10.1109/TVCG.2020.3030378 0 Arpit Narechania、Arjun Srinivasan 和 John Stasko 来自美国佐治亚州亚特兰大市佐治亚理工学院。 电子邮件:{arpitnarechania,arjun010}@gatech.edu,stasko@cc.gatech.edu。 *作者的贡献均等。 Biv 等人:全球照明的乐趣和利润
NL4DV:用于从自然语言查询生成数据可视化分析规范
的工具包
摘要
自然语言界面(NLI)在可视化数据分析方面展现出了巨大的前景,使人们能够灵活地指定可视化并与可视化进行交互。 然而,开发可视化 NLI 仍然是一项具有挑战性的任务,需要自然语言处理 (NLP) 技术的低级实现以及视觉分析任务和可视化设计的知识。 我们推出了 NL4DV,一个用于自然语言驱动的数据可视化的工具包。 NL4DV 是一个 Python 包,它将表格数据集和有关该数据集的自然语言查询作为输入。 作为响应,该工具包返回一个建模为 JSON 对象的分析规范,其中包含数据属性、分析任务以及与输入查询相关的 Vega-Lite 规范列表。 在此过程中,NL4DV 可以帮助没有 NLP 背景的可视化开发人员,使他们能够创建新的可视化 NLI 或将自然语言输入合并到现有系统中。 我们通过四个示例演示 NL4DV 的用法和功能:1) 在 Jupyter Notebook 中使用自然语言渲染可视化,2) 开发 NLI 来指定和编辑 Vega-Lite 图表,3) 从 DataTone 系统重新创建数据歧义小部件,以及 4)结合语音输入来创建多模式可视化系统。
关键词:
自然语言界面;可视化工具包;K.6.1计算和信息系统管理项目和人员管理生命周期; K.7.m计算职业杂项道德
![[Uncaptioned image]](x1.png) 说明自然语言查询在指定数据可视化方面的灵活性的示例。
NL4DV 处理所有三个查询变体,推断
,
或者 , 和
对属性、任务和可视化的引用。
还显示了 NL4DV 针对各个查询建议的相应可视化结果。
说明自然语言查询在指定数据可视化方面的灵活性的示例。
NL4DV 处理所有三个查询变体,推断
,
或者 , 和
对属性、任务和可视化的引用。
还显示了 NL4DV 针对各个查询建议的相应可视化结果。
介绍
用于可视化的自然语言界面 (NLI) 在学术研究(例如 [13, 46, 22, 52, 69])和商业软件 [34, 55 ]。 从高层次来看,可视化 NLI 允许人们提出与数据相关的查询并生成可视化来响应这些查询。 为了从自然语言 (NL) 查询生成可视化效果,NLI 首先根据数据属性和低级分析任务[1, 9] 对输入查询进行建模(例如,过滤器、相关性、趋势)。 然后,系统使用此信息确定哪些可视化最适合作为对输入查询的响应。 虽然 NLI 在提出数据相关问题方面提供了灵活性,但 NL 的固有特征(例如模糊性和不规范)使得实现 NLI 进行数据可视化成为一项具有挑战性的任务。
要创建可视化 NLI,除了实现图形用户界面 (GUI) 和渲染视图之外,可视化系统开发人员还必须实现自然语言处理 (NLP) 模块来解释查询。 尽管存在支持 GUI 和可视化设计的工具(例如 D3.js [6]、Vega-Lite [43]),但开发人员目前必须实现自定义模块查询解释。 然而,对于没有 NLP 技术和工具包(例如 NLTK [31]、spaCy [21])经验的开发人员来说,实现此管道并非易事,需要他们花费大量时间和精力学习和实施不同的 NLP 技术。
考虑图中的查询范围 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 发布用于在 IMDb 电影数据集的背景下创建可视化,该数据集具有不同的属性,包括全球票房、类型和发行年份等(为了保持一致性,我们在本文中使用该电影数据集作为示例)。 查询“创建显示 IMDB 评分分布的直方图”(图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 a) 显式引用数据属性(IMDB 评分)、低级分析任务(分布),并请求特定的可视化类型(直方图) t2>)。 从系统的角度来看,这是一个理想的解释场景,因为查询明确列出了生成可视化所需的所有组件。
另一方面,第二个查询“显示科幻小说和奇幻电影跨类型的平均总收入”(图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 b) 没有明确说明可视化类型或属性创意类型。 相反,它通过 "毛利 "和 "流派 "明确引用了属性 Worldwide Gross 和 Genre,并通过值 "科幻小说 "和 "奇幻 "隐式引用了 Creative Type。 此外,通过指定广告素材类型属性的数据值和“平均”一词,查询还提到了两个预期的分析任务:过滤和计算派生值 分别。 第二个查询更具挑战性,因为它要求系统隐式推断属性之一,然后根据识别的属性和任务确定可视化类型。
最后,第三个查询“可视化评级和预算”(图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 c) 的解释更具挑战性,因为它既没有明确说明所需的可视化类型,也没有明确说明预期的分析任务。 此外,虽然它明确引用了一个属性(生产预算通过“预算”),但对第二个属性的引用不明确(“评级”可以映射到IMDB评级,内容评级,或烂番茄评级)。
为了适应这种查询变化,可视化 NLI 采用复杂的 NLP 技术(例如,依存分析、语义词匹配)来识别查询中的相关信息,并基于可视化概念(例如,分析任务)和设计原则(例如,选择基于图形的编码)属性类型)以生成适当的可视化。 例如,给出图中的查询 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 b, after detecting the data attributes and analytic tasks, a visualization NLI should select a visualization (e.g., bar chart) that is well-suited to support the task of displaying Derived Values (average) for Worldwide Gross (a quantitative attribute) across different Genres (a nominal attribute). 同样,在图中的场景中 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 c,NLI 必须首先检测输入查询属性中的歧义,确定适合呈现这些属性组合的可视化(例如,两个定量属性的散点图),并最终根据这些属性推断分析任务和可视化(例如,散点图可能暗示用户有兴趣寻找相关性)。
为了支持数据可视化的 NLI 原型设计,我们提供了自然语言驱动的数据可视化 (NL4DV) 工具包。 NL4DV 是一个 Python 包,开发人员可以使用表格数据集进行初始化。 初始化后,NL4DV 会处理有关数据集的后续 NL 查询,从这些查询中推断数据属性和分析任务。 此外,通过使用属性、任务和可视化之间的内置映射,NL4DV 还返回与这些查询相关的 Vega-Lite 规范的有序列表。 通过提供高级 API 将 NL 查询转换为可视化,NL4DV 抽象出解释 NL 查询的核心任务,并提供基于任务的可视化建议作为即插即用功能。 使用 NL4DV,开发人员可以创建新的可视化 NLI,并将 NL 查询功能合并到现有的可视化系统中。
在本文中,我们讨论了 NL4DV 的设计目标,并描述了该工具包如何从 NL 查询推断数据属性、分析任务和可视化规范。 此外,我们将推断的信息形式化为基于 JSON 的分析规范,可视化开发人员可以通过编程方式对其进行解析。 最后,通过示例应用程序,我们展示了这种形式化如何提供帮助:1)从头开始实现可视化 NLI,2)将 NL 输入合并到现有可视化系统中,3)支持数据科学编程环境中的可视化规范。
为了支持未来系统的开发,我们还提供 NL4DV 和所描述的应用程序作为开源软件,网址为:https://nl4dv.github.io/nl4dv/
