VisImages:细粒度专家注释可视化数据集
摘要
可视化出版物中的图像包含丰富的信息,例如新颖的可视化设计和可视化的隐式设计模式。 这些图像的系统收集可以在许多方面为社区做出贡献,例如文献分析和可视化自动化任务。 在本文中,我们构建并公开了一个数据集 VisImages,该数据集收集了来自 IEEE InfoVis 和 VAST 中 1,397 篇论文的 12,267 张带有标题的图像。 该数据集基于全面的可视化分类法,包含 35,096 个可视化及其图像中的边界框。 我们通过三个用例展示了 VisImages 的实用性:1)使用 VisImages Explorer 研究出版物中可视化的使用,2)用于可视化分类的训练和基准模型,以及 3)自动本地化可视化分析系统中的可视化。
索引术语:
可视化数据集、众包、文献分析、可视化分类、可视化检测1 简介
图像对于可视化社区(例如 IEEE VIS)中的出版物至关重要,展示视觉设计、系统框架、模型细节、实验结果等。 这些图像包含丰富的视觉信息(例如,图形元素的配色方案和形状)和语义信息(例如,图表的不同组合),可以促进对该领域的理解和可视化人工智能(AI4VIS)的研究[1]。
首先,图像中包含的信息可以极大地有利于可视化文献的分析,可视化文献主要使用关键字、引文和共同作者[2]等出版物元数据。 将图像数据纳入文献分析,可以从更多维度理解可视化领域(例如,历年不同场所经常使用什么类型的图表;不同的研究主题如何使用不同的图表?) 并激发新的研究问题(例如,如何将不同的图表组织在一起以更好地表示数据?)。
此外,来自可视化出版物的可视化数据集为AI4VIS的应用提供了新的机会。 现有研究[3,4,5]在线收集图表图像和用于可视化任务(例如图表分类)的计算机视觉模型。 由于数据源的原因,这些数据集中的图像通常包含常见的图表类型和简单的布局。 因此,在处理具有复杂设计的图表(例如具有多个图表的系统界面)时,在这些数据集上训练的模型可能会失败。 因此,来自可视化出版物的新可视化数据集可以推进机器学习模型开发的研究,并作为测试模型的通用性和鲁棒性的基准。

然而,可视化出版物中的图像不能直接用于上述任务,因为它们缺乏描述图像中语义信息的足够注释。 例如,在分析可视化文献时,需要图像中可视化类型的信息来索引和搜索感兴趣的图像以进行深入分析。 此外,缺乏将前沿机器学习模型应用于可视化任务(例如,解构视觉分析系统或生成可视化)的适当标签。 特别是,对象检测模型需要图像中可视化的边界框,而图像文本翻译模型需要有关图像的文本描述。

为了方便图像的使用,我们从可视化出版物中构建并公开了可视化数据集 VisImages。 VisImages 中的数据分为三个层次,即论文、图像和可视化(图1)。 论文数据包括论文的元数据(即标题、作者、会议和年份)和图像数据。 论文的元数据编码自 vispubdata.org [10]。 图像数据是每个图像的数据列表,其中包括图像文件名、文本标题、图像在论文中的位置(即边界框)和可视化数据。 可视化数据是每个可视化的数据列表,包括图像中的可视化类型和可视化位置(即边界框)。 该数据集总共包含 1,397 篇论文、12,267 张图像和 35,096 个可视化的数据。
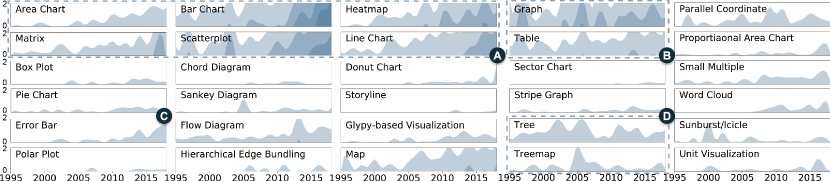
创建这样的数据集面临三个主要挑战。 第一个挑战是对不同的可视化进行分类。 尽管人们提出了各种分类法来定义和区分不同的可视化类型[11, 12],但它们无法完全涵盖可视化出版物中的各种设计,例如新颖的字形(图2) >-A) 或现有可视化的变体 (图2-B)。 此外,注释可视化类型需要广泛的可视化专业知识。 其次,出版物中多样化的布局(图2-C&D)和大量的可视化使得识别可视化的位置变得困难和乏味。 第三,由于注释者的知识专业知识多样且缺乏“基本事实”,确保注释的质量也具有挑战性。 解决冲突和减少偏见对于数据至关重要。
为了解决第一个挑战,我们使用 Borkin 等人 [12] 提出的综合分类法,并将可视化视为不同可视化 [13] 的组合来注释可视化。 基于分类法,我们邀请可视化从业者来注释可视化类型。 对于第二个挑战,我们建立了一系列用于分解和定位图像中的可视化的标准。 根据标准,我们招募经过培训的人群工作人员来注释每个可视化的边界框。 针对第三个挑战,我们采取了一系列的质量控制措施,包括金标准[14]、多数投票、抽样测试等。 我们的贡献是三重的。
-
•
我们从 IEEE VAST 和 InfoVis 构建了一个名为 VisImages 的新颖数据集,用于文献分析和 AI4VIS 的研究。 我们在https://visimages.github.io/发布了数据集和数据收集代码。
-
•
我们概述了可视化出版物中可视化的使用,并将其与从公共来源收集的图像进行比较。 通过分析,我们深入了解了学术出版物中可视化的特殊性。
-
•
我们通过三个用例展示 VisImages 的实用性,即 1)使用 VisImages Explorer 探索和分析出版物中可视化的演变,2)评估可视化分类模型的通用性和鲁棒性,以及 3)在视觉界面中本地化可视化自动分析系统。
2 相关工作
本节介绍可视化数据集和可视化文献分析的相关研究。
2.1 可视化中的图像数据集
我们首先介绍现有的可视化图像数据集,并证明 VisImages 由于其独特的数据源可视化出版物可以极大地促进可视化研究。 此外,据我们所知,VisImages 在可视化数量、布局复杂性、标签类型等方面是最全面的。
可视化社区构建了各种布局简单的基本图表(例如条形图或散点图)的图像数据集。 这些数据集中的图像主要从互联网收集,例如社交媒体(例如 Twitter)和媒体渠道(例如 BBC),或由可视化库生成(例如 D3 [15], Vega-Lite [16])。 例如,Battle 等人[3]收集了超过 41,000 个基于 SVG 的图表,手动将每个图表标记为 24 种图表类型之一,并训练分类模型来分析网络上的图表分布。 Jung 等人[17]收集了由10种图表类型组成的5,659张图像来开发图表分类模型,并提出了用于数据提取的ChartSense。 Savva 等人[4]交付了包含 10 个类别 2,601 个单图表图像的数据集。 该数据集用于开发一个名为 ReVision 的系统,以重新设计图表以获得更好的视觉风格。 同样,Poco等人[18]收集了超过5,000张位图图像和带注释的图表类型(面积、折线、条形和散点)以及图表的文本注释(轴和图例的标签和标题) 。 该数据集用于使用声明性语法重建原始图表,例如 Vega-Lite [16]。 Borkin 等人 [12, 19] 开发了用于记忆研究的 MassVis。 他们收集了 2000 多个单图表可视化,并将它们分为 12 个类别。 对于每幅图像,他们通过众包评估了数据墨水比率和视觉密度。 他们还注释了 396 个图像的子集以获取详细信息(例如注释、轴和数据)。 Lee等人[20]收集了科学出版物中的图像,并将其分类为方程、照片、图表等。
| Dataset | Audience | Layout | #Annotated Visualizations | #Images | #Annotated Categories | Label Types | How to label? | ||
| type | bbox | caption | |||||||
| MassVis [12] | general users | single | 2000 | 2000 | 12 | - | - | manual annotation | |
| REV [18] | general users | single | 5000 | 5000 | 4 | - | - | machine generation + manual refinement | |
| Beagle [3] | general users | single | 33,778 | 33,778 | 24 | - | - | manual annotation | |
| ChartSense [17] | general users | single | 2000 | 2000 | 10 | - | - | search engine + manual refinement | |
| VizioMetrics [20] | general users | - | - | 4,986,302* | 5 | - | - | object classfication + manual annotation | |
