具有持续学习功能的图神经网络用于社交媒体假新闻检测
摘要。
尽管我们在事实核查方面付出了巨大的努力,但社交媒体上假新闻的盛行仍然是一个严重的问题,这对正义、公众信任和整个社会产生了深远的影响。 在这项工作中,我们专注于基于传播的假新闻检测,因为最近的研究表明假新闻和真实新闻在网上的传播方式不同。 具体来说,考虑到图神经网络(GNN)处理非欧几里得数据的能力,我们使用 GNN 来区分社交媒体上假新闻和真实新闻的传播模式。 我们特别关注两个问题:(1)在不依赖任何文本信息(例如推文内容、回复和用户描述)的情况下,GNN 识别假新闻的准确度如何? 众所周知,机器学习模型容易受到对抗性攻击,避免对基于文本的特征的依赖可以使模型不易受到高级假新闻制造者的操纵。 (2) 如何处理新的、未见过的数据? 换句话说,在给定数据集上训练的 GNN 在新的且可能截然不同的数据集上表现如何? 如果它的性能不令人满意,我们如何解决问题,而不需要从头开始在整个数据上重新训练模型,随着数据量的增长,这在实践中会变得非常昂贵? 我们在两个包含数千个标记新闻项的数据集上研究了上述问题,我们的结果表明:(1)GNN 可以在没有任何文本信息的情况下实现与最先进方法相当或更好的性能。 (2) 在给定数据集上训练的 GNN 可能在新的、未见过的数据上表现不佳,直接增量无法解决问题——这个问题在之前应用 GNN 进行假新闻检测的工作中尚未得到解决。 为了解决这个问题,我们提出了一种方法,通过使用从持续学习到增量训练 GNN 的技术,在现有数据集和新数据集上实现平衡的性能。
1. 介绍
虽然社交媒体促进了世界各地各种类型信息的及时传递,但其结果是新闻以前所未有的速度出现,使得事实核查变得越来越困难。 近年来发生的一系列事件表明,假新闻对社会造成的巨大危害。 因此,如何在假新闻广泛传播之前自动、准确地识别它已成为研究的紧迫挑战。 这里我们使用(Zhou and Zafarani,2018)中的定义:假新闻是新闻媒体故意发布的、可验证的虚假新闻——类似的定义也被用在之前的文章中。假新闻检测研究(Monti 等人,2019;Shu 等人,2019a,2017;Ruchansky 等人,2017)。
在我们的工作中,我们专注于基于传播的假新闻检测方法。 换句话说,我们利用新闻在社交媒体上的传播模式,例如,推特上新闻的推文和转发,来判断新闻是否虚假。 这种方法的可行性建立在(1)经验证据表明假新闻和真实新闻在网上的传播方式不同(Vosoughi等人,2018); (2)图神经网络(GNN)的最新进展(Bruna 等人,2013;Niepert 等人,2016;Ying 等人,2018;Wu 等人,2019)增强了机器学习模型在非欧几里得数据上的性能。 此外,正如(Monti等人,2019)中指出的,基于内容的方法需要句法和语义分析,而基于传播的方法与语言无关,并且不太容易受到对抗性攻击(Szegedy 等人,2013;Goodfellow 等人,2014),高级新闻制造者小心地操纵内容以绕过检测。
利用传播模式来检测假新闻的想法已经在之前的一些研究中得到了探索(Wu等人,2015;Ma等人,2017;Wu和Liu,2018;Liu和Wu,2018;Zhou和Zafarani , 2019; Shu 等人, 2019b),其中考虑了不同类型的模型:Wu et al. (Wu 等人, 2015) 使用混合支持向量机(SVM),Ma等人(Ma等人,2017)使用Propagation Tree Kernel; Wu 等人 (Wu and Liu,2018)将长短期记忆(LSTM)单元纳入循环神经网络(RNN)模型; Liu 等人 (Liu and Wu,2018)同时使用 RNN 和卷积神经网络 (CNN); Shu 等人 (Shu 等人,2019b)0>和周等人1> (Zhou 和 Zafarani,2019)2> 提出不同类型的特征并比较多种常用的机器学习模型。 最相关的作品包括(Monti 等人, 2019; Lu and Li, 2020; Bian 等人, 2020),它们也应用 GNN 来研究传播模式。 然而,除了选择专门为图分类设计的不同GNN算法(进一步解释请参阅第2节)外,我们的工作主要集中在以下问题:
-
•
问题 1:在不依赖任何文本信息(例如推文内容、回复和用户描述)的情况下,GNN 识别假新闻的准确度如何? 3 节证明,即使我们的模型仅限于从用户个人资料和时间线推文中获得的一组有限的非文本特征,GNN 也可以根据传播模式和这些特征进行训练,以实现可比较的目标或优于需要对推文内容、用户回复等进行复杂分析的最先进方法的性能。我们认为,有限的功能集可以进一步增强我们的模型抵御对抗性攻击的安全性,正如之前的工作所表明的那样高维度有利于对抗样本的生成,从而导致攻击面增加(王等人,2016)。
-
•
问题2:如何处理新的、未见过的数据? 上述问题仅涉及 GNN 在单个数据集上的性能。 然而,经过训练的模型在实践中可能面临截然不同的数据,进一步研究模型在这种情况下的表现非常重要。 具体来说,我们发现在给定数据集上训练的 GNN 在另一个数据集上可能表现不佳,直接增量训练无法解决问题——这个问题在之前使用 GNN 进行假新闻检测的工作中尚未讨论过。 为了解决这个问题,我们提出了一种方法,将持续学习的技术逐步应用于训练 GNN,以便它们在现有数据集和新数据集上实现平衡的性能。 该方法避免了从头开始在整个数据上重新训练模型——新数据总是存在,随着数据量的增长,这会变得极其昂贵。
2. 图神经网络背景
尽管深度学习在图像分类、自然语言处理和语音识别等广泛应用中取得了巨大成功,但它主要处理欧几里得空间中的数据。 相比之下,GNN (Bruna 等人,2013;Niepert 等人,2016;Ying 等人,2018;Wu 等人,2019) 旨在处理从非欧几里得域生成的数据。
考虑一个具有 顶点/节点和 边的图 ,其中 是邻接矩阵。 如果存在从节点 到节点 的边,否则为 ; 是特征矩阵,即每个节点都有个特征。 给定 和 作为输入,GNN 的输出,即节点嵌入,在 步骤之后是:,其中是由参数化的传播函数,由特征矩阵初始化,即。
传播函数有多种实现方式。 该函数的简单形式是:,其中是非线性激活函数,例如是修正线性单元(ReLU)函数, 是层 的权重矩阵。该函数的一个流行实现是 (Kipf 和 Welling,2017):,其中 、。 更多功能选择请参考(Wu 等人, 2019)。