1 相关工作
1.1 数据可视化的自然语言接口
2001 年,Cox 等人[10] 提出了 NLI 的初始原型,该原型支持使用结构良好的命令来指定可视化。 从那时起,随着 NL 理解技术和数据库 NLI 的出现(例如,[40, 4, 29, 39, 71, 60, 17, 20]),NLI 出现了激增数据可视化[54,13,46,22,52,69,49,47,50,27,24,25],尤其是近年来。 Srinivasan 和 Stasko [51] 总结了这些 NLI 的子集,根据其支持的功能来表征系统,包括以可视化为中心的功能(例如,指定可视化或与可视化交互),以数据为中心的功能(例如,通过计算回答有关数据集的问题),以及以系统控制为中心的功能(例如,增强图形用户界面操作,例如使用NL移动窗口)。 沿着这些思路,NL4DV 当前的重点主要是支持可视化规范。 考虑到这一范围,下面我们重点介绍作为 NL4DV 开发动力并且与我们的工作最相关的系统。
Articulate [54] 是一种可视化 NLI,它允许人们通过导出用户查询中的任务和数据属性之间的映射来生成可视化。 DataTone [13] 使用词法、选区和依存解析的组合来让人们通过 NL 指定可视化。 此外,在检测输入查询中的歧义时,DataTone 利用混合主动交互通过 GUI 小部件(例如下拉菜单)来解决这些歧义。 FlowSense [69] 使用语义解析技术来支持数据流系统内的 NL 交互,允许人们指定和连接组件,而无需学习操作数据流系统的复杂性。 Eviza [46] 结合了基于概率语法的方法和有限状态机,允许人们与给定的可视化进行交互。 Evizeon [22] 扩展了 Eviza 的功能并融入了额外的语用学概念,允许通过独立和后续话语指定可视化并与之交互。 Eviza 和 Evizeon 中的想法也被用于设计 Tableau [55] 中的“数据问答”功能。 Ask Data 内部使用 Arklang [47],这是一种中间语言,旨在以结构化格式描述 NL 查询,Tableau 的 VizQL [53] 可以解析该结构化格式以生成可视化效果。
上述系统都呈现出不同的接口和功能,通过语法和/或词汇解析技术支持 NL 交互。 然而,其底层 NLP 管道的一个共同点是使用数据属性和分析任务(例如相关性、分布)来确定用户生成系统响应的意图。 基于这个中心观察和先前的系统实现(例如,字符串相似性度量和阈值[13,46,52],解析规则[13,69,25]), NL4DV 使用词法和基于依存分析的技术相结合,从 NL 查询中推断属性和任务。 然而,与以前实现自定义 NLP 引擎和将 NL 查询转换为系统操作的语言的系统不同,我们将 NL4DV 开发为与接口无关的工具包。 在此过程中,我们将从 NL 查询推断出的属性和任务形式化为可由开发人员以编程方式解析的结构化 JSON 对象。
1.2 可视化工具包和语法
从根本上说,我们的研究属于用户界面工具包[37,38,28]这一广泛类别。 因此,我们不是提出单一的新技术或界面,而是强调降低开发粘度,降低开发技能障碍,并实现复制和创造性探索。 在可视化研究中,存在许多具有类似目标的可视化工具包,它们特别注重简化指定和渲染可视化的开发工作。 此类工具包的示例包括 Prefuse [19]、Protovis [5] 和 D3 [6]。 随着移动设备和 AR/VR 等替代平台上可视化的出现,一系列新的工具包也正在创建中,以协助这些当代平台上的可视化开发。 例如,EasyPZ.js [45] 支持在桌面和移动设备上将导航技术(平移和缩放)合并到基于 Web 的可视化中。 DXR [48] 等工具包支持在 Unity [57] 中开发富有表现力的交互式可视化,并可部署在 AR/VR 环境中。 NL4DV 使可视化系统开发人员能够更轻松地解释 NL 查询,而无需学习或实现 NLP 技术,从而扩展了新模式和平台工具包的工作范围。
除了帮助以编程方式创建可视化的工具包之外,研究人员还制定了可视化语法,为构建可视化提供高级抽象,以减少软件工程知识[18]。 沿着这些思路,基于图形语法[62],最近开发了可视化语法,例如Vega [44]和Vega-Lite [43] 通过声明式规范支持可视化设计,实现快速可视化设计和原型设计。 NL4DV 的主要目标是返回可视化结果以响应 NL 查询。 为此,除了从查询推断出的属性和任务的结构化表示之外,NL4DV 还需要返回与输入查询最相关的可视化规范。 鉴于 Vega-Lite 的简洁性及其在基于 Web 的可视化系统和基于 Python 的可视化数据分析中的日益增长的使用,NL4DV 使用 Vega-Lite 作为其底层可视化语法。
1.3 自然语言处理工具包
NLTK [31]、Stanford CoreNLP [33] 和 NER [11] 以及 spaCy [21] 等工具包> 帮助开发人员执行 NLP 任务,例如词性 (POS) 标记、实体识别和依存分析等。 然而,由于这些是通用工具包,为了实现可视化 NLI,开发人员需要学习使用该工具包并了解底层 NLP 技术/概念(例如,知道解析查询时要遍历哪些依赖路径、了解语义相似性度量) 。 此外,为了实现可视化系统,开发人员需要编写额外的代码来将 NLP 工具包的输出转换为可视化相关的概念(例如,用于应用数据过滤器的属性和值),这可能既复杂又乏味。 为了应对这些挑战,NL4DV 在内部使用 NLTK [31]、Stanford CoreNLP [33] 和 spaCy [21],但提供了封装的 API并隐藏底层 NLP 实现细节。 这使得可视化开发人员能够更多地关注与用户界面和交互相关的前端代码,同时调用高级函数来解释 NL 查询。
2 NL4DV概述
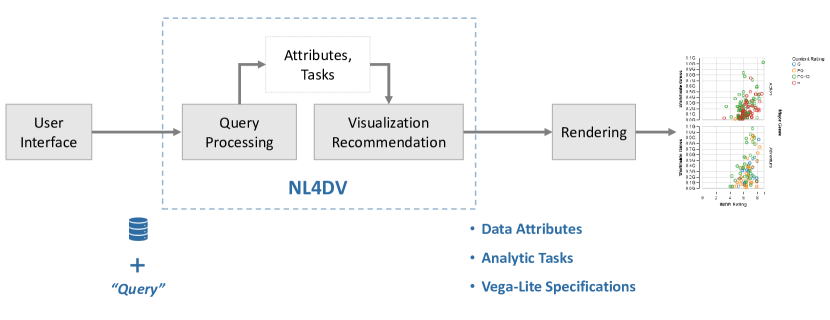
图 1 概述了用于实现 NLI 的典型管道的概述,该管道生成响应 NL 查询的可视化。 在高层,一旦通过用户界面收集输入查询,查询处理器就会从输入查询中推断出相关信息,例如数据属性和分析任务。 然后,该信息被传递到可视化推荐引擎,该引擎生成与输入查询相关的可视化规范列表。 这些规范最终通过开发人员选择的库(例如 D3 [6])呈现。 在此管道的上下文中,NL4DV 提供了一个高级 API,用于处理 NL 查询并生成与输入查询相关的 Vega-Lite 规范。 开发人员可以选择直接渲染 Vega-Lite 规范来创建视图(例如,使用 Vega-Embed [59])或使用 NL4DV 推断的属性和任务来对其系统界面进行自定义更改。
2.1设计目标
四个关键设计目标推动了 NL4DV 的开发。 我们根据对先前可视化 NLI [54,13,46,22,52,69] 的设计目标和系统实现以及支持新平台和模式上的可视化开发的最新工具包的审查来编制这些目标(例如,[45, 48])。
DG1。 最小化 NLP 学习曲线。 NL4DV 的主要目标用户是没有 NLP 技术背景或经验的开发人员。 相应地,让学习曲线尽可能平坦也很重要。 换句话说,我们希望开发人员能够使用 NL4DV 的输出,而无需花时间学习如何从 NL 查询中提取信息的机制。 在工具包设计方面,这种考虑转化为提供高级函数来解释 NL 查询并设计一个响应结构,该结构通过强调与可视化相关的信息(例如分析任务(例如过滤器、相关性)和数据)而针对可视化系统开发进行了优化属性和值。
DG2。 生成模块化输出并支持与现有系统组件的集成。 默认情况下,NL4DV 推荐 Vega-Lite 规范来响应 NL 查询。 但是,开发人员可能更喜欢使用不同的库(例如 D3)渲染可视化,或者可能希望使用自定义可视化推荐引擎(例如 [65, 36, 30]),仅利用 NL4DV 来识别属性和/或输入查询中的任务。 为了支持这一目标,我们需要确保 NL4DV 的输出是模块化的(允许开发人员选择是否需要属性、任务和/或可视化),并且开发人员无需大幅修改现有的系统架构即可使用 NL4DV。 在工具包设计方面,除了使用标准化语法进行可视化(在我们的例子中,Vega-Lite)之外,这些考虑因素还转化为设计数据属性和分析任务的形式化表示,开发人员可以通过编程方式解析这些数据,将 NL4DV 的输出链接到其他数据。他们的系统中的组件。
