优化器SGD,除非另有说明。
6.1.4 成人数据集(Dua 和 Graff,2017 年)
按照AFL (Mohri 等人,, 2019)中的设置,我们根据教育将Adult数据集分为两个不重叠的域属性 - phd 域和非 phd 域。 生成的 FL 设置由两个用户组成,每个用户都拥有来自两个域之一的数据。 此外,数据按照Li等人,2020b中的方式进行预处理,以具有二进制特征。 我们对主论文中提到的所有 FL 算法都使用逻辑回归模型。 本地数据分为训练集、验证集和测试集,百分比分别为 %、% 和 %。 在每一轮中,两个用户都参与,服务器汇总他们的损失和梯度(或权重)。 所有算法共享的联合超参数包括:总通信轮次、本地批量大小、本地历元、本地学习率,除非另有说明,本地优化器是没有动量的 SGD。 算法特定的超参数将在下面适当的地方提到。 一个重要的注意事项是 phd 域仅具有 个样本,而 non-phd 域具有 个样本,因此split 非常不平衡,而由于样本量不足,在 phd 域上训练 only 在所有域上的性能较差。
6.1.5 超参数
我们使用各种超参数评估不同算法的性能,总结在表5中。 特别是,按照 Anstreicher 和 Wolsey (2009),我们在服务器上尝试了次线性 和指数衰减 学习率 ,以及用于客户端更新的固定本地学习率。 最终我们决定每 步将 衰减 倍:,其中 和 是通信轮次的总数(例如 decay = )。 我们注意到,Reddi 等人,(2020) 也发现指数衰减在他们的实验中最有效。 我们使用网格搜索来为所有算法选择合适的局部学习率。

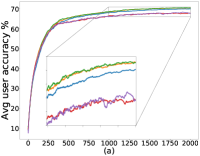
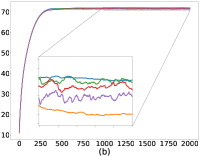
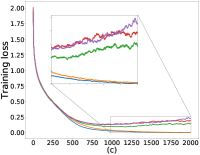
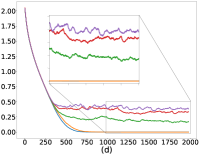

我们在几个公共数据集上评估我们的算法 FedMGDA+:CIFAR-10 (Krizhevsky,, 2009)、F-MNIST (Xiao 等人,, 2017)、联邦 EMNIST (Caldas 等人,, 2018)、莎士比亚 (Li 等人, 2020a, ) 和成人 (Dua 和 Graff,, 2017) ,并与现有的 FL 系统进行比较,包括 FedAvg (McMahan 等人,, 2017)、FedProx (李等人, 2020a, )0>, q-FedAvg1> (李等人, 2020b, )2>, 以及 澳大利亚足球联盟333AFL实验AFL实验 在原始工作 (Mohri 等人,, 2019) 和后来与之比较的工作中(例如 (Li 等人, 2020b, ))在数据集上报告了非常客户很少(或),可能是由于适用性原因。 我们在工作中遵循了这一惯例。 (毛利等人,2019)。 此外,根据§5中的讨论,人们可以设想现有算法的几种潜在扩展,以提高其性能。 因此,我们还与以下扩展进行比较:FedAvg-n,它是带有梯度归一化的FedAvg,以及MGDA-Prox,它是 FedMGDA+ 在每个用户的损失函数中添加了近端正则化器。444也可以将梯度归一化的思想应用到q-FedAvg上;然而,我们从实验中观察到,生成的算法不稳定,特别是对于较大的 值。 我们区分 FedMGDA+ 和 FedMGDA,后者是 MGDA 到 FL 的普通扩展。