GNN 可以根据需求执行节点回归、节点分类、链接预测、边缘分类或图分类。 在我们的工作中,由于目标是标记每条新闻的传播模式,这是一个图,因此我们选择专门为图设计的 DiffPool (Ying 等人, 2018) 算法分类。 DiffPool 通过进一步考虑图的结构信息来扩展任何现有的 GNN 模型。 在每一层,DiffPool 获取原始输出 和邻接矩阵 ,并学习 节点的粗化图,其中邻接矩阵 和节点嵌入 。
3. 基于传播的假新闻检测
正如引言中提到的,我们使用(Zhou and Zafarani,2018)中的定义,假新闻是新闻媒体故意发布的、可验证的虚假新闻。 一条新闻发布后,可能会被多个用户发布推文。 我们将这些直接引用新闻 URL 的推文称为 root 推文。 他们中的每一个以及他们的转发形成了一个单独的级联(Vosoughi等人,2018),所有级联形成了一条新闻的传播模式。 这项工作的目的是利用新闻的传播模式来确定新闻的有效性。
正式地,我们将基于传播的假新闻检测问题定义如下:给定一组标记图,其中是新闻的传播模式,是图的标签,目标是学习标记每个图的映射。
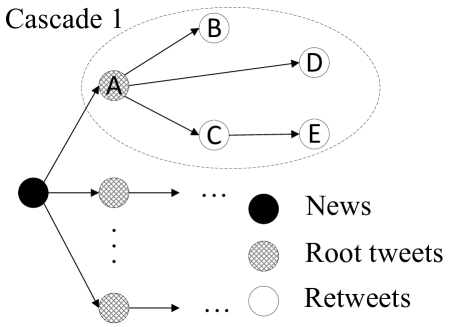
3.1. 数据生成
为了生成新闻传播模式,我们使用 FakeNewsNet (Shu 等人, 2018) 的数据集,该数据集是专门为虚假新闻检测而收集的。 FakeNewsNet 包含来自两个网站的带标签新闻:politifact.com111https://www.politifact.com/ 和 gossipcop.com222https://www.gossipcop.com/——新闻内容包括语言和视觉信息,每条新闻的所有推文和转发,以及对应的Twitter用户的信息(参见(Shu等)人,2018)2> 了解更多详情)。
邻接矩阵。 如图1所示,每条新闻都被表示为一个图,其中一个节点指的是一条推文(包括相应的用户)——要么是引用该新闻的根推文,要么是它的转发。 一种特殊情况是添加一个代表新闻的额外节点将所有级联连接在一起。 该节点的所有特征值均设置为零。 这里的边代表信息流,即新闻如何从一个人传递到另一个人。 然而,Twitter API 不提供转发的直接来源,例如,在图1的级联 1 中,Twitter API 只显示和 是 的转发,但 实际上是 的转发。为了解决这个问题,在每个级联中,我们首先按时间戳对推文进行排序,然后从之前发布的所有推文中搜索转发的来源。 具体来说,从节点到节点有一条边 333节点在节点之前发布,信息从用户发送到用户。 如果:
-
•
节点的用户在推文中提及了节点的用户,例如,用户转发了新闻条目,并且还通过提及将其推荐给用户;
-
•
推文是公开的,推文是在推文之后的一段时间内发布的。 我们测试了从一小时到十小时的不同时间限制。
请注意,边仅存在于同一级联内的节点之间。 我们还通过进一步考虑关注者和关注关系来比较差异,但我们的结果表明没有显着的改进。 此外,由于Twitter对相应的API应用了更严格的速率限制,因此这些类型的信息可能无法实时获得,特别是在需要在检测期限内同时验证多个新闻条目的情况下。 下一小节将提供更多详细信息。
特征矩阵。 如前所述,我们在这项工作中不依赖任何文本信息,包括推文内容、用户回复或用户描述,并且仅从用户配置文件中选择以下信息作为每个节点的特征:
-
•
用户是否经过验证;
-
•
用户创建时的时间戳,编码为自 2006 年 3 月(Twitter 成立时间)以来的月数;
-
•
关注者数量;
-
•
好友数量;
-
•
列表的数量;
-
•
收藏夹的数量;
-
•
状态数量;
-
•
推文的时间戳,编码为自第一条推文引用新闻发布以来的秒数。
我们选择上述功能的另一个重要原因是它们最容易访问——它们可以在tweet对象中直接使用,这对于在线检测来说是更可取的。
此外,基于可信度较低的用户比可信度较高的用户更有可能形成更大的集群的假设(Shu等人,2020),我们从用户时间轴推文中提取另一组特征来检查是否他们可以进一步提高我们模型的性能。 具体来说,我们收集新闻条目传播模式中所有用户的时间轴推文(每个用户最多收集 200 条推文),并构建另一个图,其中每个节点代表一个用户,而如果用户 提到用户 ,则从节点 到节点 之间存在一条边,边的权重是用户 被用户 提到的次数。 最后,在构建图表后,我们计算每个节点 的以下特征:
-
•
入度,即提及过用户的用户数量;
-
•
出度,即被用户提及的用户数量
-
•
加权入度,即用户被提及的次数;
-
•
加权出度,即用户提及他人的次数;
-
•
hop-2 邻居的数量;
-
•
hop-2 外邻居的数量;
-
•
收集的时间线推文数量。
研究这些特征的基本原理是,可信度较低的用户更有可能相互协作,并且这种行为可以通过上述特征来捕获。
在我们的实验中,我们首先仅使用用户个人资料中的特征来训练模型,然后与(1)时间线推文特征上的训练模型和(2)两组特征组合上的训练模型进行比较。
3.2. 实验验证
使用上一小节中介绍的方法来生成图(邻接矩阵和特征矩阵),我们测试了具有一系列不同架构的多个 DiffPool 模型:2-4 个池层、16-128 个隐藏维度和 16-128 个嵌入维度(本节后面给出了不同设置下选择的超参数)。 根据(Ying等人,2018)中作者的建议,我们使用构建在GraphSage之上的DiffPool(Hamilton等人,2017)。
为了使我们的结果与 (Shu 等人, 2019a) 中报告的结果具有可比性(因为他们也在同一数据集上测试了假新闻检测算法),我们按照相同的程序进行训练并测试GNN:随机选择 75% 的新闻作为训练数据,其余的作为测试数据,最终结果是五次重复的平均性能。 此外,还使用以下常用指标来评估模型:准确度、精确度、召回率和 F1 分数。 我们不在所有实验中使用相同的训练和测试数据分割的主要原因是,算法可能在一个数据分割上表现得非常好,但在另一个数据分割上表现不佳。 因此,所有算法都在多次随机分割的数据上进行测试,以便获得的结果更接近其真实性能。
| Dataset | Metric | User profile features only | Timeline tweets features only | Combined | |||
|---|---|---|---|---|---|---|---|
| Without follower/ | With follower/ | Without follower/ | With follower/ | Without follower/ | With follower/ | ||