| VIS30K [21] | visualization experts | - | - | 30,000 | 4 | - | - | object detection + manual refinement | |
| MV Dataset [22] | visualization experts | multiple | not reported | 360 | 14 | - | manual annotation | ||
| VisImages | visualization experts* | multiple* | 35,096* | 12,267 | 34* | manual annotation | |||
除了基本的图表之外,可视化出版物中的图像还包含可视化专家创建的新颖设计,例如系统界面,这是许多研究的兴趣所在。 例如,Li等人[23]从IEEE SciVis收集图像并进行用户研究,以了解记忆性和图像特征之间的关系。 Chen 等人 [21] 采用对象检测模型(Faster-RCNN [24] 和 YOLOv3 [25])来裁剪图形和表格来自可视化出版物和提议的 VIS30K(图形和表格数据集)。 同样,Zeng等人[26]收集了IEEE VIS的数据来可视化和分析数据的演变。 但是,其数据集中不考虑视觉设计的详细信息,例如图表类型、图表位置和标题。 Chen等人[22]从出版物中收集了多视图可视化(MV)的图片,并注释了视图位置和类型。 他们提供了 360 张 MV 图像的语料库,并对视图类型和布局进行了统计分析。 我们从目标受众、可视化布局、数量、类别和标签类型等角度对 VisImages 和现有数据集进行了详细比较,如表I所示。
与现有数据集相比,VisImages 对于可视化研究来说是新颖的,因为它对于可视化理解非常有用,并且由于综合注释而具有可用性。 首先,VisImages 包含由可视化研究人员创建的具有复杂配置的新鲜设计。 同时,现有的数据集,例如VizioMetrics [20]、Beagle [3]、ChartSense [17]、MassVis [19、 12] 和 REV [18],从公共来源收集数据并包含大部分基本图表。 独特的数据源使 VisImages 成为研究常见可视化类型的变化或组合以及创新视觉设计的引人注目的数据集。 此外,VisImages 中新颖的视觉设计为新的研究方法提供了具有挑战性的基准,促进了 AI4VIS [1] 的研究。
其次,VisImages的突出特点是标注全面,非常适合各种场景。 1) 标注粒度:与 VIS30K [21] 和 VizioMetrics [20] 相比,后者根据图像的目标或用途对图像进行分类(例如,图表) 、方程、照片、绘图和表格)在图像级别,VisImages 通过细粒度分类进一步指定图像内的可视化类型和边界框。 2) 设计复杂性: 与主要由单图表可视化组成的 MassVis [19, 12] 和 REV [18] 相比,VisImages 包含了对多图表可视化的详细注释,例如视觉分析系统。 3) 可视化数量: 除了复杂性之外,VisImages还涵盖了大量的可视化内容(大约是MV数据集[22]数量的100倍),可以满足训练深度学习模型的要求。 凭借上述特性,VisImages可以直接用于分类、定位等多种场景,这对于AI4VIS的研究具有实用性。
2.2 可视化文献分析与数据集
文献分析是索引和理解出版物的重要研究领域。 目前的研究主要使用以下四种类型的数据:文本、引文、作者和元数据[2]。
许多可视化出版物的数据集[27,28,29,30,10]用于支持交互式文献分析。 最新的是 vispubdata.org [10],其中包含 IEEE VIS 分会中出版物的元数据。 出版数据,例如作者、参考文献和关键词,是从电子会议记录中收集的。 在vispubdata.org的基础上提出了CiteVis2、CiteMatrix、VisList[10]等一系列可视化分析工具。 Ponsard 等人[31]提出了PaperQuest,这是一个搜索用户感兴趣的相关论文的工具。 一些研究[32, 33]也尝试根据研究主题组织出版物。 Chuang等人[32]介绍了一个使用主题建模来分析InfoVis语料库的框架。 Isenberg等人提出了KeyVis[33],提取可视化论文的关键词。 然而,上述研究都没有调查图像数据。 VisImages 包含具有丰富注释的大型图像数据集,可以为文献分析提供额外的维度。
3 数据集构建
在本节中,我们概述了 VisImages 的构造。

| Categories | Sub-types |
| Area | area chart, proportional area chart (PAC) |
| Bar | bar chart |
| Circle | donut chart, pie chart |
| Diagram | flow diagram, chord diagram, Sankey diagram, Venn diagram |
| Statistic | box plot, error bar, stripe graph |
| Table | table |
| Line | contour graph, line chart, storyline, polar plot, parallel coordinate (PCP), surface graph, vector graph |
| Map | map |
| Point | scatter plot |
| Grid & Matrix | heatmap, matrix |
| Text | phrase net, word cloud, word tree |
| Graph & Tree | graph, tree, treemap, hierarchical edge bundling (HEB), sunburst/icicle plot |
| Special | glyph-based visualization, unit visualization |
3.1 数据预处理
为了构建 VisImages,我们首先从顶级可视化出版物中收集图像(图3-A)。 在本研究中,我们专注于 2D 静态可视化,并从 VAST(IEEE 视觉分析科学与技术会议)和 InfoVis(IEEE 信息可视化会议)收集图像。 我们排除了 SciVis(IEEE 科学可视化会议)论文,因为这些论文通常包含大量描述 3D 渲染结果的图像,这超出了本文的范围。 我们首先根据 vispubdata.org [10] 中提供的数字对象标识符(DOI)下载论文的 PDF 文件。 接下来,我们使用PDFFigures 2.0 [34]从文件中提取图像和标题,并手动检查和纠正结果。 我们重点关注由 Figure 和 Table 索引的图形和表格以及没有标题的内嵌图形。 我们总共处理了 1996 年至 2018 年 VAST 和 InfoVis 中的 1,397 篇论文,并收集了 12,267 张图像和 12,057 个文本标题。
3.2 可视化分类
为了对可视化进行分类,我们使用了 Borkin 等人[12]提出的分类法,将可视化分为两级结构,即 12 个类别和子类型。 该分类法根据视觉编码(例如条形和面积)、视觉任务(例如统计)和视觉布局对公众(即信息图表、新闻媒体、科学期刊以及政府和世界组织)使用的可视化进行分类(例如图表)。 然而,我们发现原始分类法有一些定义相似的子类型,例如条形图和直方图。 为了避免歧义,我们将这些类型合并在一起。 此外,我们还发现一些可视化类型未在分类中列出,例如冰柱图和基于字形的可视化。 因此,我们将这些类型添加到原始分类中。 我们的数据集中使用的分类法由 13 个类别和 34 个子类型组成,如表II所示。
3.3 数据管道标注
为了注释图像中的可视化类型和边界框,我们设计了一个利用可视化从业者的专业知识和众包的可扩展性的管道。
4 数据标注流程
我们根据精细的分类法和标注管道来标记可视化类型和边界框。
4.1 可视化类型标注
识别可视化及其变化具有挑战性,需要广泛的可视化知识。 因此,我们招募了具有可视化研究经验的研究人员和学生来注释图像中出现的可视化类型。 请注意,术语“类型”指的是表II中的可视化子类型。
参与者。 我们招募了 25 名参与者,其中 1 名具有六年可视化研究经验的高级可视化专家,13 名博士。具有可视化研究兴趣的博士生,信息可视化专业硕士研究生7名,数据可视化本科生4名。 他们中的大多数(15/25)在IEEE VIS 上发表过论文。