DG3。 突出推理类型和歧义。 NL 通常不明确且含糊不清。 换句话说,输入查询可能仅包含对数据属性的部分引用,或者可能隐式引用预期的任务和可视化(例如,图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 b、c) [56]。 除了从解释的角度解决这些挑战之外,让开发人员意识到 NL4DV 输出中由此产生的不确定性也很重要,以便他们可以选择使用/丢弃输出并提供适当的视觉提示(例如,歧义小部件 [13] )在他们的系统界面中。 就工具包设计而言,这转化为结构化 NL4DV 的输出,因此它指示信息是通过显式(例如,查询子字符串与属性名称匹配)还是隐式(例如,查询通过属性值引用数据属性)引用推断的,并突出显示其响应中潜在的歧义(例如,两个或多个属性映射到输入查询中的同一个单词,如图所示 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 C)。
DG4。 支持添加别名和覆盖工具包默认值。 可视化系统经常用于分析特定领域的数据集(例如销售、医疗记录、体育)。 给定一个域,数据属性通常具有缩写或别名(例如,“GDP”代表国内生产总值,“投资”代表资本),或者值对于数据集来说是唯一的(例如,字母“A”可以指课程成绩数据集中的值,但默认情况下会被视为停用词并被大多数 NLP 算法忽略)。 在工具包设计方面,这些特定于数据集的注意事项转化为向开发人员提供帮助函数来指定 NL4DV 应为给定数据集考虑/排除的别名或特殊单词列表。
3NL4DV设计与实现
在本节中,我们将详细介绍 NL4DV 的设计和实现,重点介绍关键功能并描述该工具包如何解释 NL 查询。 我们将在下一节讨论使用 NL4DV 开发的示例应用程序。
清单2显示了使用NL4DV的基本Python代码。 给定一个数据集(作为 CSV、TSV 或 JSON)和一个查询字符串,通过单个函数调用 analyze_query(query),NL4DV推断属性、任务和可视化,并将它们作为 JSON 对象 (DG1) 返回。 具体来说,NL4DV 的响应对象具有一个由推断的数据集属性组成的 attributeMap、一个由推断的分析任务组成的 taskMap 以及一个 visList、一个与输入查询相关的可视化规范列表。 通过在响应对象中提供属性、任务和可视化作为单独的键,NL4DV 允许开发人员有选择地提取和使用其输出的一部分 (DG2)。
3.1数据解读
使用数据集初始化后(列表 2,第 2 行),NL4DV 会迭代底层数据项值以推断包括属性类型的元数据(Q定量、N ominal、Ordinal、Temporal)以及每个属性值的范围和域。 在解释查询时使用此属性元数据来推断适当的分析任务并生成相关的可视化规范。
由于 NL4DV 使用数据值来推断属性类型,因此可能会做出错误的解释。 例如,数据集可能具有属性 Day,其值在 范围内。 默认情况下,检测一系列整数值时,NL4DV 会将 Day 推断为定量属性而不是时间属性。 这种误解可能会导致 NL4DV 在根据推断的属性选择可视化时做出糟糕的设计选择(例如,定量属性可能会生成直方图而不是折线图)。 为了克服由数据质量或数据集语义引起的此类问题,NL4DV 允许开发人员使用 get_metadata() 验证推断的元数据。 该函数返回属性的哈希映射及其推断的元数据。 如果发现错误,开发人员可以使用其他辅助函数(例如 set_attribute_type(attribute,type))来覆盖默认解释 (DG4)。
3.2查询解释
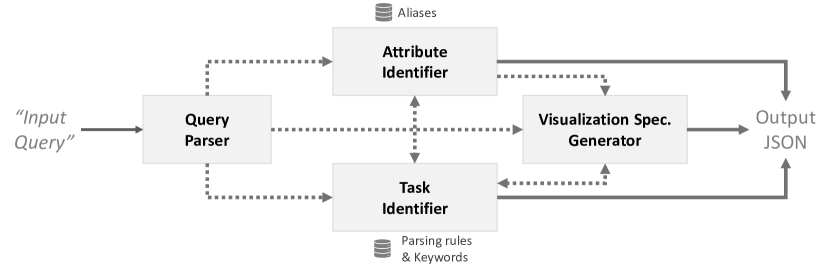
为了生成可视化来响应查询,可视化 NLI 需要识别查询中的信息短语,这些短语映射到数据属性和值、分析任务和可视化类型等相关概念。 图 3 显示了清单 2 中的查询“显示总收入超过 1 亿的动作和冒险电影的预算与评分之间的关系” 带有这样的带注释的短语(我们在本节中使用此查询作为运行示例来描述 NL4DV 的查询解释策略)。 为了识别相关短语并生成attributeMap、taskMap和visList,NL4DV执行四个步骤:1)查询解析、2) 属性推断、3) 任务推断、4) 可视化规范生成。 图4概述了NL4DV的底层架构。 下面我们描述各个查询解释步骤(任务推理分为两个步骤以帮助解释)并总结图5中的管道。

3.2.1 查询解析
查询解析器对输入字符串运行一系列 NLP 函数,以提取可用于检测相关短语的详细信息。 在此步骤中,NL4DV 首先预处理查询,将任何特殊符号或字符转换为数据集相关值(例如,将 100M 转换为数字 100000000)。 接下来,该工具包使用以下方法识别每个词符的词性标签(例如,NN:名词,JJ:形容词,CC:并列连词)斯坦福大学的 CoreNLP [33]。 此外,为了理解查询中不同短语之间的关系,NL4DV 使用 CoreNLP 的依存解析器来创建依存树。 然后,除了连词/析取术语(例如“and”、“or”)和一些介词(例如“ Between”、“ over”)和副词(例如“ except”、“ not”)之外,NL4DV通过删除所有停用词来修剪输入查询并执行词干提取(例如,“grossed”“gross”)。 最后,工具包从修剪后的查询字符串生成所有 N-gram。 查询解析器的输出(POS 标签、依存树、N 元语法)如图 5a 所示,并在查询解释的其余阶段由 NL4DV 在内部使用。

3.2.2 属性推断
解析输入查询后,NL4DV 查找显式(例如,通过直接引用属性名称)和隐式(例如,通过引用属性的值)。 开发人员还可以配置别名(例如,生产预算的“投资”)以支持数据集和特定域的属性引用(DG4)。 为此,开发人员可以提供一个由属性(作为键)和别名列表(作为值)组成的 JSON 对象。 在初始化 NL4DV 时(清单 2 第 2 行)或使用辅助函数 set_alias_map(alias_map, url="") 时,可以通过可选参数 alias_map 或 alias_map_url 传递此对象。
为了推断属性,NL4DV 迭代查询解析器生成的 N-gram,检查 N-gram 与由数据属性、别名和数据组成的词典之间的句法(例如,拼写错误的单词)和语义(例如,同义词)相似性。价值观。 为了检查语法相似性,NL4DV 计算 N 元语法 i 和标记化词汇实体 j 之间的余弦相似性 。 的可能值范围为 [0,1],其中 1 表示字符串是等效的。 对于语义相似性,工具包会检查 N-gram i 和词符化词条 j 之间的 Wu-Palmer 相似性得分 [67] 。 此分数返回 WordNet 图形 [35] 中 p 和 a 的词干版本之间的距离,并且是 ,值越高意味着相似度越高。 如果或,NL4DV将N元语法i映射到与j对应的属性,同时将该属性添加为attributeMap 中的键。
3.2.3 显式任务推理
在检测到映射到数据属性的 N 元语法后,NL4DV 检查剩余的 N 元语法以获取对分析任务的引用。 NL4DV 目前识别五个低级分析任务 [1],包括四个基本任务:相关性、分布、派生值、趋势 和第五个过滤 任务。 我们将基本任务与过滤器分开,因为基本任务用于确定适当的可视化(例如,散点图的相关图),而过滤器应用于不同类型的可视化。 我们重点关注这五个任务作为起始组,因为它们在之前的 NLI [54,13,47,69,24] 中得到普遍支持,并且与 NL4DV 通过 NL 支持可视化规范的主要目标最相关(与与给定图表 [46, 52] 或回答问题 [25] 交互相反)。
虽然可以通过数据值(例如“动作”、“喜剧”)来检测过滤器以检测基本任务,但 NL4DV 将查询标记与预定义的任务关键字列表(例如“关联”、“关系”等)进行比较。 ,对于 Correlation 任务,“range”、“spread”等,对于 Distribution 任务,“average”、“sum”等,对于 衍生价值)。 然而,仅检测对属性、值和任务的引用不足以推断用户意图。 为了对查询短语之间的关系进行建模并填充任务详细信息,NL4DV 利用 POS 标签和查询解析器生成的依赖树。 具体来说,使用词符类型和依赖类型(例如,nmod、conj、nsubj)和距离,NL4DV 识别属性、值之间的映射和任务。 然后使用这些映射对 taskMap 进行建模。 任务关键字和依存解析规则是根据先前可视化 NLI [54, 46, 13, 22, 69] 以及 200 个问题的查询模式和示例定义的由 Amar 等人 [1] 在制定分析任务分类法时收集。
