跨域对齐的图最优传输
摘要
两组实体(例如图像中的物体、句子中的单词)之间的跨域对齐是计算机视觉和自然语言处理的基础。 现有方法主要集中于设计高级注意力机制来模拟软对齐,没有训练信号来明确鼓励对齐。 学习到的注意力矩阵也很密集并且缺乏可解释性。 我们提出了图最优传输(GOT),这是一个源于最优传输(OT)最新进展的原则框架。 在 GOT 中,通过将实体表示为动态构建的图,跨域对齐被表述为图匹配问题。 考虑两种类型的 OT 距离: () 用于节点(实体)匹配的 Wasserstein 距离(WD); () 用于边缘(结构)匹配的 Gromov-Wasserstein 距离 (GWD)。 WD 和 GWD 都可以合并到现有的神经网络模型中,有效地充当嵌入式正则化器。 推断的传输计划还产生稀疏和自我标准化对齐,从而增强了学习模型的可解释性。 实验表明,在图像文本检索、视觉问答、图像字幕、机器翻译和文本摘要等多种任务中,GOT 的性能始终优于基线。
1简介
跨域对齐(CDA)旨在关联不同域中的相关实体,在图像文本检索等广泛的深度学习任务中发挥着核心作用(Karpathy & Fei-Fei,2015;Lee等人,2018),视觉问答(VQA)(Malinowski & Fritz,2014;Antol 等人,2015),以及机器翻译(Bahdanau 等人,2015;等人,2015)。 Vaswani 等人,2017)。 以 VQA 为例,为了理解图像和问题中的上下文,模型需要解释输入图像中的区域与问题中的单词之间的潜在对齐。 具体来说,一个好的模型应该:()识别图像(例如、对象/区域)和问题(例如)中感兴趣的实体,单词/短语),()量化这些实体之间的域内(图像或句子内)和跨域关系,然后()设计良好的指标用于测量从这些关系中得出的跨域对齐的质量,以便优化以获得更好的结果。
CDA 特别具有挑战性,因为它构成了一项弱监督学习任务。 也就是说,只给出了实体的配对空间(例如,与问题配对的图像),而没有提供这些实体之间的真实关系(例如,图像中与问题中的“狗”一词对齐的“狗”区域没有监督信号)。 最先进的方法主要集中在设计先进的注意力机制来模拟软对齐(Bahdanau等人,2015;Xu等人,2015;Yang等人,2016b,a;Vaswani等人,2017). 例如,Lee 等人 (2018); Kim 等人 (2018); Yu等人(2019)表明,学习到的共同注意力可以对实体之间的密集交互进行建模,并推断视觉和语言任务的跨域潜在对齐。 图注意力也被应用于图像描述(Yao等人,2018)和VQA(Li等人,2019a)的关系推理,例如图注意力网络(GAT) ) (Veličković 等人, 2018) 用于通过屏蔽注意力捕获图中实体之间的关系,图匹配网络 (GMN) (Li 等人, 2019b) 用于图通过跨图软注意力对齐。 然而,传统的注意力机制是由特定任务的损失引导的,没有训练信号来明确鼓励对齐。 而且学习到的注意力矩阵通常是密集且难以解释的,从而导致关系推理效率较低。
我们讨论是否存在更原则性的方法来可扩展地发现跨域关系。 为了探索这个问题,我们提出了图最优传输(GOT),111Maretic 等人 (2019) 提出了另一个 GOT 框架用于图形比较。 我们对所提出的算法使用相同的首字母缩略词;然而,我们的方法与他们的方法有很大不同。 一个新的跨域对齐框架,利用了最佳传输 (OT) 的最新进展。 基于 OT 的学习旨在通过最小化将一个分布传输到另一个分布的成本来优化分布匹配。 我们将其扩展到 CDA(这里的域可以是语言、图像、视频等)。 因此,传输计划被重新定义为将嵌入的分布从一个域(例如,语言)传输到另一个域(例如,图像)。 通过最小化所学传输计划的成本,我们明确地最小化了域之间的嵌入距离,即,从而优化了跨域对齐。
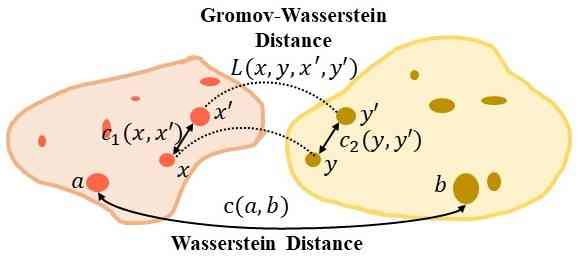
具体来说,我们将每个域(例如、图像、句子)中的实体(例如、对象、单词)转换为图,其中每个实体由特征向量表示,并且图表示通过图传播不断更新。 然后可以将跨域对齐公式化为图匹配问题,并通过基于图距离计算匹配分数来解决。 在我们的 GOT 框架中,我们利用两种类型的 OT 距离: () Wasserstein 距离 (WD) (Peyré 等人, 2019) 应用于节点(实体)匹配, () Gromov-Wasserstein距离(GWD)(Peyré等人, 2016)用于边缘(结构)匹配。 WD 仅测量跨域的节点嵌入之间的距离,而不考虑图中编码的拓扑信息。 另一方面,GWD 通过测量每个图中一对节点之间的距离来比较图结构。 当融合在一起时,这两个距离允许所提出的 GOT 框架有效地考虑节点和边缘信息,以实现更好的图匹配。