6.2实验结果
在本小节中,我们将报告有关我们提出的算法 FedMGDA+ 的实验结果,并将其与各种性能指标(包括准确性、鲁棒性和公平性)下的最先进 (SOTA) 替代方案进行比较。 我们提醒一下,准确度指标正是 FedAvg 在训练期间旨在优化的目标,因此它在该指标上比其他替代算法(例如 FedMGDA+、)具有一些优势AFL 和 q-FedAvg 都旨在为用户带来一定的公平性,也许偶尔会造成一些准确性损失,但希望损失很小。
6.2.1 恢复FedAvg
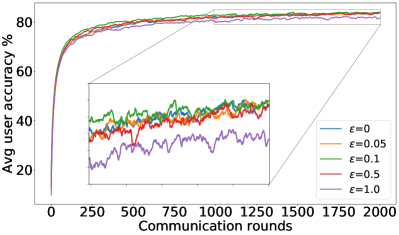
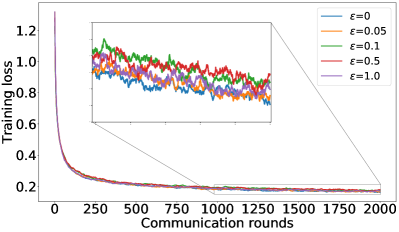
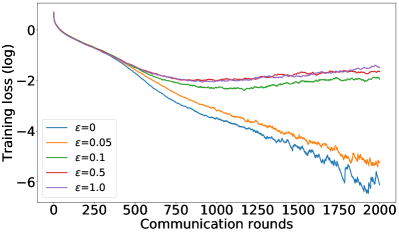
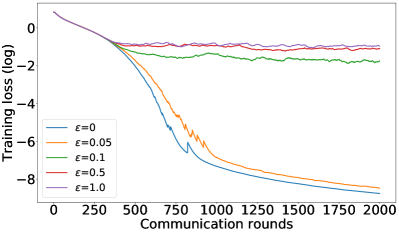
正如§5中提到的,我们可以通过调整方程中的约束来控制用户平均性能和公平性之间的平衡25。 设置 恢复 FedAvg,设置 恢复 FedMGDA。 为了凭经验验证这一点,我们使用不同的 运行 (25),并在 图 1 中报告 CIFAR-10 的结果 对于数据的独立同分布和非独立同分布(F-MNIST 上的结果,请参阅部分 B.1)。 这些结果证实,将 从 更改为 会产生 FedAvg 和 FedMGDA 之间的插值,正如预期的那样。 由于 FedAvg 本质上优化了(均匀)平均训练损失,因此它自然在此指标下表现最好(图 1 (c) 和 (d))。 尽管如此,值得注意的是,在非独立同分布设置中,一些中间值实际上比FedAvg带来更好的用户准确性( 图 1 (a))。

6.2.2稳健性
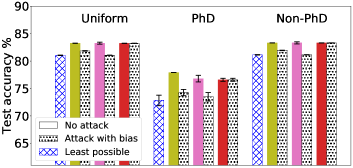
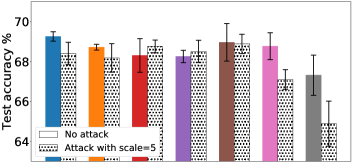
我们之前在§5中讨论过,梯度归一化和 MGDA 的内置稳健性允许 FedMGDA+ 在实际 FL 部署中对抗某些对抗性攻击。 我们现在根据经验评估 FedMGDA+ 针对这些攻击的稳健性。 我们在单个恶意用户存在的情况下运行各种 FL 算法,该用户旨在通过夸大其损失来操纵系统。 我们考虑一种对抗性设置,其中攻击者参与每一轮通信,并通过 (i) 添加偏差,或 (ii) 将其乘以缩放因子(称为偏差)来夸大其损失函数,并且分别进行缩放攻击。 在第一个实验中,我们通过向代表性不足的用户(即 PhD 域)添加恒定偏差来模拟对 Adult 数据集的偏差攻击,因为更自然地预期攻击者由小型用户组成用户数量。 在此设置中,我们可以获得的最差性能仅限于仅使用 PhD 数据 训练模型。 偏置攻击下的结果如图图2(左)所示;另请参阅部分B.2了解更多结果。 我们观察到,在没有攻击的情况下,AFL 和 q-FedAvg 的表现略好于 FedMGDA+;然而,它们的性能在受到攻击时会恶化到接近最坏情况的水平。 相比之下,FedMGDA+ 不会受到任何偏见攻击的影响,这从经验上支持了我们在第 §5 中的主张。 请注意,我们在此比较中没有包含 FedAvg,因为从其定义可以清楚地看出,FedAvg 与 FedMGDA+ 一样,不受偏差的影响攻击。 图 2(右)显示了使用和不使用对抗性缩放的不同算法在 CIFAR-10 上的结果。 