测量大规模多任务
语言理解
摘要
我们提出了一种新的测试来衡量文本模型的多任务准确性。 该测试涵盖了基础数学、美国历史、计算机科学、法律等 57 项任务。 为了在这项测试中获得高精度,模型必须具备广泛的世界知识和解决问题的能力。 我们发现,虽然大多数最新模型的准确性接近随机机会,但最大的 GPT-3 模型比随机机会平均提高了近 20 个百分点。 然而,在 57 项任务中的每一项上,最好的模型仍需要大量改进才能达到专家级的准确性。 模型也有不平衡的表现,并且常常不知道自己什么时候出错了。 更糟糕的是,它们在道德和法律等一些社会重要主题上仍然具有近乎随机的准确性。 通过全面评估模型学术和专业理解的广度和深度,我们的测试可用于分析跨许多任务的模型并识别重要的缺点。
1简介
自然语言处理 (NLP) 模型在许多最近提出的基准测试中取得了超人的性能。 然而,这些模型在整体语言理解方面仍然远低于人类水平,这表明我们的基准与这些模型的实际功能之间存在脱节。 通用语言理解评估基准(GLUE)(Wang 等人,2018)于 2018 年推出,用于评估广泛的 NLP 任务的性能,顶级模型在一年内就实现了超人的性能。 为了解决 GLUE 的缺点,研究人员设计了具有更困难任务的 SuperGLUE 基准(Wang 等人,2019)。 自 SuperGLUE 发布大约一年以来,性能再次基本达到人类水平(Raffel 等人,2019)。 虽然这些基准更多的是评估语言技能而不是整体语言理解,但人们提出了一系列常识性基准来衡量基本推理和日常知识(Zellers等人,2019;Huang等人,2019;Bisk等人,2019). 然而,这些最近的基准测试同样取得了快速进展(Khashabi 等人,2020)。 总体而言,这些基准测试的接近人类水平的表现表明它们没有捕捉到语言理解的重要方面。
Transformer 模型通过在海量文本语料库(包括所有维基百科、数千本书和众多网站)上进行预训练推动了这一最新进展。 因此,这些模型会看到有关专业主题的大量信息,其中大部分信息并未由现有 NLP 基准进行评估。 因此,当前的语言模型在学习和应用多个领域的知识方面的能力如何仍然是一个悬而未决的问题。
为了弥合模型在预训练过程中看到的广泛知识与现有成功衡量标准之间的差距,我们引入了一个新的基准来评估人类学习的各种科目的模型。 我们设计了基准,通过仅在零样本和少样本设置中评估模型来衡量预训练期间获得的知识。 这使得基准测试更具挑战性,也更类似于我们评估人类的方式。 该基准涵盖 STEM、人文、社会科学等学科。 它的难度从初级到专业高级,既考验世界知识,又考验解决问题的能力。 科目范围从数学和历史等传统领域到法律和伦理等更专业的领域(Hendrycks 等人,2020)。 主题的粒度和广度使基准成为识别模型盲点的理想选择。
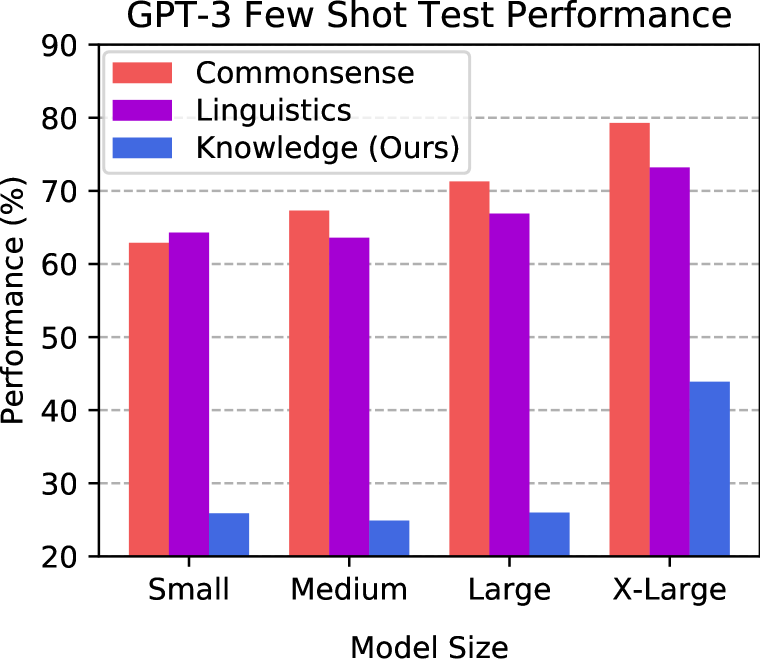
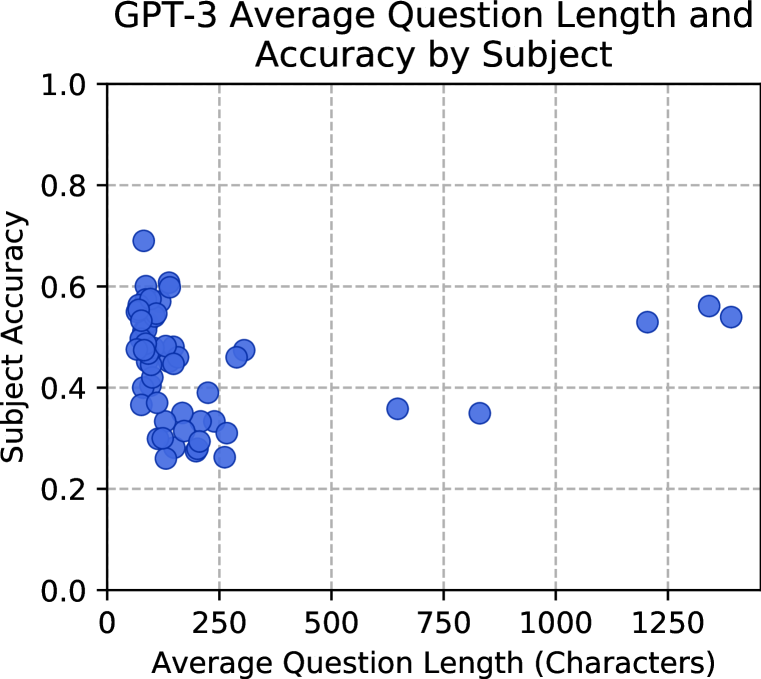
我们发现我们的基准只有在最近几个月才有可能取得有意义的进展。 特别是,少样本模型达到十亿个参数(Brown等人,2020)实现了精度的随机机会性能,但是十亿参数GPT-3模型达到了更高的精度(参见图1(b) )。 另一方面,与人类专业人士不同,GPT-3 并不擅长任何单一科目。 相反,我们发现表现是不平衡的,GPT-3 在其最佳主题上几乎具有 准确率,但在其他几个主题上的表现几乎是随机的。
我们的结果表明,虽然最近的进展令人印象深刻,但最先进的模型在学习和应用预训练知识方面仍然存在困难。 具有近乎随机精度的任务包括物理和数学等计算密集型科目以及与人类价值观相关的科目(例如法律和道德)。 第二个弱点尤其令人担忧,因为对于未来的模型来说,深入了解什么是合法的、什么是道德的非常重要。 令人担忧的是,我们还发现 GPT-3 无法准确地了解它知道什么或不知道什么,因为它的平均置信度可能与其实际准确性相差。 我们通过涵盖人类有动机学习的众多主题来全面评估模型文本理解的广度和深度。 由于我们的测试包含 任务,因此它可用于分析跨任务的模型的聚合属性并跟踪重要的缺点。 测试和代码可在 github.com/hendrycks/test 获取。

2相关工作
预训练。
NLP 的主导范式是在海量文本语料库(包括教育书籍和网站)上预训练大型模型。 在此过程中,这些模型会接触到有关广泛主题的信息。 Petroni 等人 (2019) 发现最近的模型从预训练中学习了足够的信息,可以作为知识库。 然而,之前的工作还没有全面衡量跨许多现实世界领域的知识模型。
直到最近,研究人员主要在下游任务上使用微调模型(Devlin 等人,2019)。 然而,像 GPT-3 (Brown 等人, 2020) 这样的更大的预训练模型已经可以通过使用少样本学习来实现无需微调的竞争性能,从而消除了对大量微调的需要。调音组。 随着强大的零样本和少样本学习的出现,现在可以策划一组多样化的评估任务,并消除“虚假线索”模型的可能性(Geirhos等人,2020;Hendrycks等人, 2019b) 在数据集中实现高性能。
基准。
最近的许多基准测试旨在通过测试模型的“常识”来评估模型的一般世界知识和基本推理能力。去年提出了许多常识性基准,但最近的模型在其中几个方面已经接近人类水平的性能,包括 HellaSwag (Zellers 等人,2019)、Physical IQA (Bisk 等人,2019),以及 CosmosQA (Huang 等人,2019)。 按照设计,这些数据集评估几乎每个孩子都具备的能力。 相比之下,我们包括人们必须学习才能学习的更难的专业科目。
一些研究人员建议,NLP 评估的未来应重点关注自然语言生成(NLG)(Zellers 等人,2020),这个想法可以追溯到图灵测试(Turing,1950) )。 然而,NLG 是出了名的难以评估,并且缺乏标准指标(Sai 等人,2020)。 因此,我们创建了一个易于评估的测试来衡量多项选择问题的分类准确性。
虽然存在一些问答基准,但它们的范围相对有限。 大多数都涵盖简单的主题,例如模型已经可以取得出色表现的小学科目(Clark 等人,2018;Khot 等人,2019;Mihaylov 等人,2018;Clark 等人,2019),或者以阅读理解的形式关注语言理解(Lai等人,2017;Richardson等人,2013)。 相比之下,我们涵盖了一系列远远超出语言理解范围的困难科目。
3 多任务测试