过程。 标注过程包括训练和正式学习。 在训练课程中,我们首先通过示例介绍了每个可视化子类型的分类和定义。 然后我们介绍了标注任务的细节。 具体来说,在我们的研究中,注释图像的可视化类型是一项多标签任务。 在这样的任务中,向参与者展示了一张图像,并要求参与者根据我们的分类法选择图像中出现的所有可视化子类型。 如果参与者认为图像不包含我们分类中的可视化类型,他们可以选择附加选项“其他”。介绍后,参与者被要求进行测试,以确保他们正确理解分类法。 该测试包含 20 张涵盖所有可视化类型的图像(一张图像可能包含多种类型),只有正确注释了 18 张以上图像的参与者才被视为有资格参加正式研究。 所有参与者都在第一次尝试时就通过了测试。
在正式研究中,所有参与者都独立对图像进行注释。 在标注之前,参与者必须输入自己的姓名作为身份证明。 所有带注释的数据都记录了参与者的姓名。 标注期间,参与者看不到其他人的结果。 我们开发并部署了数据标注在线界面。 数据存储在后端服务器中,该服务器记录标注日志并管理任务分配。
每轮标注包含 40 项任务。 完成一轮大约需要10分钟。 每个参与者最多分配 40 轮。 为了避免超载,参与者被允许在五天内完成所有图像。 我们为每项接受的任务支付 0.05 美元。
质量控制。 我们采用黄金标准和多数投票的方法进行质量控制。 黄金标准是手动选择并插入到每轮中的图像,以测试参与者是否专注于任务。 黄金标准图像包含放置在明显位置的简单图表,并且参与者被期望能够轻松正确地指定可视化类型。 每轮包括八张具有黄金标准的图像。 如果参与者在一轮中未能达到多个黄金标准,则该轮的所有结果都将被拒绝,我们会将这些图像重新分配给其他参与者。 最终,我们获得了 940 轮接受的轮次和 102 轮拒绝的轮次。 在已接受的轮次中,参与者按照黄金标准获得了 96.4% 的准确率。
此外,我们使用多数投票来解决标注中的歧义。 具体来说,每张图像将由三名参与者独立注释。 参与者对可视化子类型的选择将被视为“投票”。 对于每个图像,具有至少两票的子类型将被接受为图像包含这些可视化子类型的实例的事实。 否则,子类型将被暂停以进行进一步讨论。 由于多数投票,整个标注过程至少包含 12,267 个图像 3 个重复 = 36,801 个注释。 我们计算了参与者的接受率,以评估他/她的注释与接受的结果之间的相似性。 总体而言,参与者的平均接受率为 88.3%。 此外,我们使用 Krippendorff 的 Alpha-Reliability [35] 计算间编码器可靠性,它支持在一个标注任务中使用多个标签和多个观察者。 我们使用“nltk.metrics.agreement”[36]中的Python实现来计算alpha值。 最终,我们获得了 76.8% 的间编码器可靠性值。
最后,我们发现 12,267 张图像中的 10,289 张被分配了可视化子类型的标签。 我们调查了其余的图像,发现这些图像通常是低分辨率的图像,解释方法、模型或算法的图像,照片、3D渲染或艺术作品的图像,以及纯文本的图像。 因此,我们给剩下的人贴上了“其他”的标签。各子类型的分布如表III所示。
4.2 边界框标注
通过每个图像中指定的可视化子类型,我们进一步注释了这些可视化的边界框(即图像中的位置)。 为了提高效率,我们聘请了来自专业数据标注公司的众包工作人员,他们在为机器学习任务绘制边界框方面接受过良好的培训。

标准。 我们的标准基于可视化的组成,即带坐标或不带坐标的可视化。 对于带有坐标的可视化,边界框应覆盖坐标的所有组成部分,例如轴名称、轴标签、图表标题和图例,如果它们靠近视觉表示的主体(图4-B)。 如果多个子类型共享相同的坐标(例如图4-B中的误差条和条形图),则它们的边界框的面积应该相同。 对于没有坐标的可视化,我们确定两种情况,即1)与其他可视化没有任何连接或重叠的独立可视化,2)与其他可视化连接或重叠的可视化。 对于第一种情况,内容是可视化本身(图4-A1)。 对于第二种情况,我们只关注所请求的子类型的内容。 例如,图4-C中的树连接到桑基图,图4-D中的词云覆盖在面积图上。 边界框应仅分别覆盖树和词云的内容。 此外,还有一个例外情况需要进一步规范。 某些可视化包含多个相同子类型的较小可视化(例如,图4-A2 中地图中的圆环图)。 在这种情况下,当数字大于10时,我们用带有“小倍数”标签的单个框对其进行整体注释。
过程。 标注过程包括训练和正式标注。 为了减少训练负担,每个众包工作者被要求只专注于一种子类型。 因此,在训练课程中,向众包工作者介绍了一种特定的可视化子类型,包括定义、示例和上述标注标准。 之后,众包工作人员被要求进行测试,以确保他们理解子类型和要求。 只有通过测试的众包工作者才能进入正式的标注。 然后,他们被分配包含特定可视化子类型的图像,并需要绘制此类可视化的边界框。 标注期间采取抽样检测,确保质量。

质量测量与控制。 我们评估了边界框和任务的正确性,以控制标注质量。 边界框的正确性通过并集 [38](IoU,如图5-A 所示)与真实边界框的交集来测量。 只有当边界框与groundtruth的IoU高于0.9时,边界框才被接受。 此外,一系列任务的质量是通过 分数来衡量的,这是一个平衡召回率和精度的指标。 召回率、精度和分数的计算如图5-B所示。
为了保证质量,我们采取了批次级和工人级的抽样检测。 我们将 10,289 张图像平均分为 5 批,并逐批进行注释。 批量标注完成后进行批量级抽样测试。 我们随机抽取 10% 的结果并评估 分数。 如果低于95%,整批标注将被拒收。 被拒绝的批次将再次被注释,直到 分数达到 95%。 Worker级抽样测试是在一批标注过程中进行的,随机抽取Worker的15%标注进行评分评估。 如果低于95%,则该worker在该批次中完成的所有任务都将被拒绝并重新注释。 对于抽检不合格的工人,下次抽检时抽检率增加5%。 每个接受的边界框需支付 0.03 美元。
5 可见图像
在本节中,我们将概述 VisImages 数据,并将 VisImages 中的可视化分布与其他来源的分布进行比较[12]。
| Sub-type | #bbox | #img | Sub-type | #bbox | #img. |
| bar chart | 5053 | 2058 | pie chart | 371 | 153 |
| scatterplot | 4269 | 1754 | PAC | 288 | 130 |
| graph | 3722 | 1615 | box plot | 277 | 147 |
| heatmap | 3202 | 1187 | unit visualization | 275 | 107 |
| line chart | 3004 | 1300 | sunburst/icicle | 260 | 120 |
| table | 2172 | 1676 | sankey diagram | 260 | 147 |
| map | 2106 | 986 | stripe graph | 239 | 123 |
| matrix | 1611 | 656 | HEB | 185 | 61 |
| tree | 1292 | 667 | chord diagram | 128 | 72 |
| area chart | 1125 | 527 | polar plot | 123 | 56 |
| flow diagram | 1118 | 873 | storyline | 46 | 25 |
| PCP | 975 | 541 | contour graph | 16 | 12 |
| error bar | 709 | 342 | surface graph | 13 | 7 |
| treemap | 554 | 268 | word tree | 9 | 9 |
| glyph-based | 523 | 259 | phrase net | 7 | 7 |
| word cloud | 392 | 184 | Venn Diagram | 4 | 4 |
| donut chart | 376 | 143 | vector graph | 4 | 2 |
| others | - | 1978 |
5.1 数据概述
