医疗配送外检测的基准
摘要
动机:部署用于医疗任务的深度学习模型可以配备分布外检测(OoDD)方法,以避免错误的预测。 然而,尚不清楚在实践中应使用哪种 OoDD 方法。
具体问题: 不能指望针对某一特定图像领域训练的系统能够在不同领域的图像上准确执行。 在诊断之前应通过 OoDD 方法对这些图像进行标记。
我们的方法: 本文定义了 3 类 OoD 示例,并对医学成像三个领域中流行的 OoDD 方法进行了基准测试:胸部 X 射线、眼底成像和组织学幻灯片。
结果:我们的实验表明,尽管方法在某些类别的分布外样本上产生了良好的结果,但它们无法识别接近训练分布的图像。
结论:我们发现一个简单的二元分类器在特征表示上具有最好的准确率和平均 AUPRC。 使用这些 OoDD 方法的诊断工具的用户仍应保持警惕,非常接近训练分布但不在其中的图像可能会产生意外结果。
1简介
安全的医疗诊断系统应该拒绝对其经过验证的专业知识之外的病例进行诊断。 对于机器学习 (ML) 系统,专业知识是通过训练期间使用的数据分布的验证分数来定义的,因为系统的性能可以在从相同分布中抽取的样本上进行验证(根据 PAC 学习 (英勇,1984))。 这种限制可以转化为分布外检测(OoDD)的任务,其目标是区分诊断系统分布内外的样本(缩写为输入和输出数据)。
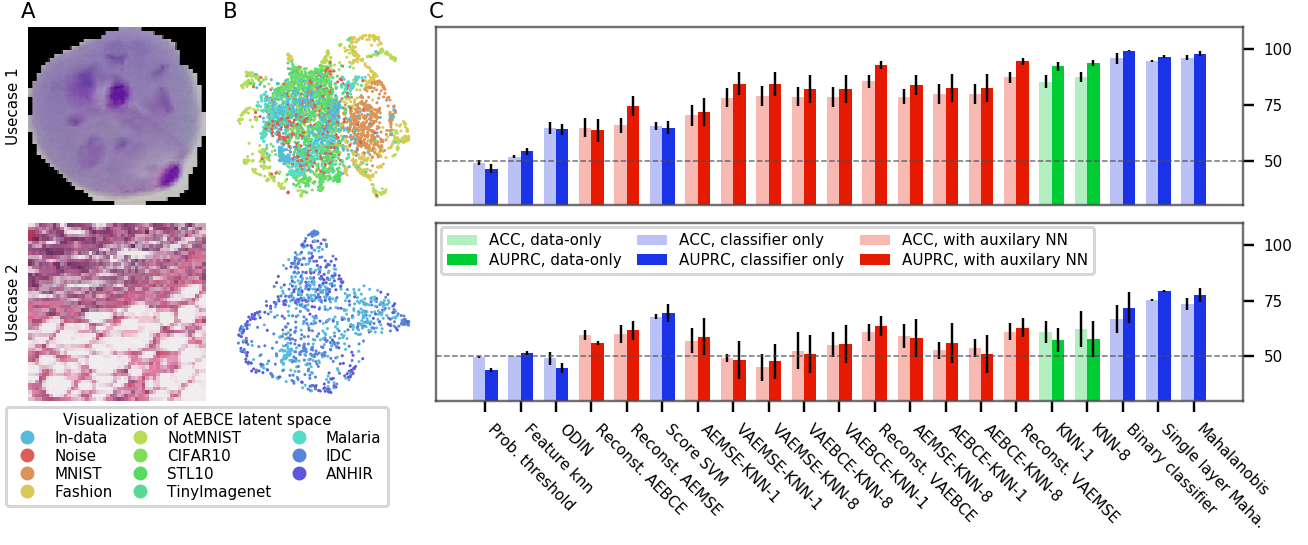
与自然图像分析相反,医学图像分析必须经常处理方向不变性(例如在细胞图像中)、特征尺度的高方差(在 X 射线图像中)和区域特定特征(例如 CT)(Razzak 等人,2017)。 针对医学图像领域特定应用的 OoDD 方法的系统评估仍然缺乏,导致从业者不知道哪些 OoDD 方法表现良好以及在什么情况下表现良好。 本文通过在四种医学图像类型(正面和侧面胸部 X 射线、眼底成像和组织学)下对许多当前的 OoDD 方法进行基准测试来填补这一空白。 我们的实证研究表明,当前的 OoDD 方法在检测训练数据中未表示的正确获取的图像时表现不佳。 我们还发现一些简单的方法,例如在 In 数据上训练的特征的二元分类器,其性能与更复杂的方法相当(见图 4)。 我们希望这项工作能够激发更多关于 OoDD 在医学图像领域的独特挑战的讨论和未来的工作。
2 定义医疗数据中的 OoD
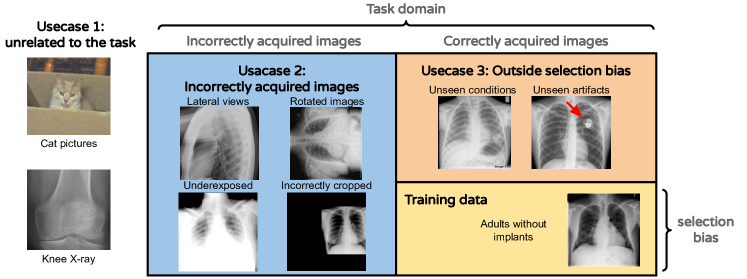
给定一个In分布数据集,我们应该如何定义Out数据的构成? 为了解决这个问题,我们确定了三个不同的分布外类别:
-
•
use-case 1 拒绝与评估无关的输入。 这包括来自不同领域的明显错误图像(例如,使用 X 射线图像训练的模型处理的 MRI 图像)和不太明显错误的图像(例如,使用胸部 X 射线训练的模型处理的手腕 X 射线图像)。
-
•
用例 2 拒绝准备不正确的输入 例如,对于胸部 X 射线图像:图像模糊、对比度差、解剖视图不正确(使用经过训练的模型处理的侧视图)正面视图)、文件格式或应用了不正确的预处理的图像)或数据采集协议的更改。
-
•
use-case 3 拒绝由于数据选择偏差而看不见的输入(例如具有看不见的疾病的图像),这可能会产生意想不到的结果。
我们通过列举数据采集的不同阶段可能发生的不同类型的错误或偏差来证明这些用例的合理性。 图 1 直观地表示了这一点。 我们构建实验来评估 OoDD 方法在每个类别上的性能。