这项工作的主要贡献总结如下。 () 我们提出了图最优传输(GOT),这是一种新框架,通过采用最优传输进行图匹配来解决跨域对齐问题。 () GOT 与现有的神经网络模型兼容,充当原始目标的有效插入式正则化器。 () 为了证明所提出方法的通用泛化能力,我们对五种不同的任务进行了实验:图像文本检索、视觉问答、图像字幕、机器翻译和文本摘要。 结果表明,GOT 在所有任务的强大基线上提供了一致的性能增强。
2 图最优传输框架
2.1 问题表述
假设我们有来自两个不同域的两组实体(表示为 和 )。 对于每个集合,每个实体都由一个特征向量表示,即、和,其中和 分别是每个域中的实体数量。 本文的范围主要集中在涉及图像和文本的任务,因此这里的实体对应于图像中的对象或句子中的单词。 图像可以表示为一组检测到的对象,每个对象都与一个特征向量相关联(例如,来自预先训练的 Faster RCNN (Anderson 等人,2018)) 。 通过词嵌入层,句子可以表示为词特征向量序列。
深度神经网络 可以设计为将 和 作为初始输入,并生成上下文表示:
| (1) |
其中、和高级注意力机制(Bahdanau等人,2015;Vaswani等人,2017)可以应用于 模拟软对齐。 然后使用最终的监督信号来学习,即,训练目标定义为:
| (2) |
不同任务的几个实例总结如下:()图像文本检索。 和分别是图像和文本特征。 是二值标签,表示输入图像和句子是否配对。 这里可以是SCAN模型(Lee等人, 2018),对应排名损失(Faghri等人, 2018; Chechik等人,2010)。 () VQA。 这里 表示真实答案, 可以是 BUTD 或 BAN 模型 (Anderson 等人, 2018; Kim 等人, 2018), 是交叉熵损失。 () 机器翻译。 和 分别是源句子和目标句子的文本特征。 这里可以是编码器-解码器Transformer模型(Vaswani等人,2017),对应于对条件分布进行建模的交叉熵损失,这里不需要。 为了简化后续讨论,所有任务都被抽象为和。
在之前的大多数工作中,学习到的注意力可以解释为 和 之间的软对齐。 然而,只有最终的监督信号用于模型训练,因此缺乏明确鼓励跨域对齐的目标。 为了强制对齐并对模型训练施加正则化效果,我们提出了跨域对齐的新目标:
| (3) |
其中 是一个正则化项,它鼓励明确地对齐,而 是一个平衡这两项的超参数。 通过梯度反向传播,学习到的支持更有效的关系推理。 在2.4节中我们详细描述了。
2.2动态图构建
图像和文本数据本质上包含丰富的顺序/空间结构。 通过将它们表示为图并执行图对齐,不仅可以对跨域关系进行建模,还可以利用域内关系(例如,图像中检测到的对象之间的语义/空间关系(李等人,2019a))。
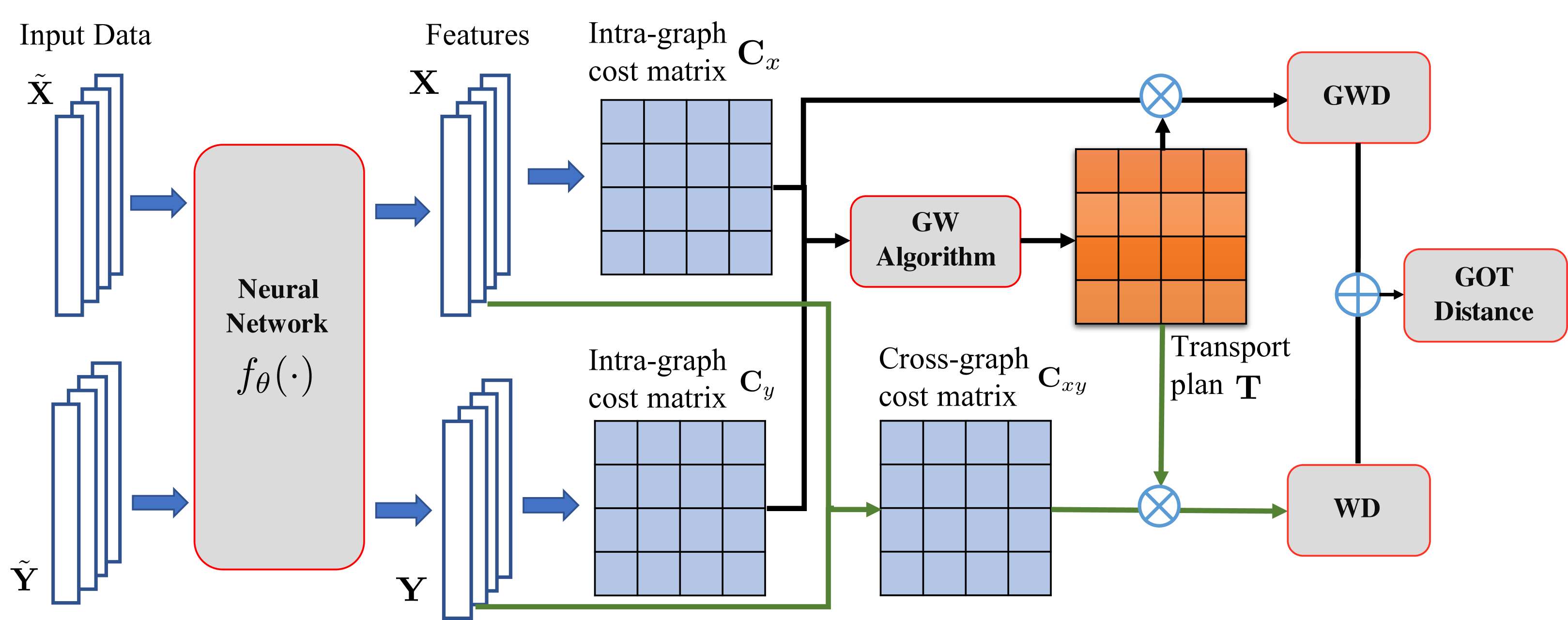
给定,我们的目标是构建一个图,其中每个节点由特征向量表示。 为了添加边,我们首先计算图中一对实体之间的相似度:。 此外,我们定义,其中是图成本矩阵的阈值超参数。 根据经验, 设置为 。 如果,则在节点和之间添加一条边。 给定,可以类似地构建另一个图。 由于和都是在训练过程中通过参数的更新而演变的,因此这个图构建过程被认为是“动态” 。 通过将两个域中的实体表示为图,跨域对齐自然地转化为图匹配问题。
在我们提出的框架中,我们使用最佳传输(OT)进行图匹配,其中学习传输计划来优化和之间的对齐。 OT 具有多种特殊特性,使其成为解决 CDA 问题的良好选择。 () 自归一化:的所有元素之和为1(Peyré等人, 2019)。 () 稀疏性:精确求解时,OT 会生成最多包含 个非零元素的稀疏解 ,其中,导致更可解释和更稳健的对齐(De Goes等人,2011)。 () 效率:与传统的线性规划求解器相比,我们的解决方案可以通过迭代过程轻松获得,只需要矩阵向量乘积(Xie等人,2018 ),因此很容易适用于大型深度神经网络。
2.3 最佳运输距离
如图1所示,我们的图匹配采用了两种类型的OT距离:用于节点匹配的Wasserstein距离和用于边匹配的Gromov-Wasserstein距离。
瓦瑟斯坦距离
Wasserstein 距离 (WD) 通常用于匹配两个分布(例如,两组节点嵌入)。 在我们的设置中,离散WD可以用作网络流和二分匹配的求解器(Luise等人,2018)。 WD的定义如下。
Definition 2.1。
让表示两个离散分布,公式为和,其中作为以。 表示所有联合分布 ,带有边际 和 。 权重向量 和 分别属于 和 维单纯形(即) >, ),其中 和 都是概率分布。 两个离散分布 之间的 Wasserstein 距离定义为:
| (4) |