VisImages 包含来自 22 年 VAST 和 InfoVis 出版物的 12,267 张图像,以及 12,057 个标题和 35,096 个可视化边界框。 表III显示了每个子类型的图像(#img)和边界框(#bbox)的数量。 对于频繁类型,我们观察到某些子类型(例如条形图和散点图)的边界框数量大约是图像数量的两倍。 也就是说,这些子类型的多个实例同时出现在一张图像中。 对于条形图和散点图,原因可能是它们是基本图表,通常用作小倍数的单位(例如散点图矩阵)。 相反,表格和流程图具有相似数量的边界框和图像。 我们发现它们通常占据整个图像,因为表格是独立使用来显示实验或研究的结果,而流程图则用于显示方法的流程或框架。
图6使用水平图描绘了1996年至2018年各子类型的分布情况,颜色暗度编码了边界框的数量。 几种可视化子类型变得越来越流行,例如条形图、面积图、散点图、矩阵、折线图和热图(图6-A)。 我们注意到图可视化的暗区在各个年份中均匀分布(图6-B),这表明图可视化长期以来在可视化社区中被频繁使用[39, 40]。 同样,表格一直是出版物中常见的可视化类型(图6-B)。 此外,我们观察到树状图的面积在2005年突然变大,而树状图的面积在2003年和2005年达到峰值(图6-D)。 树和树图可视化的增加意味着对分层数据[41]的更流行的研究。 而且,近年来误差棒的数量不断增加(图6-C),表明对误差的统计分析正在增加,例如用户研究和模型实验。
5.2 比较不同领域的可视化
此外,我们还分析了面向普通受众的学术可视化出版物和材料中的可视化分布。 我们使用 MassVis [12] 中的统计数据进行比较(表 IV),它从四个不同来源收集图像,即科学出版物(自然)、信息图表、新闻、以及政府和世界组织。
可以直接进行比较,因为类别级别的分类法是相同的,如表II所示。 从表IV中,我们注意到可视化出版物的分布比其他出版物更加平衡。 图和树在可视化出版物中占据最大份额,这在其他来源中并不常见。 原因可能是我们社区中的大量研究侧重于可视化分层或网络数据。 另一方面,新闻媒体和政府及世界组织更喜欢基本的视觉表示,例如 Bar、Table 和 Line,因为他们主要处理数据目前的内容比较简单,以表格的形式呈现。 科学论文更喜欢用图、线和点来表达方法论和实验结果。 我们注意到,文本(包括词云、词树和短语网)在可视化出版物中占据了一定比例,但很少出现在其他来源中。 许多可视化研究研究词云的变化,以使其更具信息性和有效性,例如 ManiWordle [42] 和动态词云 [43]。 然而,在公共场合,鉴于最常用的媒体是文本,作者可能希望使用文本以外的图形元素来提高表现力。
| Source | VisImages | MassVis | |||
| Scientific | Infographics | News | Government | ||
| Area | 4.0% | 1.9% | 4.4% | 4.4% | 3.5% |
| Bar | 12.1% | 6.4% | 5.9% | 40.2% | 36.9% |
| Circle | 1.8% | 0.3% | 4.7% | 1.3% | 6.6% |
| Diag. | 6.3% | 27.4% | 30.6% | 7.2% | 5.0% |
| Stat. | 3.7% | 3.2% | 0.3% | 0.3% | 1.3% |
| Table | 9.8% | 8.3% | 32.8% | 8.2% | 21.5% |
| Line | 11.2% | 19.1% | 1.6% | 19.1% | 12.9% |
| Map | 6.0% | 9.2% | 9.1% | 13.5% | 7.3% |
| Point | 10.6% | 16.6% | 2.8% | 5.0% | 0.5% |
| Grid | 7.2% | 2.5% | 1.9% | 0% | 0% |
| Text | 1.1% | 0% | 0% | 0.5% | 0% |
| Graph | 16.7% | 5.1% | 5.9% | 0.3% | 0% |
| Special | 9.5% | ||||
| #Vis. | 10,289 | 348 | 490 | 704 | 528 |
6 用例
我们在本节中介绍三个用例来展示 VisImages 的有用性。 具体来说,第一个案例演示了所有元数据和注释的使用,第二个案例演示了可视化类型数据的使用,第三个案例演示了边界框数据的使用。


6.1 调查可视化的使用
VisImages 包含来自 IEEE VIS 出版物的丰富信息,包括图像、可视化类型及其边界框、标题和出版物元数据。 这些信息可用于理解视觉设计和论文,这对于初级可视化研究人员和新手可视化设计师可能很有用。 因此,为了帮助这些用户进行数据探索,我们开发了VisImages Explorer来进行高效的数据过滤和搜索。
VisImages Explorer 由论文搜索面板、图像库视图、可视化分布视图和词云视图组成。 论文搜索面板(图8-A)允许用户按标题、年份、会议和作者过滤论文。 显示直方图以显示多年来不同会议的出版物数量。 然后,图像库视图(图8-B)会根据论文搜索结果显示所有图像。 用户可以通过可视化类型(图8-B1)和标题中的关键字进一步过滤图像。 用户可以通过单击图像在详细视图中检查每个图像的注释。 此外,浏览器还有一个显示可视化数量的可视化分布视图(图8-C)和一个词云视图(图8-D) 可视化过滤图像的标题中的词频。 为了演示 VisImages 的实用性,我们为初级可视化研究人员和新手可视化设计人员提供了两个场景。
场景一:审阅图形可视化论文。 假设 James 是一名大三博士生,正在调查 IEEE VIS 中有关图形可视化的论文以了解该领域。 论文标题中可能没有明确提及“图”,因此他决定直接搜索图像。 他转到图片库视图并过滤标题包含“graph”关键字的图片(图7-A2)。 由于图形数据可以用矩阵或节点链接图表示,他首先过滤包含“矩阵”子类型的图像,但只检索到 58 张图像。 然后他用“节点链接图”子类型(在本工作中表示为“图”,如图7-A1所示)对图像进行过滤,并检索到385张图像,这意味着节点链接图可能是图形数据更流行的表示类型。 由于VAST和InfoVis的研究对象不同,James分别进一步研究了两个会议的图像。 他发现两个会议的词云视图中排名靠前的词是不同的。 除了“图形”和“视觉”这两个词之外,InfoVis 中最常见的词是“布局”和“边缘”(图7-A3),而 VAST 中最常见的词是“视图”和“集群”(图7-A6)。
在深入探索 InfoVis 的标题时,James 发现这些图像主要是应用布局优化算法后的图形可视化结果(图7-A4)。 单击词云视图中的“布局”一词,如果图像的标题包含该词,则图像将被进一步过滤。 他立即发现这些论文的标题包含描述算法的关键词,例如“拓扑鱼眼”、“应力主化”和“分割边捆绑”(图7-A5)。 因此,他获得了一本关于图布局优化的论文集以供进一步阅读,这对他的研究生涯来说是一个很好的起点。
James 进一步探索了 VAST 中的图像,其中标题中经常出现“视图”和“集群”一词。 与 InfoVis 不同,VAST 图像中的图形可视化通常出现在视觉分析 (VA) 系统的视图中。 因此,“视图”一词通常与标题中的“图表”一词同时出现。 此外,图的“簇”模式是带有图的 VA 系统中描述最多的模式。 然后,他单击词云视图中的“集群”一词并研究标题。 从标题中,他了解到集群暗示着兴趣模式,有助于引导用户进一步探索。
场景 2:鼓舞人心的视觉设计。 假设玛丽是一名初级可视化设计师,正在为地理空间数据设计地图可视化。 她想知道是否有任何设计策略可以改进地图可视化以表示更多数据属性。 她首先过滤包含地图的图像。 可视化分布视图中的流图表明热图和条形图是与地图同时出现的最常见子类型(图7-B)。 热图可以直观地显示地图上的密度数据,但玛丽不清楚条形图如何与地图一起显示。 因此,她另外选择了条形图,并且过滤了同时包含地图和条形图的图像。 直方图显示了过滤图像中条形图和地图的分布(图7-C)。 通过研究图像,她发现条形图和地图可以在不重叠的情况下进行组织,例如将它们并排放置(图7-D1)或用圆形条形图围绕地图(图7-D2)。 当存在重叠时,条形图可以是浮动在地图上的工具提示(图7-D3)或位于感兴趣地点的字形(图7-D4)。 玛丽受到检索到的图像中的设计的启发,并根据设计要求决定合适的设计。
6.2 使用 VisImage 进行分类基准测试
对象分类已在许多可视化场景中得到采用,例如可视化逆向工程[18,44,45]、可视化人口统计分析[3]、图表数据提取[17]。 在本例中,我们展示了 VisImages 如何使用可视化子类型的注释作为可视化分类模型的基准。