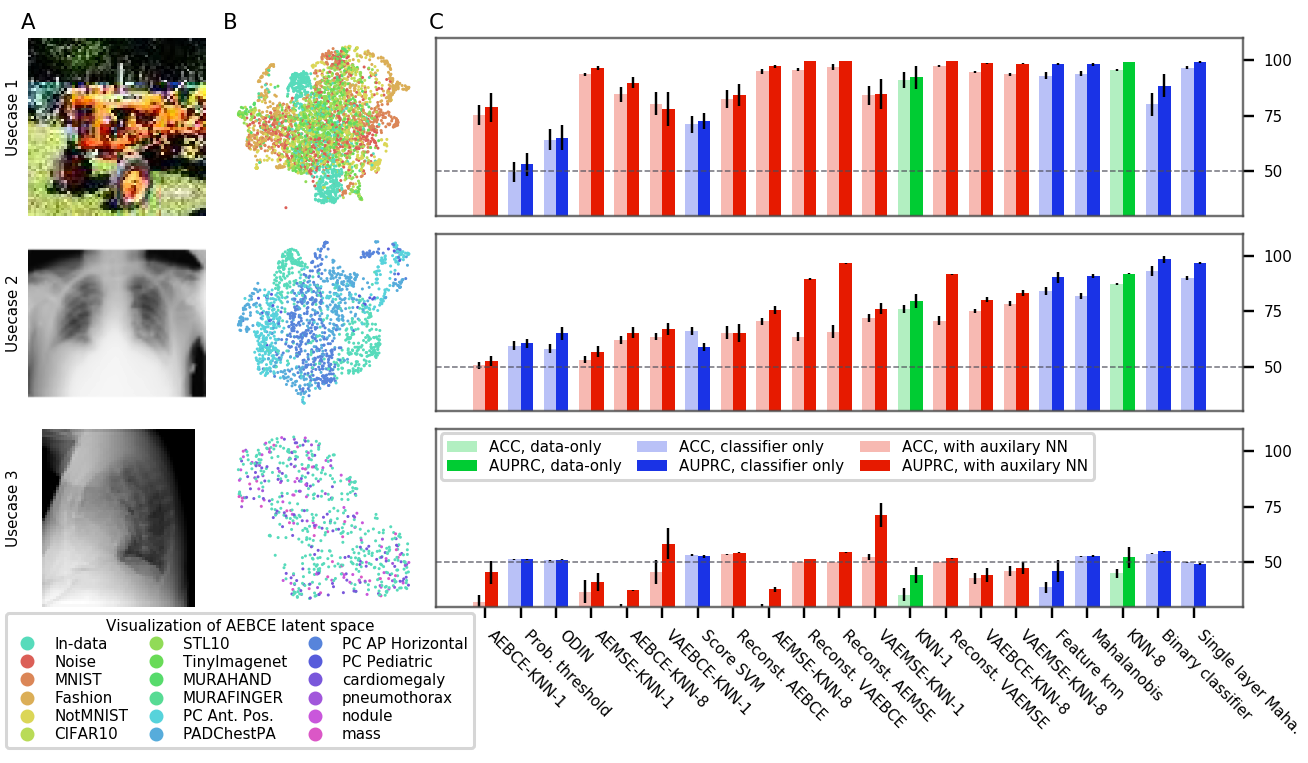
实施例1
作为运行示例,我们将使用我们的第一个评估,其中 In 数据由正面胸部 X 光片组成。 In 数据包含 NIH 胸部 X 射线数据集中的 10 种肺部疾病(Wang 等人,2017)。 在用例 1 中,我们包括自然图像、符号和文本图像以及骨骼 X 射线图像。 用例 2 包含侧视图、背视图和儿科胸部 X 光检查。 最后,用例 3 包括 In 数据中不存在的四种肺部疾病的正面胸部 X 光检查。
3任务制定
在本文中,我们假设下游任务是使用深度神经网络(我们称之为任务网络)执行分类。 让我们将用于任务网络的 In 训练 数据样本表示为 。 某些 OoDD 方法所需的辅助模型也需要在 上进行训练。 然后,在“验证集”(In 和 Out 样本的并集)上训练 OoDD 方法 (标记为“输入”或“输出”)。 还可以使用任务网络学习到的特征,从而也利用。 最后,在测试集 上评估 ,该测试集也由 In 和 Out 样本组成。 每个元组构成一个实验。 这三个步骤的过程如图2所示。
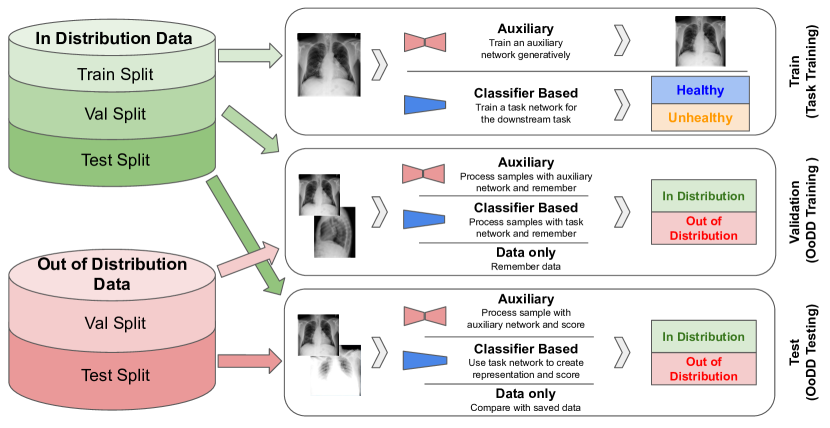
3.1 OoDD的方法()
我们考虑三类 OoDD 方法。 仅数据方法不依赖于任何预训练模型,直接在 上学习。 仅分类器方法假设访问经过训练以对 In 数据 () 进行分类的下游分类器。 使用辅助模型的方法需要使用图像重建等其他目标对In数据进行神经网络的预训练。
纯数据方法
最简单且易于实现的纯数据基线是 k-最近邻 (KNN),它只需要观察训练数据。 这是在图像上执行的,作为我们评估的基线。 对于速度,仅使用 中的 1000 个样本来计算邻居距离。 使用中的样本确定阈值。
仅分类器方法
仅分类器方法利用下游分类器来执行 OoDD。 与仅数据方法相比,它们需要更少的存储,但是它们的适用性仅限于分类为下游任务的情况。 概率阈值 (Hendrycks 和 Gimpel,2017) 使用分类器预测置信度的阈值来执行 OoDD。 Score SVM 将分类器的 logits 作为特征来训练 SVM,概括概率阈值。 二元分类器基于分类器倒数第二层的特征进行训练。 特征 KNN 使用与二元分类器相同的特征,但构造一个 KNN 分类器来代替逻辑回归。 ODIN (Liang 等人, 2017) 是一种概率阈值方法,通过对输入图像采取梯度步长来对输入进行预处理,以增加 In 之间的差异 和输出 数据。 Mahalanobis (Lee 等人, 2018) 将 In 数据的分类器特征建模为高斯混合,将数据预处理为 ODin,并阈值特征的可能性。
具有辅助模型的方法
本节中的 OoDD 方法需要一个在 In 数据上训练的辅助模型。 当下游分类器随时可用时,这会导致额外的设置时间和资源。 然而,当下游任务不是分类(例如回归)时,这也可能是有利的,因为方法可能难以适应。 自动编码器重建对自动编码器的重建损失进行阈值处理,以实现OOD检测。 直观上,自动编码器仅针对重建In数据进行优化,因此由于自动编码器的瓶颈,Out数据的重建质量预计会很差。 在这项工作中,我们考虑自动编码器的三种变体:仅使用重建损失训练的标准自动编码器(AE)、使用变分下界(VAE)训练的变分自动编码器(Kingma和Welling,2014)以及解码器+使用对抗性损失训练编码器(ALI (Dumoulin 等人, 2016)、BiGAN (Donahue 等人, 2017))。 此外,我们在基准测试中包含两种不同的重建损失函数:均方误差(MSE)和二元交叉熵(BCE)。 最后,AE KNN根据编码器输出的特征构建KNN分类器。