taskMap 包含分析任务作为键。 任务被分解为一个对象列表,其中包含一个 inferenceType 字段,以指示任务是显式陈述的(例如,通过关键字)还是隐式派生的(例如,如果查询请求折线图,可能会隐含趋势任务)以及执行任务时要应用的参数。 其中包括任务映射到的属性、要使用的运算符(例如,GT、EQ、AVG、SUM)和值。 如果任务参数存在歧义(例如,“小说”一词可能指代值“科幻小说”、“当代小说”、“历史小说”),NL4DV 会添加其他字段(例如,isValueAmbigouslytrue)以突出显示它们(DG3)。 除了任务本身之外,taskMap 的这种结构还允许开发人员检测:(1) 执行任务所需的参数(属性、运算符,值),(2)运算符和值级别的歧义(例如,isValueAmbigously),以及(3)任务是否明确或隐含地陈述(推理类型)。
考虑图3中查询的taskMap(图5c)。 使用图 5a 中的依赖关系树,NL4DV 推断单词“relationship”映射到 Correlation 任务,并链接到标记“budget”和“ rating”,它们分别是依次由连词“and”链接。接下来,返回到 attributeMap,NL4DV 将单词“budget”和“ rating”映射到它们各自的数据属性,添加与相关性相对应的三个对象属性 [制作预算、IMDB 评分]、[制作预算、内容评分] 和 [制作预算、烂番茄评级]到相关性任务。 利用标记“Action”和“Adventure”,NL4DV 还推断查询引用了 attribute Genre 上的 Filter 任务,其中值在列表中 (IN) [动作、冒险]。 最后,利用短语“gross over 100M”中标记之间的依赖关系,NL4DV 添加一个具有属性 Worldwide Gross 的对象,即 大于 (GT) 运算符,以及值字段中的100000000。 在填充 filter 任务时,NL4DV 还会使用键 encodeFalse 更新 attributeMap 中的相应属性(图5b)。 这有助于开发人员检测某个属性是否用于过滤且未在推荐图表中进行可视化编码。
3.2.4 可视化生成
NL4DV 使用 Vega-Lite 作为底层可视化语法。 该工具包目前支持 Vega-Lite marks:bar、tick、line、area、点、弧、箱线图、文本和编码:x0>、y1>、颜色2>、大小3>、列4>、行5>, theta6> 一次可视化最多三个属性。 这种标记和编码的组合使 NL4DV 支持一系列常见的可视化类型,包括直方图、条形图、条形图(包括堆叠和分组)条形图)、折线图和面积图、饼图、散点图、箱线图 和热图。 为了确定与输入查询相关的可视化,NL4DV 检查查询中是否有对可视化类型的显式请求(例如,图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 a) 或从属性和任务隐式推断可视化(例如,图 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 乙、 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 c、3)。
通过将查询 N-gram 与预定义的可视化关键字列表(例如“散点图”、“直方图”、“条形图”)进行比较来识别显式可视化请求。 例如图中的查询 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 a 通过词符 "直方图 "指定可视化类型,导致 NL4DV 将 bar 设置为 mark 类型,并将二进制 IMDB Rating 设置为底层 Vega-Lite 规范中的 x encoding 类型。
为了隐式确定可视化,NL4DV 使用从查询推断的属性和任务的组合。 NL4DV 首先通过应用属性和可视化之间众所周知的映射,使用检测到的属性列出所有可能的可视化(表 1)。 这些映射是根据 Show Me [32] 和 Voyager [64, 66] 等先前系统中使用的启发式在 NL4DV 中预先配置的。 如前所述,当从属性生成可视化时,NL4DV 不会对用作过滤器的属性进行视觉编码。 相反,过滤器属性在 Vega-Lite 中作为 filter transform 添加。 当查询包含多个过滤器时,这样做有助于避免属性的组合爆炸(例如,包含图 3 中查询的过滤器属性将需要生成对四个属性而不是两个属性进行编码的可视化效果)。
除了属性之外,如果在查询中明确说明了任务,NL4DV 会将它们用作附加指标来修改、修剪和/或对生成的可视化进行排名。 考虑图 3 中的查询。 类似于图中的查询 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 c,如果仅使用属性来确定图表,NL4DV 将输出两个散点图(对于 QxQ)和一个条形图(对于 N) >xQ)。 但是,由于查询包含词符“关系”,它映射到 Correlation 任务,NL4DV 强制使用散点图作为图表类型,在 Vega- 中设置 mark Lite 规格达到点。 此外,由于相关性在 QxQ 图表中更为明显,NL4DV 还对两个 QxQ 图表进行排名更高,返回图5d所示的三个可视化规范。这些任务 x 可视化映射(表 1)是基于先前的可视化系统 [36, 8, 14] 和研究 [26, 42]< 在 NL4DV 中配置的/t9>.
| Attributes (x, y, color/size/row/column) | Visualizations | Task | ||
|---|---|---|---|---|
| Q x Q x {N, O, Q, T} | Scatterplot | Correlation | ||
| N, O x Q x {N, O, Q, T} | Bar Chart | Derived Value | ||
| Q, N, O x {N, O, Q, T} x {Q} |
|
Distribution | ||
| T x {Q} x {N, O} | Line Chart | Trend |
NL4DV 将推断的可视化结果整理到 visList 中(图 5d)。 此列表中的每个对象均由包含图表 Vega-Lite 规范的 vlSpec 和用于突出显示 NL4DV 显式或隐式推断是否请求可视化的 inferenceType 字段组成,以及可视化映射到的属性和任务列表。 开发人员可以使用 visList 在其系统中直接渲染可视化(通过 vlSpec)。 或者,忽略 visList,开发人员还可以使用 attributeMap 和 taskMap 仅提取属性和任务,并将它们作为其他可视化推荐的输入引擎(例如,[65, 30])(DG2)。
3.2.5 隐式任务推理
当输入查询缺少引用分析任务的显式关键字时,NL4DV 首先检查查询是否请求特定的可视化类型。 如果是这样,该工具包将使用表 1 中的可视化 x 任务之间的映射来推断任务(例如,直方图的 distribution 、线条的 trend图表,散点图的相关性)。
或者,如果查询仅提及属性,NL4DV 首先根据这些属性列出可能的可视化。 然后,使用推断的可视化,工具包隐式推断任务(再次利用表 1 中的可视化 x 任务映射)。 考虑图中的示例 NL4DV:用于从自然语言查询生成数据可视化分析规范 的工具包 C。在本例中,任务 Correlation 和 Derived Value 是根据使用属性组合 QxQ 和 NxQ。 在通过可视化隐式推断任务的情况下,NL4DV 还会将 taskMap 中的 inferenceType 设置为隐式。
4示例应用程序
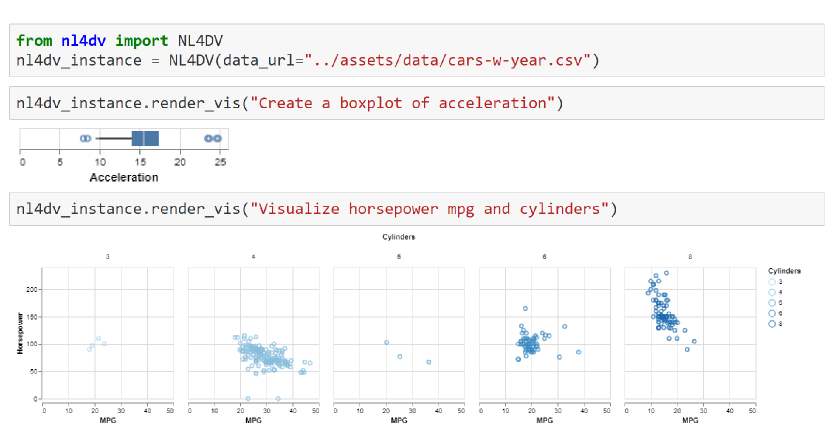
4.1 在 Jupyter Notebook 中使用 NL4DV