6.2.1 实验设置
为了比较训练分类模型中的 VisImages 和其他数据集,我们设置了实验来相互评估在不同数据集上训练的模型。 具体来说,我们在一个数据集上训练模型并在另一个数据集上评估它们,并研究它们在不同情况下的性能。 我们选择 Beagle [3] 作为训练分类模型的基线数据集,因为 Beagle 与 VisImages 的共同类别最多,并且是现有数据集中最大的样本数和类别数。
数据处理。 我们从 VisImages 和 Beagle 中选择了 17 个常见的类。 我们将 Beagle 中的图像转换为位图图像以进行模型训练和评估,因为它们最初是 SVG 格式。 对于 VisImages 中的图像,我们从图像中裁剪可视化并按子类型对它们进行分类(表示为 VisImages-cropped)。 在实验之前,我们将 Beagle 和 VisImages 随机分为训练集(75%)和测试集(25%)。
型号。 在实验中,我们选择了两种广泛使用的不同层数的对象分类模型,即ResNet-50、ResNet-101 [46]、VGG-16和VGG-19 [47]。 以图像作为输入,模型将输出图像所属特定类别的概率。
训练。 我们遵循 Krizhevsky 等人 [48] 描述的类似训练过程,所有模型都分两个阶段进行训练,权重在 ImageNet [49] 上预先训练。 在第一阶段,我们冻结卷积层的权重并训练分类头。 在第二阶段,我们解冻卷积层并微调总体权重。 在每个阶段,模型都使用步长的随机梯度下降(SGD)进行训练。 ResNets 和 VGGNets 的初始学习率分别为 和 。 我们使用分类交叉熵作为损失函数。 由于不同类别之间的分布不平衡,我们引入类别权重进行损失计算,以减少特定类别的过度拟合。
指标。 遵循多分类问题的标准评估协议[46],我们使用top-k准确率作为度量,这意味着,如果ground-truth标签出现在top k预测中,则分类被认为是正确的。 top-1 和 top-3 精度如表 V 所示。
| Training Set | (A) Beagles | (B) VisImages | ||
| Test Set | Beagle | VisImages (Acc) | VisImages | Beagle (Acc) |
| ResNet-50 | 79.3/99.0 | 32.6/38.8 | 78.3/92.6 | 10.6/9.5 |
| ResNet-101 | 80.6/98.9 | 26.0/33.2 | 78.9/94.4 | 11.5/9.4 |
| VGG-16 | 79.9/98.7 | 36.7/43.8 | 77.5/92.7 | 8.7/7.1 |
| VGG-19 | 80.1/98.7 | 34.8/40.4 | 76.9/92.2 | 8.3/6.0 |

6.2.2分类性能分析
我们从不同方面分析模型性能。
CNN 模型比较。 我们首先观察不同模型的性能,发现 ResNet-101 在训练期间在 VisImages 和 Beagle 上实现了最佳性能(第二行中下划线的值)。 结果符合何等人[46]得出的结论,即ResNets更深的架构使得模型在物体分类方面比VGGNets取得更好的结果。
尽管 CNN 在位图可视化分类方面取得了令人满意的性能,但与其他方法相比,模型可能会遇到一些挫折。 Battle等人[3]用决策树对Beagle中的可视化进行分类,取得了86.5%的top-1准确率,优于CNN的性能。 不同的是,决策树采用 SVG 可视化的手工制作特征,而不是从位图图像中提取的视觉特征。 具体来说,这些特征包括样式特征(例如,填充和边框颜色的数量以及描边宽度)和每个元素的特征(例如,CSS 类名称、圆形元素和矩形元素)。 这些功能可能提供有关可视化的语义信息,这对可视化分类有用。 因此,CNN 在可视化分类方面可能存在一些局限性,这符合 Haehn 等人[50]提供的见解,即“CNN 架构在自然图像上的性能并不是一个很好的预测器”图形感知任务的性能。”
训练数据集比较。 训练数据对于模型的通用性至关重要。 总体而言,我们发现在 Beagle 上训练的模型比在 VisImages 上训练的模型具有更高的准确性。 然而,这种比较并不公平,因为测试集并不相同。 因此,我们通过在一个数据集上训练模型并在另一个数据集上测试它们来进行交叉评估。 首先,我们使用 VisImages 评估在 Beagle 上训练的模型。 在 VisImages 上进行测试时,模型的 top-1 (26%-34.8%) 和 top-3 (33.2%-40.4%) 准确率均急剧下降(表 V(A))。 其次,我们评估了在 Beagle 上的 VisImages 上训练的模型,发现模型的 top-1 (8.3%-11.5%) 和 top-3 (6.0%-9.5%) 准确率也出现下降(表 V(B))。 不过,与之前相比,下降幅度要小得多。 由于泛化误差[51],在具有不同“数据生成过程”的数据集上测试模型时,模型性能可能会下降。 模型性能下降的抑制表明,与 Beagle 相比,在 VisImages 上训练的模型可能具有更好的泛化性。
混乱分析。 为了进一步研究在 VisImages 上测试时在 Beagle 上训练的模型性能下降的原因,我们可视化了 ResNet-101 的混淆矩阵,它实现了最佳性能(图9,左)。 矩阵的行对真实标签进行编码,列对预测标签进行编码。 我们按照 Beagle 中类的样本数量递减排列行和列标签。 该矩阵按行归一化,因此对角线上的单元格代表召回率。
在矩阵中,虽然对角线上的大多数单元格为深蓝色,但也有一些单元格为浅色,例如热图、桑基图和词云,表明这些类别的召回率较低。 通过从两个数据集中随机选择这些类的样本,我们发现 VisImages 中这些类的可视化在外观上更加多样化,例如布局、颜色和形状,但 Beagle 中的可视化在设计上相似,如下所示图9,右。 原因可能是 Beagle 中的图表是由类似的可视化库(例如 D3 和 Plotly)使用默认样式设置生成的。 然而,在 VisImages 中,VisImages 中的许多图表是使用设计工具(例如 Adobe Illustrator)或低级编程语言(例如 Javascript)从头开始创建的。 由于样本布局和设计的多样性较高,VisImages 可以作为现有数据集的良好基准和补充。
此外,我们发现混淆矩阵的左下角有蓝色簇,尤其是前三列。 聚类表明模型通常将可视化错误分类为折线图、散点图和条形图。 我们推断,混乱可能是由这三个类别的大量样本(约 90%)引起的,尽管我们引入了类别权重来缓解这些类别的过度拟合。 此外,VisImages 训练中的许多测试样本可能具有模型在训练过程中“看不到”的不同样式。 因此,当这些样本出现时,模型可能倾向于用流行的类别来“猜测”它们的标签。 为了减少混乱,平衡类分布并向较小的类添加更多样本可能是一个实用的解决方案,例如将 Beagle 和 VisImages 组合为训练集。
6.3 使用 VisImages 进行可视化本地化
虽然 VIS30K [21] 和 Viziometrics [20] 仅关注论文中图像使用的分类(例如方程、图表、照片和绘图),但 VisImages进一步指定图像中可视化的位置(即边界框)。 在本例中,我们展示了可视化训练边界框的使用,这是 VisImages 数据集的一个特征维度,可用于对象定位模型。 具体来说,这些模型可用于定位图像中的可视化,以进行视觉分析 (VA) 系统的逆向工程和可视化位置分析。
6.3.1 训练可视化本地化模型
我们首先训练 Faster R-CNN [24](最广泛使用的对象定位模型之一)来预测图像中可视化的位置。 我们使用 80% 的图像进行训练,20% 的图像用于测试。 遵循 Ren 等人 [24] 的类似流程,我们使用 SGD 优化器以 的学习率为 15k 小批量训练模型。 采用0.9的动量和的权重衰减。

| Sub-type | |||
| graph | 0.96 | 0.96 | 0.70 |
| table | 0.95 | 0.90 | 0.69 |
| scatterplot | 0.83 | 0.77 | 0.29 |
| line chart | 0.82 | 0.71 | 0.23 |
| heatmap | 0.80 | 0.80 | 0.40 |
| flow diagram | 0.75 | 0.70 | 0.46 |