如前所述,具有梯度归一化的 q-FedAvg 非常不稳定,特别是在缩放攻击下,因此我们在这里没有包含其结果。 从图2(右)可以立即看出(i)缩放攻击会影响所有不采用梯度归一化的算法; (ii) q-FedAvg 在此攻击中受影响最大; (iii) 令人惊讶的是,与无扩展攻击下的结果相比,FedMGDA+ 以及在较小程度上 MGDA-Prox 实际上收敛到稍微更好的 Pareto 解决方案。 上述结果凭经验验证了 FedMGDA+ 在最常见的偏差和扩展攻击下的鲁棒性。
6.2.3 公平性
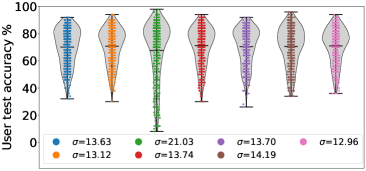
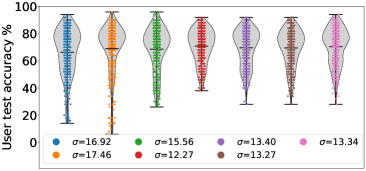
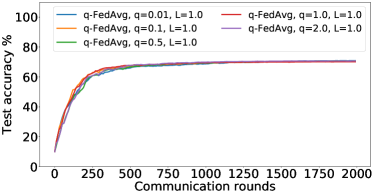
最后,我们在 CIFAR-10 上使用不同的公平概念,将 FedMGDA+ 与现有的 FL 算法进行比较。 对于第一个实验,我们采用与(Li等人, 2020b, )相同的公平性度量,并通过计算用户测试误差的方差来衡量公平性。 我们使用不同的超参数运行每个算法,并在结果中选择平均准确度最好的算法,如 图 3 ;完整的结果表可以在部分B.3中找到。 从该图中,我们观察到 (i) FedMGDA+ 实现了最佳平均精度,而其标准差与 q-FedAvg 相当; (ii) FedMGDA+ 显着优于 FedMGDA,这清楚地证明了我们在 算法 1 中提出的修改方案 香草 MGDA; (iii) 在平均准确度和标准差方面,FedMGDA+ 优于 FedAvg-n,后者使用与 FedMGDA+ 相同的标准化步骤。 这些观察结果证实了 FedMGDA+ 在促进公平方面的有效性。 我们在 Federated EMNIST 数据集上进行了相同的实验,观察到了类似的结果,可以在 Table 6 和 节 B.4。
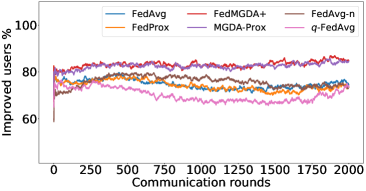
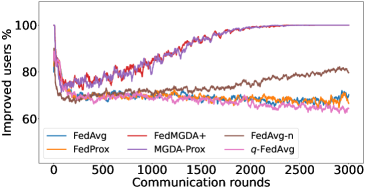
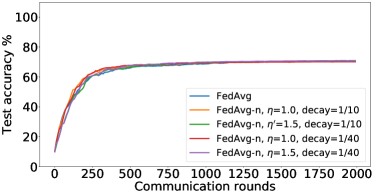
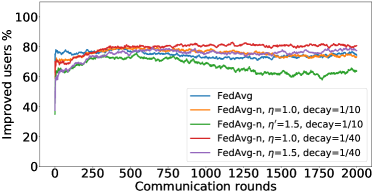
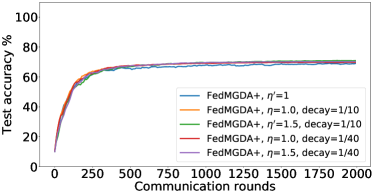
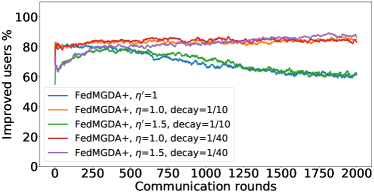
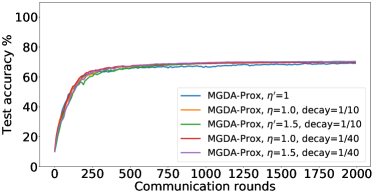
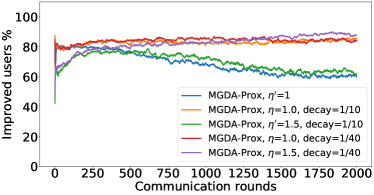
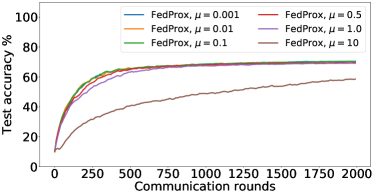
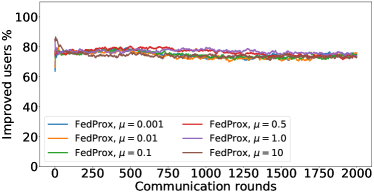
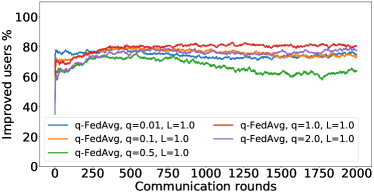
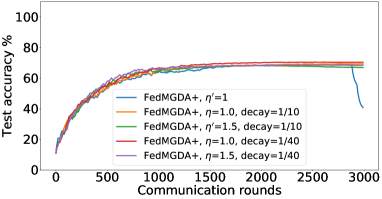
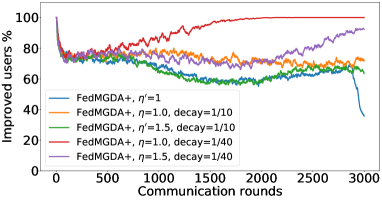
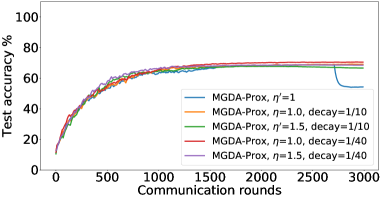
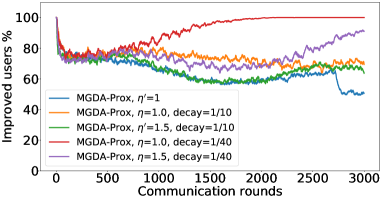