| following | following | following | following | following | following | ||
| PolitiFact | Acc | 0.811 | 0.805 | 0.699 | 0.696 | 0.792 | 0.803 |
| Pre | 0.809 | 0.806 | 0.700 | 0.694 | 0.792 | 0.806 | |
| Rec | 0.809 | 0.801 | 0.695 | 0.695 | 0.792 | 0.801 | |
| F1 | 0.808 | 0.801 | 0.693 | 0.691 | 0.791 | 0.801 | |
| GossipCop | Acc | 0.844 | 0.841 | 0.853 | 0.853 | 0.849 | 0.841 |
| Pre | 0.823 | 0.821 | 0.834 | 0.831 | 0.829 | 0.820 | |
| Rec | 0.833 | 0.834 | 0.852 | 0.846 | 0.840 | 0.831 | |
| F1 | 0.827 | 0.826 | 0.841 | 0.837 | 0.833 | 0.825 | |
3.2.1. 在完整数据集上进行训练
我们首先在 PolitiFact/GossipCop 的整个数据集上训练 GNN,仅使用用户个人资料中的特征,而不考虑关注者/关注关系。 在测试了一系列超参数后,我们发现具有 64 个隐藏维度和 64 个嵌入维度的四层 GNN 最适合 PolitiFact 的数据集,而对于 GossipCop 来说,层数应该减少到两层,因为新闻明显更多该数据集中的项目。
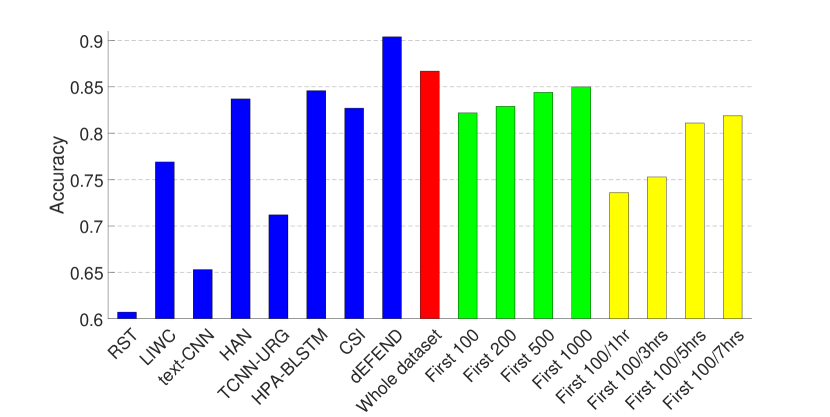
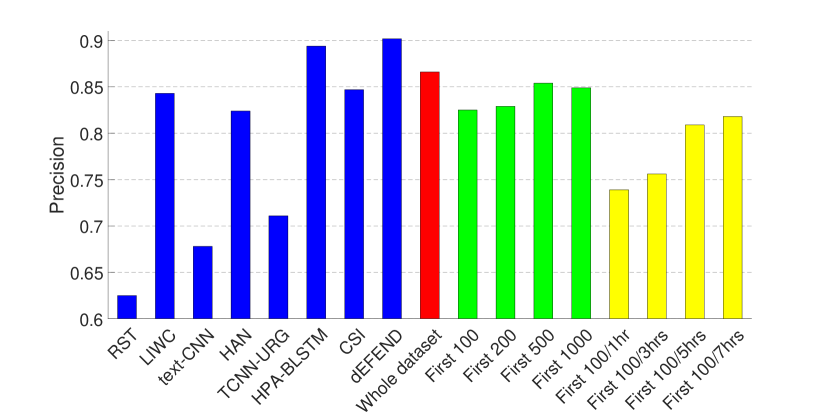
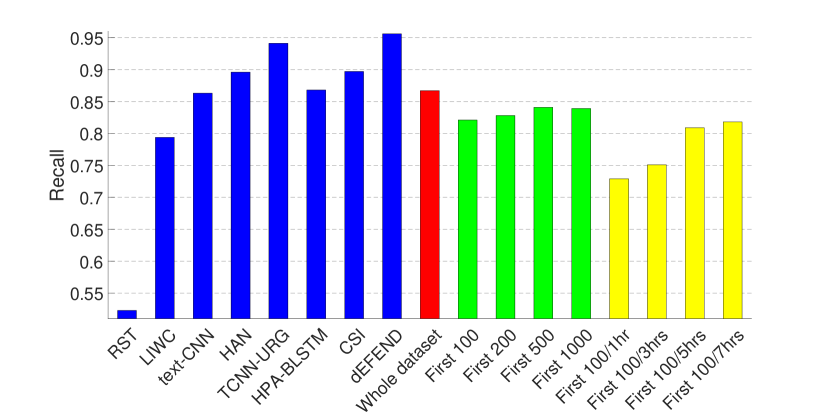
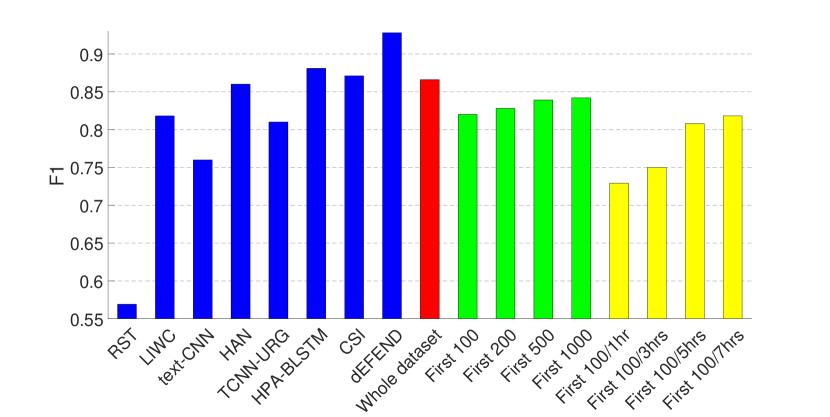
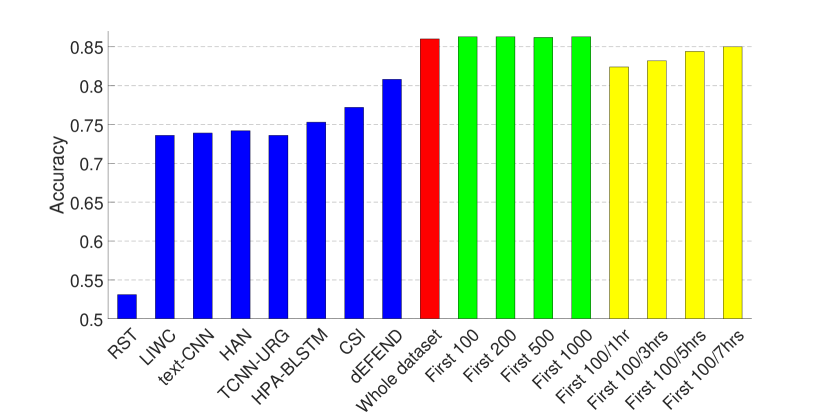
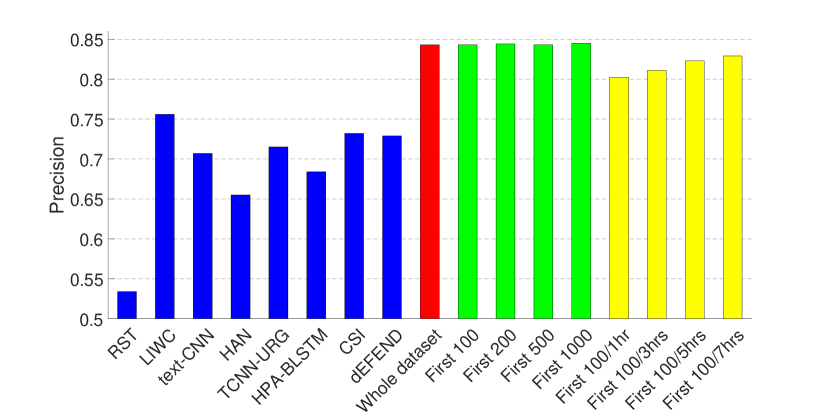
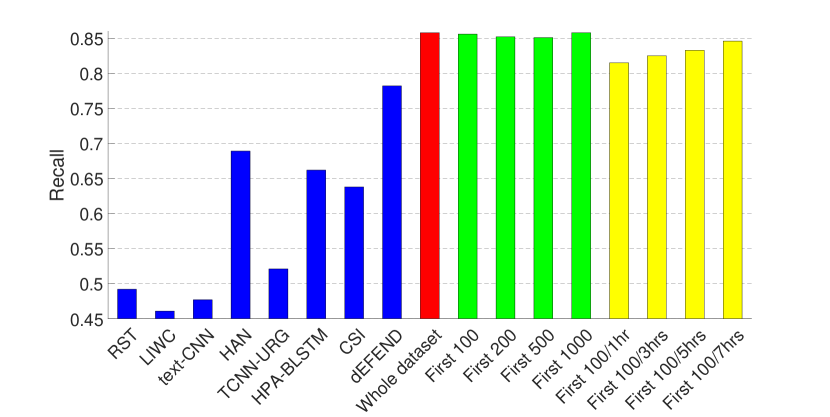
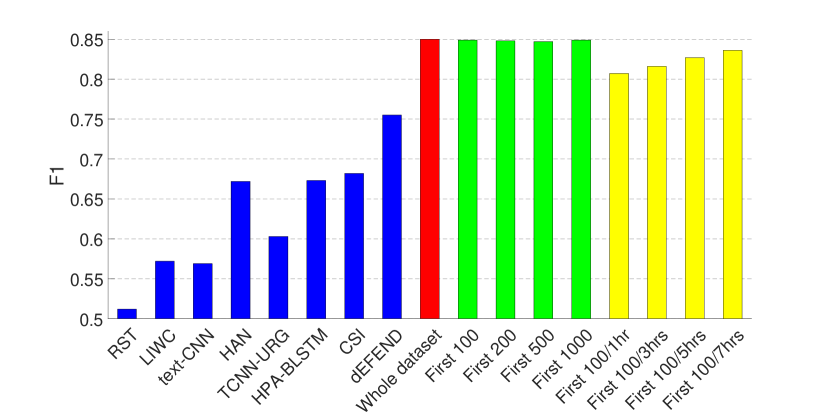
实验结果如图1和图2所示。 2和3,其中(1)前八个条对应于(Shu等人,2019a)中报道的八种假新闻检测算法的结果 在同一数据集上——RST (Rubin 等人, 2015), LIWC (Pennebaker 等人, 2015), HAN (Yang 等人, 2016) )、text-CNN (Kim, 2014)、TCNN-URG (钱等人, 2018)、HPA-BLSTM (郭等人, 2018)0>、CSI (Ruchansky 等人, 2017)1> 和 dEFEND (Shu 等人, 2019a)2>。 请注意,所有这些方法都需要对文本信息(例如)、推文内容和用户回复进行分析。 (2) 第九个红色条是我们在整个数据集上训练的基于传播的方法的结果。
从图中可以看出,仅依靠3.1节中介绍的有限的非文本特征集,我们的模型就可以在 PolitiFact 数据集上实现可比的性能,并且在GossipCop 的数据集。
3.2.2. 在部分数据集上进行训练以进行早期检测
在假新闻广泛传播之前尽早发现它至关重要,因为假新闻传播得越广,人们就越有可能相信它(Boehm,1994),并且很难纠正人们的错误对某个问题的看法,即使之前的印象不准确(keersmaecker 和 Roets,2017)。
因此,我们在包含每个新闻项 (1) 的前 100、200、500、1000 条推文(图 1 和 2 中的绿色条)的剪辑数据集上训练 GNN。 2 和 3); (2) 前 100 条推文或第一、三、五或七小时内的推文,以较小者为准(图 1 和 2 中的黄色条)。 2 和 3)。 这里的超参数与上一组实验相同,除了包含前 100 条推文(有和没有不同时间限制)的剪辑 GossipCop 数据集,池化层的数量为 3。
结果表明,即使每个新闻条目的推文数量有限,我们的模型也可以实现不错的性能,尤其是在 GossipCop 的数据集上,这可能是由于数据集较大的缘故。
3.2.3. 用户时间线推文中的其他非文本特征
在这里,我们研究了从用户时间线推文中提取的一组非文本特征的影响,如第 3.1 节中所述。
请注意,从这里开始,我们重点关注在剪裁数据集上训练的模型,其中包含前 100 条推文或每条新闻的前 5 个小时的推文,因为之前的结果表明,在此数据集上训练的模型可以实现相当接近的性能在完整数据集上训练的模型,更重要的是,在假新闻广泛传播之前检测到它们至关重要。
3.2.4. 进一步考虑关注者和关注关系
之前在构建邻接矩阵时,我们没有考虑Twitter用户之间的关注者和关注关系。 在本小节中,我们将研究是否可以通过加入这些类型的信息来进一步改进结果,即如果用户跟随用户,则从节点到节点添加一条边。
表1表明,当模型根据用户个人资料、时间线推文或两者的特征进行训练时,考虑和不考虑关注者/关注关系没有任何显着差异。 因此,该关系不包含在我们的模型中。
模型效率。 在训练和测试我们的模型时,我们还发现 GNN 收敛得非常快——大多数时候,模型只需要几十个 epoch 就可以在四个指标上达到与最终模型相似的性能,而每个 epoch 只持续从几秒钟到几分钟,具体取决于不同的模型结构和数据集的大小。
所有这些结果为 GNN 在基于传播的假新闻检测中的应用提供了强有力的支持。
4. 处理新数据
虽然上述结果证明了我们提出的方法在单个数据集上的有效性,但本节进一步研究了新数据上的模型性能。
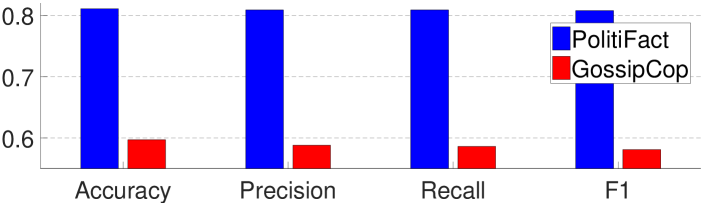
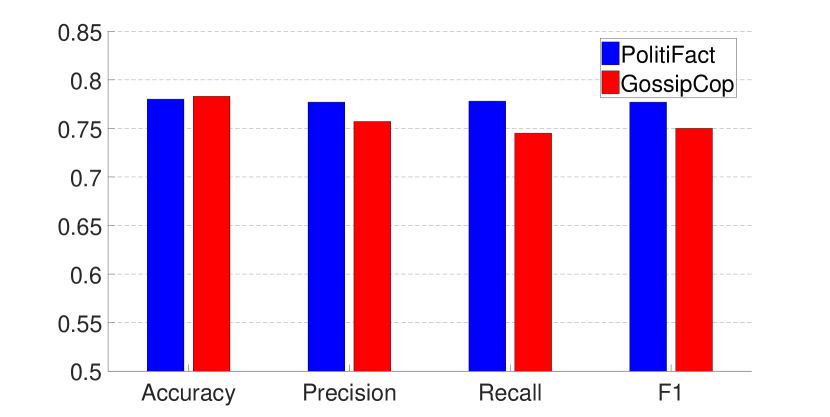
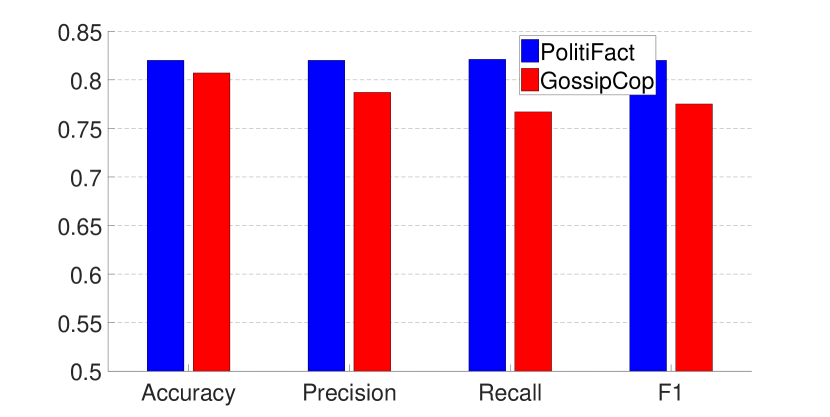
设一个数据集(例如,PolitiFact)代表我们的模型训练过的现有数据,另一个数据集(例如,GossipCop)代表我们的模型训练的未知数据我们发现在 PolitiFact 上训练的模型在 GossipCop 上表现不佳(图 4),反之亦然(由于相似,本案例的图被省略)。