| bar chart | 0.69 | 0.58 | 0.10 |
| map | 0.68 | 0.64 | 0.54 |
| parallel coordinate | 0.67 | 0.52 | 0.28 |
| 0.78 | 0.78 | 0.52 |
6.3.2 VA 系统的模型推理
在训练完可视化定位模型后,我们进一步将模型应用到VA系统接口上。 我们使用多视图可视化 (MV) 数据集 [22] 中的图像,其中包含从出版物数据中裁剪的 360 个 VA 界面。 推理结果示例如图10所示。 总的来说,我们发现使用 VisImages 训练的 Faster-RCNN 可以成功定位界面中的不同可视化(或视图)。 此外,该模型还可以处理各种具有挑战性的情况:1)具有子结构的可视化,例如具有子图的图(图10-A4); 2)复合子类型的可视化,例如热图+地图(图10-A9、A13)和热图+矩阵(图10-A10); 3) 具有极端纵横比的可视化(图10-A7)。 结果表明,通过考虑数据流和视图之间的交互[53,54,55],使用计算机视觉模型对出版物中的 VA 系统设计进行逆向工程的潜力。
6.3.3 本地化性能分析
我们结合 AP 和 VA 系统样本分析了模型的定位性能。
总体而言,VisImages 上的 mAP 为 0.78 (IoU=0.50)、0.78 (IoU=0.75) 和 0.52 (IoU=0.90)。 该图达到了最高的AP(IoU=0.50)0.96,其次是表格、散点图和折线图。 有趣的是,尽管条形图的样本比例最大,但其AP仅排名(IoU=0.50)。 在详细研究时,基本图表(即条形图、折线图和散点图,通常通过坐标系实现)的 AP 随着 IoU 阈值的上升而急剧下降,这表明精确确定这些可视化的边界框对模型来说具有挑战性。 例如,当相同类型的可视化紧密对齐时(图10-A2),模型将无法确定可视化的区域。 通过探索样本,我们发现这些子类型具有不同的配置(有或没有坐标轴)和大小,可能使模型对这些可视化的精确边界感到困惑。 不同的是,图表(图10-A4、A5、A6、A8)、表格(图10-A11)和地图(图10 -A9,A13)通常在图像中占据很大的区域,这可能使模型对这些子类型的定位相对简单。
6.3.4 VA系统中可视化的空间分布
VA 系统的模型推理可以帮助我们理解不同可视化类型在空间上的分布情况。 尽管推论可能并不完全正确,但我们认为,由于表 VI 中显示了可接受的 AP,因此结果可以指示可视化的一般分布。 我们使用热图来可视化特定类型可视化的空间分布。 为了绘制热图,我们将所有 VA 系统图像转换为相同的比例,导出可视化的转换后的边界框,并将所有边界框覆盖在同一画布上。 热图通过此类边界框的总数进行标准化。 为了便于比较,我们对不同的可视化类型使用一致的亮度等级。 在图10-B中,我们对 VA 示例中最流行的可视化的热图进行了可视化。
从图中,我们发现一些热图具有非常明亮的区域,即图形和热图可视化。 因此,与其他可视化相比,图形和热图可视化在明亮区域具有更高的可视化密度。 此外,这些可视化通常分布在VA系统的左上角,通常作为系统的主视图。 相反,表格、散点图、折线图和条形图可视化并不具有极端的集中性,但这些可视化也具有特定的分布模式。 例如,表格可视化更多地出现在左侧,可能作为原始数据参考的辅助视图;折线图更多分布在顶部;散点图也更多地分布在左上角;条形图是最常用的可视化效果,在界面中表现出相对均匀的分布。
7 讨论
我们将 VisImages 视为一个令人兴奋的起点,可以利用可视化社区本身的智能,并开辟一条通往高质量、细粒度和大规模可视化数据集的道路。 我们预计 VisImages 可以为增进我们对该领域的了解和 AI4VIS [1] 的研究提供机会。
有利于文献分析。 VisImages 为进行可视化文献分析提供了新的可能性,并帮助了解该领域的发展。 例如,VisImages Explorer(第 6.1 节)展示了帮助用户发现感兴趣的论文并激发新手研究人员和设计师的设计想法的潜力。 我们为社区提供浏览器以发现更多见解。 此外,研究人员可以结合现有的出版物元数据集合(例如 keyvis [33])来研究 VisImages,这应该会揭示新的见解。 例如,分析不同领域和主题下的视觉设计模式。
AI4VIS 的机会。 VisImages可以作为有用的AI4VIS数据集[1],例如可视化分类(第6.2节)、本地化(第6.3节)、可视化-文本翻译、推荐。 可视化文本翻译旨在构建文本描述和可视化之间的关系。 VisImages 中带有详细说明的图像自然可以成为训练此类模型的合格资源,用于视觉讲故事 [56, 57, 58] 等场景。 此外,一系列研究致力于可视化推荐[59, 60],例如,建议设计中不同可视化类型的潜在布局和组合[22]。 VisImages 包含针对不同主题精心设计的 VA 系统的图像,例如体育分析 [61] 和城市规划 [62]。 除了可视化类型和位置的注释之外,该数据集还为此类任务的训练模型提供了宝贵的资源。
限制。 尽管 VisImages 具有重要意义和实用性,但它仍然有局限性。 首先,我们通过金标准、多数表决、抽样检测等一系列措施,尽力确保我们的标注质量。 错误标记是不可避免的,特别是在识别可视化及其变化需要大量专业知识的情况下。 作为替代方案,我们非常欢迎可视化社区,尤其是出版物的作者,检查并可能纠正错误标记的可视化。 其次,我们的数据集目前包含三种主要类型的标签(即图像标题、可视化类型和边界框),留下大量未探索的信息,例如轴标题和标记。 凭借更丰富的信息,VisImages可以用于更广泛的应用并支持更复杂的任务。 第三,我们的示例用例仅演示 VisImages 的特色用法。 例如,在6.2节中,我们首先将VisImages与Beagle进行比较,因为Beagle具有最多的共同类和最大的样本。 与更多数据集(例如 ChartSense [17] 和 VizioMetrics [20])的进一步比较也可能有利于低级和高级特征的分析,以及模型性能。 对广泛数据集的探索超出了本文的范围,但我们的用例为设计实验和为未来的工作进行分析提供了指导。 对 VisImages 进行更深入的研究可以提供具有启发性的见解并产生广泛的影响。
8 结论和未来工作
在本文中,我们创建并提供 VisImages,这是来自顶级可视化出版物的可视化数据集。 VisImages 包含 12,267 张图像,以及来自 IEEE InfoVis 和 VAST 1,397 篇论文的标题。 每幅图像都用可视化类型及其在图像中的位置进行注释,总共产生 35,096 个边界框。 我们进一步研究 VisImages,概述跨年份和类型的可视化分布。 此外,与可视化领域其他最先进的数据集相比,VisImages 在可视化类型上呈现出更加平衡的分布。 VisImages 的实用性和重要性通过三个用例来证明,包括视觉文献综述、可视化分类和可视化本地化。 我们预计 VisImages 可以拓宽可视化研究的多样性[63]并激发新的研究机会。
然而,VisImages 只是探索可视化出版物中的图像迈出了第一步。 未来,我们打算扩展 VisImages 以涵盖更多来自其他顶级期刊和会议的图像,例如 TVCG、CHI 和 EuroVis。 其次,鉴于图像数量不断增加,我们计划开发一种利用人类和机器智能的半自动标注方法[64]。 第三,我们计划逐步细化和完善分类法,以满足可视化设计日益多样化的需求。
致谢
该工作得到了国家自然科学基金(62072400、62002331)以及教育部和浙江省政府(ZJU)人工智能协同创新中心的支持。 这项工作还得到了之江实验室(2020KE0AA02、2021KE0AC02)和微软亚洲研究院的部分资助。 我们最深切地感谢匿名审稿人的宝贵意见,他们的宝贵意见帮助我们大幅改进了本文。 我们衷心感谢浙江大学和之江实验室的研究人员和学生在数据标注方面付出的时间和精力。 具体来说,我们感谢Mengye Xu 在设计 VisImages 徽标和记录数据标注训练材料方面做出的贡献。
参考
- [1] A. Wu, Y. Wang, X. Shu, D. Moritz, W. Cui, H. Zhang, D. Zhang, and H. Qu, “AI4VIS: Survey on artificial intelligence approaches for data visualization,” IEEE Transactions on Visualization and Computer Graphics, To appear.