其中,表示维全一向量,是评估 和 。 例如,余弦距离 是一个流行的选择。 矩阵表示传输计划,其中表示从转移到的质量量。
定义了最佳传输距离,用于测量两个域中每对样本之间的差异。 在我们的图匹配中,这是节点(实体)匹配的自然选择。
格罗莫夫-瓦瑟施泰因距离
Gromov-Wasserstein 距离 (GWD) (Peyré 等人, 2016; Chowdhury & Mémoli, 2019) 可用于计算节点对之间的距离,而不是像 WD 那样直接计算两组节点之间的距离。每个域内的节点,以及测量这些距离与对应域中的距离的比较。 离散匹配设置中的 GWD 可以表述如下。
Definition 2.2。
遵循与定义 2.1 中相同的符号, 之间的 Gromov-Wasserstein 距离定义为:
| (5) |
其中是评估两对节点和之间图内结构相似性的成本函数,即,,其中 是评估同一图中节点相似度的函数(例如,余弦相似度)。
与WD类似,在GWD设置中,和(对应于边)可以被视为对偶图中的两个节点(Van Lint等人,2001) ),其中边被投影到节点中。 学习到的矩阵 现在成为一个传输计划,有助于对齐不同图中的边。 请注意,相同的 和 也用于第 2 节中的图构造。 2.2。
2.4 通过OT距离进行图匹配
虽然GWD能够捕获图之间的边相似度,但它不能直接应用于图对齐,因为只考虑和之间的相似度,而不考虑节点表示。 例如,单词对(“boy”、“girl”)与单词对(“football”、“篮球”),但是这两对的语义完全不同,不应该匹配。
另一方面,WD 可以匹配不同图中的节点,但无法捕获边之间的相似性。 如果同一个图中存在由不同节点表示的重复实体,WD 会将它们视为相同的并忽略它们的相邻关系。 例如,给定一个句子“蓝色桌子上有一本红色的书”与包含几张不同颜色的桌子和书籍的图像配对,很难正确识别图像中的哪本书是该句子指的是不理解图像中物体之间的关系。
为了最好地结合 WD 和 GWD 并以互利的方式统一这两个距离,我们提出了 WD 和 GWD 共享的运输计划。 与天真地采用两种不同的传输计划相比,我们观察到这种联合计划效果更好(见表8),而且速度更快,因为我们只需要解决一次(而不是两次)。 直观上,通过共享传输计划,WD 和 GWD 可以有效地相互增强,因为 同时利用节点和边缘信息。 正式地,建议的 GOT 距离定义为:
| (6) |
我们应用Sinkhorn算法(Cuturi,2013;Cuturi & Peyré,2017)通过熵正则化器(Benamou等人,2015)求解WD(2.1) :
| (7) |
其中和是控制熵项重要性的超参数。 算法1中提供了详细信息。 GWD 的求解器可以根据算法 1 轻松开发,其中 被定义为均匀分布(如算法 2 所示),遵循 Alvarez-Melis & Jaakkola (2018)。 借助Sinkhorn算法,GOT可以在流行的深度学习库(例如PyTorch和TensorFlow)中高效实现。
为了获得 GOT 距离的统一求解器,我们将统一成本函数定义为:
| (8) |
其中是用于控制不同成本函数重要性的超参数。 而不是像 Xu 等人 (2019b, a) 中那样使用投影梯度下降或共轭梯度下降; Vayer等人(2018),我们可以通过在算法2中添加回来近似运输计划,使得第9行算法2有助于同时求解WD和GWD的,从而有效地同时匹配节点和边。 计算GOT距离的求解器如图2所示,详细算法总结在算法3中。 计算出的GOT距离作为(3)中的跨域对齐损失,作为更新参数的正则化器。
3相关工作
最佳运输
Wasserstein 距离 (WD),又名 Earth Mover 的距离,已广泛应用于机器学习任务。 在计算机视觉领域,Rubner等人(1998)使用WD来发现颜色分布的结构以进行图像搜索。 在自然语言处理中,WD已应用于文档检索(Kusner等人,2015)和序列到序列学习(Chen等人,2019a)。 还有在生成对抗网络(GAN)中采用WD的研究(Goodfellow等人,2014;Salimans等人,2018;Chen等人,2018;Mroueh等人,2018;Zhang等人,2020) 缓解模式崩溃问题。 最近,它还被用于视觉和语言预训练,以鼓励单词区域对齐(Chen等人,2019b)。 除了WD之外,Gromov-Wassersten距离(Peyré等人,2016)也被提出用于分布式度量匹配,并应用于无监督机器翻译(Alvarez-Melis & Jaakkola,2018) 。