示例 1(续)
我们将使用自动编码器重建以及使用 MSE 损失训练的 VAE(Reconst. VAEMASE)作为我们运行示例的 OoDD 方法。 在第一阶段,我们通过在 MSE 标准下最大化证据下界(ELBO)作为证据来训练 上的辅助 VAE。 然后,在第二阶段,我们计算 样本的重建损失,并校准重建损失的阈值,以分离 In 和 Out 样本。 最后,我们通过根据重建损失预测其标签(“in”或“out”)并与真实情况进行比较来评估 。
3.2 在数据集中 ()
| Domain | Eval | In data | use-case 1 Out data | use-case 2 Out data | use-case 3 Out data |
| Chest X-ray | 1 | NIH (In split) | UC-1 Common, MURA | PC-Lateral, PC-AP, PC-PED, PC-AP-Horizontal | NIH-Cardiomegaly, NIH-Nodule, NIH-Mass, NIH-Pneumothorax |
| 2 | PC-Lateral (In split) | UC-1 Common, MURA | PC-AP, PC-PED, PC-AP-Horizontal, PC-PA | PC-Cardiomegaly, PC-Nodule, PC-Mass, PC-Pneumothorax | |
| Fundus Imaging | 3 | DRD | UC-1 Common | DRIMDB | RIGA |
| Histology | 4 | PCAM | UC-1 Common, Malaria | ANHIR, IDC | None |
对于 ,我们从涵盖三种医学成像模式的四个医学数据集中进行选择。 每个数据集都被随机分为三种方式用于 、 和 。 每个数据集还包含一个分类任务。 由于大多数机器学习应用程序仅处理一种图像类型(即医疗应用程序不会同时诊断胸部疾病和糖尿病视网膜病变),因此我们将每个 In 分布数据集视为不同的评估,并且不考虑它们的组合。 每个评估的In数据集为:
-
1.
正面视图胸部 X 射线图像。 任务是预测 NIH 胸部 X 射线数据集(Wang 等人,2017) 定义的 14 个放射学结果中的 10 个。 其余条件保留用于用例 3。
-
2.
胸部 X 射线侧视图 (PC-Lateral)。 任务与评估 1 相同,但数据来自 PADChest (PC) 数据集(Bustos 等人, 2019) 中的侧视图图像。 其余条件也适用于用例 3。
-
3.
眼底/视网膜(眼睛后部)图像。 任务是检测 DRD(糖尿病视网膜病变检测)数据集定义的视网膜中的糖尿病视网膜病变。 (Kaggle 和 EyePacs,2015)
-
4.