由于 NL4DV 生成 Vega-Lite 规范,因此在支持渲染 Vega-Lite 图表的环境中,该工具包可用于通过 Python 中的 NL 创建可视化。 具体来说,NL4DV 提供了一个包装函数 render_vis(query),它自动渲染 visList 中的第一个可视化。 通过在 Jupyter Notebook 等环境中渲染可视化以响应 NL 查询,NL4DV 使 Python 数据科学家和程序员新手能够进行可视化分析,而无需了解可视化设计或 Python 可视化包(例如 Matplotlib、Plotly)。 图 6 显示了 Jupyter Notebook 的实例,演示了如何使用 NL4DV 为汽车数据集创建可视化效果。 对于第一个查询“创建加速度箱线图”,检测到显式可视化请求,NL4DV 呈现一个箱线图,显示属性加速度的值。 对于第二个查询“可视化马力、英里数和气缸数”,NL4DV 使用推断属性(马力、MPG 隐式选择散点图作为适当的可视化效果,气缸)。
4.2 使用 NL4DV 创建可视化系统
上面的示例说明了如何使用 NL4DV 生成的 visList 在基于 Python 的数据科学环境中创建可视化。 以下两个示例展示了 NL4DV 如何协助开发基于 Web 的 NLI 以实现数据可视化。
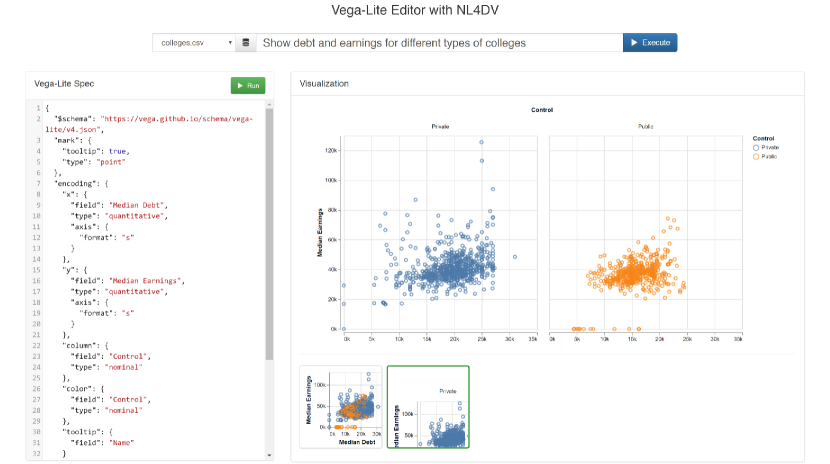
4.2.1 NL 驱动的 Vega-Lite 编辑器
尽管 Vega-Lite 的声明性性质使其成为指定可视化的直观方式,但不了解可视化术语的新手可能需要花费大量时间和精力来查看示例并学习规范语法。 在这种情况下,NL 输入是一种很有前途的解决方案,可以帮助船上用户学习 Vega-Lite。 使用 NLI,用户可以加载数据并通过 NL 表达他们想要的图表。 响应的系统可以同时呈现图表和相应的 Vega-Lite 规范,允许用户通过自己感兴趣的图表来学习底层语法。 图7说明了这个想法是作为Vega-Lite编辑器[58]的替代版本实现的,支持NL输入。 用户可以通过页面顶部的文本输入框输入查询来指定图表,并编辑左侧的规范来修改生成的可视化效果。 除了响应 NL 查询返回的主要可视化之外,该界面还提供了使用与 Voyager 系统 [64, 66] 类似的不同编码的替代可视化。
此示例是按照经典的客户端-服务器架构开发的,并作为 Python Flask [12] 应用程序实现。 从开发的角度来看,该应用程序的客户端是使用 HTML 和 JavaScript 从头开始编写的。 在 Python 服务器端,对 NL4DV 的 analyze_query(query) 函数进行一次调用,其中 query 被收集并通过 JavaScript 传递。 如前面所示(列表 2),该函数返回一个由 attributeMap、taskMap 和 visList 组成的 JSON 对象>。 对于此示例,NL4DV 返回的 visList 在 JavaScript 中进行解析,以呈现主图表以及替代设计(列表 8,第 5-8 行)。 可视化效果使用 Vega-Embed [59] 进行渲染。
4.2.2 在 DataTone 中重新创建歧义小部件
考虑第二个示例,其中我们使用 NL4DV 来复制 DataTone 系统 [13] 的功能。 给定 NL 查询,DataTone 会识别查询中的歧义,并通过“歧义小部件”(下拉菜单)将其显示出来,用户可以与之交互以澄清其意图。
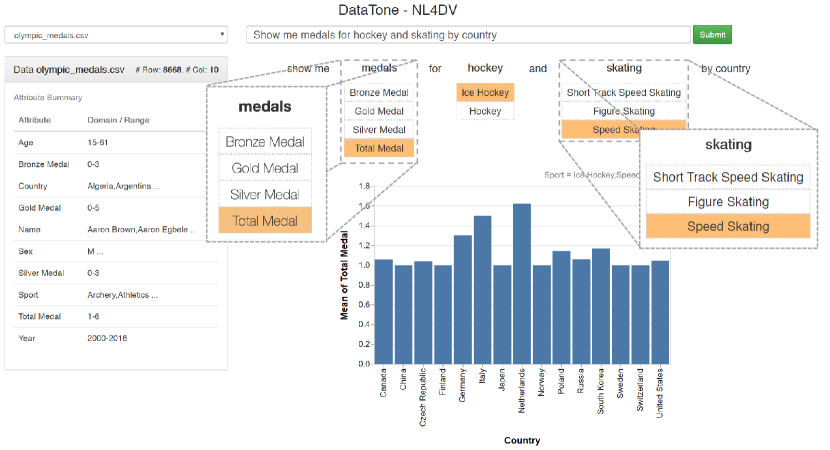
图9显示了使用NL4DV实现的类似DataTone的接口。 该系统还在客户端使用 HTML 和 JavaSript 实现为 Flask Web 应用程序。 图 9 中的示例说明了针对奥运会奖牌获得者数据集执行查询“按国家/地区显示曲棍球和滑冰奖牌”的结果(重复使用 DataTone 论文中的查询) [13])。 这里,“medals”是对四个数据属性的不明确引用 - 三种奖牌类型(Bronze、Silver、Gold)和 奖牌总数。 同样,“曲棍球”和“滑冰”是与 Sport 属性相对应的值级歧义(例如,“曲棍球”[冰球, 曲棍球])。
与 Vega-Lite 编辑器应用程序类似,服务器端代码仅涉及使用活动数据集初始化 NL4DV 并调用 analyze_query(query) 函数来处理用户查询。 如清单 10 中详述,在客户端,为了突出显示查询中属性和值级别的歧义,我们解析 attributeMap 和 taskMap 由 JavaScript 中的 NL4DV 返回,检查 isAmbigously 字段。 Vega-Embed 再次用于渲染作为 NL4DV 的 visList 的一部分返回的 vlSpec。 请注意,在此示例中,我们仅关注数据歧义小部件,而不显示设计歧义小部件(例如,用于在可视化类型之间切换的下拉菜单)。 然而,要生成设计模糊性小部件,开发人员可以解析 visList,将 Vega-Lite 标记 和 编码 转换为下拉菜单选项。
4.3 将 NL 输入添加到现有可视化系统
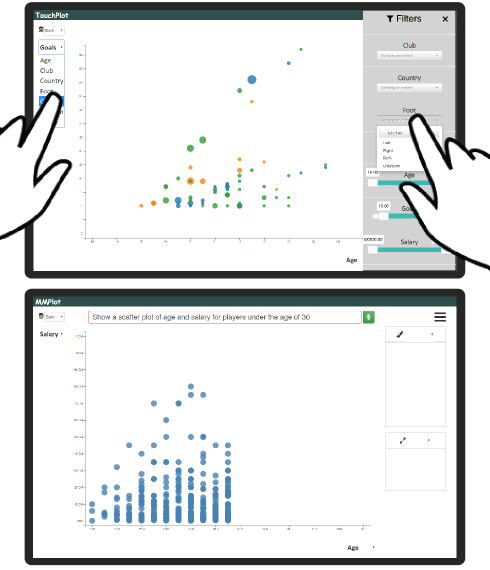
NL4DV 还可用于通过 NL 输入增强现有可视化系统。 例如,考虑 TouchPlot(图11-顶部),这是一个在平板电脑上运行的基于触摸的散点图可视化系统。 我们根据散点图可视化系统 Tangere [41] 的界面和功能对 TouchPlot 进行建模。 具体来说,用户可以通过直接与图表画布交互来选择点和缩放/平移,使用轴和图例上的下拉菜单将属性绑定到位置、颜色和大小编码,或者使用侧面板应用过滤器。 TouchPlot 使用 HTML 和 JavaScript 实现,D3 用于创建可视化。
最近的研究表明,通过语音补充触摸交互可以在平板电脑上的视觉分析过程中支持更流畅的交互体验[49]。 例如,虽然触摸可以支持与标记的细粒度交互,但语音可以允许指定过滤器,而无需打开侧面板并与侧面板交互,从而节省屏幕空间并保留用户工作流程。 为了探索这种流畅的交互,我们开发了MMPlot(图11-底部),它是TouchPlot的修改版本,支持多模式触摸和语音输入。 除了触摸交互之外,MMPlot 还允许发出语音命令来指定图表(例如,“按国家/地区关联年龄和工资”)和过滤点(例如,“删除 30 岁以上的玩家”)。
为了支持这些交互,我们记录语音输入并使用 Web Speech API [61] 将其转换为文本字符串。 然后,该查询字符串被传递到服务器,我们在服务器上调用 NL4DV 的 analyze_query(query)。 通过在 JavaScript 中解析 NL4DV 的响应,TouchPlot 被修改为支持所需的语音交互(列表 12)。 特别是,我们解析 taskMap 以检测并应用作为查询一部分请求的任何过滤器(第 6-12 行)。 接下来,我们检查输入查询是否指定了系统可以渲染的新散点图,并相应地调整视图映射(第 13-16 行)。 这种对 taskMap 和 visList 的顺序解析允许使用语音来应用过滤器、指定新的散点图或通过单个查询执行这两项操作(图 11) 。 与之前的示例不同,由于此应用程序使用 D3(而不是 Vega-Lite)来创建可视化,因此在解析 NL4DV 的输出时,我们执行了调用更新视图所需的 D3 代码的附加步骤(第 17 行)。
实现上述示例(基于 NL 的 Vega-Lite 编辑器、DataTone 的歧义小部件、MMPlot)通常需要开发人员编写数百行代码(除了前端代码),同时需要 NLP和可视化设计知识(图1)。 如上所示,使用 NL4DV,开发人员只需调用一次 analyze_query() 以及几行额外的代码来解析 NL4DV 的响应即可实现所需的 NLI 功能,从而使他们能够专注于界面设计和用户体验。
5 讨论和未来工作
5.1 评估