- [2] P. Federico, F. Heimerl, S. Koch, and S. Miksch, “A survey on visual approaches for analyzing scientific literature and patents,” IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 9, pp. 2179–2198, 2017.
- [3] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, and M. Stonebraker, “Beagle: Automated extraction and interpretation of visualizations from the web,” in Proceedings of the CHI Conference on Human Factors in Computing Systems, 2018, pp. 1–8.
- [4] M. Savva, N. Kong, A. Chhajta, L. Fei-Fei, M. Agrawala, and J. Heer, “ReVision: Automated classification, analysis and redesign of chart images,” in Proceedings of ACM Symposium on User Interface Software and Technology, 2011, pp. 393–402.
- [5] N. Siegel, Z. Horvitz, R. Levin, S. Divvala, and A. Farhadi, “FigureSeer: Parsing result-figures in research papers,” in Proceedings of European Conference on Computer Vision, 2016, pp. 664–680.
- [6] Y. Wu, F. Wei, S. Liu, N. Au, W. Cui, H. Zhou, and H. Qu, “OpinionSeer: Interactive visualization of hotel customer feedback,” IEEE Transactions on Visualization and Computer Graphics, vol. 16, no. 6, pp. 1109–1118, 2010.
- [7] D. A. Keim, M. C. Hao, U. Dayal, and M. Hsu, “Pixel Bar Charts: A visualization technique for very large multi-attribute data sets,” Information Visualization, vol. 1, no. 1, pp. 20–34, 2002.
- [8] D. Liu, P. Xu, and L. Ren, “TPFlow: Progressive partition and multidimensional pattern extraction for large-scale spatio-temporal data analysis,” IEEE Transactions on Visualization and Computer Graphics, vol. 25, no. 1, pp. 1–11, 2019.
- [9] A. Lex, M. Streit, C. Partl, K. Kashofer, and D. Schmalstieg, “Comparative analysis of multidimensional, quantitative data,” IEEE Transactions on Visualization and Computer Graphics, vol. 16, no. 6, pp. 1027–1035, 2010.
- [10] P. Isenberg, F. Heimerl, S. Koch, T. Isenberg, P. Xu, C. D. Stolper, M. Sedlmair, J. Chen, T. Möller, and J. Stasko, “Vispubdata.org: A metadata collection about IEEE visualization (VIS) publications,” IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 9, pp. 2199–2206, 2017.
- [11] B. Shneiderman, “The eyes have it: A task by data type taxonomy for information visualizations,” in Proceedings of IEEE Symposium on Visual Languages, 1996, pp. 336–343.
- [12] M. A. Borkin, A. A. Vo, Z. Bylinskii, P. Isola, S. Sunkavalli, A. Oliva, and H. Pfister, “What makes a visualization memorable?” IEEE Transactions on Visualization and Computer Graphics, vol. 19, no. 12, pp. 2306–2315, 2013.
- [13] W. Javed and N. Elmqvist, “Exploring the design space of composite visualization,” in Proceedings of IEEE Pacific Visualization Symposium, 2012, pp. 1–8.
- [14] H. Su, J. Deng, and L. Fei-Fei, “Crowdsourcing annotations for visual object detection,” in Proceedings of AAAI Conference on Artificial Intelligence Workshop, 2012.
- [15] B. Michael, O. Vadim, and J. Heer, “D3: Data-driven documents,” IEEE Transactions on Visualization and Computer Graphics, vol. 17, no. 12, pp. 2301–2309, 2011.
- [16] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer, “Vega-Lite: A grammar of interactive graphics,” IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 1, pp. 341–350, 2017.
- [17] D. Jung, W. Kim, H. Song, J.-i. Hwang, B. Lee, B. Kim, and J. Seo, “ChartSense: Interactive data extraction from chart images,” in Proceedings of CHI Conference on Human Factors in Computing Systems, 2017, pp. 6706–6717.
- [18] J. Poco and J. Heer, “Reverse-Engineering Visualizations: Recovering visual encodings from chart images,” Computer Graphics Forum, vol. 36, no. 3, pp. 353–363, 2017.
- [19] M. A. Borkin, Z. Bylinskii, N. W. Kim, C. M. Bainbridge, C. S. Yeh, D. Borkin, H. Pfister, and A. Oliva, “Beyond memorability: Visualization recognition and recall,” IEEE Transactions on Visualization and Computer Graphics, vol. 22, no. 1, pp. 519–528, 2016.
- [20] P.-S. Lee, J. D. West, and B. Howe, “Viziometrics: Analyzing visual information in the scientific literature,” IEEE Transactions on Big Data, vol. 4, no. 1, pp. 117–129, 2018.
- [21] J. Chen, M. Ling, R. Li, P. Isenberg, T. Isenberg, M. Sedlmair, T. Möller, R. S. Laramee, H.-W. Shen, K. Wünsche, and Q. Wang, “VIS30K: A collection of figures and tables from ieee visualization conference publications,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 9, pp. 3826–3833, 2021.
- [22] X. Chen, W. Zeng, Y. Lin, H. M. AI-maneea, J. Roberts, and R. Chang, “Composition and configuration patterns in multiple-view visualizations,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 2, pp. 1514–1524, 2021.
- [23] R. Li and J. Chen, “Toward a deep understanding of what makes a scientific visualization memorable,” in Proceedings of IEEE Scientific Visualization Conference, 2018, pp. 26–31.
- [24] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2017.
- [25] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [26] W. Zeng, A. Dong, X. Chen, and Z.-l. Cheng, “VIStory: Interactive storyboard for exploring visual information in scientific publications,” Journal of Visualization, vol. 24, no. 1, pp. 69–84, 2021.
- [27] J.-D. Fekete, G. Grinstein, and C. Plaisant, “InfoVis 2004 contest: The history of InfoVis,” http://www.cs.umd.edu/hcil/iv04contest, 2004.
- [28] L. Xie, “Visualizing citation patterns of computer science conferences,” Blog post: http://cm.cecs.anu.edu.au/post/citation_vis/, 2016.
- [29] C. Plaisant, J.-D. Fekete, and G. Grinstein, “Promoting insight-based evaluation of visualizations: From contest to benchmark repository,” IEEE Transactions on Visualization and Computer Graphics, vol. 14, no. 1, pp. 120–134, 2008.
- [30] K. Cook, G. Grinstein, and M. Whiting, “Introduction: The VAST challenge: History, scope, and outcomes: An introduction to the special issue,” Information Visualization, vol. 13, no. 4, pp. 301–312, 2014.
- [31] A. Ponsard, F. Escalona, and T. Munzner, “PaperQuest: A visualization tool to support literature review,” in Proceedings of CHI Conference Extended Abstracts on Human Factors in Computing Systems, 2016, pp. 2264–2271.
- [32] J. Chuang, S. Gupta, C. Manning, and J. Heer, “Topic model diagnostics: Assessing domain relevance via topical alignment,” in Proceedings of International Conference on Machine Learning, 2013, pp. 612–620.
- [33] P. Isenberg, T. Isenberg, M. Sedlmair, J. Chen, and T. Möller, “Visualization as seen through its research paper keywords,” IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 1, pp. 771–780, 2017.
- [34] C. Clark and S. Divvala, “PDFFigures 2.0: Mining figures from research papers,” in Proceedings of ACM/IEEE-CS on Joint Conference on Digital Libraries, 2016, pp. 143–152.
- [35] K. Krippendorff, “Computing krippendorff’s alpha-reliability,” 2011.
- [36] “NLTK library: nltk.metrics.agreement,” https://www.nltk.org/_modules/nltk/metrics/agreement.html, online; accessed 28 October 2021.
- [37] P. Xu, Y. Wu, E. Wei, T.-Q. Peng, S. Liu, J. J. Zhu, and H. Qu, “Visual analysis of topic competition on social media,” IEEE Transactions on Visualization and Computer Graphics, vol. 19, no. 12, pp. 2012–2021, 2013.