我们创建了一个大规模的多任务测试,其中包含来自各个知识分支的多项选择题。 该测试涵盖人文科学、社会科学、硬科学和其他对某些人来说很重要的学习领域的科目。 总共有个任务,也是Atari游戏的数量(Bellemare等人,2013),所有这些都列在附录<中/t3>B。 数据集中的问题是研究生和本科生从免费的在线资源中手动收集的。 其中包括研究生入学考试和美国医学执照考试等考试的练习题。 它还包括为本科课程设计的问题和为牛津大学出版社书籍的读者设计的问题。 有些任务涵盖一个主题,例如心理学,但具有特定的难度级别,例如“小学”、“高中”、“大学”或“专业”。例如,“专业心理学”任务借鉴了心理学专业实践考试免费提供的练习题中的问题,而“高中心理学”任务则采用了类似于先修心理学考试中的问题。
我们总共收集了 个问题,并将其分为少样本开发集、验证集和测试集。 少样本开发集每个主题有 个问题,验证集可用于选择超参数并由 个问题组成,测试集有 问题。 每个主题至少包含 个测试示例,这比大多数旨在评估人员的考试都要长。

该测试的人类准确度各不相同。 来自 Amazon Mechanical Turk 的非专业人士在此测试中获得了 准确度。 同时,专家级的表现可以更高。 例如,在美国医学执业资格考试中,考生的实际准确率约为第 95 百分位,这些问题构成了我们的 "专业医学 "任务。 如果我们在构建测试的考试中采用 95% 的人类应试者准确度,并且如果我们在无法获得此类信息时进行有根据的猜测,那么我们估计专家级准确度约为 。
由于我们的测试汇总了不同的主题和多个难度级别,因此我们衡量的不仅仅是简单的常识或狭隘的语言理解。 相反,我们测量任意现实世界的文本理解。 由于模型是在互联网上预先训练的,这使我们能够测试它们从海量语料库中提取有用知识的能力。 使用此测试的未来模型可以是单一模型或专家模型的混合。 为了在我们的测试中取得成功,未来的模型应该是全面的,拥有广泛的世界知识,并培养专家级的问题解决能力。 这些特性使得该测试可能成为持久且信息丰富的目标。
3.1人文学科
人文学科是一组利用定性分析和分析方法而不是科学实证方法的学科。 人文学科的分支包括法学、哲学、历史学等(附录B)。 掌握这些科目需要多种技能。 例如,法律理解需要了解如何将规则和标准应用于复杂的场景,并提供带有规定和解释的答案。 我们在图2中对此进行了说明。 法律理解对于理解和遵守规则和法规也是必要的,这是约束开放世界机器学习模型的必要能力。 对于哲学,我们的问题涵盖逻辑谬误、形式逻辑和著名的哲学论证等概念。 它还涵盖了道德场景,包括来自 ETHICS 数据集(Hendrycks 等人,2020) 的问题,这些问题通过预测关于各种日常场景的广泛道德直觉来测试模型对规范陈述的理解。 最后,我们的历史问题涵盖了广泛的时间段和地理位置,包括史前史和其他高级学科。
3.2社会科学
社会科学包括研究人类行为和社会的知识分支。 学科领域包括经济学、社会学、政治学、地理学、心理学等。 有关示例问题,请参阅图 3。 我们的经济学问题包括微观经济学、宏观经济学和计量经济学,涵盖不同类型的问题,包括需要混合世界知识、定性推理或定量推理的问题。 我们还包括重要但更深奥的主题,例如安全研究,以测试预训练期间所经历和学到的内容的界限。 社会科学还包括心理学,这一领域对于获得对人类的细致入微的理解可能特别重要。
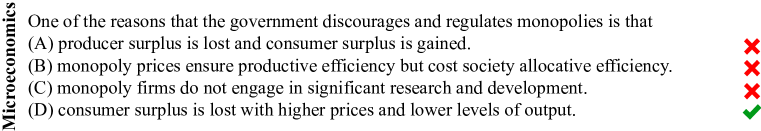

3.3科学、技术、工程和数学 (STEM)
STEM 科目包括物理、计算机科学、数学等。 图4中显示了两个示例。 概念物理测试对简单物理原理的理解,可以被认为是物理常识基准物理 IQA (Bisk 等人,2019)的更难版本。 我们还测试从初级到大学各个难度级别的数学问题解决能力。 大学数学问题,就像 GRE 数学科目考试中的问题一样,通常需要推理链和摘要知识。 为了对数学表达式进行编码,我们使用 LaTeX 或 * 和 ^ 等符号分别表示乘法和求幂。 STEM 科目需要经验方法、流体智力和程序知识方面的知识。
3.4其他
有很多主题要么不完全符合前面三个类别中的任何一个,要么没有数以千计的免费问题。 我们将这些主题放入“其他”中。 这一部分包括专业医学任务,其中有一些困难的问题,需要人类多年的学习才能掌握。 图5中描述了一个示例。 本部分还包含金融、会计和营销等商业主题,以及全球事实知识。 后者包括不同国家随时间推移的贫困统计数据,这对于在国际上建立准确的世界模型可能是必要的。

4实验
| Model | Humanities | Social Science | STEM | Other | Average |
| Random Baseline | 25.0 | 25.0 | 25.0 | 25.0 | 25.0 |
| RoBERTa | 27.9 | 28.8 | 27.0 | 27.7 | 27.9 |
| ALBERT | 27.2 | 25.7 | 27.7 | 27.9 | 27.1 |
| GPT-2 | 32.8 | 33.3 | 30.2 | 33.1 | 32.4 |
| UnifiedQA | 45.6 | 56.6 | 40.2 | 54.6 | 48.9 |
| GPT-3 Small (few-shot) | 24.4 | 30.9 | 26.0 | 24.1 | 25.9 |
| GPT-3 Medium (few-shot) | 26.1 | 21.6 | 25.6 | 25.5 | 24.9 |
| GPT-3 Large (few-shot) | 27.1 | 25.6 | 24.3 | 26.5 | 26.0 |
| GPT-3 X-Large (few-shot) | 40.8 | 50.4 | 36.7 | 48.8 | 43.9 |
4.1设置
评估和模型。
为了衡量多任务测试的性能,我们计算所有示例和任务的分类准确性。 我们评估 GPT-3 (Brown 等人, 2020) 和 UnifiedQA (Khashabi 等人, 2020)。 对于 GPT-3,我们使用 OpenAI API,它提供对四种模型变体的访问:“Ada”、“Babbage”、“Curie”和“Davinci”,我们将其称为“Small”( 十亿个参数)、“中”( 十亿)、“大”( 十亿)和“超大”( 十亿)。 UnifiedQA 使用 T5 (Raffel 等人, 2019) 文本到文本骨干网,并在之前提出的问答数据集 (Lai 等人, 2017) 上进行了微调,其中预测是与 UnifiedQA 的文本输出词符重叠最高的类。 由于 UnifiedQA 在其他数据集上进行了微调,因此我们无需进一步调整即可评估其传输准确性。 我们还在 UnifiedQA 数据和我们的 dev+val 集上训练了 RoBERTa-base、ALBERT-xxlarge 和 GPT-2。 在本文档的其余部分中,我们主要关注 UnifiedQA 和 GPT-3,但对 RoBERTa、ALBERT 和 GPT-2 的其他讨论在附录 A.