求解OT距离有不同的方法,例如线性规划。 然而,该求解器是不可微的,因此不能应用于深度学习框架。 最近,WGAN (Arjovsky 等人, 2017)提出通过对判别器施加 1-Lipschitz 约束来近似 WD 的对偶形式。 请注意,用于 WGAN 的对偶性仅限于 W-1 距离 、。 Sinkhorn 算法首先在 Cuturi (2013) 中提出,作为计算熵正则化 OT 距离的求解器。 得益于包络定理(Cuturi & Peyré,2017),Sinkhorn 算法可以高效计算并轻松应用于神经网络。 最近,Vayer 等人 (2018) 提出了用于图匹配的融合 GWD。 我们提出的 GOT 框架兼具 Sinkhorn 算法和融合 GWD 的优点:它 () 能够通过结合 WD 和 GWD 来捕获更多结构化信息; () 可扩展到大型数据集并可通过深度神经网络进行训练。
| Sentence Retrieval | Image Retrieval | ||||||
|---|---|---|---|---|---|---|---|
| Method | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | Rsum |
| VSE++ (ResNet) (Faghri et al., 2018) | 52.9 | – | 87.2 | 39.6 | – | 79.5 | – |
| DPC (ResNet) (Zheng et al., 2020) | 55.6 | 81.9 | 89.5 | 39.1 | 69.2 | 80.9 | 416.2 |
| DAN (ResNet) (Nam et al., 2017) | 55.0 | 81.8 | 89.0 | 39.4 | 69.2 | 79.1 | 413.5 |
| SCO (ResNet) (Huang et al., 2018) | 55.5 | 82.0 | 89.3 | 41.1 | 70.5 | 80.1 | 418.5 |
| SCAN (Faster R-CNN, ResNet) (Lee et al., 2018) | 67.7 | 88.9 | 94.0 | 44.0 | 74.2 | 82.6 | 452.2 |
| Ours (Faster R-CNN, ResNet): | |||||||
| SCAN + WD | 70.9 | 92.3 | 95.2 | 49.7 | 78.2 | 86.0 | 472.3 |
| SCAN + GWD | 69.5 | 91.2 | 95.2 | 48.8 | 78.1 | 85.8 | 468.6 |
| SCAN + GOT | 70.9 | 92.8 | 95.5 | 50.7 | 78.7 | 86.2 | 474.8 |
| VSE++ (ResNet) (Faghri et al., 2018) | 41.3 | – | 81.2 | 30.3 | – | 72.4 | – |
| DPC (ResNet) (Zheng et al., 2020) | 41.2 | 70.5 | 81.1 | 25.3 | 53.4 | 66.4 | 337.9 |
| GXN (ResNet) (Gu et al., 2018) | 42.0 | – | 84.7 | 31.7 | – | 74.6 | – |
| SCO (ResNet) (Huang et al., 2018) | 42.8 | 72.3 | 83.0 | 33.1 | 62.9 | 75.5 | 369.6 |
| SCAN (Faster R-CNN, ResNet)(Lee et al., 2018) | 46.4 | 77.4 | 87.2 | 34.4 | 63.7 | 75.7 | 384.8 |
| Ours (Faster R-CNN, ResNet): | |||||||
| SCAN + WD | 50.2 | 80.1 | 89.5 | 37.9 | 66.8 | 78.1 | 402.6 |
| SCAN + GWD | 47.2 | 78.3 | 87.5 | 34.9 | 64.4 | 76.3 | 388.6 |
| SCAN + GOT | 50.5 | 80.2 | 89.8 | 38.1 | 66.8 | 78.5 | 403.9 |
图神经网络
Gori 等人 (2005) 首次使用循环神经网络引入了对图数据进行操作的神经网络。 后来,Duvenaud 等人 (2015) 提出了一种基于图的卷积神经网络用于分类任务。 然而,这些方法存在可扩展性问题,因为它们需要学习大型图的特定于节点度的权重矩阵。 为了缓解这个问题,Kipf & Welling (2016)提出在神经网络中每层使用单个权重矩阵,它能够通过对神经网络的邻接矩阵进行适当的归一化来处理不同的节点度。数据。 为了进一步提高分类精度,通过使用学习的权重矩阵代替邻接矩阵,提出了图注意网络(GAT)(Veličković等人,2018),并对聚合节点邻域信息进行屏蔽注意。