在本文中,我们通过在不同数据集上执行的示例查询来说明 NL4DV 的查询解释功能111其他查询请访问: https://nl4dv.github.io/nl4dv/showcase.html. 作为初始验证的一部分,我们使用 NL4DV 查询包含 300-6000 行和最多 27 个属性的表格数据集。 该工具包对这些查询的响应时间在 1-18 秒之间。 (平均:3 秒)222Reported based on a MacBook Pro with a 6-core 2.9GHz processor and 16GB RAM running MacOS Catalina version 10.15.5。 除了示例查询之外,我们还展示了使用 NL4DV 的应用程序,以强调该工具包如何降低开发粘度并降低技能障碍(就 NLP 工具和技术的先验知识而言)[38]。 然而,评估工具包的可用性和实用性可能需要通过两种方式进行更详细的评估。 首先,我们需要通过针对大型 NL 查询语料库执行 NL4DV 来正式对其性能进行基准测试。 为此,未来工作的一个重要领域是收集人们用来指定可视化的话语的标记数据,并用它来对 NL4DV 和其他可视化 NLI 进行基准测试。 其次,我们需要结合可视化和 NLP 开发人员的反馈进行纵向研究。 展望未来,我们希望这项研究的开源性质将帮助我们在野外进行此类研究,使我们能够评估 NL4DV 的实际可用性、识别潜在问题并了解可能应用的广度。
5.2 支持后续查询
NL 输入提供了通过对话交互(而不是一次性话语)支持更丰富的视觉分析对话的机会。 例如,可以向第一个发出更短的查询,而不是包含可视化规范和过滤请求的单个查询(例如,“显示仅突出显示动作和冒险电影的总收入和预算的散点图”)通过指定可视化来获得概述(例如,“显示总和预算的散点图”),然后发出后续查询以应用过滤器(例如,“现在只显示操作和冒险电影”)。 然而,通过与接口无关的工具包支持这样的对话具有挑战性,因为它要求工具包具有发出查询的系统状态的上下文。 此外,并非对话中的所有查询都可以是后续查询。 虽然 Evizeon [22] 等当前系统允许用户重置画布以重置查询上下文,但在操作与接口无关的工具包时显式指定何时应保留/清除上下文是不切实际的。
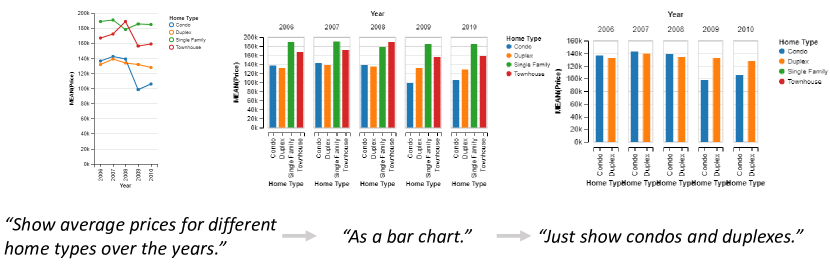
NL4DV目前不支持后续查询。 然而,作为解决这些挑战的第一步,我们正在尝试为 analyze_query() 和 render_vis() 添加一个额外的 dialog 参数,以支持涉及过滤和编码更改的后续查询。 具体来说,设置 dialogtrue 会通知 NL4DV 检查后续查询。 NL4DV 使用类似于先前可视化 NLI [22, 52, 50] 的对话居中技术 [15, 16] 来识别基于查询的缺失属性、任务或可视化详细信息关于工具包之前的响应。 考虑图 13 中的示例,该示例显示了在住房数据集上下文中发出的查询。 为了响应第一个查询“显示多年来不同房屋类型的平均价格”,NL4DV 通过检测属性价格、房屋类型<生成折线图。 /t2> 和年份,以及任务派生值(使用运算符AVG)。 接下来,给定后续查询“作为条形图,”,NL4DV 从之前的响应中推断属性和任务,更新 mark 类型和 encoding Vega-Lite 规范中的通道,用于创建分组条形图。 最后,通过第三个查询“Just show condos and duplexes,”将“condos”和“duplexes”检测为数据值,NL4DV 修改底层 taskMap 并应用过滤器在房屋类型属性上。 除了实现额外的参数和函数来支持 NL4DV 中的对话交互之外,未来的一个普遍研究挑战是研究如何将界面上下文(例如,主动编码、选择)建模为可以由与界面无关的工具包(如 NL4DV)解释的结构化格式。
5.3 改进查询解释并启用其他查询类型
通过初步测试,我们已经确定了 NL4DV 解释流程中需要改进的一些领域。 其中之一是在初始化时更好地推断属性类型。 为此,我们正在研究如何使用同时使用属性名称和值(例如 [70, 23])的最新语义数据类型检测模型来增强 NL4DV 的数据解释管道。 另一个需要改进的领域是任务检测。 NL4DV 目前利用基于词典和基于依赖关系的方法的组合来推断任务。 尽管这是一个可行的起点,但当任务关键字存在不确定性时,它的可靠性较低(例如,单词“relationship”可能并不总是映射到Correlation任务)或关键字与数据属性冲突(例如,查询“按地区显示学校的平均成本”当前会在 上应用派生值任务平均成本属性,即使平均成本已经代表派生值)。 随着我们收集更多的用户查询,我们正在探索用语义解析器(例如,[2, 3])和当代深度学习模型(例如,[68, 7] 来补充当前方法的方法) ]),可以根据查询短语和结构推断任务。 最后,第三个需要改进的领域是将 NL4DV 连接到 WolframAlpha [63] 等知识库,以在语义上理解输入查询中的单词。 合并此类连接将有助于解决数据值的模糊谓词(例如“大”、“昂贵”、“接近”)[46, 47],并且还可以减少开发人员手动配置属性的需要别名。
除了改进查询解释之外,未来工作的另一个主题是支持其他查询类型。 如前所述,NL4DV 目前主要用于支持面向可视化规范的查询(例如,“全球总票房和内容收视率之间有什么关系?,”“创建一个条形图,显示各州的平均利润”)。 然而,为了帮助开发成熟的可视化系统,该工具包需要支持与主动可视化的更紧密耦合,并启用其他任务,例如回答问题[25](例如,“票房破亿的电影有多少?,” “两只股票之间的差异何时最大?”)和格式化可视化(例如,“将 SUV 涂成绿色”、“突出显示人口超过 2 亿的国家/地区的标签”)。 合并这些新的查询类型将需要对解释策略(以识别新的任务类别及其参数)和输出格式(以包括计算的“答案”和对视图的更改)进行更改。
5.4 平衡简单性和定制化
NL4DV 目前针对可能不具备强大 NLP 背景的可视化开发人员 (DG1)。 像这样, NL4DV 使用许多默认设置(例如,依存解析的预设规则、根据经验设置属性检测的阈值)来最小化学习曲线并促进易用性。 开发人员可以覆盖其中一些默认设置(例如,用 spaCy [21] 替换 CoreNLP,调整相似性匹配阈值),还可以配置数据集特定的设置以改进查询解释(例如,属性别名、引用的特殊词)数据值,要忽略的附加停用词)(DG4)。 此外,通过调用 analyze_query() 并将 debug 参数设置为 true,开发人员还可以获得其他详细信息,例如检测到属性的原因 (例如,语义与句法匹配以及匹配分数)或如何隐式推断图表(例如,使用属性与属性和任务)。
然而,NLP 或可视化专家可能更喜欢 使用自定义模块进行查询处理或可视化推荐。 为此,可视化开发人员可以使用推断的属性和任务作为其自定义模块的输入来覆盖工具包的默认推荐引擎(即忽略 visList)。 然而,NL4DV 目前不支持使用自定义 NLP 模型进行属性和任务推理(例如,使用词嵌入技术来检测同义词或分类模型来识别任务)。 展望未来,当我们收集有关开发人员喜欢的自定义类型的反馈时,我们希望为开发人员提供用现代 ML 模型/技术替换 NL4DV 启发式模块的选项。 然而,考虑到帮助可视化 NLI 原型设计的最终目标,支持这种定制的一个挑战是确保定制模型的输出可以编译到 NL4DV 的输出规范中,或者修改 NL4DV 的规范以容纳附加信息(例如,分类)精度)由自定义模型生成。
6结论
我们推出了 NL4DV,这是一个支持原型可视化 NLI 的工具包。 给定一个数据集和一个 NL 查询,NL4DV 生成一个基于 JSON 的分析规范,由从查询推断出的属性、任务和可视化组成。 通过示例应用程序,我们展示了开发人员如何使用此 JSON 响应通过 NL 在 Jupyter 笔记本中创建可视化,开发基于 Web 的可视化 NLI,并通过 NL 交互增强现有可视化工具。 我们以开源软件的形式提供 NL4DV 和示例应用程序 (https://nl4dv.github.io/nl4dv/),并希望这些能够成为推进数据可视化 NLI 研究的宝贵资源。
致谢。
这项工作得到了国家科学基金会拨款 IIS-1717111 的部分支持。参考
- [1] R. Amar, J. Eagan, and J. Stasko. Low-level components of analytic activity in information visualization. In Proceedings of IEEE InfoVis, pages 111–117, 2005.