少样本提示。
我们提供 GPT-3 提示,如图1(a)所示。 我们以“以下是关于[主题]的多项选择题(含答案)开始每个提示。”对于零样本评估,我们将问题附加到提示中。 对于少样本评估,我们在附加问题之前添加 个演示示例以及提示答案。 所有提示均以“Answer:”结尾。 然后,模型生成标记“A”、“B”、“C”和“D”的概率,我们将最高概率选项视为预测。 为了保持一致的评估,我们为每个主题创建了一个包含 固定少样本示例的开发集。
4.2结果
模型尺寸和精度。
我们在表1中比较了每个GPT-3尺寸的少样本准确性。 我们发现三个较小的 GPT-3 模型具有接近随机的精度(大约 )。 相比之下,我们发现 X-Large 十亿参数 GPT-3 模型的性能明显优于随机模型,准确度为 。 我们还在零样本设置中发现了类似的定性结果。 虽然较小的模型具有大约零样本精度,但附录中的图11 t5> A 显示最大的 GPT-3 模型具有更高的零样本精度,约为 。 Brown 等人 (2020) 还观察到,较大的 GPT-3 模型表现更好,尽管进展往往更加稳定。 在图 1(b)中,我们表明,与评估数据集相比,最近的大型少样本模型出现了多任务测试的非随机准确性常识和语言理解。
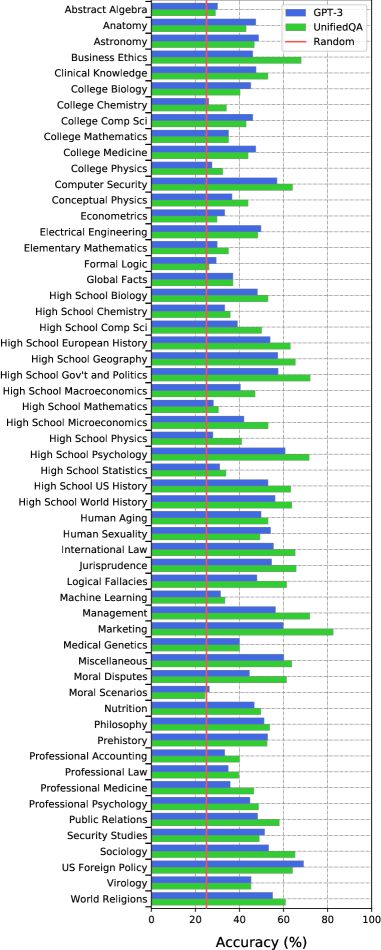
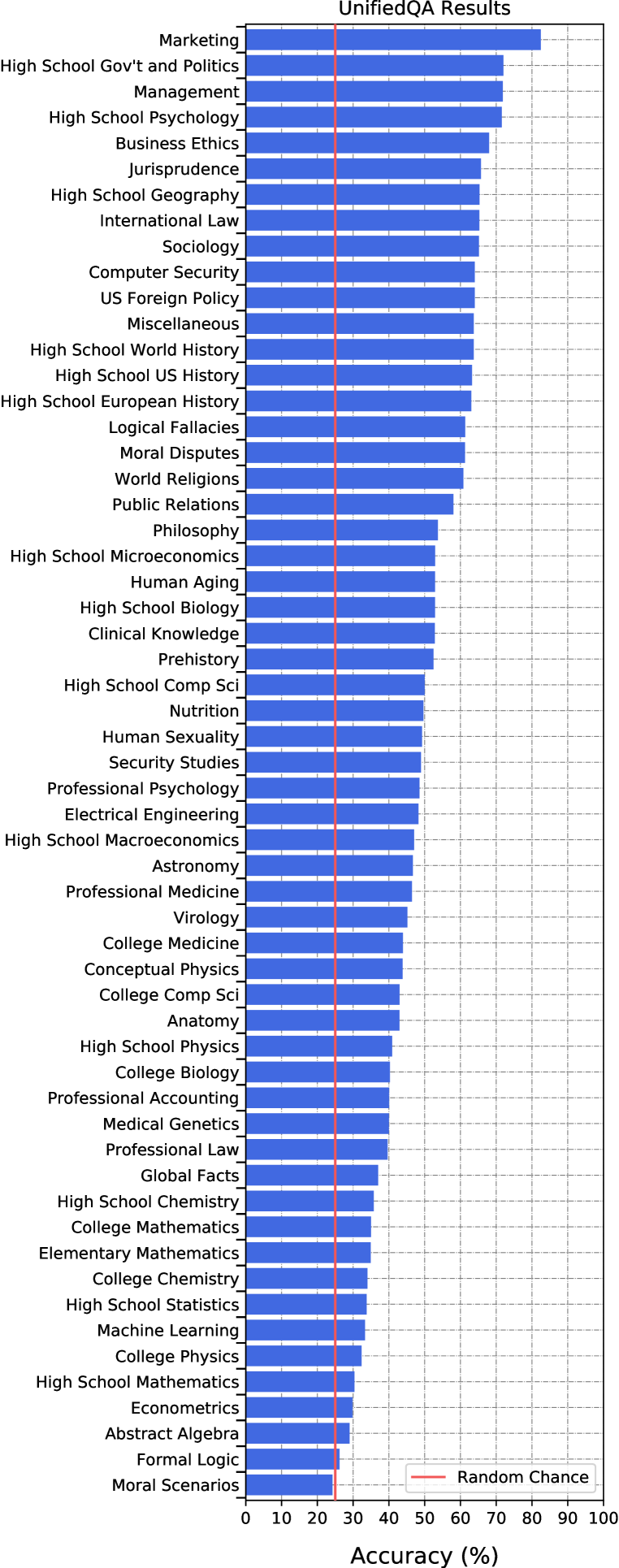
为了测试微调而不是少样本学习的有用性,我们还评估了 UnifiedQA 模型。 与 GPT-3 不同,UnifiedQA 的优点是可以在其他问答数据集上进行微调。 我们通过评估其传输性能来评估 UnifiedQA,无需任何额外的微调。 我们测试的最大的 UnifiedQA 模型有 十亿个参数,比 GPT-3 Large 略小。 尽管如此,我们在 Table 1 中显示它达到了 精度。 尽管 UnifiedQA 的参数少了一个数量级,但它的性能比少样本 GPT-3 XL 模型要好。 我们还发现,即使是最小的 UnifiedQA 变体,只有 万个参数,也具有大约 的准确性。 这些结果表明,虽然模型大小是实现强大性能的关键因素,但微调也有帮助。
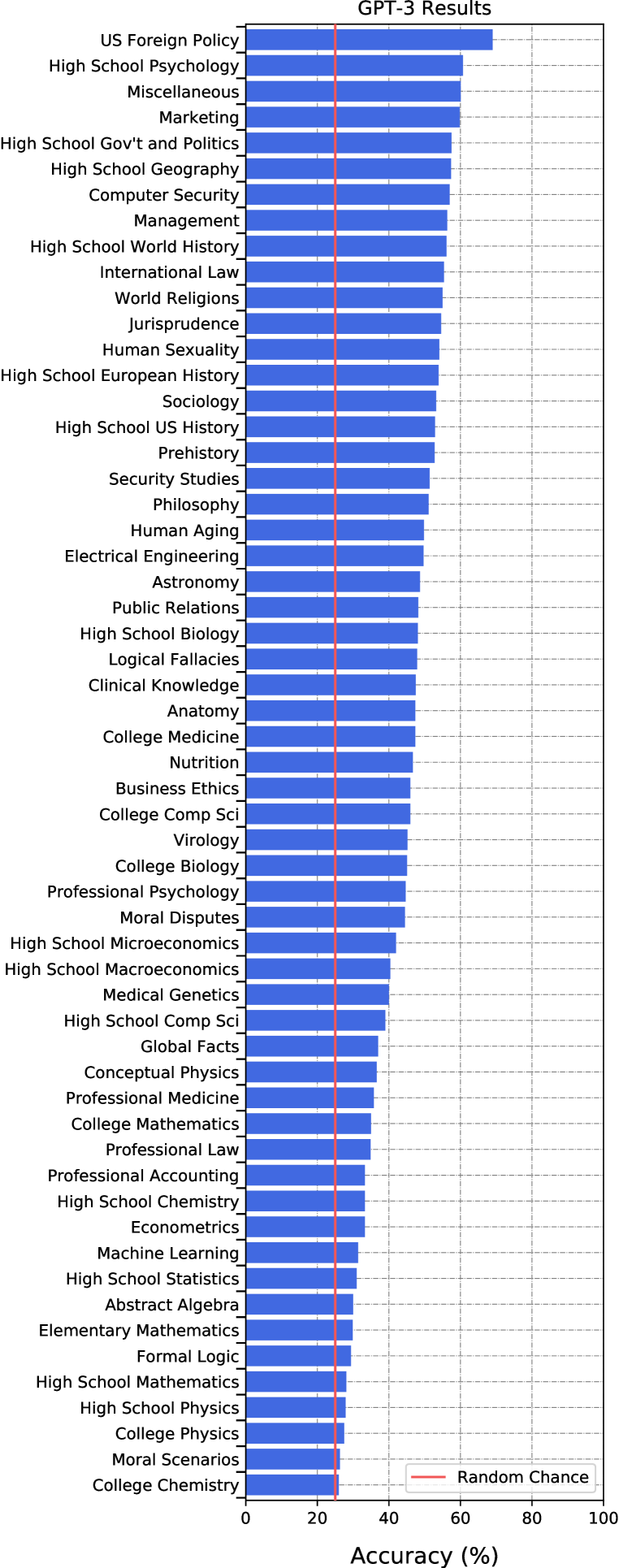
比较学科。 通过我们的测试,我们发现 GPT-3 和 UnifiedQA 的性能不平衡,并且存在一些重大的知识差距。 图6显示了GPT-3(少样本)和UnifiedQA对于所有任务的准确性。 它显示这两个模型在所有任务上都低于专家水平,GPT-3 的准确度范围从美国外交政策的 到大学化学的 。 UnifiedQA 在营销方面表现最好,准确度为。
总体而言,模型在高度程序性问题上表现不佳。 图6显示,与语言科目相比,计算量大的 STEM 科目的准确性往往较低。 对于 GPT-3, 最低准确度任务中的 是强调数学或计算的 STEM 科目。 我们推测这部分是因为 GPT-3 比程序性知识更容易获取声明性知识。 例如,初等数学中的许多问题都需要应用算术运算顺序,这由缩写 PEMDAS(括号指数乘法除法加减法)来描述。 在图8中,我们确认GPT-3知道缩写PEMDAS。 然而,它并没有始终如一地应用 PEMDAS 来解决实际问题。 另一方面,程序理解并不是其唯一的弱点。 我们发现,一些口头任务,如Hendrycks 等人(2020)的道德情景和专业法律,准确率也特别低。
我们的测试还表明,GPT-3 获取知识的方式与人类非常不同。 例如,GPT-3 以教学上不寻常的顺序学习主题。 GPT-3 在大学医学 () 和大学数学 () 上的表现优于计算密集型初等数学 ()。 GPT-3 展示了不同寻常的广度,但它并没有掌握单一主题。 与此同时,我们怀疑人类掌握了多个学科,但没有那么广泛。 这样一来,我们的测试表明GPT-3存在很多知识盲点,并且具有不平衡的能力。

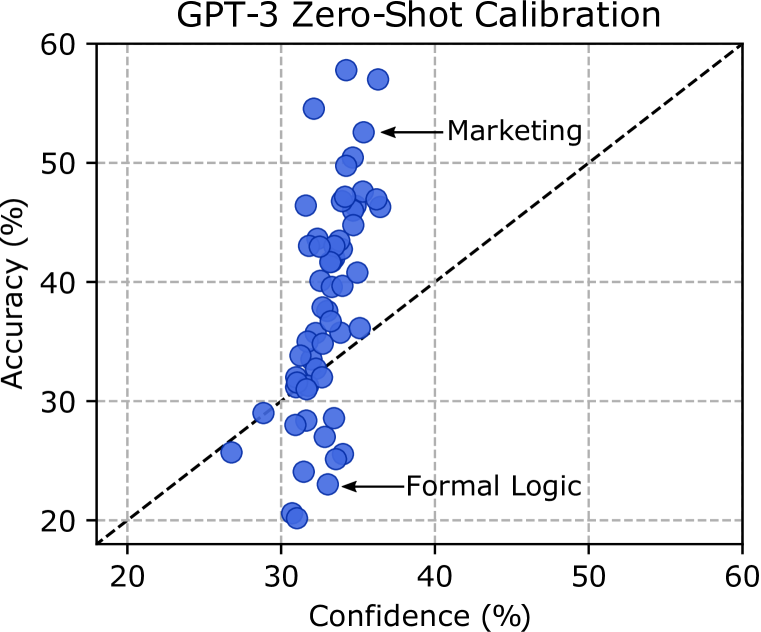
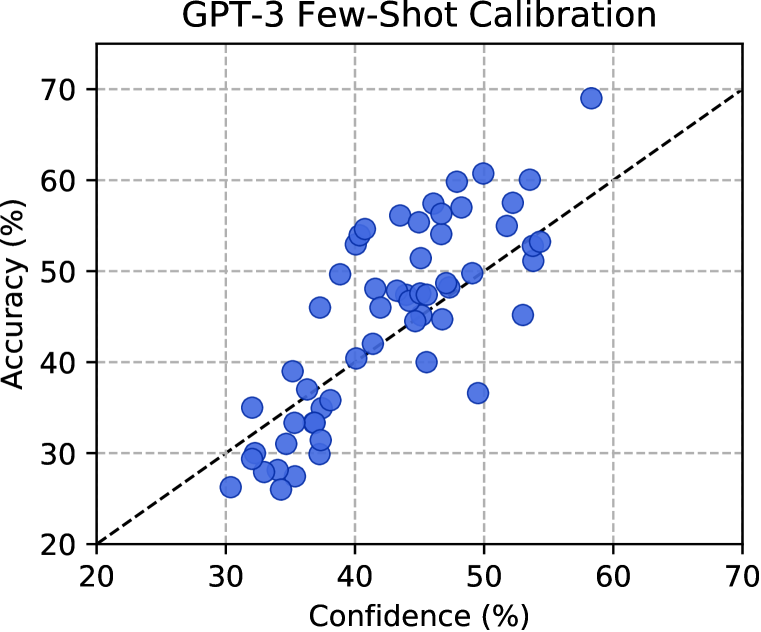
校准。 除非模型经过校准,否则我们不应该相信模型的预测,这意味着它的置信度是对预测正确的实际概率的良好估计。 然而,大型神经网络经常被错误校准(Guo等人,2017),特别是在分布变化的情况下(Ovadia等人,2019)。 我们通过测试 GPT-3 的平均置信度对每个受试者的实际准确性的估计程度来评估 GPT-3 的校准。 我们在图8中展示了结果,这表明GPT-3未经校准。 事实上,它的置信度与其在零样本设置中的实际准确性只有微弱的相关性,对于某些受试者,其准确性和置信度之间的差异达到。 另一种校准措施是均方根(RMS)校准误差(Hendrycks等人,2019a;Kumar等人,2019)。 许多任务都有错误校准的预测,例如初等数学的零样本 RMS 校准误差为 19.4%。 模型仅在少样本设置中进行了一些校准,如附录A所示。 这些结果表明模型校准还有很大的改进空间。
5讨论