对图的检查表明,PolitiFact 和 GossipCop 生成的图在节点和边的数量方面存在很大差异,这解释了观察到的行为的原因。
为什么不直接在两个数据集上进行训练? 一个自然的想法是在两个数据集上重新训练模型,但这可能不可行,或者至少在实践中并不理想:总会有我们的模型以前没有见过的新数据,并且没有意义每次获得新数据集时,都要在整个数据上从头开始重新训练模型,特别是随着数据大小的增长,这可能会变得非常昂贵。 在本节的其余部分中,我们将解决处理新的、未见过的数据的问题。
4.1. 增量训练
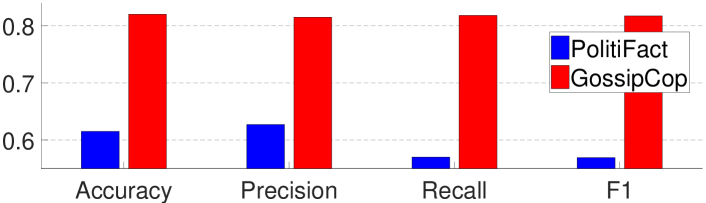
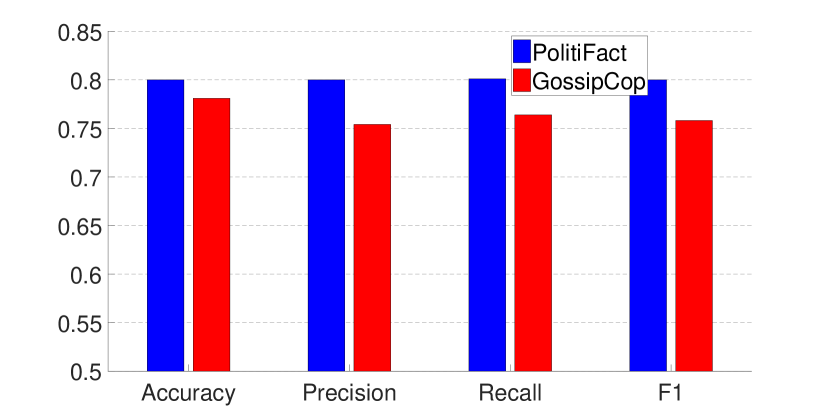
我们首先在 GossipCop(或 PolitiFact)的另一个数据集上测试增量训练,即,进一步训练从 PolitiFact(或 GossipCop)获得的模型。 然而,如图5所示,模型仅在训练它们的后一个数据集上表现良好,而在前一个数据集上获得了退化的结果(该图为首先在 GossipCop 上训练的模型)然后由于相似而省略了 PolitiFact)。 请注意,在增量训练过程中,我们仍然随机选择 75% 的图作为训练数据,其余作为测试数据。
这类似于持续学习领域中的灾难性遗忘问题(McCloskey and Cohen, 1989; Ratcliff, 1990; McClelland 等人, 1995; French, 1999):当深度神经网络处于经过训练来学习一系列任务,它在学习新任务后会降低其在先前任务上的表现,因为新任务会覆盖权重。
在我们的例子中,每个新数据集都可以被视为一个新任务。 在下一小节中,我们将研究如何通过应用持续学习的技术来解决问题。
4.2. 持续学习
为了应对灾难性遗忘,人们提出了多种方法,大致可分为三类(Parisi等人,2018):(1)基于正则化的方法,添加额外的约束损失函数防止先前知识的损失; (2)基于架构的方法,有选择地为每个任务训练一部分网络,并在新任务需要时扩展网络; (3)基于双记忆的方法,建立在互补学习系统(CLS)理论之上(McClelland等人,1995;Kumaran等人,2016),并重放样本以进行记忆巩固。
在本文中,我们选择以下两种流行的方法:
-
•
梯度情景记忆 (GEM) (Lopez-Paz 和 Ranzato,2017) - GEM 使用情景记忆来存储先前任务的大量样本,并在学习新任务时 ,与任务学习完成时相比,它不允许内存中保存的样本的损失增加;
-
•
弹性权重合并(EWC)(Kirkpatrick等人,2017)——其损失函数由参数变化的二次惩罚项组成,以防止对那些重要参数进行剧烈更新旧任务。
在我们的例子中,两个数据集( 和 )的学习被视为两个任务。 当模型学习第一个任务时,它会像平常一样进行训练;然后在第二个任务的学习过程中,我们应用GEM和EWC:
-
•
设为第一个任务后的模型参数,为从第一个数据集中采样的实例集合,则GEM下的优化问题变为:
-
•
假设 是正则化权重, 是费雪信息矩阵, 是 EWC 用来近似 后验的高斯分布参数,则 EWC 下的损失函数为:
请注意,在估计 Fisher 信息矩阵 时,我们对一组实例 () 进行采样,并比较不同样本大小下的模型性能。
在参数方面,我们测试样本大小(所有样本都是随机选择的)和(仅适用于EWC)。 此外,由于模型架构必须在两个阶段保持一致(即首先在一个数据集上进行训练,然后在另一个数据集上增量训练),因此池化层的数量设置为三。
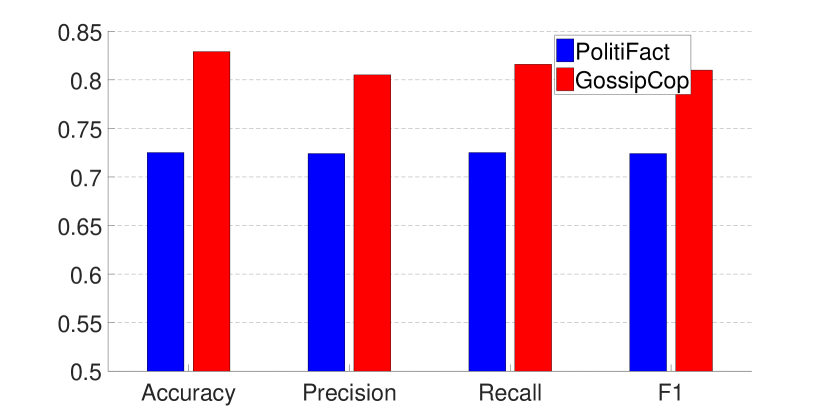
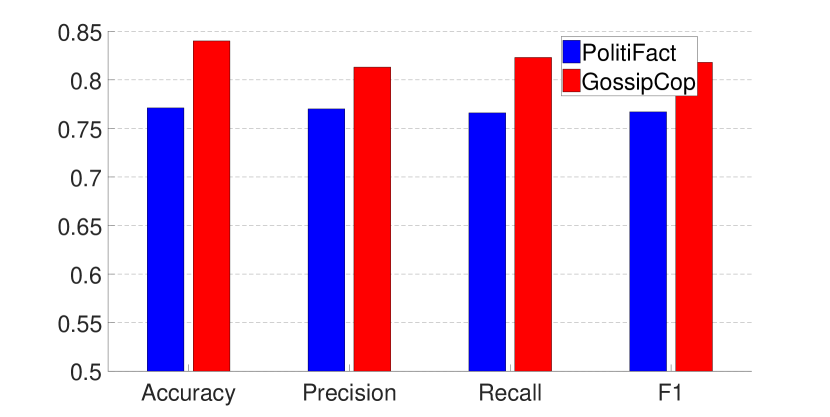
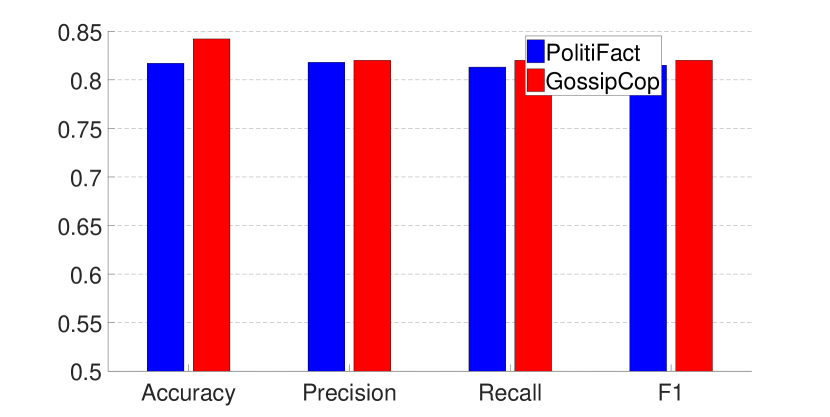
无花果。 6、7 和表 2 显示了使用 GEM 和 EWC 训练的模型的性能(对于 EWC,结果为 由于篇幅限制,省略)。 结果表明,虽然两种方法都可以在两个数据集上实现相对平衡的性能,但 GEM 训练的模型总体上比 EWC 训练的模型效果更好。 此外,我们还在整个数据集上使用GEM增量训练模型,性能可以进一步提高。
还有一点值得一提的是,在EWC训练过程中需要更多的微调。 例如,当使用 EWC 训练模型时,我们需要应用提前停止来确保两个数据集上的结果平衡。
效率。 在效率方面,我们在两个数据集上的实验可以得出以下结论:(1)与正常过程相比,GEM和EWC的训练需要稍多的时间; (2) GEM和EWC的训练时间没有显着差异; (3)参数即样本大小和对训练时间的影响也不显着。
| Models first trained on PolitiFact | Models first trained on GossipCop | |||||||||||||||
| and then on GossipCop | and then on PolitiFact | |||||||||||||||
| PolitiFact | GossipCop | PolitiFact | GossipCop | |||||||||||||
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | |
| 1 | 0.665 | 0.681 | 0.647 | 0.640 | 0.784 | 0.762 | 0.734 | 0.744 | 0.729 | 0.724 | 0.730 | 0.724 | 0.742 | 0.727 | 0.654 | 0.663 |
| 3 | 0.649 | 0.657 | 0.633 | 0.627 | 0.795 | 0.776 | 0.752 | 0.761 | 0.733 | 0.730 | 0.729 | 0.729 | 0.771 | 0.760 | 0.698 | 0.712 |
| 10 | 0.677 | 0.684 | 0.662 | 0.660 | 0.777 | 0.758 | 0.724 | 0.735 | 0.731 | 0.732 | 0.728 | 0.728 | 0.766 | 0.746 | 0.701 | 0.713 |
| 30 | 0.675 | 0.681 | 0.662 | 0.660 | 0.777 | 0.762 | 0.722 | 0.734 | 0.720 | 0.717 | 0.718 | 0.717 | 0.736 | 0.708 | 0.662 | 0.672 |