- [2] J. Berant, A. Chou, R. Frostig, and P. Liang. Semantic parsing on freebase from question-answer pairs. In Proceedings of the EMNLP, pages 1533–1544. ACL, 2013.
- [3] J. Berant and P. Liang. Semantic parsing via paraphrasing. In Proceedings of the 52nd Annual Meeting of the ACL (Volume 1: Long Papers), pages 1415–1425, 2014.
- [4] L. Blunschi, C. Jossen, D. Kossmann, M. Mori, and K. Stockinger. Soda: Generating sql for business users. Proceedings of the VLDB Endowment, 5(10):932–943, 2012.
- [5] M. Bostock and J. Heer. Protovis: A graphical toolkit for visualization. IEEE Transactions on Visualization and Computer Graphics, 15(6):1121–1128, 2009.
- [6] M. Bostock, V. Ogievetsky, and J. Heer. D3: data-driven documents. IEEE Transactions on Visualization and Computer Graphics, 17(12):2301–2309, 2011.
- [7] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- [8] S. M. Casner. Task-analytic approach to the automated design of graphic presentations. ACM Transactions on Graphics (ToG), 10(2):111–151, 1991.
- [9] Y. Chen, J. Yang, and W. Ribarsky. Toward effective insight management in visual analytics systems. In Proceedings of IEEE PacificVis, pages 49–56, 2009.
- [10] K. Cox, R. E. Grinter, S. L. Hibino, L. J. Jagadeesan, and D. Mantilla. A multi-modal natural language interface to an information visualization environment. International Journal of Speech Technology, 4(3-4):297–314, 2001.
- [11] J. R. Finkel, T. Grenager, and C. Manning. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of ACL, pages 363–370, 2005.
- [12] Flask. https://palletsprojects.com/p/flask/.
- [13] T. Gao, M. Dontcheva, E. Adar, Z. Liu, and K. G. Karahalios. DataTone: Managing ambiguity in natural language interfaces for data visualization. In Proceedings of ACM UIST, pages 489–500, 2015.
- [14] D. Gotz and Z. Wen. Behavior-driven visualization recommendation. In Proceedings of ACM IUI, pages 315–324, 2009.
- [15] B. J. Grosz and C. L. Sidner. Attention, intentions, and the structure of discourse. Computational linguistics, 12(3):175–204, 1986.
- [16] B. J. Grosz, S. Weinstein, and A. K. Joshi. Centering: A framework for modeling the local coherence of discourse. Computational linguistics, 21(2):203–225, 1995.
- [17] P. He, Y. Mao, K. Chakrabarti, and W. Chen. X-SQL: reinforce schema representation with context. arXiv preprint arXiv:1908.08113, 2019.
- [18] J. Heer and M. Bostock. Declarative language design for interactive visualization. IEEE Transactions on Visualization and Computer Graphics, 16(6):1149–1156, 2010.
- [19] J. Heer, S. K. Card, and J. A. Landay. Prefuse: a toolkit for interactive information visualization. In Proceedings of ACM CHI, pages 421–430, 2005.
- [20] J. Herzig, P. K. Nowak, T. Müller, F. Piccinno, and J. M. Eisenschlos. TAPAS: Weakly Supervised Table Parsing via Pre-training. arXiv preprint arXiv:2004.02349, 2020.
- [21] M. Honnibal and I. Montani. spacy 2: Natural language understanding with bloom embeddings. Convolutional Neural Networks and Incremental Parsing, 2017.
- [22] E. Hoque, V. Setlur, M. Tory, and I. Dykeman. Applying pragmatics principles for interaction with visual analytics. IEEE Transactions on Visualization and Computer Graphics, 24(1):309–318, 2018.
- [23] M. Hulsebos, K. Hu, M. Bakker, E. Zgraggen, A. Satyanarayan, T. Kraska, c. Demiralp, and C. Hidalgo. Sherlock: A deep learning approach to semantic data type detection. In Proceedings of SIGKDD. ACM, 2019.
- [24] J.-F. Kassel and M. Rohs. Valletto: A multimodal interface for ubiquitous visual analytics. In ACM CHI ’18 Extended Abstracts, 2018.