多模式理解。 虽然文本能够传达大量关于世界的概念,但许多重要概念主要通过其他方式来传达,例如图像、音频和物理交互(Bisk等人,2020)。 现有的大规模 NLP 模型(例如 GPT-3)不包含多模态信息,因此我们设计基准以纯文本格式捕获各种任务。 然而,随着模型获得处理多模式输入的能力,应该设计基准来反映这种变化。 其中一个基准可能是“Turk Test”,其中包括 Amazon Mechanical Turk 人类智能任务。 这些是明确定义的任务,需要模型与灵活的格式交互并展示多模式理解。
互联网作为训练集。 我们的基准测试与之前的多任务 NLP 基准测试之间的一个主要区别是我们不需要大型训练集。 相反,我们假设模型已经通过阅读互联网上大量不同的文本获得了必要的知识。 这个过程通常被称为预训练,但它本身可以被认为是训练,其中下游评估展示了我们期望人类从阅读相同文本中获得的任何知识。
这促使我们提出一种方法上的改变,以便模型的训练更像人类的学习方式。 虽然大多数以前的机器学习基准测试都让模型从大型问题库中学习,但人类主要通过阅读书籍和听别人谈论该主题来学习新主题。 对于专业法等专业科目,可以使用大量法律语料库,例如 164 卷的法律百科全书 Corpus Juris Secundum,但可用的多州律师考试问题不到 5,000 条。 仅通过少量的练习测试来学习整个法律是难以置信的,因此未来的模型必须在预习过程中学习更多。
因此,我们在零样本、少样本或传输设置中评估预训练模型,并为每个任务提供开发集、验证集和测试集。 开发集用于少样本提示,验证集可用于超参数调整,测试集用于计算最终精度。 重要的是,我们的评估格式与预训练期间获取信息的格式并不相同。 这样做的好处是消除了对虚假训练训练集标注伪影的担忧(Geirhos等人,2020;Hendrycks等人,2019b),并且与之前相同分布和测试集的范例形成鲜明对比。 这一变化还可以收集更广泛和多样化的任务集进行评估。 我们预计,随着模型在从不同在线来源提取信息方面的改进,我们的方法将变得更加广泛。
模型限制。 我们发现目前的大型Transformers还有很大的改进空间。 他们在模拟人类(不)认可方面尤其糟糕,从专业法律和道德场景任务中的低表现就可以看出这一点。 为了使未来的系统与人类价值观保持一致,这些任务的高性能至关重要(Hendrycks等人,2020),因此未来的研究应特别致力于提高这些任务的准确性。 模型在执行计算方面也存在困难,以至于它们在初等数学和许多其他存在“即插即用”问题的 STEM 科目上表现不佳。 此外,他们在任何科目上都无法达到专家水平的表现(90%),因此对于所有科目而言,它们都是非人类的。 平均而言,模型现在才开始超越随机机会的准确度水平。
解决这些缺点可能具有挑战性。 为了说明这一点,我们尝试通过专业数据的预训练来创建更好的专业法律模型,但只取得了有限的成功。 我们收集了大约 2,000 个额外的专业法律训练示例。 使用此自定义训练集对基于 RoBERTa 的模型 (Liu 等人, 2019) 进行微调后,我们的模型获得了 测试精度。 为了测试额外专业训练数据的影响,我们还让 RoBERTa 使用哈佛法律图书馆判例法语料库 case.law 对大约 160 万个法律案例摘要进行预训练,但微调后仅达到了 准确度。 这表明,虽然对相关高质量文本进行额外的预训练可以有所帮助,但可能不足以大幅提高当前模型的性能。
目前尚不清楚简单地扩展现有语言模型是否能够解决该测试。 目前的理解表明,模型大小的增加必然伴随着数据的近似增加(Kaplan等人,2020)。 除了创建数万亿参数语言模型的巨大费用之外,数据也可能成为瓶颈,因为有关深奥知识分支的文字远少于有关日常情况的文字。
6结论
我们引入了一项新测试,用于衡量文本模型学习和应用预演期间遇到的知识的能力。 该测试涵盖了不同难度级别的 57 个科目,比之前的基准测试更广泛、更深入地评估语言理解能力。 我们发现,模型最近有可能在测试中取得有意义的进展,但最先进的模型表现不平衡,很少能在任何单个任务上表现出色。 我们还表明,当前的模型未经校准,并且难以完成需要计算的任务。 令人担忧的是,模特在道德和法律等社会相关主题上的表现也特别差。 我们广泛的测试可以帮助研究人员查明模型的重要缺陷,从而更容易地更清晰地了解最先进的功能。
致谢
我们要感谢以下人士提供的有益评论:Oyvind Tafjord、Jan Leike、David Krueger、Alex Tamkin、Girish Sastry 和 Henry Zhu。 DH 得到 NSF GRFP 奖学金和开放慈善项目奖学金的支持。 这项研究还得到了 NSF Frontier Award 1804794 的支持。
参考
- Bellemare et al. (2013) M. G. Bellemare, Y. Naddaf, J. Veness, and M. Bowling. The arcade learning environment: An evaluation platform for general agents (extended abstract). J. Artif. Intell. Res., 47:253–279, 2013.