在接下来的实验中,我们将展示 FedMGDA+ 不仅能产生公平的最终解决方案,而且还能在整个训练过程中保持公平性,即在每一轮中,它都不会为了提高整体性能而牺牲任何 参与用户的性能。 据我们所知,“训练期间的公平性”以前从未被研究过,尽管它具有很大的实际意义——它鼓励用户参与。 为了检验这种公平性,我们在 CIFAR-10 上进行了多项实验,并测量了每轮沟通中改善的参与者的百分比。 具体来说,我们测量所有参与用户每轮前后的训练损失,并报告改进或保持不变的百分比。555 时刻改进用户的百分比定义为 ,其中 是时刻选择的用户,是事件的指示函数。 图4显示了两个代表性案例的训练损失在每轮沟通中改善的参与用户的百分比;请参阅部分B.5了解不同超参数的完整结果。
我们可以看到,FedMGDA+ 在用户改进百分比方面始终优于其他算法,这意味着通过使用 FedMGDA+,每次参与后性能变差的用户会减少。 此外,我们从图4(左)注意到,在本地批量大小的情况下,改进用户的百分比小于%,这可以解释如下:对于小批量(即,其中表示本地数据集),接收到的更新来自用户的不是给定全局模型的用户损失的真实梯度(即);它们是真实梯度的噪声估计。 因此,MGDA 计算的共同下降方向存在噪声,并且可能并不总是适用于所有参与用户。 为了消除这种噪声的影响,我们设置了 ,它允许我们从用户那里恢复真实的梯度。 结果如图 4(右)所示,它证实了当步长衰减(过冲较少)时,改进用户的百分比正如预期的那样,FedMGDA+ 训练期间达到 %。
| Algorithm | Average (%) | Std. (%) |
|---|---|---|
| FedMGDA | ||
| FedMGDA+ | ||
| MGDA-Prox | ||
| FedAvg | ||
| FedAvg-n | ||
| FedProx | ||
| q-FedAvg |
7结论
我们提出了一种用于联邦学习的新颖算法FedMGDA+。 FedMGDA+ 基于多目标优化,旨在收敛到 Pareto 平稳解。 FedMGDA+ 易于实现,需要调整的超参数较少,并且可以很好地补充现有的 FL 系统。 最重要的是,FedMGDA+ 能够抵御加法和乘法对抗性操作,并确保所有参与用户之间的公平性。 我们为FedMGDA+建立了基础知识收敛保证,指出了其与最新FL算法的联系,并进行了大量的实验来验证其有效性。 未来,我们计划正式量化多个本地更新引起的权衡,并为 FedMGDA+ 建立一些隐私保证。
致谢
用于准备本研究的资源部分由安大略省、加拿大政府通过 CIFAR 以及赞助 Vector Institute 的公司提供。 我们衷心感谢 NSERC、加拿大 CIFAR 人工智能主席计划和滑铁卢-华为联合创新实验室的资助支持。 我们感谢 NVIDIA Corporation(数据科学资助)捐赠了两个 Titan V GPU,它们在一定程度上支持了本工作的计算。
参考
- Albuquerque et al., (2019) Albuquerque, I., Monteiro, J., Doan, T., Considine, B., Falk, T., and Mitliagkas, I. (2019). Multi-objective training of Generative Adversarial Networks with multiple discriminators. In ICML.