| 0.683 | 0.687 | 0.671 | 0.670 | 0.780 | 0.764 | 0.720 | 0.733 | 0.720 | 0.718 | 0.719 | 0.717 | 0.740 | 0.719 | 0.657 | 0.667 | |
| 0.689 | 0.705 | 0.672 | 0.668 | 0.778 | 0.750 | 0.739 | 0.743 | 0.729 | 0.733 | 0.729 | 0.726 | 0.759 | 0.748 | 0.680 | 0.692 | |
| 0.689 | 0.697 | 0.675 | 0.674 | 0.770 | 0.747 | 0.717 | 0.727 | 0.713 | 0.713 | 0.713 | 0.712 | 0.755 | 0.735 | 0.684 | 0.693 | |
| 0.695 | 0.703 | 0.681 | 0.680 | 0.770 | 0.745 | 0.711 | 0.722 | 0.718 | 0.720 | 0.718 | 0.717 | 0.733 | 0.704 | 0.660 | 0.669 | |
| 0.706 | 0.711 | 0.695 | 0.695 | 0.775 | 0.752 | 0.713 | 0.724 | 0.718 | 0.721 | 0.713 | 0.712 | 0.786 | 0.769 | 0.732 | 0.744 | |
| 0.726 | 0.735 | 0.714 | 0.714 | 0.761 | 0.739 | 0.697 | 0.707 | 0.722 | 0.717 | 0.715 | 0.715 | 0.764 | 0.738 | 0.705 | 0.715 | |
| 0.737 | 0.746 | 0.726 | 0.727 | 0.750 | 0.733 | 0.663 | 0.675 | 0.709 | 0.708 | 0.706 | 0.706 | 0.770 | 0.748 | 0.707 | 0.718 | |
5. 相关工作
近年来,检测社交媒体上的假新闻一直是一个热门的研究问题。 在本节中,我们简要回顾一下有关该主题的先前工作。 具体来说,与(Shu等人,2017;Pieri and Ceri,2019)类似,我们将现有工作分为三类:基于内容的方法、基于上下文的方法和混合方法,前两类是正如它们的名字所暗示的,它们分别主要依靠新闻内容和社交上下文来提取特征进行检测。
5.1. 基于内容的方法
基于内容的方法使用新闻标题和正文内容来验证新闻的有效性。 它可以进一步分为两类:基于知识的和基于风格的(Shu等人,2017;Zhou和Zafarani,2018)。
5.1.1. 基于知识的检测
为了使这种方法发挥作用,必须首先构建知识库或知识图(Nickel等人,2016)。 这里,知识可以用三元组的格式表示:(主语、谓语、宾语),即 SPO 三元组(noa,1999)。 然后,为了验证一条新闻,将从其内容中提取的知识与知识图谱中的事实进行比较(Wu等人,2014;Ciampaglia等人,2015;Shi和Weninger,2016)。 如果知识图谱中缺少三元组,则可以使用不同的链接预测算法来计算从节点到节点存在标记为的边的概率节点。
5.1.2. 基于风格的检测
根据法医心理学研究(Undeutsch,1967),基于现实生活经历的陈述在内容和质量上与来自捏造或虚构的陈述存在显着差异。 由于假新闻的目的是误导公众,因此它们往往表现出真实新闻中很少见的独特写作风格。 因此,基于风格的方法旨在识别这些特征。 例如,Perez-Rosas et al. (Pérez-Rosas 等人, 2018) 在以下语言特征上训练线性 SVM 来检测假新闻:一元语法、二元语法、标点符号、心理语言学、可读性和语法特征。 属于这一类的其他方法包括(Horne和Adali,2017;Volkova等人,2017;Wang,2017;Potthast等人,2018)。
除了文字信息外,还对社交媒体上发布的图片进行了调查,以方便检测假新闻(金等人,2017;杨等人,2018;王等人,2018;周等人,2020) 。
5.2. 基于情境的方法
这里的社交上下文是指用户之间的交互,包括推文、转发、回复、提及和关注。 这些活动为识别社交媒体上传播的虚假新闻提供了有价值的信息。 例如,Jin et al. (Jin 等人, 2016) 构建了一个立场网络,其中边的权重代表每对帖子相互支持或否定的程度。 然后,假新闻检测基于估计与新闻项目相关的所有帖子的可信度,这可以形式化为图优化问题。
Tacchini 等人 (Tacchini 等人, 2017) 提出根据用户交互(即在 Facebook 上点赞的用户)检测虚假新闻。 他们的实验表明,基于逻辑回归的方法和基于调和布尔标签众包的方法都可以实现高精度。
与上述有监督方法不同,Yang等人(Yang等人,2019)提出了一种无监督方法。 它构建了贝叶斯概率图模型来捕获新闻有效性、用户意见和用户可信度之间的生成过程。
请注意,引言中提到的基于传播的方法也属于这一类。
5.3. 混合方法
混合方法使用新闻内容和社交媒体上的相关用户交互来区分假新闻和真实新闻。
Ruchansky et al. (Ruchansky 等人, 2017) 设计了一个三模块架构,结合了新闻文章的文本、收到的用户响应和新闻来源:(1)第一个模块以用户响应、新闻内容和用户特征作为输入,训练循环神经网络(RNN)来捕获文章的时间表示; (2) 第二个模块输入用户特征,为每个用户生成分数和低维表示; (3) 第三个模块采用前两个模块的输出并训练神经网络来标记新闻项。
张 等人 (Zhang 等人, 2018)提出使用预先提取的词集从新闻内容、用户个人资料和新闻主题描述中构建显式特征,同时使用 RNN 学习潜在特征,例如新闻文章内容信息的不一致和个人资料潜在模式。 一旦获得特征,就会建立一个深度扩散网络来学习新闻文章、创作者和主题的表示。
Shu et al. (Shu 等人, 2019c)利用发布者、新闻文章和用户之间的三重关系来检测虚假新闻。 具体来说,非负矩阵分解用于学习新闻内容和用户的潜在表示,并且问题被形式化为对每个关系的线性组合的优化。 测试了多种机器学习算法来解决优化问题,结果证明了其有效性。