- Bisk et al. (2019) Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi. Piqa: Reasoning about physical commonsense in natural language, 2019.
- Bisk et al. (2020) Y. Bisk, A. Holtzman, J. Thomason, J. Andreas, Y. Bengio, J. Chai, M. Lapata, A. Lazaridou, J. May, A. Nisnevich, N. Pinto, and J. Turian. Experience grounds language, 2020.
- Brown et al. (2020) T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners, 2020.
- Clark et al. (2018) P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018.
- Clark et al. (2019) P. Clark, O. Etzioni, D. Khashabi, T. Khot, B. D. Mishra, K. Richardson, A. Sabharwal, C. Schoenick, O. Tafjord, N. Tandon, S. Bhakthavatsalam, D. Groeneveld, M. Guerquin, and M. Schmitz. From ’f’ to ’a’ on the n.y. regents science exams: An overview of the aristo project. ArXiv, abs/1909.01958, 2019.
- Devlin et al. (2019) J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv, abs/1810.04805, 2019.
- Geirhos et al. (2020) R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann. Shortcut learning in deep neural networks, 2020.
- Guo et al. (2017) C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On calibration of modern neural networks. ICML, 2017.
- Hendrycks et al. (2019a) D. Hendrycks, M. Mazeika, and T. Dietterich. Deep anomaly detection with outlier exposure. ICLR, 2019a.
- Hendrycks et al. (2019b) D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song. Natural adversarial examples. ArXiv, abs/1907.07174, 2019b.
- Hendrycks et al. (2020) D. Hendrycks, C. Burns, S. Basart, A. Critch, J. Li, D. Song, and J. Steinhardt. Aligning ai with shared human values, 2020.
- Huang et al. (2019) L. Huang, R. L. Bras, C. Bhagavatula, and Y. Choi. Cosmos qa: Machine reading comprehension with contextual commonsense reasoning, 2019.
- Kaplan et al. (2020) J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models, 2020.
- Khashabi et al. (2020) D. Khashabi, T. Khot, A. Sabharwal, O. Tafjord, P. Clark, and H. Hajishirzi. Unifiedqa: Crossing format boundaries with a single qa system, 2020.
- Khot et al. (2019) T. Khot, P. Clark, M. Guerquin, P. Jansen, and A. Sabharwal. Qasc: A dataset for question answering via sentence composition, 2019.
- Kumar et al. (2019) A. Kumar, P. Liang, and T. Ma. Verified uncertainty calibration, 2019.
- Lai et al. (2017) G. Lai, Q. Xie, H. Liu, Y. Yang, and E. Hovy. Race: Large-scale reading comprehension dataset from examinations, 2017.
- Lan et al. (2020) Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. Albert: A lite bert for self-supervised learning of language representations. ArXiv, abs/1909.11942, 2020.
- Liu et al. (2019) Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692, 2019.
- Mihaylov et al. (2018) T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018.
- Ovadia et al. (2019) Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. V. Dillon, B. Lakshminarayanan, and J. Snoek. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. NeurIPS, 2019.
- Petroni et al. (2019) F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, and S. Riedel. Language models as knowledge bases?, 2019.
- Radford et al. (2019) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners. 2019.
- Raffel et al. (2019) C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2019.
- Richardson et al. (2013) M. Richardson, C. J. Burges, and E. Renshaw. MCTest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 193–203, Seattle, Washington, USA, Oct. 2013. Association for Computational Linguistics.
- Sai et al. (2020) A. B. Sai, A. K. Mohankumar, and M. M. Khapra. A survey of evaluation metrics used for nlg systems. 2020.
- Turing (1950) A. Turing. Computing machinery and intelligence. 1950.
- Wang et al. (2018) A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding, 2018.
- Wang et al. (2019) A. Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems, 2019.
- Zellers et al. (2019) R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. Hellaswag: Can a machine really finish your sentence?, 2019.
- Zellers et al. (2020) R. Zellers, A. Holtzman, E. Clark, L. Qin, A. Farhadi, and Y. Choi. Evaluating machines by their real-world language use, 2020.
附录A附加分析
A.1 使用更多微调模型进行分析
我们主要分析了论文正文中参数超过十亿的模型。 在本节中,我们分析较小的模型,包括 RoBERTa-base(1.25 亿个参数)[Liu 等人,2019]、ALBERT-xxlarge(2.23 亿个参数)[Lan 等人,2020] 和 GPT-2(15.58 亿个参数)[Radford 等人,2019]。 使用 UnifiedQA MCQ 问题和我们的 dev+val 集对模型进行微调,以预测四个类别之一。 我们在多任务测试集上进行测试。
我们观察到这些较小的模型可以获得比随机更好的精度。 RoBERTa-base 的总体准确度为 ,人文学科的准确度为 ,社会科学的准确度为 ,STEM 的准确度为 ,和 为其他。 ALBERT-xxlarge 的准确度为 ,人文学科的准确度为 ,社会科学的准确度为 ,STEM 的准确度为 ,和 为其他。 GPT-2 的准确度为 ,人文学科的准确度为 ,社会科学的准确度为 ,STEM 的准确度为 ,和 为其他。
将此与 UnifiedQA 的最小变体进行比较,后者只有 万个参数和大约 准确度。 尽管参数较少,但它比 RoBERTa 和 ALBERT 获得了更高的精度。 这表明其更大的预训练数据集可以实现更高的准确性。 同样,具有 十亿个参数的 UnifiedQA 达到 ,而具有 十亿个参数的类似大小的 GPT-2 模型达到 精度。 这再次表明 T5 较大的预训练数据集大小(以及 UnifiedQA 的预训练数据集大小)可以提高准确性。
A.2错误分析
我们定性分析 GPT-3 何时犯高置信度错误。 我们发现,虽然其中许多错误显然是错误的,但许多错误是人类可能犯的。 例如,它出错的一个问题是“所有人类体细胞含有多少条染色体?”正确答案是,而少样本GPT-3预测的置信度是。 如果问题询问的是染色体对的数量,那么这个答案就是正确的。 同样,许多其他高置信度错误也是对略有不同的问题的正确答案。
A.3格式敏感性
虽然不同的问题格式选择通常会导致类似的 GPT-3 准确性,但我们发现 UnifiedQA 更敏感。 UnifiedQA 的输入格式为以下形式
QUESTION1 \\n (A) CHOICE1 (B) CHOICE2 (C) CHOICE3 (D) CHOICE4</s>
其中问题和选择被标准化并小写。 如果我们从输入中删除 ,准确性会下降几个百分点。
附录 B测试详细信息
B.1 任务描述和示例
B.2 确切的问题和答案污染
由于语言模型是在大量文本语料库上进行训练的,因此他们有可能在预习过程中看到了确切的问题和答案。 如果他们记住了确切的问题和答案,那么他们将获得比他们真实能力更高的准确性。 同样,如果记住一个问题,它的熵会特别低。 记忆的问题和答案应该具有低熵和高精度。 然而,在图 13中,我们看到准确率和问题熵并不是正相关,这表明测试的低熵问题并不对应记住(从而正确预测)答案。 这表明我们的确切问题没有被记住。 然而,在预训练过程中,模型通过处理维基百科遇到了与我们的问题相关的文本。 我们还注意到,我们的大多数问题来自 PDF 或网站,其中问题和答案位于不同的页面上。
有关污染的先前讨论,请参阅 Brown 等人 [2020],表明这种现象几乎不会影响性能。 为了降低未来模型在测试期间遇到确切问题的可能性,我们将提供问题源列表。