- Anstreicher and Wolsey, (2009) Anstreicher, K. M. and Wolsey, L. A. (2009). Two “well-known” properties of subgradient optimization. Mathematical Programming, 120(1):213–220.
- Bagdasaryan et al., (2020) Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., and Shmatikov, V. (2020). How To Backdoor Federated Learning. In AISTATS, Proceedings of Machine Learning Research, pages 2938–2948.
- Bauschke et al., (2008) Bauschke, H. H., Goebel, R., Lucet, Y., and Wang, X. (2008). The Proximal Average: Basic Theory. SIAM Journal on Optimization, 19(2):766–785.
- Bhagoji et al., (2019) Bhagoji, A. N., Chakraborty, S., Mittal, P., and Calo, S. (2019). Analyzing Federated Learning through an Adversarial Lens. In ICML, pages 634–643.
- Blanchard et al., (2017) Blanchard, P., El Mhamdi, E. M., Guerraoui, R., and Stainer, J. (2017). Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent. In NeurIPS.
- Caldas et al., (2018) Caldas, S., Wu, P., Li, T., Konecny, J., McMahan, H. B., Smith, V., and Talwalkar, A. (2018). Leaf: A benchmark for federated settings. arXiv:1812.01097.
- Désidéri, (2012) Désidéri, J.-A. (2012). Multiple-gradient descent algorithm (MGDA) for multiobjective optimization. Comptes Rendus Mathematique, 350(5):313–318.
- Diakonikolas et al., (2019) Diakonikolas, I., Kamath, G., Kane, D., Li, J., Steinhardt, J., and Stewart, A. (2019). Sever: A Robust Meta-Algorithm for Stochastic Optimization. In ICML.
- Dua and Graff, (2017) Dua, D. and Graff, C. (2017). UCI Machine Learning Repository.
- Fliege and Svaiter, (2000) Fliege, J. and Svaiter, B. F. (2000). Steepest descent methods for multicriteria optimization. Mathematical Methods of Operations Research, 51(3):479–494.
- Fliege et al., (2019) Fliege, J., Vaz, A. I. F., and Vicente, L. N. (2019). Complexity of gradient descent for multiobjective optimization. Optimization Methods and Software, 34(5):949–959.
- He et al., (2020) He, C., Li, S., So, J., Zhang, M., Wang, H., Wang, X., Vepakomma, P., Singh, A., Qiu, H., Shen, L., et al. (2020). FedML: A research library and benchmark for federated machine learning. arXiv:2007.13518.
- Huo et al., (2020) Huo, Z., Yang, Q., Gu, B., Carin, L., and Huang, H. (2020). Faster On-Device Training Using New Federated Momentum Algorithm. arXiv:2002.02090.
- Jahn, (2009) Jahn, J. (2009). Vector optimization. Springer.
- Kairouz et al., (2019) Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., D’Oliveira, R. G. L., Rouayheb, S. E., Evans, D., Gardner, J., Garrett, Z., Gascón, A., Ghazi, B., Gibbons, P. B., Gruteser, M., Harchaoui, Z., He, C., He, L., Huo, Z., Hutchinson, B., Hsu, J., Jaggi, M., Javidi, T., Joshi, G., Khodak, M., Konečný, J., Korolova, A., Koushanfar, F., Koyejo, S., Lepoint, T., Liu, Y., Mittal, P., Mohri, M., Nock, R., Özgür, A., Pagh, R., Raykova, M., Qi, H., Ramage, D., Raskar, R., Song, D., Song, W., Stich, S. U., Sun, Z., Suresh, A. T., Tramèr, F., Vepakomma, P., Wang, J., Xiong, L., Xu, Z., Yang, Q., Yu, F. X., Yu, H., and Zhao, S. (2019). Advances and Open Problems in Federated Learning. arXiv:1912.04977.