- [38] J. Redmon, S. Divvala, R. B. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 779–788, 2016.
- [39] D. Han, J. Pan, X. Zhao, and W. Chen, “NetV. js: A web-based library for high-efficiency visualization of large-scale graphs and networks,” Visual Informatics, vol. 5, no. 1, pp. 61–66, 2021.
- [40] Y. Wang, Z. Bai, Z. Lin, X. Dong, Y. Feng, J. Pan, and W. Chen, “G6: A web-based library for graph visualization,” Visual Informatics, vol. 5, no. 4, pp. 49–55, 2021.
- [41] H. Schulz, “Treevis.net: A tree visualization reference,” IEEE Computer Graphics and Applications, vol. 31, no. 6, pp. 11–15, 2011.
- [42] K. Koh, B. Lee, B. Kim, and J. Seo, “ManiWordle: Providing flexible control over wordle,” IEEE Transactions on Visualization and Computer Graphics, vol. 16, no. 6, pp. 1190–1197, 2010.
- [43] W. Cui, Y. Wu, S. Liu, F. Wei, M. X. Zhou, and H. Qu, “Context preserving dynamic word cloud visualization,” in Proceedings of IEEE Pacific Visualization Symposium, 2010, pp. 121–128.
- [44] F. Zhou, Y. Zhao, W. Chen, Y. Tan, Y. Xu, Y. Chen, C. Liu, and Y. Zhao, “Reverse-engineering bar charts using neural networks,” Journal of Visualization, vol. 24, no. 2, pp. 419–435, 2021.
- [45] L. Ying, T. Tangl, Y. Luo, L. Shen, X. Xie, L. Yu, and Y. Wu, “GlyphCreator: Towards example-based automatic generation of circular glyphs,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 400–410, 2022.
- [46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [47] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” 2015.
- [48] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proceedings of Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [49] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255.
- [50] D. Haehn, J. Tompkin, and H. Pfister, “Evaluating ‘graphical perception’ with CNNs,” IEEE Transactions on Visualization and Computer Graphics, vol. 25, no. 1, pp. 641–650, 2019.
- [51] Y. Bengio, I. Goodfellow, and A. Courville, Deep learning. MIT press, 2017, vol. 1.
- [52] M. Everingham, S. M. Eslami, L. Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,” International Journal of Computer Vision, vol. 111, no. 1, pp. 98–136, 2015.
- [53] R. Chen, X. Shu, J. Chen, D. Weng, J. Tang, S. Fu, and Y. Wu, “Nebula: A coordinating grammar of graphics,” IEEE Transactions on Visualization and Computer Graphics, To appear.
- [54] C. Su, C. Yang, Y. Chen, F. Wang, F. Wang, Y. Wu, and X. Zhang, “Natural multimodal interaction in immersive flow visualization,” Visual Informatics, vol. 5, no. 4, pp. 56–66, 2021.
- [55] C. Tominski, G. Andrienko, N. Andrienko, S. Bleisch, S. I. Fabrikant, E. Mayr, S. Miksch, M. Pohl, and A. Skupin, “Toward flexible visual analytics augmented through smooth display transitions,” Visual Informatics, vol. 5, no. 3, pp. 28–38, 2021.
- [56] X. Shu, J. Wu, X. Wu, H. Liang, W. Cui, Y. Wu, and H. Qu, “Dancingwords: exploring animated word clouds to tell stories,” Journal of Visualization, vol. 24, no. 1, pp. 85–100, 2021.
- [57] X. Shu, A. Wu, J. Tang, B. Bach, Y. Wu, and H. Qu, “What makes a Data-GIF understandable?” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 2, pp. 1492–1502, 2020.
- [58] W. Zhang, Q. Ma, R. Pan, and W. Chen, “Visual storytelling of song ci and the poets in the social–cultural context of song dynasty,” Visual Informatics, vol. 5, no. 4, pp. 34–40, 2021.
- [59] H. Li, Y. Wang, S. Zhang, Y. Song, and H. Qu, “KG4Vis: A knowledge graph-based approach for visualization recommendation,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 195–205, 2021.
- [60] A. Wu, Y. Wang, M. Zhou, X. He, H. Zhang, H. Qu, and D. Zhang, “MultiVision: Designing analytical dashboards with deep learning based recommendation,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 162–172, 2022.
- [61] J. Wang, J. Wu, A. Cao, Z. Zhou, H. Zhang, and Y. Wu, “Tac-Miner: Visual tactic mining for multiple table tennis matches,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 6, pp. 2770–2782, 2021.
- [62] Z. Deng, D. Weng, X. Xie, J. Bao, Y. Zheng, M. Xu, W. Chen, and Y. Wu, “Compass: Towards better causal analysis of urban time series,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 1051–1061, 2021.
- [63] B. Lee, K. Isaacs, D. A. Szafir, G. E. Marai, C. Turkay, M. Tory, S. Carpendale, and A. Endert, “Broadening intellectual diversity in visualization research papers,” IEEE Computer Graphics and Applications, vol. 39, no. 4, pp. 78–85, 2019.
- [64] D. Deng, J. Wu, J. Wang, Y. Wu, X. Xie, Z. Zhou, H. Zhang, X. L. Zhang, and Y. Wu, “EventAnchor: Reducing human interactions in event annotation of racket sports videos,” in Proceedings of CHI Conference on Human Factors in Computing Systems, 2021, pp. 1–13.
![[Uncaptioned image]](dengdazhen.jpg) |
Dazhen Deng is currently a Ph.D. student in the State Key Lab of CAD&CG, Zhejiang University. He received the B.E. degree in Applied Mathematics from Zhejiang University in 2018. His research interests mainly lie in sports visualization and machine learning for visual analytics. For more information, please visit https://dazhendeng.github.io/. |
![[Uncaptioned image]](wuyihong.jpg) |
Yihong Wu is currently a Ph.D. student in the State Key Lab of CAD&CG, Zhejiang University. He received the B.E. degree from Zhejiang University in 2020. His research interests mainly lie in computer vision and visual analytics. |
![[Uncaptioned image]](shuxinhuan.jpg) |
Xinhuan Shu is currently a postdoctoral researcher in the Department of Computer Science and Engineering at the Hong Kong University of Science and Technology (HKUST). She received her Ph.D. degree from HKUST and her B.E. degree in Computer Science and Technology from Zhejiang University, China. Her research interests include visual data communication, animated visualization, and visual analytics. |
![[Uncaptioned image]](wujiang.jpg) |
Jiang Wu is currently a Ph.D. student in the State Key Lab of CAD&CG, Zhejiang University. He received the B.E. degree in Computer Science and Technology from Zhejiang University, China. His research interests mainly lie in sports visualizations and event sequence analysis. |
![[Uncaptioned image]](fusiwei.jpg) |
Siwei Fu is an associate research scientist in Zhejiang Lab. His main research interests include visual analytics, intelligent user interface, and natural language interface. He received his Ph.D. degree in Computer Science and Engineering from the Hong Kong University of Science and Technology. For more information, please visit https://fusiwei339.bitbucket.io/ |
![[Uncaptioned image]](cuiweiwei.jpg) |
Weiwei Cui is a Principal Researcher at Microsoft Research Asia, China. He received his Ph.D. in Computer Science and Engineering from the Hong Kong University of Science and Technology and his B.S. in Computer Science and Technology from Tsinghua University, China. His primary research interests lie in visualization, with focuses on text, graph, and social media. For more information, please visit http://research.microsoft.com/en-us/um/people/weiweicu/ |
![[Uncaptioned image]](wuyingcai.jpg) |
Yingcai Wu is a Professor at the State Key Lab of CAD&CG, Zhejiang University. His main research interests are in information visualization and visual analytics, with focuses on sports science and urban computing. He received his Ph.D. degree in Computer Science from the Hong Kong University of Science and Technology. Prior to his current position, Dr. Wu was a postdoctoral researcher at the University of California, Davis from 2010 to 2012, and a researcher in Microsoft Research Asia from 2012 to 2015. For more information, please visit http://www.ycwu.org. |