Task Tested Concepts Supercategory Abstract Algebra Groups, rings, fields, vector spaces, … STEM Anatomy Central nervous system, circulatory system, … STEM Astronomy Solar system, galaxies, asteroids, … STEM Business Ethics Corporate responsibility, stakeholders, regulation, … Other Clinical Knowledge Spot diagnosis, joints, abdominal examination, … Other College Biology Cellular structure, molecular biology, ecology, … STEM College Chemistry Analytical, organic, inorganic, physical, … STEM College Computer Science Algorithms, systems, graphs, recursion, … STEM College Mathematics Differential equations, real analysis, combinatorics, … STEM College Medicine Introductory biochemistry, sociology, reasoning, … Other College Physics Electromagnetism, thermodynamics, special relativity, … STEM Computer Security Cryptography, malware, side channels, fuzzing, … STEM Conceptual Physics Newton’s laws, rotational motion, gravity, sound, … STEM Econometrics Volatility, long-run relationships, forecasting, … Social Sciences Electrical Engineering Circuits, power systems, electrical drives, … STEM Elementary Mathematics Word problems, multiplication, remainders, rounding, … STEM Formal Logic Propositions, predicate logic, first-order logic, … Humanities Global Facts Extreme poverty, literacy rates, life expectancy, … Other High School Biology Natural selection, heredity, cell cycle, Krebs cycle, … STEM High School Chemistry Chemical reactions, ions, acids and bases, … STEM High School Computer Science Arrays, conditionals, iteration, inheritance, … STEM High School European History Renaissance, reformation, industrialization, … Humanities High School Geography Population migration, rural land-use, urban processes, … Social Sciences High School Gov’t and Politics Branches of government, civil liberties, political ideologies, … Social Sciences High School Macroeconomics Economic indicators, national income, international trade, … Social Sciences High School Mathematics Pre-algebra, algebra, trigonometry, calculus, … STEM High School Microeconomics Supply and demand, imperfect competition, market failure, … Social Sciences High School Physics Kinematics, energy, torque, fluid pressure, … STEM High School Psychology Behavior, personality, emotions, learning, … Social Sciences High School Statistics Random variables, sampling distributions, chi-square tests, … STEM High School US History Civil War, the Great Depression, The Great Society, … Humanities High School World History Ottoman empire, economic imperialism, World War I, … Humanities Human Aging Senescence, dementia, longevity, personality changes, … Other Human Sexuality Pregnancy, sexual differentiation, sexual orientation, … Social Sciences International Law Human rights, sovereignty, law of the sea, use of force, … Humanities Jurisprudence Natural law, classical legal positivism, legal realism, … Humanities Logical Fallacies No true Scotsman, base rate fallacy, composition fallacy, … Humanities Machine Learning SVMs, VC dimension, deep learning architectures, … STEM Management Organizing, communication, organizational structure, … Other Marketing Segmentation, pricing, market research, … Other Medical Genetics Genes and cancer, common chromosome disorders, … Other Miscellaneous Agriculture, Fermi estimation, pop culture, … Other Moral Disputes Freedom of speech, addiction, the death penalty, … Humanities Moral Scenarios Detecting physical violence, stealing, externalities, … Humanities Nutrition Metabolism, water-soluble vitamins, diabetes, … Other Philosophy Skepticism, phronesis, skepticism, Singer’s Drowning Child, … Humanities Prehistory Neanderthals, Mesoamerica, extinction, stone tools, … Humanities Professional Accounting Auditing, reporting, regulation, valuation, … Other Professional Law Torts, criminal law, contracts, property, evidence, … Humanities Professional Medicine Diagnosis, pharmacotherapy, disease prevention, … Other Professional Psychology Diagnosis, biology and behavior, lifespan development, … Social Sciences Public Relations Media theory, crisis management, intelligence gathering, … Social Sciences Security Studies Environmental security, terrorism, weapons of mass destruction, … Social Sciences Sociology Socialization, cities and community, inequality and wealth, … Social Sciences US Foreign Policy Soft power, Cold War foreign policy, isolationism, … Social Sciences Virology Epidemiology, coronaviruses, retroviruses, herpesviruses, … Other World Religions Judaism, Christianity, Islam, Buddhism, Jainism, … Humanities
查找 中的所有 ,使得 是一个字段。 (A) 0 (B) 1 (C) 2 (D) 3
舌骨的胚胎学起源是什么? (A) 第一咽弓 (B) 第一、第二咽弓 (C) 第二咽弓 (D) 第二、第三咽弓
为什么小行星带所在的行星没有? (A) 一颗行星曾在此形成,但因灾难性碰撞而分裂。 (B) 太阳星云的这一部分没有足够的物质来形成行星。 (C) 岩石物质太多,无法形成类地行星,但气态物质却不足以形成木行星。 (D) 与木星的共振阻止了物质聚集在一起形成行星。
CSO 为实现其目标可以采用三种截然不同的策略:(通常涉及研究和沟通)(可能涉及对公司运营进行物理攻击)或 ,通常涉及某种形式的。
(A) 非暴力直接行动、暴力直接行动、间接行动、抵制
(B) 间接行动、工具性行动、非暴力直接行动、信息宣传活动
(C) 间接行动、暴力直接行动、非暴力直接行动抵制。
(D) 非暴力直接行动、工具性行动、间接行动、信息宣传活动
在将工作交给资深同事之前,您应该尝试多少次为患者插管? (A) 4 (B) 3 (C) 2 (D) 1
在特定人群中,每 400 人中就有 1 人患有由完全隐性等位基因引起的癌症,b。 假设群体处于 Hardy-Weinberg 平衡,下列哪项是携带 b 等位基因但预计不会患癌症的个体的预期比例? (A) 1/400 (B) 19/400 (C) 20/400 (D) 38/400
以下关于镧系元素的说法哪一项是不正确的? (A) 镧系元素最常见的氧化态是+3。 (B) 镧系元素络合物通常具有高配位数 (> 6)。 (C) 所有的镧系元素与酸水溶液反应释放氢气。 (D) 从 La 到 Lu 期间,镧系元素的原子半径不断增加。
考虑一种计算机设计,其中多个处理器(每个处理器都有一个专用高速缓存)使用单个总线共享全局内存。 该总线是关键的系统资源。 只要其本地缓存满足内存引用,每个处理器就可以每 500 纳秒执行一条指令。 当发生缓存未命中时,处理器会额外延迟 2,000 纳秒。 在这个额外延迟的一半期间,总线专用于处理高速缓存未命中。 在另一半期间,处理器无法继续运行,但总线可以自由地服务来自其他处理器的请求。 平均而言,每条指令需要 2 个内存引用。 平均而言,缓存未命中发生在 1% 的引用上。 忽略由于其他处理器的竞争而导致的延迟,单个处理器将消耗多少比例的总线容量? (A) 1/50 (B) 1/27 (C) 1/25 (D) 2/27
令 为实数 矩阵。 以下哪项陈述一定是正确的? 我。 的所有条目都是非负的。 二. 的行列式是非负的。 三. 如果 A 有两个不同的特征值,则 有两个不同的特征值。 (A) 仅 I (B) 仅 II (C) 仅 III (D) 仅 II 和 III
在对新生儿进行基因测试时,发现一种罕见的遗传性疾病,具有 X 连锁隐性传播。 关于这种疾病的谱系,以下哪项陈述可能是正确的?
(A) 母方的所有后代都会患有该疾病。
(B) 在这个家庭中,女性受到的影响大约是男性的两倍。
(C) 受影响男性的所有女儿都将受到影响。
(D) 受影响的男性和女性将平等分配。
一根长度为 2L、截面积为 A 的镍铬合金线的一端连接到另一根长度为 L、截面积为 2A 的镍铬合金线的一端。 如果较长导线的自由端的电势为 8.0 伏,较短导线的自由端的电势为 1.0 伏,则两根导线连接处的电势最接近等于
(一)2.4V
(二)3.3V
(C)4.5V
(D)5.7V
为什么反病毒扫描程序无法发现 Heartbleed 的利用? (A) 这是一个空洞的问题:Heartbleed 只在缓冲区外读取,因此不可能被利用 (B) 防病毒扫描程序倾向于查找病毒和其他恶意软件 (C) Heartbleed 攻击防病毒扫描程序本身 (D) 防病毒扫描程序倾向于查找病毒和其他恶意代码,但 Heartbleed 漏洞无需注入任何代码即可窃取机密
模型飞机迎风飞行时飞行速度较慢,逆风飞行时飞行速度较快。 当与风(侧风)成直角发射时,其地速与在静止空气中飞行相比 (A) 相同 (B) 较大 (C) 较小 (D) 取决于风速较大或较小
考虑以下 AR(1) 模型,其扰动均值为零且单位方差 将给出 的(无条件)平均值通过 (A) 0.2 (B) 0.4 (C) 0.5 (D) 0.33
点杆的强度为 韦伯。 韦伯点极距其 10 厘米处所受的力(以牛顿为单位)为 (一)15N。 (B) 20 牛。(C) 7.5 牛。(D) 3.75 牛。
共有30名球员将在公园打篮球。 每支球队将有 5 名球员。 哪项陈述正确地解释了如何找到所需团队的数量?
(A) 将 5 加到 30 得到 35 支球队。
(B) 将 30 除以 5 得到 6 支球队。
(C) 30 乘以 5 得出 150 个团队。
(D) 从 30 中减去 5 得到 25 支球队。
判断这些陈述在逻辑上是等价的还是矛盾的。 如果两者都不是,则确定它们是一致还是不一致。
和
(A) 逻辑上等价
(二)矛盾
(C) 逻辑上既不等同也不矛盾,但一致
(D) 不一致
截至 2017 年,当今世界上有多少 1 岁儿童接种了某种疾病的疫苗?