- Krizhevsky, (2009) Krizhevsky, A. (2009). Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto.
- Li et al., (2019) Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2019). Federated learning: Challenges, methods, and future directions. arXiv:1908.07873.
- (19) Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V. (2020a). Federated Optimization in Heterogeneous Networks. In MLSys, pages 429–450.
- (20) Li, T., Sanjabi, M., Beirami, A., and Smith, V. (2020b). Fair Resource Allocation in Federated Learning. In ICLR.
- Li et al., (2020) Li, X., Huang, K., Yang, W., Wang, S., and Zhang, Z. (2020). On the Convergence of FedAvg on Non-IID Data. In ICLR.
- Lin et al., (2019) Lin, X., Zhen, H.-L., Li, Z., Zhang, Q.-F., and Kwong, S. (2019). Pareto Multi-Task Learning. In NeurIPS.
- McMahan et al., (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. In AISTATS, pages 1273–1282.
- Mercier et al., (2018) Mercier, Q., Poirion, F., and Désidéri, J.-A. (2018). A stochastic multiple gradient descent algorithm. European Journal of Operational Research, 271(3):808–817.
- Miettinen, (1998) Miettinen, K. M. (1998). Nonlinear Multiobjective Optimization. Springer.
- Mohri et al., (2019) Mohri, M., Sivek, G., and Suresh, A. T. (2019). Agnostic Federated Learning. In ICML, volume 97, pages 4615–4625.
- Mukai, (1980) Mukai, H. (1980). Algorithms for multicriterion optimization. IEEE Transactions on Automatic Control, 25(2):177–186.
- Pathak and Wainwright, (2020) Pathak, R. and Wainwright, M. J. (2020). FedSplit: An algorithmic framework for fast federated optimization. In NeurIPS.
- Reddi et al., (2020) Reddi, S., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konečny, J., Kumar, S., and McMahan, H. B. (2020). Adaptive Federated Optimization. arXiv:2003.00295.
- Sener and Koltun, (2018) Sener, O. and Koltun, V. (2018). Multi-Task Learning as Multi-Objective Optimization. In NeurIPS.
- Stich, (2019) Stich, S. U. (2019). Local SGD converges fast and communicates little. In ICLR.
- Sun et al., (2019) Sun, Z., Kairouz, P., Suresh, A. T., and McMahan, H. B. (2019). Can You Really Backdoor Federated Learning? arXiv:1911.07963.
- (33) Wang, H., Sreenivasan, K., Rajput, S., Vishwakarma, H., Agarwal, S., Sohn, J.-y., Lee, K., and Papailiopoulos, D. (2020a). Attack of the Tails: Yes, You Really Can Backdoor Federated Learning. In NeurIPS, volume 33, pages 16070–16084.
- (34) Wang, H., Yurochkin, M., Sun, Y., Papailiopoulos, D., and Khazaeni, Y. (2020b). Federated Learning with Matched Averaging. In ICLR.
- Xiao et al., (2017) Xiao, H., Rasul, K., and Vollgraf, R. (2017). Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:1708.07747.
- Xie et al., (2019) Xie, C., Koyejo, S., and Gupta, I. (2019). Fall of Empires: Breaking Byzantine-tolerant SGD by Inner Product Manipulation. In UAI.
- Yang et al., (2019) Yang, Q., Liu, Y., Chen, T., and Tong, Y. (2019). Federated Machine Learning: Concept and Applications. ACM Transactions on Intelligent Systems and Technology, 10(2).
- Yin et al., (2018) Yin, D., Chen, Y., Kannan, R., and Bartlett, P. (2018). Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In ICML.
- Yu, (2013) Yu, Y. (2013). Better Approximation and Faster Algorithm Using the Proximal Average. In NeurIPS.
- Yu et al., (2015) Yu, Y., Zheng, X., Marchetti-Bowick, M., and Xing, E. P. (2015). Minimizing Nonconvex Non-Separable Functions. In AISTATS, pages 1107–1115.
- Yurochkin et al., (2019) Yurochkin, M., Agarwal, M., Ghosh, S., Greenewald, K., Hoang, N., and Khazaeni, Y. (2019). Bayesian Nonparametric Federated Learning of Neural Networks. In ICML, pages 7252–7261.
附录A证明
Theorem 1a (完整版).