H&E 对淋巴结的组织学切片进行染色。 任务是预测图像块是否包含 PCAM 数据集 (Veeling 等人,2018) 定义的癌组织。
3.3 Out 数据集( 和 )
我们根据部分2中描述的用例选择Out数据集。 由于用户可能对特定用例独立感兴趣,因此我们评估每个用例的 OoDD 方法。 显然,每个用例的特征是相对于 In 分布定义的,因此我们可能需要为每个 In 数据集选择不同的 Out 数据集。
对于用例1下的和,我们采用自然图像和符号数据集的组合,我们称之为UC-1 Common. 这用于每个 In 数据。 对于用例2,我们使用与In分布相同模态的数据集,但捕获不正确。 例如,胸部区域的不同视图(例如侧面与正面)用作评估 1 和 2 的 和 。 最后,对于用例3,我们使用不同状况/疾病的图像作为Out数据。 对于评估 1 和 2,四个保留条件用作用例 3 Out 数据。 由于缺乏可用数据,我们没有包含组织学幻灯片的用例 3 Out 数据集。 表1总结了我们的In和Out数据集名册。 每个 Out 数据集均按 50/50 分为 和 。 子采样用于平衡和中In和Out样本的数量。
如何在 和 之间分割 Out 数据仍有待确定。 一个常见但过于乐观的假设是 Out 数据彼此相似,因此 OoDD 方法是在同一 OoD 数据集的不同分割上进行训练和评估的。 在我们的运行示例中,这需要校准 NIH Chest 数据与 MNIST 训练分割的重建损失阈值,然后评估 NIH Chest 数据与 MNIST 测试分割的情况。 在另一个极端,假设我们无法访问分布外的数据,从而将任务转变为一类分类任务,其中除了测试之外不使用 Out 数据。 在现实环境中,开发人员将在许多不同的数据集上训练 OoDD 方法,以涵盖不同模式的 OoD 数据,但部署时看到的数据具有开发人员选择的数据无法解释的可变性。 因此,对于每个用例,我们选择数据集的子样本来训练 OoDD 方法,并使用剩余的数据集进行评估。
示例 1。 (续)
对于运行示例的用例 1,我们将 Out 数据分为 14 个分区(UC-1 Common 中的 9 个数据集,以及 MURA 骨骼 X 射线数据集中的 5 个身体区域) 。 我们对 采样 3 个分区,无需替换,并在 中使用其余部分。 在用例 2 中,我们将侧视图、儿科视图 (PED)、背视图 (AP) 和水平背视图 (AP-Horizontal) 作为四个 Out 分割。 我们随机选择一个作为 并使用剩余的作为 。 我们对用例 3 执行相同的操作,它也有四个 Out 拆分。
4实验和结果
在此基准测试中,我们报告了每种 OoDD 方法在每个评估和用例中的性能。 我们测量 上的准确率和精确召回曲线下面积 (AUPRC),每种方法总共有 11 对性能数据。 由于 是类平衡的,因此准确性提供了 I 类和 II 类错误的无偏差表示。 AUPRC 表征了预测值(我们为获得分类而设定的阈值)中In和Out样本的可分离性。 实验设置的详细信息参见附录B。
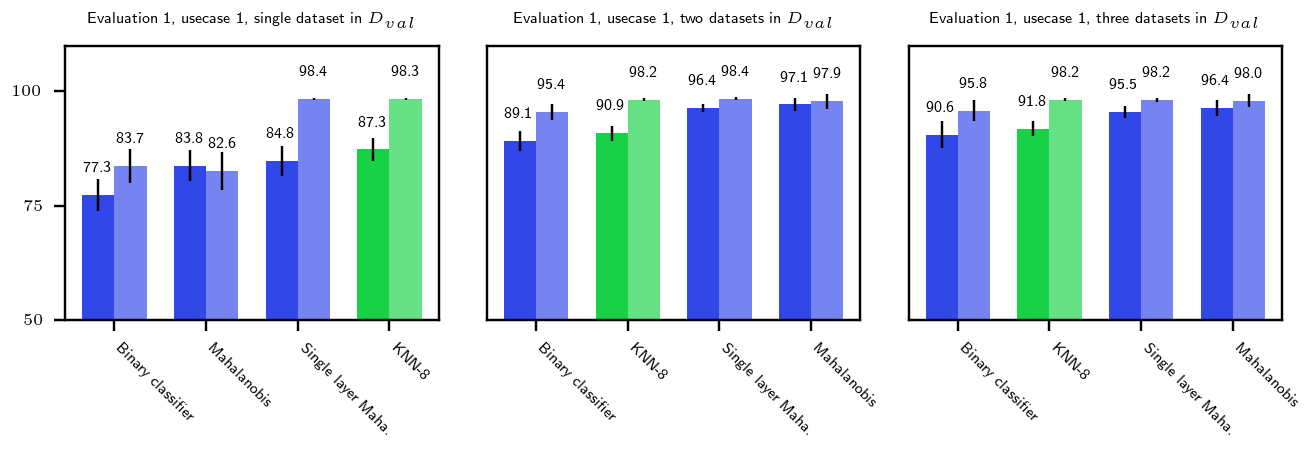
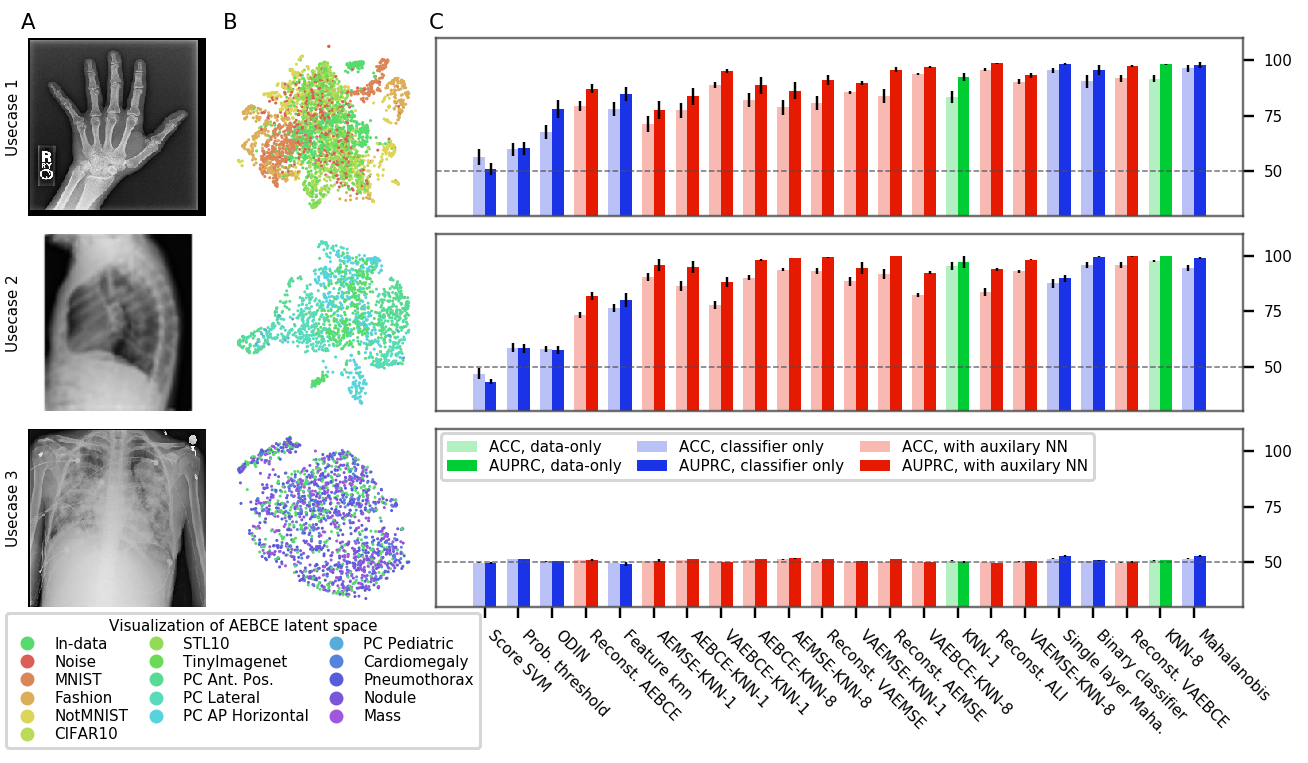
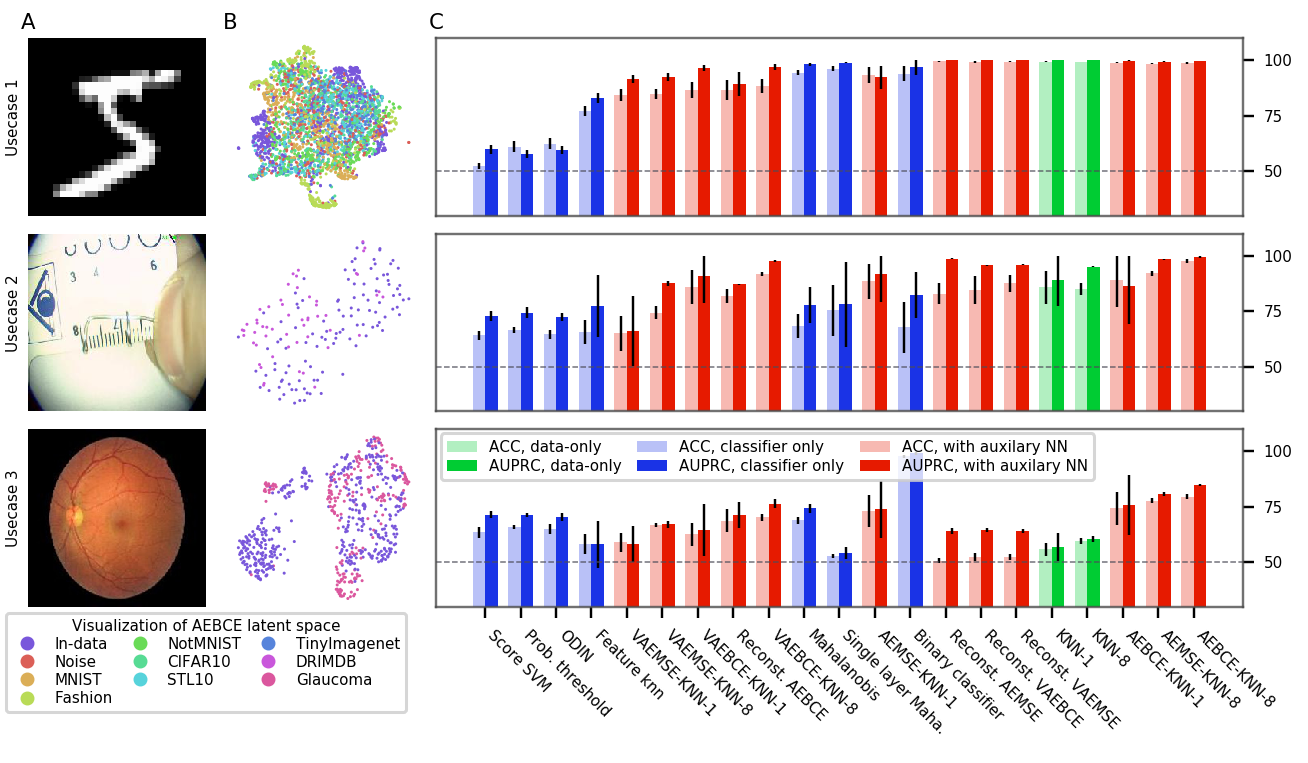