(一)80%
(二) 60%
(三)40%
(四) 20%
同源结构经常被引用作为自然选择过程的证据。 以下所有都是同源结构的例子,除了 (A) 鸟的翅膀和蝙蝠的翅膀 (B) 鲸鱼的鳍和人的手臂 (C) 鼠海豚的胸鳍和海豹的鳍状肢 (D)昆虫的前肢和狗的前肢
根据溶解度规则,下列哪项是正确的? (A) 所有氯化物、溴化物和碘化物都是可溶的 (B) 所有硫酸盐都是可溶的 (C) 所有氢氧化物都是可溶的 (D) 所有含铵化合物都是可溶的
数字列表有 n 个元素,索引从 1 到 n。以下算法旨在显示列表中值大于 100 的元素数量。 该算法使用变量计数和位置。 缺少步骤 3 和 4。
步骤 1:将计数设置为 0,将位置设置为 1。
步骤2:如果索引位置的元素的值更大
大于 100,将 count 值加 1。
步骤3:(缺少步骤)
第4步:(缺少步骤)
步骤5:显示计数值。
可以使用以下哪项来替换步骤 3 和 4,以使算法按预期工作?
(A) 步骤 3:将位置值增加 1。
步骤4:重复步骤2和3,直到count的值大于100。
(B) 步骤 3:将位置值增加 1。
步骤4:重复步骤2和3,直到position的值大于n。
(C) 步骤 3:重复步骤 2,直到 count 的值大于 100。
步骤4:将position值增加1。
(D) 步骤3:重复步骤2,直到position的值大于n。
第4步:将count的值加1。
这个问题参考了以下信息。 尽管国王陛下公正合理地是并且应该是英国国教的最高元首,并且因此在其集会中得到了这个领域的神职人员的认可,但无论如何,为了证实和确认这一点,并为了增加英国国教的美德,基督的宗教在英格兰境内,并镇压和根除迄今为止在同一领域使用的所有错误、异端和其他暴行和滥用职权,由本届议会的权力颁布,国王,我们的主权领主,他的继承人这个王国的继承者、国王,将被选为、接受并被誉为英国国教地球上唯一的最高元首,称为英国圣公会教会;并应拥有并享受附属于并统一于该领域的皇冠及其头衔和风格,以及所有荣誉、尊严、卓越、管辖权、特权、权威、豁免、利润和商品,以达到上述尊严属于同一教会的最高元首;我们所说的至高无上的主,他的继承人和继任者,这个王国的国王,将拥有充分的权力和权威,不时地访问、镇压、纠正、记录、命令、纠正、限制和修正所有这些错误、异端,虐待、冒犯、蔑视和暴行,无论是什么,都应该或可以合法地通过任何方式的精神权威或管辖权进行改革、镇压、命令、纠正、纠正、限制或修正,最令全能的上帝高兴,增加基督宗教的美德,维护这个领域的和平、团结和安宁;任何用法、外国土地、外国当局、规定或任何其他与本协议相反的事物。 英国议会,至高无上的法案,1534 年 从这段文字中,人们可以推断英国议会希望主张至高无上的法案将 (A) 赋予英国国王新的权力地位 (B) 将英国国教领袖的职位单独授予亨利八世,并排除他的继承人 (C) 将加尔文主义确立为英国唯一真正的神学 (D) 结束困扰英国教会的各种形式的腐败
在人口转变模型的第三阶段,以下哪项是正确的?
(A) 出生率上升,人口增长率放缓。
(B) 出生率下降,人口增长率放缓。
(C) 出生率上升,人口增长率上升。
(D) 出生率下降,人口增长率上升。
以下哪一项最好地阐述了詹姆斯·麦迪逊在《联邦党人文集》第 10 期中提出的论点?
(A) 诚实的政治家可以防止派系发展。
(B) 大共和国比小共和国更容易发生派系斗争。
(C) 共和政府可以减少派系斗争的负面影响。
(D) 自由选举是人民对抗派系斗争的最佳防御手段。
以下哪项不包含在美国 GDP 中?
(A) 美军在外国开设新基地,驻有 1000 名美军人员。
(B) 日本消费者购买数千张美国生产的 CD。
(C) 一位美国流行歌手在巴黎举办一场门票全部售完的音乐会。
(D) 一部法国戏剧作品在美国数十个城市巡演。
乔负责舞会的灯光。 红灯每两秒闪烁一次,黄灯每三秒闪烁一次,蓝灯每五秒闪烁一次。 如果我们包括舞蹈的开始和结束,那么在七分钟的舞蹈中,所有灯光会同时亮起多少次? (假设在舞蹈开始时所有三个灯同时闪烁。)
(一)3
(二)15
(三)6
(四)5
如果政府补贴完全竞争市场中的生产者,那么
(一)产品需求量将增加
(B)产品的需求量将会减少
(三)消费者剩余增加
D、消费者剩余减少
点电荷 Q = +1 mC,固定在原点。 将电荷 Q = +8 µC 从点 (0, 4 米) 移动到点 (3 米, 0) 需要多少功?
(一)3.5焦耳
(B) 6.0 焦耳
(三) 22.5 焦耳
(D) 40 焦耳
当伊万在海里游泳时,还没来得及辨别影子是什么,就被水中的黑影吓坏了。 以下哪一项最能描述这次恐惧事件期间发生的突触连接?
(A) 信息从丘脑直接发送到杏仁核。
(B) 信息从丘脑发送到“什么”和“哪里”路径。
(C) 信息从副交感神经系统发送到大脑皮层。
(D) 信息从额叶发送到垂体。
乔纳森在统计考试中获得了 80 分,位于第 90 个百分点。 假设每个人的分数加五分。 乔纳森的新分数将是
(A) 第 80 个百分位。
(B) 第 85 个百分位。
(C) 第 90 个百分位。
(D) 第 95 个百分位。
这个问题参考了以下信息。
“每个国家的社会都是一种福气,但即使在最好的状态下,政府也只是一种不可避免的罪恶;在最坏的情况下是无法忍受的;因为当我们遭受苦难,或者遭受政府带来的同样的苦难时,我们可能会在一个没有政府的国家中遭遇同样的苦难,如果我们想到我们为我们的苦难提供了手段,我们的灾难就会加剧。 政府就像衣着一样,是失去纯真的标志;国王的宫殿建在天堂凉亭的废墟上。 因为如果良心的冲动是清晰的、一致的和不可抗拒的服从的话,人类就不需要其他的立法者了。但事实并非如此,他发现有必要放弃部分财产,以提供保护其余财产的手段;他之所以这样做,是出于同样的谨慎,在其他情况下,这种谨慎会建议他两害相权取其轻。 因此,安全是政府的真正设计和目的,毫无疑问,无论哪种形式最有可能以最少的费用和最大的利益确保我们的安全,都比其他所有形式都更可取。”
托马斯·潘恩,《常识》,1776 年
上面提到的以下哪一种“苦难”最受革命后时代的反联邦党人谴责?
(A) 有组织地回应培根的叛乱。
(B) 联邦对谢斯叛乱的反应。
(C) 联邦政府对威士忌叛乱的反应。
(D) 联邦对庞蒂亚克叛乱的反应。
这个问题参考了以下信息。
“工人真正的不满是他的生存没有安全感;他不确定自己是否会永远有工作,他不确定自己是否会永远健康,并且他预见有一天自己会变老,不再适合工作。 如果他陷入贫困,即使只是因为长期患病,他也会完全无助,只能靠自己的努力,除了对穷人的通常帮助之外,社会目前不承认对他有任何真正的义务,即使他已经一直以来都如此忠实和勤奋地工作。 然而,对穷人的通常帮助还有很多不足之处,特别是在大城市,情况比乡村要糟糕得多。”
奥托·冯·俾斯麦,1884 年
奥托·冯·俾斯麦发表此演讲可能是针对以下哪些问题?
(A) 社会对童工的接受程度。
(B) 德国的预期寿命下降。
(C) 对德国贸易关税的批评。
(D) 工业资本主义的负面影响。
在其他条件相同的情况下,以下哪一个人更有可能患有骨质疏松症?
(A) 一位年长的西班牙裔美国妇女
(B) 一位年长的非洲裔美国妇女
(C) 一位年长的亚裔美国女性
(D) 一位年长的美洲原住民妇女
孕吐通常是一个问题:
(A) 妊娠早期
(B) 妊娠中期
(C) 妊娠晚期
(D) 整个怀孕期间
在当代实践中,对《公民权利和政治权利国际公约》中酷刑定义的保留可以接受吗?
(A) 如果保留国的立法采用不同的定义,则这是可接受的保留
(B) 这是不可接受的保留,因为它违背了《公民权利和政治权利国际公约》的目标和宗旨
(C) 这是不可接受的保留,因为《公民权利和政治权利国际公约》中酷刑的定义符合习惯国际法
(D) 这是可接受的保留,因为根据一般国际法,各国有权对条约提出保留
罗尔斯认为哪种立场最不可能被 POP(处于原始立场的人)采纳?