除了上述工作之外,最近的一些论文也开始研究可解释性,即即为什么他们的模型将某些新闻标记为假新闻(Popat 等人,2018;Shu 等人, 2019a;卢和李,2020)。
6. 结论和未来的工作
社交媒体上假新闻的盛行已成为一个严重的社会问题。 在本文中,我们提出了一种基于传播的假新闻检测方法,该方法使用 GNN 来区分假新闻和真实新闻在社交网络上的不同传播模式。 尽管该方法只需要从社会上下文中获得有限数量的特征,并且不依赖于任何文本信息,但它可以实现与需要句法和语义分析的最先进方法相当或更好的性能。
此外,我们还发现在给定数据集上训练的 GNN 在图结构差异很大的新数据上可能表现不佳,直接增量训练无法解决该问题。 由于这类似于持续学习中的灾难性遗忘问题,我们提出了一种在增量训练期间应用两种流行方法(GEM 和 EWC)的技术,以便在现有数据和新数据上实现平衡的性能。 这可以避免对整个数据进行重新训练,因为随着数据大小的增长,重新训练的成本会变得非常昂贵。
对于未来的工作,我们将研究是否在某种程度上可以通过特征的选择来减轻这种情况下的灾难性遗忘现象——包括更多的特征,或者找到尽管图形结构不同但仍能正常工作的“通用”特征。
参考
- (1)
- noa (1999) 1999. Resource Description Framework (RDF) Model and Syntax Specification. https://www.w3.org/TR/PR-rdf-syntax/
- Bian et al. (2020) Tian Bian, Xi Xiao, Tingyang Xu, Peilin Zhao, Wenbing Huang, Yu Rong, and Junzhou Huang. 2020. Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks. (2020), arXiv:2001.06362.
- Boehm (1994) Lawrence E. Boehm. 1994. The Validity Effect: A Search for Mediating Variables. Personality and Social Psychology Bulletin 20, 3 (1994), 285–293.
- Bruna et al. (2013) Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. 2013. Spectral Networks and Locally Connected Networks on Graphs. arXiv e-prints (2013), arXiv:1312.6203.
- Ciampaglia et al. (2015) Giovanni Luca Ciampaglia, Prashant Shiralkar, Luis M. Rocha, Johan Bollen, Filippo Menczer, and Alessandro Flammini. 2015. Computational Fact Checking from Knowledge Networks. PLOS ONE 10, 6 (2015), 1–13.
- French (1999) Robert M. French. 1999. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences 3, 4 (1999), 128 – 135.
- Goodfellow et al. (2014) Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and Harnessing Adversarial Examples. eprint arXiv:1412.6572 (2014).
- Guo et al. (2018) Han Guo, Juan Cao, Yazi Zhang, Junbo Guo, and Jintao Li. 2018. Rumor Detection with Hierarchical Social Attention Network. In Proceedings of the 27th CIKM. Torino, Italy, 943–951.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In NIPS-2017. Curran Associates, Inc., 1024–1034.
- Horne and Adali (2017) Benjamin D. Horne and Sibel Adali. 2017. This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News. arXiv e-prints (2017), arXiv:1703.09398.
- Jin et al. (2016) Zhiwei Jin, Juan Cao, Yongdong Zhang, and Jiebo Luo. 2016. News Verification by Exploiting Conflicting Social Viewpoints in Microblogs. In Proceedings of the 30th AAAI (AAAI’16). Phoenix, Arizona, 2972–2978.
- Jin et al. (2017) Z. Jin, J. Cao, Y. Zhang, J. Zhou, and Q. Tian. 2017. Novel Visual and Statistical Image Features for Microblogs News Verification. TMM 19, 3 (2017), 598–608.
- keersmaecker and Roets (2017) Jonas De keersmaecker and Arne Roets. 2017. ‘Fake news’: Incorrect, but hard to correct. The role of cognitive ability on the impact of false information on social impressions. Intelligence 65 (2017), 107 – 110.