图3、6、7和8显示了OoDD方法在四个评估中的性能。 一般来说,我们观察到我们选择的数据集为 OoDD 方法创建了一系列从简单到困难的测试用例。 虽然许多方法可以在评估 1-3 中充分解决用例 1 和用例 2,但事实证明,用例 3 对于所有测试的方法来说都很困难。 这反映在 AE 潜在空间的 UMAP 可视化中(图 3 至 7 的 B 列),其中我们观察到 In数据点很容易与用例 1 和 2 中的 Out 数据分离,但与用例 3 中的 Out 数据很好地混合。 令人惊讶的是,在所有重复试验中,在评估 1 和 2 的用例 3 中,没有任何方法能够实现比随机方法显着更高的准确性。 这说明检测看不见的/新发疾病是极其困难的,这也证实了任等人(2019)的研究结果。
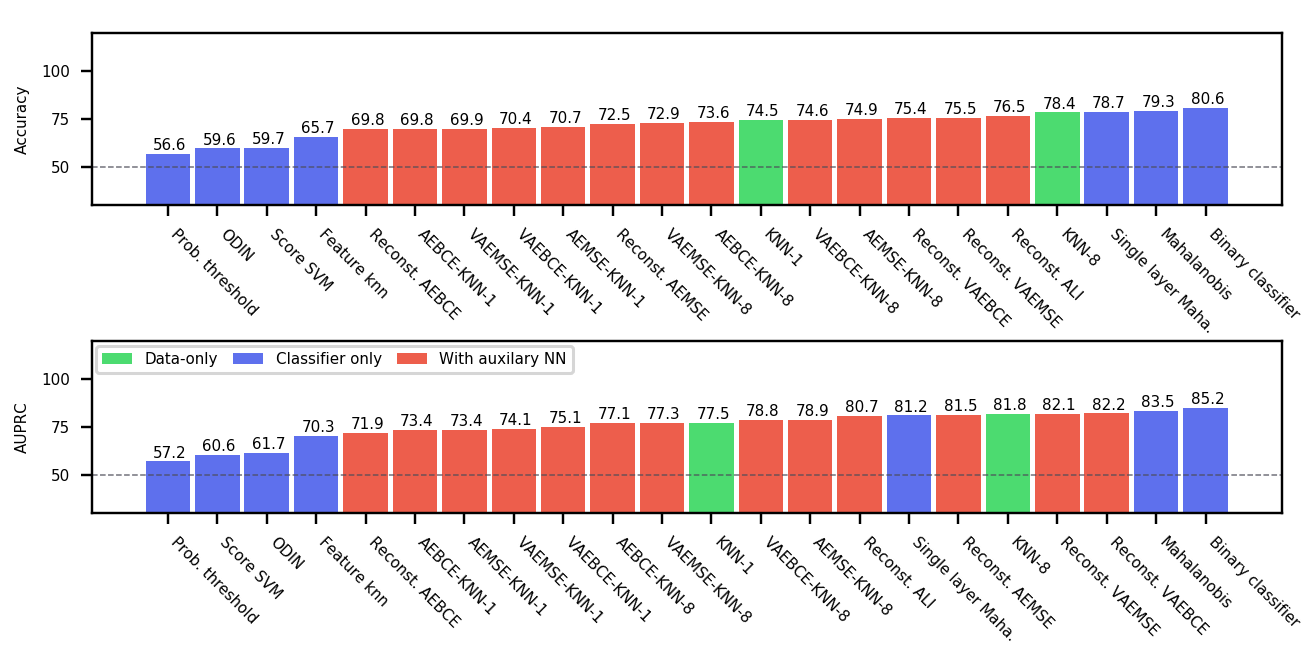
整体性能 在评估中,性能更好的仅分类器方法与使用辅助模型的方法具有竞争力。 当所有评估的性能汇总时(图4),最好的仅分类器方法(马哈拉诺比斯和二元分类器)在准确性方面优于辅助模型。 尽管方法简单,但二元分类器的性能很强。 我们怀疑这种强大的性能是由于我们在构建 时随机采样了 3 个 Out 数据集,而不是选择单个 Out 数据集。 Out 数据中增加的多样性通过强制执行更稳定的决策边界来提高泛化能力。 我们使用较少的 Out 数据集对方法和任务的子集进行了额外的实验。 附录图9中的结果显示,随着中更多的Out数据集,前4种方法之间的差距迅速缩小。
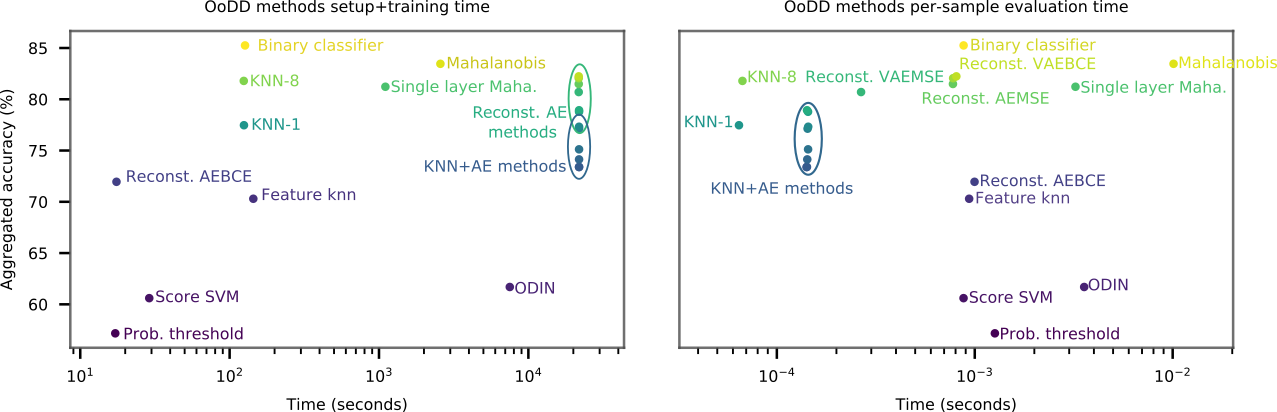
计算成本
我们从设置时间和运行时间方面考虑每种方法的计算成本。 设置时间被测量为超参数搜索和 的挂钟计算训练时间。 对于具有辅助模型的方法,辅助神经网络的训练时间也包含在设置时间中。 运行时间以测试时每个样本的计算时间(固定批量大小的平均值)来衡量。 图 5 绘制了模型在各自设置和运行时间上的准确性。 所有方法都可以相当快地做出预测,从而允许潜在的在线使用。 Mahalanobis 及其单层变体比其他分类器方法需要更多的时间来设置和运行。 KNN-8 以其较短的设置时间和良好的性能表现出最佳的时间与性能权衡。 然而,由于它需要存储训练图像来进行预测,因此它可能不适合在内存受限的平台(例如移动设备)上或当训练数据隐私受到关注时使用。
5讨论
OoDD 的必要性有两个考虑因素支持。 首先是可用性。 当我们将机器学习工具从研究实验室转移到最终用户手中时,这些工具的可用性对其成功至关重要。 良好可用性的一个共同特征是在处理用户错误时优雅地失败。 在机器学习辅助诊断工具中,这意味着该工具能够拒绝对错误输入数据的预测,从而防止出现“垃圾输入、垃圾输出”的情况。 对于面向计算机科学界之外的用户的机器学习工具来说,这种清晰度尤其重要。 OoDD 必要的第二个原因是安全性的要求。 在机器学习辅助诊断等应用中,系统的性能与患者的安全直接相关。 机器学习预测器训练的一个有据可查的失败模式是预测器尝试根据其数据分布之外的输入进行推断。 OoDD 提供了一种安全机制,可以防止预测器故障通过不准确的预测来伤害用户。
6结论
总体而言,前三种仅分类器方法比除眼底成像之外的所有具有辅助模型的方法获得更好的精度。 二元分类器的平均准确率和 AUPRC 最好,并且实现简单。 因此,我们推荐二元分类器作为医学图像领域 OoDD 的默认方法。 我们发现效果最好的方法几乎与 Shafaei 等人 (2018) 相反,尽管使用相同的代码来实现重叠方法。 这些研究之间的主要区别在于它们评估的是自然图像而不是医学图像。 我们对所有方法进行了广泛的超参数搜索,并得出结论:这种差异是由于我们定义的特定数据和任务造成的。 虽然用例 1 和 2 可以使用不复杂的模型轻松解决,但几乎所有任务中的大多数模型都未能显着解决用例 3,这与 Ahmed 和 Courville (2019) 的发现是一致的。 使用这些 OoDD 方法的诊断工具的用户仍应保持警惕,非常接近训练分布但不在其中的图像(以及用例 3 的假阴性)可能会产生意外结果。 在缺乏在用例 3 上具有良好性能的 OoDD 方法的情况下,另一种方法是开发将系统地推广到这些示例的方法。