假设每个用户函数 是 -Lipschitz 平滑(即 )和 -Lipschitz 连续。 然后,对于步长 我们有
| (31) |
其中 是随机共同方向的方差。 此外,如果某个用户函数 从下面有界,并且可以选择 以便 ,则 (31) 收敛到 0。
证明。
让,其中是每个用户的随机梯度的串联,并且
| (32) |
对于后者,如果第 个用户没有参与第 轮,我们也会限制 。然后,应用二次界和更新规则(我们提醒向量和标量之间的比较应该理解为分量方式):
| (33) | ||||
| (34) | ||||
| (35) |
其中我们使用 Lipschitz 连续性 和 的一阶最优性条件,以便
| (36) |
令,取期望并重新排列我们得到
| (37) |
其中。 ∎
Theorem 1b (完整版).
假设每个用户函数 是 -Lipschitz 平滑(即 )和 -Lipschitz 连续。 然后,对于任意数量的局部更新,具有全局学习率、确定性梯度更新和局部学习率,我们有
| (38) |
其中 是精确权重和近似权重之间的偏差。 此外,如果某个用户函数 从下方有界,则 (38) 中的左侧只要 、 和 与 。
证明。
让
| (39) |
和 ,其中 是每个用户累积更新 的串联。 形式上, 表示用户 的初始 与 本地更新后的最终 之间的差值。 (请注意,为了简单起见,我们在这里滥用了符号 和 ,因为它们不区分用户 。 这不是一个大问题,因为上下文很清楚。)
令 和 为局部优化步骤。
然后,
| (40) | ||||
| (41) | ||||
| (42) |
因此, 和渐变 之间的差异受以下限制:
| (44) | ||||
| (45) | ||||
| (46) |
因此,
| (47) | ||||
| (48) | ||||
| (49) |
最后一步来自第一项的矩阵范数不等式和第二项的三角不等式。 请注意, 在 和 时消失。
然后,应用二次上限,我们有
| (50) | ||||
| (51) | ||||
| (52) |
最后,如果 和 ,则 以及 (38) 中的右侧 当 时,在这种情况下,左侧 也会收敛到 。 ∎
Theorem 2 (完整版).
假设每个用户函数是-强凸(即)和-Lipschitz连续。 假设在每一轮 FedMGDA 包含一些函数 使得
| (54) |
其中 是 到 (11) 帕累托平稳集 的投影。 假设,那么
| (55) |
其中 和 。 尤其,
-
•
如果,则和收敛几乎肯定会达到帕累托平稳集;
-
•
有了选择我们有
(56)
证明。
对于每个用户,让我们定义函数
| (57) |
其中随机变量 指示哪个用户参与特定回合。 显然,我们有。 因此,我们的多目标最小化问题等效为:
| (58) |
因为正缩放不会改变帕累托平稳性。 (如果愿意,我们还可以对随机函数 进行归一化,以使无偏属性 成立。)
我们现在按照 Mercier 等人,(2018) 进行,并提供稍微更清晰的分析。 让我们表示 到 (58) 的帕累托平稳集 的投影,即,
| (59) |
然后,
| (60) | ||||
| (61) | ||||
| (62) |
为了限制中间项,我们根据假设得出:
| (63) | ||||
| (64) |
其中第二个不等式来自 的定义。 所以,
| (65) | ||||
| (66) | ||||
| (67) | ||||
| (68) |
从 (62) 继续并取条件期望:
| (69) |
其中。 取期望,我们得到熟悉的递归:
| (70) |
从中我们得出
| (71) |
其中 和 。 从开始,我们知道
| (72) |
如果 和 。
设置我们得到并通过归纳
| (73) |
何处
| (74) |
使用标准的超鞅论证我们还可以证明
| (75) |
该证明在随机优化中众所周知,因此省略(或参见Mercier 等人, (2018, Theorem 5) 了解详细信息)。 ∎
附录B完整的实验结果
在本节中,我们提供了主要论文中未提及的其他结果。
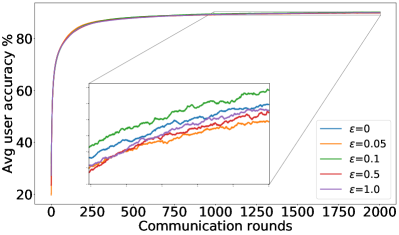
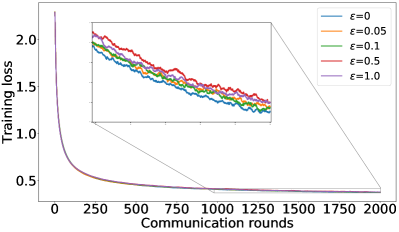
B.1 恢复 FedAvg 完整结果:Fashion-MNIST 和 CIFAR-10 的结果
补充图1、图5<中显示的结果/t3>和图6总结了F-MNIST数据集上的类似结果,而图0>71> 以对数尺度描述了 CIFAR-10 数据集上的训练损失。
B.2 鲁棒性完整结果:对成人数据集的偏见攻击
表 7显示了图 2中的实验的完整结果>(左)。