(A) POP 将选择平等而非自由。
(B) POP 将选择“最大最小”策略。
(C) POP 将选择“差异原则”。
(D) POP 将拒绝“自然自由制度”。
约翰·斯图尔特·密尔:每个人的幸福对其个人来说都是一件好事,因此,普遍的幸福对所有人的集体来说都是一件好事。
(A) 合成谬误
(B) 除法谬误
(C) 赌徒谬误
(D) 含糊其辞
一个 6 面骰子滚动 15 次,结果是:面 1 出现 0 次;面 1 出现 0 次;面 1 出现 0 次。第2面:1次;第3面:2次;第4面:3次;第5面:4次;第六面:5次。 根据这些结果,使用 Add-1 平滑时出现第 3 面的概率是多少? (A) 2/15 (B) 1/7 (C) 3/16 (D) 1/5
根据 Lewin、Lippet 和 White 1939 年的实验,哪种领导形式为参与者带来了最多的工作?
(A) 自由放任
(B) 民主
(三) 独裁主义
(D) 自由放任与民主的结合
社会中最容易受到参照群体影响的单一群体是: (A) 感觉有些被忽视的老年消费者。 (B) 已婚妇女,其中许多人感到生活需要稳定。 (C) 真正想要融入新文化的新移民。 (D) 儿童,他们的大部分购买决定取决于外界的影响。
下列哪种情况不表现出多因素遗传? (一)幽门狭窄 (二) 精神分裂症 (C) 脊柱裂(神经管缺陷) (D) 马凡综合征
如果以下每一餐提供相同数量的卡路里,哪一餐需要最多的土地来生产食物?
(A) 红豆和大米
(B) 牛排和烤土豆
(C) 玉米饼和豆泥
(D) 扁豆汤和黑面包
针对桑德尔的“社会正义”论点,卡姆认为 (A) 即使我们能够提升自己或他人,我们也没有义务这样做。 (B) (i) 选择一个人具有某种特质和 (ii) 负责承担该选择的成本之间是有区别的。 (C) 拥有增强选项将减少需要他人帮助的情况。 (D) 以上所有
对于这两种情况中的哪一种,主角(使用“我/我/我的”)做了明显道德错误的事情?
场景1 |当我在赛道上时,我开得很快。
场景2 |当我在郊区时,我开得很快。
(一)错了,错了
(B) 错误,没有错误
(C) 没有错,就是错
(D) 没有错,没有错
对于膳食纤维对结肠癌的保护作用,以下哪一项是最合理的解释?
(A) 结肠纤维发酵过程中形成的丙酸抑制肝脏脂肪酸合成
(B) 结肠纤维发酵过程中形成的丁酸刺激 SLC5A8 肿瘤抑制基因的“沉默”
(C) 结肠纤维发酵过程中形成的丁酸可刺激结肠中的抗氧化防御
(D) 这些选项都不正确
根据摩尔的“理想功利主义”,正确的行动能够带来最大的效果:
(荣幸。
(二)幸福。
(三)好。
(四)美德。
研究人员现在认为玛雅人的衰落主要是由于:
(A) 某种灾难,例如地震、火山或海啸。
(B) 刀耕火种耕作技术造成的生态退化。
(C) 邻近玛雅城邦之间无休止的战争。
(D) 杂交导致先天性疾病急剧增加。
克雷特是一名未婚纳税人,收入全部来自工资。 截至第一年 12 月 31 日,Krete 的雇主已预扣 16,000 美元的联邦所得税,而 Krete 尚未缴纳任何估计税款。 第二年 4 月 15 日,Krete 及时提出个人纳税申报延期申请,并缴纳了 300 美元的额外税款。 当 Krete 在第二年 4 月 30 日及时提交纳税申报表时,她第一年的纳税义务为 16,500 美元,并支付了剩余的纳税义务余额。 少缴估计税款将受到多少金额的罚款?
(一) 0 美元
(B) 500 美元
(C) $1,650
(D) 16,500 美元
律师考试前一天晚上,考生的隔壁邻居正在举办派对。 邻居家的音乐声太大,考生无法入睡。 考生打电话给邻居,请她保持安静。 然后邻居就突然挂断了电话。 考生一怒之下,走进衣柜拿了一把枪。 他走到外面,从邻居客厅的窗户开了一枪。 考生并没有打算开枪射击任何人,而是以子弹击中天花板的角度开枪。 他只是想对邻居的家造成一些破坏,以缓解他的愤怒。 然而,子弹从天花板上弹起,击中一名参加聚会的人的背部,导致他死亡。 该司法管辖区规定,在公共场合开枪属于轻罪。 考生最有可能因以下与参加聚会的人的死亡有关的哪项罪行而被判有罪?
(一)谋杀。
(B) 非自愿过失杀人。
(C) 故意杀人。
(D) 在公共场所开枪。
一名 63 岁男子因 4 天来左腿疼痛日益严重且左小腿肿胀而被送往急诊室。 他还有 1 个月的上胸背部疼痛日益严重的病史。 在此期间,尽管食欲没有变化,但他的体重减轻了 9 公斤(20 磅)。 他没有重大疾病史。 他唯一的药物是布洛芬。 他身高 180 厘米(5 英尺 11 英寸),体重 82 公斤(180 磅);体重指数为25公斤/平方米。 他的生命体征在正常范围内。 检查时,双侧下肢脉搏可触及。 其余身体检查未见异常。 胸椎 X 光检查未见异常。 腹部 CT 扫描显示胰腺体内有一个 3 厘米的肿块;有肝转移和肠系膜上动脉包绕。 左下肢超声检查显示股腘静脉血栓。 以下哪一项最可能是导致该患者出现症状的原因?
(A) 类癌综合征
(B) 晚期恶性肿瘤引起的高凝状态
(C) 多发性内分泌肿瘤
(四)左下肢脾动脉瘤及栓塞性疾病
对于打别人、撕毁课本的孩子来说,最有可能立即改善其行为的方法是
(A) 对适当行为的强化与对不当行为的温和惩罚相结合
(B) 差别正强化
(C) 因不当行为而丧失特权
(四)整形
您在一家公用事业公司工作,该公司正在社区建设生物质工厂。 您的雇主要求您就工厂和未来运营进行一系列社区演讲。 您在预定发表由您的直接主管准备的演讲前几个小时参观了工厂。 在参观工厂的过程中,您发现演讲中的一些说法并不真实。 你做什么工作? (A) 撰写并发表一篇您知道完全正确的新演讲。 (B) 取消所有演讲,直到您和您的主管能够弄清楚信息。 (C) 发表准备好的演讲,然后与你的主管讨论不准确的地方。 (D) 立即向您的主管提出不准确之处,并在发表演讲之前进行必要的更正。
《化学武器公约》(CWC)禁止拥有或部署化学武器;然而,它未能执行要求签署国申报其现有化学武器库存、查明曾经参与化学生产的设施或宣布何时销毁其现有库存的规定。 (A) 《化学武器公约》禁止拥有或部署化学武器;然而,它未能执行要求签署国申报其现有化学武器库存、查明曾经参与化学生产的设施或宣布何时销毁其现有库存的规定。 (B) 《化学武器公约》在使用和拥有化学武器以及销毁现有库存方面取得了一些重要进展。 然而,该条约未能建立一个有权检查条约遵守情况的独立机构。 缺乏超国家权威削弱了执行这些发展的能力。 鉴于国际社会的无政府性质,保留库存可能符合国家安全利益。 (三)化学武器继续对国际社会产生决定性影响。 早在 20 世纪 70 年代,军事战略家就确信化学武器可能具有威慑作用,可与核威慑的二次打击生存逻辑相媲美。 战略家的偏好导致武器的持续制造和储存,造成国际稳定危机。 (D) 虽然《化学武器公约》已得到国际社会大多数国家的批准,但一些拥有大量化学能力的国家尚未加入该条约。 然而,一些分析人士认为,其军事破坏潜力有限,对常规战争中装备精良的军队影响不大。 化学武库本质上属于“穷人”武器的范畴,简单且廉价,但军事用途有限。 然而,恐怖分子化学袭击可能对平民造成的预期影响仍然令人担忧。
以下哪项陈述与微分关联理论最接近?
(A) 如果你所有的朋友都从桥上跳下去,我想你也会跳下去。
(B) 您应该为成为这个组织的一员而感到自豪。
(C) 如果门关着,请尝试打开窗户。
(D) 一日为贼,终生为贼。
为什么国会反对威尔逊的国际联盟提案?
(A) 它担心国联会鼓励苏联在美国的影响力
(B) 它担心联盟会反民主
(C) 它担心国联会让美国加入国际联盟
(D) a 和 b
一项针对糖尿病患者的观察性研究评估了血浆纤维蛋白原水平升高对心脏事件风险的影响。 对 130 名糖尿病患者进行了为期 5 年的随访,以评估急性冠脉综合征的发展情况。 在 60 名基线血浆纤维蛋白原水平正常的患者中,20 名患者出现急性冠脉综合征,40 名则没有。 在 70 名基线血浆纤维蛋白原水平较高的患者中,40 名患者出现急性冠脉综合征,30 名则没有。 与基线血浆纤维蛋白原水平正常的患者相比,以下哪一项是对基线血浆纤维蛋白原水平高的患者相对风险的最佳估计?
(一)(40/30)/(20/40)
(乙)(40*40)/(20*30)
(三)(40*70)/(20*60)
(D) (40/70)/(20/60)
《大云经》预言了哪一个人即将到来? (A) 弥勒佛 (二)佛陀 (C) 周敦颐 (四)王阳明