致谢
我们感谢 Tobias Würfl、Faruk Ahmed 和 Ronald Summers 提出的有用评论。 这项工作利用了加拿大计算局和魁北克计算局管理的超级计算设施。 我们感谢AcademicTorrents.com 为我们的研究提供数据。
参考
- Ahmed and Courville (2019) Faruk Ahmed and Aaron Courville. Detecting semantic anomalies. In Association for the Advancement of Artificial Intelligence, aug 2019. URL http://arxiv.org/abs/1908.04388.
- Bustos et al. (2019) Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria de la Iglesia-Vayá. PadChest: A large chest x-ray image dataset with multi-label annotated reports. arXiv preprint, jan 2019. URL http://arxiv.org/abs/1901.07441.
- Donahue et al. (2017) Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial Feature Learning. In International Conference on Learning Representations (ICLR), 2017. URL http://arxiv.org/abs/1605.09782.
- Dumoulin et al. (2016) Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Olivier Mastropietro, Alex Lamb, Martin Arjovsky, and Aaron Courville. Adversarially Learned Inference. International Conference on Learning Representations, 2016. URL http://arxiv.org/abs/1606.00704.
- Hendrycks and Gimpel (2017) Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations, 2017.
- Huang et al. (2017) Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely Connected Convolutional Networks. In Computer Vision and Pattern Recognition, 2017. URL https://arxiv.org/abs/1608.06993.