| Name | Bias | Uniform | PhD | Non-PhD |
|---|---|---|---|---|
| AFL | ||||
| AFL | ||||
| AFL | ||||
| AFL | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| q-FedAvg, | ||||
| FedMGDA+ | Arbitrary | |||
| Baseline_PhD |
Figure 2 的超参数设置。 左:AFL的步长、和偏差; ,以及q-FedAvg的偏差; 、decay= 以及 FedMGDA+0> 的任意偏差。 右:代表FedProx; 和 用于 q-FedAvg;对于FedMGDA+和FedAvg-n,和decay=。 每轮模拟均以 % 用户参与 () 运行,这降低了对手的效率,因为与我们的默认设置相比,它需要参与更大的用户池设置。
B.3 公平性完整结果:CIFAR-10 上的首次实验
Tables 8, LABEL:, 9, LABEL:, 10, LABEL: and 11 report the full results of the experiment presented in Figure 3 for different batch sizes and fractions of user participation.
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
B.4 公平性完整结果:联邦 EMNIST 上的首次实验
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| Algorithm | Average (%) | Std. (%) | Worst % (%) | Best % (%) | ||
| Name | decay | |||||
| FedMGDA | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| FedMGDA+ | ||||||
| Name | decay | |||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| MGDA-Prox | ||||||
| Name | decay | |||||
| FedAvg | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| FedAvg-n | ||||||
| Name | ||||||
| FedProx | ||||||
| FedProx | ||||||
| FedProx | ||||||
| Name | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
| q-FedAvg | ||||||
B.5 公平性完整结果:第二次实验
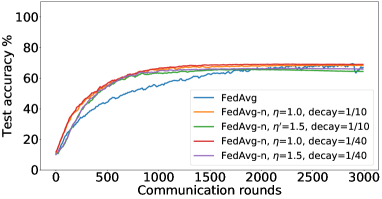
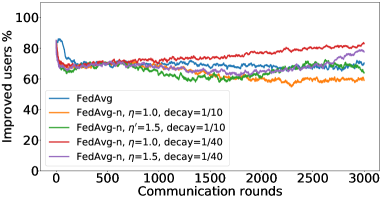
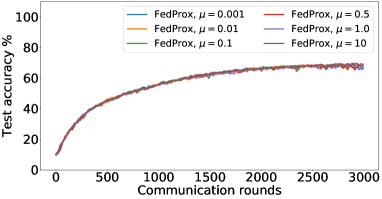
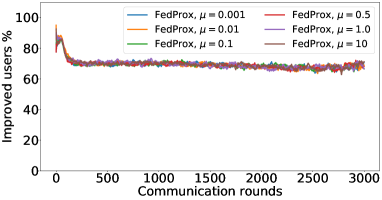
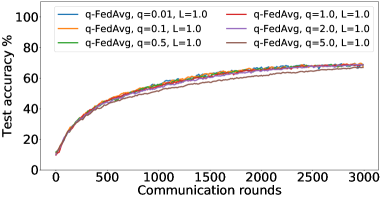
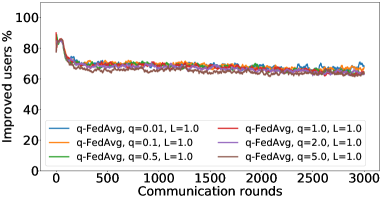
B.6 结果:莎士比亚数据集
| Algorithm | Avg (client) (%) | Avg (data) (%) | Std. (%) | Worst (%) | Best (%) | ||
| Name | momentum | ||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| FedAvg | |||||||
| Name | momentum | ||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| FedProx | |||||||
| Name | decay | ||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| FedMGDA+ | |||||||
| Name | decay | ||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||
| FedAvg-n | |||||||