- [25] D. H. Kim, E. Hoque, and M. Agrawala. Answering questions about charts and generating visual explanations. In Proceedings of ACM CHI, pages :1–:13, 2020.
- [26] Y. Kim and J. Heer. Assessing effects of task and data distribution on the effectiveness of visual encodings. In Computer Graphics Forum, volume 37, pages 157–167. Wiley Online Library, 2018.
- [27] A. Kumar, J. Aurisano, B. Di Eugenio, A. Johnson, A. Gonzalez, and J. Leigh. Towards a dialogue system that supports rich visualizations of data. In Proceedings of the SIGDIAL, pages 304–309, 2016.
- [28] D. Ledo, S. Houben, J. Vermeulen, N. Marquardt, L. Oehlberg, and S. Greenberg. Evaluation strategies for hci toolkit research. In Proceedings of ACM CHI, pages 1–17, 2018.
- [29] F. Li and H. V. Jagadish. NaLIR: an interactive natural language interface for querying relational databases. In Proceedings of the ACM SIGMOD, pages 709–712, 2014.
- [30] H. Lin, D. Moritz, and J. Heer. Dziban: Balancing agency & automation in visualization design via anchored recommendations. In Proceedings of ACM CHI, pages 751:1–751:12, 2020.
- [31] E. Loper and S. Bird. NLTK: The natural language toolkit. In Proceedings of ACL Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, pages 63–70, 2002.
- [32] J. Mackinlay, P. Hanrahan, and C. Stolte. Show Me: Automatic presentation for visual analysis. IEEE Transactions on Visualization and Computer Graphics, 13(6):1137–1144, 2007.
- [33] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky. The Stanford CoreNLP natural language processing toolkit. In Proceedings of ACL: System Demonstrations, pages 55–60, 2014.
- [34] Microsoft Power BI. https://powerbi.microsoft.com/en-us.
- [35] G. A. Miller. WordNet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
- [36] D. Moritz, C. Wang, G. L. Nelson, H. Lin, A. M. Smith, B. Howe, and J. Heer. Formalizing visualization design knowledge as constraints: Actionable and extensible models in draco. IEEE Transactions on Visualization and Computer Graphics, 25(1):438–448, 2018.
- [37] B. Myers, S. E. Hudson, and R. Pausch. Past, present, and future of user interface software tools. ACM Transactions on Computer-Human Interaction, 7(1):3–28, 2000.
- [38] D. R. Olsen Jr. Evaluating user interface systems research. In Proceedings of ACM UIST, pages 251–258, 2007.
- [39] P. Pasupat and P. Liang. Compositional semantic parsing on semi-structured tables. In Proceedings of IJCNLP, pages 1470–1480. ACL, 2015.
- [40] A.-M. Popescu, O. Etzioni, and H. Kautz. Towards a theory of natural language interfaces to databases. In Proceedings of IUI, pages 149–157. ACM, 2003.
- [41] R. Sadana and J. Stasko. Designing and implementing an interactive scatterplot visualization for a tablet computer. In Proceedings of AVI, pages 265–272, 2014.
- [42] B. Saket, A. Endert, and Ç. Demiralp. Task-based effectiveness of basic visualizations. IEEE Transactions on Visualization and Computer Graphics, 25(7):2505–2512, 2018.
- [43] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer. Vega-Lite: A grammar of interactive graphics. IEEE Transactions on Visualization and Computer Graphics, 23(1):341–350, 2016.
- [44] A. Satyanarayan, R. Russell, J. Hoffswell, and J. Heer. Reactive vega: A streaming dataflow architecture for declarative interactive visualization. IEEE Transactions on Visualization and Computer Graphics, 22(1):659–668, 2015.
- [45] M. Schwab, J. Tompkin, J. Huang, and M. A. Borkin. Easypz. js: Interaction binding for pan and zoom visualizations. In Proceedings of IEEE VIS: Short Papers, pages 31–35, 2019.
- [46] V. Setlur, S. E. Battersby, M. Tory, R. Gossweiler, and A. X. Chang. Eviza: A natural language interface for visual analysis. In Proceedings of ACM UIST, pages 365–377, 2016.
- [47] V. Setlur, M. Tory, and A. Djalali. Inferencing underspecified natural language utterances in visual analysis. In Proceedings of ACM IUI, pages 40–51, 2019.
- [48] R. Sicat, J. Li, J. Choi, M. Cordeil, W.-K. Jeong, B. Bach, and H. Pfister. Dxr: A toolkit for building immersive data visualizations. IEEE Transactions on Visualization and Computer Graphics, 25(1):715–725, 2018.
- [49] A. Srinivasan, B. Lee, N. H. Riche, S. M. Drucker, and K. Hinckley. InChorus: Designing consistent multimodal interactions for data visualization on tablet devices. In Proceedings of ACM CHI, pages 653:1–653:13, 2020.
- [50] A. Srinivasan, B. Lee, and J. T. Stasko. Interweaving multimodal interaction with flexible unit visualizations for data exploration. IEEE Transactions on Visualization and Computer Graphics, 2020.
- [51] A. Srinivasan and J. Stasko. Natural language interfaces for data analysis with visualization: Considering what has and could be asked. In Proceedings of EuroVis: Short Papers, pages 55–59, 2017.
- [52] A. Srinivasan and J. Stasko. Orko: Facilitating multimodal interaction for visual exploration and analysis of networks. IEEE Transactions on Visualization and Computer Graphics, 24(1):511–521, 2018.
- [53] C. Stolte, D. Tang, and P. Hanrahan. Polaris: A system for query, analysis, and visualization of multidimensional relational databases. IEEE Transactions on Visualization and Computer Graphics, 8(1):52–65, 2002.
- [54] Y. Sun, J. Leigh, A. Johnson, and S. Lee. Articulate: A semi-automated model for translating natural language queries into meaningful visualizations. In Proceedings of the International Symposium on Smart Graphics, pages 184–195, 2010.
- [55] Tableau Ask Data. https://www.tableau.com/about/blog/2018/10/announcing-20191-beta-96449.
- [56] M. Tory and V. Setlur. Do what i mean, not what i say! design considerations for supporting intent and context in analytical conversation. In Proceedings of IEEE VAST, pages 93–103, 2019.
- [57] Unity. https://unity.com/.
- [58] Vega editor. https://vega.github.io/editor/.
- [59] Vega-embed. https://github.com/vega/vega-embed.
- [60] C. Wang, K. Tatwawadi, M. Brockschmidt, P.-S. Huang, Y. Mao, O. Polozov, and R. Singh. Robust Text-to-SQL generation with execution-guided decoding. arXiv preprint arXiv:1807.03100, 2018.
- [61] https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API, 2019.
- [62] L. Wilkinson. The grammar of graphics. Springer Science & Business Media, 2013.
- [63] WolframAlpha. https://www.wolframalpha.com/.
- [64] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe, and J. Heer. Voyager: Exploratory analysis via faceted browsing of visualization recommendations. IEEE transactions on visualization and computer graphics, 22(1):649–658, 2015.
- [65] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe, and J. Heer. Towards a general-purpose query language for visualization recommendation. In Proceedings of the HILDA Workshop, pages 1–6, 2016.
- [66] K. Wongsuphasawat, Z. Qu, D. Moritz, R. Chang, F. Ouk, A. Anand, J. Mackinlay, B. Howe, and J. Heer. Voyager 2: Augmenting visual analysis with partial view specifications. In Proceedings of ACM CHI, pages 2648–2659, 2017.
- [67] Z. Wu and M. Palmer. Verbs semantics and lexical selection. In Proceedings of ACL, pages 133–138, 1994.
- [68] T. Young, D. Hazarika, S. Poria, and E. Cambria. Recent trends in deep learning based natural language processing. IEEE Computational Intelligence magazine, 13(3):55–75, 2018.
- [69] B. Yu and C. T. Silva. FlowSense: A natural language interface for visual data exploration within a dataflow system. IEEE Transactions on Visualization and Computer Graphics, 26(1):1–11, 2019.
- [70] D. Zhang, Y. Suhara, J. Li, M. Hulsebos, Ç. Demiralp, and W.-C. Tan. Sato: Contextual semantic type detection in tables. arXiv preprint arXiv:1911.06311, 2019.
- [71] V. Zhong, C. Xiong, and R. Socher. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. CoRR, abs/1709.00103, 2017.