- Kaggle and EyePacs (2015) Kaggle and EyePacs. Kaggle diabetic retinopathy detection, jul 2015. URL https://www.kaggle.com/c/diabetic-retinopathy-detection/data.
- Kingma and Welling (2014) Diederik P Kingma and Max Welling. Auto-Encoding Variational Bayes. In International Conference on Learning Representations, 2014. URL http://arxiv.org/abs/1312.6114.
- Lee et al. (2018) Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. jul 2018. URL http://arxiv.org/abs/1807.03888.
- Liang et al. (2017) Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks. jun 2017. URL http://arxiv.org/abs/1706.02690.
- Razzak et al. (2017) Muhammad Imran Razzak, Saeeda Naz, and Ahmad Zaib. Deep learning for medical image processing: Overview, challenges and the future. Classification in BioApps, page 323–350, Nov 2017. ISSN 2212-9413. doi: 10.1007/978-3-319-65981-7˙12. URL http://dx.doi.org/10.1007/978-3-319-65981-7_12.
- Ren et al. (2019) Jie Ren, Peter J. Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark A. DePristo, Joshua V. Dillon, and Balaji Lakshminarayanan. Likelihood ratios for out-of-distribution detection, 2019.
- Shafaei et al. (2018) Alireza Shafaei, Mark Schmidt, and James J. Little. Does Your Model Know the Digit 6 Is Not a Cat? A Less Biased Evaluation of ”Outlier” Detectors. arxiv, sep 2018. URL http://arxiv.org/abs/1809.04729.
- Valiant (1984) L. G. Valiant. A theory of the learnable. In Proceedings of the Annual ACM Symposium on Theory of Computing, pages 436–445. Association for Computing Machinery, dec 1984. ISBN 0897911334. doi: 10.1145/800057.808710.