最近,图神经网络已扩展到分类之外的其他任务。 Li等人(2019b)提出了图匹配网络(GMN)来学习图之间的相似性。 与 GAT 类似,屏蔽注意力应用于聚合图中每个节点的信息,并通过软注意力进一步利用跨图信息。 然后使用特定于任务的损失来指导模型训练。 在这种设置中,可以直接从数据中获得邻接矩阵,并使用软注意力来诱导对齐。 相比之下,我们的 GOT 框架不依赖于数据中显式的图结构,而是使用 OT 进行图对齐。
4实验
为了验证所提出的 GOT 框架的有效性,我们评估了一系列不同任务的性能。 我们首先考虑视觉和语言理解,包括:()图像文本检索和()视觉问答。 我们进一步考虑文本生成任务,包括:()图像字幕、()机器翻译和()抽象文本摘要。 代码可在 https://github.com/LiqunChen0606/Graph-Optimal-Transport 获取。
4.1 视觉和语言任务
图文检索
对于图像文本检索任务,我们使用预训练的 Faster R-CNN (Ren 等人, 2015) 来提取自下而上的注意力特征(Anderson 等人, 2018)(Anderson 等人, 2018) t1> 作为图像表示。 为每个图像创建一组 36 个特征,每个特征由一个 2048 维向量表示。 对于字幕,使用双向 GRU (Schuster & Paliwal,1997;Bahdanau 等人,2015) 来获取文本特征。
我们在 Flickr30K (Plummer 等人, 2015) 和 COCO (Lin 等人, 2014) 数据集上评估我们的模型。 Flickr30K 包含 、 图像,每个图像有五个人工注释的标题。 我们遵循之前的工作(Karpathy&Fei-Fei,2015;Faghri等人,2018)进行数据分割:,,、 和 、 图像分别用于训练、验证和测试。 COCO包含,图像,每个图像还附有五个标题。 我们按照Faghri 等人 (2018) 中的数据拆分,其中 ,, , 和 、 图像分别用于验证和测试。
我们在 (R@) (Karpathy & Fei-Fei, 2015) 上测量图像检索和句子检索在 Recall 上的性能,定义为在排名最高的结果中检索正确图像/句子的查询的百分比。 在我们的实验中,使用和Rsum (Huang 等人, 2017)(对所有R@求和)来评估整体性能。 结果总结于表1中。 WD和GWD都可以提升SCAN模型的性能,而WD比GWD获得更大的裕度。 这表明单独使用时,GWD 可能不是图形对齐的良好指标。 当将两个距离结合在一起时,GOT 实现了最佳性能。
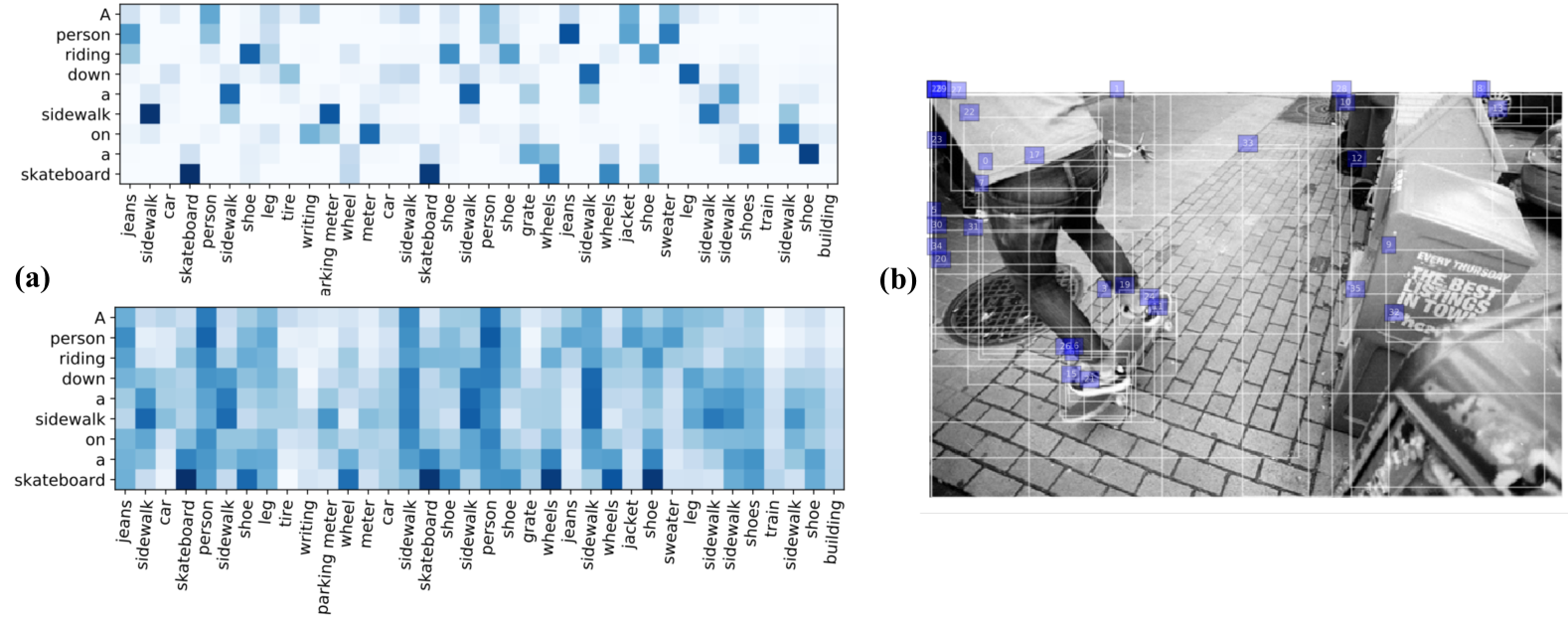
图3提供了GOT中学习到的传输计划和SCAN中学习到的注意力矩阵的可视化。 两者都可以作为代理来深入了解学习到的对齐方式。 如图所示,SCAN 的注意力矩阵比 GOT 推断的传输计划密集得多,噪声也大得多。 这表明我们的模型可以更好地发现图像-文本对之间的跨域关系,因为推断的传输计划更具可解释性并且歧义性更少。 例如,单词“sidewalk”和“skateboard”都与相应的图像区域非常匹配。
由于包络定理(Cuturi & Peyré, 2017),仅在模型 的前向阶段需要计算 GOT 。 因此,它不会引入太多额外的计算时间。 例如,使用同一台机器进行图文检索实验时,SCAN 需要 6 小时 34 分钟,SCAN+GOT 需要 6 小时 57 分钟。
视觉问答
| Model | BAN | BAN+GWD | BAN+WD | BAN+GOT |
|---|---|---|---|---|
| Score | 66.00 | 66.21 | 66.26 | 66.44 |
| Model | BUTD | BAN-1 | BAN-2 | BAN-4 | BAN-8 |
|---|---|---|---|---|---|
| w/o GOT | 63.37 | 65.37 | 65.61 | 65.81 | 66.00 |
| w/ GOT | 65.01 | 65.68 | 65.88 | 66.10 | 66.44 |
我们还考虑了 VQA 2.0 数据集(Goyal 等人,2017),其中包含 COCO 图像上人工注释的 QA 对(Lin 等人,2014)。 对于每张图像,平均收集 个问题,每个问题有 个候选答案。 选择注释者最常见的答案作为正确答案。 继之前的工作(Kim等人,2018)之后,我们将训练集中出现超过9次的答案作为候选答案,从而产生个候选答案。 采用分类准确率作为评价指标,定义为 .