- Kim (2014) Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 EMNLP. 1746–1751.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th ICLR. Palais des Congrès Neptune, Toulon, France.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences 114, 13 (2017), 3521.
- Kumaran et al. (2016) Dharshan Kumaran, Demis Hassabis, and James L. McClelland. 2016. What Learning Systems do Intelligent Agents Need? Complementary Learning Systems Theory Updated. Trends in Cognitive Sciences 20, 7 (2016), 512–534.
- Liu and Wu (2018) Yang Liu and Yi-fang Brook Wu. 2018. Early Detection of Fake News on Social Media Through Propagation Path Classification with Recurrent and Convolutional Networks. In Proceedings of the 32nd AAAI. 354–361.
- Lopez-Paz and Ranzato (2017) David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient Episodic Memory for Continual Learning. In NIPS-2017. Curran Associates, Inc., 6467–6476.
- Lu and Li (2020) Yi-Ju Lu and Cheng-Te Li. 2020. GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media. (2020), arXiv:2004.11648.
- Ma et al. (2017) Jing Ma, Wei Gao, and Kam-Fai Wong. 2017. Detect Rumors in Microblog Posts Using Propagation Structure via Kernel Learning. In 55th ACL. 708–717.
- McClelland et al. (1995) James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. 1995. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological Review 102, 3 (1995), 419–457.
- McCloskey and Cohen (1989) Michael McCloskey and Neal J. Cohen. 1989. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Psychology of Learning and Motivation. Vol. 24. Academic Press, 109 – 165.
- Monti et al. (2019) Federico Monti, Fabrizio Frasca, Davide Eynard, Damon Mannion, and Michael M. Bronstein. 2019. Fake News Detection on Social Media using Geometric Deep Learning. arXiv e-prints (2019), arXiv:1902.06673.
- Nickel et al. (2016) M. Nickel, K. Murphy, V. Tresp, and E. Gabrilovich. 2016. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 104, 1 (2016), 11–33.
- Niepert et al. (2016) Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. 2016. Learning Convolutional Neural Networks for Graphs. In Proceedings of the 33rd ICML - Volume 48. 2014–2023.
- Parisi et al. (2018) German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. 2018. Continual Lifelong Learning with Neural Networks: A Review. arXiv e-prints (2018), arXiv:1802.07569.
- Pennebaker et al. (2015) James W. Pennebaker, Ryan L. Boyd, Kayla Jordan, and Kate Blackburn. 2015. The Development and Psychometric Properties of LIWC2015. Technical Report. https://repositories.lib.utexas.edu/handle/2152/31333
- Pierri and Ceri (2019) Francesco Pierri and Stefano Ceri. 2019. False News On Social Media: A Data-Driven Survey. SIGMOD Record 48, 2 (2019), 18–27.