- Veeling et al. (2018) Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation Equivariant CNNs for Digital Pathology. In Medical Image Computing & Computer Assisted Intervention (MICCAI), jun 2018. URL http://arxiv.org/abs/1806.03962.
- Wang et al. (2017) Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M. Summers. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Computer Vision and Pattern Recognition, 2017. doi: 10.1109/CVPR.2017.369. URL http://arxiv.org/abs/1705.02315.
A 数据集描述
UC-1 Common 中使用以下数据集:
-
•
MNIST111http://yann.lecun.com/exdb/mnist/ 28x28黑白手写数字数据。 原始测试分割用于 UC-1 Common。
-
•
notMNIST 222http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html 各种字体的字母 A-J。 黑白,分辨率为 28x28。 使用测试分割。
-
•
CIFAR10 和 CIFAR100333https://www.cs.toronto.edu/ kriz/cifar.html 32x32自然图像。 UC-1 Common 中使用的原始测试拆分。
-
•
TinyImagenet444https://tiny-imagenet.herokuapp.com/ ILSVRC2012 的 96x96 下采样子集。 UC-1 Common 中使用的验证拆分。
-
•
时尚MNIST555https://www.kaggle.com/zalando-research/fashionmnist 衣服和鞋子的灰度 28x28 图像。 验证分割用于 UC-1 Common 中。
-
•
STL-10666https://ai.stanford.edu/ acoates/stl10/ 大小为 96x96 的自然图像数据集。 UC-1 Common 使用了 8000 张测试图像。
-
•
噪声 在任何所需分辨率下生成的白噪声。
使用以下医疗数据集:
-
•
ANHIR777https://anhir.grand-challenge.org/ 自动非刚性组织学图像配准挑战。 用不同染料染色的组织病理学组织样本的显微镜图像。 评估 4、用例 2 中使用了肠道和肾脏组织的图像。
-
•
DRD 888https://www.kaggle.com/c/diabetic-retinopathy-detection/data高分辨率视网膜图像,每张图像中存在糖尿病视网膜病变,并以 0 到 4 的等级进行标记。 我们将其转换为分类任务,其中 0 对应于健康,1-4 对应于不健康。
-
•
DRIMDB 各种质量的眼底图像标记为好/坏/异常值。 我们在评估 3、用例 2 中使用标记为不良/异常值的图像。
-
•
疟疾 999https://lhncbc.nlm.nih.gov/publication/pub9932 从健康人和疟疾患者身上采集的血涂片显微镜下的细胞图像。 用于评估 4 用例 1。
-
•
MURA101010https://stanfordmlgroup.github.io/competitions/mura/ MUsculoskeletal RAdiographs 是骨骼 X 射线的大型数据集。 我们在评估 1 和 2 的用例 1 中使用其验证分割。 图像是灰度的并且正方形被裁剪。
-
•
NIH 宝箱 111111https://www.kaggle.com/nih-chest-xrays/data 该 NIH 胸部 X 射线数据集由 112,120 张 X 射线图像和 14 个状况标签组成。 X 射线图像为前后视图(X 射线从后到前)。
-
•
PAD宝箱 121212https://bimcv.cipf.es/bimcv-projects/padchest/ 这是一个大规模胸部 X 射线数据集。 它标有 117 个放射学结果 - 我们使用与 NIH Chest 数据集中的 14 个状况标签相对应的子集。 图像有 5 种不同的视图:后-前 (PA)、前-后 (AP)、横向、AP 水平和儿科。
-
•
PCAM 131313https://github.com/basveeling/pcam Patch Camelyon 数据集由淋巴结切片的组织病理学扫描组成。 图像上标记有癌组织的存在。
-
•
用于青光眼分析的RIGA眼底成像数据集。 医生在图像上标记疾病区域。 我们使用该数据集进行评估 3、用例 3。
B实验流程详情
B.1 网络训练
对于分类器模型,我们使用带有 Imagenet 预训练权重的 DenseNet-121 架构(Huang 等人,2017)。 最后一层重新初始化,整个网络在 上进行微调。 由于 NIH 和 PC-Lateral 数据集仅包含灰度图像,因此第一层中特征的预训练权重在微调之前在各个通道上进行平均。
对于所有自动编码器,我们使用 12 层 CNN 架构,所有评估的瓶颈维度均为 512。 由于计算限制,所有图像在输入自动编码器时都会被下采样到 。 这些 AE 在各自的 上从头开始进行 MSE 损失和 BCE 损失训练。 我们还使用相同的架构训练 VAE,不同之处在于瓶颈维度加倍至 1024,以允许将代码拆分为均值和方差。
此外,我们在评估 1 中探索了使用 ALI 进行训练编码器+解码器的潜在好处。 我们使用与 Dumoulin 等人 (2016) 中提出的相同的网络架构,权重在 Imagenet 上预训练并在 NIH In 类上进行微调。 由于训练 GAN 增加了复杂性,并且与常规 AE 相比,OoDD 性能缺乏显着改进(参见§4),我们没有将 ALI 模型用于其他三个评估。
为了衡量训练进度和过度拟合,我们保留 中的 作为验证集。 我们选择 上错误率最低的训练检查点用于 OoDD 方法。
B.2 OoDD方法训练
当为用例 1 训练 OoDD 方法时,会随机选择三个 Out 数据集用于 ,而其余数据集用于 。 对于用例 2 和 3,我们枚举了配置,其中每个 Out 数据集用作 ,其余数据集用作 。 和 通过对相同数量的 In 和 Out 样本进行二次采样来实现类平衡。 此外,某些方法(ODIN 和 Mahalanobis)需要额外的超参数选择。 因此,我们进一步将细分为“”拆分和“验证”拆分;方法在“训练”部分进行训练/优化,并在“验证”部分进行提前停止/校准。 在需要时进行超参数扫描。 每次评估都会进行 10 次重复试验,并重新采样 和 。
C 其他结果