以BAN模型(Kim等人,2018)为基线,与原始代码库进行公平比较。 结果总结于表2中。 WD 和 GWD 都改进了验证集上的 BAN 模型,GOT 实现了进一步的性能提升。
我们还研究了不同的架构设计是否会影响性能增益。 我们将 BUTD (Anderson 等人, 2018) 作为附加基线,并将不同数量的瞥见 应用于 BAN 模型,表示为 BAN-。 结果总结在表3中,观察结果如下:() 当测试模型中的参数数量较少时,例如BUTD,GOT带来的改进为更有意义。 () BAN-4是比BAN-8更简单的模型,与GOT结合使用时,在不使用GOT的情况下可以超越BAN-8(66.10 vs. 66.00)。 () 对于 BAN-8 等可能改进空间有限的复杂模型,GOT 仍然能够实现性能增益。
| Method | CIDEr | BLEU-4 | BLUE-3 | BLEU-2 | BLEU-1 | ROUGE | METEOR |
|---|---|---|---|---|---|---|---|
| Soft Attention (Xu et al., 2015) | - | 24.3 | 34.4 | 49.2 | 70.7 | - | 23.9 |
| Hard Attention (Xu et al., 2015) | - | 25.0 | 35.7 | 50.4 | 71.8 | - | 23.0 |
| Show & Tell (Vinyals et al., 2015) | 85.5 | 27.7 | - | - | - | - | 23.7 |
| ATT-FCN (You et al., 2016) | - | 30.4 | 40.2 | 53.7 | 70.9 | - | 24.3 |
| SCN-LSTM (Gan et al., 2017) | 101.2 | 33.0 | 43.3 | 56.6 | 72.8 | - | 25.7 |
| Adaptive Attention (Lu et al., 2017) | 108.5 | 33.2 | 43.9 | 58.0 | 74.2 | - | 26.6 |
| MLE | 106.3 | 34.3 | 45.3 | 59.3 | 75.6 | 55.2 | 26.2 |
| MLE + WD | 107.9 | 34.8 | 46.1 | 60.1 | 76.2 | 55.6 | 26.5 |
| MLE + GWD | 106.6 | 33.3 | 45.2 | 59.1 | 75.7 | 55.0 | 25.9 |
| MLE + GOT | 109.2 | 35.1 | 46.5 | 60.3 | 77.0 | 56.2 | 26.7 |
| Model | EN-VI uncased | EN-VI cased | EN-DE uncased | EN-DE cased |
|---|---|---|---|---|
| Transformer (Vaswani et al., 2017) | ||||
| Transformer + WD | ||||
| Transformer + GWD | ||||
| Transformer + GOT |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| ABS+ (Rush et al., 2015) | |||
| LSTM (Hu et al., 2018) | |||
| LSTM + GWD | |||
| LSTM + WD | |||
| LSTM + GOT |
4.2 文本生成任务
图像字幕
我们使用相同的 COCO 数据集进行图像字幕实验。 这里采用与图像文本检索相同的自下而上的注意力特征(Anderson等人,2018)。 文本解码器是具有 256 个隐藏单元的一层 LSTM。 词嵌入维度设置为256。 结果总结于表4中。 GOT 也引入了类似的性能提升。 从 WD 到 GOT 相对于 CIDEr 分数的相对性能提升为:。 这归功于 GOT 中引入的额外 GWD,它可以帮助对图像和字幕中隐式的域内关系进行建模,从而生成更准确的字幕。
机器翻译
在机器翻译(和抽象摘要)中,源句子和目标句子的词嵌入空间不同,可以认为是不同的域。 因此,GOT 可以用来对齐源句子和目标句子之间具有相似语义的单词,以实现更好的翻译/总结。 我们选择两个机器翻译基准进行实验:() 英语-越南语 TED-talks 语料库,其中包含来自 IWSLT 评估活动的 K 对句子 (Cettolo 等人,2015); () 包含 M 对句子的大规模英德平行语料库,来自 WMT 评估活动(Vaswani 等人,2017)。 我们的实验中使用了 Texar 代码库 (Hu 等人, 2018)。
我们将 GOT 应用于 Transformer 模型(Vaswani 等人,2017),并使用 BLEU 分数(Papineni 等人,2002)作为评估指标。 结果总结于表5中。 正如 Chen 等人 (2019a) 中所观察到的,使用 WD 可以提高 Transformer 进行序列到序列学习的性能。 然而,如果仅使用GWD,测试BLEU分数会下降。 由于 GWD 只能匹配边,因此它忽略了来自节点表示的监督信号。 这作为经验证据支持我们的假设,即单独使用 GWD 可能不足以提高性能。 然而,GWD 可以作为一种补充方法来捕获 WD 可能会错过的图形信息。 因此,当两者结合在一起时,GOT可以获得最佳的性能。 表 7 中提供了翻译示例。

| Reference: | India’s new prime minister, Narendra Modi, is meeting his Japanese counterpart, Shinzo Abe, in Tokyo to discuss |
|---|---|
| economic and security ties, on his first major foreign visit since winning May’s election. | |
| MLE: | India ‘ s new prime minister , Narendra Modi , meets his Japanese counterpart , Shinzo Abe , in Tokyo , during his |
| first major foreign visit in May to discuss economic and security relations . | |
| GOT: | India ’ s new prime minister , Narendra Modi , is meeting his Japanese counterpart Shinzo Abe in Tokyo in his first |
| major foreign visit since his election victory in May to discuss economic and security relations. | |
| Reference: | Chinese leaders presented the Sunday ruling as a democratic breakthrough because it gives Hong Kongers a direct |
| vote, but the decision also makes clear that Chinese leaders would retain a firm hold on the process through a | |
| nominating committee tightly controlled by Beijing. | |
| MLE: | The Chinese leadership presented the decision of Sunday as a democratic breakthrough , because it gives Hong |
| Kong citizens a direct right to vote , but the decision also makes it clear that the Chinese leadership maintains the | |
| expiration of a nomination committee closely controlled by Beijing . | |
| GOT: | The Chinese leadership presented the decision on Sunday as a democratic breakthrough , because Hong Kong |
| citizens have a direct electoral right , but the decision also makes it clear that the Chinese leadership remains | |
| firmly in hand with a nominating committee controlled by Beijing. |
抽象概括
4.3消融研究
我们对机器翻译的 EN-VI 和 EN-DE 数据集进行了额外的消融研究。
共享交通计划
正如第 2 节中所讨论的。 2.4,我们使用共享传输计划来解决GOT距离。 另一种方法是不共享此 矩阵。 比较结果如表8所示。 具有共享传输计划的 GOT 比替代方案取得了更好的性能。 由于我们只需要运行迭代 Sinkhorn 算法一次,因此它也比非共享情况节省了训练时间。
| Model | EN-VI uncased | EN-DE uncased |
|---|---|---|
| GOT (shared) | ||
| GOT (unshared) |
| 0 | 0.1 | 0.3 | 0.5 | 0.8 | 1.0 | |