- Popat et al. (2018) Kashyap Popat, Subhabrata Mukherjee, Andrew Yates, and Gerhard Weikum. 2018. DeClarE: Debunking Fake News and False Claims using Evidence-Aware Deep Learning. In Proceedings of the 2018 EMNLP. 22–32.
- Potthast et al. (2018) Martin Potthast, Johannes Kiesel, Kevin Reinartz, Janek Bevendorff, and Benno Stein. 2018. A Stylometric Inquiry into Hyperpartisan and Fake News. In Proceedings of the 56th ACL. 231–240.
- Pérez-Rosas et al. (2018) Verónica Pérez-Rosas, Bennett Kleinberg, Alexandra Lefevre, and Rada Mihalcea. 2018. Automatic Detection of Fake News. In Proceedings of the 27th International Conference on Computational Linguistics. 3391–3401.
- Qian et al. (2018) Feng Qian, Chengyue Gong, Karishma Sharma, and Yan Liu. 2018. Neural User Response Generator: Fake News Detection with Collective User Intelligence. In Proceedings of the 27th IJCAI. Stockholm, Sweden, 3834–3840.
- Ratcliff (1990) R. Ratcliff. 1990. Connectionist models of recognition memory: constraints imposed by learning and forgetting functions. Psychol Rev 97, 2 (1990), 285–308.
- Rubin et al. (2015) Victoria Rubin, Nadia Conroy, and Yimin Chen. 2015. Towards News Verification: Deception Detection Methods for News Discourse. In Proceedings of the 48th Hawaii International Conference on System Sciences (HICSS48).
- Ruchansky et al. (2017) Natali Ruchansky, Sungyong Seo, and Yan Liu. 2017. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the 26th CIKM. Singapore, 797–806.
- Shi and Weninger (2016) Baoxu Shi and Tim Weninger. 2016. Fact Checking in Heterogeneous Information Networks. In Proceedings of the 25th WWW. Montréal, Canada, 101–102.
- Shu et al. (2019a) Kai Shu, Limeng Cui, Suhang Wang, Dongwon Lee, and Huan Liu. 2019a. DEFEND: Explainable Fake News Detection. In Proceedings of the 25th KDD. 395–405.
- Shu et al. (2018) Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2018. FakeNewsNet: A Data Repository with News Content, Social Context and Spatialtemporal Information for Studying Fake News on Social Media. arXiv e-prints (2018), arXiv:1809.01286.
- Shu et al. (2019b) Kai Shu, Deepak Mahudeswaran, Suhang Wang, and Huan Liu. 2019b. Hierarchical Propagation Networks for Fake News Detection: Investigation and Exploitation. arXiv e-prints (2019), arXiv:1903.09196.
- Shu et al. (2017) Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. 2017. Fake News Detection on Social Media: A Data Mining Perspective. SIGKDD Explorations Newsletter 19, 1 (2017), 22–36.
- Shu et al. (2019c) Kai Shu, Suhang Wang, and Huan Liu. 2019c. Beyond News Contents: The Role of Social Context for Fake News Detection. In Proceedings of the Twelfth WSDM. Melbourne, VIC, Australia, 312–320.
- Shu et al. (2020) Kai Shu, Guoqing Zheng, Yichuan Li, Subhabrata Mukherjee, Ahmed Hassan Awadallah, Scott Ruston, and Huan Liu. 2020. Leveraging Multi-Source Weak Social Supervision for Early Detection of Fake News. (2020), arXiv:2004.01732.
- Szegedy et al. (2013) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. Intriguing Properties of Neural Networks. eprint arXiv:1312.6199 (2013).
- Tacchini et al. (2017) Eugenio Tacchini, Gabriele Ballarin, Marco L. Della Vedova, Stefano Moret, and Luca de Alfaro. 2017. Some Like it Hoax: Automated Fake News Detection in Social Networks. arXiv e-prints (2017), arXiv:1704.07506.
- Undeutsch (1967) Udo Undeutsch. 1967. Beurteilung der Glaubhaftigkeit von Aussagen. Handbuch der Psychologie, Band 11: Forensische Psychologie (1967), 26–181.
- Volkova et al. (2017) Svitlana Volkova, Kyle Shaffer, Jin Yea Jang, and Nathan Hodas. 2017. Separating Facts from Fiction: Linguistic Models to Classify Suspicious and Trusted News Posts on Twitter. In Proceedings of the 55th ACL. 647–653.
- Vosoughi et al. (2018) Soroush Vosoughi, Deb Roy, and Sinan Aral. 2018. The spread of true and false news online. Science 359, 6380 (2018), 1146–1151.
- Wang et al. (2016) Beilun Wang, Ji Gao, and Yanjun Qi. 2016. A Theoretical Framework for Robustness of (Deep) Classifiers against Adversarial Examples. arXiv:1612.00334 (2016).
- Wang (2017) William Yang Wang. 2017. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th ACL. 422–426.
- Wang et al. (2018) Yaqing Wang, Fenglong Ma, Zhiwei Jin, Ye Yuan, Guangxu Xun, Kishlay Jha, Lu Su, and Jing Gao. 2018. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In Proceedings of the 24th KDD. 849–857.
- Wu et al. (2015) K. Wu, S. Yang, and K. Q. Zhu. 2015. False rumors detection on Sina Weibo by propagation structures. In 2015 IEEE 31st ICDE. 651–662.
- Wu and Liu (2018) Liang Wu and Huan Liu. 2018. Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate. In Proceedings of the Eleventh WSDM. Marina Del Rey, CA, USA, 637–645.
- Wu et al. (2014) You Wu, Pankaj K. Agarwal, Chengkai Li, Jun Yang, and Cong Yu. 2014. Toward Computational Fact-Checking. Proc. VLDB Endow. 7, 7 (2014), 589–600.
- Wu et al. (2019) Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. 2019. A Comprehensive Survey on Graph Neural Networks. arXiv e-prints (2019), arXiv:1901.00596.
- Yang et al. (2019) Shuo Yang, Kai Shu, Suhang Wang, Renjie Gu, Fan Wu, and Huan Liu. 2019. Unsupervised Fake News Detection on Social Media: A Generative Approach. Proceedings of the 33rd AAAI 33 (2019), 5644–5651.
- Yang et al. (2018) Yang Yang, Lei Zheng, Jiawei Zhang, Qingcai Cui, Zhoujun Li, and Philip S. Yu. 2018. TI-CNN: Convolutional Neural Networks for Fake News Detection. arXiv e-prints (2018), arXiv:1806.00749.
- Yang et al. (2016) Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 NAACL. 1480–1489.
- Ying et al. (2018) Rex Ying, Jiaxuan You, Christopher Morris, Xiang Ren, William L. Hamilton, and Jure Leskovec. 2018. Hierarchical Graph Representation Learning with Differentiable Pooling. In Proceedings of the 32nd NIPS. 4805–4815.
- Zhang et al. (2018) Jiawei Zhang, Bowen Dong, and Philip S. Yu. 2018. FAKEDETECTOR: Effective Fake News Detection with Deep Diffusive Neural Network. arXiv e-prints (2018), arXiv:1805.08751.
- Zhou et al. (2020) Xinyi Zhou, Jindi Wu, and Reza Zafarani. 2020. SAFE: Similarity-Aware Multi-modal Fake News Detection. In Advances in Knowledge Discovery and Data Mining. Springer International Publishing, 354–367.
- Zhou and Zafarani (2018) Xinyi Zhou and Reza Zafarani. 2018. Fake News: A Survey of Research, Detection Methods, and Opportunities. arXiv:1812.00315 [cs] (2018). arXiv:1812.00315
- Zhou and Zafarani (2019) Xinyi Zhou and Reza Zafarani. 2019. Network-based Fake News Detection: A Pattern-driven Approach. arXiv e-prints (2019), arXiv:1906.04210.