|---|---|---|---|---|---|---|
| BLEU | 29.92 |
超参数
5结论
我们提出了图最优传输(Graph Optimal Transport),这是一个跨域对齐的原则框架。 利用 Wasserstein 和 Gromov-Wasserstein 距离,可以捕获域内和跨域关系,以便更好地对齐。 根据经验,我们观察到强制对齐可以作为模型训练的有效正则化器。 大量实验表明,所提出的方法是一个通用框架,可以应用于广泛的跨领域任务。 对于未来的工作,我们计划将所提出的框架应用于自监督表示学习。
致谢
作者要感谢匿名审稿人富有洞察力的评论。 杜克大学的这项研究得到了 DARPA、DOE、NIH、NSF 和 ONR 的部分支持。
参考
- Alvarez-Melis & Jaakkola (2018) Alvarez-Melis, D. and Jaakkola, T. S. Gromov-wasserstein alignment of word embedding spaces. arXiv:1809.00013, 2018.
- Anderson et al. (2018) Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., and Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, 2018.
- Antol et al. (2015) Antol, S. et al. Vqa: Visual question answering. In ICCV, 2015.
- Arjovsky et al. (2017) Arjovsky, M. et al. Wasserstein generative adversarial networks. In ICML, 2017.
- Bahdanau et al. (2015) Bahdanau, D., Cho, K., and Bengio, Y. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
- Benamou et al. (2015) Benamou, J.-D., Carlier, G., Cuturi, M., Nenna, L., and Peyré, G. Iterative bregman projections for regularized transportation problems. SIAM Journal on Scientific Computing, 2015.
- Cettolo et al. (2015) Cettolo, M., Niehues, J., Stüker, S., Bentivogli, L., Cattoni, R., and Federico, M. The IWSLT 2015 evaluation campaign. In International Workshop on Spoken Language Translation, 2015.
- Chechik et al. (2010) Chechik, G., Sharma, V., Shalit, U., and Bengio, S. Large scale online learning of image similarity through ranking. Journal of Machine Learning Research, 2010.
- Chen et al. (2018) Chen, L., Dai, S., Tao, C., Zhang, H., Gan, Z., Shen, D., Zhang, Y., Wang, G., Zhang, R., and Carin, L. Adversarial text generation via feature-mover’s distance. In NeurIPS, 2018.
- Chen et al. (2019a) Chen, L., Zhang, Y., Zhang, R., Tao, C., Gan, Z., Zhang, H., Li, B., Shen, D., Chen, C., and Carin, L. Improving sequence-to-sequence learning via optimal transport. arXiv preprint arXiv:1901.06283, 2019a.
- Chen et al. (2019b) Chen, Y.-C., Li, L., Yu, L., Kholy, A. E., Ahmed, F., Gan, Z., Cheng, Y., and Liu, J. Uniter: Learning universal image-text representations. arXiv preprint arXiv:1909.11740, 2019b.
- Chowdhury & Mémoli (2019) Chowdhury, S. and Mémoli, F. The gromov–wasserstein distance between networks and stable network invariants. Information and Inference: A Journal of the IMA, 2019.
- Cuturi (2013) Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. In NeurIPS, 2013.
- Cuturi & Peyré (2017) Cuturi, M. and Peyré, G. Computational optimal transport. 2017.
- De Goes et al. (2011) De Goes, F. et al. An optimal transport approach to robust reconstruction and simplification of 2d shapes. In Computer Graphics Forum, 2011.
- Duvenaud et al. (2015) Duvenaud, D. K., Maclaurin, D., Iparraguirre, J., Bombarell, R., Hirzel, T., Aspuru-Guzik, A., and Adams, R. P. Convolutional networks on graphs for learning molecular fingerprints. In NeurIPS, 2015.
- Faghri et al. (2018) Faghri, F., Fleet, D. J., Kiros, J. R., and Fidler, S. Vse++: Improved visual-semantic embeddings. In BMVC, 2018.
- Gan et al. (2017) Gan, Z., Gan, C., He, X., Pu, Y., Tran, K., Gao, J., Carin, L., and Deng, L. Semantic compositional networks for visual captioning. In CVPR, 2017.
- Goodfellow et al. (2014) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In NeurIPS, 2014.
- Gori et al. (2005) Gori, M., Monfardini, G., and Scarselli, F. A new model for learning in graph domains. In IEEE International Joint Conference on Neural Networks, 2005.
- Goyal et al. (2017) Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., and Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017.
- Graff et al. (2003) Graff, D., Kong, J., Chen, K., and Maeda, K. English gigaword. Linguistic Data Consortium, Philadelphia, 2003.
- Gu et al. (2018) Gu, J., Cai, J., Joty, S. R., Niu, L., and Wang, G. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models. In CVPR, 2018.
- Hu et al. (2018) Hu, Z., Shi, H., Yang, Z., Tan, B., Zhao, T., He, J., Wang, W., Yu, X., Qin, L., Wang, D., et al. Texar: A modularized, versatile, and extensible toolkit for text generation. arXiv preprint arXiv:1809.00794, 2018.
- Huang et al. (2017) Huang, Y., Wang, W., and Wang, L. Instance-aware image and sentence matching with selective multimodal lstm. In CVPR, 2017.
- Huang et al. (2018) Huang, Y., Wu, Q., Song, C., and Wang, L. Learning semantic concepts and order for image and sentence matching. In CVPR, 2018.
- Karpathy & Fei-Fei (2015) Karpathy, A. and Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In CVPR, 2015.
- Kim et al. (2018) Kim, J.-H., Jun, J., and Zhang, B.-T. Bilinear attention networks. In NeurIPS, 2018.
- Kipf & Welling (2016) Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. arXiv:1609.02907, 2016.
- Kusner et al. (2015) Kusner, M., Sun, Y., Kolkin, N., and Weinberger, K. From word embeddings to document distances. In ICML, 2015.
- Lee et al. (2018) Lee, K.-H. et al. Stacked cross attention for image-text matching. In ECCV, 2018.
- Li et al. (2019a) Li, L., Gan, Z., Cheng, Y., and Liu, J. Relation-aware graph attention network for visual question answering. In ICCV, 2019a.
- Li et al. (2019b) Li, Y., Gu, C., Dullien, T., Vinyals, O., and Kohli, P. Graph matching networks for learning the similarity of graph structured objects. In ICML, 2019b.
- Lin (2004) Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. Text Summarization Branches Out, 2004.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft COCO: Common objects in context. In ECCV, 2014.
- Lu et al. (2017) Lu, J., Xiong, C., Parikh, D., and Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In CVPR, 2017.
- Luise et al. (2018) Luise, G., Rudi, A., Pontil, M., and Ciliberto, C. Differential properties of sinkhorn approximation for learning with wasserstein distance. arXiv:1805.11897, 2018.
- Malinowski & Fritz (2014) Malinowski, M. and Fritz, M. A multi-world approach to question answering about real-world scenes based on uncertain input. In NeurIPS, 2014.
- Maretic et al. (2019) Maretic, H. P., El Gheche, M., Chierchia, G., and Frossard, P. Got: an optimal transport framework for graph comparison. In NeurIPS, 2019.
- Mroueh et al. (2018) Mroueh, Y., Li, C.-L., Sercu, T., Raj, A., and Cheng, Y. Sobolev GAN. In ICLR, 2018.
- Nam et al. (2017) Nam, H., Ha, J.-W., and Kim, J. Dual attention networks for multimodal reasoning and matching. In CVPR, 2017.
- Papineni et al. (2002) Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. BLEU: a method for automatic evaluation of machine translation. In ACL, 2002.
- Peyré et al. (2016) Peyré, G., Cuturi, M., and Solomon, J. Gromov-wasserstein averaging of kernel and distance matrices. In ICML, 2016.
- Peyré et al. (2019) Peyré, G., Cuturi, M., et al. Computational optimal transport. Foundations and Trends® in Machine Learning, 2019.
- Plummer et al. (2015) Plummer, B. A. et al. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, 2015.
- Ren et al. (2015) Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
- Rubner et al. (1998) Rubner, Y., Tomasi, C., and Guibas, L. J. A metric for distributions with applications to image databases. In ICCV, 1998.
- Rush et al. (2015) Rush, A. M., Chopra, S., and Weston, J. A neural attention model for abstractive sentence summarization. In EMNLP, 2015.
- Salimans et al. (2018) Salimans, T., Zhang, H., Radford, A., and Metaxas, D. Improving GANs using optimal transport. In ICLR, 2018.
- Schuster & Paliwal (1997) Schuster, M. and Paliwal, K. K. Bidirectional recurrent neural networks. Transactions on Signal Processing, 1997.
- Van Lint et al. (2001) Van Lint, J. H., Wilson, R. M., and Wilson, R. M. A course in combinatorics. Cambridge university press, 2001.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. In NeurIPS, 2017.
- Vayer et al. (2018) Vayer, T., Chapel, L., Flamary, R., Tavenard, R., and Courty, N. Optimal transport for structured data with application on graphs. arXiv:1805.09114, 2018.
- Veličković et al. (2018) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y. Graph attention networks. In ICLR, 2018.
- Vinyals et al. (2015) Vinyals, O., Toshev, A., Bengio, S., and Erhan, D. Show and tell: A neural image caption generator. In CVPR, 2015.
- Xie et al. (2018) Xie, Y., Wang, X., Wang, R., and Zha, H. A fast proximal point method for Wasserstein distance. In arXiv:1802.04307, 2018.
- Xu et al. (2019a) Xu, H., Luo, D., and Carin, L. Scalable gromov-wasserstein learning for graph partitioning and matching. In NeurIPS, 2019a.
- Xu et al. (2019b) Xu, H., Luo, D., Zha, H., and Carin, L. Gromov-wasserstein learning for graph matching and node embedding. In ICML, 2019b.
- Xu et al. (2015) Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A. C., Salakhutdinov, R., Zemel, R. S., and Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
- Yang et al. (2016a) Yang, Z., He, X., Gao, J., Deng, L., and Smola, A. Stacked attention networks for image question answering. In CVPR, 2016a.
- Yang et al. (2016b) Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., and Hovy, E. Hierarchical attention networks for document classification. In NAACL, 2016b.
- Yao et al. (2018) Yao, T., Pan, Y., Li, Y., and Mei, T. Exploring visual relationship for image captioning. In ECCV, 2018.
- You et al. (2016) You, Q., Jin, H., Wang, Z., Fang, C., and Luo, J. Image captioning with semantic attention. In CVPR, 2016.
- Yu et al. (2019) Yu, Z., Yu, J., Cui, Y., Tao, D., and Tian, Q. Deep modular co-attention networks for visual question answering. In CVPR, 2019.
- Zhang et al. (2020) Zhang, R., Chen, C., Gan, Z., Wen, Z., Wang, W., and Carin, L. Nested-wasserstein self-imitation learning for sequence generation. arXiv:2001.06944, 2020.
- Zheng et al. (2020) Zheng, Z., Zheng, L., Garrett, M., Yang, Y., Xu, M., and Shen, Y.-D. Dual-path convolutional image-text embeddings with instance loss. TOMM, 2020.